
Abstract
Research on predicting the growth trend of natural gas reserves and production will help provide a scientific basis for natural gas exploration and development. The metabolically improved modified weight coefficient GM(1,n) method is applied to the multi-cycle Hubbert model to predict the trend of new proven natural gas reserves in the Sichuan Basin. The ultimate recoverable reserves (URR) is introduced as a boundary condition in the production-time series to predict the natural gas production growth. The research results show that: (1) The annual newly added proven natural gas reserves of the Sichuan Basin maintain a multi-cycle growth trend, which will reach the peak reserves in 2034, at which time the proven rate of natural gas will reach 36%. (2) Based on the predicted results of proven reserves, the final recoverable reserves of natural gas are estimated to be \(5.25-5.75\times {10}^{12}{m}^{3}\). The production in 2035 will reach \(750-810\times {10}^{8}{\mathrm{m}}^{3}/\mathrm{a}\), and production will grow rapidly. The exploration and development of natural gas in the basin will be prospective for a long time.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The Sichuan Basin is a large superimposed basin formed after multiple periods of tectonic movement. According to the latest resource evaluation, the total natural gas resources in the Sichuan Basin are close to \(40\times {10}^{12}{\mathrm{m}}^{3}\), ranking first in the country. The proven rate of natural gas in the Sichuan Basin is only 12.5%. Exploration is still in its early stages, but there are indications of a rich resource potential. The Sichuan Basin has developed an advanced natural gas industrial technology system that includes a complete natural gas regional pipeline network and a mature natural gas energy market. PetroChina as China’s natural gas industrial base has identified it. All aspects of the natural gas development in the basin are therefore mature (Resnikoff 2011; Alipour et al. 2019; Zou et al. 2020). Research on gas production and the prediction of the growth trend of natural gas reserves in the Sichuan Basin will advance the development and utilization of natural gas resources. Presently, extensive research has been carried out on gas production and the prediction of the growth trend of natural gas reserves.
Based on statistical research on the actual dynamic data of a large number of oil and gas field developments, many scholars have derived and proposed a series of natural gas storage and production prediction models, such as the life cycle method (Abdullah and Hasan 2021), the grey system method (Ramezanianpour and Sivakumar 2017), and the neural network method (Karahan and Ayvaz.2006), amongst others. Most oil and gas field reserves and production growth trends conform to the peak model theory. In 1956, Hubbert predicted the future US oil supply by fitting the historical oil production curve. The prediction is based on two assumptions: First, that production will eventually decline exponentially, and second, that the area enclosed by the curve must be equal to the ultimate recoverable oil resources of the USA. Using the industry’s universally predicted US ultimate recoverable resources (150–200 billion barrels), Hubbert predicted that US oil production will reach its peak during 1965–1971 (Hubbert 1949; Kaufmann and Cleveland 2001a; Abdideh and Fatha Ba 2013).
In 1984, Weng proposed the Poisson Cycle model. He believed that oil and gas discovery also has a natural cycle similar to "rise-growth-boom-death", which is usually called the Weng model (Zhou et al. 2017). In 1996, Chen completed the theoretical derivation of Weng model and proposed the generalized Weng model (Zheng and Liu 2019). Since then, a large number of research institutions and scholars have carried out studies on the trend of oil and gas resource discovery, including the Hu Chenzhang (HCZ) model, the Hu Chen (HC) model, the lognormal distribution model, the Rayleigh model, the t model, the generalized I type mathematical model and the generalized type II mathematical models, and scholars Chen, Hu, and Zhang who proposed Weibull model (Yang et al. 2017; Pan et al. 2020; Senthil et al. 2019).
