
Abstract
Numerous studies have investigated the long-term monitoring of natural frequencies, primarily focusing on medium–large highway bridges, using expensive monitoring systems with a large array of sensors. However, this paper addresses the less explored issue of monitoring a footbridge, examining four critical aspects: (i) sensing system, (ii) frequency extraction method, (iii) data modelling techniques, and (iv) damage detection. The paper proposes a low-cost all-in-one sensor/logger unit instead of a conventional sensing system to address the first issue. For the second issue, many studies use natural frequency data extracted from measured acceleration for data modelling, the paper highlights the impact of the input parameters used in the automated frequency extraction process, which affects the number and quality of frequency data points extracted and subsequently influences the data models that can be created. After that, the paper proposes a modified PCA model optimised for computational efficiency, designed explicitly for sparse data from a low-cost monitoring system, and suitable for future on-board computation. It also explores the capabilities and limitations of a data model developed using a limited data set. The paper demonstrates these aspects using data collected from a 108 m cable-stayed footbridge over several months. Finally, the detection of damage is achieved by employing the one-class SVM machine learning technique, which utilises the outcomes obtained from data modelling. In summary, this paper addresses the challenges associated with the long-term monitoring of a footbridge, including selecting a suitable sensing system, automated frequency extraction, data modelling techniques, and damage detection. The proposed solutions offer a cost-effective and efficient approach to monitoring footbridges while considering the challenges of sparse data sets.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The idea of tracking the natural frequency of a bridge as an indication of its health/condition has been around. This study looks at the specific case of a footbridge monitored with low-cost instrumentation. Furthermore, it demonstrates the quality/usefulness of the information that could be obtained from a data model developed using this information. Structural health monitoring (SHM) provides information used by bridge managers to make decisions about the operation and maintenance of bridges. Paper [1] identifies four stages of complexity in SHM information: existence, location, severity, and prognostics. All four stages involve detecting damage, which is generally the minimum goal of most SHM studies. To this end, the designer of the SHM systems needs to monitor a bridge feature that is a damage indicator. One such indicator is the natural frequency due to its link with the structure’s stiffness. Numerous studies have used natural frequency to detect damage, such as Hu et al. [2] and Laory et al. [3]. A review of many studies has been carried out by Brownjohn et al. [4], as well as the lessons that can be taken from reviewing these studies. Of the studies that use natural frequency as a damage indicator, only a small number are undertaken on footbridges. Some of these include Hu et al. [2], in which a stress-ribbon footbridge was monitored continuously for 4 years and Hu et al. [5], in which the natural frequency of a footbridge was monitored for 3 years. One of the largest problems with using natural frequency as a damage indicator is that it is also affected by the environmental and operational fluctuations that are experienced by the bridge on a daily cycle. This problem is highlighted in [6,7,8,9,10,11,12,13,14,15,16,17] where the variations caused by the environmental effects are studied. These papers also show that this variation can mask the presence of any variation caused by damage. To overcome this problem, other methods, such as data models and regressions, are needed in conjunction with tracking natural frequency to detect damage.
Natural frequency cannot be directly measured from a system. Numerous studies have used FFT to extract natural frequencies and damage detection. A selection can be found in the review paper [18]. Frequency domain decomposition (FFD) is another method that is user-friendly, because it works directly with spectral data, and it is easier to determine the physical information from the structure. FFD was developed by Brincker et al. [19] and used singular value decomposition (SVD) to decompose the power spectrum into all the mode shapes within a given signal. However, one of the disadvantages of FFD is that the peak identification needed for the method becomes difficult when there is a high level of noise in the signal or the mode shapes get more complex, leading to mode mixing [20]. Applications and a further review of FDD can be found in Rainieri et al. [21] and Magalhaes et al. [22]. Stochastic subspace identification (SSI) is one of the most commonly extracted frequencies in recent years. SSI technique has two common types: data-driven SSI (SSI-DATA) and covariance-driven SSI (SSI-COV). The SSI-DATA is directly to cope with the raw data through orthogonal vector projection, which projects past output data to future output data. By contrast, the SSI-COV approach is to convert the raw data to the covariance matrix (Toeplitz matrix) and extracts the correlated system dynamic characteristic [23]. SSI’s popularity is due to the use of robust numerical techniques, such as QR-factorisation, SVD, and least squares. These techniques help to deal with any noise in the data as well as have a significant effect on data reduction [24]. Some recent studies that included the use of SSI for frequency include Wang et al. [25] and Neu et al. [26].
Data modelling is one of the techniques used to overcome the problem of the variation in the natural frequency caused by environmental and operational effects. Data models are generally comprised of several different methods. They are used to simulate the behaviour of the structures based on collected data and possibly data from simulated FE models. Regression methods are commonplace in data models and are used to estimate the relationship between two variables. In the case of civil SHM and specific natural frequency monitoring, regressions are used to estimate frequency based on the changing environment and operational conditions. The simplest form of regression is linear regression, in which the relationship between the variable can be as simple as a straight line. Linear regression has been used in such studies as Peeters et al. [7] and Magalhaes et al. [27]. Regression can also take the form of more complicated techniques. For example, Gaussian process regression (GPR) integrates a Bayesian approach to determine the probability distributions of values of the estimation equation (kernel function) [28,29,30,31,32]. The GPR is different from the formula-based linear regression method. As GPR is a more complex model, it has been used in many studies to model the dynamic behaviour of structures. Shi et al. [33] proposed a method to combine GPR with cointegration to deal with the environmental and operational variation of the natural frequency in real-world data. The more specific detail of the GPR applied in the civil structure data modelling will be summarised and presented in Sect. 5.3.1.
An important aspect to consider is the effect of outliers in data. In the context of data modelling, the presence of outliers when training the data model can cause the presence of damage to be missed when the data model is later used to detect any abnormal behaviour. Outlier detection methods are generally used to detect anomalies in the data model results. An example of this is studied in Farreras-Alcover et al. [34], allowing damage detection. The outlier detection methods are generally used in conjunction with other data modelling techniques to create a data model that is more sensitive to damage. One of the most common methods used is the minimum covariance determinant (MCD). The use of MCD in civil SHM has been reviewed in Dervilis et al. [35] and a procedure for improving the method by combining it with minimum volume enclosing ellipsoid (MVEE). Worden et al. [36] present a study that discusses some underlying principles behind outlier detection and damage detection and application to real-world case studies. The moving median outlier method is one of the outlier removal techniques that will select for application to clean the real collected data of the structural response. Further detail will be presented in Sect. 5.2.2.
Principle component analysis (PCA) has been used to re-express local/global Cartesian coordinate multivariate independent SHM data sets to new set variables (principle components). The principle components (PCs) are obtained using original coordinates axes variables to project on the orthogonal coordinate new axes through linear combinations technique. In SHM features, the order of PCs accounts for the amount of variance in the data on each axis. High variance is trapped in higher principle components that are induced by environmental and operational conditions [37,38,39,40]. The PCA is to reduce the collected dataset’s dimensionality to ease the analysis of high dimensionality. Similarly, the new PCs could use in regression to predict the feature data (i.e., frequency in our case) [41, 42]. Further information on the multivariate PCA application will present in Sect. 5.3.2. This paper presents an enhanced version of the PCA model that has been tailored to prioritise computational efficiency. This modified model is specifically designed to handle sparse data obtained from a low-cost monitoring system.
One-class support vector machines (SVMs) [43, 44] were proposed for information retrieval in conjunction with the neural network method to provide robust classification. Papers [45,46,47] introduce a novel test technique utilising one-class SVMs for machine fault detection and classification based on vibration measurements. Sheikh et al. [48] presented a fall detection system, that uses a low-cost, lightweight inertial sensing method, a hybrid multi-sensor fusion strategy, and an unsupervised one-class SVM for detecting falls, which demonstrated a fall-detection accuracy, overcomes the need for large datasets required by supervised learning methods. A single-classification support vector machine (SVM)-based model [28] was proposed for personnel safety status detection and early warning in tunnel construction, achieving over 90% accuracy rate and providing a more efficient detection method.
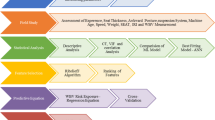
A proposed framework outlining the process of data modelling and damage detection for a footbridge structure is shown in Fig. 1. Each of these key processes will be comprehensively addressed in separate sections of this paper. Section 2 describes a footbridge used in this study. As described in the abstract, this paper looks at four important issues, namely; (i) sensing system, (ii) frequency extraction method, (iii) data modelling techniques, and (iv) damage detection. Section 3 presents the customised low-cost monitoring system developed for data collection and a sample of the acceleration signals obtained. Section 4 addresses the important issue of frequency extraction. Several papers extract the frequencies but give little thought/time to illustrate how it is done, so this paper uses SSI-COV, discusses parameter settings used in applying SSI-COV, and demonstrates the different effects of parameters on the frequency data returned. Section 5.3 proposes outlier removal enhance PCA (OREPCA) concept on the long-term bridge monitoring of ’regular’ bridges with relatively limited data sets. It is noted that the proposed OREPCA data modelling method, including data correction and data cleaning, is to construct a data model for indicating the accuracy level with limited data, which is not suggesting OREPCA is the best method to deal with the limited data, and it is beyond the scope of this paper. Finally, the one-class support vector machine (SVM) is utilised to classify the regression features, enabling the identification of damage within both the training and testing datasets.

