
Abstract
A nonparametric test labelled ‘Rao Spacing-frequencies test’ is explored and developed for testing whether two circular samples come from the same population. Its exact distribution and performance relative to comparable tests such as the Wheeler-Watson test and the Dixon test in small samples, are discussed. Although this test statistic is shown to be asymptotically normal, as one would expect, this large sample distribution does not provide satisfactory approximations for small to moderate samples. Exact critical values for small samples are obtained and tables provided here, using combinatorial techniques, and asymptotic critical regions are assessed against these. For moderate sample sizes in-between i.e. when the samples are too large making combinatorial techniques computationally prohibitive but yet asymptotic regions do not provide a good approximation, we provide a simple Monte Carlo procedure that gives very accurate critical values. As is well-known, the large number of usual rank-based tests are not applicable in the context of circular data since the values of such ranks depend on the arbitrary choice of origin and the sense of rotation used (clockwise or anti-clockwise). Tests that are invariant under the group of rotations, depend on the data through the so-called ‘spacing frequencies’, the frequencies of one sample that fall in between the spacings (or gaps) made by the other. The Wheeler-Watson, Dixon, and the proposed Rao tests are of this form and are explicitly useful for circular data, but they also have the added advantage of being valid and useful for comparing any two samples on the real line. Our study and simulations establish the ‘Rao spacing-frequencies test’ as a desirable, and indeed preferable test in a wide variety of contexts for comparing two circular samples, and as a viable competitor even for data on the real line. Computational help for implementing any of these tests, is made available online “TwoCircles” R package and is part of this paper.
Similar content being viewed by others



Avoid common mistakes on your manuscript.
1 Introduction
The primary goal of this paper is to explore and develop a test for comparing two circular samples, study its small sample distribution, and make it available to practitioners through tables of critical values, and an R code. Its small sample performance is assessed relative to comparable tests that are used in this context, and it is shown to be valid and superior in a broader context. When such samples are on the real line, there is a great deal of literature on tests based on the ranks of one of these samples in the combined sample, such as the Wilcoxon test (see e.g. the classical text by Hájek et al., 1999 or more recent texts such as Wasserman, 2006 or Gibbons and Chakraborti, 2011. However on a circle, ranks are not uniquely defined as their values depend on the choice of origin and the sense of rotation (i.e. clockwise/anticlockwise), which are both arbitrary. Discussions on circular data can be found, for example, in Rao and SenGupta (2001) and Mardia and Jupp (2009). An important alternative to rank tests is to consider tests based on the spacing frequencies which are the counts or the frequencies of one sample that fall in between the spacings or gaps made by the other sample. These frequencies remain unchanged under different choices of zero direction and the sense of rotation, and indeed, as the maximal invariant under the rotation group, they play a central role for testing problems that arise in connection with circular data (see e.g. Gatto and Rao, 2015).
The objective of this paper is to provide the exact distribution theory for a few important ones among these tests, namely the Wheeler-Watson test, the Dixon test and the newly introduced Rao test, provide their exact distribution theory and critical values, and evaluate their relative power performance in small samples. As two-sample tests for circular data come up widely in many physical and natural sciences (see e.g. Taylor and Burns, 2016), our results providing accurate critical values for such tests based on spacing-frequencies, have important practical implications when dealing with small and moderate sample sizes.
Although the main purpose of this new test lies in its use for comparing two circular samples, it is equally useful for comparing any two samples on the real line. Just to demonstrate this and to see how well it performs in that context, in Section 7 we make a power comparison with just one such test that is commonly used on the line, viz. the Wilcoxon test.
2 Spacing-Frequencies Tests for Comparing two Circular Populations
A special note about the notations: while m observations on a circle make up an equal number of spacings, on the real line (m − 1) observations break up the real line into m spacings. So in order to accommodate this quirk, we start with (m − 1) observations for one of the samples as if they are on the line, and all the theory works equally well when there are m observations on the circle, which is our sample space of interest.
