
Abstract
Hospital readmission shortly after discharge threatens the quality of patient care and leads to increased medical care costs. In the United States, hospitals with high readmission rates are subject to federal financial penalties. This concern calls for incentives for healthcare facilities to reduce their readmission rates by predicting patients who are at high risk of readmission. Conventional practices involve the use of rule-based assessment scores and traditional statistical methods, such as logistic regression, in developing risk prediction models. The recent advancements in machine learning driven by improved computing power and sophisticated algorithms have the potential to produce highly accurate predictions. However, the value of such models could be overrated. Meanwhile, the use of other flexible models that leverage simple algorithms offer great transparency in terms of feature interpretation, which is beneficial in clinical settings. This work presents an overview of the current trends in risk prediction models developed in the field of readmission. The various techniques adopted by researchers in recent years are described, and the topic of whether complex models outperform simple ones in readmission risk stratification is investigated.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Current healthcare systems face many changes, such as aging population, increased use of technologies, and high expectations from citizens. These changes have transformed healthcare settings into patient-centered and value-based models. However, the effort to improve quality of health while limiting costs is a major roadblock for various stakeholders [1]. In this context, data and information can help healthcare providers to deliver optimum health outcomes in unprecedented ways. The availability of electronic clinical data has skyrocketed because of the development of information technology and the use of electronic medical records (EMRs). Given the huge amount of available data, traditional software is no longer computationally sufficient to store, manage, and analyse high volumes of information. The implementation of machine learning (ML) algorithms, such as decision trees (DTs), neural networks (NNs), and other techniques, is necessary in converting data into actionable insights for automated decision making and precision medicine. By 2025, the data subject to analysis are expected to balloon to 5.2 ZB, of which 1.4 ZB will be attributed to ML systems [2].
Predictive modeling is at the forefront of improving quality of care. With ML models, massive amounts of data can be analyzed to predict outcomes for individual patients. Predicting a patient’s risk of readmission is an exemplar application for ML models. Hospital readmission can be defined as an admission to a hospital within a specified time interval (typically 30 days) after previous discharge by the same patient [3]. Readmission could be costly, with the cost of care associated with readmission increasing to above $10,000 per patient [4]. In the United States, the Affordable Care Act requires healthcare providers to establish the Hospital Readmissions Reduction Program (HRRP) to reduce readmission rates by imposing penalties to hospitals with excess readmissions. The total penalties hit $500 million of hospitals’ overall Medicare payments annually [5]. Identifying patients at high risk of getting readmitted is a key strategy to reduce the number of hospital readmissions and the associated costs. Accurate predictions from algorithms are important in supporting care providers in their decision regarding whether a patient is ready for discharge or should be targeted for interventions. In this way, such predictions mitigate the risk of unplanned readmission and curb increased healthcare costs.
Many risk factors have been highlighted to be associated with a high risk of readmission. Common associations include sociodemographic factors such as high age and poor living conditions [6], patient comorbidities [7, 8], premature discharge [9], insufficient post-discharge support [10], complications from previous medical care, and adverse drug events [11]. Among these factors, clinical errors could be a major contributor to avoidable readmissions. Of the 20% of patients who experience adverse events (AE) following discharge, three-quarters of cases are related to medications, with diagnostic or therapeutic errors contributing to more than one-fifth of AE [11]. Examples of medication errors include patients being discharged without prescriptions for necessary medications, improper dosage, and inadequate monitoring for drug side effects. Therapeutic errors can be attributed to the failure to adequately monitor treatments. Preventing these errors is crucial to ensure patient safety after hospital discharge. In addition, targeted interventions to prevent readmission can be provided to patients by ensuring safe care transitions prior to discharge. Interventions such as medication reconciliation, structured discharge summaries, facilitated communication between hospital and primary care providers, and patient and family education have been shown to have positive impacts on readmission rates [12]. Predictive modeling is therefore necessary for healthcare facilities to identify patients at a high risk of readmission.
1.1 Work Motivation
Mining clinical data for insights and modeling is a tedious aspect of developing analytic solutions in healthcare. The area under receiver operating characteristic curve (AUC) is a standard measure of prediction performance that indicates the ability to discriminate between two or more target populations. Generally, a model with 0.5 AUC performs no better than chance, a range of 0.7–0.8 is modest and acceptable, and an excellent model has 0.8–0.9 discriminative ability; high values are rarely observed and are believed to be at a high risk of overfitting [13]. Despite increasing pressure to mitigate readmission rates, existing works often reported moderate performance (AUC < = 0.75) in identifying positive cases, even with the emergence of ML algorithms [14, 15]. In 2018, Artetxe and colleagues [16] presented what is probably the most recent systematic review that covers a general overview of prediction models in the field. The study reported that traditional statistical models, such as logistic regression (LR) and survival analysis, are still widely used in health analytics, with other complex ML techniques showing promising results over classical methods. Emerging algorithms such as deep learning (DL) also show immense potential in yielding excellent results. Nevertheless, further studies are needed to assess the real impact of complex models in the domain of readmission prediction.
The present study aims to:
-
(1)
Present the current trends in the predictive approach to readmission research by describing the recent methods used for model building.
-
(2)
Investigate the impact of complex models on predictive performance.
-
(3)
Discuss some of the challenges in using these models as a decision support tool in future.
The paper is organized as follows. Section 2 describes the various reviews that provide rich insights into the use of predictive modeling in readmission research. Section 3 covers a general introduction to the methods of prediction. A full description of the models is beyond the scope of this study. Section 4 describes the data sources used for clinical predictive modeling. Sections 5 and 6, respectively, focus on existing methods for predicting readmission in particular patient subpopulations (disease-specific) and on models that fit the entire dataset. Section 7 highlights the discussion for readmission research. Section 8 concludes the study.
1.2 Methodology
In this work, related works were considered in the review of readmission by covering the following search strings: “readmission,” “rehospitalization,” “predictive,” “prediction,” and “review” published in 2010 onwards. In terms of the list of studies to be included in Section 3 onwards, a literature search was performed using the following search query: (“Readmission” OR “Rehospitalization”) AND (“Machine learning” OR “Deep learning” OR “Prediction” OR “Predictive” OR “Predicting” OR “Predict” OR “Model” OR “Modeling”). We refined our search to works published in the past two years, i.e., 2019 and 2020, to investigate the current trends in readmission research. The studies that met the following inclusion criteria and those published in the English language were retained for further analyses.
The eligibility criteria were as follows:
-
(1)
The objective of the study should answer a simple question: What is the probability of readmission of an adult patient at any time point during the hospitalization period?
-
(2)
The original research should present the development of prediction models by using traditional regression methods, such as LR and Cox regression; ML models, such as artificial neural networks (ANNs), DTs, and support vector machine (SVM); or other complex DL algorithms, such as deep neural networks (DNNs).
-
(3)
Articles with full text available to ensure quality assessment.
-
(4)
The titles or abstracts of the articles should show the relevant search terms, and the search terms should have the same meaning as intended for the review in the current work.
-
(5)
The outcomes of the studies must be the prediction of the likelihood of patients’ readmission with conditions and procedures specified in HRRP, hospital-wide, and cardiovascular-, psychiatric-, and diabetes- related studies. The studies wherein the targets are disease-specific post-surgery readmission were excluded as predictors are unique to each surgical procedure. In the entire selection process, a citation management tool (EndNote X9; Thomson Reuters Corporation, New York, NY) was used to manage all citations. Unlike conventional systematic review studies, the current work aims to answer the following questions: “What are the current trends in modeling readmission?” “Do complex models perform better than simple ones?” “Do state-of-the-art algorithms bring high value?” “How should complex event predictions be dealt with?”
