
Abstract
Cross-docking is a new warehousing policy in logistics which is widely used all over the world and attracts many researchers attention to study about in last decade. In the literature, economic aspects has been often studied, while one of the most significant factors for being successful in the competitive global market is improving quality of customer servicing and focusing on customer satisfaction. In this paper, we introduce a vehicle routing and scheduling problem with cross-docking and time windows in a three-echelon supply chain that considers customer satisfaction. A set of homogeneous vehicles collect products from suppliers and after consolidation process in the cross-dock, immediately deliver them to customers. A mixed integer linear programming model is presented for this problem to minimize transportation cost and early/tardy deliveries with scheduling of inbound and outbound vehicles to increase customer satisfaction. A two phase genetic algorithm (GA) is developed for the problem. For investigating the performance of the algorithm, it was compared with exact and lower bound solutions in small and large-size instances, respectively. Results show that there are at least 86.6% customer satisfaction by the proposed method, whereas customer satisfaction in the classical model is at most 33.3%. Numerical examples results show that the proposed two phase algorithm could achieve optimal solutions in small-size instances. Also in large-size instances, the proposed two phase algorithm could achieve better solutions with less gap from the lower bound in less computational time in comparison with the classic GA.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Cross-docking is a distribution strategy that enables the consolidation of products from origins to destinations. In a cross-dock, products are unloaded from inbound trucks and directly reloaded to outbound trucks without long storage in it. It is proved that the cross-docking in compare with traditional distribution centers dealing with cost and storage reduction, has shorter delivery lead time, better customer servicing, fast inventory turn and less loss and damage risks (Apte and Viswanathan 2000). Implementation of the cross-docking can decrease warehousing costs up to 70% (Vahdani and Zandieh 2010) and decreases transportation costs by using full trucks and consolidating shipments (Apte and Viswanathan 2000). The most important constraint in the cross-docking is the limited time for products storage inside the cross-dock (e.g., 24 h) (Schaffer 1998). In some cases like frozen products or some kinds of drugs, the storage time might be even less than an hour. Because of this characteristic, vehicle routing and scheduling of inbound and outbound trucks play important role in applying a cross-docking system (Lee et al. 2006).
The vehicle routing and scheduling problem that is a well-known combinatorial optimization problem is studied more over the past decades. Transportation costs can be reduced more by scheduling of trucks to visit customers. Therefore, the vehicle routing and scheduling of inbound and outbound trucks and consolidation process in a cross-dock are the most important decisions in this kind of warehousing. In addition, markets in the world become more and more competitive, so companies must improve their servicing to satisfy clients; beside of finding best strategies to reduce their logistics cost (Anderson et al. 1997). One of the most important factors for customer satisfaction is to deliver products in the period of time which customers incline to receive their demands. Usually preferred time limit is shorter than a regular time window; for example, consider a shop as a retailer/customer in a supply chain which its time window is formed from 8 a.m. to 8 p.m. Vehicles can deliver products within its time window, but the shopkeeper prefers to deliver demands between 1 and 3 p.m. since the shop is not crowded. Violation from the preferred time window is allowed but might decrease customer satisfaction. It can be concluded that the customer satisfaction level is straightly related to routing plans and truck scheduling of distribution companies.
In this work, we present a new approach to solve the vehicle routing with cross-docking and time windows focusing on customer satisfaction. The proposed approach uses a two phase genetic algorithm to minimize travel time and the number of unsatisfied customers. The paper structure is organized as follows:
In “Literature review”, a brief review on the literature is presented. Problem description and mathematical formulation are presented in the “Problem definition” and “Mathematic formulation”, respectively. “Validity of the proposed mathematical model” considers the mathematical model validity. The proposed algorithm is described in “Proposed genetic algorithm”. “Computational experiments” reports the results of computational experiments and discusses a sensitivity analysis. Finally, the conclusion and directions for future research are given in “Conclusion and future researches”.
Literature review
Vehicle routing problem (VRP) is a famous optimization problem. The classic VRP consists of planning the best tours to serve a set of customers with known demands by a fleet of vehicles from a single distribution center (Mosheiov 1998). The goal of this problem is to design a set of tours for the vehicles, start and end their tours at the distribution center such that all customers are visited with minimum transportation cost (Çatay 2010). One of the extensions of VRP is VRP with hard time window (VRPHTW). In such models, vehicles must visit customers in a limited period of time and early or tardy visits are not permitted (Desaulniers et al. 2014). Some of the VRP papers have been published in recent years considered various characteristics for the problem (Afshar-Bakeshloo et al. 2016; Barkaoui et al. 2015; Cheng and Wang 2009; Desaulniers et al. 2014; Hashimoto et al. 2006; Lahyani et al. 2015; Lalla-Ruiz et al. 2016; Lin et al. 2009; Mirabi et al. 2010; Respen et al. 2014; Semet et al. 2014; Zibaei et al. 2016). The pickup and delivery as a VRP extension has been considered by Mosheiov (1998) and was solved by two heuristic algorithms to minimize transportation cost and maximize vehicles efficiency.