Block diagram of the proposed framework for data modelling and damage detection in footbridge structures
2 Bridge to be monitored
2.1 Baker bridge
Baker bridge in Exeter, UK, carries pedestrians/cyclists over the A397 carriageway, as shown in Fig. 2a. The footbridge was designed to provide the primary pedestrian access to a rugby stadium. Baker bridge is a cable-stayed bridge with a 42 m high steel. A-frame tower was built with 14 tendons for supporting the deck. The asymmetric design results in left and right deck spans (see Fig. 2a) of 38 m and 72 m, respectively. The bridge’s total length is 110 m, and the width is 3 m, as shown in Fig. 2b.

Baker bridge
Paper [49] was given the modal properties result of ambient vibration testing (AVT), including natural frequencies, modal damping, and mode shapes, as shown in Fig. 3. The red dot on the figure gives an idea of the accelerometer’s location. This relevance will be discussed further in Sect. 3.1.

Mode shapes and modal properties of the Baker bridge (after [49])
3 Monitoring system and data collection
3.1 Low-cost monitoring system
The equipment needed for this test essentially consists of an accelerometer (with an external battery) and a digital thermometer/data logger (to record air temperature). The accelerometer used in this test is a microelectromechanical (MEMS) accelerometer X2-2 logger [50], as shown in Fig. 4a. The X2–5 is a sensor that provides high resolution (20-bit), selectable sample rate up to 2000 Hz, and digital filtering options, with a range of 2 g/8 g. The accelerometer has a small internal battery; however, this would only give about 10 h of recording time, which is insufficient for long-term monitoring. Therefore, extra battery capacity has been added in the form of two rechargeable lithiumion batteries which should give a recording time of approximately 20 days. Data are downloaded to a PC from the accelerometer through the USB connection on the accelerometer.
In this monitoring campaign, the ambient air temperature will be recorded using a digital thermometer (/data logger) which will be placed under the deck on the south (right-hand side of the bridge) abutment and secured to prevent animals disturbing it. Figure 4b shows a photo of the digital thermometer. Data from the temperature data logger are downloaded to a PC through the USB connection on the data logger.

Sensors in use for long-term monitoring
The accelerometer described in Figs. 4a will be housed in a plastic enclosure, as shown in Fig. 4c, which is high-sensitivity, low-noise 3-axis accelerometer with 2 g and 8 g range modes. The enclosure was sealed up and mounted on the footbridge. The placement of the enclosure is shown in Fig. 5. Figure 5a shows the west elevation of the bridge, and the location of the sensor enclosure is indicated. It is proposed to mount the sensor enclosure on the underside of the lowest parapet rail approximately above where cable 5 (count from the left to the right) is connected to the deck. The enclosure was not over the roadway based on the consideration of health and safety (H & S) and the minimising disturbance to occupants. Figure 5c shows the enclosure mounted on the underside of the parapet rail using a threaded metal strap (’jubilee clip’). The enclosure was mounted adjacent to the parapet post to ensure that the accelerometer did not pick up any vibrations from the parapet rail.

Sensors setup and correlated location on the bridge
3.2 Sample data from pedestrian loading events
3.2.1 Regular day: response to sparse pedestrian loading
Figure 6 shows a normal daily use of the footbridge by occupants where typically the bridge only has one or two people on it at a time.

Normal daily use of bridge by occupants
In Fig. 7a, monitoring one of the regular day data (2015-12-01 02: 00:00 to 00:00) and the period from 03:00 to 07:00 is quiet with most of the energy in the remaining 3/4 of the day. The time history plot, as shown in Fig. 7b, includes a zoom-in view to show a 5-s decay following a pedestrian loading event.
In Fig. 7c, Fourier transform in power spectrum analysis [51], with 30 min window shows the frequency content, and these correspond with the modes shown in Sect. 3.1 as indicated the position of the sensor enclosure had to be positioned above the central median zone for health and safety reasons. Therefore, no sensor location would allow us to capture all modes with one sensor, so we managed to find a location that gave us 5 of the modes, but unfortunately, this point was practically the node of mode 4 (2.28 Hz). Therefore, the contribution of mode 4 is not evident in the plot in Fig. 7c that is correlated power spectral density (PSD) plot in the frequency domain.

Normal regular day data of the Baker bridge (2015-12-01 02 from 0:00a.m to 0:00a.m)
Figure 8 using the same data set of Fig. 7a shows a spectrogram of the 24 h. The spectrogram is a tool to give a visual representation of frequencies of a signal varying with time, demonstrating that each mode frequency’s variance has stabilised state and similar magnitude over time.

Frequency–time-varying spectrogram on one of the regular day data
3.2.2 Match day: response to congested pedestrian loading
Figure 9 shows one of the match day photos. The footbridge was under full human loading conditions.

Full loading on the bridge on match day
Figure 10a shows the acceleration time history has a big magnitude and variation around mid-day to that night period, which was caused by the human loading engagement [52]. PSD plot is shown in Fig. 10b. The original second mode from Fig. 7c obviously separated into two new modes (1.475 Hz and 1.6 Hz) caused by humanity dynamics to the structure as similar as low damping mass–spring–damper added, especially, there was full loading on the bridge, as shown in Fig. 9a.

Match day data of Baker bridge (28th November 2015)
The frequency–time-varying plot is shown in Fig. 11. It can be clearly seen that the variation had been changed over the match time on 28th November 2015 (before and after 15:00), which had a big magnitude. Particularly, the second and third modes happened the mode coupling. In addition, Fig. 12 gives the continuous wavelet transform to different duration acceleration data of the match day. The natural frequency of the bridge between 1.5 and 2 Hz was varied by human–structure dynamics/interaction [53] and [54] due to full/part human loading on the structure deck, which is analogous to adding mass–spring–damper to the structure.

