
Abstract
Introduction
Many studies have been conducted worldwide to estimate herpes zoster (HZ) incidence rates. We synthesized studies of HZ incidence rates in the general population using meta-analysis models.
Methods
A random effects meta-analysis was conducted to estimate HZ incidence from a published worldwide systematic literature review (SLR) including only individuals aged 50 years and older. Meta-regression was used to explore whether variability in incidence rates could be explained by a combination of study-specific characteristics including age, gender, continent and year of study data. The impact of adding additional covariates—case detection method (general practitioner surveillance, healthcare database, sentinel network, etc.), case definition (medical record-based, self-reported), study design (retrospective passive surveillance, retrospective active surveillance, etc.), incidence type (cumulative incidence/1000 persons or incidence rate/1000 person-years), patient type (outpatients or in- and out-patients) and latitude to the base model—was also assessed.
Results
Sixty-one records from 59 studies were included in the analysis: 25, 20, 11 and 5 from Europe, North America, Asia and Oceania, respectively. There was variation in study methodology and outcomes. Heterogeneity of incidence rates was greatest among studies conducted in Asia. Meta-analysis showed that incidence increased with age, was lower in males compared to females, tended to be lower in Europe and North America compared to Asia and Oceania and increased with year of study data. The data-driven meta-regression model included continent, year of study data, gender, age and an age × gender interaction term. The difference in incidence between males and females was greater in younger ages (e.g., 50–59) compared to older age groups (e.g., 80+). None of the additional covariates contributed significantly to the model.
Conclusion
Incidence rates were shown to vary by age, gender, continent and year of study data.
Graphical Plain Language Summary

Similar content being viewed by others


Avoid common mistakes on your manuscript.
Shingles is a burdensome viral disease whose main symptoms are rash, which lasts for 1 to 2 weeks, and pain that may last for several weeks or months. |
The previous literature was reviewed to estimate the incidence of shingles worldwide in people > 50 years of age and the impact of several variables on this incidence. |
From 61 reports conducted in 29 countries, we found that incidence increases with age, is lower in males compared to females, increases over time and is lower in Europe and North America compared to Asia and Oceania. |
These estimates may help guide public health immunization policies for herpes zoster (HZ) prevention. |
Digital Features
This article is published with digital features, including a graphical plain language summary, to facilitate understanding of the article. To view digital features for this article go to https://doi.org/10.6084/m9.figshare.16989667.
Introduction
The varicella-zoster virus (VZV) causes two distinct diseases with different clinical presentations: varicella (chickenpox) and shingles (herpes zoster, HZ). Following varicella (usually in childhood), VZV remains dormant in nerve ganglia. Latent VZV can reactivate years later as HZ, as a result of (1) an age-related decline in immunity and/or (2) an immunodeficiency or immunosuppression caused by disease or therapy. The pain associated with HZ has been described as “throbbing, sharp, shooting and stabbing” [1]. Individuals with HZ may also experience altered sensitivity to touch, pain provoked by trivial stimuli and unbearable itching [2]. In the United States of America (US), 99.5% of adults aged > 40 years are infected with VZV and are thus at risk of developing shingles, while approximately 30% of the population will develop HZ during their lifetime [3]. It is estimated that HZ incidence has increased over time, combined with aging of population demographics, resulting in an increasing burden to the health care system [4, 5].
A previous systematic literature review (SLR) conducted in 2014 provided a comprehensive overview of HZ as a significant global health burden [6] and demonstrated substantial heterogeneity across studies. While age, gender, ethnicity and comorbidities are well-known risk factors that may impact incident rates for HZ [7], other factors such as study design (e.g., prospective versus retrospective), case ascertainment (International Classification of Diseases [ICD] versus prescribed therapeutic codes), study population (e.g., age distribution, year(s) of study, setting [(country or region]) and sample size may also have an impact on the results of a study [8,9,10]. Consequently, generalizability and comparability of study results likely require consideration of other factors that potentially influence outcomes. Selecting inputs for both epidemiological and health economic models may prove challenging because of the numerous choices of data sources available from literature. Consequently, health technology assessment bodies encourage “evidence synthesis for decision making” [11]. Meta-analysis methods are frequently used as a means of summarizing results from multiple data sources, to obtain single point estimates (with confidence intervals for sensitivity analyses). These statistical methods can be employed to identify the possible causes of heterogeneity and subsequently adjust for the explained variability [12]. In this study, we performed a SLR to provide a comprehensive evidence base on the worldwide incidence of HZ, focusing on individuals ≥ 50 years old. The results of the SLR are presented elsewhere [8]. In this manuscript, we explore the relationship between study covariates and the incidence of HZ. We focus on two generalizations of meta-analysis: random-effect meta-analysis and meta-regression [12].
