
Abstract
We present and review an algorithmic and theoretical framework for improving neural network architecture design via momentum. As case studies, we consider how momentum can improve the architecture design for recurrent neural networks (RNNs), neural ordinary differential equations (ODEs), and transformers. We show that integrating momentum into neural network architectures has several remarkable theoretical and empirical benefits, including (1) integrating momentum into RNNs and neural ODEs can overcome the vanishing gradient issues in training RNNs and neural ODEs, resulting in effective learning long-term dependencies; (2) momentum in neural ODEs can reduce the stiffness of the ODE dynamics, which significantly enhances the computational efficiency in training and testing; (3) momentum can improve the efficiency and accuracy of transformers.















Similar content being viewed by others

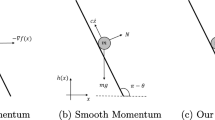
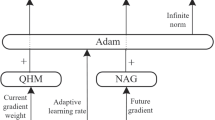
Data and Code Availability
All related code and data have been made available on Github.
Notes
Here, for the sake of exposition, we omit the bias corrections.
In the vanishing gradient scenario, \(\Vert {{\varvec{U}}}\Vert _2\) is small; also it can be controlled by regularizing the loss function.
In contrast to Adam, we do not normalize \({{\varvec{p}}}_t\) and \({{\varvec{m}}}_t\) since they can be absorbed in the weight matrices.
Here, we exclude an \({{\varvec{h}}}^3\) term that appeared in the original Duffing oscillator model because including it would result in finite-time explosion.
HBNODE can be seen as a special GHBNODE with \(\xi =0\) and \(\sigma \) be the identity map.
We set \(p=0, 5, 4, 4, 5/0,10,9,9,9\) on MNIST/CIFAR10 for NODE, ANODE, SONODE, HBNODE, and GHBNODE, respectively.
We omit the nonlinearity (a two-layer feedforward network) compared to [40].
References
Ainslie, J., Ontanon, S., Alberti, C., Cvicek, V., Fisher, Z., Pham, P., Ravula, A., Sanghai, S., Wang, Q., Yang, L.: ETC: Encoding long and structured inputs in transformers. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pp. 268–284 (2020)
Al-Rfou, R., Choe, D.K., Constant, N., Guo, M., Jones, L.: Character-level language modeling with deeper self-attention. In: Thirty-Third AAAI Conference on Artificial Intelligence (2019)
Arjovsky, M., Shah, A., Bengio, Y.: Unitary evolution recurrent neural networks. In: International Conference on Machine Learning, pp. 1120–1128 (2016)
Attouch, H., Goudou, X., Redont, P.: The heavy ball with friction method, I. The continuous dynamical system: global exploration of the local minima of a real-valued function by asymptotic analysis of a dissipative dynamical system. Commun. Contemp. Math. 2(01), 1–34 (2000)
Beltagy, I., Peters, M.E., Cohan, A.: Longformer: The long-document transformer. (2020). arXiv preprint arXiv:2004.05150
Bengio, Y., Simard, P., Frasconi, P.: Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 5(2), 157–166 (1994)
Blanc, G., Rendle, S.: Adaptive sampled softmax with kernel based sampling. In: Dy, J., Krause, A. (eds.), Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp. 590–599. PMLR (2018)
Brockman, G., Cheung, V., Pettersson, L., Schneider, J., Schulman, J., Tang, J., Zaremba, W.: OpenAI Gym (2016). cite arxiv:1606.01540
Brown, T., et al.: Language models are few-shot learners. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H. (eds), Advances in Neural Information Processing Systems, Vol. 33, pp. 1877–1901 (2020)
Casado, M.L.: Optimization with orthogonal constraints and on general manifolds. (2019). https://github.com/Lezcano/expRNN
Casado, M.L.: Trivializations for gradient-based optimization on manifolds. In: Advances in Neural Information Processing Systems, pp. 9154–9164 (2019)
