
Abstract
Purpose of Review
Omics-based technologies were suggested to provide an advanced understanding of obesity etiology and its metabolic consequences. This review highlights the recent developments in “omics”-based research aimed to identify obesity-related biomarkers.
Recent Findings
Recent advances in obesity and metabolism research increasingly rely on new technologies to identify mechanisms in the development of obesity using various “omics” platforms. Genetic and epigenetic biomarkers that translate into changes in transcriptome, proteome, and metabolome could serve as targets for obesity prevention. Despite a number of promising candidate biomarkers, there is an increased demand for larger prospective cohort studies to validate findings and determine biomarker reproducibility before they can find applications in primary care and public health.
Summary
“Omics” biomarkers have advanced our knowledge on the etiology of obesity and its links with chronic diseases. They bring substantial promise in identifying effective public health strategies that pave the way towards patient stratification and precision prevention.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The obesity pandemic has emerged as a leading global public health threat of the twenty-first century increasingly spreading across both developed and developing countries with the most vulnerable and socially disadvantaged population groups being most affected [1, 2]. Despite the growing recognition of the problem, obesity prevalence has nearly tripled since 1975 affecting billions of people around the world. According to estimates of the World Health Organization (WHO), in 2016, 1.9 billion people (40% of the world population) were overweight, and of these, over 650 million (13% of the world population) were obese [3]. There is a worrying tendency of climbing rates of morbid obesity, especially among children [4].
Long considered a merely intermediate chronic disease “risk factor” or socially unacceptable behavior reflecting a lack of willpower, obesity was recently recognized as a systemic chronic disease related to excessive and abnormal accumulation of body fat leading to adverse health effects. Obesity was defined as a multi-causal chronic disease recognized across the life span resulting from long-term positive energy balance with the development of excess adiposity that over time leads to structural abnormalities, physiological derangements, and functional impairments [5]. Obesity increases the risk of developing numerous comorbidities (e.g., type 2 diabetes, non-alcoholic fatty liver disease, cardiovascular disease, and certain types of cancer) and increased premature mortality [6]. Despite its rapidly increasing prevalence across the globe, obesity as a public health threat has not yet received the same urgent attention as it has rapidly spreading infectious diseases. Until today, public health initiatives have not been able to reverse the accumulating burden of obesity in any population [7]. So far, there is little evidence of successful population-level intervention strategies that reduce the high prevalence of obesity in populations across the globe effectively. With most recently published statistics on the alarming magnitude of the pandemic, the urgency of better strategies for preventing and management of obesity has never been more obvious. The pathogenesis of obesity is far more complex than just an imbalance between energy intake and expenditure leading to passive accumulation of excess weight. Recent research has highlighted the importance of the gene-environment interactions (epigenetic modifications), and complex and persistent hormonal, metabolic, neurochemical, and immune-inflammatory disturbances involved in obesity development [8]. To date, the specific regulatory alterations and metabolic consequences of excess and prolonged accumulation of body fat are not clearly understood.
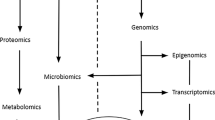
Technology advancements during the last decades and the paralleled “omics” revolution have brought forward an accelerated research incentive and a new promise for an improved understanding of the mechanisms explaining the complex biology behind obesity [9]. The identification of novel “omics” biomarkers could bring forward the knowledge on the etiology of obesity and its pathophysiological links with chronic diseases [10]. Furthermore, “omics” biomarkers could aid in getting a refined characterization of obesity phenotypes and serve as targets for precision prevention and therapy [9, 11]. Intensified efforts in “omics” research have been invested in the identification of genes (genomics), messenger RNA (mRNA) and microRNAs (miRNAs) (transcriptomics), proteins (proteomics), and metabolites (metabolomics) [12]. Other “omics” platforms that provide insights into the regulation of biological pathways include epigenetic markers—mostly DNA methylation—of gene expression and phenotype (epigenomics) and gut microbiota (microbiomics). Different analytical platforms and bioinformatic tools have been developed to explore the abundance of generated data such as individual omics-based approaches, pathways, and/or network analyses. Newer trends include integrative approaches such as multi-omics and trans-omics analyses [13] (Fig. 1. “Omics” platforms in obesity research).

“Omics” platforms in obesity research
This narrative review presents an overview of the development and recent highlights in published research on “omics” biomarkers in obesity from human epidemiological studies in understanding the etiology and pathophysiology of obesity and its phenotypic characterization.
Search Strategy and Selection Criteria
References were identified by searches of PubMed with the terms “obesity,” “adiposity,” “central obesity,” “body mass index,” “waist circumference,” “waist-to-hip ratio,” “BMI,” “WHR,” “body fat,” “fat mass” in combination with the terms “omics,” “biomarkers,” “genome,” “genomics,” “genome wide association study,” “GWAS,” “epigenome,” “epigenomics,” “transcriptome,” “transcriptomics,” “miRNA,” “metabolomics,” “proteomics,” “lipidomics,” “glycome,” “glycomics,” “microbiome,” and “microbiomics.” Bibliography lists of the identified publications were also screened to identify additional articles. The search mainly focused on papers published from January 1, 2015 to March 31, 2020; however, previous review articles and key publications that shaped the field were also included.
Genomics
Evidence on genetic origins of obesity emerged in the 1970s with twin and adoption studies, providing first clues on genetic heritability of obesity that has been estimated to be 40 to 70% [14]. In the 1990s, the discovery of leptin and leptin receptor genes and the leptin-driven melanocortin 4 signaling pathways prompted a sequence of genetic studies that uncovered rare mutations in single genes regulating appetite leading to early-onset extreme obesity [15]. This rare monogenic form of obesity is largely caused by high-risk genetic variations involved in the control of appetite and energy maintenance along the leptin-melanocortin pathway [15]. A number of variants involved in monogenic obesity have been described in the literature [15, 16]. However, for the majority of the population, obesity is multifactorial and genetic susceptibility is determined by the influence of multiple genetic variants [16, 17]. Genomic research has rapidly developed in the last two decades due to the development of DNA-microarrays-based techniques and next-generation sequencing (NGS) that allow mapping of the generated sequences and analyses of population-specific genetic traits [18]. With the emergence of genome-wide association studies (GWASs), hundreds of genetic variants involved in different biological pathways (e.g., central nervous system control of food intake and energy expenditure, food sensing and digestion, adipocyte differentiation, and insulin signaling) have been associated with polygenic obesity [19,20,21]. A recent GWAS based on 700,000 individuals identified 941 near-independent single-nucleotide polymorphisms (SNPs) associated with BMI [22]. Among specific genes explored in the different GWASs, the FTO and MC4R genes have emerged as major contributors to all polygenic obesity phenotypes [17, 23]. Notably, the genes at different loci seem to work in interaction with each other converging on certain pathways and networks differentially reflecting biological processes associated with fat accumulation and fat distribution [24]. Despite the enormous number of discovered loci, these collectively explained less than 3% of the variance of BMI observed [22]. Part of the gap between the explained genetic variance of BMI and the estimated heritability (40–70%) could be accounted for by the inability of GWASs to detect loci that are associated with traits whose effect sizes are too small to reach genome-wide statistical significance. To address this aspect, a number of studies attempted to develop effective multi-locus profiles of genetic risk for obesity, known as genetic risk scores (GRS). However, these scores only showed a relatively low correlation with measured BMI ranging from 0.01 to 0.12 [17]. Obtaining meaningful predictive power of a polygenic score is dependent on the information from multiple common variants. As compared to scores that were based on a restricted number of loci, a new GRS has been generated to predict BMI based on 2.1 million common genetic variants measured in 306,135 individuals [25]. This GRS outperformed previous scores from the GWAS that reached genome-wide statistical significance in predicting obesity and weight gain [25]. For instance, the 2.1 million-variant score showed a stronger correlation with BMI (correlation coefficient 0.29) as compared with the 141-variant score (correlation coefficient 0.13) [25]. Larger discovery GWASs and computational algorithms would likely lead to an increased ability of future GRS to identify high-risk individuals and could facilitate targeted strategies for obesity prevention that can start already in early childhood. Furthermore, since individuals at elevated genetic risk are also most susceptible to risk posed by obesogenic environments, GRS could be helpful in guiding lifestyle interventions targeted at high-risk individuals [26].
