
Abstract
Information systems have to deal with an increasing amount of data that is heterogeneous, unstructured, or incomplete. In order to align and complete data, systems may rely on taxonomies and background knowledge that are provided in the form of an ontology. This survey gives an overview of research work on the use of ontologies for accessing incomplete and/or heterogeneous data.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In the digital age, we are dealing with a huge and growing amount of data in research, medicine, business and further areas. Information systems help us process and interpret that data. This is a challenging task because data used for a single purpose is often coming from heterogeneous sources, and is often unstructured and incomplete. In order to deal with these problems, ontologies provide taxonomies and background knowledge, which is useful (not only) for completion and alignment of data. In this survey we provide an overview of research on the use of ontologies for accessing incomplete and/or heterogeneous data. Since it is impossible to give a complete and detailed account of this broad and highly active research field, this overview treats most aspects briefly and omits others completely. In particular, we will focus on a family of ontology languages based on the so-called Description Logics, and only touch on other languages.
This survey begins with a discussion of ontology languages and available reasoning systems (Sect. 2). The main part of the survey (Sect. 3) treats the variety of research topics revolving around ontologies and data, divided into core topics (Sect. 3.1), extensions (Sect. 3.2), design-phase considerations (Sect. 3.3), and further topics (Sect. 3.4). We also give a brief overview of available resources (Sect. 4) and finish with a conclusion and a list of research challenges (Sect. 5).
2 Ontologies
Ontologies originate from the philosophical branch of metaphysics, which studies existence. Since the 1970s, they have been used in the Knowledge Representation (KR) subfield of Artificial Intelligence (AI) for modeling the knowledge about various domains of interest, including (bio-)medicine, software engineering, cultural heritage, business processes, multimedia annotation, and the semantic web [142, 363]. Using an ontology, information systems have access to the represented knowledge and, via automated reasoning, can compute inferences. Early KR systems date back to the 1980s and early 1990s [83, 286, 288, 298, 323]. Thomas Gruber defined the notion of an ontology in the context of computer science as an “explicit specification of a conceptualization”, which is not limited to a taxonomy or a set of (conservative) definitions, but may also contain knowledge about the world [190].
In the following, we provide a brief account of available ontology languages and systems. A complete review of these topics would certainly require a separate survey article; hence we do not aim for completeness. Further information is provided in several books and book chapters [30, 33, 129, 363].
2.1 Ontology Languages
Researchers have proposed ontology languages based on various formalisms. Frame-based languages such as F-Logic [11] are probably the earliest examples; they rely on the KR mechanism of frames [290], and their semantics is specified only operationally. In contrast, logic-based languages employ the formal semantics of their underlying logic, usually a suitable Description Logic (DL) or first-order logic (FO). FO-based ontology languages, such as Common Logic [359] and the Knowledge Interchange Format (KIF) [169] feature all or most of the high expressive power of FO, but provide limited support for automated reasoning, given the undecidability of the basic reasoning problems in FO.
DLs comprise a prominent family of KR languages almost all of which are technically fragments of FO, although they use a different, variable-free syntax, tailored to KR. Unlike FO, DLs are typically decidable. We refer the reader to [30, 33] for details on the foundations of DLs. The various members of the DL family have been designed to provide a balance between expressive power and computational properties of the relevant reasoning problems that is suitable for various applications. Despite their restricted expressivity, DLs are powerful enough to formalize in a logic-based language (fragments of) popular modeling languages, such as UML and ER diagrams [13, 58]. Originating in frame-based languages, DLs have been studied since the 1980s, and this field is still active, as witnessed by the dedicated series of DL workshops.Footnote 1
Among DL-based ontology languages, the Web Ontology Language OWL [211] stands out, being a W3C standard.Footnote 2 A large number of ontologies is nowadays written in OWL, as witnessed by large corpora such as the NCBO BioPortal repository with over 860 bio-medical ontologiesFootnote 3 [345], the ontology repository at the University of Oxford with over 780 ontologies,Footnote 4 or the OWL corpus at the University of Manchester with over 4500 ontologiesFootnote 5 [287].
The current standard OWL 2 is based on an expressive DL called \(\mathcal {SROIQ}\) [208] and supports additional features such as datatypes [292] and a “safe” form of key constraints [322]. OWL 2 also provides the profiles EL, QL, and RL, which are considered lightweight ontology languages particularly suited to certain application areas. OWL 2 EL is based on the \({\mathcal {EL}}\) family of DLs and ensures efficient standard reasoning (e.g., classification) in polynomial time [29] via consequence-based reasoning algorithms. OWL 2 EL is used in healthcare and life-science ontologies, including SNOMED CT ontology (Systematized Nomenclature of Medicine—Clinical Terms), which systematizes the meaning of over 400,000 medical terms and is used in the healthcare systems of the US, the UK, and other countries [362]. OWL 2 QL is based on the DL-Lite family of DLs and enables very efficient sound and complete query answering using standard relational database technology [14]. We further discuss DL-Lite in Sect. 3.1. See also [38] for an introduction to lightweight DLs.
Inspired by database tradition, at least three families of logic-based ontology languages with features of relational databases have been developed to varying extents. The first family is based on existential rules, also known as tuple-generating dependencies (TGDs) [93, 297]. These languages embed into the well-understood Horn fragment of FO and conveniently generalize lightweight DLs such as those underlying OWL 2 EL and QL. They have been designed particularly towards enabling effective and efficient query answering. Among the three families, this one is most covered and best understood in the literature. We will discuss them in Sect. 3.2, together with further rule-based languages.
The second family comprises various extensions of DLs that support (legacy) database features, such as DLs with identification constraints and (path-)functional dependencies [100, 289, 334, 376], and variants of lightweight DLs with the bag (i.e., multiset) semantics [302].
The third family is in a much more experimental stage than the previous families, and consists of attributed DLs [250, 314]. Those have been designed to represent and reason with meta-knowledge, in the presence of knowledge graphs such as Wikidata [380] and DBpedia [256]. Attributed DLs are based on lightweight as well as expressive DLs.
Given the many reasons for using logic-based, and especially DL-based, ontology languages as well as the vast amount of available literature and ontologies, the remainder of this survey focuses almost exclusively on ontologies based on DLs.
2.2 Ontology Systems
Developing, maintaining, and using ontologies requires tools such as editors, APIs and reasoners; the W3C website provides a brief overview of available implementations.Footnote 6 Modern reasoners are typically based on sound and complete techniques for solving standard reasoning problems such as consistency checking, satisfiability testing, or classification, but there are also tools that solve more advanced relevant reasoning tasks such as query answering, module extraction, forgetting, explanation generation, abduction, etc.
The most common methods for solving standard reasoning problems include tableaux [207], hypertableaux [295], resolution [291], and consequence-based techniques. The latter were originally developed for Horn DLs such as tractable members of the \({\mathcal {EL}}\) family, resulting in highly efficient reasoning procedures based on completion rules [29]. The completion-based approach later became known as consequence-based reasoning and was carried over to more expressive Horn and even non-Horn DLs [53, 224]. In general, the technique of consequence-based reasoning combines ideas from hypertableaux and resolution. See also a recent survey [131].
A large number of DL reasoners are based on successful implementations and optimizations of these methods: (hyper)tableau-based reasoners such as FaCT++ [378], Pellet [358], HermiT [173], or Konclude [366] typically cover all of OWL 2. For OWL 2 EL, highly efficient consequence-based reasoners exist, such as CEL [37] or ELK [225]. Consequence-based reasoners for more expressive DLs include CB [224] and Sequoia [132].
We also note that there are hybrid reasoners that combine several other reasoners for more efficiency, sometimes relying on module extraction. Examples include Chainsaw [379], MORe [336], and PAGOdA [391].
For more information, see the proceedings of the ORE workshopFootnote 7 and the list of reasoners maintained by the Information Management Group at the University of Manchester (last updated in June 2018).Footnote 8
3 Ontologies and Data
3.1 Core Topics
We now discuss some of the basic topics related to the use of DLs to build ontologies, and employ such ontologies in the context of data management.
Basic reasoning problems DLs allow to model the domain of interest using only unary and binary predicate symbols, called concept names and role names, respectively. Different DLs support different constructors for building complex concepts and roles, and for expressing relationships among them. A knowledge base (KB) expressed in a DL is usually a pair \({\mathcal {K}}= ({\mathcal {T}},{\mathcal {A}})\), where \({\mathcal {T}}\) is a set of inclusion axioms (called TBox), and \({\mathcal {A}}\) is a set of facts (called ABox). In particular, ABoxes consist of concept membership assertions and role membership assertions. In the DL literature, the term “ontology” has at least two common usages: often it is used to refer to a whole KB \({\mathcal {K}}\) as above (this is especially true in the context of OWL ontologies), or to refer to the TBox of a KB. Intuitively, in the latter case, a DL KB consists of an ontology that is paired with some data in the form ABox assertions. Given the nature of this survey, we adopt this usage and use the term “ontology” (instead of “TBox”) to refer to the set \({\mathcal {T}}\) of inclusion axioms in a KB \({\mathcal {K}}= ({\mathcal {T}},{\mathcal {A}})\). In terms of classical logic, inclusion axioms can be seen as a special kind of closed formulas in first-order logic, and concept and role membership assertions are just a kind of ground atomic formulas.Footnote 9 Sometimes it is convenient to think of an ABox simply as a collection of unary and binary (database) relations.
For an example, consider a KB \({\mathcal {K}}=({\mathcal {T}},{\mathcal {A}})\), where the ontology \({\mathcal {T}}\) contains the following inclusion axioms (all supported, e.g., in the basic DL \(\mathcal {ALC}\)):
The above ontology tells us that exchange students are students, that students are persons, and that a student must attend at least one course. Let the ABox \({\mathcal {A}}\) consist of the following assertions, whose meaning is obvious:
The most basic reasoning task in DLs is satisfiability testing, that is, checking the existence of a model of a plain ontology \({\mathcal {T}}\), or a fully-fledged KB \({\mathcal {K}}= ({\mathcal {T}},{\mathcal {A}})\). Roughly speaking, a model \({\mathcal {I}}\) of \({\mathcal {T}}\) is a (possibly infinite) relational structure that satisfies all the inclusion axioms (i.e., all closed formulas) in \({\mathcal {T}}\). Furthermore, the structure \({\mathcal {I}}\) is a model of the full KB \({\mathcal {K}}\) if it additionally agrees with all the facts in \({\mathcal {A}}\). We remark that \({\mathcal {T}}\) or \({\mathcal {K}}\) may have (possibly infinitely) many models, or no model at all. Another standard reasoning task is subsumption testing, which consists of deciding whether one concept is at least as general as another concept, possibly in the context of other ontological axioms. This corresponds to checking whether an inclusion \(C\sqsubseteq D\) seen as a logic sentence is valid, or is a logical consequence of some ontology \({\mathcal {T}}\). For example, \(\mathsf {ExchangeStudent} \sqsubseteq \mathsf {Person}\) is a logical consequence of the above ontology \({\mathcal {T}}\), while \(\mathsf {Person} \sqsubseteq \exists {\mathsf {attends}}.{\mathsf {Course}}\) is not. Another important task, which already points to data management, is answering instance queries. It consists of retrieving, given an ontology and an ABox, all instances of a given concept or role, i.e., all objects that can be inferred to belong to a certain concept, or pairs of objects connected by a role.
Most DLs can be seen as fragments of \({\mathcal {C}}^2\), the two-variable fragment of first-order logic with counting quantifiers [71, 374]. Unlike in full first-order logic, satisfiability testing is decidable in \({\mathcal {C}}^2\) [188, 319, 329]. The computational complexity of reasoning in DLs is a central topic of investigation in the DL literature, and it is well understood for most of the common DLs and for a wide variety of reasoning tasks, ranging from satisfiability testing to query answering. In fact, DLs vary greatly in terms of expressiveness and complexity of reasoning; e.g., lightweight DLs of the DL-Lite and \({\mathcal {EL}}\) families provide a limited set of constructors and thus are usually tractable. More expressive DLs like \(\mathcal {SROIQ}\) [208] are not tractable.
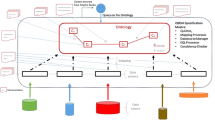
Ontology-based data access A major application of DLs is in Ontology-based Data Access (OBDA) [328] (see also [385] for a dedicated survey). This data integration paradigm aims at providing seamless access to multiple, possibly heterogeneous data sources. In OBDA, an ontology expressed in a DL provides a conceptual view of the application domain, while mappings relate the various data sources to the terms in the ontology. A user of the system poses a query using the vocabulary of the ontology, i.e., over the conceptual view. The OBDA system is then tasked to answer the user query by incorporating the information from the various information sources, possibly employing the domain knowledge in the ontology to infer new information. See Fig. 1 for an overview of OBDA.

OBDA in a nutshell: a logic reasoner equipped with an ontology mediates access by multiple applications to multiple, possibly heterogeneous data sources
For understanding the computational aspects and expressiveness of OBDA, the notion of an ontology-mediated query (OMQ) is very convenient. An OMQ is usually given as a pair \(Q=({\mathcal {T}},{\mathcal {Q}})\), where \({\mathcal {T}}\) is an ontology, and \({\mathcal {Q}}\) is a (user) query. Intuitively, while \({\mathcal {T}}\) is meant to be constructed and maintained by domain experts, \({\mathcal {Q}}\) is an information request that can be made by a user of an OBDA system, who need not be a domain expert. Usually, standard database query languages, e.g., conjunctive queries (CQs), are used to express user queries. In the spirit of classical database queries, OMQs are evaluated over ABoxes (recall that ABoxes can be seen as relational databases). The evaluation of an OMQ Q over an ABox \({\mathcal {A}}\) yields a relation, which is called the query answer (to Q over \({\mathcal {A}}\)). Roughly speaking, the answer to \(Q=({\mathcal {T}},{\mathcal {Q}})\) over an ABox \({\mathcal {A}}\) contains a tuple \(\mathbf {t} \) if and only if \(\mathbf {t}\) is in the answer to the query \({\mathcal {Q}}\) in all models \({\mathcal {I}}\) of the KB \({\mathcal {K}} = ({\mathcal {T}},{\mathcal {A}})\). This is an example of the certain answer semantics, which is well known in databases.
Example 1
Consider an OMQ \(Q=({\mathcal {T}},{\mathcal {Q}})\), where the ontology \({\mathcal {T}}\) is defined above, and the query \({\mathcal {Q}}\) is a CQ written as follows:
The query \({\mathcal {Q}}\) asks for all persons who attend something and are members of the Computer Science department. We note the expression (1) is a simple example of a rule: the atom \({\mathsf {q}}(x)\) is called the head atom, while the atoms on the right-hand side of “\(\leftarrow \)” are called the body atoms of this rule. We will discuss more general rules later.
Consider the ABox \({\mathcal {A}}\) from above. Recall that our example ontology says that exchange students are a kind of students, that students are persons, and that every student must attend some course. Computing the certain answer to \(Q=({\mathcal {T}},{\mathcal {Q}})\) over \({\mathcal {A}}\) yields precisely the constants (or, individuals) \(\mathrm {John}\) and \(\mathrm {Ann}\). The certain presence of \(\mathrm {John}\) in the answer is due to \({\mathcal {A}}\) and the second inclusion in \({\mathcal {T}}\), which tells us that \(\mathrm {John}\) is a person (slightly more precisely, \(\mathrm {John}\) is a person in any model of \({\mathcal {K}}=({\mathcal {T}},{\mathcal {A}})\)). In particular, if we evaluate \({\mathcal {Q}}\) in any model \({\mathcal {I}}\) of \({\mathcal {K}}=({\mathcal {T}},{\mathcal {A}})\), \(\mathrm {John}\) is present in the query answer. The same is true for \(\mathrm {Ann}\), but now all three inclusions of \({\mathcal {T}}\) play a role: the first one tells us that \(\mathrm {Ann}\) is a student, and consequently from the second and the third inclusions we know that in any model of \({\mathcal {K}}=({\mathcal {T}},{\mathcal {A}})\) we have that \(\mathrm {Ann}\) is person who attends some course. The individual \(\mathrm {Bob}\) is not in the certain answer to Q over \({\mathcal {A}}\) because from the given assertions and inclusion axioms we cannot infer that \(\mathrm {Bob}\) is actually a person. \(\square \)
The computational aspects of answering OMQs is a popular research topic, covering a range of DLs and (user) query languages. For instance, lightweight DLs of the DL-Lite and \(\mathcal {EL}\) families support OMQ answering that is computationally not significantly more expensive than queries in the standard relational database setting (see, e.g., [14, 239]). However, answering OMQs based on CQs and expressive DLs is significantly more expensive in the worst-case (under standard assumptions in complexity theory), already because core tasks like satisfiability are ExpTime-hard for the basic expressive DLs like \(\mathcal {ALC}\) [349]. ExpTime-completeness of answering OMQs based on CQs for \(\mathcal {ALC}\) ontologies was established in [272, 312]. The problem is 2ExpTime-complete for extensions of \(\mathcal {ALC}\) with inverse roles [272], with nominals [299], with role hierarchies and transitivity [152], or for positive first-order queries in plain \(\mathcal {ALC}\) [311]. Algorithms for these problems have been obtained using a variety of techniques, e.g., reductions to consistency testing [175, 272], modified tableaux algorithms [307], resolution [214, 326], techniques based on tree automata [106, 309], type elimination [152, 153], and even combinations of some of the mentioned techniques [391]. Many of the above papers deal with computational complexity measured in the combined size of all input components (i.e., the size of the OMQ and the input ABox); they deal with the combined complexity of a problem at hand. However, motivated by the database perspective, the data complexity of query answering (i.e., the complexity measured in the size of the input ABox only, disregarding the size of the OMQ) has also received significant attention (see, e.g., [98, 213, 307]). For most common DLs, the data complexity ranges from very low (in particular, membership in AC\(^0\) for DL-Lite) to coNP-completeness for expressive DLs (see Table 3 in [310]). Unfortunately, for the very expressive DLs that feature inverse roles, number restrictions, and nominals, in the best case decidability is established, but no tighter complexity results are available; this applies, e.g., to the DL \(\mathcal {ALCOIQ}\) [346].
Horn DLs As mentioned above, expressive DLs suffer from intractable data complexity, which hinders their application in data management scenarios. This raised a natural question whether there exist useful fragments of expressive DLs like \(\mathcal {SHIQ}\) that have tractable data complexity. The authors of [213] have identified Horn-\(\mathcal {SHIQ}\) as one such DL, in which (the decision problem corresponding to) instance query answering is \({\textsc {PTime}}\)-complete in data complexity. In [148] this tractability result was extended to CQs. Most DLs of the DL-Lite and \(\mathcal {EL}\) families are considered to be Horn DLs, e.g., they are generalized by Horn-\(\mathcal {SHIQ}\) [251]. The complexity of query answering in variants of \(\mathcal {EL}\) was explored in [248, 252, 342], yielding complexity results that range from tractability to undecidability. The complexity of standard reasoning and conjunctive query answering in the expressive DLs Horn-\(\mathcal {SHOIQ}\) and Horn-\(\mathcal {SROIQ}\) has been studied in [308, 309], showing that these problems are ExpTime-complete in combined complexity, but are tractable in data complexity.
