
Abstract
This paper presents a study on the use of multi-task neural networks (MTNs) for voice-based soft biometrics recognition, e.g., gender, age, and emotion, in social robots. MTNs enable efficient analysis of audio signals for various tasks on low-power embedded devices, thus eliminating the need for cloud-based solutions that introduce network latency. However, the strict dataset requirements for training limit the potential of MTNs, which are commonly used to optimize a single reference problem. In this paper, we propose three MTN architectures with varying accuracy-complexity trade-offs for voice-based soft biometrics recognition. In addition, we adopt a learnable voice representation, that allows to adapt the specific cognitive robotics application to the environmental conditions. We evaluate the performance of these models on standard large-scale benchmarks, and our results show that the proposed architectures outperform baseline models for most individual tasks. Furthermore, one of our proposed models achieves state-of-the-art performance on three out of four of the considered benchmarks. The experimental results demonstrate that the proposed MTNs have the potential for being part of effective and efficient voice-based soft biometrics recognition in social robots.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
In recent years, the scientific community assisted to a growing interest in social robotics applications, focusing on robots capable of engaging in conversations with humans, be it casual chit-chat or task-oriented interactions [1, 2]. A critical aspect for such social robots is the ability to interact empathically with people [3]. Consider, for instance, a robotic concierge assisting customers in booking hotel services or finding nearby restaurants. Personalization is crucial to enhance user experience, achieved through sensor-equipped robots utilizing artificial intelligence (AI) algorithms to recognize soft biometrics such as age, gender, emotions, and interlocutor identity.
Deep learning advancements have empowered convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to excel in the soft biometrics recognition of the interlocutor [4,5,6,7]. While the visual domain has been extensively investigated, attention is increasingly shifting towards audio modality, especially in cognitive robotics, where diverse modalities enable robust biometric recognition in challenging environments [8]. In this paper, we focus on voice analysis.
The computational demand of the simultaneous processing of audio and video streams with multiple neural networks poses a challenge for low-power embedded devices with limited GPU and memory resources [9]. While cloud solutions may be effective, unstable internet connections and potential latency hinder real-time performance [10, 11]. Hence, there is a pressing need to efficiently analyze audio streams on-board the robot, eliminating network latency for real-time tasks.
Multi-task neural networks (MTNs) are emerging as a promising solution. MTNs employ a shared feature extraction backbone, followed by specialized branches for different tasks. This shared network reduces model loading memory and inference time [12,13,14]. Nevertheless, the speech analysis field primarily emphasizes single-task optimization approaches, leveraging related tasks (e.g., gender recognition) to enhance the accuracy of the main task [15, 16].
The current state of multi-task neural networks (MTNs) deals with several challenges. Firstly, it heavily depends on datasets that have labels for all tasks, limiting the potential for increasing sample sizes and, consequently, the ability of the MTN to generalize [17, 18]. Furthermore, addressing the imbalance in losses resulting from different loss functions adds complexity [19]. Prior attempts have relied on adjusting weights, which involves additional time-consuming hyperparameter optimization [20, 21].
Additionally, the choice of MTN architecture is crucial to achieve a good trade-off between accuracy and processing latency. While some MTNs share most layers except for the output ones for computational efficiency [22,23,24], this may lead to inadequate feature vectors for optimal task performance. Alternative strategies involve sharing only a portion of the network and creating task-specific branches [15, 25]. However, the impact of these design choices on task performance has not been thoroughly investigated.
In this paper, we present three multi-task neural networks designed to address speaker re-identification, gender recognition, age estimation, and emotion recognition from speech signals simultaneously. These multi-task network architectures offer a balance between computational complexity, achieved through varying levels of layer sharing. For feature extraction, we employ the ResNet18 convolutional neural network due to its efficiency.
To the best of our knowledge, these tasks have not been collectively tackled, due to the lack of a unified dataset with all the required labels. To address this, we introduce a training procedure that accounts for multiple datasets and missing labels using label masking. Additionally, we address the issue of loss balancing by relying on the GradNorm balancing strategy, which dynamically tunes loss function weights during training. Furthermore, our multi-task models are based on a robust and efficient audio representation tailored for social robotics applications.
We validate these models on standard benchmark datasets, including VoxCeleb 1 and 2, IEMOCAP, Mozilla Common Voice, and CMU-MOSEI. Our results demonstrate that our multi-task models not only outperform single-task baselines in three out of four tasks, but also overcome more complex state-of-the-art models in gender recognition, emotion recognition, and age estimation tasks.
Related Work
In prior research, Chen et al. [22] employed a deep neural network (DNN) model for speaker verification. Their approach involved recording predefined phrases from each speaker and adapting the model to classify these spoken phrases. The rationale behind this method was the recognition of real-world variations in speaker pronunciation. In contrast, Sarma et al. [23] used a convolutional recurrent neural network (CRNN) model to address gender recognition and age estimation challenges. More recently, Montalvo et al. [26] applied a convolutional neural network (CNN) model for speaker classification, enhancing model generalization by incorporating gender and nativeness recognition as auxiliary tasks.
