
Abstract
Hydrometric stations are important in most countries because of the application and importance of the data obtained from these stations. It is necessary to choose the best place for their establishment according to the cost of constructing hydrometric stations. The aim and innovation of this research are to optimize the location of hydrometric stations using Bat's meta-heuristic algorithm and interpolation methods, which information transfer entropy theory and Bat's algorithm were used to maximize the average amount of information transfer entropy. For this purpose, the data of 43 hydrometric stations of Karkheh basin in western Iran in period of 1991–2015 were used. In this research, two scenarios were investigated in order to improve the entropy of information transmission between stations. In the first scenario, using the kriging method to prepare the flow distribution map in the region and choosing normal kriging with spherical variogram as the best model to fit the average annual flow data and using the Bat algorithm to increase the correlation coefficient between the data and assuming no none of the available stations, 43 points were used to redeploy stations with higher average entropy in the region. The results of this scenario showed the concentration of new stations in the central and eastern areas of the basin. In the second scenario, the amount of entropy of information transfer at the regional level was calculated and 18 potential points were recommended for the establishment of new stations. The obtained variogram for the discharge of the basin showed that the range of influence is low and it is necessary to establish the stations at a close distance.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Hydrometry is the study of the factors of the hydrological cycle, which includes rainfall, groundwater characteristics (Boiten 2000), water quality, and surface water discharge characteristics. The root of the term hydrometry is derived from the Greek word hydro, which means water, and Metros, which means measurement. Therefore, a hydrometric network can be defined as a series of information-gathering activities for different dimensions of the hydrometric cycle that are designed and implemented to focus on a single goal or a series of related goals (Mishra and Coulibaly 2009). The hydrometric data collected from a basin are the basis for the design of various water resource projects, such as the design of reservoirs, water distribution systems, irrigation networks, and studying the impact of climate change on water resources. It is obvious that there are many users of hydrometric information: hydrologists, agricultural specialists, meteorologists, water specialists, water resource managers and planners, researchers of various organizations and government and private sector decision makers. The design of hydrometer network is used to monitor surface water in order to solve a wide range of environmental and water resources problems and issues. The historical review of hydrometer network design is presented with a discussion about developments and new challenges in optimal network design, the growing importance of optimal network design in the context of climate change and land use. An extensive review of the developments, finding the method in the design of the hydrometer network along with the discussion of the issue of uncertainty in the hydrometer network design and evolution in the information collection methods and technology, is provided. Based on the purpose of the water measurement network, it can be called a surface water network, a groundwater network or a water quality network. This research focuses on the design of the surface water network, which includes both the water caused by precipitation and the discharge of the spring. Therefore, the term hydrometer network here is related to surface water networks to manage the discharge and precipitations of springs. Li et al. (2020) developed a criterion for hydrometric grid optimization based on information theory and copula. The results showed that the dual entropy-trans information criterion (DETC) can effectively prioritize stations according to their importance and combine priority decision-making on information content and information redundancy. Chebbi et al. (2017) optimized a hydrometric grid extension using specific flow, kriging and simulated annealing. Examining the optimized locations showed full compliance with the location of the new sites, and the new locations showed a better spatial coverage of the studied area. Hynds et al. (2019) evaluated the effectiveness of the hydrometric network in the Republic of Ireland using expert opinion and statistical analysis. The results showed that 50.5% of the surveyed people consider the current network insufficient for their professional needs. A significant majority (85.4%) of respondents indicate that future resiliency is best achieved by modifying network density, with more than 60% of network enhancements focused on geographic and distributed. Sreeparvathy and Srinivas (2020) evaluated a fuzzy entropy approach for designing hydrometric networks. The results showed that the proposed method looks promising and provides a context for application in monitoring networks of various other weather and water variables. Leach et al. (2015) designed the hydrometric network using hydrological change indices. The results showed that the optimal locations for the new stations were well captured by the objective functions. Also, when hydrological indicators were considered, the new stations covered a wider area and increased the target performances. Karami Hosseini et al. (2010) determined the location of new rain gauge stations using 30-year rainfall data for Gavkhouni basin. Two sequential and genetic algorithms were used for locating, and the objective function in both algorithms was to maximize the minimum entropy of information transfer and the average entropy of transfer. By examining and comparing these two algorithms, it was found that the genetic algorithm performed better in both objective functions. Mohammadi (1999) used the kriging method to study the spatial changes of soil salinity in Ramhormoz region of Khuzestan in Iran, using kriging. Taj showed that the overall similarity between benchmark data and kriging results was greater than the salinity map obtained from free geodetic surveying. Also, maps based on kriging method were more reliable for determining the location of salinity classes. Merz and Blöschl (2005) investigated the efficiency of multiple regional flood forecasting methods in basins without statistics. The results of the investigations showed that the spatial proximity is a better predictor than the characteristics of the basin in the regional flood frequency. Masoumi and Kerachian (2010) used transition–distance (T–D) curves and measured information transfer in discrete entropy theory in order to check the efficiency of sampling locations and the number of sampling times in a monitoring network in the aquifer of the Tehran in Iran. The results pointed to the efficiency of the model in the optimal redesign of groundwater monitoring systems, which can jointly determine both the spatial distance of the wells and the sampling time of the wells in order to cover all the issues related to quantity and optimized the quality of groundwater. Laaha et al. (2014) compared co-kriging and local regression and found that at sites with no upstream data points, the performance of the two methods was similar. Their study found cross-validation coefficients of 0.75 for the regional regression method with nested watersheds and 0.68 for high kriging. One of the advantages of the kriging method described above is the ability to continuously estimate the spatial variation of a given flow across a channel network. However, this study does not require the continuous estimation of specific runoff volumes. Therefore, in our opinion, a small increase in explanatory power does not justify such an investment in computational time, especially since the kriging procedure is repeated as many times as necessary to optimize the objective function. Ursulak and Coulibaly (2021) integrated the hydrological models with entropy and multi-objective optimization-based methods to design streamflow monitoring networks for specific needs. The results showed that embedding the model in the optimization algorithm yields consistently superior network configurations compared to those identified using the traditional methods. It is shown that small-sized optimal networks outperforming large networks can be directly identified by the proposed method. de Oliveira Simoyama et al. (2022) reviewed the optimization of rain gauge networks. The results demonstrate various applications, goals, methods, models, and algorithms aimed at optimizing rain gauge networks. Conclusions are drawn in the light of future research opportunities on this topic. Mishra and Coulibaly (2010) evaluated the hydrometric network in Canadian watersheds using entropy theory. They used daily discharge data and information coefficients such as marginal entropy, joint entropy and trans-information index to identify critical areas and such important stations. The results of the investigations showed that all the main basins of Canada have inefficient hydrometric networks. The three regions of Alberta, Northern Ontario and the Northwest Territories had the greatest shortages. Keum et al. (2018) investigated a snow monitoring network strategy to predict maximum spring discharge by means of dual entropy and multi-objective optimization (DEMO) with snow data collection system and hydrological models. The combination of two DEMO methods with hydrological models showed an efficient method for the optimal design of snow networks. The advantage of optimization through entropy is to determine the optimal networks with the maximum amount of information and the minimum amount of frequency. Based on various studies, it is possible to understand the necessity of proper location of the stations. Therefore, the aim of the current research is to optimize and locate hydrometric stations in Karkheh basin in the southwest of Iran.
Materials and methods
Study area
The study area is the catchment area of the Karkheh River in the southwest of Iran and is located in the middle and southwest of the Zagros Mountain range. In terms of geographical coordinates, this basin is located between 46° 6′ and 49° 10′ east longitude and between 30° 58´ and 34° 56´ north latitudes. The area of this basin is about 50,764 square kilometers, which about 27,645 square kilometers are mountainous areas and about 23,119 square kilometers are plains and foothills. In this research, 43 stations with a record period of 25 years have been used. The location of stations is shown in Fig. 1.

