
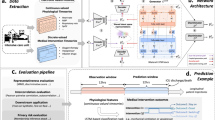
Abstract
Purpose
Electronic Health Records (EHRs) are invaluable sources of information for healthcare research and decision-making. However, laws protecting patient privacy restrict the sharing of real EHR data thus impeding the development of advanced AI based healthcare technology which require large volumes of quality data. To bridge this gap, synthetic data (SD) has emerged as a potential privacy-preserving alternative to real data. While SD can serve as a proxy to real data in many practical scenarios, its true potential is still unexploited because of insufficient empirical evidence Nevertheless lack of sufficient empirical evidence supporting its efficacy has led to skepticism and decreased trust in SD among the stakeholders. This research article presents the result of extensive experimentation with SD in prediction of Cardiovascular Disease (CVD) mortality.
Methods
Generative adversarial networks (GANs) are a popular choice for generating SD, especially in the medical domain. We perform two controlled experiments to evaluate the effectiveness of the state-of-the-art GAN models for CVD SD generation, and to study the impact of increasing data-dimensionality upon the utility of generated SD.
Results
The results demonstrate that GAN-generated SD performs well in predicting CVD, with comparable accuracy to that of real data, and highlights the potential of SD for disease prediction.
Conclusion
We believe that our results will leverage better trust on practical use cases of SD among medical practitioners and user stakeholders for applications such as decision support systems, health monitoring and planning, and mobile health systems.





Similar content being viewed by others


Data availability
The datasets utilized in the experiments are publicly available.
References
Ngom F, Fall I, Camara MS, Alassane BA. A study on predicting and diagnosing non-communicable diseases: case of cardiovascular diseases. In: 2020 International Conference on Intelligent Systems and Computer Vision (ISCV). IEEE; 2020. p. 1–8.
Cowie MR, et al. Electronic health records to facilitate clinical research. Clin Res Cardiol. 2017;106(1):1. https://doi.org/10.1007/s00392-016-1025-6.
Hossain ME, Khan A, Moni MA, Uddin S. Use of electronic health data for disease prediction: A comprehensive literature review. IEEE/ACM Trans Computat Biol Bioinform. 2019;18(2):745–58.
Nithya B, Ilango V. Predictive analytics in health care using machine learning tools and techniques. In 2017 International Conference on Intelligent Computing and Control Systems (ICICCS). 2017;492–499. https://doi.org/10.1109/ICCONS.2017.8250771.
Dove ES, Phillips M. Privacy law, data sharing policies, and medical data: a comparative perspective. In: Gkoulalas-Divanis A, Loukides G, editors. Medical data privacy handbook. Cham: Springer International Publishing; 2015. p. 639–78. https://doi.org/10.1007/978-3-319-23633-9_24.
Jacobs B, Popma J. Medical research, big data and the need for privacy by design. Big Data Soc. 2019;6(1):1. https://doi.org/10.1177/2053951718824352.
Murthy S, Bakar AA, Rahim FA, Ramli R. A comparative study of data anonymization techniques. In: 2019 IEEE 5th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing, (HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS). IEEE; 2019. p. 306–9.
Khan SI, Hoque ASM. Digital health data: a comprehensive review of privacy and security risks and some recommendations. Comp Sci J Moldova. 2016;71(2):273–92.
Dankar FK, Ibrahim M. Fake it till you make it: guidelines for effective synthetic data generation. Appl Sci. 2021;11(5):5. https://doi.org/10.3390/app11052158.
Jordon J, et al. Synthetic Data -- what, why and how? arXiv. 2022. http://arxiv.org/abs/2205.03257. Accessed 09 Aug 2022.
Kaabachi B, et al. Can we trust synthetic data in medicine? A scoping review of privacy and utility metrics. medRxiv. 2023;2023.11.28.23299124. https://doi.org/10.1101/2023.11.28.23299124.
Abowd JM, Vilhuber L. How protective are synthetic data? In: Domingo-Ferrer J, Saygın Y, editors. Privacy in statistical databases. Berlin: Springer; 2008. p. 239–46. https://doi.org/10.1007/978-3-540-87471-3_20. Lecture Notes in Computer Science.
Giuffrè M, Shung DL. Harnessing the power of synthetic data in healthcare: innovation, application, and privacy. Npj Digit Med. 2023;6(1):1. https://doi.org/10.1038/s41746-023-00927-3.
Rahim A, et al. An integrated machine learning framework for effective prediction of cardiovascular diseases. IEEE Access. 2021;9:1065–88.
Zhou B, Pei J, Luk W. A brief survey on anonymization techniques for privacy-preserving publishing of social network data. SIGKDD Explor Newsl. 2008;10(2):12–22.
