
Abstract
Horizontal alignment greatly affects the speed of vehicles at rural roads. Therefore, it is necessary to analyze and predict vehicles speed on curve sections. Numerous studies took rural two-lane as research subjects and provided models for predicting operating speeds. However, less attention has been paid to multi-lane highways especially in Egypt. In this research, field operating speed data of both cars and trucks on 78 curve sections of four multi-lane highways is collected. With the data, correlation between operating speed (V85) and alignment is analyzed. The paper includes two separate relevant analyses. The first analysis uses the regression models to investigate the relationships between V85 as dependent variable, and horizontal alignment and roadway factors as independent variables. This analysis proposes two predicting models for cars and trucks. The second analysis uses the artificial neural networks (ANNs) to explore the previous relationships. It is found that the ANN modeling gives the best prediction model. The most influential variable on V85 for cars is the radius of curve. Also, for V85 for trucks, the most influential variable is the median width. Finally, the derived models have statistics within the acceptable regions and they are conceptually reasonable.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Horizontal curves have long been recognized as having a significant effect on vehicle speeds. They have therefore been afforded a great deal of attention by researchers. Design features for multi-lane roadways, such as curvature and superelevation, are directly related to, and vary appreciably with, design speed. Other features, such as widths of lanes and shoulders are not directly related to design speed, but they also affect vehicle speeds. Therefore, wider lanes and shoulders should be considered for higher design speed [1]. In this work, a driver’s speed under free-flow conditions avoids the effect of traffic flow on vehicle speed, as only the effect of horizontal curves and highway geometry on operating speed is considered, as executed by Hashim [2]. The 85th-percentile value of the distribution of observed speeds (V85) is the most frequently used in characterizing measure of operating speed associated with a particular location or geometric feature.
Past researches did a lot of work for two-lane rural [3–7]. A large number of studies used radius as an explanatory variable for operating speed prediction while a few used length of curve. Previous research for speed prediction on two-lane rural highways indicates that there are several important elements in determining speed on horizontal curves. Curve radius, superelevation, deflection angle, degree of curvature, length of curve, and cross section are examples of variables that have been used in the regression equations to predict operating speeds on horizontal curves. Curve radius is considered to be the most important element in determining operating speed on horizontal curves; therefore, most researchers have used it as the dominant independent variable in their regression analyses [8].
Gong and Stamatiadis [9] studied 50 horizontal curves that are located in rural four-lane highways in Kentucky. They derived two models for operating speed. The first one was for inside lane and the other was for outside lane, respectively. For the first one, they concluded that a surfaced shoulder and logarithm of horizontal curve length were positively correlated with V85. For the other model, a surfaced shoulder, horizontal curve radius, and the ratio of the horizontal curve length to radius were positively correlated with V85. In addition, the first model explained nearly 65 % of the variability in the 85th-percentile inside lane operating speeds. Also, the other model explained approximately 43 % of the variability in the 85th-percentile outside lane operating speeds.
Cheng et al. [10] studied 30 horizontal curves that are located in HU-Ning expressway, Jiangsu province, China. The correlation analysis results showed better correlations between V85 (operating speed) and alignment. This study proposed four speed predicting models (linear or curve fitting models), respectively, of cars and trucks. Results of modeling showed that deflection angle and radius of curve were the two most important parameters for predicting operating speeds of cars and trucks.
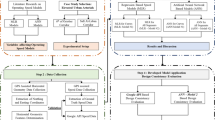
Prediction and estimation of speeds on multi-lane rural highways are of great significance to planners and designers; therefore, all proposed speed prediction models should be validated, and the accuracy of their results should be evaluated. In this paper, the first part in the analysis involves the prediction of operating speed for cars and trucks on horizontal curves using conventional regression models. The modeling of operating speed on curved roadway using ANN models is another aspect of this paper.
2 Study sites and field data and methodology
2.1 Study sites and field data
This work uses 78 horizontal curves from two categories of multi-lane highways in Egypt. These categories are as follows:
-
(1)
Agricultural highways category which includes two roads as Cairo-Alexandria agricultural highway (CAA) and Tanta-Damietta agricultural highway (TDA).
