
Abstract
A flexible class of multivariate distributions for continuous lifetimes is proposed. The distribution is defined in terms of the age-at-death of m siblings. The expression for the joint density is derived using classical results from mathematical demography. The parameters of the distribution are the age-specific birth and death rates, in addition to a vector of relative death times for the m siblings. For the case of constant birth and death rates we are able to derive an explicit expression for the bivariate sibling density, which is proven to be MTP2, and hence has positive dependence. Further, we show that a special case of the sibling distribution belongs to the Block-Basu class of multivariate distribution. In the general case, with age-dependent birth and death rates, evaluation of the density involves numerical integration, but is still feasible.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Classes of multivariate densities for multivariate life time and survival data are well studied in the statistical and demographic literature (Hougaard, 2001; Barreto-Souza and Mayrink, 2019). A common approach for making survival times positively dependent goes via “shared frailties” (Hougaard, 2001, Chpt. 7). A frailty is a latent random variable that proportionally scales the hazard rate in a group of individuals, hence inducing dependence between otherwise independent lifetimes. In the present paper we introduce a new class of latent variable models, named the “sibling distribution”, which is defined in terms of the age-at-death for each of m half siblings. There is no information available about their common mother, except that she had m offspring in total, and was alive at a specified point in time, taken to be t = 0 for convenience. The two latent variables of the model are the mother’s birth and death times. The building blocks of the sibling distribution are the individual birth rates β(a) and death rates ϕ(a), where a is the age of an individual. We define the distribution for general functions, β(a) and ϕ(a), but for most part we shall assume that β(a) and ϕ(a) are constants as functions of a.
The positive dependence between the sibling’s life times comes from conditioning on their (absolute) times of death, in combination with a shared dependence on the mother’s life span. The times-of-death become parameters of the distribution. This somewhat implicit construction will be seen to be a mixture distribution, and can be studied using general theory for multivariate dependence (Shaked and Spizzichino, 1998; Khaledi and Kochar, 2001). We prove that the bivariate constant-rate sibling distribution is multivariate totally positive of order 2 (Karlin and Rinott, 1980), which for instance imply that the correlation is positive.
The constant-rate sibling distribution turns out to have marginal distributions that are perturbated exponential distributions. The exponential distribution plays a special role for univariate life times and several multivariate extensions can be found in the literature (Marshall and Olkin, 1967; Freund, 1961; Block and Basu, 1974; Arnold and Strauss, 1988; Gumbel, 1960; Hougaard, 1986; Sarkar, 1987). One of these extensions was introduced by Block and Basu (Block and Basu, 1974). The Block-Basu bivariate lifetime distribution can be derived by omitting the singular part of a bivariate exponential distribution as outlined by Marshall and Olkin (Marshall and Olkin, 1967), but can also be viewed as a reparametrization of Freund’s distribution (Freund, 1961). We will see that the constant-rate (birth and death) sibling distribution reduces to a Block-Basu distribution, which will be used to shed light on the sibling distribution.
An alternative route to construction of multivariate life time distributions goes via copulae (Andersen, 2005). The implication also goes in the other direction; our sibling distribution induces a novel symmetric two-parameter copula.
The remaining part of the paper is organized as follows. In Section 2 we introduce the general sibling distribution. Explicit expressions in the bivariate case, along with positive dependence property, are derived in Section 3. In Section 4 we discuss the relationship to the Block-Basu distribution and in Section 5 we address simulation and parameter estimation. Finally, we provide a discussion in Section 6.
2 The Sibling Age Distribution
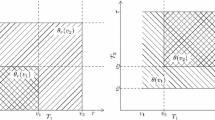
Consider a female who over her lifespan is known to have had m offspring. Denote by tj and xj the time of death and age-at-death, respectively, of the j’th offspring. The offspring are arbitrarily ordered, not according to the time of birth. We shall view t and x as random variables taking values on the real line. For notational simplicity we let j = 0 refer to the mother, and we condition on the fact that the mother was alive at time t = 0, i.e. on the event that t0 − x0 ≤ 0 ≤ t0. This assumption should be kept in mind at all times when reading this paper. We define a0 = x0 − t0 as the age of the mother at t = 0, and we denote the joint density of (a0, t0) by g(a0, t0). Let yj = tj − xj, be the birth time of the j’th offspring. Please refer to Fig. 1 for an illustration of key quantities.

