
Abstract
This research study focused on the dynamic response and mechanical performance of fiber-reinforced concrete columns using hybrid numerical algorithms. Whereas test data has non-linearity, an artificial intelligence (AI) algorithm has been incorporated with different metaheuristic algorithms. About 317 datasets have been applied from the real test results to detect the promising factor of strength subjected to the seismic loads. Adaptive neuro-fuzzy inference system (ANFIS) was carried out as an AI beside the combination of particle swarm optimization (PSO) and genetic algorithm (GA). Extreme Machine Learning (ELM) was also performed in order to approve the obtained results. According to the findings, it is demonstrated that ANFIS–PSO predicts the lateral load with promising evaluation indexes [R2 (test) = 0.86, R2 (train) = 0.90]. Mechanical performance prediction was also carried out in this study, and the results showed that ELM predicts the compressive strength with promising evaluation indexes [R2 (test) = 0.66, R2 (train) = 0.86]. Finally, both ANFIS–GA and ANFIS–PSO techniques illustrated a reliable performance for prediction, which encourage scholars to replace costly and time-consuming experimental tests with predicting utilities.
Similar content being viewed by others


1 Introduction
Concrete is often considered as the most widely used construction material in the world (Rasekh et al. 2020; Jahandari et al. 2019, 2020; Saberian et al. 2017; Mohammadi et al. 2019a, b). Fibres application in concrete can decline the requirement of transverse reinforcement in fiber-reinforced concrete (FRC) members, particularly in their seismic design (Khorami et al. 2017; Bossio et al. 2017; Park et al. 2016; Ghassemieh and Bahadori 2015; Shahi et al. 2013; Jalali et al. 2012; McMullin et al. 1993; Bahrololoumi and Dargazany 2019; Mohammadi et al. 2019a, b). Fibers play an important role in some critical members which require many reinforcements such as beam to column joints (Kazemi et al. 2020a, b; Afshar et al. 2020; Sadeghian et al. 2020). Although the mathematical modelling for the ultimate strength prediction of FRC rectangular columns subjected to simulated seismic loading is suggested in few studies (Aghakhani et al. 2015; Thai et al. 2012; McCulloch and Pitts 1943; Bahrololoumi and Dargazany 2019), the major objective of this research is to avoid the high nonlinearity of mathematical methods by applying soft computing methods.
Soft computing methods do not require the knowledge of internal system while providing a compact solution for multi-variable problems. Artificial intelligence (AI) techniques have recently played a significant role in the progression of engineering goals (Armaghani et al. 2019; Shariati et al. 2019a). Different prediction techniques have been introduced for estimation and optimization applications. Prediction quality depends on a variety of variables such as error, soft computing approach, estimation problems in front of the prediction process, etc. (Xu et al. 2019; Shariati et al. 2019b, 2020; Taheri et al. 2019, 2020; Toghroli et al. 2020; Taheri et al. 2019, 2020). AI techniques are proposed to alleviate many estimation problems. By interlacing with classical optimization algorithms, AI techniques have become among the most important prediction methods (Ghassemieh and Bahadori 2015). Machine Learning (ML) is another type of artificial technique which has been employed and developed during the estimation applications. Prediction of different objectives or characteristics are now achieved by using two main algorithms, called metaheuristic MT and heuristic algorithms. Since MT algorithms require no problem definition for operators, they have become among the most popular approaches for prediction. Generally, continuing the improvement of MT algorithms could be a reliable approach to enhance AI techniques and prediction applications.
Employing these techniques for prediction, describing runoff volume, debris volume, and sediment texture as input for algorithms could give the sediment load in place of output (Shahi et al. 2013; Jalali et al. 2012; McMullin et al. 1993). Back propagation (BP) approaches, which are placed among classic techniques, have been generally proposed to train artificial neural networks (ANN) (McCulloch and Pitts 1943). Being stuck in local extremums and troubles in solving plateaus of the error function landscape are the malfunctions of the classic algorithms (Ghassemieh and Bahadori 2015; Bahrololoumi et al. 2020). In order to address classic algorithm deficiencies, MT approaches such as GA (Aghakhani et al. 2015), PSO (Shariati et al. 2019a, b), and imperialist competitive algorithm (ICA) (Sadeghian et al. 2020) have been proposed and utilized in different prediction cases. Chen et al. (2018) conducted the ANN-PSO algorithm to predict the shear strength of reinforced concrete (RC) walls. ANN-PSO model has indicated some majorities against other MT predictive models. Chen et al. (2019) also evaluated ANN-GA and ANN-ICA hybrid models in a fascinating study to enhance and secure retaining walls during seismic events. In this case, the ANN-ICA model could reach better performance indices. ANN-PSO, ANN-GA, ANN-ICA, and ANN-ABC have been evaluated in comparison to each other (Toghroli et al. 2020). Results of this investigation showed the superior capability of the ANN-PSO model over the other studied models. ANN-PSO model has also been performed to estimate flyrock distance incomplete with ANN-GA, and ANN-ICA. This investigation also demonstrated the better performance of ANN-PSO in the prediction of targets (Al-Qaness et al. 2020a). By and large, PSO and GA algorithm has been proved as a reliable technique to combine with MT algorithms. Intelligent algorithms have been employed in medical applications as well. In a new study, marine predator algorithm has been successfully carried out on Covid-19 confirmed cases to predict the number of infected patients (Al-Qaness et al. 2020a). An enhanced ANFIS algorithm has been developed for forecasting the number of confirmed flu cases, where two separate MT algorithms, called sine cosine (SCA) and flower pollination algorithms were integrated with ANFIS (Al-Qaness et al. 2020b). ANFIS algorithm has been combined with two optimization techniques, called salp swarm and flower pollination algorithms, in order to cover the shortcomings of ANFIS. A new hybrid ANFIS algorithm was employed to predict the number of infected people by Covid-19 in China (Al-Qaness et al. 2020c). Combination of ANFIS with separate optimization technique has already been carried out in different studies. In a study, ANFIS was combined with multi-verse optimizer (MVO) technique, and the new hybrid algorithm was employed in favor of data estimation. MVO-ANFIS has been used to calculate the oil consumption and to forecast it from a data set of two countries (Al-Qaness et al. 2019). ANFIS-SCA algorithm has also been successfully employed to forecast oil consumption from records of petroleum products datasets (Al-Qaness et al. 2018). Bengar et al. (2016) estimated the ductility of reinforced concrete (RC) beams, concluding that ANN could be taken in the predictions with less scatter than the statistical methods. Fedutenko et al. (2019) and Amirian et al. (2018a, b) studied the application of ANN in the modelling of compaction-dilation data and evaluated the performance of unconventional oil reservoirs while focusing on ANNs in the performance evaluation of oil reservoirs. AI can be well suited to optimize, estimate and predict the structural characteristics of fibrous concrete. The current study, as hybrid MT methods based on fuzzy-inference techniques, has performed ANFIS–PSO and ANFIS–GA algorithms to predict both lateral the seismic load as dynamic response and compressive strength of FRC. In this regard, a verified experimental database was adopted from Cai and Degée (2017) which investigates the seismic response of FRC rectangular columns. The variable selection procedure was considered to select the most predominant parameters affecting the ultimate strengths of FRC rectangular columns subjected to simulated seismic loading. ELM algorithm was also employed, as a generally proved AI, to evaluate the presented results which have been ultimately discussed and compared.
2 Methodology
In the presence of reinforcing fibres inside the concrete matrix, fibrous concrete becomes a composite material with tremendously increased tensile and compressive strengths. Fibrous concrete, with functional integrity and consistency, can raise the use of concrete to produce high-strength materials. Fibrous concrete is also known as a highly energy-absorbing material that can not be easily defeated under the impact loadings. Moreover, it has some other functional properties such as high strength, excellent ductility, high energy absorption rate, and high cracking resistance with many applications. The mechanical and physical properties of polymeric fibres and their approximate costs are shown in Table 1.
Employing different fibres in concrete has been investigated by many researchers. This paper presents some theoretical and experimental background of the study from which the database is derived.
2.1 Flexural strength models
According to the American Concrete Institute provisions for RC columns, by employing 0.85fc as the mean compressive strength and 0.003 as the ultimate compressive strength, theoretical flexural strength of RC column could be achieved. Based on the moment equilibrium in the cross-section of the columns, the flexural capacity of RC column could be obtained through the use of Eq. (1). Other required variables has been provided in Eqs. (2) and (3).
where; Z = the inner lever arm, X = concrete compressive zone, f1c=real compressive strength, fy1=reinforcement yield stress, Asl=area of longitudinal steel, mm, \( \omega_{1} \) =mechanical reinforcement ratio, kc=affecting factor for maximum stress of block.
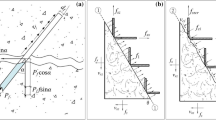
Following the Fig. 1 , the flexural capacity zone of RC column has included three main parts such as: (1) concrete contribution (\( V_{\text{c}} \)), (2) truss-mechanism component (\( V_{\text{s}} \)), and (3) the contribution from axial load (\( V_{\text{p}} \)).