In 2020, Long summarized and evaluated the characteristics and applicability of the commonly used production prediction models in natural gas fields, and concluded that the generalized type I prediction model and the generalized type II prediction model are not restricted by the positive integer value of the model classification factor. These two models and the generalized Weng model are commonly applied to conventional natural gas production in the Sichuan Basin for full life cycle prediction (Long et al. 2020). In 2019, Peng et al. analysed the exploration and development history of the Ordos Basin. They combined the multi-peak Gauss model with the multi-peak characteristics of oil reserves and production growth in the Ordos Basin to fit the historical curve of oil reserves and production in Ordos Basin and ultimately predict the growth trend of reserves and production in the basin from 2006 to 2030 (Peng et al. 2019). In 2019, Yang used a multimodal Gaussian model to predict the growth trend of natural gas production because of the multimodal characteristics of natural gas production growth in the Sichuan Basin. Wang introduced the final recoverable reserves as a boundary condition in the production-time series and applied this in the mid-to-long-term production trend study to quantitatively predict the whole life cycle (Yang et al. 2019).
The current prediction methods are mostly based on a single model to predict the trend of oil and gas reserves and production. Due to the complex geology in the Sichuan Basin, the discovery of reserves and the growth of gas production have obvious fluctuations. Multiple methods can be combined with single model prediction methods to predict gas reserves and production. By analysing the historical changes of natural gas reserves in the Sichuan Basin, the multi-cycle Hubbert model can be combined with the improved GM(1,n) grey prediction model to predict the development trend of natural gas reserves for the Sichuan Basin. Based on reserve prediction results, the ultimate recoverable reserves (URR) is introduced as the boundary condition into the production prediction study, which can reasonably predict the growth trend of natural gas production in the Sichuan Basin and provide a scientific basis for the planning of the medium and long-term development plan.
Natural gas reserves and production prediction theory
Hubbert prediction model
Unimodal peak Hubbert prediction model
Hubbert model is the main research method of peak prediction model. The model mainly has the following two characteristics:
(1) For limited resources, the production curve goes from \(t=0\) to \(t=\infty \), and after experiencing several maximum (local peaks) productions, the final production value is 0.
(2)The cumulative production \(A={\int }_{0}^{{x}_{i}}y\mathrm{d}x\).
The Hubbert model can be expressed as:
In the formula, Q represents annual production where the unit is \({10}^{8}{\mathrm{m}}^{3}/\mathrm{a}\); P represents cumulative production where the unit is \({10}^{8}{\mathrm{m}}^{3}/\mathrm{a}\); URR represents the ultimate recoverable reserves where the unit is \({10}^{8}{\mathrm{m}}^{3}/\mathrm{a}\); \({t}_{m}\) represents the peak production time where the unit is the year, and b represents the peak slope(Kaufmann and Cleveland 2001b).
Formulas (1 and 2) and transformed to produce
By making \(\mathrm{Y}=Q/P\)、\(\mathrm{a}=-b/\mathrm{URR}\), and amending formula (3) you get the formula
Formula (5) is often used to estimate the linear fitting parameters \(a\) and \(\mathrm{b}\) by the least square method, to calculate the parameters \({t}_{m}\) and \(\mathrm{URR}\), and to obtain the corresponding Hubbert oil and gas peak model.
Multimodal Hubbert prediction model
After stacking multiple unimodal Hubbert models, a new multimodal Hubbert model is obtained as
In the formula, \({Q}_{m}\) represents the peak annual production; \(k\) represents the number of multi-cycle peaks, and \(i\) represents the number of cycles.
If there is progress in natural gas exploration and development results during the change of the model curve, the curve will first rise and then fall periodically. If large and medium sized gas fields are discovered or technologically advanced more frequently, multiple periodic changes may occur, that is, multimodal phenomenon (Xu and Zhu 2020).
The multi-cycle Hubbert model is used to predict the multiple periodic future changes of natural gas reserve discoveries and their production. The number and time of the Hubbert cycles should be determined based on existing gas reserves and production peaks. The geological resource and other information of the prediction are used to determine the cycle parameters and finally superimpose the Hubbert cycle curve obtained by prediction to obtain a new prediction curve.
