
Abstract
In this paper, we propose a random noise suppression and super-resolution reconstruction algorithm for seismic profiles based on Generative Adversarial Networks, in anticipation of reducing the influence of random noise and low resolution on seismic profiles. Firstly, the algorithm used the residual learning strategy to construct a de-noising subnet to accurate separate the interference noise on the basis of protecting the effective signal. Furthermore, it iterated the back-projection unit to complete the reconstruction of the high-resolution seismic sections image, while responsed sampling error to enhance the super-resolution performance of the algorithm. For seismic data characteristics, designed the discriminator to be a fully convolutional neural network, used a larger convolution kernels to extract data features and continuously strengthened the supervision of the generator performance optimization during the training process. The results on the synthetic data and the actual data indicated that the algorithm could improve the quality of seismic cross-section, make ideal signal-to-noise ratio and further improve the resolution of the reconstructed cross-sectional image. Besides, the observations of geological structures such as fractures were also clearer.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
The seismic profile can accurately describe the subsurface geological structure and is an important basis for the exploration of resources such as oil and gas reservoirs. The seismic imaging resolution is impacted negatively by surface structure, acquisition environment and complex subsurface structure. Seismic noise contamination is another factor that is not conducive to subsequent processing, inversion and interpretation. Many solutions have been proposed and published to tackle this problem. For example, de-noising aspects such as f-k domain filtering (Margrave 2001), wavelet transform (Zhang and Guanquan 1997), curvelet transform (Sun Chengyu and Juncai 2019), etc., using filtering noise reduction or transform domain methods to separate effective waves, better filtering out coherent interference and random interference. In terms of resolution enhancement, such as de-convolution (Yan et al. 2014), inverse Q filtering (Dai et al. 2018) and spectral whitening (Chen chuanren, Zhou Xixiang, 2000), the resolution is enhanced by some ways such as compressing the duration of seismic wavelet and broadening the effective frequency band of the signal.
With the daily use of massive seismic data, traditional filtering, de-convolution and other methods are inadequate in processing seismic data. Rapid developments in computer technology are being adopted by petroleum industry for improving the quality of seismic data through techniques such as image processing. Among them, there are de-noising and super-resolution reconstruction algorithm based on deep learning (Dong et al. 2014). These techniques can quickly achieve high-quality seismic section reconstruction, effectively improving the signal-to-noise ratio and resolution and is widely used in the improvement of seismic profile quality by learning the mapping relationship between high- and low-quality data. Han et al. (Weixue and Yatong, 2018) constructed a deep CNN model for seismic profile de-noising and used the learning residual method to better separate random noise. Liu et al. (2018) raised a deep learning algorithm to suppress imaging noise and scattering noise. It achieved good application results in three-dimensional post-stack seismic data. Yuan et al. (2019) combined super-resolution reconstruction technology and came up with a seismic profile reconstruction method based on convolutional neural network (CNN) (Simonyan and Zisserman 1409). Choi et al. (2019) increased the depth of the model and used multilayer convolution and pooling operations to extract feature information in the image. Ultimately they realized the end-to-end mapping between high-resolution and low-resolution profile images. Halpert (2018) applied Generative Adversarial Network (Goodfellow et al. 2014) (GAN) to improve the quality of seismic profile images. Compared with CNN-based algorithms, the resolution of seismic profile was further improved. The above algorithms have made breakthroughs in removing section noise and improving the resolution of the section image. However, the present research regards de-noising and super-resolution reconstruction as separate parts, which increases the time complexity of the algorithms. Moreover, most super-resolution algorithms are sensitive to noisy data (Wang 2020). When reconstructing the low-resolution noisy seismic sections, they are less effective.
In 2020, Li et al. (2020) completed de-noising and super-resolution reconstruction in the same model as well as presented a collaborative seismic data de-noising and super-resolution reconstruction algorithm (Deep Learning for simultaneous seismic image super-resolution and de-noising, SSRDN), which enhanced the processing power of the model noisy data, reduced the effective loss of information and improved the quality of seismic profile after the reconstruction. SSRDN is based on the U-Net structure (Ronneberger et al. 2015). It still has shortcomings in the processing of high-frequency details. Conversely, it provides new ideas for the processing of noisy low-resolution seismic sections and promotes the advancement of high-quality seismic section reconstruction techniques.
