
Abstract
With the increasing availability of Cooperative Intelligent Transport Systems, the Local Dynamic Map (LDM) is becoming a key technology for integrating static, temporary, and dynamic information in a geographical context. However, existing ideas do not leverage the full potential of the LDM approach, as an LDM contains streaming data and varying implicit information which are not captured by current models. We aim to provide a semantically enriched LDM that applies Semantic Web technologies, in particular ontologies, in combination with spatial stream databases. This allows us to define an enhanced world model, to derive model properties, to infer new information, and to offer expressive query capabilities over streams. We introduce our envisioned architecture which includes an LDM ontology, an integration and annotation framework, and a stream query answering component. We also sketch three application scenarios that illustrate the usability and benefits of our approach, thus we provide an in-depth validation of the scenarios in an experimental prototype.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
For Cooperative Intelligent Transport Systems (C-ITS), the integration of static, temporary, and dynamic information in a geographical context is a crucial feature for the understanding and processing of complex traffic scenes. Different ITS systems collect (sensor) data and exchange it by vehicle-to-vehicle (V2V), vehicle-to-infrastructure (V2I), or combined (V2X) communication, which naturally contains temporal data (e.g., traffic light signal phases) and geospatial data (e.g., GPS location) of traffic participants. Different types of messages are broadcast at most every 100 ms by traffic participants and roadside C-ITS stations to inform other participants about the current local state, e.g. about position and speed. The main types of V2X messages are:
-
Cooperative Awareness Messages (CAM) provide high frequency status updates of a vehicle’s position, speed, vehicle type, etc.;
-
Map Data Messages (MAP) describe the detailed topology of an intersection, including its lanes and their connections;
-
Signal Phase and Timing Messages (SPaT) give the projected signal phases (e.g., green) for each lane; and
-
Decentralized Environmental Notification Messages (DENM) in
Since V2X communication is a key technology to enable autonomous driving, many projects regarding this technology have been carried out. The SAFESPOT [1] and CVIS [30] projects are of particular interest, since they are motivated by improving road safety. In these projects, the concept of the Local Dynamic Map (LDM) was introduced, which acts as an integration platform to combine static digital maps, also called geographic information system (GIS) maps, with dynamic environmental objects representing, e.g., vehicles or pedestrians. As shown in Fig. 1, the LDM consists of the following four layers:
-
(1)
Permanent Static: the first layer contains static information obtained from GIS maps that include roads, intersections, and points-of-interest (POIs);
-
(2)
Transient Static: the second layer extends the static map by traffic attributes, roadside ITS stations, landmarks, and intersection features such as more detailed topological data that include lanes and their connections;
-
(3)
Transient Dynamic: the third layer contains temporary regional information like weather, road or traffic conditions, e.g., traffic jams, and traffic light signal phases;
-
(4)
Highly Dynamic: the fourth layer contains dynamic fast-changing information, mainly V2X messages of road users including their GPS position, heading, and speed.

The four layers of an LDM [1]
We recognize that the LDM is a key technology for data integration in cooperative ITS systems, which is indicated by its initial standardization as ETSI [24, 25] and ISO ([27, 28]) technical recommendations. Influenced by the ongoing standardization efforts, there is a common understanding that the LDM should include a high-level API, a GIS database (DB), and have SQL as a query language. Thus, the LDM is a conceptual data store in an ITS station, which integrates GIS maps, sensor data, and V2X messages.
To realize the LDM, the authors of [1] and [34] suggest an object-oriented schema, called world model, a topology of geospatial objects, and an object associator. The object associator connects different objects like vehicles and roadside units to the world model. Yet, the existing ideas do not address the “streaming” nature of the data in combination with the complex world model, which would allow to leverage the full potential of the LDM approach. The LDM can become a powerful integration tool for sensor data and V2X messages in general, allowing complex scene recognition by utilizing implicit information in the streaming data. Such an advanced integration can be used to provide new or enhanced functionality for ITS applications. For instance, by combining the lane direction, the trajectory, and the role of a vehicle (e.g., ambulances) a wrong-way driver can be detected by querying the stream of V2X messages. By implicit information, we mean all the data that is not directly represented either by V2X messages or by static information from the GIS map. We identified the following list of important implicit information in an LDM:
-
Part-Whole relations, e.g., a traffic light is part of an intersection;
-
Spatial relations, e.g., a car is crossing a stop lane that is within an intersection;
-
Connectivity, e.g., one intersection is connected to another intersections via a road;
-
Functionality, e.g., if two objects have the same identifier (ID), they are the same.
In this paper, we aim to provide a semantically enriched LDM that applies Semantic Web technologies to the standard LDM approach, which include ontologies (an enhanced world model), spatial-stream databases, the related stream processing, and ontology-based data access (OBDA) [15, 40] for connecting the ontology with the database. Essentially, OBDA is the technique for accessing databases through the ontology by queries (typically, conjunctive queries). Although adding another layer increases complexity, but we gain the following advantages from a semantically enriched LDM:
-
World Model: our notion of a world model is captured by an LDM ontology, which is based on the W3C standard OWL [31] and simply modifiable and extendable. Extensions can be made without altering the database and its relational schema.
-
Model Properties: the formal models of an ontology and the data have defined properties, which can be used for verification, simplification, and optimization on the conceptual level. For instance, by defining constraints in the ontology, inconsistencies in the data can be found; e.g., by stating disjointness of the concepts car and bicycle, that a an object can not be both a car and a bicycle.
-
Inference: OBDA allows us to infer new information at query time (e.g., class hierarchies), which reveals implicit information and keeps the amount of stored data small.
-
Expressive Queries: the queries are posed through the ontology extending the vocabulary beyond database relations. The query language of conjunctive queriesFootnote 1 (CQ) is simple and yet powerful. Furthermore, by examining the structure of the ontology, we can obtain meaningful combinations of query atoms, which aid in building and validating user queries.
By semantically enriching the LDM, we highlight the following contributions and related challenges, which we aim to address in this paper:
-
Modeling: besides the mentioned ETSI/ISO standards, mobility vocabularies are defined in Schema.org and Mobivoc.Footnote 2 Yet, there are no comprehensive ontologies available that allow to capture an LDM and related V2X messages. The latter are standardized and thoroughly specified, but based on a different (modeling) language, namely the Abstract Syntax Notation One (ASN.1). The specifications of V2X messages in ASN.1 are tree-like and must be converted into triples of an RDF-graph, as needed by the ontology standards in the Semantic Web.
-
Integration and Annotation: after the conversions to triples is completed, the V2X messages and the GIS database have to be mapped to the given vocabulary of the ontology. Due to the tree-like structure of the messages, not all relations between objects are available, hence we need to calculate the missing relations, e.g., spatial relations. The integration and annotation steps have to handle static and streaming data in a uniform way and should be easily extendable and maintainable.
-
Stream query answering: the combination of the methods and respective techniques for query answering (QA) over streams are challenging regarding performance and scalability. With OBDA, there is a trend to lightweight query answering over ontologies; we thus can benefit from recent results which improve performance and scalability (cf. [15, 40]). On the other hand, for query evaluation on stream database systems such as PipelineDBFootnote 3, most implementations are designed toward efficiency, but not for complex query evaluation using ontologies and/or geospatial data; both aspects add complexity and diminish scalability.