Query rewriting Database research is very mature, and a lot of highly optimized database systems exist and are used in almost any organization. For instance, the popular relational database management systems (DBMSs) provide efficient implementations for the SQL query language. CQs that are used in OBDA are closely related to select-project-join queries in SQL. Thus of course it makes sense to reuse existing DBMSs as much as possible, and the positive theoretic and practical results in this respect are one of the main reasons for the success of OBDA. Most OBDA systems—like Mastro [97] and Ontop [335]—use versions of DL-Lite as the ontology language. This lightweight DL has a very useful property, called first-order rewritability (FO-rewritability). In particular, OMQs \(Q=({\mathcal {T}},{\mathcal {Q}})\), where \({\mathcal {T}}\) is a DL-Lite ontology and \({\mathcal {Q}}\) is a CQ, can be translated into unions of conjunctive queries (UCQs), which are a mild generalization of CQs [14, 99]. That is, from Q we can obtain a UCQ \(Q'\) such that evaluating \(Q'\) over \({\mathcal {A}}\) (seen as a plain relational database) yields the answer to the OMQ Q over \({\mathcal {A}}\), for any possible input ABox \({\mathcal {A}}\). This shows very low data complexity (in particular, membership in AC\(^0\)), and opens the way for handling large amounts of data by reusing available database systems.
Unfortunately, the UCQ \(Q'\) can easily become of exponential size in the size of the original OMQ Q. For this reason, the succinctness aspect of various rewritings for DL-Lite has received significant attention [64, 181, 186, 344]. E.g., the authors of [186] showed that polynomially sized non-recursive Datalog programs can be constructed for OMQs formulated using DL-Lite ontologies. Datalog is a standard rule-based language in (deductive) databases, with several efficient implementations. FO-rewritability for existential rules that often generalize members of the DL-Lite family have also received significant attention [42, 95, 127, 372].
Unfortunately, FO-rewritability is impossible for DLs whose data complexity (e.g., of consistency testing) is higher than AC\(^0\), and this applies to most richer DLs discussed above. Fortunately, for many common DLs there exist rewritings into Datalog and its extensions, which have led to implemented tools (see, e.g., [154, 326, 377]). The seminal paper [214] showed that instance queries mediated by ontologies expressed in the DL \(\mathcal {SHIQ}\) can be rewritten into disjunctive Datalog programs, which unfortunately could be of exponential size in the worst case. This rewriting is achieved by converting the input ontology into standard clauses in first-order logic, saturating the resulting theory using a resolution calculus, and then obtaining a disjunctive Datalog program by deleting all clauses with function symbols. Polynomial time rewritings into variants of Datalog were presented, e.g., in [5, 308]. The deep connections between OMQs and variants of Datalog (like monadic or frontier-guarded disjunctive Datalog) were also studied in [62].
The combined approach Query rewritings have been applied in several settings, from lightweight DLs to expressive DLs. The target languages change depending on the data complexity of the considered query answering problem. While for members of the DL-Lite family we usually have FO-rewritability, already for DLs as simple as \(\mathcal {EL}\) FO-rewritability is impossible and we need a more expressive target language if we want to achieve rewritability. As an alternative to (pure) query rewritings, Lutz et al. introduced the combined approach to query answering in DLs, demonstrating the idea for the DL \(\mathcal {EL}\) [280]. The idea is that the data is completed using the ontological knowledge only, in a query-independent way. This structure over-approximates query answers, i.e., it might provide answers that are not intended according to the certain answer semantics. Thus the next step is the filtration step that eliminates the non-answers from the candidate set. This approach was extended to rich fragments of DL-Lite in [238, 239, 276]. Lifting the combined approach to extensions of \(\mathcal {EL}\) up to Horn-\(\mathcal {ALCHOIQ}\) has been explored in [112, 160, 364]. Two techniques for eliminating unsound answers exist: query rewriting and reusing a database engine at hand [238, 239, 280], or implementing a separate post-processing procedure [276, 364].
Navigational queries Since in standard DLs we only use unary and binary predicate symbols, DLs are naturally related to graph-structured data and to graph databases. However, CQs discussed previously lack navigational features that are central in query languages for graph databases [50, 51, 128]. In particular, they lack constructs for the declarative specification of possibly complex paths that are to be traversed in a given structure, like a model of a DL ontology. Navigational queries like regular path queries (RPQs) in graph databases allow to specify complex paths by means of regular expressions built from roles [2, 104]. In recent years, several important generalizations of RPQs have emerged. For instance, conjunctive regular path queries (CRPQs) allow for flexible ways to specify joins of different RPQs [103, 109, 163], while nested RPQs are a close relative of the XPath query language for XML data [52]. These query languages are popular choices to access not only graph databases but also the graph-structured data on the Web, as they allow for recursion that is both computationally well-behaved and sufficient for expressing (variations of) reachability queries. The SPARQL 1.1 query language recommended by W3C as a standard for querying RDF data [381] includes the specification of property paths, which makes CRPQs one of the key building blocks for constructing queries in SPARQL 1.1.
Answering navigational queries mediated by DL ontologies has received significant attention in the literature. E.g., algorithms and complexity bounds for navigational queries in lightweight DLs have been studied in [61, 66, 245, 365]. Calvanese et al. have shown that CRPQ answering is 2ExpTime-complete for the very expressive DLs \(\mathcal {ZIQ}\), \(\mathcal {ZIO}\), and \(\mathcal {ZOQ}\) [106, 107]. Recently this result was sharpened in [55], by showing that the complexity result holds even under the binary encoding of numbers, and by proving ExpTime-completeness of the query entailment problem for CRPQs with a bounded number of atoms. We note that \(\mathcal {ZIQ}\), \(\mathcal {ZIO}\), and \(\mathcal {ZOQ}\) extend the more well-known DLs \(\mathcal {ALCHIQ}\), \(\mathcal {ALCHIO}\) and \(\mathcal {ALCHOQ}\) with regular expressions as role constructors. Automata-based algorithms for CRPQs mediated by Horn-\(\mathcal {SHOIQ}\) and Horn-\(\mathcal {SROIQ}\) ontologies were proposed in [309], resulting in worst-case optimal ExpTime and 2ExpTime upper bounds, respectively. The work in [191] shows a 2ExpTime upper bound for CRPQs over \(\mathcal {SQ}\) ontologies, where number restrictions are allowed both on transitive and non-transitive roles. We note that in some of the works above, generalizations of CRPQs to positive regular path queries are considered, and sometimes the ability to “walk” both along roles and role inverses is explicitly indicated by introducing “2-way” queries. Hence, the acronyms like 2RPQs, C2RPQs or P2RPQs can be encountered in the literature.
Inconsistency-tolerant query answering In real-world data we often observe significant quality problems. In the presence of an ontology, some facts of a real-world ABox might easily become contradictory, which causes a logical inconsistency and renders query answering under the classical semantics meaningless. Several authors have considered inconsistency-tolerant semantics for query answering with DL ontologies, which are specifically geared towards inferring meaningful query answers in the presence of inconsistency. For more details on this important topic, we refer the reader to a dedicated survey included in this special issue [59].
Closed-world and open-world assumptions In the traditional database setting one makes the closed-world assumption. If a fact is not explicitly present in the database, then it is assumed to be false. This is not adequate for data integration scenarios, where information incompleteness naturally occurs. For this reason, standard OBDA settings drop this assumption, and make the so-called open-world assumption instead. It has been acknowledged however that that both of these assumptions are too strong, and that there is the need to explicitly control which parts of the knowledge should be considered complete and which could be seen as incomplete. E.g., in an OBDA system that integrates information about a city’s restaurants and bus routes, it may be useful to view the municipality-provided data about existing bus routes as complete, while a crowd-sourced collection of restaurants as incomplete. One way to achieve such control is via the so-called closed predicates (or DBoxes) [165, 278, 357]. In particular, we may know that the extensions of certain concepts and roles are complete, and thus should not vary in the different models of a given knowledge base. Unfortunately, reasoning in this mixed setting is computationally more challenging, e.g., the data complexity of query answering becomes NP-hard if closed predicates are added to (the core fragment of) DL-Lite [165]. Some ways to regain tractability in the presence of closed predicates in DL-Lite were presented in [278]. The recent work in [279] deals with more fine-grained notions of complexity as well as with the identification of first-order rewritable cases. The combined complexity of query answering in the presence of closed predicates was investigated in [299]. In general, the problem of combining the closed-world and the open-world assumptions has received significant attention. One can observe two lines of research here. First are the various combinations of DLs with non-monotonic rule-based languages, which we briefly discuss in Sect. 3.2. Another direction are the extensions of DLs with non-monotonic features (without a direct involvement of rules); see, e.g., [32, 69, 70, 82, 90, 91, 114, 115, 171, 187, 231, 249, 325, 331].
Finite model reasoning Most works on reasoning in DLs make the assumption that the domain of models may be infinite, and reasoning algorithms are often tailored to build finite representations of possibly infinite models. However, it has been acknowledged that in some data management applications one should only consider structures over finite domains. This is the case, e.g., when DLs are used to model relational databases. For instance, if we use a DL ontology to express some integrity constraints on a relational database, the models of the ontology should exactly be the finite databases that satisfy the constraints. This topic, known as finite model reasoning, has always been considered of interest in the DL community, but it is less developed than reasoning about possibly infinite models, mostly because it is significantly more challenging [217, 273, 343]. In this area integer programming has been very fruitfully applied [273, 329]. Another technique that has been studied for finite model reasoning in the so-called Horn DLs is the cycle reversion technique, which allows to reduce basic finite model reasoning problems to standard reasoning problems, i.e., reasoning over possibly infinite structures [217, 343]. We also recommend to see [161, 177, 179], where finite model reasoning for answering complex queries in the presence of ontologies in expressive languages is considered.
Explanation services In order for ontology-based systems to be truly useful to users, they must provide services to explain the outcomes of automated reasoning. For instance, if some inclusion is logically entailed by a possibly very large ontology, we may want to see which axioms of the ontology are actually responsible for the observed entailment. The task of computing such a justification is also known as axiom pinpointing and has received significant attention in the literature [39, 206, 222, 351]. We refer the reader to [324] for a dedicated survey.
The techniques developed for explaining entailments cannot be directly used for explaining non-entailments, such as missing answers to a query. That problem is addressed by abductive reasoning, which has also received significant attention, particularly the task of ABox abduction [138, 143, 156, 198, 226]: we are required to compute a collection of ABox assertions (an explanation) whose addition to the available knowledge base would imply some given fact (the observation). This task is non-trivial, not least because the space of possible explanations is infinite in general. The above ideas have also been applied in the context of query answering in DLs, where services are provided to explain why some tuple is or is not present in the answer of some OMQ [72, 111, 117, 118, 144].
Evolving data In most of the works discussed so far, data that is managed and queried with the help of ontologies is mostly assumed to be static. However, in most realistic scenarios data is not fixed, but it evolves because users are performing some data-manipulating actions, new information becomes available, some information becomes outdated, and so on. Reasoning about evolving data in the presence of ontologies is a core topic that is closely related to the classic AI area of reasoning about actions and change [333]. Many works in this classic area, especially the ones on decidable formalisms and actual systems, are in the realm of propositional theories. Reasoning about evolving data is more challenging, because the propositional setting is often not sufficient (e.g., it may require reasoning about a transition system with an infinite number of states). Reasoning about actions in DLs has received significant attention; see, e.g., [24, 36, 137, 260] for some positive decidability results. Further decidability and complexity results on reasoning (e.g., verification) in dynamic systems that involve databases or domain knowledge expressed using DLs can be found in [31, 35, 105, 108, 110, 201, 387]. This topic is closely related to the larger area of temporal DLs, which we will review in the next section.
3.2 Extensions of Standard Ontology Languages
Even the most expressive DLs have a restricted ability to capture particular aspects of knowledge and/or data such as temporal changes, probabilistic behavior, or vagueness. In order to design ontology languages that overcome these limitations, several extensions of DLs have been studied, such as temporal, probabilistic, or fuzzy DLs, as well as generalizations of DLs with relations of higher arities, and combinations of DLs with rules.
Temporal DLs In many applications, data is changing over time, or the background knowledge has an inherently temporal component (e.g., in a medical context, one may think of patient records, or diseases and treatments having effects on a patient in the future). Standard ontology languages cannot capture temporal data or knowledge conveniently. For this reason, temporal extensions of ontology languages have been considered. Temporal DLs (TDLs) comprise a large and diverse family of DLs equipped with the ability to represent and reason over time. There are several ways to represent time: (1) in the point-based setting, discrete time points are assumed and operators from temporal logics such as LTL, CTL, and CTL* [157,158,159, 327] are used; (2) in the interval-based setting, time is represented by intervals and fragments of the Halpern-Shoham logic [200] are employed; (3) dense time is usually represented via variants of LTL that provide quantitative temporal operators [6, 7, 282]. Further ways to represent time include the use of datatypes [271] or formalisms in the spirit of action logics [15], but we focus on (1)–(3) here. Much of the work on TDLs since Schmiedel’s and Schild’s seminal papers [350, 352] is concerned with identifying combinations that provide a useful balance between expressive power on the one hand, and decidability and feasibility of the reasoning problems on the other hand.
(1) Point-based variants of TDLs date back to Schild [350] and have been receiving particular attention in the past two decades, as witnessed by several surveys [16, 17, 20, 34, 167, 285]. Many point-based TDLs are fragments of 2-sorted FOL [375] and correspond to combinations of modal logics, such as fusions or products; the extensive study of many-dimensional modal logics [167] has had a significant impact on their study.
There are several degrees of freedom when combining a DL and a temporal logic; the respective design choices affect the expressive power and computational behavior, and sometimes drastically so. The design choices are of syntactic nature (such as the underlying DL and temporal logic, the amount of integration of the temporal operators) and semantic nature (whether to assume domains to be constant or varying over time, whether to admit time-invariant predicates, and more).
TDLs with temporal concepts—i.e., the use of temporal operators as concept constructors—are useful for referring to the temporal evolution of concepts (unary predicates). A “person who will be a student at some time in the future” is a possible temporal concept. TDLs with temporal concepts have been studied based on \(\mathcal {ALC}\) and the temporal logics LTL and CTL. They provide only limited interaction between the DL and temporal components, and are computationally well-behaved, i.e., their standard reasoning problems—concept satisfiability, consistency—typically are not harder than in the component logics [18, 193, 285, 350, 384]. The interaction between both dimensions is increased significantly by adding rigid roles, i.e., the ability to assert that certain binary predicates are constant over time. This desirable modeling feature already makes combinations of LTL or CTL and the lightweight DL \(\mathcal {EL}\) undecidable [21, 195], unless severe syntactic restrictions are imposed [196].
TDLs with temporal roles but without temporal concepts offer an “intermediate” amount of interaction between the dimensions and typically have decidable standard reasoning problems, with an increase in complexity compared to the component logics [23].
TDLs with temporal axioms allow for the use of temporal and Boolean operators on DL axioms (ontology or ABox or both), which again strongly limits the interaction between the components. For these TDLs, the standard reasoning problems as well as temporal ontology-mediated query answering has been studied extensively. The standard reasoning problems for the combination of \(\mathcal {ALC}\) and LTL are not harder than the component logics in the case of, even when temporal concepts are added [31, 167, 285, 384]; decidability is preserved even when fixpoints are added [166] or the DL component becomes more expressive, e.g., \(\mathcal {SHIQ}\) [285]. If the temporal component is replaced with a branching-time logic, then decidability is much harder (in the case of CTL) or undecidable (with CTL*) [54, 204]. Rigid roles lead to undecidability already in the presence of \(\mathcal {EL}\), but not of DL-Lite [21].
For temporal ontology-mediated query answering (TOMQA), data and combined complexity are the most relevant complexity measures, and the notion of rewritability into standard query languages is strongly related. In this context, the data (ABox) is usually assumed to consist of time-stamped facts, the queries are equipped with temporal operators, and the background knowledge (ontology) is either considered static or uses temporal operators as well. Typically, constant domains and a linear flow of time (the naturals, the reals, or an interval thereof) is assumed.
For TOMQA with static ontologies, with LTL-based temporal CQs (TCQs), and with and without rigid symbols, data and combined complexity have been studied [27, 75, 76]. The ontology languages considered in these works range from lightweight to expressive DLs. We briefly summarize the results: for data complexity, tractability holds for ontologies in (a) “very light” DL-Lite dialects or (b) \({\mathcal {EL}}\) without rigid symbols; many cases that involve ontology languages up to \(\mathcal {SHQ}\) are coNP-complete. In all cases, there is an ExpTime upper bound on data complexity. For the combined complexity, the results range from PSpace-completeness for the above cases (a) and (b) to 2ExpTime-completeness for the most expressive settings (\(\mathcal {SHQ}\) with rigid symbols, or “heavier” DL-Lite dialects with role inclusions).
Rewritability has been investigated in the context of the temporal database monitoring problem [73], where a fixed temporal query is evaluated over temporal segments of a database. Three approaches have been developed [73]: rewritings into a temporal extension of SQL such as ATSQL [125], rewritings that only discard future operators from the query and allow the use of an algorithm based on bounded history encoding [124], and an extension of the latter algorithm that can handle future operators. An alternative approach to the monitoring problem consists in the streaming data scenario [315,316,317], leading to the Stream-Temporal Query Language STARQL [318], which again permits rewritings to SQL [360].
Temporal extensions of DL-Lite with temporal (LTL) concepts have been tailored carefully to ensure FO-rewritability of OMQs based on full two-sorted CQs or queries consisting of positive temporal concepts/roles [17, 19, 246]. A similar extension of \(\mathcal {EL}\) ensures Datalog-rewritability for OMQs based on atomic queries [192].
TOMQA has also been studied for clausal fragments of LTL, where the ontology language is in the style of DL-Lite but additionally allows temporal operators in front of concept names, and the query language consists of atomic or positive temporal concepts, i.e., essentially LTL formulas without negation. Results on data complexity and rewritability into 2-sorted FOL and monadic second-order logic (MSO) have been obtained [19].
(2) Interval-based TDLs have also been considered for TOMQA. Decidable fragments of the Halpern-Shoham interval temporal logic \(\mathcal {HS}\) [88, 89, 200] were combined with DL-Lite for answering atomic OMQs 22]; this setting was extended to CQs and fragments of multidimensional \(\mathcal {HS}\) combined with Datalog [240].
(3) TDLs with dense time provide the ability to express that events take place within certain time intervals. Metric TDLs have been studied under several of the above design choices, i.e., with and without temporal concepts, temporal axioms and interval-rigid concepts and roles; most combinations are decidable, although often of higher complexity [26, 194, 215]. TOMQA has been studied for Datalog combined with Metric Temporal Logic [6, 247] and atomic queries; in particular, the data complexity for the non-recursive fragment is AC\(^0\) [84]. This TDL has been used in practice in the contexts of turbine monitoring and weather monitoring [84], and in a video search system for ballet learners [332]; an implementation and evaluation have been described [84, 85].
DLs with uncertainty and vagueness The necessity to represent uncertain or vague information has fostered the study of probabilistic, possibilistic, and fuzzy extensions of DLs.