GM(1,n) grey prediction model
GM(1,n) prediction model with modified weight coefficient
The GM(1,n) model represents a grey model established by first-order differential equations for numerous variables-\({x}_{1}\), \({x}_{2}\)…(\({x}_{n}\)Luo et al. 2020). Assuming that
The traditional GM(1,n) prediction method directly accumulates the first order of \({{x}_{i}}^{(0)}\) to generate a new accumulation sequence \({{x}_{i}}^{(1)}\)
In the formula, \(k=\mathrm{1,2}\dots p; i=\mathrm{1,2}\dots n\)
The accumulation sequence \({{x}_{i}}^{(1)}\) is used to establish the simplified differential equation of GM(1,n) to obtain the prediction model. Research shows that if there is a local numerical mutation in \({{x}_{i}}^{(0)}\), it will affect the overall accuracy of the prediction model. Therefore, the modified weight coefficient \(\alpha \) is introduced at the numerical mutation to reduce the error of the prediction model.
The revised cumulative formula is
In the formula, \(\alpha \) represents the modified weight coefficient.
Sequence \({{x}_{i}}^{(1)}\) is used to establish a simplified differential equation
The discrete format of the above formula can be rewritten as
If it is assumed that
Then, according to the above algorithm, GM(1,n) grey prediction model can be determined as:
Through the prediction model, the new sequence \({{x}_{i}}^{(1)}\) can be solved. The sequence \({{x}_{i}}^{(0)}\) is obtained by correcting the first-order reduction of the weight coefficient, which is the new prediction result.
Modified weight coefficient GM(1,n) method based on improved metabolism
The GM(1,n) model is a continuous-time function, continuously calculating from the initial value \({{x}_{i}}^{\left(0\right)}\) to any time period in the future. As time goes by, the old data increase continuously, and these cumulative old data often cannot represent new variation trends. Each calculation of a new digital value will accumulate old data, thereby it will increase the calculation workload, and affect the numerical rule of the prediction result, so a correction method is needed to increase the accuracy of the prediction.
When the raw data sequence \({{x}_{i}}^{\left(0\right)}\) shows irregular changes, the original GM(1,n) model may not be able to make accurate predictions. In the calculative process of \({{x}_{i}}^{\left(1\right)}\), sliding average processing can be carried out, and the metabolic method can be adopted at the same time. After each round of data prediction, the data at the forefront of the sequence are removed, and the newly predicted data are substituted into the sequence for a new round of prediction. The prediction process is as follows:
First, create a new raw data sequence \({{x}_{i}}^{''\left(0\right)}\), and perform a sliding average processing on \({{x}_{i}}^{''\left(0\right)}\).The calculation process is as follows:
In the formula, N is the prediction length.
Then, the new sequence \({{x}_{i}}^{''\left(0\right)}\) can be calculated according to Eq. (8) to obtain the new accumulative sequence \({{x}_{i}}^{''\left(1\right)}\) and calculate \({{x}_{i}}^{''\left(1\right)}(N+1)\). Through Eq. (9), the prediction model \({{x}_{i}}^{''\left(1\right)}(t)\) is obtained, so as to obtain \({{x}_{i}}^{''\left(0\right)}(N+1)\);
In the end, add \({{x}_{i}}^{''\left(0\right)}(\mathrm{N}+1)\) to the original sequence \({{x}_{i}}^{''\left(0\right)}\), and remove the farthest data \({{x}_{i}}^{''\left(1\right)}(1)\). Perform recursive operations.
The metabolic method is adopted to replace the old data with the new predicted data, which can reduce the error interference of the old data to the new prediction process and make the prediction trend in a dynamic and stable state. The predicted result will be closer to the ideal situation.
Model accuracy inspection
The result obtained by the improved grey model prediction needs to be tested for accuracy. The test index has two parameters: the post-checking deviation ratio C and the small error probability P:
In the formula, \({S}_{1}\) represents the standard deviation of the original data, \({S}_{2}\) represents the standard deviation of the predicted data, \(\varepsilon \left({t}_{k}\right)\) represents the model residual, and \(\overline{\varepsilon \left({t}_{k}\right)}\) represents the mean value of the model residual.
According to these two parameters, the prediction accuracy can be divided into four accuracy classes (Table 1).
