
Abstract
Visual Question Answering (VQA) is the problem of automatically answering a natural language question about a given image or video. Standard Arabic is the sixth most spoken language around the world. However, to the best of our knowledge, there are neither research attempts nor datasets for VQA in Arabic. In this paper, we generate the first Visual Arabic Question Answering (VAQA) dataset, which is fully automatically generated. The dataset consists of almost 138k Image-Question-Answer (IQA) triplets and is specialized in yes/no questions about real-world images. A novel database schema and an IQA ground-truth generation algorithm are specially designed to facilitate automatic VAQA dataset creation. We propose the first Arabic-VQA system, where the VQA task is formulated as a binary classification problem. The proposed system consists of five modules, namely visual features extraction, question pre-processing, textual features extraction, feature fusion, and answer prediction. Since it is the first research for VQA in Arabic, we investigate several approaches in the question channel, to identify the most effective approaches for Arabic question pre-processing and representation. For this purpose, 24 Arabic-VQA models are developed, where two question-tokenization approaches, three word-embedding algorithms, and four LSTM networks with different architectures are investigated. A comprehensive performance comparison is conducted between all these Arabic-VQA models on the VAQA dataset. Experiments indicate that the performance of all Arabic-VQA models ranges from 80.8 to 84.9%, while utilizing Arabic-specified question pre-processing approaches of considering the special case of separating the question tool  and embedding the question words using fine-tuned Word2Vec models from AraVec2.0 have significantly improved the performance. The best-performing model is which treats the question tool
and embedding the question words using fine-tuned Word2Vec models from AraVec2.0 have significantly improved the performance. The best-performing model is which treats the question tool  as a separate token, embeds the question words using AraVec2.0 Skip-Gram model, and extracts the textual feature using one-layer unidirectional LSTM. Further, our best Arabic-VQA model is compared with related VQA models developed on other popular VQA datasets in a different natural language, considering their performance only on yes/no questions according to the scope of this paper, showing a very comparable performance.
as a separate token, embeds the question words using AraVec2.0 Skip-Gram model, and extracts the textual feature using one-layer unidirectional LSTM. Further, our best Arabic-VQA model is compared with related VQA models developed on other popular VQA datasets in a different natural language, considering their performance only on yes/no questions according to the scope of this paper, showing a very comparable performance.
Similar content being viewed by others



Avoid common mistakes on your manuscript.
1 Introduction
Visual question answering (VQA) is a multidisciplinary task that integrates the computer vision and natural language processing (NLP) fields. Compared with other computer vision tasks, VQA is a cognitive task that involves not only recognition but also reasoning [1]. Tasks like image classification, object detection/recognition, or biometrics are of narrower scope, where a holistic understanding of the image scene isn’t required. Comped with a relevant natural language processing task, VQA can be considered a complicated extension of the textual question-answering task with an extra modality, that requires a joint perception of information from both modalities and capturing interactions between them to infer the appropriate answer. Moreover, VQA is more challenging, as images can be noisier and represent more complex and rich details of the real world to be analyzed than pure text with a higher level of abstraction [2].
Automated VQA systems can be used in many potential applications such as helping blind people to access visual information, interactive educational tools [3], investigation of medical images [4,5,6,7], smart cameras for food images [8], providing navigation guidance without having to ask someone [8], and presence verification of specific objects in surveillance videos. The integration between computer vision and NLP would greatly improve human–computer interaction. It can inspire other applications such as automatic organization, retrieval, and summarization of visual data through natural language. Lastly, solving the VQA problem requires a system with high-level perceptual abilities such as object detection/recognition, attribute recognition, counting, scene recognition, positional reasoning, and making comparisons. Thus, it can serve as a Turing Test to automatically assess the reasoning capabilities of AI agents in both fields [9].
VQA is a recent research problem, which was first proposed in 2014 [10]. Most of the existing VQA studies are in the English language. This is because a universal annual challenge is conducted for VQA in English since 2016 [11], where many teams around the world are participating, hoping to accelerate research in this field. Standard Arabic is the sixth most spoken language around the world [12]. About 422 million people in 23 countries speak Arabic in its various dialects [13]. However, according to our knowledge, there are no studies conducted for VQA in Arabic, yet. Accordingly, several datasets are released for VQA in English, while there is no VQA dataset in Arabic.
In this paper, our contributions are:
-
(1)
Creating the first VQA dataset in Arabic, that is fully automatically generated. We release our VAQA dataset as a first step for re-directing the VQA research community toward the Arabic language. The dataset contains 5000 images, 2712 unique questions, and two answers, which totally form 137,888 IQA ground-truth triplets. Images are of everyday common objects in their natural contexts, which exhibit the richness and complexity of the real world. All questions are automatically generated and can be categorized according to their tasks into three groups: object presence verification, super-category presence verification, and image scene recognition. All answers are limited to
 and
and 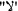 .
. -
(2)
A novel database schema for the VAQA dataset is specially designed to support automatic dataset generation, using approaches of Relational Database Management Systems (RDBMS). In addition, an algorithm for automatic IQA ground-truth triplet generation is proposed, using images from a dataset designed for object detection and segmentation purposes. Both the database schema and the automatic IQA triplet generation algorithm can be re-used for generating more VQA datasets in any natural language.
-
(3)
Developing the first Arabic-VQA system, where the VQA task is formulated as a classification problem. In this work, we need to determine how to pre-process and represent Arabic questions within an Arabic-VQA system. Hence, two question tokenization approaches, three algorithms of word embedding, and four LSTM networks with different architectures are investigated in the Arabic-question channel. By investigating all possible combinations of these approaches, a comparative performance analysis is performed between 24 Arabic-VQA models that are built on the VAQA dataset, where all variations on these models are performed in the question channel.
 and
and 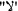 .
.The rest of the paper is organized as follows: Sect. 2 presents a literature review of most VQA studies including highly cited studies, papers that introduced new approaches to VQA, and annual winners of the VQA workshop challenge [11]. It also discusses the available VQA datasets and the performance evaluation metrics. Section 3 describes our VAQA dataset structure and how it is automatically created, while Sect. 4 demonstrates the proposed Arabic-VQA system. Section 5 exhibits and discusses the experimental results of all the investigated Arabic-VQA models, as well as a comparison with related VQA models in another natural language. Finally, Sect. 6 concludes the paper with a summary of the proposed system, along with an outlook for the potential future work.
2 Literature Review
The earliest attempt at the VQA field was proposed in [10], where the first VQA dataset was released. In [14], a VQA baseline was proposed and considered as a benchmark for the VQA task in English, where the basic modules of an end-to-end framework have been defined. The VQA general framework consists of four main modules, namely visual features extraction, textual features extraction, features fusion from both modalities, and lastly the answer generation module. Recently, some studies have incorporated the attention module into the VQA model before the fusion operation. Below in this section, we enumerate the developments and variations that have occurred in each module since the advent of VQA to date, as well as listing most of the available VQA datasets and metrics used to assess performance.
For image representation, pre-trained Convolutional Neural Networks (CNNs) are mostly utilized, where image representation techniques can be classified into three categories, namely Image Level (IL), Spatial Grid (SG), and Bottom-Up (BU) features. Early studies, as in [14,15,16,17,18], have adopted the image level technique, where a feature vector is extracted from the whole image. Then, the spatial grid technique has been utilized for a while, as in [19,20,21,22,23,24,25,26], where the image is divided into a grid of regions and an individual feature vector is extracted from each region. Teney et al. in [27] introduced the Bottom-Up attention technique to the VQA task and won the VQA workshop challenge in 2017. The idea is to use an object detector model to identify the salient objects in an image, followed by another CNN model to obtain region-specific feature representations.
Regarding textual features extraction, few early works, as in [14, 17], have represented the input question as a Bag-of-Words (BoW). On the other hand, most studies have adopted deep learning approaches for question representation, using Recurrent Neural Networks (RNNs) such as the Long Short-Term Memory (LSTM), Bidirectional-LSTM, and Gated Recurrent Unit (GRU) models.
The attention module is recently introduced to the VQA task to pay more attention to the important question words and image regions that can facilitate answer generation, by assigning them higher weights. The single-hop visual attention mechanism has been first proposed in [22], where an attention weight vector is calculated through a single pass on the image embedding. Thereafter, the multi-hop visual attention method was proposed in [19], where the image embedding is visited multiple times to infer the answer progressively. In addition to the visual attention, the Question Representation Update (QRU) model was proposed in [28] for performing multi-hop textual attention, where multi-layer reasoning is used for making the question more specific. Then, several studies have utilized the co-attention approach, where two attention weight vectors are derived for both visual and textual modalities. Some studies, as in [19, 29, 30], have considered the attention approach as one form of fusion between the two channels, as it requires the use of one modality as guidance to identify the important clues in the other modality. In [31], a deep co-attention learning model has been proposed, that won the VQA workshop challenge 2019. In [32, 33], both guided-attention (GA) and self-attention (SA) mechanisms were utilized, to infer the inter-modal relationships as well as the intra-modal interactions within each modality. Till now, there are no VQA models that rely only on textual attention and ignore visual attention, but vice versa is correct.
