
Abstract
A detailed understanding of the drilling fluid rheology and filtration properties is essential to assuring reduced fluid loss during the transport process. As per literature review, silica nanoparticle is an exceptional additive to enhance drilling fluid rheology and filtration properties enhancement. However, a correlation based on nano-SiO2-water-based drilling fluid that can quantify the rheology and filtration properties of nanofluids is not available. Thus, two data-driven machine learning approaches are proposed for prediction, i.e. artificial-neural-network and least-square-support-vector-machine (LSSVM). Parameters involved for the prediction of shear stress are SiO2 concentration, temperature, and shear rate, whereas SiO2 nanoparticle concentration, temperature, and time are the inputs to simulate filtration volume. A feed-forward multilayer perceptron is constructed and optimised using the Levenberg–Marquardt learning algorithm. The parameters for the LSSVM are optimised using Couple Simulated Annealing. The performance of each model is evaluated based on several statistical parameters. The predicted results achieved R2 (coefficient of determination) value higher than 0.99 and MAE (mean absolute error) and MAPE (mean absolute percentage error) value below 7% for both the models. The developed models are further validated with experimental data that reveals an excellent agreement between predicted and experimental data.
Similar content being viewed by others

Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
Introduction
The success of oil and gas well drilling operation is highly dependent on the selection and design of an appropriate drilling fluid. Generally, the expenditure of drilling fluid in a drilling operation ranges from 5 to 15%, but it may potentially cause significant drilling challenges (Smith et al. 2018; Agwu et al. 2018). The three main broad categories of drilling fluids are water-based mud (WBM), oil-based mud (OBM) and synthetic-based mud (SBM). WBM is commonly preferred amongst the other types due to its economic advantage, lower toxicity, and lower waste and environment challenges (Mahmoud et al. 2016; Smith et al. 2018). Drilling fluid has diverse functions in a drilling operation such as circulating drill cuttings and acting as the primary barrier for well control by exerting hydrostatic pressure on the formation. It also suspends the drill cuttings during a drilling break, cools and lubricates the drill bit, and maintains the wellbore stability in uncased section (Agarwal et al. 2011; Alvi et al. 2018).
Rheological properties of drilling fluid are critical to achieve an optimum drilling performance as it affects the hole cleaning process and rate of penetration in drilling (Gowida et al. 2019). Losing the basic required mud rheology such as plastic viscosity (PV), yield point (YP), and gel strength (GS) may lead to the occurrence of severe drilling complications (Abdo and Haneef 2013). Drilling fluid that penetrates the permeable formation or the fluid loss will result in an invasion process and the formation of mud cake. It is crucial to mitigate an excessive fluid loss into formation as it will lead to formation of damage and affect the productivity and injectivity of a well (Contreras et al. 2014). Additives such as polymers and bentonite clay are commonly added in drilling fluid to function as a rheology modifier and fluid loss controller in drilling fluid. However, some weighting material and the polymeric additives tend to undergo degradation or breakdown at high-temperature condition, and it results in varying drilling mud rheology (Agarwal et al. 2011). According to Zakaria et al. (2012), conventional usage of a macro- or micro-drilling fluid often failed to reduce the fluid loss due to its size and limited functional ability.
Since the emergence of nanotechnology in the past decade, there were numerous experimental studies and research on the advantages of several nanoparticles on conventional drilling fluid. Silica (SiO2) can be found abundantly in sand or quartz; it is one of the most commercialised nanoparticles due to its well-known preparation method (Riley et al. 2012). Recent research by Keshavarz Moraveji et al. (2020) showed that SiO2 nanoparticles had improved the apparent viscosity, plastic viscosity and yield point of drilling mud compared to the base fluid. The thermal stability of the drilling fluid is improved proven by the less severe reduction in rheological behaviour after the hot rolling process in the presence of nanoparticles. The filtration loss (FL) of the drilling fluid also reduced with the increasing weight fraction of nanoparticles. A flow loop experiment conducted by Gbadamosi et al. (2019) using SiO2 nanoparticle water-based drilling fluid demonstrated an improvement in borehole cleaning efficiency indicated by the increase in lifting efficiency of 13%. The enhancement in the drilling fluid rheology has enabled a better suspension and transport of cuttings to the surface. Mao et al. (2015) found that nanoparticle-assisted drilling fluid can effectively plug the micro-pores and micro-cracks through cross-linking and bridging. The formation of thin but dense mud cake aids to minimise the mud filtration loss as well as improve the pressure bearing capability of formation. Nanoparticles with ultra-fine sizes minimise the issue of accessing micropores or surfaces of the near-wellbore formations (Vryzas et al. 2015). According to Mao et al. (2015), SiO2 in nano-scale exhibit high surface energy, rigidity, thermal and dimensional stability. It can function efficiently and effectively, along with the presence of other foreign molecules such as Acrylamide, sulfonic acid, Maleic anhydride, and Styren. Table 1 summarises the other applications of nanoparticles in the water-based drilling fluid. The effect of SiO2 on drilling fluids had been extensively investigated showing positive results to rheological behaviour and filtration properties.
Recently, artificial intelligence (AI) has aroused attention and adaptability in the oil and gas industry. Machine learning, as a subset of AI, is defined as a technique that is capable of processing multifaceted attributes from a historical database to deal with nonlinear problems for prediction and generalisation with high efficiency (Bello et al. 2015). As drilling is one of the most expensive operations in the industry, AI is reported in numerous studies as a proficient solution to reduce drilling cost (Bello et al. 2015). Artificial neural network (ANN), fuzzy logic, support vector machines (SVM), hybrid intelligent system (HIS), case-based reasoning (CBR) are some popular implementations in machine learning. According to the review by Agwu et al. (2018), both ANN and SVM have been utilised in the prediction of rheological properties and filtration loss with promising results. However, the predictions performed only account for conventional drilling fluid without the inclusion of nanoparticles. Artificial neural network (ANN) was the first AI tool to be implemented in the oil and gas industry, and it is one of the most employed techniques of AI (Popa and Cassidy 2012). Other than the prediction of rheology and filtration loss, ANN has been applied in prediction of mud density, lost circulation, mudflow pattern, hole cleaning, cutting transport efficiency, settling velocity of cuttings and frictional pressure loss (Osman and Aggour 2003; Ozbayoglu and Ozbayoglu 2007; Al-Azani et al. 2019; Alkinani et al. 2020; Alanazi et al. 2022). The feed-forward multilayer perceptron (FFMLP) architecture, paired with a back-propagation learning algorithm, is the most widely used ANN. Most networks comprised of one hidden layer adopting Levenberg–Marquardt (LM) as the optimisation method for weights and biases. The application of LM algorithm in ANN has demonstrated to outperform other algorithms such as Scaled Conjugate Gradient and Resilient Back-Propagation due to its fast and stable convergence (Sapna 2012; Du and Stephanus 2018; Yu and Wilamowski 2018; Liu et al. 2020). According to Yu and Wilamowski (2018), this algorithm is more robust and efficient in training small and medium-sized problem. It is noticeable that most of the predictions involve a conventional drilling fluid, and there are limited studies that involve the application of nanoparticles in drilling fluid. Table 2 shows the application of ANN in drilling fluids.