Frequency–time-varying spectrogram on one of the match day (28th November 2015)

Continuous wavelet transform on match day (28th November 2015)
3.3 Selecting modes for long-term monitoring
Section 3.2.2 was shown that mode 2 might have a problem regarding pedestrian loading, though the matchday duration was short. Therefore, all these five modes in Fig. 7c are still used for long-term monitoring. For the discussion on frequency extraction in Sect. 4, the first mode will only be focused on, named mode 1, to make the discussion easier to follow but that the points made and the advice given is equally relevant to the other modes.
4 Offline frequency extraction
This section aims to give an understanding of the nuances of offline frequency extraction and some of the trade-offs that need to be made/understood. In this paper, SSI-COV is selected as the method to focus on frequency extraction, so the specific variables looked at are specifically related to SSI-COV. However, many of these issues relate to things like decimation, and window length relates to other extraction methods, albeit the variables have different names. Key variables [decimation, time-lag i (TLI), model order and spread] will be introduced in this section. The implications of the key variables are demonstrated graphically in Sect. 4.1 as well as some guidance on selecting appropriate values of these variables for the signal being processed. Finally, Sect. 4.2 presents the frequency values extracted.
4.1 Demonstrating influence of SSI-COV parameters
The main inputs for SSI-COV are decimation (n), lag of Hankel matrix (time-lag i (TLI)), model order (order) of system matrix, and number of spread (spread) (related to extended observability matrix), and these are discussed in Sects. 4.1.1–4.1.4, respectively [55,56,57,58,59,60]. For presentation purposes, they are presented as separate sections; however, they should not be seen as 4 entirely independent parameters. For example, once the value of decimation is selected, it influences the range of TLI values that are sensible to use. Similarly, model order and spread are closely related, and the analyst must understand these subtleties when processing the data. Further details on this interrelationship between the different input parameters are provided below. Finally, while modal analysis and system identification are a quite mathematical process, the first paragraphs of each of Sects. 4.1.1–4.1.4 try to give a simplified overview of what each of the input parameters is controlling.
4.1.1 Decimation of the measured data
Modal analysis is a curve fitting/optimisation process to identify the approximate system matrix and, consequently, the mode shapes and frequencies. Therefore, the input signals must be sufficiently densely sampled to represent the true measured signal accurately but are not so highly sampled that experimental noise in the signal makes the curve fit unnecessarily complicated. Therefore, appropriate decimation of the signal is often very important.
Picking an example of the first mode time series using a band-pass filter to retrieve 0.8\(-\)0.98 Hz. From the visualisation of the following graph, as shown in Fig. 13, the decimation number equals 2 (n = 2) has a better representation of the data. In contrast, \(n\,=\,4\) has a marginal fit, and other options have bad representation. It is noted that the original sampling rate of the data was 128 Hz.

Representation of different decimation on acceleration time history in frequency 1
4.1.2 Lag of the Hankel matrix
The modal analysis uses time-shifted sections of a signal to look for patterns, and time-lag i (TLI) can be thought of as how far the signal is shifted in time. Once mode frequencies were known, the approximate length of the free decay for those frequencies and the level of decimation that is being used is an approximate way of setting a lower limit for TLI, in that TLI need to be large enough to capture most of the cycles of the free decay of the lower frequencies.
Figure 14 shows free decay acceleration history after decimating at n = 2. It is noted that the TLI value of the first mode (0.94 Hz) needs to have a large value, since the duration of decay time is relatively long. Note that the x-axis in part (b) is plotted with respect to index (rather than time) as it is easier to visualise an appropriate value for TLI.

Free decay acceleration time history of first mode
The model order keeps in 30 (choose the value by experience, model order selection will be discussed in Sect. 4.1.3) and then varies the TLI in 200, 400, 600, 800, and 1000 and discusses for visualisation. The left and right columns of Fig. 15 show the frequencies extracted for TLI=200 and TLI=1000, respectively. Figure 16 shows summary results for all TLI values used. Once Fig. 15 was plotted, it can be known how many data points are approximately in the free decay. From the decayed part, it is not difficult to see that the index number is over 12,000 for frequency 1, which is a high number. In other words, the free decay took a long while, which is in the 2500 index roughly; therefore, a sensible value of TLI needs to be selected and ensure TLI index selection could provide adequate cycles of the free decay.
In Fig. 15, there are approximately 12 days of data to show the frequency extraction by varying the time-lag i (TLI) when the model order in 30. Figure 15a is using TLI=200, while Fig. 15b is using TLI=1000. The extracted frequency point number of TLI=200 is smaller than TLI=1000 2–3 times. Moreover, the mean (\(\mu\)) value of both TLIs is similar, indicating that the extracted frequency range is steady and reliable. Compared with the variance (sigma squared symbol) of both TLIs, the TLI=1000 is smaller than TLI=200 around 4–14 times, which gives evidence to show that TLP=1000 extracted data are mean value-centric. It is noted that the higher value of TLI was tested, which gave similar mean and variance values as TLI=1000.

First frequency extraction by varying the time-lag i (TLI) when model order is 30
Keeping the decimation in 2, spread in 20, and model order in 30, Fig. 16 shows the mean, variance and sample point number with respect to different value of TLI. It can be seen that the mean value does not have much variation, while the variance and sample point number are affected by the different TLI values.
In addition, the TLI value selected is bigger. Therefore, the first mode frequency extraction will have a smaller variance trend, whereas the sample point number has more extracted points. In comparison with other frequencies might have slightly different trends; hence, different frequencies might have to choose different TLI values to accomplish a better target of data extraction. Consequently, mode 1 takes TLI=1000 for further years of raw data frequency extraction.

Trends of mean, variance, and sample point number with respect to different TLI values of frequency 1
4.1.3 Model order
In modal analysis, a model is employed to align with the measured data, where the complexity of the model determines the proportional order for fitting the data. Therefore, a sufficiently detailed model is selected to capture the complexity of measured data (i.e., system). On the other hand, if the model order is miss-selected, it could induce the overfit of the system. A concept of entropy energy will be briefly introduced in this subsection to demonstrate how the model order is affected by the selected TLI. Further detail can find it in [61].
Singular value decomposition and singular entropy increment concepts assist the determination of the model order [61]. It is based on the energy of the singular value of the Toeplitz matrix, in which to calculate each order energy and then stack on it. The idea is to take a sequence of the Toeplitz matrix’s eigenvalues and calculate the system matrix’s entropy, which is related to the specific probability calculation of each eigenmode. The time series data from a regular day of the Baker bridge is selected to use and prepare TLI in 200 and 1000 and model order in 60. This section also keeps varying the TLI in 200 and 1000 as a demonstration.
In the case of TLI=200, Fig. 17a shows the singular values of Toeplitz matrix with respect to model order, and then converts all the singular values to singular entropy increment and its variation values, as shown in Fig. 17b. The blue plot is given an idea of singular entropy increment per each model order. The red plot is simply the difference between consecutive blue data markers. Both of them are given a similar message to assist model order selection. Using the approach from Qin et al. 2016 [61], the model order must be selected not under 35 roughly. If the model order is selected under 35, some dynamic properties or features will be missed. Also, this might cause uncompleted system identification. On the other hand, if the model order is higher than 35, there is no energy contribution; even selecting higher order will not give more information from the measured data. Therefore, using the energy concept can give the minimum value of the model order selection.

Model order selection (TLI=200)
If the model order is lower than the required order number, the system matrix might only partially include all measured dynamic features of the structure. In other words, it could not give an accurate presentation from the fitting to the measurement. Hence, to consider the aforementioned energy plot, since the TLI decided to choose 1000 in the previous subsection, the singular value decomposition of the Toeplitz matrix is shown in 18a. Therefore, the model order from Fig. 18b can be shown around 30 is appropriate to demonstrate the system matrix order. Accordingly, when the TLI is 1000, the model order will be used in 30 for further long-term data analysis.