Methods
This article is based on previously conducted studies and does not contain any new studies with human participants or animals performed by any of the authors. We performed a SLR following the guidelines specified in the Cochrane Handbook [13] and Preferred Reporting Items for Systematic Literature Reviews and Meta-Analyses (PRISMA) [13,14,15]. Details of the SLR are provided elsewhere [8]. The methodological quality of each peer-reviewed article was assessed as follows: studies were deemed to be of poor quality if there was not a valid case definition for the diagnosis of HZ and/or if the denominator to calculate HZ incidence was not clearly defined [8].
The HZ incidence in published studies was expressed as either the number of HZ cases per 1000 population (i.e., cumulative incidence) or as number of HZ cases per 1000 person-years (i.e., incidence rate). To allow all studies to be included in the analysis, we assumed that cumulative incidence was assessed over a 1-year study period. We tested the validity of this assumption by exploring whether there was any effect of incidence type (i.e., cumulative incidence versus incidence rate) on incidence estimates.
When the sample size was not provided, the sample size was estimated based on the precision estimates and confidence interval values provided, depending on the analytic method used by the authors.
Some studies within the same country reported data (1) for several populations [16,17,18,19] (e.g., general and immunocompetent) and (2) using different case definitions. For those studies, we used data from the general population using ICD codes where available. Some authors presented study data in separate publications [20, 21]. In those situations, the manuscript with the most complete dataset was kept. Some incidence data were presented in graphical format only [22,23,24] and were excluded since estimation of numerical data was not feasible, e.g., overlapping lines and/or confidence intervals not provided.
The primary objective of the study was to estimate incidence of HZ and explore the relationship and impact of various clinical and methodological factors including age, gender, year of study data and continent. Secondary objectives included exploring the additional predictive and explanatory power of alternative models that account for (individually or collectively) additional covariates and non-linear components for age.
The primary covariates in the random effects meta-analysis model were extracted from the SLR as follows:
-
Age: 50–54, 55–59, 60–64, 65–69, 70–74, 75–79, 80–84, ≥ 85 years.
-
Gender: female (reference group), male, pooled (i.e., not defined, pooled male/female)
-
Continent: Asia, Europe (reference group), North America or Oceania
-
Year of study data: < 1998, 1998–2002, 2003–2007, 2008–2012, ≥ 2013
In meta-regression analysis, age, centered at 50 years (corresponding to the intercept), and year of study data, centered at year 2000, were treated as linear predictors.
Random-effects meta-analysis, to account for additional ‘between-study’ heterogeneity, was applied. Between-study variance was estimated from the data and incorporated into the study weights while pooling the estimates across studies for a subpopulation (e.g., Asia). All random-effects meta-analyses were conducted using the rma function in metafor package, in R 3.5.1, using restricted-maximum likelihood estimation for the random-effects component \({\tau }^{2}\) [25].