The remainder of the paper is organized as follows. Section 2 describes the state-of-the-art of the LDM approach. In Section 3 we introduce Semantic Web and stream-processing technologies. Section 4 presents our envisioned architecture to illustrate how Semantic Web technologies can be used for the LDM. Section 5 describes the stream query answering component, which is a central component of the architecture. In Section 6 we present three application scenarios to show the benefits of a semantically enriched LDM, which is evaluated in Section 7. Section 8 concludes with possible future works and refinements.
2 State-of-the-art of the LDM
In this section, we have a closer look at state-of-the-art efforts regarding the LDM approach.
SAFESPOT Project
The SAFESPOT project initiated the term and definition of the LDM in work package D 7.3.1 [1]. The authors recognized that the data model “has a hierarchical structure using associations between classes to describe their relationships”. However, they dropped an object-orient model in favor of a relational model tailored to a Relational Database Management System (RDBMS) due to performance concerns. The authors also suggested two implementations based on commercial geospatial RDBMS: PG-LDM and NAVTEQ-LDM. PG-LDM is developed by Tele Atlas and built on top of PostGIS.Footnote 4 This is a natural choice, as the first and second layer contain largely static GIS maps. NAVTEQ-LDM is built by NavteqFootnote 5 and uses SQLiteFootnote 6 as its geospatial RDBMS. It is thus well-suited for the first and second LDM layer and already targets the deployment on mobile devices. In SAFESPOT, also a relational database schema was introduced, which represents the four layers with different groups of tables that include static features, moving objects, conceptual objects, and relationships. Finally, it defined an API that supports custom functions such as to access all lanes of a road element (called getLanesForRoadElement) and a direct interface to submit SQL queries.
ETSI/ISO Standards
The initial standard was by the ETSI TR 102 863 (V1.1.1) report [25], where an LDM was defined as “a conceptual data store located within an ITS station … containing information that is relevant to the safe and successful operation of ITS applications.” The report locates the LDM in the facilities layer of the ITS station reference architecture and connects the four layers with possible ITS applications. For example, speed limitation is defined in the third layer and can be used for co-operative speed management. The report also recognizes that the LDM architecture is made of a management and a data store that can be accessed through an API with three interfaces, called AF-SAP for applications, NF-SAP for networking, and SF-SAP for security. It also addresses the topic of how the LDM can be linked to the road network of a static GIS map (the first layer), called dynamic location referencing. In the ETSI EN 302 895 (V1.1.0) final draft [24], the work of the previous report was extended with new functionalities, introducing LDM Data Objects, which are compositional data structures, and LDM Data Providers/Customers. Also a new interface for LDM services and maintenance was defined. Via the interface Data Objects can be fetched with SQL-like filtering and selection statements. We view a semantically enriched LDM as an extension of LDM Data Objects and Providers. With a more international focus, the ISO/TS 17931:2013 [27] and ISO/TS 18750:2015 [28] reports defined comparable standards to ETSI, which include an LDM architecture, data models, and an embedding into the ITS architecture.
Recent Research
Netten et al. [34] introduced DynaMap, which is an extension to the LDM architecture. They recognized that previous work on the LDM was car-centric and thus focussed on roadside ITS stations. Netten et al. defined a novel architecture that includes data sources, a world model, world objects, and data sinks. World objects are created by the world object associator based on the streamed input from the different data sources which includes V2X messages and sensor readings. The world model resembles an ontology and defines the relationships between all the objects including their hierarchical relations and a running history of data items. They also recognize that each object has a reference position that connects it to a spatial topology.
Koenders et al. [29] developed an “open Local Dynamic Map”, where they point out that the LDM cannot store all objects and their data items permanently. Hence, they introduced a “simple” streamed filtering technique, by deleting the objects that are too far from the ITS station. They designed their own relational schema having tables for areas, objects, and roads including a spatial topology. They also provided additional functions to the LDM, which include map-matching and a security layer. Shimada et al. [42] implemented the initial (RDBMS-centric) approach by SAFESPOT and evaluated it in a complex collision detection application scenario. For the evaluation, a traffic simulation tool was used to generate V2X messages for different numbers of vehicles. The authors also recognized that GIS maps and tools can be open-source and extracted the road graph from collaborative mapping project OpenStreetMap (OSM).Footnote 7
Ulbrich et al. [45] introduced a graph-based context representation of the static and dynamic environment used by an ego vehicle. For the context representation, they developed an ontology that includes classes for actions, traffic objects, and situations. The ontology is part of an “overall” context model that includes (a) a geometric layer, (b) a topological layer, and (c) a semantic layer, which are all linked to each other. Besides the context model, the authors described an approach for information aggregation in order to enrich the model. Furthermore, they provided a quantitative evaluation of the approach in the context of their Stadtpilot project.
Zoghby et al. [48], investigated an approach to improve the environmental perception of vehicles by cooperative perception. They extended the individual LDM of each vehicle with an extension called Dynamic Public Map (DPM) that is based on Dynamic Distributed Maps (DDM), which are exchanged between the vehicles. They provided an algorithm for calculating the DPM using (i) a discounting step with confidence evaluation, (ii) a prediction step using spatial and temporal alignment, and (iii) a fusion step using an existing association algorithm. An extensive experimental evaluation showed that the DPM improves the detection of surrounding vehicles and their classification.
Colored spatio-temporal Petri nets as introduced by Zhao et al. [47] are intended to model traffic control cyber-physical systems. We believe that these nets are an orthogonal approach, but could be extended to streamify the LDM.
Current Shortcomings
The above efforts are already mature and allow an elaborate usage of the LDM. However, they are of limited use in a complex, fast-changing environment with vehicles that update information at high frequency. We believe the following shortcomings are still present:
-
Database-centric: besides DynaMap, all other efforts have a database-centric model of the LDM using a static schema, where the LDM objects are directly mapped to relational tables. New types of objects need a modification of the schema, which makes it harder to add new domains, e.g., traffic regulations. Furthermore, the database schema cannot simply capture and query class hierarchies and the dependencies between the different objects as it is not graph-based.
-
Stream processing: except DynaMap, other efforts are designed to work on top of a GIS database (e.g., PostGIS) and neglect the streaming nature of the LDM data, since it should allow for real-time queries over large amounts of data “in-stream”, i.e., without storing. Stream processing needs a clear data model (e.g., a point-based model) and a defined query language that supports window operators (e.g., having sliding windows), stream joins, and aggregation over streams (e.g., average speed over 30 s). These features are either entirely missing or only considered in external components.
-
Sound integration: the integration of all layers and the model of a complex intersection could lead to incomplete or inconsistent data. A MAP message allows integrity constrains to check for wrongly connected lanes. However they are only implicit in the database definitions and do not cover for all possible integrity cases (e.g., disjointness between classes).
As already mentioned, DynaMap and Stadtpilot address to some extent the above shortcomings, but differs from our work in three points: (a) our world model is based on a standard language using ontologies, thus existing approaches and algorithms can be applied directly; (b) their streaming support is based on “monitors” or “vector of points” that do not provide the power of a full query language, hence, this makes a flexible processing, optimization, and integration harder; and (c) checking inconsistencies is not an aim of both projects. Thus, our emphasis is more on query answering over streams with ontologies, whereas DynaMap and Stadtpilot have an object-oriented data model and use custom processing techniques such as a point-in-lane-segment algorithm.
