
Abstract
Accurate prediction of reference evapotranspiration (ETo) is crucial for many water-related fields, including crop modelling, hydrologic simulations, irrigation scheduling and sustainable water management. This study compares the performance of different soft computing models such as artificial neural network (ANN), wavelet-coupled ANN (WANN), adaptive neuro-fuzzy inference systems (ANFIS) and multiple nonlinear regression (MNLR) for predicting ETo. The Gamma test technique was adopted to select the suitable input combination of meteorological variables. The performance of the models was quantitatively and qualitatively evaluated using several statistical criteria. The study showed that the ANN-10 model performed superior to the ANFIS-06, WANN-11 and MNLR models. The proposed ANN-10 model was more appropriate and efficient than the ANFIS-06, WANN-11 and MNLR models for predicting daily ETo. Solar radiation was found to be the most sensitive input variable. In contrast, actual vapour pressure was the least sensitive parameter based on sensitivity analysis.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Water is essential for agriculture production and constitutes the major component of sustainable growth in the agriculture sector (Kumar et al. 2012, 2017; Kumar and Haroon 2021). It is the main component on which several hydro-meteorological processes rely (Kushwaha et al. 2016). The primary source of water on our planet is precipitation, which is available in various forms such as rainfall, snowfall, hail, fog and dew (Kurzyca and Frankowski 2019) and supply of water at different locations worldwide depends greatly on the event and rainfall, a key factor of the hydrological cycle. Land and water are two basic needs for agrarian and economic improvement worldwide. Both land and water are important natural resources and provide a regulatory role in the production of agriculture. Among several sectors, it is reported that the agricultural industry consumes more than 55% of the freshwater, especially for irrigation purposes (Dias et al. 2018). In several regions where water supplies are limited, estimating the loss of evapotranspiration becomes crucial for irrigation purposes (Jensen and Allen 2016). Evapotranspiration is the major component of the water balance in irrigation planning and management practices (Zeleke and Wade 2012) and the major consumptive use of irrigation water in agriculture (Elhag et al. 2011). In Mousinram near Cherrapunji, India (a temperate region) receives the highest rainfall globally (Saikia 2009), even though water shortage also occurs almost every year in the dry season (Kumar et al. 2005). Reference evapotranspiration (ETo) is quantified worldwide according to the recommendation of the FAO (Allen et al. 1998; Pereira et al. 2015). The Penman–Monteith FAO-56 (P-M FAO-56) is considered the reference approach and is mainly adopted worldwide in the absence of direct measurement using lysimeters (Sentelhas et al. 2010).
Soft computing techniques have the capacity over conventional approaches to solving complex problems of various hydrologic processes (Chandwani et al. 2015). Regarding its capability to handle highly complex nonlinear problems, the application of various soft computing approaches has attracted the interest of many international researchers during the last few years (Bajirao et al. 2021; Tulla et al. 2024). Hence, techniques like ANN, ANFIS, gene expression programming (GEP) and deep learning (DL), among others, have been the extraordinary technology of reference evapotranspiration modelling (Kisi and Alizamir 2018; Tikhamarine et al. 2020; Kushwaha et al. 2022).
Lee et al. (2010) present the development and evaluation of artificial neural network (ANN) models for estimating future reference evapotranspiration (ETo) based on climate change scenarios. The models were trained and validated for Suwon, Korea, using four climate factors as input parameters and the FAO Penman–Monteith equation as the target values. The study found that the ANN models achieved good performance in estimating future reference crop evapotranspiration. Shiri et al. (2011) apply adaptive neuro-fuzzy inference system (ANFIS) and artificial neural network (ANN) approaches to model daily pan evaporation using daily climatic parameters in the State of Illinois, USA. The feasibility of ANFIS and ANN evaporation modelling from limited climatic parameters is demonstrated, showing the potential for accurate estimation of daily pan evaporation. Üneş et al. (2018) focus on estimating daily reference evapotranspiration (ETo) using different empirical methods and comparing the results with an artificial neural network (ANN) model. The study concludes that the ANN model outperforms traditional empirical equations in estimating daily ETo. Wu et al. (2019) explore the use of eight machine learning models and the Hargreaves-Samani equation for estimating reference evapotranspiration (ETo) using temperature data from local or cross stations. The results show that the tree-based models (RF, GBDT and XGBoost) perform better in local applications.
In contrast, MARS and SVM models are more suitable when only temperature data is available. In the absence of temperature data at the target station, MARS, SVM and KNEA models are recommended. Kushwaha et al. (2022) compare different models (additive regression (AdR), random subspace (RSS), M5 pruning tree (M5P) independently and four novel permutated hybrid combinations of these algorithms) with sequential inclusion of six meteorological input variables to estimate reference evapotranspiration (ETo) using machine learning algorithms. The model AdR6, which included all six selected meteorological variables, outperformed other models in terms of prediction accuracies. At the same time, the RSS algorithm failed to capture observed trends even with all input variables.
The extreme learning machine (ELM) was applied to predict the ETo in south China by Wu et al. (2021) and Liu et al. (2021). Sanikhani et al. (2019) considered six artificial intelligence (AI) models, i.e. the ANN, the (GRNN), the RBFNN, two ANFIS models (i.e. with gird partition and subtractive clustering partition: GP and SC) and GEP, for forecasting the ETo by using only three meteorological variables (i.e. Tmin, Tmax and Solar radiation). The study concluded that the GEP and GRNN were more accurate compared to the other models at Antalya station. On the other hand, the RBNN and ANFIS-SC were the best models at the Isparta station. A cross-station scenario examination is applied to predict the reference evapotranspiration of any station using the input data of the nearby station. Using cross-station scenarios, all the AI models were more successfully employed than the other empirical methods except the MLPNN model for modelling the ETo. A comparison between single and hybrid ANFIS models was made by Roy et al. (2021), highlighting the superiority of the hybrid models. Furthermore, several other studies have reported the superiority of the hybrid models compared to the single models (Ahmadi et al. 2021).
An essential task is to do a sensitivity analysis on the possible change in ETo in response to the currently available climatic conditions. Evaporation rates were initially studied by McCuen (1973), who looked at how changes in meteorological conditions affected the rate of evaporation and how measurement errors affected rates. ETo estimates and weather-related sensitivity analyses for various areas have been studied extensively. Many studies have been done (Goyal 2004) reporting that (i) the solar radiation climatic variable (SR) was the most important factor in the ETo calculation (Emeka et al. 2021), (ii) Tmax and Tmin significantly impact the model's output, as shown by Ley et al. (1994). Beven (1979) and Gong et al. (2006) studied the effect of input data errors on estimates of actual crop evapotranspiration (ETa, crop) in England and Wales. A mass transfer-based equation to calculate evaporation in Vaud, Switzerland (Singh and Xu 1997). Systematic and random errors of 5, 10 and 20% were added to the original data before evaluating the change in evaporation. It was discovered that the vapour pressure gradient, wind speed and air temperature data did not affect evaporation. Goyal (2004) investigated the variability of the ETo in response to the fluctuation of four climatic variables (i.e. Tmean, Rn, U2, and ea) within a range of ± 20% in Rajasthan (India). According to Goyal's findings, the ETo in the research region increased by 14.8% when the mean air temperature was raised by 20% (maximum of 8 °C). ETo was less responsive (11% less sensitive). Even a 20% increase in ea (say, 4.3%) slightly negatively affects ETo. In another study, Gong et al. (2006), conducted in China, investigated the fluctuation of ETo derived from the PM FAO-56 to changes in climatic variables and found that SR, Tmean and U2 are significantly affected by relative humidity. Irmak et al. (2006) undertook an examination of climate change sensitivity in the various climate areas of the USA. Sunshine duration has been discovered to be an important factor in determining the susceptibility of ETo to climate factors in China's Yellow River basin. It has been shown that ETo is more responsive to solar radiation and less susceptible to Tmean in studies conducted Liu et al. (2019) during the growing season. Using data from 57 weather stations, Liu et al. (2016) discovered that ETo was more responsive to U2 and Tmean than other climatic factors in south-eastern China. The sensitivity of the PM FAO-56 using the Monte Carlo (MC) method to check variability in the meteorological data is considered as input (Kovoor and Nandagiri 2018). The study was conducted in India using data from four stations. The analysis was performed separately for four climatic stations representing different climate regions of India, such as Jodhpur-1453, Hyderabad-1044, Bangalore-1368 and Pattambi-1275. The U2 Wind speed was the superior input variable, and the net radiation was found to be a critical variable. Many other researchers investigate sensitivity analysis ETo in many parts of the world (Ndiaye et al. 2021; Poddar et al. 2021).
Regional and seasonal differences in ETo sensitivity have received less attention in studies using a single station than in studies involving many stations. The chosen Indian station has not conducted a comprehensive investigation on the sensitivity of ETo to major climatic elements under various scenarios, while in India, less information is available. In addition, a wide range of meteorological factors has been altered due to global warming. Therefore, the purpose of the present study was to evaluate various ML models, namely ANN, wavelet-ANN (WANN), ANFIS and MNLR, for predicting daily ETo in the state of Karnataka, India, to determine the sensitivity of ETo to standard climate observation variables at climate stations and their contributions to changes in yearly ETo.
Materials and methods
Study area
This study was conducted at the Gandhi Krishi Vignana Kendra (GKVK) station at Bengaluru north taluk of Bengaluru (Urban) district in Karnataka state. It belongs to the eastern dry zone (Zone-V), which includes Kolar, Tumkur, Bengaluru (Urban), Bengaluru (Rural), Chikkaballapura and Ramanagara. The eastern dry zone comes under the Southern Plateau and Hills region (X) of agro-climatic zones. Geographically, the GKVK station is located at 12° 58° N latitude and 77° 30° E longitude with an altitude of 930 m above the average sea level. The location of GKVK is shown in Fig. 1. The area of GKVK is considered a semi-arid sub-tropical that falls in a sub-tropical zone. The mean annual rainfall of the station is 867.9 mm. In the winter season, there is low rainfall compared to the summer season. January and February months receive the lowest rainfall, whereas the major portion of precipitation is received during April-November, with two peaks in May and September. The mean annual temperature is in the range of 18.2–29.5 °C. The monthly temperature data of the station reveals that December is the coolest month of the year, having a daily mean temperature ranging between 15.8 and 26.9 °C, and April is the warmest month of the year as the daily mean temperature lies between 21.2 and 34.1 °C. In Karnataka, most of the area is covered by sandy loam soil, having low organic matter content and low moisture retention capacity. Ragi, maize, paddy, groundnut, finger millet and sunflower are considered the major crops growing in this area.