Concerning information fusion from both modalities, the visual and textual embeddings \({V}_{I}\) and \({V}_{Q}\), whether they are attended or not, are fused into a joint representation \({V}_{F}\). Early works utilized simple vector-based operations, including vector concatenation, and element-wise summation/multiplication. Bilinear pooling was found to be ineffective for the VQA task due to the huge parameter space issue. Therefore, multiple attempts were proposed to compress the bilinear pooling operation, including the Multi-modal Compact Bilinear pooling (MCB) method [23] that won the VQA workshop challenge 2016, Multi-modal low-rank Bilinear pooling (MLB) [34], Multi-modal Factorized Bilinear pooling (MFB) [24], Multi-modal Tucker Fusion (MUTAN) [25], Multi-modal Factorized High-order pooling (MFH) [26], and Bilinear Attention Networks (BAN) [35]. Another fusion strategy is to adopt a deep neural network as an encoder to learn a joint embedding of the visual and textual features. In [15, 16], an LSTM-based fusion approach was utilized, where the image feature \({V}_{I}\) was embedded into the words embedding space and treated as one of the question words, then both features are fed to the LSTM for fusion. On the other hand, in [36], an end-to-end CNN-based VQA model was proposed, where both image and question embeddings are extracted and fused using CNN models.
Finally, the answer generation can be formulated as a classification problem over a closed set of answers, or a sequence generation problem for generating variable-length answers, depending on the research scope. Few early works, as in [15, 36], have represented this phase as a sequence generation problem, by using an RNN as a decoder to generate variable-length answers. On the other hand, most studies have solved the VQA problem as a multi-label classification task over a predefined list of the top-N most frequent answers in the dataset, for generating a closed set of answers. Only [21, 27, 37] have adopted the sigmoid activation function in the last fully connected classification layer for allowing multiple correct answers per question, which were the winners of the VQA workshop challenge in 2017, 2018, and 2020, respectively. In contrast, most studies have adopted the softmax function for generating only a single answer per question.
Since 2014, numerous VQA datasets have been published. Most of these datasets are in English, while some are in Chinese [36] and Korean [38]. Several datasets are specialized in real-world images. Only a few datasets contain synthetic images [39], or graphical plots [18]. On the other hand, the VQA1.0 dataset [14] contains both real-world and clipart images. Most datasets are about Open-Ended (OE) questions, including counting, object presence verification, scene recognition, object recognition, attribute recognition, or activity recognition tasks. Few datasets are about fill-in-the-blank questions [40] or Multiple-Choice (MC) questions [14, 41].
The dataset collection procedure is another characteristic that differentiates datasets. Many datasets are collected by humans, some are automatically generated, and others are created by using both methods together. Most often, automatically generated datasets are created using a predefined set of question templates, where questions can be automatically assigned to an image and answered based on its content. In contrast, the COCO-QA [16], VQ2A-COCO [42], and VQ2A-CC3M [42] datasets have been automatically generated by converting the image captions into question–answer pairs. However, both VQ2A-COCO and VQ2A-CC3M datasets provide ten identical answers for each image-question pair. In many human-collected datasets, every question about a given image is answered by multiple answers, each provided by a different human annotator. This is to overcome the potential contradiction between human answers for the same Image-Question (IQ) pair, where the correct answer is considered to be the most common answer. Table 1 summarizes the characteristics of almost all the publicly available datasets for VQA.
For model performance evaluation, the utilized evaluation metric highly depends on the format of predicted answers. For models that predict variable-length answers for open-ended questions, the Wu-Palmer Similarity (WUPS) [49] is preferred. This is because in most cases the predicted answer string may not be identical to the ground-truth answer. WUPS tries to measure the difference between the predicted answer and the ground-truth answer, in terms of their semantic meaning. In contrast, WUPS is inappropriate for classification based VQA models. Some studies, such as [36, 48], have required human evaluation to assess the quality of predicted answers, which is impractical. Accuracy is the most widely used evaluation metric for both multiple-choice questions and open-ended questions in the case of classification based VQA models. Simple accuracy can be used in both cases whether the dataset provides single or multiple answers for each Image-Question (IQ) pair. However, in [14], the authors have slightly modified the accuracy metric to handle the multi-answer provided for each IQ pair.
Lastly, it can be concluded that there are no datasets or research for VQA in Arabic, so far. The following section describes an automatic generation procedure for the first VQA dataset in Arabic. Section 4 proposes the first Arabic-VQA system, where several algorithms of text pre-processing and feature extraction are investigated.
3 Automatic Generation of the VAQA Dataset
The VAQA dataset contains 5000 real-world images taken from the MS-COCO dataset [50], with 137,888 IQA triplets. The MS-COCO segmentation annotations are used for automatically assigning questions and answers to COCO images. All questions in the VAQA dataset are of type yes/no questions, with three different tasks: COCO object presence verification, super-category presence verification, and image scene recognition. During the VAQA dataset creation, we ensured that both answers are equally presented to avoid a biased dataset. This prevents the VQA models from exploiting answer frequencies to predict the correct answer without reasoning.
3.1 Dataset Structure
This section exhibits the database schema of the VAQA dataset that is specially designed to facilitate the automatic generation of IQA ground-truth triplets, using approaches of relational database management. MS-COCO is a large-scale object detection and segmentation dataset, where each pixel in an image is labeled with an object category. It defines 91 COCO objects that belong to 12 super-categories, with a total of 2.5 million labeled instances in 328k images.
Each COCO image can contain one or more instances from one or multiple COCO objects/super-categories. On other hand, some images may not contain any COCO object at all. Instances of each COCO object can appear in multiple images. In the VAQA dataset, each image should be assigned at least one question, even if it does not contain any COCO object or super-category. Each question asks about a certain COCO object/super-category, while multiple questions may ask about the same COCO object/super-category. Each question can be assigned to multiple images, where each image-question pair has exactly one answer. Each answer can suit multiple questions about multiple images. Hence, five main entities in the VAQA dataset are defined, that are described as follows:
-
1.
COCO_object: is uniquely identified by an "Object_ID", and described by its English "COCO_name" from the MS-COCO dataset. Super-categories from the MS-COCO dataset are also considered in our VAQA dataset, where each super-category is assigned an Object_ID and stored with the same attributes as COCO objects. Thus, a unary relationship is established, where each COCO object belongs to exactly one super-category, while each super-category contains at least one COCO object.
-
2.
Arabic_object: is generated by translating each COCO object and super-category into several Arabic translations. Hence, each COCO object has several Arabic names. Each of these Arabic names has two other attributes. The first attribute is the "Name_form", which represents whether this name is in the singular or plural form. The second attribute is the "Name_type", which describes whether this name is
 , etc. Each Arabic name of each COCO object is uniquely identified by the "Object_ID" and "Name_index" together as a composite primary key, where each of them is represented as a partial primary key.
, etc. Each Arabic name of each COCO object is uniquely identified by the "Object_ID" and "Name_index" together as a composite primary key, where each of them is represented as a partial primary key. -
3.
Image: is uniquely identified by an "Image_ID" that is identical to its name in the MS-COCO dataset. It is described by "Num_objects" and "Num_categories" that represent the number of COCO objects and the number of super-categories it contains, respectively.
-
4.
Question: is uniquely identified by a "Question_ID" and described by its type (i.e., yes/no questions), the "Question_task" (i.e., object presence verification, super-category presence verification, or scene recognition), the Arabic question text, "Question_form" that specifies whether this question is in the singular or plural form, and "Image_num_objects" that defines whether this question is suitable for single-object images or multiple-object images.
-
5.
Answer: is uniquely identified by an "Answer_ID" and described by the Arabic answer text and how frequently each answer appeared in the training set.
 , etc. Each Arabic name of each COCO object is uniquely identified by the "Object_ID" and "Name_index" together as a composite primary key, where each of them is represented as a partial primary key.
, etc. Each Arabic name of each COCO object is uniquely identified by the "Object_ID" and "Name_index" together as a composite primary key, where each of them is represented as a partial primary key.In addition, the VQA and Image_content entities are included as associative entities, which are described as follows:
-
1.
VQA: represents the image-question–answer triplets, where the Image_ID and Question_ID together are considered as a composite primary key. The Answer_ID is not considered a part of the VQA primary key, since each image-question pair has exactly one answer. Thus, each IQA triplet can be uniquely identified by just Image_ID and Question_ID together.
-
2.
Image_content: contains information about the COCO objects contained in the image, and the number of instances of each COCO object. In the case of super-categories, the number of instances is defined as the number of COCO objects belonging to each super-category present in the image. For example, if an image contains 5 dogs and 3 cats, the number of instances for the "Dog" object will be 5 and the number of instances for the "Cat" object will be 3, while the number of instances for the "Animal" super-category will be 2.
Figure 1 exhibits the Entity Relationship Diagram (ERD) of the VAQA dataset, while Fig. 2 demonstrates the database schema expressed as a relational model. In Fig. 2, the Category_ID is added as a foreign key in the COCO_object relation, to identify the super-category of each COCO object, while the Category_ID is set to − 1 for super-categories. Further, the Object_ID is added as a foreign key in the question relation, to specify the COCO object that each question asks about. It should be noted that each of the three splits (i.e., training, validation, and testing) has its own tables of the image, image_content, question, and VQA that store its data. In contrast, the answer, COCO_object, and Arabic_object tables are common for the three splits.