We start with a brief overview of probabilistic logics. The literature on probabilistic first-order and probabilistic DLs distinguishes two types of probabilistic information to be represented [40, 199, 388]: (1) statistical information about the world, via asserting probabilities for a randomly chosen individual to belong to a class/property; (2) epistemic information, via asserting a degree of belief that a certain individual belongs to a class/property. Probabilistic extensions of DLs have been reviewed and categorized via the two types by Zese [388, Chapter 12]; we provide a summary:
Type 1 only: A simple extension of \(\mathcal {ALC}\) with probabilistic axioms has been devised and equipped with incomplete local inference rules [203, 218].
Type 2 only: Prob-\(\mathcal {ALC}\) [275] allows probabilistic concept expressions and assertions in the style of Halpern’s probabilistic first-order logic of type 2 [199]. PR-OWL [113] adds the first-order probabilistic logic MEBN [255] to OWL. \(\mathcal {EL}^{++}\)-LL [300] combines the DL underlying the OWL EL profile with probabilistic log-linear models; reasoning has been implemented in E-LOG [303]. Several probabilistic extensions of DLs of varying expressivity are based on, or translatable into Bayesian networks [136, 141, 233, 386]; Recently, for a Bayesian extension of DL [121] the reasoner BORN [119] was implemented and query answering was studied [120]. Ontology-based access to probabilistic data and ontological data exchange were investigated under various semantics and based on various DLs and existential rules [86, 162, 182, 220, 266, 267]. Combinations of DLs with probabilistic logic programs were introduced for query answering and learning [96, 388] (the latter with a reasoner TRILL) and representing ontology mappings [268].
Type 1 and 2: P-\(\mathcal {SHOQ}(D)\) and P-\(\mathcal {SHIQ}(D)\) [172, 263, 265] are based on a semantics from probabilistic default reasoning; for P-\(\mathcal {SROIQ}\), satisfiability and entailment checking are implemented in the reasoner PRONTO [229, 230]. cr\(\mathcal {ALC}\) [130] admits reasoning by translations to relational Bayesian networks and has also been studied in the context of learning [270].
As an alternative to probabilistic DLs, an extension of \(\mathcal {ALC}\) (and more expressive DLs) based on possibilistic logic has been devised and implemented in the PossDL reasoner [205, 330]. Possibilistic \(\mathcal {ALC}\) allows the annotation of axioms with weights, which are interpreted as lower bounds of necessity degrees based on the fuzzy set semantics of possibilistic logic [145, 259].
Yet another approach to modeling vagueness and imprecision is taken by fuzzy extensions of DLs which are related to classical fuzzy logics [126, 197] and many-valued logics [176, 228, 262]. They can model vagueness and imprecision by adding new degrees of truth to the standard values “true” and “false”. There are several semantics for fuzzy logics; they all are based on (non-Boolean) functions interpreting the Boolean operators. Fuzzy logics thus enjoy “truth functionality” in contrast to probabilistic or possibilistic logics: the truth degree of a formula in fuzzy logic is uniquely determined by the truth degrees of its subformulas.
Fuzzy DLs have been studied based on several (expressive and inexpressive) DLs and under several fuzzy semantics. Standard reasoning tasks as well as conjunctive query answering have been considered and implemented in several reasoners and ontology editor plug-ins. We limit ourselves to mentioning that essentially every truly fuzzy DL that allows for expressing terminological cycles is undecidable, see the discussion in a recent project report [28]. For a concise overview of fuzzy DLs, we refer the interested reader to a recent survey article [74], which also contains information on diverse applications of fuzzy DLs.
Higher-arity relations Recall that—with just a few exceptions (see, e.g., [101])—DLs allow building ontologies using only unary and binary relation symbols. Recall also that most DLs can be seen as fragments of \({\mathcal {C}}^2\), which in turn is a decidable fragment of first-order logic with counting quantifiers. Another prominent decidable fragment of first-order logic is the guarded fragment (GF), which also captures many DLs yet features relations with higher arities and allows for formulas with an arbitrary number of variables [9, 216]. An even more expressive yet decidable fragment is the guarded negation fragment [47], which combines the ideas behind GF and another fragment called the unary negation fragment [353]. Another decidable fragment, called the triguarded fragment, combines GF with the two-variable fragment of first-order logic [347] (see also [81, 223]).
The ideas behind GF have spurred efforts to develop new expressive ontology languages that support higher-arity relations, often resulting in formalisms that are orthogonal to DLs in terms of expressiveness. One prominent example is guarded tuple-generating dependencies (TGDs) (also known as guarded existential rules) [93]. Roughly speaking, an ontology here is a set of rules with possibly existentially quantified variables in head atoms. Decidability of reasoning is ensured by requiring TGDs to be guarded: each rule is required to have a body atom (a guard) that contains all universally quantified variables of the given rule. The authors of [93] also relaxed this condition to weak guardedness, which excludes from guarding the variables that can be safely assumed to range over a small collection of known values. The notion of frontier-guarded rules, which generalizes guarded rules, was proposed in [42, 43]. Frontier-guarded rules are defined as guarded rules except that a guard in a rule is not required to contain all of the rule’s universal variables, but must contain all universal variables that occur in the head of the rule.
Many of the above and other related languages have been studied in various aspects, including decidability, data and combined complexity, query answering, expressive power, rewritability, and others. Query answering has naturally received most attention; see, e.g., [41, 48, 80, 93,94,95, 221]. Rewritability of query answering—targeting first-order logic (FO-rewritability) or more expressive languages like variants of Datalog—is an important tool in many of these paper, but sometimes it is studied on its own right (see, e.g., [4, 46, 185]). The combined approach (to query answering), discussed in Sect. 3.1 for DLs, was explored for existential rules in [183, 373]. Reasoning in the presence of closed predicates, which we discussed previously, has also received some attention [56, 60]. Please also see [184, 296] for tutorials on existential rules.
Ontologies and rules We have seen that in the area of query answering in DLs, CQs provide a basic way to specify what needs to be retrieved from the available data while taking into account a given ontology. We have also mentioned that CQs are an example of simple rules (see Example 1). Naturally, many authors have considered the use of more complex rules and rule sets in combination with ontologies; see, e.g., [154, 189, 209, 210, 253, 254, 258, 294]. This is a challenging topic as here usually recursion is considered, which brings a lot of expressiveness yet can easily lead to undecidability if no syntactic restrictions on rules are applied. Several authors considered extending rules with default negation (or, negation as failure), which allows rules to infer new facts based on the absence of information. Since such facts can be retracted after new information becomes available, inference with such rules is non-monotonic, which brings additional challenges. Often the so-called answer set semantics and the well-founded semantics known from logic programming are used to handle ontologies equipped rules with default negation; see, e.g., [8, 44, 149, 155, 231, 232, 264, 269, 293, 339,340,341]. We note that in these and other related works the level of separation between the ontology and the rules varies significantly, and often rules are an integral part of the knowledge representation toolkit, rather than just being tools for specifying user queries.
3.3 Design-Phase Considerations
Most of the works discussed so far aim at providing intelligent services to the users of an ontology-based system. However, the development of such systems also requires reasoning support, which is often challenging since we do not have concrete data available (such problems are often called static analysis problems). Reasoning support for the development and optimization of queries, for building correct and accurate ontologies, as well as for the development and debugging of mappings in OBDA systems have received attention in the literature. We next discuss some of the reasoning services related to queries and ontologies, which is a rather well-established area. The development of OBDA mappings has received less attention; we only point to [67, 257] for some examples.
Query containment The most prominent example of a static analysis problem is query containment [3], which is a key task in contexts like query optimization, information integration, knowledge base verification (see, e.g., [116, 258] and the references therein). Given a pair \(Q_1,Q_2\) of database queries, the query containment problem is to decide whether all the tuples in the answer to \(Q_1\) are included in the answer to \(Q_2\), for any possible input database D. The complexity of query containment has been studied extensively in database theory, starting from the classical NP-completeness result for plain CQs [122]. In the context of ontologies, a more representative problem is that of query containment under constraints, where the containment of query answers is tested quantifying over all databases that satisfy a given set of constraints. E.g., this problem has been considered for various database integrity constraints [219], and for queries over XML documents under DTD constraints [116]. In the context of ontology-mediated queries, this problem corresponds to checking query containment in the models of a given ontology. In this setting, the initial results for (unions of) CQs were presented in [101, 212]. A tight 2ExpTime upper bound for (an extension of) CRPQs was obtained in [106], but under the restriction that inverse roles and role functionality are not present together as language features. Decidability and tight upper bounds in the case when both inverses and functionality are allowed were presented in [109].
A more general setting, where the containment is tested for a pair of OMQs with two possibly different ontologies, has been explored in [65]. The authors show that this richer setting remains decidable for many common DLs and query languages, but higher computational costs are incurred. E.g., containment of instance queries mediated by lightweight DLs of the DL-Lite and \(\mathcal {EL}\) families easily becomes intractable or even ExpTime-hard. Several 2NExpTime-completeness results for OMQ containment in expressive DLs can be found in [79]. A notable exception to decidability results is the case when functionality of roles or number restrictions are supported by the DL, e.g., containment of instance queries mediated by \(\mathcal {ALCF}\) ontologies is undecidable [65]. The query containment problem for some important Horn DLs was studied in [63]. This problem for ontologies expressed using existential rules was studied in [49].
Query emptiness Another important static analysis problem is deciding query emptiness, which was first studied for DLs in [261]. Roughly speaking, given an OMQ \(Q=({\mathcal {T}},{\mathcal {Q}})\), we would like to know if the answer to Q over \({\mathcal {A}}\) is empty, for any ABox \({\mathcal {A}}\) that is consistent with \({\mathcal {T}}\). If that is the case, then Q is clearly erroneous and should be corrected. Often in OBDA applications the signature of input ABoxes is significantly smaller than the signature of the ontology. Thus it is more suitable to narrow down the quantification from all ABoxes to ABoxes constructed using a restricted set of relation symbols. However, this restricted quantification often causes intractability and even undecidability [25]. In fact, several intractability and undecidability results for query containment in [65] are inherited from the lower bounds for query non-emptiness in [25]. For navigational queries, the closest work is [57], which considers satisfiability of XPath queries with DTD constraints. The query emptiness problem plays an important role also in other applications of ontologies in data management; for example, it is used for ontology focusing algorithms in [178].
Modularity Modern ontologies can reach considerable sizes; SNOMED CT (mentioned in Sect. 2.1) and the NCI Thesaurus [180] are prominent examples with (much) more than 100,000 axioms. Large ontologies pose serious challenges not only to the best optimized reasoners, but to all constituents of the ontology development process, such as navigation, editing, comprehension, and debugging. Module extraction and modularization help alleviate these problems and support application scenarios such as reuse, collaborative development, or versioning; see also [320]. Modularity has been studied extensively both theoretically and practically; see, e.g., [369]. The studied approaches can be divided into a-priori and a-posteriori approaches.
A-priori approaches allow the developer to impose a modular structure on an ontology at the time of development. They comprise suitable extensions of standard ontology languages, such as package-based DLs [45], distributed DLs [356], and \({\mathcal {E}}\)-connections [134].
A-posteriori approaches can be applied to a given monolithic ontology to either extract a single module, or decompose an ontology into several modules. The term “module” can be understood in a broad sense: often it is a subset of the given ontology with certain logical guarantees that ensure an encapsulation of knowledge; however, logical guarantees as well as the subset requirement are not postulated by all a-posteriori approaches.
Module extraction and decomposition approaches without logical guarantees are usually based on some form of syntactic traversal of an ontology’s class hierarchy or other representation [305, 354, 370]. In contrast, approaches with logical guarantees are based on the notion of a conservative extension (CE), which ensures that a subset \({\mathcal {M}}\) of an ontology \({\mathcal {O}}\) encapsulates all the knowledge in \({\mathcal {O}}\) about a given signature (part of \({\mathcal {O}}\)’s vocabulary) [170]. CEs come in several variants (deductive, query-based, model-theoretic) and are generalized by the notion of inseparability [236], see also a recent survey on CEs [77]. Since inseparability and CEs are very hard or even undecidable for most DLs [170, 281, 283], most logic-based a-posteriori module notions either apply to inexpressive DLs [168, 235, 241] or approximate minimal modules while guaranteeing conservativity [133, 304, 337]; the latter often provide further guarantees such as self-containment and depletingness [242]. Among those, locality-based modules (LBMs) [133] are particularly versatile, well-behaved [139, 348], and available in the OWL APIFootnote 10; they have recently been generalized via an approach based on Datalog reasoning [337].Footnote 11 Other studies have investigated the size of modules depending on the chosen module notion [168, 304]; further implementations exist (such as AMEX, or in the CEL reasoner; see the links in the original articles).
Decomposition approaches with logical guarantees exist in the form of signature decomposition [234, 321] or “true” ontology decomposition [135, 140]. The former induce modules of the input ontology that are no longer subsets (and related to interpolants, see below) and which exist only under certain conditions, which limits the benefits of these approaches for practical applications. Of the latter two approaches, the atomic decomposition (AD) partitions an ontology into atoms that are connected via a logically meaningful dependency relation [140]. The AD is implemented in the OWL API tools.Footnote 12
Uniform interpolation and forgetting As just indicated, interpolants are related to modules; in particular, uniform interpolants (UIs) can be regarded as (non-subset) modules with very similar logical guarantees. UIs have been studied widely for DLs of various expressivity [243, 244, 277, 284, 301, 371, 383]. The same holds for the dual notion of forgetting, which is important for applications that require information hiding [123, 150, 237, 382, 389, 390]; see also a recent survey in this journal [151].
3.4 Further topics
In addition to the topics discussed so far, further topics are being studied. The work on these topics is more ongoing or of a more specific interest. Here we list a few examples and refrain from a detailed discussion.
-
Learning (ontologies and queries): see the survey [313]
-
Stream reasoning with ontologies and/or (temporal) rules: see [92, 318, 338]
-
Abstraction refinement for ontology materialization: see [87, 174]
-
Interactive query formulation and answering: see [10, 12, 164, 360, 361]
-
Ranking OMQ answers: see [368]
4 Resources
There are recent and comprehensive textbooks and handbooks on ontologies [363], DLs [30, 33] and, more generally, on knowledge representation [202] and Semantic Web technologies [142]. The proceedings of the Reasoning Web summer schools provide tutorial notes introducing a wide variety of topics; see the DBLP entry.Footnote 13 There is also a recent survey on OBDA [385], and a recent Festschrift [274] gives an overview on active research topics in DLs.
Pointers to various tools, such as reasoners, ontology repositories, and web applications, can be found on the OWL web page at the University of Manchester.Footnote 14
A list of related events can be found in the editorial of this special issue.
5 Conclusion and Challenges
In this survey we have provided a rather broad overview of DL research that either directly envisions the use of ontologies in data management, or plays some important supporting role in this vision. While many works have been visited here, this survey is not meant to provide a full picture, or a complete review of the available literature of the field. Our goal was to discuss some representative works so that a newcomer can use them to start exploring the vast body of related literature.
Despite the big research efforts of the last years, many challenges remain to be addressed in order to realize the potential of ontologies in data management. For example, we need methods and techniques that enable interactive query answering, context-aware data access, managing information change, managing streaming data, assessing data quality, data analytics, a finer analysis of computational complexity. The challenges are too many to be discussed here, but luckily they have been collected and discussed in detail in Section 6 of [385] and in Section 5 of [1], which we recommend to read.
Notes
We are making a simplifying assumption here. ABoxes, in general, are allowed to contain more sophisticated assertions, but this usually does not add expressiveness to the formalism at hand, and thus we ignore them for the sake of presentation.