Epigenomics
Recent years witnessed an unprecedented boost of research on understanding the role of the human epigenome in health and disease. Epigenetic regulation can involve DNA modifications (e.g., DNA methylation), histone modifications, and non-coding RNAs (e.g., miRNAs), and may affect all DNA-based processes without altering the DNA sequence [27]. Epigenomic biomarkers, mostly defined based on DNA methylation of cytosines in cytosine-guanine dinucleotides (CpG), are prone to changes in response to environmental factors and could reflect different developmental windows over the human life span. Such biomarkers can be determined based on whole-genome bisulfite sequencing and epigenomic array-based technologies [28]. The importance of epigenetic changes has been first acknowledged by human epidemiological studies that provided evidence that prenatal and early postnatal environmental factors influence behavioral disorders and exert increased chronic disease risk later in life [29, 30]. In particular, early-life exposures to stress, under- or overnutrition during gestation or lactation, are associated with overweight or obesity in later adulthood [31]. Epigenetic dysregulation through DNA methylation of genes involved in growth, inflammation, lipid metabolism, glycolysis, or adipogenesis may explain these associations [32, 33]. Data from the Dutch Hunger Winter Families study suggested significant differences in DNA methylation patterns associated with periconceptional famine exposure [34, 35]. Recently, epigenome-wide association studies (EWASs) provided new lines of evidence on the association between genome-wide (array-based) DNA methylation and obesity or related phenotypes [36,37,38,39]. For example, a recent EWAS using whole-blood samples from 5387 individuals from the EPICOR, KORA, and LOLIPOP cohorts identified changes in DNA methylation of 187 genetic loci associated with BMI. Gene set enrichment analysis revealed that altered patterns were observed in genes involved in lipid and lipoprotein metabolism, substrate transport, and inflammatory pathways [36]. In another EWAS study based on a sample of 641 participants in the REGICOR study and a validation sample of 2515 participants in the Framingham Offspring cohort, 70 CpG regions were associated with BMI and 33 CpG regions [37]. These markers explained ~ 26% and ~ 29% of the variability of BMI and waist circumference, respectively [37]. Of note, very few methylation pattern variations of the CpG regions were consistently associated with obesity across published studies, which may indicate a large number of false-positive findings in EWAS studies [40]. Due to methodological challenges, human studies on histone modifications in obesity have been sparse. Especially, omics-based studies have been lacking. So far, one study used the chromatin immunoprecipitation (ChIP) method to analyze histone methylations in adipose tissue of a cohort of 39 patients with different metabolic profiles [41]. The results suggested that H3K4me3 enrichment in the promoter of several factors involved in adipogenesis, lipid metabolism, and inflammation in visceral adipose tissue, i.e., LEP, PPARG, IL6, and TNF, were directly associated with higher BMI and metabolic deterioration [41]. Observations like these support the role of epigenetics in obesity risk. Further epigenomic analyses using novel “omics” techniques, such as CHIP sequencing, would be warranted to evaluate histone modification biomarkers in human obesity research.
Overall, epigenetic changes are plastic and dynamic, and finding out if they are a cause or a consequence of disease has been challenging. Methylation patterns and histone modifications vary across different cell types and over time [42] and can be influenced by multiple extrinsic and intrinsic factors, making epidemiological data difficult to interpret [43].
Transcriptomics
Transcriptomics may bridge the gap between GWAS and physiological studies by deciphering information residing in genes [44]. Transcriptomic biomarkers include protein-coding RNAs (mRNAs) and non-coding RNAs (ncRNAs) that can be measured using RNA sequencing and array-based gene expression methods [45]. Tissue-specific analyses of the mRNA transcriptome of adipocytes from visceral and subcutaneous fat cells revealed more than a thousand genes whose expression was altered in obese as compared to lean individuals [46, 47]. Due to the rare availability of tissue samples in large epidemiological studies, alteration in the peripheral blood transcriptome was used as a valid alternative in the identification of transcriptomic biomarkers in obesity [47]. Whole-blood mRNA levels determined by array-based transcriptional profiling were correlated with BMI in two large independent population-based cohort studies (KORA F4 and SHIP-TREND) comprising a total of 1977 individuals [46]. The obesity-associated gene expression signatures pointed to key metabolic pathways involved in protein synthesis, enhanced cell death from proinflammatory or lipotoxic stimuli, enhanced insulin signaling, and reduced defense control against reactive oxygen species [46]. Protein-coding genes represent less than 2% of the total genomic sequence, whereas about 98% of the DNAs are transcribed as ncRNAs [48]. The development of high-throughput sequencing technologies allowed the identification of ncRNAs, such as miRNAs and long ncRNAs (lncRNAs) [48]. miRNAs elicit post-transcriptional repression of gene expression and several studies suggested that specific miRNAs were differentially expressed in adipose tissue of obese individuals as compared to those with normal weight [49]. miRNAs have shown to exert important regulatory roles in adipogenesis, adipocyte differentiation, and insulin signaling [50, 51]. Although these findings require invasive methods for sample collection (biopsies of adipose tissue) and consequently are based on an only a limited number of participants—often from clinical studies—they provide valuable insights into the mechanistic understanding of the ongoing progressive disbalances observed during obesity progression [52, 53]. On the other hand, circulating miRNAs (cmiRNAs) are released by tissues into the bloodstream and, therefore, are regarded as promising candidate biomarkers for further clinical application since samples can be collected by minimally invasive methods [44]. As cmiRNAs are released into the bloodstream, they serve as key messengers between cells and tissues, participating in the metabolic organ crosstalk [54]. A recent systematic review identified 33 cmiRNAs with dysregulated expression in serum or plasma in people with obesity compared to lean controls that have been replicated by two or more independent research groups [55]. A majority of the genes identified via obesity-related cmiRNAs is involved in fatty acid metabolism and phosphoinositide 3-kinase (PI3K-Akt) pathways [55]. In addition to the miRNAs, recently, lncRNAs also gained importance in obesity research as key regulators of adipogenesis, inflammation, and insulin sensitivity [56,57,58,59,60]. For example, a functional lncRNA arising from the CEBPα locus involved in adipogenesis was shown to prevent CEBPα gene methylation, resulting in elevated expression of the CEBPα mRNA [61]. Overall, transcriptomic studies face innumerous challenges, including the fact that the transcriptome varies by tissues and cell types as well as within these tissues and over time. Although an exciting prospect, the isolation and profiling of cmiRNAs from human samples remains challenging, mostly due to their extremely low concentrations. Differences in sample extraction, cmiRNA isolation, quantification, or profiling methods may yield inaccurate and/or non-reproducible results [62]. More research on ncRNAs that integrates experimental and bioinformatic tools is needed to gain a better knowledge of whether they could be successfully applied in preventive and clinical care.