The application of LSSVM in the oil and gas industry is less prominent compared to the long-established ANN. Least square support vector machine (LSSVM), proposed by Suykens and Vandewalle in 1999, is an improvised machine learning approach of SVM that was developed by Cortes and Vapnik in 1995 (Chen et al. 2020). The SVM incorporates the idea of mapping nonlinear inputs from the primal to a higher dimensional space through a kernel function. The primary advantage of SVM compared to an ANN is that the computation process does not require hidden nodes, and it has fewer parameters to be optimised (Ghorbani et al. 2020). It has a better generalisation and a lower tendency to overfit. The quadratic programming algorithm in SVM involves variables subjected to linear constraints, commonly results in a more rapid convergence than ANN. However, SVM has a major downside due to its model complexity and required constrained optimisation programming that may cause a longer computation time (Wang and Hu 2005). The introduction of LSSVM has increased the efficiency and accuracy of a traditional SVM by using a sum-squared-error cost function which is a form of a linear system known as Karush–Kuhn–Tucker (KKT) instead of inequality constraints which is quadratic (Wang and Hu 2005; Asadi et al. 2021). Similar to SVM, LSSVM transforms the data from its defined dimension to a higher dimensional space to convert a nonlinear problem to be approximately linear (Ma et al. 2018). Radial basis function, also known as Gaussian, is the most capable and widely used kernel among the other kernels such as linear and polynomial. (Wang and Hu 2005; Ma et al. 2018; Uma Maheswari and Umamaheswari 2020). Table 3 summarises the studies of LSSVM in drilling operations.
Drilling fluid is a non-Newtonian fluid that violates the Newton’s Law of Viscosity where the shear stress is not proportional to the shear rate applied. The rheology of a non-Newtonian drilling fluid can be described by the Bingham Plastic, Herschel–Bulkley and Power Law fluid model. The most widely used model, Bingham Plastic is a two-parameters rheological model. Based on a Bingham Plastic fluid shear stress versus shear rate graph, the intersection point depicts the yield point, and the slope represents the plastic viscosity of a fluid. The pioneer analytical model to estimate the viscosity of mixtures or composites was developed by Einstein (1906). Modified models were proposed based on the Einstein model namely Brinkman model, Batchelor model and Graham model, mainly considering the interfacial layer on the nanoparticle (Udawattha et al. 2019). A correlation to determine nanofluid viscosity based on Brownian motion of nanoparticle developed in 2009, but it was contended to be negligible in 2016 (Masoumi et al. 2009; Moratis 2016). Researchers later started to discover the impact of temperature, size of particle, and concentration on viscosity through experiments (Udawattha et al. 2019). However, no exact correlation can provide the viscosity of nanofluids over a wide range of concentration. The static filtration behaviour of drilling fluid is determined through a static filter press test by applying a differential pressure at elevated temperature to simulate the borehole condition according to API specifications.
Mud formulations are often determined from laboratory experiments through trial and errors depending on the experience of the mud engineer to achieve the desirable properties (Shadravan et al. 2015). Laboratory experiments are time-consuming and expensive to conduct over a wide range of controlling parameters as it involves the preparation of base fluid and nanoparticles, dispersion and stabilisation of the nanoparticles in the solvent to achieve a favourable result (Shahsavar et al. 2019). Therefore, the incorporation of machine learning is essential in developing a system that utilises the available data and trends from past cases which will provide better insight for the mud engineer to increase efficiency and reduces the cost of experimenting. This research aimed to develop two machine learning models using ANN and LSSVM to predict the shear stress and filtration volume of SiO2 nanoparticle water-based drilling fluid. The network performance for each prediction is evaluated by statistical parameters such as the coefficient of determination (R2), root mean square error (RMSE), mean absolute percentage error (MAPE) and mean absolute error (MAE). The trend of predicted shear stress and filtration loss at varying input parameters is validated with the experimental trendline to gain intuition on the dependency of the outputs on the controlling factors.
Methodology
Data acquisition and normalisation
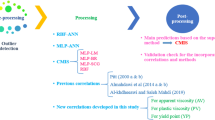
The foundation of a machine learning model is established based on historical data. To date, there are an appreciable number of experimental studies to examine the effect of SiO2 nanoparticles on the properties of water-based drilling fluid with different variables. Figure 1 is the overall flowchart of the methodology adopted in this research work.

General workflow to develop the machine learning models
The input parameters utilised for the prediction of shear stress include shear rate, nanoparticle concentration and temperature. One hundred fifty-six (156) data points are gathered from three (3) published experimental results (Vryzas et al. 2015; Mahmoud et al. 2016, 2018). The WBM formulation for all the studies contained seven (7) wt% bentonite prepared according to the requirement of API Specifications 13A. The nano-silica used in all studies had an average size of 12 nm. The experiment was conducted at varying nanoparticles concentration from 0 to 2.5 wt% and temperature from 78 °F to 200 °F at atmospheric pressure. The shear stress of the drilling fluid was measured at shear rates ranges in 4 s−1 to 1200 s−1.
Two hundred fifty-four (254) data points comprised of nanoparticle concentration, temperature and time from another published literature have contributed as the inputs for the prediction of filtration loss (Parizad et al. 2018). The average grain size for the SiO2 nanoparticles used in this research range from 10 to 15 nm. The filtration loss of SiO2 nanoparticle drilling fluid was measured by conducting API filtration test at a varying concentration from 0 to 7.5 wt% and temperature from 77 °F to 199.4 °F at a fixed differential pressure of 100 psig. The filtration volume was recorded at a different interval within 30 min. Tables 4 and 5 are the statistical descriptions of the datasets for the prediction of shear stress and filtration volume, respectively.
All data parameters are normalised based on the minimum and maximum value according to Eq. (1). Data normalisation is a good practice prior to training to adjust the data distribution so that the mean of all data points is close to zero (Razi et al. 2013; Liu et al. 2020). Normalised data can increase the efficiency of training and speed up the network convergence. The illustrations of data distribution for prediction of shear stress and filtration loss after normalisation are shown in Fig. 2 and Fig. 3, respectively.

