
Abstract
Background
Huntington’s disease (HD) is a progressive neurodegenerative disease caused by a CAG trinucleotide expansion in the huntingtin gene. The length of the CAG repeat is inversely correlated with disease onset. HD is characterized by hyperkinetic movement disorder, psychiatric symptoms, and cognitive deficits, which greatly impact patient’s quality of life. Despite this clear genetic course, high variability of HD patients’ symptoms can be observed. Current clinical diagnosis of HD solely relies on the presence of motor signs, disregarding the other important aspects of the disease. By incorporating a broader approach that encompasses motor as well as non-motor aspects of HD, predictive, preventive, and personalized (3P) medicine can enhance diagnostic accuracy and improve patient care.
Methods
Multisymptom disease trajectories of HD patients collected from the Enroll-HD study were first aligned on a common disease timescale to account for heterogeneity in disease symptom onset and diagnosis. Following this, the aligned disease trajectories were clustered using the previously published Variational Deep Embedding with Recurrence (VaDER) algorithm and resulting progression subtypes were clinically characterized. Lastly, an AI/ML model was learned to predict the progression subtype from only first visit data or with data from additional follow-up visits.
Results
Results demonstrate two distinct subtypes, one large cluster (n = 7122) showing a relative stable disease progression and a second, smaller cluster (n = 411) showing a dramatically more progressive disease trajectory. Clinical characterization of the two subtypes correlates with CAG repeat length, as well as several neurobehavioral, psychiatric, and cognitive scores. In fact, cognitive impairment was found to be the major difference between the two subtypes. Additionally, a prognostic model shows the ability to predict HD subtypes from patients’ first visit only.
Conclusion
In summary, this study aims towards the paradigm shift from reactive to preventive and personalized medicine by showing that non-motor symptoms are of vital importance for predicting and categorizing each patients’ disease progression pattern, as cognitive decline is oftentimes more reflective of HD progression than its motor aspects. Considering these aspects while counseling and therapy definition will personalize each individuals’ treatment. The ability to provide patients with an objective assessment of their disease progression and thus a perspective for their life with HD is the key to improving their quality of life. By conducting additional analysis on biological data from both subtypes, it is possible to gain a deeper understanding of these subtypes and uncover the underlying biological factors of the disease. This greatly aligns with the goal of shifting towards 3P medicine.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The role of CAG repeat length in predicting disease onset
Huntington’s disease (HD) is a progressive, autosomal-dominantly inherited neurodegenerative disease, caused by a CAG trinucleotide expansion in the huntingtin gene [1]. CAG repeat lengths > 39 show full penetrance, and length of the CAG repeat is inversely correlated with disease onset [2, 3]. Core feature of HD is a hyperkinetic movement disorder, called chorea. In addition, psychiatric symptoms and cognitive deficits are an essential part [4,5,6], predominantly influencing patient’s quality of life [7,8,9,10], and are often early signs of HD [4, 11]. This gives great potential for predictive, preventive, and personalized medicine (3PM) to improve diagnostic and treatment of patients.
The “CAG age product” (CAP) that is, as the name intends, based on age and CAG repeat length can predict the age of onset of the disease [12, 13]. The CAP is commonly collected and used in clinical studies to determine the pre-manifest status of the patients or to assess the disease stage in terms of being close to or far away from predicted onset at study entry [12, 14,15,16]. Nevertheless, although CAG repeat length is often measured in a predictive manner in HD patient’s relatives, no preventive actions are taken, as no preventive treatment is available.
Taking into account the genetic component and the clear psychiatric symptoms and cognitive deficits in HD patients, there is great potential for the aspects of 3P medicine, as the clinical diagnosis of manifest HD is only based on the presence of unequivocal motor signs in CAG repeat expansion carriers and ignores the other aspects [17,18,19].
The need for a 3PM approach
Although there is such a clear genetic background in HD, the multifactorial and progressive nature of HD, in combination with a long pre-manifest phase again strengthens the need for 3PM concepts in HD, as there is a high variability of symptoms in HD patients that challenges counseling [6, 20, 21].
Commonly, clinical diagnostic criteria feature a pre-manifest phase (prior to motor diagnosis), followed by the motor-manifest period, divided into five stages [17]. More recently, a biological classification system has been established to characterize individuals for research purposes [22] and longitudinal data-driven machine-learning algorithms identified even nine distinct disease stages [23].
These results have tremendously helped to better understand the natural course of HD on a population level and paves the way for significantly earlier and correct diagnosis, enabling the paradigm shift from delayed intervention towards predictive and personalized medicine. Earlier diagnosis in the end helps to identify and apply effective early interventions for HD patients in early disease stages [19, 24, 25].
Therefore, the urgent need for personalized medicine has to be addressed. Here, identifying patient subtypes with a similar disease trajectory could help to untangle disease-modifying factors and define patient stratification [21, 24, 26,27,28,29]. Such an approach aims, on the one hand, to identify the best treatment strategy for each individual disease subtype, but, on the other hand, also helps to understand the disease characteristics itself, which in the end will contribute to a better prediction of disease progression, as well [24, 29].
State of the art in subtype identification in neurodegenerative diseases
Several models have been developed that cluster and predict patient subtypes based on their longitudinal trajectories, but most of them do not account for variations in the dynamics of the disease progression or identified markers discriminating pre-defined progression groups [21, 23]. In fact, a fully multivariate data-driven approach to unravel potential underlying disease progression groups, that otherwise can be overseen, is still missing. In this regard, methods from the field of data science and artificial intelligence (AI) pose a great opportunity to come closer to the vision of a predictive, personalized, and preventive medicine (3PM).
In the past, data-driven clustering of multisymptom disease trajectories has shown promising results in other neurodegenerative disorders, such as Alzheimer’s or Parkinson’s [28, 30, 31]. The rate of progression is typically variable across the disease trajectory in HD, with the steepest decline in function being seen in early to mid-disease stages [32]. Also, patients may be initially diagnosed at different stages of their disease. Thus, there is a need for alignment of trajectories observed for an individual patient along a population average disease trajectory [33, 34]. This can be done by modeling a continuous common disease timescale, e.g., with the help of non-linear mixed effect models. These models enable a removal of the effect of the actual time point of symptom onset on the overall trajectories by assessing a latent time estimate and adjust all patients’ trajectories across a common disease timescale [33, 35, 36].