Proteomics
Proteomics has emerged as a powerful tool in the identification and biochemical characterization of proteins that are associated with obesity and its comorbidities. It has the advantage of being capable of detecting protein post-translational modifications and protein interactions that cannot be detected by genomics and transcriptomics. The most common bioanalytical platforms for proteomic analysis include matrix-assisted laser desorption/ionization-coupled with time-of-flight mass spectrometry (MALDI-TOF-MS), liquid chromatography coupled with electrospray ionization mass spectrometry (LC-ESI-MS), surface-enhanced laser desorption/ionization mass spectrometry (SELDI-TOF-MS), and protein microarray [63]. Secreted proteins constitute an important class of molecules expressed by approximately 10% of the human genome [64]; therefore, serum/plasma proteome provides a useful resource for monitoring molecular events of pathophysiological changes that occur in obesity [63]. Most population-based proteomic studies in obesity have been based on small samples and had limited analytical and outcome reproducibility [65,66,67,68,69]. A recent study characterized and compared the plasma proteomes of two large independent cohorts of obese patients in Canada and Europe including 1002 obese and overweight individuals using shotgun MS-based proteomic measurements. Statistically significant associations with BMI could be seen for the following biomarkers: complement factor B (CFAB), complement factor H (CFAH), complement factor I (CFAI), C-reactive protein (CRP), proline-rich acidic protein 1 (PRAP1), and the calprotectin complex formed by proteins S100-A8 and S100-A9 [70]. Among these proteins, CRP showed the strongest association with BMI and it was also associated with all identified biomarkers. Altogether, these findings suggest that chronic inflammation in obese persons could represent the underlying reason for the associations of these biomarkers with obesity [70]. Further well-designed epidemiological studies based on proteomic analyses are warranted to determine signature proteins that can serve as biomarkers for obesity and related diseases.
Metabolomics
Metabolomics pursues to measure the totality of metabolites in a given biological system [71]. Metabolites represent a diverse group of low-molecular-weight structures among them lipids, amino acids, peptides, organic acids, and carbohydrates. Most recently, lipidomics emerged as an important branch of metabolomics with special relevance to obesity research [72]. There are two analytical approaches, untargeted and targeted metabolomics which can be based on nuclear magnetic resonance (NMR) spectroscopy or MS technologies. On the one hand, untargeted metabolomics uses an exploratory design and simultaneously measures up to several thousand metabolites, but many of them may remain unidentified. On the other hand, targeted metabolomics is limited to a predefined set of metabolites but provides metabolite identity and often quantitative data. Both strategies found distinct metabolic alterations in obese compared to lean subjects across different study populations, including higher plasma levels of branched-chain amino acids (BCAA) and aromatic amino acids and lower plasma levels of glycine, as well as higher plasma levels of acylcarnitines, fatty acids, and certain phospholipids [73,74,75,76]. Higher concentrations of BCAA and aromatic amino acids and lower concentrations of glycine have also been linked to insulin resistance [77] and a higher risk of type 2 diabetes [78, 79]. Increased levels of BCAA were also suggested to enhance activation of the mammalian target of rapamycin (mTOR) signaling, oxidative stress, mitochondrial dysfunction, and apoptosis [80]. Via these pathways, BCAA may be involved in the pathophysiology of obesity and associated diseases and may therefore serve as a promising target biomarker. Further mechanistic and epidemiological studies are needed to understand the role of BCAA in these chronic diseases and might lead to the recommendation to limit BCAA intake (e.g., to those at higher risk of developing these chronic diseases) , and the establishment of therapeutic intervention that might ameliorate BCAA-driven dysregulation in cellular signaling and consequent maladaptive phenotypes [80]. Overall, metabolomics has a high potential to improve precision medicine of serious metabolic diseases such as obesity through a more precise patient stratification and monitoring and might lead to the development of intervention strategies, including drug discovery and testing [81].
Lipidomics
Lipidomics is a branch of metabolomics that is focused on measuring lipid species in a given biological system [72]. Divided into fatty acyls, glycerolipids, glycerophospholipids, sphingolipids, sterols, and prenols [82], the large chemical diversity of these molecules and their dynamic change in response to physiological and environmental factors represent challenges for their analytical determination and quantification and for understanding their biological roles. A combination of different bioanalytical techniques is necessary to achieve high sensitivity and high specificity of complex untargeted and targeted lipidomic experiments [83, 84]. For decades, simple lipid profile analysis has been a fundamental tool in clinical practice to assess dyslipidemia [85]. Technological advancements in MS allowed understanding that numerous other plasma lipids are mediators of metabolic dysfunction and disease progression in obesity and obesity-related chronic diseases, transcending the clinical commonly used lipid panel [86]. Previous lipidomic studies identified higher concentrations of short- and medium-chain acylcarnitines in obese compared to lean subjects which may result from impaired fatty acid biosynthesis and oxidation [87]. In addition, plasma concentrations of free fatty acids, in particular, proinflammatory omega-6-fatty acids, were shown to be increased in obesity as a result of stress to adipose tissue [75]. Using targeted metabolomics in the EPIC-Potsdam study, we previously found that mostly phospholipids from the diacyl-phosphatidylcholine subclass were positively correlated with BMI and waist circumference, whereas acyl-alkyl-phosphatidylcholines and some lysophosphatidylcholines were negatively correlated with these obesity measures [74]. Other studies confirmed distinct phospholipid profiles in obesity [73, 76]. Phosphatidylcholines are primarily synthesized hepatically and secreted as part of blood lipoproteins [88]. We previously showed in the EPIC-Potsdam study that diacyl-phosphatidylcholines were positively correlated with triglyceride concentrations, whereas acyl-alkyl-phosphatidylcholines were positively correlated with high-density lipoprotein cholesterol [79]. Thus, they may represent a more complex picture of dyslipidemia in obesity. In addition, an intervention study suggests that high-fiber diets may beneficially alter metabolic profiles of phospholipids in obese individuals [89]. This study provides one example of the application of lipidomics in the development of obesity prevention strategies.
Glycomics
Glycans are ubiquitously present in all cells. They are essential for cellular physiological processes and are linked to other biomolecules such as lipids (glycolipids) and proteins (glycoproteins and proteoglycans) through glycosidic linkages to form glycoconjugates [90]. Around 70% of the proteins in the human body are glycosylated. Protein-bound glycans can be N or O linked and represent the two major types of glycans [91]. Around 700 proteins integrate the glycosylation machinery, making glycan biosynthesis intensively more complex than protein synthesis [92]. Glycosylation is essential for a multitude of biological functions [93] and alterations in glycosylation during the transition from health to disease and disease progression have boosted the scientific interest in studying the glycome [92, 94]. In comparison to other “omics,” however, glycomic databases are still underdeveloped, owning to the complexity of glycan composition, heterogeneity, and the vast variation of branching [95]. In glycomic LC-MALDI-MS, capillary electrophoresis (CE)-ESI-MS and LC-ESI-MS are the most common applied bioanalytical techniques [91]. The glycome could provide a key in understanding the mechanistic links between obesity and metabolic diseases. Recent epidemiological studies suggested that IgG N-glycosylation pattern variations, including lower galactosylation, correlate with measures of obesity and central adiposity [96,97,98,99]. IgG galactosylation strongly decreases its proinflammatory activity [96] and its decrease observed in obese individuals could contribute to chronic inflammatory state featured in obesity. Further glycomic research might lead to the discovery of novel inflammatory biomarkers that contribute to obesity development, persistence, and progression.