Let {Xi, i = 1,…,m − 1} and {Yj, j = 1,…,n} be independent samples from two continuous distributions F and G respectively, on the real line. We want to test the classical null hypothesis H0 : F = G against suitable alternatives. On the real line, let X(i), i = 1,…,m − 1 be the order statistics of the Xi’s, with the notation \(X_{(0)} \equiv -\infty \ \text {and} \ X_{(m)} \equiv \infty \). For k = 1,…,m, let Sk denote the number of Yj’s in the interval [X(k− 1),X(k)), i.e.

On the circle, one may start with any one of the observations as the “origin” and consider either sense of rotation (clockwise or anticlockwise) and define the frequency of Yj’s in the arc-lengths formed by the sample X(i)’s, i = 1,…,m. These Sk’s are referred to as spacing frequencies, and their distribution theory remains the same.
Unlike the ranks which are not well-defined for circular data, such spacing frequencies have the rotational invariance property and play a prominent role in comparing two samples on the circle. They are equally useful on the line as they represent rank-differences (see Gatto and Rao, 2015 for details). Large sample theory for families of nonparametric tests of the form \({\sum }_{k=1}^{m} h(S_{k})\) which are symmetric in these spacing-frequencies as well as for the more general statistics of the form \({\sum }_{k} h_{k}(S_{k})\) are studied in Holst and Rao (1980). But as shown in Gatto and Rao (2015), symmetric statistics based on spacing-frequencies have the rotational invariance property and hence are appropriate in the circular context.
In this paper, we consider three such nonparametric tests based on spacing frequencies for comparing any two circular samples, and these are listed in Table 1 below.
Note that, under the null hypothesis, the expected value of Sk is given by n/m. While the Dixon statistic (1940) looks at the squared L2 norm of \((S_{k}- \mathbb {E}[S_{k}])\) (which can be seen as also equivalent to \(\sum {S_{k}^{2}}\)), the Rao spacing-frequencies statistic given above, looks at the L1 norm of \((S_{k} - \mathbb {E}[S_{k}])\). As we show below, it is equal to the simple sum \(2{\sum }_{k=1}^{m} \max \limits \left (S_{k}-\frac {n}{m},0\right )\). This is because
since
This statistic may be seen as the two-sample analog of the frequently used “Rao’s spacings test” for testing uniformity or isotropy for a single sample of circular data (see Rao, 1976). The exact distribution theory, critical values, and the relative performance of this statistic T1 are being studied in some detail here for the first time. The Wheeler-Watson test (see Wheeler and Watson, 1964) is based on what are called uniform scores and can be written in the above form in terms of spacing frequencies.
Remark 1.
One may construct tests of the same functional form based on the “dual” spacing-frequencies, namely the number of X-observations that fall in between the spacings made by the Y-observations, but as discussed in some detail in Gatto and Rao (2015) there is a one-to-one correspondence between these two sets, and one may proceed either way to obtain comparable conclusions. This duality may be seen as somewhat analogous to choosing the ranks of one of the two samples in the combined sample, in the theory of rank tests. Rao and Murthy (1981) consider a statistic based on the squared frequencies of both kinds and show that in large samples, this does not add to further efficiency compared to squaring just one set of frequencies as does the Dixon statistic mentioned below. Given this, the authors suggest taking the smaller of the two samples as the X’s to make up the spacings, and the larger sample as the Y’s for obtaining the frequencies in order to avoid many empty cells with zero frequencies (in analogy with having more balls than cells).
3 Asymptotic Distributions
The asymptotic distributions of the Rao statistic, as well as the Dixon statistic, can be obtained using the general results of Holst and Rao (1980), in particular their Theorem 4.1, stated below.
Theorem 1 (Holst and Rao, 1980).
Let T be a symmetric statistic of the form \({\sum }_{k=1}^{m} h(S_{k})\). Let η be a geometric (ρ) random variable where
Let
Then, under the null hypothesis H0 that the two populations are identical, the asymptotic distribution of T is given by
We conclude this section with the special case when the sample sizes from the two populations are equal, just in order to explore the divergence between this large sample result and the exact values, which we do in Fig. 1 later. In this case, Eq. 2 has a very simple expression for both these tests, as shown in the following corollary.