Karkheh watershed
Data used
The annual average discharge of 43 hydrometric stations was selected for this study. The way of selecting the stations was done in such a way that the stations that had at least 25 statistical years from 1991 to 2015 and the number of missing data is less than or equal to 5, which is equivalent to 20% of the statistical base of each station, were chosen. The annual average discharge was also calculated by adding up the monthly discharges in one year and then dividing the sum of these values in each year divide by 12 (the number of months in a year) to get the average. This was done every year.
Specific discharge
In order to eliminate the influence of the areas under the basins in interpolation, it is necessary to extract the specific discharge and then standardize the discharges using the relation (1). Specific discharge is calculated using the following formula.
In order to standardize the data, a hypothetical area was included for the data, and the standardized discharge rate is calculated based on Eq. (2) (Merz and Blöschl 2005).
Ai: the area of the sub-basin where the ith station is located. Qi: discharge rate for each sub-basin. The β factor is also obtained by drawing a logarithmic diagram of the specific discharge value against the sub-basin area of each station. Ais: the area of the hypothetical basin, which is equivalent to 100 square kilometers. Qs: hypothetical sub-basin discharge.
To use the kriging method, which will be mentioned later, it is necessary that the data follow the normal distribution. EasyFit 5.5 Professional and Minitab software were used to check the normality of average annual discharge data and their dependence on geographic coordinates and altitude and the significance of explanatory coefficients. In this software, two tests, Kolmogorov Smirnov and Anderson–Darling, are used to check normality and p-value for significance. The data related to the area of the sub-basins, the height and the location of the water measuring stations, were obtained from the Ministry of Energy, and the data related to the amount of discharge recorded for each station were obtained from the Iranian Water Resources Management Company. Also, discharge data can be accessed through this company's website (Fig. 2).

