
Abstract
The Innovation and Value Initiative started the Open-Source Value Project with the aim to improve the credibility and relevance of model-based value assessment in the context of the US healthcare environment. As a core activity of the Open-Source Value Project, the Innovation and Value Initiative develops and provides access to flexible open-source economic models that are developed iteratively based on public feedback and input. In this article, we describe our experience to date with the development of two currently released, Open-Source Value Project models, one in rheumatoid arthritis and one in epidermal growth factor receptor-positive non-small-cell lung cancer. We developed both Open-Source Value Project models using the statistical programming language R instead of spreadsheet software (i.e., Excel), which allows the models to capture multiple model structures, model sequential treatment with individual patient simulations, and improve integration with formal evidence synthesis. By developing the models in R, we were also able to use version control systems to manage changes to the source code, which is needed for iterative and collaborative model development. Similarly, Open-Source Value Project models are freely available to the public to provide maximum transparency and facilitate collaboration. Development of the rheumatoid arthritis and non-small-cell lung cancer model platforms has presented multiple challenges. The development of multiple components of the model platform tailored to different audiences, including web interfaces, required more resources than a cost-effectiveness analysis for a publication would. Furthermore, we faced methodological hurdles, in particular related to the incorporation of multiple competing model structures and novel elements of value. The iterative development based on public feedback also posed some challenges during the review phase, where methodological experts did not always understand feedback from clinicians and vice versa. Response to the Open-Source Value Project by the modeling community and patient organizations has been positive, but feedback from US decision makers has been limited to date. As we progress with this project, we hope to learn more about the feasibility, benefits, and challenges of an open-source and collaborative approach to model development for value assessment.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
To date, the Innovation and Value Initiative has released two flexible open-source economic models that are developed iteratively based on public feedback and input—one focused on rheumatoid arthritis and one focused on epidermal growth factor receptor-positive non-small-cell lung cancer |
Models were developed in R along with web-based user interfaces because we are of the opinion that it has advantages in terms of transparency, reproducibility, modifiability, and computational efficiency over using spreadsheet software |
Development of the rheumatoid arthritis and non-small-cell lung cancer models has presented multiple challenges, particularly related to the development of multiple components that characterize the platforms, methodological aspects, and iterative development based on public feedback |
In the health economics and modeling community, there is a growing discussion about transparency and open-source model development, and the models developed by the Innovation and Value Initiative seem to be recognized as a welcome effort |
1 Introduction
The rise in US healthcare spending has led to an increased interest in understanding the value of health technologies, in particular new biopharmaceuticals, among payers and provider organizations [1]. In principle, quantifying the value of a treatment is a matter of comparing its benefits, risks, and costs with alternative treatment options for the target patient population of interest. However, the different US value frameworks that have been proposed to help guide the utilization of therapies illustrate that there is no consensus among stakeholders on what elements of value, perspective, evidence, and approach should be considered [2].
Whether a cost-effectiveness analysis (CEA) based on quality-adjusted life-years and net costs [3] is used as the framework of choice for value assessment, an augmented CEA with novel elements of value [4], or a multiple-criteria decision analysis (MCDA) [5,6,7,8], credible estimates must first be obtained for the clinical and economic outcomes associated with the alternative treatment options. Unfortunately, there is typically no empirical study available that compares all of the alternative treatment options simultaneously and provides estimates regarding the benefits, risks, and costs of interest that define value. Lacking such a study, we need to integrate multiple sources of evidence to estimate the expected outcomes of interest, with each source providing a piece of the required information. Resulting decision models combine relevant evidence on: the course of disease and expected outcomes with the standard of care; relative treatment effects for alternative interventions; and resource use, cost, and utility estimates for the different disease states. Whereas these sources of evidence are typically obtained in a relatively transparent and reproducible manner with systematic literature reviews and meta-analyses, decisions regarding the actual model structure are less transparent, may be made in an arbitrary fashion, or lack valid justification. Typically, there is no formal process to elicit a structure that reflects the latest clinical understanding of how the course of a disease, treatment, and relevant outcomes are related. The sensitivity of model findings can be assessed by means of sensitivity analyses, but these are typically limited to varying the model input parameters. Assessment of the impact of model structure seldom occurs, but can be substantial [9]. Despite the well-intended efforts of researchers, there is often dispute about the credibility of modeling studies to quantify the value of a health technology.