The shear transfer mechanisms consideration in RC/FRC columns (Cai and Degée 2017)
At the same time, the lateral component force, attained from the non-directive tensile actions of fibre at main diagonal cracked section, could maintain the fourth shear contribution to the total shear resisting of FRC columns, has been provided by fibre \( V_{f} \) (Fig. 1b). Subsequently, to represent the positive impacts of fibre, the compressive depth \( C_{\text{R}} \) of FRC column under seismic action could be regarded as 50% of the overall column depth. Thus, the original Priestley et al. (1994) model was initially modified as \( V_{Priestley} \). The relationship between the volume fraction of fibre and the relative nominalized difference ratios are presented in Fig. 2.

Ratio of fiber volume with respect to ratio of relative difference (Cai and Degée 2017)
2.2 Ultimate flexure capacity
Modifying the moment calculation of FRC column is calculated using Eqs. (4) and (5):
where; MFRC=fiber reinforced concrete moment, Ksp=a/d affecting factor to moment, Kn=axial load affecting factor to moment, Xf=depth of compression zone of columns, mm, \( d' \) =effective depth of column, mm.
Therefore, based on the current database, \( k_{sp} \) was considered to be 0.95. The proposed moment model is capable to evaluate the experimental outcomes with a better agreement compared to the existing models.
3 Analytical assessment
There are many available techniques for data predictions and validations such as employing ANNs. In this case, performing the artificial intelligence algorithms is a potential method to avoid non-linearity and sophisticated analysis of the nanoscale problems. Even novel MT artificial techniques could be employed to predict the most influential parameters on the performance of the CFRPs (Shariati et al. 2019a, b).
3.1 Performed analytical techniques
The employed analytical techniques in this study have been discussed in the following, and their architecture has also been demonstrated for better understanding.
3.1.1 ANFIS algorithm and architecture
ANFIS is a direct-feed algorithm which includes number of nodes connected by directed links. Nodes play an especial role in producing an output through input signals. Figure 3 indicates the ANFIS architecture consisting of five layers such as product layer, de-fuzzy layer, fuzzy layer, normalized layer and total output layer. The major purpose of ANFIS is to delineate the optimal variables of equivalent fuzzy inference system (FIS) parameters by using a learning algorithm. The optimization process would took a place along the training phase in which the minimized error achived.