Previous studies have demonstrated that utilizing a multi-task paradigm improves the performance of models in completing individual tasks. However, the proposed solution is unique in its goal of achieving optimal results and optimal computational complexity for all tasks simultaneously in social robotics applications. Furthermore, previous research has relied on a hard-weighted loss tuning method, which increases tuning time, while the proposed solution employs a self-adapting weighting strategy. On the other hand, our algorithm adopts adaptive loss weights in the loss function, enabling their optimization in a single training.
The previous methods were trained using a single dataset containing all of the required labels. However, Kim et al. [17] employed a long short-term memory (LSTM) model to address the challenges of emotion, gender, and naturalness recognition. The authors jointly trained the model on five different datasets that shared the same set of labels for all tasks. In contrast, Luu et al. [18] adopted a transfer learning approach based on x-vectors to tackle the tasks of speaker verification, age estimation, and nationality recognition. These methods could not handle different datasets simultaneously while managing missing labels, unlike the ones proposed in this work. Additionally, to the best of our knowledge, no studies have explored the trade-off between the accuracy and computational requirements of CNNs.
Proposed Method
In the “Problem Formulation” section, we formalize the definition of the considered voice analysis tasks, namely gender recognition, age estimation, emotion recognition, and speaker verification. We are going to detail the three different architectures for multi-task learning that we propose in this paper in the “Multi-task Network Architectures” section. The representation proposed and the backbone adopted are described in Sections “Learnable Audio Representation” and “CNN Backbone,” respectively; in the latter, we also give details about the adaptation of the convolutional backbone to the three multi-task architectures. We describe the single-task loss functions in the “Single-Task Loss Functions” section and the multi-task network loss in the “Multi-task Loss Function” section.
Problem Formulation
In this paper, we deal with the task that a social robot has to perform in order to obtain personalized and emphatic conversations, namely the recognition of gender, age, emotion, and identity by analyzing the voice of the speaker. The tasks are all approached relying only on the audio modality.
We formalized the various tasks according to the best practices described in the literature and in line with the annotations available in the public datasets. Gender recognition is formulated as a binary classification problem among male and female categories. Age estimation is treated as a regression problem, training the neural network to predict a value in the range [0, 92]. Emotion recognition is formalized as a multi-class classification problem among the following four categories: neutral, angry, happy, and sad. To the best of our knowledge, models performing speaker re-identification are not compared on a standard benchmark; trivially, it is possible to re-identify people by storing utterances from people we would like to re-identify, and each time an input utterance is available, compare it with the stored reference set. The common strategy is to formalize the problem as speaker verification, i.e., deciding if two utterances have been pronounced by the same speaker or not. We follow this state-of-the-art strategy and treat speaker verification as a binary classification task, in which the neural network must analyze a couple of voice samples and decide whether they are pronounced by the same speaker or by different speakers.
We framed our aim of optimizing all the tasks together as a multi-objective optimization problem, as represented in the following equation:
where \(\theta\) represents the model’s parameters and \(\Theta\) is the set of all possible parameters. \(f_i\) is the performance function of each task (from 1 to T). For the sake of readability, every task is framed as a maximization problem. It is worth saying that a specific task formulation can easily be changed by multiplying the task objective by \(-1\). In our specific case, the task objective functions have been chosen according to the state of the art (refer to “Single-Task Loss Functions” and “Multi-task Loss Function” sections for more details).
Multi-task Network Architectures
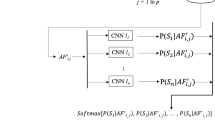
The multi-task network architectures are reported in Fig. 1 and detailed in the following subsections. For the sake of readability, in the following, we will refer to the three versions as MTN vA, vB, and vC

Trained multi-task networks. Shared layers are colored in yellow while a different color is used to represent each task-related layer. MTN vA relies on a CNN to extract a single representation which is averaged along time using a Global Average Pooling (GAP) layer; the obtained representation is projected in a task-specific subspace to make the related prediction through fully connected (FC) layers. Differently from vA, MTN vB is characterized by multiple task-specific layers (also convolutional). Finally, MTN vC linearly combines task-specific features through a cross-stitch layer
MTN vA
MTN vA is a multi-task architecture specifically designed to exploit the inter-dependencies between the involved tasks in a very efficient and simple way. It is composed of a single CNN backbone network which is adopted to extract a shared representation between the tasks. Then, the obtained feature tensor is passed to a Global Average Pooling (GAP) layer to obtain a length-invariant audio representation. Finally, a task-specific fully connected (FC) layer is used to infer the label for each of the tasks.
The main advantage of MTN vA is that just a single processing step is required (for the four tasks) before the prediction one, obtaining a speedup proportional to the number of tasks. Moreover, also, the number of parameters is significantly reduced leading to a two-fold effect. First, a simpler model better deals with small-sized training datasets, reducing the risk of overfitting. Second, the low number of parameters reduces the size of the model in memory proportionally, again, to the number of tasks. The MTN vA generally performs well when a single set of features can be exploited by different tasks, each one performing a regularization action on the others. As a drawback, when each task needs for its specific features, a fixed size representation in output from a single backbone may be not sufficient and may cause a predominance of a task with respect to the others.