2 Related Works
Using the vastly available clinical data for readmission, modeling has gained increasing attention from researchers. The increasing adoption of EMRs has created opportunities for researchers to leverage patient-centered records, which are usually ill-understood. An EMR contains a patient’s medical history, including demographic information, medical diagnoses, laboratory test results, treatment plans, and medications. According to the National Physician Survey, about 65% of physicians have indicated that EMRs improve the quality of patient care [17]. The effect of EMRs on the clinical workflow has been positive. However, few studies have discussed a complete set of techniques that can be explored to mine EMRs for readmission modeling. Table 1 shows a number of reviews in the readmission field, along with their research summaries.
Many related review studies have reported moderate predictive performance with AUC < = 0.70. Although the predictive ability of readmission risk models in recent years has improved to AUCs above 0.70, other complex ML models struggle to reach parsimony state because of the lack of transparency in the feature selection process. Moreover, performance varies greatly depending on the target population because of different risk factors. Previously published review studies assessed various predictive models up to January 2019 [14] regardless of the methodology used for study selection. Gaps exist in the knowledge about the recent trends in this field of research and the models that leverage newer models, such as DL, for prediction. The current study focused on identifying the approaches to predicting high-risk patients in the last two years.
3 Modeling the Likelihood of Clinical Outcomes
Most studies modeled readmission as a dichotomous outcome, in which the target regarding readmission can be true or false within a certain time frame [21]. Survival analysis is another important method for estimating the readmission days survived from previous discharge. Regardless the natures of modeling, all algorithms are designed to detect the complex relationships between explanatory variables and observations. Traditional rule-based scoring, such as the LACE score and HOSPITAL score [22], is the simplest to employ. A high LACE score is directly proportional to a high risk of readmission. Despite the plethora of work that used the LACE model in developing readmission risk prediction models, the optimum cutoff score to capture high-risk patients varies according to study populations. Thus, models based on clinical rules help in facility-level decision making. In predictive methods based on multivariable modeling, the relationships between single independent variables with desired health outcome events can be examined. Learning-based prediction is crucial to predict readmission at the individual level. Figure 1 depicts an overview of the learning-based approaches in predictive modeling.

General overview of techniques used for predictive modeling
3.1 Statistical Learning
LR is a fundamental model that uses a logistic function to solve classification problems. Being the most commonly used method when predicting binary outcomes, LR can be used to identify the relationship weight (whether positive or negative) between independent variables (features) and dependent variables (study outcomes). Penalized regressions, such as ridge [23], lasso [24], and elastic net [25], are useful as they provide an approach to variable selection other than statistical significance. These penalizations address the over fitting issue by shrinking the magnitude of variable coefficients. Overall, the goal of LR is to find the best fitting model to describe the relationship between a set of predictors and target variables.
An alternative statistical-based approach to model prognosis is survival analysis, which aims to predict the time to readmission. A key aspect of survival analysis is censored observation, in which readmission has not occurred during the study period. Without the presence of censoring, standard LR could be used. Traditionally, the Cox proportional hazard (CPH) model has been the most widely used model to analyse censored data, but the CPH model often works for small datasets and does not scale well to high dimensions and large volumes of clinical data [26].
3.2 Machine Learning
Unlike statistical learning, ML is an interdisciplinary field comprising statistics, mathematics, and computer science elements. It provides an approach to develop machines that are “intelligent” enough to perform complex tasks. This approach is commonly known as artificial intelligence (AI). AI is able to imitate human intelligence driven by advanced algorithms and careful training over a large pool of data [27]. The idea of ML is to learn from examples and experiences (data) and is thus different from rule-based symbolic AI. Once trained, model will learn an optimized function on the basis of data and draw predictions for specific tasks. Such data-driven approach is now the state-of-the-art methodology for various domains, such as computer vision [28], natural language processing [29], and real industrial clinical applications [30]. Standard ML techniques can be broadly classified into three main categories, namely, support SVM, naïve Bayes (NB), and tree-based methods.
In healthcare, regression techniques always serve as a baseline model for clinical tasks. However, the potential disadvantage could be their inferior performance [31]. The use of various ML models in clinical settings is often a sensible approach. SVM was first introduced in 1995 and is a powerful learning approach to classification [32]. SVM is similar to LR, in which the end training output is a hyperplane that separates data points into two or more categories. However, different from LR, SVM is a non-probabilistic classifier. Given a set of inputs, SVM takes these inputs and attempts to find which of two possible classes forms the output; the decision boundary represents the largest separation between the two classes. This feature also means that the hyperplane may not be defined by a simple function. SVM is also able to work well in nonlinear separable data. This task can be realized using a method called “kernel trick.” In this kernel space, non-separable data are separable with a linear hyperplane. Linear, polynomial, and radial basis functions are the commonly used kernels. The advantage of using SVM is that over fitting is unlikely to occur in cases where the model only needs to learn the hyperplane in the mapped space. The disadvantage is the inferior interpretability being a “black box” model.
NB is a Bayes rule-based probabilistic classifier that has been used in research for over 50 years [33]. Most predictive models in ML generate a number between 0 and 1 to order the instances typically from the most likely to the least likely to be positive. A Bayes-based probabilistic model assigns the posterior probability of a class given a set of features. The naming “naive” comes from the assumption that individual features are independent from one another. Although this independence assumption is often violated, NB classifiers in practice still tend to perform well [34]. Different from other models, NB is simple, computationally efficient, and robust to noise and missing data [35]. It is also a potential classifier to be used in real applications because of its naturality toward medical prognosis and diagnosis as it uses all available attributes for prediction [36]. This approach is also used by physicians in diagnosis, in which every piece of information is crucial.
DT is a type of rule-based classifier that generates predictions with IF–THEN rules [37]. A DT consists of nodes (a dyadic Boolean operator to split data points on the basis of the satisfaction of condition rules), branches (outcomes of splitting according to instances’ feature values), and leaf nodes (final class assigned to instances from the entire decision-making process). Using the decision algorithm, data points are split at each node, thereby resulting in the largest information gain. The whole process provides DTs with their nonparametric properties. This feature also indicates that no distribution assumption is needed for input data. Hence, DTs are different from other classifiers that make certain assumptions, such as linearity. Nonparametric features give DTs high adaptability to fit numerical or categorical feature types across different datasets. Thus, tree-based classifiers often perform relatively well. DTs alone are unstable as small variations in datasets result in large differences in the structure and in model predictions. To compensate for this issue, ensemble learning outputs predictions by leveraging multiple classifiers. Two popular ensemble learning techniques are bagging and boosting [38]. In the bagging procedure, multiple random subsets (bags) of data are created with replacement. A base model is built on each individual subset, and the models are trained in parallel. Boosting involves training a number of individual models sequentially. Instead of running models in parallel, each subsequent model in boosting attempts to rectify the errors of the previous model by assigning high weights to misclassified data points (corrective boosting). Some examples include random forest (RF), which is bagged DT; and AdaBoost and gradient boosting, which are boosting learners. Overall, the biggest advantage of DTs is their interpretability for actionable decisions. However, for complex datasets, trees can become too large to visualize and interpret, and they are prone to over fitting [39].
3.3 Deep Learning
One major limitation of conventional ML models is the need to perform complex data preprocessing to extract requisite predictive features [40]. Therefore, significant domain knowledge and feature extraction expertise are required in model training. DL is a promising ML tool that can learn abstract features directly from raw data sources. A single well-trained network can yield state-of-the-art results in many fields without domain experts. DL is an extremely powerful tool in terms of processing and learning complex data to solve complicated tasks on the basis of inputs. However, it is not a one-size-fits-all tool in biomedical analytics applications [41].