The geographical location of the study area
Data acquisition, pre-analysis and formulation of data
The present study was conducted using daily weather data of maximum and minimum air temperatures (Tmin, Tmax), relative humidity (RH), wind velocity at 2 m height (ws) and sunshine hour (Sh) for the period of 12 years and ten months (4687 days, from January 2007 to October 2019) which were recorded by the Agro Meteorology station of University of Agriculture Sciences (UAS), GKVK, Bengaluru. These data were downloaded from the UAS Bangalore (Agro Meteorology system) portal (www.uasbangalore.edu.in/). For this study region, the data set of various climatic variables such as Tmin, Tmax, ws, Sh and RHmean were considered as inputs to CROPWAT 8.0 software for calculating PM FAO-56 ETo. The estimated PM FAO-56 ETo values were utilised as output data. Time series and Box and Whisker plots of observed daily climatic variables with computed ETo (PM) are shown in Figs. 2 and 3, respectively, which provide the basic idea about the variability of the dataset with time. In this study, various input climatic variables, viz. mean air temperature (Tmean), mean relative humidity (RHmean), wind speed (ws), sunshine hour (Sh), saturated vapour pressure (es), actual vapour pressure (ea) and solar radiation (Rs), were combined to derive the best input combination data set with applying Gamma test (GT) algorithm. Several statistical parameters were considered for pre-analysis of the time series dataset shown in Table S1. Out of the whole data set (4687 days), 70% of data (3281 days, 01/01/2007 to 25/12/2015) were used for training purposes, and the remaining 30% of data (1406 days, 26/12/2015 to 31/10/2019) were used for testing purposes. The ML models are developed and trained on the training dataset, and further, the performance evaluation is carried out using the unseen test dataset.

Graphical presentation of daily climatic time series data (2007–2019)

Box and Whisker plots of the daily climatic for parameters
Development of models
In this research, various artificial intelligence techniques, such as ANN, ANFIS, WANN and MNLR techniques, were developed to simulate the daily ETo. The flowchart of the proposed is illustrated in Fig. 4.