Microbiomics
The human microbiome comprises the sum of all human-associated microorganisms (microbiota) living within a well-defined habitat within the human body [100]. Dysbiosis was coined as a term more than 100 years ago to denote the imbalance in the composition and metabolic capacity of the microbiota [101, 102]. Microbiomic studies focus on the better characterization of the microbial structure, function, and composition [100]. Several approaches and analytical techniques have been applied in microbiomics such as sequencing data of the gene that encodes the RNA component of the small ribosomal subunit (16S rRNA) for profiling taxonomic abundance of microorganisms, NGS technologies for metagenomic studies comprising gene identification [100, 103], and microarray-based technologies for meta-transcriptomic analysis [104]. Metabolomic and multi-omics approaches have been also recently applied to study the microbiome function and composition and assess the consequences of host-microbiome interactions [104,105,106]. Altered gut microbiota composition as measured by a relative increase in the Firmicutes/Bacteroidetes ratio has been commonly reported in obese individuals [107,108,109]. However, the effect sizes of observed associations of taxonomic composition and obesity in epidemiological studies were generally weak [110] and inconsistent [111]. Beyond taxonomic composition revealed by genomic studies, metagenomic studies reveal information on the genetic functional diversity of the gut microbiota. A recent meta-analysis has shown that gut microbiome metagenomic functional diversity traits and patterns correlate with obesity (e.g., N-glycosylation by oligosaccharyltransferase is depleted in obese individuals), highlighting the importance of the microbiome function over its composition [112]. A recent systematic review comparing concentrations of short-chain fatty acids (SCFA) between obese and lean individuals concluded that obese individuals had higher concentrations of acetate in blood and feces, propionate and valerate in feces, and butyrate in feces produced by fermentation of dietary fiber in the gut. These SCFAs were suggested to play roles in metabolic modulation, appetite regulation, and immune function [113, 114]. Diverse epidemiological studies have shown that exposure to antibiotics in the first year of life is associated with an increased risk of obesity during childhood and adolescence [115,116,117,118]. Antibiotic-induced dysbiosis in early life was suggested to lead to obesity development by diverse mechanisms including a decrease of metabolic protective species, by affecting the amount of calories absorbed from the diet, alteration of hepatic function, and hormone secretion, and impaired metabolic signaling [115]. A recent meta-analysis reported a significant dose-response relationship between antibiotic exposure in very early life and childhood adiposity, showing elevated risk with repeated doses [117]. Microbiomic studies also allowed the assessment of probiotics, synbiotics, and prebiotics in the management of obesity. For example, supplementation with synbiotics containing specific strains (e.g., Lactobacillus gasseri strains) exerted anti-inflammatory properties and led to efficient weight loss in obese patients [119]. Although research has not succeeded in fully defining the parameters for a health advantageous gut microbiome, studies that emphasize function over composition will be a trend future microbiomic research [120]. Improvement of the knowledge in the interactions between the microbiome and the host health might aid in understanding its etiological role in obesity and in the identification of new targets for precision prevention and therapy.
“Omics” Biomarkers as Targets for Bariatric Surgery and Weight-Loss Interventions
“Omics” biomarkers have been increasingly explored to assess the effects of weight-loss interventions on the epigenome, transcriptome, metabolome, and microbiome. Bariatric surgery is regarded as the most effective treatment strategy of severe obesity alleviating the risk of obesity-related comorbidities (e.g., type 2 diabetes, cardiovascular diseases) [121]. Changes in “omics” biomarkers could provide additional insight on the pathophysiological mechanisms mediating beneficial effects of weight loss. In this vein, several studies demonstrated significant changes in DNA methylation patterns following bariatric surgery, highlighting the role of the epigenome in mediating beneficial effect of weight loss intervention on metabolic disturbances in obesity [122,123,124]. Adipose tissue-specific and whole-blood transcriptomic profiles have also shown to be altered after bariatric surgery [121, 123, 125]. Bariatric surgery could especially strongly influence human metabolism captured by metabolomic changes in amino acid, lipids, carbohydrates, or gut microbiome alterations [126]. For example, a small intervention study of 39 morbidly obese patients quantified acylcarnitines, (lyso)phosphatidylcholines, sphingomyelins, amino acids, biogenic amines, and hexoses in serum samples before and 1, 3, and 6 months after bariatric surgery [127]. The findings demonstrated beneficial effects of bariatric surgery on metabolic health by the restoration of the sphingolipid-phospholipid metabolism through the improvement of the lipoprotein profile [127]. Due to the small scale of most bariatric surgery intervention studies, interpretation of complex and extensive data outputs from “omics” data should be done with caution. Meta-analytical and advanced bioinformatic modeling that combine results from multiple intervention studies could provide additional insights on obesity pathophysiology but also evaluate “omics” biomarkers as treatment targets [124].
Integrative Multi-“omics” and Bioinformatics
The high amount and complexity of data generated by the different high-throughput analytical assays required the development and application of a number of bioinformatic and biostatistic tools to “make sense” of the generated “omics” data [18]. Novel machine learning algorithms, such as deep learning and artificial neural networks, have been gaining popularity as powerful approaches for analysis of heterogeneous and complex data [9]. Advanced bioinformatic methods are especially advantageous in analyzing combinations of “omics” datasets [128]. Integrated multi-“omics” approaches have further emerged as a collective field aiming to obtain a better understanding of the complexity and interactions of the biological systems including those predisposing obesity [129]. Nevertheless, the application of multi-omics approaches has faced a number of challenges including multiple sources of bias arising from differences in study designs, sample collection, measurement, and data analysis methods [128]. Despite the increased availability of analytical and programming options, available bioinformatic approaches bear their own limitations and their application requires further evaluation [130]. Strong epidemiological study design, high laboratory precision and validation, and sound research hypotheses remain fundamental in interpreting integrative “omics”-based analyses along with the integration of multiple “omics” via complex bioinformatic data analysis. Further work is needed to develop analytical infrastructures able to generate, analyze, and interpret multi-“omics” data as a basis for guiding precision prevention strategies.
Conclusion
Recent technological advances allowed the identification of a number of “omics” biomarkers that brought forward the etiological insights into the mechanisms involved in obesity development. Understanding the role of genetic and epigenetic factors and their influences in the transcriptome, proteome, metabolome, and microbiome became the new frontier in obesity and metabolism research. However, the transformation of large and heterogeneous “omics” data into biological knowledge has proven challenging especially when different methods applied in the same population yield inconsistent results. In this regard, cautious interpretation of findings and further statistical or biological validation of results should represent an important focus of future research. There is an increased demand for larger prospective cohort studies to validate findings and determine biomarker reproducibility before they can find applications in primary care and public health. Despite the current challenges, obesity-related “omics” biomarkers bring substantial promise in identifying new intervention targets and effective public health strategies that pave the way towards patient stratification and precision prevention.
References
Arroyo-Johnson C, Mincey KD. Obesity epidemiology worldwide. Gastroenterol Clin N Am. 2016;45(4):571–9. https://doi.org/10.1016/j.gtc.2016.07.012.
Collaboration NCDRF. Trends in adult body-mass index in 200 countries from 1975 to 2014: a pooled analysis of 1698 population-based measurement studies with 19.2 million participants. Lancet. 2016;387(10026):1377–96. https://doi.org/10.1016/S0140-6736(16)30054-X.
https://www.who.int/news-room/fact-sheets/detail/obesity-and-overweight WFsOaoUMO.
Williamson K, Nimegeer A, Lean M. Rising prevalence of BMI >/=40 kg/m(2): a high-demand epidemic needing better documentation. Obes Rev. 2020;21(4):e12986. https://doi.org/10.1111/obr.12986.
Jastreboff AM, Kotz CM, Kahan S, Kelly AS, Heymsfield SB. Obesity as a disease: the obesity society 2018 position statement. Obesity (Silver Spring). 2019;27(1):7–9. https://doi.org/10.1002/oby.22378.
Abdelaal M, le Roux CW, Docherty NG. Morbidity and mortality associated with obesity. Ann Transl Med. 2017;5(7):161. doi: https://doi.org/10.21037/atm.2017.03.107.
Berry EM. The obesity pandemic-whose responsibility? No blame, no shame, not more of the same Front Nutr 2020;7:2. doi: https://doi.org/10.3389/fnut.2020.00002.
Bluher M. Obesity: global epidemiology and pathogenesis. Nat Rev Endocrinol. 2019;15(5):288–98. https://doi.org/10.1038/s41574-019-0176-8.
Martorell-Marugan J, Tabik S, Benhammou Y, del Val C, Zwir I, Herrera F, et al. Deep learning in omics data analysis and precision medicine. In: Husi H, editor. Computational biology. Brisbane (AU)2019.
Ikram MA. Molecular pathological epidemiology: the role of epidemiology in the omics-era. Eur J Epidemiol. 2015;30(10):1077–8. https://doi.org/10.1007/s10654-015-0093-7.