The basic architecture of ANFIS
In order to enhance the error, different optimization techniques could be employed following the MFs. The parameter set of an adaptive network allows fuzzy systems to learn from the modelled data. It is assumed that the adaptive system under consideration has two inputs A1 and A2 and one output f. A first-order Takagi, Sugeno and Kang (TSK) FIS containing two rules is evaluated as follows:
(1): If (v is A1) and (l is L1) then \( f_{1} = m_{1} v + z_{1} l + o_{1} \).
(2): If (v is A2) and (l is L2) then \( f_{2} = m_{2} v + z_{2} l + o_{2} \).
m1, m2, z1, z2, o1, o2 = direct parameters.
A1, A2, L1, L2 = undirect parameters.
A1, L1 = the MFs of ANFIS.
m1, z1, o1 = the following parameters.
Circle and square are used to reflect the adaptive capabilities, while a circle represents a fixed node and square shows an adaptive node. These parameters could be altered during adapting or training. Neural network (NN) has many inputs and multiple outputs, however, the fuzzy logic has many inputs and one single output, thus the combination of these two is called ANFIS (Walia et al. 2015). The central core of the ANFIS network is a FIS. The first layer receives inputs and converts them to fuzzy values by the MFs (Sedghi et al. 2018; Hamdia et al. 2015; Toghroli et al. 2014; Toghroli 2015; Sari et al. 2020). Every node in the first layer is selected as an adaptive node with a node function:
\( A_{i} \) = a linguistic label, \( O_{i}^{1} \) = the membership function of \( A_{i} \).
The bell-shaped membership function is usually selected due to its high capacity for the regression of nonlinear data (Sedghi et al. 2018). Also, it functions with the maximum value of 1 and the minimum value of 0:
\( \left\{ {a_{i} , b_{i} ,c_{i} ,d_{i} } \right\} \) = parameters set, \( x \) = the input.
The parameters of the first layer are known as premise parameters. The second layer multiplies the incoming signals and sends their product to the next layer:
Each output of the nodes shows the firing strength of a rule.
In the rule layer (the third one), the ratio of \( i^{th} \) node firing strength of rule to other nodes is calculated:
The outcomes \( w_{i}^{*} \) are known as normalised firing strength.
In the defuzzification layer (fourth layer), each node has a node function as below:
where \( w_{i}^{*} \) = the output of the third layer, \( \left\{ {p_{i} ,q_{i} ,r_{i} } \right\} \) = the parameters of forth layer known as following parameters.
Fifth layer includes the last layer (ouput) in which the overall output is calculated by summing all the incoming signals:
A target value has already been set between the train and test values. By continuing, the following parameters would be obtained by the least-squares model. In case this value is greater than the considered target, the premise parameters are updated with respect to the gradient descent method. The process should be followed until the error becomes less than the target.
3.1.2 Particle swarm optimization
PSO is an intelligence evolutionary approach which mimics the social behavior of bird flocking. Kennedy and Eberhart (1997) proposed the PSO algorithm. The PSO application could be used in the problem solving of multi-objective integer programming, optimization, clustering, classification, combinatorial optimization, and min–max drawbacks, or many other engineering applications. PSO algorithm has a very fast convergence rate in comparison to the other evolutionary algorithms (EA) (Khan and Ahai 2012). Hence, it has been successfully employed to solve different engineering problems (Bao et al. 2013; Hasanipanah et al. 2016; Mohamad et al. 2018; Mohandes 2012). In PSO algorithm, a cost function that should be maximized or minimized is initially well-defined. After that, a swarm of particles is produced and distributed in the dimensional space of the problem.. Figure 4 shows the sequential steps of the PSO algorithm.

The flowchart of sequential steps of PSO algorithm
3.1.3 Genetic algorithm
GA as is a MT algorithm, belonging to the larger class of EA (Xu et al. 2019; Shariati et al. 2019b; Beyene et al. 2006; Whitley 1994), is an algorithm that benefits from the natural biological evolution roles. Generally, GA has been conducted to obtain reliable estimations to the search of shortcomings and optimization by relying on bio-inspired operators such as mutation, crossover and selection followed by Holland (1960) to introduce GA and Goldberg (1989) (Sadeghian et al. 2020). In GA, the variables of a problem are encoded as chromosomes initially selected, and then are overlapped and mutated in an evolutionary procedure. After many evolution times, the best individual is gained. Regarding the convergence and robustness of GA, it takes much less time with a more accuracy in finding an optimal solution (Jalali et al. 2012).
GA has three operators (1) selection, (2) crossover, and (3) mutation which are applied to the population of all possible resolutions for developing their fitness function in each iteration or generation (McMullin et al. 1993) (Fig. 5). Align with the purpose of this study, the GA code was rewritten in MATLAB (version 2019). Thus, a uniform crossover was applied while genes were randomly selected by one of Roulette wheel selection, Tournament selection and Random selection methods. GA implementation included 5 primary steps 1) Setting the structure of gene (2) deciding the evaluation criteria of gene (objective function) (3) generating an initial population of genes, (4) selecting an offspring generation mechanism, and (5) coding the procedure in a computer program (Bahrololoumi and Dargazany 2019).

The flowchart of sequential steps of the GA algorithm
3.1.4 Extreme machine learning
ELM as a version of machine learning system benefits from a single layer or multiple layers, which avoids time-consuming iterative training process and enhances the generalization performance. As an authenticate algorithm, ELM is a direct-feed algorithm for the sparse approximation, clustering, regression, classification, compression and feature learning in which the parameters of hidden nodes are not tuned and used to interpret the other results. Moreover, each layer contains a number of hidden neurons where the input weights are assigned randomly. ELMs use the concept of random projection and early perceptron models to perform specific kinds of problem-solving methods. Huang et al. (2006) provided the extreme Machine Learning as an AI tool for unique-layer direct-feed NN architecture. These hidden nodes could be randomly assigned and never updated, or can be inherited from their ancestors without alteration. In most cases, the output weights of hidden nodes are generally learned in a single step, which are significant amounts to learn a linear model. Figure 6 shows the sequential steps of the ELM algorithm.