The basic building block of DL models is the feed forward NN. An NN model is characterized by an activation function to convert inputs into outputs, and it is applied by a series of interconnected processing nodes. The overall idea of training an NN model relies on updating the weights of each node so that the deviation cost of prediction from true labels is minimized. This process is also known as gradient descent. Various advanced optimization functions have been proposed for effective training; they include RMS Prop, AdaBoost, and Adam [42]. Multilayer perceptron (MLP) is the simplest form of NN with three layers, namely, input, hidden, and output layers. Each layer can be composed of one or several neurons.
An NN with multiple hidden layers is called the DNN. With multiple layers, a DNN can extract more abstract features than a single-layer NN. The two commonly used DNN models with varying architectures are the recurrent neural networks (RNNs) and convolutional neural networks (CNNs). RNNs are a special type of NN that is designed to effectively process sequential information [43]. In RNNs, the hidden state at time t is computed by combining the current input and the hidden state at t − 1. Thus, the relationship between historical events and future outcomes can be established. This property is important in modeling long-term dependencies in clinical care as historical illness, and procedures may critically affect future outcomes, such as readmission and mortality. Two prominent RNN variants, namely, long short-term memory (LSTM) [44] and gated recurrent unit (GRU) [45], are widely used by researchers. Their gated mechanisms are designed to tackle the vanishing gradient problem of vanilla RNN. The gate operations in LSTM and GRU control how much information should be stored in the current state, how much is forgotten, and what information is to be passed down to the next step. In this way, the LSTM and GRU are able to learn long-term dependencies. In terms of structural differences, the GRU has fewer parameters than the LSTM and thus performs computations faster [46]. However, no concrete conclusion has identified which of the two RNN variants is better. This fact has also been proved in another work [47]. Researchers usually conduct multiple experiments to identify which model works best for their use case.
The CNN is special algorithm that can yield good results in image classification problems. Instead of modeling temporal information, the CNN effectively captures local temporal dependencies among clinical data [48]; specifically, convolutional layers with filters are applied to each region of the input (local features). Originally invented for computer vision, CNN models are also shown to be effective in handling laboratory results [49], medical feature embedding [50], and text classification [51]. Overall, the CNN is effective in mining semantic clues in contextual windows. An advantage of the convolutional operations in the CNN is that they are more parallelizable than the operations in the RNN, thus making the CNN relatively quick to train. At every time step, the CNN depends only on the local context rather than all the past states as in the RNN. One persistent downside of the CNN is its inability to model long-term semantic dependencies in a sequence. Nevertheless, the CNN performs essentially well in extracting features and in tasks in which feature recognition in the text is important.
Several challenges could hinder the efficacy of DL methods. Current challenges include poor data quality, inconsistent patient information, and lack of model interpretability [52, 53]. Model transparency also becomes a roadblock when putting these models into real use, in which case the mechanisms on how they operate cannot be easily understood. These difficulties need to be dealt with for DL to bring direct clinical impacts.
4 Data Sources of Clinical Predictive Modeling
Clinical data stored in EMRs can be classified into two types: structured and unstructured data. Structured data contain demographic information (such as age, nationality, address), basic information (such as height and weight), vital signs, laboratory results, drugs taken, comorbidity, and treatments/procedures. This type of data is generally stored in fixed-mode databases. Hospitals can choose their desired database systems from different vendors, and different systems can have different levels of retrieval capabilities.
Even if ML technology was developed on a structured data field, over 80% of medical data, such as clinical notes, remain unstructured [54]. Unstructured text is one type of narrative data, and it contains rich health information, such as history, diagnoses, symptoms, radiology reports, daily nursing notes, discharge records, and prescriptions. Clinical narratives provide a comprehensive picture of a patient by storing extensive valuable medical information. The text mining approach is required to discover the hidden knowledge underlying unstructured clinical notes.
5 Results
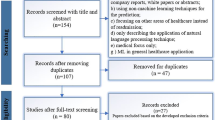
A total of 255 articles were gathered for possible inclusion in this review (Fig. 2). After the first level of title and abstract screening, 195 articles were retained for the Stage 1 review. A further review at Stage 2 excluded 115 articles that did not fulfill the predefined eligibility criteria. In the Stage 3 screening, 23 articles were excluded for being outside the prediction scope. The final set included 57 articles; 2 articles were review articles described in the Related Works section, and 55 were included for the assessment of study outcomes.

Screening flow diagram of study selection Process
6 Application to Readmission
Identifying patients at high risk of getting readmitted is a key strategy to reduce the number of hospital readmissions and the associated costs. Some measures of hospital readmissions are as follows: (1) condition-based, such as acute myocardial infarction (AMI), heart failure (HF), chronic obstructive pulmonary disease (COPD), and pneumonia; (2) procedure-based, such as coronary artery bypass grafting (CABG) and total joint arthroplasty (TJA); (3) hospital-wide all-cause readmission. The final 55 articles that met the inclusion criteria were divided on the basis of their study population cohorts into hospital-wide populations (including intensive care unit and emergency department readmission, n = 19) and patient-specific populations (n = 36). Figure 3 depicts the number of papers (only the studies included in the review) by prediction cohort. Most patient-specific models focused on heart conditions [55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72]. The remaining studies worked on readmission among patients with diabetes [73,74,75,76,77,78,79], psychiatric conditions [80,81,82,83], TJA [84, 85], COPD [86, 87], CABG [88, 89], and pneumonia [90].

Distribution of publications related to prediction by population cohort
6.1 Diagnosis-Specific Readmission
Table 2 summarizes the characteristics and predictive performances of diagnosis-specific models according to their population cohorts. Prediction performance was assessed on the basis of AUC, the commonly used metrics in binary classification, and sensitivity, which indicates the ability to detect readmission. Sensitivity is important in clinical settings as a low number of false negatives shows the ability of a model to detect all relevant readmissions within a population.
Among all diagnosis-specific studies, half of them (50%) built models to predict readmission among patients with heart-specific conditions. Among the 18 studies focused on heart conditions, 13 papers predicted readmissions among the HF population [56,57,58,59,60, 63, 65,66,67,68,69,70,71], 2 worked on AMI cohorts [61, 62], 2 developed models on general cardiovascular disease patients [55, 72], and 1 worked on the stroke population [64]. As shown in Fig. 3, this set is followed by readmission related to diabetes (n = 7), psychiatry (n = 4), COPD (n = 2), CABG (n = 2), TJA (n = 2), and pneumonia (n = 1).
Readmission risk has been modeled from different perspectives. Even with the emergence of the ML algorithm, 29 out of 36 articles adopted traditional statistical methods. Among these studies, ~ 90% used LR either as a baseline [56, 58, 60, 62,63,64, 68, 73, 74, 76,77,78, 83, 85,86,87] or the main model in prediction [60, 69, 71, 82, 88,89,90], and 3 studies derived their own risk scores on the basis of LR variable coefficients [61, 66, 84]. In the remaining 3 papers, the prognosis of readmission was carried out with Cox regression survival analysis. DT and its variants, such as RF, GBM, AdaBoost, CHAID, and SVM, remain popular models for predictive modeling, with 19 studies leveraging them in diagnosis-specific readmission [58, 62,63,64, 67, 68, 70, 73,74,75,76, 78,79,80,81, 83, 85,86,87]. NB and KNN were less commonly used. Being a potential approach that could improve the predictive ability of models, NN-based models were adopted by nearly half of the studies (n = 15) in their high-risk identification [56,57,58,59, 62, 64, 67, 68, 70, 73, 76,77,78, 86, 87]. Of these NN models, ANN or MLP have been widely used, and only 5 articles explored the applicability of RNN and CNN-based models [56, 57, 67, 86, 87].