Birth (y0) and death (t0) times of mother, and corresponding times (yj and tj) for the j’th offspring. Further, a0 is the age of the mother at the reference point t = 0
We denote random variables by capital letters. Conditionally on (A0, T0) = (a0, t0), and hence on X0 = x0 = a0 + t0, the density of Yj is
where β(a) is the age-specific rate at which the mother produces offspring. We shorten our notation for conditional densities, e.g. we write fY rather than the full \(f_{Y|A_{0},T_{0}}\). The joint conditional density of (Xj, Tj) is
on the support
where \(z_{+}=\max \limits (z,0)\). The constraints on xj express the fact that xj ≥ 0 and y0 ≤ yj ≤ t0, i.e. the offspring must be born in the time window when the mother is alive (see Fig. 1). The latter is related to Eq. 2.3 via the algebraic equivalence y0 ≤ yj ≤ t0 ⇔ tj − t0 ≤ tj − yj ≤ tj − y0. Further, the marginal density fX(xj) in Eq. 2.2 is defined in terms of the survival function \(l(x_{j})=\Pr (X>x_{j})\) via \(f_{X}(x_{j})=-l^{\prime }(x_{j})\). Finally, the marginal density of Tj is obtained from Eq. 2.2 and Eq. 2.3,
The births and deaths of the m siblings are assumed to be conditionally independent, given (A0, T0) = (a0, t0), so the joint density of X1:m = (X1,…,Xm) and T1:m = (T1,…,Tm) is \({\prod }_{j=1}^{m}f_{X,T}(x_{j},t_{j}|a_{0},t_{0})\), where the density fX, T(xj, tj|a0, t0) is given by Eq. 2.2. We are now in position to define the sibling distribution as the conditional distribution of X1:m, given T1:m = t1:m.
Remark 1.
The sibling distribution of X1:m has density
where fX, T and fT are given by Eqs. 2.2 and 2.4, respectively, and g is the joint density of (A0, T0) for which we will derive the density (2.7) below.
The parameters of the sibling distribution are t1:m ∈ Rm, in addition to whatever parameters are hidden in the functional forms of the functions β(a) and l(a). Note that the tj are not restricted to be positive, i.e. the offspring may have died before t = 0. Mostly, we shall parameterize l(a) in terms of the age-specific death rate ϕ(a), which is related to the survival function through the well known relationship \(l(x)=\exp \left (-{{\int \limits }_{0}^{x}}\phi (a)da\right )\).
In order to derive an expression for the density g(a0, t0), occurring in Eq. 2.5, we use the theory for stable age distributions from mathematical demography (Caswell and Keyfitz, 2005), which we now briefly review. A population in which the age-specific rates ϕ(a) and β(a) do not change with time will settle into a stable age distribution. Further, the population will grow at a rate r given as the solution to the “characteristic equation”
The stable age distribution has density \(f_{A}(a)= l(a)e^{-ra}/{{\int \limits }_{0}^{a}}l(u)e^{-ru}du\), for a ≥ 0. Our point of view is that the mother is randomly selected among all females alive at t = 0, so that the density of A0 is given by fA. This is yet not taking into account the fact that she has m offspring over her life time. The joint density of A0 and T0 is
where \(f_{T_{0}|A_{0}}(t_{0}|a_{0})=-l^{\prime }(a_{0}+t_{0})/l(a_{0})\). Conditionally on A0 and T0, and hence on the length of the time period X0 = A0 + T0 that she is alive, her total number of offspring M is Poisson distributed with mean \(B(x_{0})={\int \limits }_{0}^{x_{0}}\beta (u)du\). Knowing that the mother had m offspring over her lifetime perturbs the distribution (2.6) as follows
We have now completely specified the sibling distribution via its density (2.5). Instead of providing results about its properties in the general case, we turn to a special case in which explicit results can be found. In Section 6 we briefly return with some discussion of the general case.
3 Constant Birth and Death Rates
We shall refer to the situation
as the constant-rate sibling distribution. Under this assumption it follows that the conditional densities (2.1) and (2.2) reduce respectively to
and
Further, the marginal density (2.4) becomes
and the joint density (2.7) becomes
Using these expressions we are able to find an explicit expression for the sibling distribution (2.5) of order m = 2. We shall first assume that t1 = t2 which simplifies expressions somewhat. Derivations for the case t1 ≠ t2 are very similar.
Consider the distribution of the life times X1 and X2, given that T1 = T2 = t, where t is the common time of death of the two siblings. We have the following expression for the sibling density, which due to symmetry is presented only for x1 ≤ x2.
Theorem 1.
With constant-rates (3.1), the sibling density (2.5) with m = 2 becomes (for t > 0):
and for t < 0:
where C1 and C2 are normalizing constants.
Proof.
See Appendix A. □
By integrating over three branches in Eq. 3.6 we obtain the following expression for the normalizing constant:
and similarly integration of Eq. 3.7 yields
Note that f(x1, x2) does not depend on t when t < 0. When we in addition set β = 0 (interpreted as a limit), X1 and X2 become independent, exponentially distributed. Further interpretation of the case that t < 0 is given in Section 4 below.
Like the exponential distribution, the constant-rate sibling distribution is closed under change of scale. If we define \(X_{j}^{\prime }=c X_{j}\) for c > 0, the parameters of the resulting sibling distribution are \(\phi ^{\prime }=c^{-1}\phi \), \(\beta ^{\prime }=c^{-1}\beta \) and \(t^{\prime }=c t\). Hence, we may set ϕ = 1 and reparameterize the distribution in terms of (c, β, t), which for some purposes is useful.
As seen from Eq. 3.6, the density has a piecewise definition. When using symmetry to include also the case x1 > x2, the definition of the sibling density splits the first quadrant, x1, x2 ≥ 0, into six regions (Fig. 2 with t1 = t2). We see that \(\log \{f(x_{1},x_{2})\}\) is piecewise linear over these regions, and is continuous (but not differentiable) across the boundaries of the regions. The density is unimodal, with the mode at (x1, x2) = (0,0) when β < ϕ, and while β > ϕ the mode is at (x1, x2) = (t, t). Figure 3 shows f(x1, x2) for three different parameter.