Even when a published modeling study to quantify the value of a health technology is credible, there may still be hurdles preventing its use in actual decision making. First, decision makers may find it difficult to fully understand, and therefore appreciate, the findings of an analysis without detailed documentation or access to the actual model. Second, the published study may have limited relevance for users whose perspective, local context, or patient population varies from that of the reported analysis. Third, economic evolutions of novel interventions may become quickly outdated given the pace of new clinical evidence generation and introduction of new therapies. Modeling studies to quantify the value of health technologies only have direct relevance for local decision making when they reflect the totality of the latest evidence, are deemed credible by decision makers, and are representative of the local decision problem.
To overcome the above-mentioned limitations on the credibility and relevance of published modeling studies to quantify the value of a health technology, several authors have proposed the use of open-source models [10,11,12]: models that are publicly available for use and provide access to the underlying source code and calculations, which can be updated if of interest. However, few key stakeholders have an incentive to take on this task, and there are few examples of open-source models.
In 2017, the Innovation and Value Initiative (IVI) started the Open-Source Value Project (OSVP), with the aim to improve the credibility and relevance of value assessment in the context of the decentralized decision-making environment of the USA by developing and providing access to flexible open-source economic models. The purpose of these models is two-fold. First, to facilitate a more constructive dialogue among stakeholders regarding relevant evidence, modeling approaches, and value perspectives; and second, to provide local decision makers with the tools to perform a credible value assessment reflective of the local setting in an efficient manner. In this article, we describe our current experience with the development of these open-source models.
2 Open-Source Models Developed to Date
At the time of writing, the IVI has released two OSVP models: one focused on rheumatoid arthritis (RA) [9] and one on epidermal growth factor receptor-positive non-small cell lung cancer (NSCLC) [13]. The IVI-RA model (released November 2017) is designed to assess the value of sequential biologic treatment strategies for patients with moderate to severe RA who did not respond to conventional disease-modifying anti-rheumatic drugs. The IVI-NSCLC model (released January 2019) can be used to estimate the value of alternative sequential treatment strategies for patients with metastatic epidermal growth factor receptor-positive NSCLC starting with first-line treatment, followed by second-line treatment, and treatment beyond second line. Both the IVI-RA and IVI-NSCLC models allow users to evaluate the impact of uncertainty in model input parameters on estimates of value. In addition, the impact of alternative model structures, novel elements of value (i.e., insurance value and value of hope), alternative perspectives, and decision frameworks of choice can be assessed.
In an attempt to make the IVI-RA and IVI-NSCLC models transparent and accessible to multiple end users, both platforms consist of the following components: (1) R and C++ source code; (2) an R-package to run the model for custom CEA and MCDA; (3) an advanced web application to allow full control over the model and perform custom analyses via a point and click interface; (4) a basic web application that functions as a general audience educational tool regarding value assessment; and (5) technical model documentation.
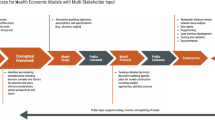
The development of the OSVP models is characterized by a four-step iterative process: Step (1) release of the initial version of the model; Step (2) obtain public feedback, which can range from high-level comments to proposed changes to the source code; Step (3) review of feedback by a technical expert panel (TEP) and prioritize recommendations for model revision according to a modified Delphi process; and Step (4) revise model and re-release. In principle, this four-step process will be repeated over time to refine the model based on new evidence and insights.
At the time of writing this article, Step 3 (feedback from the TEP) had been completed for the IVI-RA model, and Step 1 (release of the initial version) had been completed for the IVI-NSCLC model.
3 Challenges
Development of the RA and NSCLC models has presented multiple challenges, particularly related to the development of multiple components that characterize the platforms, methodological aspects, and iterative development based on public feedback.
The main arguments in favor of an open-source approach to decision models are that it will improve transparency and increase efficiency in updating the analyses [10, 12]. Only providing public access to the software code used to implement the model may not be sufficient to meet these goals because many end users may not have the technical expertise or time to review and potentially update elaborate source code or model calculations in a spreadsheet. Providing publicly available (web-based) user interfaces to fully interact with the model facilitates pressure testing the model and modifying the evaluation in a more efficient manner. Development of the multiple components tailored to both technical and non-technical end users that characterize the flexible OSVP model platforms, as described above, has required much more resources to date than what a specific model-based CEA for a publication would require without public access to the model or analysis.