-
(2)
Desert highways category which includes two roads as Cairo-Alexandria desert highway (CAD) and Cairo-Ismailia desert highway (CID).
The collected data are divided into road geometric and spot speed data.
2.1.1 Road geometric data
This data presents the key independent variables in the analysis. Some of this data are collected directly from site investigation which includes lane width, right shoulder width, number of lanes in each direction, median width, and pavement width. The horizontal curves data are extracted from Abdalla [11] who worked with the survey team of General Authority of Roads, Bridges and Land Transport in Egypt (GARBLT) [12]. The horizontal curve properties include radius of curve, deflection angle, length of curve, and superelevation. All the previous variables, their symbols, and statistical analysis are provided in Table 1.
2.1.2 Spot speed data
Speed data presents the key dependent variables in analysis, which are divided into operating speed for cars and trucks separately. In this work, a driver’s speed under free-flow conditions avoids the effect of traffic flow on vehicle speed, as only the effect of horizontal curves and highway geometry on operating speed is considered. Free-flow speeds are collected for passenger cars and trucks. The passenger cars include taxis, private cars, vans, and jeeps. While the term “truck” refers to any combination of single- or multi-unit vehicles having at least one axle with dual wheels. The trucks contain trucks, trucks with trailers, semi-trailers, and multiple trailer road trains. Spot speed data are collected using radar gun (version LASER 500 with ±1 km/h accuracy) placed at many points along each horizontal curve in hidden places outside road so as not to be visible to drivers (see Fig. 1). Vehicles traveling in free-flow conditions are considered to have time headways of at least 5 s. Then, the main dependent variable is the average operating speed of a curve. The number of speeds collected at each horizontal curve ranges from 100 to 160 for each cars and trucks, which lead to nearly 18,000 spot speeds. Speeds are carried out in working days, during daylight hours. During all data collection periods, the weather is clear and the pavement is dry and in a good condition. Generally, to assure validity of Pearson correlation, there is a demand that each set of selected data should follow normal distribution. Using Kolmogorov–Smirnov test, it is found that the distribution of the data is normal and could not be rejected at the 95 % confidence level. Operating speed at each observation point is defined as the 85th percentiles of collected speed data (V85). Then, the 85th percentiles of collected speed data of each observation point (V85), respectively, of cars and trucks, are calculated for further correlation analysis and modeling as stated by Hashim [2]. The sample size requirements for V85 were determined by [1]:
where N is the least number of sample size, σ is the estimated sample standard deviation, K is the constant corresponding to the desired confidence level of 95 % (K=1.96), E is the permitted error in the average speed estimation (±2 km/h), and u is the constant corresponding to the V85u=1.04.

Schematic location of radar meters on horizontal curves
The operating speed values for cars (V85C) and trucks (V85T) at each horizontal curve are provided in Table 2.
2.2 Methodology
The methodology of operating speed prediction in the present research includes two main methods: (1) regression models and (2) ANN models.
2.2.1 Regression models
There are nine independent variables (geometric variables) and two dependent variables (speed variables) as stated in the previous section. The present research proposes two speed predicting models, respectively, of cars and trucks. To obtain the best model for the prediction, multiple linear regression method is used in modeling.
First, the correlation between V85 and the selected independent variables is analyzed. The significant variables from the correlation analysis are chosen for the final prediction model. Second, stepwise regression analysis is used to select the most statistically significant independent variables with V85 in one model. Stepwise regression starts with no model terms. At each step, it adds the most statistically significant term (the one with lowest P value) until the addition of the next variable makes no significant difference. An important assumption behind the method is that some input variables in a multiple regression do not have an important explanatory effect on the response. Stepwise regression keeps only the statistically significant terms in the model. Finally, the adjusted R2 and root mean square error (RMSE) values are calculated for each model. Several precautions are taken into consideration to ensure integrity of the model as follows [13]:
-
(1)
The signs of the multiple linear regression coefficients should agree with the signs of the simple linear regression of the individual independent variables and agree with intuitive engineering judgment;
-
(2)
There should be no multicollinearity among the final selected independent variables; and
-
(3)
The model with the smallest number of independent variables, minimum RMSE, and highest R2 value is selected.