MTN vB
MTN vB is a multi-task network architecture designed to overcome the limitations of MTN vA. Differently from the latter, MTN vB is characterized by a smaller shared CNN backbone and deeper task-specific branches. The backbone is in charge of computing low-level audio features (supporting the choice of a smaller model), which are common to the involved tasks. After that, each branch creates a disentangled representation at a higher abstraction level starting from the low-level features; the resulting level of abstraction depends on the number of layers in the task-specific branch. For the sake of simplicity, the number of layers in each branch is the same for all the tasks and structured as the base architecture of the backbone (more details in the “CNN Backbone” section). Of course, a different choice may result in a better result but it exponentially enlarges the search space of the hyper-parameters.
MTN vB inherits from MTN vA the reduced, even if not drastically, number of parameters and the exploitation of low-level inter-dependencies between tasks through a shared CNN backbone. The increased number of parameters is offset by the possibility for each task to create its own high-level representation without being constrained by the other ones. The main challenge of designing this architecture is to identify the right point in which the task-specific sub-networks should start. In particular, there is a trade-off between the need of more degrees of freedom for some tasks and the regularization effect between the remaining ones.
MTN vC
MTN vC is finally proposed to overcome the issues identified in MTN vB. MTN vC shares with MTN vB the number of task-specific layers, but it inserts a shared cross-stitch layer [27] between each couple of task-specific layers. This layer linearly aggregates the feature vectors in output from the task-specific layers at the same abstraction level. The aggregation weights are learned by the layer itself and are independent for each task. In this way, each task-specific branch can get, if needed, features from the others at a higher level and, therefore, apply a regularization action on it. The main difference between MTN vA and MTN vC consists of the fostering of task-specific branch to affect other branches only if needed.
The MTN vC architecture has the same advantages of MTN vB while, at a negligible computational cost, overcoming its disadvantages. Trivially, the cross-stitch layer only models linear inter-dependencies between task-specific features. As a drawback, MTN vC is still sensible to the point in which the branching is performed, which regulates the trade-off between efficiency and obtained performance.
Learnable Audio Representation
Speech-related convolutional neural networks commonly rely on the Mel-Spectrogram time-frequency representation [28]. The Mel-spectrogram approximates the human auditory system response. Moreover, a time-frequency representation, having two dimensions (time and frequency), can be approached exploiting well-studied 2D CNNs. Nevertheless, being designed through hand-crafted filters, this audio representation may limit the achievable performance.
For this reason, in this paper, we decide to use a trainable representation [29]; indeed, the filters applied to the spectrogram are trained together with the CNN backbone. In this way, the model can learn input features specialized for the problem we are dealing with directly from raw data, as done for the image domain [30]. We choose band-pass filters to learn our representation as done in [31] because they proved to well adapt to frequencies of interest for the problem we are dealing with. Being the filters applied in the frequency domain, we modeled the multiplicative filters through the Butterworth window:
where g represents the impulsive response of a band-pass filter centered at the frequency \(\alpha\) and having a scaling factor equal to \(\beta\). The window order is represented with n, while f is the independent variable of the filter function in the frequency domain.
To improve the robustness of the model to additive background noise, which is a common working environment in social robotics, we apply an attention layer on the top of the audio representation as suggested in [32]. Differently from it, in this paper, we apply the squeeze-excitation spatial and channel attention [33]. In this way, the audio representation is not only able to de-noise frequencies in which additive sounds are present, but also to enhance the time frame in which the event of interest is present.
CNN Backbone
The CNN we use as backbone, in order to extract audio features from the previously described time-frequency representations, is ResNet18 [34]. The standard ResNet18 architecture is reported in Table 1. It relies on a Global Average Pooling (GAP) layer to deal with input utterances of different length. It collapses the input features tensor into a fixed-length vector with a size equal to the number of feature maps (i.e., 512). The main block of ResNet18 and residual networks in general is the residual block. It learns a residual function of the input. Thanks to the direct (residual) connections between the input and the output, this kind of model alleviates the vanishing gradient effect and, therefore, is easier to optimize. Thanks to these properties, residual learning layers are a standard in deep learning models to date.
We consider the feature vector in output from the GAP layer as the shared representation of MTN vA. At this point of the model, we define a fully connected layer to make a prediction for each of the task.
Regarding models vB and vC, we share the CNN backbone architecture up to the conv4 residual block (Table 1) to obtain a good trade-off between efficiency and the needed abstraction of shared features. This choice is the result of a grid search analysis.
In the MTN vC architecture, we insert a cross-stitch layer before and after the GAP layer. We avoided to modify the residual block in order to avoid changes in its structure that can drastically affect the results [35].