Distribution of normalised data for prediction of shear stress

Distribution of normalised data for prediction of filtration loss
The data points marked beyond the minimum and maximum line indicate the outliers. Generally, the filtration loss datasets have a better quality than shear stress as there were ten (10) outliers out of 156 data of experimental shear stress values. For the experimental of filtration loss, there were only two (2) outliers out of 254 data points.
Artificial neural network (ANN)
Every artificial neuron comprises multiplication, summation and activation function represented by the mathematical model in Eq. 2. Multiple artificial neurons must be combined to harvest the capability of an ANN completely. There are several possible ways to connect the neurons, and the terminology to describe the interconnection of neurons is known as topology or architecture. A multilayer feed-forward ANN architecture where information generally flows in a forward direction from input to output is employed in this research. The activation function for the input layer and hidden layers follows the nonlinear function, whereas the linear activation function is selected for the output layer to assure the outcome to be in the acceptable range. Tansig (Hyperbolic tangent sigmoid function) is employed as an activation function for input and hidden layer, and Purelin (Linear transfer function) is used as an activation function for the output layer. Figure 4 and Fig. 5 illustrate the architecture of ANN for the prediction of shear stress and filtration loss, respectively.

ANN architecture for prediction of shear stress

ANN architecture for prediction of filtration volume
where \(y\) is the output, \(x\) is the input, \(w\) is the weight, \(b\) is the bias, \(i\) is the data index, and \(n{ }\) is the total number of data points. The initial weight of the ANN model is selected randomly in the range of \(\left( {\frac{ - 1}{{\sqrt {i_{{\text{n}}} } }},\frac{1}{{\sqrt {i_{{\text{n}}} } }}} \right)\), where ‘in’ is the total input to a neuron.
ANN model may consist of single or multiple hidden layers depending on the complexity of the problem and optimisation process. The presence of hidden layers with neurons provides an extrasynaptic connection and dimension of neural interactions (Cohen 1994). A trial-and-error approach by manipulating the number of hidden layers and neurons is adopted to finalise a topology best suited for the predictions. The loss/error function is set to the root mean square error (RMSE). The RMSE depicts the error in the new developed model by indicating the deviation between actual data and predicted data. This error is used to evaluate and compare the different ANN architecture with varying neurons and hidden layer to determine the best topology. An optimal number of neurons in the hidden layers is vital to avoid underfitting or overfitting due to excessive or insufficient neurons. A back-propagation learning algorithm Levenberg–Marquardt is used to optimise the weights and biases. The entire model is established using a simulation tool, MATLAB (R2020a).
The proportion of the training, validation, and testing vectors for the construction of ANN to predict shear stress and filtration volume is 70:15:15 and 80:10:10, respectively. The validation datasets act as the stopping criteria of a training process. The network training will halt if the performance of the validation samples failed to improve or remains for six (6) consecutive epochs in a row. Mean square error (MSE) is the indicator of the improvement in the prediction.
Least square support vector machine (LSSVM)
The LSSVM network has a simpler architecture as it involves fewer tuning parameters and no hidden nodes involved compared to ANN. According to Asadi et al. (2021), the linear form of the input and output vectors in an LSSVM model can be generally represented by Eq. 3 where \(\varphi\) is the mapping of inputs, \(X_{{\text{i}}}\) to a higher dimension. The weight, W and bias, b are determined from the cost function in Eq. 4 in which a regularisation parameter, gamma (γ), is involved. A final form of LSSVM is shown in Eq. 5 which \(K\) features the kernel trick to be applied in the LSSVM model. Radial basis function will be the kernel trick in this research, and it is formulated in Eq. 6, where sigma (\(\sigma )\) is the kernel parameter to be optimised.
The proportion of training for the testing dataset in the LSSVM model to predict shear stress and filtration volume has a ratio of 80:20 and 70:30, respectively. The tuning parameters, which includes the kernel (σ2) and regularisation (γ) parameter, are optimised by the Couple Simulated Annealing (CSA) algorithm. CSA is a modified technique from simulated annealing (SA) that exhibits a higher convergence speed and accuracy (Dashti et al. 2020; Ghorbani et al. 2020). The best-optimised parameters are finalised after an iterative process of training, testing and performance evaluation. Figure 6 and Fig. 7 exhibit the LSSVM architecture for prediction of shear stress and filtration volume, respectively.

LSSVM architecture for prediction of shear stress

LSSVM architecture for prediction of filtration volume
Model performance evaluation
The statistical parameters used to evaluate the performance or accuracy of the network are the coefficient of determination (R2), root mean square error (RMSE) and mean absolute percentage error (MAPE) and mean absolute error (MAE). These values are computed for all the predicted output from training, validation and testing. R2 measures how close the outputs are fitted to the target values. RMSE, MAPE and MAE depict the difference between the experimental and predicted values. R2 value close to 1 or a low value of RMSE, MAPE and MAE indicates a favourable prediction result. R2, RMSE, MAPE and MAE are expressed mathematically as Eq. (7) to (10), respectively, where, \(y_{{\text{i}}}^{A}\) is the original used data and \(y_{{\text{i}}}^{p}\) is the predicted data.
Results and discussion
Prediction of shear stress
Artificial neural network (ANN)
Twenty (20) iterations were performed by manipulating the number of the hidden layer(s) from 1 to 2 and the number of hidden node(s) from 1 to 50. The network configuration with the lowest overall RMSE is the optimum network architecture, and its topology will be selected for further prediction. Figure 8 plots the RMSE of the predicted training, validation and testing outputs obtained from the best iteration. Based on the plots, the increase in neurons does not guarantee an increase in accuracy as weight and biases are continually changing in every run. Table 6 quantifies the RMSE and R2 of the best quantity of hidden neuron(s) using 1 and 2 hidden layer(s). The overall RMSE and R2 values are averaged from the RMSE and R2 values of training, validation and testing vectors. A well-tuned model should be capable of yielding high accuracy for the prediction of all the training, validation and testing vectors without jeopardising the accuracy of one another. Based on Table 6, one (1) hidden layer generally performed better than the two (2) hidden layers networks as it has a lower RMSE and higher R2 values. The best performance is achieved with one (1) hidden layer consisting of 18 hidden nodes with an overall RMSE of 2.0235 lbf/ft2 and R2 of 0.9924. Therefore, a topology of 3–18-1 is selected for the prediction of shear stress.