Model order selection (TLI=1000)
4.1.4 Returned eigen-information index (spread)
Many people are familiar with a frequency stabilisation diagram; the spread is an automated frequency extraction process. Spread can be defined as the number of stable poles that users need to take into account to determine the presence of a particular mode. The spread is a quality check that a human eye would carry out when looking at the stabilisation diagram. Before looking at the impact, the spread has on the results, and it is first useful to briefly look at a stabilisation diagram.
Explaining stabilisation diagram is two y-axes plot with order on the left and magnitude on the right, as shown in Fig. 19, which was selected decimation in 2, model order in 30, TLI in 1000, and spread in 20. From the two y-axes plot, the blue plot is plotted with the right axis, and it is not dissimilar to any PSD plot or PSD plot and is quite useful for visualisation. The algorithm identifies if a pole is stable for a given model order at each discretised frequency. A data marker is placed “o” on the stabilisation diagram if it is stable. Then, the model order is increased, and the process is repeated. At the end of the algorithm, if a number of data markers (poles) appear on the same vertical frequency line, it indicates that this is a mode, so it is expected to correspond with the frequency peaks of the PSD. In that case, fewer poles will be shown on the stabilisation diagram as fewer poles will be considered stable poles, similar to increasing the condition threshold. In an automated process, users will not be looking at this figure, so the spread is essentially the no. of stable poles that users require to consider a mode present.

Stabilisation diagram using decimation=2, model order=30, TLI=1000, and spread=20
The spread is similar to a criteria index which is to be set up in the SSI-COV process for returning the modal properties when the pole of the SSI-COV fitting is stable. To collect all the stable poles and then average them until the value index is below the required tolerance, then the corresponding eigen-properties (e.g., mode frequency and damping ratio) will be returned. Table 1 summarises the returned value of frequency and damping ratio when choosing a different value of the spread. The symbol “Y” means “Yes” (these values be returned), while “N” means “No” (not returned).
It can be seen that the spread=10 and 20 returned more reasonable modal properties as well as the stabilisation diagram shows a consistent result, while when spread=40, the lower 1 Hz modal properties will be missed as they failed the returned value criteria, which is contradictory to the correlated stabilisation diagram. Also, from the stabilisation diagram, the frequency 3 Hz might not be the true eigenmode frequency based on our measured data. Therefore, the spread is selected to 20 in this study.
4.1.5 Combination of different values
Based on the aforementioned discussion, the selection of SSI-COV parameters was provided. It should be noted that there is no definitive answer for parameter selection as it depends on various circumstances and data types. In this paper, we utilised a limited dataset from the bridge and demonstrated several potential methods to reduce uncertainty in parameter settings when using SSI-COV for long-term monitoring frequency extraction. These methods can be tailored to suit specific purposes and different cases.
Section 4.1.1 reasonably suggests that decimation by a factor of 2 yields a better fit to the measured data. Furthermore, in Sect. 4.1.3, it is illustrated that a model order of 30 is appropriate when the Total Lag Index (TLI) is 1000. However, when using different TLI values, the model order may need to be set at over 35 or higher, as indicated in Figs. 17 and 18. It is important to note that higher model orders require more computational time for constructing the Toeplitz matrix and other steps of SSI-COV.
To further investigate the relationship between spread and TLI values, we present statistical parameters such as variance and sample point number. These parameters can assist in the selection of fitting parameters for SSI-COV by providing insights into the impact of varying spread and TLI values.
It should be observed that to enhance the visibility of the 3D surface, the x- and y-axes of Figs. 20a and 21a, which depict frequencies 1 and 4 as examples, need to be inverted. Subsequently, Figs. 20b and 21b are presented in the conventional manner. This adjustment is necessary due to the fact that when the desired data variance is low, larger values may be required for both TLI and spread. Additionally, increasing the sample point number necessitates higher TLI values and smaller spread values.
Considering this perspective, the selection process does not have a definitive approach. It remains optional and relies on which specific aspects of the results and data are being processed. Therefore, this section provides a conceptual framework and some guidelines to understand the expected outcomes when varying the parameters. However, it is crucial to note that there is no singular ’best’ set of values. The optimal parameter selection depends on the objectives users aim to accomplish, and they must find a balance that aligns with their goals.

Relationship among statistical values, TLI, and spread (Frequency 1)

Relationship among statistical values, TLI, and spread (Frequency 4)
4.2 Full data set
The first set of collecting data was acceleration time history in the z-direction that will be used to extract frequency through the SSI-COV method. According to Sects. 4.1.1–4.1.4 findings, the long-term monitoring data of Baker bridge in this study will set up decimation in 2, model order in 30, TLI in 1000, and spread in 20 to retrieve each mode frequency data. The resulting 1st and 4th frequencies are shown in Fig. 22. It should note that we have approximately 374 days of data; however, these are from different monitoring periods and do not amount to a continuous 374 days. In addition, the data set of frequencies 1 and 4 has a certain amount of data points clearly out of the central part of the data. They might be the outlier. Further evidence and illustration will be presented in Sect. 5.2.

Resulting frequency form SSI-COV method
Figure 23a shows the first mode extracted frequency with respect to time and two y-axes plots with air temperature, in which over a week zoom-in plot is also given in Fig. 23b. In the zoom-in plot, it is not difficult to find that the extracted frequency and air temperature have inverse proportion relationships. Each mode extracted frequency is taken as a dependent variable, and air temperature is an independent variable/predictor.

Overlaid extracted eigen-frequency and air temperature time history of each eigen-mode
5 Data modelling
People use data models for bridge structures when physics-based is complex. Therefore, the data model could increase bridges’ healthy awareness (e.g., recognise and identify damage) after training the long-term data. Many different types of data models are mentioned in Sect. 1, and for all approaches, the more input data were given to train, the more likely accurate the model will have.
For some bridges, e.g., large cable-supported bridges, there is plenty of data available, but for most ’regular’ bridges, which are the focus of this paper, there were likely to be much more limited data available. Therefore, this study tries a relatively new approach of combing PCA with GPR. The advantage of the approach over straight GPR is computational efficiency which could be important for future on-board processing. However, it is trialled here on a much more modest data set from a footbridge that was collected using low-cost instrumentation.
As many data modelling methods are available, the authors are saying something other than the approach used is necessarily the best. It is beyond the scope of the paper to trail all of them to establish this. Instead of our interest, it is to get an indication of the level of accuracy that can realistically be achieved with limited data. However, irrespective of what data model is being used, the issues around data correlation and data cleansing are relevant and important to understand, and these are discussed in Sects. 5.1 and 5.2. The results of our data model are shown in Sects. 5.3 and 5.4.
5.1 Discussion of the collecting Baker bridge data (raw data)
This section selects a regression analysis to create an SHM data model. Based on the supervising learning technique in machine learning, frequency (defined in Sect. 4) will be set in the target function (dependent variable). In contrast, several predictors (independent variables) must be used and input to the regression model. It is noted that the first frequency will be used in this section for demonstration, but that other modes could equally select to create the regression model.
Section 4.2 already mentioned one of the measured input data (air temperature); otherwise, other potential available inputs will also define in this section, such as a few hours ago temperature, time, and wind speed. The predictors in use in this study are shown below:
-
AirT: Air temperature
-
AirT1: Air temperature one hour ago
-
AirT6: Air temperature 6 h ago
-
Hour: Index of hour
-
SPD: Wind speed per hour.
To check the frequency (dependent variables) and other input variables (independent variables) relationship and relationships between all independent variables. A correlation matrix plot is selected to show these multi-variated autocorrelations and cross-correlations, as shown in Fig. 24. Different variables’ names; for example, Freq1 stands for frequency 1. Other short-form names are the same as the above bullet point definition, including different type representations of temperature.