Exact and asymptotic distributions for the Rao and Dixon statistics for the case of m = 9 and n = 10
Corollary 1.
When the sample sizes from the two populations are equal, the limiting null distribution of the Rao statistic is given by
while the asymptotic distribution of the Dixon statistic is given by
Proof
From Eq. 1, when the sample sizes are equal, η denotes a random variable with a Geometric \(\left (1/2\right )\) distribution, and therefore we have \(\mathbb {E}[\eta ]=1\), \(\mathbb {E}[\eta ^{2}]=3\), V [η] = 2, \(\mathbb {E}[\eta ^{3}]=13\) and \(\mathbb {E}[\eta ^{4}]=75\).
Thus for the Rao statistic with h(x) = |x − 1|, we can check that \(\mathbb {E}\left [|\eta -1|\right ] = 1\). Moreover, we have \(V[h(\eta )]= \mathbb {E}\left [(\eta -1)^{2}\right ]-\mathbb {E}^{2}[|\eta -1|] = 1\) and \(Cov(h(\eta ),\eta ) = \mathbb {E}[\eta |\eta -1|]-1 = 1\).
Similarly for the Dixon statistic with h(x) = x2, therefore we have \(V[h(\eta )]= V[\eta ^{2}] = \mathbb {E}[\eta ^{4}] - \mathbb {E}^{2}[\eta ^{2}] = 66\), and \(Cov(h(\eta ),\eta ) =Cov(\eta ^{2},\eta ) = \mathbb {E}[\eta ^{3}]-\mathbb {E}[\eta ^{2}]\mathbb {E}[\eta ] = 10\), from which the result follows. □
4 Exact Distributions
Mirakhmedov et al. (2014) provide improvements to the limiting normal approximation given in Theorem 1 through Edgeworth expansions. Gatto and Rao (1999) discuss the use of saddle-point approximations which lead to accurate numerical approximations that compare well with Monte Carlo simulations. However these are still attempts to get closer to the exact distributions, which is the primary focus of this paper.
The exact distributions of these test statistics can be found by considering the joint distribution of \(\mathbf {S}=\left (S_{1}, S_{2}, \ldots , S_{m}\right )\). Since under the null hypothesis the Xi’s and Yi’s come from the same distribution, all possible permutations of the Xi’s and Yi’s are equally likely. Hence the distribution of S is found by looking at the number of ways Yi’s can be distributed among the spaces between the order statistics of X. Since there are m spaces generated by the X(k)’s and n objects are to be inserted into these m cells, which is the classical combinatorial problem, and can be done in \(\binom {n+m-1}{m-1}\) equally likely ways. Hence each possible configuration of \(\mathbf {S}=\left (S_{1}, S_{2}, \ldots , S_{m}\right )\) has probability \(\binom {n+m-1}{m-1}^{-1}\). In order to derive the probability for any specific value of a given statistic, we need to add the probabilities of all combinations of S that correspond to this value. This involves increasingly complex combinatorial computations, for which we provide an R package.
4.1 Computation of the Exact Critical Regions
We now consider the small sample case and provide the exact critical values for these test statistics, corresponding to commonly used significance levels of α = 0.10 and α = 0.05. Since these test statistics are all discrete, for any given significance level α, we sandwich such an α between upper tail probabilities p1 and p2 with the corresponding critical values c1 and c2 as follows. For each value of α, we give a pair of bracketing points (c1,c2) and corresponding upper tail probabilities (p1,p2), where c1 < c2 and p1 > p2. Using ci,i = 1,2 as the critical value and \([c_{i},\infty )\) as the critical region so that any observed value of T larger than or equal to ci leads to H0 being rejected, we have a test of significance level pi,i = 1,2. The points (c1,c2) are chosen to be successive values of T so that P(T ∈ (c1,c2)|H0) = 0 and p1 = P(T ≥ c1|H0) ≤ α, p2 = P(T ≥ c2|H0) > α. The upper 10% and 5% critical values for the Rao, Dixon, and the Wheeler-Watson tests are given in Tables 3 to 5 in the Appendix, for small samples (values of m ≤ 12, n ≤ 11). For other choices of m and n, such critical values can be computed using the “TwoCircles” R packageFootnote 1 that we make available.
