
Abstract
Against the background of global climate change, the increasing heat health risk from the combined effect of changes in high temperature, exposure, vulnerability, and other factors has become a growing concern. Yet the low number of temperature observation stations is insufficient to represent the complex changes in urban heatwaves, and subdistrict-scale (town, township, neighborhood committee, and equivalent) heat health risk and adaptability assessments are still limited. In this study, we built daytime and nighttime high-temperature interpolation models supported by data from 225 meteorological stations in Beijing. The models performed well at interpolating the cumulative hours of high temperature and the interpolation quality at night was better than that during the day. We further established a methodological framework for heat health risk and adaptability assessments based on heat hazard, population exposure, social vulnerability, and adaptability at the subdistrict scale in Beijing. Our results show that the heat health risk hotspots were mainly located in the central urban area, with 81 hotspots during the day and 76 at night. The average value of the heat health risk index of urban areas was 5.60 times higher than that of suburban areas in the daytime, and 6.70 times higher than that of suburban areas in the night. Greater population density and higher intensity of heat hazards were the main reasons for the high risk in most heat health risk hotspots. Combined with a heat-adaptive-capacity evaluation for hotspot areas, this study suggests that 11 high-risk and low-adaptation subdistricts are priority areas for government action to reduce heat health risk in policy formulation and urban development.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In the context of global climate change, extreme climate events occur frequently and greatly affect the health of humans and socioeconomic systems (Patz et al. 2005; Luber and McGeehin 2008). Compared with earthquakes, floods, tsunamis, and other extreme climate events that directly result in human casualties, extreme high-temperature events increase mortality associated with cardiovascular, respiratory, digestive, and other diseases (Curriero et al. 2002). These health outcomes pose a threat to human health that cannot be ignored. In July 1995, a heatwave event in Chicago resulted in more than 700 deaths (Semenza et al. 1996), and a European heatwave event in 2003 resulted in more than 70,000 deaths (Stott et al. 2004). The death toll from the Russian heatwave event in 2010 was estimated to be approximately 55,005 (Barriopedro et al. 2011). Given the trend of increased frequency, intensity, and duration of heatwave disasters, sufficient attention should be given to evaluating the impact of extreme high-temperature events on human health. Therefore, in recent years, more studies on the identification of vulnerable populations and the assessment of heat health risks have been conducted.
Previously, many thermal risk assessments based on heat hazards, exposure, and vulnerability have been developed, but quantitative assessments of adaptation to such risks were often overlooked (Tomlinson et al. 2011; Morabito et al. 2015). The Intergovernmental Panel on Climate Change (IPCC) pointed out the importance of adaptive capacity in the assessment of climate change vulnerability in its Fourth Assessment Report, and further emphasized the need for disaster mitigation measures by government policymakers from the perspective of adaptive capacity in the Fifth Assessment Report (IPCC 2007, 2014). A few studies constructed a vulnerability assessment framework for heatwave disasters by taking exposure, sensitivity, and adaptability as a unified whole (Wolf and McGregor 2013; Zhu et al. 2014; El-Zein and Tonmoy 2015). Although adaptation research has been carried out, heat health risk assessment research in recent years is still conducted around heat hazards, exposure, and vulnerability. To avoid the indicator system becoming too large, adaptability has not been included in heat health risk assessment studies (Hu et al. 2017; Hua et al. 2021). In addition, most of the existing heat health risk assessment studies have been conducted at the county (urban district) scale (Xie et al. 2015a; Luo et al. 2016; Hu et al. 2017; Zhang and Li 2020; Li et al. 2022), and there is a lack of research at the subdistrict scale.
Depicting the spatial distribution of heat health risk is a major concern in heat health risk assessment (Wolf et al. 2015); determining the spatial distribution pattern of extreme high-temperature events also is a key step in these efforts. In previous studies, meteorological data interpolation has commonly used ordinary kriging interpolation or thin-plate spline interpolation (Xie et al. 2015a; Hu et al. 2017). Because temperature levels are closely related to urban surface morphology (Weng et al. 2004; Chander et al. 2009; Kestens et al. 2011), developing temperature interpolation models based on land-use regression methods has become a new research hotspot. Shi et al. (2019) used hourly temperature data from 40 meteorological stations in Hong Kong to develop a land-use regression model and generate a daytime and nighttime cumulative high-temperature hour distribution map with a resolution of 10 m to achieve a spatial understanding of extreme high-temperature weather conditions in Hong Kong. Li et al. (2022) predicted and evaluated the spatial distribution of ozone and urban heat islands using data from 134 meteorological stations in Xi’an, and also incorporated machine learning to improve land-use regression methods. Their research showed that the interpolation results of the land-use regression method were limited by the small number of meteorological stations, which was insufficient to represent the complex surface morphology of cities.
Our study was a subdistrict-scale study in Beijing. It constructed a heat health risk and adaptability assessment framework based on heat hazard, population exposure, social vulnerability, and adaptability. We then explored the spatial distribution pattern and driving mechanism of heat health risk at the subdistrict scale in Beijing, while carrying out high-temperature adaptability evaluations for high risk areas. We identified high-risk and low-adaptation subdistricts in this study, and put forward recommendations on how to deal with the problem. The temperature observation data from 225 meteorological stations in Beijing were obtained in cooperation with the Beijing Meteorological Disaster Prevention Center, and the daytime and nighttime high-temperature interpolation models were built based on urban land surface features.
2 Materials and Methods
The data used in this study mainly include meteorological, land cover, demographic, GDP, digital elevation model (DEM), and point of interest (POI) data. The data were preprocessed and their accuracies were evaluated. Then, a heat health risk and adaptability framework based on heat hazard, population exposure, social vulnerability, and adaptability at the subdistrict scale was constructed.