Flowchart of the methodology of the study
Artificial neural network (ANN)
An artificial neural network (ANN) is an machine learning (ML) model composed of several processing elements and can display complex relationships between inputs and outputs. The functioning of the ANN is similar to the way neurons work in the human nervous system, and the architecture consists of input, hidden and output layers (Fig. S1). The input layer of the ANN is the first layer that receives the various types of input data, such as image pixels, texts and numbers. The data passes through one or more hidden layers; the hidden layer performs mathematical computation on the data received (Hassoun 1995). The number of hidden layers in the ANN model is mainly related to the task being solved. The output layer is the last year in the ANN and is responsible for producing the output. An ANN fine-tunes its weights and improves the performance through the backpropagation algorithms, which is the central pillar of the neural network training process. The functional composition of a neural network is the most popular structure, which is represented in Fig. S2. A neuron applies the net function and activation function on input variables to determine the output variable value. The xi and wi are input vectors and their respective connection weights from an ith neuron in the input layer (where i = 1, 2…., n). The net function (a) is represented in the linear form that is determined based on the product of the input vector with their corresponding connection weights (Wi) and the value of bias or threshold value (wo) associated with that node. In a neural network system, a nonlinear activation function f(.) is used to show its nonlinearity between input variables and output variables as well as to transform net function (a) at the hidden node into output (y) of the node, which is expressed as:
By varying the transfer function and altering the parameter, such as thresholds or gains, the output of neurons can be modified. An appropriate learning algorithm is utilised to adjust the connection weights using the training data set in a neural network. The purpose of changing the connection weights value is to minimise the error of prediction results during the learning process. Because weight shows the effect of any input on output. Several nonlinear activation functions are available, as presented in Table 1, which are mostly utilised for the modelling of the hydrological process. The hyperbolic tangent sigmoid (tensing) activation function is used to establish the hydrology process's neural network models, shown in Fig. S3. The mathematical formula of tansig activation function is expressed as:
In this study, the multi-layer perceptron neural network (MLP) is used. The general architecture of a feed-forward MLP neural network with a single hidden layer appears in Fig. S4.
Adaptive neuro-fuzzy inference system (ANFIS)
Adaptive neuro-fuzzy inference system (ANFIS) is an ML developed from the combination of the ANN and fuzzy inference systems (FIS). Jang (1993) proposed the ANFIS model and its principles, applied to various hydrological and other modelling problems. The ANFIS model is a universal estimator, taking full advantage of the FIS and the IF–THEN rules. The basic architecture of ANFIS comprises five layers: fuzzification layer, product layer, normalisation layer, defuzzification layer and output layer (AL-Oqla and Al-Jarrah 2021). Figure S5 shows the schematic diagram of the ANFIS. The circle and square nodes represent the fixed and the adaptive nodes, respectively. The number of nodes in each layer is decided according to the specific research requirement. In the present study, six different membership functions were utilised, whose shapes appear in Figs. S6 and S7. ANFIS has various types of FIS for the learning process. The Sugeno-type fuzzy system is the most popular and commonly used fuzzy system.
Wavelet-coupled artificial neural network (WANN)
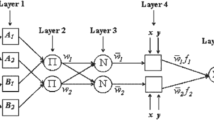
Wavelet artificial neural networks combine the ANN with wavelet analysis. The wavelet analysis is used as a pre-processing data strategy to improve the accuracy (Fig. S8). WANN is considered a feed-forward neural network that uses a wavelet as its activation function (Esmaeilzadeh et al. 2017). It introduces wavelet decomposition property into an ANN. The amalgamation of the frequency location of the wavelet transform and the self-learning feature of ANN makes it a powerful tool. An additional layer is introduced to traditional ANN. The dilation, translation and weight parameters are updated during the model training (Mobtaker et al. 2016). A backpropagation algorithm is usually employed to train the wavelet artificial neural networks. Since this hybrid approach enhances the existing model and achieves improved nonlinear approximations, WANN successfully models function approximations and forecasting. The ANN, WANN and ANFIS models were calibrated based on the different training variables and assigned values given in Tables 2 and 3.
Multivariate nonlinear regression (MNLR)
Linking a set of independent variables to one dependent variable is a challenging task. Nonlinear regression analysis is utilised to define the quantitative relationships between the dependent variable and various independent variables. The multivariate nonlinear regression (MNLR) technique is the most widely recognised type of nonlinear regression analysis, which is used for linking a suite of independent variables to one dependent variable by fitting them through the function of the nonlinear equation (Vishwakarma et al. 2022a). Eventually, this technique succeeds based on the least square technique and as the best-fit line to model the nonlinear behaviour between dependent and independent variables of observational data. Here, the mathematical expression of the MNLR technique is expressed as:
where Y is the dependent variable, \({\beta }_{0}\) is the intercept (constant), \({\alpha }_{1}\dots \dots \dots {\alpha }_{n}\) are the regression slope coefficient for the nonlinear relation and X1, X2, ………, Xn are the independent variables. The model formulation of a nonlinear equation can be transformed into the linear form by taking a log of Eq. (5) to solve the problem of the MNLR technique, which establishes the linear relationship between dependent and independent variables on log paper:
Equation (5) denotes a regression of log (Y) on log (X1), log (X2), …, log (Xn), which is used to estimate the regression coefficient. \({\beta }_{0}, {\alpha }_{1}, {\alpha }_{2}, {\alpha }_{3},\dots ..{\alpha }_{n}\). PM FAO-56 -based daily ETo was considered as the dependent variable (Y). In contrast, meteorological variables were used as independent variables (X1, X2, …, Xn).
Gamma test (GT)
The mechanism of evapotranspiration is part of hydrological processes that are typically nonlinear, complex and dynamic (Vishwakarma et al. 2022b; Raza et al. 2022). Due to the trial-and-error procedure, looking for the best input combination is a challenging task optimal for hydrological modelling (Bajirao et al. 2021). This procedure needs calibration and testing to establish the best model based on input combinations. The Gamma test (GT) minimises the workload required for model creation by considering all input combinations of input parameters, guiding the selection of input parameters for creating a reliable, smooth model (Malik et al. 2020). The choice of input parameters is an important step towards creating a robust regressor. The used input variables led to a complicated structure for which the model’s parameters were updated; consequently, the model’s performances were also affected. GT is a nonparametric test and nonlinearity analysing tool that examines the nonlinear relationship between input and output variables (Singh et al. 2018). A major advantage of this tool is its speed in massive datasets because GT takes a few moments to run. The GT algorithm uses a set of M input/output variables as:
where M is the total number of data, X is the input matrix and Y is the corresponding output variable, for which a hypothesis for a possible link between X and Y is available. The gamma coefficient (Г) is calculated using a simple linear regression between X and Y as follows:
where f is a smooth function and Г is a random variable representing noise. This study selected the best input combination based on the minimum V ratio and gamma (Г) value for predicting ETo. WinGamma™ software was utilised to apply the gamma test.
CROPWAT 8.0 software
CROPWAT 8.0 software is a water system management and planning model that recreates the unpredictable relationship between the atmosphere, soil and crop cultivation parameters. The FAO developed it to encourage the estimation of reference evapotranspiration (ETo), crop evapotranspiration, the need for agriculture water and irrigation scheduling with different cropping patterns for irrigation planning. In water necessity and water system improvement (irrigation) planning, the computation of reference evapotranspiration is vitally important. General information on the spatial circulation of reference evapotranspiration is still crude, irrespective of its significance for global ecosystem research. It is difficult to observe one reason for ETo because it depends on a few weather parameters seen at stations. The monthly ETo was calculated using CROPWAT 8.0 software based on the necessary climatic variables for Gandhi Krishi Vignana Kendra (GKVK) Bengaluru stations. In CROPWAT 8.0, the PM FAO-56 PM is used, and its theoretical description can be found in (Allen et al. 1998).
Model performance evaluation indices
In this study, numerous performance indices were utilised to test the performance of the ANN, WANN, ANFIS and MNLR models, including root mean-squared error (RMSE), coefficient of determination (R2), Willmott index (WI) and Nash–Sutcliffe efficiency (CE). The mentioned parameters are defined as:
Statistical parameters | Value range | optimal value | |
|---|---|---|---|
\({\text{RMSE}} = \left( {\mathop \sum \limits_{{i = 1}}^{n} {\text{~}}\frac{1}{N}\left( {{\text{ET}}_{{{\text{PM}},{\text{~i}}}} - {\text{ET}}_{{{\text{m}},{\text{~i}}}} } \right)^{2} } \right)^{{0.5}}\) | 0 < RMSE < ∞ | 0 | (7) |
\(R^{2} = \left( {\frac{{\mathop \sum \nolimits_{{i = 1}}^{N} \left( {{\text{ET}}_{{{\mathrm{PM}},i}} - \overline{{{\text{ET}}_{{{\mathrm{PM}}}} }} } \right)\left( {{\text{ET}}_{{m,i}} - \overline{{{\text{ET}}_{m} }} } \right)}}{{\left( {\sqrt {\left( {\mathop \sum \nolimits_{{i = 1}}^{N} \left( {{\text{ET}}_{{{\mathrm{PM}},i}} - \overline{{{\text{ET}}_{{{\mathrm{PM}}}} }} } \right)^{2} } \right)\left( {\mathop \sum \nolimits_{{{\text{i}} = 1}}^{{\mathrm{N}}} \left( {{\text{ET}}_{{m,i}} - \overline{{{\text{ET}}_{m} }} } \right)^{2} } \right)} } \right)}}} \right)^{2}\) | 0 < R2 ≤ 1 | 1 | (8) |
\({\text{WI}} = 1 - {\text{~}}\frac{{\mathop \sum \limits_{{{\text{i}} = 1}}^{{\text{N}}} \left( {{\text{ET}}_{{{\text{PM}},{\text{~}}i}} - {\text{ET}}_{{m,~i}} } \right)^{2} }}{{\mathop \sum \limits_{{i = 1}}^{N} \left( {\left| {{\text{ET}}_{{m,~i}} - \bar{{{\text{ET}}_{{{\text{PM}}}} }} } \right| + \left| {{\text{ET}}_{{{\text{PM}},{\text{~}}i}} - \bar{{{\text{ET}}_{{{\text{PM}}}} }} } \right|} \right)^{2} }}\) | 0 < WI ≤ 1 | 1 | (9) |
\({\text{CE}} = {\text{~}}1 - \left( {\frac{{\mathop \sum \limits_{{i = 1}}^{N} \left( {{\text{ET}}_{{{\text{PM}},{\text{~}}i}} - {\text{ET}}_{{m,~i}} } \right)^{2} }}{{\mathop \sum \limits_{{i = 1}}^{N} \left( {{\text{ET}}_{{{\text{PM}},{\text{~}}i}} - \overline{{{\text{ET}}_{m} }} } \right)^{2} }}} \right)\) | − ∞ < CE ≤ 1 | 1 | (10) |
where \({{\text{ET}}}_{{\text{PM}}}, {{\text{ET}}}_{m}, \overline{{{\text{ET}} }_{{\text{PM}}}} {\text{and}} \overline{{{\text{ET}} }_{m}}\) are the values of the PM FAO-56-based observed and model-based estimated, average values of PM FAO-56 observed and PM FAO-56 equation-based estimated values, respectively. The models with higher CE, R2 and WI values and lower RMSE are adjudged relatively the better model for monthly ETo estimation (Vishwakarma et al. 2022b).
Sensitivity analysis
Sensitivity analysis is a tool used to control the reliability of modelling by determining the cause-and-effect of an ensemble of input to an output variable for a developed model (Hosseini et al. 2022). It plays a significant role in finding the most sensitive parameter from different input parameters whose deviation significantly changes the predicted output. The sensitivity analysis also finds irrelevant inputs eliminated from the created model for simplicity. So it may improve the model’s performance. It disables the built model's learning not to affect network weights. In the present study, input parameters such as relative humidity, wind speed, sunshine hour, actual and saturated vapour pressure and solar radiation were selected to perform sensitivity analysis for the best model that influences the predicted values of reference evapotranspiration. The sensitivity analysis was performed by increasing 10% and decreasing 10% of the input parameter values. For each input parameter, this procedure is repeated to evaluate the sensitivity of the output concerning changes in input values. The mathematical expression of relative sensitivity is used to determine the sensitivity order of selected input parameters. Using the equation, relative sensitivity (RS) has been computed after calculating the individual value of each day's sensitivity as:
where x and y are the original input parameter and the originally predicted output for a given day, respectively. x1 = (x + ∆x) and x2 = (x − ∆x) are increasing and decreasing input parameter values, respectively, where ∆x = 0.1 × x. y1 and y2 are the results of predicted output concerning x1 and x2, respectively.
Results
Best input combination-Gamma test (GT)
To simulate artificial intelligence and statistical techniques-based reference evapotranspiration models, a gamma test (GT) can be utilised to choose the best input combination of climatic variables. It can minimise the necessary workload for conducting cumbersome trial-and-error methods. Therefore, this study chose the best input combination of meteorological predictors by applying the GT to predict PM FAO-56. In the GT, the meteorological variables, i.e. Tmean, RHmean, ws and Rs, were combined to predict the PM FAO-56. These input variables were used to form various possible input combinations, as shown in z 4. The best input combination of climatic variables was selected based on the lower gamma and Vratio (Vishwakarma et al. 2023). It can provide better outcomes during the development of AI models. According to Table 4, model M-41 (RHmean, ws, Sh, es, ea, Rs) represented the minimum value of gamma and V ratio. It was considered the best input combination, which was further used for the calibration of ANN, WANN, ANFIS and MNLR models to predict reference evapotranspiration.
A selected input combination of climatic variables was employed for the prediction of daily reference evapotranspiration, which is functionally expressed as:
The structure of the ANN and ANFIS models is shown in Fig. S9. For developing the WANN model, the decomposed components of selected input variables obtained by applying DWT were used as inputs to ANN mode (Fig. S10).
In this study, the Haar-type wavelet function was considered to decompose the original time series of selected input variables into different sub-series at appropriate decomposition levels, which was taken as 3. Therefore, each input variable was decomposed into four sub-series comprising one approximate (A3) and three detail (D1, D2, D3) sub-series. Based on the best input combination (RHmean, ws, Sh, es, ea, Rs), 24 (6 × 4) subseries were produced and considered as input variables. After this, these 24 input variables were fed to the ANN system for simulation of reference evapotranspiration as shown in Fig. S10, and it is also functionally expressed as:
Model performances evaluation
This study applied the Levenberg–Marquardt-based backpropagation learning algorithm to calibrate both ANN and WANN-based ETo models. Both models used the Tan-sigmoid activation function for the hidden neurons and a linear function for the output neuron. Different architectures of ANN and WANN models were built by varying the total number of neurons in the hidden layer. In the ANN model, the number of neurons in the hidden layer was varied from one to 2n + 1, where n is the number of inputs. Therefore, 13 (2 × 6 + 1) ANN architecture was built to develop the ANN-based ETo model. In the case of the WANN model, a total of 49 (2 × 24 + 1) architectures were built as 24 input signals (a decomposed form of selected input variables) were taken to train the ANN system. Based on performance evaluation such as qualitative and quantitative (R2, RMSE, CE and WI) evaluation, the best model was selected from various ANN/WANN model architectures to predict reference evapotranspiration.
MLP-ANN models
Using data from KGVK Campus Bengaluru meteorological stations, the performance of all MLP-ANN (1–13) for predicting daily ETo was examined. For this, many statistical metrics and graphical performance assessment methodologies were applied. All obtained numerical performances are depicted in Table 5. As indicated in Table 5, the best model was determined to be the ANN-10 model with 6-10-1 architecture. Based on qualitative analysis, the performance of developed models was examined using a graphical representation of simulated ETo versus computed ETo. From all network structures of ANN, ANN-10 was selected as the best model (Table 5). As shown in Fig. 5, the calculated and predicted values of daily reference evapotranspiration were analysed through a time series graph to be in remarkably close agreement during both training and testing periods, respectively; however, the model very slightly under-predicted the higher magnitude of ETo as indicated through 1:1 line of scatter plot which is also shown in Fig. 5a during training. As shown in Fig. 5b, the chosen ANN-10 model is slightly under-predicted, over-predicted medium values and greatly under-predicted high values of ETo, respectively, based on a 1:1 line during the testing period. The quantitative analysis was performed based on statistical and hydrological indices, employing the best ANN model for ETo prediction. The results of various performance evaluation indices (R2, RMSE, CE and WI) for all 13 ANNs are reported in Table 5. The values of R2, RMSE, CE and WI varied from 0.9823 to 0.9995 and 0.9792–0.9923; 0.0219–0.1350 mm/day and 0.0905–0.1488 mm/day; 0.9823–0.9995 and 0.9790–0.9922, and 0.9429–0.9901 and 0.9466–0.9859 during training and testing, respectively. The ANN-13 model was observed to be better than the ANN-10 model during training. Nevertheless, as per testing results, the ANN-10 model with architecture (6-10-1) was found to be the most accurate model among all ANN models. During the training period, the results could be due to the over-fitting problem, which influenced the model’s actual performance; therefore, only testing period outcomes were considered to select the best ANN model. The R2, RMSE, CE and WI values for the ANN-10 model were obtained as 0.9995, 0.0236 mm/day, 0.9995 and 0.9999, respectively, during training and 0.9992 0.0209 mm/day, 0.9991 and 0.9998, during testing. The residual plot for the training and testing periods (Fig. 6) shows that the highest errors occur in the range of − 0.28 to 0.14, − 0.24 to 0.24 mm.

