
Abstract
In the prediction of total stock index, we are faced with some parameters as they are uncertain in future and they can undergo changes, and this uncertainty has a few risks, and for a true analysis, the calculations should be performed under risk conditions. One of the evaluation methods under risk and uncertainty conditions is using geometric Brownian motion random differential equation and simulation by Monte Carlo and quasi-Monte Carlo methods as applied in this study. In Monte Carlo method, pseudo-random sequences are used to generate pseudo-random numbers, but in quasi-Monte Carlo method, quasi-random sequences are used with better uniformity and more rapid convergence compared with pseudo-random sequences. The predictions of total stock index and value at risk by this method are better and more exact than Monte Carlo method. This study at first evaluates random differential equation of geometric Brownian motion and its simulation by quasi-Monte Carlo method, and then its application in the predictions of total stock market index and value at risk can be evaluated.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Like other fields of management knowledge and its application, risk management applies knowledge, principles, and specific rules to estimate predictions and achieve predefined goals. This field aims to help in ensuring the continuous protection of the people, and in safeguarding their assets and activities against the adverse events, as historically they are associated with risk.
In Iran, for 14 years, this issue has been paid serious attention. To fulfill the 20-year vision of Islamic Republic of Iran and to fulfill the development goals, the management and planning organization of the country emphasizes the effective implementation of plans by means of evaluations of economic and technical methods, and project management system by means of new management principles such as value engineering and risk management.
One of the famous methods to measure, predict, and manage risk is value at risk (VAR) that has been receiving great attention in recent years of managers of capital markets of various countries. VAR is a statistical criterion presenting quantitatively the maximum probable portfolio loss incurred during a definite period [5].
The calculation of VAR is done by two methods: parametric and nonparametric. In the parametric method, the main hypothesis is the normality of distribution of return on asset, and it is not an ideal hypothesis for application under real and practical conditions. As assets do not follow normal distribution under these conditions, this study applies nonparametric and Monte Carlo and quasi-Monte Carlo simulation techniques. In this method, by simulation of samples through computer and MATLAB software and random differential equation of geometric Brownian motion, the prediction is performed. The study aimed to evaluate the performance of Monte Carlo and quasi-Monte Carlo simulation methods to calculate total index and VAR of stock market to quantify the maximum probable loss with the lowest percentage error for the investment in stock market by considering the volatilities in the market.
This issue is of great importance for stock managers.
In recent years, by introducing VAR as a tool to calculate risk and Monte Carlo and quasi-Monte Carlo simulation techniques, various researches have been conducted, and some of them are described hereunder.
Giles et al. [2] in their study showed that quasi-Monte Carlo method in financial calculations is better than Monte Carlo method as the former can achieve similar precision with lower calculation cost, and their study refers to three important components of Sobol sequence and network points: dimension effect reduction by principal component analysis (PCA); random selection to present nonbiased estimators with a definite confidence interval; and the application of Brownian motion and Brownian bridge in their calculations.
Huang [3] applied Monte Carlo simulation method and Brownian motion to calculate VAR and obtained optimal VAR by adjustment coefficient, and his study results showed that optimal VAR was efficient and estimated the maximum expected loss with high confidence interval. In this paper, we begin with considering the review of the literature followed by the theoretical basics of study. Next, a comparison is made between quasi-random sequences and pseudo-random sequences, then definitions of the terms that are used regarding stock market are given, and finally conclusions are drawn.
Brownian motion
Let (P, Ω, A) be a probability space. In a random process, Wt: Ω → R, {W(t), ∘ ≤ t ≤ T} is called a Brownian motion, if the following conditions are satisfied:
-
1.
For all Ω ∊ ω, t → W t (ω) is a continuous function on [0, T] interval.
-
2.
Each group of {W(t ∘), W(t 1) − W(t ∘), W(t 2) − W(t 1), …, W(t k ) − W(t k−1)}intervals with 0 ≤ t 0 < t 1 < ··· < t k ≤ T is independent.
-
3.
