
Abstract
The existence of reliable rain-gauge networks is a necessity in managing water sources and the relevant environmental issues in any basin. The present study aimed to investigate the rain-gauge network and rank the rain-gauge stations in the Tazehkand sub-basin in the southwest of Lake Urmia, Iran, using the entropy–copula approach using the data obtained from six rain-gauge stations in the Siminehrood basin in Northwestern Iran between 1981 and 2019. The interaction effects of the stations were investigated using the copula simulation approach instead of the multivariate regression analysis. The R-vine was selected as the most convenient copula after investigating various vines using the statistics related to error investigation. Then, the interaction effects of the stations were investigated using the R-vine. The rainfall in each station was estimated by considering the rainfall of other stations. Moreover, the more prevalent multivariate regression analysis was implemented, and its results were compared with the results obtained from the vine simulation approach. The results of the comparison according to the NSE statistic showed that the vine simulation approach was above 90% across all stations. The estimates for the ITI and N(i) indices of each station using the entropy theory showed the shortage of stations in the investigated area. The stations were in average, above-average, and surplus modes according to the ITI index. The rating concerning the N(i) index indicated that the Dashband station was the most appropriate one in terms of communicating with other stations and conveniently covering the plain.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Over the past few years, the damages of natural disasters have soared due to the increase in the frequency of severe climatic issues resulting from climate change across the globe. Natural disasters related to drought, rain, and flood are among the most significant causes of social and economic issues (Lee et al. 2017). The damages related to rain and flood could be prevented by analyzing hydrological data. Recording the observed data of hydrological phenomena and creating time series about them is useful in the establishment of a preliminary understanding concerning the management of rainfall and the prediction of future occurrences (Shah et al. 2020). The assumption that increasing the number of rain-gauge stations can reduce the error and increase the accuracy of illustrating the reality is almost justified. Nevertheless, increasing the number of stations is constrained by factors like—among others—cost and regional conditions, and the optimal placement of a minimum number of stations can produce highly reliable observational data (Kwon et al. 2020; Fanny et al. 2013). While design goals are among the main challenges in developing optimal networks, the information theory has made it possible to deal with such problems and consider the goals of network design by offering various indicators (Keum et al. 2017).
The entropy technique as a modern method of assessing the performance of rain-gauge networks has attracted a lot of attention for the latter purpose (Zhang and Singh 2015; Nazeri Tahroudi et al. 2019). The theory of entropy investigates the information provided by the existing stations and makes it possible to remove the surplus stations and add the ones required in other areas by taking a statistical-probabilistic stance concerning the stations that exist in the network, their recorded information, and the communication between the existing stations (Karimi Googhari and Khalifeh 2013). The technique did not attract a lot of attention until the first half of the twentieth century due to its conceptual and calculation challenges. However, Shanon (1948) conducted extensive studies on the implementation of the theory and introduced some unknown concepts related to it (Valipoor et al. 2020). Moreover, a lot of studies have been conducted in the field of assessing and designing monitoring systems for water resources according to the entropy theory. Chen et al. (2008) proposed a composite method consisting of geo-statistics and entropy to determine the optimal number and distribution of rain-gauge stations in the north of Taiwan. They implemented the Kriging method to interpolate the rates of rainfall observed in the new locations of the rain-gauges and the entropy method to find a sufficient number of rain-gauges so that they can represent monthly rainfall. Moreover, they ranked the stations in terms of importance by calculating the entropy of information transmission and the shared entropy. Keum et al. (2017) made a brief investigation on the entropy terms implemented in the design of water monitoring systems. Then, they classified the recent applications of entropy into four groups (including precipitation, streamflow and water level, water quality, and soil moisture and groundwater networks) and investigated them. Joo et al. (2019) investigated and redesigned a hydrometric station by implementing two objective functions (i.e., changes in entropy information and the importance of each station according to their priority) using the Euclidean distance. They showed that 8 stations can be implemented instead of 12 ones so that the combination of the selected stations could reflect both the changes of entropy information and the importance of each station. Recent hydrological studies have combined the entropy and copula, and an extended introduction to this can be found in Hao and Singh (2013) where two main ways of combining the two concepts have