The flowchart of sequential steps of the ELM algorithm
3.2 Hybrid ANFIS–PSO/GA architecture
Following the previous descriptions of ANFIS and optimization approaches about the fascinating points for prediction cases, hybrid algorithms were designed and written. The flowchart of circuit ANFIS and PSO/GA integration is shown in Fig. 7 (Zollo 1997). In PSO, swarm begins with a group of random solutions named a particle while si⇀ shows the particle’s position. Likewise, a particle swarm moves in the problem space in which vi⇀ shows the particle’s velocity. Function f is verified at each time slap by the input si⇀. Each particle records its best position associated to the best fitness obtained to this point in pi⇀ vector. pig⇀ tracks the most appropriate position defined by any neighborhood member. In a standard PSO, pig⇀ shows the most proper point within the whole population. A new velocity is gained for any particle i in each iteration based on the best individual positions, pi(t)⇀, and p⇀ig(t) neighborhood, thus the new velocity could be represented by:
w = inertia weight.

The flowchart of circuit integration of ANFIS–PSO and ANFIS–GA algorithm
The positive acceleration coefficients are depicted by c1 and c2. ∅1⇀, while ∅2⇀ shows the uniformly-distributed random vectors as (0,1) in which a random value is tried for every dimension. vi⇀limited in the [-vmax⇀, vmax⇀] series rely on the problem provided that the velocity has sometimes exceeded the mentioned limit and rearranged in its suitable curbs. Based on their velocities, every particle has changed its position as:
Regarding vi⇀ and si⇀, the particle population tends to cluster around the best.
3.3 Performance evaluation
To assess the performance of the models, 70% of the data was randomly dedicated to the training phase, and the rest 30% was devoted to the testing part. Afterwards, Pearson correlation coefficient (r), root mean squared error (RMSE), and determination coefficient (R2) were employed as performance indices of the models. Pearson’s correlation coefficient is the test statistics that measures the statistical relationship, or association, between two continuous variables. It is known as the best method of measuring the association between variables of interest because it is based on the method of covariance. RMSE is a frequently used measure of the differences between values (sample or population values) predicted by a model or an estimator and the values observed. R2 is a statistical measure that represents the proportion of the variance for a dependent variable that’s explained by an independent variable or variables in a regression model. These statistical indicators are described in the following:
\( P_{i} \), \( T_{i} \) = the predicted and observed values, S = number of considered data, \( \overline{{T_{k} }} or \overline{{P_{k} }} \) = mean predicted and observed values.
In other to compare the performance of ANFIS–PSO, ANFIS–GA and ELM were also performed using MATLAB (version 2019). Moreover, all the codes were run in one computer system with no external compiler or toolbox.
3.4 Statistical data
The selected attributes were gained based on the importance and quality of the experimental data in the next section. The collected database was composed of 317 datasets. Experimental data of Width (mm), Height (mm), Fibre Fraction Ratio (%), Maximum Lateral Force (kN), Concrete Compressive Strength (MPa), Fibre Yielding Strength (MPa), and Shear Span Ratio (a/d) were used as inputs in each model for prediction and optimization (Table 2).
4 Models development
As previously mentioned, the purpose of this article was to find the most compelling optimizing algorithm and to predict the seismic response. Thus, the impact of a critical portion of fibre-reinforced concrete could be analysed. After that, by comparing the obtained results from their placement in AI models, the quality of their impact and determination were obtained (Table 3).
The temperature characteristics of fibre should be presented in all datasets due to its importance in FRC properties. Therefore, the database was set for the hardened concrete variables, and the lateral seismic load and compressive strength were directly related to each other due to the experimental study. On the other hand, load and strength could be substituted as either input or output.
5 Results
All the three employed algorithms in this study were separately tuned. In order to optimize the coefficients of the parameters related to each algorithm, the other parameters were kept constant. By changing the coefficient, the best value was delineated, and then the process was continued to the other parameters. In this case, algorithms were repeatedly implemented and revised until being developed, and finally, the following results were obtained (Table 4).
5.1 ANFIS–PSO
ANFIS–PSO which operates based on the random population generation and also based on the modelling and simulation of avian mass flight behavior or mass movement of fish, is a global minimization method that deals with the shortcomings whose answer is a point or surface in n-dimensional space. In this case, a random population is assumed, and an elementary velocity is assigned as well as the channels of communication between the particles which move through the response space followed by the results that are calculated on a “merit basis” after each time interval. Particles accelerate towards the particles of higher competence in the same communication group during the time. Despite the good performance of each method towards the problems, there is a great success in solving continuous optimization problems. The results of regression graphs and comparative graphs are shown in Figs. 8 and 9. The processing results analysis is also presented (Table 5). According to Fig. 8 and Table 5, ANFIS–PSO is more capable in predicting the lateral load than the compressive strength due to its properties or in principle to more predictable output. Also, the test results in lateral load prediction are very close to the Train results, while the compressive strength output is more significant, indicating that it is more reliable for predicting the lateral load. Though the outputs of other type are acceptable, the discrepancy of test results and train results reduced our confidence over the outputs (Fig. 10).