Langarizadeh M, et al. Effectiveness of anonymization methods in preserving patients' privacy: A systematic literature review. eHealth. 2018;248:80–7.
Abufadda M, Mansour K. A survey of synthetic data generation for machine learning. In: 2021 22nd International Arab Conference on Information Technology (ACIT). 2021. p. 1–7. https://doi.org/10.1109/ACIT53391.2021.9677302.
El Emam K, Mosquera L, Hoptroff R. Practical synthetic data generation - balancing privacy and the broad availability of data. 1st ed. O’Reilly; 2020.
Goodfellow I, et al. Generative adversarial nets. Adv Neural Inform Process Sys. 2014;27.
Georges-Filteau J, Cirillo E. Synthetic Observational Health Data with GANs: from slow adoption to a boom in medical research and ultimately digital twins?. arXiv preprint arXiv:2005.13510;2020.
Murtaza H, Ahmed M, Khan NF, Murtaza G, Zafar S, Bano A. Synthetic data generation: state of the art in health care domain. Comput Sci Rev. 2023;48:100546. https://doi.org/10.1016/j.cosrev.2023.100546.
Brekke PH, et al. Synthetic data for annotation and extraction of family history information from clinical text. J Biomed Semantics. 2021;12:1–11.
Buczak AL, Babin S, Moniz L. Data-driven approach for creating synthetic electronic medical records. BMC Med Inform Decis Mak. 2010;10(1):1–28.
Coutinho-Almeida J, Rodrigues PP, Cruz-Correia RJ. GANs for tabular healthcare data generation: a review on utility and privacy. In: Soares C, Torgo L, editors. Discovery science. Cham: Springer International Publishing; 2021. p. 282–91. https://doi.org/10.1007/978-3-030-88942-5_22. Lecture Notes in Computer Science.
Abedi M, et al. GAN-based approaches for generating structured data in the medical domain. Appl Sci. 2022;12(14):7075.
World Health Organization (WHO). https://www.who.int. Accessed 26 Aug 2023.
Hasan NI, Bhattacharjee A. Deep learning approach to cardiovascular disease classification employing modified ECG signal from empirical mode decomposition. Biomed Signal Process Control. 2019;52:128–40.
Venugopal R, Shafqat N, Venugopal I, Tillbury BMJ, Stafford HD, Bourazeri A. Privacy preserving generative adversarial networks to model electronic health records. Neural Netw. 2022;153:339–48. https://doi.org/10.1016/j.neunet.2022.06.022.
Azizi Z, Zheng C, Mosquera L, Pilote L, El Emam K. Can synthetic data be a proxy for real clinical trial data? A validation study. BMJ Open. 2021;11(4):e043497.
El Emam K. Seven ways to evaluate the utility of synthetic data. IEEE Secur Priv. 2020;18(4):4. https://doi.org/10.1109/MSEC.2020.2992821.
Kuppa A, Lamine A, Nhien-An L-K. Towards improving privacy of synthetic datasets. In: Annual privacy forum. Cham: Springer International Publishing; 2021.
Bourou S, El Saer A, Velivassaki T-H, Voulkidis A, Zahariadis T. A review of tabular data synthesis using GANs on an IDS dataset. Information. 2021;12(9):375.
García-Vicente C, et al. Evaluation of synthetic categorical data generation techniques for predicting cardiovascular diseases and post-hoc interpretability of the risk factors. Appl Sci. 2023;13(7):4119.
Rashidian S. SMOOTH-GAN: towards sharp and smooth synthetic EHR data generation. In: Michalowski M, Moskovitch R, editors. Artificial intelligence in medicine. Cham: Springer International Publishing; 2020. p. 37–48. https://doi.org/10.1007/978-3-030-59137-3_4. Lecture Notes in Computer Science.
Tucker A, Wang Z, Rotalinti Y, Myles P. Generating high-fidelity synthetic patient data for assessing machine learning healthcare software. Npj Digit Med. 2020;3(1):1. https://doi.org/10.1038/s41746-020-00353-9.
Abdelfattah SM, Abdelrahman GM, Wang M. Augmenting the size of EEG datasets using generative adversarial networks. In: 2018 International Joint Conference on Neural Networks (IJCNN). 2018;1–6. https://doi.org/10.1109/IJCNN.2018.8489727.
Rodriguez-Almeida AJ, et al. Synthetic patient data generation and evaluation in disease prediction using small and imbalanced datasets. IEEE J Biomed Health Inform. 2023;27(6):2670–80. https://doi.org/10.1109/JBHI.2022.3196697.