Aleksandrova K, Mozaffarian D, Pischon T. Addressing the perfect storm: biomarkers in obesity and pathophysiology of cardiometabolic risk. Clin Chem. 2018;64(1):142–53. https://doi.org/10.1373/clinchem.2017.275172.
Ordovas Munoz JM. Predictors of obesity: the “power” of the omics. Nutr Hosp 2013;28 Suppl 5:63–71. doi: https://doi.org/10.3305/nh.2013.28.sup5.6919.
Misra BB, Langefeld CD, Olivier M, Cox LA. Integrated omics: tools, advances, and future approaches. J Mol Endocrinol. 2018:R21–45. https://doi.org/10.1530/JME-18-0055.
Silventoinen K, Konttinen H. Obesity and eating behavior from the perspective of twin and genetic research. Neurosci Biobehav Rev. 2020;109:150–65. https://doi.org/10.1016/j.neubiorev.2019.12.012.
Pigeyre M, Yazdi FT, Kaur Y, Meyre D. Recent progress in genetics, epigenetics and metagenomics unveils the pathophysiology of human obesity. Clin Sci (Lond). 2016;130(12):943–86. https://doi.org/10.1042/CS20160136.
Stryjecki C, Alyass A, Meyre D. Ethnic and population differences in the genetic predisposition to human obesity. Obes Rev. 2018;19(1):62–80. https://doi.org/10.1111/obr.12604.
Loos RJF, Janssens A. Predicting polygenic obesity using genetic information. Cell Metab. 2017;25(3):535–43. https://doi.org/10.1016/j.cmet.2017.02.013.
Manzoni C, Kia DA, Vandrovcova J, Hardy J, Wood NW, Lewis PA, et al. Genome, transcriptome and proteome: the rise of omics data and their integration in biomedical sciences. Brief Bioinform. 2018;19(2):286–302. https://doi.org/10.1093/bib/bbw114.
Torkamani A, Topol E. Polygenic risk scores expand to obesity. Cell. 2019;177(3):518–20. https://doi.org/10.1016/j.cell.2019.03.051.
Fang J, Gong C, Wan Y, Xu Y, Tao F, Sun Y. Polygenic risk, adherence to a healthy lifestyle, and childhood obesity. Pediatr Obes. 2019;14(4):e12489. https://doi.org/10.1111/ijpo.12489.
Abadi A, Alyass A, Robiou du Pont S, Bolker B, Singh P, Mohan V, et al. Penetrance of polygenic obesity susceptibility loci across the body mass index distribution. Am J Hum Genet. 2017;101(6):925–38. https://doi.org/10.1016/j.ajhg.2017.10.007.
Yengo L, Sidorenko J, Kemper KE, Zheng Z, Wood AR, Weedon MN, et al. Meta-analysis of genome-wide association studies for height and body mass index in approximately 700000 individuals of European ancestry. Hum Mol Genet. 2018;27(20):3641–9. https://doi.org/10.1093/hmg/ddy271.
Goodarzi MO. Genetics of obesity: what genetic association studies have taught us about the biology of obesity and its complications. Lancet Diabetes Endocrinol. 2018;6(3):223–36. https://doi.org/10.1016/S2213-8587(17)30200-0.
Fu J, Hofker M, Wijmenga C. Apple or pear: size and shape matter. Cell Metab. 2015;21(4):507–8. https://doi.org/10.1016/j.cmet.2015.03.016.
Khera AV, Chaffin M, Wade KH, Zahid S, Brancale J, Xia R, et al. Polygenic prediction of weight and obesity trajectories from birth to adulthood. Cell. 2019;177(3):587–96 e9. https://doi.org/10.1016/j.cell.2019.03.028.
Tyrrell J, Wood AR, Ames RM, Yaghootkar H, Beaumont RN, Jones SE, et al. Gene-obesogenic environment interactions in the UK Biobank study. Int J Epidemiol. 2017;46(2):559–75. https://doi.org/10.1093/ije/dyw337.
Murr R. Interplay between different epigenetic modifications and mechanisms. Adv Genet. 2010;70:101–41. https://doi.org/10.1016/B978-0-12-380866-0.60005-8.
Cazaly E, Saad J, Wang W, Heckman C, Ollikainen M, Tang J. Making sense of the epigenome using data integration approaches. Front Pharmacol. 2019;10:126. https://doi.org/10.3389/fphar.2019.00126.
Skinner MK. Environmental epigenomics and disease susceptibility. EMBO Rep. 2011;12(7):620–2. https://doi.org/10.1038/embor.2011.125.
Fransen HP, Peeters PH, Beulens JW, Boer JM, de Wit GA, Onland-Moret NC, et al. Exposure to famine at a young age and unhealthy lifestyle behavior later in life. PLoS One. 2016;11(5):e0156609. https://doi.org/10.1371/journal.pone.0156609.
Zhou J, Zhang L, Xuan P, Fan Y, Yang L, Hu C, et al. The relationship between famine exposure during early life and body mass index in adulthood: a systematic review and meta-analysis. PLoS One. 2018;13(2):e0192212. https://doi.org/10.1371/journal.pone.0192212.
Tobi EW, Slieker RC, Stein AD, Suchiman HE, Slagboom PE, van Zwet EW, et al. Early gestation as the critical time-window for changes in the prenatal environment to affect the adult human blood methylome. Int J Epidemiol. 2015;44(4):1211–23. https://doi.org/10.1093/ije/dyv043.
Kaushik P, Anderson JT. Obesity: epigenetic aspects. Biomol Concepts. 2016;7(3):145–55. https://doi.org/10.1515/bmc-2016-0010.
Heijmans BT, Tobi EW, Stein AD, Putter H, Blauw GJ, Susser ES, et al. Persistent epigenetic differences associated with prenatal exposure to famine in humans. Proc Natl Acad Sci U S A. 2008;105(44):17046–9. https://doi.org/10.1073/pnas.0806560105.
Tobi EW, Slieker RC, Luijk R, Dekkers KF, Stein AD, Xu KM, et al. DNA methylation as a mediator of the association between prenatal adversity and risk factors for metabolic disease in adulthood. Sci Adv. 2018;4(1):eaao4364. doi: https://doi.org/10.1126/sciadv.aao4364.
Wahl S, Drong A, Lehne B, Loh M, Scott WR, Kunze S, et al. Epigenome-wide association study of body mass index, and the adverse outcomes of adiposity. Nature. 2017;541(7635):81–6. https://doi.org/10.1038/nature20784.
Sayols-Baixeras S, Subirana I, Fernandez-Sanles A, Senti M, Lluis-Ganella C, Marrugat J, et al. DNA methylation and obesity traits: an epigenome-wide association study. The REGICOR study Epigenetics. 2017;12(10):909–16. https://doi.org/10.1080/15592294.2017.1363951.
Ling C, Ronn T. Epigenetics in human obesity and type 2 diabetes. Cell Metab. 2019;29(5):1028–44. https://doi.org/10.1016/j.cmet.2019.03.009.
Loh M, Zhou L, Ng HK, Chambers JC. Epigenetic disturbances in obesity and diabetes: epidemiological and functional insights. Mol Metab. 2019;27S:S33–41. https://doi.org/10.1016/j.molmet.2019.06.011.
Lafortuna CL, Tovar AR, Rastelli F, Tabozzi SA, Caramenti M, Orozco-Ruiz X, et al. Clinical, functional, behavioural and epigenomic biomarkers of obesity. Front Biosci (Landmark Ed). 2017;22:1655–81. doi: https://doi.org/10.2741/4564.
Castellano-Castillo D, Denechaud PD, Fajas L, Moreno-Indias I, Oliva-Olivera W, Tinahones F, et al. Human adipose tissue H3K4me3 histone mark in adipogenic, lipid metabolism and inflammatory genes is positively associated with BMI and HOMA-IR. PLoS One. 2019;14(4):e0215083. https://doi.org/10.1371/journal.pone.0215083.