3 Background Technology and Methods
In this section, we give a brief introduction to the methods and technologies that we envision to use for achieving a semantically enriched LDM.
Semantic Web Technologies
Semantic Web technologies provide a common framework for sharing and reusing data across boundaries. We refer to the seminal article of Berners-Lee et al. [10] for an outline of the ideas and architectural overview to the Semantic Web stackFootnote 8 The Resource Description Framework (RDF) [13, 41] serves as a flat, graph-based unified data model which is based on URIs as identifiers for objects and relations. An RDF graph is represented by triples 〈S,P,O〉 of a subject S, a predicate P, and an object O. Ontologies are used for modeling knowledge domains, by expressing relations between terms with a restricted vocabulary and by modeling them as class hierarchies. In the Semantic Web context, OWL [31] plays a central role as the standard modeling language of ontologies with its (formal) logical underpinning of Description Logics (DL) [6]. The vocabulary of a DL consists of objects (called individuals), classes (called concepts), and properties (called roles). Furthermore, a knowledge base (KB) consists of a terminological box (TBox), which contains axioms about relations between classes and properties, and instance data in an assertion box (ABox), which contains factual knowledge about individuals by the following assertions represented as N-triples (cf. [6]):
-
Class assertions 〈id1 typeClass〉: states object id1 is of type Class, e.g., Vehicle;
-
Object property assertions 〈id1 property1id2〉: states object id1 is related by property1 to object id2, e.g., 〈lane1 isPartOf intersection2〉;
-
Data property assertions 〈id1 property2value〉: states object id1 has a property2 with a numeric value, e.g., 〈car1 hasSpeed 20〉.
In the light of data-intensive applications, there is a trend to move from the expressive OWL 2 language toward more scalable and tractable fragments called OWL 2 Profiles [33]. These research efforts have been focused on efficient query answering techniques over lightweight ontology languages, such as OWL2 QL [15] and OWL2 EL [5]. Conjunctive query evaluation over OWL2 QL ontologies can be delegated by SQL query rewriting to a RDBMS, which facilitates scalable query processing. Ontologies modeled with OWL2 QL are well-suited for defining the conceptual level. The Ontop system [40] is an example for an ontology-based data access (OBDA) system, where a global schema is defined as an OWL2 QL ontology, and the source schemas are mapped to the global schema by SQL queries. OBDA has been extended to non-standard data formats such as GIS [9, 20], temporal data [4, 11], and streamed data [14, 35].
Stream Processing and Stream Reasoning
Relational stream processing has been investigated for long. An important step was the Continuous Query Language (CQL) [3] with the design goals of a clear syntax based on SQL-99 and a multi-set (bag) semantics. The authors defined streams and relations as data types and use the following operators that map between them: (1) stream-to-relation, (2) relation-to-relation, and (3) relation-to-stream. For (1), they introduced various window operators n order to select tuples rom a stream.Among them are time-based sliding, tuple-based sliding, and partitioned window operators.
(2) is taken directly from the relational database setting; for (3), they defined insert stream, delete stream, and relation stream operators. Based on the operators, they developed a method for query execution and benchmarked a prototype implementation of a highway tolling application scenario in order to show the applicability of their approach.
Stream reasoning studies how to introduce reasoning processes into scenarios that involve streams of continuously produced information. In that, domain models provide background knowledge for the reasoning and lift streams to a “semantic” level. Particular aspects of stream reasoning are incremental and repeated evaluation, either push-based, i.e. on data arrival, or pull-based at given points in time, and using data snapshots (called windows) to reduce the data volume. Windows can be obtained by selecting data based on temporal conditions (called time-based windows) or data counts. Besides the seminal CQL, many formalisms and languages for stream reasoning exist. Among them are
-
(1)
extensions of the SPARQL web query language, e.g., C-SPARQL [7], Morph-streams [14], and CQELS [36];
-
(2)
extensions of ontology languages to streams e.g., by Ren and Pan [39], STARQL [35], and Cayuga [39]; and
-
(3)
rule-based formalisms e.g., ETALIS [2], Reactive ASP [26], Teymourian et al. [44], LARS [8], metric Datalog [12], and Streamlog [46].
LARS [8] provides a rule-based formalism with generic windows as first class citizens. Windows can be nested, and modal operators allow to reason about points in a window. LARS provides a monotonic and an answer set programming (ASP) semantics that generalizes the standard ASP semantics. It offers nondeterminism and nonmonotonicity to deal with missing information. The ETALIS system [2], which was applied to traffic management, offers a rule-based language to express complex event patterns enriched with a background KB. The patterns are expressed with predicates like after(e1,e2) and are combined with the KB and causal parts for query answering. The standard Prolog query evaluation is altered to an event-driven backward chaining (EDBC) of rules. A Prolog system is then triggered to evaluate a query and the EDBC rules when new data is passing by. The STARQL framework [35] is an effort for streamifying ontology-based data access (OBDA) by introducing an extensible query language and uses temporal reasoning over sequences of ABoxes. The framework extends the first-order query rewriting of DL-Lite with Intra-ABox reasoning.
4 Architecture of a Semantically Enriched LDM
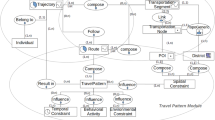
Our envisioned architecture is shown in Fig. 2 and illustrates how Semantic Web technologies can be used to enrich the LDM. In this paper, we focus on the main methods and related techniques the architecture and leave parts of the technical analysis to (existing) in-depth work (see [22] and [23]). Also, we show how the architecture is implemented.

LDM system architecture and ontology
We apply and extend two different methods for the semantic enrichment: first, rule-based methods are used to (semantically) complete the LDM by materializing newly derived data. This is applied to slower changing data of the first, second, and third layers of the LDM, but is is also needed for more complex tasks like consistency checking and diagnosis. Second, OBDA-based methods are applied to (semantically) complete queries on demand by encoding axioms (e.g., sub-class axioms) of the ontologies into the query, called query rewriting. This approach is suitable for large amounts of fast changing data that occur in the fourth layer. The queries can be used for data aggregation and (complex) event detection (details are shown in Section 5). The starting points for the methods are the works on rule-based spatial data extraction [21], spatial query answering (QA) [20], and spatial-stream QA [23]. Next we describe the LDM ontology, as well as the integration, annotation, and linking framework.
LDM Ontology
With the support of ITS domain experts, we have modeled an ontology to capture the four levels of the LDM architecture as well as elements of a traffic scene.Footnote 9 The LDM ontology is represented by the W3C standard OWL2 QL [15] for OBDA and partially rendered in Fig. 2b. Besides the restriction to OWL2 QL, our methods are ontology-agnostic, hence other ontologies could be used as well. We follow a layered approach starting at the bottom with a simple separation between the following classes:
-
V2XFeature is the spatial representation of V2X objects;
-
GeoFeature represents the GIS aspects of the LDM including POIs and the road networks;
-
Geometry is the geometrical representation of features;
-
Actor is an individual actor involved in a transport scene;
-
Event describes events that happen in a transport scene;
-
CategoricalValues such as allowed maneuvers or vehicle roles (e.g., emergency vehicle).