The six different regions of the sibling density when t1 = 9 and t2 = 5. The dashed line indicates ages where the siblings are born at the same time (y1 = y2)

Bivariate sibling density f(x1, x2) with parameters ϕ = 1, β = 0.8,1.0,1.2 (left to right) and (t1, t2) = (4,4). The red dots show expected value (μ, μ). The dashed white curve is the contour c = 1 of c(x1, x2) given by Eq. 3.15
In order to present the sibling distribution for the case t1 ≠ t2, it is advantageous to introduce a general piecewise log-linear density f over the regions R1,…,R6 in Fig. 2:
Here, b1:6 = (b1,…,b6), c1:6 = (c1,…,c6) and d1:6 = (d1,…,d6) are constants satisfying the constraints c2, c3, c4, d3, d4, d5 < 0, which are needed for f to be a proper density. Straightforward, but tedious, integration yields the normalization constant:
where c1 + d1≠ 0 and c6 + d6≠ 0 in addition to the constraint c2, c3, c4, d3, d4, d5 < 0. The constants C1 and C2 in Theorem 1 are special cases of this.
It is easy to derive the moment generating function of Eq. 3.10:
where c1:6 + s1 = (c1 + s1,…,c6 + s1) and d1:6 + s2 = (d1 + s2,…,d6 + s2). Moments of X1 and X2 of various orders can be obtained by repeated differentiation of M(s1, s2) at s1 = s2 = 0. The resulting expressions are complex, and not well suited for interpretation, but are nevertheless useful for numerical evaluation.
Theorem 2.
With constant rates (3.1), the sibling density (2.5) with m = 2 and t1 ≠ t2 has density given by Eq. 3.10 with coefficients as specified in Table 1.
Proof.
The proof is very similar to that of Theorem 1 and is omitted. □
3.1 Positive Association
Intuitively, X1 and X2 are positively associated under the sibling distribution, due to their dependence of the lifespan (−A0, T0) of their shared mother. Further, for each marginal (j = 1,2) we must have that Xj is stochastically increasing in the parameter tj. The informal argument for the latter is that since the mother is known to have been alive at t = 0, the larger the death time tj the older (xj) the individual is likely to be. We now set out to prove these claims rigorously.
We start out by proving the positive association between X1 and X2. An appropriate notion of positive association is the so-called Multivariate Total Positivity of order 2 (MTP2). A bivariate density f(x), x ∈ R2, is is said to be MTP2 if
for any x, z ∈ R2, where \(x\vee z=(\max \limits (x_{1},z_{1}),\max \limits (x_{2},z_{2}))\) and \(x\wedge z=(\min \limits (x_{1},z_{1}),\min \limits (x_{2},z_{2}))\). See Karlin and Rinott (1980) for a comprehensive overview of properties of MTP2 distributions.
Theorem 3.
The sibling densities (3.6) and (3.7) are MTP2.
This is proved in Appendix C using the definition Eq. 3.13 of MTP2 directly. We believe that an alternative proof may be based on the fact that mixture distributions, of which the numerator of Eq. 2.5 is an example, under certain conditions are MTP2 (Khaledi and Kochar, 2001; Shaked and Spizzichino, 1998). Using this approach it may be possible to prove that more general sibling distributions than (3.6) are MTP2.
MTP2 is a strong positive dependence property, which among other things imply that cov(X1, X2) ≥ 0. Although covariance is (arguably) not the most relevant dependence measure for life times, it nevertheless the most common dependence measure in general, and it is therefore useful to have establish this result.
3.2 Marginal Distribution and Copula
The marginal densities in Eq. 3.6 are both given as
where C1 is given by Eq. 3.8. As a local measure of dependency between X1 and X2 we introduce
The c = 1 contour of c(x1, x2) is displayed in Fig. 3. The region in which c(x1, x2) > 1 is located around the diagonal x1 = x2. This reflects the positive dependence in the sibling distribution.
We can obtain an analytical expression for the cumulative joint distribution F(x1, x2) by integrating Eq. 3.6. Similarly, we get an expression for the cumulative marginal distribution function G(x) by integrating Eq. 3.14. Then we can define a copula (Nelsen, 2007), \(F\left (G^{-1}(x_{1}),G^{-1}(x_{2})\right )\), based on the sibling distribution, where G− 1 denotes the inverse of G. Because the sibling distribution is closed under change of scale, we set ϕ = 1, and the copula thus has β and t as free parameters. We do not explore this copula further in this paper.
We next prove that X (X1 or X2) is stochastically increasing in t, in the sense of the following theorem.
Theorem 4.
For any \(t^{\prime }>t>0\) we have
It turns out to be easier to prove the more general statement that (X1, X2) is multivariate stochastically increasing (Shaked and Shanthikumar, 2007, p. 265), which imply Eq. 3.16. The reason this is simpler is that the key quantity, the ratio \(f(x;t^{\prime })/f(x;t)\), which is involved in Theorem 6.B.8. of Shaked and Shanthikumar (2007, p. 265), takes on a simpler form for the bivariate density (3.6) than for the univariate density (3.14). The details of the proof are given in Appendix D.
