
Abstract
Reservoirs provide rural and municipal water supply for various purposes such as drinking water, irrigation, hydropower, industrial purposes and recreational activities. Supplying these demands depends strongly on the dam reservoir capacity. Hence, reservoir storage capacity prediction is a determining factor in water resources planning and management, drought risk management, flood risk assessment and management. In the present study, imperialist competitive algorithm as a relatively new socio-political-based global search technique introduced for solving different optimization problems employed to predict reservoir storage capacity of Shaharchay dam located in the Urmia lake basin in northwest of Iran. The high convergence rate of imperialist competitive algorithm along with its capability in finding global optimal is striking aspect of the algorithm. The results obtained from this algorithm were compared with those of Artificial Neural Network. The comparison of the results with the measured ones by means of error measures indicates the superiority of imperialist competitive algorithm over Artificial Neural Network.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The limitation of water resources besides growing water demands due to the ever-increasing population growth are imposing a great pressure on water resources around the world. It is believed that the available water resources may not be able to meet the future water demands (Ahmad et al. 2018). The limited water resources along with their unbalanced distribution make a competition among water demand sectors to reach the maximum amount of allocated water (Ahmad et al. 2018; Al Radif 1999). This shows the importance of decisions made to allocate the available water to different sectors. Construction of dams to store the water in a suitable location of river valley is considered as a solution to reduce the effects of uneven distribution of available water resources. Construction of dams as a long-standing strategy reduces the spatio-temporal variability of regional water resources and provides the possibility of utilizing the riverine flows in order to supply the water for several purposes (Ehsani et al. 2017). The water stored in reservoirs requires to supply the considered water demands even during natural disasters such as floods and droughts which may cause ecologic, economic, societal and sanitary problems (Obringer and Nateghi 2018). In addition to the demands supply level, reservoir storage capacity has a great potential to change the riverine flow regime and its morphologic behavior as well (Kibler 2017; Proff and Hart 2002). Hence, the location of dams and their optimal storage are key parameters in the operation of available surface water resources located in the dam basin. To achieve the optimal storage of a reservoir in a specified location, it may solve as an optimization problem considering the existing limitations such as stream flows and evaporation amounts.
Actually, different purposes of a reservoir, such as drinking, agricultural, industrial and flood control, may have conflict with each other. In order to consider all the above-mentioned objectives simultaneously, the optimal operation of multi-objective reservoir must be achieved (Chang et al 2005). Different optimization methods, e.g., Ant Colony Optimization Algorithm, Particle Swarm Optimization algorithm, Genetic Algorithm, Tabu Search Techniques and Artificial Neural Networks, have been proposed to predict the reservoirs storage capacity (Anand et al. 2018; Bozorg-Haddad et al. 2016; Wang et al. 2011; Ji et al. 2011; Yeh 1985). In the optimization of dam reservoir capacity, the purpose is to find the reservoir storage capacity for abstracting sufficient amount of water from the dam reservoir (Kilinç and Ciğizoğlu 2012; Thair et al. 2015). Due to high efficiency of Artificial Neural Networks (ANNs) and Evolutionary Algorithms (EAs), many researchers have applied these methods to optimize and predict different complex hydrological processes. The ANN methods have high efficiency and are commonly used in practical hydrologic projects (Thair et al. 2015). Imperialist Competitive Algorithm, hereafter denoted as ICA, is a type of EAs with a difference which is inspired by imperialistic competition. ICA was proposed by Atashpaz-Gargari and Lucas (2007). ICA is a specially crafted algorithm which finds a heuristic solution to a problem, using evolutionary concepts like countries, colonies, assimilation policy, revolution and imperialist competitive which is inspired by imperialistic competition (Atashpaz-Gargari and Lucas 2007). The notable investigations on dam reservoir optimization have been carried out by Krishnakumar and Goldberg (1992), Karamouz et al. (1992), Fahmy et al. (1994), East and Hall (1994), Ritzel et al. (1994), Franchini (1996), Dandy and Maier (1993), Ahmed and Sarma (2005) and Bozorg-Haddad et al. (2008).