For each ∘ ≤ s < t ≤ T, we have
$$ W\,(t) - W\,(s)\,\,\, \to \,\,\,N\,( \circ \,,\,t - s) $$(1)
Based on above properties, we can say for each ∘ < t ≤ T, we have W(t) ∼ N(∘, t).
d-dimensional Brownian motion
Let (P, Ω, A) be a probability space and d ∊ N. In random process, Wt: Ω → R, {W(t), ∘ ≤ t ≤ T} is called d-dimensional Brownian motion, if the following conditions are satisfied:
-
1.
For all, ω Ω ∊, t → W t (ω) is a continuous function on [∘, T] interval.
-
2.
Each group of {W(t ∘), W(t 1) − W(t ∘), W(t 2) − W(t 1), …, W(t k ) − W(t k−1)} intervals, by assuming 0 ≤ t 0 < t 1 < ··· < t k ≤ T, is independent.
-
3.
For each ∘ ≤ s < t ≤ T, we have
$$ W\,(t) - W\,(s)\,\,\, \to \,\,\,N\,( \circ \,,(\,t - s)I_{d} ) $$(2)
Brownian motion is also called a Standard Brownian Motion, if the following equation is established definitely:
W 0 = 0.
As long as Brownian motion can have negative values, its direct use is doubtful for modeling the stock prices. Thus, we introduce a nonnegative type of Brownian motion called Geometric Brownian Motion. Geometric Brownian motion is always positive as the exponential function has positive values. Geometric Brownian Motion is defined as S(t) = S 0 eX(t), where X(t) = σW(t) + µt is a Brownian motion with deviation, S(0) = S 0 > 0
Taking logarithm of the above equation, we have
Thus, ln (s(t)) has normal distribution with mean ln (s 0) + µt and variance σ 2 t, and for each t value, s(t) has normal log distribution [10].
If we let \( \bar{r} = \mu + \frac{{\sigma^{2} }}{2},E\left( {s\left( t \right)} \right) = e^{{\bar{r}t}} s_{0} {\text{ and }}\bar{r} \gg r \) where r is the share growth rate under risk-free conditions as investment in banks, and \( \bar{r} \) is the share growth rate under risk conditions as investment in stock market, then \( \bar{r} \) is the share growth rate under risky conditions as investment in stock market. The share growth rate under risky conditions should be much more than that under risk-free conditions to motivate the investors to investment.
Theorem 2.1
At constant time t, geometric Brownian motion has normal log distribution with mean ln (s 0 ) + µt and variance σ 2 t.
Proof
\( \begin{aligned} F\left( x \right) &= P\left( {X \le x} \right) = \, P\left( {s_{0} {\text{esp}}\left( {\mu t \, + \, \sigma \, W\left( t \right)} \right) \, \le x} \right) \\ &= P\left( {\mu t \, + \, \sigma \, W\left( t \right) \le \ln \, \left( {{x \mathord{\left/ {\vphantom {x {s_{0} }}} \right. \kern-0pt} {s_{0} }}} \right)} \right) \\ &= P\left( {W\left( t \right) \le \left( {\ln \, \left( {{x \mathord{\left/ {\vphantom {x {s_{0} }}} \right. \kern-0pt} {s_{0} }}} \right) \, - \, \mu t} \right)/\sigma } \right) \\ &= P\left( {{{W\left( t \right)} \mathord{\left/ {\vphantom {{W\left( t \right)} {\sqrt t }}} \right. \kern-0pt} {\sqrt t }} \le {{\left( {\ln \left( {{x \mathord{\left/ {\vphantom {x {s_{0} }}} \right. \kern-0pt} {s_{0} }}} \right) - \mu t} \right)} \mathord{\left/ {\vphantom {{\left( {\ln \left( {{x \mathord{\left/ {\vphantom {x {s_{0} }}} \right. \kern-0pt} {s_{0} }}} \right) - \mu t} \right)} {\left( {\sigma \sqrt t } \right)}}} \right. \kern-0pt} {\left( {\sigma \sqrt t } \right)}}} \right) \\ &= \int_{ - \infty }^{{(\ln \left( {{x \mathord{\left/ {\vphantom {x {s_{0} }}} \right. \kern-0pt} {s_{0} }}} \right) - \mu t)/(\sigma \sqrt t ))}} {\frac{1}{{\sqrt {2\pi } }}\exp \left( { - \frac{{y^{2} }}{2}} \right){\text{d}}y } \\ \end{aligned} \)
If we calculate the derivative of the above equation with respect to X, then we have
For 0 = t 0 < t 1 < ···<t n = t, ratios \( 1 \le i \le n , Li = \frac{{s(t_{i} )}}{{s(t_{i - 1} )}} \), random independent variables of log are normal, indicating the percent changes of the share value as it is not independent of real changes. \( s(t_{i} ) - s(t_{i - 1} ) .\)