From the perspective of synchronous noise removal and super-resolution reconstruction, this paper provided seismic random noise suppression and super-resolution reconstruction algorithm based on GAN. The de-noising module of the algorithm combined the residual learning idea to directly learn the characteristic distribution of noise and indirectly obtain the noise-free seismic section by difference calculation. The super-resolution reconstruction module used the principle of back projection (Li et al. 2020) to improve the accuracy of sampling layer mapping. Simultaneously, it completes the reconstruction of high-resolution seismic sections in multiple steps through iterative upper and lower projection units. The algorithm was supported by the generator and the discriminator. The de-noising and super-resolution reconstruction of the seismic profile had significant effects, effectively polishing up the signal-to-noise ratio and resolution of the seismic profile.
Materials and methods
Generative adversarial network
The Generative Adversarial Network (GAN) (Goodfellow et al. 2014) is an unsupervised deep learning framework composed of generators and discriminators. The design is inspired by the “two-person zero-sum game” in game theory. The structure is shown in Fig. 1.

Generative adversarial network structure
GAN adopts the method of confrontation training to cross-optimize the generator (Generator, G) and the discriminator (Discriminator, D), and the objective function (Goodfellow et al. 2014) is as Eq. (1).
In the formula (1), \(x\) is real data; \(p_{{{\text{data}}}}\) is the real data distribution; \(z\) is randomly distributed noise data; \(E\) represents expected value; \(\log D(x)\) is the authenticity judgment of the input data by the discriminator; \(G(z)\) is the output result of the noise data after the generator.
During GAN training, first fix the generator to optimize the discriminator. The discriminator is responsible for outputting a real value in the range of [0, 1] to indicate the probability of whether the input data are true or not. Its purpose is to maximize the objective function. When the discriminator reaches the optimum, start training the generator and the generator uses the interaction with the discriminator to continuously optimize its own parameters, thereby generating "real data" that the discriminator cannot distinguish. The optimization process of D and G (Goodfellow et al. 2014) can be expressed by Eqs. (2) and (3).
In the above two equations, \(D_{G}^{*}\) and \(G^{*}\) are the optimal solutions of the discriminator and generator, respectively.
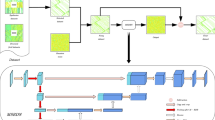
The model structure of this article
Aiming at the particularity and complexity of seismic profile data, a neural network structure based on GAN was designed and an algorithm for simultaneous de-noising and super-resolution reconstruction was proposed to ameliorate the quality of low-signal-to-noise ratio and low-resolution seismic profiles. The generator G and the discriminator D constituted the main body of the network model. The generator was a deep convolutional neural network structure. It took noisy low-resolution seismic profile images as input. Through residual learning de-noising and upper and lower back projection units, it achieved super-resolution reconstruction of the data and finally mapped the features to the output space step by step and generate high-resolution seismic images without noise. The discriminator was a fully convolutional neural network. It took the generator output data and real data as input. After the hidden layer, the features were sampled and transformed. The judgment matrix representing authenticity was output. The average value of the matrix elements was taken as the probability value of the judgment input source. G and D influenced each other during iterative update, which promoted the continuous improvement of image reconstruction quality.
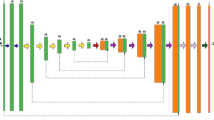
Generator
The generator consists of two parts, a de-noising module and a super-resolution reconstruction module. The structure is shown in Fig. 2. Among them, the first 5 layers are de-noising sub-networks with the combination of 3 × 3 convolution, batch normalization and LeakyReLU activation layer as the core unit. They remove the clean data in the hidden layer implicitly and separate the noise from the noisy image. With an aim to alleviate the training pressure of deep neural networks, this paper used the method of predicting residual images (Zhang et al. 2016) to learn the data distribution of noise, corrected the learning direction with the mean square error (MSE) loss of noise and used the difference calculation to get the feature image without noise, which was employed in the next stage of super-resolution reconstruction work. The network de-noising process (Zhang et al. 2016) is shown in Eq. (4).