Most of researches and publications on cross-docking are done in the last decade. Several cross-dock decisions have been studied over these years. The problem is classified into three categories: strategic, tactical and operational (Van Belle et al. 2012). According to this classification, cross-docking decisions can be analyses in these fields: location of cross-dock, layout of facilities inside the cross-dock, dock door assignment, truck scheduling, transportation, routing and consolidation process. Napolitano et al. (2000) has introduced different type of cross-docking operations and benefits of cross-docking strategy. Physical characteristics of cross-docks were studied by (Bartholdi and Gue 2000, 2004; Ratliff et al. 1999; Tsui and Chang 1992; Vis and Roodbergen 2008). Some papers focused on cross-docks design to reduce the transportation cost (Apte and Viswanathan 2000). Some authors have studied cross-docking as a network and considered cross-docks in a supply chain system that cross-docks location and customer allocations are decision variables (Jayaraman and Ross 2003; Mousavi et al. 2014; Ross and Jayaraman 2008; Seyedhoseini et al. 2015). In addition, most of the papers related to the operational decisions focused on the trucks scheduling in cross-docking system (Alpan et al. 2011; Arabani et al. 2011; Donaldson et al. 1998b; Gholami et al. 2015; Konur and Golias 2013a, b; Kuo 2013; Liao et al. 2014, 2013; Mohtashami 2015; Soltani and Sadjadi 2010; Vahdani and Zandieh 2010; Yu and Egbelu 2008). In addition, in the cross-docking literature, a few number of researches considered both vehicle routing and cross-docking together. Integrating these two decisions can play an important role on system performance and can reduce cross-docking system costs.
The vehicle routing problem with cross-docking was first introduced by Lee et al. (2006). The objective was minimizing the transportation and fixed costs of using vehicles and it was solved by the Tabu search algorithm. In their work products were transferred from suppliers to customers by homogeneous vehicles in the time horizon. In their model it was assumed that the vehicles must arrive to the cross-dock simultaneously for simplifying the model. Liao et al. (2010) proposed another Tabu search to solve the same problem in better computational time and less used trucks. They reported 10–36% improvement in the objective function comparing to previous solution algorithm. In another work, Prince (2004) introduced a hybrid algorithm of PSO (particle swarm optimization), VNS (variable neighborhood search) and SA (simulated annealing) for solving the model and used Taguchi method for parameter tuning. The proposed algorithm leads to better results. Wen et al. (2009) considered same problem with consolidation which orders after pickup phase are consolidated at a cross-dock then immediately are delivered to customers. In consolidation phase, orders are unloaded from inbound trucks and reloaded to outbound trucks, while if a truck must deliver an order that picked it up itself, consolidation is not necessary. The goal of the model was minimizing transportation time and it was formulated as a MILP and solved by Tabu search for large instances. Musa et al. (2010) considered a transportation problem in a network of cross-docks as an extension of introduced model by Donaldson et al. (1998a) with two types of transportation: (1) transferring from suppliers to customers directly and (2) transferring through cross-docks. They used the Ant colony algorithm to solve the problem.
Santos et al. (2011) worked on a Branch and Price algorithm to solve the vehicle routing problem with cross-docking for minimizing loading and unloading cost in addition to transportation cost. They showed that B&P has better performance than the Branch and bound algorithm for the problem. Hasani-Goodarzi and Tavakkoli-Moghaddam (2012) introduced a vehicle routing problem with split delivery with undefined number of vehicles with different capacities. In addition each supplier and customer could be visited with one or more vehicles. The model was solved in small size with GAMS software. Then, Santos et al. (2013) considered direct shipment from suppliers to customers to minimize total transportation cost and they proposed a Branch and Price algorithm to solve the problem.
Dondo et al. (2011) have formulated vehicle routing problem with cross-docking as a MILP model that considered a network with cross-docking strategy with direct shipments. Although many characteristics have been considered in the integration of VRP and cross-docking but as authors best of knowledge customer satisfaction has not been focused in the previous studies of VRP with cross-docking concept. In this paper, a mixed integer linear programming model is presented for a vehicle routing scheduling problem with cross-docking focusing on customer satisfaction and then a two phase genetic algorithm is proposed to solve the problem.
Problem definition
The vehicle routing with cross-docking problem considered in this paper is a transportation problem in a three-echelon supply chain that includes: suppliers, cross-dock and retailers (customers). In this problem, orders are collected from suppliers by a homogeneous fleet of trucks and moved to the cross-dock for consolidation process, then immediately delivered to customers. The temporary storage in the cross-dock is not allowed and orders must be delivered to customers without interval. So beside of routing decisions, consolidation and time-dependent decisions are important too. Hence, we are faced with vehicle routing, scheduling and consolidation decisions.
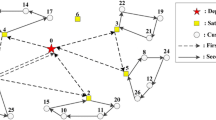
Figure 1 represents a small instance of our problem including five suppliers, five customers and a cross-dock. Trucks should pickup orders from suppliers and deliver them to corresponding customers. Thus, customer A’ must receive its order from the supplier A and other customers must receive orders from their corresponding suppliers. All inbound trucks of the cross-dock start their routes from the cross-dock and collect products from suppliers. After finishing of the picking up operation, each truck must return to the cross-dock for probable consolidation process. Subsequently consolidated products should be reloaded to outbound trucks to be delivered to customers. There are some kinds of strategies in cross docking such as: one-to-one, few-to-many, many-to-many and many-to-few (Napolitano et al. 2000). All mentioned strategies are utilized by different companies in the world. The proposed problem is according to the first strategy. In the case that products are unique and should be delivered to predetermined destinations, the first strategy is utilized to establish the cross docking system. For example, postal services companies in all over the worlds have the same condition as the mentioned assumption. US Postal Service where 148 Area Distribution Centers serve as cross docks, is one of the largest companies of this kind of systems. The mails should be picked up from origins and should be delivered to their predetermined destinations. In such systems, the pickup and delivery nodes are corresponding and there is a one-to-one relationship between supplier and customer. In addition, for the companies which products are not unique with no predetermined destinations, other types of strategies can be utilized.