We also introduce the following properties:
-
properties for partonomies, e.g., isPartOf;
-
spatial relations, e.g., intersects;
-
connectivity, e.g., connected; and
-
standard properties, e.g., isAllowed, hasRole, isManaged, or positions.
The sub-classes of GeoFeature are linked to the GeoOWL and GeoNames ontologies for embedding it into existing work.Footnote 10V2XFeature is the domain specific modeling of the MAP topology and describes the details of an intersection including its lanes, allowed maneuvers, and traffic lights. The Actor class includes persons, vehicles, as well as roadside ITS stations. Objects of the Actor class have their autonomous behavior and are a generator of streamed data.
Static and Stream Databases
In an LDM, we have to deal with spatial-relational data that never or infrequently change (the first and second layer), and the streaming data (third and fourth layer) that changes at higher frequency (at most 100 ms). Besides the TBox T that consists of the ontology axioms, we distinguish between a (standard) static ABox A that is a static database, a stream database F, a static spatial database SA, and a spatial database with stream support SF. These sources can be combined in different ways as shown below, where angled brackets show that the sources are the same physical and logical entity:
-
(i) 〈A,F,SA,SF〉 as a “universal” database, which allows for streamed and spatial data;
-
(ii) A,F, 〈SA,SF〉 as a normal database for A, a stream database for F, and a spatial database which allows for time stamps;
-
(iii) A,SA, 〈F,SF〉 as a normal database for A, a spatial database for SA, and a stream database with limited support for spatial data;
-
(iv) A,F,SA,SF as separate databases that are only connected by query atoms at query time.
Our work builds on combination (iii), therefore we enhance a stream database (in our case PipelineDB) with the support for spatial data. The spatial data includes the static spatial objects of the GIS maps such as POIs (e.g., petrol stations). Furthermore, V2X objects like intersection topologies are also kept in the spatial database. After integration and annotation of a V2x message, most of the objects have a geometrical representation, i.e., polygons or points. Objects of the first layer are initially added from OSM instances (e.g., Vienna) and stored in the spatial database. Objects of the second layer might be predefined for a roadside unit or frequently updated by incoming MAP messages.
The third and fourth layer are represented by a stream database and include relations such as streams and continuous views (named as in PipelineDB). The database is modeled such that there are one-to-one mappings from stream relations to continuous views, and further to the TBox classes and properties. For instance, vehicle positions are fed into the relation stream_pos that is accessed by view_pos, which then is mapped to the property positions. The stream relations keep the raw message data, which are only accessible via the continuous views over the streams.
Integration and Annotation Framework
The integration framework represents the initial layer that is responsible for (continuously) receiving the V2X messages. The raw message data is extracted and added either to normal relations (i.e., relational tables) of the static database or the stream relations (called streams) of the stream database, which are managed by PipelineDB. Note that in PipelineDB streams are write-only, so the query component has to create (read-only) continuous views on-demand for querying the streams of data. Redundancy and duplication of received message data is handled in this layer. Since we have a one-to-one mapping between classes (e.g., vehicles) resp. properties (e.g., speed) and database relations, we split the message content into tuples and add them to the respective relations. For instance, we add the tuples 〈car1〉 resp. 〈car1 hasSpeed50〉 to the unary table Vehicle resp. binary stream hasSpeed.
Furthermore, we align the data items to our system timeline using the time injected by the data sources (called application time). If the application time is missing, we add the (implicit) arrival time. In addition to the alignment, we erase duplicate data items in the working storage based on the unique identification by object ID, message ID, and application time. Duplicate data items might occur due to the multi-hop propagation of V2X messages. Note that we do not have distributed and redundant LDMs here, as we consider in our system design only single roadside ITS stations.
For the first three layers, we can take advantage of our work on an OSM data extraction tool, which combines Datalog rules with simple extract, transform, and load (ETL) features [21]. Note that only the coarse road network and POIs can be extracted from OSM, since detailed topologies that include lanes are often not available or inaccurate. Hence, we have to model the topologies single-handed or extract it from other sources. In the ETL tool, each rule is simply a mapping from a source to target with an optional transformation step in between.
Example 1
The following rules create class and property triples for police stations in a city, where and extract the OSM points that are tagged as “police”:Footnote 11 ∧ →. ∧ ∧ ∧ ∧ →.
Linking Framework
The linking framework (LF) computes and stores links between objects that are not directly represented in the data. The linking could be computed offline or on-demand using similar Datalog rules as in the annotation framework. For the linking, spatial relations are the main focus, where we follow the standard approach called Dimensionally Extended Nine-Intersection Model (DE-9IM), which supports relations like touches, intersects, or disjoint. For instance, one important link is the adjacency of lanes.
Example 2
The following rule calculates the lanes that are adjacent to other lanes: ∧ ∧ ∧ ∧ →.
The atom extracts the lane objects from the incoming MAP message and returns the polygons of these objects, which are checked in if the polygons touch each other. Another important link is the connection of the MAP intersection object to its representation in OSM, which is a node in the road network. For this, the OSM representation has to be matched to the closest MAP intersection, thus anchoring the V2X features in the OSM road network.
Stream Reasoning and Problem Solving
Simple events can be detected by the stream QA component (details are given in Section 5), but complex events like multiple-vehicle collisions, which are a chain of simple events satisfying specific temporal relations, are not expressible by simple queries. This requires a more powerful stream reasoning component, which could by enabled by a more expressive rule-based formalism such as Answer Set Programming (ASP) [19] that offers nondeterminism and nonmonotonicity. Adding a long-term memory for detected events (called observations), the stream reasoning component could also be geared toward model-based diagnosis [37, 38], which would allow one to find the cause for complex traffic problems like traffic jams. This is a topic for future work.
API
The LDM is defined as a data integration platform that provides services to external applications. We aim to support different types of APIs. First we aim to support the standard API requirement by the ETSI TR 102 863 [25]. We assume that the SF-SAP is handled by the ITS station; thus it is not in the scope of our work. As described in the standard, the NF-SAP interface connects the LDM to the communication functions of the ITS station and receives the V2X messages, which are then forwarded to the integration layer.
5 Query Answering over Streams
The QA component is central to the usage of a semantically enriched LDM, since it allows us to access the streamed data in the LDM. We focus on pull-based queries that evaluate a query at a single point in time called the query time \(\mathbb {T}_{i}\).
Example 3
The following query should illustrate the component as it detects red-light violations on intersections by searching for vehicles y with speed above 30km/h on lanes x whose signals will turn red in 4s:
Query q exhibits the different dimensions that need to be combined:
-
Vehicle(y) and isManaged(x,z) are ontology atoms, which have to be unfolded with respect to the ITS domain that is modeled in the LDM ontology;
-
intersects(u,v) and hasLocation(x,u) are spatial atoms, where the first checks spatial intersection and the second the assignment of geometries to objects;
-
speed[avg,4s](y,v) resp. pos[line,4s](y,r) defines a window operator that aggregates the average speed resp. positions (as points) of the vehicles over the streams speed and pos; hasState[first,−4s](z,Stop) gives us the traffic lights, which switch in 4s to the state “Stop”.