Generator structure
In this formula, \(I_{{{\text{input}}}}\) was the input noise-containing low-resolution seismic image; \(I_{{{\text{noise}}}}\) was the included noise data; \(I_{{{\text{denoise}}}}\) was the noise-reduced data. The purpose of the de-noising subnet was to learn \(I_{{{\text{noise}}}}\) and indirectly obtained \(I_{{{\text{denoise}}}}\). In addition, so as to avoid edge artifacts, this paper adopted zero-value padding to keep the feature map size consistent.
With regard to the characteristics of high density of seismic sections and complex textures, the algorithm constructed interconnected upper and lower projection units, and applied the corrective feedback mechanism of alternating up- and down-sampling to achieve the restoration of more detailed features. The network selected transposed convolution as the up-sampling layer and convolution as the down-sampling layer to calculate the projection error to complete the self-correction of the sampling layer. The structure of the projection unit is shown in Fig. 3.

Projection unit structure
Convolve down-sampling:
Calculate the up-sampling error:
Error up-sampling:
Output high-resolution features:
Assume that the low-resolution feature data input to the upper projection unit was \(L^{t - 1}\). After transposed convolution, it was mapped to high-resolution space to obtain \(H_{0}^{t}\). On the one hand, it was used as the input of the lower projection unit. On the other hand, it performed convolution operation to obtain the sampling error, and then re-downsample \(H_{0}^{t}\) to the low-resolution space to obtain \(L_{0}^{t}\). The error \(e_{t}^{l}\) is calculated from the difference with the \(L^{t - 1}\) and \(L_{0}^{t}\). \(e_{t}^{l}\) was transposed and convolution up-sampled and then fused with \(H_{0}^{t}\) to obtain the final high-resolution output result \(H^{t}\). The calculation process of the upper projection unit (Haris et al. 2018) was as formula (5–9):
Transpose the up-sampling convolution
In the formula, \(*\) is the convolution operation; \(p_{t}\) and \(g_{t}\), respectively, represent transposed convolution and ordinary convolution; \(s\) is sampling factor. The lower projection unit mapped the high-resolution feature map to the low-resolution space. The process was similar to that of the upper projection unit. The calculation process (Haris et al. 2018) was as shown in Eqs. (10–14):
The cascaded upper and lower projection units represent different image degradation and high-resolution components. In order to obtain high-frequency information of different dimensions, this article combined the high-resolution feature maps of multiple upper projection units to enrich the content of the reconstructed image. Furthermore, 1 × 1 convolution was used to fuse and reduced the dimensionality of features, which could promote feature flow propagation and increase network convergence speed while avoiding feature redundancy in this paper.
Convolve downsampling:
Transpose the up-sampling convolution:
Calculate the down-sampling error:
Error down-sampling:
Output low-resolution features:
Discriminator
There were 7 layers of discriminators in the model in this paper. Feature extraction is performed on the input data to obtain low-dimensional discrimination information. The output size was a matrix \(X\) of 30 × 30 × 1. Each value \(X_{(i,j)}\) in the matrix represents the authenticity judgment of the corresponding area in the input image. The probability value in the range of 0–1 could be obtained by averaging all (Isola et al. 2017) \(X_{(i,j)}\), which could be used as a basis for judging whether the input image was true and natural. As a discriminator, it was similar to the “loss function” of the training generator and its structure is shown in Fig. 4.

Discriminator structure
For the purpose of increasing the size of the receptive field in the deep neural network and obtaining information in a larger neighborhood of the input data, the convolutional layer in the discriminator used a convolution kernel with a size of 4 × 4 and a step size of 2. At the same time, to avoid network over-fitting, the maximum pooling layer was adopted to reduce the feature scale and the number of data and parameters in the network.
