
Abstract
We review sublinear computational time modeling using momentum-space renormalization group approaches in the statistical machine learning algorithms. The modeling scheme has been proposed and the basic frameworks have been briefly explained in a short note (Tanaka et al. in J. Phys. Soc. Jpn, 87(8), Article ID: 085001, 2018). We present their detailed formulations and some numerical experimental results of sublinear computational time modeling based on the momentum-space renormalization scheme.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Probabilistic graphical models have useful applications in statistical machine learning theory, and many authors are investigating their applications in artificial intelligent computational systems [1, 2]. Realizations of statistical machine learning systems with probabilistic graphical models entail massive computational time. For avoiding such problems, some statistical–mechanical techniques have been introduced, for example, advanced mean-field methods including belief propagations [3,4,5,6,7,8]. However, it is very difficult to reduce the computational time to the sublinear time for each system size in such advanced mean-field methods although they can achieve the linear computational time modeling. Recent research in data sciences has helped understand the necessity to treat high-dimensional state vectors, and it is necessary to achieve novel sublinear computational time modeling schemes in probabilistic graphical models. Sublinear computational time modeling is used to reduce the computational time for solving the given problem to the order of sublinear time with respect to the system size.
The renormalization group (RG) theory [9,10,11,12,13] is one of important theories in statistical mechanics. The RG theory was introduced to investigate a universality class of phase transitions in probabilistic graphical models by considering spatially coarse-graining procedures. The RG scheme can be divided to two kinds: real-space renormalization group (RSRG) schemes and momentum-space renormalization group (MSRG) schemes. MSRG schemes are implemented in the spectrum space of the Fourier transformations in the probabilistic graphical model and have produced many successful results in combination with perturbation techniques.
Recently, the present authors have proposed applications of RG techniques to achieve sublinear computational time modeling schemes in the statistical machine learning theory. In physics, it is well known that the RG scheme is typically used to capture critical phenomena characterized by certain diverging statistical quantities, particularly, the correlation length. It might seem that the achievements of the sublinear time computational time modeling in the statistical machine learning theory are far from the standard physical applications of the RG schemes, because the statistical models for data sciences have finite sizes and no critical phenomena are expected. However, it has become necessary to treat many high-dimensional state vectors in recent data sciences and it is important to achieve to reduce the computational time in the statistical models containing such high-dimensional state vectors. The present authors have considered introducing RG techniques to systematically reduce the system size in the statistical model while applying the statistical machine learning schemes, systematically. One way to accomplish them is to apply the RSRG scheme to probabilistic image segmentations, in which a Potts model is employed as a prior probability [14]. The other one is to introduce the momentum-space renormalization scheme to probabilistic noise reductions, in which a Gaussian graphical model is introduced as a prior probability [15]. The most important aspect of the statistical machine learning algorithms is how the computational time of the estimation of hyperparameters from data vectors should be reduced. One of familiar and practical estimation schemes involving hyperparameters is the expectation-maximization (EM) algorithm [16, 17]. However, the EM algorithm needs some commutations of statistical quantities in the massive probabilistic graphical model. Two of the works by the present authors applied the RG approaches to estimate the hyperparameters by means of the EM algorithm.
The present paper is not an original paper but a review paper of the sublinear computational time modeling using the MSRG approaches in the EM algorithm for statistical machine learning system based on the Gaussian graphical models which has been published as a short note paper [15] and their background formulations. In the present paper, we provide their detailed formulations and some numerical experimental results of the sublinear computational time modeling based on the momentum-space renormalization scheme. Their essential part of the sublinear computational time modeling scheme has been proposed and the most important numerical experimental results have been shown as the above short note paper. In Sect. 2, we present the sublinear computational time modeling of statistical machine learning systems for probabilistic noise reductions by introducing the momentum-space renormalization schemes. Section 3 shows practical schemes of the sublinear computational time EM algorithm. In Sect. 4, statistical performance analysis of the hyperparameter estimations using the sublinear computational time EM algorithm is given. In Sect. 5, we mention some concluding remarks.
2 Momentum-Space Renormalization Group Scheme of Gaussian Graphical Model
In this section, we review fundamental formulations of momentum-space renormalization group approaches in Gaussian graphical models. Gaussian graphical models are sometimes referred also to as Gaussian–Markov random fields [4, 18,19,20,21,22,23,24], and are familiar probabilistic graphical models for Bayesian noise reduction systems with the EM algorithm. In noise reductions of image processing in particular, the graphical structures are usually square grid graphs and then unitary matrices based on discrete Fourier transformations are useful. Although scale transformations in the MSRG approaches are achieved through the wave-number space in the discrete Fourier transformations, we mention that they differ from low-pass filters in conventional signal processing.