Carter AC, Chang HY, Church G, Dombkowski A, Ecker JR, Gil E, et al. Challenges and recommendations for epigenomics in precision health. Nat Biotechnol. 2017;35(12):1128–32. https://doi.org/10.1038/nbt.4030.
Lafave LM, Levine RL. Mining the epigenetic landscape in ALL. Nat Genet. 2013;45(11):1269–70. https://doi.org/10.1038/ng.2808.
Thomou T, Mori MA, Dreyfuss JM, Konishi M, Sakaguchi M, Wolfrum C, et al. Adipose-derived circulating miRNAs regulate gene expression in other tissues. Nature. 2017;542(7642):450–5. https://doi.org/10.1038/nature21365.
Reuter JA, Spacek DV, Snyder MP. High-throughput sequencing technologies. Mol Cell. 2015;58(4):586–97. https://doi.org/10.1016/j.molcel.2015.05.004.
Homuth G, Wahl S, Muller C, Schurmann C, Mader U, Blankenberg S, et al. Extensive alterations of the whole-blood transcriptome are associated with body mass index: results of an mRNA profiling study involving two large population-based cohorts. BMC Med Genet. 2015;8:65. https://doi.org/10.1186/s12920-015-0141-x.
Ghosh S, Dent R, Harper ME, Gorman SA, Stuart JS, McPherson R. Gene expression profiling in whole blood identifies distinct biological pathways associated with obesity. BMC Med Genet. 2010;3:56. https://doi.org/10.1186/1755-8794-3-56.
Guttman M, Amit I, Garber M, French C, Lin MF, Feldser D, et al. Chromatin signature reveals over a thousand highly conserved large non-coding RNAs in mammals. Nature. 2009;458(7235):223–7. https://doi.org/10.1038/nature07672.
Ortega FJ, Moreno-Navarrete JM, Pardo G, Sabater M, Hummel M, Ferrer A, et al. MiRNA expression profile of human subcutaneous adipose and during adipocyte differentiation. PLoS One. 2010;5(2):e9022. https://doi.org/10.1371/journal.pone.0009022.
Iacomino G, Siani A. Role of microRNAs in obesity and obesity-related diseases. Genes Nutr. 2017;12:23. https://doi.org/10.1186/s12263-017-0577-z.
Landrier JF, Derghal A, Mounien L. MicroRNAs in obesity and related metabolic disorders. Cells. 2019;8(8). doi: https://doi.org/10.3390/cells8080859.
Del Corno M, Baldassarre A, Calura E, Conti L, Martini P, Romualdi C, et al. Transcriptome profiles of human visceral adipocytes in obesity and colorectal cancer unravel the effects of body mass index and polyunsaturated fatty acids on genes and biological processes related to tumorigenesis. Front Immunol. 2019;10:265. https://doi.org/10.3389/fimmu.2019.00265.
Klimcakova E, Roussel B, Marquez-Quinones A, Kovacova Z, Kovacikova M, Combes M, et al. Worsening of obesity and metabolic status yields similar molecular adaptations in human subcutaneous and visceral adipose tissue: decreased metabolism and increased immune response. J Clin Endocrinol Metab. 2011;96(1):E73–82. https://doi.org/10.1210/jc.2010-1575.
Ji C, Guo X. The clinical potential of circulating microRNAs in obesity. Nat Rev Endocrinol. 2019;15(12):731–43. https://doi.org/10.1038/s41574-019-0260-0.
Ortiz-Dosal A, Rodil-Garcia P, Salazar-Olivo LA. Circulating microRNAs in human obesity: a systematic review. Biomarkers. 2019;24(6):499–509. https://doi.org/10.1080/1354750X.2019.1606279.
Sun L, Goff LA, Trapnell C, Alexander R, Lo KA, Hacisuleyman E, et al. Long noncoding RNAs regulate adipogenesis. Proc Natl Acad Sci U S A. 2013;110(9):3387–92. https://doi.org/10.1073/pnas.1222643110.
Zhao XY, Lin JD. Long noncoding RNAs: a new regulatory code in metabolic control. Trends Biochem Sci. 2015;40(10):586–96. https://doi.org/10.1016/j.tibs.2015.08.002.
Alexander M, O’Connell RM. Noncoding RNAs and chronic inflammation: micro-managing the fire within. Bioessays. 2015;37(9):1005–15. https://doi.org/10.1002/bies.201500054.
Sun M, Kraus WL. From discovery to function: the expanding roles of long noncoding RNAs in physiology and disease. Endocr Rev. 2015;36(1):25–64. https://doi.org/10.1210/er.2014-1034.
Wei S, Du M, Jiang Z, Hausman GJ, Zhang L, Dodson MV. Long noncoding RNAs in regulating adipogenesis: new RNAs shed lights on obesity. Cell Mol Life Sci. 2016;73(10):2079–87. https://doi.org/10.1007/s00018-016-2169-2.
Di Ruscio A, Ebralidze AK, Benoukraf T, Amabile G, Goff LA, Terragni J, et al. DNMT1-interacting RNAs block gene-specific DNA methylation. Nature. 2013;503(7476):371–6. https://doi.org/10.1038/nature12598.
Kukurba KR, Montgomery SB. RNA sequencing and analysis. Cold Spring Harb Protoc. 2015;2015(11):951–69. https://doi.org/10.1101/pdb.top084970.
Masood A, Benabdelkamel H, Alfadda AA. Obesity proteomics: an update on the strategies and tools employed in the study of human obesity. High Throughput. 2018;7(3). doi: https://doi.org/10.3390/ht7030027.
Pardo M, Roca-Rivada A, Seoane LM, Casanueva FF. Obesidomics: contribution of adipose tissue secretome analysis to obesity research. Endocrine. 2012;41(3):374–83. https://doi.org/10.1007/s12020-012-9617-z.
Geyer PE, Wewer Albrechtsen NJ, Tyanova S, Grassl N, Iepsen EW, Lundgren J, et al. Proteomics reveals the effects of sustained weight loss on the human plasma proteome. Mol Syst Biol. 2016;12(12):901. doi: https://doi.org/10.15252/msb.20167357.
Sahebekhtiari N, Saraswat M, Joenvaara S, Jokinen R, Lovric A, Kaye S, et al. Plasma proteomics analysis reveals dysregulation of complement proteins and inflammation in acquired obesity-a study on rare BMI-discordant monozygotic twin pairs. Proteomics Clin Appl. 2019;13(4):e1800173. https://doi.org/10.1002/prca.201800173.
Garrison CB, Lastwika KJ, Zhang Y, Li CI, Lampe PD. Proteomic analysis, immune dysregulation, and pathway interconnections with obesity. J Proteome Res. 2017;16(1):274–87. https://doi.org/10.1021/acs.jproteome.6b00611.
Al-Daghri NM, Manousopoulou A, Alokail MS, Yakout S, Alenad A, Garay-Baquero DJ, et al. Sex-specific correlation of IGFBP-2 and IGFBP-3 with vitamin D status in adults with obesity: a cross-sectional serum proteomics study. Nutr Diabetes. 2018;8(1):54. https://doi.org/10.1038/s41387-018-0063-8.
Doumatey AP, Zhou J, Zhou M, Prieto D, Rotimi CN, Adeyemo A. Proinflammatory and lipid biomarkers mediate metabolically healthy obesity: a proteomics study. Obesity (Silver Spring). 2016;24(6):1257–65. https://doi.org/10.1002/oby.21482.
Cominetti O, Nunez Galindo A, Corthesy J, Valsesia A, Irincheeva I, Kussmann M, et al. Obesity shows preserved plasma proteome in large independent clinical cohorts. Sci Rep. 2018;8(1):16981. https://doi.org/10.1038/s41598-018-35321-7.
Griffiths WJ, Koal T, Wang Y, Kohl M, Enot DP, Deigner HP. Targeted metabolomics for biomarker discovery. Angew Chem Int Ed Engl. 2010;49(32):5426–45. https://doi.org/10.1002/anie.200905579.