Novelty beyond the state of the art
After diagnosis, accurate and early prognosis of the progression of the disease is of core relevance for those living with HD. For a patient, it is important to know her prospective symptom development in order to adapt life accordingly. In addition, a concrete prognosis could help doctors to better organize and manage therapies. This is where our work contributes to. For the first time, to our knowledge, HD subtypes based on multisymptom disease trajectories were identified and validated. Here, not only motor symptoms were evaluated but also cognitive symptoms are taken into account for subtype identification, as psychiatric symptoms and cognitive deficit are an essential part of the disease and also early signs of HD that are ignored in the diagnosis of manifest HD [4,5,6, 11, 17,18,19].
With the help of an AI/ML model that allows for predicting the disease progression subtypes based on only the first visit or by including additional follow-up visits, we addressed important 3PM aspects, because such a model could support a better individualized disease management via optimized counseling as well as support patient in their own life decisions.
Working hypothesis
In the current study, we hypothesize that manifest HD patients define heterogeneous progression subtypes that can be identified by advanced AI methods. Subtype identification will allow the classification of patients into one of the multisymptom trajectory clusters based on their first visit data only or by including additional follow-up visits. This will in the end result into a better personalized and preventive treatment for HD patients as patient counseling can be optimized. Additionally, patients can be provided with a better indication of their prognosis.
Therefore, we clustered HD patients on the basis of their longitudinal trajectories using our previously introduced Variational Deep Embedding with Recurrence (VaDER) neural network algorithm [30]. As such trajectories are often temporally related to the study baseline, this study aims to adjust for this confounding effect using a non-linear mixed effect model, originally introduced by Raket [36], which assumes that the longitudinal trajectories of pre-manifest and manifest HD patients are adjustable along a common disease timescale. An early prognosis of disease progression for each patient, reflecting the predictive and personalized aspect of 3PM, will be achieved by developing, evaluating, and validating a machine learning-based prediction model.
Methods
Dataset and patient selection criteria
Data used in this work were generously provided by the participants in the Enroll-HD study [37] (ClinicalTrials.gov Identifier: NCT01574053) and made available by CHDI Foundation, Inc. Enroll-HD is a global clinical research platform designed to facilitate clinical research in Huntington’s disease. Core datasets are collected annually from all research participants as part of this multicenter longitudinal observational study. Data are monitored for quality and accuracy using a risk-based monitoring approach. All sites are required to obtain and maintain local ethical approval. Overall, up to now, over 20,000 patients from 21 countries at 159 sites were recruited [38]. Enroll-HD provides data from HD patients, including manifest and pre-manifest patients. The study has collected clinical score data and demographics during annual visits. During these visits, patients undergo a core battery of test, including demographics, medical history, and clinical assessments of the four HD domains: motor, cognitive, behavioral, and functional. A CAG genotyping was done for each participant to get their CAG repeat length.
During this study, we used the fifth release of the Enroll-HD data from October 2020 that was released in December 2020. Within this release, we selected the information from scheduled visits of manifest and pre-manifest patients that had at least one follow-up visit after the baseline screening. Control participants were excluded for the purpose of this study. Participant category was assessed at each visit by the study examiner. Details about the definition of pre-manifest and manifest patient group can be found in the Supplementary Material.
Used features during modeling and clustering of trajectories are the Unified Huntington’s Disease Rating Scale (UHDRS) [39] and the mini-mental state examination (MMSE). The UHDRS consists of four different domains: motor, cognitive, behavioral, and functional, where each of the domains relates to different fields of possible symptoms. Additionally, the MMSE was used as a cognitive test. In total, we used three different features, coming from two different assessments, namely, UHDRS total motor score (TMS), UHDRS symbol digit modality test (SDMT), and the total MMSE score (MMSE). Furthermore, age and sex were used as covariates. Characteristics of all used patients can be found in Table 1.
Shown are statistics of patients used for the subtype analysis as training (manifest) and validation (pre-manifest) set. Statistics are shown at patients’ baseline visit for manifest and first manifest visit for pre-manifest patients after conversion. The age, CAG repeat length, and clinical scores are described by their mean and standard deviation.
Model building methods
In the following analysis, both manifest and pre-manifest patients were used for modeling common disease time trajectories with a non-linear mixed effect (NLME) model. VaDER clustering and prediction models were then trained on manifest patients only, while validating these models afterwards on pre-manifest patients. Common disease timescale trajectories of pre-manifest patients were therefore shortened to their manifestation phase, meaning that the first visit when manifesting the disease was considered the start of their used trajectory.
Non-linear mixed effect model
The here-used model follows the rational described earlier [33, 36]. Shortly, it is a non-linear mixed effect model with a mean curve defined by the fixed effects and random effects describing the deviation of each patient from that mean curve. During the here-described analysis, the mean curve is formulated as a generalized logistic function:
where \(A\) is the left and \(K\) the right asymptotic value which reflects the minimal and maximal possible value of a specific clinical measure. Parameters \(B\) and \(v\) define the curvature of the function, with \(B\) as time scaling parameter and \(v\) as an asymmetry parameter. A shift in time is modelled by \(s\) as horizontal shift and a vertical shift can be modelled by \(c\).
During the modeling, the values of \(A\) and \(K\) are fixed according to the actual modelled clinical score. Fixed effects can be modelled for specific covariates, e.g., the manifestation status of the patients at baseline, such that the parameter estimate of \(s\) describes the mean difference in time between the pre-manifest and manifest patient groups over the continuous common disease timescale. This difference is modelled relative to the pre-manifest patient group, meaning that \(t=0\) on the common disease timescale corresponds to the average status of the pre-manifest patients at the time of conversion into manifest disease status.
The model was built with the help of the progmod R-package [40] which is based on the nlme package [41]. More details on the model formulation can be found in the Supplements.