A cross-docking system
Figure 2 illustrates a consolidation process. In consolidation phase, orders are unloaded from inbound trucks and reloaded to outbound trucks while if a truck must deliver an order that picked it up itself, loading and unloading is not necessary. According to aforementioned figures, orders 1 and 2 are collected from suppliers A and B by truck 1 and they are delivered to corresponding customers by truck 2, so products 1 and 2 should be unloaded from truck 1 at receiving doors and reloaded to outbound truck 2 at shipping doors. Similarly product 3 should be unloaded from inbound truck 2 and reloaded to outbound truck 3. Product 4 is picked up from supplier D by truck 3 and is delivered to customer D′ by the same truck without any loading or unloading but product 5 should be unloaded from vehicle 3 and reloaded to outbound truck 1.

Consolidation process
In this problem, we have a vehicle routing and scheduling problem with time windows. There are two types of time windows, first one is the time window which has defined for all suppliers and customers. In this way, all suppliers and customers must be visited during their own time window and violation from this time is not allowed. In real cases each customer has a tighter preferable time window and product delivery during mentioned time will have more customer satisfaction, so in this study customer satisfaction time window (TWS) is considered inside of a hard time window (HTW). The customer satisfaction time window is the time window in which customers incline to receive their demands. Deviations from this time window are allowed but these deviations are accounted for in the objective function as a dissatisfaction measure. Figure 3 represents these two types of time windows. According to this problem, trucks should wait at customer nodes until the hard time window is reached in case of earlier arrival. Customers can not be visited after their hard time window.

Schema for two types of time windows
The assumption and characteristics of our model are presented below:
-
A set of homogeneous vehicles pickup products from suppliers and deliver to corresponding customers. In the other words, trucks first accomplish the pickup tours and subsequently perform the delivery tours. A complete tour contains a pickup and delivery tour.
-
Each node must be visited by only one truck, i.e., orders are not splittable.
-
Pickup and delivery tours should be started/end from/at the cross-dock.
-
Each customer demand has a predefined supplier, it means products must be delivered to their corresponding destination.
-
Each truck has limited capacity.
-
Unloading process for each truck must be finished then reloading process can be started.
-
Unloading process is started immediately after arriving trucks at the cross-dock without any waiting time.
-
For loading and unloading process at the cross-dock, fixed and variable times are considered. Variable time depends on the product volume.
-
Interrupting of loading and unloading process are not allowed, e.g., pre-emption.
-
The products which are picked up and delivered by the same truck are not needed to be unloaded and reloaded at the cross-dock, so remain inside the truck.
-
There is no inventory at the cross-dock at the end of planning horizon, so the total number of products unloaded at the cross-dock must be equal to the total number of products reloaded to outbound trucks.
Mathematic formulation
A mixed integer linear programming formulation is proposed for the problem which is formulated as follows:
Equation (1) minimizes the total transportation cost and the cost of deviation from customer satisfaction time windows. Constraints (2) and (3) ensure that each truck visits each node once and each node is visited by one truck for pickup and delivery process, respectively. Constraints (4) and (5) imply that each inbound truck must start from the cross-dock and each outbound truck must start from the cross-dock. In addition all of the trucks must be utilized. Constraints (6) and (7) ensure that vehicles will return to the cross-dock at the end of their tours. Constraints (8) and (9) ensure that the total volume of transported products by inbound and outbound trucks must not exceed their capacity. Constraints (10) and (11) indicate the routs continuity, i.e., for each node if a truck travels from node i to node j it must leave node j for both pickup and delivery tours. Constraints (12) and (13) determine the traveling time between two nodes if they are traveled consecutively by the same truck. Constraint (14) implies that trucks must visit nodes within their hard time windows. Constraints (15) and (16) compute the deviation from customer satisfaction time windows. Consolidation decisions are determined by constraints (17) and (18). According to these constraints: if products are picked up from supplier i by truck k and delivered to its corresponding customer i + n, loading and unloading is not necessary and products remain into the truck; if products are picked up from supplier i by truck k but are not delivered to its corresponding customer i + n, products must be unloaded at the receiving doors of the cross-dock; if products are not picked up from supplier i by truck k but must be delivered to its corresponding customer i + n by that truck, products must be reloaded to truck k at shipping door of the cross-dock. Constraint (19) implies that truck k has a loading/unloading process or not. Constraint (20) calculates total loading/unloading time in the cross-dock for each vehicle. Constraints (21)–(23) imply that reloading process should be started after completing of unloading process of all products. Constraints (24) and (25) are similar to (19) and (20) for the reloading process.
Validity of the proposed mathematical model
In this section, we analyze the model validity by different sensitivity analysis. Because of high needed computational time, we utilized a high performance computer and solved a real instance from a dataset introduced by wen et al. (Wen et al. 2009) with 40 nodes including 20 suppliers and 20 customers with one cross-dock. The model was coded in GAMS software version 24 without time limitation and a high performance computer are used to optimally solve the problem on an Intel® Core™ i7 3.3 GHz CPU and 16 GB RAM. To test performance of the proposed model, results of different sensitivity analysis are reported. Figures 4, 5 and 6 show the results obtained for a real instance by analyzing of different parameters.