Location of stations in Karkheh basin
Methodology
Reconstruction of unregistered data
In some of the discharge stations, no data were recorded in some years. To reconstruct missing or unrecorded annual discharge data, linear regression method was used between nearby stations (Crambes and Henchiri 2019; Guo et al. 2019). In this way, a linear regression equation was obtained between all the stations adjacent to the station without statistics, and the station that had the highest coefficient of determination with the desired station was selected to reconstruct the unrecorded data. In this research, the regression equation was used for stations where the number of missing or unrecorded data was less than or equal to 5% of the statistical period (25 years). Because average annual discharge has the effect of rainfall, the linear regression equation can be used to reconstruct the missing data in it.
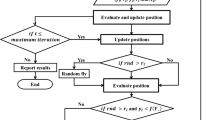
Bat algorithm
The Bat algorithm has six main steps, which will be mentioned below (Eslamian and Eslamian 2023):
First step: initializing the problem and algorithm parameters
The general optimization function can be formulated as follows:
f(x) is the objective function for evaluating any problem x = (x1, x2, …, xd) of length d. Each decision variable xi with index i in the problem has a specific value such that \({X}_{i}\in [{\mathrm{LB}}_{i},{\mathrm{UB}}_{i}]\) where \({\mathrm{LB}}_{i}\) is the lower limit and \({\mathrm{UB}}_{i}\) is the upper limit for the decision variable xi Is. In this objective function research, maximizing the function \(T=-\frac{1}{2}\times \mathrm{Ln}(1-{r}^{2})\) was considered. Also, the lower limit was assumed to be equal to the lowest recorded discharge rate, which was equal to zero, and the upper limit, which was equal to 342 cubic meters per second (during the selected 25-year statistical period). d was set equal to 43, which was to the number of stations. The parameters of the Bat algorithm are also set at this stage. N: the number of places of artificial bats, which is similar to the size of the population, and here it was 25, equivalent to the length of the statistical period. \({f}_{\mathrm{max}}\) and \({f}_{\mathrm{min}}\): the maximum and minimum frequency limits responsible for determining the part of the best Bat location that should be included in the current bat position. Here, 2 and zero were included, respectively. \({v}_{j}\): is the velocity vector for each bat that serves to modify the bat's current position by adding a value to produce a location that is closer to the best solution. The velocities were initially assumed to be zero and then changed during the algorithm. \({A}_{j}\): loudness rate is a vector of values for all bats, which helps in updating the position of bats, and it was assumed equal to 0.01. \({r}_{j}\): pulse rate, which is a vector for all bats that controls the variation in the Bat algorithm. \({r}_{j}^{0}\): The initial pulse rate for each bat is different in determining the size. In this research, this parameter was considered equal to 0.5. α and γ: two fixed parameters that are between zero and one and equal to 0.5 were considered to be used in updating the loudness rate \({A}_{j}\) and the pulse rate \({r}_{j}\). ε: Bandwidth limits for determining the size of each gradient reduction in different phases with a range between [−1, 1]. This parameter was set here equal to 0.001.
The second step: setting the collective memory of the bat
A set of bats' position vectors is stored in the collective bat Memory, whose number is considered to be N. These vectors are randomly generated as follows:
\({x}_{i}^{j}={LB}_{i}+\left({\mathrm{UB}}_{i}-{\mathrm{LB}}_{i}\right)\times U\left(\mathrm{0,1}\right) ,\forall i=\mathrm{1,2},\dots ,d\) and \(\forall j=\mathrm{1,2},\dots ,N\) and \(U(\mathrm{0,1})\) generates random numbers between 0 and 1.
These values will be stored in BM in ascending order according to the objective function. The best position of the bat \({x}^{\mathrm{Gbest}}\) is maintained with the largest value of the objective function. The BM matrix here is a 25*43 matrix.
The third step: reproduction of the bat population
At this stage, the position of each bat that is stored in BM is regenerated with three operators: increase, variety and selection. In the increment operator, ∀i = 1, 2, …, d and ∀j = 1, 2, …, N, each bat \({x}^{j}\) flies with a speed \({v}^{j}\) generated by a randomly generated frequency \({f}_{j}\) slow. Then, the new position of the bat \({x}^{{\prime} j}\) is generated in the search space as follows:
In the diversity operator, the new position of the bat is generated using the search method around \({x}^{\mathrm{Gbest}}\) with a range of possible pulse rates \({r}_{j}\). Then, the new position of the bat \({x}^{{\prime} j}\) is generated as follows:
\({\widehat{A}}_{j}\) is the average loudness of all bats. To summarize the increment and diversity operators, the new position of the bat can be generated as:
In the selection operator, for each bat stored in BM, the new position of the bat \(x^{{\prime} j}\) is replaced if it is better than its current position \(x^{j}\) or if its loudness is not higher than \(U\left( {0,1} \right) < A_{j}\). Also, the best position of the bat \(x^{{{\text{Gbest}}}}\) is updated under the condition that \(f\left( {x^{{\prime} j} } \right) < f\left( {x^{{{\text{Gbest}}}} } \right)\). When \(x^{{{\text{Gbest}}}}\) changes (updates), the value of pulse rate rj and loudness Aj will also change as:
In fact, \({\text{itr}}\) is the generation number in the current time step. If \({\text{itr}}\) moves to infinity, the average loudness of the bat sound will tend to zero, while the pulse emission rate will increase to its initial value (Yang 2013), which can be expressed as follows:
The fourth step: stopping criterion
In this stage, the third stage is repeated until the set stop criterion is reached. In this research, the stop criterion of maximizing the entropy value of information transfer was considered.
The various stages of the Bat algorithm in order to optimize the entropy function and, as a result, obtain suitable locations for the re-establishment of the station in the scenario, were done by coding in MATLAB software; the results of which are presented in the results section.
Variogram calculation
A variogram is a second-order moment, which is defined as follows:
For the general state, it can be written:
In this regard, the triple integral over the volume is briefly shown, where V is the geometric field of the point x. As mentioned before, half of the variogram value is called semivariogram. Therefore, its value will be equal to γ(h), which is obtained by dividing the above relationship by 2. Since in practice, a limited number of samples are taken from the studied unit, both the variance value and the calculated variogram value are more than the actual variance and variogram value in the studied unit. The estimated variogram has been shown with the symbol 2γ*. In general, the sign * is used to indicate estimated values. Therefore, by using the numerical relation (15), the value of the experimental variogram can be calculated.
In the above relationship, N(h) is the number of pairs of samples used in the calculation for each interval such as h. Therefore, the number of pairs is a function of h. Usually, as h increases, the number of pairs decreases.
Kriging method
The name of this geostatistical estimator was named Kriging in honor of one of the pioneers of geostatistical science named Kriage, who was a South African mining engineer. Kriging method is based on weighted moving average and can be called the best unbiased linear estimator. The general formula of the kriging method, like other estimators, is defined as follows:
where \({Z}^{*}\left({x}_{i}\right)\) is the estimated value of the variable at the desired point, λi is the weight or importance of the i-th sample, n is the number of observations and Z(xi) is the observed value of the variable. The condition of using the above linear kriging is that the investigated variable follows a normal distribution. Otherwise, one should use nonlinear kriging or convert the desired variable to normal by using transformation and then apply linear kriging on them (Chebbi et al. 2017).
Types of kriging
Different kriging methods differ in the way of weighting the points, and they are classified accordingly (Chebbi et al. 2017).
Simple kriging, in addition to the assumption that the mean is independent of the coordinates and there is no trend, the mean value of the variable must be known. Normal kriging, where the mean value is unknown, but it is assumed that the value is independent of coordinates. Global kriging is the best option among geostatistical estimators. In this method, kriging is combined with a first- or second-order polynomial. Variogram can be used to find out the trend. In general, variograms that do not reach a fixed ceiling in the desired range can be a trend property (Chebbi et al. 2017). Kriging maps were used in all three cases mentioned by ArcGIS software to observe the distribution of annual average discharge and entropy of data transmission at the basin level.
Validation of kriging interpolation methods
In geostatistical studies, the correctness of all assumptions and methods must be controlled. Validity control is actually the estimation of each sampled point in an area using the neighboring sample values with interpolation methods. For this purpose, after fitting the model to the variogram and determining the parameters of the model, control the validity of the variogram along with the estimation samples for the variables under investigation using the cross-evaluation method and taking into account two statistical parameters, the mean bias error (MBE) and the residual sum of squares (RMSE) is performed (Hynds et al. 2019).
Rs: estimated value, R0: measured value and n: number of samples, SST: sum of total square root and SSE: sum of error square root.
Entropy of information transfer
In this research, maximization of the entropy equation of information transfer was used as the objective function. If the data follow a normal distribution, instead of using the main formula of information transfer entropy (20), formula (21) can be used (Li et al. 2020).
r in formula (21–2) is the correlation coefficient between two stations.
To calculate the entropy of information transfer for each station, the correlation coefficient matrix was calculated between station i and other stations, and the sum of the entropies of the i-th station and its average was estimated for each station.
The amount of entropy was interpolated for Karkheh basin in order to compare its distribution at the level of the region and to determine which areas have the least entropy of information transfer and need to build or change the location of discharge measurement stations. The amount of entropy is divided into five categories: excellent (< 0.8), good (0.6–0.8), average (0.4–0.6), poor (0.2–0.4) and very poor (0.2–0) was divided.
Considered scenarios
According to the considered assumptions of increasing the entropy of information transfer between stations, two scenarios were defined in this research.
Scenario number one
Assuming the absence of any of the primary stations, using the discharge map and using the Bat algorithm, the objective function, which in this research was to maximize the average entropy of information transfer, was used. By using the Bat algorithm, a series of data were generated according to the criteria of the problem, and based on them, the average amount (average discharge) by averaging from each column of data and introducing it as the average annual discharge and their entropy (each column of data) was calculated and the resulting points are marked on the map. The purpose of this scenario was to estimate the effectiveness of the Bat algorithm in areas without any hydrometric stations.
Scenario number two
According to the existing stations and the transfer entropy map obtained by the kriging method, the proposed stations in the basin were determined. Two criteria were considered for these stations: (a) low entropy level in the area and (b) the place where waterways connect to each other. The purpose of this scenario was to improve the existing stations.
Results and discussion
According to the two scenarios defined in this research and in order to increase the entropy of the hydrometric stations in the Karkheh basin as the main goal, the required data and maps were prepared, the results of which are given below. Is. Since the water measuring stations need to be established on the discharge paths, it is necessary to prepare a map of the waterways. To prepare waterways, it is necessary to prepare a digital-elevation map (DEM) of the area. For this purpose, using Google Earth software, the elevation points of the studied area (Karkheh) were prepared. Then, using ArcGIS software and Arc Hydro extension, a map of waterways was prepared (Fig. 3).