For example:
are independent and normal log, and x(t 1) and x(t 2) − x(t 1) are independent with normal distribution. Now, we can rewrite geometric Brownian motion as S(t) = S 0 L1 L2 … Ln as an n-variate normal log. For example, assume that we sample share value at the end of each day. We can use t i = I, and thus, we have \( Li = \frac{s(i)}{s(i - 1)} \) which shows the percent of change during a day. Now, we can use the above formula in this regard. When for each i, t i − t i−1 = 1, Li is distributed uniformly, ln (Li) has normal distribution with mean µ and variance σ 2.
Geometric Brownian motion not only solves negation problem, but based on basic economic principles, it is also considered as a good model for stock value. As stock price reacts rapidly to new information, geometric Brownian motion model as Markov process is used for it.
If a geometric Brownian motion is defined with differential equation\( {\text{d}}S = rS\,{\text{d}}t + \sigma S\;{\text{d}}W,S\left( 0 \right) = s_{0} \), then geometric Brownian motion is equal to:
As geometric Brownian motion has normal log distribution with parameters \( \ln \left( {s_{0} } \right) + rt - \frac{1}{2}\sigma^{2} t{\text{ and }}\sigma^{2} t, \) the mean and variance of geometric Brownian motion are given by
If the main issue is geometric Brownian motion S(t) = s 0 exp (µt + σWt), then its random differential equation formula is as follows:
As geometric Brownian motion has normal log distribution with parameters ln (s 0) + µt and σ 2 t, the mean of geometric Brownian motion is equal to \( s_{0} \exp \left( {\mu t + \frac{1}{2}\sigma^{2} t} \right), \) and its variance is as per the following formula:
[10].
Later, geometric Brownian motion for values N = 100, t = 1, σ 2 = 0.05, µ = 0.05 can be simulated by MCMC method, and the corresponding chart is shown in Fig. 1.

Simulation of random differential equation of geometric Brownian motion with N = 100, t = 1, σ 2 = 0.05 and µ = 0.05 parameters
The theoretical basics and initial concepts of risk
Risk
Webster dictionary defines—Value at Risk (VAR) and investment dictionary defines it as potential loss of investment as calculated.
Accident
An accident is a sudden event (such as a crash) that is not planned or intended and that causes damage or injury (Merriam-Webster Dictionary). The adverse accident occurrence probability is the uncertainty regarding the future condition of a phenomenon, and unpredictability and probability of damages can be considered as main elements in the definitions. It seems that common concept in these elements is the one of uncertainty.
Uncertainty
Uncertainty is something that is doubtful or unknown: something that is uncertain (Merriam-Webster Dictionary).
Risk dimensions
Productive and unproductive risk
Productive risk is the one assuring value added, but unproductive risk is without value added (investment in mine exploration project includes productive risk of economic type, but attending gambling, for example, where risking one’s property to achieve much greater money, is called unproductive risk).
Controllable and uncontrollable risk
Controllable risk can be controlled by decision maker, while in uncontrollable risk, the decision maker has no control on risk (controllable risk is called reactive risk, and uncontrollable risk is called chance risk).
Profit-and-loss risk
Risk is divided into real (net) risk and involves winning and losing. The real risk includes loss (as car owner incurs damage in case of accident; otherwise it is not changed), and speculative risk includes loss and profit (its good example is the ownership of a factory or company). Simply put, risk can include loss (negative risk) and profit (positive risk) [1].