References
Abiteboul S, Arenas M, Barceló P, Bienvenu M, Calvanese D, David C, Hull R, Hüllermeier E, Kimelfeld B, Libkin L, Martens W, Milo T, Murlak F, Neven F, Ortiz M, Schwentick T, Stoyanovich J, Su J, Suciu D, Vianu V, Yi K (2018) Research directions for principles of data management (dagstuhl perspectives workshop 16151). Dagstuhl Manif 7(1):1–29. https://doi.org/10.4230/DagMan.7.1.1
Abiteboul S, Buneman P, Suciu D (1999) Data on the web: from relations to semistructured data and XML. Morgan Kaufmann, Burlington
Abiteboul S, Hull R, Vianu V (1995) Foundations of databases. Addison-Wesley, Boston
Ahmetaj S, Ortiz M, Šimkus M (2018) Rewriting guarded existential rules into small datalog programs. In: Proceedings of the 21st international conference on database theory (ICDT 2018), LIPIcs, vol 98. Schloss Dagstuhl. pp 4:1–4:24. https://doi.org/10.4230/LIPIcs.ICDT.2018.4
Ahmetaj S, Ortiz M, Šimkus M (2020) Polynomial rewritings from expressive description logics with closed predicates to variants of datalog. Artif Intell 280:103220. https://doi.org/10.1016/j.artint.2019.103220
Alur R, Henzinger TA (1993) Real-time logics: complexity and expressiveness. Inf Comput 104(1):35–77
Alur R, Henzinger TA (1994) A really temporal logic. J ACM 41(1):181–204
Alviano M, Morak M, Pieris A (2017) Stable model semantics for tuple-generating dependencies revisited. In: Proceedings of the 36th ACM SIGMOD-SIGACT-SIGAI symposium on principles of database systems (PODS 2017). ACM, pp 377–388. https://doi.org/10.1145/3034786.3034794
Andréka H, Németi I, van Benthem J (1998) Modal languages and bounded fragments of predicate logic. J Philos Log 27(3):217–274. https://doi.org/10.1023/A:1004275029985
Andresel M, Ibáñez-García Y, Ortiz M, Šimkus M (2019) Relaxing and restraining queries for OBDA. In: Proceedings of the 33rd AAAI conference on artificial intelligence (AAAI 2019). AAAI Press, pp 2654–2661. https://doi.org/10.1609/aaai.v33i01.33012654
Angele J, Kifer M, Lausen G (2009) Ontologies in F-Logic. In: Staab and Studer [363]. pp 45–70. https://doi.org/10.1007/978-3-540-92673-3
Arenas M, Cuenca Grau B, Kharlamov E, Marciuska S, Zheleznyakov D (2016) Faceted search over RDF-based knowledge graphs. J Web Semant 37–38:55–74. https://doi.org/10.1016/j.websem.2015.12.002
Artale A, Calvanese D, Kontchakov R, Ryzhikov V, Zakharyaschev M (2007) Reasoning over extended ER models. In: Proceedings of the 26th international conference on conceptual modeling (ER 2007), lecture notes in computer science, vol 4801. Springer, Berlin, pp 277–292. https://doi.org/10.1007/978-3-540-75563-0_20
Artale A, Calvanese D, Kontchakov R, Zakharyaschev M (2009) The DL-Lite family and relations. J Artif Intell Res 36:1–69. https://doi.org/10.1613/jair.2820
Artale A, Franconi E (1998) A temporal description logic for reasoning about actions and plans. J Artif Intell Res 9:463–506. https://doi.org/10.1613/jair.516
Artale A, Franconi E (2000) A survey of temporal extensions of description logics. Ann Math Artif Intell 30(1–4):171–210. https://doi.org/10.1023/A:1016636131405
Artale A, Franconi E (2005) Temporal description logics. In: Handbook of Temporal reasoning in artificial intelligence, foundations of artificial intelligence, vol 1. Elsevier, pp 375–388. https://doi.org/10.1016/S1574-6526(05)80014-8
Artale A, Franconi E, Wolter F, Zakharyaschev M (2002) A temporal description logic for reasoning over conceptual schemas and queries. In: Proceedings of the European Conference on logics in artificial intelligence (JELIA 2002), lecture notes in computer science, vol 2424. Springer, Berlin, pp 98–110. https://doi.org/10.1007/3-540-45757-7_9
Artale A, Kontchakov R, Kovtunova A, Ryzhikov V, Wolter F, Zakharyaschev M (2015) First-order rewritability of temporal ontology-mediated queries. In: Proceedings of the 24th international joint conference on artificial intelligence (IJCAI 2015). AAAI Press, pp 2706–2712. http://ijcai.org/Abstract/15/383
Artale A, Kontchakov R, Kovtunova A, Ryzhikov V, Wolter F, Zakharyaschev M (2017) Ontology-mediated query answering over temporal data: a survey (invited talk). In: Proceedings of the 24th international symposium on temporal representation and reasoning (TIME 2017), LIPIcs, vol 90. Schloss Dagstuhl, pp 1:1–1:37. https://doi.org/10.4230/LIPIcs.TIME.2017.1
Artale A, Kontchakov R, Lutz C, Wolter F, Zakharyaschev M (2007) Temporalising tractable description logics. In: Proceedings of the 14th international symposium on temporal representation and reasoning (TIME 2007). IEEE Computer Society, pp 11–22. https://doi.org/10.1109/TIME.2007.62
Artale A, Kontchakov R, Ryzhikov V, Zakharyaschev M (2015) Tractable interval temporal propositional and description logics. In: Proceedings of the 29th AAAI conference on artificial intelligence (AAAI 2015). AAAI Press, pp 1417–1423. http://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/view/9638
Artale A, Lutz C, Toman D (2006) A description logic of change. In: Proceedings of the international workshop on description logics (DL2006), CEUR Workshop proceedings, vol 189. CEUR-WS.org. http://ceur-ws.org/Vol-189/submission_35.pdf
Artale A, Lutz C, Toman D (2007) A description logic of change. In: Proceedings of the 20th international joint conference on artificial intelligence (IJCAI 2007). pp 218–223. http://ijcai.org/Proceedings/07/Papers/033.pdf
Baader F, Bienvenu M, Lutz C, Wolter F (2016) Query and predicate emptiness in ontology-based data access. J Artif Intell Res 56:1–59. https://doi.org/10.1613/jair.4866
Baader F, Borgwardt S, Koopmann P, Ozaki A, Thost V (2017) Metric temporal description logics with interval-rigid names. In: Proceedings of the 11th international symposium on frontiers of combining systems (FroCoS 2017), lecture notes in computer science, vol 10483. Springer, Berlin, pp 60–76. https://doi.org/10.1007/978-3-319-66167-4_4
Baader F, Borgwardt S, Lippmann M (2015) Temporal query entailment in the description logic \(\cal{SHQ}\). J Web Semant 33:71–93. https://doi.org/10.1016/j.websem.2014.11.008
Baader F, Borgwardt S, Peñaloza R (2017) Decidability and complexity of fuzzy description logics. KI 31(1):85–90. https://doi.org/10.1007/s13218-016-0459-3
Baader F, Brandt S, Lutz C (2005) Pushing the \(\cal{EL}\) envelope. In: Proceedings of the 19th international joint conference on artificial intelligence (IJCAI 2005). Professional Book Center, pp 364–369. http://ijcai.org/Proceedings/05/Papers/0372.pdf
Baader F, Calvanese D, McGuinness DL, Nardi D, Patel-Schneider PF (eds) (2003) The description logic handbook: theory, implementation, and applications. Cambridge University Press, Cambridge
Baader F, Ghilardi S, Lutz C (2012) LTL over description logic axioms. ACM Trans Comput Log 13(3):21:1–21:32. https://doi.org/10.1145/2287718.2287721
Baader F, Hollunder B (1995) Embedding defaults into terminological knowledge representation formalisms. J Autom Reason 14(1):149–180. https://doi.org/10.1007/BF00883932
Baader F, Horrocks I, Lutz C, Sattler U (2017) An introduction to description logic. Cambridge University Press, Cambridge
Baader F, Küsters R, Wolter F (2003) Extensions to description logics. In: Baader et al. [30]. pp 219–261
Baader F, Lippmann M (2014) Runtime verification using the temporal description logic \(\cal{ALC}\)-LTL revisited. J Appl Log 12(4):584–613. https://doi.org/10.1016/j.jal.2014.09.001
Baader F, Lutz C, Milicic M, Sattler U, Wolter F (2005) Integrating description logics and action formalisms: first results. In: Proceedings of the 20th national conference on artificial intelligence (AAAI 2005). AAAI Press/The MIT Press, pp 572–577. http://www.aaai.org/Library/AAAI/2005/aaai05-089.php
Baader F, Lutz C, Suntisrivaraporn B (2006) CEL—a polynomial-time reasoner for life science ontologies. In: Proceedings of the 3rd international joint conference on automated reasoning (IJCAR 2006), lecture notes in computer science, vol 4130. Springer, Berlin, pp 287–291. https://doi.org/10.1007/11814771_25
Baader F, Lutz C, Turhan A (2010) Small is again beautiful in description logics. KI 24(1):25–33. https://doi.org/10.1007/s13218-010-0004-8
Baader F, Peñaloza R (2010) Axiom pinpointing in general tableaux. J Log Comput 20(1):5–34. https://doi.org/10.1093/logcom/exn058
Bacchus F (1990) Representing and reasoning with probabilistic knowledge: a logical approach to probabilities. MIT Press, Cambridge
Baget J, Bienvenu M, Mugnier M, Thomazo M (2017) Answering conjunctive regular path queries over guarded existential rules. In: Proceedings of the 26th international joint conference on artificial intelligence (IJCAI 2017). pp 793–799. ijcai.org. https://doi.org/10.24963/ijcai.2017/110
Baget J, Leclère M, Mugnier M, Salvat E (2011) On rules with existential variables: walking the decidability line. Artif Intell 175(9–10):1620–1654. https://doi.org/10.1016/j.artint.2011.03.002
Baget J, Mugnier M, Rudolph S, Thomazo M (2011) Walking the complexity lines for generalized guarded existential rules. In: Proceedings of the 22nd international joint conference on artificial intelligence (IJCAI 2011). IJCAI/AAAI, pp 712–717. https://doi.org/10.5591/978-1-57735-516-8/IJCAI11-126
Bajraktari L, Ortiz M, Šimkus M (2018) Combining rules and ontologies into clopen knowledge bases. In: Proceedings of the 32nd AAAI conference on artificial intelligence (AAAI 2018). AAAI Press, pp 1728–1735. https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/16991
Bao J, Voutsadakis G, Slutzki G, Honavar VG (2009) Package-based description logics. In: Stuckenschmidt et al. [369]. pp 349–371. https://doi.org/10.1007/978-3-642-01907-4_16
Bárány V, Benedikt M, ten Cate B (2013) Rewriting guarded negation queries. In: Proceedings of the 38th international symposium on mathematical foundations of computer science (MFCS 2013), lecture notes in computer science, vol 8087. Springer, pp 98–110. https://doi.org/10.1007/978-3-642-40313-2_11
Bárány V, ten Cate B, Segoufin L (2015) Guarded negation. J ACM 62(3):22:1–22:26. https://doi.org/10.1145/2701414
Bárány V, Gottlob G, Otto M (2010) Querying the guarded fragment. In: Proceedings of the 25th annual IEEE symposium on logic in computer science (LICS 2010). IEEE Computer Society, pp 1–10. https://doi.org/10.1109/LICS.2010.26
Barceló P, Berger G, Pieris A (2018) Containment for rule-based ontology-mediated queries. In: Proceedings of the 37th ACM SIGMOD-SIGACT-SIGAI symposium on principles of database systems (PODS 2018). ACM, pp 267–279. https://doi.org/10.1145/3196959.3196963
Barceló P, Hurtado CA, Libkin L, Wood PT (2010) Expressive languages for path queries over graph-structured data. In: Proceedings of the 29th ACM SIGMOD-SIGACT-SIGART symposium on principles of database systems (PODS 2010). ACM, pp 3–14. https://doi.org/10.1145/1807085.1807089
Barceló P, Libkin L, Reutter JL (2014) Querying regular graph patterns. J ACM 61(1):8:1–8:54. https://doi.org/10.1145/2559905
Barceló P, Pérez J, Reutter JL (2012) Relative expressiveness of nested regular expressions. In: Proceedings of the 6th Alberto Mendelzon international workshop on foundations of data management (AMW 2012), CEUR workshop proceedings, vol 866. pp 180–195. CEUR-WS.org. http://ceur-ws.org/Vol-866/paper13.pdf
Bate A, Motik B, Grau BC, Cucala DT, Simancik F, Horrocks I (2018) Consequence-based reasoning for description logics with disjunctions and number restrictions. J Artif Intell Res 63:625–690. https://doi.org/10.1613/jair.1.11257
Bauer S, Hodkinson IM, Wolter F, Zakharyaschev M (2004) On non-local propositional and weak monodic quantified CTL. J Log Comput 14(1):3–22. https://doi.org/10.1093/logcom/14.1.3
Bednarczyk B, Rudolph S (2019) Worst-case optimal querying of very expressive description logics with path expressions and succinct counting. In: Proceedings of the 28th international joint conference on artificial intelligence (IJCAI 2019). pp 1530–1536. ijcai.org. https://doi.org/10.24963/ijcai.2019/212
Benedikt M, Bourhis P, ten Cate B, Puppis G (2016) Querying visible and invisible information. In: Proceedings of the 31st annual ACM/IEEE symposium on logic in computer science (LICS 2016). ACM, pp 297–306. https://doi.org/10.1145/2933575.2935306
Benedikt M, Fan W, Geerts F (2008) Xpath satisfiability in the presence of DTDS. J ACM 55(2):8:1–8:79. https://doi.org/10.1145/1346330.1346333
Berardi D, Calvanese D, De Giacomo G (2005) Reasoning on UML class diagrams. Artif Intell 168(1–2):70–118. https://doi.org/10.1016/j.artint.2005.05.003
Bienvenu M (2020) A short survey on inconsistency handling in ontology-mediated query answering. KI 34(4)
Bienvenu M, Bourhis P (2019) Mixed-world reasoning with existential rules under active-domain semantics. In: Proceedings of the 28th international joint conference on artificial intelligence (IJCAI 2019). pp 1558–1565. ijcai.org. https://doi.org/10.24963/ijcai.2019/216
Bienvenu M, Calvanese D, Ortiz M, Šimkus M (2014) Nested regular path queries in description logics. In: Proceedings of the 14th international conference on principles of knowledge representation and reasoning (KR 2014). AAAI Press. http://www.aaai.org/ocs/index.php/KR/KR14/paper/view/8000
Bienvenu M, ten Cate B, Lutz C, Wolter F (2014) Ontology-based data access: a study through disjunctive datalog, CSP, and MMSNP. ACM Trans Database Syst 39(4):33:1–33:44. https://doi.org/10.1145/2661643
Bienvenu M, Hansen P, Lutz C, Wolter F (2016) First order-rewritability and containment of conjunctive queries in Horn description logics. In: Proceedings of the 25th international joint conference on artificial intelligence (IJCAI 2016). IJCAI/AAAI Press, pp 965–971. http://www.ijcai.org/Abstract/16/141
Bienvenu M, Kikot S, Kontchakov R, Podolskii VV, Zakharyaschev M (2018) Ontology-mediated queries: combined complexity and succinctness of rewritings via circuit complexity. J ACM 65(5):28:1–28:51. https://doi.org/10.1145/3191832
Bienvenu M, Lutz C, Wolter F (2012) Query containment in description logics reconsidered. In: Proceedings of the 13th international conference on principles of knowledge representation and reasoning (KR 2012). AAAI Press. http://www.aaai.org/ocs/index.php/KR/KR12/paper/view/4535
Bienvenu M, Ortiz M, Šimkus M (2015) Regular path queries in lightweight description logics: complexity and algorithms. J Artif Intell Res 53:315–374. https://doi.org/10.1613/jair.4577
Bienvenu M, Rosati R (2016) Query-based comparison of mappings in ontology-based data access. In: Proceedings of the 15th international conference on principles of knowledge representation and reasoning (KR 2016). AAAI Press, pp 197–206. http://www.aaai.org/ocs/index.php/KR/KR16/paper/view/12902
Böhme S, Lippmann M (2015) Decidable description logics of context with rigid roles. In: Proceedings of the 10th international symposium on frontiers of combining systems (FroCoS’15), lecture notes in artificial intelligence, vol 9322. Springer
Bonatti PA (2019) Rational closure for all description logics. Artif Intell 274:197–223. https://doi.org/10.1016/j.artint.2019.04.001
Bonatti PA, Lutz C, Wolter F (2009) The complexity of circumscription in DLS. J Artif Intell Res 35:717–773. https://doi.org/10.1613/jair.2763
Borgida A (1996) On the relative expressiveness of description logics and predicate logics. Artif Intell 82(1–2):353–367. https://doi.org/10.1016/0004-3702(96)00004-5
Borgida A, Calvanese D, Rodriguez-Muro M (2008) Explanation in the DL-Lite family of description logics. In: On the move to meaningful internet systems: OTM, proceedings, Part II, lecture notes in computer science, vol 5332. Springer, Berlin, pp 1440–1457. https://doi.org/10.1007/978-3-540-88873-4_35
Borgwardt S, Lippmann M, Thost V (2015) Temporalizing rewritable query languages over knowledge bases. J Web Semant 33:50–70. https://doi.org/10.1016/j.websem.2014.11.007
Borgwardt S, Peñaloza R (2017) Fuzzy description logics—a survey. In: Proceedings of the 11th international conference on scalable uncertainty management (SUM 2017), lecture notes in computer science, vol 10564. Springer, Berlin, pp 31–45. https://doi.org/10.1007/978-3-319-67582-4_3
Borgwardt S, Thost V (2015) Temporal query answering in DL-Lite with negation. In: Proceedings of the global conference on artificial intelligence (GCAI 2015), EPiC series in computing, vol 36. EasyChair, pp 51–65. http://www.easychair.org/publications/paper/245305
Borgwardt S, Thost V (2015) Temporal query answering in the description logic \(\cal{EL}\). In: Proceedings of the 24th international joint conference on artificial intelligence (IJCAI 2015). AAAI Press, pp 2819–2825. http://ijcai.org/Abstract/15/399
Botoeva E, Konev B, Lutz C, Ryzhikov V, Wolter F, Zakharyaschev M (2016) Inseparability and conservative extensions of description logic ontologies: a survey. In: Proceedings of the 12th reasoning web international summer school (RW 2016), lecture notes in computer science, vol 9885. Springer, Berlin, pp 27–89. https://doi.org/10.1007/978-3-319-49493-7_2
Bouquet P, Giunchiglia F, van Harmelen F, Serafini L, Stuckenschmidt H (2004) Contextualizing ontologies. J Web Semant 1(4):325–343. https://doi.org/10.1016/j.websem.2004.07.001
Bourhis P, Lutz C (2016) Containment in monadic disjunctive datalog, MMSNP, and expressive description logics. In: Proceedings of the 15th international conference on principles of knowledge representation and reasoning (KR 2016). AAAI Press, pp 207–216. http://www.aaai.org/ocs/index.php/KR/KR16/paper/view/12847
Bourhis P, Manna M, Morak M, Pieris A (2016) Guarded-based disjunctive tuple-generating dependencies. ACM Trans Database Syst 41(4):27:1–27:45. https://doi.org/10.1145/2976736
Bourhis P, Morak M, Pieris A (2017) Making cross products and guarded ontology languages compatible. In: Proceedings of the 26th international joint conference on artificial intelligence (IJCAI 2017). pp 880–886. ijcai.org. https://doi.org/10.24963/ijcai.2017/122
Bozzato L, Eiter T, Serafini L (2019) Reasoning on \({\mathit{DL-Lite}}_{R}\) with defeasibility in ASP. In: Proceedings of the 3rd international joint conference on rules and reasoning (RuleML+RR 2019), lecture notes in computer science, vol 11784. Springer. https://doi.org/10.1007/978-3-030-31095-0_2