ANFIS–PSO prediction vs experimental results regression for a lateral load test phase, b lateral load train phase, c compressive strength test phase, d compressive strength train phase

ANFIS–PSO prediction vs experimental diagram for a lateral load test phase, b lateral load train phase, c compressive strength test phase, d compressive strength train phase

ANFIS–PSO error histogram for a lateral load test phase, b lateral load train phase, c compressive strength test phase, d compressive strength train phase
According to Fig. 7, another point deducted from the regression diagram (c) is that the low results of the compressive strength output test are due to 2–3 points with high error rates and the other samples that provide acceptable results and also due to the standard deviation results for this output. While the Std difference in two phases of Test and Train for the lateral load is 14%, this difference for the compressive strength is 33%, indicating less concentration of errors in the second output than that of the first output (Fig. 9).
5.2 ANFIS–GA
GA is a special type of EA to gain the optimal formula for the prediction or pattern matching. GA is a good option for the regression-based prediction techniques. It is also a programming technique in problem-solving including inputs that are transformed into solutions during a patterned process of genetic evolution. The solutions are verified candidates by the Fitness Function, and the algorithm is terminated if the problem exit condition is provided. Generally, it is an iteration-based algorithm in which many parts are randomly selected. The results of ANFIS–GA neural network are presented in Table 7 and Figs. 11, 12. Besides, the combination settings used for this hybrid grid are shown in Table 6.

ANFIS–GA prediction vs experimental results regression for a lateral load test phase, b lateral load train phase, c compressive strength test phase, d compressive strength train phase

ANFIS–GA prediction vs experimental diagram for a lateral load test phase, b lateral load train phase, c compressive strength test phase, d compressive strength train phase
In ANFIS–GA method, the results of the lateral load output are more reliable than that of the compressive strength, and the there is no a significant difference between the test and train phase results for the first output.
Given the low result of R2, average result of r, and considering the regression graph (c) and (d) in Fig. 13, the approximation NN results for the second output at the boundary are unacceptable. Higher error results were likely occurred, particularly during the testing phase. According to the graphs in Fig. 13, lower error for the compressive strength data below 40 MPa and higher error for the data above 40 MPa were observed. During the test phase, it seems that NN for the second output with a value higher than 40 MPa was not well trained due to a large number of samples below 40 MPa (Fig. 12).

ANFIS–GA error histogram for a lateral load test phase, b lateral load train phase, c compressive strength test phase, d compressive strength train phase
5.3 Extreme learning machine
ELM as the final NN is used in the settings shown in Table 8. The obtained results are acceptable for both outputs. However, as shown in Table 9, it was found that by comparing the lateral load output performance parameters to the compressive strength, and by comparing the Test and Train results, the lateral load outputs are very close, while it is very different for the other output (Fig. 14).

ELM prediction vs experimental results regression for a lateral load test phase, b lateral load train phase, c compressive strength test phase, d compressive strength train phase
By examining the standard deviation as well as the error histogram diagram (Fig. 15), errors with a greater focus on the lateral load make the outputs more reliable. Compressive strength outputs might provide appropriate results, however, due to the lack of focus on center-axis of errors, an unprecedented response could likely provide high and unacceptable errors (Fig. 16).

ELM prediction vs experimental diagram for: a lateral load test phase, b lateral load train phase, c compressive strength test phase, d compressive strength train phase

ELM error histogram for a lateral load test phase, b lateral load train phase, c compressive strength test phase, d compressive strength train phase
6 Discussion
ANFIS is trained for each input to separately delineate the inputs of RMSE, R2 and r to define the effect of every input on the output. The input with the smallest training RMSE has the most significant effect on output. Testing RMSE is applied to track the overfitting between training and testing data. A higher testing RMSE means that the regression of data is not useful. Thus, the combination of two inputs in order to obtain the most potent combinations of inputs on the output could be further studied. The training and testing RMSE for the combinations of two inputs are shown (Table 2). According to the training RMSE, the combination of inputs 2 and 3 provides the optimal combination with the most substantial effect on the output parameter. The quality of the estimations made by the algorithms and used in this paper, beside the actual points used in Cai and Degee paper (2017), along with the regression lines of each algorithm, are presented in Fig. 17. Comparing the regression results obtained from the Test section, GA and ELM algorithms are closer to each other than the PSO algorithm, even if the PSO regression covers more data range (Fig. 17a). Also, considering the results of the Train section, the PSO regressions are closer to the main points than the other regressions (Fig. 17b, d). Finally, the most significant difference between regressions with the main points is seen in Fig. 17c. In Fig. 17c, the alignment of the regression lines with the real points is highly different from the other parts. Also, ELM shows the highest difference among the other algorithms, while GA and PSO indicate consistent regressions.

The comparisons between a flexural load test phase, b flexural load train phase, c deflection test phase, d deflection train phase
Considering the responses received from all methods, it is clear that the lateral load is excessively predictable than the compressive strength, which might be due to the type of inputs or type of NN. For the lateral load output, the best result for ANFIS–PSO method provides the performance parameters of R2= 0.8756 r = 0.9357, and RMSE = 11.2026. Other approaches have provided close and acceptable responses (Fig. 18). By observing the histogram of test phase error (Figs. 10, 12, and 16), in terms of concentration, all three graphs have a good concentration around the centre, while due to the smaller error interval in ANFIS–PSO method, it is concluded that the probability of receiving a high error response in this method is lower than the other methods.

The comparisons between performed algorithms results of lateral load based on analytical parameters as a RMSE, b determination coefficient, c Pearson’s correlation value
For the compressive strength output, ELM method also provides the best response (Fig. 19). The test phase evaluation criteria for this method are R2= 0.6574, r = 0.810771741, and RMSE = 5.474340963. Therefore, the response presented by ANFIS–GA method in the test phase is almost unacceptable. Although it is reliable for data with less than 40 MPa, high errors in data over 40 MPa have caused system failure. Therefore, the test phase error diagrams at this output are not significantly different except the ANFIS–PSO diagram that has the widest range and no centralization. However, given that only one output with an error is high, the diagram of this method can be taken close to the other two methods.