4.2 Exact Versus Asymptotic Distributions
Such exact null distributions can now be compared to the asymptotic results given by Corollary 1. Figure 1 presents such a comparison for the Rao and Dixon statistics, taking for illustration m = 9 and n = 10,which are nearly equal size samples. This illustrates, as expected, that for small sample sizes the asymptotic distribution provides a very poor approximation to the exact one, especially for the Dixon statistic.
We further illustrate the deficiency of using the asymptotic critical values instead of using the exact values obtained by the combinatorial methods. We do this by comparing the finite sample type I errors for the Dixon and Rao statistics obtained from the exact and the asymptotic rejection regions. These results are obtained by taking equal sample sizes (i.e. n = m − 1) with n = 2,3,…,12 and at level α = 0.1. The results are presented on the left panel of Fig. 2. As expected, the exact rejection regions lead to type I errors which are systematically closer to α than the ones obtained using asymptotic results. In the right panel of Fig. 2 we investigate by Monte Carlo simulations (under H0: \(X_{i} \sim \mathcal {N}(0,1)\) and \(Y_{i} \sim \mathcal {N}(0,1), i = 1,\ldots ,n\)) the relationship between the sample size n and the empirical type I error obtained from asymptotic rejection regions. The results suggest that a sample size of a several thousands are needed to obtain a correct type I error. Overall conclusion is that the asymptotic distribution differs considerably from the exact distribution even for moderately large sample sizes. This calls for better approximations for dealing with moderate sample sizes, which is what we explore next.

a Type I errors for the Dixon and Rao statistics obtained from the exact and asymptotic rejection regions. b The relationship between the sample size n and the type I error obtained from asymptotic rejection regions. The error bars correspond to the standard errors obtained by resampling techniques
5 Critical Values for Moderate Sample Sizes via Simulation
For moderately large values of m and n, the calculation of the exact sampling distribution through exhaustive enumeration of all possible combinations may be too computationally intensive and, consequently, infeasible. However, these values may at the same time be too small for the asymptotic distribution to deliver a reliable approximation of the sampling distribution. Such cases may typically arise when \({\min \limits } (n, m) > 20\) and \(\max \limits (n, m) < 1000\). To address this issue, we consider a simple and computationally efficient Monte Carlo approach to compute fairly accurate critical regions and p-values. This approach tends to reproduce the idea behind random permutations in general non-parametric context, while taking advantage of the known properties of the spacing-frequencies Sk under the null hypothesis.
This approach can be summarized in the following algorithm which is based on B Monte Carlo replications:
-
1.
Let b = 1.
-
2.
Draw the following two samples \(\{X_{i}^{\ast }, \ \ i=1, \ldots , m-1\}\) and \(\{Y_{j}^{\ast }, \ \ j=1, \ldots , n\}\) where \(X_{i}^{\ast } \sim \mathcal {U}(0,1)\) and \(Y_{j}^{\ast } \sim \mathcal {U}(0,1)\).
-
3.
Compute the spacing-frequencies based on two samples obtained from the previous step, i.e.
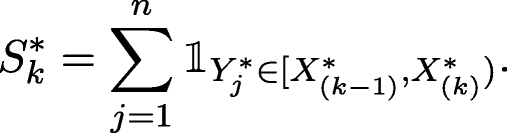
-
4.
Compute the test statistic of interest based on the \(S_{k}^{\ast }\)’s previously obtained and define \(T_{b}^{\ast }\) as follows:
$$ T_{b}^{\ast} = \sum\limits_{k = 1}^{m} h(S_{k}^{\ast}). $$ -
5.
If b < B go to step 2 and define b = b + 1, otherwise end the procedure.