In response, we have taken steps to improve the efficiency of model development. First, we have learned from our experiences developing user interfaces. For example, we conducted a number of user interviews with clinicians and patients to make the web interfaces for the IVI-RA model as relevant as possible. One of the main points that arose was the great variety in levels of understanding about what value assessment entails and how value is quantified based on the evidence available, which made us decide to opt for a technical as well as a non-technical web-interface. Furthermore, the organization of the interfaces has been heavily influenced by the feedback from the users. The information obtained from these interviews was relevant for the development of the web interfaces of the IVI-NSCLC model as well. Similarly, the source code and user interfaces of the IVI-NSCLC model can be applied in a relatively straightforward manner to other future models we have planned. Second, we have developed the open-source general-purpose R package hesim for simulating decision models and performing CEAs [14]. This package was used to simulate the IVI-NSCLC multi-state model and to represent decision uncertainty in both the IVI-RA and IVI-NSCLC models. In short, developing the OSVP modeling platforms has been resource intensive, but future efficiencies are expected.
The OSVP models are characterized by three important features: the incorporation of novel elements of value, the ability to evaluate structural uncertainty, and the quantification of value within both CEA and MCDA frameworks. Each of these features posed specific challenges during development. In the first case, the IVI-RA model provides the option to incorporate insurance value [15], and the IVI-NSCLC model has the option to include value of hope [16]. These novel elements of value were introduced relatively recently, and actual implementation of them has been very limited so far [17]. We had to make assumptions to translate these novel concepts into model-ready equations, and evidence for parameters was sparse. Second, to facilitate evaluating the impact of structural uncertainty, the models have the option to select alternative model structures. With the IVI-RA model, more than 300 structures can be created based on the multiple options available for the different components that define a model structure [9]. In the case of the IVI-NSCLC model, a three- or four-state model can be selected, and the impact of alternative survival functions for the time-varying transition rates between the different health states can be evaluated [13]. Programming of these options along with estimation of the required input parameter estimates was a time-consuming process. Finally, regarding the MCDA modules, we have not yet been able to empirically determine users’ preference weights and the shape of partial value functions, given our resource constraints.
The iterative four-step process for developing the OSVP models has resulted in its own challenges. An essential part of the OSVP is public feedback (Step 2). The time it requires for interested stakeholders to review the model and subsequently provide informative comments should not be underestimated. Moving forward, we need to think about the optimal approach to ensure ongoing engagement from relevant parties. As part of the modified Delphi process (Step 3), the TEP members (n = 5; a patient, a rheumatologist, an epidemiologist, and two health economists) were asked to rank order the suggested model changes according to priority and elaborate on their reasoning using a web-based survey. Areas of agreement and disagreement were identified and summarized in a second survey by which the TEP was asked to confirm the areas of agreement, and re-rank areas of disagreement. The TEP members were able to see the anonymized rationale behind the individual priority scores of their colleagues. During this process, it became apparent that methodological experts did not always understand feedback from clinicians and vice versa, which required additional effort on our part to ensure the information extracted from this process was both accurate and meaningful. In addition, IVI developers must not only revise the models based on the recommendation of the expert panel (Step 4), but also fix bugs and respond to proposed minor changes to a repository (pull requests) on an ongoing basis, which requires further resources.
4 Software
Decision models for value assessment of health technologies are frequently developed using spreadsheet software, i.e. Microsoft Excel. However, we opted for the statistical programming language R to develop the open-source models for several reasons.
Although Excel is sufficient for relatively simple analyses, such as clock-forward state-transition models or partitioned survival models, efficiently implementing more complex models, such as a clock-reset semi-Markov model, may not be feasible. In the case of the IVI-RA model, for example, we used an individual-patient simulation to allow modeling sequential treatment strategies for which individual treatment duration is not limited to an exponential distribution, and to make it possible for both morbidity and mortality to depend on prior history of the course of disease [9]. In the IVI-NSCLC case, we used a multi-state model that was parameterized using parametric (i.e., Weibull) and flexibly parametric (i.e., fractional polynomial) models; in addition, we considered sequential treatment so that transition rates depended on time since entering intermediate states, rather than time since treatment initiation [13]. We consequently needed to simulate outcomes based on a semi-Markov model using an individual-level simulation [18], which a spreadsheet is not suitable to implement in an efficient manner. A script-based programming language, such as R, makes implementation of individual-level simulation models more straightforward.
