
Abstract
Considering the recent significant drop in the groundwater level (GWL) in most of world regions, the importance of an accurate method to estimate GWL (in order to obtain a better insight into groundwater conditions) has been emphasized by researchers. In this study, artificial neural network (ANN) and support vector regression (SVR) models were initially employed to model the GWL of the Aspas aquifer. Secondly, in order to improve the accuracy of the models, two preprocessing tools, wavelet transform (WT) and complementary ensemble empirical mode decomposition (CEEMD), were combined with former methods which generated four hybrid models including W-ANN, W-SVR, CEEMD-ANN, and CEEMD-SVR. After these methods were implemented, models outcomes were obtained and analyzed. Finally, the results of each model were compared with the unit hydrograph of Aspas aquifer groundwater based on different statistical indexes to assess which modeling technique provides more accurate GWL estimation. The evaluation of the models results indicated that the ANN model outperformed the SVR model. Moreover, it was found that combining these two models with the preprocessing tools WT and CEEMD improved their performances. Coefficient of determination (R2) which indicates model accuracy was increased from 0.927 in the ANN model to 0.938 and 0.998 in the W-ANN and CEEMD-ANN models, respectively. It was also improved from 0.919 in the SVR model to 0.949 and 0.948 in the W-SVR and CEEMD-SVR models, respectively. According to these results, the hybrid CEEMD-ANN model is found to be the most accurate method to predict the GWL in aquifers, especially the Aspas aquifer.
Similar content being viewed by others

Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
Introduction
The population growth, industrial and agricultural development, and occurrence of droughts in recent years have exerted pressure on groundwater in Iran, such that most aquifers have experienced medium to high groundwater level drops. Consequently, many aqueducts have been dried out, and most of permanent springs have experienced remarkable reductions in their water yield. More than 50% of the need for drinking water in Iran is supplied through groundwater. Accordingly, investigating the current condition of groundwater sources can assist managers in terms of more efficient planning and decision-making. The literature review of the field reveals that the most of the studies performed on groundwater have used intelligence models to estimate groundwater level (GWL). Among these intelligence models, the support vector regression (SVR) and artificial neural network (ANN) models have shown to have a good performance. In the following, some of the studies on groundwater using these models are presented.
Sattari et al. (2017) used the SVR and M5 tree models to predict the GWL in Ardabil city plain. Their results showed that both models had satisfactory performances, but the M5 model was easier to implement and interpret. In a review paper, Rajaei et al. (2019) assessed the artificial intelligence models used in groundwater modeling. Mirarabi et al. (2019) investigated SVR and ANN models for the GWL prediction. The outcomes indicated the better performance of the SVR model than the ANN model.
Preprocessing tools such as wavelet transform (WT) and empirical code decomposition (EMD) have received attention in different fields over recent years, such that the combination of these tools with different models has resulted in hybrid models with higher accuracy. The EMD is a thoroughly effective method for extracting signals from data and is used to decompose signals in the time–frequency domain (Huang et al. 2009). The complementary ensemble empirical mode decomposition (CEEMD) method is the completed form of EMD. In this method, a pair of positive and negative white noise is added to the main data to create two series of IMF. Therefore, a combination of the main data and the additional noise is obtained in which the sum of IMFs equals the main signal. Sang et al. (2012) employed the EMD method to analyze nonlinear data in hydrology.
In the following, some of the studies on the use of the two preprocessing tools are discussed.
Adamowski and Chan (2011) applied the wavelet artificial neural network (W-ANN) to predict the GWL in the Quebec Province of Canada. The ANN and autoregressive integrated moving average (ARIMA) models were also used. The results indicated the high capability of the W-ANN compared to the other two models. Moosavi et al. (2014) optimized hybrid models of wavelet transform-adaptive neuro-fuzzy inference system (W-ANFIS) and W-ANN using the Taguchi method to predict the GWL in Mashhad, Iran. In this study, different structures were evaluated for both integrated models. According to the results, the W-ANFIS model had better performance than the W-ANN model. Suryanarayana et al. (2014) used the ANN, SVR, wavelet transform-support vector regression (W-SVR) and ARIMA to forecast monthly fluctuations of the GWL in Visakhapatnam, India. This research used monthly data of precipitation, average temperature, maximum temperature, and groundwater depth for a 13-year period (2001–2012). The results showed that the W-SVR had better performance than other models.
Eskandari et al. (2018) simulated the GWL fluctuations of the Borazjan plain using an integration of the support vector machine (SVM) and WT. The outcomes indicated the better performance of the hybrid model than the SVM model. Eskandari et al. (2019) assessed the combination of the adaptive neuro-fuzzy inference system (ANFIS) and WT in modeling and predicting the GWL of the Dalaki basin in Bushehr Province in Iran. Their results indicated that the use of the WT improved the performance of the ANFIS model by 14%. Salehi et al. (2019) predicted the GWL of Firuzabad plain using the combined model of time series-WT. They reported that the combined model outperformed the time series model.