Single-Task Loss Functions
We consider the cross entropy loss as an objective function for the tasks of gender and emotion recognition. For the age estimation task, we use the MAE loss instead. Finally, we use ArcFace [36] as an objective function for the speaker verification task. ArcFace proved to over-perform the triplet loss for the task of face verification, and in addition, it avoids triplets-related problems (e.g., hard triplet sampling) [37]. We reported the ArcFace objective function in Eq. (3).
where \(\theta _{y_{j}}\) is the angular distance between the output audio embedding and the reference embedding of the speaker i (also the one who pronounced the utterance) and N is the number of speakers in the training set. In this equation, \(y_i\) is used as a subscript to accent that the angular distance is computed with respect to the ground truth identity. The hyper-parameters s and m are the norm scaling factor and the loss margin. As suggested by the reference paper, we set them to 64 and 0.5, respectively.
Multi-task Loss Function
One of the main difficulties in training a multi-task neural network consists of the data acquisition. It is hard to find a training dataset where each sample is labeled with all the tasks we need to deal with. Training only decision layers of the network while freezing feature extraction ones may result in a sub-optimal solution.
To overcome this issue, we train the multi-task models subject of this paper propagating the loss gradients only for labels available on the current sample. The resulting loss function is reported in Eq. (4):
where
\(L_k\) is the loss computed at the training step k, M the number of samples and T the number of tasks. \(\hat{y}_{i,t}\) and \(y_{i,t}\) are respectively the model prediction and the ground truth for the sample i on the task t. \(L_t\) is the loss function used for the task t. \(\alpha _{i,t}\) is a weight equal to 1 if the label \(y_{i,t}\) is contained in the available label set Y, 0 otherwise (see Eq. 5). This approach allows to deal with multiple datasets even if they are labeled for completely different tasks.
It is important, in order to avoid unbalancing, to construct batches representing all the tasks. Being the value of \(\alpha\) just one within the set [0, 1], the resulting loss L can be mainly influenced by the most represented task. Nevertheless, constructing the batch oversampling samples for the unrepresented tasks may lead to the same result. This behavior is drastically amplified in the case that the losses nature is different (e.g., mean square error and cross entropy) and the losses have different magnitudes.
To overcome this behavior, we decide to dynamically adjust the weights of each task during the training through the GradNorm algorithm [19]. The updated loss function is thus as follows:
with
where \(w_{t,k}\) represents the weight of the task t at the training step k.
To explain the GradNorm optimization algorithm, we have to define the following quantities:
-
\(\overline{G}_k\) is the average \(L^2\) norm of the gradient computed for each task (\(|G_{t,k}|\)) at the training step k.
-
\(\tilde{L}_{t,k}\) is the inverse training rate and computed as the ratio between the loss for the task t at the training step k divided by the initial loss.
-
\(r_{t,k}\) is the normalized inverse training rate, obtained by dividing the inverse training rate by the average value computed over all the tasks.
GradNorm updates each task weight \(w_{t,k}\) by minimizing the following loss function:
This loss function has two objectives: first, it adapt the weight of the task t to obtain a \(L^2\) norm of the gradient similar for all the tasks; regarding the second objective, let us consider \(\tilde{L}_{t,k}\) as an inverse indicator of how far is the model w.r.t. the initial point for a particular task, and consequently, \(r_{t,k}\) is the same index but projected in the range [0, 1]. In this perspective, GradNorm reduces the reference norm of the gradients, and then the priority with which a task should be learned, by multiplying it by \(r_{t,k}\) for the tasks that are learning faster w.r.t. the others. In this way, the algorithms allow to keep similar the learning pace of the considered tasks.
Experimental Framework
In this section, we detail the experimental setup, so as to make the experiments easily repeatable.
Datasets
The datasets used in this work are reported in Table 2, together with their statistics and related tasks.
CMU-MOSEI [38] is one of the largest multimodal datasets for sentiment and emotion recognition to date. It is composed of more than 23k utterances obtained from YouTube videos. The videos are related to 1000 YouTube speakers. We included CMU-MOSEI in the training set considering the labels for both the tasks of emotion and gender recognition.
IEMOCAP [39] is a multimodal emotion recognition dataset acquired from recited interactions. It is composed of more than 10k utterances obtained in controlled environments. In the literature, IEMOCAP has been used for emotion recognition considering several sub-sets of emotion classes. To the purposes of this paper and according to [40], we considered for IEMOCAP and CMU-MOSEI only the following emotions: neutral, angry, happy, and sad. We included IEMOCAP in both the training and test sets.
Mozilla Common Voice [41] is a large-scale crowd-sourced multilingual speech recognition dataset. It is composed of around 73k utterances obtained in non-controlled recording conditions also labeled for the task of gender recognition [42]. We included Mozilla Common Voice as a test set for the task of gender recognition. Being a dataset with a sample distribution different from the training one, it makes the model validation more reliable.