been discussed. A simple way is to combine the entropy and copula to extract the copula distribution function based on the Principle of Maximum Entropy (POME) or the Minimum Cross-entropy (Kong et al. 2015; Liu et al. 2017), while another way is to estimate mutual information using the copula function (Xu et al. 2018). Moreover, entropy-based multipurpose criteria have been developed to evaluate and optimize hydrometric networks, and the copula functions have been usually implemented in analyzing the hydrological frequency for modeling multivariate dependence structures (Li et al. 2019). Li et al. (2019) used the copula theory to develop an entropy for the optimization of the hydrometric network of Taihu basin in China. They found that the DETC can effectively rank stations according to their importance and combine the decision-making priorities concerning the information content and redundancy. They developed a Dual Entropy–Transinformation Criterion (DETC) to detect and prioritize the most important stations and optimize the nominated network. The best models were selected out of the three Archimedean copula functions (i.e., Gamble, Frank, and Clayton). The DETC was evaluated by the DEMO criterion and was compared with the Minimum Transinformation (MinT) index to optimize the network. The results showed that the DETC can effectively rank the stations according to their importance and combine the decision-making priorities concerning the information content and data redundancy. Kwon et al. (2020) compared the conditional and joint entropy techniques to optimize the rain-gauge networks in Daegu and Gyeongbuk in South Korea and compared the results using the RMSE criterion. They found that the conditional entropy was more convenient than the joint entropy technique. Moreover, they showed that the rain-gauge stations were more predisposed to environmental rain-gauges. First, the stations were selected, and the central stations were added later. The efficient management of river basins requires that sufficient data related to rainfall are recorded so that the necessary managerial arrangements can be implemented after modeling and prediction. The quality of the data may be reduced due to irrelevant, insufficient, and inefficient data obtained from inconvenient locations, and this can influence the accuracy of the estimates. Thus, it is not acceptable that more data can better illustrate realities and overcome the limitations and problems that arise from data insufficiency. On the other hand, the lack of standard procedures to design optimal rain-gauge stations, the costs of adding new stations, and regional constraints limit the achievement of the intended goals. Thus, rating the existing stations, finding a convenient location for each station, and determining a sufficient number of stations to establish a network of rain-gauge monitoring are necessary to attain the goals of water resource management at the level of basins. While similar studies have implemented the multivariate regression analysis to investigate the interaction effects of the sites, the present study considered the statistical distribution of the data and the copula-based simulation to investigate the interaction effects.
Materials and methods
The investigated area
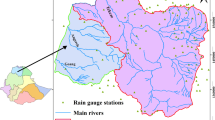
Tazehkand sub-basin is among the sub-basins of Siminehrood River around Lake Urmia in Northwestern Iran. Siminehrood is 200 km long, and its basin covered by the Tazehkand station is almost 3173km2. Its discharge is 9.67 l/s. Figure 1 illustrates the locations of the investigated rain-gauge stations in Tazehkand sub-basin. The present study implemented the annual rainfall data obtained from the rain-gauge stations in Tazehkand sub-basin the southwest of Lake Urmia during the 1981 to 2019 period. The sub-basin has 5 rain-gauge stations with adequate length and data whose statistical characteristics are given in Table 1.

The geographical location of Tazehkand sub-basin, Northwestern Iran
The theory of entropy
Entropy means chaos; in other words, as the chaos of a system is higher, it means its entropy is higher. According to Shanon’s definition, for the two variables x and y where xi, i = 1,2,3, …, n and yi, j = 1,2,3, …, m on the same probability space, each one will have the occurrence probability of p(xi)، p(xi, yj) and the co-occurrence probability of xi، yj and p(xi│yj). The overall state of entropy is as follows:
where E(I(x)) indicates the expected value of the data. Indeed, according to the definition, the mean of the data (I(x) mean) has been implemented as a measure of uncertainty. The joint entropy indicates the data that exist both in x and y.
For the two random variables x and y, the conditional entropy indicates the data in x that do not exist in y (Mogheir and Singh 2003).
It has been interpreted as a reduction in uncertainty in x based on an awareness concerning the random variable y. Moreover, it can be defined as the information related to x that exists in y (Lubbe 1996).
In the above equations, p(x) is the probability for the occurrence of x, p(x,y) is the probability for the joint occurrence of x and y, and p(x│y) is the probability of the occurrence of x dependent on y (Jessop 1995). It should be noted that T(x,y) = T(y,x) can be calculated using the following ways, as well:
Information transfer can also be expressed using a normalized Information Transfer Index (ITI), which indicates the amount of standard information transferred from one place to another. The classification of the rate of information transfer is given in Table 2.