Stochastic monotonicity of a random variable X implies that E(X) is an increasing function of t (Shaked and Shanthikumar, 2007, p. 4). This means that, for given ϕ and β, there is a one-to-one correspondence between t and μ = E(X). This fact will play a crucial role when we later devise an estimator for the parameters ϕ, β and t.
3.3 The Role of β and t
Because the family of constant-rate sibling distributions is closed under change of scale we set ϕ = 1. In this section we will study the effect of varying β and t on two characteristics: the correlation (COR) between X1 and X2 and \(\text {CV}(X_{j})=\sqrt {\text {Var}(X_{j})}/\mathrm E(X_{j})\). Without conditioning on Tj = t, we have that Xj is exponentially distributed with rate ϕ = 1. The process of conditioning on Tj can be expected to deduce CV(Xj). Rather than trying to prove this formally, we provide numerical evidence.
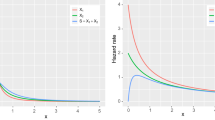
Figure 4 shows correlation and CV as functions of β (top) and t (bottom), and indeed we see that CV ≤ 1 for all β and t. When β and t are both close to zero we have CV ≈ 1 and COR ≈ 0, which reflects the fact that X1 and X2 are then approximately independent and exponentially distributed. For increasing β the correlation increases, but not necessarily monotonically, and approaches an asymptotic level (top-left). From the corresponding plot of the CV (top-right) we notice that the overall trend is that the CV decreases as the value of β increases. The decrease is steepest for the highest values of t.

Correlation (left) and CV (right) of the sibling distribution (ϕ = 1) as a function of its parameters. The parameter ϕ is set to 1 and the plots on the top row are plotted as a function of β for five different values of t. The plots on the bottom are plotted as a function of t for five different values of β
Further, we see from the bottom row of Fig. 4 that the correlation increases as a function of t, except for very small t. It can be shown that when β = ϕ the correlation approaches 1 as \(t\rightarrow \infty \). When β≠ϕ, the correlation does not approach 1 as \(t\rightarrow \infty \), but flattens out at a lower value which depends on the value of β. The CV decrease quickly as a function of t, especially for the higher values of β. When β < ϕ we see that the CV first decrease, then starts to increase for higher values of t.
4 Relationship to the Block-Basu Distribution
In this section we clarify the relationship between the constant-rate sibling distribution and the Block-Basu distribution (Block and Basu, 1974), and we shall use this relationship to interpret the sibling distribution. One way of deriving the Block-Basu distribution goes via (Freund, 1961), and we will refer to this as the “Freund interpretation”. Let now X1 and X2 be the lifetimes of two components assumed to be independently exponentially distributed with rate parameters α1 and α2, respectively. When one of the component fails, the rate for the remaining component changes from α1 to \(\alpha _{1}^{*}\) or from α2 to \(\alpha _{2}^{*}\), depending on which component fails first. The resulting density (see Freund (1961)) is
When setting
we see that Eq. 4.1 reduces to the symmetric sibling density (3.7) with t ≤ 0. Since t = 0 is the time point at which the mother is known to have been alive, we are effectively considering a sibling distribution where both offspring are dying before their mother.
The Freund interpretation yields that \(X^{(1)}=\min \limits (X_{1},X_{2})\), i.e. the age of the youngest sibling, has an exponential distribution with rate parameter α1 + α2 = 2(β + ϕ). Further, the age difference between the oldest and the youngest, X(2) = \(\max \limits (X_{1},X_{2})-\min \limits (X_{1},X_{2})\), has an exponential distribution with rate parameter α∗ = 2β + ϕ. In the following paragraphs we interpret the rates (4.2) in the context of the sibling distribution.
If we consider the case with t = 0, we know that the mother and her two offspring were all alive at (or just prior to) t = 0. The Freund interpretation requires us to look backwards in time, starting from t = 0. The “failure” of a component corresponds to an offspring being born. We first look at the event X(1) > x, which can be broken into three sub events:
-
(i)
The mother was born prior to t = −x, i.e. a0 > x. Because the stable age distribution of A0 is exponential with rate β, we have \(P(A_{0}>x)=\exp (-\beta x)\).
-
(ii)
Both offspring were born prior to − x, and because we are conditioning on there being m = 2 siblings in total, this implies that there were no additional births in (−x,0). The latter has probability exp(−βx).
-
(iii)
Both offspring survived the interval (−x,0), which has probability \(\exp (-2\phi x)\).
When combining the independent events i)–iii) we get the Freund interpretation \(P\left (X^{(1)}>x\right )=\exp \left [-2(\beta +\phi )x\right ]\).
The event X(2) > x can be interpreted similarly, but we must shift our point of view backwards in time to t = −x(1) when the youngest sibling was born. The mother would have to be born prior to t = −(x + x(1)). Using the stable age distribution of A0, this has conditional probability
Secondly, there couldn’t have been any births between \(t=-\left (x+x^{(1)}\right )\) and t = −x(1), which has probability \(\exp \left (-\beta x\right )\). Finally, the offspring that was born at t = −x(2) survived from \(t=-\left (x+x^{(1)}\right )\) until t = −x(1), which has probability \(\exp \left (-\phi x\right )\). In total we get \(P\left (X^{(2)} > x\right ) = \exp \left [-(2\beta +\phi )x\right ]\), which is the Freund interpretation of the sibling distribution. Similar arguments applies to the situation t < 0.