VoxCeleb 1 and 2 [43, 44] are two large-scale speaker recognition datasets acquired in uncontrolled environments and state-of-the-art benchmarks for speaker-related tasks. They are composed by 153k and 1.13M of utterances, respectively. Recently, the dataset has been labeled with age labels in [45]. We adopted VoxCeleb 1 as a test set and VoxCeleb 2 as a training set as commonly done in speaker verification benchmarks. There is no overlap of subjects between the selected sets. We also used VoxCeleb 2 as a test set for the age estimation task. Unfortunately, the test set defined in [45], namely VoxCeleb 2 Enriched, overlaps with the training set of the speaker verification task. For this reason, we remove from the training set all the identities contained in the test set for a fair performance evaluation.
Evaluation Metrics
We report in this section the evaluation metrics adopted to estimate the performance of the trained models for each of the tasks. We consider the most common performance indices used for each of them.
We evaluated the performance on the speaker verification task in terms of equal error rate (EER) [43]. Let us consider that we are dealing with a binary classification problem where a true positive is a pair of utterances correctly classified as pronounced from the same speaker. We can compute the EER by identifying the threshold value \(t_{EER}\) that allows the model to obtain a true positive rate (TPR) equal to the true negative rate (TNR), i.e., the Type-I and Type-II errors are equal. The resulting error value is the EER index.
For both the tasks of gender and emotion recognition, we evaluated the performance in terms of accuracy [40]. The accuracy score is computed as the number of utterances correctly classified divided by the total number of utterances (S) considered for the evaluation of that particular task.
In this formula, \(C_{ii}\) is the total number of correctly recognized utterance of class i. Z is the total number of classes for a particular task.
Finally, we evaluated the performance for the task of age estimation in terms of mean absolute error (MAE) [45]. It is computed as the sum of the absolute differences between the model prediction \(\hat{y}_i\) and the ground truth \(y_i\) divided by the total number of utterances considered in the evaluation.
Implementation Details
As anticipated in the “Datasets” section, the test sets adopted in our experiments are VoxCeleb 1 for speaker verification, Common Voice for gender recognition, IEMOCAP for emotion recognition, and VoxCeleb2 for age estimation; the choice of these standard test sets is necessary for a fair comparison with state of the art methods. The training set has been divided 80–20% to train and validate the methods, respectively; a k-fold cross-validation has been avoided since it would not be compliant with the usage of standard pre-defined test sets.
The learning procedure and the values of the hyperparameters adopted for the optimization of the models have been inherited from the best practices suggested in related works [12, 40, 42, 45,46,47]. Since various methods have been taken into account, a set of possible values has been considered for the learning rate, its decay factor, the early stopping epochs, and the patience: the definitive values have been selected with a careful grid search, choosing the ones achieving the best performance on the validation set. Therefore, we trained the models using the Adam optimization algorithm with a learning rate equal to 1e\(-\)4. In order to avoid overfitting on the training data, we stop the training if the performance on the validation set does not improve for ten consecutive epochs. We consider the performance on the most difficult task, i.e., speaker verification, as a reference metric for the early stopping. Moreover, we reduce the learning rate of a decay factor of 0.3 to avoid optimization plateau if the performance on the validation set does not improve for seven consecutive epochs.
Experimental Results
We report the obtained results in Table 3. In the first line of the table, the state-of-the-art results [40, 42, 45, 46] obtained by published single-task supervised models are reported for a fair comparison of the performance. Moreover, in addition to the results of the proposed multi-task models, we report the performance achieved by single-task models characterized by the same CNN backbone.
The proposed multi-task models always outperform the state-of-the-art counterparts at least on two tasks over four and, in the case of the model MTN vC, on three tasks over four. In particular, on the task of gender recognition, the multi-task models MTN vA, MTN vB, and MTN vC achieve an accuracy score of 95.78%, 96.65%, and 96.40% compared to the 94.32% of the state of art. On the other hand, on the emotion recognition task, they obtain an accuracy score equal to 55.62%, 54.88%, and 57.54%; in this case, only the multi-task model MTN vC outperforms the state of art, obtaining an accuracy of 56.94%. The mean average error at the state of the art for the age estimation task is 9.44 years; all the proposed multi-task models obtained a better performance achieving a MAE index of 8.74, 8.94, and 8.86, respectively. Finally, the proposed multi-task models were not able to achieve results comparable with the state of the art on the task of speaker verification, obtaining an average EER equal to 9.7% on the standard and pair E test sets of VoxCeleb 1 and 17% on the Pair H one; on the other hand, the more complex single-task model based on ResNext [46] is able to better fit the training data, with and average EER of 1.46% and 2.72% respectively on the two sets. This result can be further justified by the lower amount of training data for the speaker verification task, due to the deletion from our training set of the samples in common between VoxCeleb 2 and VoxCeleb 2 Enriched.
Looking at the results obtained by single-task models it can be seen that only the Gender Recognition model is able to narrowly outperform the state of the art with an accuracy score equal to 94.69%. Comparing the results obtained by single-task models on the related task with multi-task ones, it is evident that the multi-task learning framework helps to obtain better generalization capabilities with respect to the single-task one. The table shows how the gender recognition, emotion recognition, and age estimation tasks always improve their performance in a multi-task setup; on the other hand, the speaker verification performance slightly decreases. We speculate that this result is due to the higher complexity of the considered task w.r.t. others and the need to obtain a good representation for all the tasks given a very simple model (ResNet18). Nevertheless, this behavior is expected due to the adoption of a light model in combination with a multi-task loss function which tries to balance the learning pace of the different tasks.