Prediction of natural gas reserves in Sichuan Basin
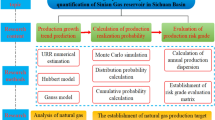
The research methods explained in "Hubbert prediction model" and GM(1,n) grey prediction model sections) are used to carry out research on natural gas reserves and production prediction models. The research process is shown in Fig. 1. The main research process is divided into 4 steps.

Flow chart of research on natural gas reserves and production prediction
Step one diversify the prediction parameters of the Hubbert model to predict the growth law of reserves in known years ("Prediction of reserve growth trend" section).
The improved multi-cycle Hubbert model is used to fit the natural gas reserve curve for known years. The diversified parameters of the Hubbert model can improve the accuracy of reserve prediction. The Hubbert model parameters of the natural gas reserve curve in a known year are used and to analyse reserve growth in known years to provide a basis for the prediction of natural gas reserves in the future.
Step two combine the Hubbert model with the modified weight coefficient GM(1,n) method based on improved metabolism to predict the growth law of reserves in future years ("Prediction of reserve growth trend" and Comprehensive evaluation section). The improved multi-cycle Hubbert model can only predict natural gas reserves based on parameters. Therefore, the modified weight coefficient GM(1,n) method based on metabolism is used in the multi-cycle Hubbert model to predict the future Hubbert parameter, which is used to predict future natural gas reserves.
Step three combine the production baseline prediction based on the Weng model with the multi-cycle Hubbert model to predict the prediction growth law in known years ("Development history" section).
The natural gas production in the Sichuan Basin in a known year has maintained a multi-cycle growth trend under the overall exponential growth trend. The production curve is therefore divided into two parts, the baseline, and the multi-cycle life curve. The Weng model is used to predict the baseline, and the multi-cycle Hubbert model is used to predict the multi-cycle life curve. In this way, the accuracy of the yield prediction results in a known year can be improved.
Step four use the ultimate recoverable reserves (URR) as a boundary condition. Introduce URR into the improved single-cycle Hubbert model to predict production growth in future years ("Ultimate recoverable reserves estimation", "Natural gas production growth trend prediction", and "Comprehensive evaluation").
Estimate the URR based on the prediction results of natural gas reserves. The URR is used as the upper limit condition to restrict the single-cycle Hubbert model to predict natural gas production. At the same time, study the yield prediction results under different URR conditions. Then, comprehensively evaluate the natural gas resources in the Sichuan Basin.
Prediction of reserve growth trend
The characteristics of change of natural gas reserves are a multi-cycle state. The multi-cycle parameter fitting is performed based on the known years, and the obtained reserve prediction curve for the known years is shown in Fig. 2. The parameters of the multi-cycle curve are shown in Table 2. It can be seen from Table 2 that the grey prediction post-checking deviation ratio C is 0.095 and the small error probability P is 0.988. Therefore, the prediction accuracy of newly added proven reserves is considerable. The Exploration and Development Research Institute of PetroChina Southwest Oil and Gas Field Company, who count the annual proven reserves of natural gas in each natural gas area in the Sichuan Basin and determine the reserve growth curve, provide the known reserves data in Fig. 2.

Prediction results of new proved geological reserves of natural gas from 1956 to 2019
The existing model is the developed Hubbert model (2.1. Hubbert prediction model). Because the existing Hubbert model possess only one slope parameter (b), the peak-edge reserve peaks of this model are symmetrical about the reserve peak appearance time \(({\mathrm{t}}_{m}\)). This model can only predict a multi-cycle model with symmetric left and right peaks. However, most of the peaks of the common natural gas reserves growth curve are asymmetric peaks. Therefore, the existing Hubbert model must be improved to more accurately reflect reality.
In the reserve prediction, the peak reserve \(({N}_{m})\) and the peak reserve appearance time \({(\mathrm{t}}_{m})\) can be obtained through data statistics, and the parameter \((\mathrm{b}\)) that characterizes the peak slope, must be obtained through data fitting. The multi-cycle Hubbert model function is used to fit the reserve growth data in known years. To improve the prediction accuracy, the slope parameter \(\mathrm{b}\) is divided into a left peak slope \({(b}_{Left}\)) and a right peak slope \({(b}_{Right})\), while the reserve peak appearance time \(({\mathrm{t}}_{m})\) is divided into a peak value appearance time (\({\mathrm{t}}_{m})\) and a peak valley appearance time \(({\mathrm{t}}_{min})\). The improved Hubbert model diversifies the prediction parameters and solves the limitation that of the original Hubbert model that cannot predict asymmetric peaks.