The information received by x from y can be defined in the following manner in terms of entropy:
It can be expressed as a reduction in the uncertainty of when y is known; in other words, it is a measure of the rate of the information received by well ‘x’ from well ‘y’. Like the information sent from x to y, it can be defined in the following manner:
The above equations express the relationships between the two variables x and y. The same argument can be implemented for each station using Eqs. (10) and (11). Moreover, the information sent and received by the ith station can be defined in the following manner:
X(i) expresses the data of the ith station and \(\hat{x}(i)\) refers to the data estimate of the value of x(i). The latter is typically obtained using linear regression, though the copula-based simulation was implemented in the present study.
The higher values of R(i) and S(i) indicate the more significant received and sent information between the ith station or other stations in the network, respectively. In other words, they are measures of the more efficient communications between the stations.
In this way, the higher values of R(i) and S(i) for a particular station indicate the higher value of the station, and it is recommended to maintain and preserve such stations. On the other hand, the N(i) index or the ‘net exchanged information’ is defined in the following manner:
The N(i) index is important as it is used to assess the value of each station. It expresses the total net information of each well, and the station with the lowest N(i) index is assigned the lowest rank and importance in the monitoring network (Markus et al. 2003).
Investigating the interaction effects of the stations using copula functions
Vine copulas make different forms of dependence possible in various pairs and can easily model higher dimensions—e.g., 10 times—(Tahroudi et al. 2020a). The D-vine and C-vine copulas are the typical tree types. In a C-vine tree, dependence is modeled by bivariate copulas for each pair according to a particular variable (as the first root node). Thus, the dependencies of other pairs are selected according to the second variable (also called the second root node). In general, a root node is selected for each tree, and all pair dependencies are modeled according to this node and performed based on all previous root nodes. The R-Vine copula is more flexible than the C or D types as it provides a more extensive spectrum of structures. Figure 2 is a schematic representation of a 7-dimensional R-Vine copula. For instance, the pairs (1,2), (2,3), (3,4), (5,2), 3,6), and (6,7) are estimated at the first level of the 7-dimensional tree. On the other hand, the second level contains pairs like—among others—(1,2), (1,3|2), (2,6|3), (3,7|6), (3,5|2), and (2,4|3). The selection of copulas in lower levels has a significant effect on the conditional copulas of upper levels. Thus, the selection of copula families influences the other families.

A sample of the seven-dimensional R-Vine copula (Dißmanna et al. 2013)
Assume that (x1,…xd) is a set of variables with joint distribution F and density f. Its structure is considered as follows:
where F(·|·) and f(·|·) indicate the CFD and conditional density, respectively. As the second element, Sklar’s theorem for the d = 2 dimensions is as follows:
where c12 (·,·) indicates the bivariate optional copula density. Using the above equation, it can be stated that the conditional density X1 considering X2 can be obtained as follows (Aas et al. 2007):
The following can be expressed for the distinct values i, j, i1,···,ik with i < j and i1 < ··· < ik:
Using Eq. 16 for the conditional distribution (Xt, X1) considering X2,…, Xt−1, f(xt|x1,···, xt−1) can be expressed as follows:
Implementing the above equation in Eq. 14 and s = i, t = i + j, the following can be obtained (Aas et al. 2007):
The decomposition of the copula density consisting of the copula densities ci, j|i1,···,ik(·,·) is performed using the distribution function F(xi|xi1,…,xik) and F(xj|xi1,…,xik) for the specified indicators i, j,i1,…,ikand the marginal densities fk. It is for this reason that such an air-copula division is performed. Such a classification was called the D-vine copula by Bedford and Cooke (2001). There is a second class of analysis. When Eq. 16 with the condition distribution X1, Xt−2, (Xt−1) is considered, the following relationships can be developed:
Using Eq. (20) instead of Eq. (18) in Eq. (14) and considering j = t − k, j + i = t, the following results are obtained:
According to Bedford and Cooke (2001), this pair-copula construction (PCC) is called the canonical vine or the C-vine.
The error estimation statistics
The present study implemented the root-mean-square error (RMSE), Akaike information criterion (AIC), and the Nash–Sutcliffe (NSE) statistics (Zhang and Singh 2006; Ma and Sun 2011).