Fang et al. (2014) proposed a new storage allocation rule based on target storage curves. They utilized a simulation–optimization model for a multi-reservoir system in northern China, including a water transfer-supply project. The results showed the proposed operating rules are suitable for complex systems. Thair et al. (2015) applied ANN for Mosul-dam reservoir operation. The earning rate, momentum rate, number of cycles and number of hidden layers were chosen equal to 0.001, 1, 0.9, 50,000 and 9, respectively. The high performance of ANN in finding missing data and the accurate prediction of monthly outflows were the main results of their study. Piri and Rezaei Kahkha (2016) employed ANN, Adaptive Neuro-Fuzzy Inference System and Cuckoo optimization algorithms to forecast the fluctuations of Chahnimeh reservoirs water levels in Zabol. Three determining variables in the reservoir water-level fluctuations including evaporation, wind speed and daily average temperature were applied as inputs to these models. Results showed the superiority of the Adaptive Neuro-Fuzzy Inference System over the other models. Heydari et al. (2016) optimized the operation of several multipurpose reservoirs using matrix structure of six storage dams constructed on Karun and Dez rivers in Iran. They concluded that the role of objective function structure for generating hydropower energy in weighting method algorithm is more significant than water supply. Yazdi (2017) developed a stochastic model and Monte Carlo simulation, linked to an evolutionary optimization tool and an ANN model to assign the optimal sites and number of check dams on a riverine network. The results indicated that optimal strategies are able to mitigate peak flood discharges by up to 50%, with significant economic superiority. Ghatfan and Badia (2017) predicted the water levels in 16th Tishreen dam reservoir using ANN and concluded that Feed Forward Back-Propagation Artificial Neural Networks (FFBP-ANNs) considering the daily measured water level as output predicted reliably the water levels in the dam reservoir. Saha et al. (2017) applied HEC-5 model to simulate the performance of five multipurpose reservoirs system in the East of India. Markov autoregressive-based model was utilized for scenario generation and performance measures employed to evaluate the performance of the system. They found that strategy of demand management and marginal reallocation of reservoir storage capacity is practicable choice for the performance enhancement of the system of reservoirs. Ahmadianfar et al. (2017) employed fuzzy set theory and NSGA-II for optimized operation of a multi-reservoir system. The objective was comprised of agriculture water needs and water supply of minimum flow over a simulation period. The modified shortage index for calculating the objective function was obtained by combination of a monthly simulation model and nondominated sorting genetic algorithm. Gudmundsdottir and Horne (2018) explored the applicability of statistical methods for reservoir characterization and its capacity prediction as well. For this aim, three methods including Ant Colony Optimization Algorithm, k-means Clustering and Canonical Functional Component Analysis were analyzed and applied on a synthetic library of fracture networks. The predicted range of thermal responses for production wells reduced significantly. In this method, data-prediction relationships become less linear due to introducing more complex data. Sangiorgio and Guariso (2018) studied the management of multi-reservoir systems using artificial neural network-based optimization. The objectives were maximization of hydropower benefits with minimizing the deficit of irrigation needs. The model was applied to four natural and artificial reservoirs considering different hydrological elements in Nile river basin. Anand et al. (2018) utilized coupled SWAT and genetic algorithm to derive an optimal operating policy for a multipurpose reservoir system in the Ganga river. The optimization performed to minimize the squared derivation with respect to desired irrigation water needs and desired storage volume. The efficiency and effectiveness of genetic algorithm in the operation strategies for multipurpose reservoirs was the main result of their study. Satish and Ramesh (2019) used five different ANN models by varying number of hidden layer neurons to estimate the storage capacity of Harangi reservoir. They utilized data of 2010–2012 for training and remaining 2-year data of 2013–2014 to test the models. Results showed that ANN model with five hidden neurons performs well compared to other examined models for prediction of reservoir storage estimation. Zhang et al. (2019) employed a deep learning algorithm to predict the Xiluoudu reservoir outflows. Comparison of the model performance with three models showed that the models have proper capabilities in the operating regulation and making decisions for flood control and power generation. Changes in the effective parameters of reservoir operation and their significance were the other finding of the study.