Chakraborty, A., Alam, M., Dey, V., Chattopadhyay, A., Mukhopadhyay, D.: Adversarial attacks and defences: a survey. (2018). arXiv preprint arXiv:1810.00069
Chandar, S., Sankar, C., Vorontsov, E., Kahou, S.E., Bengio, Y.: Towards non-saturating recurrent units for modelling long-term dependencies. In: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33, pp. 3280–3287 (2019)
Chen, R.T.Q., Rubanova, Y., Bettencourt, J., Duvenaud, D.: Neural ordinary differential equations. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems, pp. 6572–6583 (2018)
Child, R., Gray, S., Radford, A., Sutskever, I.: Generating long sequences with sparse transformers. (2019). arXiv preprint arXiv:1904.10509
Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., Bengio, Y.: Learning phrase representations using rnn encoder-decoder for statistical machine translation. (2014). arXiv preprint arXiv:1406.1078
Choromanski, K.M., et al.: Rethinking attention with performers. In: International Conference on Learning Representations (2021)
Chung, J., Gulcehre, C., Cho, K., Bengio, Y.: Gated feedback recurrent neural networks. In: International Conference on Machine Learning, pp. 2067–2075 (2015)
Dai, Z., Yang, Z., Yang, Y., Carbonell, J., Le, Q.V., Salakhutdinov, R.: Transformer-xl: Attentive language models beyond a fixed-length context. (2019). arXiv preprint arXiv:1901.02860
Daulbaev, T., Katrutsa, A., Markeeva, L., Gusak, J., Cichocki, A., Oseledets, I.: Interpolation technique to speed up gradients propagation in neural odes. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H. (eds), Advances in Neural Information Processing Systems, volume 33, pp. 16689–16700. Curran Associates, Inc. (2020)
Dehghani, M., Gouws, S., Vinyals, O., Uszkoreit, J., Kaiser, L.: Universal transformers. (2018). arXiv preprint arXiv:1807.03819
Devlin, J., Chang, M.-W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidirectional transformers for language understanding. (2018). arXiv preprint arXiv:1810.04805
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. (2020). arXiv preprint arXiv:2010.11929
Du, J., Joseph, D.-V., Finale: Model-based reinforcement learning for semi-markov decision processes with neural odes. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H. (eds.), Advances in Neural Information Processing Systems, Vol. 33, pp. 19805–19816. Curran Associates, Inc. (2020)
Dupont, E., Doucet, A., Teh, Y.W.: Augmented neural odes. In: Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc. (2019)
Elman, J.L.: Finding structure in time. Cogn. Sci. 14(2), 179–211 (1990)
Finlay, C., Jacobsen, J.-H., Nurbekyan, L., Oberman, A.: How to train your neural ODE: the world of Jacobian and kinetic regularization. In: Hal Daumé, III., Singh, A. (eds.), Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pp. 3154–3164. PMLR, 13–18 (2020)
Garofolo, J.S.: Timit acoustic phonetic continuous speech corpus. Linguistic Data Consortium (1993)
Ghosh, A., Behl, H., Dupont, E., Torr, P., Namboodiri, V.: Steer : Simple temporal regularization for neural ode. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H. (eds), Advances in Neural Information Processing Systems, volume 33, pp. 14831–14843. Curran Associates, Inc. (2020)
Grathwohl, W., Chen, R.T.Q., Bettencourt, J., Duvenaud, D.: Scalable reversible generative models with free-form continuous dynamics. In: International Conference on Learning Representations (2019)
Haber, E., Ruthotto, L.: Stable architectures for deep neural networks. Inverse Prob. 34(1), 014004 (2017)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385 (2015)
He, K., Zhang, X., Ren, S., Sun, J.: Identity mappings in deep residual networks. In: European Conference on Computer Vision, pp. 630–645. Springer (2016)
Helfrich, K., Willmott, D., Ye, Q.: Orthogonal recurrent neural networks with scaled Cayley transform. In: Dy, J., Krause, A., (eds), Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp. 1969–1978, Stockholmsmässan, Stockholm Sweden, 10–15 (2018). PMLR