VAQA dataset ERD

VAQA database schema
3.2 Dataset Generation
This section describes how the IQA ground-truth triplets are automatically generated with minimal human supervision, by exploiting the segmentation annotations of COCO images. The VAQA dataset is designed so that each of the training, validation, and testing splits contains a distinct set of images and a distinct set of questions, to guarantee a reliable dataset. The dataset is created in two phases. Firstly, all questions are generated for all COCO objects and super-categories, for the three splits. Then, questions and answers are assigned to each image according to the COCO objects and super-categories it contains. The following two sub-sections describe the two phases in detail.
3.2.1 Automatic Questions Generation
Since all images in the VAQA dataset are taken from the MS-COCO dataset, all generated questions are related to its objects and super-categories. MS-COCO dataset defines 91 objects, while only 80 objects are included across its images. These objects are classified into 12 super-categories. Each COCO object and super-category is translated into 2–10 Arabic translations (i.e., up to 5 translations in the singular form, and up to 5 translations in the plural form). Most of these Arabic translations are extracted from two Arabic dictionaries, namely  [51] and
[51] and  [52]. Only a few vocabularies from the vernacular dialect of the Arabic language are included. The length of each Arabic translation varies from one to five words. Table 2 states Arabic translations for some objects and super-categories from the MS-COCO dataset.
[52]. Only a few vocabularies from the vernacular dialect of the Arabic language are included. The length of each Arabic translation varies from one to five words. Table 2 states Arabic translations for some objects and super-categories from the MS-COCO dataset.
All Arabic names of each COCO object and super-category are used for question generation for the three splits. The basic structure of yes/no questions used for asking about the existence of an object/super-category (k) in an image can be formulated as follows:

Several values for each of these question components are used to generate a variety of questions. In the Arabic language, question tools for yes/no questions are  and
and  . The question tool
. The question tool  comes as a separate word, while
comes as a separate word, while  is always connected to its next word whether it is a verb, noun, or pronoun. Fifteen main verbs, four modal verbs with six nouns, and four different types of demonstrative pronouns are utilized for question generation. For each question, either a verb or a pronoun is used, where pronouns are selected according to the type of the Arabic object’s name in each question (i.e., whether this name is
is always connected to its next word whether it is a verb, noun, or pronoun. Fifteen main verbs, four modal verbs with six nouns, and four different types of demonstrative pronouns are utilized for question generation. For each question, either a verb or a pronoun is used, where pronouns are selected according to the type of the Arabic object’s name in each question (i.e., whether this name is  , etc.). Table 3 exhibits the values of components used for yes/no questions generation.
, etc.). Table 3 exhibits the values of components used for yes/no questions generation.
By using all possible combinations of these components, 94 question templates are created and used through our dataset, as shown in Table 4. These question templates are divided into two groups according to their meanings:
-
The first group is those questions that contain the nineteen verbs (i.e., main verbs and modal verbs) and the pronouns
 and
and  . These questions are suitable for any COCO image, whether this image contains single or multiple COCO objects/ super-categories. Hence, their attribute "Image_num_objects" equals "Single/Multiple".
. These questions are suitable for any COCO image, whether this image contains single or multiple COCO objects/ super-categories. Hence, their attribute "Image_num_objects" equals "Single/Multiple". -
The second group is those questions that contain all the other demonstrative pronouns
 . These questions are suitable only for images containing a single COCO object/super-category. Thus, their attribute "Image_num_objects" equals "Single".
. These questions are suitable only for images containing a single COCO object/super-category. Thus, their attribute "Image_num_objects" equals "Single".
 and
and  . These questions are suitable for any COCO image, whether this image contains single or multiple COCO objects/ super-categories. Hence, their attribute "Image_num_objects" equals "Single/Multiple".
. These questions are suitable for any COCO image, whether this image contains single or multiple COCO objects/ super-categories. Hence, their attribute "Image_num_objects" equals "Single/Multiple". . These questions are suitable only for images containing a single COCO object/super-category. Thus, their attribute "Image_num_objects" equals "Single".
. These questions are suitable only for images containing a single COCO object/super-category. Thus, their attribute "Image_num_objects" equals "Single".Hence, for each Arabic name (x) of each COCO object/super-category (k), a distinct set of two questions is generated for each of the three splits. The first question has a value of "Image_num_objects" equal to "Single/Multiple", and the second question has a value of "Image_num_objects" equal to "Single".
By generating questions with all Arabic names for all COCO objects and super-categories, questions can be furtherly classified into three categories, according to the form of object_name (x) in each question, whether this name is in the singular form, plural form, or this name carries both meanings:
-
The first category is those questions with "Question_form" equal to "Singular", which can be used for images with only a single instance of the COCO object/super-category (k).
-
The second category is those questions with "Question_form" equal to "Plural", which can be used for images with multiple instances of the COCO object/super-category (k).
-
Some COCO objects and super-categories are translated into Arabic vocabularies that do not have a plural or singular form, as they have both meanings and can be used for both cases. For example, the COCO object "hot dog" is translated into
 and
and  . In this case, the "Question_form" attribute is set to "Singular/Plural". Hence, these questions can be used for images with single or multiple instances of the COCO object/super-category (k).
. In this case, the "Question_form" attribute is set to "Singular/Plural". Hence, these questions can be used for images with single or multiple instances of the COCO object/super-category (k).
 and
and  . In this case, the "Question_form" attribute is set to "Singular/Plural". Hence, these questions can be used for images with single or multiple instances of the COCO object/super-category (k).
. In this case, the "Question_form" attribute is set to "Singular/Plural". Hence, these questions can be used for images with single or multiple instances of the COCO object/super-category (k).For each COCO object or super-category, the question-generation process is divided into two stages. Questions with "Image_num_objects" equal to "Single/Multiple" are first generated, then questions with "Image_num_objects" equal to "Single". In each stage, for generating questions for an object/super-category (k), two matrices are utilized, as shown in Figs. 3 and 4. In each matrix, each row represents the values used among the three splits for an Arabic name (x), while each column represents the values used within the same split for all Arabic names of this object/super-category (k). For example, the COCO object named "Bowl" has ten Arabic names, while the object named "Carrot" has only two Arabic names, as shown in Table 2. Thus, the two matrices will have ten rows for the object "Bowl", but only two rows for the object "Carrot". This is to guarantee distinct questions between the three splits for each Arabic name (x) of each COCO object/super-category (k). Also, ensuring maximum diversity among generated questions for all Arabic names of a COCO object/super-category (k) within the same split. Thus, creating a reliable dataset with a wide variety of questions.

a Question tools matrix, b verbs and pronouns matrix used for generating questions of the COCO object named "Bowl" with "Image_num_objects" attribute equals "Single/Multiple"

a Question tools matrix, b pronouns matrix used for generating questions of the COCO object named "Bowl" with "Image_num_objects" attribute equals "Single"
Regarding generating questions with "Image_num_objects" equal to "Single/Multiple", the nineteen verbs, six nouns, and the pronouns  and
and  are used. Figure 3 shows an example of the distributions of question tools, verbs, and pronouns used for the COCO object "Bowl" which has ten Arabic names. The first matrix is randomly filled with question tools so that none of the question tools is repeated more than twice within the same row, and at most five times within the same column. Further, within each row, the selected question tools for training and testing should be different. The second matrix is randomly filled with the nineteen verbs and two pronouns, where none of them is repeated more than once within the same row and once within the same column, while it can be repeated at most twice through the entire matrix if needed (i.e., the matrix size is larger than the number of the nineteen verbs and the two pronouns). Further, none of the six nouns is repeated more than once through the entire matrix.
are used. Figure 3 shows an example of the distributions of question tools, verbs, and pronouns used for the COCO object "Bowl" which has ten Arabic names. The first matrix is randomly filled with question tools so that none of the question tools is repeated more than twice within the same row, and at most five times within the same column. Further, within each row, the selected question tools for training and testing should be different. The second matrix is randomly filled with the nineteen verbs and two pronouns, where none of them is repeated more than once within the same row and once within the same column, while it can be repeated at most twice through the entire matrix if needed (i.e., the matrix size is larger than the number of the nineteen verbs and the two pronouns). Further, none of the six nouns is repeated more than once through the entire matrix.