Brachman RJ, Schmolze JG (1985) An overview of the KL-ONE knowledge representation system. Cognit Sci 9(2):171–216. https://doi.org/10.1207/s15516709cog0902_1
Brandt S, Kalayci EG, Kontchakov R, Ryzhikov V, Xiao G, Zakharyaschev M (2017) Ontology-based data access with a Horn fragment of metric temporal logic. In: Proceedings of the 31st AAAI conference on artificial intelligence (AAAI 2017). AAAI Press, pp 1070–1076. http://aaai.org/ocs/index.php/AAAI/AAAI17/paper/view/14881
Brandt S, Kalayci EG, Ryzhikov V, Xiao G, Zakharyaschev M (2018) Querying log data with metric temporal logic. J Artif Intell Res 62:829–877. https://doi.org/10.1613/jair.1.11229
van Bremen T, Dries A, Jung JC (2019) Ontology-mediated queries over probabilistic data via probabilistic logic programming. In: Proceedings of the 28th ACM international conference on information and knowledge management (CIKM 2019). ACM, pp 2437–2440
Brenner M, Glimm B (2018) Embracing change by abstraction materialization maintenance for large ABoxes. In: Proceedings of the 27th international joint conference on artificial intelligence (IJCAI 2018). pp 1767–1773. ijcai.org. https://doi.org/10.24963/ijcai.2018/244
Bresolin D, Kurucz A, Muñoz-Velasco E, Ryzhikov V, Sciavicco G, Zakharyaschev M (2017) Horn fragments of the Halpern–Shoham interval temporal logic. ACM Trans Comput Log 18(3):22:1–22:39. https://doi.org/10.1145/3105909
Bresolin D, Monica DD, Goranko V, Montanari A, Sciavicco G (2008) Decidable and undecidable fragments of Halpern and Shoham’s interval temporal logic: towards a complete classification. In: Proceedings of the 15th international conference on logic for programming, artificial intelligence, and reasoning (LPAR 2008), lecture notes in computer science, vol 5330. Springer, Berlin, pp 590–604
Britz K, Casini G, Meyer T, Moodley K, Sattler U, Varzinczak I (2019) Theoretical foundations of defeasible description logics. CoRR. arXiv:1904.07559
Britz K, Meyer T, Varzinczak IJ (2011) Semantic foundation for preferential description logics. In: Proceedings of the 24th Australasian joint conference on advances in artificial intelligence (AI 2011), lecture notes in computer science, vol 7106. Springer, Berlin, pp 491–500. https://doi.org/10.1007/978-3-642-25832-9_50
Calbimonte J, Corcho Ó, Gray AJG (2010) Enabling ontology-based access to streaming data sources. In: Proceedings of the 9th international semantic web conference (ISWC 2010), lecture notes in computer science, vol 6496. Springer, Berlin, pp 96–111. https://doi.org/10.1007/978-3-642-17746-0_7
Calì A, Gottlob G, Kifer M (2013) Taming the infinite chase: query answering under expressive relational constraints. J Artif Intell Res 48:115–174. https://doi.org/10.1613/jair.3873
Calì A, Gottlob G, Lukasiewicz T (2012) A general datalog-based framework for tractable query answering over ontologies. J Web Semant 14:57–83. https://doi.org/10.1016/j.websem.2012.03.001
Calì A, Gottlob G, Pieris A (2012) Towards more expressive ontology languages: The query answering problem. Artif Intell 193:87–128. https://doi.org/10.1016/j.artint.2012.08.002
Calì A, Lukasiewicz T, Predoiu L, Stuckenschmidt H (2009) Tightly coupled probabilistic description logic programs for the semantic web. J Data Semanti 12:95–130. https://doi.org/10.1007/978-3-642-00685-2_4
Calvanese D, De Giacomo G, Lembo D, Lenzerini M, Poggi A, Rodriguez-Muro M, Rosati R, Ruzzi M, Savo DF (2011) The MASTRO system for ontology-based data access. Semant Web 2(1):43–53. https://doi.org/10.3233/SW-2011-0029
Calvanese D, De Giacomo G, Lembo D, Lenzerini M, Rosati R (2006) Data complexity of query answering in description logics. In: Proceedings of the 10th international conference on principles of knowledge representation and reasoning (KR 2006). AAAI Press, pp 260–270. http://www.aaai.org/Library/KR/2006/kr06-028.php
Calvanese D, De Giacomo G, Lembo D, Lenzerini M, Rosati R (2007) Tractable reasoning and efficient query answering in description logics: The DL-Lite family. J Autom Reason 39(3):385–429. https://doi.org/10.1007/s10817-007-9078-x
Calvanese D, De Giacomo G, Lenzerini M (2001) Identification constraints and functional dependencies in description logics. In: Proceedings of the 17th international joint conference on artificial intelligence (IJCAI 2001). Morgan Kaufmann, pp 155–160
Calvanese D, De Giacomo G, Lenzerini M (2008) Conjunctive query containment and answering under description logic constraints. ACM Trans Comput Log 9(3):22:1–22:31. https://doi.org/10.1145/1352582.1352590
Calvanese D, De Giacomo G, Lenzerini M, Rosati R (2012) View-based query answering in description logics: semantics and complexity. J Comput Syst Sci 78(1):26–46. https://doi.org/10.1016/j.jcss.2011.02.011
Calvanese D, De Giacomo G, Lenzerini M, Vardi MY (2000) Containment of conjunctive regular path queries with inverse. In: Proceedings of the 7th international conference on principles of knowledge representation and reasoning (KR 2000). Morgan Kaufmann, pp 176–185
Calvanese D, De Giacomo G, Lenzerini M, Vardi MY (2002) Rewriting of regular expressions and regular path queries. J Comput Syst Sci 64(3):443–465. https://doi.org/10.1006/jcss.2001.1805
Calvanese D, De Giacomo G, Montali M (2013) Foundations of data-aware process analysis: a database theory perspective. In: Proceedings of the 32nd ACM SIGMOD-SIGACT-SIGART symposium on principles of database systems (PODS 2013). ACM, pp 1–12. https://doi.org/10.1145/2463664.2467796
Calvanese D, Eiter T, Ortiz M (2009) Regular path queries in expressive description logics with nominals. In: Proceedings of the 21st international joint conference on artificial intelligence (IJCAI 2009). pp 714–720. http://ijcai.org/Proceedings/09/Papers/124.pdf
Calvanese D, Eiter T, Ortiz M (2014) Answering regular path queries in expressive description logics via alternating tree-automata. Inf Comput 237:12–55. https://doi.org/10.1016/j.ic.2014.04.002
Calvanese D, Montali M, Patrizi F, Stawowy M (2016) Plan synthesis for knowledge and action bases. In: Proceedings of the 25th international joint conference on artificial intelligence (IJCAI 2016). IJCAI/AAAI Press, pp 1022–1029. http://www.ijcai.org/Abstract/16/149
Calvanese D, Ortiz M, Šimkus M (2011) Containment of regular path queries under description logic constraints. In: Proceedings of the 22nd international joint conference on artificial intelligence (IJCAI 2011). IJCAI/AAAI, pp 805–812. https://doi.org/10.5591/978-1-57735-516-8/IJCAI11-141
Calvanese D, Ortiz M, Šimkus M (2016) Verification of evolving graph-structured data under expressive path constraints. In: Proceedings of the 19th international conference on database theory (ICDT 2016), LIPIcs, vol 48. Schloss Dagstuhl-Leibniz-Zentrum für Informatik. pp 15:1–15:19. https://doi.org/10.4230/LIPIcs.ICDT.2016.15
Calvanese D, Ortiz M, Šimkus M, Stefanoni G (2013) Reasoning about explanations for negative query answers in DL-Lite. J Artif Intell Res 48:635–669. https://doi.org/10.1613/jair.3870
Carral D, Dragoste I, Krötzsch M (2018) The combined approach to query answering in Horn-\(\cal{ALCHOIQ}\). In: Proceedings of the 16th international conference on principles of knowledge representation and reasoning (KR 2018). AAAI Press, pp 339–348. https://aaai.org/ocs/index.php/KR/KR18/paper/view/18076
Carvalho RN, Laskey KB, da Costa PCG (2017) PR-OWL: a language for defining probabilistic ontologies. Int J Approx Reason 91:56–79
Casini G, Straccia U (2010) Rational closure for defeasible description logics. In: Proceedings of the 12th European conference on logics in artificial intelligence (JELIA 2010), lecture notes in computer science, vol 6341. Springer, Berlin, pp 77–90. https://doi.org/10.1007/978-3-642-15675-5_9
Casini G, Straccia U (2013) Defeasible inheritance-based description logics. J Artif Intell Res 48:415–473. https://doi.org/10.1613/jair.4062
ten Cate B, Lutz C (2009) The complexity of query containment in expressive fragments of xpath 2.0. J ACM 56(6):31:1–31:48. https://doi.org/10.1145/1568318.1568321
Ceylan İİ, Lukasiewicz T, Malizia E, Vaicenavicius A (2019) Explanations for query answers under existential rules. In: Proceedings of the 28th international joint conference on artificial intelligence (IJCAI 2019). pp 1639–1646. ijcai.org. https://doi.org/10.24963/ijcai.2019/227
Ceylan İİ, Lukasiewicz T, Malizia E, Vaicenavičius A (2020) Explanations for ontology-mediated query answering in description logics. In: Proceedings of the 24th European conference on artificial intelligence (ECAI 2020)
Ceylan İİ, Mendez J, Peñaloza R (2015) The Bayesian ontology reasoner is BORN! In: Informal proceedings of the 4th international workshop on owl reasoner evaluation (ORE 2015), CEUR workshop proceedings, vol 1387, pp 8–14. CEUR-WS.org. http://ceur-ws.org/Vol-1387/paper_5.pdf
Ceylan İİ, Peñaloza R (2015) Probabilistic query answering in the Bayesian description logic \(\cal{BEL}\). In: Proceedings of the 9th international conference on scalable uncertainty management (SUM 2015), lecture notes in computer science, vol 9310. Springer, Berlin, pp 21–35. https://doi.org/10.1007/978-3-319-23540-0_2
Ceylan İİ, Peñaloza R (2017) The Bayesian ontology language \(\cal{BEL}\). J Autom Reason 58(1):67–95. https://doi.org/10.1007/s10817-016-9386-0
Chandra AK, Merlin PM (1977) Optimal implementation of conjunctive queries in relational data bases. In: Proceedings of the 9th annual ACM symposium on theory of computing (STOC 1977). ACM, pp 77–90. https://doi.org/10.1145/800105.803397
Chen J, Alghamdi G, Schmidt RA, Walther D, Gao Y (2019) Ontology extraction for large ontologies via modularity and forgetting. In: Proceedings of the 10th international conference on knowledge capture (K-CAP 2019). ACM, pp 45–52. https://doi.org/10.1145/3360901.3364424
Chomicki J (1995) Efficient checking of temporal integrity constraints using bounded history encoding. ACM Trans Database Syst 20(2):149–186
Chomicki J, Toman D, Böhlen MH (2001) Querying ATSQL databases with temporal logic. ACM Trans Database Syst 26(2):145–178
Cintula P, Hájek P, Noguera C (eds) (2011) Handbook of mathematical fuzzy logic, studies in logic, vol 37–38. College Publications, Albania
Civili C, Rosati R (2012) A broad class of first-order rewritable tuple-generating dependencies. In: Proceedings of the 2nd international workshop on datalog in Academia and industry (Datalog 2.0), lecture notes in computer science, vol. 7494. Springer, Berlin, pp 68–80. https://doi.org/10.1007/978-3-642-32925-8_8
Consens MP, Mendelzon AO (1990) Graphlog: a visual formalism for real life recursion. In: Proceedings of the 9th ACM SIGACT-SIGMOD-SIGART symposium on principles of database systems (PODS 1990), ACM Press, pp 404–416. https://doi.org/10.1145/298514.298591
Corcho Ó, Fernández-López M, Gómez-Pérez A (2006) Ontological engineering: principles, methods, tools and languages. In: Ontologies for software engineering and software technology. Springer, Berlin, pp 1–48
Cozman FG, Polastro RB (2008) Loopy propagation in a probabilistic description logic. In: Proceedings of the 2nd international conference on scalable uncertainty management (SUM 2008), lecture notes in computer science, vol 5291. Springer, Berlin, pp 120–133. https://doi.org/10.1007/978-3-540-87993-0_11
Cucala DT, Cuenca Grau B, Horrocks I (2019) 15 years of consequence-based reasoning. In: Lutz et al. [274]. pp 573–587. https://doi.org/10.1007/978-3-030-22102-7_27
Cucala DT, Cuenca Grau B, Horrocks I (2019) Sequoia: a consequence based reasoner for \(\cal{SROIQ}\). In: Proceedings of the 32nd international workshop on description logics (DL 2019), CEUR workshop proceedings, vol 2373. CEUR-WS.org. http://ceur-ws.org/Vol-2373/paper-27.pdf
Cuenca Grau B, Horrocks I, Kazakov Y, Sattler U (2009) Extracting modules from ontologies: a logic-based approach. In: Stuckenschmidt et al. [369]. pp 159–186. https://doi.org/10.1007/978-3-642-01907-4_8
Cuenca Grau B, Parsia B, Sirin E (2009) Ontology integration using \({\cal{E}}\)-connections. In: Stuckenschmidt et al. [369]. pp 293–320. https://doi.org/10.1007/978-3-642-01907-4_14
Cuenca Grau B, Parsia B, Sirin E, Kalyanpur A (2006) Modularity and web ontologies. In: Proceedings of the 10th international conference on principles of knowledge representation and reasoning (KR 2006). AAAI Press, pp 198–209. http://www.aaai.org/Library/KR/2006/kr06-022.php
d’Amato C, Fanizzi N, Lukasiewicz T (2008) Tractable reasoning with Bayesian description logics. In: Proceedings of the 2nd international conference on scalable uncertainty management (SUM 2008), lecture notes in computer science, vol 5291. Springer, Berlin, pp 146–159. https://doi.org/10.1007/978-3-540-87993-0_13
De Giacomo G, Lenzerini M, Poggi A, Rosati R (2009) On instance-level update and erasure in description logic ontologies. J Log Comput 19(5):745–770. https://doi.org/10.1093/logcom/exn051
Del-Pinto W, Schmidt RA (2019) ABox abduction via forgetting in \(\cal{ALC}\). In: The 33rd AAAI conference on artificial intelligence (AAAI 2019). AAAI Press, pp 2768–2775. https://doi.org/10.1609/aaai.v33i01.33012768
Del Vescovo C, Klinov P, Parsia B, Sattler U, Schneider T, Tsarkov D (2013) Empirical study of logic-based modules: Cheap is cheerful. In: Proceedings of the 12th international semantic web conference (ISWC 2013), lecture notes in computer science, vol 8218. Springer, Berlin, pp 84–100. https://doi.org/10.1007/978-3-642-41335-3_6
Del Vescovo C, Parsia B, Sattler U, Schneider T (2011) The modular structure of an ontology: atomic decomposition. In: Proceedings of the 22nd international joint conference on artificial intelligence (IJCAI 2011). IJCAI/AAAI, pp 2232–2237. https://doi.org/10.5591/978-1-57735-516-8/IJCAI11-372
Ding Z, Peng Y (2004) A probabilistic extension to ontology language OWL. In: 37th Hawaii international conference on system sciences (HICSS-37), CD-ROM/Abstracts proceedings. IEEE Computer Society
Domingue J, Fensel D, Hendler JA (eds) (2011) Handbook of semantic web technologies. Springer, Berlin. https://doi.org/10.1007/978-3-540-92913-0
Du J, Qi G, Shen Y, Pan JZ (2012) Towards practical ABox abduction in large description logic ontologies. Int J Semant Web Inf Syst 8(2):1–33. https://doi.org/10.4018/jswis.2012040101
Du J, Wang K, Shen Y (2014) A tractable approach to ABox abduction over description logic ontologies. In: Proceedings of the 28th AAAI conference on artificial intelligence (AAAI 2014). AAAI Press, pp 1034–1040. http://www.aaai.org/ocs/index.php/AAAI/AAAI14/paper/view/8191
Dubois D, Prade H (2004) Possibilistic logic: a retrospective and prospective view. Fuzzy Sets Syst 144(1):3–23
Ecke A, Pensel M, Turhan A (2015) Elastiq: answering similarity-threshold instance queries in \(\cal{EL}\). In: Proceedings of the 28th international workshop on description logics (DL 2015), CEUR workshop proceedings, vol 1350. CEUR-WS.org. http://ceur-ws.org/Vol-1350/paper-49.pdf
Ecke A, Peñaloza R, Turhan AY (2015) Similarity-based relaxed instance queries. J Appl Log 13(4, Part 1):480–508
Eiter T, Gottlob G, Ortiz M, Šimkus M (2008) Query answering in the description logic Horn-\(\cal{SHIQ}\). In: Proceedings of the 11th European conference on logics in artificial intelligence (JELIA 2008), lecture notes in computer science, vol 5293. Springer, Berlin, pp 166–179. https://doi.org/10.1007/978-3-540-87803-2_15
Eiter T, Ianni G, Lukasiewicz T, Schindlauer R, Tompits H (2008) Combining answer set programming with description logics for the semantic web. Artif Intell 172(12–13):1495–1539. https://doi.org/10.1016/j.artint.2008.04.002
Eiter T, Ianni G, Schindlauer R, Tompits H, Wang K (2006) Forgetting in managing rules and ontologies. In: 2006 IEEE/WIC/ACM International conference on web intelligence (WI). IEEE computer society, pp 411–419. https://doi.org/10.1109/WI.2006.83
Eiter T, Kern-Isberner G (2019) A brief survey on forgetting from a knowledge representation and reasoning perspective. KI 33(1):9–33. https://doi.org/10.1007/s13218-018-0564-6
Eiter T, Lutz C, Ortiz M, Šimkus M (2009) Query answering in description logics with transitive roles. In: Proceedings of the 21st international joint conference on artificial intelligence (IJCAI 2009), pp 759–764. http://ijcai.org/Proceedings/09/Papers/131.pdf
Eiter T, Ortiz M, Šimkus M (2012) Conjunctive query answering in the description logic SH using knots. J Comput Syst Sci 78(1):47–85. https://doi.org/10.1016/j.jcss.2011.02.012
Eiter T, Ortiz M, Šimkus M, Tran T, Xiao G (2012) Query rewriting for Horn-\(\cal{SHIQ}\) plus rules. In: Proceedings of the 26th AAAI conference on artificial intelligence (AAAI 2012). AAAI Press. http://www.aaai.org/ocs/index.php/AAAI/AAAI12/paper/view/4931
Eiter T, Šimkus M (2015) Linking open-world knowledge bases using nonmonotonic rules. In: Proceedings of the 13th international conference on logic programming and nonmonotonic reasoning (LPNMR 2015), lecture notes in computer science, vol 9345. Springer, Berlin, pp 294–308. https://doi.org/10.1007/978-3-319-23264-5_25
Elsenbroich C, Kutz O, Sattler U (2006) A case for abductive reasoning over ontologies. In: Proceedings of the OWLED*06 Workshop on OWL: experiences and directions, CEUR workshop proceedings, vol 216. CEUR-WS.org. http://ceur-ws.org/Vol-216/submission_25.pdf
Emerson EA (1990) Temporal and modal logic. In: Handbook of theoretical computer science, volume b: formal models and semantics. Elsevier and MIT Press, pp 995–1072
Emerson EA, Clarke EM (1982) Using branching time temporal logic to synthesize synchronization skeletons. Sci Comput Program 2(3):241–266
Emerson EA, Halpern JY (1986) “Sometimes” and “Not Never” revisited: on branching versus linear time temporal logic. J ACM 33(1):151–178
Feier C, Carral D, Stefanoni G, Cuenca Grau B, Horrocks I (2015) The combined approach to query answering beyond the OWL 2 profiles. In: Proceedings of the 24th international joint conference on artificial intelligence (IJCAI 2015). AAAI Press, pp 2971–2977. http://ijcai.org/Abstract/15/420
Figueira D, Figueira S, Pin Baque E (2020) Finite controllability for ontology-mediated query answering of CRPQ. https://hal.archives-ouvertes.fr/hal-02508782. Working paper or preprint