The methodology suggested by van Houwelingen et al. was used to model the incidence using meta-regression [12]. Incidence (i) was modeled for each study using a logistic function:
Random effects meta-regressions were performed to add to the meta-analytic model by adjusting for the effect of one or more covariates. In the current study, a multilevel model was used to account for the fact that many studies presented subgroup data (e.g., results for age subcategories, or separate data for males and females or pooled). For each covariate, a test of its additional partial explanatory power was conducted by assessing Qmod, the variance in the logit incidence explained by the covariate. All multivariate meta-regressions were performed using the rma.mv function in metafor package, in R 3.5.1. Model fit for analyses was investigated by consideration of improvement on the Akaike information criterion (AIC) [26]. Outliers for individual incidence estimates (e.g., for specific age and/or gender incidence values) within studies were identified using the Cook’s distance statistic (> upper hinge = Q3 + 3 × IQR [Q3, third quartile, IQR, interquartile range of Cook’s distances]) in the multivariate meta-regression model [27].
Two multivariate regression models were developed: (1) a model that was pre-specified (using “primary covariates”) and (2) a data-driven model. The data-driven model was derived including “secondary covariates” (see below), with additional non-linear components for age (squared and cubic) examined. The data-driven model was derived using a stepwise approach based on differences in AIC. The following “secondary covariates” were explored in the data-driven model:
-
case detection method: general practitioner surveillance (reference group), health insurance, healthcare database, pharma register, sentinel network or survey,
-
case definition: medical record-based (e.g., ICD code) or self-reported (reference group),
-
study design: retrospective passive surveillance (reference group), retrospective active surveillance, unmatched retrospective cohort or prospective active surveillance or prospective passive surveillance,
-
incidence type: cumulative incidence/1000 persons (reference group) or incidence rate/1000 person-years,
-
latitude: distance from the equator,
-
patient type: outpatients or in- and out-patients (reference group).
Results
A total of 69 study publications were included in the SLR [8]. Supplementary text Fig. S1 provides an overview of the records included in the meta-regression analysis. Sixty-one records were included, of which 25 were from Europe, 20 from North America, 11 from Asia and 5 from Oceania. Study methodology was assessed as poor in 26 records (i.e., not a valid case definition, and/or denominator not clearly defined) and good in 35 records. The case detection method was based on general practitioner surveillance (n = 7 records), health insurance (n = 25), healthcare database (n = 18), pharma register (n = 1), sentinel network (n = 4) or survey (n = 6). The case definition was based on medical records (n = 56) and self-report (n = 5). The study design was retrospective passive surveillance (n = 44), retrospective active surveillance (n = 5), unmatched retrospective cohort (n = 3), prospective active surveillance (n = 8) and prospective passive surveillance study (n = 1). The incidence type was cumulative incidence (n = 36) or incidence rate (n = 25) and the patient type was outpatient (n = 27) or in- and out-patient (n = 34). Details of the studies and results of the quality assessment are provided elsewhere [8].
Figure 1 presents a forest plot with individual study effects for the age category 70–74 years as an example of the heterogeneity within age groups and the patterns of HZ data reported across studies. Many results have extremely small sampling errors due to the large sample sizes. Variation across studies, as measured by tau (τ), was 0.305.

Forest plot of pooled incidences (95% CIs): meta-analyses for age 70–74 years. CI confidence interval, I2 percentage of variance due to true heterogeneity, tau between-study (data) standard deviation, Qp the p value in the Cochran’s Q test of homogeneity, k number of studies being pooled
Meta-analysis results across univariate subgroups of age classes, gender, continent and year of study data are presented in Fig. 2. The results show that incidence increases with age, is lower in males compared to females and tended to be higher in Asia and Oceania compared to Europe and North America, and there also was a trend for an increase from the period up to 2002 to after 2002. For the four primary covariates of interest (age, gender, continent and year-of-study data), meta-analyses of aggregated data found that age was the strongest predictor of variation across strata; the meta-analytic incidence for the youngest individuals (50–54; 5.15/1000) was less than half that for the oldest (≥ 85; 11.27/1000). The total variability across age categories when age is ignored is τ2 = 0.174, which is reduced to an average of approximately 0.10 within the individual age categories (a reduction of around 40%). The incidence appeared to be lower in studies with data collected in the years 2008–2012 and ≥ 2013 compared to data collected in 2003–2007. However, the data from the five studies with data collected in or after 2013 included three studies from Europe and one from the US (i.e., continents where the incidence was lowest, see Fig. S3). Similarly, it appears that the incidence for gender is higher when data were not broken down by gender (i.e., pooled category, see Fig. 2). However, it was observed that older studies in North America presented data broken down by gender whereas more recent studies presented data with gender pooled (see supplemental Fig. S4).