Comparing the different multi-task models, it can be seen that the architecture MTN vA, even if characterized by the lowest amount of parameters, allows to obtain good performance compared to the single-task models. In particular, we can see an accuracy improvement of around 1% and 6% on the gender and emotion recognition tasks respectively. Moreover, it obtains an improvement in terms of MAE of around 1.5 years. Moving from architectures MTN vA to MTN vB, we only see an improvement on the gender recognition task, reaching state-of-the-art performance with an accuracy score equal to 96.65%. On the other hand, the performance on the other tasks decreases. This result suggests that the correlation between the considered tasks is strong, and therefore, it is important to share features between them. This assumption is further confirmed if we look to the results obtained by architecture MTN vC, which is able to outperform the state-of-the-art models on three tasks over four while combining the increasing of parameters to train with the feature sharing through the cross-stitch layers.
Another important contribution of the proposed paper is the learnable audio representation. In order to prove the effectiveness of this choice, we also perform a comparison obtained by training the multi-task architecture with and without the proposed layers. For a fair comparison, we carry out experiments using the Mel spectrogram representation with the same number of filters of the proposed one. The results, reported in Table 4, show how all the multi-task models trained with the proposed representation outperforms over all the tasks the Mel counterpart, unless of the MTN vA model which obtains worse results only on the gender recognition tasks. The proposed representation allows to gain an average EER improvement of 3% on the speaker verification task and a decreasing of the MAE around 1 year for the age estimation one. This performance gain proves that the proposed representation effectively deals with the noise characterizing the VoxCeleb 1 and VoxCeleb 2 datasets.
Finally, we report in Fig. 2 the latency of the proposed multi-task architecture compared to the time needed to run all the single-task counterparts. Given social robotics as our reference applications, we evaluate the performance over an embedded device equipped with GPU, namely the NVIDIA Jetson AGX. The latency estimation has been made by averaging 1000 prediction timings over audio signals with a length equal to 3 s (common audio length in social robotics applications). As one can expect, the latency of the multi-task model MTN vA (0.369 s) is around 1/4 of the time needed to run single-task models (1.489 s) while achieving big performance gains on three dealt tasks. A similar behavior can be seen for the multi-task model MTN vB, where the earlier branching causes a latency increasing w.r.t. MTN vA of around 0.167 s. Finally, the multi-task model MTN vC slightly increases the latency w.r.t. model MTN vB, but gaining in accuracy. Nevertheless, both models MTN vB and MTN vC gain around 1 s if compared to single-task models. In general, we conclude that MTN vC is the best trade-off between accuracy and computational load.

Inference time required by the trained multi-task networks (MTN vA, vB, and vC) and single-task counterpart (STN). The latency has been computed on an average audio length of 3 s over the NVIDIA Jetson AGX Embedded System
Conclusions
In this paper, we introduced and evaluated three multi-task neural network (MTN) models for gender recognition, emotion recognition, age estimation, and speaker re-identification. Our findings suggest that these models can achieve high accuracy while reducing computational requirements compared to their single-task counterparts. We have shown that each MTN architecture offers a different trade-off between feature sharing and model parameters, enabling better generalization of the model in very limited setups or when higher accuracy is required.
The CNN backbone, ResNet18, and the learnable filter audio representation proved to be effective in the multi-task setting, the latter outperforming also the Mel spectrogram representation. We propose a training loss that allows for different datasets even without labels for all tasks and use the GradNorm algorithm to prevent unbalanced task performance.
Our models were evaluated on standard benchmarks for the considered tasks, including VoxCeleb 1, VoxCeleb 2, Mozilla Common Voice, and IEMOCAP. Results show that our proposed MTN architectures outperform state-of-the-art models on three out of four tasks, demonstrating their effectiveness. Furthermore, the multi-task approach improved the performance of gender recognition, emotion recognition, and age estimation compared to single-task models, supporting the hypothesis that MTNs can improve generalization capabilities. Overall, this study highlights the potential of MTNs for audio-based soft biometric recognition and provides useful insights into their design and evaluation.
The proposed solution represents an important tool for the development of social robots or, more generally, for cyber-physical social systems. In fact, real-time voice analysis allows to profile the interlocutor very quickly, with an immediate and natural human-robot interface. Such functionality is crucial to personalize the dialogue and actions of the social robot for the specific user. The adoption of a multi-task solution allows to have a responsive and compact neural network, compatible with the parallel use of other artificial intelligence modules for image analysis and natural language understanding on low-power embedded devices which is in turn required in social robots [48].