The comparisons between performed algorithms results of compressive strength based on analytical parameters as a RMSE, b determination coefficient, c Pearson’s correlation value
7 Conclusions
The prediction of the most influential factors on the ultimate strengths of FRC rectangular columns subjected to simulated seismic loading is very complicated because of the existence of many parameters. In the current research study, a soft computing method was carried out to overcome this prediction difficulty by eliminating some extra input parameters. ANFIS was applied to choose the most dominant parameters for the prediction of the most influential factor on the ultimate strengths of FRC rectangular columns subjected to the simulated seismic loading. In this research, ANN and backed-up data from the experimental results of 317 rows Width (mm), Height (mm), Fibre Fraction Ratio (%), Maximum Lateral Force (kN), Fibre Yielding Strength (MPa), Concrete Compressive Strength (MPa), and Shear Span Ratio (a/d) are related to the prediction values of the two types of outputs as lateral load and compressive strength.
-
ANFIS–PSO results for the lateral load output in the test phase are R2= 0.8756 and r = 0.9357, and RMSE = 11.2026. Also, the results for the compressive strength are R2= 0.5069, r = 0.712, and RMSE = 5.34938145.
-
ANFIS–GA results for the lateral load are R2=0.856, r =0.9252, and RMSE =13.3085, which is not the best answer, but satisfactory. The results of compressive strength are R2=0.5069, r =0.712, and RMSE =5.3494 which are not acceptable.
-
The results of Lateral load prediction by ELM algorithm are R2=0.8502, r =0.9221, and RMSE =15.3661, which are not the best, but acceptable. For the compressive strength, ELM provides the best results as R2= 0.6574, r =0.8108, and RMSE =5.4743.
To sum up, although the prediction results of lateral seismic loads by all three methods are outstanding and reasonable, ANFIS–PSO method provides the best results. Moreover, for the compressive strength, the best results belong to ELM neural network. Although the results of this output are not as reliable as the first output results, the results of ANFIS–GA method could also be unacceptable. Consequently, the ANFIS–GA and ANFIS–PSO methods are identified to be suitable for the lateral load prediction and compressive strength due to the abysmal results, recommending to use ELM method in the case of neural network with better results. For future studies, investigating the performance of triple hybrid MT algorithms with combination of ANFIS–PSO such as ANFIS–PSO-GA is highly recommended.
Abbreviations
- ABC:
-
Artificial bee colony
- AI:
-
Artificial intelligence
- ANFIS:
-
Adaptive neuro-fuzzy inference system
- ANN:
-
Artificial neural networks
- BP:
-
Back propagation
- CFRP:
-
Carbon fiber reinforced polymer
- EA:
-
Evolutionary algorithms
- ELM:
-
Extreme learning machine
- FIS:
-
Fuzzy inference system
- FRC:
-
Fiber-reinforced concrete
- GA:
-
Genetic algorithm
- ICA:
-
Imperialist competitive algorithm
- ML:
-
Machine learning
- MF:
-
Membership function
- MT:
-
Metaheuristic
- MVO:
-
Multi-verse optimizer
- PE:
-
Polyethylene
- PP:
-
Polypropylene
- PSO:
-
Particle swarm optimization
- RC:
-
Reinforced concrete
- RMSE:
-
Root mean squared error
- SCA:
-
Sine cosine
- ST:
-
Steel
- TSK:
-
Takagi, Sugeno and Kang
References
Afshar A, Jahandari S, Rasekh H, Shariati M, Afshar A, Shokrgozar A (2020) Corrosion resistance evaluation of rebars with various primers and coatings in concrete modified with different additives. Constr Build Mater 262:120034
Aghakhani M, Suhatril M, Mohammadhassani M, Daie M, Toghroli A (2015) A simple modification of homotopy perturbation method for the solution of Blasius equation in semi-infinite domains. Math Probl Eng 2015:1–7
Al-Qaness MA, Abd Elaziz M, Ewees AA (2018) Oil consumption forecasting using optimized adaptive neuro-fuzzy inference system based on sine cosine algorithm. IEEE Access 6:68394–68402
Al-Qaness MA, Abd Elaziz M, Ewees AA, Cui X (2019) A modified adaptive neuro-fuzzy inference system using multi-verse optimizer algorithm for oil consumption forecasting. Elecg J 8(10):1071
Al-Qaness MA, Ewees AA, Fan H, Abualigah L, Abd Elaziz M (2020a) Marine predators algorithm for forecasting confirmed cases of COVID-19 in Italy, USA, Iran and Korea. Int J Environ Res Public Health 17(10):3520
Al-Qaness MA, Ewees AA, Fan H, Abd Elaziz M (2020b) Optimized forecasting method for weekly influenza confirmed cases. Int J Environ Res Public Health 17(10):3510
Al-Qaness MA, Ewees AA, Fan H, Abd El Aziz M (2020c) Optimization method for forecasting confirmed cases of COVID-19 in China. J Clin Med 9(3):674
Amirian E, Dejam M, Chen Z (2018a) Performance forecasting for polymer flooding in heavy oil reservoirs. Fuel 216:83–100
Amirian E, Fedutenko E, Yang C, Chen Z, Nghiem L (2018b) Artificial neural network modeling and forecasting of oil reservoir performance. Applications of data management and analysis. Springer, Cham, pp 43–67