Forest plot of pooled incidences (95% CIs): meta-analyses for age, gender, continent and year of study data. CI confidence interval
Regression estimates for the pre-specified model univariable and multivariable regressions are presented in Tables 1 and S1. Figure 3 shows predicted incidences from the pre-specified model of all four main covariates for combinations of geographic area and gender (male and female) across age. Heterogeneity within continent was high for all four continents, but for the Asian analysis especially (τ = 0.529). Note that estimated incidences for Asia ranged from 3.43 to 19.46 per 1000 person-years (see Fig. S5). While heterogeneity—in both relative and absolute terms—was high, there were no individual studies that appeared as substantial outliers. That said, there were individual incidence estimates (e.g., for specific age and gender incidence values) within studies that were identified as outliers using the Cook’s distance statistic as follows for the regions (see supplemental Fig. S6): Europe (Italy [28], Sweden [29]); North America (US [5, 30]); Asia (China [31,32,33], Japan [10, 34, 35], South Korea [36]); Oceania (Australia [37], New Zealand [38]). The outliers tended to be low incidence values for Europe and North America incidence outliers. The three studies from China [31,32,33] had three of the five lowest incidence values across all publications (the other two being Di Legami et al. [28] and Krishnarajah et al. [30]), and the study conducted by Kim et al. in South Korea has notably high incidences [36]. Without these studies, the Asia results are approximately as heterogeneous as those seen in any other continent. In fact, sensitivity analysis excluding low-quality studies had the greatest impact on the parameter estimate for Continent: Asia, whereby the incidence estimates were higher after exclusion of low-quality studies (see supplementary Table S2).

Estimated incidence based on the pre-specified model for the year 2000 and 2020 by region, gender and age
Additional covariates were explored to determine their potential explanatory power for HZ incidence. Figure S7 presents the meta-analysis results across univariate subgroups of classes for case detection, case definition, study design, incidence type and patient type. Although there were apparent trends for differences between classes on a univariate level for these additional covariates, when included in the multivariate model differences in case detection, case definition, study design, incidence type and patient type were all not significant as were latitude and the interaction term for age by year of study data. However, the effect of age × gender was extremely significant (P < 0.001). The results suggest that the difference in incidence rates between males and females is greatest in younger age (e.g., 50–54), whereas in the oldest age groups the incidence rates are similar in males and females (e.g., ≥ 80) (see Fig. 4).

Predicted incidence based on the data-driven model for the year 2020 by region, gender and age
Exploration of all covariates and the changes in model fit (based on differences in AIC) leads to the proposal of a final data-driven model that adds components for squared and cubic terms for age as well as an age × gender interaction term (see Table 2). The AIC of the final data-driven model was 17080.8 compared with 25998.2 for the pre-specified model. Table S3 and Fig. 4 provide estimates of predicted incidence values for males and females by age and continent, using the final data-driven model.
Discussion
This analysis provides the most recent synthesis of the worldwide incidence of HZ in the general population aged ≥ 50 years. For the pre-specified analysis, we focused on four study characteristics, i.e., incidence rate by continent, age, gender and year of study data collection. This was to ensure that the model was robust and in line with broad statistical recommendations [39] with respect to the number of parameters estimated and the number of data points available for analysis.
Age was the most important factor influencing incidence rate. As HZ incidence rates increase with age and population demographics are changing over time, the study period and age distribution of the study population should be kept in mind when interpreting data. Interestingly, the data-driven model suggested that the incidence was higher in females and that the difference in incidence rates was greatest between males and females in younger age groups whereas this difference was less in older adults. There was a trend for incidence rates to be lower in Europe followed by North America, Asia and Oceania in this analysis of data synthesized from many studies with much heterogeneity in study methodology and outcomes. However, the same trend was observed in the placebo groups of two large randomized clinical trials of a HZ vaccine, where the case definition and study methodology were consistent across all study participants and continents [40].