Multivariate clustering of clinical trajectories
The previously published Variational Deep Embedding with Recurrence (VaDER) [30] was used to cluster the shifted time series that are the output of the nlme model. Based on a variational deep embedding framework for learning low-dimensional representation of data points, two long short-term memory networks that model the multivariate time series, and an implicit imputation layer, the VaDER method allows to model and cluster short time series with large amount of missingness. More details can be found in the original publication [30] and in the Supplements. Training of the VaDER was based on manifest patients only, but pre-manifest patients were used as validation cohort in the later phase of the study.
Machine learning classifiers
Random Forest [42] and XGBoost [43] classifiers were trained on baseline data only (BL), as well as baseline and follow-up data (BLtoFU1 and BLtoFU2) from manifest patients. We here used the labels of the VaDER approach, the cluster assignment, as the classes that need to be predicted. As predictors, multiple cognitive, motor, functional, and neurobehavioral scores were used. Those can be found in Supplementary Table 3. A hyperparameter optimization with randomized search with 100 parameter settings preceded a tenfold nested cross-validation implemented with scikit-learn [44] and XGBoost [43] packages. Hyperparameter spaces and optimal hyperparameters, found based on the best AU-ROC, can be found in the Supplementary Material. Cross-validation results of both Random Forest and XGBoost are shown in the Supplementary Material, along with the decision to choose XGBoost for final modeling due to higher prediction performance. These trained XGBoost models were then applied on the pre-manifest patients as a validation set in the later phase of the study.
Feature importance analysis
For feature importance analysis, SHAP values [45] for each feature in the model were calculated with the implementation of the python package shap. For interpretation, the natural additive behavior of SHAP values was used to calculate aggregated SHAP values for specific domains of clinical tests, such as functional, cognitive, or neurobehavioral tests. This was done by summarizing SHAP values from clinical tests belonging to each of the domains. The scores belonging to each of the domains are listed in Supplementary Table S3.
Statistical testing
Statistical testing was following the SHAP analysis for all single features underlying the top aggregated features. Depending on the type of variable, either Kruskal–Wallis (numerical), Fisher’s exact (bi-categorical), or chi-square independence test (multicategorical) was used to test the distribution of the respective features within the found subtypes. Age and sex were included as possible confounders in all tests and p-values were corrected for multiple testing using the Benjamini–Hochberg procedure.
The analysis of medications for specific indications across progression subtypes was performed using Fisher’s exact test, and p-values were corrected for multiple testing using Benjamini–Hochberg procedure.
Results
Data
Data used in this study comes from the Enroll-HD study (ClinicalTrials.gov Identifier: NCT01574053) [37] (Data Cut 10/2020). In total, 11,093 patients (7548 manifest and 3545 pre-manifest) were used in this work for the longitudinal modeling over a common disease timescale, of which 7905 patients (7533 manifest and 372 pre-manifest) were eligible for the later analysis regarding the subtypes. For pre-manifest patients, only their manifest phase was used in the later analysis as independent validation set, explaining the large drop in the number of patients. An overview of the characteristics of patients used for the subtype analysis at their first included visit is presented in Table 1.
Enroll-HD is a longitudinal study, collecting data from patients at multiple annually scheduled follow-up visits. The number of available patients per follow-up visit is shown in Table 2.
Shown is the number of manifest and pre-manifest patients used in the subtype analysis having the respective visits available; e.g., 7066 manifest patients had a first follow-up visit, while 4817 manifest patients also had a second follow-up visit. For manifest patients, available visits over 6 years were summarized for visual reasons. The maximum number of visits a manifest patient had was 14. Baseline visit for pre-manifest patients relates to their first manifest visit, after conversion from pre-manifest status.
Non-linear mixed effect model
A non-linear mixed effect (NLME) model was fitted to longitudinal data of 11,093 manifest and pre-manifest patients in a multivariate manner, modeling the Unified Huntington’s Disease Rating Scale (UHDRS) total motor score (TMS), UHDRS symbol digit modality test (SDMT), and mini-mental state examination (MMSE). These scores represent current gold standard scores addressing motor and cognitive aspects of the disease [46, 47]. The NLME model gives the opportunity to align trajectories on a common, potentially unobserved (i.e. latent), disease timescale. Figure 1a–c shows the aligned trajectories of pre-manifest and manifest patients of the three modeled clinical scores along the common disease timescale. As expected, the original trajectories of pre-manifest patients are mostly shifted towards the left (back in time). Vice versa, manifest patients’ trajectories are mostly shifted to the right, as patients naturally are in pre-manifest state before their disease manifests. Resulting latent time estimates, indicating the difference between the actual time axis and the common disease timescale, are validated by correlating the predicted age at time 0 (i.e. manifestation time) for each individual against the observed age at first diagnosis and first motor symptoms. Hereby, a linear regression with a slope of 1 would indicate that observed diagnosis and predicted symptom onset are consistent and therefore, trajectories would be perfectly aligned. Results (Fig. 1d, e) in this study show slopes of 0.999 (diagnosis) and 1.002 (first motor symptoms), demonstrating a good fit of the NLME model to the observed data. Hence, estimates of latent time seem reliable.

Multivariate NLME modeling. a–c Disease trajectories of pre-manifest (red) and manifest (blue) patients aligned along a common disease timescale based on the estimated random effects representing the latent time. Three different outcomes are shown: Unified Huntington’s Disease Rating Scale (UHDRS) total motor score (TMS), symbol digit modality test (SDMT), and mini-mental state examination (MMSE). For visualization reasons, 1000 trajectories were randomly selected for plotting. The black curve shows the underlying mean curve estimated by the NLME model. The grey dashed line marks time equals 0 on the common disease timescale. d, e Validation plots of time alignment, where age at diagnosis (d) and first motor symptom (e) are plotted against the age at predicted disease time 0 fitted with linear models resulting from the NLME approach
VaDER clustering results in two subtypes
Aligned trajectories of 7533 manifest HD patients were used to train a VaDER model for clustering patients into subtypes [30]. This resulted in two clusters, of which one cluster was a large one with 7122 patients included, while the second cluster only contained 411 patients (Fig. 2). While the second cluster shows a steep decline of SDMT and MMSE and rise of TMS starting from around day 200 on the common disease timescale, the first cluster demonstrates almost no impairment of patients over all three outcome scores and the whole common disease timescale, meaning that the large cluster and thus most HD patients show a stable pattern in the clinical scores after a minimal worsening in the beginning of their disease. However, a smaller subset of particularly vulnerable patients represents faster disease progression than most HD patients. Additionally, SDMT progression patterns of the two clusters are strictly distinguished of each other. Here, the baseline levels are already different, whereas both clusters are not separable in the beginning when looking at the MMSE or TMS.