Now we consider images on the square grid graph with the periodic boundary conditions for the abscissa and the ordinate. In the position vector for each pixel of the present square grid graph, the abscissa and the ordinate are denoted by x and y, respectively, such that the position vector of the pixel is denoted by (x, y). The periodic boundary conditions for the abscissa and ordinate mean that \(x=M\) and \(y=N\) are interpreted as \(x=0\) and \(y=0\), respectively. We introduce the set of all the pixels by a notation \(V(M,N)={\{(x,y) |x=0,1,{\ldots },M-1; y=0,1,{\ldots },N-1 \}}\). We remark that V(M, N) can be regarded as an ordered set by considering the two-dimensional position vector (x, y) as
where the notation \({\lfloor }a{\rfloor }\) is the floor function defined by \({\lfloor }a{\rfloor }{\equiv }a-a\,{\mathrm{mod}}\,1\).
We define the state variables \(f_{x,y}\) and \(g_{x,y}\) (\((x,y){\in }V(M,N)\)) of a light intensity at each pixel (x, y), in the original images and the degraded images. The state variable \(f_{x,y}\) and \(g_{x,y}\) take any real values in the interval \((-{\infty },+{\infty })\). The state vector \({\varvec{f}}\) and \({\varvec{g}}\) are defined by \({\varvec{f}} \equiv {(f_{x,y}|(x,y){\in }V(M,N))}\) and \({\varvec{g}} \equiv { (g_{x,y}|(x,y){\in }V(M,N))}\), respectively.
We consider a prior probability density function \({\rho }^{(M,N)}{({\varvec{f}} |{\alpha },{\gamma })}\) defined by
for original images \({\varvec{f}}\). Here \(Z_{M,N}({\alpha },{\gamma })\) is a normalization constant of \({\rho }^{(M,N)}({\varvec{f}}|{\alpha },{\gamma })\), which is defined by
Degraded images \({\varvec{g}}\) are generated from a given original image \({\varvec{f}}\) according to the following conditional probability density function:
Here, we remark that \({\alpha }\) and \({\beta }\) are referred to as hyperparameters in the statistical machine learning theory. \({\alpha }\) is an interaction between the nearest neighbour pairs of pixels. Equation (4) means that the additive white Gaussian noise is assumed as a degradation process, and \({\beta }\) corresponds to the inverse of the variance of the additive White Gaussian noise.
The prior probability density function \({\rho }^{(M,N)}({\varvec{f}}|{{\widehat{\alpha }}},{{\widehat{\gamma }}})\) in Eq. (2) can be rewritten as
Here \({\varvec{C}}(M,N)\) and \({\varvec{I}}(M,N)\) denote an \(MN\,{\times }\,MN\) matrix whose \((x,y|x',y')\)-components \({\langle }x,y\big |{\varvec{C}}(M,N)\big |x',y'{\rangle }\) and \({\langle }x,y\big |{\varvec{I}}(M,N)\big |x',y'{\rangle }\) (\((x,y){\in }V(M,N)\), \((x',y'){\in }V(M,N)\)) are defined by the following two-dimensional representations as
and
respectively. Here, we remark that \({\langle }x,y |{\varvec{C}}(M,N) |x',y'{\rangle }\) refers to the \((i,i')\)-elements \(({\varvec{C}}(M,N))_{i,i'}\) of the matrix \({\varvec{C}}(M,N)\) for the relationships \({\varvec{r}}_{i}=(x,y)\) and \({\varvec{r}}_{i'}=(x',y')\) by Eq. (1). Moreover, \({\langle }x,y|{\varvec{I}}(M,N) |x',y'{\rangle }\) denotes the \((i,i')\)-elements \(({\varvec{I}}(M,N))_{i,i'}\) of matrix \({\varvec{I}}(M,N)\) in similar arguments. Hereafter, we use similar representations for the elements of the other matrix.
We introduce an \(MN\,{\times }\,MN\) unitary matrix \({\varvec{U}}(M,N)\) and its conjugate matrix \({\varvec{U}}^{\dag }(M,N)\) as follows:
where \({\varvec{U}}^{\dag }(M,N)\equiv {\overline{{\varvec{U}}(M,N)}}^{\mathrm{{T}}}\) is the adjoint matrix of \({\varvec{U}}(M,N)\). We can confirm the following relations for \({\varvec{U}}(M,N)\) and \({\varvec{U}}^{\dag }(M,N)\):
where
We remark that W(M, N) can be also regarded as an ordered set by considering the two-dimensional wave-number-dependent vector (k, l) as
in the similar arguments for Eqs. (1). Equations (10) and (11) mean that \({\varvec{U}}(M,N){\varvec{U}}^{\dag }(M,N) ={\varvec{U}}^{\dag }(M,N){\varvec{U}}(M,N)={\varvec{I}}(M,N)\), where \({\varvec{I}}(M,N)\) is an \(MN\,{\times }\,MN\) identity matrix such that we have \({\varvec{U}}^{\dag }(M,N)={\varvec{U}}^{-1}(M,N)\). We confirm that \({\varvec{C}}(M,N)\) is diagonalized by the unitary matrix \({\varvec{U}}(M,N)\) as follows:
where
The prior probability density function can be rewritten as
Here we remark that \({\varvec{U}}(M,N){\varvec{f}}\) and \({\varvec{f}}^{\mathrm{{T}}}{\varvec{U}}^{\dag }(M,N)\) are the column vector and row vector, respectively. Also \({\langle }k,l| {\varvec{U}}(M,N){\varvec{f}}\) and \({\varvec{f}}^{\mathrm{{T}}}{\varvec{U}}^{\dag }(M,N) |k,l{\rangle }\) are their i-th elements \(\left( {\varvec{U}}(M,N){\varvec{f}}\right) _{i}\) and \(\left( {\varvec{f}}^{\mathrm{{T}}}{\varvec{U}}^{\dag }(M,N)\right) _{i}\) with the relationship \({\varvec{p}}_{i}=(k,l)\) as per Eq. (13).
Now we introduce a new state vector \({\varvec{F}}\) as
and a prior probability density function \({\rho }^{(M,N)}{ ({\varvec{F}}|{\alpha },{\gamma })}\) for the state vector \({\varvec{F}}\):
By introducing a new state variable in a subspace as
the marginal probability density function \(R^{(m,n)} {( {\{ {{\tilde{F}}}{({\frac{2{\pi }k}{m}},{\frac{2{\pi }l}{n}})} |(k,l){\in }W(m,n)\}} |{\alpha },{\gamma })}\) in the momentum-space can be calculated as follows:
We remark that the high-frequency modes are not ignored but are marginalized. Only low-frequency modes are rescaled or extended to recover the same frequency range as that of the original probabilistic Gaussian graphical model. The marginalization is referred to as the “trace Out” in the RG techniques in the physics. Again, we remark again that the present algorithm does the trace out; rather, it merely rescales instead of just ignoring the high-frequency modes. We consider that it is based on the standard RG.
Now we set new positive integers m and n with \(m{\le }M\) and \(n{\le }N\), respectively, and introduce the following scale transformation from the state vectors \({\varvec{f}}\) in the space V(M, N) to the new state vectors \({\varvec{{\tilde{f}}}} = {({{\tilde{f}}}_{x,y} |(x,y){\in }V(m,n))}\)
such that
where
and \({\varvec{U}}^{\dag }(m,n)\equiv {\overline{{\varvec{U}}(m,n)}}^{\mathrm{{T}}}\) is the adjoint matrix of \({\varvec{U}}(m,n)\). Equation (23) is one of MSRG transformations and is visualized as Fig. 1. Some examples obtained by applying the MSRG transformation in Eq. (23) to the original images \({\varvec{f}}^{*}\) in Fig.2 are shown in Figs. 3, 4 and 5.