Bahmani et al. (2020) simulated GWL using GEP and M5 tree models and their combination with WT. According to the results, the combined models had better performance than GEP and M5 models. Moreover, the performance of the two combined models (W-GEP and W-M5) was similar. It was also observed that choosing the proper level of decomposition significantly affected the accuracy of the combined models.
Bahmani and Ouarda (2021) modeled GWL by combining artificial intelligence techniques. They used four observation wells in Delfan plain in Iran. They combined gene expression programming (GEP) and M5 models with WT and CEEMD techniques. The results indicated the better performance of the model combined with GEP.
Awajan et al. (2019) presented a review on empirical mode decomposition in forecasting time series from 1998 to 2017. Wang et al. (2019) provided a wind power short-term forecasting hybrid model based on the CEEMD-SE method in a Chinese wind farm. This method was obtained after integration processing CEEMD, sample entropy (SE), and harmony search (HS) with an extreme learning machine with the kernel (KELM). The results showed the hybrid method (CEEMD-SE-HS-KELM) had higher forecasting accuracy than EMD-SE-HS-KELM, HS-KELM, KELM, and the extreme learning machine (ELM) model.
Niu et al. (2020) provided short-term photovoltaic (PV) power generation forecasting based on random forest feature selection and CEEMD. A hybrid forecasting model was created combining random forest (RF), improved gray ideal value approximation (IGIVA), CEEMD, the particle swarm optimization algorithm based on dynamic inertia factor (DIFPSO), and backpropagation neural network (BPNN), called RF-CEEMD-DIFPSO-BPNN. Results revealed that RF-CEEMD-DIFPSO-BPNN was a promising approach in terms of PV power generation forecasting.
The GWL has considerably dropped in the Tashk–Bakhtegan basin and Maharlu lakes over recent years (Ashraf et al. 2021). The Aspas aquifer is one of the aquifers in the Basin that a high drop in GWL has experienced. The aquifer is located upstream of the basin. Due to the drop in the groundwater level, the effluent rivers have turned into influents rivers. Rivers in Aspas are of the head branches of the Kor River, and their drying or low water causes drying up of the Kor River and Bakhtegan Wetland.
Based on the review of the sources, two artificial intelligence models (ANN and SVR) have performed well. Thus, these models were used to investigate the GWL in the Aspas plain. To increase this models accuracy were used preprocessing tools. Two preprocessing tools WT and CEEMD have had a good performance in different studies, so in this study have been used. After the emergence of four combined models W-ANN, W-SVR, CEEMD-ANN, and CEEMD-SVR, the results were compared with the ANN and SVR models, and the best intelligent model was determined.
The main differences between our study and the latest studies (Bahmani et al. 2020; Bahmani and Quarda 2021) are as follows: (i) in exception to this study, they used minimal local data, usually 3 to 8 observation wells. In this study, we used the aquifer unit hydrograph (extracted from the data of 40 observation wells) and the isohyetal, isothermal and isoevaporation maps that provide a global estimation of the aquifer accurately. (ii) The proposed hybrid approaches increased the accuracy of the intelligent models.
Materials and methods
Study area
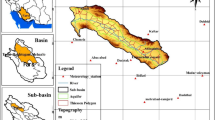
The Tashk–Bakhtegan and Maharlu lakes basin, with an area of 31,451.8 km2, is located in Fars Province in Iran. The basin is divided into two basins, namely Tashk–Bakhtegan and Maharlu, and 27 sub-basins. The Aspas study area with the code 4321 is located in the northwest of the basin. The region has a total area of 1590.5 km2, including the plain (764.9 km2), highlands (816.5 km2), and lake (9.1 km2). The maximum height of the region is 3495 m (the peak of Bar Aftab mountain in the east), while the minimum height is 2061 m (Oujan river in the central plains). The most important city of the region is Sadeh. Figure 1 depicts the location of the study area and the Aspas aquifer in the Tashk–Bakhtegan and Maharlu lakes basin in Fars Province of Iran.

Location of the Aspas aquifer in Iran
Data preparation
According to the data of the Aspas aquifer, 40 observation wells with a better reference period were selected. After introducing the GWL data of the observation wells in the HEC-4 software, the reference period of 2002–2020 was chosen to plot the unit hydrograph. The box plot method was used to assess the outlier data. In case of encountering any outlier data, they were removed and regenerated using the HEC-4 software. Ultimately, the unit hydrograph of the groundwater (water level variations) was plotted in a monthly scale for the Aspas aquifer, as shown in Fig. 2. Table 1 provides the location of the used meteorology stations inside and outside the Aspas aquifer. After evaluating and extending the data using the HEC-4 software and examining the outlier data, the monthly isohyetal maps were plotted for the Aspas study area, using 13 meteorology stations inside and outside it. Afterward, the monthly precipitation values were extracted for the aquifer. According to the maps, the average precipitation on the aquifer in the 19-year reference period (2002–2020) was 427 mm.