For the evaluation of this query, we have to adapt OBDA to handle spatial and streaming data, which is not considered in the standard approaches like [15]. For that, we extend our preliminary work [20] with a window operator, which (a) collects a set of data items (e.g., positions or speed) for each query atom from the underlying stream; and (b) calculates different aggregation functions on the set of numerical (e.g., sum), sequential (e.g., first), and spatial (e.g., line) data items.
Data Model and Query Language
Our data model is point-based (in contrast to an interval-based model) and captures the valid time, extracted from the V2X messages, saying that some data item is valid at that time point. To capture streaming data, we introduce the timeline\(\mathbb {T}\), which is a closed interval of (\(\mathbb {N},\le )\). A (data) stream is a triple \(F=(\mathbb {T}, v, P) \), where \(\mathbb {T}\) is a timeline, \(v: \mathbb {T} \rightarrow \left \langle F, S_F \right \rangle \) is a function that assigns to each element of \(\mathbb {T}\) (called timestamp) data items of 〈F,SF〉, where F (resp. SF) is a stream (resp. spatial with streams) database, and P is an integer called pulse defining the general interval of consecutive data items on the timeline (cf. [35]). A pulse generates a stream of data items with the frequency derived from the interval length. We always have a main pulse with a fixed interval length (usually 1) that defines the lowest granularity of the validity of data points. The pulse also aligns the data items, which arrive asynchronously in the database (DB), to the timeline. We allow additional larger pulses that generate streams at lower frequency and thus of larger intervals; this can be utilized to perform optimizations such as e.g. caching.
Our query language is based on ordinary conjunctive queries (CQs) and adds spatial-stream capabilites. Thus, queries may contain ontology, spatial, and stream atoms. A spatial-stream CQ q(x) is a formula:
where x are the distinguished (answer) variables, y are either non-distinguished (existentially quantified) variables, objects, or constant values:
-
each \(Q_{O_{i}}(\mathbf {x},\mathbf {y})\) has the form A(z) or P(z,z′), where A is a class name, P is a property name of the LDM ontology, and z,z′ are from x ∪y;
-
each atom \(Q_{S_{j}}(\mathbf {x},\mathbf {y})\) is from the vocabulary of spatial relations and of the form S(z,z′), where z,z′ is as before and S is one of the following spatial relation rel ∈{intersects,contains,nextTo, equals,inside,disjoint,outside};
-
\(Q_{F_{j}}(\mathbf {x},\mathbf {y})\) is similar to \(Q_{O_{i}}(\mathbf {x},\mathbf {y})\) but adds the vocabulary for stream operators, which are taken from [8] and relate to CQL operators [3]. We have a window [agr,l] over a stream Fj, where l is the window size in time units (positive for past, or negative for future). The aggregate functionagr ∈{count,sum,first,…} (see below for details) is applied to the data items in the window:Footnote 12
-
[agr,l]: represents the aggregate of last or next l time units of stream Fj;
-
[l]: represents the single tuple of Fj at index l with l = 0 if it is the current tuple;
-
[agr,b,e]: represents the aggregate on a window between b and e in the past/future of a stream. This extension is inspired by [12] and allows to query historic data (e.g., logs), if they are stored as streams.
-
Query Rewriting by Stream Aggregation
We aim at answering pull-based queries at a single time point \(\mathbb {T}_{i}\) with stream atoms that define aggregate functions on different windows sizes relative to \(\mathbb {T}_{i}\). For this, we consider a semantics based on epistemic aggregate queries (EAQ) over ontologies [16] by dropping the order of time points for the data and handling the streamed data items as bags (multi-sets). This is similar to classic stream processing approaches. Roughly, we perform two steps, where we (1) calculate only “known” solutions, and (2) evaluate the rewritten query, which includes the TBox axioms as well, over these solutions. Each EAQ is evaluated over one or more filtered and merged temporal ABoxes. The filtering and merging, relative to the window size and \(\mathbb {T}_{i}\), creates for each EAQ ϕ one (so-called) windowed ABox \(A_{\boxplus _{\phi }}\), which is the union of the static ABox A and the filtered streaming data items from 〈F,SF〉. The EAQ are then applied on \(A_{\boxplus _{\phi }}\) by grouping and aggregating the normal objects, constant values, and spatial objects.
We introduce a bag-based epistemic semantics for the queries, where we locally close the world for the specific window and avoid “wrong” aggregations due to the open world semantics of OWL2 QL. Further details on the algorithm for EAQ evaluation are provided in [18, 23].
For normal objects and constant values, we allow different aggregate functions such as count, min, max, sum,avg, first, last on the data items of a stream. For last and first, we need to search the bag of data items as the sequence of time points is lost. This is achieved by iteratively checking whether we have a match at one of the time points. In the implementation, the first and last match can be simply cached while processing the stream.
For spatial objects, geometric aggregate functions are applied to the bag of data items, which are usually geometries. As with last, the order of the items is lost, hence, we need to rearrange them to create a valid geometry g(s), which is a sequence p = (p1,…,pn) of points pi. We also introduce new aggregate functions to create new geometries:
-
point: we evaluate last to get the last available position p1;
-
line: we create p = (p1,…,pn), where p1≠pn and determine a total order on the bag of points, such that we have a starting point using last and iterate backwards finding the next point by Euclidean distance;
-
line_angle: this aggregate function determines angles (in degrees) in a geometry by (1) applying the function line, (2) obtaining a simplified geometry using smoothing, and (3) calculating the angles between the lines of the simplified geometry.
-
polygon: similar to line, but we create a polygon (p1,…,pn), where p1 = pn by: (1) determining the convex hull of the bag of points, and (2) extracting all pairs of points representing the convex hull;
-
trajectory: The simplest approach to calculate a trajectory is by using the function line. However, this is often not sufficient, and more complex smoothing and map matching functions might be needed. For the prediction of the future paths, we allow different projections such a linear or curvature-based models. As additional information, we need to include the maximal distance and step size for each time point, where the current speed could be taken as simple approximation. Also more elaborate models using velocity profiles could be applied.
Besides the above aggregate functions, more functions such as computing a minimum spanning tree could be applied.
Query Evaluation by Hypertree Decomposition
A main challenge relates to the handling of three types of query atoms that need different evaluation techniques over possibly separate databases. Ontology atoms are evaluated over the static ABox A using a “standard” OWL2 QL query rewriting, i.e., PerfectRef [15]. For spatial atoms, we need to dereference the bindings to the spatial ABox SA and evaluate the spatial relations (e.g., inside) on the spatial objects. Stream atoms are computed via EAQs over the windowed ABoxes extracted from F and the spatial-stream ABox SF .
In [20], we introduced two spatial query evaluation strategies based on the assumptions that no bounded variables occur in spatial atoms and that the CQ is acyclic (roughly no proper cycle between join variables exists). As shown in [20], one of them is based on the query hypergraph and the derived join plan. This strategy is well-suited for a lifting to spatial-stream CQs, since it allows us fine-grained caching, the full control over the evaluation, and possibly the handling of different database entities. We omit here decomposing an acyclic query into a hypergraph and the related join tree (details in [32]). The main steps of our query evaluation strategies are:
-
(1)
construct the acyclic hypergraph Hq from q and label each hyperedge in Hq with lO, lS, and lF, if it represents an ontology, spatial, or stream atom, resp. the combination of them; lF gets the window size assigned, e.g., lF,2 for speed[avg,2s](y,v).