AIC values corresponding to maximum likelihood can be calculated using the following equation:
where, Pei and Pi are empirical and theoretical probabilities, respectively; N is number of data; m is the number of parameters and L is the maximum likelihood function value for the model.
Results and discussion
The present study implemented the rain-gauge stations in the Siminehrood Basin in Northwestern Iran during the 1981–2019 period. Six rain-gauge stations were implemented, and the characteristics of the stations are given in Table. As was mentioned before, multivariate regression was implemented to investigate the interaction effects of the sites. In the present study, the interaction effects of the stations were investigated by considering the statistical distribution of the data and the copula-based simulation. The first stage in the copula-based simulation was to investigate the correlation between the variables of the study using Kendall’s Tau statistic as it is the basis of the copula-based research studies. The results of investigating Kendall’s Tau are given in Fig. 3. Thus, the results showed that a significant correlation existed between the total annual rainfall values of the investigated stations. Thus, the preliminary and main conditions of the simulation and the investigation of the copula functions were fulfilled. The most significant correlation was observed in the Dashband-Ghezel Gonbad pair (0.79), while the least significant correlation was observed in the Rahimkhan-Tazehkand pair (0.37). Moreover, an average correlation of 0.52 was observed between all pairs of the variables.

The correlation between the annual rainfall records of the stations using Kendall’s Tau coefficient
Investigating the tree structure of the investigated variable pairs
After confirming the correlations between the observed values, the R-family copula functions, and their tree structures were investigated. In this regard, various types of copula functions related to the family including the C, D, and R-vine, and their dependent and independent modes were investigated. The results of the best tree structures of the investigated copula functions according to the AIC and BIC criteria are given in Table 3. Furthermore, the tree structures of the best copulas are given in Table 4 and Fig. 4. According to Table 3 and the AIC and Log-Likelihood criteria, it can be observed that the R-Vine and R-Vine Independent showed similar performance according to the AIC criterion. On the other hand, the Log-Likelihood showed that the R-Vine was the best copula to investigate and simulate the 6-variable values of the annual rainfall in the studied stations. Moreover, the D-Vine got the lowest rank according to the investigated vines as it was assigned with the lowest value by the Log-Likelihood. Though selecting the R-Vine copula increased calculation complexities due to its extensive tree structure, it increases the accuracy of simulation and modeling.

The tree structure of the best copula
Finally, investigating the Vine-family copula functions during the multivariate simulation of the total rainfall values considering the annual rainfall values of other stations in the Siminehrood basin showed that the R-Vine copula had the highest fit with the investigated variables, and it was introduced as the best copula compared to other according to the offered tree structure. Table 4 shows that 54% of the internal copulas were rotary. Due to the application of rotary copulas in the complete coverage of dependency directions, implementing them can increase the accuracy and performance of modeling.
Figure 4 shows that the R-vine had the best tree structure among the vine-family copulas. The figure illustrates the tree structure in six dimensions. The structure consists of five trees that show the connection modes of various parameters and their conditional states.
Numbers 1 to 6 indicate the rainfall values recorded in Dashband, Ghezel Gonbad, Kavlan, Tezahkand, Rahimabad, and Norouzlou stations, respectively (Fig. 4).
Copula-based simulation
After determining the best vine, its tree structures, and the internal copulas, the h-function and the probability density function of the copula functions were used to simultaneously simulate the annual rainfall values of the investigated stations according to the copula-based model. The simulation was multivariate, and the lack of rainfall in all stations was also taken into account. The correlations between the simulations and observations were investigated. In Fig. 5, the red numbers and shapes indicate the observational data, while the black ones are the simulated information. The results showed a significant correlation between the simulated rainfall values across the investigated stations. In most cases, the simulated values for various stations had higher correlations compared to the observational mode, and this showed the Vine simulation approach was a convenient way to simulate the annual rainfall values in the stations. Moreover, the convenient distribution and fit of the observed and simulated values were confirmed in all stations. The accuracy of the simulation procedure is given in Table 5. As can be seen in the table, the accuracy and efficiency of the Vine simulation approach were confirmed.