Similarly, for generating questions with "Image_num_objects" equal to "Single", two other matrices are utilized. The first matrix is filled with question tools so that the value of each cell is the opposite value of its corresponding cell in the previous question tools matrix. In the resultant matrix, there will be none of the question tools repeated more than twice within the same row, and at most five times within the same column. Also, the selected question tools for training and testing will be different within each row. The second matrix is filled with the demonstrative pronouns  , where pronouns of each row are selected according to the type of its object_name (x). Figure 4 exhibits the distributions of question tools and pronouns used for generating questions with "Image_num_objects" equal to "Single" for the COCO object "Bowl". The singular names of this object are a combination of types
, where pronouns of each row are selected according to the type of its object_name (x). Figure 4 exhibits the distributions of question tools and pronouns used for generating questions with "Image_num_objects" equal to "Single" for the COCO object "Bowl". The singular names of this object are a combination of types  . Thus, pronouns used in questions with "Image_num_objects" equal to "Single" and "Question_form" equal to "Singular" are a combination of types
. Thus, pronouns used in questions with "Image_num_objects" equal to "Single" and "Question_form" equal to "Singular" are a combination of types  . In contrast, since all its plural names are of type
. In contrast, since all its plural names are of type  , pronouns used in questions with "Image_num_objects" equal to "Single" and "Question_form" equal to "Plural" are limited to
, pronouns used in questions with "Image_num_objects" equal to "Single" and "Question_form" equal to "Plural" are limited to  . After determining pronouns for each row, the pronouns matrix is randomly filled so that none of the pronouns is repeated more than twice within the same row, and at most five times within the same column if needed (i.e., all Arabic names of the current COCO object use the same pronouns set such as
. After determining pronouns for each row, the pronouns matrix is randomly filled so that none of the pronouns is repeated more than twice within the same row, and at most five times within the same column if needed (i.e., all Arabic names of the current COCO object use the same pronouns set such as  ). Within each row, the selected pronouns for training and testing should be different, while the combination of question tool and pronoun selected for validation should be different from those selected for training and testing. Table 5 illustrates questions generated for the COCO object "Bowl" for the three splits.
). Within each row, the selected pronouns for training and testing should be different, while the combination of question tool and pronoun selected for validation should be different from those selected for training and testing. Table 5 illustrates questions generated for the COCO object "Bowl" for the three splits.
Lastly, the two super-categories "Indoor" and "Outdoor" are used to ask whether an image is an indoor or outdoor scene. Table 6 states the Arabic translations of both super-categories that are used for image scene recognition.
Two formulas of yes/no questions are used to ask about the image scene, which can be represented as follows:


Table 7 exposes the values of each component. By using all possible combinations of these components, 16 additional question templates are obtained, resulting in a total of 110 yes/no question templates that are used through our VAQA dataset.
For each of both super-categories, three matrices are utilized for scene recognition question generation. Figure 5 shows an example of the distributions of question tools, nouns, and demonstrative pronouns used for the super-category "Outdoor". The first matrix is randomly filled with question tools so that none of the question tools is repeated more than twice within the same row and twice within the same column. Within each row, the selected question tools for training and testing should be different. The second matrix is randomly filled with nouns, where none of them is repeated more than once within the same row and once within the same column. The third matrix is filled with demonstrative pronouns, where pronouns of each row are selected according to the type of Question_word. The pronouns matrix is randomly filled so that none of the pronouns is repeated more than twice within the same row and once within the same column. Within each row, the selected pronoun for training and testing should be different, while the combination of the question tool and pronoun generated for validation should be different from those generated for training and testing.

a Question tools matrix, b nouns matrix, c pronouns matrix used for generating scene recognition questions for the super-category named "Outdoor"
Totally, 2712 unique questions are automatically generated, where each split contains a distinct set of 904 questions for all COCO objects and super-categories. The length of questions varies from 3 words/question up to 12 words/question, while the average length of questions is about 5 words/question.
3.2.2 Automatic Image-Question-Answer (IQA) Triplet Generation
The VAQA dataset contains 5000 images, which are randomly divided into 60%: 20%: 20% for training, validation, and testing, respectively. Regarding IQA ground-truth generation, several questions with answers  and
and  are assigned to each image according to COCO objects and super-categories it contains. Images in a split (s) are assigned questions from those specified to its split. For minimizing ambiguity, tiny instances of COCO objects with areas smaller than 150 pixels in an image are excluded from all records of this image in our VAQA dataset, while retaining the larger instances.
are assigned to each image according to COCO objects and super-categories it contains. Images in a split (s) are assigned questions from those specified to its split. For minimizing ambiguity, tiny instances of COCO objects with areas smaller than 150 pixels in an image are excluded from all records of this image in our VAQA dataset, while retaining the larger instances.
For each image within a split (s), questions with the answer  are collected so that questions of each COCO object/super-category (k) contained in this image are grabbed and filtered according to two factors:
are collected so that questions of each COCO object/super-category (k) contained in this image are grabbed and filtered according to two factors:
-
1.
The number of COCO objects/super-categories in the image.
-
If the image contains multiple COCO objects/super-categories other than this COCO object/super-category (k), then questions with "Image_num_objects" equal to "Single/Multiple" are assigned.
-
If the image contains only this COCO object/super-category (k), then questions with "Image_num_objects" equal to "Single/Multiple" and "Single" are assigned.
-
-
2.
The number of instances of this COCO object/super-category (k).
-
If the image contains only a single instance of this COCO object/super-category, then questions with "Question_form" equal to "Singular" and "Singular/Plural" are assigned.
-
If the image contains multiple instances of this COCO object/super-category, then questions with "Question_form" equal to "Plural" and "Singular/Plural" are assigned.
-
For example, suppose an image contains multiple instances of the COCO object "Bowl", that has 5 plural Arabic names. This image will be assigned either 5 or 10 questions about this COCO object, where each of these plural Arabic names appears in either one or two of these questions, depending on whether this image contains only this object or other COCO objects as well. All these questions have "Question_form" equal to "Plural" and are answered with  . Hence, the number of questions answered with
. Hence, the number of questions answered with  assigned to an image is directly proportional to the number of COCO objects it contains, and the number of Arabic names generated for each of those COCO objects either in the singular or plural form.
assigned to an image is directly proportional to the number of COCO objects it contains, and the number of Arabic names generated for each of those COCO objects either in the singular or plural form.
For ensuring evenly distributed answers in the dataset, the number of assigned questions with the answer  to an image in a split (s) is set to \(\mu_{{{\text{yes}}}}^{{{\text{split}}}}\), which is the average number of assigned questions per image with the answer
to an image in a split (s) is set to \(\mu_{{{\text{yes}}}}^{{{\text{split}}}}\), which is the average number of assigned questions per image with the answer  in this split. For each image, questions with the answer
in this split. For each image, questions with the answer  are collected by randomly selecting a number of COCO objects equal to two-thirds of \(\mu_{{{\text{yes}}}}^{{{\text{split}}}}\) and a number of super-categories equal to one-third of \(\mu_{{{\text{yes}}}}^{{{\text{split}}}}\) that are not in this image. For each of these COCO objects and super-categories, one of its questions is randomly selected and assigned to this image, where questions are filtered according only to the number of COCO objects/super-categories in the image.
are collected by randomly selecting a number of COCO objects equal to two-thirds of \(\mu_{{{\text{yes}}}}^{{{\text{split}}}}\) and a number of super-categories equal to one-third of \(\mu_{{{\text{yes}}}}^{{{\text{split}}}}\) that are not in this image. For each of these COCO objects and super-categories, one of its questions is randomly selected and assigned to this image, where questions are filtered according only to the number of COCO objects/super-categories in the image.
Those few images that don't contain any COCO object or super-category, are assigned all questions answered with  only. Similarly, a number of questions equal to \(\mu_{{{\text{yes}}}}^{{{\text{split}}}}\) are assigned to each of these images, where two-thirds of questions ask about randomly selected COCO objects, and one-third of questions ask about randomly selected super-categories. In this case, questions are randomly selected without filtration, as these questions can be formulated in any form.
only. Similarly, a number of questions equal to \(\mu_{{{\text{yes}}}}^{{{\text{split}}}}\) are assigned to each of these images, where two-thirds of questions ask about randomly selected COCO objects, and one-third of questions ask about randomly selected super-categories. In this case, questions are randomly selected without filtration, as these questions can be formulated in any form.
Figure 6 shows some examples of automatically generated IQA triplets in the VAQA dataset, where each image is shown with samples of its assigned QA pairs, not all. Figure 6a exhibits an image containing multiple COCO objects, where it is typically assigned more questions answered by  . It is worth noting that the more Arabic names for a COCO object, the more questions generated for this object, and the more questions about this object with the answer
. It is worth noting that the more Arabic names for a COCO object, the more questions generated for this object, and the more questions about this object with the answer  assigned to an image containing it. In contrast, all images in each split are assigned the same number of questions answered by
assigned to an image containing it. In contrast, all images in each split are assigned the same number of questions answered by  . Figure 6b presents an image containing a single COCO object that belongs to a single super-category, where all questions having the answer
. Figure 6b presents an image containing a single COCO object that belongs to a single super-category, where all questions having the answer  ask only about this COCO object and its super-category. Figure 6c illustrates an image having neither COCO objects nor super-categories, which have all questions answered by
ask only about this COCO object and its super-category. Figure 6c illustrates an image having neither COCO objects nor super-categories, which have all questions answered by  only. Table 8 exposes the VAQA dataset partitioning, where the average number of QA pairs per image is 27.58 QA/image.
only. Table 8 exposes the VAQA dataset partitioning, where the average number of QA pairs per image is 27.58 QA/image.