Loss function
The loss function of the algorithm was the weighted sum of content loss and counter loss, where content loss was composed of noise MSE loss and image MSE loss (Guo et al. 2019). The specific definition of the loss function is shown in Eq. (15).

In the formula, the function of \(\lambda_{1}\) and \(\lambda_{2}\) was to weigh multiple loss functions so that they could work at the same level.
The content loss was composed of the average MSE loss between the residual image and the expected noise image, and the average MSE loss between the seismic image was reconstructed by the generator and the actual high-resolution seismic image. The purpose of designing content loss was to ensure the accuracy of noise prediction and the integrity of the low-frequency part of the image. The smaller the MSE value, the better the algorithm performance. The noise MSE loss function and the image MSE loss function (Nicolson and Paliwal 2019) were as Eqs. (16) and (17).
\(N\) was pairs of \(N\) the noise-free low-resolution-no-noise high-resolution seismic image; \(y^{n}\) was the predicted noise; \(y^{r}\) was the real noise; \(y^{l}\) represented the noise-free high-resolution image; \(y^{s}\) was a real high-resolution seismic image without noise.
Apart from the content loss, this paper combined the characteristics of the generated confrontation network, added the confrontation loss to the overall loss function and encouraged the generator to strengthen the ability of image de-noising and super-resolution reconstruction. Additionally, it also enhanced the perceptual quality of the reconstructed image. The anti-loss (Ledig et al. 2017) is defined in Eq. (18).
\(G_{{\theta_{G} }} (I^{{{\text{input}}}} )\) stands for the seismic profile image after the generator de-noises and improves the resolution; \(D_{{\theta_{D} }} (G_{{\theta_{G} }} (I^{{{\text{input}}}} ))\) is the probability that the discriminator judged the generator data to be true.
Experiment and results
Model training
Before the training of de-noising and super-resolution reconstruction models, a large number of noise-free high-resolution two-dimensional seismic sections needed to be prepared as training samples. However, the seismic data collected on-site cannot meet the high-standard experimental requirements. In this paper, a forward simulation method was used to synthesize multiple 3D seismic data volumes, and a total of 800 pairs of training samples are extracted to be used in the training of the network model. First the 2D seismic profile was extracted from the high-quality 3D synthetic data as a reference sample for training, then Gaussian white noise was added to the 3D synthetic data, and the noisy 2D seismic profile was collected from the 3D synthetic data. After down-sampling by 2 times, the final input of the network was obtained data. Figure 5 shows part of the training samples, where the size of the three-dimensional synthetic data volume is 256 × 256 × 306, and Fig. 5e is an example of the input data for the network model of this article.

a Noise-free high-resolution 3D data volumes. b 3D seismic data after adding random noise. c Noise-free high-resolution two-dimensional profile. d Noisy two-dimensional profile. e Noisy low-resolution two-dimensional profile. f The partial area in Figure e is zoomed in
To avoid network over-fitting, cross-validation training was used and 200 pairs of experimental data were applied as the validation set to evaluate the model performance and make timely adjustments. The experiment chooses Adam (Kingma and Adam 2014) as the optimization algorithm, sets the batch size (batch_size) to 16, the number of iterations (epochs) to 500, and the initial value of the learning rate to 1e-4, and fine-tuned it in each iteration. The hyperparameters involved in the article are \(\lambda_{1} { = }0.5\) and \(\lambda_{2} { = }0.03\).