Correlation matrix among dependent variable (frequency 1) and independent variable (predictors)
The diagonal plots of the correlation matrix are given a histogram of each variable. The distribution trend is close to normal distribution. To compare the plots in the first column of rows 2–4, frequency and each type of temperature (AirT, AirT1, and AirT6) have a certain amount of proportion relationship associated with the fundamental physics phenomenon.
Otherwise, the plots in column 2 of rows 3–4 show the correlation between AirT, AirT1, and AirT6. The correlation coefficient that results in the null hypothesis process is also given on the plots. Unsurprisingly, the AirT and AirT1 correlate highly with a 0.95 correlation coefficient. Also, AirT6 has well but lower correlation with AirT with a correlation coefficient of 0.68. However, the other correlation relationships and correlation coefficients are noted on the plots. As the figure is symmetric, the upper triangle of the matrix above the diagonal is as same as the lower triangle below the diagonal.
The reason for showing only a selection 3 dependent variables on the correlation plot is that the correlation plot for 6 variables would appear very small and difficult to read. In addition, the independent variables’ plot did not show any strange tail at the two edges of the data.
5.2 Outlier removal (cleansing data)
Several authors [37, 62, 63] have discussed the issue of cleansing data when making data modelling. This section will present raw frequency data quality checking and the data outlier removal technique, which provides a reason on cleansing long-term monitoring data.
5.2.1 Quality checking of the frequency data
Using first frequency data to illustrate some odd points of the extracted frequency versus the sample point number, as shown in Fig. 25, three arbitrary black colour points (marked in different symbol) are selected to show their reliability.

Odd point data illustration on the first resonant frequency
It is not difficult to obverse that from Fig. 25, the mean value of the varying first mode frequency is 0.936 Hz. The current frequency variation is \(\pm 7.6\%\). This kind of variation might cause by environmental and operational conditions on the measured data. Also, from the physical point of view, frequency points variation seldom has a big jump immediately; consequently, this might be against physical behaviour.
Figure 26 shows the three arbitrary points in time and frequency domains. These three points were in dark markers to indicate the correlated locations. In the frequency domain, PSD and peak-picking techniques are selected to apply. The normal peak is around 0.936 Hz, while the zoom-in subplot shows relevant large and small peaks (around 0.865\(-\)0.895 Hz) detected and returned to the SSI-COV output consistently. This evidence gives an idea to prove that some returned frequency points might not be reliable.

Demonstration the unusual point of first frequency in time and frequency domain
Figure 27a shows the distribution diagram on the measured frequency 1. The shape of the distribution is skewed, which is not a perfectly normal distribution. To give another idea about the data distribution, the concept of probability plot is introduced, as shown in Fig. 27b, which plots each data point in the y-axis (marker symbols) and draws a reference line (red dashed line) that represents the theoretical distribution (in this case assume normal distribution). If the sample data has a normal distribution, the data points appear along the reference line, and the fitted curve (solid green line) will match the reference line. From Fig. 27b, two long tails are far from the centre part of the data, which need to clean out and then keep the data modelling representative and reliable.

Distribution and probability plots of the first mode frequency
5.2.2 Application moving median outlier method the data
Data smoothing and outlier detection techniques could be applied to achieve the cleansing data for some idiocrasy frequency data points. Data smoothing is a method used to eliminate unwanted noise or behaviour in the data. Moreover, outlier detection identifies data points that are significantly different from the rest of the well-behaved data. The moving median (MOVM) approach is selected to produce further data processing in this study. The MOVM is one of the moving window methods based on splitting down the data set in fixed window length. The core calculation of MOVM is related to a concept of median absolute deviation (MAD) [64].
In statistics, the scaled MAD is used to find the distance from the centre of a set of observation points. The distance is as upper and lower boundaries. It is the use of against outliers to amplify the effects of outliers and more clearly detect outliers from normal observations. Therefore, applying MOVM to the target response function, if the local median of samples over the fixed window length is more than three times of local scaled MAD, the samples will be returned as outliers.
Figure 28 shows the MOVM outlier detection method applying to the measured target response function (frequency), in which window length is set in 5. The red cross symbol represents outliers. There have 66 outliers be detected. The correlated centre value, lower and upper threshold are also shown in green colour, which could provide a visualised way to identify the outliers.

MOVM outlier detection on the response function
After the use of MOVM cleansing data process, the normalised response data with respect to the sample point numbers is shown in Fig. 29. Obviously, data are much cleaner than Fig. 25, and the frequency-varying trend can be observed easily.

Response function (first mode frequency) after MOVM outlier
The distribution and probability plot can be processed again using the cleaned data, as shown in Fig. 30. The distribution from skew distribution changes to a good normal distribution, which could be proven from the updated probability plot, since the cleaned data almost lay on the red dashed line, which is the assumption of normal distribution. And then, the original two long tails of the data edge were practically disappeared. Hence, the MOVM method has successfully tidied the data to achieve the outcome of the outlier removal in this study.

Distribution and probability plots of the normalised first mode frequency after applying MOVM outlier
After outlier removal on the original data and before implementing the further steps of OREPCA, the need for pre-understanding of the data is investigated, as shown in Fig. 31, that is re-performed correlation matrix among target response function and other significant predictors. Some proportions between frequency and all types of temperature trends are given, and the predictor variables are almost close to independent through a 5 % confident interval p test, in which the correlation coefficient is noted in red digit on the graph. Therefore, the cleaned predictors can be used for the next step of OREPCA.

Correlation matrix after outliers’ removal among independent variable (frequency 1) and dependence variable (predictors)
5.3 Data modelling
This section mainly summarises data modelling methods, including Gaussian process regression (GPR) and principle component analysis (PCA). Once all these tools are ready, the later Sect. 5.4 will combine and propose a new application methodology for getting improvement on the data modelling in the case of the low-cost long-term monitoring of bridges.
5.3.1 Introduction of a Gaussian process regression (GPR)
The linear regression model, a linear approach, is one of the data models describing a relationship between the target function (response) and predictor(s). The linear regression can apply to univariate or multivariate variables regression analysis.
The least-square linear regression method commonly uses the predictors (independent variable) with a formula-based model to fit the response (dependent variable). The principle of the model selection can be variously decided by experience. However, this is the need to determine a big number set of regression parameters for the parametric model. Accordingly, a Gaussian process regression (GPR) will be presented in this section to improve this situation.
GPR is a rigorous finer approach with less parametric form (not a free form) of the supervised machine learning technique [65]. Also, GPR uses using Bayesian machine learning approach to deal with the regression prediction within confidence intervals. The GPR can be extended to multivariate Gaussian distributions over the range of observed data (variables) with a finite subset of samples that are joint Gaussian distributions. A Gaussian process can be specifically defined as the mean function \(\varvec{\mu } \left( \varvec{x} \right)\) and covariance function \(\varvec{k}\left( {\varvec{x},\varvec{x'}} \right)\). The estimated response will be a normal distribution for any random input variables according to the mean and covariance functions.
The first procedure for applying GPR to the data modelling is to find an appropriate prior assumption on the mean and covariance functions (kernel function). The reliability of the GPR relies on selecting the covariance function, in which the parameters (hyperparameters) of the covariance function in the model using the maximum-likelihood approach need to be chosen sensibly. Hence, the multivariate optimisation algorithm (e.g. Newton–Raphson method, conjugate gradients, Nelder–Mead simplex, etc.) can be used. Then, based on the fully defined functions, the mean and covariance values of the new input observations can be calculated according to the predictive joint distribution of known and unknown training data points. After the calculation, the maximum posterior estimation of hyperparameters will be integrated to evaluate the selected kernel parameters. Further vital definitions and concepts could reference a textbook [65].
Using the concept above and Sect. 5.1 predictors to perform the GPR analysis of the cleaned data, the estimated target response and measured response values are shown in Fig. 32. The blue line is the measured target response (first frequency), while the red line is the estimated response. Also, the grey fill represents the 99% confident interval of predictive probability.