Visualization of the MSRG transformation of the prior probability density function of Eq. (26)

Original images \({\varvec{f}}^{*}\) (\(M=N=256\)). a Parrots. b Couple. c Mandrill

Reduced images \({\varvec{{\tilde{f}}}}^{*} \equiv {\varvec{U}}^{\dag }(m,n){\varvec{B}}(m,n|M,N){\varvec{U}}(M,N){\varvec{f}}^{*}\) for \(m=n=192\), such that \({\frac{m}{M}}={\frac{n}{N}}={\frac{3}{4}}\) for each original image \({\varvec{f}}^{*}\) in Fig. 1. a Parrots. b Couple. c Mandrill

Reduced images \({\varvec{{\tilde{f}}}}^{*} \equiv {\varvec{U}}^{\dag }(m,n){\varvec{B}}(m,n|M,N){\varvec{U}}(M,N){\varvec{f}}^{*}\) for \(m=n=128\), such that \({\frac{m}{M}}={\frac{n}{N}}={\frac{1}{2}}\) for each original image \({\varvec{f}}^{*}\) in Fig. 1. a Parrots. b Couple. c Mandrill

Reduced images \({\varvec{{\tilde{f}}}}^{*} \equiv {\varvec{U}}^{\dag }(m,n){\varvec{B}}(m,n|M,N){\varvec{U}}(M,N){\varvec{f}}^{*}\) for \(m=n=64\), such that \({\frac{m}{M}}={\frac{n}{N}}={\frac{1}{4}}\) for each original image \({\varvec{f}}^{*}\) in Fig. 1. a Parrots. b Couple. c Mandrill
We assume that the prior probability density function of \({\varvec{{\tilde{f}}}}\) is given as
The conditional probability density function \({\rho }^{(M,N)}({\varvec{g}}|{\varvec{f}},{\beta })\) in Eq. (4) can be rewritten as
Now we introduce a new state vector \({\varvec{F}}\) as
and the conditional probability density function \({\rho }^{(M,N)}({\varvec{g}}|{\varvec{f}},{\beta })\) in Eq. (4) can be regarded as the conditional probability density function \(R^{(M,N)}({\varvec{G}}|{\varvec{F}},{\beta })\) in the momentum-space:
We introduce the scale transformation
in the momentum-space, and the marginal probability density function \(R^{(m,n)}{({( {{\tilde{G}}}{({\frac{2{\pi }k}{m}},{\frac{2{\pi }l}{n}})} \big |(k,l){\in }W(m,n))} | {\{ {{\tilde{F}}}{({\frac{2{\pi }k}{m}},{\frac{2{\pi }l}{n}})} \big |(k,l){\in }W(m,n)\}},{\beta })}\) in the momentum space can be calculated as follows:
We introduce the following scale transformation from the state vector \({\varvec{g}}\) in the space V(M, N) to new state vectors \({\varvec{{\tilde{g}}}} = { ({{\tilde{g}}}_{x,y} |(x,y){\in }V(m,n))}\)
such that
Some examples obtained by applying the MSRG transformation in Eq. (33) to degraded images \({\varvec{g}}\) in Fig. 6 are shown in Figs. 7, 8 and 9.

Degraded images \({\varvec{g}}^{*}\) generated from the original images \({\varvec{f}}^{*}\) in Fig. 2 by according to the additive white Gaussian noise with average 0 and variance \(1/{\beta }^{*}=40^{2}\) (\(M=N=256\)). a Parrots. b Couple. c Mandrill

Reduced images \({\varvec{{\tilde{g}}}}^{*} \equiv {\varvec{U}}^{\dag }(m,n){\varvec{B}}(m,n|M,N){\varvec{U}}(M,N){\varvec{g}}^{*}\) for \(m=n=192\), such that \({\frac{m}{M}}={\frac{n}{N}}={\frac{3}{4}}\) for each degraded image \({\varvec{g}}^{*}\) in Fig. 6. a Parrots. b Couple. cMandrill

Reduced images \({\varvec{{\tilde{g}}}}^{*} \equiv {\varvec{U}}^{\dag }(m,n){\varvec{B}}(m,n|M,N){\varvec{U}}(M,N){\varvec{g}}^{*}\) for \(m=n=128\), such that \({\frac{m}{M}}={\frac{n}{N}}={\frac{1}{2}}\) for each degraded image \({\varvec{g}}^{*}\) in Fig. 6. a Parrots. b Couple. c Mandrill