In this paper, the signal-to-noise ratio (SNR) (Hui et al. 2020), peak-signal-to-noise ratio (PSNR) (Yubing et al. 2006), and structural similarity (SSIM) (Yubing et al. 2006) were selected as objective evaluation indicators to measure the effect of the experiment, which were employed to quantitatively explain the de-noising of data and reconstruction accuracy. SNR and PSNR were used to measure the de-noising ability of the algorithm, both in dB. SSIM was used to measure the super-resolution reconstruction quality of the algorithm. The value range was [0, 1]. The larger the value, the higher the resolution of the reconstructed image. The three were defined as:
\(y\) is a high-resolution seismic profile image without noise; \(y^{\prime}\) was the reconstructed image; \(W\) and \(H\), respectively, represent the number of columns and rows of the image; \(f_{{{\text{MSE}}}}\) is the mean square error function; \(\mu_{{\mathbf{y}}}\) and \(\mu_{{{\mathbf{y^{\prime}}}}}\), respectively, represent the mean value of \(y\) and \(y^{\prime}\); \(\sigma_{{\mathbf{y}}}\) and \(\sigma_{{{\mathbf{y^{\prime}}}}}\) are the variance of \(y\) and \(y^{\prime}\), respectively; \(\sigma_{{yy^{\prime}}}\) is the covariance of \(y\) and \(y^{\prime}\).
The model training results are shown in Fig. 6. When the iterations were 400 times, the fluctuation of the loss curve and the average peak signal-to-noise ratio curve of the validation set was small, but there was still a trend of change. When the number of iterations is close to 500, the loss and the average peak signal-to-noise ratio of the verification set tended to converge.

Training result. a Loss function curve b PSNR value change curve of the verification set
Model experiment
Synthetic seismic data were used to conduct model experiments to verify the effectiveness of the algorithm in this paper. Randomly tested with noisy and low-resolution two-dimensional synthetic data. The experimental results are shown in Fig. 7. Figure 7 a is a high-quality data image with well-imaging faults and stratums, and Fig. 7 b adds Gaussian random noise on the basis of Figure a and down-sampling by 2 times. The SNR value is 6.281 dB, the PSNR value is 13.307 dB, and the SSIM value is 0.392. Figure 7 c is obtained after de-noising and improving the resolution by the algorithm in this paper. Comparing Fig. 7 a and c, it could be seen that the seismic profile image reconstructed by the algorithm was basically the same as that before degradation, with complete structural features and clear geological edges, which effectively removed noise interference and effectively improved the clarity of the fault distribution (as indicated by the arrow).

Experimental results of the algorithm in this paper on synthetic data. a High-quality two-dimensional synthetic seismic profile image. b Add noise and down-sampling 2 times (SNR = 6.281 dB, PSNR = 13.307 dB, SSIM = 0.392). c The cross-sectional image reconstructed by the algorithm in this paper. d Figure a The middle red box is enlarged. e Figure b The middle red box is enlarged. f Figure c The middle red box is enlarged
Objective evaluation indicators to evaluate the reconstruction effect of this paper are shown in Fig. 7, and the results are given in Table 1. The SNR value of the seismic profile after reconstruction by the algorithm increased by 15.772 dB, and the PSNR value increased by 17.168 dB, indicating that the signal-to-noise ratio of the reconstructed profile image has improved and the interference noise was effectively removed. The SSIM value increased by 0.434 compared to the input data, denoting the reconstruction. The seismic profile had been greatly improved in terms of structure and contrast. The image quality and resolution have been effectively ameliorated.
To highlight the advanced nature of the model in this paper, compared with the SSRDN of wavelet transform, synchronous seismic data de-noising and reconstruction algorithm, the objective data and subjective quality of the reconstructed profile image were compared. In order to better observe the improvement effect of the seismic profile resolution after reconstruction by the algorithm, the high-quality synthetic seismic profile image taken at random a was down-sampled by 2 times to obtain a low-resolution seismic profile Figure b. Figure c was obtained after adding Gaussian noise on the basis of Figure b. Figure c has an SNR value of 9.046 dB, a PSNR value of 16.135 dB, and an SSIM value of 0.417. Figure c is used as the input data of each algorithm for de-noising and super-resolution processing.