Unit Hydrograph of groundwater in the Aspas aquifer
The data of eight meteorology stations inside and outside the Aspas sub-basin were employed to evaluate the temperature of the aquifer. After investigating the data and extending them using the method of differences, the outlier data were examined. The monthly isothermal maps were plotted for the study area. Then, the monthly temperature values were extracted for the Aspas aquifer. The average annual temperature of the Aspas aquifer was obtained 13 °C. The data of eight meteorology stations inside and outside the Aspas study area were employed to evaluate the evaporation of the aquifer. After assessing the data and extending them based on the temperature-evaporation relationship for each station and examining their outlier data, the isoevaporation maps were plotted for the study area. Afterward, the monthly evaporation values were extracted for the aquifer. The average evaporation of the Aspas aquifer was obtained at 2273 mm.
The modeling was performed after determining the monthly data of the GWL, precipitation, temperature, and evaporation. Before using the data, they were standardized (changed to values between zero and one). For this purpose, Eq. 1 was used as recommended by Solgi et al. (2017). The input parameters of the model included precipitation, temperature, evaporation, and the GWL in a given month, and the output parameter was the GWL in the next month. Of the whole data, 75% were used for training, and 25% were used for testing. The input parameters of the model included: precipitation (\({P}_{\mathrm{t}}\)), temperature (\({T}_{\mathrm{t}}\)), evaporation (\({E}_{\mathrm{t}}\)), and groundwater level (\({\mathrm{GWL}}_{\mathrm{t}}\)) at time t and groundwater level at time t + 1 (\({\mathrm{GWL}}_{\mathrm{t}+1}\)).
In Eq. (1), x is the desired data, \(\overline{x }\) is the average data, xmax is the maximum data, xmin is the minimum data, and y is the standardized data.
Figure 3 shows the general flowchart of the work steps. As can be seen in this fig., first are received the data of observation wells and meteorological stations. Then, the data are completed and extended by Hec-4 software. The boxplot method is used to check outlier data. The unit hydrograph of groundwater is drawn. Maps of isohyetal, isotemperature and isoevaporation are drawn in the GIS software. Then, monthly values for the aquifer are extracted from these maps. These values are entered as input data to tools based on data analysis. The main signal is decomposed, and the sub-signals are extracted. The sub-signals of each input parameter are entered as input to artificial intelligence models. After modeling by artificial intelligence models, the results of each model are compared by observed values. If the results are acceptable, the model results are extracted, otherwise, the models are run again to improve the results by changing the effective factors in the modeling. In the end, the results of all models are compared based on evaluation criteria and the best model is selected.

Flowchart of work steps in this study
Artificial intelligence models
According to the evaluations of the intelligence models, two of them that had good performance in previous studies, i.e., ANN and SVR, were used. Afterward, two preprocessing tools, namely the WT and CEEMD, were employed to enhance the performance of the models.
ANN model
The following are effective in modeling artificial neural networks (ANNs) (Solgi 2014):
-
1.
Sufficient training,
-
2.
Number of layers in a network,
-
3.
Number of neurons of the middle layers,
-
4.
Training laws,
-
5.
Simulation functions (transmission)
An important criterion in training a network is the number of iterations (epochs) or repetitions the network experiences while training. In training a network, determining the proper number of iterations is of great importance. In general, the more the number of iterations in training a network, the smaller the simulation (prediction) error. However, when the number of iterations exceeds a given value, the testing group error increases. The best number of iterations minimizes the errors in both training and testing groups.
The number of layers in a network is among the main criteria in designing ANNs. These networks are usually comprised of several layers. These layers include an input layer, middle layers, and an output layer. The number of the middle layers is determined by trial and error. In general, it is recommended to use ANNs with lower middle layers.
In ANNs, the number of neurons of the input and output layers is a function of the type of problem. However, there is no particular relationship for the number of neurons in the middle layers, and these neurons are determined based on trial and error for each middle layer.
The internal mode of a neuron caused by the activation function is known as the activity level or action. Generally, each neuron sends its activity level to one or more of the other neurons in the form of a single signal. The activation functions of a layer's neurons are typically, but not essentially, the same. Moreover, these activation functions are nonlinear for the neurons of the hidden layer while being identity functions for the input layer's neurons. Using a reaction function, a neuron produces outputs for various inputs. Linear and sigmoid functions are two well-known functions (Karamuz and Araghinezhad 2010). An activation function is chosen based on the specific need of a problem that should be solved by the ANN. In practice, a limited number of activation functions is used, as listed in Fig. 4 (Alborzi 2001).

A number of activation functions used in the ANN (Alborzi 2001)
The network architecture in solving a problem refers to choosing the proper number of layers, the number of neurons in each layer, the way connections are made between neurons, and the proper activation functions for neurons, along with determining the training algorithm and the way the weights are adjusted.
Another major parameter of an ANN is the training function. Table 2 lists the training functions used in the current study.
