
Abstract
Genome-wide association studies (GWAS) have allowed the identification of disease-associated variants, which can be leveraged to build polygenic scores (PGSs). Even though PGSs can be a valuable tool in personalized medicine, their predictive power is limited in populations of non-European ancestry, particularly in admixed populations. Recent efforts have focused on increasing racial and ethnic diversity in GWAS, thus, addressing some of the limitations of genetic risk prediction in these populations. Even with these efforts, few studies focus exclusively on Hispanics/Latinos. Additionally, Hispanic/Latino populations are often considered a single population despite varying admixture proportions between and within ethnic groups, diverse genetic heterogeneity, and demographic history. Combined with highly heterogeneous environmental and socioeconomic exposures, this diversity can reduce the transferability of genetic risk prediction models. Given the recent increase of genomic studies that include Hispanics/Latinos, we review the milestones and efforts that focus on genetic risk prediction, summarize the potential for improving PGS transferability, and highlight the challenges yet to be addressed. Additionally, we summarize social-ethical considerations and provide ideas to promote genetic risk prediction models that can be implemented equitably.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Hispanic/Latino is a common nomenclature used in epidemiological studies, likely because it is the nomenclature used by the US Census Bureau (United States Census Bureau 2022a). The terms “Hispanic” and “Latino,” as described by the US Office of Management and Budget and the US Census Bureau, are almost exclusively used in the USA, and they broadly refer to individuals from Latin America and/or Spanish-speaking countries (Lavange et al. 2010). Notably, while not primarily Spanish-speaking, Brazil is included in the “Latino” designation and Spain is often included as a “Hispanic” country. Additionally, this term is extended to the offspring of these individuals (Lavange et al. 2010) and individuals whose ancestors resided on modern US territory at a time that predated the establishment of the USA. Latin America has a complex demographic history, first occupied by Indigenous Americans then shaped by European colonization and the forced relocation of African individuals. The timing and magnitude of relocation have shaped the different admixture patterns and proportions of continental genetic ancestry throughout Latin America. Therefore, Hispanics/Latinos are known to be a genetically admixed population with unique demographic histories (Homburger et al. 2015).
Multiple studies have already documented the genetic admixture differences in Hispanics/Latinos (Bryc et al. 2015; Conomos et al. 2016). These differences are not only observed in the USA but also in Latin America as well (Belbin et al. 2018; Soares-Souza et al. 2018). For example, some individuals from South America have country-specific local patterns of genetic variation that are not observed outside certain sub-continental regions. Furthermore, Indigenous American and European ancestral components are significantly different throughout South American populations. Importantly, Indigenous American components are highly correlated with geography while European components are mainly from the Iberian Peninsula, even though some countries harbor components from Southern European regions (Homburger et al. 2015). On average, individuals from mainland backgrounds have higher Indigenous American ancestry proportions and lower African ancestry proportions than those from Caribbean countries. For instance, individuals from the Dominican Republic and Puerto Rico have a higher proportion of African genetic ancestry than those from Mexico or Central America (Bryc et al. 2015; Conomos et al. 2016). These different patterns of genetic ancestry impact variation in complex biomedical traits (Belbin et al. 2018)
Thousands of genetic variants associated with disease phenotypes and traits have been identified through genome-wide association studies (GWAS). As of September 2023, the GWAS catalog contained 6574 publications and 552,954 associations (Sollis et al. 2023). GWAS summary data is accessible through the catalog and can be leveraged to build polygenic scores (PGSs). Given the polygenicity of complex traits, PGSs aim to use individuals’ genomic data to make predictions of common complex diseases such as type 2 diabetes (T2D), asthma, and cardiovascular disease, among others. However, most genomic studies have historically focused on populations of European ancestry, limiting the utility of genetic risk prediction in populations that are genetically distant from most GWAS summary data (Kim et al. 2018). In the last decade, the US National Institutes of Health (NIH) has encouraged the inclusion of non-European participants in the genomic studies it funds. While this has led to an increase of studies that include populations of Asian ancestry, there has been minimal increase of Hispanics/Latinos and individuals of African ancestry. Importantly, these same populations that are underrepresented in genomic studies are also the ones traditionally underserved in the USA (Popejoy and Fullerton 2016). Therefore, the clinical implementation of PGSs constructed from European-ancestry GWAS summary data can potentially further deprive underserved communities from the benefits of personalized medicine.
Accuracy and portability of PGSs vary across global populations (Kim et al. 2018). To better understand the genetic architecture of complex biomedical traits in diverse populations, there have been increasing efforts to include ancestrally diverse populations in genomic studies. Among these efforts is the Population Architecture using Genomics and Epidemiology (PAGE) study. The goal of PAGE is to better understand the genetic susceptibility of disease in ancestrally diverse populations by collaborating with several US institutions, cohorts, and biobanks to conduct genetic analyses (Wojcik et al. 2019). However, one of the remaining limitations is the continued grouping of Hispanics/Latinos as a homogenous population, particularly in GWAS and polygenic risk prediction models. Additionally, Hispanic/Latino ethnic groups can have different disease rates and prevalence. For example, rates of asthma are approximately 3× higher in Puerto Ricans compared to Mexicans. The rate of asthma in Mexicans, in turn, is nearly 30% lower than the rate of asthma in non-Hispanic White individuals (US Department of Health and Human Services Office of Minority Health 2021). The vast genetic admixture diversity of Hispanics/Latinos (Conomos et al. 2016; Homburger et al. 2015), combined with different environmental factors, can lead to different health outcomes between ethnic groups (Belbin et al. 2018). Even though computational methods exist to account for population structure, challenges remain in the equitable implementation of PGSs in Hispanics/Latinos. Lastly, limited research has focused on the ethical, legal, and social implications of the use of genomic data in these populations and the subsequent clinical implementation of genetic risk scores. Throughout this review, we refer to these scores as polygenic scores or PGSs for short. Readers may be familiar with terms such as genetic risk scores, polygenic risk scores, or genetic risk prediction, which can all be viewed as a form of capturing the genomic contribution to a phenotype analogous to polygenic scoring.
Using genomic data to understand disease susceptibility in Hispanics/Latinos: milestones
According to the 2020 US Census Bureau, Hispanics/Latinos are the largest growing minority group in the USA, making up approximately 18.7% of the total US population (Jones et al. 2021). Hispanics/Latinos experience higher rates of chronic diseases, notably diabetes and obesity, when compared to non-Hispanic Whites (U.S. Department of Health and Human Services Office of Minority Health 2021). Genomic biomedical research has focused on identifying the possible genetic factors driving disease, creating an opportunity for precision medicine intiatives to potentially address existing health disparities in Hispanics/Latinos. In this section, we review a few diseases burdening Hispanic/Latino populations to show how genomic data is being used to better understand disease etiology.