The effect of increasing time of unload and reload

The effect of increasing time of unload and reload on the number of reload and unload

The comparing between VRPCDTW and VRPCDTWS
There are two parameters for unloading and reloading products at the cross-dock including fix and variable time for each vehicle. Figure 4, confirms that the transportation cost will be increased by increasing of unloading and reloading time. According to the Fig. 5, it can be concluded that the number of unloads/reloads will be decreased by increasing of unloading and reloading time in the cross-dock. It shows that the model decides to suffer more cost to prevent violating from the time windows.
Figure 6 compares results of two models VRPCDTW and VRPCDTWS, in different scenarios. In the first one we assumed that the length of customer satisfaction time window is 40 min and in the next scenarios we increased its length up to 120 min equal to hard time window. The results have been reported in Fig. 6. It shows that when the customer satisfaction time window is 120 min there is no difference between two models and VRPCDTW and VRPCDTWS will construct same network and routing plans while with tightening of TWS, their performance gap will be increased. Mentioned analysis confirms that the presented model is valid and has reasonable performance.
Proposed genetic algorithm
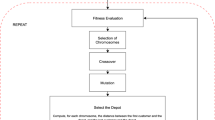
Evolutionary algorithms are widely used by researchers to solve complex problems and hard optimizations (Coello 2002; dos Santos and da Silva Formiga 2015; Ghezavati and Beigi 2016). Genetic algorithm as an evolutionary algorithm has been successfully used for solving NP-hard problems, such as different supply chain management problems (Izadi and Kimiagari 2014; Kannan et al. 2010; Kuo and Han 2011; Raj and Rajendran 2012) and different VRP problems (Elhassania et al. 2014; Karakatič and Podgorelec 2015). In a GA, we have an initial population including individuals that evolves during the algorithm by genetic operators, i.e., selection, cross over and mutation. Solution representation, initial population, GA operators, termination criterion and selection methods are effective parameters in performance of GA algorithm. Due to the NP-hardness of this problem, in this paper a two phase genetic algorithm is proposed. In the first phase a genetic algorithm is applied for delivery process to find the best feasible solution in a short time. In this phase just a VRPTW problem is solved to find the best feasible solution for starting the next phase.
In the second phase, GA keeps delivery solution that was found by first phase and create a set of pickup solutions. The set of pickup solutions beside of delivery solution (obtained by the first phase), construct a set of complete solutions including pickup and delivery tours together. It means that we have a set of complete tours (including pickup and delivery) which have different pickup tours with same delivery tour. Again a genetic algorithm is applied for complete solutions to find the best feasible pickup tours for selected delivery tour by the first phase. In this phase consolidation decisions like: loaded/unloaded products, fix and variable time for loading/unloading and customer satisfaction time windows are considered during the search. The main framework of the proposed two phase GA is presented in Fig. 7.

Proposed two phase GA structure
Solution representation
A solution representation is a string that indicates problem individuals used by algorithm to search the solution space. So defining a good encoding method is really effective on performance of the algorithm. The solution of our problem with P pickup and D delivery nodes and K vehicles is represented by a permutation of (P + K − 1) numbers for pickup, (D + K − 1) for delivery and (P + D + 2K − 2) for a complete solution. The chromosome of this paper is presented in Fig. 8 containing 5 suppliers, five customers and three vehicles. As mentioned before, a complete chromosome contains two parts. First one is for pickup tours and the second one for delivery tours. For example in pickup solution with P suppliers and K trucks we have P + K − 1 genes for each chromosome. Numbers from 1 to P determine nodes and others are for separating tours by each vehicle. In this example, genes 1–5 are suppliers and 6, 7 are separators. The reported chromosome in Fig. 8 shows that in pickup part, suppliers 1 and 2 are visited by the first truck, supplier 3 is visited by the second truck while it is between two separators and finally suppliers 4 and 5 are visited by the third truck in the delivery part.

Solution representation of a pickup and delivery process
Fitness evaluation in phase 2
In this study to satisfy all constraints, some penalty terms are added to the objective function to guide searching process to the feasible region. There are two main constraints which are related to the customers hard time windows and vehicles capacities, so the objective function of Eq. (1) should be changed to the following function considering penalty cost of violating from mentioned constraints:
where γ and λ are the penalties for violations from each unit of the time window and capacity constraints, respectively. Let TWV n (n = 1, 2, 3, 4) and CV m (m = 1, 2) denote amount of violation from time window and capacity constraints. According to constraint (14) for each chromosome the violation of all customers’ time windows for pickup or delivery tours are calculated according to Eqs. (27)–(30):
where TWV1 is total lateness from the hard time windows for pickup tours of all suppliers.
where TWV2 is total earliness from the hard time windows for pickup tours of all suppliers.
where TWV3 and TWV4 are lateness and earliness from the hard time windows for delivery tours of all customers, respectively.
According to constraint (8), the violation of inbound trucks capacity (CV1) is calculated as follows:
And for the violation of outbound trucks (CV2) is calculated by Eq. (32).
Computational experiments
In the following sub sections, numerical results are presented to show the performance of the proposed algorithm. The model has been coded in the GAMS software version 24 and solved using CPLEX solver for small instances. The algorithm has been coded in the MATLAB programming language and run on Intel® Core™ i7 2 GHz CPU and 8 GB RAM. The used data set was introduced by wen et al. (2009). It is generated from a real data set belonging to a Danish logistics consultancy from Copenhagen.