The above studies show that limited investigations carried out in the artificial intelligence applications for estimation of reservoirs storage capacity. Despite many studies deal with the optimal operation of reservoirs, limited researches have been carried out on the prediction of optimum storage capacity of reservoirs, especially after operation of a reservoir and gathering a considerable data of different releases from the reservoir. In the current study, a newly introduced Evolutionary Algorithm that is inspired by imperialistic competition is utilized along with ANN method to predict the optimal reservoir storage. To do this, the goal is to find the minimum amount of storage (chromatic number) that supplies the water demands during different months. The remainder of the paper is organized as follows. The first section is devoted to describe the details of ICA and ANN algorithms along with the studied area and used data of studied storage reservoir. This is followed by results of implementation of the models to the studied reservoir. The paper concludes with the concluding remarks in the last section.
Materials and methods
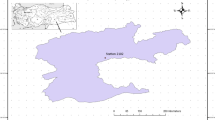
In this paper, ICA and ANN models were applied to estimate the storage capacity of Shaharchay dam located in the northwest of Iran. The basin area is about 369 km2. The dam is operated for three main purposes: irrigation, drinking and industry. Figure 1 shows the location of the studied area in Iran. The Shaharchay dam has been built on Shaharchay River at around 35 km away from Urmia city. The dam is located at the elevation of 1519 m above the sea-level, at 44.904 °E-longitude and 37.447 °N-latitude. The designed storage of reservoir at normal water level is 213 million cubic meters. This storage volume can supply irrigation water demands for 12,500 hectares of farm lands. Some specifications of the dam are given in Table 1.

Map of studied area
The minimum storage volume of reservoir is 7 million cubic meters. The maximum, mean and minimum annual flow rate of Shaharchay River at the dam site are 172 m3/s, 102 m3/s and 18 m3/s, respectively (Urmia Shahrchay dam Project 2019). In this study, the monthly stream flows of the Shaharchay River have been utilized.
Imperialist competitive algorithm
During recent years, many optimization problems have been studied by ICA due to its advantages including its high speed and accuracy to find optimal solutions (Kaveh and Talatahari 2010; Khorani and Disfani 2011; Hadji and Vahidi 2012; Taher et al. 2014; Sedighizadeh and Eisapour-Moarref 2017; Pan et al. 2018). The algorithm begins with an initial random population. Each member of the population is known as a country. The countries are divided to imperialists and colonies by means of their cost and setting a specified cost as criterion of the division. Based on the total power of the imperialists, the colonies are distributed among the imperialists. An empire is established by an imperialist together with its colonies. By making use of assimilation policy on the colonies in every empire, the colonies move toward the relevant imperialist. There are several methods to implement assimilation policy as operator. The operator like the crossover operator in genetic algorithm may be used here (Deb 2001). A combination of the power of both the imperialist and its colonies forms the empire power. The power of an empire is computed by the imperialist power plus a percentage of average power of its colonies. Every empire makes effort to take the possession of the colonies of other empires and control them (Atashpaz-Gargari and Lucas 2007). Figure 2 shows the flowchart of ICA.

Flowchart of ICA algorithm (Khalili et al. 2016)
-
(a)
Generating initial empires
An optimization problem searches the feasible domain to arrive at an optimal solution based on the effective variables. In ICA, an array of variables called country to be optimized. In an optimization problem with Nvar dimension, a country is a 1×Nvar array and is defined by:
The values of variables in any country are displayed as floating point numbers. The cost of any country is calculated by the cost function f for any variable:
The generation of initial population of size Npop is the starting point of optimization process. Nimp of the most powerful countries are selected to produce the empires. The other countries of the population, Ncol, will be the colonies of empires. Then two kinds of countries exist: imperialist and colony. To establish the primary empires, the colonies are distributed among imperialists regarding their power. The primary number of colonies of an empire is a direct function of its power. To distribute the colonies among imperialists, the normalized cost of an imperialist is defined as:
in which cn is the cost of nth imperialist and Cn is its normalized cost. Knowing the normalized cost of all imperialists, the normalized power of each imperialist can be computed by:
Indeed, the normalized power of an imperialist is the component of colonies to be possessed by the imperialist. The initial number of colonies for any empire will be:
where NCn is the initial number of colonies of nth empire and Ncol is the number of all colonies. By randomly choose of NCn of the colonies, they are apportioned among imperialists. An empire is formed by colonies and an imperialist. Figure 3 displays the generating of primary population of any empire. As seen in this figure, the number of colonies of any empire depends directly on the empire power.