In Fig. 2, part (a) is the prediction result of the existing model, and part (b) is the prediction result of the improved model. As shown in Fig. 2 part (a), the existing Hubbert model cannot predict the multi-cycle reserve curve very accurately. Because the existing Hubbert model can only predict symmetric peaks, the resulting curve of predicted reserves does not fit the asymmetric peaks of the known reserves curve well. Since the left peak slope \({(b}_{Left})\) and right peak slope \(({b}_{Right})\) are regarded as predictors at the same time, the accuracy of the prediction results is greatly improved, which solves the problem that the left peak and the right peak cannot be accurately predicted at the same time. At the same time, due to the introduction of the new variable peak valley appearance time \(({\mathrm{t}}_{min})\), the prediction effect of the prediction result at \(({\mathrm{t}}_{min})\) is also very good.
According to the modified weight coefficient GM(1,n) method, the reserve parameters of the Hubbert model in future years (\({b}_{Left}\), \({b}_{Right}\), \({N}_{m}\), \({\mathrm{t}}_{m}\), \({\mathrm{t}}_{min}\)) are used to predict future growth. Four groups of independent variables and one group of dependent variables are used to make predictions. By using the grey prediction GM(1,4) method, the value of the remaining four parameters is used as the original data to predict the change of the fifth parameter in each model. Then, the newly predicted parameter values are used as the original data for the next round of prediction. The metabolism method is adopted to avoid prediction process problems. Each time a new set of parameter values is obtained, the front-end set of data should be removed from the original prediction data, and the newly predicted parameter values replace the new prediction original data, and then a new round of predictions is done. At the same time, the correction weight coefficient (α) is used to correct the discontinuity of the predicted data. The prediction principle is shown in Fig. 3.

Grey GM(1,n) natural gas reserves multi-cycle parameter prediction process
The improved grey prediction theory and Hubbert prediction model now provide the growth trend of proven natural gas reserves for the future (see Fig. 4 and Table 3). The reserve prediction results show that the annual proven natural gas reserves in the Sichuan Basin will generally show a rapid upward trend over the next twenty years. The reserves will reach their highest peak in 2034 at 8225 × 108 m3, with a proved rate of 36%, while the average annual proven reserves will exceed 5000 × 108 m3. Thereafter, there will be a slow downward trend. The improved Hubbert model also predicts that there will be more reserve exploration peaks in the future and that the average annual proven reserves will exceed 3000 × 108 m3. In 2060, the annual proven reserves will fall to 1802 × 108 m3, and the cumulative proven reserves will be 19.1 × 1012 m3 while the proven degree will reach 67%. According to the improved Hubbert model, the Sichuan Basin will enter the late stage of natural gas exploration in 2060.

Results of natural gas proven reserves growth trend prediction of the Sichuan Basin
Comprehensive evaluation
The multi-cycle Hubbert model is combined with an improved metabolic grey prediction model to optimize natural gas reserve predictions. The natural gas reserve data from 1956 to 2019 were selected for fitting in the Sichuan Basin, and then the reserve fitting curve obtained in this period is consistent with the actual reserve curve. The grey prediction post-checking deviation ratio C is 0.095 and the small error probability P is 0.988, it conforms to the accuracy-test requirement of grey prediction, while the prediction accuracy is high.
Currently, the proven rate of natural gas is only 12.5% in the Sichuan Basin, which is still in the early stages of exploration. Based on the production growth in the most petroliferous basins of the world, the proven rate of natural gas in mature basins ranges from 30 to 60%. Large gas fields have also recently been discovered, and the rate of reserve discovery has accelerated. The prediction results of the newly added proven reserves of natural gas in the Sichuan Basin indicate that the future reserves will maintain a high and rapid growth trend, which is in line with the general law of production growth in the world petroliferous basins. After reaching the peak, the reserve curve maintains a multi-cycle change trend to the point of decline, which is consistent with the multi-cycle change trends of historical reserve curves.