Map of waterways in the Karkheh basin
ArcGIS software processes and prepares the route of the waterways in this way, which first defines the slope map of the basin using certain height points and the direction of the slopes. Then, among several cells, it finds the height that is lower and connects these points continuously. Since the discharge of water moves toward the points with a low height, the course of the waterways is determined. Figure 4, prepared from 22,400 elevation points, collects the points by Google Earth from Karkheh Basin. These data include points from the height of − 2.5 to the height of 3585.8. To prepare the map in Fig. 5, the coordinates of the area were transferred to Google Earth software in a special format so that the target area can be specified in the software. Then, the points were collected. After preparing the points, their height coordinates were obtained using the website gpsvisualizer.com.

Digital-altitude map of the Karkheh watershed

Beta estimation diagram in the specific discharge standardization formula. β = 1
To calculate β, the value of the logarithm of specific discharge values (discharge divided by the area of the corresponding sub-basin) in each station was plotted against the logarithm of the area of the sub-basin of each station for different values of β, and the β that produced the highest \({R}^{2}\) as the best of discharge was chosen. In this research, the value of β for \({R}^{2}\)=0.52 was equal to 1.
To neutralize the effect of area in discharges, their values were calculated for the area of hypothetical basins with a fixed area of 100 square kilometers (Relation 2), which are called standardized discharges. Using standardized discharges and kriging interpolation methods, Karkheh basin was interpolated for the amount of discharge distribution. In this research, three methods of ordinary kriging, simple kriging and global kriging were evaluated, and among them, the chosen method for discharge interpolation, global kriging and the corresponding circular and spherical variogram was obtained, with R2 = 0.63 and RMSE = 0.63. The comparison of these three methods is given in Table 1. The amount of predicted error was calculated for each station. In this way, the difference between the predicted amount and the actual amount of the variable was calculated in each station, which is presented in Table 1 for the chosen method. For each station, the annual average discharges during 25 years were added together and then divided by 25 years, and then, their normality was checked by the Kolmogorov–Smirnov and Anderson–Darling method, and it was determined that the average annual discharges do not have a normal distribution. Then, the logarithm was taken from them and after that their normality was checked again and it was determined that after taking the logarithm, the normality of the data was confirmed.
According to Fig. 6, the value of P-value in the Anderson–Darling test, which is given as an example, is less than 0.05, which indicates that the data are not normal, and the null hypothesis that the data is normal. The hypothesis is rejected at the 0.05 probability level.