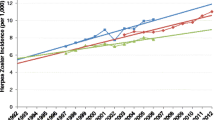
A trend was observed for an increase in incidence over time. Data from several independent studies demonstrated a steady increase in HZ incidence over time (see Fig. 4 from van Oorschot et al. [8]). There was no significant effect of incidence type (i.e., cumulative incidence versus incidence rate) on incidence rate in the meta-regression model supporting our hypothesis that studies assessing cumulative incidence had a study duration of 1 year. Most of the studies were passive surveillance studies that utilized a retrospective design. These studies used either electronic medical databases or health insurance databases and utilized diagnostic codes to identify HZ cases. Consequently, the statistical power to detect significant differences for the variables case detection, case definition, study design and patient type was likely to be low.
Several studies with outliers were identified, in particular for the Asian region. It was notable that high incidence rates were observed by Kim et al. in South Korea [36]. The authors noted this observation also suggesting that the high incidence values could be explained by the medical service system (i.e., high insurance coverage and low medical costs) and the high public disease awareness of herpes zoster. Three studies from China [31,32,33] had three of the five lowest incidence rates of all 61 records. These studies were all conducted as self-report, house-to-house surveys, followed by face-to-face interviews with those having reported HZ. Self-report studies are subject to many biases and are therefore generally considered low quality.
The estimated incidence values from this study may be used in cost-effectiveness (CE) models for countries where there are no specific incidence data available or where data are outdated (see Figs. 3, 4 and Table S3). In epidemiological and economic models, some data may be considered “transferable”, i.e., data from other sources outside that country may be used. To ensure the reliability of the model, the analyst must determine whether data are transferable or not. For example, the Guidance Document: Global Pharmacoeconomic Model Adaption Strategies noted that where country-specific epidemiologic data are not available, random-effect meta-analysis may be used to derive estimates for inputs for CE models [41].
Table S3 and Fig. 4 provide the predicted incidence estimates for age, gender and continent for the year 2020. These data could be used as inputs in modeling exercises of the public health impact and cost-effectiveness of vaccination. Using these incidence rates from the data-driven model in conjunction with population estimates by continent, we estimated that 14.9 million HZ cases occurred in 2020 worldwide in individuals aged ≥ 50 [42]. Due to the global trend of aging populations worldwide, assuming no increase in age-specific incidence rates from 2020 and in the absence of vaccination, the total number of HZ cases in individuals aged ≥ 50 would be expected to increase to 17.0 million in 2025 and 19.1 million cases by 2030. These estimates may be conservative, as they do not account for under-reporting. Using incidence rates estimated in the placebo group of the ZOE-50 study, where individuals were followed up prospectively to monitor HZ cases, > 20 million HZ cases worldwide occurred in 2020 (see Table S4). Of course, there are also limitations to using data from a clinical trial, but it does suggest that our estimate of 14.9 million cases worldwide in 2020 may be conservative. Further HZ vaccine recommendations and increases in vaccination uptake could lead to a decrease of HZ incidence over time.
Several limitations of this review are worth noting in the interpretation of the overall findings. We assumed that studies assessing cumulative incidence had a study duration of 1 year. Although this assumption appears valid and was deemed to be appropriate in the multivariate model, it is not possible to ascertain whether it was an appropriate assumption or not. Second, in most studies the proportion of subjects with comorbidities and immunocompromising conditions was unknown. When reporting study results, it is important whenever possible to provide granular data, in tabular format, e.g., in the supplementary texts of manuscripts. Granular data of incidence broken down by influential covariates not only help the reader to interpret the data and assess potential biases but allow for further synthesis of the data in meta-regression analysis. The fitted models can be useful for prediction. However, the interpretation of the parameters estimated is complex and should be done with care. For example, life-expectancy is increasing over time, and gender and age are correlated (females live longer than males). One strength in terms of prediction is that while the COVID-19 pandemic has an impact on the incidence rates of many infectious diseases, as HZ is caused by the reactivation of the varicella zoster virus (i.e., VZV remains dormant in nerve cells), even individuals who are isolating are at risk of HZ.