Armaghani DJ, Hasanipanah M, Amnieh HB, Bui DT, Mehrabi P, Khorami M (2019) Development of a novel hybrid intelligent model for solving engineering problems using GS-GMDH algorithm. Eng Comput 36:1379–1391
Bahrololoumi A, Dargazany R (2019) Hydrolytic aging in rubber-like materials: a micro-mechanical approach to modeling. In: ASME international mechanical engineering congress and exposition. American Society of Mechanical Engineers, 59469: V009T11A029
Bao Y, Xiong T, Hu Z (2013) PSO-MISMO modeling strategy for multistep-ahead time series prediction. IEEE Trans Cybern 44(5):655–668
Behfarnia K, Behravan A (2014) Application of high performance polypropylene fibers in concrete lining of water tunnels. Mater Des 55:274–279
Bengar HA, Abdollahtabar M, Shayanfar J (2016) Predicting the ductility of RC beams using nonlinear regression and ANN. IJSTC 40(4):297–310
Bentur A, Mindess S (2006) Fibre reinforced cementitious composites. CRC Press, Boca Raton
Beyene Y, Botha AM, Myburg AA (2006) Genetic diversity in traditional Ethiopian highland maize accessions assessed by AFLP markers and morphological traits. Biodivers Conserv 15(8):2655–2671
Bossio A, Lignola G. P, Fabbrocino F, Prota A, Manfredi G (2017) Evaluation of seismic behavior of corroded reinforced concrete structures. In: Proceedings of the 15th international forum world heritage and disaster, Capri, Italy, pp 15–17
Cai G, Degée H (2017) Ultimate strengths of FRC rectangular columns subjected to simulated seismic loading: experimental database and new models. Arch Civ Mech Eng 17:96–120
Chen XL, Fu JP, Yao JL, Gan JF (2018) Prediction of shear strength for squat RC walls using a hybrid ANN–PSO model. Eng Comput 34(2):367–383
Chen H, Asteris PG, Jahed Armaghani D, Gordan B, Pham BT (2019) Assessing dynamic conditions of the retaining wall: developing two hybrid intelligent models. Appl Sci 9(6):1042
Deng Z, Li J (2006) Mechanical behaviors of concrete combined with steel and synthetic macro-fibers. Int J Phys Sci 1(2):57–66
Fedutenko E, Nghiem L, Yang C, Chen T, Seifi M (2019) Artificial neural network modeling of compaction-dilation data for unconventional oil reservoirs. In: SPE reservoir simulation conference. society of petroleum engineers
Ghassemieh M, Bahadori A (2015) Seismic evaluation of a steel moment frame with cover plate connection considering flexibility by component method. In: Proceedings of the 2015 world congress on Advances in Structural Engineering and Mechanics, Incheon, Korea
Hamdia KM, Lahmer T, Nguyen-Thoi T, Rabczuk T (2015) Predicting the fracture toughness of PNCs: a stochastic approach based on ANN and ANFIS. Comput Mater Sci 102:304–313
Hasanipanah M, Noorian-Bidgoli M, Armaghani DJ, Khamesi H (2016) Feasibility of PSO-ANN model for predicting surface settlement caused by tunneling. Eng Comput 32(4):705–715
Huang GB, Zhu QY, Siew CK (2006) Extreme learning machine: theory and applications. Neurocomputing 70(1–3):489–501
Jahandari S, Saberian M, Tao Z, Mojtahedi SF, Li J, Ghasemi M, Li W (2019) Effects of saturation degrees, freezing-thawing, and curing on geotechnical properties of lime and lime-cement concretes. Cold Reg Sci Technol 160:242–251
Jahandari S, Mojtahedi SF, Zivari F, Jafari M, Mahmoudi MR, Shokrgozar A, Jalalifar H (2020) The impact of long-term curing period on the mechanical features of lime-geogrid treated soils. Geomech Geoeng. https://doi.org/10.1080/17486025.2020.1739753
Jalali A, Daie M, Nazhadan SVM, Kazemi-Arbat P, Shariati M (2012) Seismic performance of structures with pre-bent strips as a damper. Int J Phys Sci 7(26):4061–4072
Kazemi M, Hajforoush M, Talebi PK, Daneshfar M, Shokrgozar A, Jahandari S, Li J (2020a) In-situ strength estimation of polypropylene fibre reinforced recycled aggregate concrete using Schmidt rebound hammer and point load test. JSCM. https://doi.org/10.1080/21650373.2020.1734983
Kazemi M, Li J, Harehdasht SL, Yousefieh N, Jahandari S, Saberian M (2020b) Non-linear behaviour of concrete beams reinforced with GFRP and CFRP bars grouted in sleeves. Structures 23:87–102
Kennedy J, Eberhart RC (1997) A discrete binary version of the particle swarm algorithm. In 1997 IEEE International conference on systems, man, and cybernetics. Comput Cybern Simul 5:4104–4108
Khan K, Ahai A (2012) A comparison of BA, GA, PSO, BP and LM for training feed forward neural networks in e-learning context. Int J Intell Syst Appl 4(7):23
Khorami M, Khorami M, Motahar H, Alvansazyazdi M, Shariati M, Jalali A, Tahir MM (2017) Evaluation of the seismic performance of special moment frames using incremental nonlinear dynamic analysis. Struct Eng Mech 63(2):259–268
McCulloch WS, Pitts W (1943) A logical calculus of the ideas immanent in nervous activity. Bull Math Biol 5(4):115–133
McMullin K, Astaneh-Asl A, Fenves G. L, Fukuzawa E (1993) Innovative semi-rigid steel frames for control of the seismic response of buildings. University of California, Rep. No. UCB/CE-Steel-93, 2
Mohamad ET, Armaghani DJ, Momeni E, Yazdavar AH, Ebrahimi M (2018) Rock strength estimation: a PSO-based BP approach. Neural Comput Appl 30(5):1635–1646
Mohammadi H, Bahrololoumi A, Chen Y, Dargazany R (2019a) A micro-mechanical model for constitutive behavior of elastomers during thermo-oxidative aging. In: Constitutive models for rubber XI, pp 542–547