The correlation between the observed and simulated annual rainfall values of the stations (red: observed data; black, simulated data)
In Table 5, the error rate and efficiency of the model in simulating the multivariate values of annual rainfall are provided by the RMSE and NSE statistics, respectively. It can be observed the efficiency of the Vine simulation approach in all stations was above 92%. Moreover, the error rates ranged between 20.93 and 20.75 mm. Table 5 also illustrates the simulated values for the annual rainfall of the investigated stations in the Tazehkand sub-basin using the multivariate regression technique. As was mentioned above, multivariate regression is the typical method in the theory of entropy to investigate the interaction effects of stations. The results of comparing the RMSE values in the multivariate regression and the Vine simulation approach showed that the RMSE values obtained for the Dashband,Ghezel Gonbad, Kavlan, Tazehkand, Rahimabad, and Norouzlou stations improved by almost 41, 52, 80, 54, and 41%, respectively. Moreover, the improved rates of performance for the above stations according to the NSE measure were around 4, 8, 78, 33, 16, and 19%, respectively. In addition to the excellence of the Vine-based simulation technique according to the error statistics, the approach indicated higher certainty in simulation as it implemented a convenient marginal distribution with each time series and joint analysis (Table 6). Figure 6 shows the violin plot of the observed and simulated values concerning the annual rainfall of the investigated stations. Figure 6 indicates a complete fit between the observed and simulated values for the annual rainfall recorded in Dashband, Ghzel Gonbad, Kavlan, and Norouzlou stations. Though some underestimation can be observed in the case of Tazehkand station, the observed and simulated values have a convenient fit in terms of their variations. Moreover, the observed and simulated values for Rahimabad station were not fully fit. The figure indicates the efficiency and certainty of the Vine simulation approach in investigating the interaction effects of the rain-gauge stations in Tazehkand basin.

The violin plot of the variations between the simulated and observed values of the total annual rainfall of the investigated stations according to the 6-variable Vine simulation method
After the accuracy and performance of the Vine simulation approach in investigating the interaction effects of the rain-gauge stations were confirmed, the entropy theory was implemented to estimate the ITI and N(i) indicators. The results of investigating the area in terms of the ITI index are given in Table 6, and the rating of the investigated stations is given in Table 7.
The results of the ITI index (Table 6) in the investigated area showed that Norouzlou station was average in terms of transferring rainfall information, Dashband and Ghezel Gonbad stations were in the surplus mode, and the remaining stations were above average. In general, no shortage of rain-gauge stations was observed in the investigated area concerning the rain-gauge monitoring network. In other words, the best monitoring could be achieved in terms of the rainfall data using the available stations in the region. Monitoring rain-gauge networks in each area or basin can provide accurate information about the spatial and temporal variations in rainfall values, and this is essential due to the climate change and the rainfall variations observed over the past few decades. Iran is located on the global dry belt, and recent droughts have had devastating impacts on it. This has been pointed out in many studies like Khalili et al. (2016), Khozeymehnezhad and Tahroudi (2019), Ramezani et al. (2019), Tahroudi et al. (2019a, b, c), and Tahroudi et al. (2020a, b). Understanding variations in rainfall and monitoring rain-gauge networks can have outstanding effects on the management of basins. Another important index in monitoring the rain-gauge networks is N(i) given in Table 7. Marcus et al. (2003) argued that the station with positive values of the N(i) should be maintained. Implementing the N(i) index to estimate the worth of each station and rank the investigated stations showed that Norouzlou station ranked last. This showed that the station sent and received less information compared to other stations in the network. Moreover, it was shown that the station had weaker communications with other stations. On the other hand, Dashband station ranked first, which showed its superiority in the investigated area. If a station is supposed to be eliminated, it is advisable to select the stations with lower ranks and negative N(i) values. Moreover, if a station is supposed to be introduced as the base station in the investigated area, Dashband station is the best choice. That is because the information provided by the station can be a convenient representation of the area in terms of rain-gauge information exchange. In general, the results of the entropy index offer accurate and all-inclusive information concerning the monitoring network of any area. Tahroudi et al. (2019a, b, c) confirmed the accuracy of the entropy theory in improving the monitoring network. Implementing all indicators of the entropy theory can illustrate a full image of the variations in the monitoring network.