As a result of this procedure, the empirical distribution \(T_{1}^{\ast }, ..., T_{B}^{\ast }\) can be used to estimate the bracketing points (\(c^{\ast }_{1},c^{\ast }_{2}\)) together with the pair of significance levels (\(p^{\ast }_{1},p^{\ast }_{2}\)). Naturally, this approach can also be employed to calculate empirical p-values, which are simply defined as (see e.g. Davison and Hinkley, 1997)

Moreover, the precision of the above approximations can be assessed using different techniques such as e.g. applying the standard non-parametric bootstrap on theTb’s, allowing to select a value of B that leads to the desired level of precision. The algorithm described in this section is implemented in the “TwoCircles” R packageFootnote 2 that we make available.
6 Relative Performance of the Three Tests—Simulated Powers
Holst and Rao (1980) provide a comprehensive treatment on the asymptotic distribution theory and asymptotic efficiencies for tests based on spacing-frequencies. However, to calculate the exact distributions of these test statistics under alternatives, one needs the probability distribution of the vector S under the alternatives, which is quite complex and is given by the following
Remark 2.
When f is the density of X, G the density of Y
with n1 + n2 + ⋯nm = n.
In view of this complexity, in this section, we investigate the finite sample performance of the Rao test, compared with the Dixon and the Wheeler-Watson tests via simulations, focusing on circular alternatives since these are primarily meant for circular situations. Different scenarios are considered, each corresponding to a different type of departure from the null hypothesis H0. Simulation 1 considers the case when the two samples come from two von Mises distributions with the same concentration, but as the difference in their mean directions increases.
Simulation 1.
We consider the following setting:
An equally spaced grid of 20 values for μ was employed ranging from 0 to π. Two combinations of sample sizes were used for m and n. The empirical power curves (based on 104 Monte Carlo replications) of the different tests considered in Table 1 are presented in Fig. 3. It can be observed that the Wheeler-Watson test appears superior in this simulation to both the Rao and Dixon tests.

a Power curve for 20 equally spaced values of μ between 0 to π (see Simulation 1) for the Rao, Dixon, and Wheeler-Watson tests with m = 4 and n = 12. b Similar to Case (a) but for the values m = 8 and n = 8.
In the next simulation we consider again the case when the two samples come from two von Mises distributions with the same mean (at 0), but as the difference in their concentration increases.
Simulation 2.
In this simulation we consider the following setting:
An equally spaced grid of 20 values for δ was employed ranging from 0 to 20. Two combinations of sample sizes were used for m and n. The empirical power curves (based on 104 Monte Carlo replications) are presented in Fig. 4. In this simulation, the Rao test appears to provide a better power than Wheeler-Watson and Dixon tests.

a Power curve for an equally spaced grid of 20 values for δ (see Simulation 2) ranging from 0 to 100 for the Rao, Dixon and Wheeler-Watson tests. The values m = 6 and n = 12 were considered in this case. b Similar to point (a) but for the values m = 6 and n = 16
Next, we examine the performance of these tests when one of the samples is from a Uniform distribution on [0, 2π) (which is the same as a vM with zero concentration) while the other is from a mixture of two von Mises distributions.
Simulation 3.
We consider the following setting:
An equally spaced grid of 20 values for δ was employed ranging from 0 to 20. Two combinations of values were used for m and n such that the sum of the sample sizes was kept to 28. The empirical power curves (based on 104 Monte Carlo replications) are presented in Fig. 5. Under this scenario, the Rao test clearly outperforms both the Wheeler-Watson and Dixon tests. One can observe that Wheeler-Watson test provides particularly poor performance in detecting departures from H0. This phenomenon is very similar to the one-sample situation where for testing uniformity, the Rayleigh test (which is based on the resultant length) fares poorly compared to the Rao’s Spacings test, when the samples come from a symmetric multimodal distribution, like axial data. See again Gatto and Rao (2015) for more details on this issue.

a Power curve based for an equally spaced grid of 20 values for δ (see Simulation 3) ranging from 0 to 20 for the Rao, Dixon and Wheeler-Watson tests. The values m = 6 and n = 22 were considered in this case. b Similar to point (a) but for the values m = 8 and n = 20
In the following simulation, we consider a different case of von Mises mixtures
Simulation 4.