Samples from the VAQA dataset, a IQA triplets for an image containing multiple COCO objects, b IQA triplets for an image containing a single COCO object, c IQA triplets for an image containing neither COCO objects nor super-categories
4 Proposed Arabic-VQA System
Given an image and a text-based question, the proposed end-to-end Arabic-VQA system consists of five modules: (1) visual features extraction, where expressive features are extracted from the input image, (2) question pre-processing, where the raw question is firstly normalized, cleaned, tokenized, and the meaning of each word is numerically represented, (3) textual features extraction, where the semantic features and relationships between question words are extracted using an LSTM network, (4) feature fusion, where features from the two modalities are fused into a joint representation, and (5) answer prediction, where the extracted joint embedding is passed through a classifier to predict the appropriate answer. Figure 7 illustrates the general framework of our VQA system, in Arabic. Since we develop a baseline Arabic-VQA system that we aim to benchmark for the VQA task in Arabic, we have followed the VQA framework proposed in [13], where several basic techniques and strategies are utilized for the image representation, fusion, and answer prediction modules. In contrast, in the question channel, several approaches have been investigated on the question preprocessing and features extraction modules, to determine the appropriate techniques for the Arabic language.

General framework of the Arabic-VQA system
4.1 Visual Features Extraction
The Image Level (IL) representation is the basic technique for visual features representation, which we have adopted where a feature vector is extracted from the entire image. VGG networks are widely used among VQA research mainly for the IL representation technique, as in [14, 16,17,18, 43], and for the two other techniques as well. A pre-trained VGG-16 model [53] trained on the ImageNet dataset [54] is utilized, where its parameters are kept frozen without fine-tuning during training of the full Arabic-VQA model. The last fully connected classification layer of the VGG-16 network is discarded, where the image representation is obtained from the last hidden layer. The input image is firstly resized into 448 × 448 pixels and then fed into the VGG-16 network to extract the image representation as a 4096-dim feature vector. The extracted 4096-dim feature vector is reshaped into a 1024-dim embedding, by passing through a fully connected layer of 1024 hidden units with a Hyperbolic Tangent (Tanh) activation function. This is to match the dimensions of both image embedding and question embedding for the feature fusion step. Suppose that \(z\) is the 4096-dim feature vector, the resultant 1024-dim embedding is calculated as follows:
4.2 Question Pre-processing
The raw question is firstly pre-processed through several steps, that are described as follows:
-
1.
Question cleaning: The input question is cleaned by eliminating all the non-alphabetic and non-numeric symbols, such as diacritics and punctuations (e.g., commas, question marks, and special characters) [55].
-
2.
Question normalization: It is an essential step for any Arabic text to reduce confusion for automated systems, where letters that can appear in different forms are rendered into a single form. For example, the hamza on characters
 are normalized into
are normalized into  , and the characters
, and the characters  are normalized into
are normalized into  [55].
[55]. -
3.
Question Tokenization: It is the process of word segmentation, where the question is tokenized into individual words. However, splitting the question text into tokens according only to blanks is not always sufficient. We need to examine whether the question tool
 should be separated and treated as a distinct token or not. For example, a single word, such as
should be separated and treated as a distinct token or not. For example, a single word, such as  , could be separated into two tokens
, could be separated into two tokens 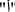 and
and  . This is because
. This is because  is a question tool equivalent to
is a question tool equivalent to  , which always comes as a separate word but
, which always comes as a separate word but  does not. Hence, the two approaches are investigated for question tokenization, which are:
does not. Hence, the two approaches are investigated for question tokenization, which are:-
Tokenizing questions by considering only blanks. Thus, each separate word is considered as a token, including
 and so on.
and so on. -
Considering the special case of splitting the question tool
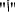 into a separate token.
into a separate token.
-
-
4.
Word embedding (WE): It is a technique for making machines understand textual data, by encoding individual words into numerical representations that capture their meanings and the contexts where they are used, so that words with similar meanings have similar representations. Three different models are investigated for word embedding, which can be described as follows:
-
An embedding fully connected layer is used to encode all question words found in the training split into 300-dim embeddings, as mentioned in [14]. This layer is fully trained as a part of the entire model during training. It is sometimes called a simple lookup table that stores embeddings of a fixed dictionary.
-
Two pre-trained Word2Vec models from Aravec2.0 [55] are utilized, one with Continuous Bag of Words (CBOW) architecture and one with the Skip-Gram (SG) architecture. Aravec2.0 is a free pre-trained word embedding tool dedicated to the Arabic language. In Aravec2.0, the CBOW and SG models have been trained on three different Arabic content domains separately, namely Twitter, Wikipedia, and World Wide Web (WWW) pages. By applying these models to our VAQA dataset, we have found that all of them have some missing question words, in both cases of separating or non-separating the question tool
 into a separate token. These missing question words differ according to their Arabic source domains. From Table 9, it is found that models trained on the Web pages source domain have the fewest missing question words. Hence, for our system, we have employed the CBOW and SG models trained on the Web pages rather than the other two source domains. These two models have been trained on 132,750,000 documents with a vocabulary size of 234,961 unique Arabic words, to generate a 300-dim embedding vector size. To handle the missing question words, we have fine-tuned these models with all questions of our VAQA dataset, and then we have kept them frozen during training of the full Arabic-VQA model.
into a separate token. These missing question words differ according to their Arabic source domains. From Table 9, it is found that models trained on the Web pages source domain have the fewest missing question words. Hence, for our system, we have employed the CBOW and SG models trained on the Web pages rather than the other two source domains. These two models have been trained on 132,750,000 documents with a vocabulary size of 234,961 unique Arabic words, to generate a 300-dim embedding vector size. To handle the missing question words, we have fine-tuned these models with all questions of our VAQA dataset, and then we have kept them frozen during training of the full Arabic-VQA model.
-
-
5.
Merging and padding: As previously mentioned, the length of questions in our dataset varies from 3 words/question up to 12 words/question. However, important words that identify the question’s meaning and should be fed into the system, such as the object name around which the whole question revolves, exist up to the tenth word. Thus, all questions are trimmed to a fixed length \(l=10\) words, where shorter questions are end-padded with zeros. All word embedding vectors of a given question are then merged into a single matrix of size \(10\times 300\).
 are normalized into
are normalized into  , and the characters
, and the characters  are normalized into
are normalized into  [
[ should be separated and treated as a distinct token or not. For example, a single word, such as
should be separated and treated as a distinct token or not. For example, a single word, such as  , could be separated into two tokens
, could be separated into two tokens 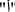 and
and  . This is because
. This is because  is a question tool equivalent to
is a question tool equivalent to  , which always comes as a separate word but
, which always comes as a separate word but  does not. Hence, the two approaches are investigated for question tokenization, which are:
does not. Hence, the two approaches are investigated for question tokenization, which are: and so on.
and so on.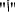 into a separate token.
into a separate token. into a separate token. These missing question words differ according to their Arabic source domains. From Table
into a separate token. These missing question words differ according to their Arabic source domains. From Table 4.3 Textual Features Extraction
The obtained word embedding cannot be considered as a question representation because the sequence information and semantic relationships between these embeddings are missing. Thus, it is necessary to utilize one of the RNNs because they are effective for processing sequential data. Long Short-Term Memory networks (LSTMs) and Gate Recurrent Unit networks (GRUs) are special forms of RNNs, that were designed to overcome the vanishing gradients problem of the standard RNN and accelerate the training process [56]. However, LSTMs are preferred over Gate Recurrent Unit networks (GRU) in the case of short text and large datasets and vice versa [57]. Hence, LSTM is chosen to capture the semantic features \({V}_{Q}\) of the input Arabic question. This is because the question length in the VAQA dataset varies from 3 up to 12 words, while all questions are pre-processed to be trimmed to a fixed length \(l=10\) words.
In this work, we investigate LSTM in all its various architectures, including unidirectional LSTM [58] and bidirectional LSTM [59] networks. Two unidirectional LSTM networks are investigated, one with a single hidden layer and the other with two hidden layers. Also, two bidirectional LSTM networks are investigated, one with a single hidden layer and the other with two hidden layers. The size of the cell state and hidden state in all these LSTM networks is set to 512. The obtained question embedding from each network can be described as follows:
-
One-layer Uni-LSTM produces a 1024-dim question embedding. This embedding is the concatenation of outputs from the last cell state and the last hidden state in the hidden layer. Each of these two outputs is 512-dim, resulting in 1024-dim embedding (i.e., \(2 \mathrm{outputs}\times 512 \mathrm{dim}\)).
-
Two-layer Uni-LSTM produces a 2048-dim question embedding, which is the concatenation of outputs from the last cell state and the last hidden state from each hidden layer. Each of these two outputs in each layer is 512-dim, resulting in 2048-dim embedding (i.e., \(2 \mathrm{outputs}\times 2 \mathrm{layer}\times 512 \mathrm{dim}\)).
-
One-layer Bi-LSTM produces a 2048-dim question embedding, which is the concatenation of outputs from the last cell state and the last hidden state from both directions. Each of these two outputs is 512-dim in each direction, resulting in 2048-dim embedding (i.e., \(2 \mathrm{outputs}\times 2 \mathrm{directions}\times 512 \mathrm{dim}\)).
-
Two-layer Bi-LSTM produces a 4096-dim question embedding. This embedding is the concatenation of outputs from the last cell state and the last hidden state from both directions from each hidden layer. Each of these two outputs is 512-dim in each direction in each layer, resulting in 4096-dim embedding (i.e., \(2 \mathrm{outputs}\times 2 \mathrm{directions}\times 2 \mathrm{layers}\times 512 \mathrm{dim}\)).