RMSE of ANN for prediction of shear stress
The weights and biases of every neuron optimised by LM algorithm are extracted from the finalised network configurations for further training, validation and testing process. Figure 9 shows the MSE at every epoch for the prediction of shear stress. Epoch is the measure of how many times the training vectors are passed back from the output layer to update the weights and biases. The best result for the validation dataset is achieved at zeroth epoch with the lowest MSE of 0.24453 lbf/ft2. Since there is no noticeable improvement for six (6) consecutive epochs, the stopping criterion is triggered, and the training cycle is ceased. Based on Fig. 9, MSE for all the train, validation and test vectors stabilises after the fourth epoch, this is where the network found the optimal solution for the weights and biases.

MSE at different epochs of ANN for prediction of shear stress
Figure 10 shows the parity plots of the predicted outputs versus actual shear stress. The training, validation and testing R2 values are 0.993, 0.998 and 0.999, respectively. The coefficient of determination of both test and validation vectors exceeds 0.995, although training data sets yield a slightly lower value. The R2 infers that the network has an excellent generalisation to the new testing data points and does not overfit. The calculated RMSE based on the predicted and experimental outputs from training, validation, testing is 2.029 lbf/ft2, 0.495 lbf/ft2, and 0.466 lbf/ft2.

Parity plots of ANN for prediction of shear stress: a Overall Data b Training Data c Validation Data d Testing Data
A graphical plot of the error distributions is presented in Fig. 11 to demonstrate the error in the prediction of the developed ANN model. Based on the plot, the maximum relative error between the predicted and actual shear stress ranges from about − 40 to 30%.

Relative error of ANN for prediction of shear stress
Least square support vector machine (LSSVM)
Twenty (20) iterations with 100 runs each were performed to determine the radial basis function kernel parameter (σ) and regularisation parameter (γ). These parameters are initialised randomly and optimised by CSA. The best performance from each iteration is ranked based on the lowest RMSE, and the results are plotted in Fig. 12. Based on the figure, the 16th iteration yields the lowest overall RMSE with a value of 1.452 lbf/ft2. The kernel and the regularisation parameters are acquired from the optimal iteration with the values of 1.5706e + 05 and 13.5046.

RMSE of LSSVM for prediction of shear stress
The RMSE of prediction of shear stress for training and testing datasets is 1.696 lbf/ft2 and 1.209 lbf/ft2. Figure 13 (a–c) shows the parity plots for the training and testing vectors of prediction of filtration volume with R2 of 0.994 and 0.995, respectively. The R2 values, which are very close to 1.0, demonstrate the capability of LSSVM to predict the shear stress accurately. The reasonably low RMSE and high R2 of testing datasets proved the model has a low tendency to overfit the training vectors. The relative error is plotted in Fig. 13 (d). The predicted output deviates with a maximum relative error from − 18.2 to 26.8%.

Parity plots of LSSVM for prediction of shear stress: a Overall Data b Training Data c Testing Data; d Relative error of LSSVM for prediction of shear stress
Prediction of filtration volume
Artificial neural network (ANN)
The methodology to determine the architecture for prediction of filtration loss is similar to the approach in prediction of shear stress. Figure 14 shows the plot of the lowest RMSE generated from 1 to 50 neurons from ANN comprised of 1 and 2 hidden layers. It can be observed that one (1) hidden layer network generally outperforms two (2) hidden layers networks for the majority number of hidden nodes. As referred to Table 7, the network with (1) hidden layer and 24 hidden nodes yields the best prediction results with RMSE of 0.2103 mL and R2 of 0.9993. Therefore, the final network architecture of ANN for prediction of filtration volume is determined to be 3–24-1.

RMSE of ANN for prediction of filtration volume
The best validation performance is achieved with MSE of 0.04844 mL at epoch 15, as observed from Fig. 15. The RMSE computed based on the predicted outputs is 0.115 mL, 0.220 mL and 0.195 mL for the training, validation and testing datasets. As compared to the prediction of shear stress, the network for the prediction of filtration volume consumed more computation steps as the curves flatten after 18 epochs. The trendline of MSE before the tenth epoch indicates the network is prone to underfit as the MSE of the training vector is relatively high compared to the MSE after the fifteenth epoch.

MSE at different epochs of ANN for prediction of filtration volume
Figure 16 shows the parity plots for different data environments. The predicted outputs are mostly overlying with the designated slope at R2 = 1; this indicates that the prediction is highly accurate. The R2 values for all the training, validation and testing are 0.9998, 0.9994 and 0.9993. According to Fig. 17, the relative errors of predicted output for filtration loss are relatively lower compared to the prediction of the shear rate as the maximum relative error lies between − 12.7 and 23.5%.

Parity plots of ANN for prediction of filtration volume: a Overall Data b Training Data c Validation Data d Testing Data

Relative error of ANN for prediction of filtration volume
Least square support vector machine (LSSVM-FV)
The approach to select the kernel parameters in the prediction of shear stress is adopted in this section. Figure 18 shows that the 7th iteration yields the lowest RMSE with a value of 0.231 ml. The kernel and regularisation parameters at this iteration are 1.2484e + 08 and 66.8216.