We consider the following setting:
An equally spaced grid of 20 values for δ was employed ranging from 0 to 20. Two combinations of values were used for m and n such that the sum of the sample sizes was kept to 28. The empirical power curves (based on 104 Monte Carlo replications) are presented in Fig. 6. Similar to the previous simulation, the Rao test clearly outperforms both the Wheeler-Watson and Dixon tests.

a Power curve based for an equally spaced grid of 20 values for δ (see Simulation 4) ranging from 0 to 20 for the Rao, Dixon and Wheeler-Watson tests. The values m = 10 and n = 18 were considered in this case. b Similar to point (a) but for the values m = 8 and n = 20
The examples presented here are but a sample of exhaustive small sample power study of these test statistics that we have undertaken. Based on these as well as the cases presented here, we can draw several useful conclusions. Among these 3 tests, the Wheeler-Watson test appears to perform better than the other two in detecting location shifts as indicated in Simulation 1. The Rao test appears preferable when one suspects that one of the samples may be from a mixture-distribution i.e. when one sample is transformed to be uniform on the circle, the other sample comes close to any symmetric bimodal or multimodal alternative such as a mixture of 2 von Mises distributions, as is the case in Simulations 3 and 4. This conclusion coincides with similar results obtained by Gatto and Rao (2015). The Dixon and Rao tests which are omnibus tests, perform well even in such situations. Although it is shown in Theorem 4.2 of Holst and Rao (1980) that the Dixon statistic is asymptotically Locally Most Powerful among symmetric functions of spacing-frequencies, we see that its performance in small samples is not as good as that of Rao test in all our simulations. The inevitable conclusion seems to be that one should use this Rao spacing-frequencies test if one suspects multimodal alternatives, or if the sample sizes are small to moderate - the case for which this paper provides tables and necessary R code.
7 A Comparison with a Test on the Real Line
As stated earlier, let X(i)’s, i = 1,…,m − 1 denote the order statistics of Xi on the line with the notation \(X_{(0)} \equiv -\infty \) and \(X_{(m)}\equiv \infty \), and Sk, k = 1,…,m denote the number of Yj’s in the interval [X(k− 1),X(k)).
In order to make a simple comparison with two-sample nonparametric tests on the line, we consider one of the most commonly used tests namely the Wilcoxon test (see Wilcoxon (1945)) as a proxy. As shown in the lemma below, the Wilcoxon statistic is also a simple linear function of the spacing frequencies and belongs to this general class of tests. However it is not symmetric in these spacing-frequencies and hence takes different values depending on the choice of the origin. Because of this lack of rotational invariance, it cannot be used as such, for comparing two circular samples.
Lemma 1.
The Wilcoxon rank sum test statistic W can be written as:
in terms of {Sk : k = 1,…,m}.
Proof
If Ri denotes the rank of X(i) in the combined sample, the Wilcoxon statistic \(W={\sum }_{i=1}^{m-1} R_{i}\). Since \(R_{i}={\sum }_{k=1}^{i} (S_{k}+1)\), we have
Since \({\sum }_{k=1}^{m} S_{k} = n\), we have \({\sum }_{k=1}^{m} (m-k)S_{k} = mn- {\sum }_{k=1}^{m} kS_{k}\) and the assertion follows. □
Remark 3.
A centered version of W is sometimes used, namely the Mann-Whitney statistic \(U=W-\frac {m(m-1)}{2}\), which can be written as
To briefly assess how the three tests considered in this paper fare with respect to competitors on the line, using the Wilcoxon test as a proxy, we consider a simple simulation, viz. Simulation 5.
Simulation 5.
We consider the following setting:
An equally spaced grid of 20 values for p was employed ranging from 0 to 1. Two combinations of values were used for m and n. The empirical power curves (based on 104 Monte Carlo replications) of the tests considered in Table 1 as well as the Wilcoxon rank test, is presented in Fig. 7. Similar to the results presented in Section 6, Rao test clearly outperforms Wheeler-Watson, Dixon and even the Wilcoxon rank test. It can also be observed that the Wilcoxon rank test, and to a lesser extent the Wheeler-Watson test, provide a particularly poor performance in detecting departure from H0. This may be be partly explained by the fact that the distribution remains symmetric under the alternative.