Finger M, Wassermann R, Cozman FG (2011) Satisfiability in \(\cal{EL}\) with sets of probabilistic ABoxes. In: Proceedings of the 24th international workshop on description logics (DL), CEUR workshop proceedings, vol 745. CEUR-WS.org. http://ceur-ws.org/Vol-745/paper_14.pdf
Florescu D, Levy AY, Suciu D (1998) Query containment for conjunctive queries with regular expressions. In: Proceedings of the 17th ACM SIGACT-SIGMOD-SIGART symposium on principles of database systems (PODS 1998). ACM Press, pp 139–148. https://doi.org/10.1145/275487.275503
Franconi E, Guagliardo P, Trevisan M, Tessaris S (2011) Quelo: an ontology-driven query interface. In: Proceedings of the 24th international workshop on description logics (DL 2011), CEUR workshop proceedings, vol 745. CEUR-WS.org. http://ceur-ws.org/Vol-745/paper_58.pdf
Franconi E, Ibáñez-García YA, Seylan I (2011) Query answering with DBoxes is hard. Electr Notes Theor Comput Sci 278:71–84. https://doi.org/10.1016/j.entcs.2011.10.007
Franconi E, Toman D (2011) Fixpoints in temporal description logics. In: Proceedings of the 22nd international joint conference on artificial intelligence (IJCAI 2011). IJCAI/AAAI, pp 875–880. https://doi.org/10.5591/978-1-57735-516-8/IJCAI11-152
Gabbay D, Kurucz A, Wolter F, Zakharyaschev M (2003) Many-dimensional modal logics: theory and applications, studies in Logic, vol 148. Elsevier Science Publishers (North-Holland), Amsterdam
Gatens W, Konev B, Wolter F (2014) Lower and upper approximations for depleting modules of description logic ontologies. In: Proceedings of the 21st European conference on artificial intelligence (ECAI 2014), frontiers in artificial intelligence and applications, vol 263. IOS Press, pp 345–350. https://doi.org/10.3233/978-1-61499-419-0-345
Genesereth MR (1991) Knowledge interchange format. In: Proceedings of the 2nd international conference on principles of knowledge representation and reasoning (KR 1991). Morgan Kaufmann, pp 599–600
Ghilardi S, Lutz C, Wolter F (2006) Did I damage my ontology? A case for conservative extensions in description logics. In: Proceedings of the 10th international conference on principles of knowledge representation and reasoning (KR 2006). AAAI Press, pp 187–197. http://www.aaai.org/Library/KR/2006/kr06-021.php
Giordano L, Gliozzi V, Olivetti N, Pozzato GL (2013) A non-monotonic description logic for reasoning about typicality. Artif Intell 195:165–202. https://doi.org/10.1016/j.artint.2012.10.004
Giugno R, Lukasiewicz T (2002) P-\(\cal{SHOQ}({\cal{D}})\): A probabilistic extension of \(\cal{SHOQ}({\cal{D}})\) for probabilistic ontologies in the semantic web. In: Proceedings of the European conference on logics in artificial intelligence (JELIA 2002), lecture notes in computer science, vol 2424. Springer, Berlin, pp 86–97. https://doi.org/10.1007/3-540-45757-7_8
Glimm B, Horrocks I, Motik B, Stoilos G, Wang Z (2014) Hermit: an OWL 2 reasoner. J. Autom. Reason. 53(3):245–269. https://doi.org/10.1007/s10817-014-9305-1
Glimm B, Kazakov Y, Liebig T, Tran T, Vialard V (2014) Abstraction refinement for ontology materialization. In: Proceedings of the 13th international semantic web conference (ISWC 2014), lecture notes in computer science, vol 8797. Springer, Berlin, pp 180–195. https://doi.org/10.1007/978-3-319-11915-1_12
Glimm B, Lutz C, Horrocks I, Sattler U (2008) Conjunctive query answering for the description logic \(\cal{SHIQ}\). J Artif Intell Res 31:157–204. https://doi.org/10.1613/jair.2372
Gödel K (1932) Zum intuitionistischen Aussagenkalkül. Anzeiger der Akademie der Wissenschaften in Wien 69:286–295 Reprinted 1986
Gogacz T, Gutiérrez-Basulto V, Ibáñez-García Y, Jung JC, Murlak F (2019) On finite and unrestricted query entailment beyond \(\cal{SQ}\) with number restrictions on transitive roles. In: Proceedings of the 28th international joint conference on artificial intelligence (IJCAI 2019). pp 1719–1725. ijcai.org. https://doi.org/10.24963/ijcai.2019/238
Gogacz T, Gutiérrez-Basulto V, Ibáñez-García YA, Murlak F, Ortiz M, Šimkus M (2020) Ontology focusing: knowledge-enriched databases on demand. In: Proceedings of the 24th European conference on artificial intelligence (ECAI 2020)
Gogacz T, Ibáñez-García YA, Murlak F (2018) Finite query answering in expressive description logics with transitive roles. In: Proceedings of the 16th international conference on principles of knowledge representation and reasoning (KR 2018). AAAI Press, pp 369–378. https://aaai.org/ocs/index.php/KR/KR18/paper/view/18062
Golbeck J, Fragoso G, Hartel FW, Hendler JA, Oberthaler J, Parsia B (2003) The national cancer institute’s thésaurus and ontology. J Web Semant 1(1):75–80. https://doi.org/10.1016/j.websem.2003.07.007
Gottlob G, Kikot S, Kontchakov R, Podolskii VV, Schwentick T, Zakharyaschev M (2014) The price of query rewriting in ontology-based data access. Artif Intell 213:42–59. https://doi.org/10.1016/j.artint.2014.04.004
Gottlob G, Lukasiewicz T, Simari GI (2011) Conjunctive query answering in probabilistic Datalog+/- ontologies. In: Proceedings of the 5th international conference on web reasoning and rule systems (RR 2011), lecture notes in computer science, vol 6902. Springer, Berlin, pp 77–92. https://doi.org/10.1007/978-3-642-23580-1_7
Gottlob G, Manna M, Pieris A (2014) Polynomial combined rewritings for existential rules. In: Proceedings of the 14th international conference on principles of knowledge representation and reasoning (KR 2014). AAAI Press. http://www.aaai.org/ocs/index.php/KR/KR14/paper/view/7973
Gottlob G, Orsi G, Pieris A, Šimkus M (2012) Datalog and its extensions for semantic web databases. In: Proceedings of the 8th reasoning web international summer school (RW 2012), lecture notes in computer science, vol 7487. Springer, Berlin, pp 54–77. https://doi.org/10.1007/978-3-642-33158-9_2
Gottlob G, Rudolph S, Šimkus M (2014) Expressiveness of guarded existential rule languages. In: Proceedings of the 33rd ACM SIGMOD-SIGACT-SIGART symposium on principles of database systems (PODS 2014). ACM, pp 27–38. https://doi.org/10.1145/2594538.2594556
Gottlob G, Schwentick T (2012) Rewriting ontological queries into small nonrecursive datalog programs. In: Proceedings of the 13th international conference on principles of knowledge representation and reasoning (KR 2012). AAAI Press. http://www.aaai.org/ocs/index.php/KR/KR12/paper/view/4510
Governatori G (2004) Defeasible description logics. In: Proceedings of the 3rd international workshop on rules and rule markup languages for the semantic web (RuleML 2004), lecture notes in computer science, vol 3323. Springer, Berlin, pp 98–112. https://doi.org/10.1007/978-3-540-30504-0_8
Grädel E, Otto M, Rosen E (1997) Two-variable logic with counting is decidable. In: Proceedings of the 12th annual IEEE symposium on logic in computer science (LICS 1997). IEEE Computer Society, pp 306–317. https://doi.org/10.1109/LICS.1997.614957
Grosof BN, Horrocks I, Volz R, Decker S (2003) Description logic programs: combining logic programs with description logic. In: Proceedings of the 12th international world wide web conference (WWW 2003). ACM, pp 48–57. https://doi.org/10.1145/775152.775160
Gruber TR (1995) Toward principles for the design of ontologies used for knowledge sharing? Int J Hum Comput Stud 43(5–6):907–928. https://doi.org/10.1006/ijhc.1995.1081
Gutiérrez-Basulto V, Ibáñez-García, YA, Jung JC (2018) Answering regular path queries over \(\cal{SQ}\) ontologies. In: Proceedings of the 32nd AAAI conference on artificial intelligence (AAAI 2018). AAAI Press, pp 1845–1852. https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/16242
Gutiérrez-Basulto V, Jung JC, Kontchakov R (2016) Temporalized \(\cal{EL}\) ontologies for accessing temporal data: complexity of atomic queries. In: Proceedings of the 25th international joint conference on artificial intelligence (IJCAI 2016). IJCAI/AAAI Press, pp 1102–1108. http://www.ijcai.org/Abstract/16/160
Gutiérrez-Basulto V, Jung JC, Lutz C (2012) Complexity of branching temporal description logics. In: Proceedings of the 20th European conference on artificial intelligence (ECAI 2012), frontiers in artificial intelligence and applications, vol 242. IOS Press, pp 390–395. https://doi.org/10.3233/978-1-61499-098-7-390
Gutiérrez-Basulto V, Jung JC, Ozaki A (2016) On metric temporal description logics. In: Proceedings of the 22nd European conference on artificial intelligence (ECAI 2016), frontiers in artificial intelligence and applications, vol 285. IOS Press, pp 837–845. https://doi.org/10.3233/978-1-61499-672-9-837
Gutiérrez-Basulto V, Jung JC, Schneider T (2014) Lightweight description logics and branching time: a troublesome marriage. In: Proceedings of the 14th international conference on principles of knowledge representation and reasoning (KR 2014). AAAI Press. http://www.aaai.org/ocs/index.php/KR/KR14/paper/view/7802
Gutiérrez-Basulto V, Jung JC, Schneider T (2015) Lightweight temporal description logics with rigid roles and restricted TBoxes. In: Proceedings of the 24th international joint conference on artificial intelligence (IJCAI 2015). AAAI Press, pp 3015–3021. http://ijcai.org/Abstract/15/426
Hájek P (1998) Metamathematics of fuzzy logic, trends in logic, vol 4. Kluwer, Amsterdam
Halland K, Britz K (2012) ABox abduction in \(\cal{ALC}\) using a DL tableau. In: 2012 South African Institute of computer scientists and information technologists conference, SAICSIT. ACM, pp 51–58. https://doi.org/10.1145/2389836.2389843
Halpern JY (1990) An analysis of first-order logics of probability. Artif Intell 46(3):311–350
Halpern JY, Shoham Y (1991) A propositional modal logic of time intervals. J ACM 38(4):935–962
Hariri BB, Calvanese D, De Giacomo G, Deutsch A, Montali M (2013) Verification of relational data-centric dynamic systems with external services. In: Proceedings of the 32nd ACM SIGMOD-SIGACT-SIGART symposium on principles of database systems (PODS 2013). ACM, pp 163–174. https://doi.org/10.1145/2463664.2465221
van Harmelen F, Lifschitz V, Porter BW (eds) (2008) Handbook of knowledge representation, foundations of artificial intelligence, vol 3. Elsevier, New York
Heinsohn J (1994) Probabilistic description logics. In: Proceedings of the 10th annual conference on uncertainty in artificial intelligence (UAI 1994). Morgan Kaufmann, pp 311–318
Hodkinson IM, Wolter F, Zakharyaschev M (2002) Decidable and undecidable fragments of first-order branching temporal logics. In: Proceedings of the 17th IEEE symposium on logic in computer science (LICS 2002). IEEE Comput Soc, pp 393–402. https://doi.org/10.1109/LICS.2002.1029847
Hollunder B (1995) An alternative proof method for possibilistic logic and its application to terminological logics. Int J Approx Reason 12(2):85–109
Horridge M, Parsia B, Sattler U (2008) Laconic and precise justifications in OWL. In: Proceedings of the 7th international semantic web conference (ISWC 2008), lecture notes in computer science, vol 5318. Springer, Berlin, pp 323–338. https://doi.org/10.1007/978-3-540-88564-1_21
Horrocks I (1998) Using an expressive description logic: fact or fiction? In: Proceedings of the 6th international conference on principles of knowledge representation and reasoning (KR’98). Morgan Kaufmann, pp 636–649
Horrocks I, Kutz O, Sattler U (2006) The even more irresistible \(\cal{SROIQ}\). In: Proceedings of the 10th international conference on principles of knowledge representation and reasoning (KR 2006). AAAI Press, pp 57–67. http://www.aaai.org/Library/KR/2006/kr06-009.php
Horrocks I, Patel-Schneider PF (2004) A proposal for an OWL rules language. In: Proceedings of the 13th international conference on World Wide Web (WWW 2004). ACM, pp 723–731. https://doi.org/10.1145/988672.988771
Horrocks I, Patel-Schneider PF, Bechhofer S, Tsarkov D (2005) OWL rules: a proposal and prototype implementation. J Web Semant 3(1):23–40. https://doi.org/10.1016/j.websem.2005.05.003
Horrocks I, Patel-Schneider PF, van Harmelen F (2003) From \(\cal{SHIQ}\) and RDF to OWL: the making of a web ontology language. J Web Semant 1(1):7–26. https://doi.org/10.1016/j.websem.2003.07.001
Horrocks I, Sattler U, Tessaris S, Tobies S (2000) How to decide query containment under constraints using a description logic. In: Proceedings of the 7th international conference on logic for programming and automated reasoning (LPAR 2000), lecture notes in computer science, vol 1955. Springer, Berlin, pp 326–343. https://doi.org/10.1007/3-540-44404-1_21
Hustadt U, Motik B, Sattler U (2005) Data complexity of reasoning in very expressive description logics. In: Proceedings of the 19th international joint conference on artificial intelligence (IJCAI 2005). Professional Book Center, pp 466–471. http://ijcai.org/Proceedings/05/Papers/0326.pdf
Hustadt U, Motik B, Sattler U (2007) Reasoning in description logics by a reduction to disjunctive datalog. J Autom Reason 39(3):351–384. https://doi.org/10.1007/s10817-007-9080-3
Hustadt U, Ozaki A, Dixon C (2017) Theorem proving for metric temporal logic over the naturals. In: Proceedings of the 26th international conference on automated deduction (CADE-26), lecture notes in computer science, vol 10395. Springer, Berlin, pp 326–343. https://doi.org/10.1007/978-3-319-63046-5_20
Hustadt U, Schmidt RA, Georgieva L (2004) A survey of decidable first-order fragments and description logics. J Relat Methods Comput Sci 1(251–276):3
Ibáñez-García YA, Lutz C, Schneider T (2014) Finite model reasoning in Horn description logics. In: Proceedings of the 14th international conference on principles of knowledge representation and reasoning (KR 2014). AAAI Press. http://www.aaai.org/ocs/index.php/KR/KR14/paper/view/7927
Jaeger M (1994) Probabilistic reasoning in terminological logics. In: Proceedings of the 4th international conference on principles of knowledge representation and reasoning (KR 1994). Morgan Kaufmann, pp 305–316
Johnson DS, Klug AC (1984) Testing containment of conjunctive queries under functional and inclusion dependencies. J Comput Syst Sci 28(1):167–189. https://doi.org/10.1016/0022-0000(84)90081-3
Jung JC, Lutz C (2012) Ontology-based access to probabilistic data with OWL QL. In: Proceedings of the 11th international semantic web conference (ISWC 2012), lecture notes in computer science, vol 7649. Springer, Berlin, pp 182–197. https://doi.org/10.1007/978-3-642-35176-1_12
Jung JC, Lutz C, Martel M, Schneider T (2018) Querying the unary negation fragment with regular path expressions. In: Proceedings of the 21st international conference on database theory (ICDT 2018), LIPIcs, vol 98. Schloss Dagstuhl, pp 15:1–15:18. https://doi.org/10.4230/LIPIcs.ICDT.2018.15
Kalyanpur A, Parsia B, Horridge M, Sirin E (2007) Finding all justifications of OWL DL entailments. In: The semantic web, 6th international semantic web conference, 2nd Asian semantic web conference, ISWC + ASWC, lecture notes in computer science, vol 4825. Springer, Berlin, pp 267–280. https://doi.org/10.1007/978-3-540-76298-0_20
Kazakov Y (2006) Saturation-based decision procedures for extensions of the guarded fragment. Ph.D. thesis, Universität des Saarlandes, Saarbrücken, Germany
Kazakov Y (2009) Consequence-driven reasoning for Horn \(\cal{SHIQ}\) ontologies. In: Proceedings of the 21st international joint conference on artificial intelligence (IJCAI 2009). pp 2040–2045. http://ijcai.org/Proceedings/09/Papers/336.pdf
Kazakov Y, Krötzsch M, Simancik F (2014) The incredible ELK: from polynomial procedures to efficient reasoning with \(\cal{EL}\) ontologies. J Autom Reason 53(1):1–61. https://doi.org/10.1007/s10817-013-9296-3
Klarman S, Endriss U, Schlobach S (2011) ABox abduction in the description logic \(\cal{ALC}\). J Autom Reason 46(1):43–80. https://doi.org/10.1007/s10817-010-9168-z
Klarman S, Gutiérrez-Basulto V (2016) Description logics of context. J Log Comput 26(3):817–854. https://doi.org/10.1093/logcom/ext011
Kleene SC (1952) Introduction to metamathematics. Van Nostrand, New York
Klinov P (2008) Pronto: a non-monotonic probabilistic description logic reasoner. In: Proceedings of the 5th European semantic web conference (ESWC 2008), lecture notes in computer science, vol 5021. Springer, Berlin, pp 822–826. https://doi.org/10.1007/978-3-540-68234-9_66
Klinov P, Parsia B (2013) Pronto: a practical probabilistic description logic reasoner. In: Uncertainty reasoning for the semantic web II, international workshops URSW, revised selected papers, lecture notes in computer science, vol 7123. Springer, Berlin, pp 59–79. https://doi.org/10.1007/978-3-642-35975-0_4
Knorr M, Alferes JJ, Hitzler P (2011) Local closed world reasoning with description logics under the well-founded semantics. Artif Intell 175(9–10):1528–1554. https://doi.org/10.1016/j.artint.2011.01.007
Knorr M, Hitzler P, Maier F (2012) Reconciling OWL and non-monotonic rules for the semantic web. In: Proceedings of the 20th European conference on artificial intelligence (ECAI 2012), frontiers in artificial intelligence and applications, vol 242. IOS Press, pp 474–479. https://doi.org/10.3233/978-1-61499-098-7-474
Koller D, Levy AY, Pfeffer A (1997) P-CLASSIC: a tractable probablistic description logic. In: Proceedings of the 14th national conference on artificial intelligence (AAAI 1997), pp 390–397
Konev B, Lutz C, Ponomaryov DK, Wolter F (2010) Decomposing description logic ontologies. In: Proceedings of the 12th international conference on principles of knowledge representation and reasoning (KR 2010). AAAI Press. http://aaai.org/ocs/index.php/KR/KR2010/paper/view/1356
Konev B, Lutz C, Walther D, Wolter F (2008) Semantic modularity and module extraction in description logics. In: Proceedings of the 18th European conference on artificial intelligence (ECAI 2008), frontiers in artificial intelligence and applications, vol 178. IOS Press, pp 55–59. https://doi.org/10.3233/978-1-58603-891-5-55
Konev B, Lutz C, Walther D, Wolter F (2009) Formal properties of modularisation. In: Stuckenschmidt et al. [369]. pp 25–66. https://doi.org/10.1007/978-3-642-01907-4_3