Henaff, M., Szlam, A., LeCun, Y.: Recurrent orthogonal networks and long-memory tasks. In: Balcan, M.F., Weinberger, K.Q. (eds), Proceedings of The 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pp. 2034–2042. New York, New York, USA 20–22 (2016). PMLR
Ho, J., Kalchbrenner, N., Weissenborn, D., Salimans, T.: Axial attention in multidimensional transformers. (2019). arXiv preprint arXiv:1912.12180
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Howard, J., Ruder, S.: Universal language model fine-tuning for text classification. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 328–339. Melbourne, Australia (2018). Association for Computational Linguistics
Huang, C.-Z.A., Vaswani, A., Uszkoreit, J., Simon, I., Hawthorne, C., Shazeer, N., Dai, A.M., Hoffman, M.D., Dinculescu, M, Eck, D.: Music transformer: Generating music with long-term structure. In: International Conference on Learning Representations (2018)
Katharopoulos, A., Vyas, A., Pappas, N., Fleuret, F.: Transformers are rnns: Fast autoregressive transformers with linear attention. In: International Conference on Machine Learning, pp. 5156–5165. PMLR (2020)
Kelly, J., Bettencourt, J., Johnson, M.J., Duvenaud, D.K.: Learning differential equations that are easy to solve. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp. 4370–4380. Curran Associates, Inc. (2020)
Kidger, P., Morrill, J., Foster, J., Lyons, T.J.: Neural controlled differential equations for irregular time series. In: NeurIPS (2020)
Kim, Y., Denton, C., Hoang, L., Rush, A.M.: Structured attention networks. (2017). arXiv preprint arXiv:1702.00887
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. (2014). arXiv preprint arXiv:1412.6980
Kitaev, N., Kaiser, L., Levskaya, A.: Reformer: The efficient transformer. (2020). arXiv preprint arXiv:2001.04451
Koehn, P., et al.: Moses: Open source toolkit for statistical machine translation. In: Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics Companion Volume Proceedings of the Demo and Poster Sessions, pp. 177–180 (2007)
Le, Q.V., Jaitly, N., Hinton, G.E: A simple way to initialize recurrent networks of rectified linear units. (2015). arXiv preprint arXiv:1504.00941
Lechner, M., Hasani, R.: Learning long-term dependencies in irregularly-sampled time series (2020)
LeCun, Y., Bengio, Y., Hinton, G.: Deep learning. nature 521(7553), 436–444 (2015)
LeCun, Y., Cortes, C., Burges, C.J.: MNIST handwritten digit database. 2, (2010). ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist
Lee, J., Mansimov, E., Cho, K.: Deterministic non-autoregressive neural sequence modeling by iterative refinement. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 1173–1182 (2018)
Lezcano-Casado, M., Martínez-Rubio, D.: Cheap orthogonal constraints in neural networks: A simple parametrization of the orthogonal and unitary group. In: International Conference on Machine Learning (ICML), pp. 3794–3803 (2019)
Li, H., Yang, Y., Chen, D., Lin, Z.: Optimization algorithm inspired deep neural network structure design. In: Asian Conference on Machine Learning, pp. 614–629. PMLR (2018)
Liu, P.J., Saleh, M., Pot, E., Goodrich, B., Sepassi, R., Kaiser, L., Shazeer, N.: Generating wikipedia by summarizing long sequences. In: International Conference on Learning Representations (2018)
Liu, P.J., Saleh, M., Pot, E., Goodrich, B., Sepassi, R., Kaiser, L., Shazeer, N.: Generating wikipedia by summarizing long sequences. (2018). arXiv preprint arXiv:1801.10198
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., Vladu, A.: Towards deep learning models resistant to adversarial attacks. In: International Conference on Learning Representations (2018)