2.1 Study Area
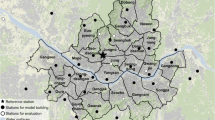
Beijing is located between 115.7° E–117.4° E and 39.4° N–41.6° N, with an elevation range of 6–2303 m. It had 16 districts and 331 subdistricts—this is, towns, townships, neighborhood committees, and equivalents—covering an area of 16,410.54 km2—in 2015 (Fig. 1a). At the end of 2020, Beijing’s permanent population was 21.89 million, of which the urban population was 19.64 million, accounting for 89.7% of the total.Footnote 1 The GDP of Beijing was 3.6 trillion yuan, and the city is an international metropolis and is representative of China’s rapid urbanization (Fig. 1b). The region has a typical temperate subhumid continental monsoon climate with high temperature and plenty of rainfall in the summer. From 2011 to 2020, the average temperature in summer (June–August) in Beijing increased by 0.64 ℃, and the number of high-temperature days with daily maximum temperature > 35 °C increased from 38 to 49, making Beijing one of the hottest cities in China.

The study area. a Elevation and meteorological station (MS) locations in Beijing Municipality. b Land cover types. The thick black lines represent the administrative boundary of the districts; the thin gray lines represent the administrative boundary of the subdistricts.
2.2 Data Collection and Preprocessing
2.2.1 Meteorological Data
Hourly temperature data from the Beijing meteorological station locations were collected from June to August in 2011 to 2020 and provided by the National Meteorological Information Center.Footnote 2 A total of 225 meteorological stations [20 national weather stations (NWSs), 205 automatic weather stations (AWSs)] established before June 2011 and still in use until September 2020 was selected (Fig. 1a). Most NWSs are responsible for regional or national weather information exchange and are the main data source of the national weather and climate website. The observation data obtained by AWSs are mainly used for weather services in their own provinces (autonomous regions, municipalities) and localities, and complement the observation data on the national weather and climate website. Strict quality control measures were applied to the hourly measured temperature data to eliminate random errors found in the original data.
2.2.2 Land Cover
The GlobeLand30 V2020 land cover dataFootnote 3 have a spatial resolution of 30 m and include 10 land cover types, namely, cropland, woodland, grassland, shrubland, wetland, water, tundra, urban land, bare land, and glacier. The overall accuracy of the GlobeLand30 V2020 data was 85.72%, and the Kappa coefficient was 0.82.
2.2.3 Demographic Data
Demographic data included the subdistrict-scale data and the raster grid-scale data. The subdistrict-level population data were obtained from the seventh census report.Footnote 4 This report does not cover the age structure, gender, and ethnicity of a subdistrict’s inhabitants, so we made an estimate using the relevant proportions in the sixth census report.Footnote 5
The raster grid-scale population data in 2020 from the Institute of Geographic Sciences and Natural Resources Research (IGSNRR),Footnote 6 with a resolution of 1 km, were used. Each grid represents the population in the grid, and the value unit is persons/km2. The ArcGIS zoning statistical tool was used to calculate the cumulative population of each district in Beijing, and the result was verified using the number of permanent residents in each district in the seventh census report. The correlation between the two was very strong, with an R2 value of 0.99.
Data on air conditioner ownership per 100 households in each district of Beijing were obtained from the Beijing Municipal Bureau of Statistics (Beijing Regional Statistical Yearbook, 2013).Footnote 7
2.2.4 GDP
One kilometer grid data of China’s GDP in 2020 from the IGSNRR, with a resolution of 1 km, also were used. Each grid represents the total GDP in the grid with value unit of 10,000 yuan/km2. The cumulative GDP of each district in Beijing was calculated using the ArcGIS zoning statistical tool and verified using the total GDP of each district in the Beijing Regional Statistical Yearbook 2021.Footnote 8 The two showed a strong correlation with an R2 value of 0.96.
2.2.5 DEM Data
Digital elevation model (DEM) data were from the Resource and Environmental Science and Data CenterFootnote 9 with a resolution of 250 m. The data were projected using WGS84 ellipsoids.
2.2.6 POI Data
We employed point of interest (POI), also known as “point of information” or “information point” data of national interest in 2020 from the IGSNRR. The “park” category in 2020 scenic spot POI data was selected as the park POI data in this study. The data of general hospitals, grade A hospitals, and health centers in the 2020 POI data were selected as the POI data of medical institutions in this study.
2.3 Heat Health Risk and Adaptability Assessment Framework
A framework for the heat health risk and adaptability assessments was established based on heat hazard, population exposure, social vulnerability, and adaptability at the subdistrict scale (Fig. 2).

Heat health risk and adaptability assessment framework
2.3.1 Heat Health Risk Assessment
Heat health risk is described as a function of heat hazard, exposure, and vulnerability. It was calculated by multiplying three indices: heat hazard, exposure, and vulnerability (Fig. 2). The three indices are regarded as having equal weights, and the specific calculation method is as follows:
where HHI represents the heat hazard index, EI represents the exposure index, VI represents the vulnerability index, and HHRI represents the heat health risk index.
To map the spatial distribution of daytime high-temperature hours (DHs) and nighttime high-temperature hours (NHs), population density, vulnerability, and heat health risk, the standard deviation classification method was used. This method classifies the data based on the mean and standard deviation; the greater the difference is between the data values and the mean, the more levels the data set is divided into.