Conclusion
The present study investigated the interaction effects of the stations using the copula-based simulation approach instead of the more typical method (i.e., multivariate regression analysis). In addition to investigating and confirming the correlations between the annual rainfall values of the stations using Kendall’s Tau, various Vine copulas including the C, D, and R Vines, and their Gaussian and dependent modes were compared. Ultimately, the R-Vine was selected as the best copula using the error investigation statistics. The results of investigating the internal R-Vine copulas showed that above 50% of the copulas were rotary, which made full coverage in all directions. In the end, the selected copula and its tree structure were used to investigate the interaction effects of the rain-gauge stations, and the rainfall values of the stations were estimated according to the values of other stations. The RMSE and NSE statistics were implemented to investigate the error rate and the efficiency of the Vine simulation approach. Moreover, the typical multivariate regression technique was implemented, and its results were compared with the results obtained for the vine simulation approach. The NSE statistic showed that the efficiency of all investigated stations was above 92%. In addition to the RMSE and NSE statistics, the results of the violin plot confirmed the certitude and performance of the Vine simulation approach. Comparing results of the multivariate regression and the Vine simulation technique confirmed the enhancement of the performance and reduction of the error rate of the latter in all stations. Thus, it was found that the Vine simulation approach had acceptable accuracy in estimating and simulating the rainfall values of each station according to the values recorded by the neighboring stations. The implemented approach provided values that were close to the real-world conditions as it used the copula functions and marginal distribution functions proportionate to the investigated series. Thus, the certitude of the model increases. In addition, the values of ITI and N(i) indicators were calculated for each station using the theory of entropy, and the results showed that the stations in the investigated area were sufficient. The investigated stations were on average, above-average, and surplus modes according to the ITI index, and this showed the area was conveniently monitored in terms of its rainfall. According to the N(i) index, Dashband station ranked as the best station in terms of communication with other stations and its convenient coverage of the plain. In other words, Dashband station was convenient in terms of offering rainfall variation data, and the information offered by it could be generalized to the whole area.
Availability of data and material
Data collected by the author and secondary data are cited.
References
Aas K, Czado C, Frigessi A, Bakken HJ (2009) Pair-copula constructions of multiple dependence. Insurance Math Econom 44(2):182–198
Bedford T, Cooke RM (2001) Probability density decomposition for conditionally dependent random variables modeled by vines. Ann Math Artif Intell 32(1–4):245–268
Chen YC, Weiand C, Yeh HC (2008) Rainfall network design using kriging and entropy. Hydrol Process 22:340–346
Dißmanna J, Brechmann EC, Czado C, Kurowicka D (2013) Selecting and estimating regular vine copulae and application to financial returns. Comput Stat Data Anal 59:52–69
Fanny M, Khalifeh S, Khalifeh A, Aflatouni M (2013) Raingauge network evaluation using the discrete entropy (case study: great karoun basin). Journal of Science and Irrigation Engineering 38(4):1–13 ((in Persian))
Hao Z, Singh VP (2013) Modeling multisite streamflow dependence with maximum entropy copula. Water Resources Res 49(10):7139–7143.
Jessop A (1995) Informed assessments: an introduction to information, entropy, and statistics. Ellis Horwood, Delhi
Joo H, Lee J, Jun H, Kim K, Hong S, Kim J, Kim HS (2019) Optimal stream gauge network design using entropy theory and importance of stream gauge stations. Entropy 21(10):991
Karimi-Googhari Sh, Khalifeh S (2013) Hydrometric network evaluation for bakhtegan-maharlu watershed using the discrete entropy. Journal of Watershed Management Research 2(3):34–50 ((in Persian))
Keum J, Kornelsen K, Leach J, Coulibaly P (2017) Entropy applications to water monitoring network design: a review. Entropy 19(11):613. https://doi.org/10.3390/e19110613.