Finally, we discuss a few additional insights gained from the Freund interpretation (4.2). First, the age difference between the siblings, X1 − X2 follows a Laplace distribution with rate 2β + ϕ. Further, note that \(\alpha _{j}^{*}\rightarrow \alpha _{j}=\phi \) as \(\beta \rightarrow 0\). Hence, X1 and X2 are independent in the limit \(\beta \rightarrow 0\), each having an exponential distribution with rate ϕ.
5 Simulation, Estimation and Application to Real Data
We first devise an algorithm for sampling (x1, x2) from the density (3.6). Rather than sampling directly from Eq. 3.6, which would be feasible albeit a bit technical, we choose to go back to the definition of the sibling distribution. This involves explicitly sampling (a0, t0) for the mother. As a byproduct, our algorithm sheds light on the sibling distribution, through an expression for the conditional density of (A0, T0), given (T1, T2).
We also construct a hybrid moment/maximum likelihood estimator for the parameter vector 𝜃 = (β, ϕ, t). The statistical properties of this estimator are investigated on simulated data.
5.1 Simulation
The joint density of (A0, T0), (X1, T1) and (X2, T2) is given by
where for notational simplicity we suppress subscripts on densities and range of variables in this section. The quantities on the left-hand side are given by Eqs. 3.3 and 3.5, while the right-hand side is a generic refactoring of the joint density in terms of conditional densities. Dividing through by f(t1, t2) in Eq. 5.1 we obtain the target distribution, and the right-hand side (5.1) suggests the following algorithm for sampling (X1, X2) conditionally on (T1, T2):
-
(i)
Sample (A0, T0) from f(a0, t0|t1, t2),
-
(ii)
Using (a0, t0) from (i), draw Xj from f(xj|tj, a0, t0), independently for j = 1,2.
Step (ii) is straight forward, and is seen from Eq. 3.3 to amount to sampling from an exponential distribution with xj constrained to a certain interval. Step (i) requires more careful consideration. We have
where f(tj|a0, t0) is given by Eq. 3.4 and g(a0, t0) by Eq. 3.5. We have found experimentally for t1 = t2 that the following two-step procedure works well. We start by independently drawing A0 and T0 from exponential distributions with rates 2β and \(\min \limits (\phi +\beta ,t_{1}^{-1},t_{2}^{-1})\), respectively. This is repeated K times to get a pre-sample {(A0k, T0k),k = 1…,K}, from which a single pair (A0, T0) is drawn with probabilities
5.2 Estimation
Consider n observation pairs {(x1i, x2i);i = 1,…,n} from Eq. 3.6. While f(x1, x2) is continuous as a function of 𝜃 = (β, ϕ, t), it is not differentiable in t at t = x1 and t = x2. This implies that the log-likelihood
has 2n points where the derivative is not differentiable. Standard numerical optimization algorithms typically either do not use derivative information at all, or requires the objective function to be continuously differentiable in all variables. The former types of algorithms are slow and unstable, and the latter type are not directly applicable to our setting. We thus devise a special two-stage estimation algorithm.
Because X1 and X2 have the same marginal distribution we define the overall sample mean \(\bar x=(2n)^{-1}{\sum }_{i=1}^{n}(x_{1i}+x_{2i})\). We denote by μ(β, ϕ, t) the expectation of X1 and X2, and impose the constraint \(\mu (\beta ,\phi ,t)=\bar x\) on the parameter estimation problem. An analytical expression for μ(β, ϕ, t) is given in Appendix 7.4. The expression is complicated, but nevertheless well suited for numerical evaluation. Recall that we have proven earlier that μ(β, ϕ, t) is increasing as a function of t.
Our estimation algorithm iterates between the following two steps:
-
1.
For given \(\hat t\), let \(\hat \beta \) and \(\hat \phi \) be the maximizer of \(l(\beta ,\phi ,\hat t)\).
-
2.
For given \(\hat \beta \) and \(\hat \phi \), let \(\hat t\) be the solution of the equation \(\mu (\hat \beta ,\hat \phi ,t)=\bar x\).
Both 1) and 2) are solved numerically using the software TMB (Kristensen et al. 2016).
5.3 Simulation Experiment
Using the algorithm of Section 5.1, we sampled n = 1000 observation pairs (x1, x2) to which the estimator of Section 5.2 was applied. This process was repeated 1000 times to assess the statistical properties of the estimator. Table 2 shows the results for 20 different parameter combinations (one row per combination). Moments characterizing the distribution of (X1, X2), obtained from the moment generating function (3.12), are also given in the table.