In our IVI-NSCLC model, the statistical model used for parameter estimation was seamlessly integrated with the simulation model. We developed a multi-state network meta-analysis model to estimate relative treatment effects that had the same structure as the state-transition model used for the simulations. This highlights a key advantage of R, namely, that because it is designed specifically for statistical computing, parameter estimation and the subsequent simulation of model outcomes can be performed in a consistent manner in one environment without the need to unnecessarily simplify the structure of the simulation model. Conversely, Excel frequently prevents the structure of the decision model describing development of outcomes over time and the impact of treatment from being closely aligned with the statistical model used for parameter estimation.
Quantifying the impact of parameter uncertainty on decision uncertainty is typically done by means of a probabilistic sensitivity analysis (PSA). The uncertainty in the model input parameters is propagated through the model by randomly sampling values for the input parameters from suitable probability distributions. Although a PSA can be performed in Excel using Visual Basic for Applications, R has validated functions for sampling from multiple univariate and multivariate distributions that make it a natural programming language for performing a PSA [19]. In addition, R has packages (such as hesim and BCEA) to produce cost-effectiveness planes, cost-effectiveness acceptability curves, and the cost-effectiveness acceptability frontier [14, 20,21,22,23]. Implementation of a PSA in R can be implemented more efficiently than with Visual Basic for Applications by using efficient programming techniques such as vectorization, linking to compiled languages (e.g., C/C++), or through parallel computing. This is imperative for computationally intensive, individual-level simulation models, such as the IVI-RA and IVI-NSCLC models. In fact, simulations with these models could not have been performed in a reasonable amount of time if implemented with Excel and Visual Basic for Applications. Computational speed is also an important consideration when a web-based user interface is being provided to interact with the model.
A clear benefit of a script-based programming language, like R, is that the complete analysis from parameter estimation to simulation of model outcomes and quantification of decision uncertainty can be performed using a reproducible script [24]. We believe this has the potential to improve transparency of decision and economic modeling studies considerably. Furthermore, with R, model documentation can be created in which each figure, table, and number cited in the text is based directly on the output of the code run in the script. For examples, we like to refer to the online tutorials of the IVI-RA and IVI-NSCLC models (https://innovationvalueinitiative.github.io/IVI-RA/articles/00-intro.html; https://innovationvalueinitiative.github.io/IVI-NSCLC/articles/tutorial.html) and corresponding technical reports (https://innovationvalueinitiative.github.io/IVI-RA/model-description/model-description.pdf; https://innovationvalueinitiative.github.io/IVI-NSCLC/model-doc/model-doc.pdf).
Whereas R is a commonly accepted and frequently used programming language for data analysis and statistical modeling, it has not been the primary software of choice for the development of economic models in the context of a health technology assessment. However, R has an active user and developer community and with the availability of recent packages, such as heemod, hesim, and BCEA, it is increasingly well suited for the development of decision and economic models as well. Some in the health technology assessment community might argue that R is less transparent than Excel, but we are of the opinion that this is confusing transparency with software familiarity. Workshops such as those by the Decision Analysis in R for Health Technologies in Health (DARTH) team, published tutorials [25, 26], and our OSVP models hopefully make R a more obvious choice for the development of decision models.
While Excel may be adequate in some circumstances, what we set out to do with the OSVP models requires software with capabilities beyond Excel. Even if Excel would be sufficiently flexible, it is in our opinion still suboptimal relative to R in terms of transparency, reproducibility, modifiability, and computational efficiency.
5 Model Quality and Maintenance
By developing the IVI-RA and IVI-NSCLC models in R, we were able to use version control systems to manage changes to the source code of the models. We use Git for version control and make code freely available in public GitHub repositories. Model users can therefore not only view the source code, but its entire history as it is developed over time.
To reduce errors, we used a number of software engineering best practices. The R unit testing framework testthat is used to validate the individual functions that comprise the larger code base. Then, each time the code is updated (i.e., “committed” and “pushed” to GitHub), the entire R package is rebuilt and tested on an external Ubuntu machine with the continuous integration service Travis CI. At the same time, Codecov is used to report the percentage of source code that has been tested with testthat.
The IVI developers maintain the GitHub repositories and are responsible for maintaining their integrity. Non-IVI developers may also modify the code, but they will typically not be given write access. Instead, external contributors can create “pull requests”. The IVI developers will only accept (i.e., “merge”) a “pull request” after a thorough review of the code changes, whether the Travis CI build passed, and the Codecov report. The type of code modification is a key consideration in any code review. Code changes that fix bugs or improve performance may be immediately accepted, while code modifications that affect the scientific approach or evidence considered will only be incorporated after a review by the TEP.