Conclusion
A plain language summary of the context and main findings of this article is presented below the abstract. In this synthesis of HZ incidence rates worldwide, in the general population over the age of 50 years, age was illustrated to be the most important factor predicting HZ incidence. The world’s population is continuing to age, in particular the oldest-old, where herpes zoster rates are highest and are continuing to grow [43]. Effective vaccines to prevent HZ and the associated disease burden are available and, if employed, could contribute to the reduction of the future global burden of HZ [4, 44]. The continent-specific incidence estimates may help guide public health immunization policies for HZ prevention.
References
Mizukami A, Sato K, Adachi K, et al. Impact of herpes zoster and post-herpetic neuralgia on health-related quality of life in Japanese adults aged 60 years or older: results from a prospective, observational cohort study. Clin Drug Investig. 2018;38(1):29–37.
Harpaz R, Ortega-Sanchez IR, Seward JF. Prevention of herpes zoster: recommendations of the Advisory Committee on Immunization Practices (ACIP). MMWR Recomm Rep. 2008;57(RR-5):1–30.
Centers for Disease Control and Prevention. Shingles (Herpes Zoster). 2018. https://www.cdc.gov/shingles/about/index.html. Accessed July 12, 2021
Varghese L, Standaert B, Olivieri A, Curran D. The temporal impact of aging on the burden of herpes zoster. BMC Geriatr. 2017;17(1):30.
Kawai K, Yawn BP, Wollan P, Harpaz R. Increasing incidence of herpes zoster over a 60-year period from a population-based study. Clin Infect Dis. 2016;63(2):221–6.
Kawai K, Gebremeskel BG, Acosta CJ. Systematic review of incidence and complications of herpes zoster: towards a global perspective. BMJ Open. 2014;4(6):e004833.
Kawai K, Yawn BP. Risk factors for herpes zoster: a systematic review and meta-analysis. Mayo Clin Proc. 2017;92(12):1806–21.
van Oorschot D, Vroling H, Bunge E, Diaz-Decaro J, Curran D, Yawn B. A systematic literature review of herpes zoster incidence worldwide. Hum Vaccin Immunother. 2021;17(6):1714–32.
Terlinden A, Varghese L, Curran D. Meta-regression on European zoster incidence. Value Health. 2014;17(7):A666–7.
Toyama N, Shiraki K, Members of the Society of the Miyazaki Prefecture D. Epidemiology of herpes zoster and its relationship to varicella in Japan: a 10-year survey of 48,388 herpes zoster cases in Miyazaki prefecture. J Med Virol. 2009;81(12):2053–8.
Welton NJ, Sutton AJ, Cooper N, Abrams KR, Ades AE. Evidence synthesis for decision making in healthcare. Sons JW. 2012.
van Houwelingen HC, Arends LR, Stijnen T. Advanced methods in meta-analysis: multivariate approach and meta-regression. Stat Med. 2002;21(4):589–624.
Higgins JP, Green S. Cochrane handbook for systematic reviews of interventions, version 5.0.0. 2008. www.cochrane-handbook.org. Accessed Aug 26, 2021
Liberati A, Altman DG, Tetzlaff J, et al. The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate healthcare interventions: explanation and elaboration. BMJ. 2009;339:b2700.
Moher D, Liberati A, Tetzlaff J, Altman DG, for the Prisma Group. Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. PLoS Med. 2009;6(7):e1000097.
Insinga RP, Itzler RF, Pellissier JM, Saddier P, Nikas AA. The incidence of herpes zoster in a United States administrative database. J Gen Intern Med. 2005;20(8):748–53.
Langan SM, Smeeth L, Margolis DJ, Thomas SL. Herpes zoster vaccine effectiveness against incident herpes zoster and post-herpetic neuralgia in an older US population: a cohort study. PLoS Med. 2013;10(4):e1001420.
Schiffner-Rohe J, Jow S, Lilie HM, Köster I, Schubert I. Herpes zoster in Germany. A retrospective analyse of SHL data. MMW Fortschr Med. 2010;151(Suppl 4):193–7.