(1) Heat Hazards
In previous studies for Beijing by Du et al. (2014) and Zhang and Li (2020), only 18 shared meteorological stations or interpolation data based on limited meteorological stations were used when assessing heat hazards. In our study, the data from 225 meteorological stations in Beijing for 2011–2020 were obtained by cooperation with the Beijing Meteorological Disaster Prevention Center. This provided an expanded dataset with the largest number of stations and abundant data. The hourly temperature data during the daytime (7:00–18:00) and nighttime (18:00–7:00) in the 10-year period were sorted from low to high, and the 90% quantile was taken as the high-temperature threshold. The daytime high-temperature threshold was 33.1 °C, and the nighttime high-temperature threshold was 27.9 °C. The cumulative number of daytime hours of each site in which the temperature exceeded the high-temperature threshold in summer (June to August) in the 10-year period was calculated and abbreviated as DHs. The cumulative number of hours of each site in which the temperature was above the high-temperature threshold during summer nights over the decade was calculated and abbreviated as NHs. The DHs and NHs quantified the extreme heat hazards in Beijing by combining the intensity and duration of high temperatures.
Land cover (cropland, woodland, grassland, shrubland, wetland, water, urban land, and bare land), population density, DEM, and GDP were used as the predictors of the spatial distribution of high temperature. Then, high-temperature interpolation models of DHs and NHs were established based on urban land surface features. The high-temperature interpolation model is as follows:
Buffer analysis is based on point, line, and surface features, and it creates a polygon layer of the buffer zone within a certain width around the feature of concern. We overlay this layer and the target layer to analyze and obtain the required results. To identify the spatial scale at which the strongest correlation between various factors and DHs and NHs is observed, 100 buffer widths ranging from 1 to 100 km were set around the 225 meteorological stations, and the land cover grid data were cropped with the vector files of the buffers. Using the spatial analysis function of ArcGIS, the areas of eight land cover types in the 100 buffer zones at each of the 225 meteorological stations were obtained (8 × 100 = 800 variables). The DEM, GDP, and population density data were point data (3 variables). As a result, 803 predictor variables were prepared.
Pearson correlation coefficient can be used to calculate the type of linear relationship between two variables (positive, negative, none) and the strength of this relationship (weak, moderate, strong). We used Pearson correlation coefficient to analyze the correlation between each predictor variable and DHs and NHs. Due to the low correlations between shrubland, wetland, water areas, and bare land and DHs and NHs within the 1–100 km buffer, these variables were removed. Then, the buffer widths with the highest correlations with DHs and NHs were determined among the 100 buffer widths for the remaining land cover types—cropland, woodland, grassland, and urban land. Stepwise linear regressions were performed with DHs and NHs as dependent variables, and cropland, woodland, grassland, urban land, population density, DEM, and GDP as independent variables. Then, multiple linear regression equations, called high-temperature interpolation models of DHs and NHs (HIM-D, HIM-N) for the study area, were obtained. The equation for DHs is as follows:
and the equation for NHs is as follows:
The statistical analysis by F test showed that the correlations were highly significant at p < 0.01; in other words, the linear relationships between the predictor variables entering Eqs. (3) and (4) and the cumulative hours of high temperature were very close. From the adjusted R2 (HIM-D: 0.76; HIM-N: 0.84), the dependent variables have a high degree of explanation for the independent variables and the models fit well.
Regular 1 km × 1 km grids and grid points were generated in the study area, the values of the independent variables and the values of the dependent variables, DH and NH, of each grid point were calculated, and then these values of the grid point were assigned to the grid to obtain the spatial distribution map of the high-temperature hazard with a resolution of 1 km.
(2) Exposure to Hazard
Exposure refers to the exposure of lives and property, human health, ecosystems, resources and the environment, and infrastructure to certain hazards (Yin et al. 2013). As the vulnerability indicators selected in this study mainly involved the population, exposure in this study was referred to as the population exposure to heat hazards. In the past, scholars have used the sixth population census data to calculate the population exposure at the county level. In this study, the seventh population census data were used to calculate the population density of each subdistrict by dividing the permanent population of each subdistrict by the area of each subdistrict, and the unit was persons/km2.
(3) Vulnerability Assessment
Different from previous vulnerability studies based on the county scale, this study calculated vulnerability at the subdistrict scale in Beijing. Factors unfavorable to people’s coping with heat hazards were selected as vulnerability indicators: (1) Proportion of resident female population. Compared to that of men, the physical resistance of women may be weaker, and their economic strength is generally inferior to that of men; therefore, it is more difficult for them to recover after disasters (Cutter et al. 2003; Xie et al. 2015b); (2) Proportion of the resident population aged 0–4. Compared to young adults, children have poorer physical resistance, less self-protection ability, and poorer disaster response capabilities (Cutter and Finch 2008); (3) Proportion of permanent population over the age of 65. Elderly individuals over the age of 65, especially those suffering from cardiovascular and cerebrovascular diseases, are more susceptible to high temperatures due to body dysregulation. They are also susceptible to high-temperature diseases (Cutter and Finch 2008); (4) Proportion of resident minority population. Cultural and language barriers hinder ethnic minority evacuation and rescue during disasters (Reid et al. 2009); (5) Proportion of people living alone. People who live alone have less contact with their surroundings and may not receive effective assistance when disasters occur (Reid et al. 2009); and (6) Proportion of the population with an education level below high school. It is generally believed that people with higher education levels have better disaster awareness. Moreover, they have stronger economic strength for disaster adaptation and post-disaster recovery (Uejio et al. 2011). The entropy weight method was adopted to determine the weight of each indicator (Table 1), and then the addition method was adopted to generate the vulnerability index:
where VI represents the vulnerability index; I1, I2, I3, I4, I5, I6 represent indicator 1 (proportion of resident female population), indicator 2 (proportion of resident population aged 0–4), indicator 3 (proportion of permanent population over the age of 65), indicator 4 (proportion of resident minority population), indicator 5 (proportion of people living alone), and indicator 6 (proportion of population with education level below high school), respectively.