Natural gas production prediction in the Sichuan Basin
Development history
The natural gas production in the Sichuan Basin maintains a multi-cycle growth trend under the overall class exponential growth trend (see Fig. 5). According to the smoothness of the production curve, the production curve is divided into two parts (see Fig. 6), which are the baseline characterizing the overall change trend of the yield and the multi-cycle life curve characterizing the details of the output change. The multi-cycle number is 3. The Exploration and Development Research Institute of the PetroChina Southwest Oil and Gas Field Company, who collects data on the natural gas production of each natural gas area in the Sichuan Basin and determines a production growth curve, provide the known production data in Fig. 5.

Natural gas production growth curve from 1956 to 2019

Natural gas growth curve division from 1956 to 2019
The production prediction process is divided into two parts to predict variation tendency. First, a baseline segment is determined by screening the gentle part of the multiple cycle peak and then fitting it and using the Weng model to obtain the baseline. This can then be used to predict gas reserves in the future. The Hubbert multi-cycle model prediction can then be used to obtain the parameters of the three peaks of the multi-cycle curve in Fig. 6.
To highlight the effectiveness of the research results of the improved model, the multi-cycle Hubbert model is selected as the existing research model and compared with the improved model.
In Fig. 7, part (a) is the prediction result of the existing model, and part (b) is the prediction result of the improved model. It can be seen from Fig. 7 part (a) that the known natural gas production curve does not completely show the multi-cycle characteristics. Only the natural gas production curve of the multi-cycle peak part can therefore be accurately predicted. Because the smooth part of the curve has larger prediction errors, an improved method that combines the baseline prediction and the multi-cycle prediction is needed.

Natural gas production prediction curve from 1956 to 2019
Table 4 shows the parameters of the natural gas production growth curve. Here, the grey prediction post-checking deviation ratio © is 0.101 and the small error probability (P) is 0.973. The accuracy of the production prediction is therefore high. Because the known production is considered as the sum of the baseline and Hubbert life cycle model, each cycle peak can be calculated by subtracting the baseline from the original production curve. By comparing the data in Table 4 and Fig. 5, it can be noted that the newly obtained production peak (\({N}_{m})\) significantly decreased and that the peak time \({(t}_{m})\) changed slightly. The 1956–2019 natural gas production prediction results are shown in Fig. 7. The prediction baseline for the future sustains an upward trend, and it is consistent with the continuously increasing trend in natural gas production observed in the Sichuan Basin.
Ultimate recoverable reserves estimation
There are only three polycyclic peaks in the production growth trend, and it is not possible to simply use the grey prediction model to predict the parameters of future polycyclic peaks. The ultimate recoverable reserves (URR) should be calculated to predict the future production growth trend.
According to the definition of ultimate recoverable reserves, URR is comprised of four components of resources: cumulative gas production, remaining recoverable reserves, reserves escalation, and yet to be realized reserves. Cumulative gas production and remaining recoverable reserves are the known data in the natural gas area, the reserves escalation is converted according to the conversion ratio of prediction reserves and control reserves, while reserves to be discovered are cumulative newly added reserves. According to predictions, the Sichuan Basin will enter the late exploration stage around 2060, and the subsequent newly added proven reserves will have a small impact on the peak production. The reserves to be discovered are therefore converted from the predicted results of cumulative new proven reserves from 2020 to 2060. After a comprehensive analysis, it is therefore concluded that the final recoverable reserves of natural gas in the Sichuan Basin are between 5.25–5.75 × 1012m3.
Natural gas production growth trend prediction
The production growth equation for different situations can be calculated by substituting the URR into Eq. 1.
The prediction results show that the calculated peak yields under the three different URR scenarios are different. The greater the final recoverable reserves and the greater the peak production, the more obvious the unevenness of the predicted production curve (seen in Fig. 8).