-
(2)
build the join tree Jq of Hq and extract the subtrees \(J_{\phi _{i}}\) in Hq, such that each node is covered by the same label lF,n. The intention is to extract subtree CQs that share the same window size l (where static queries have l = 0); they can be jointly evaluated and cached for future query evaluations.
-
(3)
apply detemporalization as described above, where for each subtree \(J_{\phi _{i}}\) the stream CQ \(q_{\phi _{i}}\) is extracted and computed. The results are stored in a (virtual) relation \(R_{\phi _{i}}\), and each \(J_{\phi _{i}}\) is replaced with a query atom pointing to Rϕ.
-
(4)
traverse Jq bottom up, left-to-right, to evaluate the CQ \(q_{\phi _{i}}\) for each subtree \(J_{\phi _{i}}\) (now without stream atoms) and keep the results in memory for future steps. Ontology atoms and spatial atoms are evaluated as described before.
Caching for future queries is achieved by storing the intermediate results in memory with an expiration time according to l; static results never expire. Implementation details are given in Section 7.
6 Application Scenarios
In this section, we give three application scenarios that illustrate the usability and benefits of our approach. The scenarios are related to the deployment of roadside ITS stations on complex road intersections. The ITS stations receive arbitrary V2X messages and are capable of sending signal phases (SPaT) and the local intersection topology (MAP) messages. The first scenario is concerned with static data, where the consistency of a topology is validated offline. The second and third scenario deal with streaming data arising from vehicle movements (CAM) and SPaT messages.
Application Scenario 1 (S1) - Consistency Checks
The LDM is defined as a data integration platform that provides services such as message validation to external applications. Hence, this scenario is related to the first and second layer of the LDM and shows that data inconsistency can be detected using Datalog rules. Inconsistencies occur in individual messages, but also the integration of different messages such as MAP and SPaT might lead to it, due to wrongly generated or not up-to-date information. The following rules show possible consistency checks.
Example 4
This rule checks if each ingress lane x connects to an outgress lane y: ∧ not ∧ ∧ ∧ →.
Note that not is the negation as failure for saying that the clause will succeed, if there is no match of x and y in the relation .
Example 5
The following rule checks if each ingress lane x has at least one maneuver, e.g., turn left: ∧ ∧ ∧ →.
Application Scenario 2 (S2) - Data Aggregation
The focus of this stream scenario is the collection of statistical data and vehicle moving patterns by observing the streaming data on a specific intersection. Data aggregation can be accomplished as an independent task, but is also a preliminary step for more complicated reasoning task such as diagnosis. The aggregation will be often based on the CAM messages, but also SPaT aggregation is interesting, as monitoring of traffic lights could be desired to detect faulty behavior.
Example 6
The following query returns the last signal phase u of each lane x on intersection I1 in an interval of 20 seconds:
A more challenging task is the analysis of driving patterns based on vehicles maneuvers (e.g., u-turns), which then can be used for event detection or gathering local traffic statistics.
Example 7
The following query returns all vehicles x and their brands y that are moving above 30km/h and have been heading straight during the last 5 seconds:
Application Scenario 3 (S3) - Event Detection
This stream scenario deals with the detection of emergency vehicles and red light violation. Emergency detection aims at giving preference to emergency vehicles, e.g., ambulances or fire trucks, by switching to a green phase for the incoming vehicle. For this case, we need to integrate CAM and MAP messages and use the LDM to detect whether a vehicle is an emergency vehicle and is moving on one of the incoming lanes of an intersection.
Example 8
This query returns the emergency vehicles z that are the last 10 seconds on incoming lanes of intersection I1:
In this example, we can see the interaction of all mentioned atoms. The stream atom position[line,10s](z,v) specifies a time-based window of 10s at query time, where the GPS positions are used to construct a path using the aggregate function line; intersects(u,v) checks whether the path crosses the bounding box of any incoming lane.
The detection of red light violations is driven by improving road safety on a heavily frequented intersection with bad visibility. This is our most challenging case, as all types of V2X messages have to be combined. We use the LDM to detect, whether a vehicle is moving above 30km/h on a lane, whose current signal phase will turn red in 4 seconds. Note that the parameter -4s relies on the capabilities of the signal controller to predicts its future state.
Example 9
This query is a small extension of Ex. 3 by limiting it to a single intersection. It returns all vehicles y that are moving above 30km/h and violate the signal phase stop of a lane x:
The examples above are just samples of possible queries, since our approach could also be used for other scenarios as collecting road tolls, surveillance, or route planning.
7 Implementation and Experiments
We have implemented a prototype for our spatial-stream query answering approach in Java 1.8 using the open-source PipelineDB 9.6.1Footnote 13 as the spatial-stream RDBMS. As a preprocessing step for each query, the hypertree decomposition is computed using the implementation of Gottlob et al. [17].Footnote 14 Based on it, each sub CQ is evaluated separately and (spatial) joined in-memory. For the query rewriting of OWL 2 QL, we used the implementation of Owlgres 0.1 [43]; more recent (and more efficient) implementations for query rewriting (e.g., [40]) are available.
The experiments are based on our scenarios of data aggregation and event detection located (a) on a single intersection and (b) on a network of locally connected intersections, both managed by a single roadside C-ITS station. The ontology, nine queries (see Table 1), the experimental setup with logs, and the implementation are available on our project website.Footnote 15 The nine queries are composed of three queries of Scenario 2, three queries of Scenario 3, and three queries that are synthetic and test specific aspects of the query evaluation. We use our LDM ontology (see Section 4) with 119 concepts having 113 inclusion assertions (e.g., sub-classes); 34 roles and 28 data roles having 31 inclusion assertions.
For (a), we have a T-shaped intersection as shown in Fig. 3a. It represents a real-world deployment of an experimental C-ITS station in Vienna, and connects two roads with 13 lanes and 3 signal groups linked to the lanes. We have developed a synthetic data generator that simulates the movement of a varying number of vehicles (10, 100, 500, 1000, 2500, and 5000) on a single intersection updating the streams every 50 ms on average. This allows us to generate streams with up to 10000 data items per stream and second.Footnote 16 We chose random starting points and simulated linear movements on a constant pace, creating a stream of vehicle positions. We also simulated simple signal phases for each traffic light that toggle between red and green every three seconds. This scenario aims to show the scalability of our approach with many vehicles that have simple driving patterns.
For (b), we use a realistic traffic simulation of 9 intersections in a grid (see Fig. 3b), developed with the microscopic traffic simulation tool PTV Vissim,Footnote 17 which allows us to simulate realistic driving behavior and signal phases. The intersection structure, driving patterns and signal phases are more complex, but the number of vehicles is smaler (max. 300) than in (a), as quickly traffic jams emerge. We developed an adapter to extract the actual state of each simulation step, allowing us to replay the simulation from the logs. To vary data throughput, we ran the replay with 0ms (no delay), 100ms (real-time), 250ms and 500ms delay.

Schematic representation of the scenarios
Results
We conducted our experiments on a Mac OS X 10.6.8 system with an Intel Core i7 2.66GHz, 8GB of RAM, and a 500GB hard disk drive. The average of 11 runs for query rewriting time and evaluation time was calculated, where the largest outlier was dropped. The results are shown in Table 2, where we present the query type (O for ontology, F for stream, and S for spatial atoms), the number of subqueries #Q, size of rewritten atoms #A, and the average evaluation time (AET) t in seconds for n vehicles or the delay in ms.