2.2.2 ANN models
In general, ANNs consist of three layers, namely, the input, the hidden, and the output layers. In statistical terms, the input layer contains the independent variables and the output layer contains the dependent variables. ANNs typically start out with randomized weights for all their neurons. When a satisfactory level of performance is reached the training is ended and the network uses these weights to make a decision [14].
The experience in this field is extracted from Semeida [15, 16]. In his research, the multi-layer perceptron (MLP) neural network models give the best performance of all models. In addition, this network is usually preferred in engineering applications because many learning algorithm might be used in MLP. One of the commonly used learning algorithms in ANN applications is back propagation algorithm (BP) [17], which is also used in this work.
The overall dataset of 78 curve sections is divided into a training dataset and a testing dataset. As in [18], the training data set varies from 70 % to 90 % and the testing data set varies from 10 % to 30 %. Model performances are RMSE and R2 for testing and training data set in one hand and for all data set in the other hand.
So many trials are done to reach the suitable percentage between training and testing data that gives the best performance for cars and trucks speed models. In addition, over fitting can be avoided by randomizing the 78 curves before training the network to reach the best performance for both training and testing data. The performance of testing data must be good as training data (R2 must not be smaller than 0.7) [19].
3 Data analysis, results, and final models
3.1 Correlation analysis
The correlations among V85C and V85T on curve sections and the nine independent variables are analyzed. As shown in Tables 3 and 4, respectively, Pearson correlation coefficient and the value of significant are calculated by SPSS. It can be seen from Table 3, there are relatively significant correlations among V85C and six independent variables. These variables are SW, MW, LC, DA, e, and R. Also, Table 4 shows significant correlations among V85T and these six independent variables. Then, these variables are introduced into the multiple linear regression models. Consequently, stepwise regression analysis is used to select the most statistically significant independent variables with V85C and V85T in one model. Also, these variables are included in final ANN models.
3.2 Final models
3.2.1 Regression models
Car models There are two models that are statistically significant with V85C after stepwise regression using SSPS Package. All the variables are significant at the 5 % significance level (95 % confidence level) for these two models. In other words, P value is less than 0.05 for all independent variables. Finally, many models are excluded due to poor significance with V85. Therefore, the best models are shown in Eqs. (2) and (3), and in Fig. 2.
whereas R 2adj = 0.79, and RMSE = 10.1,
whereas R 2adj = 0.892, and RMSE = 7.2.

Measured and predicted V85C for models 1 (a) and 2 (b)
Investigation of the previous results shows that:
-
Model 2 is better than model 1 as it has better R 2adj , and lower RMSE.
-
The negative sign of the coefficient for DA means that V85C decreases with the increase of DA. Then, the higher DA for curves is more disturbing for drivers. This result is similar to Ref [20] and consistent with logic.
-
The positive sign of the coefficient for MW means that V85C increases with the increase of MW. In other word, the wider median width encourages the drivers to increase their speed on horizontal curve as the opposite traffic is far from the field of vision. This result is similar to Refs [9, 21], and consistent with logic.
-
Although SW, R, e, and LC have considerable effect on operating speed, but they are excluded from the statistical model, because there is multicollinearity among these independent variables. Therefore, the modeling with other technique is necessary to assure these results.
Truck models The same steps are used to reach the best truck models as car models. There are two models that are statistically significant with V85T. These models are shown in Eqs. (4) and (5), and in Fig. 3.
whereas R 2adj = 0.791, and RMSE = 9.19,
whereas R 2adj = 0.915, and RMSE = 5.49.

Measured and predicted V85T for models 1 (a) and 2 (b)
Investigation of the previous results shows that:
-
Model 2 is the best model as it has the maximum R 2adj , and the lowest RMSE.
-
As car model, the coefficients of DA and MW have similar signs. Then, the same conclusions can be extracted.