Different demographic, clinical, laboratory, and social-economical features were included in models to predict readmission. Only 2 studies used unstructured data, namely, physicians’ notes and discharge summary, in their analysis of patient history embedded within clinical prose [67, 69]. The choice of readmission threshold is also an important aspect that influences study outcomes. According to Table 2, a 30-day period is the most widely used threshold, and it was used by 72% of the reviewed papers (n = 26), although some time spans did range from 90 days up to 2 years. Model performance varied greatly across different studies. The average AUCs among the 30-day readmission studies for heart condition, diabetes, psychiatry, and CABG were 0.633, 0.969, 0.761, and 0.677, respectively.
Only 2 studies worked on TJA by using 90 days as a threshold, and only 1 study reported an AUC of 0.665 [84]. In another study, a180-day COPD readmission was modeled with a discrimination of 0.737 [87]. One study worked on pneumonia-related readmission; however, AUC was not reported. With regard to AUC, most studies reported modest scores, with only 26% of 30-day models achieving a discrimination ability of above 0.75.
6.2 Hospital-Wide Readmission
For hospital-wide readmission, model types are described herein with their corresponding performances on the basis of readmission occurring within 30 days. For studies that used different readmission thresholds, the time spans were included in the descriptions.
In terms of hospital-wide prediction, Zebin and colleagues [91] proposed an LSTM + CNN model and achieved an AUC and recall of 0.821 and 0.742, respectively. AdaBoost showed a similar performance of 0.76 for both metrics in another work [92]. Pauly et al.[93] derived a rule-based risk score on the basis of the coefficient of the LR model and achieved moderate discrimination ability (AUC = 0.74). The authors of [94, 95] used LR and produced low to moderate performance (AUC = 0.712 and 0.661, respectively). GBM gave an AUC of 0.699 in predicting readmission among patients in skilled nursing facilities [96]. However, LR with lasso was shown to perform better than GBM in another research [97]. A poor discrimination of 0.60 was observed with LR prediction based on claims data available during admission [98]. Flaks-Manov et al.[99] employed the previously validated Preadmission Readmission Detection Model and added hospital data. Their model performed moderately with an AUC of 0.68. Lin et al.[100] used an advanced DL model to capture sudden fluctuations in clinical data, and LSTM was able to identify readmission at a sensitivity rate of 0.742 and AUC of 0.791. Table 3 shows the list of eligible studies on hospital-wide readmission.
In a 90-day hospital readmission problem, the LR model did not perform sufficiently well (0.65 AUC) as a screening tool [101]. The study of Barbieri et al.[102] showed promising results with regard to the use of the RNN with code embeddings computed by neural ordinary differential equations; the study achieved a sensitivity of 0.672 (AUC = 0.739). Yu and Xie [103] proposed an ensemble model that combines the weight boosting model with the stacking algorithm; they improved the recall to 0.891 and AUC to 0.879. One study attained a high discrimination of 0.866 with gradient-boosted trees [104], with LR obtaining a comparable performance. The HOSPITAL score model was shown to output a similar performance as in original studies (AUC = 0.66) [105]. Hammer et al.[106] used LR to derive a score-based model that yielded a discrimination of 0.78 among intensive care unit (ICU) patients. The AUC for the model derived with LR in one study was 0.71, but the model performed well with mortality prediction [107]. Saleh et al.[108] assessed how well a 30-day model predicts 7-day readmission and proved that a 7-day model had a similar discrimination of 0.66 to LR. Li and colleagues [109] explored different ML algorithms and reported an AUC of 0.79 at admission with RF and 0.88 at discharge with GBM.
Generally, all the articles shown in Table 3 included structured data in their modeling. A 30-day period was the most commonly used threshold in hospital-wide readmission (90% of studies), except 1 article that focused on 90-day readmission [101]; in another study, the threshold was not specified [106]. Of the 19 studies, 5 worked on ICU readmission with a mean AUC of 0.725. Mišić et al. [104] attempted to predict postoperative readmissions with a high discrimination of 0.866. The remaining studies developed general models with a mean AUC of 0.73. Unlike diagnosis-specific prediction, this study identified that about 42% of the models produced AUCs above 0.75.
6.3 COVID-19
Coronavirus disease 2019 (COVID-19) is a complex clinical illness with potential complications that might impact quality of life and require ongoing care [110, 111]. Although numerous patients have survived from it, concern arises with regard to the outcomes after initial hospitalization. Nearly 1 in 10 patients were readmitted within 2 months after receiving inpatient care for COVID-19 [112]. The rate of readmission or death has been proved to be higher than that of pneumonia or HF within 10 days following COVID-19 discharge [113]. Understanding the risk factors underlying readmission can assist clinicians in making informed decisions on the discharge process. In addition, relevant health authorities are able to arrange proper healthcare planning so that hospitals have sufficient resources for the acute care of patients. This aspect is crucial because the high hospital attendance rate of COVID-19 has reduced the capability of hospitals to treat other serious diseases [114].
To understand the causes of readmission from various aspects, this study described some works that focused on the risk factors associated with readmission among COVID-19 patients. Jeon et al.[115] used an LR model to analyse the factors affecting readmission. The results of the model showed that patients who are male, are 65 years of age or older, own medical benefits, and had a shorter length of stay were associated with a high risk of readmission. Another study performed a statistical analysis and found that the percentage of hypertension and malignancy cases was relatively high among readmitted patients [116]. Lavery et al.[112] similarly identified that older age increases the odds of readmission, as well as the presence of chronic conditions, i.e., COPD, HF, diabetes, chronic kidney disease, and obesity [body mass index ≥ 30 kg/m2]. With LR and statistical testing, Parra et al.[117] found increased risk among immune compromised patients and those who presented fever within 48 h prior to discharge.
Overall, COVID-19 infection is still prevalent, and further outbreaks remain possible. Further research of readmitted patients should be encouraged to refine relevant risk factors that could help discharge patients safely. As a 30-day readmission rate is a common quality indicator for diseases such as HF and COPD, comprehensive studies are necessary to reveal the predictors of COVID-19 and to investigate the usefulness of this readmission rate in representing the quality of patient care among COVID-19 patients. Nevertheless, the studies included in this work suggest the need to have continued health interventions to prevent adverse post-discharge events, such as readmission among older patients and those with underlying medical comorbidities.
7 Discussion
This overview included 55 studies that reported the development of readmission risk prediction models regardless of their readmission threshold, model type, and population cohort. These studies were analyzed to answer the initial problem statement: (1) “What are the current trends in modeling readmission?” (2) “Do complex models perform better than simple ones?” (3) “How should complex event predictions be dealt with?” This overview study presents the current trends in such models in the readmission domain.
The penalties charged to hospitals with high readmission rates in the HRRP (particularly the six conditions or procedure-specific 30-day readmission) have increased the number of papers related to this issue. In this work, 36 of 55 unique models (65%) were found to be specific to certain diseases. Among these models, 35% predicted readmission among patients hospitalized with HF. Out of all the included studies, only 2 studies leveraged unstructured clinical notes to discover salient information that could be missing in structured data. Most studies included regression models either as a baseline or as a main method in modeling readmission as a dichotomous target (74.5%). A total of 4 studies used LR to derive simple score-based models that are easy to use. A total of 3 disease-specific studies modeled outcomes as a survival function with Cox proportional hazard regression, which allowed flexibility in handling censored data. In terms of ML methods, the most frequently used model is tree-based (44% of all studies and 75% of studies using ML techniques). In fact, RF is the most utilized algorithm among tree-based models (79%). Of these ML models, 62.5% used NN-based classifiers, followed by SVM (40.62%). This work observed a substantial growth in the literature that incorporated NNs in prediction relative to the 23.5% adoption rate reported by recent reviews in 2018 [16].