Reduced images \({\varvec{{\tilde{g}}}}^{*} \equiv {\varvec{U}}^{\dag }(m,n){\varvec{B}}(m,n|M,N){\varvec{U}}(M,N){\varvec{g}}^{*}\) for \(m=n=64\), such that \({\frac{m}{M}}={\frac{n}{N}}={\frac{1}{4}}\) for each degraded image \({\varvec{g}}^{*}\) in Fig. 6. a Parrots. b Couple. c Mandrill
Moreover, we introduce the conditional probability density function of the degraded image \({\varvec{{\tilde{g}}}}\equiv {({{\tilde{g}}}_{x,y}| (x,y){\in }V(m,n))}\), where the original image \({\varvec{{\tilde{f}}}}\) given in the reduced space V(m, n), is assumed to satisfy
3 Momentum-Space Renormalization Group Approaches in EM Algorithm
In this section, we provide a practical scheme of the EM algorithm in the MSRG approaches. The fundamental framework is based on the maximization of marginal likelihood. We first formulate the probability density function of \({\varvec{{\tilde{g}}}}\) and regard it as a marginal likelihood function of \({\alpha }\), \({\beta }\) and \({\gamma }\).
Under some assumptions in the previous section, the marginal likelihood \({\rho }^{(m,n)}({\varvec{{\tilde{g}}}} | {\alpha },{\beta },{\gamma })\) in the space V(m, n) is defined by
Our proposed framework is designed to achieve the estimation of the hyperparameters \({\alpha }\), \({\beta }\) and \({\gamma }\) by maximizing \({\rho }^{(m,n)}{({\varvec{{\tilde{g}}}} \Big |{\alpha },{\beta },{\gamma })}\) as follows:
Estimates of hyperparameters, \({{\widehat{\alpha }}}_{m,n}({\varvec{g}})\), \({{\widehat{\beta }}}_{m,n}({\varvec{g}})\) and \({{\widehat{\gamma }}}_{m,n}({\varvec{g}})\), are determined so as to maximize the marginal likelihood \({\rho }^{(m,n)}{({\varvec{{\tilde{g}}}} ={\varvec{U}}^{\dag }(m,n){\varvec{B}}(m,n|M,N){\varvec{U}}(M,N){\varvec{g}} | {\alpha },{\beta },{\gamma })}\) with respect to \({\alpha }\), \({\beta }\) and \({\gamma }\), respectively, as follows:
By considering the extremum conditions of \({\rho }^{(m,n)}{({\varvec{{\tilde{g}}}} ={\varvec{U}}^{\dag }(m,n){\varvec{B}}(m,n|M,N){\varvec{U}}(M,N){\varvec{g}} |{\alpha },{\beta },{\gamma })}\) with respect to \({\alpha }\), \({\beta }\) and \({\gamma }\), the simultaneous deterministic equations for the estimates of hyperparameters, \({{\widehat{\alpha }}}_{m,n}({\varvec{g}})\), \({{\widehat{\beta }}}_{m,n}({\varvec{g}})\) and \({{\widehat{\gamma }}}_{m,n}({\varvec{g}})\), are derived as follows:
The practical algorithm to solve Eqs. (38), (39) and (40) with respect to \({{\widehat{\alpha }}}_{m,n}({\varvec{g}})\), \({{\widehat{\beta }}}_{m,n}({\varvec{g}})\) and \({{\widehat{\gamma }}}_{m,n}({\varvec{g}})\) is given as follows:
4 Hyperparameter Estimation and Noise Reduction Algorithm
- Step 1: :
-
Input a given data point \({\varvec{g}}\) and the set of positive integers (m, n). Compute \({{\tilde{G}}}(k,l)\) using
$$\begin{aligned}&{{\tilde{G}}}(k,l) \Leftarrow {\frac{1}{\sqrt{mn}}} {\sum _{(x,y){\in }V(m,n)}} {\varvec{g}}^{\mathrm{{T}}}{\varvec{B}}^{\mathrm{{T}}}(m,n|M,N)\big |x,y{\rangle } {\exp }{\left( -i{\frac{2{\pi }kx}{m}}-i{\frac{2{\pi }ly}{n}}\right) } \nonumber \\&\quad {\left( (k,l){\in }W(m,n) \right) }. \end{aligned}$$(41)Set \({\alpha }(t)\), \({\beta }(t)\) and \({\gamma }(t)\) as initial values, and \(t{\Leftarrow }0\).
- Step 2: :
-
Update t by \(t{\Leftarrow }t+1\) and compute u, v and \({\beta }(t)\) from \({\alpha }(t-1)\), \({\beta }(t-1)\) and \({\gamma }(t-1)\) as follows:
$$\begin{aligned}&u \Leftarrow {\frac{1}{2mn}} {\sum _{(k,l){\in }W(m,n)}} {\frac{{\lambda }{\left( {\frac{2{\pi }k}{M}},{\frac{2{\pi }l}{N}}\right) }}{{\left( {\beta }(t-1)+{\gamma }(t-1) +{\alpha }(t-1) {\lambda }{\left( {\frac{2{\pi }k}{M}},{\frac{2{\pi }l}{N}}\right) } \right) } }} \nonumber \\&\quad +{\frac{1}{2mn}} {\sum _{(k,l){\in }W(m,n)}} |{{\tilde{G}}}(k,l)|^{2} {\frac{{\beta }(t-1)^{2} {\lambda }{\left( {\frac{2{\pi }k}{M}},{\frac{2{\pi }l}{N}}\right) }}{{\left( {\left( {\beta }(t-1) +{\gamma }(t-1)+{\alpha }(t-1) {\lambda }{\left( {\frac{2{\pi }k}{M}},{\frac{2{\pi }l}{N}}\right) } \right) } \right) }^{2}}}, \end{aligned}$$(42)$$\begin{aligned}&v \Leftarrow {\frac{1}{2mn}} {\sum _{(k,l){\in }W(m,n)}} {\frac{1}{{\left( {\beta }(t-1) +{\gamma }(t-1) +{\alpha }(t-1) {\lambda }{\left( {\frac{2{\pi }k}{M}},{\frac{2{\pi }l}{N}}\right) } \right) } }} \nonumber \\&\quad +{\frac{1}{2mn}} {\sum _{(k,l){\in }W(m,n)}} |{{\tilde{G}}}(k,l)|^{2} {\frac{{\beta }(t-1)^{2} }{{\left( {\left( {\beta }(t-1)+{\gamma }(t-1) +{\alpha }(t-1) {\lambda }{\left( {\frac{2{\pi }k}{M}},{\frac{2{\pi }l}{N}}\right) } \right) } \right) }^{2}}}, \end{aligned}$$(43)$$\begin{aligned}&{\beta }(t) \Leftarrow \left( {\frac{1}{mn}} {\sum _{(k,l){\in }W(m,n)}} {\frac{1}{{\left( {\beta }(t-1)+{\gamma }(t-1) +{\alpha }(t-1) {\lambda }{\left( {\frac{2{\pi }k}{M}},{\frac{2{\pi }l}{N}}\right) } \right) } }} \right. \nonumber \\&\left. \quad +{\frac{1}{mn}} {\sum _{(k,l){\in }W(m,n)}} |{{\tilde{G}}}(k,l)|^{2} {\frac{ {\left( ({\gamma }(t-1) +{\alpha }(t-1) {\lambda }{\left( {\frac{2{\pi }k}{M}},{\frac{2{\pi }l}{N}}\right) } \right) }^{2}}{{\left( {\beta }(t-1)+{\gamma }(t-1) +{\alpha }(t-1) {\lambda }{\left( {\frac{2{\pi }k}{M}},{\frac{2{\pi }l}{N}}\right) } \right) }^{2}}} \right) ^{-1}. \end{aligned}$$(44) - Step 3: :
-
Repeat the following updates for \({\alpha }(t)\) and \({\gamma }(t)\) until they converge:
$$\begin{aligned}&\left( \begin{array}{cccc} {\alpha }(t)\\ {\gamma }(t)\\ \end{array} \right) \Leftarrow \left( \begin{array}{cccc} {\varvec{\alpha }}(t) \left( {\frac{1}{2mnu}} {\displaystyle { {\sum _{(k,l){\in }W(m,n)}} }} {\frac{ {\lambda }{\left( {\frac{2{\pi }k}{M}},{\frac{2{\pi }l}{N}}\right) } }{ {\left( {\gamma }(t) +{\alpha }(t) {\lambda }{\left( {\frac{2{\pi }k}{M}},{\frac{2{\pi }l}{N}}\right) } \right) } }} \right) ^{1/2}\\ {\gamma }(t) \left( {\frac{1}{2mnv}} {\displaystyle { {\sum _{(k,l){\in }W(m,n)}} }} {\frac{1}{ {\left( {\gamma }(t) +{\alpha }(t) {\lambda }{\left( {\frac{2{\pi }k}{M}},{\frac{2{\pi }l}{N}}\right) } \right) } }} \right) ^{1/2}\\ \end{array} \right) . \end{aligned}$$(45) - Step 4: :
-
Set \({{\widehat{\alpha }}}_{m,n}({\varvec{g}}){\Leftarrow }{\alpha }(t)\), \({{\widehat{\beta }}}_{m,n}({\varvec{g}}){\Leftarrow }{\beta }(t)\), \({{\widehat{\gamma }}}_{m,n}({\varvec{g}}){\Leftarrow }{\gamma }(t)\). Go to Step 5 if \({{\widehat{\alpha }}}_{m,n}({\varvec{g}})\), \({{\widehat{\beta }}}_{m,n}({\varvec{g}})\) and \({{\widehat{\gamma }}}_{m,n}({\varvec{g}})\) converge, and return to Step 2 otherwise.
- Step 5: :
-
Repeat the following update rule until \({\varvec{{\widehat{f}}}}{\left( {\varvec{{\widehat{\alpha }}}_{m,n}({\varvec{g}})},{\widehat{\beta }}_{m,n}({\varvec{g}}),{{\widehat{\gamma }}}({\varvec{g}})\right) }\) converges:
$$\begin{aligned}&{\varvec{{\widehat{f}}}}{\left( {\varvec{{\widehat{\alpha }}}}_{m,n}({\varvec{g}}),{\widehat{ \beta }}_{m,n}({\varvec{g}}),{{\widehat{\gamma }}}({\varvec{g}})\right) } \Leftarrow {\frac{1}{4{{\widehat{\alpha }}}_{m,n}({\varvec{g}})+{{\widehat{\beta }}}_{m,n}({\varvec{ g}})+{{\widehat{\gamma }}}_{m,n}({\varvec{g}})}} \nonumber \\&\quad {\times }\, \left( {{\widehat{\beta }}}_{m,n}({\varvec{g}}){\varvec{g}} +\left( {{\widehat{\gamma }}}_{m,n}({\varvec{g}}){\varvec{I}}(M,N)\right. \right. \nonumber \\&\quad \left. \left. +\,{{\widehat{\alpha }}}_ {m,n}({\varvec{g}}){\left( 4{\varvec{I}}(M,N)-{\varvec{C}}(M,N)\right) }\right) {\varvec{{\widehat{f}}}}{\left( {\varvec{{\widehat{\alpha }}}_{m,n}({\varvec{g}})}, {\widehat{ \beta }}_{m,n}({\varvec{g}}),{\widehat{\varvec{\gamma }}}\right) } \right) . \end{aligned}$$(46)
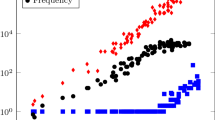
Some restored results \({\varvec{{\widehat{f}}}}{\left( {\varvec{{\widehat{\alpha }}}_{m,n}}({\varvec{g}}^{*}),{{\widehat{\beta }}}_{m,n}({\varvec{g}}^{*}),{{\widehat{\gamma }}}({\varvec{g}}^{*})\right) }\) obtained by applying the above algorithm to degraded images \({\varvec{g}}^{*}\) in Fig. 6 are shown in Figs. 10, 11, 12 and 13. Computational times in the estimation processes of hyperparameters, \({{\widehat{\alpha }}}_{m,n}({\varvec{g}})\), \({{\widehat{\beta }}}_{m,n}({\varvec{g}})\) and \({{\widehat{\gamma }}}_{m,n}({\varvec{g}})\), in the numerical experiments for the degraded images \({\varvec{g}}^{*}\) in Fig. 6 are also shown in Fig. 14. Numerical experimental results of the logarithm of the signal-to-noise ratio \(10{\log }_{10}{( {\frac{ {\mathrm{Var}}{\left[ {\varvec{f}}^{*}\right] } }{ {\Vert {\varvec{{\widehat{f}}}}(n,n)-{\varvec{f}}^{*}\Vert }^{2} }} )}\)(dB) for the degraded images \({\varvec{g}}^{*}\) in Fig. 6 are shown in Fig. 15. Here, \({\mathrm{Var}}{ [{\varvec{f}}^{*}]}\) is a variance of the light intensities for each colour, red, green and blue, on all the pixels in the original image \({\varvec{f}}^{*}\)