From Table 2 we see that the estimator for the parameter vector 𝜃 = (β, ϕ, t) is overall stable with respect to the different combinations of the input parameters. More specifically, for the parameter t in the first column, we see that the mean values of the estimates are all very close to the true value of t, but they are slightly worse in the case when β > ϕ. The same trend can be seen in the standard deviations, which are higher in these situations. For the parameter β we see that the mean of the estimates are more accurate for higher values of t, but we also see the trend with better predictions when β > ϕ. The standard deviations are however quite stable for all combinations of the input parameters. The mean values of the estimates for the parameter ϕ are all very similar and they do not seem to be affected by the different combinations of the input parameters. The standard deviations are higher when t = 2, but otherwise quite similar. Figure 5 shows the marginal density (3.14) for some of the parameter combinations used in Table 2.

5.4 Application to Real Data
We have presented the sibling distribution as a distribution for life times, but it may in fact be applied to any set of non-negative quantities with positive dependence. The constant-rate case is applicable only when the CV is less than one, and when t1 = t2 the marginals must be the same. We use the “twinData” dataset found in the R-package “OpenMx” (Neale et al. 2016) as an example. These are BMI measurements on twins (around age 18), but nevertheless satisfy the above mentioned restrictions (Table 3).
The dataset consists of BMI measurements for 3569 (male/female, monozygotic/dizygotic) twin pairs. The fitted sibling distribution is unable to accomodate the light left-hand tail of data (Fig. 6). The fitted density is huge perturbation of the unconditional (on T) distribution of X, which for the constant-rate case is an exponential distribution. This illustrates the flexibility of the distribution. Table 3 shows the parameters of the fitted distribution. The lack of fit is reflected in estimated moments not fitting the empirical moments very well. If we look at the estimated parameter values in Fig. 6 we see that these are “outside in the normal range”, in the following sense. The expected life length of an individual is \(1/\hat \phi =1/0.94=1.12\), but the mother-offspring duo spanned (mother’s birth to offspring’s death) at least \(\hat {t} =21.77\) time units.

Marginal distribution of BMI data, with fitted sibling distribution. The dashed red curve shows the sibling density (3.6)
6 Discussion
The idea of a sibling distribution was conceived during our work with the recently invented Close-Kin Mark-Recapture method (Bravington et al. 2016), in which the joint age distribution of half-siblings plays a crucial role. Its usefulness as a distribution for multivariate life time data in general remains to be explored. The fact that it is a mixture (over A0 and T0) of independent life times makes it amenable to analysis in the framework of Shaked and Spizzichino (1998). However, due to the conditioning on Tj its structure, and in particular the moments, is complicated. Moreover, the non-differentiability of the likelihood with respect to the parameter t prevents straight forward application of maximum likelihood estimation.
Our numerical experiments indicate that the constant-rate (3.1) distribution has CV ≤ 1. This is clearly limiting for a general purpose life time distribution, but this restriction can be removed by choosing a non-constant ϕ(a). We have not been able to obtain explicit expressions for the sibling density under more general conditions. In general, the sibling density (2.5) can be evaluated numerically. Both the numerator and denominator involves two-dimensional integrals (with respect to a0 and t0). The integrand of the denominator is a product of m functions on form (2.4), which each involves a one dimensional integral. This is by no means computationally prohibitive, but specially tailored numerical integration schemes would have to be devised in order for the general distribution to be practically useful.
We have shown that the constant-rate sibling distribution with t1 = t2 = 0 coincides with the exchangeable Block-Basu distribution (α1 = α2 and \(\alpha _{1}^{*}=\alpha _{2}^{*}\)). The non-exchangeable case is not a sibling distribution, as the sibling framework requires that ϕ and β are the same for both siblings. Conversely, the sibling distribution with t1 ≠ t2, or t1 = t2 > 0, is not a Block-Basu distribution. Also, when allowing age-specific rates, ϕ(a) and β(a), the sibling distribution is no longer a Block-Basu distribution. Kundu and Gupta (2010) extended the Block-Basu distribution by deriving it from components that were Weibull distributed instead of exponential. The additional shape parameter makes the extended Block-Basu distribution more flexible at the cost of being less computational tractable.
Finally, we have proven that the constant-rate sibling distribution is MTP2 and stochastically increasing in t. We conjecture, based on literature for mixture distributions (Shaked and Spizzichino, 1998, p. 273; Shaked and Shanthikumar, 2007) that these properties hold for a wider class of sibling distributions, but possibly not for all.
References
Andersen, EW (2005). Two-stage estimation in copula models used in family studies. Lifetime Data Anal. 11, 333–350.
Arnold, BC and Strauss, D (1988). Bivariate distributions with exponential conditionals. J. Am. Stat. Assoc. 83, 522–527.
Barreto-Souza, W and Mayrink, VD (2019). Semiparametric generalized exponential frailty model for clustered survival data. Ann. Inst. Stat. Math. 71, 679–701.
Block, HW and Basu, A (1974). A continuous, bivariate exponential extension. J. Am. Stat. Assoc. 69, 1031–1037.
Bravington, MV, Skaug, HJ, Anderson, EC et al. (2016). Close-kin mark-recapture. Stat. Sci. 31, 259–274.
Caswell, H and Keyfitz, N (2005). Applied mathematical demography, 3rd edn. Springer, New York.
Freund, JE (1961). A bivariate extension of the exponential distribution. J. Am. Stat. Assoc. 56, 971–977.
Gumbel, EJ (1960). Bivariate exponential distributions. J. Am. Stat. Assoc. 55, 698–707.