Type 2 diabetes (T2D) is highly prevalent in Hispanics/Latinos, with incidence rates almost twice as high compared to non-Hispanic whites (Aguayo-Mazzucato et al. 2019). With the exception of a few genomic studies focusing on Mexican-Americans and Mexicans (Below et al. 2011; Palmer et al. 2015; Parra et al. 2011), GWAS of T2D have mostly included individuals of European ancestry. In 2014, over 100 loci associated with T2D were identified through a trans-ancestry meta-analysis GWAS which included 40% of non-European individuals (DIAbetes Genetics Replication Meta-analysis Consortium, Asian Genetic Epidemiology Network Type 2 Diabetes Consortium, South Asian Type 2 Diabetes Consortium, Mexican American Type 2 Diabetes Consortium, Type 2 Diabetes Genetic Exploration by Nex-generation sequencing in multi-Ethnic Samples Consortium, et al. 2014). While this effort included almost half of the total individuals from non-European ancestry, only 2% were identified as Hispanic/Latino. More recently, a GWAS was conducted on individuals from six Hispanic/Latino ethnic groups (Central American, Cuban, Dominican, Mexican, Puerto Rican, South American) to search for novel disease-susceptibility loci and to better understand the genetic basis of T2D in Hispanic/Latino populations (Qi et al. 2017). The results led to the identification of an independent association signal shown to be African ancestry-specific in certain Hispanic/Latino ethnic groups. These findings support the importance of including Hispanics/Latinos in genomic studies to identify disease-associated variants that may appear in higher frequency in certain groups. The benefits of performing genetic analyses in diverse populations to identify novel loci and variants associated with complex traits have been well-documented (Sirugo et al. 2019; Wojcik et al. 2019; Young et al. 2018).
Asthma is a common complex disease that exhibits differential burden across Hispanics/Latinos. In the USA, Mexican-Americans have lower asthma prevalence than Puerto Ricans, who have the highest asthma burden across all populations. The variability of asthma prevalence and morbidity in different Hispanic/Latino ethnic groups has prompted research on these populations for the last two decades (Rosser et al. 2014). While the observed differences are likely multifactorial, some studies have focused on the genetic risk factors driving disease by identifying genetic variants that confer asthma susceptibility in highly burdened ethnic groups (Yan et al. 2017). Another effort towards advancing Hispanic/Latino representation in asthma genomic studies is a meta-analysis GWAS focusing on childhood-onset asthma from four independent and diverse cohorts (Yan et al. 2021). This study was prompted by the high burden of asthma complications in Latino youth resulting in increased school absences and healthcare costs. More specifically, the goal of the study was to identify genetic determinants of asthma exacerbations (e.g., hospital or clinical visits for acute care), which may be different than those of asthma itself. Yan et al. identified variants associated with asthma complications in Latino children and adolescents, thus, improving our genetic understanding of a common disease over-burdening certain Hispanic/Latino ethnic groups.
Another important study in Hispanics/Latinos was completed in 2014, specifically looking at cardiovascular risk factors in the Hispanic Community Health Study (HCHS), a Study of Latinos (SOL), often abbreviated as HCHS/SOL (Daviglus et al. 2014). This study summarizes the importance of clinical risk factors and how these may vary between Hispanic/Latino ethnic groups. The authors evaluate the lifestyle, socioeconomic, and sociocultural factors that can drive health outcome differences between ethnic groups. While these non-genetic risk factors are important to understand cardiovascular disease in Hispanics/Latinos, these are likely interacting with genetic risk factors and impacting other diseases as well. Similar studies have shown a higher risk of obesity and associated chronic diseases in Hispanics/Latinos, aiming to identify variants that may increase disease risk (Young et al. 2018). These research studies are a step forward in improving Hispanic/Latino health, yet many studies remain underpowered to properly identify population-specific variants. Therefore, the ethical recruitment and representation of Hispanics/Latinos from diverse ethnic backgrounds in genomic studies is imperative to better understand both genetic and non-genetic factors driving common complex diseases in these populations.
Recruitment of Hispanics/Latinos in genomic studies is essential to address health disparities
Cohorts specifically designed to study Hispanic/Latino health are an important tool to address health disparities in these populations. HCHS/SOL is the largest community-based Hispanic/Latino cohort in the USA. This cohort involved the recruitment of diverse Hispanic/Latino ethnic groups (Cuba, Puerto Rico, Dominican Republic, Mexico, Central America, and South America) in four different communities in the USA (Lavange et al. 2010). Another notable Hispanic/Latino cohort is the Cameron County Hispanic Cohort (CCHC), which is a community-based cohort of approximately 5000 Mexican-Americans from a US-Mexico border community (The University of Texas Health Science Center at Houston 2019). Cohorts that specifically include Hispanic/Latino populations, such as HCHS/SOL and CCHC, provide an opportunity to potentially identify variants conferring disease risk in these populations. However, cohort heterogeneity, particularly when studied as a homogenous population, can create challenges that increase genomic inflation, confounding effects, and/or other effects such as relatedness that decrease statistical power (Conomos et al. 2016). Future research must continue to address the challenges of working with admixed populations such as Hispanics/Latinos and aim to develop statistical tools and methods that can account for heterogeneous variances between and within ethnic groups.
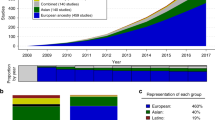
The increased number of Hispanics/Latinos in genomic and public health studies has provided unique opportunities to evaluate health disparities, however, few studies provide nationality (i.e., country of birth). Nationality is known to be an important healthcare factor with associated differences in health outcomes (Heintzman et al. 2023). The Multi-Ethnic Cohort Study (MEC), The Multiethnic Study of Atherosclerosis (MESA), and the Women’s Health Initiative (WHI) are some of the most diverse cohorts, which among others, are included in the PAGE consortium to better understand genetic susceptibility of disease in diverse populations. More recently, the All of Us research rogram is committing to enroll 1 million individuals with at least half from underrepresented or disadvantaged backgrounds (All Us Res Program Investigators 2019). As of September 2023, more than 710,000 participants have consented to join the All of Us research program, approximately 16% of them identifying as Hispanic/Latino. Notably, even with the increased number of Hispanics/Latinos in genomic studies, these only represent a small fraction of the total number of individuals enrolled, thus, still falling behind the power achieved in genomic studies of European ancestry such as is the case with the UK Biobank (Table 1). These recruitment patterns are not only observed in some cohorts but in biobanks as well.
Hispanics/Latinos make up approximately 24% of all participants in the Multi-Ethnic Cohort Study (MEC) and only 3% of the Women’s Health Initiative (WHI). In the context of Biobanks, we use the University of California Los Angeles ATLAS Community Health Initiative, abbreviated as UCLA ATLAS, as an example of Hispanic/Latino underrepresentation. UCLA ATLAS recruits participants from across the UCLA Health system in the greater Los Angeles area (Johnson et al. 2023). Even though LA County has one of the largest Hispanic/Latino populations in the country, where 49% of individuals identify as Hispanic/Latino (United States Census Bureau 2022b), only 14% of participants in the UCLA ATLAS Precision Health Biobank self-identified as Hispanic/Latino (Johnson et al. 2023). The continued underrepresentation of Hispanics/Latinos, combined with a lack of genomic research addressing the heterogeneity of Hispanic/Latino groups who have different cultures and environmental factors, remains a challenge in extending the benefits of personalized medicine to these populations. However, it is important to note ongoing active consortium-based and national initiatives occurring across Latin America, including novel, large studies coming online such as the Mexico City Prospective Study (Ziyatdinov et al. 2023), the Mexican Biobank (Sohail et al. 2023), and the trait-focused consortia Candela (Ruiz-Linares et al. 2014). These efforts both build capacity and collaboration for international researcher teams and improve our understanding of genetics across Latin America, thus, improving our knowledge of genetic architecture patterns specific to Hispanics/Latinos.