RMSE of LSSVM for prediction of filtration volume
The computed RMSE values from the prediction of filtration volume using LSSVM are 0.2309 mL and 0.2308 mL for training and testing vectors. The R2 values are 0.9992 and 0.9991 for the training and testing, respectively. The low RMSE and high R2 obtained for all vectors demonstrate the capability of LSSVM with a low tendency to overfit or underfit in the training process. Lastly, the percentage of relative error for each predicted output corresponding to the actual value is calculated and plotted in the following figure. The relative error of the predicted filtration loss lies between − 8.1 and 38.6%, as shown in Fig. 19.

Parity plots of LSSVM for prediction of filtration volume: a Overall Data b Training Data c Testing Data; d Relative error of LSSVM for prediction of filtration volume
Analysis of outlier effect
Effect of outlier on the developed model is determined by analysing the William’s plot. It is a graphical representation of standardised residuals (R) and leverage value. The leverage value variation in these plots is used to describe the outlier impact on model. Leverage values are defined as the data with extreme value of the predictor dataset (x). It is represented mathematically as Eq. (11).
where, Hi is the hat matrix (also known as projection matrix), xi is the selected datapoint from the descriptive vector and X is the matrix from the training data descriptor values. The William’s plot of all the developed models is presented in Fig. 20. Grubbs critical T value is used to separate the outlier from the valid data points on y-axis. It can be calculated using Eq. (12). The Grubbs critical T value for shear stress data is 3.91 and 4.05 for filtration volume data. The normalised leverage value is used in Fig. 20. Hence, the average of leverage is 1. Therefore, the leverage limit is arbitrarily selected the double of leverage average that is the value of 2 on x-axis. The leverage limit is used to separate high leverage value from the dataset. In Fig. 20, a square area is formed using Grubbs critical T value and leverage limit. This square area is known as applicability domain. The developed models are deemed a statistically valid model when most of the data are in this domain. As illustrated in this figure, majority of the datapoints are spotted in the applicability domain area which indicates that the models developed using ANN and LSSVM for shear stress and filtration volume prediction are reliable.

William’s plots of ANN and LSSVM for prediction of shear stress (SS) and filtration volume (FV)
where, G is the Grubbs critical T value, (n-3) is the degree of freedom and α/(2n) represents the significance level.
Comparison of ANN and LSSVM
Both applications of ANN and LSSVM showed acceptable and accurate results in predicting the shear stress and filtration loss of SiO2 nanoparticles water-based drilling fluid. Table 8 and Table 9 summarise the RMSE, R2, MAE and MAPE of the developed model. Simulated results for all models achieved overall R2 of minimum 0.990 with MAE and MAPE of not higher than 7%. Figure 21 illustrates the statistical parameters of ANN and LSSVM for further comparison.

Comparison of statistical parameters
Based on Table 8, the regression coefficient of ANN and LSSVM in the prediction of shear stress is 0.9937 and 0.9941, whereas the RMSE is 1.7235 lbf/ft2 and 1.6003 lbf/ft2, respectively. LSSVM model slightly outperforms ANN in predicting shear stress in terms of a higher R2 and lower RMSE and MAPE. The R2 of LSSVM is 0.04% higher than ANN, whereas the RMSE is 7.1% lower than ANN. According to Table 9, both models achieved an ideal prediction of filtration loss with R2 of higher than 0.999. The comparison showed that the R2 of ANN in the prediction of filtration volume is 0.05% higher than LSSVM, and RMSE is 33.7% lower than LSSVM. Hence, the prediction of ANN is more precise than LSSVM in predicting filtration loss.
Based on the analysis, both machine learning models are equally competent and capable of predicting the required parameters with high precision and accuracy. The accuracy of both machine learning models in predicting the filtration volume is generally higher than shear stress as indicated by all the statistics and the relative error distribution plot. One of the possible reasons could be due to a larger quantity of datasets available for the training.
Validation of the predicted outputs
The predicted output from the machine learning model with the best performance is plotted along with the corresponding experimental values to validate the trend of the predicted output. For the prediction of shear stress, predicted values from LSSVM is utilised in Fig. 22 as LSSVM performs better than the ANN. Figure 21 shows the rheo-grams of the SiO2 nanoparticle WBM at 78°F and 140°F at varying nanoparticles concentration. Shear-thinning behaviour can be observed from both experimental and predicted trendlines at all concentration of SiO2. The magnitude or gradient of shear-thinning is more noticeable and significant at a higher SiO2 nanoparticle concentration. This behaviour is favourable for a drilling fluid as low viscosity is preferred at a high shear rate to circulate the drilling fluid and cuttings. High viscosity at a low shear rate may ease the suspension of the drill cuttings during a drilling break.

Predicted and experimental rheo-gram. a 78 °F (b) 140 °F
The predicted filtration volume at 77 °F and 199 °F with a concentration ranging from 0 to 7.5 wt% is shown in Fig. 23. The predicted output from ANN is utilised in the plot as it has the best performance. The trend of both predicted and experimental output increases logarithmically with time, and filtration loss decreases with the increasing concentration of nanoparticles. The reduction in filtration loss can be justified by the nano-sized particles that can clog the pore throats on the filter paper compared to conventional drilling fluid particles.