The normality test of the average annual discharge of Karkheh basin
According to Fig. 7, the average annual standardized discharges (during 25 years) do not follow the normal distribution. Its P-value is less than 0.05 and the null hypothesis that the data is normal is rejected at the 0.05 level.

The normality test of the average annual standardized discharges of the Karkheh basin
Based on Fig. 8, by taking logarithms from the data of average annual standardized discharge, the data follow the normal distribution with the Anderson–Darling test. Its p value was equal to 0.86, which is higher than 0.05, and the null hypothesis that the data is assumed normal is not rejected at the 0.05 level.

The normality test of the logarithm of the average annual standardized discharges of the Karkheh basin
The discharge map has been prepared using the kriging method with the logarithm of the standardized discharge rates to determine the best-fitting equation and corresponding variogram. Also, the graph of the amount of predicted and measured data was drawn by ArcGIS software. According to Fig. 9, the closer this line is to the first quadrant, the more accurate the parameter estimation is. For this purpose, the coefficient of the linear regression equation produced by this method can be used. In this way, the closer its value is to one, the more appropriate the prediction is for the data. Its equation for the selective kriging method is given below (22).

Chart of measured values versus predicted values
Based on the above equation, the coefficient of the linear regression equation according to the selected variogram was obtained as 0.378. In Fig. 9, the amount of predicted values compared to the measured or observed values is drawn.
By examining the dependence of the average annual discharge values on the altitude, latitude and longitude points, it was found that the discharge data do not have a strong dependence on the spatial values, and the regression coefficient is likely to be low for this reason. In other words, discharge values in Karkheh basin are not significantly dependent on location. Table 2 shows the extent of these dependencies and their significance. The significance of the values in Table 2 shows that the average annual discharge parameter is dependent on the location parameter. By examining this table, it is clear that the discharge values are dependent on the geographical longitude, but its amount is small.
According to the map obtained by kriging, the discharge rate increases from east to west in the central and southeastern parts and decreases in the southwestern and northeastern regions. The value of MBE = − 0.092 was obtained, which shows that the discharge rates are estimated to be slightly less than the actual value. According to Fig. 10 and its increase as the objective function in finding the location of hydrometer stations, it seems that the correlation coefficient between the stations located in the areas the more watery or the rainier it is.

The distribution map of the logarithm of the standardized discharge in the Karkheh basin
According to the map (11), the Bat algorithm resulted in the concentration of stations in the central, western and southern parts of the basin. The map (11) was prepared in such a way that using the Bat algorithm, 25 data were prepared for each station as the average annual discharge. Then, the average of this data was calculated and one number was considered for each station. This work was repeated for all of the stations and after that the logarithm was taken from the obtained data and according to the values obtained for each station and the discharge distribution map in the region, the range of their location was obtained. It is clear from Fig. 11 that according to the results, the stations located on the east side of the basin had the less effect on increasing the entropy of the area.

The map of the existing stations and the stations added by the Bat algorithm
The normality of the discharge data recorded during the 25-year statistical period in all 43 stations was acceptable with the criteria of Kolmogorov–Smirnov and Anderson–Darling. Also, in order to use the formula (23), it is necessary to first prepare the correlation coefficient matrix, which was done by MATLAB software. The results of the new entropies obtained by the Bat algorithm are presented in Table (23).
In Table 3, the amount of entropy of information transmission of existing stations and the entropy obtained for new stations are given, which shows the increase of its amount for each of the stations. According to Table 3, the average amount of entropy increased from 22 to 27.5, which shows a significant increase of 25%. Karami Hosseini et al. (2010) were able to increase the average entropy by 0.35% for the rain gauging stations in Gavkhouni basin with genetic algorithm. It should be noted that the data generated by the Bat algorithm followed the normal distribution with the criteria mentioned above. In order to better show the entropy level of the current stations and comparing it with the entropy level of the proposed Bat stations, in the diagram below, the value of this parameter is drawn in two states.
In Fig. 12, the higher position of the line related to the entropy data obtained from the Bat algorithm compared to the previously recorded data shows the increase in the correlation between hydrometer stations.