Dettmer K, Aronov PA, Hammock BD. Mass spectrometry-based metabolomics. Mass Spectrom Rev. 2007;26(1):51–78. https://doi.org/10.1002/mas.20108.
Rangel-Huerta OD, Pastor-Villaescusa B, Gil A. Are we close to defining a metabolomic signature of human obesity? A systematic review of metabolomics studies. Metabolomics. 2019;15(6):93. https://doi.org/10.1007/s11306-019-1553-y.
Floegel A, Wientzek A, Bachlechner U, Jacobs S, Drogan D, Prehn C, et al. Linking diet, physical activity, cardiorespiratory fitness and obesity to serum metabolite networks: findings from a population-based study. Int J Obes. 2014;38(11):1388–96. https://doi.org/10.1038/ijo.2014.39.
Marco-Ramell A, Tulipani S, Palau-Rodriguez M, Gonzalez-Dominguez R, Minarro A, Jauregui O, et al. Untargeted profiling of concordant/discordant phenotypes of high insulin resistance and obesity to predict the risk of developing diabetes. J Proteome Res. 2018;17(7):2307–17. https://doi.org/10.1021/acs.jproteome.7b00855.
Tulipani S, Palau-Rodriguez M, Minarro Alonso A, Cardona F, Marco-Ramell A, Zonja B, et al. Biomarkers of morbid obesity and prediabetes by metabolomic profiling of human discordant phenotypes. Clin Chim Acta. 2016;463:53–61. https://doi.org/10.1016/j.cca.2016.10.005.
Gannon NP, Schnuck JK, Vaughan RA. BCAA metabolism and insulin sensitivity - dysregulated by metabolic status? Mol Nutr Food Res. 2018;62(6):e1700756. https://doi.org/10.1002/mnfr.201700756.
Wang TJ, Larson MG, Vasan RS, Cheng S, Rhee EP, McCabe E, et al. Metabolite profiles and the risk of developing diabetes. Nat Med. 2011;17(4):448–53. https://doi.org/10.1038/nm.2307.
Floegel A, Stefan N, Yu Z, Muhlenbruch K, Drogan D, Joost HG, et al. Identification of serum metabolites associated with risk of type 2 diabetes using a targeted metabolomic approach. Diabetes. 2013;62(2):639–48. https://doi.org/10.2337/db12-0495.
Siddik MAB, Shin AC. Recent progress on branched-Chain amino acids in obesity, diabetes, and beyond. Endocrinol Metab (Seoul). 2019;34(3):234–46. https://doi.org/10.3803/EnM.2019.34.3.234.
Wishart DS. Emerging applications of metabolomics in drug discovery and precision medicine. Nat Rev Drug Discov. 2016;15(7):473–84. https://doi.org/10.1038/nrd.2016.32.
Quehenberger O, Armando AM, Brown AH, Milne SB, Myers DS, Merrill AH, et al. Lipidomics reveals a remarkable diversity of lipids in human plasma. J Lipid Res. 2010;51(11):3299–305. https://doi.org/10.1194/jlr.M009449.
Wenk MR. Lipidomics: new tools and applications. Cell. 2010;143(6):888–95. https://doi.org/10.1016/j.cell.2010.11.033.
Yang K, Han X. Lipidomics: techniques, applications, and outcomes related to biomedical sciences. Trends Biochem Sci. 2016;41(11):954–69. https://doi.org/10.1016/j.tibs.2016.08.010.
Klop B, Elte JW, Cabezas MC. Dyslipidemia in obesity: mechanisms and potential targets. Nutrients. 2013;5(4):1218–40. https://doi.org/10.3390/nu5041218.
Mousa A, Naderpoor N, Mellett N, Wilson K, Plebanski M, Meikle PJ, et al. Lipidomic profiling reveals early-stage metabolic dysfunction in overweight or obese humans. Biochim Biophys Acta Mol Cell Biol Lipids. 2019;1864(3):335–43. https://doi.org/10.1016/j.bbalip.2018.12.014.
Piening BD, Zhou W, Contrepois K, Rost H, Gu Urban GJ, Mishra T, et al. Integrative personal omics profiles during periods of weight gain and loss. Cell Syst 2018;6(2):157–170 e8. doi: https://doi.org/10.1016/j.cels.2017.12.013.
Cole LK, Vance JE, Vance DE. Phosphatidylcholine biosynthesis and lipoprotein metabolism. Biochim Biophys Acta. 2012;1821(5):754–61. https://doi.org/10.1016/j.bbalip.2011.09.009.
Kim MJ, Yang HJ, Kim JH, Ahn CW, Lee JH, Kim KS, et al. Obesity-related metabolomic analysis of human subjects in black soybean peptide intervention study by ultraperformance liquid chromatography and quadrupole-time-of-flight mass spectrometry. J Obes. 2013;2013:874981–11. https://doi.org/10.1155/2013/874981.
Bertozzi CR, Rabuka D. Structural basis of glycan diversity. In: nd, Varki A, Cummings RD, Esko JD, Freeze HH, Stanley P, et al., editors. Essentials of glycobiology. Cold Spring Harbor (NY)2009.
Cao WQ, Liu MQ, Kong SY, Wu MX, Huang ZZ, Yang PY. Novel methods in glycomics: a 2019 update. Expert Rev Proteomics. 2020;17(1):11–25. https://doi.org/10.1080/14789450.2020.1708199.
Everest-Dass AV, Moh ESX, Ashwood C, Shathili AMM, Packer NH. Human disease glycomics: technology advances enabling protein glycosylation analysis - part 1. Expert Rev Proteomics. 2018;15(2):165–82. https://doi.org/10.1080/14789450.2018.1421946.
Rudman N, Gornik O, Lauc G. Altered N-glycosylation profiles as potential biomarkers and drug targets in diabetes. FEBS Lett. 2019;593(13):1598–615. https://doi.org/10.1002/1873-3468.13495.
Rudd P, Karlsson NG, Khoo KH, Packer NH. Glycomics and glycoproteomics. In: rd, Varki A, Cummings RD, Esko JD, Stanley P, Hart GW, et al., editors. Essentials of glycobiology. Cold Spring Harbor (NY)2015. p. 653–66.
Adua E, Russell A, Roberts P, Wang Y, Song M, Wang W. Innovation analysis on postgenomic biomarkers: glycomics for chronic diseases. OMICS. 2017;21(4):183–96. https://doi.org/10.1089/omi.2017.0035.
Kristic J, Vuckovic F, Menni C, Klaric L, Keser T, Beceheli I, et al. Glycans are a novel biomarker of chronological and biological ages. J Gerontol A Biol Sci Med Sci. 2014;69(7):779–89. https://doi.org/10.1093/gerona/glt190.
Liu D, Li Q, Dong J, Li D, Xu X, Xing W, et al. The association between normal BMI with central adiposity and proinflammatory potential immunoglobulin G N-glycosylation. Diabetes Metab Syndr Obes. 2019;12:2373–85. https://doi.org/10.2147/DMSO.S216318.
Nikolac Perkovic M, Pucic Bakovic M, Kristic J, Novokmet M, Huffman JE, Vitart V, et al. The association between galactosylation of immunoglobulin G and body mass index. Prog Neuro-Psychopharmacol Biol Psychiatry. 2014;48:20–5. https://doi.org/10.1016/j.pnpbp.2013.08.014.
Russell AC, Kepka A, Trbojevic-Akmacic I, Ugrina I, Song M, Hui J, et al. Increased central adiposity is associated with pro-inflammatory immunoglobulin G N-glycans. Immunobiology. 2019;224(1):110–5. https://doi.org/10.1016/j.imbio.2018.10.002.
Young VB. The role of the microbiome in human health and disease: an introduction for clinicians. BMJ. 2017;356:j831. https://doi.org/10.1136/bmj.j831.