Mean progression cluster trajectories of manifest HD patients. Two clusters are found as the result of training VaDER on the aligned multisymptom (TMS, SDMT, MMSE) trajectories of manifest HD patients. Cluster 1 is shown in black and contains 7122 patients, whereas Cluster 2 (red) only contains 411 patients. Dashed lines indicate the 95% confidence interval of the mean trajectories. Overall, the first cluster shows more stable patterns over time compared to the second cluster
Predicting the HD progression subtype from clinical data
We trained an XGBoost classifier to predict the progression subtype of a patient only using baseline data (BL), or additional data from the next (BLtoFU1) or next two visits (BLtoFU2). We used multiple cognitive, motor, functional, and neurobehavioral scores, as well as demographic and medical history features, as predictors. Those can be found in Supplementary Table S3. All classifiers were trained in a tenfold cross-validation scheme. That means we systematically and sequentially held 10% of the patients out for testing our classifier, while the training was performed on the rest of the data. Resulting receiver operator characteristic (ROC) curves are shown in Fig. 3 and indicate a high area under ROC curve (AUC) of 95% (BL), 99% (BLtoFU1), and 99% (BLtoFU2), respectively. This shows that classification performance grows with including additional follow-up visits, although the accuracy based on only the baseline visit is already high. Hence, first visit data alone already contains sufficient signal to make an accurate prognosis regarding subsequent progression pattern of the disease. A comparison to ground-truth models, containing either only CAG repeat, age plus sex, or all three confounders together, shows that the models using additional clinical data are significantly better (CAG 63%; age and sex 64%; age, sex, and CAG 71%).

XGBoost classifier ROC curves. Mean ROC curves from tenfold cross-validation setting, are shown for multiple cases of prediction from clinical data, based on baseline visit only (BL, blue), baseline plus first follow-up visit (BLtoFU1, orange), or baseline plus first and second follow-up visit (BLtoFU2, green). The training performance of the three classifiers is summarized via the area under the ROC curve (AUC) of the mean ROC curve and is 95%, 99%, and 99%, respectively. Additionally, ROC curves from ground-truth classifiers based on only age, sex, and CAG repeat (red); age and sex (purple); or only CAG repeat (brown) are shown. Here, AUCs are 71%, 64%, and 63%)
Feature importance analysis
We conducted an analysis using Shapley Additive Explanations (SHAP) to better understand the contribution of individual features in the machine learning classifiers. Here, multiple motor, cognitive, functional, and neurobehavioral scores were aggregated within their domains. A complete list of which scores were included in each domain can be found in Supplementary Table S3. The SHAP analysis demonstrated that cognitive scores were very important for predicting the correct HD progression subtype in all classifiers, most influencing in the BL classifier (Fig. 4). However, also motor scores played a relevant role, specifically in the BLtoFU2 classifier, which employs information of the second follow-up visit. Additionally, the number of CAG repeats was among the most influential features for the BL and BLtoFU1 classifiers. Moreover, neurobehavioral scores had a strong impact on all models. The amount of cognitive impairment, observable apathy, and a history of perseverative obsessive behaviors were among the top important features in the BL classifier, but were becoming less influencing when including more follow-up visits. Interestingly, functional scores became more important for the subtype prediction when including more follow-up visits.

SHAP values of TOP10 aggregated features. The impact of the features based on aggregated SHAP values is shown here for BL (a), BLtoFU1 (b), and BLtoFU2 (c) XGBoost classifier. Multiple features were aggregated for the SHAP analysis based on the same domain of clinical tests, namely, cognitive, motor, functional, and neurobehavioral tests. A higher positive SHAP value indicates a higher influence of a feature to predict a patient as fast progressing. A more negative value indicates a higher tendency towards predicting the patient as slow progressing. The actual value of the feature is shown in a color code. The darker the red color, the higher the feature value
Clinical characterization of progression subtypes
In addition to the SHAP analysis, statistical tests regarding the differences in the features, aggregated in the top 10 most important features for the prediction of progression subtypes, were conducted (see details in the “Methods” section). All tests were adjusted for age and sex as possible confounders and corrected for multiple testing. For the BL classifier, among the five most significantly different single features were the cognitive impairment (\(p<\) 3.3e−13) and multiple cognitive assessments, like categorical verbal fluency (\(p<\) 3.3e−14), letter verbal fluency (\(p<\) 3.3e −14), and Trail Making Test Part A (\(p<\) 3.4e−9) and B (\(p<\) 4.5e−16). The amount of patients with cognitive impairment is higher in the second, smaller cluster, which is in concordance with the result, that the time needed for completion of Trail Making Test Part A and B is higher, and the number of correct answers in the categorical and letter verbal fluency tests is lower in this cluster than in the first, large cluster. Visualization of the distribution of these features can be found in the Supplementary Material. In the case of BLtoFU1 and BLtoFU2 classifiers, cognitive assessments were among the top significantly different features as well. Here, the SDMT (BLtoFU1: \(p<\) 1.4e−32; BLtoFU2: \(p<\) 2.1e−35 (FU2)) and Stroop tests (color naming: \(p<\) 1.6e−23 (BLtoFU1), \(p<\) 4.4e−31 (BLtoFU2); inference: \(p<\) 5.7e−23 (BLtoFU1)) are present. The number of correct answers in the Stroop and SDMT is lower in the second cluster, as well. Also, the MMSE scores are significantly (BLtoFU1: \(p<\) 3.0e−30; BLtoFU2: \(p<\) 1.2e−30) lower in the second cluster. Therefore, subtypes were mostly distinguished by the amount of cognitive impairment of patients at baseline. Additionally, the TMS is significantly higher (BLtoFU1: \(p<\) 3.8e−26, BLtoFU2: \(p<\) 1.1e−48) in the second cluster. Furthermore, CAG repeat length, which is known to be a highly predictive feature of HD onset [3, 48], was also a predictive feature for subtype assignment and thus for HD progression. A complete list of the statistical test results can be found in Supplementary Table S7.