Restored images \({\varvec{{\widehat{f}}}}(M,N)\) for the degraded images \({\varvec{g}}^{*}\) in Fig. 6, such that \(m=M\) and \(n=N\). a Parrots. b Couple. c Mandrill

Restored images \({\varvec{{\widehat{f}}}}(m,n)\) for the degraded images \({\varvec{g}}^{*}\) in Fig. 6 in the case of \(m=n=256\) such that \({\frac{m}{M}}={\frac{n}{N}}={\frac{3}{4}}\). a Parrots. b Couple. c Mandrill

Restored images \({\varvec{{\widehat{f}}}}(m,n)\) for the degraded images \({\varvec{g}}^{*}\) in Fig. 6 in the case of \(m=n=256\) such that \({\frac{m}{M}}={\frac{n}{N}}={\frac{1}{2}}\). a Parrots. b Couple. c Mandrill

Restored images \({\varvec{{\widehat{f}}}}(m,n)\) for the degraded images \({\varvec{g}}^{*}\) in Fig. 6 in the case of \(m=n=64\) such that \({\frac{m}{M}}={\frac{n}{N}}={\frac{1}{4}}\). a Parrots. b Couple. c Mandrill

Computational times for the estimation processes of hyperparameters, \({{\widehat{\alpha }}}_{n,n}({\varvec{g}})\), \({{\widehat{\beta }}}_{n,n}({\varvec{g}})\) and \({{\widehat{\gamma }}}_{n,n}({\varvec{g}})\), in the numerical experiments for the degraded images \({\varvec{g}}^{*}\) in Fig. 6. a Parrots. b Couple. c Mandrill

Logarithm of the signal-to-noise ratio \(10{\log }_{10}{( {\frac{ {\mathrm{Var}}{\left[ {\varvec{f}}^{*}\right] } }{ {\Vert {\varvec{{\widehat{f}}}}(n,n)-{\varvec{f}}^{*}\Vert }^{2} }} )}\hbox {(dB)}\). The red, green and blue circles correspond to the results for each light colour intensity. a Parrots. b Couple. c Mandrill
5 Statistical Performance Estimation of Gaussian Graphical Model
In this section, we estimate the statistical performance of our framework of the maximization of the renormalized marginal likelihood \({\rho }^{(m,n)}({\varvec{{\tilde{g}}}}|{\alpha },{\beta },{\gamma })\) in Eq. (36) with Eq. (33). In the present Bayesian inference method, we assume that the data vectors \({\varvec{g}}\) are generated from the conditional probability density function \({\rho }^{(M,N)}({\varvec{g}} | {\varvec{f}},{\beta }^{*})\) in Eq. (4), under the assumption that a parameter vector \({\varvec{f}}={\varvec{f}}^{*}\) is given.
Equation (47) provides the statistical average of the hyperparameters in the EM algorithm with respect to the probability density function \({\rho }^{(M,N)}({\varvec{g}} | {\varvec{f}}={\varvec{f}}^{*},{\beta }^{*})\). For example, suppose that we generate D degraded images \({\varvec{g}}^{(1)}({\varvec{f}}^{*}),{\varvec{g}}^{(2)}({\varvec{f}}^{*}), {\ldots },{\varvec{g}}^{(D)}({\varvec{f}}^{*})\) from the given original image \({\varvec{f}}^{*}\), and calculate the estimates of hyperparameters for each degraded image \({\varvec{g}}^{(d)}({\varvec{f}}^{*})\) (\(d=1,2,{\ldots },D\)). Then we can estimate the statistical average of the estimates in the EM algorithm by the sample average of the estimates obtained by applying the EM algorithm to each degraded image \({\varvec{g}}^{(d)}({\varvec{f}}^{*})\). Equation (47) can be regarded as the statistical average of estimates in the EM algorithm with respect to the infinite number of degraded images generated from the probability density function \({\rho }^{(M,N)}({\varvec{g}} |{\varvec{f}}={\varvec{f}}^{*},{\beta }^{*})\) as follows:
The detailed analysis for the EM algorithm in the case of \(M=m\) and \(N=n\) appears in Ref. [20].
We consider the average of the logarithm of the renormalized marginal likelihood \({\ln }{({\rho }^{(m,n)}{({\varvec{{\tilde{g}}}}= {\varvec{U}}^{\dag }(m,n){\varvec{B}}(m,n|M,N){\varvec{U}}(M,N){\varvec{g}} \Big |{\alpha },{\beta },{\gamma })})}\) in the probability density function \({\rho }^{(M,N)}({\varvec{g}}|{\varvec{f}}^{*},{\beta }^{*})\) as follows:
By substituting Eq. (36) to Eq. (49), we can obtain the expression of \(L_{m,n}{({\alpha },{\beta },{\gamma }| {\beta }^{*},{\varvec{f}}^{*})}\) in terms of the original image \({\varvec{f}}^{*}\) as follows:
By integrating the fourth and fifth term of Eq. (50) with respect to \({\varvec{g}}\), we obtain
The statistical averages for the estimates of the hyperparameters are given as
The statistical performance of our proposed scheme is given by
where
Statistical averages of logarithm of the signal-to-noise ratio, \(10{\log }_{10}{( {\frac{ {\mathrm{Var}}[{\varvec{f}}^{*}] }{D_{n,n}({\beta }^{*},{\varvec{f}}^{*})}} )}\)(dB) (\(m=n\)) in Eq. (53) for the original images \({\varvec{f}}^{*}\) in Fig. 3 are shown in Fig. 16. Statistical averages of the hyperparameters, \({{\overline{\alpha }}}_{n,n}({\varvec{f}}^{*})\), \({{\overline{\beta }}}_{n,n}({\varvec{f}}^{*})\) and \({{\overline{\gamma }}}_{n,n}({\varvec{f}}^{*})\), are shown in Figs. 17, 18 and 19, respectively. Flows of estimates of the hyperparameters, \({( {{\overline{\alpha }}}_{n,n}({\varvec{f}}^{*}), {{\overline{\beta }}}_{n,n}({\varvec{f}}^{*}))}\) and \({( {{\overline{\alpha }}}_{n,n}({\varvec{f}}^{*}), {{\overline{\gamma }}}_{n,n}({\varvec{f}}^{*}))}\), in the momentum-space renormalization transformation in the EM algorithm of the Gaussian graphical model for the original images \({\varvec{f}}^{*}\) in Fig. 3 are shown in Figs. 20 and 21. These flows in Fig. 20 are drawn by plotting \({\left( {{\overline{\alpha }}}_{n,n}({\varvec{f}}^{*}), {{\overline{\beta }}}_{n,n}({\varvec{f}}^{*})\right) }\) in Figs. 17 and 18 and the flows in Fig. 21 are drawn by plotting \({\left( {{\overline{\alpha }}}_{n,n}({\varvec{f}}^{*}), {{\overline{\gamma }}}_{n,n}({\varvec{f}}^{*})\right) }\) from Figs. 17 and 19.