Future research directions in this field may concern the investigation of multi-modal human-robot interfaces, combining voice and video analysis to give the robot more awareness of the appearance of the interlocutor (face, clothes, accessories), his gestures, his actions, and so on. Moreover, an extensive analysis through user studies may be designed and implemented to evaluate qualitatively and quantitatively the satisfaction of the users in their interaction with the social robot; an ablation study may be considered to analyze the impact of each module on the naturalness of the interaction perceived by the users.
Data Availability
The manuscript has no associated data.
References
Foggia P, Greco A, Roberto A, Saggese A, Vento M. Few-shot re-identification of the speaker by social robots. Auton Robot. 2023;47(2):181–92.
Greco A, Roberto A, Saggese A, Vento M. Efficient transformers for on-robot natural language understanding. In: International Conference on Humanoid Robots (Humanoids). IEEE; 2022. p. 823–8
Ma Y, Nguyen KL, Xing FZ, Cambria E. A survey on empathetic dialogue systems. Inf Fusion. 2020;64:50–70.
Zazo R, Nidadavolu PS, Chen N, Gonzalez-Rodriguez J, Dehak N. Age estimation in short speech utterances based on LSTM recurrent neural networks. IEEE Access. 2018;6:22524–30.
Alkhawaldeh RS. DGR: Gender recognition of human speech using one-dimensional conventional neural network. Scientific Programming. 2019;2019.
Huang Z, Dong M, Mao Q, Zhan Y. Speech emotion recognition using CNN. In: ACM International Conference on Multimedia. 2014. p. 801–4.
Roberto A, Saggese A, Vento M. A challenging voice dataset for robotic applications in noisy environments. In: International Conference on Computer Analysis of Images and Patterns. Springer; 2019. p. 354–64.
Greco A, Roberto A, Saggese A, Vento M, Vigilante V. Emotion analysis from faces for social robotics. In: International Conference on Systems, Man and Cybernetics (SMC). IEEE; 2019. p. 358–64.
Foggia P, Greco A, Percannella G, Vento M, Vigilante V. A system for gender recognition on mobile robots. In: Proceedings of the 2nd International Conference on Applications of Intelligent Systems. 2019; p. 1–6.
Du Z, He L, Chen Y, Xiao Y, Gao P, Wang T. Robot cloud: bridging the power of robotics and cloud computing. Future Gener Comput Syst. 2017;74:337–48. https://doi.org/10.1016/j.future.2016.01.002.
Tanwani AK, Anand R, Gonzalez JE, Goldberg K. RILaaS: robot inference and learning as a service. IEEE Robot Autom Lett. 2020;5(3):4423–30. https://doi.org/10.1109/lra.2020.2998414.
Foggia P, Greco A, Saggese A, Vento M. Multi-task learning on the edge for effective gender, age, ethnicity and emotion recognition. Eng Appl Artif Intell. 2023;118:105651. https://doi.org/10.1016/j.engappai.2022.105651.
Tang Z, Li L, Wang D. Multi-task recurrent model for speech and speaker recognition. In: Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA). IEEE; 2016. p. 1–4.
Firdaus M, Golchha H, Ekbal A, Bhattacharyya P. A deep multi-task model for dialogue act classification, intent detection and slot filling. Cogn Comput. 2021;13(3):626–45.
Lotfian R, Busso C. Predicting categorical emotions by jointly learning primary and secondary emotions through multitask learning. Interspeech. 2018.
Ding W, He L. MTGAN: speaker verification through multitasking triplet generative adversarial networks. In: Interspeech. 2018. p. 3633–7. https://doi.org/10.21437/Interspeech.2018-1023.
Kim J, Englebienne G, Truong KP, Evers V. Towards speech emotion recognition “in the wild” using aggregated corpora and deep multi-task learning. In: Interspeech. 2017. p. 1113–7.
Luu C, Bell P, Renals S. Leveraging speaker attribute information using multi task learning for speaker verification and diarization. In: Interspeech. 2021. p. 491–5. https://doi.org/10.21437/Interspeech.2021-622.
Chen Z, Badrinarayanan V, Lee C-Y, Rabinovich A. Gradnorm: gradient normalization for adaptive loss balancing in deep multitask networks. In: International Conference on Machine Learning. PMLR; 2018. p. 794–803.
Zhang J, Peng Y, Pham VT, Xu H, Huang H, Chng ES. E2E-based multi-task learning approach to joint speech and accent recognition. In: Interspeech. 2021. p. 1519–23. https://doi.org/10.21437/Interspeech.2021-1495.
Sigtia S, Marchi E, Kajarekar S, Naik D, Bridle J. Multi-task learning for speaker verification and voice trigger detection. In: International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE; 2020. p. 6844–8.
Chen N, Qian Y, Yu K. Multi-task learning for text-dependent speaker verification. In: Interspeech 2015. 2015. p. 185–9. https://doi.org/10.21437/Interspeech.2015-81.
Sarma M, Sarma KK, Goel NK. Multi-task learning DNN to improve gender identification from speech leveraging age information of the speaker. Int J Speech Technol. 2020;23(1):223–40.