Generating the initial empires: how an imperialist possesses more colonies, the relevant ★ mark will be bigger (Khalili et al. 2016)
-
(b)
Moving the colonies toward the relevant imperialist
As mentioned before, imperialists’ policy is improving their colonies. This is fulfilled by moving the colonies toward the imperialist. The movement of colonies is depicted in Fig. 4. The new situation of the colony, which is closer to the imperialist, is indicated by a darker color. The movement direction is shown by a vector from the colony to the imperialist. The value of movement, x, can be considered as a random variable with any proper probability distribution. Hence, for the value of x we have:
in which β is a number greater than unity and d is the straight distance between the colony and the imperialist. Choosing β ˃ 1, the colonies move toward the imperialist.

Moving the colony toward the relevant imperialist (Khalili et al. 2016)
To seek other routes to reach the imperialist state, as shown in Fig. 5, a random amount of deviation to the direction of movement is considered. In Fig. 5, θ is a random number with any proper probability distribution. Then:
where γ is an adjustment parameter for the deviation from the original position. Although the values of β and γ are arbitrary, according to the previous works, e.g., Khalili et al. (2016), in most of implementations a value of about 2 for β and the value of about π/4 (radian) for γ would result in a desirable convergence to the global optimum.

Moving the colony toward the relevant imperialist in a randomly deviated route (Khalili et al. 2016)
-
(c)
Exchanging positions of the imperialist and a colony
By moving a colony toward the imperialist, its position is updated to have a lower cost than that of previous state. In this case, the colony and the imperialist will move to the previous positions of each other. Afterward, algorithm continues by new positions of the imperialist and the colonies, and colonies begin to move toward the imperialist. The exchange of a colony and the imperialist position is shown in Fig. 6a. In this figure, the red color shows the best colony, which has the lower cost among existing colonies, of the empire. Figure 6b depicts the whole empire in which the best colony of the empire has been become the new imperialist.

a Exchanging the positions of a colony and the imperialist, b the entire empire after position exchange (Khalili et al. 2016)
-
(d)
Total power of an empire
Although the colonies power has somewhat effect on the empire power, the power of the imperialist mainly forms the total power of an empire. This fact can be modeled by defining the total cost as:
in which TCn is the total cost of the nth empire and ω is a positive number which is chosen less than unity. The role of the colonies in the empire power is a function of ω. The value of 0.1 is used for ω in most implementations.
-
(e)
Imperialistic competition
Empires make efforts to seize and control other empires. This causes to intensify the imbalance in the power of empires. In order to model the competition, some of the weakest colonies of the weakest empires are chosen and a competition holds among all empires to possess these colonies. The competition process is shown in Fig. 7. During the competition, the chance of an empire to take possession of the weakest colonies depends upon its total power.

Imperialistic competition (Khalili et al. 2016
-
(f)
Eliminating the powerless empires
Some weaker empires will be powerless and will fall down during the competition process and their colonies will be possessed by other empires. Mechanism of collapsing powerless empires can be modeled by different criteria. In most cases, the collapse of an empire takes place when it loses all of its colonies.
-
(g)
Convergence
Assimilation Policy and Imperialist Competition are the most important and basic operators in the ICA. During the competition process, all empires except the most powerful one will fall down and all colonies will be possessed by the powerful empire. In this new situation, all colonies will have the same positions and same costs. In this situation, there is no difference between colonies and imperialist. In this situation, the imperialistic competition arrives at the end and the algorithm is stopped. Table 2 shows the pseudo code of the ICA. This pseudo code clarifies the basic steps of ICA proposed by Atashpaz-Gargari and Lucas (2007).