Statistical average of the logarithm of the signal-to-noise ratio, \(10{\log }_{10}{( {\frac{ {\mathrm{Var}}[{\varvec{f}}^{*}] }{D_{n,n}({\beta }^{*},{\varvec{f}}^{*})}} )}\hbox {(dB)}\) (\(m=n\)) in Eq. (53) for the original images in Fig. 3. The red, green and blue circles correspond to the results for each light colour intensity. a Parrots. b Couple. c Mandrill




Flows of \(({{\overline{\alpha }}}_{n,n}({\varvec{f}}^{*}), {{\overline{\beta }}}_{n,n}({\varvec{f}}^{*}))\) in the MSRG transformations in the EM algorithm of the Gaussian graphical model for the original images in Fig. 3. The red, green and blue circles correspond to the results for each light colour intensity. a Parrots. b Couple. c Mandrill

Flows of \(({{\overline{\alpha }}}_{n,n}({\varvec{f}}^{*}), {{\overline{\gamma }}}_{n,n}({\varvec{f}}^{*}))\) in the MSRG transformations in the EM algorithm of the Gaussian graphical model for the original images in Fig. 3. The red, green and blue circles correspond to the results for each light colour intensity. a Parrots. b Couple. c Mandrill
For the limits of \({\frac{n}{N}}{\rightarrow }+0\) and \({\frac{m}{M}}{\rightarrow }+0\), \({\rho }^{(m,n)}{({\varvec{{\tilde{f}}}}\big |{\alpha },{\gamma })}\) in Eq. (26) and \({\rho }^{(m,n)}{({\varvec{{\tilde{g}}}}| {\varvec{{\tilde{f}}}},{\alpha },{\beta })}\) in Eq. (34), are reduced to \({\rho }^{(m,n)}{({\varvec{{\tilde{f}}}} |{\alpha }=0,{\gamma })}\) and \({\rho }^{(m,n)}{ ({\varvec{{\tilde{g}}}}| {\varvec{{\tilde{f}}}},{\beta })}\), respectively. This means that the joint probability density function \({\rho }^{(m,n)}{({\varvec{{\tilde{f}}}},{\varvec{{\tilde{g}}}} |{\alpha },{\beta },{\gamma })}\) has a fixed point at \({( 0, {\beta }, {\gamma })}\) in the scale transformations in Eqs. (23) and (33). In \({\frac{n}{N}}>{\frac{1}{4}}\) and \({\frac{m}{M}}>{\frac{1}{4}}\), the estimates, \({{\widehat{\alpha }}}_{m,n}({\varvec{g}})\), \({{\widehat{\beta }}}_{m,n}({\varvec{g}})\) and \({{\widehat{\gamma }}}_{m,n}({\varvec{g}})\) are located along the flow by MSRG transformation. In \({\frac{n}{N}}<{\frac{1}{4}}\) and \({\frac{m}{M}}<{\frac{1}{4}}\), they leave from the flow. In Fig. 9, it is seen that the noise in the reduced image \({\varvec{{\tilde{g}}}}\) is hardly recognized for \({\frac{n}{N}}={\frac{1}{4}}\) and \({\frac{m}{M}}={\frac{1}{4}}\). In fact, the hyperparameter \({\beta }\) corresponds to the inverse of the variance in the additive white Gaussian noise, and then \({{\widehat{\beta }}}_{m,n}({\varvec{g}})\) rapidly increases although \({{\widehat{\alpha }}}_{m,n}({\varvec{g}})\) and \({{\widehat{\gamma }}}_{m,n}({\varvec{g}})\) remain near the renormalization flow within the limit of \({\frac{n}{N}}{\rightarrow }+0\) and \({\frac{m}{M}}{\rightarrow }+0\).
6 Concluding Remarks
In the present review paper, we have summarized the MSRG approaches for the Gaussian graphical models in a finite-size square grid graph. We have provided the formulations and a practical algorithm for noise reduction applications in image processing using the Bayesian sublinear computational time modeling. Moreover, we derive also the statistical performance schemes of the above systems. from the statistical–mechanical point of view. The estimated results of the hyperparameters are first located along the flow of the MSRG transformations in the region \({\frac{mn}{MN}}>{ ({\frac{1}{4}})}^{2}\). However, the sublinear modeling cannot recognize the noise in the reduced image \({\varvec{{\tilde{g}}}}\) in the region \({\frac{mn}{MN}}<{({\frac{1}{4}})}^{2}\) and then the estimate of the hyperparameter \({\beta }\), which corresponds to the inverse of the variance in the additive white Gaussian noise, goes to infinity with \({\frac{mn}{MN}}\) decreasing in the region.
We consider finite-size system only, and our formulation is within the discrete Fourier transformation. However, if we consider a system size with infinity as the limit, such that \(M{\rightarrow }+{\infty }\) and \(N{\rightarrow }+{\infty }\), the state vector \({\varvec{f}}\) would be composed of an infinite number of components. At this stage, \(f_{x,y}\) is a function of x and y which are any real number in \((-{\infty }+{\infty }\), and which can then be rewritten as f(x, y). \({\rho }{({\varvec{f}}|{\alpha },{\gamma })}\) is a functional of \({\varvec{f}}={\{f(x,y) |(x,y){\in }(-{\infty },+{\infty })^{2}\}}\) and is given by
instead of Eq. (2). For the probability density function in Eq. (56), the integral \({\int }({\cdots }){\text {d}}{\varvec{f}}\) means a functional integral. This is a starting point of the statistical field theory in the physics [25,26,27]. Big data sciences are characterized by extremely large dimensional state vectors, and we expect that the statistical field theory should provide powerful applications in such cases.Indeed, this theory is one of the most exciting research paradigms for sublinear computational time modeling in the data sciences.