Suaya JA, Chen S-Y, Li Q, Burstin SJ, Levin MJ. Incidence of herpes zoster and persistent post-zoster pain in adults with or without diabetes in the United States. Open Forum Infect Dis. 2014;1(2):ofu049.
Opstelten W, Van Essen GA, Schellevis F, Verheij TJM, Moons KGM. Gender as an independent risk factor for herpes zoster: a population-based prospective study. Ann Epidemiol. 2006;16(9):692–5.
Opstelten W, Mauritz JW, de Wit NJ, van Wijck AJM, Stalman WAB, van Essen GA. Herpes zoster and postherpetic neuralgia: incidence and risk indicators using a general practice research database. Fam Pract. 2002;19(5):471–5.
Hillebrand K, Bricout H, Schulze-Rath R, Schink T, Garbe E. Incidence of herpes zoster and its complications in Germany, 2005–2009. J Infect. 2015;70(2):178–86.
Jih J-S, Yi-Ju C, Lin M-W, et al. Epidemiological features and costs of herpes zoster in Taiwan: a national study 2000 to 2006. Adv Dermatol Venereol. 2009;89(6):612–6.
Rimseliene G, Vainio K, Gibory M, Salamanca BV, Flem E. Varicella-zoster virus susceptibility and primary healthcare consultations in Norway. BMC Infect Dis. 2016;16(1):254.
Viechtbauer W. Conducting meta-analyses in R with the metafor package. J Stat Softw. 2010;36(3):1–48.
Burnham KP, Anderson DR. Model selection and multimodel inference: a practical information-theoretic approach, 2nd ed. Springer; 2002.
Cook RD, Weisberg S. Residuals and influence in regression. Hall LCa; 1982.
Di Legami V, Gianino MM, Atti MCD, et al. Epidemiology and costs of herpes zoster: background data to estimate the impact of vaccination. Vaccine. 2007;25(43):7598–604.
Sundström K, Weibull CE, Söderberg-Löfdal K, Bergström T, Sparén P, Arnheim-Dahlström L. Incidence of herpes zoster and associated events including stroke—a population-based cohort study. BMC Infect Dis. 2015;15(1):488.
Krishnarajah G, Carroll C, Priest J, Arondekar B, Burstin S, Levin M. Burden of vaccine-preventable disease in adult Medicaid and commercially insured populations. Hum Vaccin Immunother. 2014;10(8):2460–7.
Zhu Q, Zheng H, Qu H, et al. Epidemiology of herpes zoster among adults aged 50 and above in Guangdong. China Hum Vaccin Immunother. 2015;11(8):2113–8.
Li Y, An Z, Yin D, et al. Disease burden due to herpes zoster among population aged ≥ 50 years old in China: a community based retrospective survey. PLoS ONE. 2016;11(4):e0152660.
Lu L, Suo L, Li J, Pang X. A retrospective survey on herpes zoster disease burden and characteristics in Beijing, China. Hum Vaccin Immunother. 2018;14(11):2632–5.
Imafuku S, Matsuki T, Mizukami A, et al. Burden of herpes zoster in the Japanese population with immunocompromised/chronic disease conditions: results from a cohort study claims database from 2005–2014. Dermatology and Therapy. 2019;9(1):117–33.
Takao Y, Miyazaki Y, Okeda M, et al. Incidences of herpes zoster and postherpetic neuralgia in Japanese adults aged 50 years and older from a community-based prospective cohort study: the SHEZ study. J Epidemiol. 2015;25(10):617–25.
Kim YJ, Lee CN, Lim C-Y, Jeon WS, Park YM. Population-based study of the epidemiology of herpes zoster in Korea. J Korean Med Sci. 2014;29(12):1706–10.
Liu B, Heywood AE, Reekie J, et al. Risk factors for herpes zoster in a large cohort of unvaccinated older adults: a prospective cohort study. Epidemiol Infect. 2015;143(13):2871–81.