The baseline spatial-stream query is q3 for 500 vehicles, where we have a loading time of 0.22s, an evaluation time for the stream (resp. ontology) atom of 0.54s (resp. 0.03s), and a spatial join time of 0.05s. Clearly, 50% of the AET is used to evaluate the stream atoms (including rewriting steps). The loading time could be reduced by pre-compiling the program; this shortens evaluation by roughly 0.2s. Initial evaluation of the queries q4, q5, q6 and q9 show that with each new stream subquery the number of results dropped down to zero, which seems an implementation issue of PipelineDB with Continuous Views on the same stream with different window sizes. We found a workaround by adding a delay of 0.2s that again increases the number of results. This delay increases the AET, e.g. by 0.76s in q9, and might be ignored with future versions of PipelineDB and other stream RDBMS. The synthetic queries with predominant ontology (q6), spatial (q7), and stream atoms (q9) clearly show that the real challenging aspect of query evaluation are stream aggregates. The good performance of PipelineDB allows us to work on condensed results (reducing the join sizes); however, stream aggregates could be further accelerated by continuously calculating inline aggregates on the DB, which are skimmed by our queries. Notably, PipelineDB does not always keep the order of inserted data items; this does not affect our bag semantics, since an order on the data items is not needed.
In conclusion, the results show that our experimental prototype for up to 500 vehicles manages evaluation within 1.5 s (except query q9). This suggests that with optimizations such as the ones mentioned, the quick detection of red-light violations on complex intersections is feasible.
8 Conclusion
In this paper, we have presented an extension of the LDM approach with Semantic Web technologies and stream processing. The technologies allow us to define a “semantic” world model, i.e., the LDM ontology, an expressive spatial-stream query language, derived model properties, and the inference of new information over streams. Our envisioned architecture is designed to show how these technologies can be applied in the context of the LDM and V2X integration. The architecture consists of an ontology, an integration and annotation framework for static, spatial and stream databases, a query answering component over streams, and a more expressive problem solving component. We have also worked on an initial version of an LDM ontology, and show how the architecture is implemented based on existing work in spatial data extraction [21] and spatial-stream query answering [20] using PipelineDB. Apart from the restriction to OWL2 QL, our methods are ontology-agnostic, hence other ontologies or evolved versions of the initial one could be used as well.
Furthermore, we have developed application scenarios for (i) consistency checking, (ii) data aggregation, and (iii) event detection to show the usability and benefits of our design. Finally, based on the scenarios we have conducted experiments utilizing the microscopic traffic simulation PTV Vissim, to show the feasibility of query answering component.
Outlook Applications
The three application scenarios are good starting points; however more complex scenarios such as signal phase optimization of traffic lights or stream-based routing could be considered. As the next step, we aim to develop a model-based diagnosis component that includes a clear definition and encoding of observations O, a (fault) model S, and a list of system components C applied to the C-ITS domain. Based on the encoding, we aim to apply a standard rule-based evaluation with a solver for calculating a diagnosis. The diagnosis component could further be complemented with a repair and/or re-configuration service for the system components, which would allow the dynamic adjustment and optimization of signal phases on a network of intersections.
Outlook Framework
Future work is directed to extend the components of the framework framework. The LDM ontology is only an initial draft and may be refined to capture more elements of the LDM and a traffic scene. An evolved version of the ontology could be taken as a first step toward standardization. The query answering component over streams could be further elaborated by realizing push-based queries by an incremental evaluation and caching, handling of inconsistency in data items, and new aggregate functions.
Since the full coverage of ITS stations in urban/rural areas is not feasible soon, the exchange and usage of (distributed) LDMs should be available to all traffic participants, e.g., cyclists. However, the computation and communication power, which is sufficient in ITS stations, might not be available for all participants, hence our methods could be optimized for embedded systems. For instance, we may realize materialization and smart indexing of static data and the usage in-memory DBs.
Along the same lines, we have yet to consider distributed LDMs as introduced by [48], which would require alignment at the ontology level (if the ITS stations and vehicles use different schemas), and data fusion including consistency checks at the stream level. Distributed LDMs would enable us to apply our methods to larger settings of distributed traffic, and may be used as a tool for (distributed) planing and optimization. Finally, the framework can be directed toward more complex methods such as model-based diagnosis or complex event detection.
Notes
CQs are a lean representation of SQL select-project-join queries: is rewritten into SELECT a.x FROM MAPLane AS a, isIngress AS b WHERE a.x = b.x AND b.y = T
now part of https://here.com/
A recent version is available at https://commons.wikimedia.org/wiki/File:Semantic_web_stack.svg
andare legible renderings of the N-Triples〈x type PoliceStation〉and〈x hasPoliceStation y〉
This would be represented in CQL as , , , etc.
The intervals vary due to the number of vehicles, so we scale the DB updates up to 12 generators.
References
Andreone, L., Brignolo, R., Damiani, S., Sommariva, F., Vivo, G., Marco, S.: Safespot final report. Technical Report D8.1.1 (2010). Available online
Anicic, D., Fodor, P., Rudolph, S., Stojanovic, N.: EP-SPARQL: a unified language for event processing and stream reasoning. In: Proceedings of WWW 2011, pp. 635–644 (2011)
Arasu, A., Babu, S., Widom, J.: The CQL continuous query language: semantic foundations and query execution. VLDB J. 15(2), 121–142 (2006)
Artale, A., Kontchakov, R., Wolter, F., Zakharyaschev, M.: Temporal description logic for ontology-based data access. In: Proceedings of IJCAI 2013, pp. 711–717 (2013)
Baader, F., Brandt, S., Lutz, C.: Pushing the \(\mathcal {{EL}}\) envelope. In: Proceedings of IJCAI 2005, pp 364–369. Morgan-Kaufmann Publishers (2005)
Baader, F., Horrocks, I., Sattler, U.: Description logics. In: Staab, S., Studer, R. (eds.) Handbook on Ontologies, pp 21–43. Springer (2009)
Barbieri, D.F., Braga, D., Ceri, S., Valle, E.D., Grossniklaus, M.: C-SPARQL: a continuous query language for RDF data streams. Int. J. Semant. Comput. 4(1), 3–25 (2010)