Entropy diagram of existing and proposed stations
According to Eq. (3), the reason for the increase in entropy is the increase in the correlation coefficient among the hydrometric stations. In other words, with the target function considered, data were generated by the Bat algorithm that showed more correlation. In the table below, the correlation coefficient before and after applying meta-heuristic algorithm for three stations is given as an example. According to Table 4, it is clear that the correlation coefficient between the stations is high. As a result, it is difficult to find the points that have a higher degree of correlation. The reason why the entropy does not increase much by using the formula (3) can be attributed to this reason.
In the second scenario, it is necessary to prepare a map of entropy distribution in the Karkheh basin area. To prepare the entropy distribution map of information transfer by kriging method, ordinary kriging was chosen and the best-fitting variogram was the Gaussian model. RMSE = 0.11 and R2 = 0.49 were obtained. Also, MBE = 0.0026, which shows that the estimates are slightly higher than their actual values. The below table shows the amount of RMSE, explanation coefficient and selected variogram in all of the three kriging models, among which the method with the lowest RMSE and the highest R2 was selected. By examining and observing the existence of a quadratic trend in entropy data, the better fit of global kriging seems reasonable (Table 5).
To use the kriging method, it is necessary that the data follow the normal distribution. Below is the diagram of normality of the entropy data of hydrometric stations. The normality of the data was checked by Anderson–Darling and Smirnov methods, and its normality was confirmed in both methods at a significant level of 0.05. The P-value greater than 0.15 was obtained in the Kolmogorov–Smirnov method, which indicates the normality of the data (Fig. 13).

The normality of information transfer entropy data measured by the Kolmogorov–Smirnov method
Stations were found to be weak or very weak according to the measured entropy data (their entropy level is less than 0.4); it is necessary to establish a new station around them. Their specifications are given in Table 6.
According to the second scenario that was mentioned above and according to the entropy distribution map at the basin, Fig. 14, the priority of the places for the establishment of new stations was discussed. In such a way that the points that had less entropy were selected as potential points, which is recommended when establishing a new station, to pay attention to the amount of discharge passing through the waterway as well as the grade of the waterways in order to determine the main waterways and the waterways Those with a higher discharge and grade should be prioritized. Other influential factors in the establishment of the stations mentioned above should also be taken into consideration. According to Fig. 15, it is clear that the northeast, northwest and parts of the south of the region have lower entropy than other regions and a new station needs to be established in order to obtain more accurate data, and the reduction of uncertainty can be seen in them. Also, most of the region has medium entropy (0.6–0.4) and the center of the basin has higher entropy than other parts. Considering the high discharge rates in the 2 stations of Sosangerd, Hofel and Shaver and the entropy is less than 0.5 in them, it is suggested to build a new station in those areas. This objective function was formed according to the two conditions of relatively good discharge (waterways with a higher grade) and entropy less than 0.5 (located in the average downward range).

Entropy distribution map of stations based on data recorded using kriging method in Karkheh basin