Reid JS, Ah Wong B. Herpes zoster (shingles) at a large New Zealand general practice: incidence over 5 years. N Zeal Med J [Internet]. 2014; 127(1407):56–60. http://europepmc.org/abstract/MED/25530332.
Harrell FE, Lee KL, Matchar DB, Reichert TA. Regression models for prognostic prediction: advantages, problems, and suggested solutions. Cancer Treat Rep. 1985;69(10):1071–7.
Willer DO, Oostvogels L, Cunningham AL, et al. Efficacy of the adjuvanted recombinant zoster vaccine (RZV) by sex, geographic region, and geographic ancestry/ethnicity: a post-hoc analysis of the ZOE-50 and ZOE-70 randomized trials. Vaccine. 2019;37(43):6262–7.
Daniel Mullins C, Onwudiwe NC, Branco de Araújo GT, et al. Guidance Document: Global Pharmacoeconomic Model Adaption Strategies. Value Health Reg Issues. 2014;5:7–13.
United Nations Department of Economic and Social Affairs. World population prospects, Standard projections. 2019. https://population.un.org/wpp/Download/Standard/Population/. Accessed Aug 26, 2021
National Institute on Aging. Why population aging matters: a global perspective. 2017. WPAM.pdf (nih.gov). Accessed Aug 26, 2021
Curran D, Patterson B, Varghese L, et al. Cost-effectiveness of an adjuvanted recombinant zoster vaccine in older adults in the United States. Vaccine. 2018;36(33):5037–45.
Acknowledgements
Funding
GlaxoSmithKline Biologicals SA funded this study (VEO-000229, HO-18-19106) and was involved in all stages of study conduct, including analysis of the data. GlaxoSmithKline Biologicals SA also took in charge all costs associated with the development and publication of this manuscript including the Jorunal's Rapid Service Fee.
Medical Writing, Editorial, and Other Assistance
The authors thank Eveline Bunge, John Diaz-Decaro and Mohamed Neine for their input into the study protocol and analysis. The authors also thank Business & Decision Life Sciences platform for editorial assistance and manuscript coordination, on behalf of GSK. Maxime Bessières coordinated manuscript development and editorial support.
Prior Presentation
Data reported in this manuscript was presented as a poster at IDWeek 29 September–3 October 2021 (Virtual conference) and as an ENCORE poster at the 17th EuGMS congress, 11–13 October 2021 (Athens, Greece).
Authorship
All named authors meet the International Committee of Medical Journal Editors (ICMJE) criteria for authorship for this article, take responsibility for the integrity of the work as a whole, and have given their approval for this version to be published.
Author Contributions
Barbara P Yawn, Desmond Curran, Désirée van Oorschot, Hilde Vroling and Kyle Fahrbach were involved in the conception and/or the design of the study. Desmond Curran, Désirée van Oorschot and Hilde Vroling participated in the data collection/generation of the study data. All authors were involved in the interpretation of the data.
Disclosures
Andrea Callegaro, Desmond Curran and Désirée van Oorschot are employed by and hold shares in the GSK group of companies. Binod Neupane and Kyle Fahrbach are employed by Evidera and received funding from the GSK group of companies to complete the work disclosed in this manuscript. Barbara P Yawn reports grants and consulting fees from the GSK group of companies outside the submitted work. Hilde Vroling reports grants from the GSK group of companies during the conduct of the study and outside the submitted work. All authors declare no other financial and non-financial relationships and activities.
Compliance with Ethics Guidelines
This article is based on previously conducted studies and does not contain any new studies with human participants or animals performed by any of the authors.
Data Availability
The datasets generated during and/or analyzed during the current study are not publicly available as the study is based on an SLR of published literature. As such all the data can be obtained from the published literature.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License, which permits any non-commercial use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc/4.0/.
About this article

Cite this article
Curran, D., Callegaro, A., Fahrbach, K. et al. Meta-Regression of Herpes Zoster Incidence Worldwide. Infect Dis Ther 11, 389–403 (2022). https://doi.org/10.1007/s40121-021-00567-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40121-021-00567-8