Predicted and experimental filtration loss. a 77 °F (b) 199 °F
Conclusions
Prediction of shear stress and filtration loss of SiO2 nanoparticles water-based drilling fluid are accomplished by two machine learning-based approaches, i.e. ANN and LSSVM. The developed models demonstrate a well generalisation and a low tendency in overfitting. The predicted results for both models achieved R2 of higher than 0.99 and both MAE and MAPE not exceeding 7%. The RMSE for the predicted shear stress and filtration volume is lower than 1.8 lbf/ft2, and 0.2 mL, respectively. The following conclusions are deduced based on the predictive performance of developed ML models.
-
1.
The assuring performances proved that both ANN and LSSVM are capable of predicting the output based on the precision of provided inputs.
-
2.
It is found that LSSVM outperforms the ANN in the prediction of shear stress, whereas for the prediction of filtration volume, ANN performs better than the another. There is no definite conclusion of which machine learning approach is more superior in this research.
-
3.
A shear-thinning behaviour is observed in the rheo-gram and a noticeable logarithmic increment of filtration loss with time.
-
4.
The developed machine learning models are comprehensive and efficient in predicting the shear stress and filtration volume of a SiO2 nanoparticles water-based drilling fluid.
Abbreviations
- b :
-
Bias value
- \(H_{{\text{i}}}\) :
-
Hat matrix or projection matrix
- T :
-
Grubb’s test critical value
- i :
-
Selected data index
- \(i_{{\text{n}}}\) :
-
Total input to a neuron
- n :
-
Number of data points
- w :
-
Weight value
- x :
-
Input data
- \(X_{{\text{i}}}\) :
-
Higher dimension value
- y :
-
Output value
- \(y_{{\text{i}}}^{A}\) :
-
Original data
- \(y_{{\text{i}}}^{P}\) :
-
Predicted data
- \(\varphi\) :
-
Mapping of input data
- \(\gamma\) :
-
Regularisation parameter
- \(\sigma\) :
-
Kernel parameter to be optimised
- ANN:
-
Artificial neural network
- API:
-
American Petroleum Institute
- CSA:
-
Couple Simulated Annealing
- FFMLP:
-
Feed-forward multilayer perceptron
- FL:
-
Filtration loss
- FV:
-
Filtration Volume
- GS:
-
Gel strength
- HPHT:
-
High pressure high temperature
- KKT:
-
Karush–Kuhn–Tucker
- LM:
-
Levenberg–Marquardt
- LSSVM:
-
Least square support vector machine
- MAE:
-
Mean absolute error
- MAPE:
-
Mean absolute percentage error
- MSE:
-
Mean square error
- NP:
-
Nanoparticle(s)
- PV:
-
Plastic viscosity
- R2:
-
Regression coefficient
- RMSE:
-
Root mean square error
- SS:
-
Shear Stress
- SVM:
-
Support vector machine
- WBM:
-
Water-based mud
- YP:
-
Yield point
References
Abdo J, Haneef MD (2013) Clay nanoparticles modified drilling fluids for drilling of deep hydrocarbon wells. Appl Clay Sci 86:76–82. https://doi.org/10.1016/j.clay.2013.10.017
Agarwal S, Tran P, Soong Y, et al (2011) Flow behaviour of nanoparticle stabilized drilling fluids and effect on high temperature aging. AADE Natl Tech Conf Exhib 1–6
Agwu OE, Akpabio JU, Alabi SB, Dosunmu A (2018) Artificial intelligence techniques and their applications in drilling fluid engineering: a review. J Pet Sci Eng 167:300–315. https://doi.org/10.1016/j.petrol.2018.04.019
Ahmadi MA (2016) Toward reliable model for prediction drilling fluid density at wellbore conditions: a LSSVM model. Neurocomputing 211:143–149. https://doi.org/10.1016/j.neucom.2016.01.106
Alanazi AK, Alizadeh SM, Nurgalieva KS et al (2022) Application of neural network and time-domain feature extraction techniques for determining volumetric percentages and the type of two phase flow regimes independent of scale layer thickness. Appl Sci 12:1336. https://doi.org/10.3390/app12031336
Al-Azani K, Elkatatny S, Ali A et al (2019) Cutting concentration prediction in horizontal and deviated wells using artificial intelligence techniques. J Pet Explor Prod Technol 9:2769–2779. https://doi.org/10.1007/S13202-019-0672-3/FIGURES/17
Al-Khdheeawi EA, Mahdi DS (2019) Apparent viscosity prediction of water-based muds using empirical correlation and an artificial neural network. Energies 12:3067. https://doi.org/10.3390/en12163067
Alkinani HH, Al-Hameedi ATT, Dunn-Norman S (2020) Artificial neural network models to predict lost circulation in natural and induced fractures. SN Appl Sci 2:1–13. https://doi.org/10.1007/S42452-020-03827-3/TABLES/6
Alvi MAA, Belayneh M, Saasen A, AadnØy BS (2018) The effect of micro-sized boron nitride BN and iron trioxide Fe2O3 nanoparticles on the properties of laboratory bentonite drilling fluid. In: society of petroleum engineers-SPE, Norway one day seminar
Al-Yasiri M, Wen D (2019) Gr-Al 2 O 3 Nanoparticles-based multifunctional drilling fluid. Ind Eng Chem Res 58:10084–10091. https://doi.org/10.1021/acs.iecr.9b00896
Aramendiz J, Imqam A (2020) Silica and graphene oxide nanoparticle formulation to improve thermal stability and inhibition capabilities of water-based drilling fluid applied to woodford shale. SPE Drill Complet 35:164–179. https://doi.org/10.2118/193567-PA
Asadi A, Alarifi IM, Nguyen HM, Moayedi H (2021) Feasibility of least-square support vector machine in predicting the effects of shear rate on the rheological properties and pumping power of MWCNT–MgO/oil hybrid nanofluid based on experimental data. J Therm Anal Calorim 143:1439–1454. https://doi.org/10.1007/s10973-020-09279-6
Barati-Harooni A, Najafi-Marghmaleki A, Tatar A et al (2016) Prediction of frictional pressure loss for multiphase flow in inclined annuli during underbalanced drilling operations. Nat Gas Ind B 3:275–282. https://doi.org/10.1016/j.ngib.2016.12.002
Bello O, Holzmann J, Yaqoob T, Teodoriu C (2015) Application of artificial intelligence methods in drilling system design and operations: a review of the state of the art. J Artif Intell Soft Comput Res 5:121–139. https://doi.org/10.1515/jaiscr-2015-0024
Cai J, Chenevert MEE, Sharma MMM, Friedheim J (2012) Decreasing water invasion into atoka shale using nonmodified silica nanoparticles. SPE Drill Complet 27:103–112. https://doi.org/10.2118/146979-PA