GPR analysis with 99% prediction intervals
It is noted that the regression process of the GPR was taken 13.57 min (814.13 sec) for 6682 data points with the corresponding computer specifications as (a) Processor: 3 GHz Intel Core i7; (b) Memory: 8 GB 1600 MHz DDR3. However, the running time is considerably long and could not achieve a faster evaluation. Therefore, the next subsection will propose a PCA method to enhance computational time.
5.3.2 Introduction of principle component analysis (PCA)
PCA is to collect multivariate independent variables (predictors) after outlier removal from Sect. 5.2 and project the predictors onto a new direction to construct a set of new variables (Principal components, PCs). The construction could be linear combinations of the raw collecting variables. Therefore, the new variables (PCs) could split the data into PC1, PC2...PC5, as shown in Fig. 33. It is noted that PC1 contains information on all independent variables (predictors); similarly, PC2 also contains information on all independent variables, and the same is true for the remaining PCs.

After outlier magnitude and accumulated percentage of variance of PCA for 5 predictors
PCA reduces the dimensionality of the data, which could allow to project of all variables onto new component directions and find out which variables can have a high proportion of the variance (low order PC). Then, the high-order PC could be released to achieve the data dimension reduction. In other words, applying the PCA can ease analysis when the data have high dimensionality and with no/limited loss of significant information. In the field of data analysis, PCA is frequently employed to examine high-dimensional correlated data. In the specific context of this study, various types of air temperature and wind-speed data were collected over 3 years, thereby satisfying the characteristics of high-dimensionality and correlation within the dataset.
There is a lack of consensus among researchers regarding the optimal number of PCs to be employed in the proposed OREPCA method. One approach suggests selecting the most effective PCs as if they were conventional variables. Conversely, another approach argues in favor of choosing a predetermined number of PCs that account for the highest variance, as advocated by [66]. Consequently, this approach involves discarding principal components that explain a low level of variance.
The PCAs only keep the first three PCs as they have a bigger proportion of the variance and high accumulated percentage, as shown in Fig. 33. Figure 34 demonstrates on PCs’ re-projection that even if the first three PCs are used. The re-project signal could more or less be reproduced. This is because collective 1–3 PCs contain almost all the information on air temperature (see Fig. 34).

Measured and regenerated predictors by PCA inverse projection
5.4 Development on potential hybrid approach: OREPCA
5.4.1 All PCAs followed by GPR on cleaned data
Ultimately, this section aims to demonstrate the effectiveness of combining PCA and GPR. This combination was presented in papers [37] and [62]. This methodology applied all the PCs with GPR to predict the target frequency response, as shown in Fig. 35 in red. It is noted that the running process of GPR with all PCs took around 29.33 s. By contrast, the green line represented only applying GPR to the predictors to estimate the target response, which is the same as Fig. 35a red dash line. It is reminded that the green line runs in 13.57 min (814.13 sec). The quality of the outlier removal of all PCAs with GPR is similar to outlier removal with GPR only. However, the running time is shorter than 28 times roughly, which could obviously observe the potential integration of outlier removal, PCA and GPR.
Figure 35b shows the residuals between outlier removal with GPR only and outlier removal of all PCAs with GPR. From the residual plot, the two methods have consistent magnitude over different sample points, which is proved that the outlier removal of all PCAs with the GPR method can keep significant information on dealing with a large dataset.

Analysis of GPR and all PCAs with GPR
5.4.2 PCA then GPR applied to only the first 4 PCs
The GPR, PCA, and outlier detection were introduced in the previous Sect. 5.3. This section tries to integrate all these approaches and proposes a method of outlier removal enhanced principle component analysis (OREPCA). The process of the OREPCA is to perform outlier detection on the target response and find outliers with their location. Then, outlier removal will be implemented on the target response and take the same removal outliers’ position to apply to all predictors. After that, all the measured data and correlated predictors are cleaned. The next step of OREPCA is to reduce the data model construction time; therefore, the PCA is used to reduce the dimensionality of all selected predictors and only keeps several high variances PCs. Finally, the last step of OREPCA is to take the selected PCs and apply the process of GPR to obtain the estimated response.
Figure 33 gives the first PC occupied a high variance and accumulated percentage. Otherwise, the 5th PC has a low magnitude and percentage. Therefore, the first four PCs will be kept for further analysis to reduce dimensionality and the trial to enhance the running regression time.
Applying the first four PCs to GPR, as shown in Fig. 36, the blue line is the measured frequency response, while the red line is the estimated response. The trend of the estimated response could successfully give a consistent pattern as the target response. Figure 36 also shows the normal outlier removal with the GPR regression curve in green, in which green and red lines are almost consistent. This could also prove that the 4 PCs’ OREPCA could give a confident result.

Four PCs selected OREPCA result
Figure 37 shows the residual of using 4 PCs’ OREPCA. Since the uncertainty of the environmental and operational conditions, the range of this study is roughly controlled within \(\pm 1\) residual, which is acceptable. From the residual plot, the OREPCA have consistent magnitude with MOVM with GPR-only case. This overlay plot proves that the 4 PCs’ OREPCA can keep significant information.
In addition, the running time of this 4 PCs’ OREPCA is 31.43 s which is shorter than 26 times of MOVM with GPR only (i.e., 13.57 min (814.13 s)), while is close to the case of outlier removal all PCAs with GPR (29.33 s). Therefore, 4 PCAs’ OREPCA could keep the quality of the regression estimation and still have a fast and reasonable running time.

Residual of OREPCA
The residual reached \(\pm 1\), as the GPR struggled to get good answers, most likely because important input information such as cable tension or bearing position were being missed. As a result, knowing which predictor is appropriate is considerably challenging.
Otherwise, Table 2 summaries different running time and RMSE values of different number PCs selection, including after the outlier GPR model, all PCs with GPR, 4 PCs with GPR, 3 PCs with GPR, 2 PCs with GPR, and 1 PC with GPR. The running time of correlated OREPCA with different numbers of PCs selection was similar. However, the running time of MOVM with GPR-only had the longest running time. Consequently, the OREPCA method could shorten running time and have robust data models to represent the target function tracking. Therefore, the novel OREPCA method could apply to data modelling of long-term monitoring of the footbridge.
The training data were used to construct a data model and had satisfying results. The further procedure uses the testing data set to verify the model. The predicted response of the testing data is to process the OREPCA method using 4 PCs, as shown in Fig. 38. Consequently, The estimated response (red line) follows the pattern of the measured target response (blue line).

OREPCA results of testing data
Figure 39 shows the residual results of the testing data in which two dashed lines are three times the residual’s standard deviation (\(3 \sigma\)). Based on the trend of residual and \(3 \sigma\) method, the structure has not given any damage information as the residual varies relatively steadily [33] and [67]. Therefore, the structure has been stated as a health condition.

Residual of testing data
To verify that the data model could have an acceptable representative, Fig. 40 shows residuals of the training data (in blue) and testing data (in red) on the same plot with as an example of the first eigen-frequency result. It is noted that it entire process of the work is equivalent to that of other eigenfrequencies. In comparison with residual amplitude on the training and testing data, they have almost consistent magnitude. Therefore, the data model was completed and could use as a based-lined model to implement further damage detection/data tracking.

Residuals of training and testing data for first mode eigen-frequency
One-class support vector machine (SVM) is a machine learning technique used for damage detection in structural systems. It is trained on a dataset containing only normal or undamaged samples, allowing it to learn the boundaries of normal behaviour in the feature space. When presented with new data, the model can classify instances as either normal or anomalous, enabling the identification of potential damage or structural abnormalities. This approach is particularly useful when labeled data for damaged samples are scarce or unavailable, as it focuses on learning the characteristics of normal behaviour to detect deviations associated with damage. Figure 41 illustrates an artificially induced damage in the training dataset, represented by the blue colour. The damage in the training data occurred specifically around the sample point at approximately 3500, resulting in a shift in frequency.