Because the OSVP models are iterative and open-source, they must be maintained and updated over time. Maintenance is typically performed based on feedback from users or the IVI developers’ experiences using the model and includes bug fixes, edits to the documentation, and code refactoring. Updates are larger changes based on the four-step development process. In the case of the IVI-RA model, the TEP (Step 3) has recommended the following: the inclusion of additional therapies; modifications to the approach used to model time to treatment discontinuation; adding additional algorithms for simulating utility values; and using new real-world data sources to estimate long-term treatment effects. The IVI is now prioritizing these recommendations while updating the model during Step 4, including performing a new systematic literature review and network meta-analysis that incorporates additional treatments.
The software development processes make updating and maintaining the model manageable. For instance, each time the code is updated, the unit tests and continuous integration services ensure that new features do not create unintended errors in the existing code. Likewise, new branches can be created to develop new features and ensure that the existing model is not affected. Moreover, the version control system allows us to track all code modifications so that old versions can be reverted to if necessary. Finally, both IVI developers and users can create issues to help identify bugs or suggest enhancements.
6 Intellectual Property
Intellectual property rights have been raised as a concern in the discussion about open-source models [27]. In this discussion, it is important to make a distinction between access to a model to assess credibility of the scientific research study for which it was used vs. being able to modify someone else’s model and use it for other purposes than the developers originally intended.
If the purpose of a model-based analysis is to inform the healthcare and scientific community about the value of a health technology, for example with a publication in the scientific literature, credibility is essential. Not providing any access to the model because of concerns that someone else might benefit at the expense of the original developer is not in the spirit of credible scientific research characterized by transparency and reproducibility. It has been stated that rejecting any concerns about intellectual property may reduce the incentive to create models [10]. However, we should not forget that the primary purpose of a cost-effectiveness evaluation is to quantify the value of the health technology and not to develop a model; the model is “just” the analytical method used to do so. (Not dissimilar from using a logistic regression model to quantify a treatment effect with an odds ratio.) Furthermore, many published CEAs are based on models that are not fundamentally different from previous analyses. Claiming intellectually property on the implementation of a relatively common modeling approach in Excel or other programming software, such as a partitioned survival model in oncology, seems a bit pointless. Recognizing the reality of how academic research is currently rewarded, a reasonable compromise between no model access and publicly available open-source models without any restrictions to modifications and use, is to make models available upon request under an agreement that prevents others from copying or altering the model for their own purposes [10].
The purpose of IVI is to improve the science of value assessment. More specifically, with the OSVP, IVI is not reporting on the value of a specific health technology, but rather focusing on improving the credibility and relevance of the economic models used for value assessment. This distinction has implications for the extent to which access to the models is required. Without collaboration, the aim of IVI's OSVP cannot be achieved. To make the discussion among interested stakeholders regarding relevant evidence, modeling approaches, and value perspectives as concrete as possible, we develop flexible models that can be updated and modified based on new evidence, insights, and beliefs. Releasing completely open-source models is the obvious approach to facilitate this—to only provide access to the models upon request and with restrictive agreements would create unnecessary hurdles and, ultimately, be antithetic to IVI’s goal. That being said, we expect anyone that uses, modifies, or builds upon the OSVP models to properly credit and reference the work. Furthermore, revised models based on the original IVI model source code cannot be referred to as an IVI OSVP model if these modifications are not shared with IVI, considered in the four-step process, and incorporated in the next iteration of the OSVP model by IVI. The work produced by IVI is open-source not only to facilitate collaboration, but also because the entire process needs to be transparent when it affects multiple stakeholders.
7 Response
We are still in the early stages of the OSVP at IVI. However, based on the formal feedback received during Step 2 of the IVI-RA model development process as well as informal feedback via other sources, the response to the IVI-RA and IVI-NSCLC models has been positive. In the health economics and modeling community, there is a growing discussion about transparency and open-source model development, and the OSVP seems to be recognized as a welcome effort. The specific feature of IVI-RA and IVI-NSCLC models to evaluate structural uncertainty by being able to select different model structures seems to be appreciated, as well as the option to use model estimates in both a CEA framework and a MCDA framework.