Different types of risks
There are different types of risks, and some of them are explained briefly.
Market risks
Market risk refers to the risk of losses in the bank’s trading book due to changes in equity prices, interest rates, credit spreads, foreign-exchange rates, commodity prices, and other indicators values of which are determined by variable factors in a public market [7].
Exchange rate risk
The exchange rate risk is defined as the variability of a firm’s value due to uncertain changes in the rate of exchange [4].
Inflation risk
Unexpected inflation is a change in prices that differs from the consensus view of what inflation is expected to be. When we talk about inflation risk, we are commonly talking about unexpected inflation. While expected inflation must be planned for in retirement budgeting, unexpected inflation causes uncertainty in prices, because it causes an element of surprise to bear upon the market. Since it cannot be predicted, managing the risk of unexpected inflation is critical [8].
Value at risk
Value at risk (VAR) as a statistical criterion defines the maximum expected loss of keeping assets in definite period and at definite confidence level. Assume that the daily value of an asset is 200 million Toman and at probability of 99 %, it is possible that the maximum reduction of this asset on the next day be 10 million Toman. Thus, VAR of this asset in a period of one day at a confidence interval of 99 % is 190 million Toman. We can say that by confidence interval of 99 %, the value of this asset on the next day will not be not less than 190 million Toman.
From math issues, VAR is shown as
where δV is the change of asset value in a definite period
The above equation states that the probability of the asset loss in future period being less than VAR is 1 − α [11] (Fig. 2).

Value at risk (risk analytics site)
In financial sciences, it is assumed that random variables price follows the path depending on Brownian motion as stock price, and one of its common models is geometric Brownian motion.
Monte Carlo Method
For a given population L, a parameter, e.g., θ, is estimated. In the Monte Carlo method, an estimate detector S(x) is first determined, in which x is a random variable with density function f x (x).
The estimate detector should satisfy the following two conditions:
-
(A)
The estimate detector should be unbiased.
$$ E\left[ {S(x)} \right] = \theta $$ -
(B)
The estimate detector should have definite variance.
$$ \text{var} \left( {S\left( x \right)} \right) = \sigma^{2} $$
Regarding the random samples X 1…. N N of the function, density of f x (x) is used.
We assume estimator number [6] as Monte Carlo estimator [6].
Monte Carlo simulation and stochastic differential equation
In this simulation, we present the expected value E[g(X(T))] for a solution, X, of a known stochastic differential equation with a known function of g. In general, bipartite approximation error contains two parts: random error and time discretization error. Statistical error estimate is based on the central limit theorem. Error estimation for the time-discretization error of the Euler method directly measures with one remained phrase the accuracy of \( \frac{1}{2} \) robust approximation.
Consider the following stochastic differential equation:
How can the value of E[g(X(T))] be calculated on \( t_{0} \le t \le T \). Monte Carlo method is based on the approximation of
where \( \mathop X\limits^{\_\_} \) is an approximation of X; according to Euler method, the error in the Monte Carlo method is
Quasi-Monte Carlo (QMC)
The basic concept of quasi-Monte Carlo method is based on moving the random sample in Monte Carlo method with definite points accurately. The criterion of selection of definite points is that the sequence in [0,1)s has better uniformity than a random sequence. Indeed, these points should be such that [0,1)s is covered uniformly. To measure uniformity, a different concept is used as explained in the following definitions.
Definition 7.1
(estimation of quasi -Monte Carlo) Assume X 1, …, X N is selected of [∘, 1)s space, estimation of quasi-Monte Carlo is done as per the formula: \( \bar{I}_{\text{QMC}} = \frac{1}{N}\sum\nolimits_{i = 1}^{N} {f(X_{i} )} \).
In an ideal model, we replace the set of x 1,…, x n points with infinite sequence x 1, x 2,… in [0,1)s. A basic condition for this sequence is that the term \( \mathop {\lim }\limits_{N\, \to \,\infty } \frac{1}{N}\sum\nolimits_{n = 1}^{N} {f(X_{n} ) = \int_{{\,[ \circ \,,\,1)^{s} }} {f(x){\text{d}}x} } \) is satisfied.