Current state of polygenic scores (PGSs) in Hispanics/Latinos
Historically, risk prediction models have focused on factors such as age, sex, family history of disease, and lifestyle. The promising advances of GWAS, particularly as studies become more diverse, have led to increased interest in predicting disease risk, onset, and outcomes from genomic data. Polygenic scores (PGSs) are traditionally calculated by aggregating the effects of disease-associated Single Nucleotide Polymorphisms (SNPs) from GWAS results (Choi et al. 2020). The GWAS summary statistics used to construct PGSs are referred to as the discovery sample; these developed PGSs are then evaluated in an independent sample (Wray et al. 2013). Because most GWASs are performed on individuals from European descent (Popejoy and Fullerton 2016), the PGSs developed from GWAS summary data (i.e., discovery samples) have a small number of Hispanics/Latinos. This limited and disproportionate sample size hinders the portability of PGSs in these populations (Kim et al. 2018). Therefore, PGSs that are developed using discovery samples from European individuals and applied to other populations, such as Hispanics/Latinos, have limited prediction accuracy (Bitarello and Mathieson 2020; Martin et al. 2017; Martin et al. 2019). The limitations of using disease SNP associations discovered in one population to predict disease in another population have been well-documented (Scutari et al. 2016; Wang et al. 2020; Wray et al. 2013).
Polygenic risk score prediction accuracy decreases in non-Europeans, particularly those individuals who are more genetically distant from Europeans. These limitations are not only a result of differences in risk allele frequencies and specific loci relevant to different populations (Kim et al. 2018) but also differences in cross-population correlations of causal SNP effects and heritability (Wang et al. 2020). Importantly, we note that the SNPs identified through GWAS are not usually the causal variants of a particular phenotype or disease. Instead, these are identified due to their association with a phenotype of interest and may be highly correlated with one or more causal variants. The correlation between the associated variant and the causal variant(s) depends on linkage disequilibrium, or genetic regions that are inherited together and persist through generations, resulting in SNPs that are highly correlated to the development of a particular disease. Different populations have different linkage disequilibrium patterns, a biological characteristic known to limit the prediction accuracy of PGSs in underrepresented populations (Wang et al. 2020; Wray et al. 2013). Additionally, the effect sizes calculated from GWAS summary data are estimated based on the discovery sample, biasing allele effect sizes that more accurately represent European individuals due to their over-representation in GWAS (Popejoy and Fullerton 2016). For these reasons, the inclusion of Hispanics/Latinos in GWAS to identify population-specific loci and effect sizes, and their subsequent incorporation in PGSs can increase risk prediction accuracy in these populations.
The complex demographic history of Hispanics/Latinos has shaped the landscape of clinical variants both in Latin America as well as Hispanics/Latinos living in the USA. This history has created conditions that have led to variants that segregate in specific Hispanic/Latino groups. Some examples include highly-penetrant founder mutations in BRCA1 and BRCA2 in germline cases of Mexico, and Caribbean-specific founder variants in PSEN1 genes that confer a risk of early-onset Alzheimer’s disease (Belbin et al. 2018). These population-specific variants, combined with genetic heterogeneity between and within Hispanic/Latino groups, highlight the importance of fine-scale population structure in the context of medical genetics in Hispanics/Latinos. In fact, fine-scale population structure affects polygenic risk prediction even in European populations that do not have the same complex demographic history and admixture of Hispanics/Latinos. For example, a recent study evaluated 245 PGSs in nine ancestry groups at a sub-continental level in the UK biobank. Their findings provide further evidence of the PGS portability problem even when working with European subpopulations (Prive et al. 2022). The authors further emphasize the relationship between genetic distance and predictive performance, even when PGSs are derived and applied in the same cohort. Therefore, it is important that PGSs are derived, trained, and evaluated in Hispanics/Latinos. Even in a large genomic database such as the UK Biobank, there is a low number of individuals that are identified as Hispanic/Latino, limiting the use of this database for these populations.
Polygenic score (PGS) challenges and future directions
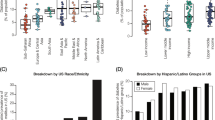
One of the leading challenges in the implementation of polygenic scores (PGSs) in Hispanics/Latinos is the lack of representation of relevant populations in PGS development, training, and evaluation. As of September 2023, the PGS catalog had 3787 polygenic scores across 640 traits in 492 publications (Lambert et al. 2021). Of these 3787 published polygenic risk scores, only 136 (3.59%) had a discovery or training sample that included Hispanics/Latinos; the number is lower for those that included Hispanics/Latinos in the evaluation sample (87 total, 2.29%). When evaluating traits, only 52 of 640 traits included Hispanics/Latinos in the discovery or training sample (8.13%). This number is less when looking at the percentage of traits that included Hispanics/Latinos in the evaluation sample (45 out of 640 total traits, totaling 7.03%) (Fig. 1). Note that these estimates are derived from the PGS catalog metadata, which we used to determine the number of polygenic risk scores and traits that had Hispanics/Latinos specifically listed in PGS development, training, and evaluation samples. Importantly, the inclusion of Hispanics/Latinos only represents a fraction of the total number of individuals included in either a discovery, training, or evaluation sample. For example, the median percent of Latinos/Hispanics included in discovery samples is only 2.2% of the total number of individuals included. This indicates that the number of Hispanics/Latinos included in either polygenic risk score development, training, or evaluation sample is a small fraction of the total number of individuals in the development of PGSs. This poses a remarkable challenge in the clinical implementation of PGSs in these populations because increasing genetic distance between training and target populations decreases prediction accuracy (Scutari et al. 2016). However, these findings are not surprising given the underrepresentation of Hispanics/Latinos in GWAS which was less than 1% in 2016 (Popejoy and Fullerton 2016) and 1.13% in 2019 (Sirugo et al. 2019).