Comparison of ANN-10 (6-10-1) model in estimating FAO-56 PM ETo in GKVK Bengaluru station: a training period and b Testing period

Residual plot of predicted ETo in ANN-10 (6-10-1) model: a training and b testing periods
WANN model
The performance of the selected model was evaluated qualitatively. For the accurate WANN-11 architecture, the calculated ETo is in close agreement with computed values of ETo (PM), which were observed through graphical representation, as shown in Fig. 7. However, the selected architecture (24-11-1)-based WANN-11 model slightly under-predicted medium and high values of ETo as denoted through a 1:1 line of scatter plot during training and testing, shown in Fig. 7a and Fig. 7b, respectively.

Comparison of WANN-11 (24-11-1) model in estimating FAO-56 PM ETo in GKVK Bengaluru station: a training period and b Testing period
In quantitative analysis, various performance indicator values were used to choose the best WANN model for the simulation of ETo. The performance evaluation indices (R2, RMSE, CE and WI) for all 49 WANN models are presented in Table 6. The values of R2, RMSE, CE and WI varied from 0.9780 to 0.9995 and 0.9651–0.9939; 0.0719–0.1505 mm/day and 0.0814–0.1928 mm/day; 0.9780–0.9950 and 0.9647–0.9937; 0.9369–0.9986 and 0.9406–0.9984 during training and testing, respectively. As per training, the outcomes of performance indices for the WANN-39 model were found to be better than the WANN-11 model. During the testing process, the WANN-11 model (24-11-1) was found to have satisfactory results using the performance criteria; therefore, this model was chosen as the best model among all WANN models. The values of R2, RMSE, CE and WI for the selected WANN-11 model were obtained as 0.9995, 0.0761 mm/day, 0.9944 and 0.9986, respectively, during training and 0.9939, 0.0808 mm/day, 0.9937 and 0.9984, respectively during testing. The residual plot for the training and testing periods (Fig. 8) shows that the highest errors occur in the range of − 0.21 to 0.22, − 0.45 to 0.45 mm.

Residual plot of predicted ETo in WANN-11 (24-11-1) model: a training and b testing periods
ANFIS models
Various ANFIS models were calibrated in MATLAB (R2019a) software using ANFIS Editor GUI (graphical user interface) to simulate reference evapotranspiration. For the training of ANFIS, TSK-type FIS was generated using the grid partition method to construct the ANFIS structure. In the generation of FIS, six types of input MFs, namely Triangular (tri), Generalised bell (gbell), P sigmoidal (psig), Gaussian (gauss), Gaussian 2 (gauss2) and Trapezoidal (trap), were used with linear type output MFs. Two MFs were used to construct one input's best possible model architecture. In the ANFIS editor, a hybrid-type learning algorithm with 100 epochs was chosen, and error tolerance was taken as 0.001 for the training of the ANFIS model. Using qualitative and quantitative analysis, the performance of the developed model was assessed.
In qualitative analysis, the performance of the selected model was evaluated graphically (time series graph and scatter plot). ANFIS-06 model with trapezoidal input membership function was found to be the best among all ANFIS models. For the selected ANFIS-06 model, the computed and predicted values of daily ETo were observed through the time series graph to be in close agreement for all values of ETo for the calibration and validation stages, as shown in Fig. 9, respectively. However, the selected model predicted good results for all values of ETo; therefore, no point deviated from the regression line and 1:1 line of scatter plot with an R2 value of 0.9996 during training, as shown in Fig. 9a while modelling slightly and slightly under-predicted for medium and high values of ETo with an R2 value of 0.9987 during testing which is shown in Fig. 9b.

Comparison of ANFIS-06 (trap 2) model in estimating FAO-56 PM ETo in GKVK Bengaluru station: a training period and b Testing period
Results obtained using ANFIS models are reported in Table 7. It was observed that the values of R2, RMSE, CE and WI varied from 0.9994 to 0.9996 and 0.8961–0.9987, 0.0193–0.0238 mm/day and 0.0374–0.3584 mm/day; 0.9994–0.9996 and 0.8780–0.9987; 0.9893–0.9999 and 0.9752–0.9997 during training and testing, respectively. From Table 7, all ANFIS models based on input MFs performed satisfactorily during training. Moreover, during training, the outcomes of performance indicators for the ANFIS-04 model (gauss-2 input MFs) were found to be better than the ANFIS-06 model (trap-2 input MFs). During the testing process, the ANFIS-06 model was found to have the most accurate results of all performance criteria except the WI result. Hence, this model was the best model among all ANFIS models. The values of R2, RMSE, CE and WI for the selected ANFIS-06 model based on trapezoidal (trap) input MFs were observed to be 0.9996, 0.0214 mm/day, 0.9996 and 0.9999, respectively, during training and 0.9987, 0.0374 mm/day, 0.9987 and 0.9997, respectively during testing. The residual plot for the training and testing periods (Fig. 10) shows that the highest errors occur in the range of − 0.01 to 0.13, − 0.3 to 0.23 mm, respectively.