Mohammadi M, Kafi MA, Kheyroddin A, Ronagh HR (2019b) Experimental and numerical investigation of an innovative buckling-restrained fuse under cyclic loading. Structures 22:186–199
Mohandes MA (2012) Modeling global solar radiation using Particle Swarm Optimization (PSO). Sol Energy 86(11):3137–3145
Park D, Lee TH, Nguyen DD, Park J (2016) Collapse mechanism of cut-and-cover tunnels under seismic loading. JGSSP 2(25):934–937
Priestley MN, Verma R, Xiao Y (1994) Seismic shear strength of reinforced concrete columns. J Struct Eng 120(8):2310–2329
Rasekh H, Joshaghani A, Jahandari S, Aslani F, Ghodrat M (2020) Rheology and workability of SCC. Self-compacting concrete: materials, properties and applications. Woodhead Publishing, Sawston, pp 31–63
Saberian M, Jahandari S, Li J, Zivari F (2017) Effect of curing, capillary action, and groundwater level increment on geotechnical properties of lime concrete: experimental and prediction studies. J Rock Mech Geotech Eng 9(4):638–647
Sadeghian F, Haddad A, Jahandari S, Rasekh H, Ozbakkaloglu T (2020) Effects of electrokinetic phenomena on the load-bearing capacity of different steel and concrete piles: a small-scale experimental study. Can Geotech J. https://doi.org/10.1139/cgj-2019-0650
Sari PA, Suhatril M, Osman N, Muazu MA, Katebi J, Abavisani A, Petkovic D (2020) Developing a hybrid adoptive neuro-fuzzy inference system in predicting safety of factors of slopes subjected to surface eco-protection techniques. Eng Comput 36(4):1347–1354
Sedghi Y, Zandi Y, Toghroli A, Safa M, Mohamad ET, Khorami M, Wakil K (2018) Application of ANFIS technique on performance of C and L shaped angle shear connectors. Smart Struct Syst 22(3):335–340
Shahi R, Lam N, Gad E, Wilson J (2013) Protocol for testing of cold-formed steel wall in regions of low-moderate seismicity. Earthq Struct 4(6):629–647
Shariati M, Trung NT, Wakil K, Mehrabi P, Safa M, Khorami M (2019a) Estimation of moment and rotation of steel rack connections using extreme learning machine. Steel Compos Struct 31(5):427–435
Shariati M, Rafie S, Zandi Y, Fooladvand R, Gharehaghaj B, Mehrabi P, Poi-Ngian S (2019b) Experimental investigation on the effect of cementitious materials on fresh and mechanical properties of self-consolidating concrete. Adv Concr Constr 8(3):225–237
Shariati M, Tahmasbi F, Mehrabi P, Bahadori A, Toghroli A (2020) Monotonic behavior of C and L shaped angle shear connectors within steel-concrete composite beams: an experimental investigation. Steel Compos Struct 35(2):237–247
Snoeck D, De Belie N (2015) From straw in bricks to modern use of microfibers in cementitious composites for improved autogenous healing—a review. Constr Build Mater 95:774–787
Taheri E, Firouzianhaji A, Usefi N, Mehrabi P, Ronagh H, Samali B (2019) Investigation of a method for strengthening perforated cold-formed steel profiles under compression loads. Appl Sci 9(23):5085
Taheri E, Firouzianhaji A, Mehrabi P, Hosseini BV, Samali B (2020) Experimental and numerical investigation of a method for strengthening cold-formed steel profiles in bending. Appl Sci 10(11):3855
Thai CH, Tran LV, Tran DT, Nguyen-Thoi T, Nguyen-Xuan H (2012) Analysis of laminated composite plates using higher-order shear deformation plate theory and node-based smoothed discrete shear gap method. Appl Math Model 36(11):5657–5677
Toghroli A (2015) Applications of the ANFIS and LR models in the prediction of shear connection in composite beams/Ali Toghroli. Doctoral dissertation, University of Malaya
Toghroli A, Mohammadhassani M, Suhatril M, Shariati M, Ibrahim Z (2014) Prediction of shear capacity of channel shear connectors using the ANFIS model. Steel Compos Struct 17(5):623–639
Toghroli A, Mehrabi P, Shariati M, Trung NT, Jahandari S, Rasekh H (2020) Evaluating the use of recycled concrete aggregate and pozzolanic additives in fiber-reinforced pervious concrete with industrial and recycled fibers. Constr Build Mater 252:118997
Walia N, Singh H, Sharma A (2015) ANFIS: adaptive neuro-fuzzy inference system-a survey. Int J Comput Appl 123(13):32–38
Whitley D (1994) A genetic algorithm tutorial. Stat Comput 4(2):65–85
Xu Y, Chung DDL (2000) Reducing the drying shrinkage of cement paste by admixture surface treatments. Cem Concr Res 30(2):241–245
Xu C, Zhang X, Haido JH, Mehrabi P, Shariati A, Mohamad ET, Wakil K (2019) Using genetic algorithms method for the paramount design of reinforced concrete structures. Struct Eng Mech 71(5):503–513
Zollo RF (1997) Fiber-reinforced concrete: an overview after 30 years of development. Cem Concr Compos 19(2):107–122
Author information
Authors and Affiliations
Corresponding authors
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Mehrabi, P., Honarbari, S., Rafiei, S. et al. Seismic response prediction of FRC rectangular columns using intelligent fuzzy-based hybrid metaheuristic techniques. J Ambient Intell Human Comput 12, 10105–10123 (2021). https://doi.org/10.1007/s12652-020-02776-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12652-020-02776-4