Subjective effects of the experiment are shown in Fig. 8. It could be seen from Fig. 8 that the wavelet transform removed part of the noise of the noisy seismic profile, but the noise still remained and the profile information disturbed by the noise cannot be fully recovered. As a pure de-noising algorithm, the wavelet transform did not change the resolution of the profile image. SSRDN had a greater improvement in de-noising and reconstruction compared to the wavelet transform. Compared with Figure c, most of the noise was effectively removed. Compared Figure b, the section resolution had also been improved (as indicated by the arrow). The values of SNR, PSNR, and SSIM are 16.392 dB, 23.504 dB, and 0.694, respectively. The reconstruction effect of the algorithm in this paper was the best, the quality of the profile was significantly improved after reconstruction, and the residual noise level dropped. Compared with Figure b, the layer-to-layer boundary was clearer and the thin. Layer resolution was also improved (as shown in the rectangular box). The values of SNR, PSNR, and SSIM were 21.025 dB, 29.382 dB and 0.863, which were 4.633 dB, 5.878 dB and 0.169, respectively, higher than SSRDN. The de-noising and super-resolution performance were better than SSRDN.

Comparison of seismic profile image effects after reconstruction of various algorithms. a High-quality two-dimensional synthetic seismic profile image. b The seismic profile after down-sampling by 2 times. c The seismic profile after down-sampling by 2 times and adding noise (SNR = 9.046 dB, PSNR = 16.135 dB, SSIM = 0.417). d Wavelet transform experimental results. e SSRDN reconstruction result. f The reconstruction results of the algorithm in this paper
Twenty synthetic seismic profile images were randomly took with different signal-to-noise ratios and divided into two groups. The average SNR, average PSNR, and average SSIM values of the input data were compared with the corresponding indexes of the reconstructed image. Then the reconstruction performance of wavelet transform, SSRDN, and the algorithm in this paper was comprehensively evaluated. The objective data are shown in Table 2. For input seismic profiles with different signal-to-noise ratios and resolutions, the algorithm could achieve ideal reconstruction results. The average SNR, PSNR, and SSIM values of the reconstructed seismic profile images were higher than those of the other two algorithms. Moreover, the average loss time was less than wavelet transform and SSRDN. Integrating subjective effects and objective data, the algorithm in this paper had the best effect in reconstructing synthetic seismic sections. This was due to the powerful feature processing capabilities of the GAN network, as well as the construction of joint de-noising and super-resolution reconstruction modules.
Discussion
For the purpose of proving the application value of the algorithm in this paper, the model trained on synthetic seismic data was used to conduct experiments on actual seismic data of the F3 block in the North Sea of the Netherlands and a block in the western part of China.
Block F3 in the North Sea of the Netherlands (Isola et al. 2017) covers an area of about 16 × 32 km2 consisting of 646 inlines and 947 crosslines with a sampling rate of 1 ms. Figure 9a is a two-dimensional post-stack seismic profile in the inline direction of the F3 block data volume. The profile quality is poor due to a certain degree of noise and low-resolution interference. Figures b, c and d are the experimental results of wavelet transform, SSRDN, and the algorithm of this paper for Figure a, respectively. Among them, the seismic profile after wavelet transform noise reduction was relatively fuzzy, and only part of the noise interference was removed. The improvement of the profile resolution contribution is minimal. In contrast to Figure a, the reconstruction of the seismic profile after SSRDN had a greater improvement in clarity and the faults were more prominent. Nevertheless, the problem of inconspicuous edge details still existed. The reconstruction effect of the algorithm in this paper was better than the other two algorithms. After reconstruction, the structure of the profile was clearer, the continuity of the event axis was enhanced, and the resolution of the weak reflection layer was affected by noise and low resolution. The distribution of small structures such as upper discontinuities was also more clear (as shown in the rectangular box). In order to better display the reconstructed discontinuity state, the part in the rectangular box was enlarged and displayed. The pictures in Figure e were the corresponding ones in Figure a, Figure b, Figure c, and Figure d from left to right. From Figure e, we could see that the resolution of the discontinuities reconstructed by the algorithm was the highest. The distribution was clearer (as indicated by the yellow arrow), and the discontinuity state in the original section was improved to a greater extent. Experiments on the F3 block proved the advantages of the synchronous de-noising and super-resolution reconstruction algorithms, as well as the effectiveness and advancement of this algorithm in improving the quality of seismic sections.