3.2.2 ANN models
Car model As a result of correlation analysis, there are six independent variables that are highly correlated with V85C. These variables are in input layer. One hidden layer is used, and one desired variable (V85C) is in output layer with 78 observations used. The architecture of the ANN model is shown in Fig. 4. The curves are divided into training data set that has 63 curves (80 % of all observations), and testing data set that has 15 curves (20 % of all sites). Many trials are done to reach this percentage between training and testing data which gives the best model performance in the present case.

MLP network architecture of V85C model
The number of neurons in hidden layer is about half of the total number of neurons at the input and output layers (thee neurons), which is set based on generally accepted knowledge in this field. Using the learning rule of momentum, the suitable number of iterations is 5,000. The previous conditions are suitable for quick convergence of the problem [15, 16]. As a result of training and testing processing, the performances of the best model for training (63 samples) and testing (15 samples) data set are presented in Table 5.
The observed versus predicted values are shown in Fig. 5. It is clear that the ANN models give better and most confident results than the regression models. In order to measure the importance of each explanatory variable, general influence (sensitivity about the mean or standard deviation) is computed based on the trained weights of ANN. For the specified independent variable, if this value (sensitivity about the mean) is higher than other variables, this indicates that the effect of this variable on dependent variable (V85C) is higher than other variables. Also, Fig. 5 shows the sensitivity of each explanatory variable in the selected model. It is found that the most influential variable on V85C is R, followed by MW. The relationships between each effective input variable and V85 C are shown in Fig. 6. It is concluded that V85C increases with the increase of R. In addition, V85C decreases with the increase of DA. These results are more accurate than the regression models and rational.

Measured and predicted V85C (a) and sensitivity analysis (b) for the best ANN model

Relations between the effective explanatory variables and V85C
Truck model The same steps are executed as car models. Also, training of 63 samples and testing of 15 samples give the best model performances. These results are presented in Table 5. The predicted versus observed values and the sensitivity analysis are shown in Fig. 7. It is found that the most influential variable on V85T is MW, followed by DA. The relationships between each effective input variable and V85T are shown in Fig. 8. It is concluded that V85T increases with the increase of MW. In addition, V85T decreases with the increase of DA. These results are more accurate than the regression models and consistent with logic.

Measured and predicted V85T (a) and sensitivity analysis (b) for the best ANN model

Relations between the effective explanatory variables and V85T
4 Conclusions
The current paper presents new modeling techniques for predicting operating speed on horizontal curves at multi-lane highways in Egypt. The findings of this paper are summarized as:
-
(1)
The ANN models give better, more confident, and logic results than the regression models in terms of predicting V85 for both cars and trucks.
-
(2)
For cars, the best ANN model gives R2 and RMSE equal to 0.932 and 5.77, respectively, for overall data set compared with the best regression model which gives R2 and RMSE equal to 0.892 and 7.2, respectively, for all data set.
-
(3)
For trucks, the best ANN model gives R2 and RMSE equal to 0.95 and 4.33, respectively, for overall data set compared with the best regression model which gives R2 and RMSE equal to 0.919 and 5.43, respectively, for all data set.
-
(4)
For ANN model, the most influential variable on V85C is R, followed by MW. The increase of R from 168 to 642 m leads to an increase of V85C from 45 to 92 km/h. In addition, the increase of MW from 3.3 to 6.8 m leads to an increase in V85C from 69 to 90 km/h.
-
(5)
For ANN model, the most influential variable on V85T is MW, followed by DA. The increase of MW from 3.4 to 6.9 m leads to an increase in V85T from 54 to 80 km/h. Also, the increase of DA from 12° to 46° leads to a decrease of V85T from 82 to 51 km/h.
The previous results are useful for controlling V85 on horizontal curves for multi-lane rural highways. V85 can be controlled by targeting curve factors to improve the safety performance of the curved sections of highways. This is so beneficial for road authorities in Egypt.
Finally, future research should be conducted to add two-lane rural roads and sloping sections to the present sites in order to explore the impact of them on operating speed.