During the model development, we engaged with disease-specific patient groups who appreciated the opportunity to provide input early on. Patient focus groups were conducted to investigate how patients with RA and NSCLC value various treatment attributes and how they prioritize these in their treatment decisions. We used this information to help define the attributes captured in the MCDA modules of the models. Although the patient-centered focus of the OSVP has been well received, we want to emphasize that we would have liked to do more justice to the information patients provided. We programmed the models to incorporate information on heterogeneous treatment effects, but the evidence available to us did not allow for a truly patient-centered approach to value assessment. We hope to be able to do so with access to patient-level data in the future.
To date, the feedback from US decision makers has been limited; the interest has been less than what we anticipated at the start of the project. Hopefully, that will change in the future, which is important to ensure our models are not only credible, but relevant as well. To that end, IVI has planned research activities to demonstrate use cases with decision makers.
8 Funding
The OSVP is both central to the IVI’s mission and the foundation for IVI’s research work, thus much of IVI’s funding is allocated to the OSVP. To date, funding for IVI’s work has been provided primarily by the biopharmaceutical industry, owing to several possible factors. First, though IVI has actively sought funding from all sectors since its inception, the biopharmaceutical industry demonstrated the greatest early enthusiasm for research on new methods and open-source approaches and willingness to invest in the nascent organization. (A full list of funders to date is available on the IVI website.) Second, the IVI began as a project within Precision Health Economics, a private health economics and outcomes research firm, which limited the possibility of funding from many public and foundation sources and may have raised concerns on the part of other funders. As of 2019, however, IVI is an independent nonprofit organization, and is transitioning to a membership funding structure designed to expand funding sources to represent all sectors including the insurance industry, patient community, health systems, physician groups, and others. This transition will also make it possible to seek grant funding from public sources and private foundations.
9 Conclusions
To date, IVI has released two models as part of the OSVP. The open-source nature of these models is designed for an iterative and collaborative approach to its refinement based on new clinical evidence and insights. The greatest challenges were the development of multiple components that characterize the platforms; methodological aspects; and iterative development based on public feedback. Response to the OSVP by the modeling community and patient organizations has been positive, but feedback from US decision makers has been limited so far. As we progress with this project, we will continue to learn about the feasibility, benefits, and challenges of our open-source approach, as well as the relevance of these models for US decision makers. The prospect of the OSVP depends on interest and support from different stakeholders. At a minimum, the OSVP will contribute to the open-source discussion in health economics modeling, which we like to believe has merit in itself.
References
Garrison LP, Carlson JJ, Bajaj PS, Towse A, Neumann PJ, Sullivan SD, et al. Private sector risk-sharing agreements in the United States: trends, barriers, and prospects. Am J Manag Care. 2015;21(9):632–40.
Willke RJ, Neumann PJ, Garrison LP Jr, Ramsey SD. Review of recent US value frameworks: a health economics approach: an ISPOR Special Task Force Report. Value Health. 2018;21(2):155–60.
Garrison LP Jr, Pauly MV, Willke RJ, Neumann PJ. An overview of value, perspective, and decision context: a health economics approach: an ISPOR Special Task Force Report. Value Health. 2018;21(2):124–30.
Lakdawalla DN, Doshi JA, Garrison LP Jr, Phelps CE, Basu A, Danzon PM. Defining elements of value in health care: a health economics approach. An ISPOR Special Task Force Report. Value Health. 2018;21(2):131–9.
Goetghebeur M, Wagner M, Khoury H, et al. Evidence and value: impact on DEcisionMaking: the EVIDEM framework and potential applications. BMC Health Serv Res. 2008;8:270.
Thokala P. Multiple criteria decision analysis for health technology assessment: report by the decision support unit, School of Health and Related Research. Sheffield: University of Sheffield. 2011.
Radaelli G, Lettieri E, Masella C, Merlino L, Strada A, Tringali M. Implementation of EunetHTA core model® in Lombardia: the VTS framework. Int J Technol Assess Health Care. 2014;30(1):105–12.
Marsh K, Lanitis T, Neasham D, Orfanos P, Caro J. Assessing the value of healthcare interventions using multi-criteria decision analysis: a review of the literature. Pharmacoeconomics. 2014;32:345–65.
Incerti D, Curtis JR, Shafrin J, Lakdawalla DN, Jansen JP. A flexible open-source decision model for value assessment of biologic treatment for rheumatoid arthritis. Pharmacoeconomics. 2019;37:829–43.
Dunlop WC, Mason N, Kenworthy J, Akehurst RL. Benefits, challenges and potential strategies of open source health economic models. Pharmacoeconomics. 2017;35:125–8.