Percent of Hispanics/Latinos included in the Polygenic Score (PGS) Catalog. Estimation of Hispanics/Latinos included in discovery and/or training and evaluation samples in the Polygenic Score Catalog (PGS). Percentages were calculated by totaling the number of either polygenic scores (PGSs) or traits that specifically included the term Hispanics or Latinos in either discovery or training samples, and evaluation samples
One of the most notable examples of using Hispanics/Latinos to increase the predictive power of PGSs was completed in 2020, aiming to improve genetic risk prediction of breast cancer in Latinas (Shieh et al. 2020). Even though the discovery of breast cancer-associated SNPs has been predominantly in European populations, some variants have been discovered in Latinas (Fejerman et al. 2014; Hoffman et al. 2019). Shieh et al. examined the performance of a PGS consisting of SNPs identified in European populations when adding those identified in Latinas. The authors concluded that the PGS with both European- and Latina-specific variants increased the predictive value in Latinas. Even though the authors show that this refined PGS has similar prediction accuracy in Europeans and across various Hispanic/Latino groups, this study highlights the importance of incorporating population-specific variants and evaluating risk prediction models to develop PGSs that maximize performance, particularly in underrepresented populations. However, one limitation is that this study only improved the predictive power of the trait studied (breast cancer), so the authors caution the over-generalization of this PGS to Latinas with different genetic ancestry proportions, as their findings are limited to the Latina ethnic group studied and those with similar distributions of genetic ancestry. Because demographic history impacts genetic risk prediction, to maximize PGS prediction accuracy, it is optimal to compute polygenic risk scores using discovery samples with similar demography history as the target population (Martin et al. 2017). This limitation is particularly pronounced in Hispanic/Latino populations who have varying genetic ancestry proportions which create further challenges in prediction accuracy.
The challenges in genetic risk prediction resulting from a lack of representation in Hispanics/Latinos are exacerbated by the lack of consistency in electronic health record (EHR) data and environmental factors that are difficult to quantify and measure, particularly in health system-associated biobanks. Studies have illustrated racial and ethnic differences in accessibility of patient portals that are linked to EHR data (Chang et al. 2018), especially impacting individuals of non-European ancestry and those with Spanish language preference (Garrido et al. 2015). The challenges that participants encounter when accessing patient portals are likely to affect phenotype harmonization, which is a key step in genomic studies and polygenic risk scoring. Another major concern is being able to fully understand genetic susceptibility in a society where access to healthcare significantly contributes to health disparities. A recent review of Hispanics/Latinos with type 2 diabetes found that cost, time, and lack of social support are among the barriers that prevent these populations from seeking and receiving the care they need (Titus and Kataoka-Yahiro 2021). Research conclusions must be carefully phrased to avoid claims that a certain population is more genetically predisposed than others, particularly because health risks can be compounded and such claims could have social and legal implications, especially for disadvantaged communities. To minimize bias in genomic research, scientists must be aware of the complex and layered risk factors that increase disease burden in Hispanic/Latino populations.
Lastly, a major limitation of PGSs is the inability to properly account for environmental factors that could be interacting with and driving risk beyond that of genomic data. For example, socioeconomic factors that affect Hispanics/Latinos may operate differently for undocumented immigrants compared to their documented counterparts, who may have higher accessibility to health care and health insurance (Cabral and Cuevas 2020). These challenges also affect disease diagnosis, which is associated with higher education completion and English literacy (Fisher-Hoch et al. 2012). To inform the clinical use of PGS-based risk stratification, it will also be necessary to examine the value of genetic risk prediction models in comparison to (or in addition to) established risk prediction equations based on clinical factors. This presents a further challenge, as even in fields such as preventive cardiology where clinical risk prediction approaches are well developed, the clinical (non-genetic) risk prediction equations have not been appropriately tailored to Hispanic/Latino populations due to lack of representation (Flores Rosario et al. 2021). The variability within Hispanic/Latino populations, both in genetic heterogeneity between and within ethnic groups, combined with a lack of representation in PGS samples and layered environmental factors, highlights the need for further research in the equitable clinical implementation of PGSs.
Clinical utility of polygenic scores (PGSs) and ethical considerations
Our enhanced understanding of the genetic etiology of complex diseases has propelled a wave of research that aims to integrate this information into risk prediction models that can be used in clinical settings. Overall, one of the goals of these precision medicine efforts is to identify individuals that may benefit from prompt preventative or treatment measures. However, researchers have already cautioned the scientific community of potentially exacerbating health disparities if PGSs are implemented without addressing the aforementioned challenges (Martin et al. 2019). These concerns have led to the increased recruitment of historically underrepresented populations in genomics; however, it is important that these recruitment efforts follow ethical guidelines already set forth by multiple organizations such as the Global Alliance for Genomics and Health (Knoppers 2014) and the US National Commission for the Protection of Human Subjects of Biomedical and Behavior Research (Sims 2010), just to name a few. Among these guidelines are ensuring that this research is benefiting the populations studied, as well as promoting health, well-being, and fair distribution of benefits (Mudd-Martin et al. 2021).
Notably, some PGSs are already being implemented in clinical settings, yet, these are likely to provide greater benefit and predictive accuracy to European populations. Some existing commercial and clinical PGS products were based on data from GWAS catalogs that were only initially available to and validated in individuals of European descent, which inherently hinders their application to underrepresented populations. For example, Myriad’s riskScore which assesses breast cancer risk was initially validated in 2017 only for women of European ancestry (Preston 2017). Therefore, for approximately 4 years, this test was only available to women of European descent, excluding entire populations that could have benefited from this type of risk assessment, particularly those from underserved communities, which includes Hispanics/Latinos. Myriad subsequently received criticism for this, and a revised riskScore applicable to women of all ancestries was released 4 years later in 2021 (Ray 2021). Myriad’s riskScore clearly highlights how the underrepresentation in genomic studies has the potential to exacerbate health disparities through the lack of access to genomic advances and technologies. This example also illustrates how the pattern of developing and validating assays first in European cohorts without careful consideration of their social implications can be harmful, and even when followed by inclusion of non-European cohorts, which can happen several years later, is ethically problematic. While the recruitment of Hispanics/Latinos in genomic studies and biobanks is a sensible next direction, there are still challenges to be addressed. For example, participant basic survey questions that aim to capture race and ethnicity as a single category can be confusing to answer for many individuals that identify as Hispanic/Latino (Allen Jr. et al. 2011). The specific questions asked can create heterogeneity in the use of race and ethnicity terms across genomic studies. Likewise, further guidance is needed to ethically capture important environmental factors such as acculturation and a proxy for documentation status, as well as language accessibility for both recruitment and dissemination of results.
It is also important to evaluate the disparities within the public health system, as these may pose potential barriers to the equitable implementation of PGSs in Hispanics/Latinos—we use the COVID-19 pandemic as a relevant case in point. The COVID-19 pandemic revealed major shortcomings embedded in the public health system, resulting in underrepresented communities bearing the highest risk of COVID-19 morbidity and mortality (Dalva-Baird et al. 2021). Even though access to health care played a major role in this outcome, other studies highlighted additional factors that contribute to the hesitancy of certain groups to engage in preventative methods, such as COVID-19 vaccines. A recent study explored these barriers in the context of COVID-19 vaccination (Butler et al. 2022); however, these are likely challenges that will burden Hispanic/Latino populations in the clinical implementation of PGSs as well. Among these findings are unclear information, language barriers, inadequate exposure to trusted sources of information, and uncertainty in eligibility to receive personalized medicine benefits (i.e., health insurance). Therefore, the utility of PGSs as a preventative tool can be hindered by accessibility barriers that are specific to Hispanics/Latinos and limit their benefit in clinical settings. Future research should focus on developing a framework that actively involves the community, evaluates participant perspectives, identifies challenges, and addresses them appropriately to maximize the benefits of personalized medicine efforts in clinical settings.