SVR model
In this case, the kernel functions are used. In this study, four common kernels as the following were used:
\(k\left(x,y\right)={(x.y+1)}^{d}\) d = 2, 3, …
These kernels are the polynomial (Poly) kernel, RBF kernel, Sigmoid kernel, and linear (Lin) kernel, respectively (Raghavendra and Deka 2014). The RBF kernel has one parameter g (Gamma). In the sigmoidal kernel, just the default values, including zero and 1/k Gamma, are used. The linear kernel does not have any parameters. The polynomial kernel has two parameters d (the degree of the polynomial) and r (an accumulative fixed number). For more information on this topic, see references (Cortes and Vapni 1995; Raghavendra and Deka 2014). As listed in Table 3, six combinations of architecture were considered to run the ANN and SVR models.
Preprocessing tools
In this study, used two tools includes the WT and CEEMD.
Wavelet transform (WT)
Wavelet transform (WT) is one of the efficient mathematical transformations in the field of signal processing. Wavelets are mathematical functions that provide a time-scale form of time series and their relationships for analyzing time series that include variables and non-constants. The wavelet function is one that has two important properties of oscillation and being short-term. The wavelet coefficients can be calculated at any point of the signal (b) and for any value of the scale (a) in the following equation (Nourani et al. 2009).
In Eq. (3), \(\psi\) is the mother wavelet function, a is scales and b translates the function. For different values of a b, the value of T is obtained.
Because the effect of time series data is differentiated before entering different models and the initial signal is decomposed into several sub-signals, it is possible to use an analysis that includes short-term and long-term effects, which in turn optimizes the model in future evaluations and estimates.
For more information on this topic, see references (Mallat 1998; Foufoula-Georgiou & Kumar 1994).
CEEMD method
The empirical mode decomposition (EMD) is a method for decomposing different signals in a process called screening. During this process, the main signal is decomposed into a number of components with different frequency contents. According to Eq. 4, the EMD method decomposes the main signal x(n) to a number of intrinsic mode functions (IMFs) (Amirat et al. 2018).
In Eq. 4, \({r}_{n}(x)\) is the remaining component after n IMFs and \({c}_{i}\left(x\right)\). C(x) is the wave-shape (harmonic) function extracted from the main signal, which does not have the conditions of the IMF. Data can have several IMFs at a time. These fluctuating modes are called intrinsic mode functions and have the two following conditions: 1. in all data, the number of extremum points equals the number of zero points or, at most, is different by a unit. 2. At each point, the average of the envelopes fitted to local maximum and minimum points should be zero.
Given the presence of alternation and noise in the signals, in some cases, the frequency-time domain distribution is interrupted, and the EMD performance is disturbed due to the difference in the modes. In order to solve this problem, Wu and Huang (2004) proposed a different method called ensemble empirical mode decomposition (EEMD). In the decomposition procedure of EEMD, a limited volume of white noise enters the main signal. By using the positive statistical aspects of the white noise, which is uniformly distributed in the frequency domain, the effect of the alternating noise is removed from the decomposition process. In the CEEMD method, a pair of positive and negative white noise is added to the main data to create two series of IMF. Therefore, a combination of the main data and the additional noise is obtained in which the sum of IMFs equals the main signal.
Combining models with the WT method
This section discusses the formation of hybrid models obtained from the combination of WT with the ANN and SVR intelligence models. When an initial signal is decomposed using the WT method, and the resulting sub-signals are used as inputs to the ANN and SVR intelligence models, the hybrid models of W-ANN and W-SVR are obtained. As shown in Fig. 4, at first, the signals of the input parameters of precipitation, temperature, evaporation, and the GWL are decomposed using the WT. Then, the obtained sub-signals are introduced as inputs in the ANN and SVR models to create W-ANN and W-SVR hybrid models. Figure 5 depicts the \(\mathrm{Pa}\left(\mathrm{t}\right),\mathrm{ Ta}\left(\mathrm{t}\right),\mathrm{ GWLa}\left(\mathrm{t}\right)\,\mathrm{ and Ea}\,(\mathrm{t})\) sub-signals of the overall scale (approximate) in the last level and other sub-signals of the detailed scale (detail) from level one to the last level.

Schematic diagram of the W-ANN and W-SVR models
Combining models with the CEEMD method
This section describes the creation of hybrid models obtained from the combination of CEEMD with the ANN and SVR intelligence models. When an initial signal is decomposed using the CEEMD method, and its sub-signals are used as inputs to the ANN and SVR intelligence models, the hybrid models of CEEMD-ANN and CEEMD-SVR are obtained. As shown in Fig. 5, at first, the signals of the input parameters of precipitation, temperature, evaporation, and the GWL are decomposed using the CEEMD. Then, the obtained sub-signals are introduced as inputs in the ANN and SVR models to create CEEMD-ANN and CEEMD-SVR hybrid models. Figure 6 depicts the \(\mathrm{Pimf}\left(\mathrm{t}\right),\mathrm{ Timf}\left(\mathrm{t}\right),\mathrm{ GWLimf}\left(\mathrm{t}\right)\,\mathrm{ and Eimf}\,(\mathrm{t})\) sub-signals of the overall scale (IMF) in the last level and other sub-signals of the residuals from level one to the last level.