AUC is the de facto metric for measuring the discrimination ability of prediction models. Sensitivity is another important measure so as not to miss any readmitted patients. Of all studies, 48 (87.3%) and 28 (50.9%) reported AUCs and sensitivities of the developed models. As the performance of the models varies depending on readmission threshold, this work compared the results in terms of AUCs for 30-day readmission (which covered ~ 78% of the selected studies, that is, 26 disease-specific studies and 17 hospital-wide studies). However, only 21 disease-specific model reported AUC. As depicted in Fig. 4, risk models derived among hospital-wide populations tend to have a high discrimination with a mean AUC of 0.7412 (median, 0.716) relative to disease-specific models (mean AUC of 0.7368, median: 0.6987). Figure 5 summarizes the relationship between predictive performance and different models. Prediction models were categorized into three classes, i.e., regression (LR and score-based), ML (NB, SVM, tree-based), and NN (MLP, RNN, CNN). Models using ML were found to perform better than those that use regression, whereas complex NN models do not achieve better discrimination in both readmission populations. There exists great variability among ML and NN models in disease-specific readmission while regression exhibits comparable variability with a mean AUC of 0.68. The fact about the adoption of complex models not leading to substantial improvements in performance was also demonstrated by some studies. For example, LR and ML models, such as SVM and RF, showed comparable performance against LSTM [91, 100]. In studies involving hospital-wide predictions, boosting tree was applied and exhibited the best performance in terms of AUC [103, 109]. Tree-based models consistently performed exceptionally well in diagnosis-specific populations by using RF. In addition to their great predictive ability, DT models facilitate interpretable decision analysis, which is particularly beneficial in clinical settings where physicians can identify which features are used to inform decisions. Models such as GBM can even handle a mix of discrete and continuous predictors and allow for missing values of predictors. The prognosis of general readmission appears to initially start with the inclusion of demographic predictors (such as age and gender), clinical biomarkers (comorbidity and illness severity), length of stay, and number of hospital stays before index admission. The inclusion of patient information in EMRs, such as medications, laboratory results, and surgical-related data, has the potential to improve the predictive ability of models [92, 94, 104, 106]. However, adding more variables increases the complexity of models and could pose a challenge in usage and implementation. Moreover, not all data are readily available across different EMRs in different health institutions [14]. Most notably, a number of studies suggested that existing predictors are sufficient to discern the highest-risk patients [93, 96, 97, 99, 105]. Readmissions associated with specific diseases are difficult to compare because they are affected by different risk factors [109]. There is also value in venturing into unstructured notes because most data are stored in such formats. Further research is needed to verify the potential benefits of linking unstructured data to high-risk readmissions.

Studies reporting AUC for 30-day readmission in diagnosis-specific population (21 models), and hospital-wide prediction (17 models). Only 8 out of 38 studies showing discriminatory power of > 0.8

Comparison of AUC performances of regression, ML, and NN models for hospital-wide and diagnosis-specific readmission. There exists greater variability among disease-specific models compared to hospital-wide models. The p-Value is reported with t-test for comparison between regression and ML (0.001), also regression and NN (0.051)
Despite the efforts exerted to model readmission, the usefulness of these models in real clinical practice remains relatively understudied. Only 2 out of all studies discussed the potential applicability of their developed models. Ashfaq et al.[57] presented possible cost savings of up to $2 million from model implementation through financial analysis (given an intervention success rate of 0.5 and $700 intervention cost). They suggested that a highly precise model will have significant cost savings if interventions are proved effective. Another study demonstrated a potential cost saving of $400 K [85]. In future, the clinical utility of readmission risk prediction models will need further attention. This application can be realized by employing models in real use cases and comparing monthly intervention costs versus control groups (readmission costs).
A worth endeavor is to apply regression and tree-based models in any readmission modeling task. First, these models perform well. Second, they offer transparency in feature selection and relative contribution of individual variables. Being labeled as having the greatest potential to boost accuracy, NNs do not necessarily outperform simple approaches, in addition to their black box nature. Moreover, future studies could consider the following aspects that can effectively contribute to clinical outcomes: the final best-performing model should be presented in a simple way to ensure the interpretability of results; clinical data that can be easily collected by health systems should be included; reporting should include not only the discrimination ability of the model but also its usefulness in clinical adoption; models should be able to identify high-risk patients as early as during the index hospital stay instead of upon discharge.
The main strength of the current study was that it involved a comprehensive search that covered the latest articles in the readmission literature. Nevertheless, this overview study has certain limitations. First, non-indexed studies might have been missed in this work. Second, studies marked as meeting or conference abstracts were excluded. These articles would have been selected if full texts were published later. Third, as predictive performance varies greatly according to study population, caution should be used when comparing models across different populations, especially for studies focused on specific diseases. Further descriptions of disease-specific models could provide a comprehensive understanding of the risk factors and characteristics of certain diseases.
8 Conclusion
The studies presented herein included 55 articles that developed prediction models for readmission risk. LR remains the commonly used approach. ML, particularly tree-based models, is a promising technique that can improve predictive ability. In the last two years, NNs, such as MLP, RNN, and CNN, have been increasingly employed. The results showed that the performance of models varies according to different target populations. Overall, ML models tend to outperform statistical models. However, state-of-the-art DL does not guarantee excellent results and exhibits a black box nature that mitigates the possibility of buy-in from investors. Although the availability of the enormous volume of electronic clinical data might further improve predictive ability, the performance of any model is limited by the absence of relevant data. Although some features, such as social factors, have been proved to be associated with a high risk of readmission, these data are not readily available in health institutions. Around 95% of past approaches are accompanied by a structured representation of patient data for the development of risk models. Considerable amounts of patient information are clearly stored in unstructured data fields. Further studies are needed to investigate the value of unstructured prose in the readmission literature. Despite models showing predictive capabilities, most studies lacked methodologies for demonstrating the clinical usefulness of models, such as how models reduce readmission rates and induce cost savings. Thus, even a model with an AUC of 0.90 may not be useful given its noncertified clinical utility.
For the successful application of ML, the process of feature extraction, manipulation, and selection is critically important. A comparative study of feature engineering techniques, such as missing value imputation and variable selection or reduction, could be useful for future research in this field. Another major challenge for ML classifiers is the imbalanced dataset. Future research should extend the current work so as to compare numerous class-balancing techniques dedicated to tackle this problem.