Pan Y, Zhang W-Q. Multi-task learning based end-to-end speaker recognition. In: International Conference on Signal Processing and Machine Learning. 2019. p. 56–61.
Liu Y, He L, Liu J, Johnson MT. Speaker embedding extraction with phonetic information. In: Interspeech. 2018. p. 2247–51. https://doi.org/10.21437/Interspeech.2018-1226.
Montalvo A, Calvo JR, Bonastre J-F. Multi-task learning for voice related recognition tasks. In: Interspeech. 2020. p. 2997–3001. https://doi.org/10.21437/Interspeech.2020-1857.
Misra I, Shrivastava A, Gupta A, Hebert M. Cross-stitch networks for multi-task learning. In: IEEE Conference on Computer Vision and Pattern Recognition. 2016. p. 3994–4003.
Greco A, Roberto A, Saggese A, Vento M. Which are the factors affecting the performance of audio surveillance systems? In: International Conference on Pattern Recognition (ICPR). IEEE; 2021. p. 7876–83.
Foggia P, Greco A, Roberto A, Saggese A, Vento M. Degramnet: effective audio analysis based on a fully learnable time–frequency representation. Neural Comput Appl. 2023; 1–13.
Krizhevsky A, Sutskever I, Hinton GE. ImageNet classification with deep convolutional neural networks. Commun ACM. 2017;60(6):84–90.
Roberto A, Saggese A, Vento M. A deep convolutionary network for automatic detection of audio events. In: International Conference on Applications of Intelligent Systems. 2020. p. 1–6.
Greco A, Roberto A, Saggese A, Vento M. DENet: a deep architecture for audio surveillance applications. Neural Comput Appl. 2021;33(17):11273–84.
Roy AG, Navab N, Wachinger C. Concurrent spatial and channel ‘squeeze & excitation’ in fully convolutional networks. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer; 2018. p. 421–9.
He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: IEEE Conference on Computer Vision and Pattern Recognition. 2016. p. 770–8.
He K, Zhang X, Ren S, Sun J. Identity mappings in deep residual networks. In: European Conference on Computer Vision. Springer; 2016. p. 630–45.
Deng J, Guo J, Xue N, Zafeiriou S. ArcFace: additive angular margin loss for deep face recognition. In: IEEE Conference on Computer Vision and Pattern Recognition. 2019. p. 4690–9.
Schroff F, Kalenichenko D, Philbin J. FaceNet: a unified embedding for face recognition and clustering. In: IEEE Conference on Computer Vision and Pattern Recognition. 2015. p. 815–23.
Zadeh AB, Liang PP, Poria S, Cambria E, Morency L-P. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph. In: Meeting of the Association for Computational Linguistics. 2018. p. 2236–46.
Busso C, Bulut M, Lee C-C, Kazemzadeh A, Mower E, Kim S, Chang JN, Lee S, Narayanan SS. IEMOCAP: interactive emotional dyadic motion capture database. Lang Resour Eval. 2008;42(4):335–59.
Wu X, Hu S, Wu Z, Liu X, Meng H. Neural architecture search for speech emotion recognition. In: International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE; 2022. p. 6902–6.
Ardila R, Branson M, Davis K, Kohler M, Meyer J, Henretty M, Morais R, Saunders L, Tyers F, Weber G. Common voice: a massively-multilingual speech corpus. In: Language Resources and Evaluation Conference. 2020. p. 4218–22.
Chachadi K, Nirmala S. Voice-based gender recognition using neural network. Inf Commun Technol Compet Strat (ICTCS). 2022;1:741–9.
Nagrani A, Chung JS, Zisserman A. VoxCeleb: a large-scale speaker identification dataset. Telephony. 2017;3:33–039.
Chung JS, Nagrani A, Zisserman A. VoxCeleb2: deep speaker recognition. Interspeech. 2018;1086–90.
Hechmi K, Trong TN, Hautamäki V, Kinnunen T. VoxCeleb enrichment for age and gender recognition. In: Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE; 2021. p. 687–93.
Zhou T, Zhao Y, Wu J. ResNeXt and Res2Net structures for speaker verification. In: Spoken Language Technology Workshop (SLT). IEEE; 2021. p. 301–7.
Greco A, Strisciuglio N, Vento M, Vigilante V. Benchmarking deep networks for facial emotion recognition in the wild. Multimed Tools Appl. 2023;82(8):11189–220.
Foggia P, Greco A, Roberto A, Saggese A, Vento M. A social robot architecture for personalized real-time human-robot interaction. IEEE Internet Things J. 2023.
Funding
Open access funding provided by Università degli Studi di Salerno within the CRUI-CARE Agreement. The authors declare no funding received.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Research Involving Human and Animal Participants
This article does not contain any studies with human participants or animals performed by any of the authors.
Competing Interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Foggia, P., Greco, A., Roberto, A. et al. Identity, Gender, Age, and Emotion Recognition from Speaker Voice with Multi-task Deep Networks for Cognitive Robotics. Cogn Comput (2024). https://doi.org/10.1007/s12559-023-10241-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12559-023-10241-5