Konev B, Walther D, Wolter F (2009) Forgetting and uniform interpolation in large-scale description logic terminologies. In: Proceedings of the 21st international joint conference on artificial intelligence (IJCAI 2009). pp 830–835. http://ijcai.org/Proceedings/09/Papers/142.pdf
Kontchakov R, Lutz C, Toman D, Wolter F, Zakharyaschev M (2010) The combined approach to query answering in DL-Lite. In: Proceedings of the 12th international conference on principles of knowledge representation and reasoning (KR 2010). AAAI Press. http://aaai.org/ocs/index.php/KR/KR2010/paper/view/1282
Kontchakov R, Lutz C, Toman D, Wolter F, Zakharyaschev M (2011) The combined approach to ontology-based data access. In: Proceedings of the 22nd international joint conference on artificial intelligence (IJCAI 2011). IJCAI/AAAI, pp 2656–2661. https://doi.org/10.5591/978-1-57735-516-8/IJCAI11-442
Kontchakov R, Pandolfo L, Pulina L, Ryzhikov V, Zakharyaschev M (2016) Temporal and spatial OBDA with many-dimensional Halpern–Shoham logic. In: Proceedings of the 25th international joint conference on artificial intelligence (IJCAI 2016). IJCAI/AAAI Press, pp 1160–1166. http://www.ijcai.org/Abstract/16/168
Kontchakov R, Pulina L, Sattler U, Schneider T, Selmer P, Wolter F, Zakharyaschev M (2009) Minimal module extraction from DL-Lite ontologies using QBF solvers. In: Proceedings of the 21st international joint conference on artificial intelligence (IJCAI 2009). pp 836–841. http://ijcai.org/Proceedings/09/Papers/143.pdf
Kontchakov R, Wolter F, Zakharyaschev M (2010) Logic-based ontology comparison and module extraction, with an application to DL-Lite. Artif Intell 174(15):1093–1141. https://doi.org/10.1016/j.artint.2010.06.003
Koopmann P, Schmidt RA (2014) Count and forget: uniform interpolation of \(\cal{SHQ}\)-ontologies. In: Proceedings of the 7th international joint conference on automated reasoning (IJCAR 2014), lecture notes in computer science, vol 8562. Springer, Berlin, pp 434–448. https://doi.org/10.1007/978-3-319-08587-6_34
Koopmann P, Schmidt RA (2015) Uniform interpolation and forgetting for \(\cal{ALC}\) ontologies with ABoxes. In: Proceedings of the 29th AAAI conference on artificial intelligence (AAAI 2015). AAAI Press, pp 175–181. http://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/view/9981
Kostylev EV, Reutter JL, Vrgoc D (2015) Xpath for DL ontologies. In: Proceedings of the 29th AAAI conference on artificial intelligence (AAAI 2015). AAAI Press, pp 1525–1531. http://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/view/9459
Kovtunova A (2017) Ontology-mediated query answering with lightweight temporal description logics. Ph.D. thesis, KRDB research centre, Faculty of Computer Science, Free University of Bozen-Bolzano
Koymans R (1990) Specifying real-time properties with metric temporal logic. Real Time Syst 2(4):255–299. https://doi.org/10.1007/BF01995674
Krisnadhi A, Lutz C (2007) Data complexity in the \(\cal{EL}\) family of description logics. In: Proceedings of the 14th international conference on logic for programming, artificial intelligence, and reasoning (LPAR 2007), lecture notes in computer science, vol 4790. Springer, Berlin, pp 333–347. https://doi.org/10.1007/978-3-540-75560-9_25
Krisnadhi AA, Sengupta K, Hitzler P (2011) Local closed world semantics: Grounded circumscription for description logics. In: Proceedings of the 5th international conference on web reasoning and rule systems (RR 2011), lecture notes in computer science, vol 6902. Springer, Berlin, pp 263–268. https://doi.org/10.1007/978-3-642-23580-1_22
Krötzsch M, Marx M, Ozaki A, Thost V (2018) Attributed description logics: reasoning on knowledge graphs. In: Proceedings of the 27th international joint conference on artificial intelligence (IJCAI 2018). pp 5309–5313. ijcai.org. https://doi.org/10.24963/ijcai.2018/743
Krötzsch M, Rudolph S, Hitzler P (2007) Complexity boundaries for Horn description logics. In: Proceedings of the 22nd AAAI conference on artificial intelligence (AAAI 2007). AAAI Press, pp 452–457. http://www.aaai.org/Library/AAAI/2007/aaai07-071.php
Krötzsch M, Rudolph S, Hitzler P (2007) Conjunctive queries for a tractable fragment of OWL 1.1. In: The semantic web, 6th international semantic web conference, 2nd Asian semantic web conference, ISWC + ASWC, lecture notes in computer science, vol 4825. Springer, Berlin, pp 310–323. https://doi.org/10.1007/978-3-540-76298-0_23
Krötzsch M, Rudolph S, Hitzler P (2008) Description logic rules. In: Proceedings of the 18th European conference on artificial intelligence (ECAI 2008), frontiers in artificial intelligence and applications, vol 178. IOS Press, pp 80–84. https://doi.org/10.3233/978-1-58603-891-5-80
Krötzsch M, Rudolph S, Hitzler P (2008) ELP: tractable rules for OWL 2. In: Proceedings of the 7th international semantic web conference (ISWC 2008), lecture notes in computer science, vol 5318. Springer, Berlin, pp 649–664. https://doi.org/10.1007/978-3-540-88564-1_41
Laskey KB, da Costa PCG (2005) Of starships and Klingons: Bayesian logic for the 23rd century. In: Proceedings of the 21st conference in uncertainty in artificial intelligence (UAI 2005). AUAI Press, pp 346–353
Lehmann J, Isele R, Jakob M, Jentzsch A, Kontokostas D, Mendes PN, Hellmann S, Morsey M, van Kleef P, Auer S, Bizer C (2015) DBpedia: a large-scale, multilingual knowledge base extracted from Wikipedia. Semant Web 6(2):167–195
Lembo D, Rosati R, Santarelli V, Savo DF, Thorstensen E (2017) Mapping repair in ontology-based data access evolving systems. In: Proceedings of the 26th international joint conference on artificial intelligence (IJCAI 2017). pp 1160–1166. ijcai.org. https://doi.org/10.24963/ijcai.2017/161
Levy AY, Rousset M (1998) Combining Horn rules and description logics in CARIN. Artif Intell 104(1–2):165–209. https://doi.org/10.1016/S0004-3702(98)00048-4
Liau C, Lin BI (1996) Possibilistic reasoning: a mini-survey and uniform semantics. Artif Intell 88(1–2):163–193
Liu H, Lutz C, Milicic M, Wolter F (2011) Foundations of instance level updates in expressive description logics. Artif Intell 175(18):2170–2197. https://doi.org/10.1016/j.artint.2011.08.003
Lubyte L, Tessaris S (2008) Supporting the design of ontologies for data access. In: Proceedings of the 21st international workshop on description logics (DL2008), CEUR workshop proceedings, vol 353. CEUR-WS.org. http://ceur-ws.org/Vol-353/LubyteTessaris.pdf
Łukasiewicz J (1920) O logice trójwartościowej. Ruch filozoficzny 5:170–171
Lukasiewicz T (2002) Probabilistic default reasoning with conditional constraints. Ann Math Artif Intell 34(1–3):35–88. https://doi.org/10.1023/A:1014445017537
Lukasiewicz T (2007) A novel combination of answer set programming with description logics for the semantic web. In: Proceedings of the 4th European semantic web conference (ESWC 2007), lecture notes in computer science, vol 4519. Springer, Berlin, pp 384–398. https://doi.org/10.1007/978-3-540-72667-8_28
Lukasiewicz T (2008) Expressive probabilistic description logics. Artif Intell 172(6–7):852–883. https://doi.org/10.1016/j.artint.2007.10.017
Lukasiewicz T, Martinez MV, Predoiu L, Simari GI (2015) Existential rules and Bayesian networks for probabilistic ontological data exchange. In: Proceedings of the 9th international ruleml symposium (RuleML 2015), lecture notes in computer science, vol 9202. Springer, Berlin, pp 294–310. https://doi.org/10.1007/978-3-319-21542-6_19
Lukasiewicz T, Martinez MV, Predoiu L, Simari GI (2016) Basic probabilistic ontological data exchange with existential rules. In: Proceedings of the 30th AAAI conference on artificial intelligence (AAAI 2016). AAAI Press, pp 1023–1029. http://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/view/12243
Lukasiewicz T, Predoiu L, Stuckenschmidt H (2011) Tightly integrated probabilistic description logic programs for representing ontology mappings. Ann Math Artif Intell 63(3–4):385–425. https://doi.org/10.1007/s10472-012-9280-3
Lukumbuzya S, Ortiz M, Šimkus M (2020) Resilient logic programs: answer set programs challenged by ontologies. In: The 34th AAAI conference on artificial intelligence (AAAI 2020). AAAI Press, pp 2917–2924. https://aaai.org/ojs/index.php/AAAI/article/view/5683
Luna JEO, Revoredo K, Cozman FG (2011) Learning probabilistic description logics: a framework and algorithms. In: Proceedings of the 10th Mexican international conference on artificial intelligence (MICAI 2011), lecture notes in computer science, vol 7094. Springer, Berlin, pp 28–39
Lutz C (2001) Interval-based temporal reasoning with general TBoxes. In: Proceedings of the 17th international joint conference on artificial intelligence (IJCAI 2001). Morgan Kaufmann, pp 89–96
Lutz C (2008) The complexity of conjunctive query answering in expressive description logics. In: Armando A, Baumgartner P, Dowek G (eds) Proceedings of the 4th international joint conference on automated reasoning (IJCAR 2008), lecture notes in computer science, vol 5195. Springer, Berlin, pp 179–193. https://doi.org/10.1007/978-3-540-71070-7_16
Lutz C, Sattler U, Tendera L (2005) The complexity of finite model reasoning in description logics. Inf Comput 199(1–2):132–171. https://doi.org/10.1016/j.ic.2004.11.002
Lutz C, Sattler U, Tinelli C, Turhan A, Wolter F (eds) (2019) Description logic, theory combination, and all that: essays dedicated to Franz Baader on the occasion of His 60th Birthday, lecture notes in computer science, vol 11560. Springer, Berlin. https://doi.org/10.1007/978-3-030-22102-7
Lutz C, Schröder L (2010) Probabilistic description logics for subjective uncertainty. In: Proceedings of the 12th international conference on principles of knowledge representation and reasoning (KR 2010). AAAI Press. http://aaai.org/ocs/index.php/KR/KR2010/paper/view/1243
Lutz C, Seylan I, Toman D, Wolter F (2013) The combined approach to OBDA: taming role hierarchies using filters. In: Proceedings of the 12th international semantic web conference (ISWC 2013), lecture notes in computer science, vol 8218. Springer, Berlin, pp 314–330. https://doi.org/10.1007/978-3-642-41335-3_20
Lutz C, Seylan I, Wolter F (2012) An automata-theoretic approach to uniform interpolation and approximation in the description logic \(\cal{EL}\). In: Proceedings of the 13th international conference on principles of knowledge representation and reasoning (KR 2012). AAAI Press. http://www.aaai.org/ocs/index.php/KR/KR12/paper/view/4511
Lutz C, Seylan I, Wolter F (2013) Ontology-based data access with closed predicates is inherently intractable(sometimes). In: Proceedings of the 23rd international joint conference on artificial intelligence (IJCAI 2013). IJCAI/AAAI, pp 1024–1030. http://www.aaai.org/ocs/index.php/IJCAI/IJCAI13/paper/view/6870
Lutz C, Seylan I, Wolter F (2015) Ontology-mediated queries with closed predicates. In: Proceedings of the 24th international joint conference on artificial intelligence (IJCAI 2015). AAAI Press, pp 3120–3126. http://ijcai.org/Abstract/15/440
Lutz C, Toman D, Wolter F (2009) Conjunctive query answering in the description logic \(\cal{EL}\) using a relational database system. In: Proceedings of the 21st international joint conference on artificial intelligence (IJCAI 2009). pp 2070–2075. http://ijcai.org/Proceedings/09/Papers/341.pdf
Lutz C, Walther D, Wolter F (2007) Conservative extensions in expressive description logics. In: Proceedings of the 20th international joint conference on artificial intelligence (IJCAI 2007). pp 453–458. http://ijcai.org/Proceedings/07/Papers/071.pdf
Lutz C, Walther D, Wolter F (2007) Quantitative temporal logics over the reals: Pspace and below. Inf Comput 205(1):99–123. https://doi.org/10.1016/j.ic.2006.08.006
Lutz C, Wolter F (2010) Deciding inseparability and conservative extensions in the description logic \(\cal{EL}\). J Symb Comput 45(2):194–228. https://doi.org/10.1016/j.jsc.2008.10.007
Lutz C, Wolter F (2011) Foundations for uniform interpolation and forgetting in expressive description logics. In: Proceedings of the 22nd international joint conference on artificial intelligence (IJCAI 2011). IJCAI/AAAI, pp 989–995. https://doi.org/10.5591/978-1-57735-516-8/IJCAI11-170
Lutz C, Wolter F, Zakharyaschev M (2008) Temporal description logics: a survey. In: Proceedings of the 15th international symposium on temporal representation and reasoning (TIME 2008). IEEE Computer Society, pp 3–14. https://doi.org/10.1109/TIME.2008.14
MacGregor RM (1991) The evolving technology of classification-based knowledge representation systems. In: Principles of semantic networks: explorations in the representation of knowledge, The Morgan Kaufmann Series in representation and reasoning. Morgan Kaufmann, pp 385–400. https://doi.org/10.1016/B978-1-4832-0771-1.50021-7
Matentzoglu N, Bail S, Parsia B (2013) A corpus of OWL DL ontologies. In: Informal proceedings of the 26th international workshop on description logics (DL 2013), CEUR workshop proceedings, vol 1014, pp 829–841. CEUR-WS.org. http://ceur-ws.org/Vol-1014/paper_59.pdf
Mays E, Dionne R, Weida RA (1991) K-rep system overview. SIGART Bull 2(3):93–97. https://doi.org/10.1145/122296.122310
McIntyre S, Toman D, Weddell GE (2019) Fundl: a family of feature-based description logics, with applications in querying structured data sources. In: Lutz et al. [274]. pp 404–430. https://doi.org/10.1007/978-3-030-22102-7_19
Minsky M (1975) A framework for representing knowledge. In: The psychology of computer vision. McGraw Hill, pp 211–277
Motik B (2009) Resolution-based reasoning for ontologies. In: Staab and Studer [363]. pp 529–550. https://doi.org/10.1007/978-3-540-92673-3_24
Motik B, Horrocks I (2008) OWL datatypes: sesign and implementation. In: Proceedings of the 7th international semantic web conference (ISWC 2008), lecture notes in computer science, vol 5318. Springer, Berlin, pp 307–322. https://doi.org/10.1007/978-3-540-88564-1_20
Motik B, Rosati R (2010) Reconciling description logics and rules. J ACM 57(5):30:1–30:62. https://doi.org/10.1145/1754399.1754403
Motik B, Sattler U, Studer R (2005) Query answering for OWL-DL with rules. J Web Semant 3(1):41–60. https://doi.org/10.1016/j.websem.2005.05.001
Motik B, Shearer R, Horrocks I (2009) Hypertableau reasoning for description logics. J Artif Intell Res 36:165–228. https://doi.org/10.1613/jair.2811
Mugnier M (2020) Data access with Horn ontologies: where existential rules and description logics meet. KI 34(4)
Mugnier M, Thomazo M (2014) An introduction to ontology-based query answering with existential rules. In: Proceedings of the 10th reasoning web international summer school (RW 2014), lecture notes in computer science, vol 8714. Springer, Berlin, pp 245–278. https://doi.org/10.1007/978-3-319-10587-1_6
Nebel B (1990) Reasoning and revision in hybrid representation systems, lecture notes in computer science, vol 422. Springer, Berlin
Ngo N, Ortiz M, Šimkus M (2016) Closed predicates in description logics: Results on combined complexity. In: Proceedings of the 15th international conference on principles of knowledge representation and reasoning (KR 2016). AAAI Press, pp 237–246. http://www.aaai.org/ocs/index.php/KR/KR16/paper/view/12906
Niepert M, Noessner J, Stuckenschmidt H (2011) Log-linear description logics. In: Proceedings of the 22nd international joint conference on artificial intelligence (IJCAI 2011). IJCAI/AAAI, pp 2153–2158
Nikitina N, Rudolph S (2014) (non-)succinctness of uniform interpolants of general terminologies in the description logic \(\cal{EL}\). Artif Intell 215:120–140. https://doi.org/10.1016/j.artint.2014.06.005
Nikolaou C, Kostylev EV, Konstantinidis G, Kaminski M, Cuenca Grau B, Horrocks I (2019) Foundations of ontology-based data access under bag semantics. Artif Intell 274:91–132. https://doi.org/10.1016/j.artint.2019.02.003
Noessner J, Niepert M (2011) ELOG: a probabilistic reasoner for OWL EL. In: Proceedings of the 5th international conference on web reasoning and rule systems (RR 2011), lecture notes in computer science, vol 6902. Springer, Berlin, pp 281–286. https://doi.org/10.1007/978-3-642-23580-1
Nortje R, Britz K, Meyer T (2013) Reachability modules for the description logic \(\cal{SRIQ}\). In: Proceedings of the 19th international conference on logic for programming, artificial intelligence, and reasoning (LPAR-19), lecture notes in computer science, vol 8312. Springer, Berlin, pp 636–652. https://doi.org/10.1007/978-3-642-45221-5_42
Noy NF, Musen MA (2009) Traversing ontologies to extract views. In: Stuckenschmidt et al. [369]. pp 245–260. https://doi.org/10.1007/978-3-642-01907-4_11
Nuradiansyah A (2020) Reasoning in description logic ontologies for privacy management. KI 34(3)
Ortiz M, Calvanese D, Eiter T (2008) Data complexity of query answering in expressive description logics via tableaux. J Autom Reason 41(1):61–98. https://doi.org/10.1007/s10817-008-9102-9
Ortiz M, Rudolph S, Šimkus M (2010) Worst-case optimal reasoning for the Horn-DL fragments of OWL 1 and 2. In: Proceedings of the 12th international conference on the principles of knowledge representation and reasoning (KR 2010). AAAI Press. http://aaai.org/ocs/index.php/KR/KR2010/paper/view/1296
Ortiz M, Rudolph S, Šimkus M (2011) Query answering in the Horn fragments of the description logics \(\cal{SHOIQ}\) and \(\cal{SROIQ}\). In: Proceedings of the 22nd international joint conference on artificial intelligence (IJCAI 2011). IJCAI/AAAI, pp 1039–1044. https://doi.org/10.5591/978-1-57735-516-8/IJCAI11-178
Ortiz M, Šimkus M (2012) Reasoning and query answering in description logics. In: Proceedings of the 8th reasoning web international summer school (RW 2012), lecture notes in computer science, vol 7487. Springer, Berlin, pp 1–53. https://doi.org/10.1007/978-3-642-33158-9_1
Ortiz M, Šimkus M (2014) Revisiting the hardness of query answering in expressive description logics. In: Proceedings of the 8th international conference on web reasoning and rule systems (RR 2014), lecture notes in computer science, vol 8741. Springer, Berlin, pp 216–223. https://doi.org/10.1007/978-3-319-11113-1_18
Ortiz M, Šimkus M, Eiter T (2008) Worst-case optimal conjunctive query answering for an expressive description logic without inverses. In: Proceedings of the 23rd AAAI conference on artificial intelligence (AAAI 2008). AAAI Press, pp 504–510. http://www.aaai.org/Library/AAAI/2008/aaai08-080.php