Recent research has captured the perspectives of diverse Spanish- and English-speaking patients on the clinical use of PGSs (Suckiel et al. 2022). The study recruited 30 biobank participants ages 35–50 years that were either self-reported as African/African American or Hispanic/Latino. These participants were part of semi-structured interviews in Spanish and English that explored their attitudes towards PGSs. Despite being told about the limited predicted power of PGSs for non-European populations, participants indicated that high-risk scores would prompt them to follow-up with their physicians and implement healthy behavior changes. They also mentioned a few barriers for the adoption of PGS-related recommendations, among these are insurance status, language, and inadequate understanding of PGSs. Larger studies that capture Hispanic/Latino attitudes towards PGSs are needed to address these challenges and ensure their equitable implementation. As highlighted earlier, in any genomic study, it is important to caution patients, physicians, and scientists from assuming that one population group is more genetically predisposed to disease versus another, as genetic risk prediction is only part of the multiple factors conferring disease risk, particularly in underrepresented populations (Belbin et al. 2021). Risk assessment should instead be performed on an individualized basis, accounting for the appropriate PGS (if/when clinically available), and relevant clinical and environmental risk factors.
Summary
The availability of genomic data has led to a rapid increase in Genome-Wide Association Studies (GWAS). Trait-associated SNPs, leveraged from the GWAS catalog, can be aggregated and used to make predictions of complex traits from individual genomic data. While recent efforts have increased the diversity of genomic studies, particularly in diseases that burden Hispanics/Latinos, lack of representation of Hispanics/Latinos in the development, training, and evaluation of polygenic scores (PGSs) remains a challenge. This lack of representation, combined with highly heterogeneous genetic, environmental, and socioeconomic exposures, affects the utility and accuracy of polygenic risk prediction in these populations. The limitations highlighted in this review can exacerbate existing health disparities and bring attention to the ethical, legal, and social implications of the clinical implementation of PGSs in Hispanics/Latinos.
References
Aguayo-Mazzucato C, Diaque P, Hernandez S, Rosas S, Kostic A, Caballero AE (2019) Understanding the growing epidemic of type 2 diabetes in the Hispanic population living in the United States. Diabetes Metab Res Rev 35(2):e3097. https://doi.org/10.1002/dmrr.3097
All Us Res Program Investigators (2019) The “All of Us” Research Program. N Engl J Med 381(7):668–676. https://doi.org/10.1056/NEJMsr1809937
Allen VC Jr, Lachance C, Rios-Ellis B, Kaphingst KA (2011) Issues in the assessment of “race” among Latinos: Implications for Research and Policy. Hisp J Behav Sci 33(4):411–424. https://doi.org/10.1177/0739986311422880
Banda Y, Kvale MN, Hoffmann TJ, Hesselson SE, Ranatunga D, Tang H, Sabatti C, Croen LA, Dispensa BP, Henderson M, Iribarren C, Jorgenson E, Kushi LH, Ludwig D, Olberg D, Quesenberry CP Jr, Rowell S, Sadler M, Sakoda LC, Risch N (2015) Characterizing race/ethnicity and genetic ancestry for 100,000 subjects in the Genetic Epidemiology Research on Adult health and aging (GERA) cohort. Genetics 200(4):1285–1295. https://doi.org/10.1534/genetics.115.178616
Belbin GM, Cullina S, Wenric S, Soper ER, Glicksberg BS, Torre D, Moscati A, Wojcik GL, Shemirani R, Beckmann ND, Cohain A, Sorokin EP, Park DS, Ambite JL, Ellis S, Auton A, Team CG, Regeneron Genetics C, Bottinger EP et al (2021) Toward a fine-scale population health monitoring system. Cell 184(8):2068–2083 e2011. https://doi.org/10.1016/j.cell.2021.03.034
Belbin GM, Nieves-Colon MA, Kenny EE, Moreno-Estrada A, Gignoux CR (2018) Genetic diversity in populations across Latin America: implications for population and medical genetic studies. Curr Opin Genet Dev 53:98–104. https://doi.org/10.1016/j.gde.2018.07.006
Below JE, Gamazon ER, Morrison JV, Konkashbaev A, Pluzhnikov A, McKeigue PM, Parra EJ, Elbein SC, Hallman DM, Nicolae DL, Bell GI, Cruz M, Cox NJ, Hanis CL (2011) Genome-wide association and meta-analysis in populations from Starr County, Texas, and Mexico City identify type 2 diabetes susceptibility loci and enrichment for expression quantitative trait loci in top signals. Diabetologia 54(8):2047–2055. https://doi.org/10.1007/s00125-011-2188-3
Bitarello BD, Mathieson I (2020) Polygenic scores for height in admixed populations. G3 (Bethesda) 10(11):4027–4036. https://doi.org/10.1534/g3.120.401658
Bryc K, Durand EY, Macpherson JM, Reich D, Mountain JL (2015) The genetic ancestry of African Americans, Latinos, and European Americans across the United States. Am J Hum Genet 96(1):37–53. https://doi.org/10.1016/j.ajhg.2014.11.010
Butler JZ, Carson M, Rios-Fetchko F, Vargas R, Cabrera A, Gallegos-Castillo A, LeSarre M, Liao M, Woo K, Ellis R, Liu K, Burra A, Ramirez M, Doyle B, Leung L, Fernandez A, Grumbach K (2022) COVID-19 vaccination readiness among multiple racial and ethnic groups in the San Francisco Bay area: a qualitative analysis. PloS One 17(5):e0266397. https://doi.org/10.1371/journal.pone.0266397
Cabral J, Cuevas AG (2020) Health Inequities Among Latinos/Hispanics: documentation status as a determinant of health. J Racial Ethn Health Disparities 7(5):874–879. https://doi.org/10.1007/s40615-020-00710-0
Chang E, Blondon K, Lyles C, Jordan L, Ralston JD (2018) Racial/ethnic variation in devices used to access patient portals. Am J Manag Care 24(1):e1–e8
Choi SW, Mak TS, O'Reilly PF (2020) Tutorial: a guide to performing polygenic risk score analyses. Nat Protoc 15(9):2759–2772. https://doi.org/10.1038/s41596-020-0353-1
