
Abstract
When dealing with very high-dimensional and functional data, rank deficiency of sample covariance matrix often complicates the tests for population mean. To alleviate this rank deficiency problem, Munk et al. (J Multivar Anal 99:815–833, 2008) proposed neighborhood hypothesis testing procedure that tests whether the population mean is within a small, pre-specified neighborhood of a known quantity, M. How could we objectively specify a reasonable neighborhood, particularly when the sample space is unbounded? What should be the size of the neighborhood? In this article, we develop the modified neighborhood hypothesis testing framework to answer these two questions. We define the neighborhood as a proportion of the total amount of variation present in the population of functions under study and proceed to derive the asymptotic null distribution of the appropriate test statistic. Power analyses suggest that our approach is appropriate when sample space is unbounded and is robust against error structures with nonzero mean. We then apply this framework to assess whether the near-default sigmoidal specification of dose-response curves is adequate for widely used CCLE database. Results suggest that our methodology could be used as a pre-processing step before using conventional efficacy metrics, obtained from sigmoid models (for example: IC\(_{50}\) or AUC), as downstream predictive targets.






Similar content being viewed by others
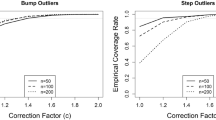

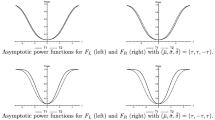
References
Arya AK, El-Fert A, Devling T, Eccles RM, Aslam MA, Carlos P, Vlatkovi’c N, Fenwick J, Lloyd BH, Sibson DR et al (2010) Nutlin-3, the small-molecule inhibitor of MDM2, promotes senescence and radiosensitises laryngeal carcinoma cells harbouring wild-type p53. Br J Cancer 103(2):186–195
Barretina B, Caponigro G, Stransky N, Venkatesan K, Margolin AA, Kim S, Wilson CJ, Lehar J, Kryukov GV, Sonkin D et al (2012) The cancer cell line encyclopedia enables predictive modelling of anticancer drug sensitivity. Nature 483(7391):603–607
Berger JO, Delampady M (1987) Testing precise hypotheses. Stat Sci 2:317–352
Cohen J (1988) Statistical power analysis for the behavioral sciences. Routledge, Milton Park
De Niz C, Rahman R, Zhao X, Pal R (2016) Algorithms for drug sensitivity prediction. Algorithms 9(4):77
Dette H, Munk A (1998) Validation of linear regression models. Ann Stat 26:778–800
Dette H, Munk A (2003) Some methodological aspects of validation of models in nonparametric regression. Stat Neerl 57:207–244
Ellingson L, Patrangenaru V, Ruymgaart FH (2013) Nonparametric estimation of means on Hilbert manifolds and extrinsic analysis of mean shapes of contours. J Multivar Anal 122:317–333
Hodges L, Lehmann L (1954) Testing the approximate validity of statistical hypotheses. J Roy Stat Soc B 16(2):261–268
Kuelbs J, Vidyashankar A (2010) Asymptotic inference for high-dimensional data. Ann Stat 38(2):836–869
Ma J, Fong SH, Yunan Luo, Bakkenist CJ, Shen JP, Mourragui S, Wessels LFA, Hafner M, Sharan R, Jian Peng et al (2021) Few-shot learning creates predictive models of drug response that translate from high-throughput screens to individual patients. Nat Cancer 2(2):233–244
Munk A, Paige R, Pang J, Patrangenaru V, Ruymgaart F (2008) The one and multi sample problem for functional data with application to projective shape analysis. J Multivar Anal 99:815–833
Patrangenaru V, Ellingson L (2015) Nonparametric statistics on manifolds and their applications to object data analysis. Chapman & Hall/CRC, London
Ramsay JO, Silverman BW (2005) Functional data analysis. In: Springer series in statistics. Springer
Safikhani Z, Smirnov P, Thu KL, Silvester J, El-Hachem N, Quevedo R, Lupien M, Mak TW, Cescon D, Haibe-Kains B (2017) Gene isoforms as expression-based biomarkers predictive of drug response in vitro. Nat Commun 8:1126
Sawilowsky S (2009) New effect size rules of thumb. J Modern Appl Stat Methods 8(2):467–474. https://doi.org/10.22237/jmasm/1257035100
Wainwright Martin J (2019) High-dimensional statistics: a non-asymptotic viewpoint, vol 48. Cambridge University Press, Cambridge
Wan Q, Pal R (2014) An ensemble based top performing approach for NCI-DREAM drug sensitivity prediction challenge. PLoS ONE 9(6):e101183
Xu M, Zhang D, Wu W (2014) L2 asymptotics for high-dimensional data. arXiv:1405.7244
Funding
The Funding was provided by National Science Foundation (CCF-2007418, CCF-2007903).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
A Proofs for Section 3 The Modified Neighborhood Hypothesis Test
A Proofs for Section 3 The Modified Neighborhood Hypothesis Test
Lemma 3.1
If \(X_{1}, \ldots , X_{n}\) are independent and identically distributed random elements in a Hilbert space \({\mathbb {H}}\) with population mean \(\mu \in {\mathbb {H}}\) and covariance operator \(\Sigma :{\mathbb {H}} \rightarrow {\mathbb {H}}\) such that \(E \left( ||X||^{4} \right) < \infty ,\) then
Proof
The test statistic \(T_1\) can be decomposed as follows:
From Patrangenaru and Ellingson (2015, pg. 179), we also know that
As such,
From Sect. 2, we know that \(Var(T_1)=1\). Combining this with the above results yields
Solving for \(\sigma _1^2\) combined with (19) yields
\(\square \)
Lemma 3.2
Under the conditions of Lemma 3.1, then
Proof
This follows immediately from (18) to (8). \(\square \)
Theorem 3.1
Under the conditions of Lemma 3.1 and the mild assumption that \({\hat{\sigma }}_1^2 >0\), we arrive at the following asymptotic result:
Proof
From the proof of Lemma 3.1 and results from nonparametric bootstrap theory, then if \({\hat{\sigma }}_1^2>0\), then it is a consistent estimator of \(\sigma _1^2\). We can then apply Slutsky’s Theorem to the result of Lemma 3.2, yielding this result. \(\square \)
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Bandara, D., Ellingson, L., Ghosh, S. et al. A Modified Neighborhood Hypothesis Test for Population Mean in Functional Data. JABES 29, 1–18 (2024). https://doi.org/10.1007/s13253-023-00549-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13253-023-00549-y