References
Pastorino, R., et al.: Benefits and challenges of Big Data in healthcare: an overview of the European initiatives. Eur. J. Public health 29(Supplement_3), 23–27 (2019)
Reinsel, D.; Gantz, J.; Rydning, J.: Data age 2025: the evolution of data to life-critical. Don’t Focus on Big Data (2017) pp. 2–24
Maali, Y.; Perez-Concha, O.; Coiera, E.; Roffe, D.; Day, R.O.; Gallego, B.: Predicting 7-day, 30-day and 60-day all-cause unplanned readmission: a case study of a Sydney hospital. BMC Med. Inf. Decis. Mak. 18(1), 1 (2018)
Lahewala, S., et al.: Heart failure: same-hospital vs. different-hospital readmission outcomes. Int. J. Cardiol. 278, 186–191 (2019)
Hoffman, G.J.; Yakusheva, O.: Association between financial incentives in medicare’s hospital readmissions reduction program and hospital readmission performance. JAMA Netw. Open 3(4), e202044–e202044 (2020)
Pedersen, M.K.; Meyer, G.; Uhrenfeldt, L.: Risk factors for acute care hospital readmission in older persons in Western countries: a systematic review. JBI Evid. Synth. 15(2), 454 (2017)
Glans, M.; Kragh Ekstam, A.; Jakobsson, U.; Bondesson, Å.; Midlöv, P.: "Risk factors for hospital readmission in older adults within 30 days of discharge: a comparative retrospective study. BMC Geriatr. 20(1), 467 (2020)
Goel, A.N.; Raghavan, G.; St John, M.A.; Long, J.L.: Risk factors, causes, and costs of hospital readmission after head and neck cancer surgery reconstruction. JAMA Facial Plast. Surg. 21(2), 137–145 (2019)
Shalchi, Z.; Saso, S.; Li, H.K.; Rowlandson, E.; Tennant, R.C.: Factors influencing hospital readmission rates after acute medical treatment. Clin. Med. 9(5), 426–430 (2009)
Felix, H.C.; Seaberg, B.; Bursac, Z.; Thostenson, J.; Stewart, M.K.: Why do patients keep coming back? Results of a readmitted patient survey. Soc. Work Health Care 54(1), 1–15 (2015)
Forster, A.J., et al.: Adverse events among medical patients after discharge from hospital. CMAJ 170(3), 345–349 (2004)
Hesselink, G., et al.: Improving patient handovers from hospital to primary care: a systematic review. Ann. Intern. Med. 157(6), 417–428 (2012)
Schneeweiss, S.; Seeger, J.D.; Maclure, M.; Wang, P.S.; Avorn, J.; Glynn, R.J.: Performance of comorbidity scores to control for confounding in epidemiologic studies using claims data. Am. J. Epidemiol. 154(9), 854–864 (2001)
Mahmoudi, E.; Kamdar, N.; Kim, N.; Gonzales, G.; Singh, K.; Waljee, A.K.: Use of electronic medical records in development and validation of risk prediction models of hospital readmission: systematic review. BMJ 369, m958 (2020)
Markazi-Moghaddam, N.; Fathi, M.; Ramezankhani, A.: Risk prediction models for intensive care unit readmission: a systematic review of methodology and applicability. Aust. Crit. Care 33(4), 367–374 (2020)
Artetxe, A.; Beristain, A.; Graña, M.: Predictive models for hospital readmission risk: a systematic review of methods. Comput. Methods Program. Biomed. 164, 49–64 (2018)
Manca, D.P.: Do electronic medical records improve quality of care? Yes. Can. Family Phys. Med. de Famille Can. 61(10), 846–851 (2015)
Kansagara, D., et al.: Risk prediction models for hospital readmission: a systematic review. JAMA 306(15), 1688–1698 (2011)
Weinreich, M., et al.: Predicting the risk of readmission in pneumonia: a systematic review of model performance. Ann. Am. Thoracic Soc. 13(9), 1607–1614 (2016)
Smith, L.N., et al.: Acute myocardial infarction readmission risk prediction models: a systematic review of model performance. Circ. Cardiovasc. Qual. Outcomes 11(1), e003885–e003885 (2018)
Mahajan, S.M.; Heidenreich, P.; Abbott, B.; Newton, A.; Ward, D.: Predictive models for identifying risk of readmission after index hospitalization for heart failure: a systematic review. Eur. J. Cardiovas. Nursing 17(8), 675–689 (2018)
van Walraven, C., et al.: Derivation and validation of an index to predict early death or unplanned readmission after discharge from hospital to the community. CMAJ Can. Med. Assoc J. 182(6), 551–557 (2010)
Hoerl, A.E.; Kennard, R.W.: Ridge regression: biased estimation for nonorthogonal problems. Technometrics 12(1), 55–67 (1970)
Tibshirani, R.: Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 58(1), 267–288 (1996)
Zou, H.; Hastie, T.: Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. 67(2), 301–320 (2005)
Spooner, A., et al.: A comparison of machine learning methods for survival analysis of high-dimensional clinical data for dementia prediction. Sci. Rep. 10(1), 20410 (2020)
Anis, S., et al.: An overview of deep learning approaches in chest radiograph. IEEE Access 8, 182347–182354 (2020)
Krizhevsky, A.; Sutskever, I.; Hinton, G.E.: ImageNet classification with deep convolutional neural networks. Commun. ACM 60(6), 84–90 (2017)
Yala, A., et al.: Using machine learning to parse breast pathology reports. Breast Cancer Res. Treatment 161(2), 203–211 (2017)
Benjamens, S.; Dhunnoo, P.; Meskó, B.: The state of artificial intelligence-based FDA-approved medical devices and algorithms: an online database. Digital Med. 3(1), 118 (2020)
Weng, W.-H.: Machine learning for clinical predictive analytics. In: Celi, L.A.; Majumder, M.S.; Ordóñez, P.; Osorio, J.S.; Paik, K.E.; Somai, M. (Eds.) Leveraging data science for global health, pp. 199–217. Springer, Cham (2020)
Cortes, C.; Vapnik, V.: Support-vector networks. Machine Learn. 20(3), 273–297 (1995)
Warner, H.R.; Toronto, A.F.; Veasey, L.G.; Stephenson, R.: A mathematical approach to medical diagnosis: application to congenital heart disease. JAMA 177(3), 177–183 (1961)
Hand, D.J.; Yu, K.: Idiot’s bayes: not so stupid after all? Int. Stat. Rev. Revue Internationale de Statistique 69(3), 385–398 (2001)
Al-Aidaroos, K.M.; Bakar, A.A.; Othman, Z.: "Naïve bayes variants in classification learning. Int. Conf. Inf. Retrieval Knowledge Manag 2010, 276–281 (2010)
Zelič, I.; Kononenko, I.; Lavrač, N.; Vuga, V.: Induction of decision trees and bayesian classification applied to diagnosis of sport injuries. J. Med. Syst. 21(6), 429–444 (1997)
Quinlan, J.R.: Induction of decision trees. Machine Learn. 1(1), 81–106 (1986)
Sutton, C.D.: 11: Classification and regression trees, bagging, and boosting. In: Rao, C.R.; Wegman, E.J.; Solka, J.L. (Eds.) Handbook of statistics, pp. 303–329. Elsevier (2005)
Vezhnevets, A.; Barinova, O.: Avoiding boosting overfitting by removing confusing samples. In Machine learning: ECML 2007, Berlin, Heidelberg, (2007) pp. 430–441
Li, Q.; Cai, W.; Wang, X.; Zhou, Y.; Feng, D. D.; Chen, M.: Medical image classification with convolutional neural network. In 2014 13th international conference on control automation robotics & vision (ICARCV) (2014) pp. 844–848
Chen, D., et al.: Deep learning and alternative learning strategies for retrospective real-world clinical data. npj Digital Med. 2(1), 43 (2019)
Wilson, A.; Roelofs, R.; Stern, M.; Srebro, N.; Recht, B. J. A.: The marginal value of adaptive gradient methods in machine learning. (2017)
Elman, J.L.: Finding structure in time. Cognitive Sci. 14(2), 179–211 (1990)
Hochreiter, S.; Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Cho, K. et al.: Learning phrase representations using RNN encoder-decoder for statistical machine translation. (2014) arXiv e-prints. http://arxiv.org/abs/1406.1078
Esteban, C.; Staeck, O.; Yang, Y.; Tresp V.: Predicting clinical events by combining static and dynamic information using recurrent neural networks. (2016) arXiv e-prints. http://arxiv.org/abs/1602.02685.