Test problems and parameter setting
A real data set was used to assess the performance of the algorithm. Data set includes 200 pairs of nodes (supplier–customer), denoted by 200a, 200b, 200c, 200d and 200e. Each set consists of nodes location (x, y). Each node has a specific time window. The time window for each node is 2 h and the time horizon is from 6:00 to 22:00. The certain request of each customer is predefined. Same trucks with capacity of 33 requests and constant speed of 60 km/h are considered. There are two types of preparing time for each trucks including 10 min to preparing for loading/unloading process as the fixed time (F) and 1 min for each request to be unloaded/reloaded (V). Also small data sets with 20, 30, 50 and 100 pairs of nodes were selected randomly from 200(a–e) to test the algorithm.
To set the parameters of the algorithm, various combinations of the numerical parameters have been tested. Results indicates that following parameters lead to better results, therefore, the parameters depicted in Table 1 are used for all problems. The maximum number of iterations is set to 500, 1000 and 2000 in the phase 1 and 150, 250 and 500 in the phase 2 for (40 and 60), 100 and 200 nodes, respectively. The following set of parameters was finally selected: N pop = 30; P c = 0.7; P s = 0.1; P r = 0.6; P i = 0.7 and P m = 0.4.
Performance evaluation and analysis of the proposed algorithm
To test performance of the proposed two phase algorithm, we compared its results with the results of the CPLEX solver in different small instances. The small instances are randomly derived from data set (20a) with 40 suppliers and customers. Table 2 indicates the comparison of two phase GA and the exact solution. Each instance was run 10 times. Average and the best objective values, run time, lower bound and the gap between the algorithm and the exact solution were reported for each instance. Solving the VRPCDTW without consolidation decisions, achieves the same results of solving two separate VRPTWs, so the solution of 2-VRPTW would be a lower bound of the main VRPCDTW. The lower bounds for small instances in the Table 2 were calculated in 60 min. It is worth to mention that the best objective value of the main problem by the Gams software has been acquired in 1000 s. The relative Gap between the best objective value obtained by the GAMS and the proposed two phase GA is calculated according to Eq. (33).
Reported results of Table 2 indicates that the proposed algorithm can find the optimal or near optimal solution. Also the results confirm that the computed lower bound is near to the exact optimal solution. It means that the computed lower bound can be considered in the large instances. It can be concluded form mention table that in small instances there is no difference between the exact and the lower bound objective values while it increases by increasing of the instance size because of growing needed loading/unloading operations for larger number of products. Note that reported values for the best solutions of the GAMS are the best solutions obtained in mentioned time limitation and the optimal values are specified by “*”. As indicated in Table 2, negative gap in the test problem ten which is the gap between the best obtained solution of GAMS in the time limitation of 1000 s which is not optimal and the genetic solution, shows that the proposed two phase genetic even in small size problems, has an acceptable performance.
Table 3 indicates the results of large instances over 10 runs. The problem of achieving the lower bound for large instances is an NP-hard problem too, so the algorithm of Kallehauge et al. (2006) was used to solve the corresponding 2-VRPTWs as a lower bound of the VRPCDTWS. Also the proposed algorithm is compared with the GA algorithm in large size problems. It is worth to mention that since the exact solutions for large size problems are not exist, the gap between lower bound and the best objective value obtained by the algorithms are reported in Table 3. So, the gap columns of Table 3 calculated like Eq. (33) but we should use lower bound instead of best solution of the GAMS. Reported results in Table 3 confirm that the proposed algorithm is efficient to solve the main problem in large instances while it contains acceptable gap from the lower bound. Also the proposed algorithm perform better than the GA to rich better solutions in less computational time.
Sensitivity analysis on the customer satisfaction
As mentioned before we considered the customer satisfaction concept during the distribution stage and it can be affected because of late delivery of products to customers. In this section, a comparison is performed between the proposed and the classical models to show the efficiency of the proposed approach considering the customer satisfaction. The proposed network plan extracted by the proposed model and the classic network for ten different instances were considered and the results were reported in Table 4. Results show that there are at least 86.6% customer satisfaction by the proposed plan, whereas customer satisfaction in the classical model is at most 33.3%. In fact by the proposed model customers receive their products during their preferred time window and it leads to better servicing. It is worth to mention that the proposed model may have more transportation cost than the classic one because of paying to customers attention.
Sensitivity analysis on the effect of consolidation process
In this section, some additional experiments were performed to investigate the importance of consolidation process on cost reduction. Figure 9 indicates the consolidation role on the transportation costs. It shows that considering of products consolidation possibility will decrease the total transportation cost, so it means that the cross docking can decrease the total transportation cost. Our experiments confirm that this characteristic exists in the proposed model as well. On the other hand, in cross docking system, when you want to organize an optimal plan to the system, the consolidation process should be considered efficiently. In the proposed model the consolidation process is considered and this leads to decrease the total transportation cost. Considering consolidation process in the model means considering integration of pickup and delivery part and pay attention to the linkage between them. Without considering this point in the planning, the loading and unloading of products in cross docking will be more. These extra operations not only increase costs, but also lead to late delivery and decrease customer satisfaction.

Effect of consolidation process on transportation cost
Difference between the proposed model and the 2-VRPTW
There are many factors that could have effect on linkage of the pickup and delivery processes, such as location of nodes, the length of time windows and the number of nodes. When the location of pickup nodes are very different from delivery ones, the length of time windows are tight or the number of nodes are large, the pickup and delivery parts are become more important. These factors influence on the difference between two models of 2-VRPTW and VRPCDTWS. This difference is increased by increasing of the problem size. Table 5 shows these results on three sets of problems. The transportation costs of different data sets in medium and large-size are compared in Table 5. Obviously, the transportation cost of 2-VRPTW is less than VRPCDTWS. The reason of difference between these two models is the linkage of pickup and delivery process in cross docking system. The pickup and delivery processes are dependent. So, as mentioned before in the case that the number of nodes are large, the difference should be more. For better comparison, the mean of difference for each set is calculated in the last column. The last column in Table 5 confirms above claim and shows that in large-size problems, the difference between 2-VRPTW and VRPCDTWS is more than medium-size problems. When the number of nodes are large, the consolidation process in cross dock is more and this leads to more difference between two models. Note that, the absolute value of the difference will be increased by increasing of problem size, however, the ratio is decreased. The reason is that by increasing of the problem size, there is a large amount of transportation cost and the ratio of consolidation saving cost by the cross dock is not large enough. So, it means that the ratio will be decreased, however, the absolute difference will be increased by increasing of the problem size.