Chen L, Duan L, Shi Y, Du C (2020) PSO_LSSVM prediction model and its MATLAB implementation. IOP Conf Ser Earth Environ Sci 428:012089. https://doi.org/10.1088/1755-1315/428/1/012089
Cheraghian G, Wu Q, Mostofi M et al (2018) Effect of a novel clay/silica nanocomposite on water-based drilling fluids: improvements in rheological and filtration properties. Colloids Surfaces A Physicochem Eng Asp 555:339–350. https://doi.org/10.1016/j.colsurfa.2018.06.072
Cohen IL (1994) An artificial neural network analogue of learning in autism. Biol Psychiatry 36:5–20. https://doi.org/10.1016/0006-3223(94)90057-4
Contreras O, Hareland G, Husein M, et al (2014) Application of in-house prepared nanoparticles as filtration control additive to reduce formation damage. In: SPE - European formation damage conference, proceedings, EFDC
da Bispo VDS, Scheid CM, Calçada LA, da Meleiro LA, C (2017) Development of an ANN-based soft-sensor to estimate the apparent viscosity of water-based drilling fluids. J Pet Sci Eng 150:69–73. https://doi.org/10.1016/j.petrol.2016.11.030
Dashti A, Raji M, Alivand MS, Mohammadi AH (2020) Estimation of CO2 equilibrium absorption in aqueous solutions of commonly used amines using different computational schemes. Fuel 264:116616. https://doi.org/10.1016/j.fuel.2019.116616
Du Y-C, Stephanus A (2018) Levenberg-marquardt neural network algorithm for degree of arteriovenous fistula stenosis classification using a dual optical photoplethysmography sensor. Sensors 18:2322. https://doi.org/10.3390/s18072322
Einstein A (1906) Eine neue bestimmung der moleküldimensionen. Ann Phys 324:289–306. https://doi.org/10.1002/andp.19063240204
Gbadamosi AO, Junin R, Abdalla Y et al (2019) Experimental investigation of the effects of silica nanoparticle on hole cleaning efficiency of water-based drilling mud. J Pet Sci Eng 172:1226–1234. https://doi.org/10.1016/j.petrol.2018.09.097
Ghanbari S, Kazemzadeh E, Soleymani M, Naderifar A (2016) A facile method for synthesis and dispersion of silica nanoparticles in water-based drilling fluid. Colloid Polym Sci 294:381–388. https://doi.org/10.1007/s00396-015-3794-2
Ghorbani H, Wood DA, Choubineh A et al (2020) Performance comparison of bubble point pressure from oil PVT data: several neurocomputing techniques compared. Exp Comput Multiph Flow 2:225–246. https://doi.org/10.1007/s42757-019-0047-5
Golsefatan A, Shahbazi K (2021) Predicting performance of SiO 2 nanoparticles on filtration volume using reliable approaches: application in water-based drilling fluids. Energy Sources, Part A Recover Util Environ Eff 43:3216–3225. https://doi.org/10.1080/15567036.2019.1639854
Gomaa I, Elkatatny S, Abdulraheem A (2020) Real-time determination of rheological properties of high over-balanced drilling fluid used for drilling ultra-deep gas wells using artificial neural network. J Nat Gas Sci Eng 77:103224. https://doi.org/10.1016/j.jngse.2020.103224
Gowida A, Elkatatny S, Ramadan E, Abdulraheem A (2019) Data-driven framework to predict the rheological properties of CaCl2 brine-based drill-in fluid using artificial neural network. Energies 12:1880. https://doi.org/10.3390/en12101880
Kang Y, She J, Zhang H et al (2016) Strengthening shale wellbore with silica nanoparticles drilling fluid. Petroleum 2:189–195. https://doi.org/10.1016/j.petlm.2016.03.005
Keshavarz Moraveji M, Ghaffarkhah A, Agin F et al (2020) Application of amorphous silica nanoparticles in improving the rheological properties, filtration and shale stability of glycol-based drilling fluids. Int Commun Heat Mass Transf 115:104625. https://doi.org/10.1016/j.icheatmasstransfer.2020.104625
Liu T-Y, Zhang P, Wang J, Ling Y-F (2020) Compressive strength prediction of PVA fiber-reinforced cementitious composites containing nano-SiO2 using BP neural network. Mater (basel) 13:521. https://doi.org/10.3390/ma13030521
Ma X, Zhang Y, Cao H et al (2018) Nonlinear regression with high-dimensional space mapping for blood component spectral quantitative analysis. J Spectrosc 2018:1–8. https://doi.org/10.1155/2018/2689750
Maghrabi S, Kulkarni D, Teke K, et al (2014) Modeling of shale-erosion behavior in aqueous drilling fluids. In: society of petroleum engineers-European unconventional resources conference and exhibition 2014: unlocking European potential
Mahmoud O, Nasr-El-Din HA, Vryzas Z, Kelessidis VC (2018) Using ferric oxide and silica nanoparticles to develop modified calcium bentonite drilling fluids. SPE Drill Complet 33:12–26. https://doi.org/10.2118/178949-PA
Mahmoud O, Nasr-El-Din HA, Vryzas Z, Kelessidis VC (2016) Nanoparticle-based drilling fluids for minimizing formation damage in HP/HT applications. In: SPE international formation damage control symposium proceedings
Maiti M, Ranjan R, Chaturvedi E et al (2021) Formulation and characterization of water-based drilling fluids for gas hydrate reservoirs with efficient inhibition properties. J Dispers Sci Technol 42:338–351. https://doi.org/10.1080/01932691.2019.1680380
Mao H, Qiu Z, Shen Z, Huang W (2015) Hydrophobic associated polymer based silica nanoparticles composite with core–shell structure as a filtrate reducer for drilling fluid at utra-high temperature. J Pet Sci Eng 129:1–14. https://doi.org/10.1016/j.petrol.2015.03.003
Masoumi N, Sohrabi N, Behzadmehr A (2009) A new model for calculating the effective viscosity of nanofluids. J Phys D Appl Phys 42:055501. https://doi.org/10.1088/0022-3727/42/5/055501
Medhi S, Chowdhury S, Kumar A et al (2020) Zirconium oxide nanoparticle as an effective additive for non-damaging drilling fluid: a study through rheology and computational fluid dynamics investigation. J Pet Sci Eng 187:106826. https://doi.org/10.1016/j.petrol.2019.106826
Meybodi MK, Naseri S, Shokrollahi A, Daryasafar A (2015) Prediction of viscosity of water-based Al2O3, TiO2, SiO2, and CuO nanofluids using a reliable approach. Chemom Intell Lab Syst 149:60–69. https://doi.org/10.1016/j.chemolab.2015.10.001