Schramm W, Sailer F, Pobiruchin M, Weiss C. PROSIT open source disease models for diabetes mellitus. Stud Health Technol Inform. 2016;226:115–8.
Cohen JT, Neumann PJ, Wong JB. A call for open-source cost-effectiveness analysis. Ann Intern Med. 2018;168(7):529.
Incerti D, Jansen JP. A description of the IVI-NSCLC model v1.0; last updated January 31, 2019. https://innovationvalueinitiative.github.io/IVI-NSCLC/modeldoc/model-doc.pdf. Accessed 26 Jul 2019.
Incerti D, Jansen JP. Hesim: an R package for high performance health-economic simulation modeling. R package version 0.2.1. 2019.
Lakdawalla D, Malani A, Julian R. The insurance value of medical innovation. J Public Econ. 2017;145:94–102.
Lakdawalla DN, Romley JA, Sanchez Y, et al. How cancer patients value hope and the implications for cost-effectiveness assessments of high-cost cancer therapies. Health Aff (Millwood). 2012;31:676–82.
Shafrin J, Skornicki M, Brauer M, Villeneuve J, Lees M, Hertel N, et al. An exploratory case study of the impact of expanding cost-effectiveness analysis for second-line nivolumab for patients with squamous non-small cell lung cancer in Canada: does it make a difference? Health Policy. 2018;122(6):607–13.
Fiocco M, Putter H, van Houwelingen HC. Reduced-rank proportional hazards regression and simulation-based prediction for multi-state models. Stat Med. 2008;27(21):4340–58.
Jalal H, Pechlivanoglou P, Krijkamp E, Alarid-Escudero F, Enns E, Hunink MGM. An overview of R in health decision sciences. Med Decis Making. 2017;37(7):735–46.
Baio G, Berardi A, Heath A. BCEA: Bayesian cost effectiveness analysis. R package version 2.2.6. 2018.
Black WC. The CE plane: a graphic representation of cost-effectiveness. Med Decis Making. 1990;10(3):212–4.
Fenwick E, Claxton K, Sculpher M. Representing uncertainty: the role of cost-effectiveness acceptability curves. Health Econ. 2001;10(8):779–87.
Barton GR, Briggs AH, Fenwick EA. Optimal cost-effectiveness decisions: the role of the cost-effectiveness acceptability curve (CEAC), the cost-effectiveness acceptability frontier (CEAF), and the expected value of perfection information (EVPI). Value Health. 2008;11(5):886–97.
Hollman C, Paulden M, Pechlivanoglou P, McCabe CJP. A comparison of four software programs for implementing decision analytic cost-effectiveness models. 2017;35(8):817–30.
Williams C, Lewsey JD, Briggs AH, Mackay DF. Cost-effectiveness analysis in R using a multi-state modeling survival analysis framework: a tutorial. Med Decis Making. 2017;37(4):340–52.
Krijkamp EM, Alarid-Escudero F, Enns EA, Jalal HJ, Hunink MM, Pechlivanoglou P. Microsimulation modeling for health decision sciences using R: a tutorial. Med Decis Making. 2018;38(3):400–22.
Eddy DM, Hollingworth W, Caro JJ, et al. Model transparency and validation: a report of the ISPOR-SMDM modeling good research practices task force-7. Med Decis Making. 2012;32(5):733–43.
Author information
Authors and Affiliations
Contributions
Jeroen P. Jansen, Devin Incerti, and Mark T. Linthicum contributed to the writing of the manuscript.
Corresponding author
Ethics declarations
Funding
Research described in this article was funded through the Innovation and Value Initiative (IVI), a non-profit multi-stakeholder research organization.
Conflict of interest
Jeroen P. Jansen, Devin Incerti, and Mark Linthicum are employees of Precision Medicine Group. Devin Incerti and Jeroen P. Jansen are shareholders of Precision Medicine Group. IVI contracted Precision Medicine Group for research activities related to this article.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution-NonCommercial 4.0 International License (http://creativecommons.org/licenses/by-nc/4.0/), which permits any noncommercial use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Jansen, J.P., Incerti, D. & Linthicum, M. Developing Open-Source Models for the US Health System: Practical Experiences and Challenges to Date with the Open-Source Value Project. PharmacoEconomics 37, 1313–1320 (2019). https://doi.org/10.1007/s40273-019-00827-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40273-019-00827-z