Residuals of training and testing healthy and damage data for first mode eigen-frequency
After implementing the one-class SVM, Fig. 42a displays the categorisation of healthy and unhealthy data samples. The true category is represented by the red circles, which serve as a means of validating the accuracy of the classifier. Conversely, the blue crosses indicate the predicted category by the one-class SVM, which exhibits a high accuracy value of 0.92 when compared to the true category. Although there are instances where some non-sensitive sample categories may not be precisely classified, overall, this training model is verified and deemed suitable for damage detection.
To further evaluate the performance, Fig. 41 presents a test dataset comprising both healthy and damaged residual data obtained from OREPCA results (with damage occurring after the 1000th set number). By applying the prepared one-class SVM model, Fig. 42b showcases the outcomes of the testing data. Notably, the healthy data are accurately classified, while the damaged portion also achieves a robust classification with a high accuracy of 0.82 when compared to the true category. Consequently, the regression results from OREPCA can be effectively utilised for damage detection, yielding satisfactory outcomes.

One-class SVM classification of training and testing data set for damage detection
6 Conclusions and discussion
This research aims to validate a wireless transducer system that is low-cost and all-in-one for creating a data model of a footbridge. Additionally, this study aims to propose an affordable framework for detecting damage in footbridge structures. To demonstrate the adequacy of the measured acceleration data in representing structural dynamics, the natural frequency was selected to be tracked and presented, with the objective of structural health monitoring. To achieve this, a frequency extraction technique was employed using the SSI-COV algorithm. The study’s significant development lies in the discussion of the SSI-COV parameter selection, which deviates from the typical automated procedure of other studies. Specifically, the decimation number, Hankel matrix lag (time-lag i, TLI), model order, and spread values were chosen to balance the number and quality of the retrieved frequency data points. Based on the results of the SSI-COV parameter analysis, the extracted frequency became the target function response (dependent variable) for the data model. The footbridge’s dynamic feature revealed the relationship between the structure’s modal frequencies and the air temperature. To incorporate independent variables (predictors) involving different types of temperature information, regular hour index and wind speed were included in the regression analysis.
In addition, to complete the low-cost SHM and damage detection framework, the moving median (MOVM) outlier detection technique was utilised to eliminate sparse data’s influence and clean up all relevant data. Subsequently, a novel method for data modelling was proposed, called the outlier removal enhanced PCA (OREPCA) method, which integrates outlier detection, modified PCA, and GPR analysis. By applying the OREPCA method to both training and testing data sets on each eigenmode, there was a noticeable improvement in running time compared to a typical GPR analysis while maintaining high-level frequency tracking in regression model studies and a small range of residual magnitude (approximately \(\pm 1\)). Subsequently, the regression residual result was subjected to a one-class SVM machine learning approach for damage detection, effectively classifying the healthy and unhealthy data with favorable outcomes. As a result, the OREPCA method provided satisfactory results and robustness for footbridge data modelling, making it suitable for long-term monitoring purposes and damage detection.
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Rytter A (1993) Vibrational based inspection of civil engineering structures. Doctor of philosophy
Hu W-H, Caetano EDS, Cunha AAMF (2013) Structural health monitoring of a stress-ribbon footbridge. Eng Struct 57:578–593
Laory I, Trinh TN, Smith IFC, Brownjohn JMW (2014) Methodologies for predicting natural frequency variation of a suspension. Eng Struct 80:211–221
Brownjohn JMW, Stefano AD, Xu Y-L, Wenzel H, Aktan AE (2011) Vibration-based monitoring of civil infrastructure: challenges and successes. J Civ Struct Health Monit 1:79–95
Hu W-H, Moutinho C, Caetano EDS, Magalhães F (2012) Continuous dynamic monitoring of a lively footbridge for serviceability assessment and damage detection. Mech Syst Signal Process 33:38–55
Hu W-H, Moutinho C, Magalhães F, Caetano E, Cunha Á (2009) Analysis and extraction of temperature effect on natural frequencies of a footbridge based on continuous dynamic monitoring. In: 3rd International Operational Modal Analysis Conference, pp 55–62
Peeters B, Maeck J, Roeck GD (2001) Vibration-based damage detection in civil engineering: excitation sources and temperature effects. Smart Mater Struct 10(3):518–527
Zhou Y, Sun L (2019) Effects of environmental and operational actions on the modal frequency variations of a sea-crossing bridge: A periodicity perspective. Mech Syst Signal Process 131(1):505–523
Sohail A, Cheema MA, Ali ME, Toosi AN, Rakha HA (2023) Data-driven approaches for road safety: a comprehensive systematic literature review. Safety Sci 158(September 2022):105949
Kwan Oh B, Seon Park H, Glisic B (2023) Time-dependent structural response estimation method for concrete structures using time information and convolutional neural networks. Eng Struct 275:115193
Aloisio A, Pasca DP, Rosso MM, Briseghella B (2023) Role of cable forces in the model updating of cable-stayed bridges. J Bridg Eng 28(7):05023002
He L, Castoro C, Aloisio A, Zhang Z, Marano GC, Gregori A, Deng C, Briseghella B (2021) Dynamic assessment, fe modelling and parametric updating of a butterfly-arch stress-ribbon pedestrian bridge. Struct Infrastruct Eng 18(7):1064–75
Ao WK, Pavic A, Kurent B, Perez F (2023) Novel frf-based fast modal testing of multi-storey clt building in operation using wirelessly synchronised data loggers. J Sound Vib 548:117551
Kurent B, Friedman N, Ao WK, Brank B (2022) Bayesian updating of tall timber building model using modal data. Eng Struct 266:114570
Kurent B, Brank B, Ao WK (2023) Model updating of seven-storey cross-laminated timber building designed on frequency-response-functions-based modal testing. Struct Infrastruct Eng 19(2):178–196
Kurent B, Ao WK, Pavic A, Pérez F, Brank B (2023) Modal testing and finite element model updating of full-scale hybrid timber-concrete building. Eng Struct 289:116250
He S, Ao WK, Ni Y-Q (2024) A unified label noise-tolerant framework of deep learning-based fault diagnosis via a bounded neural network. IEEE Trans Instrum Meas 73:1–15
Goyal D, Pabla BS (2016) The vibration monitoring methods and signal processing techniques for structural health monitoring: a review. Arch Comput Methods Eng 23:585–594
Brincker R, Zhang L, Andersen P (2000) Modal Identification from Ambient Responses using Frequency Domain Decomposition. In: IMAC 18:Proceedings of the International Modal Analysis Conference (IMAC), San Antonio, Texas, USA, February 7–10 23, pp 625–630
Cabboi A, Magalhães F, Gentile C, Cunha Á (2017) Automated modal identification and tracking: application to an iron arch bridge. Arch Comput Methods Eng 24(1):1854
Rainieri C, Fabbrocino G (2010) Automated output-only dynamic identification of civil engineering structures. Mech Syst Signal Process 24(3):678–695
Magalhães F, Cunha Á (2011) Explaining operational modal analysis with data from an arch bridge. Mech Syst Signal Process 25(5):1431–1450
Brincker R, Andersen P (2006) Understanding Stochastic Subspace Identification. In: IMAC-XXIV: Proceedings of A Conference and Exposition on Structural Dynamics Conference
Zhang G, Tang B, Tang G (2012) An improved stochastic subspace identification for operational modal analysis. Measurement 45(5):1246–1256