Milad Arabloo AS (2014) Application of SVM algorithm for frictional pressure loss calculation of three phase flow in inclined annuli. J Pet Environ Biotechnol. https://doi.org/10.4172/2157-7463.1000179
Moratis L (2016) Out of the ordinary? Appraising ISO 26000’ s CSR definition. Int J Law Manag 58:26–47. https://doi.org/10.1108/IJLMA-12-2014-0064
Osman EA, Aggour MA (2003) Determination of drilling mud density change with pressure and temperature made simple and accurate by ANN. Proc Middle East Oil Show 13:115–126. https://doi.org/10.2118/81422-MS
Ozbayoglu ME, Ozbayoglu MA (2007) Flow pattern and frictional-pressure-loss estimation using neural networks for UBD operations. IADC/SPE Manage Press Drill Underbalanced Oper OnePetro. https://doi.org/10.2118/108340-MS
Parizad A, Shahbazi K, Tanha AA (2018) SiO2 nanoparticle and KCl salt effects on filtration and thixotropical behavior of polymeric water based drilling fluid: with zeta potential and size analysis. Result Phys 9:1656–1665. https://doi.org/10.1016/j.rinp.2018.04.037
Popa AS, Cassidy S (2012) Artificial intelligence for heavy oil assets: the evolution of solutions and organization capability. In: proceedings-SPE annual technical conference and exhibition
Razi MM, Mazidi M, Razi FM et al (2013) Artificial neural network modeling of plastic viscosity, yield point, and apparent viscosity for water-based drilling fluids. J Dispers Sci Technol 34:822–827. https://doi.org/10.1080/01932691.2012.704746
Riley M, Stamatakis E, Young S, et al (2012) Wellbore stability in unconventional shale-the design of a nano-particle fluid. In: society of petroleum engineers-SPE oil and gas india conference and exhibition 2012, OGIC-further, deeper, tougher: the quest continues...
Sadegh Hassani S, Amrollahi A, Rashidi A et al (2016) The effect of nanoparticles on the heat transfer properties of drilling fluids. J Pet Sci Eng 146:183–190. https://doi.org/10.1016/j.petrol.2016.04.009
Safari H, Shokrollahi A, Jamialahmadi M et al (2014) Prediction of the aqueous solubility of BaSO4 using pitzer ion interaction model and LSSVM algorithm. Fluid Phase Equilib 374:48–62. https://doi.org/10.1016/j.fluid.2014.04.010
Sapna S (2012) Backpropagation learning algorithm based on levenberg marquardt algorithm. in: computer science and information technology (CS & IT ). Acad Ind Res Collab Cent (AIRCC) 2:393–398
Shadravan A, Tarrahi M, Amani M (2015) Intelligent tool to design fracturing, drilling, spacer and cement slurry fluids using machine learning algorithms. In: society of petroleum engineers-SPE Kuwait Oil and Gas show and conference
Shahsavar A, Bagherzadeh SA, Mahmoudi B et al (2019) Robust weighted least squares support vector regression algorithm to estimate the nanofluid thermal properties of water/graphene oxide-silicon carbide mixture. Phys A Stat Mech Its Appl 525:1418–1428. https://doi.org/10.1016/j.physa.2019.03.086
Smith SR, Rafati R, Sharifi Haddad A et al (2018) Application of aluminium oxide nanoparticles to enhance rheological and filtration properties of water based muds at HPHT conditions. Colloids Surfaces A Physicochem Eng Asp 537:361–371. https://doi.org/10.1016/j.colsurfa.2017.10.050
Tanoumand N, Hemmati-Sarapardeh A, Bahadori A (2015) A CSA-LSSVM Model to estimate diluted heavy oil viscosity in the presence of kerosene. Pet Sci Technol 33:1085–1092. https://doi.org/10.1080/10916466.2015.1034367
Tomiwa O, Oluwatosin R, Temiloluwa O, et al (2019) Improved water based mud using Solanum tuberosum formulated biopolymer and application of artificial neural network in predicting mud rheological properties. In: society of petroleum engineers-SPE Nigeria annual international conference and exhibition 2019, NAIC 2019
Udawattha DS, Narayana M, Wijayarathne UPL (2019) Predicting the effective viscosity of nanofluids based on the rheology of suspensions of solid particles. J King Saud Univ - Sci 31:412–426. https://doi.org/10.1016/j.jksus.2017.09.016
Uma Maheswari R, Umamaheswari R (2020) Adaptive data-driven nonlinear synchro squeezed transform with single class radial basis function kernel support vector machine applied to wind turbine planetary gearbox fault diagnostics. Proc Inst Mech Eng Part A J Power Energy. https://doi.org/10.1177/0957650919886227
Vargas J, Roldán LJ, Lopera SH, et al (2020) Effect of silica nanoparticles on thermal stability in bentonite free water-based drilling fluids to improve its rheological and filtration properties after aging process. In: offshore technology conference Brasil 2019, OTCB 2019
Vryzas Z, Mahmoud O, Nasr-El-din HA, Kelessidis VC (2015) Development and testing of novel drilling fluids using Fe2O3 and SiO2 nanoparticles for enhanced drilling operations. In: international petroleum technology conference, IPTC 2015
Wang H, Hu D (2005) Comparison of SVM and LS-SVM for regression. In: proceedings of 2005 international conference on neural networks and brain proceedings, ICNNB’05
Yu H, Wilamowski BM (2018) Levenberg–marquardt training. In: Bogdan M, Wilamowski J, David I (eds) intelligent systems. CRC Press
Zakaria MF, Husein M, Hareland G (2012) Novel nanoparticle-based drilling fluid with improved characteristics. In: society of petroleum engineers-SPE international oilfield nanotechnology conference 2012
Acknowledgements
This research is fully supported by the Petroleum Engineering Department and Institute of Hydrocarbon recovery at Universiti Teknologi PETRONAS, Malaysia. The financial assistance is provided by Yayasan Universiti Teknologi PETRONAS (YUTP), grant number 015LC0-231.
Funding
Funding was provided by Yayasan Universiti Teknologi PETRONAS (YUTP) (Grant Number 015LC0-231).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ning, Y.C., Ridha, S., Ilyas, S.U. et al. Application of machine learning to determine the shear stress and filtration loss properties of nano-based drilling fluid. J Petrol Explor Prod Technol 13, 1031–1052 (2023). https://doi.org/10.1007/s13202-022-01589-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13202-022-01589-9