2.3.2 Adaptability Assessment
In this study, the factors that were beneficial to people’s mitigation of heat hazards were selected as the adaptability indicators: (1) Air conditioner ownership per 100 households. Indoor cooling equipment, such as air conditioners, can effectively alleviate high temperatures and prevent high-temperature injuries to a certain extent (Klinenberg 2003); (2) GDP. To some extent, GDP can reflect people’s living and economic standards. Areas with a high quality of life and high economic level usually have more heat reduction equipment, medical institutions, and infrastructure to alleviate high temperatures; (3) Proportion of medical institutions within a 10-min walking distance. The quantity and distribution of medical resources directly affect whether timely treatment can be obtained after a disaster (Cutter et al. 2003); and (4) Proportion of parks within a 10-min walking distance. Parks are effective places in which to find both relief and escape from high temperatures, and the number and layout of parks reflect the comfort of people’s lives (Johnson et al. 2012). We set the 10-min walking distance to 600 m. The entropy weight method was adopted to determine the weight of each indicator (Table 1), and addition was adopted to generate the adaptability index:
where AI represents the adaptability index; I7, I8, I9, I10 represent indicator 7 (air conditioning ownership per 100 households), indicator 8 (GDP), indicator 9 (proportion of 10-min walking range of medical institutions), and indicator 10 (proportion of 10-min walking range of park green space), respectively.
3 Results
We plotted the spatial distribution of heat hazards (cumulative hours of high temperature), exposure (population density), and vulnerability, and analyzed their spatial distribution characteristics. The cumulative hours of high temperature, population density, and vulnerability were standardized to obtain the heat hazard index, exposure index, and vulnerability index. The heat health risk index is the product of the heat hazard index, the exposure index, and the vulnerability index. Finally, the areas with high heat health risk index values were evaluated for adaptability, and high-risk, low-adaptation subdistricts were identified.
3.1 Heat Hazards
In this study, high-temperature interpolation models of DHs and NHs based on urban land surface features were established. The HIM-D and HIM-N models were validated for performance through leave-one-out cross-validation. Comparing the simulation performance of the HIM-D and HIM-N models with ordinary kriging interpolation, the results of DHs and NHs using HIM-D and HIM-N model interpolation were significantly better than those obtained using ordinary kriging interpolation in terms of the R2, root mean square error, mean absolute error, and mean relative error (Table 2). This result shows that the HIM-D and HIM-N models had better performance than ordinary kriging interpolation in interpolating cumulative high-temperature hours.
We calculated the cumulative hours of extremely high temperatures over the set high-temperature threshold during the daytime/nighttime in Beijing, namely, DHs and NHs, with a spatial resolution of 1 km. For extreme heat conditions in the daytime, we used the standard deviation classification method to divide the DHs into six levels (Fig. 3a), with an average of 772.61 and a standard deviation of 537.94. The DHs at level 6 were the largest, ranging from 1580 to 1869 h, and were mainly distributed in Dongcheng and Xicheng Districts (See Figs. 4 or 6 for all district locations). The DHs at level 5 were the second highest, with a range of 1041 to 1579 h, and they were mainly distributed in Chaoyang, Haidian, Shijingshan, Fengtai, Daxing, Tongzhou, Shunyi, and Changping Districts.

Spatial distribution of cumulative hours of a daytime high temperature (DHs) at 1 km resolution and b nighttime high temperature (NHs) at 1 km resolution. The legend shows the result of classifying the DHs and NHs by standard deviation

Population density distribution of Beijing and its districts. The legend shows the result of classifying the population density by standard deviation. a Yanqing; b Huairou; c Miyun; d Pinggu; e Fangshan; f Mentougou; g Changping; h Shunyi; i Daxing; j Tongzhou; k Fengtai; l Chaoyang; m Haidian; n Shijingshan; o Dongcheng; p Xicheng
For extreme heat conditions at night, we used the standard deviation classification method to divide the NHs into seven levels (Fig. 3b), with an average of 593.83 and a standard deviation of 549.59. The NHs at level 7 were the largest, ranging from 1968 to 2375 h and were mainly distributed in Dongcheng and Xicheng Districts. The NHs at level 6 were the second highest, with a range of 1418 to 1967 h, mainly distributed in Chaoyang, Haidian, Shijingshan, and Fengtai Districts. The NHs were classified into more classes than the DHs. Level 7 was 2.5 to 3.2 standard deviations above the mean. This indicates that the high temperature values at night varied widely and were much higher than the average.
Both the DHs and the NHs showed a spatial pattern of high inside and low outside, high in the south and low in the north of the city. This result presents a circular structure that diverges from the central city to the suburbs, and land-use type and elevation are the main reasons for this spatial distribution. The average elevation of the central urban area is 68.52 m, and the proportions of cropland, woodland, grassland, and urban land were 8.65%, 11.75%, 5.16% and 72.93%, respectively. The proportions of urban land in Dongcheng and Xicheng Districts were 92.72% and 93.96%, respectively, and these were the two districts with the highest temperatures. The average elevation of the suburbs is 391.96 m, and the proportions of cropland, woodland, grassland, and urban land were 25.18%, 48.12%, 0.66% and 16.46%, respectively. The temperature difference between the central city and the suburbs was greater at night. The area covered by high temperatures at night was smaller than that during the daytime and was concentrated in the central urban area. During the daytime, there was a significant DH disparity between subdistricts in Huairou, Miyun, Pinggu, Changping, and Fangshan Districts. At night, in addition to these districts, there was a significant NH disparity between subdistricts in Shunyi, Tongzhou, Daxing, Haidian, and Shijingshan Districts. This is because the land-use type in the central urban area is mainly urban land, whereas the rural area has mainly arable land and forestland. Dry cement ground accumulates a large amount of heat during the day and releases heat at night, thus aggravating the nighttime high temperature in the urban area.