Massaroli, S., Poli, M., Park, J., Yamashita, A., Asma, H.: Dissecting neural odes. In: 34th Conference on Neural Information Processing Systems, NeurIPS 2020. The Neural Information Processing Systems (2020)
Mhammedi, Z., Hellicar, A., Rahman, A., Bailey, J.: Efficient orthogonal parametrisation of recurrent neural networks using householder reflections. In: Proceedings of the 34th International Conference on Machine Learning-Volume 70, pp. 2401–2409. JMLR. org (2017)
Mikolov, T., Karafiát, M., Burget, L., Černockỳ, J., Khudanpur, S.: Recurrent neural network based language model. In: Eleventh Annual Conference of the International Speech Communication Association (2010)
Nesterov, Y.: Introductory lectures on convex programming volume I: Basic course. (1998)
Nesterov, Y.E.: A method for solving the convex programming problem with convergence rate o (1/k\(^{2}\)). Dokl. Akad. Nauk SSSR 269, 543–547 (1983)
Nguyen, T., Baraniuk, R., Bertozzi, A., Osher, S., Wang, B.: MomentumRNN: integrating momentum into recurrent neural networks. In: Advances in Neural Information Processing Systems (NeurIPS 2020), (2020)
Nguyen, T.M., Suliafu, V., Osher, S.J., Chen, L., Wang, B.: Fmmformer: Efficient and flexible transformer via decomposed near-field and far-field attention. (2021). arXiv preprint arXiv:2108.02347
Noël, J.-P., Schoukens, M.: F-16 aircraft benchmark based on ground vibration test data. In: 2017 Workshop on Nonlinear System Identification Benchmarks, pp. 19–23 (2017)
Norcliffe, A., Bodnar, C., Day, B., Simidjievski, N., Liò, P.: On second order behaviour in augmented neural odes. In: Advances in Neural Information Processing Systems (2020)
Pal, A., Ma, Y., Shah, V., Rackauckas, C.V.: Opening the blackbox: Accelerating neural differential equations by regularizing internal solver heuristics. In: Meila, M., Zhang, T., (eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp. 8325–8335. PMLR (2021)
Papineni, K., Roukos, S., Ward, T., Zhu, W.-J.: Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, ACL ’02, pp. 311–318. USA (2002). Association for Computational Linguistics
Parmar, N., Vaswani, A., Uszkoreit, J., Kaiser, L., Shazeer, N., Ku, A., Tran, D.: Image transformer. In: Dy, Jennifer, Krause, Andreas, (eds.), Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp. 4055–4064. PMLR, 10–15 (Jul 2018)
Pascanu, R., Mikolov, T., Bengio, Y.: On the difficulty of training recurrent neural networks. In: International Conference on Machine Learning, pp. 1310–1318 (2013)
Peng, H., Pappas, N., Yogatama, D., Schwartz, R., Smith, N., Kong, L.: Random feature attention. In: International Conference on Learning Representations (2021)
Polyak, B.T.: Some methods of speeding up the convergence of iteration methods. USSR Comput. Math. Math. Phys. 4(5), 1–17 (1964)
Pontryagin, L.S.: Mathematical Theory of Optimal Processes. Routledge, New York (2018)
Qiu, J., Ma, H., Levy, O., Yih, S.W., Wang, S., Tang, J.: Blockwise self-attention for long document understanding. (2019). arXiv preprint arXiv:1911.02972
Quaglino, A., Gallieri, M., Masci, J., Koutník, J.: Snode: Spectral discretization of neural odes for system identification. In: International Conference on Learning Representations (2020)
Radford, A., Jeffrey, W., Child, R., Luan, D., Amodei, D., Sutskever, I.: Language models are unsupervised multitask learners. OpenAI blog 1(8), 9 (2019)
Rajpurkar, P., Zhang, J., Lopyrev, K., Liang, P.: SQuAD: 100,000+ questions for machine comprehension of text. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pp. 2383–2392, Austin, Texas, (2016). Association for Computational Linguistics
Ramesh, A., Pavlov, M., Goh, G., Gray, S., Chen, M., Child, R., Misra, V., Mishkin, P., Krueger, G., Agarwal, S., Sutskever, I.: Dalle: Creating images from text. OpenAI blog (2020)