ANN
ANN as a branch of Artificial Intelligence is a biologically inspired computational model consists of sets of artificial neurons connected via weighting coefficients to form a neural structure (Zurada 1992; Agatonovic-Kustrin and Beresford 2000; Saravanan and Sasithra 2014). They can provide output responses based on the input data. Neural networks are usually created in a layered and regular manner. The first layer in which the input data are entered is the input layer. The middle layers are hidden and the last layer that provides the output responses of the model is the output layer (Menhaj 2000). The input dataset to the ANN model is given by:
where wij is the weighting coefficient, which is determined during the learning process. In the next step, depending on the summed input values, the output signal, the value of 0 or 1, is generated by the activation function. The activation function used here is sigmoid function which is defined as follows (Fu 1994):
In the present study, the MLP model was developed to estimate reservoirs storage capacity according to Fig. 8.

The neural network architecture used in the present study
In order to achieve the high performance, the inputs and outputs normalized using the following equation:
in which Yi, XOi, Xomin and Xomax are standardized observed values, minimum observed and maximum observed values, respectively.
The process of the neural network with a back-propagation training technique is used in the present study. More details about the ANN can be found in (Menhaj 2000). One of the most common methods to avoid overfitting is basic validation using the early stopping method, which was used in the present study. In this method, the iteration stopped when the error of test data starts to increase while the error of training data is still decreasing (Fig. 9).

The early stopping method used in ANN model learning
Application of ICA and ANN models
In the current study, the goal function of the ICA model is to minimize the summation of the squared deviation of monthly irrigation demands and squared deviation of mass balance of reservoir storage:
where Rt is the monthly irrigation release for the month “t”, Dt is monthly irrigation demand for the month “t”, St is the storage in the beginning of month “t”‘, St+1 is the storage at the end of the month “t”‘, It is monthly inflow during the period “t”‘ and E is monthly evaporation loss from the reservoir during the month “t”.
Release constraint
The monthly water release for irrigation must be less than or equal to the monthly irrigation water needs and the constraint is written as:
Storage constraint
The monthly reservoir storage cannot exceed the capacity of the reservoir and on the other hand, it must be greater than the dead storage. This constraint may be expressed mathematically as:
where Smin is dead storage of the reservoir in MCM and Smax is maximum capacity of the reservoir in MCM.
Overflow constraint
When the total storage in any month exceeds the capacity of the reservoir, the constraint is given by:
Otherwise:
where Qt is the surplus volume of the reservoir during the month “t”.
Datasets
In order to evaluate the capability of ICA and ANN models, monthly statistical data from 2007 to 2014 were utilized for analysis. To train and test the proposed models, 80% (384 data) and 20% (96 data) of the dataset were used, respectively. Every pair data have been selected randomly from all possible monthly hydrological events occurred during modeling time. The reason for random selection of the data is to provide adequate training information for all events in the historical time series. Using the validation data, the accuracy and reliability of the trained model can be examined. The input and output variables used in the ANN model along with the statistical parameters can be found in Table 3.
Weighting coefficients and the constants in the input layer and hidden layer with 6 neurons are given in Tables 4 and 5.
Results and discussion
The monthly statistical data for the period of 2007–2014 are used to examine the capability of the ICA and ANN models in determining the optimal monthly storage of Shahrchay dam reservoir. Regarding the acceptable performance of ANN in wide range of water-related problems, the ANN model with momentum training algorithm is utilized.
After introducing the objective function to the models and performing the sensitivity analysis to find the optimal values of the effective factors for both algorithms and reimplementation of the models, the values of decision variables, i.e., 24 variables, of the problem are computed.
The optimal values for the ICA are given in Table 6.
Imperialist competitive function performance computes 24 variables. Variables 1 to 12 are the release from the dam and the variables 13 to 24 are the storage volumes in the same months. In the models, the outflows meet at least 90% of downstream water needs over the modeling period. The predicted monthly reservoir storages in Shaharchay dam using ICA and ANN models are indicated in Fig. 10. According to Fig. 10a, b, the maximum required storage predicted by ICA is 182.09 MCM which is occurred in May while the predicted value by ANN is 172.84 occurred in June. The occurrence of maximum required storage in May and June is in agreement with the increase of water needs in the region and reduction in inflows to the reservoir during June–August. The recorded reservoir water levels in the same period show the maximum storage by supplying all water needs is 190 MCM which has occurred in May. Figure 11 indicates the comparison of the model results and the measured maximum monthly storages in the period of 2007–2014. As indicated in this figure, the measured storages are closer to ICA results than ANN ones.