Comparison of the experimental results of different methods on the seismic section of F3 block. a F3 block Inline385. b Wavelet transform experimental results. c SSRDN algorithm reconstruction results. d Algorithm reconstruction results in this paper. e Local area zoom in the red box
In anticipation of testing the reconstruction effect of the algorithm on the actual seismic data of different blocks, a post-stack seismic section of a certain western block was used for experiments. The result is shown in Fig. 10. Figure a is a seismic profile image in the crossline direction, which was affected by a certain degree of noise and low resolution. Figures b, c, and d are the experimental results of wavelet transform, SSRDN, and the algorithm in this paper. The experiment time was 0.472 s, 0.338 s, and 0.307 s. It could be seen from Fig. 10 that the wavelet transform caused the image to be too smooth and part of the effective information was lost. The seismic profile after SSRDN reconstruction increased, but the processing of small details was insufficient, and the resolution of the thin layer was less improved than Figure a (As indicated by the red arrow). The resolution of the seismic profile image reconstructed by the algorithm was the highest. After noise interference was removed and the reconstruction of the profile distortion was decreased. The definition of the thin layer boundary is effectively improved and the continuity of the event axis was increased (as indicated by the red arrow). Moreover, the number of cracks that could be recognized by the naked eye was more than that of SSRDN (as shown in the rectangular box), and the distribution of cracks was clearer.

Comparison of experimental results of different methods on a seismic section in a western block. a Crossline 1929 in a western block. b Wavelet transform experimental results. c SSRDN algorithm reconstruction results. d Algorithm reconstruction results in this paper
Combining the experimental results of F3 block and a western block, the algorithm proposed in this paper could effectively remove the noise interference of actual seismic data, while performing super-resolution reconstruction of low-resolution seismic sections, effectively improving the signal-to-noise ratio of seismic sections and resolution by the more ideal application value.
Conclusions
Generative Adversarial Network (GAN) has powerful feature learning and generation capabilities. It has outstanding advantages in the application of reconstruction of high-quality seismic sections. In this paper, researches on synchronous de-noising and super-resolution reconstruction were carried out. A random noise suppression and super-resolution reconstruction model based on the GAN seismic profile was constructed to solve the problem of severe noise and low-resolution interference from the seismic profile. The algorithm combined residual de-noising and super-resolution reconstruction modules to remove the random noise contained in the post-stack seismic profile and employed an iterative back projection unit to further improve the resolution of the de-noised profile, which effectively improves the quality of the seismic profile. Experimental results on synthetic seismic data and actual seismic data showed that the algorithm in this paper could effectively remove the random noise in the seismic profile, improve the SNR and PSNR values of the input data and increase the resolution of the profile. After reconstruction, the definition of the geological structures such as the fractured layer in the profile was significantly improved, and the quality of the profile is further heightened. Compared with algorithms such as SSRDN, it had faster operating efficiency and better reconstruction performance, which could provide support for the reliability and accuracy of subsequent seismic and geological interpretation.
References
Chuanren C, Xixiang Z (2000) Improving the resolution of seismic data by wavelet spectrum whitening method. Pet Geophys Explor 35(6):703–709
Chengyu S, Juncai D, Wenjing L (2019) Denoising of 3D block matching seismic data based on meander noise estimation. Pet Geophys Explor 54(06):1188–1194
Choi Y, Seol SJ, Byun J et al. Vertical resolution enhancement of seismic data with convolutional U-net, In: SEG technical program expanded abstracts 2019, 2019
Dai Yu, Zhijun He, Yuan Sun et al (2018) Comparison of anti-Q filtering methods based on wave field continuation. Geophys Geochem Explor 42(2):331–338
Dong C, Loy CC, He K et al. (2014) Learning a deep convolutional network for image super-resolution, In: European conference on computer vision. Springer, Cham, pp 184–199.
Goodfellow IJ, Pouget-Abadaie J, Mirza M et al. Generative adversarial nets, In: ACM 27th International conference on neural information processing systems, December 8–13, 2014, Montreal, Canada. New York: ACM, 2014, pp 2672–2680.