Ozaki A (2020) Learning description logic ontologies five approaches. Where do they stand? KI 34(3)
Ozaki A, Krötzsch M, Rudolph S (2019) Temporally attributed description logics. In: Lutz et al. [274]. pp 441–474. https://doi.org/10.1007/978-3-030-22102-7_21
Özçep ÖL, Horrocks I, Möller R, Hubauer T, Neuenstadt C, Roshchin M, Zheleznyakov D, Kharlamov E (2013) Deliverable D5.1: a semantics for temporal and stream-based query answering in an OBDA context. Tech. Rep. Deliverable FP7-318338, EU
Özçep ÖL, Möller R (2014) Ontology based data access on temporal and streaming data. In: Proceedings of the 10th reasoning web international summer school (RW 2014), lecture notes in computer science, vol 8714. Springer, Berlin, pp 279–312. https://doi.org/10.1007/978-3-319-10587-1_7
Özçep ÖL, Möller R (2019) On bounded-memory stream data processing with description logics. In: Lutz et al. [274]. pp 639–660. https://doi.org/10.1007/978-3-030-22102-7_F30
Özçep Ö L, Möller R, Neuenstadt C (2014) A stream-temporal query language for ontology based data access. In: Proceedings of the 37th annual German conference on AI (KI 2014), lecture notes in computer science, vol 8736. Springer, Berlin, pp 183–194. https://doi.org/10.1007/978-3-319-11206-0_18
Pacholski L, Szwast W, Tendera L (1997) Complexity of two-variable logic with counting. In: Proceedings of the 12th annual IEEE symposium on logic in computer science (LICS 1997). IEEE Computer Society, pp 318–327. https://doi.org/10.1109/LICS.1997.614958
Parent C, Spaccapietra S (2009) An overview of modularity. In: Stuckenschmidt et al. [369]. pp 5–23. https://doi.org/10.1007/978-3-642-01907-4_2
Parikh R (1999) Beliefs, belief revision, and splitting languages. In: Moss LS, Ginzburg J, de Rijke M (eds) Logic, language and computation, vol 2. CSLI Publication, Cambridge University Press, Cambridge, pp 266–278
Parsia B, Sattler U, Schneider T (2008) Easy keys for OWL. In: Proceedings of the 5th OWLED Workshop on OWL: experiences and directions, CEUR workshop proceedings, vol 432. CEUR-WS.org. http://ceur-ws.org/Vol-432/owled2008eu_submission_3.pdf
Peltason C (1991) The BACK system: an overview. SIGART Bull 2(3):114–119. https://doi.org/10.1145/122296.122314
Peñaloza R (2019) Explaining axiom pinpointing. In: Lutz et al. [274]. pp 475–496. https://doi.org/10.1007/978-3-030-22102-7_22
Pensel M, Turhan AY (2018) Reasoning in the defeasible description logic \(\cal{EL}_{\bot }\)–computing standard inferences under rational and relevant semantics. Int J Approx Reason (IJAR) 103:28–70. https://doi.org/10.1016/j.ijar.2018.08.005
Pérez-Urbina H, Motik B, Horrocks I (2010) Tractable query answering and rewriting under description logic constraints. J Appl Log 8(2):186–209. https://doi.org/10.1016/j.jal.2009.09.004
Pnueli A (1977) The temporal logic of programs. In: Proceedings of the 18th annual symposium on foundations of computer science (SFCS 1977). pp 46–57
Poggi A, Lembo D, Calvanese D, De Giacomo G, Lenzerini M, Rosati R (2008) Linking data to ontologies. J Data Semant 10:133–173. https://doi.org/10.1007/978-3-540-77688-8_5
Pratt-Hartmann I (2005) Complexity of the two-variable fragment with counting quantifiers. J Log Lang Inf 14(3):369–395
Qi G, Ji Q, Pan JZ, Du J (2011) Extending description logics with uncertainty reasoning in possibilistic logic. Int J Intell Syst 26(4):353–381. https://doi.org/10.1002/int.20470
Quantz J, Royer V (1992) A preference semantics for defaults in terminological logics. In: Proceedings of the 3rd international conference on principles of knowledge representation and reasoning (KR 1992). Morgan Kaufmann, pp 294–305
Raheb KE, Mailis T, Ryzhikov V, Papapetrou N, Ioannidis YE (2017) Balonse: temporal aspects of dance movement and its ontological representation. In: Proceedings of the 14th European semantics web conference (ESWC 2017), lecture notes in computer science, vol 10250, pp 49–64. https://doi.org/10.1007/978-3-319-58451-5
Reiter R (2001) Knowledge in action: logical foundations for specifying and implementing dynamical systems. MIT Press, Cambridge
Rodriguez-Muro M, Calvanese D (2011) Dependencies: Making ontology based data access work. In: Proceedings of the 5th Alberto Mendelzon international workshop on foundations of data management (AMW 2011), CEUR workshop proceedings, vol 749. CEUR-WS.org. http://ceur-ws.org/Vol-749/paper21.pdf
Rodriguez-Muro M, Kontchakov R, Zakharyaschev M (2013) Ontology-based data access: ontop of databases. In: Proceedings of the 12th international semantic web conference (ISWC 2013), lecture notes in computer science, vol 8218. Springer, Berlin, pp 558–573. https://doi.org/10.1007/978-3-642-41335-3_35
Romero AA, Cuenca Grau B, Horrocks I (2012) More: Modular combination of OWL reasoners for ontology classification. In: Proceedings of the 11th international semantic web conference (ISWC 2012), lecture notes in computer science, vol 7649. Springer, Berlin, pp 1–16. https://doi.org/10.1007/978-3-642-35176-1_1
Romero AA, Kaminski M, Cuenca Grau B, Horrocks I (2016) Module extraction in expressive ontology languages via datalog reasoning. J Artif Intell Res 55:499–564. https://doi.org/10.1613/jair.4898
Ronca A, Kaminski M, Cuenca Grau B, Motik B, Horrocks I (2018) Stream reasoning in temporal datalog. In: Proceedings of the 32nd AAAI conference on artificial intelligence (AAAI 2018). AAAI Press, pp 1941–1948. https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/16182
Rosati R (2005) On the decidability and complexity of integrating ontologies and rules. J Web Semant 3(1):61–73. https://doi.org/10.1016/j.websem.2005.05.002
Rosati R (2006) DL+log: tight integration of description logics and disjunctive datalog. In: Proceedings of the 10th international conference on principles of knowledge representation and reasoning (KR 2006). AAAI Press, pp 68–78. http://www.aaai.org/Library/KR/2006/kr06-010.php
Rosati R (2007) The limits of querying ontologies. In: Proceedings of the 11th international conference on database theory (ICDT 2007), lecture notes in computer science, vol 4353. Springer, Berlin, pp 164–178. https://doi.org/10.1007/11965893_12
Rosati R (2007) On conjunctive query answering in \(\cal{EL}\). In: Proceedings of the 20th international workshop on description logics (DL2007), CEUR workshop proceedings, vol 250. CEUR-WS.org. http://ceur-ws.org/Vol-250/paper_83.pdf
Rosati R (2008) Finite model reasoning in DL-Lite. In: Proceedings of the 5th European semantic web conference (ESWC 2008), lecture notes in computer science, vol 5021. Springer, Berlin, pp 215–229. https://doi.org/10.1007/978-3-540-68234-9_18
Rosati R, Almatelli A (2010) Improving query answering over DL-Lite ontologies. In: Proceedings of the 12th international conference on the principles of knowledge representation and reasoning (KR 2010). AAAI Press. http://aaai.org/ocs/index.php/KR/KR2010/paper/view/1400
Rubin DL, Moreira DA, Kanjamala P, Musen MA (2008) BioPortal: a web portal to biomedical ontologies. In: Symbiotic relationships between semantic web and knowledge engineering, papers from the 2008 AAAI spring symposium. AAAI, pp 74–77. http://www.aaai.org/Library/Symposia/Spring/2008/ss08-07-011.php
Rudolph S, Glimm B (2010) Nominals, inverses, counting, and conjunctive queries or: why infinity is your friend!. J Artif Intell Res 39:429–481. https://doi.org/10.1613/jair.3029
Rudolph S, Šimkus M (2018) The triguarded fragment of first-order logic. In: Proceedings of the 22nd international conference on logic for programming, artificial intelligence and reasoning (LPAR-22), EPiC series in computing, vol 57. EasyChair, pp 604–619. http://www.easychair.org/publications/paper/wlJ3
Sattler U, Schneider T, Zakharyaschev M (2009) Which kind of module should I extract? In: Proceedings of the 22nd international workshop on description logics (DL 2009), CEUR workshop proceedings, vol 477. CEUR-WS.org. http://ceur-ws.org/Vol-477/paper_33.pdf
Schild K (1991) A correspondence theory for terminological logics: preliminary report. In: Proceedings of the 12th international joint conference on artificial intelligence (IJCAI 1991). Morgan Kaufmann, pp 466–471
Schild K (1993) Combining terminological logics with tense logic. In: Proceedings of the 6th Portuguese conference on artificial intelligence (EPIA 1993), lecture notes in computer science, vol 727. Springer, Berlin, pp 105–120
Schlobach S, Cornet R (2003) Non-standard reasoning services for the debugging of description logic terminologies. In: Proceedings of the 18th international joint conference on artificial intelligence (IJCAI 2003). Morgan Kaufmann, pp 355–362. http://ijcai.org/Proceedings/03/Papers/053.pdf
Schmiedel A (1990) Temporal terminological logic. In: Proceedings of the 8th national conference on artificial intelligence (AAAI 1990). AAAI Press/The MIT Press, pp 640–645
Segoufin L, ten Cate B (2013) Unary negation. Log Methods Comput Sci. https://doi.org/10.2168/LMCS-9(3:25)2013
Seidenberg J (2009) Web ontology segmentation: extraction, transformation, evaluation. In: Stuckenschmidt et al. [369]. pp 211–243. https://doi.org/10.1007/978-3-642-01907-4_10
Serafini L, Homola M (2012) Contextualized knowledge repositories for the semantic web. J Web Semant 12:64–87. https://doi.org/10.1016/j.websem.2011.12.003
Serafini L, Tamilin A (2009) Composing modular ontologies with distributed description logics. In: Stuckenschmidt et al. [369]. pp 321–347. https://doi.org/10.1007/978-3-642-01907-4_15
Seylan I, Franconi E, de Bruijn J (2009) Effective query rewriting with ontologies over DBoxes. In: Proceedings of the 21st international joint conference on artificial intelligence (IJCAI 2009). pp 923–925. http://ijcai.org/Proceedings/09/Papers/157.pdf
Sirin E, Parsia B, Cuenca Grau B, Kalyanpur A, Katz Y (2007) Pellet: a practical OWL-DL reasoner. J Web Semant 5(2):51–53. https://doi.org/10.1016/j.websem.2007.03.004
Sowa JF (1992) Conceptual graphs. Knowl Based Syst 5(3):171–172
Soylu A, Giese M, Schlatte R, Jiménez-Ruiz E, Kharlamov E, Özçep ÖL, Neuenstadt C, Brandt S (2017) Querying industrial stream-temporal data: an ontology-based visual approach. JAISE 9(1):77–95
Soylu A, Kharlamov E, Zheleznyakov D, Jiménez-Ruiz E, Giese M, Skjæveland MG, Hovland D, Schlatte R, Brandt S, Lie H, Horrocks I (2018) OptiqueVQS: a visual query system over ontologies for industry. Semant Web 9(5):627–660. https://doi.org/10.3233/SW-180293
Spackman KA, Campbell KE, Côté RA (1997) SNOMED RT: a reference terminology for health care. In: American medical informatics association annual symposium (AMIA-97). AMIA. http://knowledge.amia.org/amia-55142-a1997a-1.585351/t-001-1.587519/f-001-1.587520/a-127-1.587635/a-128-1.587632
Staab S, Studer R (eds) (2009) Handbook on ontologies. International handbooks on information systems. Springer, Berlin. https://doi.org/10.1007/978-3-540-92673-3
Stefanoni G, Motik B, Horrocks I (2013) Introducing nominals to the combined query answering approaches for \(\cal{EL}\). In: Proceedings of the 27th AAAI conference on artificial intelligence (AAAI 2013). AAAI Press. http://www.aaai.org/ocs/index.php/AAAI/AAAI13/paper/view/6156
Stefanoni G, Motik B, Krötzsch M, Rudolph S (2014) The complexity of answering conjunctive and navigational queries over OWL 2 EL knowledge bases. J Artif Intell Res 51:645–705. https://doi.org/10.1613/jair.4457
Steigmiller A, Liebig T, Glimm B (2014) Konclude: system description. J Web Semant 27–28:78–85. https://doi.org/10.1016/j.websem.2014.06.003
Stouppa P, Studer T (2009) Data privacy for knowledge bases. In: Proceedings of the international symposium on logical foundations of computer science (LFCS 2009), lecture notes in computer science, vol 5407. Springer, Berlin, pp 409–421. https://doi.org/10.1007/978-3-540-92687-0_28
Straccia U (2006) Towards top-k query answering in description logics: the case of DL-lite. In: Proceedings of the 10th European conference on logics in artificial intelligence (JELIA 2006), lecture notes in computer science, vol 4160. Springer, Berlin, pp 439–451. https://doi.org/10.1007/11853886_36
Stuckenschmidt H, Parent C, Spaccapietra S (eds) (2009) Modular ontologies: concepts, theories and techniques for knowledge modularization, lecture notes in computer science, vol 5445. Springer, Berlin. https://doi.org/10.1007/978-3-642-01907-4
Stuckenschmidt H, Schlicht A (2009) Structure-based partitioning of large ontologies. In: Stuckenschmidt et al. [369]. pp 187–210. https://doi.org/10.1007/978-3-642-01907-4_9
ten Cate B, Conradie W, Marx M, Venema Y (2006) Definitorially complete description logics. In: Proceedings of the 10th international conference on principles of knowledge representation and reasoning (KR 2006). AAAI Press, pp 79–89. http://www.aaai.org/Library/KR/2006/kr06-011.php
Thomazo M (2013) Compact rewritings for existential rules. In: Proceedings of the 23rd international joint conference on artificial intelligence (IJCAI 2013). IJCAI/AAAI, pp 1125–1131. http://www.aaai.org/ocs/index.php/IJCAI/IJCAI13/paper/view/6826
Thomazo M, Rudolph S (2014) Mixing materialization and query rewriting for existential rules. In: Proceedings of the 21st European conference on artificial intelligence (ECAI 2014), frontiers in artificial intelligence and applications, vol 263. IOS Press, pp 897–902. https://doi.org/10.3233/978-1-61499-419-0-897
Tobies S (2000) The complexity of reasoning with cardinality restrictions and nominals in expressive description logics. J Artif Intell Res 12:199–217. https://doi.org/10.1613/jair.705
Toman D (2003) On incompleteness of multi-dimensional first-order temporal logics. In: 10th international symposium on temporal representation and reasoning/4th international conference on temporal logic (TIME-ICTL). IEEE Computer Society, pp 99–106. https://doi.org/10.1109/TIME.2003.1214885
Toman D, Weddell GE (2008) On keys and functional dependencies as first-class citizens in description logics. J Autom Reason 40(2–3):117–132. https://doi.org/10.1007/s10817-007-9092-z
Trivela D, Stoilos G, Chortaras A, Stamou GB (2015) Optimising resolution-based rewriting algorithms for OWL ontologies. J Web Semant 33:30–49. https://doi.org/10.1016/j.websem.2015.02.001
Tsarkov D, Horrocks I (2006) Fact++ description logic reasoner: system description. In: Proceedings of the 3rd international joint conference on automated reasoning (IJCAR 2006), lecture notes in computer science, vol 4130. Springer, Berlin, pp 292–297. https://doi.org/10.1007/11814771_26
Tsarkov D, Palmisano I (2012) Chainsaw: a metareasoner for large ontologies. In: Proceedings of the 1st international workshop on OWL reasoner evaluation (ORE-2012), CEUR workshop proceedings, vol 858. CEUR-WS.org. http://ceur-ws.org/Vol-858/ore2012_paper2.pdf
Vrandecic D, Krötzsch M (2014) Wikidata: a free collaborative knowledgebase. Commun ACM 57(10):78–85. https://doi.org/10.1145/2629489
W3C Consortium (2013) SPARQL 1.1 Query Language. Tech. rep., W3C. http://www.w3.org/TR/sparql11-query
Wang K, Wang Z, Topor RW, Pan JZ, Antoniou G (2009) Concept and role forgetting in \(\cal{ALC}\) ontologies. In: Proceedings of the 8th international semantic web conference (ISWC 2009), lecture notes in computer science, vol 5823. Springer, Berlin, pp 666–681. https://doi.org/10.1007/978-3-642-04930-9_42
Wang Z, Wang K, Topor RW, Pan JZ, Antoniou G (2009) Uniform interpolation for \(\cal{ALC}\) revisited. In: Proceedings of the 22nd Australasian joint conference on advances in artificial intelligence (AI 2009), lecture notes in computer science, vol 5866. Springer, Berlin, pp 528–537. https://doi.org/10.1007/978-3-642-10439-8_53
Wolter F, Zakharyaschev M (2000) Temporalizing description logics. Frontiers of combining systems II, lecture notes in computer science, vol 1794. Springer, Berlin, pp 379–401
Xiao G, Calvanese D, Kontchakov R, Lembo D, Poggi A, Rosati R, Zakharyaschev M (2018) Ontology-based data access: a survey. In: Proceedings of the 27th international joint conference on artificial intelligence (IJCAI 2018). pp 5511–5519. ijcai.org. https://doi.org/10.24963/ijcai.2018/777
Yelland PM (2000) An alternative combination of Bayesian networks and description logics. In: Proceedings of the 7th international conference on principles of knowledge representation and reasoning (KR 2000). Morgan Kaufmann, pp 225–234
Zarrieß B, Claßen J (2015) Verification of knowledge-based programs over description logic actions. In: Proceedings of the 24th international joint conference on artificial intelligence (IJCAI 2015). AAAI Press, pp 3278–3284. http://ijcai.org/Abstract/15/462
Zese R (2017) Probabilistic semantic web, studies on the semantic web, vol 28. IOS Press, Amsterdam
Zhao Y, Schmidt RA (2017) Role forgetting for \(\cal{ALCOQH}(\bigtriangledown )\)-ontologies using an Ackermann-based approach. In: Proceedings of the 26th international joint conference on artificial intelligence (IJCAI 2017). pp 1354–1361. ijcai.org. https://doi.org/10.24963/ijcai.2017/188
Zhao Y, Schmidt RA (2018) On concept forgetting in description logics with qualified number restrictions. In: Proceedings of the 27th international joint conference on artificial intelligence (IJCAI 2018), pp 1984–1990. ijcai.org. https://doi.org/10.24963/ijcai.2018/274
Zhou Y, Cuenca Grau B, Nenov Y, Kaminski M, Horrocks I (2015) PAGOdA: Pay-as-you-go ontology query answering using a datalog reasoner. J Artif Intell Res 54:309–367. https://doi.org/10.1613/jair.4757
Acknowledgements
Open Access funding provided by Projekt DEAL. We would like to thank Anni-Yasmin Turhan, Magdalena Ortiz, and the anonymous reviewers for their useful remarks, which helped us to improve this survey. Šimkus was supported by the Vienna Business Agency, and the Austrian Science Fund (FWF) projects P30360 and P30873.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Schneider, T., Šimkus, M. Ontologies and Data Management: A Brief Survey. Künstl Intell 34, 329–353 (2020). https://doi.org/10.1007/s13218-020-00686-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13218-020-00686-3