Schematic diagram of the CEEMD-ANN and CEEMD-SVR models
The CEEMD method has two parameters, i.e., the maximum number of IMFs and £. It can be said that the number of IMFs is the level of decomposition in the WT method. In this study, the values of 0.1, 0.2, and 0.3 were used for £. Some studies have used 0.2 for this parameter. Moreover, according to the structure of the study, the number of IMFs was one to six. Accordingly, the hybrid models were used in different modes by combining six IMFs and three £ values.
Evaluation criteria
In the performance assessment of models, different qualitative and quantitative parameters should be evaluated to clearly observe the effectiveness of each input parameter on the results. Accordingly, the following parameters were used to examine the efficiency of the methods (Solgi et al. 2017; Bahmani et al. 2020).
In equations above, the parameters include:
n: number of data, i counter variable, \({{G}_{i}}_{\mathrm{obs}}\): observational data, \(\overline{{{\mathrm{G} }_{i}}_{\mathrm{obs}}}\): average of the observational data, \({{G}_{i}}_{\mathrm{pre}}\): computational data, \(\overline{{{G }_{i}}_{\mathrm{pre}}}\): average predicted data, m: number of the parameters of the model and \(Npar\): number of the trained data.
The coefficient of determination (\({R}^{2}\)) determines the agreement between the data created by the model and the real data. The values closer to one indicate better agreement and lower error. Therefore, this parameter was used to evaluate the effectiveness of each parameter, such as the type of the wavelet function, number of middle neurons, and decomposition degree of wavelet in the performance of all models. Moreover, the parameter of \(\mathrm{RMSE}\) is the root mean square error of the computational and observational data. It is clear that lower values of this parameter indicate the better training and simulation of the data. Regarding the Akaike information criterion (AIC), it can be said that lower Akaike coefficients reveal the better performance of the models. The low value of the Akaike coefficient is caused by two factors, i.e., the error of the model and the number of parameters. Therefore, it is a good criterion to evaluate models.
Results and discussion
This section provides the results of the intelligence models executed for the GWL estimation using the data obtained from the plotted isohyetal, isothermal, and isoevaporation maps and the unit hydrograph of the groundwater. Afterward, the preprocessing methods were used, and the obtained hybrid models and their results were provided. Eventually, the results of the models were compared based on the statistical criteria.
Artificial intelligence models
Results of the ANN model
The ANN was modeled by coding in the MATLAB software and using all effective parameters previously mentioned. For this purpose, different structures were evaluated in each combination. Table 4 provides the results of the best structure in each combination. As can be seen in the table, combination No. 6 with eight input parameters and three neurons in the middle layer had the best performance. Its coefficient of determination was 0.927, and its error was 0.0158. In this prior combination, the training law of trainlm and stimulation (transmission) function of tansig had the best performance compared to other training laws and transmission functions. The performance of this model can be compared with the observational values in Fig. 7. As can be seen, the ANN model had better performance in minimum points compared to the peak points.

Comparison of the ANN model with observed data
Results of the SVR model
The SVR was modeled by coding in the MATLAB software and using all effective parameters previously mentioned. For this purpose, different structures were evaluated in each combination. Table 5 provides the results of the best structure in each combination. As can be seen in the table, combinations 5 and 6 had the same coefficient of determination, but given its lower error, combination No. 6 was known as the superior combination. The coefficient of determination and error of this combination were 0.918 and 0.0168, respectively. In this superior combination, the line kernel had the best performance among all kernels. The performance of this model can be compared with the observational values in Fig. 8. As can be seen in the figure, the estimations of the SVR model in the maximum and minimum points were different from the observational values.

Comparison of the SVR model with observed data
Results of the W-ANN model
According to Nourani et al. (2009), Eq. 8 can be used as an initial estimation in determining the decomposition level in the WT method on a monthly time scale. In this equation, L denotes the decomposition level, and N is the number of data. Given the number of data in this study, which was 216, L was calculated at two. In order to improve the accuracy, the decomposition levels were considered from one to four. For this purpose, the WT method was coded in MATLAB software.
In order to execute the W-ANN model, the sub-signals obtained from the execution of the WT in different decomposition levels were introduced as inputs to the ANN model. To this end, the W-ANN model was studied in different decomposition levels with various wavelet functions in different structures, whose results are listed in Table 6. According to the table, wavelet function Sym3 in decomposition level 1 had the best performance. This superior combination had eight input neurons with four hidden layers with the training law of trainbr and the stimulation function of purelin. In this combination, RMSE = 0.0149 and R2 = 0.938, which indicated its better performance than other combinations. The performance of this model can be compared with the observational values in Fig. 9. As can be seen in the figure, the W-ANN model did not have proper performance in the peak points.