Another factor which can affect the mentioned difference is the tightness of customers’ time windows. As demonstrated in Fig. 10, by increasing length of customer time windows from 120 to 240 min, the different between 2-VRPTW and our model is decreased. It means there is approximately no different between VRPCDTWS and 2-VRPTW in the case that time windows are wide enough. Also in the case that time windows are tight and delivery time is more important, the proposed model should be more efficient.

Effect of time window (120 and 240 min) on transportation cost
Conclusion and future researches
Cross-docking as an efficient logistics strategy is widely used by many companies and plays an important role in supply chain management. Although a lot of works have been investigated vehicle routing scheduling with cross-docking, there is no study on integration of this problem considering of customer satisfaction. This paper focuses on the vehicle routing problem with cross-docking in a three-echelon supply chain including suppliers, cross-dock and customers.
In this problem orders are collected from suppliers by a homogeneous fleet of vehicles and moved to the cross-dock for consolidation process, then immediately delivered to customers. A mixed integer linear programming model was presented to minimize transportation cost, early and tardy deliveries to achieve maximum customer satisfaction.
To solve this NP-hard problem a two-phase genetic algorithm was proposed. Real data sets were used to test the performance of developed algorithm. Analysis of results to assess effect of some parameters of the model in different instances confirms the validity of the proposed model. Results determined that this model leads to high level of customer satisfaction against classic model. In addition performance of the proposed algorithm was compared with an exact solver in small-size instances and with lower bounds. Comparison between the customer satisfaction in the classic and the proposed method shows that the percentage of customer satisfaction is from 86.6 to 100% in different instances by the proposed method, whereas customer satisfaction in the classical model is from 10 to 33.3% in the classic one. Numerical examples results show that the proposed two phase algorithm could achieve optimal solutions in small-size instances. On the other hand, the proposed algorithm could achieve optimal solutions of six instances from ten small-size instances whereas GAMS could achieve only one optimal solution more than the proposed algorithm. In addition, in the last instance which the GAMS solution was not optimal, the algorithm could achieve better solution than GAMS and this shows that the algorithm has great performance. Also in large-size instances, the proposed two phase algorithm could achieve better solutions with less gap from the lower bound in less computational time in compare with the classic GA. Considering of the problem in a network environment with multiple cross-docks and multi-products with split deliveries can be as a direction for future researches. As another future study, reverse logistics from customers to suppliers would be considered. In addition, by relaxing one-by-one relation between suppliers and customers, the proposed model and solution method can be adjusted to planning other distribution strategies which can be considered as another future researches.
Abbreviations
- P :
-
Set of pickup nodes (suppliers)
- D :
-
Set of delivery nodes (customers)
- N :
-
Set of all nodes
- K :
-
Set of trucks
- i, j, h :
-
Index of nodes
- k :
-
Index of inbound/outbound trucks
- R :
-
Receiving door at the cross-dock
- S :
-
Shipping door at the cross-dock
- M :
-
An arbitrarily large constant
- c ij :
-
Transportation cost between node i and j
- t ij :
-
Transportation time between node i and j
- [a i , b i ]:
-
Hard time window for node i (i ∈ N)
- [ap i , bp i ]:
-
Customer satisfaction time window of node i (i ∈ D)
- d i :
-
Demand of node i (i ∈ P)
- T :
-
Truck capacity
- F :
-
Fixed time of preparing trucks for unloading/reloading process at the cross-dock
- V :
-
Variable time for unloading/reloading each product unit
- \( \omega \) :
-
Cost per time unit of deviation from customer satisfaction time window
- n :
-
Number of pickup/delivery nodes
- x ijk :
-
1, if vehicle k travels from node i to node j; 0, otherwise (i, j ∈ N)
- u ik :
-
1, if vehicle k unloads demand i at the cross-dock; 0, otherwise (i ∈ P, k ∈ K)
- r ik :
-
1, if vehicle k reloads demand i at the cross-dock; 0, otherwise (i ∈ P, k ∈ K)
- q k :
-
1, if vehicle k stops at the cross-dock for unloading process; 0, otherwise (k ∈ K)
- q′ k :
-
1, if vehicle k stops at the cross-dock for reloading process; 0, otherwise (k ∈ K)
- α i :
-
Positive deviation from customer satisfaction time window for node i (i ∈ D)
- β i :
-
Negative deviation from customer satisfaction time window for node i (i ∈ D)
- l ik :
-
Leaving time of truck k from node i (i ∈ N, k ∈ K)
- f k :
-
Finish time of the unloading operation of truck k at the cross-dock (k ∈ K)