Map of stations location based on points with entropy less than 0.5 on the entropy map of information transfer
In Tables 7 and 8, the location (longitude and latitude) of the proposed stations in both scenarios is presented. Table 7 shows the data related to the first scenario (stations provided by the Bat algorithm). As it is clear from Table 7, 43 points were proposed by the algorithm, many of them are located in the vicinity of the current stations, so it can be concluded that based on the assumptions of this research, its current location is acceptable and suitable. We should consider only the stations that are completely located in another area. According to the results, about 30% of the existing stations need to be relocated.
According to Table 8, 18 places were selected as potential points, which can be seen in Fig. 15. In choosing the potential points in both scenarios, the errors resulting from the interpolation methods should also be considered.
Conclusions
The checking of discharge data recorded in hydrometric gauging stations showed that in the 25 years of the considered record period, out of 93 established stations, only 73 of them had the relatively complete records, and 43 of them had many missing data such that they have less than 5-year record. The results of the Bat algorithm, which was chosen as an optimization method in this research, and the amount of entropy of information transfer as the objective function, showed that the concentration of hydrometric stations in the central and eastern parts of the basin has a greater impact on the improvement of the average amount of entropy in the whole basin; these results were considered in the form of scenario number one. The average amount of entropy before applying the algorithm was equal to 22, and after applying the algorithm, its value increased to 27.5, which shows a 25% increase, which can be increased compared to the research of Karami Hosseini et al. (2010) with the genetic algorithm. It shows an observation that indicates the efficiency of the algorithm in this research. According to the results of the first scenario assumed in this research, about 30% of the current stations need to be moved so that the amount of received information reaches its maximum value (according to the results of the algorithm). The purpose of the first scenario was to estimate the effectiveness of the Bat algorithm in areas that do not have any hydrometric stations. In the second scenario, by using the information transfer entropy map interpolated by kriging, the areas with a lack of information transfer entropy were detected, and the results showed that the northeast, northwest and parts of the south have a lower entropy than the other places.
References
Boiten W (2000) Hydrometry, 1st edn. London, CRC Press
Chebbi A, Bargaoui ZK, Abid N, da Conceição CM (2017) Optimization of a hydrometric network extension using specific flow, kriging and simulated annealing. J Hydrol 555:971–982
Crambes C, Henchiri Y (2019) Regression imputation in the functional linear model with missing values in the response. J Stat Plan Inference 201:103–119
de Oliveira Simoyama F, Croope S, de Salles Neto LL, Santos LBL (2022) Optimization of rain gauge networks—a systematic literature review. Socio-Economic Planning Sciences, 101469
Eslamian S, Eslamian F (2023) Handbook of hydroinformatics water data management best practices, vol 3. Elsevier, Amsterdam
Guo X, Song L, Fang Y, Zhu L (2019) Model checking for general linear regression with nonignorable missing response. Comput Stat Data Anal 138:1–12
Hynds PD, Nasr AE, O’Dwyer J (2019) Evaluation of hydrometric network efficacy and user requirements in the Republic of Ireland via expert opinion and statistical analysis. J Hydrol 574:851–861
Karami Hosseini A, Bozorg Haddad A, Horfar A, Ebrahimi K (2010) Location of rain gauge stations using entropy. Iran Watershed Sci Eng 4:1–12 (in Persian)
Keum J, Coulibaly P, Razavi T, Tapsoba D, Gobena A, Weber F, Pietroniro A (2018) Application of SNODAS and hydrologic models to enhance entropy-based snow monitoring network design. J Hydrol 561:688–701
Laaha G, Skøien JO, Blöschl G (2014) Spatial prediction on river networks: comparison of top-kriging with regional regression. Hydrol Process 28(2):315–324
Leach JM, Kornelsen KC, Samuel J, Coulibaly P (2015) Hydrometric network design using streamflow signatures and indicators of hydrologic alteration. J Hydrol 529:1350–1359
Li H, Wang D, Singh VP, Wang Y, Wu J, Wu J, Zhang J (2020) Developing a dual entropy-trans information criterion for hydrometric network optimization based on information theory and copulas. Environ Res 180:108813
Masoumi F, Kerachian R (2010) Optimal redesign of groundwater quality monitoring networks: a case study. Environ Monit Assess 4:247–257
Merz R, Blöschl G (2005) Flood frequency regionalisation—spatial proximity vs. catchment attributes. J Hydrol 4:283–306
Mishra AK, Coulibaly P (2009) Developments in hydrometric network design: A review. Rev Geophys 47:RG2001. https://doi.org/10.1029/2007RG000243
Mishra AK, Coulibaly P (2010) Hydrometric network evaluation for Canadian watersheds. J Hydrol 4:420–437
Mohammadi J (1999) Study of the spatial variability of soil salinity in Ramhormoz Area (Khuzestan) using geostatistical theory. Kriging J Water Soil Sci 4:49–64
Sreeparvathy V, Srinivas VV (2020) A fuzzy entropy approach for design of hydrometric monitoring networks. J Hydrol 586:124797
Ursulak J, Coulibaly P (2021) Integration of hydrological models with entropy and multi-objective optimization-based methods for designing specific needs streamflow monitoring networks. J Hydrol 593:125876
Yang XS (2013) Bat algorithm: literature review and applications. Int J Bio-Inspired Comput 5:141–149
Funding
No funding was received.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
Authors do not feel there is any conflict, disclosure of relationships and interests provides a more complete and transparent process, leading to an accurate and objective assessment of the work. Awareness of a real or perceived conflict of interest is a perspective to which the readers are entitled. This is not meant to imply that a financial relationship with an organization. Authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Eslamian, S., Fallah, K.E. & Sabzevari, Y. Evaluation and optimization of hydrometric locations using entropy theory and Bat algorithm (case study: Karkheh Basin, Iran). Appl Water Sci 13, 198 (2023). https://doi.org/10.1007/s13201-023-01992-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13201-023-01992-5