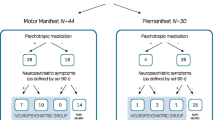
With respect to medication, intake of medication for five different indications, particularly relevant to HD, was compared between subtypes: chorea, depression, anxiety, irritability, and cognitive decline. Here, significant differences could be observed across the progression subtypes for chorea (\(p=\) 0.0002), irritability (\(p=\) 0.0037), and anxiety (\(p=\) 0.0079) and while no significant difference between the progression groups were found for depression (\(p=\) 0.0892) or cognitive disorder (\(p=\) 0.0981) medication. Distributions of each medication in each subtype can be found in Supplementary Fig. S3.
Application of model on pre-manifest patients for validation
To further validate the generalization ability of the classification models, 372 pre-manifest at baseline patients were used as a further validation set. First, their conversion point from pre-manifest to manifest status was identified, as the visit at which the diagnostic confidence level altered from “motor abnormalities are likely signs of HD” to “motor abnormalities are unequivocal signs of HD”. Then, common disease time trajectories beyond this conversion time were clustered into two subtypes by applying the previously trained VaDER model. By only using the manifest part of the disease trajectory of an originally pre-manifest patient, we ensure the applicability of the model on this independent validation set, as it had been trained on manifest patients only. As can be seen in Fig. 5, Cluster 1 (black) contains, similar to the training set, the majority of patients, 341 in total, compared to only 31 patients in Cluster 2. Additionally, the trajectories of first cluster show more stable patterns over time in contrast to the second cluster. The larger confidence band of the second cluster in comparison to the training result, is due to the small number of patients within this group.

Mean progression cluster trajectories of pre-manifest patients. Applying the previously trained VaDER model on the multisymptom (TMS, SDMT, MMSE) trajectories of pre-manifest patients as a validation set results in two main trajectory clusters. Similar to the training scenario, Cluster 1 (black) contains the majority of patients (341), while Cluster 2 (red) only contains 31 patients. Again, the trajectories of first cluster show more stable patterns over time compared to the second cluster. Confidence intervals, especially for the second cluster, are larger than in the training case because of the significantly smaller number of patients
The assigned subtype of each patient was then used to validate the previously trained prediction models, BL, BLtoFU1, and BLtoFU2. ROC curves for the three different classifiers are shown in Fig. 6. The performance of the three different classifiers, BL only, BLtoFU1, and BLtoFU2, showed AUCs of 75%, 79%, and 88%. This demonstrated the generalization ability of the classification models and also strengthened the fact that classification performance increased with inclusion of additional follow-up visits, as expected.

ROC for XGBoost classifiers applied on pre-manifest patients. The performance of the three RF classifiers BL only (blue), BLtoFU1 (orange), and BLtoFU2 (green) including different numbers of follow-up visits additional to the BL visit is presented. The area under the ROC curve (AUC) of the classifiers is 75%, 79%, and 88%, validating that classification performance increases with including additional visits
Analysis of medication for five different indications showed no significance between the two subtypes (chorea: 0.1725, depression: \(p=\) 0.8520, anxiety: \(p=\) 0.1725, irritability: \(p=\) 0.1987, cognitive decline: \(p=\) 0.3048). Distributions of each medication in each subtype can be found in Supplementary Fig. S4.
Discussion
The vision of a predictive, personalized, and preventive medicine demands to better tailor disease management and treatment to the needs of an individual patient by considering a large set of patient specific characteristics. Specifically, in the context of HD, there is an urgent need for a better personalized projection of symptom development to optimize counseling and planning of a patient’s future. In this regard, our work first identified two distinct HD subtypes within the Enroll-HD dataset, based on an AI-based clustering of patients’ disease trajectories that were aligned on a common disease timescale. From the two identified subtypes, surprisingly, one subtype relates to a large cluster showing a relatively stable disease progression, and the second, albeit smaller cluster, shows a dramatically more progressive disease trajectory. While this clustering was based on the UHDRS total motor score (TMS), UHDRS symbol digit modality test (SDMT), and the MMSE, the derived progressive subtype correlated with the CAG repeat length [49], underlining the robustness and validity of our clustering approach. In addition, the found subtypes could be replicated on an independent set of pre-manifest patients from the same cohort, further substantiating the validity of our approach.
Our approach is advantageous over other methods used and able to capture the heterogeneity in the disease course of HD, because integration of covariates into the modeling of each outcome allows to model effects of these covariates not only on disease stages but also on progression rate. Thus, we are able to adjust for potential covariate effects, such as age and gender on motor and cognitive symptoms. This approach also prevents bias in the data caused by disease diagnosis time, which is automatically considered when shifting patients to an earlier disease time on the common disease timescale, and thus, this strategy accounts for heterogeneity and uncertainty in the data. The subsequent use of VaDER for clustering the aligned disease trajectories allows then for simultaneous multivariate clustering rather than univariate clustering [30]. Furthermore, it allows for non-linear interactions across multiple scales for identification of the subtypes and not only captures a snapshot at a very specific time point in a patients’ medical history, but integrates the whole available disease course of each patient for specific clinical variables that are suggested for measuring the disease severity [30].
In addition to the above-mentioned differences in subtypes, further neurobehavioral, psychiatric, and cognitive scores were correlated with the found subtypes. In particular, the amount of cognitive impairment was the major difference between groups. Cognitive decline is correlated with the age at onset in HD patients [49]. Here, not only the scores used for clustering itself, namely, the MMSE and the SDMT, two already established scores reflecting morbidity and reduction in quality of life in HD, but also other cognitive scales, especially frontal-executive tests, as the letter verbal fluency, and Trail Making A and B, are distinguishing the subtypes. Thus, deficits in the overall cognitive performance, particularly the executive function, are associated with a drastically more progressive disease course, underlining previous data [50].