Conomos MP, Laurie CA, Stilp AM, Gogarten SM, McHugh CP, Nelson SC, Sofer T, Fernandez-Rhodes L, Justice AE, Graff M, Young KL, Seyerle AA, Avery CL, Taylor KD, Rotter JI, Talavera GA, Daviglus ML, Wassertheil-Smoller S, Schneiderman N et al (2016) Genetic diversity and association studies in US Hispanic/Latino populations: applications in the Hispanic Community Health Study/Study of Latinos. Am J Hum Genet 98(1):165–184. https://doi.org/10.1016/j.ajhg.2015.12.001
Dalva-Baird NP, Alobuia WM, Bendavid E, Bhattacharya J (2021) Racial and ethnic inequities in the early distribution of U.S. COVID-19 testing sites and mortality. Eur J Clin Invest 51(11):e13669. https://doi.org/10.1111/eci.13669
Daviglus ML, Pirzada A, Talavera GA (2014) Cardiovascular disease risk factors in the Hispanic/Latino population: lessons from the Hispanic Community Health Study/Study of Latinos (HCHS/SOL). Prog Cardiovasc Dis 57(3):230–236. https://doi.org/10.1016/j.pcad.2014.07.006
DIAbetes Genetics Replication Meta-analysis Consortium, Asian Genetic Epidemiology Network Type 2 Diabetes Consortium, South Asian Type 2 Diabetes Consortium, Mexican American Type 2 Diabetes Consortium, Type 2 Diabetes Genetic Exploration by Nex-generation sequencing in multi-Ethnic Samples Consortium, Mahajan A, Go MJ, Zhang W, Below JE, Gaulton KJ, Ferreira T, Horikoshi M, Johnson AD, Ng MC, Prokopenko I, Saleheen D, Wang X, Zeggini E, Abecasis GR et al (2014) Genome-wide trans-ancestry meta-analysis provides insight into the genetic architecture of type 2 diabetes susceptibility. Nat Genet 46(3):234–244. https://doi.org/10.1038/ng.2897
Fejerman L, Ahmadiyeh N, Hu D, Huntsman S, Beckman KB, Caswell JL, Tsung K, John EM, Torres-Mejia G, Carvajal-Carmona L, Echeverry MM, Tuazon AM, Ramirez C, Consortium C, Gignoux CR, Eng C, Gonzalez-Burchard E, Henderson B, Le Marchand L et al (2014) Genome-wide association study of breast cancer in Latinas identifies novel protective variants on 6q25. Nat Commun 5:5260. https://doi.org/10.1038/ncomms6260
Fisher-Hoch SP, Vatcheva KP, Laing ST, Hossain MM, Rahbar MH, Hanis CL, Brown HS 3rd, Rentfro AR, Reininger BM, McCormick JB (2012) Missed opportunities for diagnosis and treatment of diabetes, hypertension, and hypercholesterolemia in a Mexican American population, Cameron County Hispanic Cohort, 2003-2008. Prev Chronic Dis 9:110298. https://doi.org/10.5888/pcd9.110298
Flores Rosario K, Mehta A, Ayers C, Engel Gonzalez P, Pandey A, Khera R, Kaplan R, Blaha MJ, Khera A, Blumenthal RS, Nasir K, Rodriguez CJ, Joshi PH (2021) Performance of the pooled cohort equations in Hispanic individuals across the United States: insights from the multi-ethnic study of atherosclerosis and the Dallas heart study. J Am Heart Assoc 10(9):e018410. https://doi.org/10.1161/JAHA.120.018410
Garrido T, Kanter M, Meng D, Turley M, Wang J, Sue V, Scott L (2015) Race/ethnicity, personal health record access, and quality of care. Am J Manag Care 21(2):e103–e113 https://www.ncbi.nlm.nih.gov/pubmed/25880485
Gaziano JM, Concato J, Brophy M, Fiore L, Pyarajan S, Breeling J, Whitbourne S, Deen J, Shannon C, Humphries D, Guarino P, Aslan M, Anderson D, LaFleur R, Hammond T, Schaa K, Moser J, Huang G, Muralidhar S, O’Leary TJ (2016) Million veteran program: A mega-biobank to study genetic influences on health and disease. J Clin Epidemiol 70:214–223. https://doi.org/10.1016/j.jclinepi.2015.09.016
Heintzman J, Dinh D, Lucas JA, Byhoff E, Crookes DM, April-Sanders A, Kaufmann J, Boston D, Hsu A, Giebultowicz S, Marino M (2023) Answering calls for rigorous health equity research: a cross-sectional study leveraging electronic health records for data disaggregation in Latinos. Fam Med. Community Health 11(2). https://doi.org/10.1136/fmch-2022-001972
Hoffman J, Fejerman L, Hu D, Huntsman S, Li M, John EM, Torres-Mejia G, Kushi L, Ding YC, Weitzel J, Neuhausen SL, Lott P, Consortium C, Echeverry M, Carvajal-Carmona L, Burchard E, Eng C, Long J, Zheng W et al (2019) Identification of novel common breast cancer risk variants at the 6q25 locus among Latinas. Breast Cancer Res 21(1):3. https://doi.org/10.1186/s13058-018-1085-9
Homburger JR, Moreno-Estrada A, Gignoux CR, Nelson D, Sanchez E, Ortiz-Tello P, Pons-Estel BA, Acevedo-Vasquez E, Miranda P, Langefeld CD, Gravel S, Alarcon-Riquelme ME, Bustamante CD (2015) Genomic insights into the ancestry and demographic history of South America. PLoS Genet 11(12):e1005602. https://doi.org/10.1371/journal.pgen.1005602
Johnson R, Ding Y, Bhattacharya A, Knyazev S, Chiu A, Lajonchere C, Geschwind DH, Pasaniuc B (2023) The UCLA ATLAS Community Health initiative: promoting precision health research in a diverse biobank. Cell Genom 3(1):100243. https://doi.org/10.1016/j.xgen.2022.100243
Jones N, Marks R, Ramirez R, Rios-Vargas M (2021) 2020 Census Illuminates Racial and Ethnic Composition of the Country. United States Census Bureau Retrieved 30 April 2022 from https://www.census.gov/library/stories/2021/08/improved-race-ethnicity-measures-reveal-united-states-population-much-more-multiracial.html
Kim MS, Patel KP, Teng AK, Berens AJ, Lachance J (2018) Genetic disease risks can be misestimated across global populations. Genome Biol 19(1):179. https://doi.org/10.1186/s13059-018-1561-7
Knoppers BM (2014) Framework for responsible sharing of genomic and health-related data. Hugo J 8(1):3. https://doi.org/10.1186/s11568-014-0003-1
Lambert SA, Gil L, Jupp S, Ritchie SC, Xu Y, Buniello A, McMahon A, Abraham G, Chapman M, Parkinson H, Danesh J, MacArthur JAL, Inouye M (2021) The Polygenic Score Catalog as an open database for reproducibility and systematic evaluation. Nat Genet 53(4):420–425. https://doi.org/10.1038/s41588-021-00783-5
Lavange LM, Kalsbeek WD, Sorlie PD, Aviles-Santa LM, Kaplan RC, Barnhart J, Liu K, Giachello A, Lee DJ, Ryan J, Criqui MH, Elder JP (2010) Sample design and cohort selection in the Hispanic Community Health Study/Study of Latinos. Ann Epidemiol 20(8):642–649. https://doi.org/10.1016/j.annepidem.2010.05.006