Khalili K, Tahoudi MN, Mirabbasi R, Ahmadi F (2016) Investigation of spatial and temporal variability of precipitation in Iran over the last half century. Stoch Env Res Risk Assess 30(4):1205–1221
Khozeymehnezhad H, Tahroudi MN (2019) Annual and seasonal distribution pattern of rainfall in Iran and neighboring regions. Arab J Geosci 12(8):1–11
Kong XM, Huang GH, Fan YR, Li YP (2015) Maximum entropy-Gumbel- Hougaard copula method for simulation of monthly streamflow in Xiangxi river, China. Stoch Environ Res Risk Assess 29:833–846. https://doi.org/10.1007/s00477-014-0978-0
Kwon T, Lim J, Yoon S, Yoon S (2020) Comparison of entropy methods for an optimal rain gauge network: a case study of Daegu and Gyeongbuk Area in South Korea. Appl Sci 10(16):1–19. https://doi.org/10.3390/app10165620
Lee M, Hong JH, Kim KY (2017) Estimating damage costs from natural disasters in Korea. Nat Hazard Rev 18(4):2–19
Li H, Wang D, Singh VP, Wang Y, Wu J, Wu J, He R, Zou Y, Liu J, Zhang J (2019) Developing a dual entropy-transinformation criterion for hydrometric network optimization based on information theory and copulas. Environ Res, 10–16. https://doi.org/10.1016/j.envres.2019.108813
Liu D, Wang D, Singh VP, Wang Y, Wu J, Wang L et al (2017) Optimal moment determination in pome-copula based hydrometeorological dependence modelling. Adv Water Resour 105:39–50
Lubbe C (1996) Information theory. Cambridge University Press, Cambridge
Ma J, Sun Z (2011) Mutual information is copula entropy. Tsinghua Sci Technol 16(1):51–54
Markus M, Knapp HV, Tasker GD (2003) Entropy and generalized least square methods in assessment of the regional value of streamgages. J Hydrol 283(1–4):107–121
Mogheir Y, Singh VP (2003) Specification of information needs for groundwater management planning in developing country. Groundwater Hydrol 2:3–20
Nazeri Tahroudi M, Khashei Siuki A, Ramezani Y (2019) Redesigning and monitoring groundwater quality and quantity networks by using the entropy theory. Environ Monit Assess 191:1–17
Ramezani Y, Nazeri Tahroudi M, Ahmadi F (2019) Analyzing the droughts in Iran and its eastern neighboring countries using copula functions. Quart J Hungarian Meteorol Service 123(4):435–453
Shah SMH, Mustaffa Z, Teo FY, Imam MAH, Yusof KW, Al-Qadami EHH (2020) A review of the flood hazard and risk management in the South Asian Region, particularly Pakistan. Sci Afr 10:e00651
Shannon CE (1948) A Mathematical theory of communication. Bell Syst Tech J 27:379–423
Tahroudi MN, Khalili K, Ahmadi F, Mirabbasi R, Jhajharia D (2019a) Development and application of a new index for analyzing temperature concentration for Iran’s climate. Int J Environ Sci Technol 16(6):2693–2706
Tahroudi MN, Pourreza-Bilondi M, Ramezani Y (2019b) Toward coupling hydrological and meteorological drought characteristics in Lake Urmia Basin, Iran. Theor Appl Climatol 138(3):1511–1523
Tahroudi MN, Ramezani Y, Ahmadi F (2019c) Investigating the trend and time of precipitation and river flow rate changes in Lake Urmia basin, Iran. Arab J Geosci 12(6):1–13
Tahroudi MN, Ramezani Y, De Michele C, Mirabbasi R (2020a) A new method for joint frequency analysis of modified precipitation anomaly percentage and streamflow drought index based on the conditional density of copula functions. Water Resour Manage 34(13):4217–4231
Tahroudi MN, Ramezani Y, De Michele C, Mirabbasi R (2020b) Analyzing the conditional behavior of rainfall deficiency and groundwater level deficiency signatures by using copula functions. Hydrol Res 51(6):1332–1348
Valipoor E, Ghorbani MA, Asadi E (2020) Rainfall network optimization using information entropy and fire fly algorithm case study: East Basin of Urmia Lake. Watershed Manage Res 11(21):11–23 ((in Persian))
Xu P, Wang D, Singh VP, Wang Y, Wu J, Wang L, Zou X, Liu J, Zou Y, He R (2018) A kriging and entropy-based approach to rain gauge network design. Environ Res 161:61–75
Zhang L, Singh V (2006) Bivariate flood frequency analysis using the copula method. J Hydrol Eng 11(2):150–164
Acknowledgements
The authors would like to thank the Iran Water Resources Management Company for providing the data.
Funding
The research was not funded by any organization.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
No conflicts of interest involved.
Ethics approval
In compliance with ethical standards.
Consent to participate
Consent by all authors.
Consent for publication
Consent by all authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Tabatabaei, S.M., Dastourani, M., Eslamian, S. et al. Ranking and optimizing the rain-gauge networks using the entropy–copula approach (Case study of the Siminehrood Basin, Iran). Appl Water Sci 12, 214 (2022). https://doi.org/10.1007/s13201-022-01735-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13201-022-01735-y