Hougaard, P (1986). A class of multivariateate failure time distributions. Biometrika 73, 671–678.
Hougaard, P (2001). Analysis of multivariate survival data. Springer, New York.
Karlin, S and Rinott, Y (1980). Classes of orderings of measures and related correlation inequalities. I. Multivariate totally positive distributions. J. Multivar. Anal. 10, 467–498.
Khaledi, BE and Kochar, S (2001). Dependence properties of multivariate mixture distributions and their applications. Ann. Inst. Stat. Math. 53, 620–630.
Kristensen, K, Nielsen, A, Berg, CW, Skaug, HJ and Bell, B (2016). TMB: Automatic differentiation and Laplace approximation. J. Stat. Softw.70, 1–21.
Kundu, D and Gupta, RD (2010). A class of absolutely continuous bivariate distributions. Statistical Methodology 7, 464–477.
Marshall, AW and Olkin, I (1967). A multivariate exponential distribution. J. Am. Stat. Assoc. 62, 30–44.
Neale, M, Hunter, M, Pritikin, J, Zahery, M, Brick, T, Kirkpatrick, R, Estabrook, R, Bates, T, Maes, H and Boker, S (2016). OpenMx 2.0: Extended structural equation and statistical modeling. Psychometrika 81, 535–549.
Nelsen, RB (2007). An introduction to copulas. Springer Science & Business Media.
Sarkar, SK (1987). A continuous bivariate exponential distribution. J. Am. Stat. Assoc. 82, 667–675.
Shaked, M and Shanthikumar, JG (2007). Stochastic orders. Springer Science & Business Media.
Shaked, M and Spizzichino, F (1998). Positive dependence properties of conditionally independent random lifetimes. Math. Oper. Res. 23, 944–959.
Acknowledgments
Parts of this work have been done in the context of CEDAS (Center for Data Science, University of Bergen, Norway).
Funding
Open access funding provided by University of Bergen (incl Haukeland University Hospital).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A. Proof of Theorem 1
The quantities involved in the expression (2.5) for the sibling density are given by Eqs. 3.3, 3.4 and 3.5. The evaluation of the integrals over (a0, t0) in the numerator and denominator of Eq. 2.5 is made difficult by the constraints (2.3). Below we show how these constraints split the first quadrant of the (x1, x2) plane into six disjoint regions R1,…,R6 (see Fig. 2). In each of these the integrand is just a simple exponential function. Because the density is exchangeable when t1 = t2 it is sufficient to specify the expression only over the regions R1, R2 and R3.
Recall that yj = tj − xj denotes the birth time (j = 0,1,2). The integrand of the numerator in Eq. 2.5 is
for values of a0 and t0 such that the constraints (2.3) are satisfied for j = 1,2, and zero otherwise. The term after × does not depend on a0 and t0, but is included for later reference. Because we assume x1, x2 ≥ 0, we can replace the inequality (tj − t0)+ ≤ xj in Eq. 2.3 by t − t0 ≤ xj, which again is equivalent to t0 ≥ yj. Similarly, the last inequality xj ≤ tj − y0 in Eq. 2.3 can be re-expressed as a0 ≥−yj. Together with the basic constraints a0, t0 ≥ 0 we get \(a_{0} \geq \max \limits (0,-y_{1},-y_{2}) \ \text {and} \ t_{0} \geq \max \limits (0,y_{1},y_{2}). \) Depending on the relative values of y1 and y2, the lower bounds of the integrals over a0 and t0 will be qualitatively different. There are 6 different cases, corresponding to the partition R1,…,R6 of the (x1, x2) plane shown in Fig. 2. When integrating (A.1) with respect to a0 and t0, and replacing yj by t − xj (j = 1,2), we get
which is Eq. 3.6.
The proof when t < 0 follows in the same vein, where we start out with the integrand of the numerator in Eq. 2.5 given by Eq. A.1. We must find values of a0 and t0 such that the constraints (2.3) still hold. The inequality (tj − t0)+ ≤ xj in Eq. 2.3 which is equivalent to t0 ≥ yj can be replaced with t0 ≥ 0 since we have y1, y2 < 0 in combination with the constraint t0 ≥ 0. For the last inequality in Eq. 2.3, the above arguments still apply such that this term is replace, with by a0 ≥−yj. In total we get \(a_{0} \geq \max \limits (0,-y_{1},-y_{2})\) and t0 ≥ 0.
Appendix B. Analytical expressions
The expectation under the density (3.14) is
This expression is obtained using computer algebra system Maple.
Appendix C. Proof of Theorem 3
We shall work with \(g(x)=\log f(x)\), x ∈ R2, which for the sibling density that Eq. 3.6 is a piecewise linear function. The MTP2 property of f is equivalent supermodularity of g, i.e.
It is trivial to check that a linear function g is supermodular, so it follows directly that Eq. 3.7 is MTP2.