Residual plot of predicted ETo in ANFIS-06 (trap 2) model: (a) training and (b) testing periods
MNLR model
This study calibrated the MNLR model using a training data set of selected input variables to predict ETo. The performance of the developed model was evaluated with the testing data set by comparing the expected values of daily ETo to that of the observed one. The mathematical equation of the developed MNLR model can be expressed in the form as:
where ETo is the daily reference evapotranspiration (mm/day), RHmean is the daily basis mean relative humidity (%), U2 is the daily wind speed (km/hr), SH is the daily sunshine hour (hours/day), es and ea represent the saturated and actual vapour pressure (kPa), and Rs is the daily solar radiation (MJ/m2/day).
Qualitatively, the predicted values of reference evapotranspiration agree with computed values of ETo (PM), which was observed through the time series graph during the training and testing periods, as shown in Fig. 11, respectively. However, the selected MNLR model slightly under-predicted medium and high values of ETo as indicated through a 1:1 line of scatter plot with an R2 value of 0.9737 during training and slightly over-predicted and under-predicted high values of ETo with an R2 value of 0.9718 during testing, which is also shown in Fig. 11, respectively.

Comparison of MNLR model in estimating FAO-56 PM ETo in GKVK Bengaluru station: (a) training period and (b) testing period
The performance evaluation indices for developing the MNLR model are presented in Table 8. It was revealed that the values of R2, RMSE, CE and WI for the MNLR model were observed to be 0.9737, 0.1644 mm/day, 0.9737 and 0.9933, respectively, during training and 0.9718, 0.1725 mm/day, 0.9714 and 0.9927, during testing. The residual plot for the training and testing periods (Fig. 12) shows that the highest errors occur in the range − 1.0 to 1.0, − 0.9 to 1.8 mm, respectively.

Residual plot of Predicted ETo in MNLR model: a training and b testing periods
Sensitivity
The concept of sensitivity analysis was applied to the best-selected model to obtain the parameters that have the greatest effect on the performance of the best-developed model. Based on the results of performance indicators (R2, RMSE, CE and WI), the ANN-10 model was selected as the best model developed using selected climatic variables to predict daily reference evapotranspiration. Selected climatic variables such as RHmean, ws, Sh, es, ea, and Rs obtained from the gamma test were used for the ANN-10 model. The sensitivity analysis was done by varying the input variables up to ± 10%. For each selected input parameter of testing period data, this procedure was repeated to evaluate the sensitivity of the predicted reference evapotranspiration concerning change in input parameter chosen value based on the best-selected ANN-10 model. Using Eq. 14, the relative sensitivity corresponding to each selected input parameter was determined. The sensitivity order of selected input parameters was found based on relative sensitivity results. As presented in Table 9, the values of performance indicators such as R2, RMSE, CE and WI were determined based on the sensitivity of the original predicted ETo with 10% variation (increasing or decreasing) in each selected input parameter during the testing period of ANN-10 model to see the effect of each input parameter on the performance of the model.
As seen from Table 10, the relative sensitivity values of the selected climatic variables such as RHmean, ws, Sh, es, ea, and Rs for the ANN-10 model were found to be − 450.71, 226.16, 295.17, 770.76, − 166.82.2 and 1382.37, respectively. Based on these results, the order of sensitivity of selected climatic variables was obtained as Rs > es > RHmean > Sh > ws > ea. Solar radiation was considered the most sensitive parameter, which greatly influenced the prediction of reference evapotranspiration. While actual vapour pressure was considered the least sensitive parameter, it was found that this parameter has an inverse relation with ETo due to negative signs.
On the other hand, the sensitivity analysis result was found based on the change in output concerning variation in input. As seen from Table 10, it was obtained as the variation of ETo (%) concerning a 10% increase in each selected climatic variable based on the best-selected ANN-10 model during the testing period. The percentage values of ETo change concerning RHmean, ws, Sh, es, ea, and Rs were found as − 3.17, 1.63, 2.10, 5.42, − 1.05 and 9.72, respectively. Negative and positive signs indicate the inverse and direct relationship between input and output variables, respectively. The sensitivity order of selected input parameters based on these results was similar to the relative sensitivity results. Finally, it was concluded that solar radiation was the most relevant parameter.
In contrast, actual vapour pressure was the most irrelevant parameter among all parameters for developing the ANN-10 model to predict ETo for the GKVK station. Due to this, actual vapour pressure can be eliminated from the best-developed model for simplicity and performance enhancement of the developed model for future study. The developed models can be directly integrated with web/mobile-based applications for real-time estimation of reference evapotranspiration, assisting researchers and other stakeholders in predicting water requirements.
Discussion
Based on qualitative and quantitative performance evaluation indicators (R2, RMSE, CE and WI), the best models were selected from each technique, which were further compared with each other to choose the most reliable model for the simulation of daily reference evapotranspiration. The values of numerical metrics for the best-selected models of each technique are presented in Table 11 to evaluate predictive performance during both training and testing periods. From Table 11, the values of various indices showed a minor distinction between the two models (except the MNLR model). However, in the case of the WI indicator, a significant difference was found among all models during training and testing periods. The values of R2, RMSE, CE and WI varied from 0.9737 to 0.9996, 0.0214–0.1644, 0.9737–0.9996 and 0.9255–0.9903, respectively, during training while during testing, the values of R2, RMSE, CE and WI varied from 0.9467 to 0.9938, 0.0814–0.2390, 0.9457–0.9936 and 0.9281–0.9816, respectively.
As shown in Table 11, the ANFIS model performed as the best model among all models during training. However, the ANN-10 model performed better during testing than the other models using all performance indices (R2, RMSE, CE and WI). Because the value of WI was found to be good for the ANN model during testing, the best model should be chosen by assuming its predictive performance during the testing period. Therefore, the Haar wavelet-based ANN-10 model was considered the best model among all models during the training and testing periods, presented in Table 11. Moreover, the ANFIS-06 (trap-2) model performed better than the WANN model during the training and testing. Among all models, the MNLR model showed poor performance in daily reference evapotranspiration prediction despite mapping the nonlinear relationship of hydrological processes. The values of performance indices, viz. R2, RMSE, CE and WI, for the best-selected Haar wavelet-based ANN model were 0.9995, 0.0236, 0.9995 and 0.9999, respectively, during training 0.9992, 0.0299, 0.9991 and 0.9998, during testing.
During the training and testing phases, radar charts and Taylor diagrams were used to visually assess the performance of the ANN, ANFIS, WANN and MNLR models in monthly ETo estimates (Figs. 13 and 14). In training and testing at KVGK stations, the created models' radar charts show how they performed. As can be seen from these graphs, the ANN-10 and ANFIS-06 (trap-2) models outperformed the others during training (Fig. 13a). They outperformed all other models during testing (Fig. 13b). Based on observed data, Taylor diagrams may highlight the correctness and efficiency of models; they demonstrate two distinct characteristics (i.e. correlation coefficient and standard deviation). As shown in Fig. 14a, b, the four models above were tested and trained at KGVK stations. RMSE, standard deviation and correlation coefficient are shown in a single polar plot on the Taylor diagram. These diagrams demonstrate the better performance of ANFIS-06 (trap-2) than ANN-10, WANN-11 and MNLR for study stations in the training period (Fig. 14a), and ANN-10 performed better ANFIS-06 (trap-2), WANN-11 and MNLR for study stations in the testing period (Fig. 14b). The best performance was found for the ANN-10 model, closely followed by the ANFIS-06 (trap-2), WANN-11 and MNLR models for the training period, and the ANN-10 model closely followed by the ANFIS-06 (trap-2), WANN-11 and MNLR models for a testing period at KGVK stations (Fig. 14b). Figure 15 shows the mean bias (MBE) and mean-squared error (MSE) evaluation of the best ANN, WANN, ANFIS and MNLR models in testing. Both parameters show very little differences among all models. The order of superiority for reference evapotranspiration simulation was observed as ANN, ANFIS, WANN and MNLR models. ANN-10 model was considered superior to other models because wavelet transform unveils the hidden signal (information) of original time series data into sub-components (sub-series). Finally, the ANN model was found to be the most reliable model in ETo prediction for the area of GKVK.