3.2 Exposure
Based on the latest census data, this study calculated the population density of each subdistrict in Beijing and classified it into five levels using the standard deviation classification method (Fig. 4). The mean and standard deviation of population density were 8276 people/km2 and 9801 people/km2, respectively. The distribution characteristics of population exposure were low outside and high inside of the central city. The central city was a populated area. Of the subdistricts in the central urban area, 64.17% had a population density greater than 10,000 people/km2. Overall, 86.29% of the subdistricts in the suburbs had a population density lower than the average, and it was evenly distributed. Only a few subdistricts had a high population density, and the variation range of population density among subdistricts in Haidian District was the largest, while that in Pinggu District was the smallest. The largest population density was in Yongding Road Subdistrict of Haidian District, reaching 61,546.12 people/km2; the lowest value was in Yanshou Subdistrict, Changping District, with 6.13 people/km2.
3.3 Vulnerability
We calculated the vulnerability index of each subdistrict in Beijing according to the weights of the six vulnerability indicators (Table 1). The mean values, standard deviations, and ranges of the six vulnerability factors are listed in Table 3. The difference in the proportion of people with less than a high school education in the subdistricts was the largest (0.1832–0.9648), followed by the difference in the proportion of people living alone (0.0874–0.6767). These two variables exhibited larger standard deviations than the other variables. There was little difference in the proportion of the permanent female population, permanent population aged 0–4, permanent population over 65, and permanent minority population among different subdistricts.
The vulnerability index was divided into six levels using the standard deviation classification method (Fig. 5), with an average value of 0.2701 and a standard deviation of 0.0595. The vulnerability index showed the distribution characteristics of high in the north and low in the south of the city. The variation range of the vulnerability index among the subdistricts in Huairou District was the largest, whereas vulnerability among the subdistricts in Shijingshan District exhibited the smallest range. The maximum value of the vulnerability index appeared in the Manchus of Laogoumen in Huairou District, reaching 0.7064, and the minimum value appeared in Binhe Subdistrict in Pinggu District, at 0.1732.

Vulnerability index distribution of Beijing and its districts. The legend shows the result of classifying the vulnerability index by standard deviation. a Yanqing; b Huairou; c Miyun; d Pinggu; e Fangshan; f Mentougou; g Changping; h Shunyi; i Daxing; j Tongzhou; k Fengtai; l Chaoyang; m Haidian; n Shijingshan; o Dongcheng; p Xicheng; the blank areas (in a, g, and i) are missing data areas
3.4 Heat Health Risks
Based on high-temperature hazards, population exposure, and vulnerability, we calculated the daytime/nighttime heat health risk index at the subdistrict scale in Beijing using Eq. (1), and used the standard deviation method to divide the heat health risk index into five levels (Fig. 6a, b), with a mean value of 0.0289 (daytime) and 0.0276 (nighttime) and a standard deviation of 0.0383 (daytime) and 0.0382 (nighttime). Subdistricts with a heat health risk index of at least 0.5 standard deviations greater than the average were defined as heat health risk hotspots, and the heat health risk hotspots during the daytime and nighttime were mainly concentrated in Dongcheng, Xicheng, Chaoyang, Haidian, Shijingshan, and Fengtai Districts, and a few were scattered in the surrounding suburbs. At night, the heat health risk index of the suburban subdistricts was slightly lower, and the risk level of individual subdistricts was reduced by one level. Conversely, the heat health risk index of subdistricts located in central urban areas, particularly subdistricts closer to urban centers, increased slightly. Based on the risk assessment result, we conducted risk prevention partitioning for heat health risk hotspots according to the risk level and difference in dominant factors (Fig. 6c, d). Regions with a high temperature index, exposure index, and vulnerability index that were at least 0.5 standard deviations greater than the mean were considered the dominant areas of the factor. Among the 81 heat health risk areas during the daytime, 15 subdistricts were affected by three factors at the same time, and these sites were mainly concentrated in Xicheng, Chaoyang, and Dongcheng Districts; 55 subdistricts were affected by high temperature and exposure and were distributed in six central urban areas, with Haidian District being the most affected; three subdistricts were affected by high temperature and vulnerability and were distributed in Chaoyang and Xicheng Districts; one subdistrict was affected by exposure and vulnerability and was located in Tongzhou District; and seven subdistricts were affected by exposure and were scattered in various suburbs. Among the 76 high heat health risk areas at night, 16 subdistricts were affected by three factors at the same time, and they were mainly concentrated in Xicheng, Chaoyang, and Dongcheng Districts; 55 subdistricts were affected by high temperature and exposure and were distributed in six central urban areas, with Haidian District being the most affected; three subdistricts were affected by high temperature and vulnerability and were mainly distributed in Chaoyang and Xicheng Districts; and one subdistrict was affected by exposure and was in Fangshan District.

Heat health risk and hotspots. a Heat health risk index during the daytime; b Heat health risk index at night. The legend shows the result of classifying the heat health risk index by standard deviation; c Daytime heat health risk hotspots and areas affected by various factors; d Night heat health risk hotspots and areas affected by various factors. The thick black lines represent the administrative boundary of the districts; the thin gray lines represent the administrative boundary of the subdistricts. a is Yanqing; b is Huairou; c is Miyun; d is Pinggu; e is Fangshan; f is Mentougou; g is Changping; h is Shunyi; i is Daxing; j is Tongzhou; k is Fengtai; l is Chaoyang; m is Haidian; n is Shijingshan; o is Dongcheng; p is Xicheng; the blank areas (in a, g, and i) are missing data areas
3.5 Adaptability
We calculated the adaptability index of the subdistricts based on the weights of the four adaptability indicators (Table 1). The means, standard deviations, and numerical ranges of these indicators are shown in Table 3. The difference in GDP between subdistricts (889.13–1,087,092.5) was the largest, followed by the proportion of medical institutions within a 10-min walking distance and then the proportion of park green space within a 10-min walking distance (0.00–1.00; 0.00–0.9667)—these three variables showed larger standard deviations than the other variables. In contrast, the difference in the number of air conditioners per 100 households in each subdistrict was small.