The satisfaction of this term is achieved as sequence x 1, x 2, …, x n is distributed uniformly in [0,1)s. The difference, deviation scale of uniformity, is a sequence of points in [0,1)s.
Definition 7.2
(uniform distribution in [∘, 1)s) {X n } n∊N sequence is distributed uniformly in [∘, 1)s if for each x ∊ δ[∘, 1)s, we have
Definition 7.3
(general discrepancy) Assume p is a set of points {X 1, …, X N }, and B is the family of subsets B ∊ [∘, 1)s. Then, the general discrepancy of set of points p = {X 1, …, X N } in interval [∘, 1)s is as follows:
where D N (B, p) is always between [0, 1], and C B isan attribute function of B. Thus, \( \sum\nolimits_{n = 1}^{N} {C_{B} (X_{n} )} \) shows the number of points 1 ≤ n ≤ N and x n \( \varepsilon \) B.
Definition 7.4
(Star discrepancy) Assume J * is the family of all sub-intervals [∘, 1)sas \( \prod_{i = 1}^{s} [ \circ , u_{i} )^{s} , \circ < u_{i} \le 1 \). The star discrepancy of the set of p = {X 1,…, X N } on substituting with J* in place of B in Eq. [6] is as follows:
Theorem 7.1
(Koksma Inequality) If f has bounded changes v(f) in [0, 1], then for each set of p = {X 1 , …, X N } of [0, 1], we have
This inequality states that sequences with low discrepancy lead to low error [9].
In Monte Carlo method, there was an aggregation of points as the points were independent, and they had no awareness of each other, and there was little chance that they were very close to each other. Quasi-random sequences had better uniformity and rapid convergence compared with pseudo-random sequence. Some of the quasi-random sequences are mentioned later, and they are calculated by means of MATLAB software.
Van der corput sequence
This is the first sequence by which low discrepancy was formed.
To obtain the nth point of this sequence, at first, n on base b is defined as \( n = \sum_{j = \circ }^{m} a_{j} \left( n \right)b^{j} \) where coefficients a j (n) include {∘, 1,…, b − 1}values. We use these coefficients to achieve quasi-random values as \( X_{n} = \phi_{b} (n) = \sum\nolimits_{j = \circ }^{m} {a_{j} (n)\frac{1}{{b^{j + 1} }}} \). Some of a j (n) values are nonzero. M is the smallest integer for each j > m as a j (n) = 0 (Table 1).
Van der corput sequence is a unidimensional sequence and generates random data of this sequence; in high dimensions, they can lose their random state and follow a linear function.
Halton sequence
Halton sequence was proposed in 1960, and it is similar to Van der corput sequence. First dimension of Halton sequence is a Van der corput sequence in basis 2, and second dimension is a Van der corput sequence in basis 3. Indeed, we can say Halton sequence is the same as Van der corput sequence with basis value as the nth primary value for the nth dimension of Halton sequence. Halton sequence is a s-dimensional sequence in cubic [0, 1]s. Nth element of Halton sequence in [0, 1]s is defined as (Table 2)
Figure 3 shows 100 Halton sequences in bases 2, 3 and dimensions 1, 2 (right figure); and bases 43, 47 and dimensions 14, 15 (left figure). As shown, in low dimension, Halton sequence has suitable dispersion, but by increasing the dimension, convergence is revealed as in high dimensions, its random trend is lost and hypercube is not covered uniformly.

Halton sequence for 1, 2 and 14, 15 dimensions
Sobol sequence
Sobol sequence was proposed in 1967. Constant value of basis 2 is used in Sobol sequence for all dimensions. Thus, Sobol sequence is rapid and simpler. This feature generates random numbers with low convergence in high dimensions.
To make this sequence, at first, we write n for basis 2 according to \( n = \sum_{i = \circ }^{M} a_{i} 2^{i} \) as M is the smallest value bigger or equal to \( \log_{2}^{n} \) and a i s values are zero or one, respectively.