Plotnikoff GA, Riley D. The human microbiome. Glob Adv Health Med. 2014;3(3):4–5. https://doi.org/10.7453/gahmj.2014.023.
Wilkins LJ, Monga M, Miller AW. Defining dysbiosis for a cluster of chronic diseases. Sci Rep. 2019;9(1):12918. https://doi.org/10.1038/s41598-019-49452-y.
Song EJ, Lee ES, Nam YD. Progress of analytical tools and techniques for human gut microbiome research. J Microbiol. 2018;56(10):693–705. https://doi.org/10.1007/s12275-018-8238-5.
Shakya M, Lo CC, Chain PSG. Advances and challenges in metatranscriptomic analysis. Front Genet. 2019;10:904. https://doi.org/10.3389/fgene.2019.00904.
Lin H, He QY, Shi L, Sleeman M, Baker MS, Nice EC. Proteomics and the microbiome: pitfalls and potential. Expert Rev Proteomics. 2019;16(6):501–11. https://doi.org/10.1080/14789450.2018.1523724.
Chen MX, Wang SY, Kuo CH, Tsai IL. Metabolome analysis for investigating host-gut microbiota interactions. J Formos Med Assoc. 2019;118(Suppl 1):S10–22. https://doi.org/10.1016/j.jfma.2018.09.007.
John GK, Mullin GE. The gut microbiome and obesity. Curr Oncol Rep. 2016;18(7):45. https://doi.org/10.1007/s11912-016-0528-7.
Musso G, Gambino R, Cassader M. Interactions between gut microbiota and host metabolism predisposing to obesity and diabetes. Annu Rev Med. 2011;62:361–80. https://doi.org/10.1146/annurev-med-012510-175505.
Delzenne NM, Cani PD. Interaction between obesity and the gut microbiota: relevance in nutrition. Annu Rev Nutr. 2011;31:15–31. https://doi.org/10.1146/annurev-nutr-072610-145146.
Sze MA, Schloss PD. Looking for a signal in the noise: revisiting obesity and the microbiome. mBio. 2016;7(4). doi: https://doi.org/10.1128/mBio.01018-16.
Walters WA, Xu Z, Knight R. Meta-analyses of human gut microbes associated with obesity and IBD. FEBS Lett. 2014;588(22):4223–33. https://doi.org/10.1016/j.febslet.2014.09.039.
Armour CR, Nayfach S, Pollard KS, Sharpton TJ. A metagenomic meta-analysis reveals functional signatures of health and disease in the human gut microbiome. mSystems. 2019;4(4). doi: https://doi.org/10.1128/mSystems.00332-18.
Morrison DJ, Preston T. Formation of short chain fatty acids by the gut microbiota and their impact on human metabolism. Gut Microbes. 2016;7(3):189–200. https://doi.org/10.1080/19490976.2015.1134082.
Chambers ES, Preston T, Frost G, Morrison DJ. Role of gut microbiota-generated short-chain fatty acids in metabolic and cardiovascular health. Curr Nutr Rep. 2018;7(4):198–206. https://doi.org/10.1007/s13668-018-0248-8.
Cox LM, Blaser MJ. Antibiotics in early life and obesity. Nat Rev Endocrinol. 2015;11(3):182–90. https://doi.org/10.1038/nrendo.2014.210.
Block JP, Bailey LC, Gillman MW, Lunsford D, Daley MF, Eneli I, et al. Early antibiotic exposure and weight outcomes in young children. Pediatrics. 2018;142(6). doi: https://doi.org/10.1542/peds.2018-0290.
Shao X, Ding X, Wang B, Li L, An X, Yao Q, et al. Antibiotic exposure in early life increases risk of childhood obesity: a systematic review and meta-analysis. Front Endocrinol (Lausanne). 2017;8:170. doi: https://doi.org/10.3389/fendo.2017.00170.
Scott FI, Horton DB, Mamtani R, Haynes K, Goldberg DS, Lee DY, Lewis JD Administration of antibiotics to children before age 2 years increases risk for childhood obesity. Gastroenterology. 2016;151(1):120–129 e5. doi: https://doi.org/10.1053/j.gastro.2016.03.006.
Ferrarese R, Ceresola ER, Preti A, Canducci F. Probiotics, prebiotics and synbiotics for weight loss and metabolic syndrome in the microbiome era. Eur Rev Med Pharmacol Sci. 2018;22(21):7588–605. doi: https://doi.org/10.26355/eurrev_201811_16301.
Frame LA, Costa E, Jackson SA. Current explorations of nutrition and the gut microbiome: a comprehensive evaluation of the review literature. Nutr Rev. 2020. https://doi.org/10.1093/nutrit/nuz106.
Poitou C, Perret C, Mathieu F, Truong V, Blum Y, Durand H, et al. Bariatric surgery induces disruption in inflammatory signaling pathways mediated by immune cells in adipose tissue: a RNA-Seq study. PLoS One. 2015;10(5):e0125718. https://doi.org/10.1371/journal.pone.0125718.
Izquierdo AG, Crujeiras AB. Obesity-related epigenetic changes after bariatric surgery. Front Endocrinol (Lausanne). 2019;10:232. doi: https://doi.org/10.3389/fendo.2019.00232.
Nicoletti CF, Pinhel MAS, Noronha NY, de Oliveira BA, Salgado Junior W, Jacome A, et al. Altered pathways in methylome and transcriptome longitudinal analysis of normal weight and bariatric surgery women. Sci Rep. 2020;10(1):6515. https://doi.org/10.1038/s41598-020-60814-9.
van Dijk SJ, Molloy PL, Varinli H, Morrison JL, Muhlhausler BS, Members of Epi S. Epigenetics and human obesity. Int J Obes 2015;39(1):85–97. doi: https://doi.org/10.1038/ijo.2014.34.
Gonzalez-Plaza JJ, Santiago-Fernandez C, Gutierrez-Repiso C, Garcia-Serrano S, Rodriguez-Pacheco F, Ho-Plagaro A, et al. The changes in the transcriptomic profiling of subcutaneous adipose tissue after bariatric surgery depend on the insulin resistance state. Surg Obes Relat Dis. 2018;14(8):1182–91. https://doi.org/10.1016/j.soard.2018.04.010.
Samczuk P, Ciborowski M, Kretowski A. Application of metabolomics to study effects of bariatric surgery. J Diabetes Res. 2018;2018:6270875–13. https://doi.org/10.1155/2018/6270875.
Palau-Rodriguez M, Tulipani S, Marco-Ramell A, Minarro A, Jauregui O, Sanchez-Pla A, et al. Metabotypes of response to bariatric surgery independent of the magnitude of weight loss. PLoS One. 2018;13(6):e0198214. https://doi.org/10.1371/journal.pone.0198214.
Perakakis N, Yazdani A, Karniadakis GE, Mantzoros C. Omics, big data and machine learning as tools to propel understanding of biological mechanisms and to discover novel diagnostics and therapeutics. Metabolism. 2018;87:A1–9. https://doi.org/10.1016/j.metabol.2018.08.002.
Subramanian I, Verma S, Kumar S, Jere A, Anamika K. Multi-omics data integration, interpretation, and its application. Bioinform Biol Insights. 2020;14:1177932219899051. https://doi.org/10.1177/1177932219899051.
Conesa A, Beck S. Making multi-omics data accessible to researchers. Sci Data. 2019;6(1):251. https://doi.org/10.1038/s41597-019-0258-4.
Funding
Open Access funding provided by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no competing interests.
Human and Animal Rights and Informed Consent
This article does not contain any studies with human or animal subjects performed by any of the authors.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the Topical Collection on Metabolism
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Aleksandrova, K., Egea Rodrigues, C., Floegel, A. et al. Omics Biomarkers in Obesity: Novel Etiological Insights and Targets for Precision Prevention. Curr Obes Rep 9, 219–230 (2020). https://doi.org/10.1007/s13679-020-00393-y
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13679-020-00393-y