Martin AR, Gignoux CR, Walters RK, Wojcik GL, Neale BM, Gravel S, Daly MJ, Bustamante CD, Kenny EE (2017) Human demographic history impacts genetic risk prediction across diverse populations. Am J Hum Genet 100(4):635–649. https://doi.org/10.1016/j.ajhg.2017.03.004
Martin AR, Kanai M, Kamatani Y, Okada Y, Neale BM, Daly MJ (2019) Clinical use of current polygenic risk scores may exacerbate health disparities. Nat Genet 51(4):584–591. https://doi.org/10.1038/s41588-019-0379-x
Mudd-Martin G, Cirino AL, Barcelona V, Fox K, Hudson M, Sun YV, Taylor JY, Cameron VA, American Heart Association Council on, G., Precision, M., Council on, C., Stroke, N., & Council on Clinical, C (2021) Considerations for cardiovascular genetic and genomic research with marginalized racial and ethnic groups and indigenous peoples: a scientific statement from the American Heart Association. Circ Genom Precis Med 14(4):e000084. https://doi.org/10.1161/HCG.0000000000000084
Palmer ND, Goodarzi MO, Langefeld CD, Wang N, Guo X, Taylor KD, Fingerlin TE, Norris JM, Buchanan TA, Xiang AH, Haritunians T, Ziegler JT, Williams AH, Stefanovski D, Cui J, Mackay AW, Henkin LF, Bergman RN, Gao X et al (2015) Genetic variants associated with quantitative glucose homeostasis traits translate to type 2 diabetes in Mexican Americans: The GUARDIAN (Genetics Underlying Diabetes in Hispanics) consortium. Diabetes 64(5):1853–1866. https://doi.org/10.2337/db14-0732
Parra EJ, Below JE, Krithika S, Valladares A, Barta JL, Cox NJ, Hanis CL, Wacher N, Garcia-Mena J, Hu P, Shriver MD, Diabetes Genetics R, Meta-analysis C, Kumate J, McKeigue PM, Escobedo J, Cruz M (2011) Genome-wide association study of type 2 diabetes in a sample from Mexico City and a meta-analysis of a Mexican-American sample from Starr County, Texas. Diabetologia 54(8):2038–2046. https://doi.org/10.1007/s00125-011-2172-y
Popejoy AB, Fullerton SM (2016) Genomics is failing on diversity. Nature 538(7624):161–164. https://doi.org/10.1038/538161a
Preston J (2017) Myriad’s riskScore test for breast cancer risk adds a second layer of precision. MedCityNews. Retrieved 11 Oct 2023 from https://medcitynews.com/2017/12/myriads-riskscore-test-breast-cancer-risk-adds-second-layer-precision/
Prive F, Aschard H, Carmi S, Folkersen L, Hoggart C, O'Reilly PF, Vilhjalmsson BJ (2022) Portability of 245 polygenic scores when derived from the UK Biobank and applied to 9 ancestry groups from the same cohort. Am J Hum Genet 109(2):373. https://doi.org/10.1016/j.ajhg.2022.01.007
Qi Q, Stilp AM, Sofer T, Moon JY, Hidalgo B, Szpiro AA, Wang T, Ng MCY, Guo X, Consortium, M. E.-a. o. t. D. i. A. A, Chen YI, Taylor KD, Aviles-Santa ML, Papanicolaou G, Pankow JS, Schneiderman N, Laurie CC, Rotter JI, Kaplan RC (2017) Genetics of type 2 diabetes in U.S. Hispanic/Latino individuals: results from the Hispanic Community Health Study/Study of Latinos (HCHS/SOL). Diabetes 66(5):1419–1425. https://doi.org/10.2337/db16-1150
Ray, T. (2021). Myriad Genetics Recalibrates Breast Cancer PRS for All Ancestries in Anticipation of Broader Launch. Retrieved 02 Oct 2023 from https://www.precisionmedicineonline.com/molecular-diagnostics/myriad-genetics-recalibrates-breast-cancer-prs-all-ancestries-anticipation
Rosser FJ, Forno E, Cooper PJ, Celedon JC (2014) Asthma in Hispanics. An 8-year update. Am J Respir Crit Care Med 189(11):1316–1327. https://doi.org/10.1164/rccm.201401-0186PP
Ruiz-Linares A, Adhikari K, Acuna-Alonzo V, Quinto-Sanchez M, Jaramillo C, Arias W, Fuentes M, Pizarro M, Everardo P, de Avila F, Gomez-Valdes J, Leon-Mimila P, Hunemeier T, Ramallo V, Silva de Cerqueira CC, Burley MW, Konca E, de Oliveira MZ, Veronez MR, Gonzalez-Jose R (2014) Admixture in Latin America: geographic structure, phenotypic diversity and self-perception of ancestry based on 7,342 individuals. PLoS Genet 10(9):e1004572. https://doi.org/10.1371/journal.pgen.1004572
Scutari M, Mackay I, Balding D (2016) Using genetic distance to infer the accuracy of genomic prediction. PLoS Genet 12(9):e1006288. https://doi.org/10.1371/journal.pgen.1006288
Shieh Y, Fejerman L, Lott PC, Marker K, Sawyer SD, Hu D, Huntsman S, Torres J, Echeverry M, Bohorquez ME, Martinez-Chequer JC, Polanco-Echeverry G, Estrada-Florez AP, Consortium C, Haiman CA, John EM, Kushi LH, Torres-Mejia G, Vidaurre T et al (2020) A polygenic risk score for breast cancer in US Latinas and Latin American women. J Natl Cancer Inst 112(6):590–598. https://doi.org/10.1093/jnci/djz174
Sims JM (2010) A brief review of the Belmont report. Dimens Crit Care Nurs 29(4):173–174. https://doi.org/10.1097/DCC.0b013e3181de9ec5
Sirugo G, Williams SM, Tishkoff SA (2019) The missing diversity in human genetic studies. Cell 177(4):1080. https://doi.org/10.1016/j.cell.2019.04.032
Soares-Souza G, Borda V, Kehdy F, Tarazona-Santos E (2018) Admixture, genetics and complex diseases in Latin Americans and US Hispanics. Curr Genet Med Rep 6:208–223. https://doi.org/10.1007/s40142-018-0151z
Sohail M, Palma-Martinez MJ, Chong AY, Quinto-Cortes CD, Barberena-Jonas C, Medina-Munoz SG, Ragsdale A, Delgado-Sanchez G, Cruz-Hervert LP, Ferreyra-Reyes L, Ferreira-Guerrero E, Mongua-Rodriguez N, Canizales-Quintero S, Jimenez-Kaufmann A, Moreno-Macias H, Aguilar-Salinas CA, Auckland K, Cortes A, Acuna-Alonzo V, Moreno-Estrada A (2023) Mexican Biobank advances population and medical genomics of diverse ancestries. Nature 622(7984):775–783. https://doi.org/10.1038/s41586-023-06560-0
Sollis E, Mosaku A, Abid A, Buniello A, Cerezo M, Gil L, Groza T, Gunes O, Hall P, Hayhurst J, Ibrahim A, Ji Y, John S, Lewis E, MacArthur JAL, McMahon A, Osumi-Sutherland D, Panoutsopoulou K, Pendlington Z et al (2023) The NHGRI-EBI GWAS Catalog: knowledgebase and deposition resource. Nucleic Acids Res 51(D1):D977–D985. https://doi.org/10.1093/nar/gkac1010