We used the standard deviation classification method to divide the adaptability index into five categories. The average value was 0.2449, the standard deviation was 0.2372, the maximum value appeared in Dashila Subdistrict, Xicheng District, at 0.9650, and the minimum value appeared in Qianjiadian Town, Yanqing District, at 0.0013. Point adaptability data were used to represent the adaptive capacity of each subdistrict, and they were overlaid with the 81 heat health risk hotspots that were selected (Fig. 7). Nine subdistricts had very high adaptability, all in Xicheng District; 25 subdistricts had high adaptability and were mainly in Dongcheng District, and a few were in Xicheng and Chaoyang Districts; and 36 subdistricts had medium adaptability and were mainly in Haidian and Chaoyang Districts. Eleven subdistricts with low adaptability were mainly distributed in Fengtai and Tongzhou Districts, and a few were distributed in Miyun, Huairou, and Chaoyang Districts. Specific information is shown in Table 4.

Risk zones and their adaptability levels. The thick black lines represent the administrative boundary of the districts; the thin gray lines represent the administrative boundary of the subdistricts. a isYanqing; b is Huairou; c is Miyun; d is Pinggu; e is Fangshan; f is Mentougou; g is Changping; h is Shunyi; i is Daxing; j is Tongzhou; k is Fengtai; l is Chaoyang; m is Haidian; n is Shijingshan; o is Dongcheng; p is Xicheng
Guoyuan Subdistrict should prioritize the establishment of more medical institutions and pay attention to the spatial distribution of medical institutions to avoid over-concentration. At the same time, it should develop the economy and improve its strength; Longshan Subdistrict should be given priority to create more parks, and it should develop the economy and improve its strength; Fengtai Subdistrict should prioritize the creation of more parks and pay attention to the distribution of parks to avoid concentration; Zhongcang Subdistrict should adjust the distribution pattern of the parks, and should increase the installation of heat-relief equipment; Xinhua Subdistrict should prioritize the establishment of more medical institutions and should increase the installation of equipment for cooling; Fatou Subdistrict should prioritize the establishment of more medical institutions; Lugouqiao Subdistrict should give priority to adjusting the distribution pattern of parks to avoid concentrated distribution; Changying Town should prioritize the establishment of additional medical institutions and pay attention to their distribution; Youanmen Subdistrict should establish parks and increase green areas; Beiyuan Subdistrict should build parks, increase green space, and increase the installation of equipment for cooling; Dongtiejiangying Subdistrict should establish parks and increase green areas.
4 Discussion
In the HIM-D and HIM-N models, only the four most influential factors were selected from the broad set of candidate predictors. The predictors included in the DHs model were DEM (negative correlation with DHs), urban land area within 50 km buffer zone of the meteorological stations (positive correlation), population density (positive correlation), and grassland area within 63 km buffer zone of the meteorological stations (negative correlation). The predictors included in the NHs model were DEM (negative correlation with NHs), urban land area within 4 km buffer zone of the meteorological stations (positive correlation), population density (positive correlation), and grassland area within 74 km buffer zone of the meteorological stations (negative correlation). The optimal buffer width of urban land during the daytime (50 km) and nighttime (4 km) was quite different. This result may be related to differences in the amount of heat released by different land-use types at night. The population factor was used in both the HIM-D and the HIM-N models and in the population exposure calculation. When interpolating temperature, population density was used because human activities affect the temperature and this method better reproduces the high temperature change. Later in the exposure analysis, the population density was used to reflect the impact of high temperature on the population.
In terms of population exposure, this study used the latest seventh census data to calculate the population density of each subdistrict. In terms of vulnerability, this study selected a wealth of indicators, including gender, age, ethnicity, educational level, and living situation (living alone). Based on higher-precision subdistrict-scale heat hazard, population exposure, and vulnerability data, we calculated the heat health risk index for each subdistrict. The findings suggest that inner-city residents are at a higher heat health risk in both the daytime and nighttime compared to residents of other districts. We studied the areas affected by three risk factors (high temperature, population exposure, and vulnerability) and found that most risk areas were affected by high temperature and population exposure; some urban centers were affected by the three factors: individual subdistricts within the suburbs became high risk areas mainly owing to high population exposure.
This study evaluated the adaptability of each subdistrict from four perspectives: economic level, heat-reducing equipment, green space infrastructure, and medical resources. In particular, we considered the quantitative characteristics and distribution of parks and medical institutions and calculated the ratio of the 10-min walkable area of park green space and medical institutions. We superimposed adaptive capacity on heat health risk hotspots and finally selected 11 subdistricts with high risk and low adaptive capacity. We suggest that it is necessary to increase the number of medical institutions in Miyun’s Guoyuan Subdistrict, Tongzhou’s Xinhua Subdistrict, and Chaoyang’s Fatou Subdistrict and Changying Town so that people who are susceptible to high temperature hazards in the areas can receive timely assistance when they are affected by disasters. Zhongcang and Beiyuan Subdistrictsin Tongzhou, and Fengtai, Lugouqiao, Youanmen, and Dongtiejiangying Subdistricts in Fengtai need to build parks and green spaces, which will not only provide residents with places to avoid high temperatures but also will increase the number of woodlands and grasslands that can effectively alleviate the hazards of high temperature.