One potential confounder in our analysis may be the different intake of antichoreatic medication between groups. As our clustering is based on the TMS among others, intake of antichoreatic medication, leading to a lower TMS, may bias towards the slow progression group. However, a significantly higher amount within the fast progression cluster received antichoreatic medication. Thus, antichoreatic medication intake, likely reducing TMS motor scores, does not appear to influence clustering. Moreover, intake of antidepressive and anxiolytic medication was significantly more frequent in the fast-progressing group. These data suggest that the higher intake reflects the need to treat more advanced symptoms and does not cause a treatment bias in our clustering approach. In addition, the above-mentioned fact that cognitive scores are not used for clustering and CAG repeat length are among the strongest separating factors suggests a minor role of medication intake associated biases.
Conclusion and expert recommendation in the framework of 3PM
The study identified two distinct HD progression subtypes, one relating to a larger cluster showing relatively stable disease progression and the second, smaller cluster, showing a more progressive disease trajectory. Characterization of the two subtypes showed a major difference in the amount of cognitive impairment between the groups. Multiple cognitive scales, especially frontal-executive tests, are distinguishing the subtypes. Thus, deficits in the overall cognitive performance are associated with a drastically more progressive disease course. Therefore, cognitive tests need to be taken into account, as they are more reflective of the disease progression than motor tests in many cases.
In relation to 3PM in HD, we see the contributions of our work as follows:
-
(i)
Predictive approach: The subtype classification AI model can categorize HD patients based on their motor, as well as non-motor symptoms. Each individual patient can be assessed based on their personal profile and a clear and objectively measured disease progression is predicted. This offers HD patients a better perspective on their disease progression and allows them to organize their lives accordingly, which is the key to improving patient’s quality of life. In addition, a concrete prognosis could help doctors to optimize counseling and treatment of symptoms.
-
(ii)
Targeted prevention: Cognitive deficits commonly appear in HD patients and a clear correlation with the disease progression is also known, but until now, they have been ignored in diagnosis, prevention, and prediction. This study clearly shows that non-motor symptoms, especially cognitive decline, are of major importance and need to be addressed in an optimized patient counseling and treatment (e.g., via cognitive training) by taking the results of cognitive test into account. But further work is needed for concrete advancements towards targeted prevention based on the two HD progression subtypes.
-
(iii)
Personalization of medical services: A personalized projection of symptom development via the here-developed AI model helps to optimize counseling and thus the planning of each individual patient’s future. The individual prediction enables doctors to initiate the appropriate personalized therapies. With a reassessment at the next clinic visit and the resulting possible adjustment or refinement and concretization of the prognosis, the treatment and therapy can be adapted. Such refinements could improve the quality of patient’s life.
Conclusion
In summary, we show that non-motor symptoms are of major importance for predicting and categorizing each patients’ disease progression pattern, even though they alone are not diagnostic. Our results substantiate a clinically well-known aspect of HD: the fact that cognitive decline is oftentimes more reflective of the progression of the disease than motor aspects. As a consequence, our analysis suggests that patient counseling should take into account results of the cognitive test found to be relevant in this study.
Limitations and outlook
To further explore on our results, future work should focus on the correlation of our clustering with biological data such as MRI volumetry [51] or CSF biomarkers like neurofilament light protein [52]. This would help to delineate how far our clustering approach reflects underlying biological aspects of the disease and addresses the multimodal diagnostic concept to provide the maximum of clinically relevant information. In addition, neurobehavioral or psychiatric scores are currently underrepresented in our clustering approach, as well as in other studies [11, 46]. Yet, to include these scores in future work, we need more stable and easier to estimate non-linear mixed models allowing for the alignment of multivariate trajectories. Although, there is a multivariate version of the NLME available [33], estimating parameters of such a model is time-consuming and needs many manual steps, e.g., for finding or even tuning the start parameters for the estimation, which is inappropriate when integrating even more desired outcomes.
A further prospect regarding 3PM is to find the optimal treatment for each subtype. With the basis of our identified subtypes, clinical trial populations could now be adopted towards this vision. Enrichment of a clinical trial population with the rapid progressive subtype may help to show disease-modifying aspects of novel compounds, as this group is more likely to decline within typical trial periods of 1–2 years.
Data availability
The Enroll-HD database is available upon request from https://www.enroll-hd.org.
References
MacDonald ME, et al. A novel gene containing a trinucleotide repeat that is expanded and unstable on Huntington’s disease chromosomes. Cell. 1993;72:971–83. https://doi.org/10.1016/0092-8674(93)90585-E.
Lee J-M, et al. Identification of genetic factors that modify clinical onset of Huntington’s disease. Cell. 2015;162:516–26. https://doi.org/10.1016/j.cell.2015.07.003.
Langbehn DR, et al. A new model for prediction of the age of onset and penetrance for Huntington’s disease based on CAG length. Clin Genet. 2004;65:267–77. https://doi.org/10.1111/j.1399-0004.2004.00241.x.
Medina A, Mahjoub Y, Shaver L, Pringsheim T. Prevalence and incidence of Huntington’s disease: an updated systematic review and meta-analysis. Mov Disord Off J Mov Disord Soc. 2022;37:2327–35. https://doi.org/10.1002/mds.29228.
Horta-Barba A, et al. Measuring cognitive impairment and monitoring cognitive decline in Huntington’s disease: a comparison of assessment instruments. J Neurol. 2023;270:5408–17. https://doi.org/10.1007/s00415-023-11804-0.
Snowden JS. The neuropsychology of Huntington’s disease. Arch Clin Neuropsychol. 2017;32:876–87. https://doi.org/10.1093/arclin/acx086.
Ho AK, Gilbert AS, Mason SL, Goodman AO, Barker RA. Health-related quality of life in Huntington’s disease: which factors matter most? Mov Disord. 2009;24:574–8. https://doi.org/10.1002/mds.22412.