- s k :
-
Start time of the reloading operation of truck k at the cross-dock (k ∈ K)
- g i :
-
Finish time of the unloading operation of request i at the cross-dock (i ∈ P)
References
Afshar-Bakeshloo M, Mehrabi A, Safari H, Maleki M, Jolai F (2016) A green vehicle routing problem with customer satisfaction criteria. J Ind Eng Int 12:529–544
Alpan G, Larbi R, Penz B (2011) A bounded dynamic programming approach to schedule operations in a cross docking platform. Comput Ind Eng 60:385–396
Anderson EW, Fornell C, Rust RT (1997) Customer satisfaction, productivity, and profitability: differences between goods and services. Mark Sci 16:129–145
Apte UM, Viswanathan S (2000) Effective cross docking for improving distribution efficiencies. Int J Logist 3:291–302
Arabani AB, Ghomi SF, Zandieh M (2011) Meta-heuristics implementation for scheduling of trucks in a cross-docking system with temporary storage. Expert Syst Appl 38:1964–1979
Barkaoui M, Berger J, Boukhtouta A (2015) Customer satisfaction in dynamic vehicle routing problem with time windows. Appl Soft Comput 35:423–432
Bartholdi JJ III, Gue KR (2000) Reducing labor costs in an LTL crossdocking terminal. Oper Res 48:823–832
Bartholdi JJ, Gue KR (2004) The best shape for a crossdock. Transp Sci 38:235–244
Çatay B (2010) A new saving-based ant algorithm for the vehicle routing problem with simultaneous pickup and delivery. Expert Syst Appl 37:6809–6817
Cheng C-B, Wang K-P (2009) Solving a vehicle routing problem with time windows by a decomposition technique and a genetic algorithm. Expert Syst Appl 36:7758–7763
Coello CAC (2002) Theoretical and numerical constraint-handling techniques used with evolutionary algorithms: a survey of the state of the art. Comput Methods Appl Mech Eng 191:1245–1287
Desaulniers G, Madsen OB, Røpke S (2014) The vehicle routing problem with time windows. Veh Routing Probl Methods Appl 18:119–159
Donaldson H, Johnson EL, Ratliff HD, Zhang M (1998b) Schedule-driven cross-docking networks Georgia tech tli report. The Logistics Institute, Georgia Tech, Atlanta
Donaldson H, Johnson EL, Ratliff HD, Zhang M (1998a) Network design for schedule-driven cross-docking systems. Georgia Tech TLI Report
dos Santos DPS, da Silva Formiga JK (2015) Application of a genetic algorithm in orbital maneuvers. Comput Appl Math 34:437–450. doi:10.1007/s40314-014-0151-x
Dondo R, Méndez CA, Cerdá J (2011) The multi-echelon vehicle routing problem with cross docking in supply chain management. Comput Chem Eng 35:3002–3024
Elhassania M, Jaouad B, Ahmed EA (2014) Solving the dynamic vehicle routing problem using genetic algorithms. In: 2014 International Conference on Logistics Operations Management, 5–7 June 2014, pp 62–69. doi:10.1109/GOL.2014.6887419
Ghezavati VR, Beigi M (2016) Solving a bi-objective mathematical model for location-routing problem with time windows in multi-echelon reverse logistics using metaheuristic procedure. J Ind Eng Int 12:469–483. doi:10.1007/s40092-016-0154-x
Gholami M, Rabbani M, Samavati M (2015) Scheduling trucks in fruit cross docks as an open shop problem with edge colouring. Int J Autom Logist 1:140–149
Hasani-Goodarzi A, Tavakkoli-Moghaddam R (2012) Capacitated vehicle routing problem for multi-product cross-docking with split deliveries and pickups. Proc Soc Behav Sci 62:1360–1365
Hashimoto H, Ibaraki T, Imahori S, Yagiura M (2006) The vehicle routing problem with flexible time windows and traveling times. Discret Appl Math 154:2271–2290
Izadi A, Am Kimiagari (2014) Distribution network design under demand uncertainty using genetic algorithm and Monte Carlo simulation approach: a case study in pharmaceutical industry. J Ind Eng Int 10:1. doi:10.1186/2251-712x-10-1
Jayaraman V, Ross A (2003) A simulated annealing methodology to distribution network design and management. Eur J Oper Res 144:629–645
Kallehauge B, Larsen J, Madsen OB (2006) Lagrangian duality applied to the vehicle routing problem with time windows. Comput Oper Res 33:1464–1487
Kannan G, Sasikumar P, Devika K (2010) A genetic algorithm approach for solving a closed loop supply chain model: a case of battery recycling. Appl Math Model 34:655–670
Karakatič S, Podgorelec V (2015) A survey of genetic algorithms for solving multi depot vehicle routing problem. Appl Soft Comput 27:519–532. doi:10.1016/j.asoc.2014.11.005
Konur D, Golias MM (2013a) Analysis of different approaches to cross-dock truck scheduling with truck arrival time uncertainty. Comput Ind Eng 65:663–672
Konur D, Golias MM (2013b) Cost-stable truck scheduling at a cross-dock facility with unknown truck arrivals: a meta-heuristic approach. Transp Res Part E Logist Transp Rev 49:71–91
Kuo Y (2013) Optimizing truck sequencing and truck dock assignment in a cross docking system. Expert Syst Appl 40:5532–5541
Kuo R, Han Y (2011) A hybrid of genetic algorithm and particle swarm optimization for solving bi-level linear programming problem—a case study on supply chain model. Appl Math Model 35:3905–3917
Lahyani R, Coelho LC, Renaud J (2015) Alternative formulations and improved bounds for the multi-depot fleet size and mix vehicle routing. Technical Report CIRRELT-2015-36, Québec