The primary polynomial rank q is assumed as p = x q + c 1 x q−1 + ··· + c q−1 x + 1 in which c i s values are zero and one. m i by coefficients c i are generated as follows:
As ⊕ is an operator in computer represented as \( 1 \oplus \circ = \circ \oplus 1 = 1\; \; \; 1 \oplus 1 = \circ \oplus \circ = \circ \) m i values are odd integer values in interval [1, 2i − 1]. V(i)s are generated according to \( V\left( i \right) = \frac{{m_{i} }}{{2^{i} }}. \)
Thus, nth element of Sobol sequence is generated according to ϕ(n) = a·v(1) ⊕ a 1 v(2) ⊕ ··· ⊕ a i−1 v(i).
To facilitate Sobol sequence generation, Grey code coding is used, and its algorithm is given by \( \phi (n) = n \oplus \frac{n}{2}, \) and now the adjusted model is given by \( \phi (n) = n \oplus \frac{n}{2} \) (Table 3).
Figure 4 shows 100 points of Sobol sequences in dimensions 1, 2 (right figure) and dimensions 14, 15 (left figure). As shown, in high dimensions, this sequence has good uniformity and it makes its advantage compared to other sequences.

Sobol sequence for 1, 2 and 14, 15 dimensions
Comparison of quasi-random and pseudo-random sequences
Integral evaluation
To show which method is effective on integral evaluation, \( \int_{0}^{1} {\exp (x)\,{\text{d}}x} \) is considered. The exact answer of this integral is 1.7183. Table 4 shows the calculation of this integral by Monte Carlo and quasi-Monte Carlo method, and the integrating error is calculated.
As shown in Table 4, quasi-random sequences in integral evaluation perform better than pseudo-random sequences, and their estimation error is low. As was stated earlier, Sobol sequence in high dimensions is more efficient than Halton sequence.
Uniformity
The higher the uniformity of sequences, the lower the calculation error, and the sequence covered interval 0 to 1 very well. Table 5 shows a series of statistical features of Monte Carlo and quasi-Monte Carlo sequences in comparison with Uniform distribution.
As shown in Table 5, statistical features of quasi-random sequences are closer to uniform distribution [0, 1] than pseudo-random sequence. It means that quasi-random sequences are mostly representing U[0, 1] than pseudo-random sequence. As was said before, these sequences are associated with low discrepancy, their interval [0, 1] coverage is better, and are much more uniform. Also, Sobol sequence is more uniform than Halton sequence.
Nonconference of sequence in high dimensions
As shown in Fig. 3, by increasing dimension, convergence of Halton sequence is increased, and its trend of randomness is lost. Halton sequence has low convergence compared with Van der corput sequence in high dimensions. Sobol sequence as shown in Fig. 4 performs better than other quasi-random sequences as it applies basis 2 for all dimensions, and it leads to low convergence and high speed.
To predict total stock market index and calculation of VAR, a total index of 5 continuous years (Nov 2009–Nov 2014) was extracted from stock organization site, and it is equal to 1204 as the number of working days in these 5 years in Iran (Fig. 5).

The daily return of total stock index from Nov 2009 to Nov 2014 and the changes of total stock index from Nov 2009 to Nov 2014
As shown in Table 6, kurtosis of return is high, and it indicates that the total stock index distribution of TSE is far from normal value, and because of this, we applied Monte Carlo and quasi-Monte Carlo simulation methods, and these methods do not require normal distribution.
To obtain the prediction values of total TSE index and calculation of VAR, the following stages are considered:
-
1.
Determining time interval as one day (dt = 1).
-
2.
Generation of random numbers by Monte Carlo and quasi-Monte Carlo method and putting them in random differential model of geometric Brownian motion \( \left( {Si = Si - 1 + Si - 1\left( {r\,dt + \sigma \,\varepsilon \sqrt {{\text{d}}t } } \right)} \right) \) to predict total index.
For Stage 2 for a period of 10 days (according to Bazel committee in Swiss), simulation is performed M times, and this value is equal to 100,000 in this study.