In addition, there were still some uncertainties in this study. When constructing the high-temperature interpolation models of DHs and NHs, we considered several conventional predictors, such as land cover type, DEM, and population density. There are additional factors that were not considered, such as the 3D morphology of urban buildings, which may cause some uncertainty in the temperature simulation of central city areas because such spaces have more high-rise buildings than less central locations. For other subdistricts outside the central city area, which account for the majority of Beijing’s territory, the 3D morphology of urban buildings may have less impact.
During the summer, human health is not only affected by high temperature, but also is influenced by the combination of temperature and humidity. Our study considered only temperature and carried out high-temperature hazard assessment, ignoring the influence of humidity on human health, because hourly data for humidity are difficult to obtain.
It has been shown that people with disease are particularly vulnerable to heat, but preexisting health condition was absent in our study. Data for our vulnerability indicators were derived from the sixth census. For the vulnerability indicators, the seventh census report did not provide information on the age structure, gender, and ethnicity of the population in each subdistrict, so we made an estimate with reference to the relevant proportions in the sixth census report. There is a slight difference in the Beijing subdistrict boundaries between the seventh census report and the sixth census report, and there are eight additional subdistricts that have no data on gender, age, and ethnicity (in Yanqing District: Xiangshuiyuan, Rulin, and Baiquan Subdistricts; in Changping District: Huoying, Tiantongyuan North, and Tiantongyuan South Subdistricts; in Daxing District: National New Media Industry Base and Daxing Biomedical Industry Base). Among them, Huoying, Tiantongyuan North, and Tiantongyuan South Subdistrictsin Changping District have relatively high population exposure, are relatively close to the central city, and have high temperature hazards. However, due to the lack of vulnerability data, no risk assessment has been conducted. Therefore, this study may have underestimated the risk of heat exposure in these areas.
When calculating the risk index, we assumed that the three factors of high-temperature hazard, population exposure, and vulnerability were equally important and gave them the same weight. The importance of these three factors may be assessed in the future and assigned different weights according to their importance.
5 Conclusion
In this study, the subdistrict-scale heat health risk and adaptability in metropolitan Beijing were assessed. The conclusions are:
-
(1)
Since land use and human activities are closely related to high temperature, both the HIM-D and the HIM-N models constructed by combining land use and socioeconomic data performed well in interpolating the cumulative hours of high temperature in Beijing. Their interpolation results are better than those interpolated by ordinary kriging. The method is applicable to the study area at the city level, and the models may vary among regions due to land use and human activity differences;
-
(2)
The high-temperature hazards challenged the residents in the central urban area with a high population density, especially at night. The reasons for this day/night difference deserve to be explored in the future. The spatial distribution of the vulnerability index had no clear patterns. The selection of vulnerability indicators is the most critical step for vulnerability analysis, and equally important indicators such as income, illness status, and so on can be taken into account in future studies;
-
(3)
The heat health risk hotspots were mainly located in the central urban area, with 81 hotspots during the daytime and 76 at night. The average heat health risk index of urban areas was 5.60 times higher than that of suburban areas (daytime) and 6.70 times higher than that of suburban areas (nighttime). Higher population density and higher heat hazards were the main reasons for the high-risk index in most heat health risk hotspots;
-
(4)
The adaptability index also showed numerical distribution characteristics of low outside and high inside the central city. Eleven subdistricts with high-risk and low-adaptation were identified as priority areas for city administrators and improvement methods were proposed from six perspectives: the number of heat-reducing devices, GDP, parks, medical institutions, distribution of parks, and distribution of medical institutions. More adaptation indicators should be considered in future studies.
Notes
https://www.bjxch.gov.cn/xcsj/xxxq/pnidpv896475.html for Xicheng District, for example.
References
Barriopedro, D., E.M. Fischer, J. Luterbacher, R.M. Trigo, and R. García-Herrera. 2011. The hot summer of 2010: Redrawing the temperature record map of Europe. Science 332(6026): 220–224.
Chander, G., B.L. Markham, and D.L. Helder. 2009. Summary of current radiometric calibration coefficients for Landsat MSS, TM, ETM+, and EO-1 ALI sensors. Remote Sensing of Environment 113(5): 893–903.
Curriero, F.C., K.S. Heiner, J.M. Samet, S.L. Zeger, L. Strug, and J.A. Patz. 2002. Temperature and mortality in 11 cities of the eastern United States. American Journal of Epidemiology 155(1): 80–87.
Cutter, S.L., and C. Finch. 2008. Temporal and spatial changes in social vulnerability to natural hazards. Proceedings of the National Academy of Sciences of the United States of America 105(7): 2301–2306.
Cutter, S.L., B.J. Boruff, and W.L. Shirley. 2003. Social vulnerability to environmental hazards. Social Science Quarterly 84(2): 242–261.
Du, W., W. Quan, C. Xuan, X. Fang, and W. Guo. 2014. The study of high temperature disaster risk zoning in Beijing-Tianjin-Hebei urban agglomeration. Journal of Nanjing University (Natural Sciences) 50(6): 829–837.
El-Zein, A., and F.N. Tonmoy. 2015. Assessment of vulnerability to climate change using a multi-criteria outranking approach with application to heat stress in Sydney. Ecological Indicators 48: 207–217.
Hu, K., X. Yang, J. Zhong, F. Fei, and J. Qi. 2017. Spatially explicit mapping of heat health risk utilizing environmental and socioeconomic data. Environmental Science & Technology 51(3): 1498–1507.
Hua, J., X. Zhang, C. Ren, Y. Shi, and T.-C. Lee. 2021. Spatiotemporal assessment of extreme heat risk for high-density cities: A case study of Hong Kong from 2006 to 2016. Sustainable Cities and Society 64: Article 102507.
IPCC (Intergovernmental Panel on Climate Change). 2007. Climate change 2007: The physical science basis. Working group I contribution to the fourth assessment report of the Intergovernmental Panel on Climate Change. Cambridge, UK: Cambridge University Press.