Du, C.; Huang, L.: Text classification research with attention-based recurrent neural networks. Int. J. Comput. Commun. Control (2018). https://doi.org/10.15837/ijccc.2018.1.3142
Ma, F.; Gao, J.; Suo, Q.; You, Q.; Zhou, J.; Zhang, A.: Risk prediction on electronic health records with prior medical knowledge. Kdd ’18, (2018), pp. 1910–1919
Razavian, N.; Marcus, J.; Sontag, D.: Multi-task prediction of disease onsets from longitudinal lab tests. arXiv e-prints, (2016) http://arxiv.org/abs/1608.00647
Che, Z.; Cheng, Y.; Sun, Z.; Liu, Y.: Exploiting convolutional neural network for risk prediction with medical feature embedding. (2017) arXiv e-prints. http://arxiv.org/abs/1701.07474
Kim, Y.: Convolutional neural networks for sentence classification. In: Proceedings of the 2014 conference on empirical methods in natural language processing, (2014)
Xiao, C.; Choi, E.; Sun, J.: Opportunities and challenges in developing deep learning models using electronic health records data: a systematic review. J. Am. Med. Inf. Assoc. JAMIA 25(10), 1419–1428 (2018)
Wang, F.; Casalino, L.P.; Khullar, D.: Deep learning in medicine: promise, progress, and challenges. JAMA Intern. Med. 179(3), 293–294 (2019)
Beeksma, M.; Verberne, S.; van den Bosch, A.; Das, E.; Hendrickx, I.; Groenewoud, S.: Predicting life expectancy with a long short-term memory recurrent neural network using electronic medical records. BMC Med. Inf. Decis. Mak. 19(1), 36 (2019)
Aida, K., et al.: Usefulness of the simplified frailty scale in predicting risk of readmission or mortality in elderly patients hospitalized with cardiovascular disease. Int. Heart J. 61(3), 571–578 (2020)
Allam, A.; Nagy, M.; Thoma, G.; Krauthammer, M.: Neural networks versus Logistic regression for 30 days all-cause readmission prediction. Sci. Rep. 9(1), 9277 (2019)
Ashfaq, A.; Sant’Anna, A.; Lingman, M.; Nowaczyk, S.: Readmission prediction using deep learning on electronic health records. J. Biomed. Inf. 97, 103256 (2019)
Awan, S.E.; Bennamoun, M.; Sohel, F.; Sanfilippo, F.M.; Chow, B.J.; Dwivedi, G.: Feature selection and transformation by machine learning reduce variable numbers and improve prediction for heart failure readmission or death. PLoS One 14(6), e0218760 (2019)
Awan, S.E.; Bennamoun, M.; Sohel, F.; Sanfilippo, F.M.; Dwivedi, G.: Machine learning-based prediction of heart failure readmission or death: implications of choosing the right model and the right metrics. ESC Heart Fail 6(2), 428–435 (2019)
Brown, J.R.; Alonso, A.; Mazimba, S.; Warman, E.N.; Bilchick, K.C.: Improved 30 day heart failure rehospitalization prediction through the addition of device-measured parameters. ESC Heart Fail 7(6), 3762–3771 (2020)
Dodson, J.A., et al.: Thirty-day readmission risk model for older adults hospitalized with acute myocardial infarction. Circ. Cardiovasc. Qual Outcomes 12(5), e005320 (2019)
Gupta, S., et al.: Evaluation of machine learning algorithms for predicting readmission after acute myocardial infarction using routinely collected clinical data. Can. J. Cardiol. 36(6), 878–885 (2020)
Hu, Z.; Du, D.: A new analytical framework for missing data imputation and classification with uncertainty: Missing data imputation and heart failure readmission prediction. PLOS ONE 15(9), e0237724 (2020)
Hung, L.-C.; Sung, S.-F.; Hu, Y.-H.: A machine learning approach to predicting readmission or mortality in patients hospitalized for stroke or transient ischemic attack. Appl. Sci. 10(18), 6337 (2020)
Kono, Y., et al.: Predictive impact of early mobilization on rehospitalization for elderly Japanese heart failure patients. Heart Vessels 35(4), 531–536 (2020)
Lim, N.-K., et al.: Risk prediction for 30-day heart failure-specific readmission or death after discharge: data from the Korean acute heart failure (KorAHF) registry. J. Cardiol. 73(2), 108–113 (2019)
Liu, X.; Chen, Y.; Bae, J.; Li, H.; Johnston, J.; Sanger, T.: Predicting heart failure readmission from clinical notes using deep learning. (2019) arXiv e-prints, p. http://arxiv.org/abs/1912.10306
Mahajan, S.M.; Ghani, R.: Using ensemble machine learning methods for predicting risk of readmission for heart failure. Stud. Health Technol. Inf. 264, 243–247 (2019)
Mahajan, S.M.; Ghani, R.: Combining structured and unstructured data for predicting risk of readmission for heart failure patients. Stud. Health Technol. Inf. 264, 238–242 (2019)
Sohrabi, B.; Vanani, I.R.; Gooyavar, A.; Naderi, N.: Predicting the readmission of heart failure patients through data analytics. J. Inf. Knowledge Manag. 18(01), 1950012 (2019)
Tan, B.-Y.; Gu, J.-Y.; Wei, H.-Y.; Chen, L.; Yan, S.-L.; Deng, N.: Electronic medical record-based model to predict the risk of 90-day readmission for patients with heart failure. BMC Med. Inf. Decis. Mak. 19(1), 193 (2019)
Yao, S.-M., et al.: Predicting non-elective hospital readmission or death using a composite assessment of cognitive and physical frailty in elderly inpatients with cardiovascular disease. BMC Geriatr. 20(1), 218 (2020)
Ramírez, J.C.; Herrera, D.: Prediction of diabetic patient readmission using machine learning. IEEE Colombian Conf. Appl. Comput. Intell 2019, 1–4 (2019)
Sharma, A.; Agrawal, P.; Madaan, V.; Goyal, S.:Prediction on diabetes patient’s hospital readmission rates. Presented at the proceedings of the third international conference on advanced informatics for computing research, Shimla, India. (2019) Available: https://doi.org/10.1145/3339311.3339349
Cheng, W.; Zhu, W.: Predicting 30-day hospital readmission for diabetics based on spark. In 2019 3rd International Conference on Imaging, Signal Processing and Communication (ICISPC), pp. 125–129 (2019)
Pham, H.N., et al.: Predicting hospital readmission patterns of diabetic patients using ensemble model and cluster analysis. Int. Conf. Syst. Sci. Eng. 2019, 273–278 (2019)
Goudjerkan, T.; Jayabalan, M.: Predicting 30-day hospital readmission for diabetes patients using multilayer perceptron. Int. J. Adv. Comput. Sci. Appl. (2019). https://doi.org/10.14569/IJACSA.2019.0100236
Alajmani, S.; Elazhary, H.: Hospital readmission prediction using machine learning techniques. Int. J. Adv. Comput. Sci. Appl. (2019). https://doi.org/10.14569/IJACSA.2019.0100425
Alajmani, S.; Jambi, K.: Assessing advanced machine learning techniques for predicting hospital readmission. Int. J. Adv. Comput. Sci. Appl. (2020). https://doi.org/10.14569/IJACSA.2020.0110249
Salem, H., et al.: Borderline personality features in inpatients with bipolar disorder: impact on course and machine learning model use to predict rapid readmission. J. Psychiatr Pract. 25(4), 279–289 (2019)
Cearns, M., et al.: Predicting rehospitalization within 2 years of initial patient admission for a major depressive episode: a multimodal machine learning approach. Transl. Psychiatry 9(1), 285 (2019)
Hariman, K.; Cheng, K.M.; Lam, J.; Leung, S.K.; Lui, S.S.Y.: Clinical risk model to predict 28-day unplanned readmission via the accident and emergency department after discharge from acute psychiatric units for patients with psychotic spectrum disorders. BJPsych open 6(1), e13–e13 (2020)
Morel, D.; Yu, K.C.; Liu-Ferrara, A.; Caceres-Suriel, A.J.; Kurtz, S.G.; Tabak, Y.P.: Predicting hospital readmission in patients with mental or substance use disorders: a machine learning approach. Int. J. Med. Inf. 139, 104136 (2020)