The density (3.6) requires more careful attention due to its piecewise definition. It suffices to consider x and z such that the four points x, z, (x ∨ z) and (x ∧ z) form a non-degenerate rectangle with sides parallel to the axes. This happens when either x1 < z1 and x2 > z2 or when x1 > z1 and x2 < z2. We will consider only the former, where x is the upper-left corner (and z the lower-right corner) of the rectangle. The other case is handled in the same way. When the rectangle is degenerate (a line or a point) it can be checked that Eq. C.1 holds for any function g. Under these constraints, if x and z lie in the same region (\(R_{1},\dots ,R_{6}\)) of Fig. 7 all four corners of the rectangle lies lies in same region, and by linearity of g within each region we have that Eq. C.1 is satisfied.

The sum of two supermodular functions is again supermodular, so we may add ϕ(x1 + x2) to all three branches of the logarithm of Eq. 3.6, so that we may work with
The extension of g to all six regions of Fig. 7 (with t1 = t2 = t) is g(x1, x2) = g(x2, x2) when x1 > x2. The fact that g(x1, x2) does not depend on x2 in regions R1 and R4, and not on x2 in R3 and R6 are visualized via the a level curve (green dashed line) of g in Fig. 7. It is seen that g is unimodal, with the mode at (x1, x2) = (t, t).
We start out by restricting ourselves to the case x2 < t. Under the facts established above, and the assumed restrictions on x and z, there are only three qualitatively different cases that must be considered. Using the red part of Fig. 7 as a reference, these are: i) x = A and \(z=C^{\prime }\), ii) x = A and \(z=D^{\prime }\) and iii) x = C and \(z=D^{\prime }\). With our geometric approach, supermodularity is something that is checked for rectangles. It has the property that we can split a rectangle \((A,C,C^{\prime },A^{\prime })\) in two, \((A,B,B^{\prime },A^{\prime })\) and \((B,C,C^{\prime },B^{\prime })\), and it is sufficient to check Eq. C.1 for the two parts. Hence, to check all of i)–iii) it suffices to check all the red sub-rectangles in Fig. 7, which we will now do. First, \((A,B,B^{\prime },A^{\prime })\) lies in a single region (R6) so Eq. C.1 holds. For \((B,C,C^{\prime },B^{\prime })\) we find by looking at the level curves of g that g(C) > g(B) and \(g(C^{\prime })=g(B^{\prime })\), which imply that Eq. C.1 holds. Finally, the (solid black) vertical line x1 = t splits \((C,D,D^{\prime },C^{\prime })\) in two parts which each line entirely in R1 and R2, respectively. This completes the proof for x2 < t.
The situation that z2 > t, i.e. the red part of the figure is moved above the (solid black) horizontal line x2 = t, follows by symmetry. The remaining case, x2 > t > z1, can be handled by splitting in two the rectangle horizontally at the x-axis, for each of which we know Eq. C.1 holds. Since supermodularity is also additive when splitting a rectangle horizontally, we have completed the proof.
Appendix D. Proof of Theorem 4
We prove that f(x1, x2;t) is multivariate stochastically increasing (Shaked and Shanthikumar, 2007, Definition (6.B.1)) in the parameter t, where f(x1, x2;t) is given by Eq. 3.6. This implies Eq. 3.16, i.e. the marginals are also stochastically increasing (Shaked and Shanthikumar, 2007, Theorem 6.B.16 (c)).
We prove that the conditions in Theorem 6.B.8 in (Shaked and Shanthikumar, 2007) are satisfied. First, it follows from the MTP2 property that (X1, X2) is “associated” in the sense of the theorem (Karlin and Rinott, 1980, Eq. (1.7)). Define the function \(h(x_{1},x_{2})=\log \left [f(x_{1},x_{2};t^{\prime })/f(x_{1},x_{2};t)\right ] \). The main condition of Theorem 6.B.8 is that h(x1, x2) is increasing in (x1, x2) for \(t^{\prime }>t\). To verify this we will check that
which together with the continuity of h is sufficient.
We build on the proof of Theorem 3, and denote the six regions of Fig. 7 associated with \(t^{\prime }\) by \(R_{1}^{\prime },\ldots ,R_{6}^{\prime }\). We need to verify Eq. D.1 when \((x_{1},x_{2})\in R_{j}\cap R_{k}^{\prime }\) for different values of j and k. When j = k it follows that h(x1, x2) = 0 which implies Eq. D.1. Next, due to the fact that \(t\leq t^{\prime }\) many combinations of j and k cannot occur, and we are left with the following list to check:
(x1, x2) | h(x1, x2) |
\(R_{4}\cap R_{5}^{\prime }\) | (ϕ + β)x1 |
\(R_{4}\cap R_{6}^{\prime }\) | (ϕ + β)x1 + 2βx2 |
\(R_{5}\cap R_{6}^{\prime }\) | 2βx2 |
\(R_{3}\cap R_{2}^{\prime }\) | (ϕ + β)x2 |
\(R_{3}\cap R_{1}^{\prime }\) | (ϕ + β)x2 + 2βx1 |
\(R_{2}\cap R_{1}^{\prime }\) | 2βx1 |
For all of these combinations (D.1) holds. Note that we have skipped additive terms in h that does not depend on x1 or x2. This completes the proof.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Helgøy, I.M., Skaug, H.J. The Sibling Distribution for Multivariate Life Time Data. Sankhya B 84, 340–363 (2022). https://doi.org/10.1007/s13571-021-00259-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13571-021-00259-w