Comparison of the W-ANN model with observed data
Results of the W-SVR model
In order to execute the W-SVR model, the sub-signals obtained from the execution of the WT in different decomposition levels were introduced as inputs to the ANN model. To this end, the W-SVR model was studied in different decomposition levels with various wavelet functions in different structures, whose results are listed in Table 7. According to the table, wavelet function Coif1 in decomposition level 2 had the best performance. This superior combination had an RBF kernel. In this combination, RMSE = 0.0164 and R2 = 0.949, which indicated its better performance than other combinations. The performance of this model can be compared with the observational values in Fig. 10. As can be seen in the figure, the W-SVR model did not have proper performance in the minimum and maximum points.

Comparison of the W-SVR model with observed data
Results of the CEEMD-ANN model
The R software was employed to execute the CEEMD method. At first, the "hht" package was installed on the R software. Then, sub-signals were extracted using the CEEMD method through coding in the R software environment. The program was executed for the maximum IMF number of 10. The results showed that the maximum number of sub-signals could be six. Thus, the code of the program was executed for the IMF numbers of one to six. Afterward, the obtained sub-signals were introduced as inputs to the ANN model. The results of the evaluation are given in Table 8. According to the table, the best performance in the IMF equaled one, and the value of \(\varepsilon\) was obtained 0.2. In this superior structure, the training law of trainbr and transmission function of tansig were the best. This structure had an R2 of 0.98 and an RMSE of 0.0035. The performance of this model can be compared with the observational values in Fig. 11. As can be seen in the figure, the CEEMD-ANN model had a suitable performance in almost all points, and its estimates were close to the observational values.

Comparison of the CEEMD-ANN model with observed data
Results of the CEEMD-SVR model
The program was executed for the IMF numbers of one to six. Then, the resulting sub-signals were introduced as inputs to the SVR model to obtain the CEEMD-SVR hybrid model. Table 9 lists the results of using this hybrid model. According to the table, the best performance in the IMF equaled two, and the value of \(\varepsilon\) was obtained 0.1. Kernel Lin had the best performance. The values of R2 and RMSE were equal to 0.95 and 0.0155, respectively. The performance of this model can be compared with the observational values in Fig. 12. As can be seen in the figure, the CEEMD-SVR hybrid model did not have proper performance in the peak points.

Comparison of the CEEMD-SVR model with observed data
Comparison of the results of the models
This section compares the results obtained from the execution of different models in different modes. According to the reference period used for the data of the testing step, the different methods were compared in the years 2016 to 2020. As can be seen in Table 10, the use of preprocessing tools improved the performance of the ANN and SVR models, such that using the WT resulted in an improvement of 1.10% in the ANN model and 3.07% in the SVR model. Furthermore, the use of the CEEMD model resulted in improvements by 7.08% and 2.89% in the ANN and SVR models, respectively. A comparison of the results reveals that the hybrid CEEMD-ANN model with a coefficient of determination of 0.99 and an error of 0.0035 had the best performance. This model had an Akaike coefficient of 85.5, which was lower than other models. Figure 13 compares the different models in the testing period based on the unit hydrographs of the aquifer. As can be seen, the hybrid models had a better performance, among which the hybrid CEEMD-ANN model was closer to the observational values. Therefore, this model can be used in forecasting the GWL of the Aspas aquifer.

Comparison of the models used-step of test
The results of this study are consistent with the results of Bahmani et al. 2020; Bahmani and Ouarda 2021, based on the better performance of models combined with WT and CEEMD. It is also consistent with the results of Adamowski and Chan (2011) and Solgi et al (2017) who stated that the model combined with the artificial neural network had the best performance.
Due to the fact that preprocessing tools divide initial signals into several sub-signals and these sub-signals are included in the models, this preprocessing of the data causes the execution time of the models to be reduced and the performance to be increased. So, in the artificial neural network model, it usually reduces the number of layers and neurons, and in fewer repetitions, it achieves better results, and in the SVR model, it also shortens the execution time of the program. On the other hand, the use of the standardization formula is another effective parameter in improving the result, which was used in all simple and combined models in this study.
Selecting a suitable decomposition level affects the accuracy of hybrid models. A high level of decomposition is not always helpful to increase the accuracy of the model and an optimal decomposition level must also be identified.
The results of CEEMD-based models illustrate the importance of ε for modeling and its impact on the accuracy of the hybrid models. No specified rule for ε determination has been presented and selecting ε depends on the features of a time series such as mean and extreme values. Therefore, it is recommended to find an optimal value for ε, for a given specific hydrological time series.
Conclusions
The aim of this paper was to identify the most reliable modeling technique in prediction of GWL monthly drop through comparison of models outcomes with observed GWL in existing wells. Two intelligent modeling techniques, ANN and SVR, were combined with two preprocessing tools WT and CEEMD resulting in four hybrid models. These hybrid methods were utilized to predict the GWL variations in the Aspas alluvial aquifer located in Tashk–-Bakhtegan and Maharlu lakes basin. Model input data included precipitation, temperature, evaporation, and GWL of past months which were standardized before being used in the models. After model training process and during model testing phase, all models were implemented for the reference period 2016–2020 for which real GWL was available from existing observation wells. This allows to assess which model provides the closest fit to the real observed data. The performance of each modeling technique was evaluated by three main criteria including R2, RMSE, and AIC. The results indicated that the hybrid models outperformed the intelligence models of ANN and SVR due to decomposed and de-noised input data. Among hybrid models, CEEMD-ANN was found to be the most accurate one with 7.08% performance improvements as compared to ANN model. Therefore, it is recommended to use this hybrid model (CEEMD-ANN) in forecasting the GWL variations in the Aspas aquifer according to findings of this paper.