For the 2-layers Uni-LSTM, 1-layer Bi-LSTM, and 2-layers Bi-LSTM models, the obtained question embedding is reshaped into a 1024-dim embedding, by passing through a fully connected layer of 1024 hidden units with a tanh activation function. This is to match the dimensions of both image embedding and question embedding for the feature fusion step.
4.4 Features Fusion
After features extraction from both modalities, the image embedding \({V}_{I}\) and question embedding \({V}_{Q}\) are fused into a joint representation \({V}_{F}\). The goal is to jointly embed the visual and textual features into a common feature space, to capture the semantic intersections between them. Simple vector-based fusion is the basic strategy that has been used in several early VQA studies, including vector concatenation, element-wise summation, and element-wise multiplication. Since we build a baseline Arabic-VQA system, element-wise multiplication (i.e., Hadamard product) is utilized, which is defined in Eq. (2). As the \({V}_{I}\) and \({V}_{Q}\) are both 1024-dim embeddings, the resultant joint representation \({V}_{F}\) is also a 1024-dim embedding. In contrast, the vector concatenation approach is impractical, as it increases the joint feature space dimensionality, leading to an increase in the computational cost [60].
4.5 Answer Prediction
The answer prediction module is formulated as a binary classification problem over only two words  and
and  . A Multi-Layer Perceptron (MLP) of two fully connected layers is used, where each layer has two hidden units which is the number of candidate answers. The first layer with a tanh function is used to reshape the 1024-dim joint embedding into a vector of dimensionality equal to the number of classes. The softmax function is used in the second layer to produce the probability distribution over the two answers. Suppose that \(\overrightarrow{x}\) is the output vector of the first layer and \(k=2\) is the number of classes in the last layer, the probability distribution over each answer \(i\) is calculated as follows:
. A Multi-Layer Perceptron (MLP) of two fully connected layers is used, where each layer has two hidden units which is the number of candidate answers. The first layer with a tanh function is used to reshape the 1024-dim joint embedding into a vector of dimensionality equal to the number of classes. The softmax function is used in the second layer to produce the probability distribution over the two answers. Suppose that \(\overrightarrow{x}\) is the output vector of the first layer and \(k=2\) is the number of classes in the last layer, the probability distribution over each answer \(i\) is calculated as follows:
5 Experimental Results and Discussion
All experiments are conducted using Google Colaboratory (a.k.a. Google Colab) [61]. It is a cloud service for supporting machine learning education and research, that provides free access to a virtual machine with 12 GB of GPU with no requirements. The available GPUs in Google Colab include Nvidia K80s, T4s, and P100s, where the type of allocated GPU can vary each time. All algorithms utilized in all experimented models are implemented using the python programming language and PyTorch library.
All models are end-to-end learned with the Cross-Entropy Loss function, where the parameters of VGG-16, and both fine-tuned CBOW and SG models from Aravec2.0 are remained frozen during training. Models are trained using the Adam optimizer for 20 epochs, with an initial learning rate of 1e−3 and a batch size of 32. The learning rate is scheduled to be reduced by a multiplicative factor of 0.1 every 10 epochs. For binary classification, suppose that \(y\) is the ground-truth answer and \(p\) is the predicted answer, where each value of both is either 0 or 1, the cross-entropy loss is defined as:
As mentioned before, the VAQA dataset consists of 137,888 IQA triplets, which are divided as 60%: 20%: 20% for training, validation, and testing, respectively. Each of these splits contains distinct images and questions. The simple accuracy is adopted for performance evaluation. This is because the Arabic-VQA problem is represented as a classification task, where there are no potential variations in the predicted answer string. Further, each IQ pair has an exactly single ground-truth answer in our dataset, which can be easily compared with the predicted answer. Accuracy is defined as the ratio of correctly answered questions to all questions asked about all images. Considering the Truly Positive (TP), Truly Negative (TN), Falsely Positive (FP), and Falsely Negative (FN) answered questions, accuracy is calculated as follows:
Experiments are conducted on the Arabic-VQA system using two question-tokenization approaches, three word-embedding algorithms, and four LSTM networks with different architectures, as described in Sect. 4. This results in 24 different VQA models (i.e., 2 × 3 × 4), constructed using all possible combinations of these Arabic-question pre-processing and representation techniques. On the other hand, techniques used in the remaining modules of visual feature extraction, feature fusion from both modalities, and answer prediction are the same for all these VQA models.
Table 10 shows a comparison between all Arabic-VQA models built on top of the VAQA dataset, in terms of the achieved testing performance. The first column presents the used tokenization approach, whether the question tool  is separated into a distinct token or not. The second column illustrates the utilized word embedding approach, including the basic approach of utilizing an embedding layer, and both CBOW and SG word embedding models from Aravec2.0 that are fine-tuned on all questions in our VAQA dataset to handle the missing question words issue. The third column exhibits the LSTM network utilized for question representation, where both unidirectional LSTM (Uni-LSTM) and bidirectional LSTM (Bi-LSTM) networks are investigated, once with one hidden layer and once with two hidden layers. The last column states the performance recorded for each Arabic-VQA model.
is separated into a distinct token or not. The second column illustrates the utilized word embedding approach, including the basic approach of utilizing an embedding layer, and both CBOW and SG word embedding models from Aravec2.0 that are fine-tuned on all questions in our VAQA dataset to handle the missing question words issue. The third column exhibits the LSTM network utilized for question representation, where both unidirectional LSTM (Uni-LSTM) and bidirectional LSTM (Bi-LSTM) networks are investigated, once with one hidden layer and once with two hidden layers. The last column states the performance recorded for each Arabic-VQA model.
From Table 10, it can be noticed that the performance of all Arabic-VQA models varies within a narrow range, starting from 80.8 to 84.9%. We can observe that the VQA models containing the fine-tuned word embedding models from AraVec2.0 outperform the other VQA models that utilized a fully connected embedding layer, in both cases of separating or non-separating the question tool  . This makes sense, as these two fine-tuned embedding models were initially trained on a huge Arabic source domain with a larger vocabulary size. Further, it was noticed that those Arabic-VQA models that adopted a lookup table required more training epochs than other models to converge. This is logical, as these models have more parameters (i.e., parameters of the word embedding fully connected layer) that need to learn, while the parameters of the fine-tuned word embedding models from Aravec2.0 remain frozen during training.
. This makes sense, as these two fine-tuned embedding models were initially trained on a huge Arabic source domain with a larger vocabulary size. Further, it was noticed that those Arabic-VQA models that adopted a lookup table required more training epochs than other models to converge. This is logical, as these models have more parameters (i.e., parameters of the word embedding fully connected layer) that need to learn, while the parameters of the fine-tuned word embedding models from Aravec2.0 remain frozen during training.
For most cases, treating the question tool  as a separate token improves the performance. This is because
as a separate token improves the performance. This is because  always comes connected to its following word, while it is an equivalent question tool to
always comes connected to its following word, while it is an equivalent question tool to  which typically comes as a separate word and is treated as a distinct token. Hence, considering this special case is necessary for Arabic yes/no question tokenization. Within each combination of tokenization and word embedding approaches for question pre-processing, Arabic-VQA models perform nearly the same for the four LSTM networks with their different architectures. The performance of all Arabic-VQA models can be summarized as follows:
which typically comes as a separate word and is treated as a distinct token. Hence, considering this special case is necessary for Arabic yes/no question tokenization. Within each combination of tokenization and word embedding approaches for question pre-processing, Arabic-VQA models perform nearly the same for the four LSTM networks with their different architectures. The performance of all Arabic-VQA models can be summarized as follows:
-
Models that do not separate the question tool
 and use a lookup table perform around \(81.6\pm 0.8\%\).
and use a lookup table perform around \(81.6\pm 0.8\%\). -
Models that do not separate the question tool
 and use the fine-tuned SG perform around \(83.95\pm 0.15\%\).
and use the fine-tuned SG perform around \(83.95\pm 0.15\%\). -
Models that do not separate the question tool
 and use the fine-tuned CBOW perform around \(84.2\pm 0.4\%\).
and use the fine-tuned CBOW perform around \(84.2\pm 0.4\%\). -
Models that separate the question tool
 and use a lookup table perform around \(82.35\pm 0.75\%\).
and use a lookup table perform around \(82.35\pm 0.75\%\). -
Models that separate the question tool
 and use the fine-tuned SG perform around \(84.35\pm 0.55\%\).
and use the fine-tuned SG perform around \(84.35\pm 0.55\%\). -
Models that separate the question tool
 and use the fine-tuned CBOW perform around \(84.25\pm 0.15\%\).
and use the fine-tuned CBOW perform around \(84.25\pm 0.15\%\).
 and use a lookup table perform around
and use a lookup table perform around  and use the fine-tuned SG perform around
and use the fine-tuned SG perform around  and use the fine-tuned CBOW perform around
and use the fine-tuned CBOW perform around  and use a lookup table perform around
and use a lookup table perform around  and use the fine-tuned SG perform around
and use the fine-tuned SG perform around  and use the fine-tuned CBOW perform around
and use the fine-tuned CBOW perform around Finally, it can be concluded that the performance has significantly improved to exceed 83.8% for those Arabic-VQA models that utilized Arabic-specified question pre-processing approaches (i.e., considering the special case of separating the question tool  and embedding the question words using the fine-tuned CBOW and SG models from AraVec2.0). The best performance achieved is an accuracy of 84.936% for the Arabic-VQA model that treated the question tool
and embedding the question words using the fine-tuned CBOW and SG models from AraVec2.0). The best performance achieved is an accuracy of 84.936% for the Arabic-VQA model that treated the question tool  as a separate token, with the fine-tuned AraVec2.0 SG word embedding model, and one-layer Uni-LSTM for question representation.
as a separate token, with the fine-tuned AraVec2.0 SG word embedding model, and one-layer Uni-LSTM for question representation.