Guo S, Yan Z, Zhang K et al. (2019) Toward convolutional blind denoising of real photographs, In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 1712–1722.
Halpert AD Deep learning-enabled seismic image enhancement, In: SEG technical program expanded abstracts 2018. 2018.
Haris M, Shakhnarovich G, Ukita N (2018) Deep back-projection networks for super-resolution. arXiv. arXiv.
Hui S, Yang G, Wei C et al (2020) Seismic data denoising based on convolutional noise reduction autoencoder. Pet Geophys Prospect 55(06):1219–1161
Isola P, Zhu J Y, Zhou T, et al. Image-to-image translation with conditional adversarial networks, In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2017, pp 1125–1134.
Kingma D, Ba J (2014) Adam: a method for stochastic optimization. Comp Sci
Ledig C, Theis L, Huszár F, et al. Photo-realistic single image super-resolution using a generative adversarial network, In: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp 4681–4690.
Ledig C, Theis L, Huszár F, et al. Photo-realistic single image super-resolution using a generative adversarial network, In: Proceedings of the IEEE conference on computer vision and pattern recognition 2017, pp 4681–4690
Li J, Wu X, Hu Z. Deep learning for simultaneous seismic image super-resolution and denoising, In: SEG technical program expanded abstracts 2020. Society of Exploration Geophysicists, 2020, pp 1661–1665.
Liu D, Wang W, Chen W, et al. Random noise suppression in seismic data: What can deep learning do?, In: SEG technical program expanded abstracts 2018. Society of Exploration Geophysicists, 2018, pp 2016–2020.
Margrave GF (2001) Direct fourier migration for vertical velocity variations. Geophysics 66(5):1504–1514
Nicolson A, Paliwal KK (2019) Deep learning for minimum mean-square error approaches to speech enhancement. Speech Commun 111:44–55
Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation, In: International conference on medical image computing and computer-assisted intervention. Springer, Cham, 2015, pp 234–241.
Sanda O, Mabrouk D, Tabod TC et al (2020) The integrated approach to seismic attributes of lithological characterization of reservoirs: case of the F3 block, North Sea-Dutch Sector. Open J Earthq Res 09(3):273–288
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv preprint. arXiv:1409.1556
Wang F (2020) Research on seismic data denoising and reconstruction based on deep learning. Zhejiang University.
Weixue H, Yatong Z, Yue Chi (2018) Removal of random noise from seismic data based on deep learning convolutional neural network. Geol Prospect Pet 57(06):862–877
Yuan Z, Huang H, Jiang Y et al (2019) An enhanced fault-detection method based on adaptive spectral decomposition and super-resolution deep learning. Interpretation 7(3):1–63
Yubing T, Qishan Z, Yunping Qi (2006) Image quality evaluation model based on the combination of PSNR and SSIM. J Image Gr 12:19–24
Zhang Yu, Guanquan Z (1997) Wavelet transform for removing high frequency random noise. Pet Geophys Explor 32(3):327–337
Zhang K, Zuo W, Chen Y et al (2016) Beyond a Gaussian denoiser: residual learning of deep CNN for image denoising. IEEE Trans Image Process 26(7):3142–3155
Zhao Yan, Liu Yang, Hu Guangyi et al. (2014) High resolution seismic data processing method based on attenuation compensation. Pet Geophys Explor, 53 (001): 38–45.
Funding
This work is partially supported by the CNPC Major Science and Technology Project (ZD2019–183–006); the special fund for basic scientific research operations of central universities (20CX05017A); the National Natural Science Foundation of China under Grant 41930429.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, Jia-yue Xu states that there is no conflict of interest.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sun, QF., Xu, JY., Zhang, HX. et al. Random noise suppression and super-resolution reconstruction algorithm of seismic profile based on GAN. J Petrol Explor Prod Technol 12, 2107–2119 (2022). https://doi.org/10.1007/s13202-021-01447-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13202-021-01447-0