Comprehensive prediction results of natural gas production
Since the natural gas industry chain includes the integration of upstream, midstream, and downstream gas operations, the consumer market and the construction of the transmission and distribution pipeline network require a long stable period of natural gas supply. The peak natural gas production is defined as the period when production reaches the maximum scale and fluctuates no more than 10%.
Therefore, when the URR = \(5.25 \times 10^{12} {\text{m}}^{3}\), the peak of natural gas production is \( 904 \times 10^{8} {\text{m}}^{3}\), the stable production period is 2037–2054, and the cumulative production is \(2.9 \times 10^{12} {\text{m}}^{3}\), with a 55.2% of URR recovery.
When URR = \(5.50 \times 10^{12} {\text{m}}^{3}\), the natural gas production peak is \(929 \times 10^{8} {\text{m}}^{3}\), the stable production period is 2037–2054, the natural gas production will reach \(831 \times 10^{8} {\text{m}}^{3}\), with cumulative production of \(3 \times 10^{12} {\text{m}}^{3}\), with 54.5% of URR recovery.
When \({\text{URR}} = 5.75 \times 10^{12} {\text{m}}^{3}\), the peak of natural gas production is \(952 \times 10^{8} {\text{m}}^{3}\), the stable production period is 2037–2054, the natural gas production will reach \(833 \times 10^{8} {\text{m}}^{3}\), with cumulative production of \(3.1 \times 10^{12} {\text{m}}^{3}\), and with 53.9% of URR recovery(Table 5).
Comprehensive evaluation
The research on gas production growth trends is based on the results of reserve prediction. Because the ultimate recoverable reserves are the main controlling factor that determines future production trends, the ultimate recoverable reserves(URR) are introduced as the boundary into the production prediction study to estimate the ultimate recoverable reserves of the Sichuan Basin. This makes the prediction more reliable. The prediction results under different recoverable reserves scenarios show that in the next 30 years, the production of the Sichuan Basin will increase rapidly, with good development prospects.
Many factors directly influence the prediction trends of the URR. The current estimation of URR, therefore, has limitations, one of which is the fact that the prediction results are based on the current natural gas exploration status. Dynamic predictions are required with technological progress and economic development.
Conclusions
In this paper, the modified weight coefficient GM(1,n) method based on the improved metabolic formula is combined with the multi-cycle Hubbert model. This method of combining the two models can accurately predict the growth trend of the proven natural gas reserves in the Sichuan Basin. The predicted final recoverable reserves of natural gas within the CNPC’s mineral rights are estimated to be \(5.25 - 5.75 \times 10^{12} {\text{m}}^{3}\). The production prediction results show that in 2035, the natural gas production within the PetroChina mineral rights lease area of the Sichuan Basin will reach \(750 - 810 \times 10^{8} {\text{m}}^{3}\). Predictions show that natural gas production will enter a stable production period in 2037 and that the annual production will exceed \(822 \times 10^{8} {\text{m}}^{3} /{\text{a}}\) and that natural gas production will remain stable for about 18 years.
The ultimate recoverable reserves (URR) is introduced as the boundary in production prediction research. The improved model can reasonably predict the growth trend of natural gas production and can better guide the formulation of mid- and long-term development plans. At the same time, this research can provide a theoretical basis for the natural gas resource evaluation of other natural gas exploration and development units in the world.
Data availability
Availability of data and material All data generated or analysed during this study are included in this published article.