8 An Illustrative Example and Use of Tables
For small sample sizes (values of m ≤ 12, n ≤ 11), Appendix provides tables of critical values for these three test statistics, by giving bracketing values (closest critical value on either side) for α = 0.05,and α = 0.1. More extensive tables as well p-values can be obtained using R code available in the R package “TwoCircles”Footnote 3. We illustrate the use of this code through the following example:
> library(TwoCircles) > get_critical_values(n = 6,m = 8, test = "rao", alpha = 0.05) Bracketing values (c1, c2) corresponding to significance levels (p1, p2) for Rao test based on the significance level 0.05 c1 = 9 (p1 = 0.0862) c2 = 10.5 (p2 = 0.0047)
We now consider how these circular tests perform and their exact and asymptotic p-values, by applying them on a classic data set on homing pigeons. Homing pigeons are selectively bred pigeons that possess the ability to find their way home over extremely long distances, and are used in experiments on animal navigation. There is considerable literature on this subject (see e.g. Walcott, 1996 and the references therein). Among the early studies on homing pigeons, Schmidt-Koenig (1958) evaluated the difference in orientation abilities of a group of control and experimental birds. The experimental birds had their internal clock reset by six hours clockwise and were expected to deviate by about 90° counterclockwise with respect to the control birds upon release (see Schmidt-Koenig, 1958 for details). The release flight direction of the pigeons from the two groups were collected in different experiments and one of them is presented in Fig. 8. It can be observed that mean directions of the two groups appear to significantly differ. The experimental and control birds have a mean direction of respectively 18.9° and 104.0°, which is close to 90° (counterclockwise) expected difference.

Two sample from the experiment on the homing orientation of pigeons. The reported angles in degrees are: 75°, 75°, 80°, 80°, 80°, 95°, 130°, 170°, 210° (control group); 10°, 50°, 55°, 55°, 65°, 90°, 285°, 285°, 325°, 355° (experimental group). Adapted from Figure 22 of Schmidt-Koenig (1958)
A hypothesis of interest here is whether the observed directions of the two groups are from the same circular distribution. The three tests discussed in Section 2 can be used to perform such analysis. Their asymptotic and exact p-values are reported in Table 2. These results can be replicated using our package as illustrated through the following example:
> library(TwoCircles) > data("pigeons") > circular_test(pigeons$control, pigeons$experimental, test = "rao") Rao Two Sample Test Data: pigeons$control and pigeons$experimental Test Statistic: 15.77778 Exact P-value: 0.00185 Bracketing Points and Pair of Signif. Levels: c1 = 13.3333 (p1 = 0.0767) c2 = 13.5556 (p2 = 0.0479)
The differences between the asymptotic and exact p-values are noticeable, in particular for the Dixon test where the asymptotic and exact p-values are 12.16% and 0.19%, respectively. In such case, one would actually be likely not to reject the null hypothesis simply due to the poor approximation of the asymptotic distribution for such a small sample size.
For the sample sizes of m = 9 and n = 10 as in this example, Fig. 1 can be used to read off the asymptotic and exact p-values for the Dixon and Rao tests. The poor asymptotic approximation in the case of Dixon test is particularly apparent from this figure, which confirms the large difference reported in Table 2.
9 Concluding Remarks
A straightforward combinatorial approach is used to derive the exact distributions of several tests based on spacing frequencies. This class of tests for comparing two circular samples includes the newly introduced Rao test, the Dixon test, and the Wheeler-Watson test. For all these statistics our method provides the exact critical values and tables. Although the asymptotic theory of these statistics has been well-studied, such results often lead to a poor approximation in small to moderate samples, as we demonstrate. The comparative power performance of these various tests in small samples has been studied through extensive simulations, some of which are presented here. Based on these simulations, we find that omnibus tests like the Rao test and the Dixon test are preferable to the Wheeler-Watson test if one suspects symmetric multimodal alternatives. Again in small to moderate samples, Rao spacing frequencies test often outperforms the Dixon test. An illustrative comparison with the Wilcoxon test which is commonly used on the real line for comparing two samples, is presented to demonstrate that these tests may also be effectively used in two-sample comparisons on the real line.