Table 11 exhibits a comparison between the performance of our best Arabic-VQA model developed on the VAQA dataset with other related VQA systems, considering only their performance on yes/no open-ended questions according to the scope of our work. This comparison includes the baseline model proposed in [14] that we have followed in our system, as well as the baseline model developed on the VQA2.0 dataset [43] which is the most widely used dataset among research and in the universal annual VQA challenge. Although these VQA models were developed on other VQA datasets with a different natural language, they have adopted a similar framework with similar techniques in most of their modules. All of them used the VGG-16 model for visual feature extraction and unidirectional LSTMs for textual feature extraction, where answers were predicted using an MLP classifier. The differences between our system and these models are in the question channel that we have developed to suit the Arabic language.
From Tables 10 and 11, it can be observed that the performance of Arabic-VQA models that utilized the traditional pre-processing approaches of tokenizing questions by considering only blanks and embedding the question words using a lookup table is around \(81.6\pm 0.8\%\). This is very close to the performance of the baseline model in [14], which adopted the same techniques for question pre-processing along with unidirectional LSTMs for question representation. However, our performance has improved to achieve 84.9% due to utilizing the investigated Arabic-specified question pre-processing approaches. Moreover, the even distribution of both answers in our VAQA dataset forces the developed Arabic-VQA models to learn properly, without exploiting the most frequent answer in the dataset to predict a potential answer. Hence, the achieved performance on the VAQA dataset is good and still comparable to the performance of related VQA models developed on other VQA datasets for the same type of questions.
6 Conclusion and Future Work
In this work, we benchmark the first dataset and system for VQA in Arabic. The VAQA is a fully automatically generated dataset, which is proposed as a first step toward guiding the VQA research field to the Arabic language. The dataset contains 5000 real-world images that are taken from the MS-COCO dataset, 2712 unique questions, and two answers  and
and  , resulting in 137,888 Image-Question-Answer (IQA) triplets. All Arabic questions are automatically generated, which revolve around three different tasks: COCO object presence verification, COCO super-category presence verification, and image scene recognition. The dataset is divided into 60%: 20%: 20% for training, validation, and testing, respectively. It is designed so that each of the three splits contains a distinct set of images and a distinct set of questions, to guarantee a reliable dataset. During the dataset creation, we ensured an even distribution of answers, to avoid a biased dataset where VQA models can exploit answer frequencies to predict the correct answer without reasoning.
, resulting in 137,888 Image-Question-Answer (IQA) triplets. All Arabic questions are automatically generated, which revolve around three different tasks: COCO object presence verification, COCO super-category presence verification, and image scene recognition. The dataset is divided into 60%: 20%: 20% for training, validation, and testing, respectively. It is designed so that each of the three splits contains a distinct set of images and a distinct set of questions, to guarantee a reliable dataset. During the dataset creation, we ensured an even distribution of answers, to avoid a biased dataset where VQA models can exploit answer frequencies to predict the correct answer without reasoning.
A novel database schema for the VAQA dataset has been designed to support automatic dataset generation, using relational database management systems (RDBMS) approaches. An algorithm for automatic IQA ground-truth triplet generation has been proposed, using images from a dataset dedicated to object detection and segmentation purposes. By exploiting the segmentation annotations of COCO images, several questions are automatically assigned to each image and answered based on its content. Both the database schema and automatic IQA triplet generation algorithm can be re-used for generating more VQA datasets in any other natural language.
The proposed Arabic-VQA system consists of five modules, namely question pre-processing, textual features extraction, visual features extraction, features fusion from both modalities, and answer prediction. Our experiments for the Arabic-VQA system have concentrated on the question channel, where two question-tokenization approaches, three word-embedding approaches, and four LSTM networks with different architectures have been investigated. By considering all possible combinations of these question pre-processing and representation approaches, 24 different Arabic-VQA models have been developed on the VAQA dataset. For all these Arabic-VQA models, the techniques used in the remaining modules remained the same.
For question tokenization, we had to investigate whether splitting the question tool  into a separate token is necessary or not. Concerning question word embedding, in the beginning, we followed the traditional approach of including a fully connected embedding layer. Thereafter, two fine-tuned Word2Vec models with the CBOW and SG architectures from the Aravec2.0 tool have been investigated. Regarding textual feature representation, we have investigated both unidirectional and bidirectional LSTM networks, once with a single hidden layer and once with two hidden layers. A pre-trained VGG-16 model has been utilized for image representation. The extracted visual and textual embeddings are fused by applying element-wise multiplication. Lastly, answers are predicted using an MLP of two fully connected layers.
into a separate token is necessary or not. Concerning question word embedding, in the beginning, we followed the traditional approach of including a fully connected embedding layer. Thereafter, two fine-tuned Word2Vec models with the CBOW and SG architectures from the Aravec2.0 tool have been investigated. Regarding textual feature representation, we have investigated both unidirectional and bidirectional LSTM networks, once with a single hidden layer and once with two hidden layers. A pre-trained VGG-16 model has been utilized for image representation. The extracted visual and textual embeddings are fused by applying element-wise multiplication. Lastly, answers are predicted using an MLP of two fully connected layers.
Experiments indicate that utilizing the fine-tuned CBOW and SG word embedding models from AraVec2.0 outperform the traditional approach of training a fully connected embedding layer. The VQA model that treated the question tool  as a separate token, utilized the fine-tuned SG word embedding model from AraVec2.0, and one-layer Uni-LSTM for question representation is demonstrated to be the best Arabic-VQA model, achieving an accuracy of 84.936% on our VAQA dataset. Compared with other VQA systems with a similar framework developed on different VQA datasets in another natural language, considering only their performance on yes/no questions according to our scope, the achieved performance on the VAQA dataset is good and still comparable to the performance on other VQA datasets for the same type of questions.
as a separate token, utilized the fine-tuned SG word embedding model from AraVec2.0, and one-layer Uni-LSTM for question representation is demonstrated to be the best Arabic-VQA model, achieving an accuracy of 84.936% on our VAQA dataset. Compared with other VQA systems with a similar framework developed on different VQA datasets in another natural language, considering only their performance on yes/no questions according to our scope, the achieved performance on the VAQA dataset is good and still comparable to the performance on other VQA datasets for the same type of questions.
In future, we will devote our efforts to expanding the VAQA dataset to increase its size and complexity, by adding more images, other question types, and answers. Other plans aim to investigate how well the attention mechanism can contribute to an Arabic-VQA system in both modalities, and to investigate different approaches in the remaining modules as done in the question channel.