References
Koller, D., & Friedman, N. (2009). Probabilistic graphical models: Principles and techniques. New York: MIT Press.
Murphy, K. P. (2012). Machine learning: A probabilistic perspective. New York: MIT Press.
Opper, M., & Saad, D. (Eds.). (2001). Advanced Mean Field Methods – Theory and Practice –. MIT Press.
Tanaka, K. (2002). Statistical–mechanical approach to image processing. Journal of Physics A Mathematical and General, 35(37), R81–R150.
Yedidia, J. S., Freeman, W. T., & Weiss, Y. (2005). Constructing free-energy approximations and generalized belief propagation algorithms. IEEE Transactions on Information Theory, 51(7), 2282–2312.
Pelizzola, A. (2005). Cluster variation method in statistical physics and probabilistic graphical models. Journal of Physics A Mathematical and General, 38(33), R309–R339. (Topical Review).
Wainwright, M. J., & Jordan, M. I. (2008). Graphical Models, Exponential Families, and Variational Inference. : now Publishing Inc.
Mézard, M., & Montanari, A. (2009). Information. New York, USA: Physics and Computation Oxford University Press.
Wilson, K. G., & Kogut, J. (1974). The renormalization group and the \({\epsilon }\) expansion. Physics Report (Section C of Physics Letters), 12(2), 75–200.
Fisher, M. E. (1974). The renormalization group in the theory of critical behavior. Review of Modern Physics, 46(4), 597–616.
Wilson, K. G. (1983). The renormalization group and critical phenomena. Review of Modern Physics, 55(9), 583–600.
Amit, D. J., & Martin-Mayor, V. (2005). Field theory, the renormalization group, and critical phenomena: Graphs to computers. Singapore: World Scientific.
Nishimori, H., & Ortiz, G. (2011). Elements of phase transitions and critical phenomena. Oxford: Oxford University Press.
Tanaka, K., Kataoka, S., Yasuda, M., & Ohzeki, M. (2015). Inverse renormalization group transformation in Bayesian image segmentations. Journal of the Physical Society of Japan, 84(4), Article ID: 045001.
Tanaka, K., Nakamura, M., Kataoka, S., Ohzeki, M., & Yasuda, M. (2018). Momentum-space renormalization group transformation in Bayesian image modeling by Gaussian graphical model. Journal of the Physical Society of Japan, 87(8), Article ID: 085001.
Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society Series B (Methodological), 39(1), 1–38. (with discussions).
Mengersen, K. L., Robert, C. P., & Titterington, D. M. (2011). Mixtures: Estimation and applications. Oxford: Wiley.
Geman, D. (1990). Random fields and inverse problems in imaging (Vol. 1427, pp. 113–193)., Lecture notes in mathematics Berlin: Springer.
Rue, H., & Held, L. (2005). Gaussian Markov random fields: Theory and applications. Boca Raton: CRC.
Tanaka, K., & Titterington, D. M. (2007). Statistical trajectory of approximate EM algorithm for probabilistic image processing. Journal of Physics A Mathematical and Theoretical, 40(37), 11285–11300.
Kataoka, S., Yasuda, M., & Tanaka, K. (2012). Statistical analysis of Gaussian image inpainting problems. Journal of the Physical Society of Japan, 81(2), Article ID.025001.
Kataoka, S., Yasuda, M., Furtlehner, C., & Tanaka, K. (2014). Traffic data reconstruction based on Markov random field modeling. Inverse Problems, 30(2), Article ID: 025003.
Kuwatani, T., Nagata, K., Okada, M., & Toriumi, M. (2014). Markov-random-field modeling for linear seismic tomography. Physical Review E, 90(4), Article ID: 042137.
Kuwatani, T., Nagata, K., Okada, M., & Toriumi, M. (2014). Markov random field modeling for mapping geofluid distributions from seismic velocity structures. Earth Planets and Space, 66, Article ID: 5.
Parisi, G. (1988). Statistical field theory. Boston: Addison-Wesley.
Itzykson, C., & Drouffee, J.-M. (1989). Statistical field theory: Volume 1 from brown motion to renormalization and lattice gauge theory. Cambridge: Cambridge University Press.
Itzykson, C., & Drouffee, J.-M. (1989). Statistical field theory: Volume 2 strong coupling, Monte Carlo Methods, conformal field theory, and random systems. Cambridge: Cambridge University Press.
Acknowledgements
This work was partly supported by the JST-CREST (No.JPMJCR1402) for Japan Science and Technology Agency and the JSPS KAKENHI Grant (nos. 18H03303 and 18K11459) for Ministry of Education, Culture, Sports, Science and Technology.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Tanaka, K., Ohzeki, M. & Yasuda, M. Sublinear Computational Time Modeling by Momentum-Space Renormalization Group Theory in Statistical Machine Learning Procedures. Rev Socionetwork Strat 13, 281–306 (2019). https://doi.org/10.1007/s12626-019-00053-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12626-019-00053-1