Notes
available on GitHub: https://github.com/SMAC-Group/TwoCircles
available on GitHub: https://github.com/SMAC-Group/TwoCircles
available on GitHub: https://github.com/SMAC-Group/TwoCircles.
References
Davison, A. C. and Hinkley, D. V. (1997). Bootstrap methods and their applications. Cambridge, Cambridge University Press. MR1478673.
Dixon, W. J. (1940). A criterion for testing the hypothesis that two samples are from the same population. Ann. Math. Stat. 11, 199–204.
Gatto, R. and Rao, J.S. (1999). A conditional saddlepoint approximation for testing problems. J. Am. Stat. Assoc. 94, 533–541.
Gatto, R. and Rao, J.S. (2015). On two-sample tests for circular data based on spacing-frequencies. In: Geometry Driven Statistics, Wiley Series in Probability and Statistics, (I.L. Dryden and J.T. Kent eds.) Wiley vol. 121, pp. 129–145.
Gibbons, J. D. and Chakraborti, S (2011). Nonparametric statistical inference. CRC Press, Boca Raton.
Hájek, J., Sidak, Z. and Sen, P.K (1999). Theory of Rank Tests. Academic Press, Cambridge.
Holst, L. and Rao, J. S. (1980). Asymptotic theory for some families of two-sample nonparametric statistics. Sankhyā: The Indian Journal of Statistics Series A, 19–52.
Rao, J.S. and SenGupta, A. (2001). Topics in Circular Statistics, 5. World Scientific, Singapore.
Mardia, K. V. and Jupp, P.E. (2009). Directional Statistics, 494. Wiley, Hoboken.
Mirakhmedov, S. M., Rao, J.S. and Mohammed, I. B. (2014). On edgeworth expansions in generalized urn models. J. Theor. Probab. 27, 725–753.
Rao, J. S. (1976). Some tests based on arc-lengths for the circle. Sankhyā: The Indian Journal of Statistics Series B, 329–338.
Rao, J. S. and Murthy, V. K. (1981). A two-sample nonparametric test based on spacings frequencies. Proc. of International Statistical Institute, 43rd Session, 223–227.
Schmidt-Koenig, K. (1958). Experimentelle einflußnahme auf die 24-Stunden-Periodik bei Brieftauben und deren Auswirkungen unter besonderer berücksichtigung des heimfindevermögens. Zeitschrift für Tierpsychologie 15, 301–331.
Taylor, A. and Burns, K. (2016). Radial distributions of air plants: A comparison between epiphytes and mistletoes. Ecology 97, 819–825.
Walcott, C. (1996). Pigeon homing: observations, experiments and confusions. J. Exp. Biol. 199, 21–27.
Wasserman, L. (2006). All of Nonparametric Statistics. Springer, Berlin.
Wheeler, S. and Watson, G. (1964). A distribution-free two-sample test on a circle. Biometrika 51, 256–257.
Wilcoxon, F. (1945). Individual comparisons by ranking methods. Biometrics Bulletin 80–83.
Acknowledgments
The authors thank the reviewers for their thoughtful and detailed comments and suggestions. Thanks are also due to the editors for inviting us to contribute an article to this special issue in honour of Professor C.R. Rao during his birth centenary year.
Funding
Open Access funding provided by Université de Genève
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Stéphane Guerrier was supported in part by the SNSF Professorships Grant #176843 and by the Innosuisse-Boomerang Grant #37308.1 IP-ENG.
Available on GitHub: https://github.com/SMAC-Group/TwoCircles
Appendix A. Tables of Critical Values
Appendix A. Tables of Critical Values
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jammalamadaka, S.R., Guerrier, S. & Mangalam, V. A Two-sample Nonparametric Test for Circular Data– its Exact Distribution and Performance. Sankhya B 83 (Suppl 1), 140–166 (2021). https://doi.org/10.1007/s13571-020-00244-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13571-020-00244-9
Keywords and phrases
- Circular data
- two-sample tests
- spacing frequencies
- small sample distributions
- Wheeler-Watson
- Dixon
- Wilcoxon test
- power.