There are a number of limitations in this research which can be pursued and further developed in future studies. Firstly, the proposed models used existing observation wells data as input data which is not usually available for recent months and might revert back up to a year ago. This undermined the need and importance of up-to-date data for purposes of water resource planning and management. To remediate this issue, the authors recommend utilizing GRACE satellite data and precipitation, temperature and evaporation satellite data as input data for intelligent models which are usually available for recent months and even days. Secondly, additional intelligent models such as Random Forest can be implemented in future studies to assess whether they provide more accuracy in GWL prediction.
Abbreviations
- GWL:
-
Groundwater level
- SVR:
-
Support vector regression
- ANN:
-
Artificial neural network
- WT:
-
Wavelet Transform
- EMD:
-
Empirical mode decomposition
- CEEMD:
-
Complementary ensemble empirical mode decomposition
- W-ANN:
-
Wavelet artificial neural network
- ARIMA:
-
Autoregressive integrated moving average
- W-ANFIS:
-
Wavelet transform-adaptive neuro-fuzzy inference system
- W-SVR:
-
Wavelet transform-support vector regression
- ANFIS:
-
Adaptive neuro-fuzzy inference system
- SVM:
-
Support vector machine
- GEP:
-
Gene expression programming
- W-GEP:
-
Wavelet transform-gene expression programming
- W-M5:
-
Wavelet transform-M5
- SE:
-
Sample entropy
- HS:
-
Harmony search
- KELM:
-
Extreme learning machine with the kernel
- ELM:
-
Extreme learning machine
- PV:
-
Photovoltaic
- RF:
-
Random forest
- IGIVA:
-
Improved gray ideal value approximation
- DIFPSO:
-
The particle swarm optimization algorithm based on dynamic inertia factor
- BPNN:
-
Backpropagation neural network
- Trainlm:
-
Levenberg–Marquardt
- Trainbfg:
-
BFGS quasi-newton
- Trainrp:
-
Resilient backpropagation
- Trainscg:
-
Scaled conjugate gradient
- Trainsgb:
-
Conjugate gradient with Powell/Beale restarts
- Traincgf:
-
Fletcher–Powell conjugate gradient
- Traincgp:
-
Polak–Ribiére conjugate gradient
- Trainoss:
-
One step secant
- Traingdx:
-
Variable learning rate gradient descent
- Trainbr:
-
Bayesian regularization
- Traingdm:
-
Gradient descent with momentum
- Traingd:
-
Gradient descent
- IMF:
-
Intrinsic mode function
- EEMD:
-
Ensemble empirical mode decomposition
- R 2 :
-
Coefficient of determination
- RMSE:
-
Root mean squared error
- AIC:
-
Akaike information criterion
- Poly:
-
Polynomial
- Lin:
-
Linear
References
Adamowski J, Chan FH (2011) A wavelet neural network conjunction model for groundwater level forecasting. J Hydrol 407(1–4):28–40. https://doi.org/10.1016/j.jhydrol.2011.06.013
Alborzi M (2001) Introduction to neural networks. Scientific Publishing Institute of Industrial University Sharif, Tehran ((Persian))
Amirat Y, Benbouzidb M, Wang T, Bacha K, Feld G (2018) EEMD-based notch filter for induction machine bearing faults detection. Appl Acoust 133:202–209. https://doi.org/10.1016/j.apacoust.2017.12.030
Ashraf S, Nazemi A, AghaKouchak A (2021) Anthropogenic drought dominates groundwater depletion in Iran. Sci Rep 11(9135):1–10. https://doi.org/10.1038/s41598-021-88522-y
Awajan AM (2019) A review on empirical mode decomposition in forecasting time series. Italian J Pure Appl Math 42:301–323
Bahmani R, Ouarda TBMJ (2021) Groundwater level modeling with hybrid artificial intelligence techniques. J Hydrol 595:1–12. https://doi.org/10.1016/j.jhydrol.2020.125659
Bahmani R, Solgi A, Ouarda TBMJ (2020) Groundwater level simulation using gene expression programming and M5 model tree combined with wavelet transform. Hydrol Sci J 65(8):1430–1442. https://doi.org/10.1080/02626667.2020.1749762
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20:273–295
Eskandari A, Solgi A, Zarei H (2018) Simulating fluctuations of groundwater level using a combination of support vector machine and wavelet transform. J Irri Sci Eng 41(1):165–180 ((Persian))
Eskandari A, Faramarzyan yasuj F, Solgi A, Zarei H (2019) Evaluation of combined ANFIS with wavelet transform to modeling and forecasting groundwater level. J Water Manag Res 9(18):56–69 ((Persian))
Foufoula-Georgiou E, Kumar P (1994) Wavelet in geophysics: an introduction. Academic Press, San Diego New. https://doi.org/10.1016/B978-0-08-052087-2.50007-4