Goltz, D.E.; Ryan, S.P.; Howell, C.B.; Attarian, D.; Bolognesi, M.P.; Seyler, T.M.: A weighted index of elixhauser comorbidities for predicting 90-day readmission after total joint arthroplasty. J. Arthroplasty 34(5), 857–864 (2019)
Lee, H.K., et al.: An analytical framework for TJR readmission prediction and cost-effective intervention. IEEE J. Biomed. Health Inf. 23(4), 1760–1772 (2019)
Min, X.; Yu, B.; Wang, F.: Predictive modeling of the hospital readmission risk from patients’ claims data using machine learning: a case study on COPD. Sci. Rep. 9(1), 2362 (2019)
Chen, Z.; Lai, C.; Ren, J.: Hospital readmission prediction based on long-term and short-term information fusion. Appl. Soft Comput. 96, 106690 (2020)
Deo, S.V., et al.: Risk calculator to predict 30-day readmission after coronary artery bypass: a strategic decision support tool. Heart Lung Circ. 28(12), 1896–1903 (2019)
Lv, T., et al.: Application value of rapid predictive model for readmission risk in patients after CABG. Heart Surg. Forum 23(5), E668-e672 (2020)
Mounayar, A.-L., et al.: Development of a risk prediction model of potentially avoidable readmission for patients hospitalised with community-acquired pneumonia: study protocol and population. BMJ Open 10(11), e040573 (2020)
Zebin, T.; Chaussalet, T.J.: Design and implementation of a deep recurrent model for prediction of readmission in urgent care using electronic health records. IEEE Conf. Comput. Intell. Bioinf. Comput. Biol. 2019, 1–5 (2019)
Eckert, C., et al.: Development and prospective validation of a machine learning-based risk of readmission model in a large military hospital. Appl. Clin. Inf. 10(2), 316–325 (2019)
Pauly, V.; Mendizabal, H.; Gentile, S.; Auquier, P.; Boyer, L.: Predictive risk score for unplanned 30-day rehospitalizations in the French universal health care system based on a medico-administrative database. PLOS ONE 14(3), e0210714 (2019)
Kabue, S., et al.: The impact of pharmacy-specific predictors on the performance of 30-day readmission risk prediction models. Med. Care 57(4), 295–299 (2019)
Xue, Y.; Klabjan, D.; Luo, Y.: Predicting ICU readmission using grouped physiological and medication trends. Artif. Intell. Med. 95, 27–37 (2019)
Chandra, A., et al.: Risk of 30-day hospital readmission among patients discharged to skilled nursing facilities: development and validation of a risk-prediction model. J. Am. Med. Dir Assoc. 20(4), 444-450.e2 (2019)
Deschepper, M.; Eeckloo, K.; Vogelaers, D.; Waegeman, W.: A hospital wide predictive model for unplanned readmission using hierarchical ICD data. Comput. Methods Progr. Biomed. 173, 177–183 (2019)
Brüngger, B.; Blozik, E.: Hospital readmission risk prediction based on claims data available at admission: a pilot study in Switzerland. BMJ Open 9(6), e028409 (2019)
Flaks-Manov, N.; Topaz, M.; Hoshen, M.; Balicer, R.D.; Shadmi, E.: Identifying patients at highest-risk: the best timing to apply a readmission predictive model. BMC Med. Inf. Decis. Mak. 19(1), 118 (2019)
Lin, Y.-W.; Zhou, Y.; Faghri, F.; Shaw, M.J.; Campbell, R.H.: Analysis and prediction of unplanned intensive care unit readmission using recurrent neural networks with long short-term memory. PLOS ONE 14(7), e0218942 (2019)
Lone, N.I., et al.: Predicting risk of unplanned hospital readmission in survivors of critical illness: a population-level cohort study. Thorax 74(11), 1046–1054 (2019)
Barbieri, S., et al.: Benchmarking deep learning architectures for predicting readmission to the ICU and describing patients-at-risk. Sci. Rep. 10(1), 1111 (2020)
Yu, K.; Xie, X.: Predicting hospital readmission: a joint ensemble-learning model. IEEE J. Biomed. Health Inf. 24(2), 447–456 (2020)
Mišić, V.V.; Gabel, E.; Hofer, I.; Rajaram, K.; Mahajan, A.: Machine learning prediction of postoperative emergency department hospital readmission. Anesthesiology 132(5), 968–980 (2020)
Zhang, Y., et al.: Assessing the impact of social determinants of health on predictive models for potentially avoidable 30-day readmission or death. PLoS One 15(6), e0235064 (2020)
Hammer, M., et al.: A tool to predict readmission to the intensive care unit in surgical critical care patients-the RISC score. J. Intens. Care Med. (2020). https://doi.org/10.1177/0885066620949164
Shah, N., et al.: Clinical analytics prediction engine (CAPE): development, electronic health record integration and prospective validation of hospital mortality, 180-day mortality and 30-day readmission risk prediction models. PLOS ONE 15(8), e0238065 (2020)
Saleh, S.N.; Makam, A.N.; Halm, E.A.; Nguyen, O.K.: Can we predict early 7-day readmissions using a standard 30-day hospital readmission risk prediction model? BMC Med. Inf. Decis. Mak. 20(1), 227 (2020)
Li, Q.; Yao, X.; Échevin, D.: How good is machine learning in predicting all-cause 30-day hospital readmission? Evidence from administrative data. Value Health 23(10), 1307–1315 (2020)
Whittaker, A.; Anson, M.; Harky, A.: Neurological Manifestations of COVID-19: A systematic review and current update. Acta Neurol. Scand. 142(1), 14–22 (2020)
Liu, P.P.; Blet, A.; Smyth, D.; Li, H.: The science underlying COVID-19: implications for the cardiovascular system. Circulation 142(1), 68–78 (2020)
Lavery, A.M., et al.: Characteristics of hospitalized COVID-19 patients discharged and experiencing same-hospital readmission: United States, march-august 2020. MMWR Morb. Mortal. Wkly. Rep. 69(45), 1695–1699 (2020)
Donnelly, J.P.; Wang, X.Q.; Iwashyna, T.J.; Prescott, H.C.: Readmission and death after initial hospital discharge among patients With COVID-19 in a large multihospital system. JAMA 325(3), 304–306 (2021)
Al-Shamsi, H.O., et al.: A practical approach to the management of cancer patients during the novel coronavirus disease 2019 (COVID-19) pandemic: an international collaborative group. Oncologist 25(6), e936–e945 (2020)
Jeon, W.-H.; Seon, J.Y.; Park, S.-Y.; Oh, I.-H.: Analysis of risk factors on readmission cases of COVID-19 in the Republic of Korea: using nationwide health claims data. Int. J. Environ. Res. Public Health 17(16), 5844 (2020)
UyaroĞLu, O.A., et al.: Thirty-day readmission rate of COVID-19 patients discharged from a tertiary care university hospital in Turkey: an observational, single-center study. Int. J. Qual. Health Care (2020). https://doi.org/10.1093/intqhc/mzaa144
Parra, L.M., et al.: Hospital readmissions of discharged patients with COVID-19. Int. J. Gen. Med. 13, 1359–1366 (2020)
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
There is no conflict of interest reported by any authors.
Additional information
This work was supported by the 2020 EBC-C (Extra-Budgetary Contributions from China) Project on Promoting the Use of ICT for Achievement of Sustainable Development Goals, and University Malaya under grant IF015-2021.
Rights and permissions
About this article

Cite this article
Teo, K., Yong, C.W., Chuah, J.H. et al. Current Trends in Readmission Prediction: An Overview of Approaches. Arab J Sci Eng 48, 11117–11134 (2023). https://doi.org/10.1007/s13369-021-06040-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13369-021-06040-5