Banaszkiewicz K, et al. Huntington’s disease from the patient, caregiver and physician’s perspectives: three sides of the same coin? J Neural Transm. 2012;119:1361–5. https://doi.org/10.1007/s00702-012-0787-x.
Read J, et al. Quality of life in Huntington’s disease: a comparative study investigating the impact for those with pre-manifest and early manifest disease, and their partners. J Huntingt Dis. 2013;2:159–75. https://doi.org/10.3233/JHD-130051.
Van Walsem MR, Howe EI, Ruud GA, Frich JC, Andelic N. Health-related quality of life and unmet healthcare needs in Huntington’s disease. Health Qual Life Outcomes. 2017;15:6. https://doi.org/10.1186/s12955-016-0575-7.
Ross CA, Pantelyat A, Kogan J, Brandt J. Determinants of functional disability in Huntington’s disease: role of cognitive and motor dysfunction. Mov Disord Off J Mov Disord Soc. 2014;29:1351–8. https://doi.org/10.1002/mds.26012.
Ross CA, et al. Huntington disease: natural history, biomarkers and prospects for therapeutics. Nat Rev Neurol. 2014;10:204–16. https://doi.org/10.1038/nrneurol.2014.24.
Penney JB, Vonsattel J, Macdonald ME, Gusella JF, Myers RH. CAG repeat number governs the development rate of pathology in Huntington’s disease. Ann Neurol. 1997;41:689–92. https://doi.org/10.1002/ana.410410521.
Zhang Y, et al. Indexing disease progression at study entry with individuals at-risk for Huntington disease. Am J Med Genet B Neuropsychiatr Genet. 2011;156:751–63. https://doi.org/10.1002/ajmg.b.31232.
Orth M, et al. Observing Huntington’s disease: the European Huntington’s Disease Network’s REGISTRY. PLoS Curr. 2011;2:RRN1184. https://doi.org/10.1371/currents.RRN1184.
Dorsey ER, the Huntington Study Group COHORT Investigators. Characterization of a large group of individuals with Huntington disease and their relatives enrolled in the COHORT study. PLoS ONE. 2012;7:e29522. https://doi.org/10.1371/journal.pone.0029522.
Hogarth P, et al. Interrater agreement in the assessment of motor manifestations of Huntington’s disease. Mov Disord. 2005;20:293–7. https://doi.org/10.1002/mds.20332.
Reilmann R, Leavitt BR, Ross CA. Diagnostic criteria for Huntington’s disease based on natural history. Mov Disord. 2014;29:1335–41. https://doi.org/10.1002/mds.26011.
Mandel S, Korczyn AD. In Neurodegener. Dis. Integr. PPPM Approach Med. Future (ed. Mandel, S.) 2013;2:95–140. Springer Netherlands. https://doi.org/10.1007/978-94-007-5866-7_6
Tabrizi SJ, et al. Biological and clinical manifestations of Huntington’s disease in the longitudinal TRACK-HD study: cross-sectional analysis of baseline data. Lancet Neurol. 2009;8:791–801. https://doi.org/10.1016/S1474-4422(09)70170-X.
Abeyasinghe PM, et al. Tracking Huntingtonʼs disease progression using motor, functional, cognitive, and imaging markers. Mov Disord. 2021;36:2282–92. https://doi.org/10.1002/mds.28650.
Tabrizi SJ, et al. A biological classification of Huntington’s disease: the Integrated Staging System. Lancet Neurol. 2022;21:632–44. https://doi.org/10.1016/S1474-4422(22)00120-X.
Mohan A, et al. A machine-learning derived Huntington’s disease progression model: insights for clinical trial design. Mov Disord. 2022;37:553–62. https://doi.org/10.1002/mds.28866.
EPMA, Golubnitschaja O, Costigliola V. General report & recommendations in predictive, preventive and personalised medicine 2012: white paper of the European Association for Predictive, Preventive and Personalised Medicine. EPMA J. 2012;3:14. https://doi.org/10.1186/1878-5085-3-14
Golubnitschaja O, Kinkorova J, Costigliola V. Predictive, preventive and personalised medicine as the hardcore of ‘Horizon 2020’: EPMA position paper. EPMA J. 2014;5:6. https://doi.org/10.1186/1878-5085-5-6.
Wang M, et al. Statistical methods for studying disease subtype heterogeneity. Stat Med. 2016;35:782–800. https://doi.org/10.1002/sim.6793.
Giannoula A, Gutierrez-Sacristán A, Bravo Á, Sanz F, Furlong LI. Identifying temporal patterns in patient disease trajectories using dynamic time warping: A population-based study. Sci Rep. 2018;8:4216. https://doi.org/10.1038/s41598-018-22578-1.
Birkenbihl C, et al. Artificial intelligence-based clustering and characterization of Parkinson’s disease trajectories. Sci Rep. 2023;13:2897. https://doi.org/10.1038/s41598-023-30038-8.
Golubnitschaja O, et al. Medicine in the early twenty-first century: paradigm and anticipation - EPMA position paper 2016. EPMA J. 2016;7:23. https://doi.org/10.1186/s13167-016-0072-4.
de Jong J, et al. Deep learning for clustering of multivariate clinical patient trajectories with missing values. GigaScience. 2019;8:giz134. https://doi.org/10.1093/gigascience/giz134.
Krishnagopal S, Coelln RV, Shulman LM, Girvan M. Identifying and predicting Parkinson’s disease subtypes through trajectory clustering via bipartite networks. PLoS ONE. 2020;15: e0233296. https://doi.org/10.1371/journal.pone.0233296.
Marder K, et al. Rate of functional decline in Huntington’s disease. Neurology. 2000;54:452–452. https://doi.org/10.1212/WNL.54.2.452.
Kühnel L, Berger A-K, Markussen B, Raket LL. Simultaneous modeling of Alzheimer’s disease progression via multiple cognitive scales. Stat Med. 2021;40:3251–66. https://doi.org/10.1002/sim.8932.