Huang Y, Schmitt FG, Lu Z, Liu Y (2009) Analysis of daily river flow fluctuations using empirical mode decomposition and arbitrary order Hilbert spectral analysis. J Hydrol 373(1–2):103–111. https://doi.org/10.1016/j.jhydrol.2009.04.015
Karamooz M, Araghi Nejad SH (2010) Advanced hydrology, 2nd edn. Amirkabir University of Technology Press, Tehran, p 464 ((Persian))
Mallat S (1998) A wavelet tour of signal processing. Academic Press is an imprint of Elsevier, San Diego
Mirarabi A, Nassery HR, Nakhaei M, Adamowski J, Akbarzadeh AH, Alijani F (2019) Evaluation of data-driven models (SVR and ANN) for groundwater-level prediction in confined and unconfined systems. Environ Earth Sci 78(15):478–489. https://doi.org/10.1007/s12665-019-8474-y
Moosavi V, Vafakhah M, Shirmohammadi B, Ranjbar M (2014) Optimization of wavelet-ANFIS and wavelet-ANN hybrid models by taguchi method for groundwater level forecasting. Arabian J Sci Eng 39(3):1785–1796. https://doi.org/10.1007/s13369-013-0762-3
Niu D, Wanga K, Sun L, Wua J, Xu X (2020) Short-term photovoltaic power generation forecasting based on random forest feature selection and CEEMD: a case study. Appl Soft Comput 93:1–14. https://doi.org/10.1016/j.asoc.2020.106389
Nourani V, Komasi M, Mano A (2009) A multivariate ANN-wavelet approach for rainfall–runoff modeling. Water Res Manag 23:2877–2894. https://doi.org/10.1007/s11269-009-9414-5
Raghavendra NS, Deka PC (2014) Support vector machine applications in the field of hydrology: a review. Appl Soft Comput 19:372–386. https://doi.org/10.1016/j.asoc.2014.02.002
Rajaei T, Ebrahimi H, Nourani V (2019) A review of the artificial intelligence methods in groundwater level modeling. J Hydrol 572:336–351. https://doi.org/10.1016/j.jhydrol.2018.12.037
Salehi SM, Radmanesh F, Zarei H, Mansouri B, Solgi A (2019) A combined time series-wavelet model for prediction of groundwater level (case study:firuzabad plain). J Irri Sci Eng 41(4):1–16. https://doi.org/10.22055/JISE.2018.14057. ((Persian))
Sang YF, Wang Z, Liu C (2012) Period identification in hydrologic time series using empirical mode decomposition and maximum entropy spectral analysis. J Hydrol 424–425:154–164. https://doi.org/10.1016/j.jhydrol.2011.12.044
Sattari MT, Mirabbasi R, Shamsi Sushab R, Abraham J (2017) Prediction of groundwater level in ardebil plain using support vector regression and M5 tree model. Nat’l Groundwater Assoc 56(4):636–646. https://doi.org/10.1111/gwat.12620
Solgi A, Zarei H, Nourani V, Bahmani R (2017) A new approach to flow simulation using hybrid models. Appl Water Sci 7:3691–3706. https://doi.org/10.1007/s13201-016-0515-z
Solgi A (2014) Stream flow forecasting using combined neural network wavelet model and comparsion with adaptive neuro fuzzy inference system and artificial neural network methods (case study: Gamasyab river, Nahavand). M.Sc. Thesis, Department of Hydrology and Water Resource, Shahid Chamran University of Ahvaz
Suryanarayana CH, Sudheer CH, Mahammood V, Panigrahi BK (2014) An integrated wavelet-support vector machine for groundwater level prediction in Visakhapatnam. India Neurocomputing 145:324–335. https://doi.org/10.1016/j.neucom.2014.05.026
Wang K, Niu D, Sun L, Zhen H, Liu J, De G, Xu X (2019) Wind power short-term forecasting hybrid model based on CEEMD-SE method. Processes 7(11):843. https://doi.org/10.3390/pr7110843
Wu Z, Huang NF (2004) A study of the characteristics of white noise using the empirical mode decomposition method. Proc R.S Lond 460A:1597–1611. https://doi.org/10.1098/rspa.2003.1221
Acknowledgements
The authors are grateful to the Research Council of the Shahid Chamran University of Ahvaz for financial support. Also great thanks to the Regional Water Company of Fars and Iran Water Resources Management Company for sharing the required data.
Funding
The authors received funding from Shahid Chamran University of Ahvaz (GN: SCU.WH99.589).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing personal relationships that could have appeared to influence the work reported in this paper
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shahbazi, M., Zarei, H. & Solgi, A. De-noising groundwater level modeling using data decomposition techniques in combination with artificial intelligence (case study Aspas aquifer). Appl Water Sci 13, 88 (2023). https://doi.org/10.1007/s13201-023-01885-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13201-023-01885-7