Optimal monthly reservoir storage

Comparison of the measured and predicted reservoir storage values by ICA and ANN
The results of the ICA and ANN models for monthly reservoir storages of Shaharchay dam are presented in Table 7.
The performance of the models was evaluated by means of error measures including the correlation coefficient (R2), percentage of error, root mean square error (RMSE) and mean absolute error (MAE).
The percentage of error between the measured data and the obtained results from ICA and ANN models are shown in Fig. 12. The computed values for R2, RMSE and MAE are listed in Table 8. Although the error measures illustrate that the errors of both models are less than threshold values, e.g., is less than 10% for percentage of error, and the results of both models are satisfactory, the results of ICA are more acceptable.

Percentage of errors for the results obtained by ICA and ANN
The reservoir storage capacity is crucial to supply the monthly downstream water needs. The comparison of the outflows obtained by the models and the downstream water needs is indicated in Fig. 13. The results of ICA for outflows are in good agreement with the downstream water needs. The less errors of ICA results in finding the reservoir storage capacity along with supplying the downstream water needs show the superiority of ICA to ANN.

Comparison of downstream water needs with the obtained values by ICA and ANN
According to the above-mentioned results, both models have a satisfactory performance in predicting the storage capacity of the reservoir and downstream water needs as well. Furthermore, it is obvious that the performance of ICA is better than ANN model in predicting the reservoir storage capacity. Therefore, ICA was used to predict the required storage capacities of Shahrchay reservoir for 2018–2020. The predicted monthly storage capacities to meet the downstream water needs are indicated in Fig. 14. The results indicate that the maximum required storage will occur in May with the values of 164, 149 and 159 for 2018, 2019 and 2020, respectively. This is in agreement with the agricultural water needs of the existing downstream irrigation network and the recorded data of reservoir during the operation period. Although the ICA model is more efficient in the prediction of reservoir capacity of Shahrchay dam, it is recommended to use hybrid models to assess their capabilities in accurate prediction of reservoirs capacity.

The required storages of the reservoir during 2018-2020
Conclusion
ICA is a new meta-heuristic evolutionary global search algorithm that has been introduced for dealing with different optimization issues. This study is the first study to employ ICA in predicting the required storage capacity of a reservoir. The monthly required storage of Shahrchay dam was studied as a case study. ICA and ANN were utilized to determine the monthly optimal storage and downstream water releases for irrigation purpose during 2007–2014. The comparison of the obtained results with the measured reservoir storages and downstream water needs shows the favorable performance of ICA. Based on ICA results, the maximum required storage occurs in May that coincides with the beginning of maximum water needs for downstream farmlands. As the error measures of ICA were more satisfactory, it was used to predict the monthly required storage from 2018 to 2020. The results indicated that the maximum required storage will occur in May with the values of 164, 149 and 159 for 2018, 2019 and 2020, respectively, which are in good agreement with recorded data during the operation period of dam. The results showed the efficiency and accuracy of ICA in predicting the reservoirs storages which can be consider as a reliable decision-making tool. Although the performance of ICA is satisfactory, utilizing newly introduced hybrid models which have high capabilities in analyzing and predicting complicated systems is recommended.