References
Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.-J.; Shamma, D.A.; Bernstein, M.S.; Fei-Fei, L.: Visual genome: connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 123, 32–73 (2017)
Wu, Q.; Teney, D.; Wang, P.; Shen, C.; Dick, A.; Van Den Hengel, A.: Visual question answering: a survey of methods and datasets. Comput. Vis. Image Underst. (CVIU) 163, 21–40 (2017)
He, B.; Xia, M.; Yu, X.; Jian, P.; Meng, H.; Chen, Z.: An educational robot system of visual question answering for preschoolers. In: Proceedings of the 2nd International Conference on Robotics and Automation Engineering (ICRAE) (2017)
Gupta, D.; Suman, S.; Ekbal, A.: Hierarchical deep multi-modal network for medical visual question answering. Expert Syst. Appl. 164, 113993 (2021)
Ren, F.; Zhou, Y.: CGMVQA: a new classification and generative model for medical visual question answering. IEEE Access 8, 50626–50636 (2020)
He, X.; Cai, Z.; Wei, W.; Zhang, Y.; Mou, L.; Xing, E.; Xie, P.: Pathological visual question answering. In: Proceedings of International Conference on Learning Representations (ICLR) (2021)
Zhang, A.; Tao, W.; Li, Z.; Wang, H.; Zhang, W.: Type-aware medical visual question answering. In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore (2022)
Bigham, J.P.; Jayant, C.; Ji, H.; Little, G.; Millerγ, A.; Miller, R.C.; Tatarowicz, A.; White, B.; White, S.; Yeh, T.: Vizwiz: nearly real-time answers to visual questions. In: Proceedings of the 23nd Annual ACM Symposium on User Interface Software and Technology (UIST) (2010)
Geman, D.; Geman, S.; Hallonquist, N.; Younes, L.: Visual turing test for computer vision systems. In: Proceedings of the National Academy of Sciences (PNAS) (2015)
Malinowski, M.; Fritz, M.: A multi-world approach to question answering about real-world scenes based on uncertain input. In: Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS) (2014)
VQA Challenge. Virginia Tech and Georgia Tech, [Online]. Available: https://visualqa.org/challenge.html. [Accessed 1 April 2021]
Eberhard, D.M.; Simons, G.F.; Fennig, C.D.: What are the top 200 most spoken languages?. Ethnologue: Languages of the World. [Online]. Available: https://www.ethnologue.com/guides/ethnologue200. [Accessed 5 June 2021] (2021)
List of countries where Arabic is an official language. Wikipedia, the free encyclopedia, 4 June 2021. [Online]. Available: https://en.wikipedia.org/wiki/List_of_countries_where_Arabic_is_an_official_language. [Accessed 6 June 2021]
Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D.: VQA: visual question answering. In Proceedings of IEEE International Conference on Computer Vision (ICCV) (2015)
Malinowski, M.; Rohrbach, M.; Fritz, M.: Ask your neurons: a neural-based approach to answering questions about images. In: Proceedings of IEEE International Conference on Computer Vision (ICCV) (2015)
Ren, M.; Kiros, R.; Zemel, R.: Exploring models and data for image question answering. In: Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS) (2015)
Zhou, B.; Tian, Y.; Sukhbaatar, S.; Szlam, A.; Fergus, R.: Simple Baseline for Visual Question Answering. arXiv preprint. arXiv:1512.02167arXiv preprint:1512.02167 (2015)
Kahou, S.E.; Michalski, V.; Atkinson, A.; Kádár, Á.; Trischle, A.; Bengio, Y.: FIGUREQA: an annotated figure dataset for visual reasoning. In: Proceedings of International Conference on Learning Representations (ICLR) (2018)
Yang, Z.; He, X.; Gao, J.; Deng, L.; Smola, A.: Stacked attention networks for image question answering. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
Agrawal, A.; Batra, D.; Parikh, D.; Kembhavi, A.: Don’t just assume; Look and answer: overcoming priors for visual question answering. In: Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Jiang, H.; Misra, I.; Rohrbach, M.; Learned-Miller, E.; Chen, X.: In defense of grid features for visual question answering. In: Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020)
Shih, K.J.; Singh, S.; Hoiem, D.: Where to look: focus regions for visual question answering. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
Fukui, A.; Park, D.H.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M.: Multimodal compact bilinear pooling for visual question answering and visual grounding. In: Proceedings of conference on Empirical Methods in Natural Language Processing (EMNLP) (2016)
Yu, Z.; Yu, J.; Fan, J.; Tao, D.: Multi-modal factorized bilinear pooling with co-attention learning for visual question answering. In: Proceedings of IEEE International Conference on Computer Vision (ICCV) (2017)
Ben-younes, H.; Cadene, R.; Cord, M.; Thome, N.: MUTAN: multimodal tucker fusion for visual question answering. In: Proceedings of IEEE International Conference on Computer Vision (ICCV) (2017)
Yu, Z.; Yu, J.; Xiang, C.; Fan, J.; Tao, D.: Beyond bilinear: generalized multimodal factorized high-order pooling for visual question answering. IEEE Trans. Neural Netw. Learn. Syst. 29, 5947–5959 (2018)
Teney, D.; Anderson, P.; He, X.; Van Den Hengel, A.: Tips and tricks for visual question answering: learnings from the 2017 challenge. In: Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Li, R.; Jia, J.: Visual question answering with question representation update (QRU). In: Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain (2016)
Lu, J.; Yang, J.; Batra, D.; Parikh, D.: Hierarchical question-image co-attention for visual question answering. In: Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS) (2016)
Gao, L.; Cao, L.; Xu, X.; Shao, J.; Song, J.: Question-Led object attention for visual question answering. Neurocomputing 391, 227–233 (2020)
Yu, Z.; Yu, J.; Cui, Y.; Tao, D.; Tian, Q.: Deep modular co-attention networks for visual question answering. In: Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
Hong, J.; Park, S.; Byun, H.: Selective residual learning for visual question answering. Neurocomputing 402, 366–374 (2020)
Han, D.; Zhou, S.; Li, K.C.; de Mello, R.F.: Cross-modality co-attention networks for visual question answering. Soft Comput. 25, 5411–5421 (2021)
Kim, J.-H.; On, K.-W.: Lim, W.; Kim, J.; Ha, J.-W.; Zhang, B.-T.: Hadamard product for low-rank bilinear pooling. In: Proceedings of International Conference on Learning Representations (ICLR) (2017)
Kim, J.-H.; Jun, J.; Zhang, B.-T.: Bilinear attention networks. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems (NIPS) (2018)
Gao, H.; Mao, J.; Zhou, J.; Huang, Z.; Wang, L.; Xu, W.: Are you talking to a machine? Dataset and methods for multilingual image question answering. In: Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS) (2015)
Jiang, Y.; Natarajan, V.; Chen, X.; Rohrbach, M.; Batra, D.; Parikh, D.: Pythia v0.1: The Winning Entry to the VQA Challenge 2018. arXiv preprint. arXiv:1807.09956 (2018)
Kim, J.-H.; Lim, S.; Park, J.; Cho, H.: Korean localization of visual question answering for blind people. In: Proceedings of AI for Social Good workshop at NIPS (2019), Vancouver, Canada (2019)
Johnson, J.; Hariharan, B.; Van Der Maaten, L.; Fei-Fei, L.; Zitnick, C.L.; Girshick, R.: Clevr: a diagnostic dataset for compositional language and elementary visual reasoning. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
Yu, L.; Park, E.; Berg, A.C.; Berg, T.L.; Visual madlibs: fill in the blank description generation and question answering. In: Proceedings of IEEE International Conference on Computer Vision (ICCV) (2015)
Zhu, Y.; Groth, O.; Bernstein, M.; Fei-Fei, L.: Visual7W: grounded question answering in images. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
Changpinyo, S.; Kukliansy, D.; Szpektor, I.; Chen, X.; Ding, N.; Soricut, R.: All you may need for VQA are image captions. In: Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL), United States (2022)
Goyal, Y.; Khot, T.; Batra, D.; Parikh, D.: Making the V in VQA matter: elevating the role of image understanding in visual question answering. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
Kafle, K.; Kanan, C.: An analysis of visual question answering algorithms. In: Proceedings of IEEE International Conference on Computer Vision (ICCV) (2017)
Gurari, D.; Li, Q.; Stangl, A.J.; Guo, A.; Lin, C.; Grauman, K.; Luo, J.; Bigham, J.P.: VizWiz grand challenge: answering visual questions from blind people. In: Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Acharya, M.; Kafle, K.; Kanan, C.: Tallyqa: answering complex counting questions. In: Proceedings of the AAAI Conference on Artificial Intelligence (2019)
Wang, P.; Wu, Q.; Shen, C.; Dick, A.; Van Den Hengel, A.: FVQA: fact-based visual question answering. IEEE Trans. Pattern Anal. Mach. Intell. 40, 2413–2427 (2018)
Wang, P.; Wu, Q.; Shen, C.; Dick, A.; Van Den Hengel, A.: Explicit knowledge-based reasoning for visual question answering. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI) (2017)
Wu, Z.; Palmer, M.: Verbs semantics and lexical selection. In: Proceedings of the 32nd Annual Meeting on Association for Computational Linguistics (ACL) (1994)
Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L.: Microsoft COCO: common objects in context. In: Proceedings of the European Conference on Computer Vision (ECCV) (2014)
مجمع اللغة العربية بالقاهرة, المعجم الوسيط, مكتبة الشروق الدولية (2011)
محمد بن أبي بكر بن عبد القادر الرازي, مختار الصحاح, مكتبة لبنان (1989)
Simonyan, K.; Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: Proceedings of the 3rd International Conference on Learning Representations (ICLR) (2015)
Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L.: ImageNet: a large-scale hierarchical image database. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2009)
Soliman, A.B.; Eisa, K.; El-Beltagy, S.R.: AraVec: a set of arabic word embedding models for use in Arabic NLP. In: Proceedings of the 3rd International Conference on Arabic Computational Linguistics (ACLing), Dubai, United Arab Emirates (2017)
Hochreiter, S.: The vanishing gradient problem during learning recurrent neural nets and problem solutions. In: International Journal of Uncertainty Fuzziness and Knowledge-Based Systems (1998)
Yang, S.; Yu, X.; Zhou, Y.: LSTM and GRU neural network performance comparison study. In: Proceedings of IEEE International Workshop on Electronic Communication and Artificial Intelligence (IWECAI) (2020)
Hochreiter, S.; Schmidhuber, J.: Long short-term memory. Neural Comput. 9, 1735–1780 (1997)
Schuster, M.; Paliwal, K.K.: Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 45, 2673–2681 (1997)
Zhang, D.; Cao, R.; Wu, S.: Information fusion in visual question answering: A Survey. Elsevier Inf. Fusion 52, 268–280 (2019)
Google Colaboratory. Google, [Online]. Available: https://colab.research.google.com/. [Accessed 2 May 2021]
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
kamel, S.M., Hassan, S.I. & Elrefaei, L. VAQA: Visual Arabic Question Answering. Arab J Sci Eng 48, 10803–10823 (2023). https://doi.org/10.1007/s13369-023-07687-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13369-023-07687-y