References
Abdideh M, Di Fatha Ba MR (2013) Analysis of stress field and determination of safe mud window in borehole drilling (case study: SW Iran). J Pet Expl Prod Technol 3(2):105–110
Abdullah N, Hasan N (2021) The implementation of Water Alternating (WAG) injection to obtain optimum recovery in Cornea Field, Australia. J Pet Expl Prod 11(3):1475–1485
Alipour M, Alizadeh B, Chehrazi A (2019) Combining biodegradation in 2D petroleum system models: application to the Cretaceous petroleum system of the southern Persian Gulf basin. J Petrol Expl Prod Technol 9(4):2477–2486
Hubbert MK (1949) Energy from fossil fuels. Science 109(2823):103–109
Karahan H, Ayvaz. (2006) Forecasting aquifer parameters using artificial neural networks. J Porous Media 9(5):429–444
Kaufmann RK, Cleveland CJ (2001a) Oil production in the lower 48 states: economic, geological, and institutional determinants. Energy J 22(1):27–49
Kaufmann RK, Cleveland CJ (2001b) Oil production in the lower 48 states: economic, geological, and institutional determinants. Energy J 22(1):27–49
Long S, Cheng Z, Xu H (2020) Exploration domains and technological breakthrough directions of natural gas in SINOPEC exploratory areas Sichuan Basin, China. J Nat Gas Geosci 5(6):307–316
Luo X, Yan X, Chen Y (2020) The prediction of shale gas well production rate based on grey system theory dynamic model GM(1, N). J Petrol Expl Prod Technol 10(4):3601–3607
Pan Z, Wu Y, Shang L (2020) Progress in use of surfactant in nearly static conditions in natural gas hydrate formation. Front Energy 14(3):463–481
Peng W, Guo F, Hu G (2019) Geochemistry and accumulation process of natural gas in the Shenmu Gas Field Ordos Basin, Central China,. J Petrol Sci Eng 180(5):1022–1033
Ramezanianpour M, Sivakumar M (2017) Fouling and wetting studies relating to the vacuum membrane distillation process for brackish and grey water treatment. J Porous Media 20(6):531–547
Resnikoff M (2011) Radon in natural gas from Marcellus Shale. Ethics Biol Eng Med 2(4):317–331
Senthil S, Mahalingam S, Ravikumar S (2019) Adiabatic behavior of gas wells due to natural reservoir fines migration: analytical model and CFD study. J Petrol Expl Prod Technol 9(1):2863–2876
Xu D, Zhu Y (2020) A Copula-Hubbert model for Co(By)-product minerals. Nat Resour Res 29(5):3069–3078
Yang X, Meng Y, Shi X (2017) Influence of porosity and permeability heterogeneity on liquid invasion in tight gas reservoirs. J Nat Gas Sci Eng 37(3):169–177
Yang W, Wei G, Xie W (2019) New understanding of the sedimentary model of Lower Cambrian Longwangmiao Formation reservoirs in the Sichuan Basin. Nat Gas Ind b 6(1):86–94
Zheng M, Liu T (2019) Simulation of natural gas hydrate formation skeleton with the mathematical model for the calculation of macro-micro parameters. J Petrol Sci Eng 17(8):429–438
Zhou Z, Su Y, Wang W (2017) Application of the fractal geometry theory on fracture network simulation. J Pet Expl Prod Technol 7(2):1–10
Zou C, Yang Z, Sun S (2020) “Exploring petroleum inside source kitchen”: Shale oil and gas in Sichuan Basin. Sci China Earth Sci 63(5):934–953
Acknowledgements
This work is supported by the Fundamental Research Funds for the Central Universities (Grant No.2020CDCGJ041). The authors are grateful for the Editor and reviewers' helpful comments.
Funding
This study is supported by the Fundamental Research Funds for the Central Universities (Grant No.2020CDCGJ041). The authors are grateful for the Editor and reviewers' helpful comments.
Author information
Authors and Affiliations
Contributions
Conceptualization, HL and GY; methodology, HL; software, GY; validation, HL, YF and CW; formal analysis, DZ; investigation, YF; resources, YF; data curation, HL; writing—original draft preparation, HL; writing—review and editing, GY; visualization, YF; supervision, CW; project administration, DZ; funding acquisition, DZ. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest. The article has not been published elsewhere and has not been submitted for publication elsewhere.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yu, G., Fang, Y., Li, H. et al. Establishment and application of prediction model of natural gas reserve and production in Sichuan Basin. J Petrol Explor Prod Technol 11, 2679–2689 (2021). https://doi.org/10.1007/s13202-021-01189-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13202-021-01189-z