Availability of data and material
The used data in this research provided by ministry of energy of I.R. of Iran without any charge
References
Agatonovic-Kustrin S, Beresford R (2000) Basic concepts of artificial neural network (ANN) modeling and its application in pharmaceutical research. J Pharm Biomed Anal 22:717–727
Ahmad I, Zhang F, Liu J, Anjum MN, Zaman M, Tayyab M, Waseem M, Farid HU (2018) A linear bi-level multi-objective program for optimal allocation of water resources. PLoS ONE 13(2):e0192294. https://doi.org/10.1371/journal.pone.0192294
Ahmadianfar I, Adib A, Taghian M (2017) Optimization of multi-reservoir operation with a new hedging rule: application of fuzzy set theory and NSGA-II. Appl Water Sci 7:3075–3086
Ahmed JA, Sarma AK (2005) Genetic algorithm for optimal operating policy of a multipurpose reservoir. Water Resour Res 19(2):145–161
Al Radif A (1999) Integrated water resources management (IWRM): an approach to face the challenges of the next century and to avert future crises. Desalination 124:145–153
Anand J, Gosain AK, Khosa R (2018) Optimization of multipurpose reservoir operation by coupling soil and water assessment tool (SWAT) and genetic algorithm for optimal operating policy (case study: Ganga river basin). Sustainability 10(5):1–20
Atashpaz-Gargari E, Lucas C (2007) Imperialist competitive algorithm: an algorithm for optimization inspired by imperialistic competition. In: IEEE congress on evolutionary computation, pp 4661–4667
Bozorg-Haddad O, Afshar A, Mariño MA (2008) Honey-bee mating optimization (HBMO) algorithm in deriving optimal operation rules for reservoirs. J Hydroinform 10(3):257–264
Bozorg-Haddad O, Janbaz M, Loáiciga HA (2016) Application of the gravity search algorithm to multi-reservoir operation optimization. Adv Water Resour 98:173–185
Chang JX, Huang Q, Wang YM (2005) Genetic algorithms for optimal reservoir dispatching. J Water Resour Manag ASCE 19:321–331
Dandy G, Maier H (1993) Use of artificial neural networks for forecasting water quality. Paper Presented at the stochastic and statistical methods in hydrology and environmental engineering. An international conference in honor of professor T.E. Unny, Waterloo, Ontario, Canada
Deb K (2001) Multi-objective optimization using evolutionary algorithms. Wiley, New York
East V, Hall MJ (1994) Water resource systems optimization using genetic algorithms. Hydroinformatics 1:225–231
Ehsani N, Charles J, Vörösmarty C, Balázs M, Fekete BM, Eugene Z, Stakhiv EZ (2017) Reservoir operations under climate change: storage capacity options to mitigate risk. J Hydrol 555:435–446
Fahmy HS, King JP, Wentzel MW, Seton JA (1994) Economic optimization of river management using genetic algorithms. Paper presented at the international summer meeting: engineering for sustainable development. Paper no. 943034, ASAE, St. Joseph, MI
Fang HB, Tie-song HU, Zeng X, Feng-yan WU (2014) Simulation-optimization model of reservoir operation based on target storage curves. Water Sci Eng 7(4):433–445
Franchini M (1996) Use of a genetic algorithm combined with a local search method for the automatic calibration of conceptual rainfall-run-off models. Hydrol Sci J 41(1):21–39
Fu L (1994) Neural networks in computer intelligence. McGraw-Hill, New York
Ghatfan AA, Badia YH (2017) Water level prediction in 16th Tishreen dam reservoir using artificial neural networks. Am J Innov Res Appl Sci 150–156. https://www.american-jiras.com/Haidar-ManuscriptRef.1-ajira190417.pdf
Gudmundsdottir H, Horne RN (2018) Reservoir characterization and prediction modeling using statistical techniques. In: Proceedings of 43rd workshop on geothermal reservoir engineering. Stanford University, Stanford, CA, pp 1–12
Hadji MM, Vahidi B (2012) A solution to the unit commitment problem using imperialistic competition algorithm. IEEE Trans Power Syst 27(1):117–124
Heydari M, Othman F, Taghieh M (2016) Optimization of multiple and multipurpose reservoir system operations by using matrix structure (case study: Karun and Dez reservoir dams). PLoS ONE. https://doi.org/10.1371/journal.pone.0156276
Ji CM, Yu S, Zhou T, Yang Z, Liu F (2011) Application of ant colony algorithm for hydropower dispatching function optimization. Autom Electr Power Syst 35:103–107
Karamouz M, Houck MH, Delleur JW (1992) Optimization and simulation of multiple reservoir systems. J Water Resour Plan Manag 118(1):71–81