Rawat, A.S., Chen, J., Yu, F.X.X., Suresh, A.T., Kumar, S.: Sampled softmax with random fourier features. In: Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., (eds), Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc. (2019)
Roy, A., Saffar, M., Vaswani, A., Grangier, D.: Efficient content-based sparse attention with routing transformers. Trans. Assoc. Comput. Linguist. 9, 53–68 (2021)
Rubanova, Y., Chen, R.T.Q., Duvenaud, D.K.: Latent ordinary differential equations for irregularly-sampled time series. In: Wallach, H., Larochelle, H., Beygelzimer, A., d’ Alché-Buc, F., Fox, E., Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc. (2019)
Salesforce. Lstm and qrnn language model toolkit for pytorch. (2017). https://github.com/salesforce/awd-lstm-lm
Salimans, T., Karpathy, A., Chen, X., Kingma, D.: Pixelcnn++: Improving the pixelcnn with discretized logistic mixture likelihood and other modifications. In: International Conference on Learning Representations (2017)
Sander, M.E., Ablin, P., Blondel, M., Peyré, G.: Momentum residual neural networks. (2021). arXiv preprint arXiv:2102.07870
Schlag, I., Irie, K., Schmidhuber, J.: Linear transformers are secretly fast weight memory systems. CoRR, abs/2102.11174 (2021)
Sennrich, R., Haddow, B., Birch, A.: Neural machine translation of rare words with subword units. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1715–1725 (2016)
Shen, Z., Zhang, M., Zhao, H., Yi, S., Li, H.: Efficient attention: Attention with linear complexities. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 3531–3539 (2021)
Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., Bolton, A., et al.: Mastering the game of go without human knowledge. nature 550(7676), 354–359 (2017)
So, D.R., Liang, C., Le, Q.V.: The evolved transformer. (2019). arXiv preprint arXiv:1901.11117
Song, K., Jung, Y., Kim, D., Moon, I.-C.: Implicit kernel attention. (2021). arXiv preprint arXiv:2006.06147
Su, W., Boyd, S., Candes, E.: A differential equation for modeling nesterov’s accelerated gradient method: Theory and insights. In: Advances in Neural Information Processing Systems, pp. 2510–2518 (2014)
Sun, T., Ling, H., Shi, Z., Li, D., Wang, B.: Training deep neural networks with adaptive momentum inspired by the quadratic optimization. (2021). arXiv preprint arXiv:2110.09057
Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., Fergus, R.: Intriguing properties of neural networks. (2013). arXiv preprint arXiv:1312.6199
Tay, Y., Bahri, D., Metzler, D., Juan, D.-C., Zhao, Z., Zheng, C.: Synthesizer: Rethinking self-attention in transformer models. (2020). arXiv preprint arXiv:2005.00743
Tay, Y., Bahri, D., Yang, L., Metzler, D., Juan, D.-C.: Sparse Sinkhorn attention. In: Hal Daumé, I.I.I., Singh, Aarti (eds.), Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pp. 9438–9447. PMLR, 13–18 (2020)
Tay, Y., Dehghani, M., Abnar, S., Shen, Y., Bahri, D., Pham, P., Rao, J., Yang, L., Ruder, S., Metzler, D.: Long range arena : A benchmark for efficient transformers. In: International Conference on Learning Representations (2021)
Tay, Y., Dehghani, M., Bahri, D., Metzler, D.: Efficient transformers: A survey. (2020). arXiv preprint arXiv:2009.06732
Tieleman, T., Hinton, G.: Lecture 6.5—RmsProp: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning (2012)
Todorov, E., Erez, T., Tassa, Y.: Mujoco: A physics engine for model-based control. In: 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 5026–5033 (2012)
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jégou, H.: Training data-efficient image transformers & distillation through attention. (2020). arXiv preprint arXiv:2012.12877
Van Der Westhuizen, J., Lasenby, J.: The unreasonable effectiveness of the forget gate. (2018). arXiv preprint arXiv:1804.04849
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I.: Attention is all you need. In Advances in Neural Information Processing Systems, pp. 5998–6008 (2017)