Wang W, Jiang SF, Zhou H, Yang M, Ni Y, Ko J (2018) Time synchronization for acceleration measurement data of Jiangyin Bridge subjected to a ship collision. Struct Control Health Monit 25(1):2039
Neu E, Janser F, Khatibi AA, Orifici AC (2017) Fully automated operational modal analysis using multi-stage clustering. Mech Syst Signal Process 84(Part A):308–323
Magalhães F, Cunhaand A, Caetano E (2012) Vibration based structural health monitoring of an arch bridge: from automated OMA to damage detection. Mech Syst Signal Process 28:212–228
Huang G, Chen J, Liu L (2023) One-class svm model-based tunnel personnel safety detection technology. Appl Sci 13(3):1734
He S, Chen F, Chen H (2023) A latent representation generalizing network for domain generalization in cross-scenario monitoring. In: IEEE Transactions on Neural Networks and Learning Systems, pp 1–15
He S, Chen F, Xu N, Chen H (2022) Online monitoring for non-stationary operation via a collaborative neural network. IEEE Trans Instrum Meas 71:1–12
Chen F, He S, Li Y, Chen H (2022) Data-driven monitoring for distributed sensor networks: An end-to-end strategy based on collaborative learning. IEEE Sens J 22(22):21795–21805
Liu W, He S, Mou J, Xue T, Chen H, Xiong W (2023) Digital twins-based process monitoring for wastewater treatment processes. Reliab Eng Syst Saf 238:109416
Shi H, Worden K, Cross EJ (2016) A nonlinear cointegration approach with applications to structural health monitoring. J Phys: Conf Ser 744:012025
Farreras-Alcover I, Chryssanthopoulos MK, Andersen JE (2015) Regression models for structural health monitoring of welded bridge joints based on temperature, traffic and strain measurements. Struct Health Monit 14(6):648–662
Dervilis N, Cross EJ, Barthorpe R, Worden K (2014) Robust methods of inclusive outlier analysis for structural health monitoring. J Sound Vib 333(20):5181–5195
Worden K, Manson G, Fieller NRJ (2000) Damage detection using outlier analysis. J Sound Vib 229(3):647–667
Cross EJ (2012) On structural health monitoring in changing environmental and operational conditions. Doctor of philosophy
Cross EJ, Koo KY, Brownjohn JMW, Worden K (2013) Long-term monitoring and data analysis of the Tamar Bridge. Mech Syst Signal Process 35(1—-2):16–34
Yan AM, Kerschen G, Boe PD, Golinval JC (2005) Structural damage diagnosis under varying environmental conditions part-I: a linear analysis. Mech Syst Signal Process 19(4):847–864
Yan AM, Kerschen G, Boe PD, Golinval JC (2005) Structural damage diagnosis under varying environmental conditions part II: local PCA for non-linear cases. Mech Syst Signal Process 19(4):865–880
Jolliffe IT (2002) Principal component analysis. Springer, New York
Sharma S (1995) Applied multivariate techniques, vol 1. Wiley
Manevitz LM, Yousef M (2001) One-class svms for document classification. J Mach Learn Res 2(Dec):139–154
Alam S, Sonbhadra SK, Agarwal S, Nagabhushan P (2020) One-class support vector classifiers: a survey. Knowl-Based Syst 196:105754
Shin HJ, Eom D-H, Kim S-S (2005) One-class support vector machines-an application in machine fault detection and classification. Comput Ind Eng 48(2):395–408
Yin S, Zhu X, Jing C (2014) Fault detection based on a robust one class support vector machine. Neurocomputing 145:263–268
Erfani SM, Rajasegarar S, Karunasekera S, Leckie C (2016) High-dimensional and large-scale anomaly detection using a linear one-class svm with deep learning. Pattern Recognit 58:121–134
Sheikh SY, Jilani MT (2023) Ubiquitous wheelchair fall detection system using low-cost embedded inertial sensors and unsupervised one-class svm. J Ambient Intell Humaniz Comput 14:147–162
Brownjohn JMW, Bocian M, Hester D, Quattrone A, Hudson W, Moore D, Goh S, Lim MS (2016) Footbridge system identification using wireless inertial measurement units for force and response measurements. J Sound Vib 384(4):339–355
Concepts GCD (2023) Multifunction Extended Life (MEL) Data Logger. http://www.gcdataconcepts.com/mel.html. Accessed 17 Oct 2023
Welch P (1967) The use of fast Fourier transform for the estimation of power spectra: a method based on time averaging over short, modified periodograms. IEEE Trans Audio Electroacoust 15(2):70–73
Demartino C, Quaranta G, Maruccio C, Pakrashi V (2021) Feasibility of energy harvesting from vertical pedestrian-induced vibrations of footbridges for smart monitoring applications. Comput-Aided Civ Infrastruct Eng 37(8):1044–1065
Brownjohn JMW (2001) Energy dissipation from vibrating floor slabs due to human-structure interaction. Shock Vib 8(6):315–323
Chen J, Wang J, Brownjohn JMW (2019) Power spectral-density model for Pedestrian walking load. J Struct Eng 145(2):315–323
Peeters B, Roeck GD (2000) Reference based stochastic subspace identification in civil engineering. Inverse Probl Eng 8(1):47–74
Overschee PV, Moor BLD (1996) Subspace Identification for Linear Systems, 1st edn. Springer, Berlin
Mrabet E, Abdelghani M, Kahla NB (2014) A new criterion for the stabilization diagram used with stochastic subspace identification methods: an application to an air-craft skeleton. Shock Vib 2014:1–8
O’Higgins C, Hester D, Ao WK, McGetrick P, Robinson D (2019) Inherent uncer-tainty in the extraction of frequencies from time-domain signals. Infrastruct Asset Manag 0(0):1–12
O’Higgins C, Hester D, McGetrick P, Cross EJ, Ao WK, Brownjohn J (2023) Minimal information data-modelling (mid) and an easily implementable low-cost shm system for use on a short-span bridge. Sensors (Basel, Switzerland) 23(14):6328
O’Higgins C, Hester D, Ao WK, McGetrick P (2024) A method to maximise the information obtained from low signal-to-noise acceleration data by optimising ssi-cov input parameters. J Sound Vib 571:118101
Qin S, Kang J, Wang Q (2016) Operational modal analysis based on subspace algorithm with an improved stabilization diagram method. Shock Vib. https://doi.org/10.1155/2016/7598965
Cross EJ, Koo KY, Brownjohn JMW, Worden K (2013) Long-term monitoring and data analysis of the Tamar Bridge. Mech Syst Signal Process 35(1–2):16–34
Dervilis N, Antoniadou I, Barthorpe R, Cross EJ (2015) Robust methods for outlier detection and regression for SHM applications. Int J Sustain Mater Struct Syst 2(12):16–34
Bae I, Ji U (2019) Outlier detection and smoothing process for water level data measured by ultrasonic sensor in stream flows. Water 11(5):951
Rasmussen CE, Williams CKI (2006) Gaussian processes for machine learning. MIT Press, Cambridge
Hadi AS, Ling RF (1998) Some cautionary notes on the use of principal components regression. Am Stat 52(1):15–19
Shi K, Worden H, Cross EJ (2019) A cointegration approach for heteroscedastic data based on a time series decomposition: an application to structural health monitoring. Mech Syst Signal Process 120:16–31
Acknowledgements
This work was supported by UK Engineering and Physical Sciences Research Council (EPSRC) through a Leadership Fellowship Grant (Ref. EP/R009635/1). The authors would also like to acknowledge the support of Start-up Fund for RAPs under the Strategic Hiring Scheme of The Hong Kong Polytechnic University (Ref. 1-BD22).
Funding
Open access funding provided by The Hong Kong Polytechnic University. This study was funded by UK Engineering and Physical Sciences Research Council (EPSRC) through a Leadership Fellowship Grant (Grant No. EP/R009635/1). This study was funded by the Strategic Hiring Scheme of The Hong Kong Polytechnic University (Grant No. 1-BD22).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
Wai Kei Ao has received research grants from The Hong Kong Polytechnic University. David Hester has received research grants from UK Engineering and Physical Sciences Research Council (EPSRC). The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ao, W.K., Hester, D., O’Higgins, C. et al. Tracking long-term modal behaviour of a footbridge and identifying potential SHM approaches. J Civil Struct Health Monit 14, 1311–1337 (2024). https://doi.org/10.1007/s13349-024-00787-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13349-024-00787-9