Radar chart showing the statistical performance of the best selection of ANN-10, WANN-11, ANFIS-06 (trap-2) and MNLR during a training and b testing periods

Taylor diagrams of estimated and observed monthly ETo values by ANN-10 (6-10-1), WANN-11 (24-11-1), ANFIS-06 (trap-2) and MNLR models for the a testing and b testing period at GKVK Bengaluru station

Mean bias error (MBE) and mean-squared error (MSE) evaluate the best ANN, WANN, ANFIS and MNLR models in testing
In this study, using measured daily weather variables, i.e. Tmin, Tmax, RH percentage, U2 and Sh, four machine learning (ML) models were developed and compared for modelling daily reference ETo, i.e. the ANN, ANFIS, WANN and MNLR. The models were applied during the dry (a critical time for the growing season) and humid seasons to provide a general view of the feasibility of machine learning for ETo modelling. In this study, an approach of applying the Gamma test technique (GT) to weather data not only ensured that the best and suitable variables for modelling ETo were accurately selected but also was a successful means of selecting the best input combination. In addition to this finding, it was found that coupling the ANN with wavelet decomposition helps improve the ML model's performance. Similar to the results of several auteurs, it was found that the inclusion of the two-air temperature, i.e. Tmin, Tmax, plays a significant role in modelling the ETo and improved model predictions.
Although there have been many studies comparing several ML models for ETo modelling, the comparisons were conducted in particular, taking into account the combination of various weather variables. Ye et al. (2022) proposed a modelling Framework based on the hybridisation of a dynamic evolving neural-fuzzy inference system (DENFIS) and multivariate adaptive regression spline (MARS) with whale optimisation algorithm (WOA) and bat algorithm (BA). The hybrid models, i.e. MARS-WOA, MARS- BA, DENFIS-WOA and DENFIS-WOA, were found to be accurate, exhibiting an R2 value of approximately ≈0.940, less than the value obtained in our present study (R2≈0.998). Similar results occurred over the northeast of the Inner Mongolia Autonomous Region, China, while agreement between measured and predicted ETo was much more accurate (Zhang et al. 2022). They showed that the availability of many weather variables is beneficial to the analysis of several scenarios generated under temperature-based, humidity-based and radiation-based models. More precisely, they compared random forest regression (RFR), K-nearest neighbours (KNN), light gradient boosting machine (LGB), ANN, long short-term memory (LSTM) and temporal convolutional neural network (TCN), showing that the biggest R2 value obtained by all models does not exceed ≈0.935, which are less than the value obtained in our study by the WANN, ANN and ANFIS models (R2≈0.998).
The findings by Muhammad et al. (2022) help to explain the results from this study, suggesting that in high mountains in the central region of Peninsular Malaysia (former Malaya), the gene expression programming (GEP) model was found to be an excellent and powerful tool for evapotranspiration modelling. They obtained an R2 value of approximately ≈0.98, slightly less than the value obtained in our study. Using the multi-layer perceptron (MLPNN) and radial basis function (RBFNN), Dimitriadou and Nikolakopoulos (2022) demonstrated that ETo was directly linked to Tmean, Sh and solar radiation (Rs) in the Peloponnese is a peninsula in Southwestern Greece, suggesting that MLPNN and RBFNN are correctly capturing the variability of ETo with an R2 of approximately ≈0.980 nearly equal to the value obtained in our study. In a Modelling study by Wang et al. (2022), a priori knowledge of fewer weather variables shows that when Tmax, Tmin, U2 and Sh are introduced as input variables to the machine learning, the R2 value shifts towards higher values, but not for all algorithms. More precisely, by comparing three ML families, i.e. three tree-based models, neural network-based and three multifunction-based models, the comparison was conducted between ten algorithms. It was a statement to say that the generalised regression neural network (GRNN) and the RBFNN models will give excellent R2 values greater than ≈0.999 and ≈0.997 and RMSE values less than 0.01, which all are better than the values obtained in our study. The findings by Tejada et al. (2022) show that ETo is related to Tmax, Tmin, U2 and Rs at Region IV-A, Philippines. The support vector machines (SVM) and extreme learning machines (ELM) were a good alternative for estimating the ETo with high accuracies for which the R2 reached the values of ≈0.985 and ≈0.999, respectively.
Using weather variables collected at two stations in Tabriz and Shiraz, Iran, Mehdizadeh et al. (2021) concluded that the hybridisation of the ANFIS model using the shuffled frogleaping (SFLA) and invasive weed optimisation (IWO) algorithms has allowed to obtain excellent ETo prediction reaching an R2 of approximately ≈0.998 and ≈0.999 obtained using the ANFIS-SFLA and the ANFIS-IWO, respectively, which was similar the results obtained in our present study, despite that the same weather variables were included as input variables. From the results by Kadkhodazadeh et al. (2022), it follows that among six ML algorithms, i.e. MARS, M5Tree, RFR and least squares boost (LSBoost), the ETo prediction with its input of even standards meteorological data was very appropriate for homogeneous and heterogeneous locations, such as Tabriz, Urmia and Mahabad located in Iran. It is emphasised that excellent R2 values were obtained, reaching the value of ≈0.999 in the light of the results obtained in the present study, and this has strong implications for the use of ML for ETo estimation. Furthermore, the linear regression ML algorithms, i.e. multiple linear regression (MLR) and polynomial regression (PR) developed by Kim et al. (2022), have shown poor to moderate predictive accuracy. In this way, the R2 values do not exceed the values of ≈0.694, which are less than the values obtained in our study. Alternatively, there is a tremendous need for the application of the ensemble ML methods for predicting ETo. For example, Liu et al. (2021) compared RFR and extreme gradient boosting (XGBoost) models for modelling ETo using data collected across the humid region of China. From the obtained results, it was found that XGBoost was slightly better than the RFR, exhibiting R2 values of approximately ≈0.867 and ≈0.862, respectively, and the combination of Tmax, Tmin and Rs as inputs guaranteed the best predictive accuracies.
Basically, a large amount of ML models were proposed and successfully applied for modelling ETo. A typical difference between the analysed models revealed that all were based on linking weather variables to ETo, and a learning process with and without hybridisation was adopted. However, one of the most challenging aspects of ML is certainly the use of deep learning for solving regression tasks. For example, Sharma et al. (2022) applied two deep learning models, namely, convolution-long short-term memory (Conv-LSTM) and convolution neural network-LSTM (CNN-LSTM) for modelling ETo. They demonstrated that deep learning models are robust tools for which excellent R2 values were obtained (R2≈0.991) nearly equal to the value obtained in our study. However, considering the obtained RMSE values (RMSE≈0.019), deep learning was slightly better than the WANN and ANN proposed in our present study. Xing et al. (2022) applied the deep beliefs networks (DBN) and the LSTM deep learning models for modelling ETo and reported good predictive accuracies with R2 exhibiting a value of ≈0.940. Roy et al. (2022) compared deep learning, i.e. LSTM and BiLSTM, and a suite of ML models, i.e. SVM, MARS, M5Tree, ANFIS, probabilistic linear regression (PLR) and Gaussian process regression (GPR) for modelling ETo. It was found that BiLSTM was more accurate and exhibited excellent predictive accuracies with R2 nearly equal to the value of ≈0.996.
The potential uncertainties associated with the input meteorological variables used in the models, such as measurement errors or data gaps. The proposed modelling framework does not have any limitation such as data requirements, computational resources or model calibration. It was proposed to enhance the computation performance.
Suggested future works
This study was conducted at a single station to assess the accuracy of MNLR, ANN, ANFIS and WANN techniques. To enable a more comprehensive comparison of these models, future research should involve multiple locations simultaneously. Additional investigation could be directed towards examining the efficacy of alternative soft computing methodologies or machine learning algorithms in forecasting daily reference evapotranspiration (ETo) within tropical savanna ecosystems, extending beyond the scope of the models scrutinised in this inquiry. Future research should explore how including more meteorological variables or trying different combinations of input data affects the accuracy and effectiveness of models predicting ETo. By doing so, researchers can pinpoint which variables have the most significant impact on the predictions and consequently enhance the overall predictive capabilities of the models. It would be beneficial to conduct field validation experiments to assess the practical applicability and reliability of the proposed modelling framework in real-world scenarios. This can help validate the model's performance and provide insights into potential limitations or areas for improvement.