Koval I, et al. Forecasting individual progression trajectories in Huntington disease enables more powered clinical trials. Sci Rep. 2022;12:18928. https://doi.org/10.1038/s41598-022-18848-8.
Li D, Iddi S, Thompson WK, Donohue MC, Alzheimer’s Disease Neuroimaging Initiative. Bayesian latent time joint mixed effect models for multicohort longitudinal data. Stat Methods Med Res. 2019;28:835–45. https://doi.org/10.1177/0962280217737566.
Raket LL. Statistical disease progression modeling in Alzheimer disease. Front Big Data. 2020;3:24. https://doi.org/10.3389/fdata.2020.00024.
Landwehrmeyer GB, et al. Data analytics from Enroll-HD, a global clinical research platform for Huntington’s disease. Mov Disord Clin Pract. 2017;4:212–24. https://doi.org/10.1002/mdc3.12388.
Sathe S, et al. Enroll-HD: an integrated clinical research platform and worldwide observational study for Huntington’s disease. Front Neurol. 2021;12: 667420. https://doi.org/10.3389/fneur.2021.667420.
Kieburtz K, Penney JB, Como P, Ranen N, Shoulson I. Unified Huntington’s Disease Rating Scale: reliability and consistency. Huntington Study Group. Mov Disord Off J Mov Disord Soc. 1996;11:136–42. https://doi.org/10.1002/mds.870110204.
Raket LL. progmod. 2020. at <https://github.com/larslau/progmod>.
Pinheiro J, Bornkamp B, Glimm E, Bretz F. Model-based dose finding under model uncertainty using general parametric models. Stat Med. 2014;33:1646–61. https://doi.org/10.1002/sim.6052.
Breiman L. Random forests. Mach Learn. 2001;45:5–32. https://doi.org/10.1023/A:1010933404324.
Chen T, Guestrin C. XGBoost: a scalable tree boosting system. In: Proc. 22nd ACM SIGKDD Int. Conf. Knowl. Discov. Data Min. 785–794 (ACM, 2016). https://doi.org/10.1145/2939672.2939785
Pedregosa F, et al. Scikit-learn: machine learning in Python. J Mach Learn Res. 2011;12:2825–30.
Lundberg S, Lee S-I. A unified approach to interpreting model predictions. Preprint at https://doi.org/10.48550/arXiv.1705.07874 (2017) https://doi.org/10.48550/arXiv.1705.07874
Mestre TA, et al. Rating scales for cognition in Huntington’s disease: critique and recommendations. Mov Disord Off J Mov Disord Soc. 2018;33:187–95. https://doi.org/10.1002/mds.27227.
Mestre TA, et al. Rating scales for motor symptoms and signs in Huntington’s disease: critique and recommendations. Mov Disord Clin Pract. 2018;5:111–7. https://doi.org/10.1002/mdc3.12571.
Chao T-K, Hu J, Pringsheim T. Risk factors for the onset and progression of Huntington disease. Neurotoxicology. 2017;61:79–99. https://doi.org/10.1016/j.neuro.2017.01.005.
McAllister B, et al. Timing and impact of psychiatric, cognitive, and motor abnormalities in Huntington disease. Neurology. 2021;96:e2395–406. https://doi.org/10.1212/WNL.0000000000011893.
Tabrizi SJ, et al. Predictors of phenotypic progression and disease onset in premanifest and early-stage Huntington’s disease in the TRACK-HD study: analysis of 36-month observational data. Lancet Neurol. 2013;12:637–49. https://doi.org/10.1016/S1474-4422(13)70088-7.
Georgiou-Karistianis N, Scahill R, Tabrizi SJ, Squitieri F, Aylward E. Structural MRI in Huntington’s disease and recommendations for its potential use in clinical trials. Neurosci Biobehav Rev. 2013;37:480–90. https://doi.org/10.1016/j.neubiorev.2013.01.022.
Byrne LM, et al. Neurofilament light protein in blood as a potential biomarker of neurodegeneration in Huntington’s disease: a retrospective cohort analysis. Lancet Neurol. 2017;16:601–9. https://doi.org/10.1016/S1474-4422(17)30124-2.
Acknowledgements
Biosamples and data used in this work were generously provided by the participants in the Enroll-HD study and made available by CHDI Foundation, Inc. Enroll-HD is a clinical research platform and longitudinal observational study for Huntington’s disease families intended to accelerate progress towards therapeutics; it is sponsored by CHDI Foundation, a non-profit biomedical research organization exclusively dedicated to collaboratively developing therapeutics for HD. Enroll-HD would not be possible without the vital contribution of the research participants and their families. We would like to thank all individuals who contributed to the collections of the Enroll-HD data as listed here.
Funding
Open Access funding enabled and organized by Projekt DEAL. Tamara Raschka and Holger Fröhlich were supported by the ERA PerMed EU-wide project DIGIPD (01KU2110). Heiko Gaßner was supported by the Fraunhofer Internal Programs under Grant No. Attract 044-602140 and 044-602150. Franz Marxreiter is funded by the European Huntington‘s Disease Network (EHDN) Seed Fund program. The Department of Molecular Neurology at University Hospital Erlangen was supported by the ERA PerMed EU-wide project DIGIPD (01KU2110). The funders played no role in study design, data collection, analysis and interpretation of data, or the writing of this manuscript.
Author information
Authors and Affiliations
Contributions
F.M., H.G., and H.F. were responsible for the study conception and design. Data analysis was performed by T.R. and Z.L. T.R., F.M., and H.F. contributed to the interpretation and discussion of the results. The first draft of the manuscript was written by T.R. F.M. and H.F. substantively revised it and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
Holger Fröhlich has received grants from UCB and AbbVie outside this work. All other authors declare no competing interests.
Disclaimer
The funders played no role in the study design, data collection, analysis and interpretation of data, or the writing of this manuscript.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Raschka, T., Li, Z., Gaßner, H. et al. Unraveling progression subtypes in people with Huntington’s disease. EPMA Journal 15, 275–287 (2024). https://doi.org/10.1007/s13167-024-00368-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13167-024-00368-2