Suckiel SA, Braganza GT, Aguiniga KL, Odgis JA, Bonini KE, Kenny EE, Hamilton JG, Abul-Husn NS (2022) Perspectives of diverse Spanish- and English-speaking patients on the clinical use of polygenic risk scores. Genet Med 24(6):1217–1226. https://doi.org/10.1016/j.gim.2022.03.006
The Charles Bronfman Institute for Personalized Medicine (2022) BioMe Facts and Figures. Icahn School of Medicine at Mount Sinai. Retrieved 10 June 2022 from https://icahn.mssm.edu/research/ipm/programs/biome-biobank/facts
The Multiethnic Cohort Study (2022) Composition of the Cohort. University of Hawai’i Cancer Center Retrieved 10 June 22 from https://www.uhcancercenter.org/for-researchers/mec-cohort-composition
The Multiethnic Study of Atherosclerosis (MESA) (n.d.) About MESA. MESA Coordinating Center. Retrieved 10 June 2022 from https://www.mesa-nhlbi.org/aboutMESA.aspx
The University of Texas Health Science Center at Houston (2019) Hispanic Health Research Center, Cameron County Hispanic Cohort. UTHealth. Retrieved 10 June 2022 from https://sph.uth.edu/research/centers/hispanic-health/#TID-8d39067e-3bc7-4ebe-8734-4ed463f94bf1-2
Titus SK, Kataoka-Yahiro M (2021) barriers to access to care in Hispanics with type 2 diabetes: a systematic review. Hisp Health Care Int 19(2):118–130. https://doi.org/10.1177/1540415320956389
U.S. Department of Health and Human Services Office of Minority Health (2021) Asthma and Hispanic Americans. OMH Retrieved 18 July 2022 from https://minorityhealth.hhs.gov/omh/browse.aspx?lvl=4&lvlid=60
U.S. Department of Veterans Affairs (n.d.) Discover MVP data-MVP enables high quality health research. Retrieved 10 June 2022 from https://www.mvp.va.gov/pwa/discover-mvp-data
United States Census Bureau. (2022a). About the Hispanic population and its origin. Census. Retrieved 29 April 22 from https://www.census.gov/topics/population/hispanic-origin/about.html
United States Census Bureau. (2022b). QuickFacts: Los Angeles County, California. Retrieved 02 Oct 2023 from https://www.census.gov/quickfacts/fact/table/losangelescountycalifornia/RHI725222
Wang Y, Guo J, Ni G, Yang J, Visscher PM, Yengo L (2020) Theoretical and empirical quantification of the accuracy of polygenic scores in ancestry divergent populations. Nat Commun 11(1):3865. https://doi.org/10.1038/s41467-020-17719-y
Wiley LK, Shortt JA, Roberts ER, Lowery J, Kudron E, Lin M, Mayer DA, Wilson MP, Brunetti TM, Chavan S, Phang TL, Pozdeyev N, Lesny J, Wicks SJ, Moore E, Morgenstern JL, Roff AN, Shalowitz EL, Stewart A et al (2022) Building a vertically-integrated genomic learning health system: the Colorado Center for Personalized Medicine Biobank. medRxiv:2022.2006.2009.22276222. https://doi.org/10.1101/2022.06.09.22276222
Wojcik GL, Graff M, Nishimura KK, Tao R, Haessler J, Gignoux CR, Highland HM, Patel YM, Sorokin EP, Avery CL, Belbin GM, Bien SA, Cheng I, Cullina S, Hodonsky CJ, Hu Y, Huckins LM, Jeff J, Justice AE et al (2019) Genetic analyses of diverse populations improves discovery for complex traits. Nature 570(7762):514–518. https://doi.org/10.1038/s41586-019-1310-4
Women’s Health Initiative (2021) About WHI. WHI. Retrieved 10 June 2022 from https://www.whi.org/about-whi
Wray NR, Yang J, Hayes BJ, Price AL, Goddard ME, Visscher PM (2013) Pitfalls of predicting complex traits from SNPs. Nat Rev Genet 14(7):507–515. https://doi.org/10.1038/nrg3457
Yan Q, Brehm J, Pino-Yanes M, Forno E, Lin J, Oh SS, Acosta-Perez E, Laurie CC, Cloutier MM, Raby BA, Stilp AM, Sofer T, Hu D, Huntsman S, Eng CS, Conomos MP, Rastogi D, Rice K, Canino G et al (2017) A meta-analysis of genome-wide association studies of asthma in Puerto Ricans. Eur Respir J 49(5). https://doi.org/10.1183/13993003.01505-2016
Yan Q, Forno E, Herrera-Luis E, Pino-Yanes M, Qi C, Rios R, Han YY, Kim S, Oh S, Acosta-Perez E, Zhang R, Hu D, Eng C, Huntsman S, Avila L, Boutaoui N, Cloutier MM, Soto-Quiros ME, Xu CJ et al (2021) A genome-wide association study of severe asthma exacerbations in Latino children and adolescents. Eur Respir J 57(4). https://doi.org/10.1183/13993003.02693-2020
Young KL, Graff M, Fernandez-Rhodes L, North KE (2018) Genetics of obesity in diverse populations. Curr Diab Rep 18(12):145. https://doi.org/10.1007/s11892-018-1107-0
Zhou W, Kanai M, Wu KH, Rasheed H, Tsuo K, Hirbo JB, Wang Y, Bhattacharya A, Zhao H, Namba S, Surakka I, Wolford BN, Lo Faro V, Lopera-Maya EA, Lall K, Fave MJ, Partanen JJ, Chapman SB, Karjalainen J, Neale BM (2022) Global Biobank meta-analysis initiative: powering genetic discovery across human disease. Cell Genom 2(10):100192. https://doi.org/10.1016/j.xgen.2022.100192
Ziyatdinov A, Torres J, Alegre-Diaz J, Backman J, Mbatchou J, Turner M, Gaynor SM, Joseph T, Zou Y, Liu D, Wade R, Staples J, Panea R, Popov A, Bai X, Balasubramanian S, Habegger L, Lanche R, Lopez A, Tapia-Conyer R (2023) Genotyping, sequencing and analysis of 140,000 adults from Mexico City. Nature 622(7984):784–793. https://doi.org/10.1038/s41586-023-06595-3
Funding
This work was supported by the National Institutes of Health R01HG010297, R01HG011345, R01HL151152, and U01HG011715.
Author information
Authors and Affiliations
Contributions
B. M. wrote the main manuscript text and prepared figures. D. P., R. K., K. C., and C. G. reviewed the manuscript and provided feedback for the final version.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This article does not contain any studies with human or animal subjects performed by any of the authors.
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Maldonado, B.L., Piqué, D.G., Kaplan, R.C. et al. Genetic risk prediction in Hispanics/Latinos: milestones, challenges, and social-ethical considerations. J Community Genet 14, 543–553 (2023). https://doi.org/10.1007/s12687-023-00686-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12687-023-00686-4