Additionally, the investigation could delve into incorporating remote sensing data or satellite imagery to augment the precision and spatial resolution of ETo predictions, especially in areas where ground-based meteorological data is scarce. Furthermore, forthcoming research endeavours could explore the viability of ensemble modelling methodologies, amalgamating various models or techniques to enhance both the accuracy and resilience of ETo predictions within tropical savanna settings.
Conclusions
Reference evapotranspiration (ETo) is an important component of the hydrological cycle, and it is a critical step in the quantification of the crop water requirement. In the present study, various meteorological variables were used for the estimation of ETo using CROPWAT 8.0 software based on the Penman–Monteith equation. The estimated reference evapotranspiration values were considered as observed values. Based on the best input combination identified through the gamma test, different artificial intelligence (ANN, ANFIS, WANN) and nonlinear regression (MNLR) techniques were applied to calibrate various ETo models using MATLAB software in the present study. Statistical and hydrological performance indices, such as R2, RMSE, WI and CE, were evaluated to determine the most accurate model for the prediction of ETo. Finally, the concept of sensitive analysis was utilised for the best-developed model to see the effect of the most sensitive parameter on model performance.
According to the obtained results, some conclusions can be highlighted as follows:
-
(i)
Based on performance criteria, the ANN-10 (6-10-1) model was found to be better than the other ANN models.
-
(ii)
The wavelet-coupled ANN-11 (24-11-1) model was superior to the other WANN models for the study area.
-
(iii)
ANFIS-06 model with trapezoidal type input MFs performed better than the other input MFs based on ANFIS models.
-
(iv)
Based on the overall performance of ANN, ANFIS, WANN and MNLR models, the ANN-10 was found to be the best model for the prediction of daily ETo of the study area.
-
(v)
Solar radiation was found to be the most sensitive variable. In contrast, actual vapour pressure was less sensitive based on sensitivity analysis.
To enhance the accuracy of predictive models, the detailed explanation of the specific algorithms or mathematical principles employed in the neural network models. This research demonstrates the application and performance evaluation of different soft computing models (ANN, WANN, ANFIS, MNLR) for ETo prediction, and also delving into the underlying theoretical foundations of these models by assessing their accuracy and performance as well.
References
Ahmadi F, Mehdizadeh S, Mohammadi B et al (2021) Application of an artificial intelligence technique enhanced with intelligent water drops for monthly reference evapotranspiration estimation. Agric Water Manag 244:106622. https://doi.org/10.1016/j.agwat.2020.106622
Allen RG, Pereira LS, Raes D, Smith M (1998) Crop evapotranspiration-Guidelines for computing crop water requirements-FAO Irrigation and drainage paper 56. Fao, Rome 300:D05109
AL-Oqla FM, Al-Jarrah R (2021) A novel adaptive neuro-fuzzy inference system model to predict the intrinsic mechanical properties of various cellulosic fibers for better green composites. Cellulose 28:8541–8552. https://doi.org/10.1007/s10570-021-04077-1
Bajirao TS, Kumar P, Kumar M et al (2021) Potential of hybrid wavelet-coupled data-driven-based algorithms for daily runoff prediction in complex river basins. Theor Appl Climatol 145:1207–1231. https://doi.org/10.1007/s00704-021-03681-2
Beven K (1979) A sensitivity analysis of the Penman-Monteith actual evapotranspiration estimates. J Hydrol 44:169–190. https://doi.org/10.1016/0022-1694(79)90130-6
Chandwani V, Vyas SK, Agrawal V, Sharma G (2015) Soft computing approach for rainfall-runoff modelling: a review. Aquat Proced 4:1054–1061. https://doi.org/10.1016/j.aqpro.2015.02.133
de Dias VS, da Luz MP, Medero GM, Nascimento DTF (2018) An overview of hydropower reservoirs in Brazil: current situation, future perspectives and impacts of climate change. Water (Switzerland) 10:592. https://doi.org/10.3390/w10050592
Dimitriadou S, Nikolakopoulos KG (2022) Artificial neural networks for the prediction of the reference evapotranspiration of the Peloponnese Peninsula, Greece. Water 14:2027. https://doi.org/10.3390/w14132027
Elhag M, Psilovikos A, Manakos I, Perakis K (2011) Application of the Sebs water balance model in estimating daily evapotranspiration and evaporative fraction from remote sensing data over the Nile Delta. Water Resour Manag 25:2731–2742. https://doi.org/10.1007/s11269-011-9835-9
Emeka N, Ikenna O, Okechukwu M et al (2021) Sensitivity of FAO Penman-Monteith reference evapotranspiration (ETo) to climatic variables under different climate types in Nigeria. J Water Clim Chang 12:858–878. https://doi.org/10.2166/wcc.2020.200
Esmaeilzadeh B, Sattari MT, Samadianfard S (2017) Performance evaluation of ANNs and an M5 model tree in Sattarkhan reservoir inflow prediction. ISH J Hydraul Eng 23:283–292. https://doi.org/10.1080/09715010.2017.1308277
Gong L, Xu C, Chen D et al (2006) Sensitivity of the Penman-Monteith reference evapotranspiration to key climatic variables in the Changjiang (Yangtze River) basin. J Hydrol 329:620–629. https://doi.org/10.1016/j.jhydrol.2006.03.027
Goyal RK (2004) Sensitivity of evapotranspiration to global warming: a case study of arid zone of Rajasthan (India). Agric Water Manag 69:1–11. https://doi.org/10.1016/j.agwat.2004.03.014
Hassoun MH (1995) Fundamentals of artificial neural networks. MIT Press, Cambridge
Hosseini S, Poormirzaee R, Hajihassani M, Kalatehjari R (2022) An ANN-fuzzy cognitive map-based Z-number theory to predict Flyrock induced by blasting in open-pit mines. Rock Mech Rock Eng 55:4373–4390. https://doi.org/10.1007/s00603-022-02866-z
Irmak S, Payero JO, Martin DL et al (2006) Sensitivity analyses and sensitivity coefficients of standardized daily ASCE-Penman-Monteith equation. J Irrig Drain Eng 132:564–578. https://doi.org/10.1061/(ASCE)0733-9437(2006)132:6(564)
Jang J-SR (1993) ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans Syst Man Cybern 23:665–685. https://doi.org/10.1109/21.256541
Jensen ME, Allen RG (eds) (2016) Evaporation, evapotranspiration, and irrigation water requirements: task committee on revision of manual 70, (xxiii + 744 pp.). American Society of Civil Engineers (ASCE). cabidigitallibrary.org/doi/full/10.5555/20163352192
Kadkhodazadeh M, Valikhan Anaraki M, Morshed-Bozorgdel A, Farzin S (2022) A new methodology for reference evapotranspiration prediction and uncertainty analysis under climate change conditions based on machine learning, multi criteria decision making and Monte Carlo methods. Sustainability 14:2601. https://doi.org/10.3390/su14052601
Kim S-J, Bae S-J, Jang M-W (2022) Linear regression machine learning algorithms for estimating reference evapotranspiration using limited climate data. Sustainability 14:11674. https://doi.org/10.3390/su141811674
Kisi O, Alizamir M (2018) Modelling reference evapotranspiration using a new wavelet conjunction heuristic method: wavelet extreme learning machine vs wavelet neural networks. Agric For Meteorol 263:41–48. https://doi.org/10.1016/j.agrformet.2018.08.007
Kovoor GM, Nandagiri L (2018) Sensitivity analysis of FAO-56 Penman–Monteith reference evapotranspiration estimates using Monte Carlo simulations. In: Singh VP, Yadav S, Yadava RN (eds). Springer Singapore, Singapore, pp 73–84
Kumar R, Haroon S (2021) Water requirement and fertigation in high density planting of apples. Indian J Hortic 78:292–297. https://doi.org/10.5958/0974-0112.2021.00042.6
Kumar R, Singh RD, Sharma KD (2005) Water resources of India. Curr Sci 89:794–811
Kumar R, Jat MK, Shankar V (2012) Methods to estimate irrigated reference crop evapotranspiration—a review. Water Sci Technol 66:525–535. https://doi.org/10.2166/wst.2012.191
Kumar M, Kumar R, Rajput TBS, Patel N (2017) Efficient design of drip irrigation system using water and fertilizer application uniformity at different operating pressures in a semi-arid Region of India. Irrig Drain 66:316–326. https://doi.org/10.1002/ird.2108
Kurzyca I, Frankowski M (2019) Scavenging of nitrogen from the atmosphere by atmospheric (rain and snow) and occult (dew and frost) precipitation: comparison of urban and nonurban deposition profiles. J Geophys Res Biogeosci 124:2288–2304. https://doi.org/10.1029/2019JG005030
Kushwaha NL, Bhardwaj A, Verma VK (2016) Hydrologic response of Takarla-Ballowal watershed in Shivalik foot-hills based on morphometric analysis using remote sensing and GIS. J Indian Water Resour Soc 36:17–25