References
Abdul-Mawjoud AA, Sofia GG (2008) Development of models for predicting speed on horizontal curves for two-lane rural highways. Arab J Sci Eng 33(2B):365–377
Hashim IH (2011) Analysis of speed characteristics for rural two-lane roads: a field study from Minoufiya Governorate, Egypt. Ain Shams Eng J 2:43–52. doi:10.1016/j.asej.2011.05.005
Jessen DR, Schurr KS, McCoy PT et al (2001) Operating speed prediction on crest vertical curves of rural two-lane highways in Nebraska. Transp Res Rec 1751:67–75
Islam M, Seneviratne PN (1994) Evaluation of design consistency on two-lane highways. ITEJ 64(2):28–31
Ottesen JL, Krammes RA (2000) Speed-profile model for a design-consistency evaluation procedure in the United States. Transp Res Rec 1701:76–85
Polus A, Fitzpatrick K, Fambro DB (2000) Predicting operating speed on tangent sections of two-lane rural highways. Transp Res Rec 1737:50–57
McFadden J, Elefteriadou L (1997) Formulation and validation of operating speed-based design consistency models by bootstrapping. Transp Res Rec 1579:97–103
Bennett CR (1994) A speed prediction model for rural two-lane highways. PhD Dissertation, University of Auckland, New Zealand
Gong H, Stamatiadis N (2008) Operating speed prediction models for horizontal curves on rural four-lane highways. Transp Res Rec 2075:1–7
Cheng Y, Chen F, Huang X, Wang F, Liu M (2011) Predicting operating speed on curve sections of eight-lane expressway in plain area. In: 4th international symposium proceedings of highway geometric design, 2011
Abdalla NM (2010) Relationship between traffic flow characteristics and pavement conditions on roads in Egypt. MSc Dissertation, University of Al-Azhar, Egypt
General Authority of Roads, Bridges and Land Transport “GARBLT” (2009) System of Road Geometric Data, El-Nasr St., Cairo, Egypt. http://www.garblt.gov.eg/. Accessed 12 Feb 2009
Simpson AL, Rauhut JB, Jordahl PR et al (1994) Sensitivity analyses for selected pavement distresses. SHP report no. SHP-P-393
Singh D, Zaman M, White L (2011) Modeling of 85th percentile speed for rural highways for enhanced traffic safety. No. FHWA 2211. Oklahoma Department of Transportation, Oklahoma
Semeida AM (2013) Impact of highway geometry and posted speed on operating speed at multilane highways in Egypt. J Adv Res 4(6):515–523. doi:org/10.1016/j.jare.2012.08.014
Semeida AM (2013) New models to evaluate the level of service and capacity for rural multi-lane highways in Egypt. Alex Eng J 52(3):455–466. doi:org/10.1016/j.aej.2013.04.003
User’s Manual “NeuroSolutions 7” (2010) NeuroDimension, Inc. Gainesville
Voudris AV (2006) Analysis and forecast of capsize bulk carriers market using artificial neural networks. MSc Dissertation, Massachusetts Institute of Technology, USA
Tarefder RA, White L, Zaman M (2005) Neural network model for asphalt concrete permeability. J Mater Civil Eng 17:19–27
Hashim IH (2006) Exploring the relationship between safety and the consistency of geometry and speed on rural single carriageways. J UTSG 2(A1):1–12
Ali A, Flannery A, Venigalla M (2007) Prediction models for free flow speed on urban streets. In: 86th annual meeting of the Transportation Research Board, Washington, DC, 2007
Acknowledgments
The author acknowledges Eng. Nasser Abdalla, Department of Civil Engineering, Faculty of Engineering, Al-Azhar University for his assistance with the acquisition of spot speed and geometric curves data at sites. Also, the author acknowledges the support of the General Authority of Roads, Bridges, and Land Transport (GARBLT) for their assistance with the acquisition of sites data.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
This article is published under license to BioMed Central Ltd.Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Semeida, A.M. Application of artificial neural networks for operating speed prediction at horizontal curves: a case study in Egypt. J. Mod. Transport. 22, 20–29 (2014). https://doi.org/10.1007/s40534-014-0033-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40534-014-0033-3