Beck, H., Dao-Tran, M., Eiter, T., Fink, M.: LARS: A logic-based framework for analyzing reasoning over streams. In: Proceedings of AAAI 2015, pp. 1431–1438 (2015)
Bereta, K., Koubarakis, M.: Ontop of geospatial databases. In: Proceedings of ISWC 2016, pp. 37–52 (2016)
Berners-Lee, T., Hendler, J., Lassila, O.: The semantic web. Sci. Amer. 284(5), 34–43 (2001)
Borgwardt, S., Lippmann, M., Thost, V.: Temporalizing rewritable query languages over knowledge bases. J. Web Sem. 33, 50–70 (2015)
Brandt, S., Kalayci, E.G., Kontchakov, R., Ryzhikov, V., Xiao, G., Zakharyaschev, M.: Ontology-based data access with a horn fragment of metric temporal logic. In: Proceedings of AAAI 2017. To appear (2017)
Brickley, D., Guha, R. (eds.): RDF Vocabulary Description Language 1.0: RDF Schema. W3C Recommendation W3C (2004)
Calbimonte, J., Mora, J., Corcho, Ó.: Query rewriting in RDF stream processing. In: Proceedings of ESWC 2016, pp. 486–502 (2016)
Calvanese, D., Giacomo, G.D., Lembo, D., Lenzerini, M., Rosati, R.: Tractable reasoning and efficient query answering in description logics: The dl-lite family. J. Autom. Reason 39(3), 385–429 (2007)
Calvanese, D., Kharlamov, E., Nutt, W., Thorne, C.: Aggregate queries over ontologies. In: Proceedings of ONISW 2008, pp. 97–104 (2008)
Dermaku, A., Ganzow, T., Gottlob, G., McMahan, B.J., Musliu, N., Samer, M.: Heuristic methods for hypertree decomposition. In: Proceedings of MICAI 2008: Advances in Artificial Intelligence, pp. 1–11 (2008)
Eiter, T., Füreder, H., Kasslatter, F., Parreira, J.X., Schneider, P.: Towards a semantically enriched local dynamic map. In: Proceedings of ITSWC 2016 (2016)
Eiter, T., Ianni, G., Krennwallner, T.: Answer set programming: A primer. In: Proceedings of Reasoning Web Summer School 2009, pp. 40–110 (2009)
Eiter, T., Krennwallner, T., Schneider, P.: Lightweight spatial conjunctive query answering using keywords. In: Proceedings of ESWC 2013, pp. 243–258 (2013)
Eiter, T., Pan, J.Z., Schneider, P., Simkus, M., Xiao, G.: A rule-based framework for creating instance data from openstreetmap. In: Proceedings of RR 2015 (2015)
Eiter, T., Parreira, J.X., Schneider, P.: Towards spatial ontology-mediated query answering over mobility streams. In: Proceedings of Stream Reasoning Workshop 2016 (2016)
Eiter, T., Parreira, J.X., Schneider, P.: Spatial ontology-mediated query answering over mobility streams. In: Proceedings of ESWC 2017 (2017)
ETSI EN 302 895 (V1.1.0): Intelligent transport systems - Extension of map database specifications for Local Dynamic Map for applications of Cooperative ITS. Technical report, ETSI (2014)
ETSI TR 102 863 (V1.1.1): Intelligent Transport Systems (ITS); Vehicular Communications; Basic Set of Applications; Local Dynamic Map (LDM); Rationale for and Guidance on Standardization. Technical report, ETSI (2011)
Gebser, M., Grote, T., Kaminski, R., Obermeier, P., Sabuncu, O., Schaub, T.: Stream reasoning with answer set programming: Preliminary report. In: Proceedings of KR 2012 (2012)
ISO/TS 17931:2013: Intelligent transport systems - Extension of map database specifications for Local Dynamic Map for applications of Cooperative ITS. Technical report, ISO (2013)
ISO/TS 18750:2015: Intelligent transport systems - Cooperative systems - Definition of a global concept for Local Dynamic Maps. Technical report, ISO (2015)
Koenders, E., Oort, D., Rozema, K.: An open local dynamic map. In: Procedings of ITS European Congress 2014 (2014)
Kompfner, P.: Cvis final activity report. Technical Report D.CVIS.1.3 (2010). Available online
Krȯtzsch, M., Patel-Schneider, P.F., Rudolph, S., Hitzler, P., Parsia, B.: OWL 2 web ontology language primer. Technical report W3C (2009)
Maier, D.: The Theory of Relational Databases. Computer Science Press (1983)
Motik, B., Fokoue, A., Horrocks, I., Wu, Z., Lutz, C., Grau, B.C.: OWL 2 web ontology language profiles. W3C recommendation W3C (2009)
Netten, B., Kester, L., Wedemeijer, H., Passchier, I., Driessen, B.: Dynamap: A dynamic map for road side its stations. In: Proceedings of ITS World Congress 2013 (2013)
Özċep, Ö.L., Möller, R., Neuenstadt, C.: Stream-query compilation with ontologies. In: Proceedings of AI 2015, pp. 457–463 (2015)
Phuoc, D.L., Dao-Tran, M., Tuȧn, A.L., Duc, M.N., Hauswirth, M.: RDF stream processing with CQELS framework for real-time analysis. In: Proceedings of the 9th ACM International Conference on Distributed Event-Based Systems, DEBS 2015, pp. 285–292 (2015)
Poole, D.: A methodology for using a default and abductive reasoning system. Int. J. Intell. Syst. 5(5), 521–548 (1990)
Reiter, R.: A theory of diagnosis from first principles. Artif. Intell. 32(1), 57–95 (1987)
Ren, Y., Pan, J.Z.: Optimising ontology stream reasoning with truth maintenance system. In: Proceedings of the 20th ACM Conference on Information and Knowledge Management, CIKM 2011, pp. 831–836 (2011)
Rodriguez-Muro, M., Kontchakov, R., Zakharyaschev, M.: Ontology-based data access: Ontop of databases. In: Proceedings of ISWC 2013, pp. 558–573 (2013)
Schreiber, G., Raimond, Y., Manola, F., Miller, E., McBride, B.: Rdf 1.1 primer. W3C working group note W3C (2014)
Shimada, H., Yamaguchi, A., Takada, H., Sato, K.: Implementation and evaluation of local dynamic map in safety driving systems. J. Transp. Technol. 5(2), 102–112 (2015)
Stocker, M., Smith, M.: Owlgres: A scalable owl reasoner. In: Proceedings of OWLED 2008 (2008)
Teymourian, K., Paschke, A.: Plan-based semantic enrichment of event streams. In: Proceedings of ESWC 2014, pp. 21–35 (2014)
Ulbrich, S., Nothdurft, T., Maurer, M., Hecker, P.: Graph-based context representation, environment modeling and information aggregation for automated driving. In: Proceedings of 2014 IEEE Intelligent Vehicles Symposium Proceedings, pp. 541–547 (2014)
Zaniolo, C.: Logical foundations of continuous query languages for data streams. In: Proceedings of Datalog 2.0 Workshop 2012, pp. 177–189 (2012)
Zhao, H., Sun, D., Yue, H., Zhao, M., Cheng, S.: Using CSTPNs to model traffic control CPS. IET Softw. 11(3), 116–125 (2017)
Zoghby, N.E., Cherfaoui, V., Denoeux, T.: Evidential distributed dynamic map for cooperative perception in vanets. In: Proceedings of 2014 IEEE Intelligent Vehicles Symposium Proceedings, pp. 1421–1426 (2014)
Acknowledgements
Open access funding provided by Austrian Science Fund (FWF). We thank the reviewers for their comments, which helped to improve this article. This work has been supported by the Austrian Research Promotion Agency project LocTraffLog: Lightweight Methods of KR/R for sensor-based Local TMS Service (FFG 5886550) and the Austrian Science Fund projects P26471 and P27730.
Author information
Authors and Affiliations
Corresponding author
Additional information
Open Access
This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

{kind=link}
Cite this article
Eiter, T., Füreder, H., Kasslatter, F. et al. Towards a Semantically Enriched Local Dynamic Map. Int. J. ITS Res. 17, 32–48 (2019). https://doi.org/10.1007/s13177-018-0154-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13177-018-0154-x