Kushwaha NL, Rajput J, Sena DR et al (2022) Evaluation of data-driven hybrid machine learning algorithms for modelling daily reference evapotranspiration. Atmos Ocean 60:519–540. https://doi.org/10.1080/07055900.2022.2087589
Lee EJ, Kang MS, Park SW, Kim HK (2010) Estimation of future reference evapotranspiration using artificial neural network and climate change scenario. In: 2010 Pittsburgh, Pennsylvania, June 20 - June 23, 2010. American Society of Agricultural and Biological Engineers, St. Joseph, MI
Ley TW, Hill RW, Jensen DT (1994) Errors in Penman-Wright Alfalfa reference evapotranspiration estimates: I. Model sensitivity analyses. Trans ASAE 37:1853–1861. https://doi.org/10.13031/2013.28276
Liu T, Li L, Lai J et al (2016) Reference evapotranspiration change and its sensitivity to climate variables in southwest China. Theor Appl Climatol 125:499–508. https://doi.org/10.1007/s00704-015-1526-7
Liu QJ, Zhang HY, Gao KT et al (2019) Time-frequency analysis and simulation of the watershed suspended sediment concentration based on the Hilbert-Huang transform (HHT) and artificial neural network (ANN) methods: a case study in the Loess Plateau of China. Catena 179:107–118. https://doi.org/10.1016/j.catena.2019.03.042
Liu X, Wu L, Zhang F et al (2021) Splitting and length of years for improving tree-based models to predict reference crop evapotranspiration in the humid regions of China. Water 13:3478. https://doi.org/10.3390/w13233478
Malik A, Kumar A, Kim S et al (2020) Modeling monthly pan evaporation process over the Indian central Himalayas: application of multiple learning artificial intelligence model. Eng Appl Comput Fluid Mech 14:323–338. https://doi.org/10.1080/19942060.2020.1715845
McCuen RH (1973) The role of sensitivity analysis in hydrologic modeling. J Hydrol 18:37–53. https://doi.org/10.1016/0022-1694(73)90024-3
Mehdizadeh S, Mohammadi B, Pham QB, Duan Z (2021) Development of boosted machine learning models for estimating daily reference evapotranspiration and comparison with empirical approaches. Water 13:3489. https://doi.org/10.3390/w13243489
Mobtaker HG, Ajabshirchi Y, Ranjbar SF, Matloobi M (2016) Solar energy conservation in greenhouse: thermal analysis and experimental validation. Renew Energy 96:509–519
Muhammad MKI, Shahid S, Hamed MM et al (2022) Development of a temperature-based model using machine learning algorithms for the projection of evapotranspiration of Peninsular Malaysia. Water 14:2858. https://doi.org/10.3390/w14182858
Ndiaye PM, Bodian A, Diop L et al (2021) Future trend and sensitivity analysis of evapotranspiration in the Senegal River Basin. J Hydrol Reg Stud 35:100820. https://doi.org/10.1016/j.ejrh.2021.100820
Pereira LS, Allen RG, Smith M, Raes D (2015) Crop evapotranspiration estimation with FAO56: past and future. Agric Water Manag 147:4–20. https://doi.org/10.1016/j.agwat.2014.07.031
Poddar A, Gupta P, Kumar N et al (2021) Evaluation of reference evapotranspiration methods and sensitivity analysis of climatic parameters for sub-humid sub-tropical locations in western Himalayas (India). ISH J Hydraul Eng 27:336–346. https://doi.org/10.1080/09715010.2018.1551731
Raza A, Al-Ansari N, Hu Y et al (2022) Misconceptions of reference and potential evapotranspiration: a PRISMA-guided comprehensive review. Hydrology 9:153. https://doi.org/10.3390/hydrology9090153
Roy DK, Lal A, Sarker KK et al (2021) Optimization algorithms as training approaches for prediction of reference evapotranspiration using adaptive neuro fuzzy inference system. Agric Water Manag 255:107003. https://doi.org/10.1016/j.agwat.2021.107003
Roy DK, Sarkar TK, Kamar SSA et al (2022) Daily prediction and multi-step forward forecasting of reference evapotranspiration using LSTM and Bi-LSTM models. Agronomy 12:594. https://doi.org/10.3390/agronomy12030594
Saikia A (2009) NDVI variability in North East India. Scottish Geogr J 125:195–213. https://doi.org/10.1080/14702540903071113
Sanikhani H, Kisi O, Maroufpoor E, Yaseen ZM (2019) Temperature-based modeling of reference evapotranspiration using several artificial intelligence models: application of different modeling scenarios. Theor Appl Climatol 135:449–462. https://doi.org/10.1007/s00704-018-2390-z
Sentelhas PC, Gillespie TJ, Santos EA (2010) Evaluation of FAO Penman-Monteith and alternative methods for estimating reference evapotranspiration with missing data in Southern Ontario, Canada. Agric Water Manag 97:635–644. https://doi.org/10.1016/j.agwat.2009.12.001
Sharma G, Singh A, Jain S (2022) A hybrid deep neural network approach to estimate reference evapotranspiration using limited climate data. Neural Comput Appl 34:4013–4032. https://doi.org/10.1007/s00521-021-06661-9
Shiri J, Dierickx W, Pour-Ali Baba A et al (2011) Estimating daily pan evaporation from climatic data of the State of Illinois, USA using adaptive neuro-fuzzy inference system (ANFIS) and artificial neural network (ANN). Hydrol Res 42:491–502. https://doi.org/10.2166/nh.2011.020
Singh VP, Xu C-Y (1997) Evaluation and generalization of 13 mass-transfer equations for determining free water evaporation. Hydrol Process 11:311–323
Singh VK, Kumar D, Kashyap PS, Kisi O (2018) Simulation of suspended sediment based on gamma test, heuristic, and regression-based techniques. Environ Earth Sci 77:708. https://doi.org/10.1007/s12665-018-7892-6
Tejada AT, Ella VB, Lampayan RM, Reaño CE (2022) Modeling reference crop evapotranspiration using support vector machine (SVM) and extreme learning machine (ELM) in region IV-A, Philippines. Water 14:754. https://doi.org/10.3390/w14050754
Tikhamarine Y, Malik A, Souag-Gamane D, Kisi O (2020) Artificial intelligence models versus empirical equations for modeling monthly reference evapotranspiration. Environ Sci Pollut Res 27:30001–30019. https://doi.org/10.1007/s11356-020-08792-3
Tulla PS, Kumar P, Vishwakarma DK et al (2024) Daily suspended sediment yield estimation using soft-computing algorithms for hilly watersheds in a data-scarce situation: a case study of Bino watershed, Uttarakhand. Theor Appl Climatol. https://doi.org/10.1007/s00704-024-04862-5
Üneş F, Doğan S, Taşar B et al (2018) The evaluation and comparison of daily reference evapotranspiration with ANN and empirical methods. Nat Eng Sci 3:54–64
Vishwakarma DK, Kumar R, Kumar A et al (2022a) Evaluation and development of empirical models for wetted soil fronts under drip irrigation in high-density apple crop from a point source. Irrig Sci. https://doi.org/10.1007/s00271-022-00826-7
Vishwakarma DK, Pandey K, Kaur A et al (2022b) Methods to estimate evapotranspiration in humid and subtropical climate conditions. Agric Water Manag 261:107378. https://doi.org/10.1016/j.agwat.2021.107378
Vishwakarma DK, Kuriqi A, Abed SA et al (2023) Forecasting of stage-discharge in a non-perennial river using machine learning with gamma test. Heliyon 9:e16290. https://doi.org/10.1016/j.heliyon.2023.e16290
Wang J, Raza A, Hu Y et al (2022) Development of monthly reference evapotranspiration machine learning models and mapping of pakistan—a comparative study. Water 14:1666. https://doi.org/10.3390/w14101666
Wu L, Peng Y, Fan J, Wang Y (2019) Machine learning models for the estimation of monthly mean daily reference evapotranspiration based on cross-station and synthetic data. Hydrol Res 50:1730–1750. https://doi.org/10.2166/nh.2019.060
Wu L, Peng Y, Fan J et al (2021) A novel kernel extreme learning machine model coupled with K-means clustering and firefly algorithm for estimating monthly reference evapotranspiration in parallel computation. Agric Water Manag 245:106624. https://doi.org/10.1016/j.agwat.2020.106624
Xing L, Cui N, Guo L et al (2022) Estimating daily reference evapotranspiration using a novel hybrid deep learning model. J Hydrol 614:128567. https://doi.org/10.1016/j.jhydrol.2022.128567
Ye L, Zahra MMA, Al-Bedyry NK, Yaseen ZM (2022) Daily scale evapotranspiration prediction over the coastal region of southwest Bangladesh: new development of artificial intelligence model. Stoch Environ Res Risk Assess 36:451–471. https://doi.org/10.1007/s00477-021-02055-4
Zeleke KT, Wade LJ (2012) Evapotranspiration estimation using soil water balance, weather and crop data. In: Irmak A (ed) Evapotranspiration-remote sensing and modeling. InTech, London, pp 41–58
Zhang H, Meng F, Xu J et al (2022) Evaluation of machine learning models for daily reference evapotranspiration modeling using limited meteorological data in Eastern Inner Mongolia. North China Water 14:2890. https://doi.org/10.3390/w14182890
Acknowledgements
The authors would like to thank Researchers Supporting Project number (RSPD2024R958), King Saud University, Riyadh, Saudi Arabia.
Funding
Open access funding provided by Lulea University of Technology. Researchers Supporting Project number (RSPD2024R958), King Saud University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The author declare that they have no conflict of interest.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gupta, S., Kumar, P., Kishore, G. et al. Sensitivity of daily reference evapotranspiration to weather variables in tropical savanna: a modelling framework based on neural network. Appl Water Sci 14, 138 (2024). https://doi.org/10.1007/s13201-024-02195-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13201-024-02195-2