Lalla-Ruiz E, Expósito-Izquierdo C, Taheripour S, Voß S (2016) An improved formulation for the multi-depot open vehicle routing problem. OR Spectrum 38:175–187. doi:10.1007/s00291-015-0408-9
Lee YH, Jung JW, Lee KM (2006) Vehicle routing scheduling for cross-docking in the supply chain. Comput Ind Eng 51:247–256
Liao T, Chang P, Kuo R, Liao C-J (2014) A comparison of five hybrid metaheuristic algorithms for unrelated parallel-machine scheduling and inbound trucks sequencing in multi-door cross docking systems. Appl Soft Comput 21:180–193
Liao T, Egbelu P, Chang P-C (2013) Simultaneous dock assignment and sequencing of inbound trucks under a fixed outbound truck schedule in multi-door cross docking operations. Int J Prod Econ 141:212–229
Liao C-J, Lin Y, Shih SC (2010) Vehicle routing with cross-docking in the supply chain. Expert Syst Appl 37:6868–6873
Lin S-W, Lee Z-J, Ying K-C, Lee C-Y (2009) Applying hybrid meta-heuristics for capacitated vehicle routing problem. Expert Syst Appl 36:1505–1512
Mirabi M, Ghomi SF, Jolai F (2010) Efficient stochastic hybrid heuristics for the multi-depot vehicle routing problem. Robot Comput Integr Manuf 26:564–569
Mohtashami A (2015) A novel dynamic genetic algorithm-based method for vehicle scheduling in cross docking systems with frequent unloading operation. Comput Ind Eng 90:221–240
Mosheiov G (1998) Vehicle routing with pick-up and delivery: tour-partitioning heuristics. Comput Ind Eng 34:669–684
Mousavi SM, Vahdani B, Tavakkoli-Moghaddam R, Hashemi H (2014) Location of cross-docking centers and vehicle routing scheduling under uncertainty: a fuzzy possibilistic–stochastic programming model. Appl Math Model 38:2249–2264
Musa R, Arnaout J-P, Jung H (2010) Ant colony optimization algorithm to solve for the transportation problem of cross-docking network. Comput Ind Eng 59:85–92
Napolitano M, Education W, Gross J (2000) Making the move to cross docking: a practical guide to planning, designing, and implementing a cross dock operation. Warehousing Education and Research Council, Oak Brook
Prins C (2004) A simple and effective evolutionary algorithm for the vehicle routing problem. Comput Oper Res 31:1985–2002
Raj KAAD, Rajendran C (2012) A genetic algorithm for solving the fixed-charge transportation model: two-stage problem. Comput Oper Res 39:2016–2032
Ratliff HD, Vate JV, Zhang M (1999) Network design for load-driven cross-docking systems Georgia tech tli report. The Logistics Institute, Georgia Tech, Atlanta
Respen J, Zufferey N, Potvin J-Y (2014) Impact of online tracking on a vehicle routing problem with dynamic travel times. Working Paper at the CIRRELT, CIRRELT-2014-05
Ross A, Jayaraman V (2008) An evaluation of new heuristics for the location of cross-docks distribution centers in supply chain network design. Comput Ind Eng 55:64–79
Santos FA, Mateus GR, da Cunha AS (2011) A branch-and-price algorithm for a vehicle routing problem with cross-docking. Electron Notes Discret Math 37:249–254
Santos FA, Mateus GR, Da Cunha AS (2013) The pickup and delivery problem with cross-docking. Comput Oper Res 40:1085–1093
Schaffer B (1998) Cross docking can increase efficiency automatic ID news 14:34–36
Semet F, Toth P, Vigo D (2014) Classical exact algorithms for the capacitated vehicle routing problem. In: vehicle routing: problems, methods, and applications. SIAM Publications, Philadelphia, pp 37–57
Seyedhoseini SM, Rashid R, Teimoury E (2015) Developing a cross-docking network design model under uncertain environment. J Ind Eng Int 11:225–236. doi:10.1007/s40092-014-0088-0
Soltani R, Sadjadi SJ (2010) Scheduling trucks in cross-docking systems: a robust meta-heuristics approach. Transp Res Part E Logist Transp Rev 46:650–666
Tsui LY, Chang C-H (1992) An optimal solution to a dock door assignment problem. Comput Ind Eng 23:283-286. doi:10.1016/0360-8352(92)90117-3
Vahdani B, Zandieh M (2010) Scheduling trucks in cross-docking systems: robust meta-heuristics. Comput Ind Eng 58:12–24
Van Belle J, Valckenaers P, Cattrysse D (2012) Cross-docking: state of the art. Omega 40:827–846
Vis IF, Roodbergen KJ (2008) Positioning of goods in a cross-docking environment. Comput Ind Eng 54:677–689
Wen M, Larsen J, Clausen J, Cordeau J-F, Laporte G (2009) Vehicle routing with cross-docking. J Oper Res Soc 60:1708–1718
Yu W, Egbelu PJ (2008) Scheduling of inbound and outbound trucks in cross docking systems with temporary storage. Eur J Oper Res 184:377–396
Zibaei S, Hafezalkotob A, Ghashami SS (2016) Cooperative vehicle routing problem: an opportunity for cost saving. J Ind Eng Int 12:271–286. doi:10.1007/s40092-016-0142-1
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Baniamerian, A., Bashiri, M. & Zabihi, F. Two phase genetic algorithm for vehicle routing and scheduling problem with cross-docking and time windows considering customer satisfaction. J Ind Eng Int 14, 15–30 (2018). https://doi.org/10.1007/s40092-017-0203-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40092-017-0203-0