-
3.
Sorting total predicted indices of small to big and calculation of its first percentile to determine the VAR at confidence interval of 99 %.
-
4.
Stages 2, 3 are performed L times. As shown in this study, moving window approach is used. This means that first window includes 1000 first data, and the model applies these data to predict 1001 data. In the next stage, the window considers data 2 to 1001, and the model applies these data for prediction of 1002 data, and this window moves forward (L = 193) to include 1000 final data. As some(same) values are predicted by this method and as we have their real values, we can evaluate the validation of the model by determining prediction error (Fig. 6).
Fig. 6 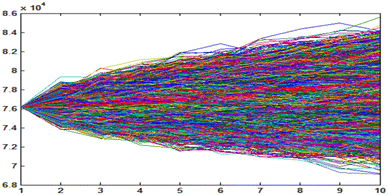
100,000 simulation paths of total TSE index for 10 days by Monte Carlo method

As shown in Fig. 7, in some cases, VAR is not predicted precisely, and TSE total index is lower than the maximum loss (Fig. 8).

Total TSE index and VAR calculated by Monte Carlo method

100,000 simulation paths of total TSE index for 10 days by quasi-Monte Carlo
As shown in Figs. 9 and 10, VAR is predicted accurately by quasi-Monte Carlo method, and the two sequences showed good results as one dimension is used for prediction.

Total TSE index and VAR calculated by quasi-Monte Carlo method (Sobol sequence)

Total TSE index and VAR calculated by quasi-Monte Carlo method (Halton sequence)
As shown in Table 7, VAR error ratio calculated by Monte Carlo method is 0.05; with higher than 0.01 as the probable error level, this method estimates low values of risk, and this leads to inadequacy of capital to resist against risk.
The results of Table 8 show that there is only one percent of chance that TSE total index under normal market conditions on Nov 18, 2014 achieves by quasi-Monte Carlo method a value of 69,994 or less, and by Monte Carlo method a value of 72,967 or below.
To investigate the adequacy of simulation model, simulated values are compared to real values of TSE site, and prediction values are calculated and shown in Table 9.
Conclusion
In this study, using TSE total index values during the 5 years from Nov 2009 to Nov 2014 and quasi-Monte Carlo and Monte Carlo methods, TSE total index and VAR are simulated and calculated, and it is shown that quasi-Monte Carlo method and Sobol sequence were better than Monte Carlo method with less error, and by confidence interval 99 %, we can invest in TSE, as for one percent of probability, TSE total index is lower than the predicted VAR.
References
Akbarian, R., Dyanati, M.: Risk management in Islamic Banking, Islamic economy quarterly (2004)
Giles, M., et al.: Quasi-Monte Carlo for finance applications. Anziam Journal, Australia (2008)
Huang, A.Y.: An optimization process in Value-at-Risk Estimation”. Rev. Finan. Econ. 19(3), 109–116 (2010)
Habibnia, A.: Exchange rate risk measurement and management, LSE Risk and Stochastic Group (2013)
Jorion, P.: Value at Risk: The New Benchmark for Managing Financial Risk, 2nd ed. McGraw-Hill (2000)
Tan, K.S.: Quasi-Monte Carlo methods, Applications in Finance and Actuarial Science (1998)
Mehta. A., et al.: Managing market risk: today and tomorrow. Mckinsey and company (2012)
Mitchem. K., Oliver, T.A.: New View on managing the risks of inflation and diversification, state street global advisors (2015)
Niederreiter, H.: Random number generation and quasi-Monte Carlo methods. Austrian Academy of Sciences (1992)
Sigman, K.: Stationary marked point processes. Springer (2006)
Willmott, P.: Quantitative Finance, England, 2nd ed (2006)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Fathi Vajargah, K., Shoghi, M. Simulation of Stochastic differential equation of geometric Brownian motion by quasi-Monte Carlo method and its application in prediction of total index of stock market and value at risk. Math Sci 9, 115–125 (2015). https://doi.org/10.1007/s40096-015-0158-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40096-015-0158-5