Vorontsov, E., Trabelsi, C., Kadoury, S., Pal, C.: On orthogonality and learning recurrent networks with long term dependencies. In: Proceedings of the 34th International Conference on Machine Learning-Volume 70, pp. 3570–3578. JMLR. org (2017)
Vyas, A., Katharopoulos, A., Fleuret, F.: Fast transformers with clustered attention. Adv. Neural Inf. Process. Syst. 33, (2020)
Wang, B., Lin, A., Yin, P., Zhu, W., Bertozzi, A.L., Osher, S.J.: Adversarial defense via the data-dependent activation, total variation minimization, and adversarial training. Inverse Problems Imaging 15(1), 129–145 (2021)
Wang, B., Luo, X., Li, Z., Zhu, W., Shi, Z., Osher, S.: Deep neural nets with interpolating function as output activation. Advances in Neural Information Processing Systems (2018)
Wang, B., Nguyen, T.M., Bertozzi, A.L., Baraniuk, R.G., Osher, S.J.: Scheduled restart momentum for accelerated stochastic gradient descent. (2020). arXiv preprint arXiv:2002.10583
Wang, B., Osher, S.J.: Graph interpolating activation improves both natural and robust accuracies in data-efficient deep learning. Eur. J. Appl. Math. 32(3), 540–569 (2021)
Wang, B., Ye, Q.: Stochastic gradient descent with nonlinear conjugate gradient-style adaptive momentum. (2020). arXiv preprint arXiv:2012.02188
Wang, B., Yuan, B., Shi, Z., Osher, S.: Resnets ensemble via the Feynman-Kac formalism to improve natural and robust accuracies. Adv. Neural Inf. Process. Syst. (2019)
Wang, S., Li, B., Khabsa, M., Fang, H., Ma, H.: Linformer: Self-attention with linear complexity. (2020). arXiv preprint arXiv:2006.04768
Wibisono, A., Wilson, A.C., Jordan, M.I.: A variational perspective on accelerated methods in optimization. Proc. Natl. Acad. Sci. 113(47), E7351–E7358 (2016)
Williams, A., Nangia, N., Bowman, S.: A broad-coverage challenge corpus for sentence understanding through inference. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pp. 1112–1122. (2018)
Wisdom, S., Powers, T., Hershey, J., Le Roux, J., Atlas, L.: Full-capacity unitary recurrent neural networks. In: Advances in Neural Information Processing Systems, pp. 4880–4888 (2016)
Xia, H., Suliafu, V., Ji, H., Nguyen, T.M., Bertozzi, A.L., Osher, S.J., Wang, B.: Heavy ball neural ordinary differential equations. (2021). arXiv preprint arXiv:2010.04840
Xiong, Y., Zeng, Z., Chakraborty, R., Tan, M., Fung, G., Li, Y., Singh, V.: Nyströmformer: A nyström-based algorithm for approximating self-attention. In: Proceedings of the AAAI Conference on Artificial Intelligence (2021)
Zaheer, M., Guruganesh, G., Dubey, A., Ainslie, J., Alberti, C., Ontanon, S., Pham, P., Ravula, A., Wang, Q., Yang, L., Ahmed, A.: Big bird: Transformers for longer sequences. (2021). arXiv preprint arXiv:2007.14062
Zhang, T., Yao, Z., Gholami, A., Gonzalez, J.E., Keutzer, K., Mahoney, M.W., Biros, G.: ANODEV2: A Coupled Neural ODE Framework. In: Wallach, H., Larochelle, H., Beygelzimer, A., d’ Alché-Buc, F., Fox, E., Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., (2019)
Zhuang, J., Dvornek, N.C., Tatikonda, S., Duncan, J.: MALI: A memory efficient and reverse accurate integrator for neural odes. In: International Conference on Learning Representations (2021)
Acknowledgements
This material is based on research sponsored by NSF Grants DMS-1924935, DMS-1952339, DMS-2110145, DMS-2152762, DMS-2208361, DOE Grant DE-SC0021142, and ONR grant N00014-18-1-2527 and the ONR MURI Grant N00014-20-1-2787.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
There is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wang, B., Xia, H., Nguyen, T. et al. How does momentum benefit deep neural networks architecture design? A few case studies. Res Math Sci 9, 57 (2022). https://doi.org/10.1007/s40687-022-00352-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40687-022-00352-0