IPCC (Intergovernmental Panel on Climate Change). 2014. Climate change 2014: Impacts, adaptation, and vulnerability. Working group II contribution to the fifth assessment report of the Intergovernmental Panel on Climate Change. Cambridge, UK and New York, USA: Cambridge University Press.
Johnson, D.P., A. Stanforth, V. Lulla, and G. Luber. 2012. Developing an applied extreme heat vulnerability index utilizing socioeconomic and environmental data. Applied Geography 35(1–2): 23–31.
Kestens, Y., A. Brand, M. Fournier, S. Goudreau, T. Kosatsky, M. Maloley, and A. Smargiassi. 2011. Modelling the variation of land surface temperature as determinant of risk of heat-related health events. International Journal of Health Geographics 10(1): Article 7.
Klinenberg, E. 2003. Heat wave: A social autopsy of disaster in Chicago. Chicago and London: University of Chicago Press.
Li, H., J. Zhao, Y. Gao, and Z. Gu. 2022. Prediction and evaluation of spatial distributions of ozone and urban heat island using a machine learning modified land use regression method. Sustainable Cities and Society 78: Article 103643.
Luber, G., and M. McGeehin. 2008. Climate change and extreme heat events. American Journal of Preventive Medicine 35(5): 429–435.
Luo, X., Y. Du, and J. Zheng. 2016. Risk regionalization of human health caused by high temperature & heat wave in Guangdong Province. Climate Change Research 12(2): 139–146.
Morabito, M., A. Crisci, B. Gioli, G. Gualtieri, P. Toscano, V. Di Stefano, S. Orlandini, and G.F. Gensini. 2015. Urban-hazard risk analysis: Mapping of heat-related risks in the elderly in major Italian cities. PLOS ONE 10(5): Article e0127277.
Patz, J.A., D. Campbell-Lendrum, T. Holloway, and J.A. Foley. 2005. Impact of regional climate change on human health. Nature 438: 310–317.
Reid, C.E., M.S. O’Neill, C.J. Gronlund, S.J. Brines, D.G. Brown, A.V. Diez-Roux, and J. Schwartz. 2009. Mapping community determinants of heat vulnerability. Environmental Health Perspectives 117(11): 1730–1736.
Semenza, J.C., C.H. Rubin, K.H. Falter, J.D. Selanikio, W.D. Flanders, H.L. Howe, and J.L. Wilhelm. 1996. Heat-related deaths during the July 1995 heat wave in Chicago. New England Journal of Medicine 335(2): 84–90.
Shi, Y., C. Ren, M. Cai, K.-L. Lau, T.-C. Lee, and W.-K. Wong. 2019. Assessing spatial variability of extreme hot weather conditions in Hong Kong: A land use regression approach. Environmental Research 171: 403–415.
Stott, P.A., D.A. Stone, and M.R. Allen. 2004. Human contribution to the European heatwave of 2003. Nature 432(7017): 610–614.
Tomlinson, C.J., L. Chapman, J.E. Thornes, and C.J. Baker. 2011. Including the urban heat island in spatial heat health risk assessment strategies: A case study for Birmingham, UK. International Journal of Health Geographics 10: Article 42.
Uejio, C.K., O.V. Wilhelmi, J.S. Golden, D.M. Mills, S.P. Gulino, and J.P. Samenow. 2011. Intra-urban societal vulnerability to extreme heat: The role of heat exposure and the built environment, socioeconomics, and neighborhood stability. Health & Place 17(2): 498–507.
Weng, Q., D. Lu, and J. Schubring. 2004. Estimation of land surface temperature–vegetation abundance relationship for urban heat island studies. Remote Sensing of Environment 89(4): 467–483.
Wolf, T., and G. McGregor. 2013. The development of a heat wave vulnerability index for London, United Kingdom. Weather and Climate Extremes 1: 59–68.
Wolf, T., W.-C. Chuang, and G. McGregor. 2015. On the science-policy bridge: Do spatial heat vulnerability assessment studies influence policy?. International Journal of Environmental Research and Public Health 12(10): 13321–13349.
Xie, P., Y. Wang, Y. Liu, and J. Peng. 2015a. Incorporating social vulnerability to assess population health risk due to heat stress in China. Acta Geographica Sinica 70(7): 1041–1051.
Xie, P., Y. Wang, Y. Liu, and J. Peng. 2015b. Health related urban heat wave vulnerability assessment: Research progress and framework. Progress in Geography 34(2): 165–174.
Yin, Z., J. Yin, and X. Zhang. 2013. Multi-scenario-based hazard analysis of high temperature extremes experienced in China during 1951–2010. Journal of Geographical Sciences 23(3): 436–446.
Zhang, M., and H. Li. 2020. Framework and application of health risk assessment of heat wave in Beijing. Journal of Environmental Health 37(1): 58–65 (in Chinese).
Zhu, Q., T. Liu, H. Lin, J. Xiao, Y. Luo, W. Zeng, S. Zeng, Y. Wei, et al. 2014. The spatial distribution of health vulnerability to heat waves in Guangdong Province, China. Global Health Action 7: Article 25051.
Acknowledgments
This work was jointly supported by the National Key Research and Development Program of China (2019YFC0507805) and the Strategic Leading Science and Technology Program of the Chinese Academy of Sciences (XDA20020202). We express our sincere appreciation to the anonymous reviewers for their constructive comments.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Su, X., Wang, F., Zhou, D. et al. Heat Health Risk and Adaptability Assessments at the Subdistrict Scale in Metropolitan Beijing. Int J Disaster Risk Sci 13, 987–1003 (2022). https://doi.org/10.1007/s13753-022-00449-8
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13753-022-00449-8