Kaveh A, Talatahari S (2010) Optimum design of skeletal structures using imperialist competitive algorithm. Comput Struct 88(21–22):1220–1229
Khalili M, Esmailpour M, Naderi B (2016) The production–distribution problem with order acceptance and package delivery: models and algorithm. Manuf Rev. https://doi.org/10.1051/mfreview/2016018
Khorani V, Disfani VR (2011) A mathematical model for urban traffic and traffic optimization using a developed ICA technique. IEEE Trans Intell Transp Syst 12(4):1024–1036
Kibler KM (2017) The hydraulic size of a dam: a metric indicating potential hydrologic impact from storage and diversion. Int J Hydrol 1(4):107–119
Kilinç I, Ciğizoğlu K (2012) Reservoir management using artificial neural networks. Paper presented at the 14th. Reg. Directorate of DSI (State Hydraulic Works), Istanbul, Turkey
Krishnakumar K, Goldberg DE (1992) Control system optimization using genetic algorithm. J Guid Control Dyn 15(3):735–740
Menhaj B (2000) The basic of neural networks. Amir Kabir Press, Tehran
Obringer R, Nateghi R (2018) Predicting urban reservoir levels using statistical learning techniques. Sci Rep. https://doi.org/10.1038/s41598-018-23509-w
Pan Z, Lei D, Zhang Q (2018) A new imperialist competitive algorithm for multi-objective low carbon parallel machines scheduling. Math Probl Eng 5914360:1–13
Piri J, Rezaei Kahkha MR (2016) Prediction of water level fluctuations of Chahnimeh reservoirs in Zabol using ANN, ANFIS and cuckoo optimization algorithm. Iran J Health Saf Environ 4(2):706–715
Proff NL, Hart DD (2002) How dams vary and why it matters for the emerging science of dam removal. Bioscience 52(8):659–668
Ritzel BJ, Eheart JW, Ranjithan S (1994) Using genetic algorithms to solve a multiple objective groundwater pollutant containment problem. Water Resour Res 30(5):1589–1603
Saha S, Roy D, Mazumdar A (2017) Performance of a system of reservoirs on futuristic front. Appl Water Sci 7:2667–2680
Sangiorgio M, Guariso G (2018) NN-based implicit stochastic optimization of multi-reservoir systems management. Water. https://doi.org/10.3390/w10030303
Saravanan K, Sasithra S (2014) Review on classification based on artificial neural networks. Int J Ambient Syst Appl 2(4):11–18
Satish P, Ramesh H (2019) Estimation of reservoir storage using artificial neural network (ANN). In: Rathinasamy M, Chandramouli S, Phanindra KBVN, Mahesh U (eds) Water resources and environmental engineering I: surface and groundwater. Springer, Berlin, pp 57–64. https://doi.org/10.1007/978-981-13-2044-6_5
Sedighizadeh M, Eisapour-Moarref A (2017) The imperialist competitive algorithm for optimal multi objective location and sizing of DSTATCOM in distribution systems considering loads uncertainty. INAE Lett 2:83–95
Taher SA, Hajiakbari Fini M, Falahati Aliabadi S (2014) Fractional order PID controller design for LFC in electric power systems using imperialist competitive algorithm. Ain Shams Eng J 5(1):121–135
Thair SK, Ayad SM, Hasan HM (2015) Reservoir operation by artificial neural network model (Mosul dam-Iraq, as a case study). Eng Technol J 33(4):1697–1714
Urmia Shahrchay dam Project. http://agrw.ir/SC.php?type=component_sections&id=229&sid=7. Accessed 20 Nov 2019 (in Persian)
Wang KW, Chang LC, Chang FJ (2011) Multi-tier interactive genetic algorithms for the optimization of long-term reservoir operation. Adv Water Resour 34:1343–1351
Yazdi J (2017) Check dam layout optimization on the stream network for flood mitigation: surrogate modelling with uncertainty handling. Hydrol Sci J 62(10):1669–1682
Yeh WWG (1985) Reservoir management and operations models. Water Resour Res 21:1797–1818
Zhang D, Peng Q, Lin J, Wang D, Liu X, Zhuang J (2019) Simulating reservoir operation using a recurrent neural network algorithm. Water 11:865. https://doi.org/10.3390/w11040865
Zurada JM (1992) Introduction to artificial neural system. West Publishing Co., Boston
Funding
This study has been carried out without any financial support or funds.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
There is not any conflict of interests in this work.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Emami, S., Parsa, J. Comparative evaluation of imperialist competitive algorithm and artificial neural networks for estimation of reservoirs storage capacity. Appl Water Sci 10, 177 (2020). https://doi.org/10.1007/s13201-020-01259-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13201-020-01259-3