García-Vicente C. Clinical synthetic data generation to predict and identify risk factors for cardiovascular diseases. In: Rezig EK, Gadepally V, Mattson T, Stonebraker M, Kraska T, Kong J, Luo G, Teng D, Wang F, editors. Heterogeneous data management, polystores, and analytics for healthcare. Cham: Springer Nature Switzerland; 2022. p. 75–91. https://doi.org/10.1007/978-3-031-23905-2_6. Lecture Notes in Computer Science.
García-Vicente C, et al. Evaluation of synthetic categorical data generation techniques for predicting cardiovascular diseases and post-hoc interpretability of the risk factors. Appl Sci. 2023;13(7):7. https://doi.org/10.3390/app13074119.
Wang Y, Dong X, Wang L, Chen W, Zhang X. Optimizing small-sample disk fault detection based on LSTM-GAN model. ACM Trans Archit Code Optim TACO. 2022;19(1):1–24.
Fang ML, Devendra Singh D, Kristian K. Dp-ctgan: Differentially private medical data generation using ctgans. In: International Conference on Artificial Intelligence in Medicine. Cham: Springer International Publishing; 2022.
Dua D, Graff C. UCI Machine learning repository: data sets. http://archive.ics.uci.edu/ml/datasets.php. Accessed 20 May 2021.
Framingham Heart Study (FHS) | NHLBI, NIH. https://www.nhlbi.nih.gov/science/framingham-heart-study-fhs. Accessed 26 Aug 2023.
Stroke Prediction Dataset. https://www.kaggle.com/datasets/fedesoriano/stroke-prediction-dataset. Accessed 26 Aug 2023.
Heart Failure Prediction | Kaggle. https://www.kaggle.com/datasets/andrewmvd/heart-failure-clinical-data. Accessed 26 Aug 2023.
Goncalves A, et al. Generation and evaluation of synthetic patient data. BMC Med Res Methodol. 2020;20:1–40.
Hernandez M, Epelde G, Alberdi A, Cilla R, Rankin D. Standardised metrics and methods for synthetic tabular data evaluation. 2021. https://doi.org/10.36227/techrxiv.16610896.
Yan C, et al. A multifaceted benchmarking of synthetic electronic health record generation models. Nat Commun. 2022;13(1):1. https://doi.org/10.1038/s41467-022-35295-1.
Choi E, Biswal S, Malin B, Duke J, Stewart WF, Sun J. Generating multi-label discrete patient records using generative adversarial networks. In: Machine Learning for Healthcare Conference, PMLR. 2017. p. 286–305. http://proceedings.mlr.press/v68/choi17a.html. Accessed 10 May 2021.
Xu L, et al. Modeling tabular data using conditional gan. Adv Neural Inform Process Sys. 2019; 32.
Bhanot K, Qi M, Erickson JS, Guyon I, Bennett KP. The problem of fairness in synthetic healthcare data. Entropy. 2021;23(9):9. https://doi.org/10.3390/e23091165.
Funding
The authors did not receive support from any organization for the submitted research article.
Author information
Authors and Affiliations
Contributions
All the authors contributed to the conception and design of the study. Research Methodology was designed by Dr. Musharraf Ahmed. Material preparation, data collection and analysis were performed by Shahzad Ahmed Khan. Hajra Murtaza and Shahzad Ahmed conducted experiments and prepared the manuscript which was reviewed by Dr. Musharraf Ahmed. All the authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethical approval
Not Applicable.
Consent to publish
All the authors agreed to publish this work in the respective journal.
Consent to participate
Not Applicable.
Conflict of interests
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1: Pearson correlation
1.1 Pearson correlation for LSTMGAN and DPGAN based SD
As described in result section we have evaluated three models. Among the three selected models CTGAN have performed well. Results of CTGAN are presented in results section, here we are presenting the results of LSTMGAN and DPGAN in Figs. 6 and 7 respective.

Pearson Correlation for LSTMGAN Experiment 1 Results: (a) LSTMGAN Observation on Framingham dataset, b LSTMGAN Observation on UCI dataset
From the above results, we can say that there is a huge gap between real and SD. The relationship among variables of the dataset in real is much different than in synthetic. But visual representation is not enough to reject the model for a further experiment that’s why we evaluate the utility of SD by tuning our model on SD and predicting the mortality of the patient on both real data and SD. The prediction results on SD are far away from the results on real data.
1.2 Result for experiment 01: DPGAN
For basic sanity check, we first find the relationship among variables by using Pearson Correlation. The visual representation is given in Fig. 7.

Pearson correlation for DPGAN experiment 1 results: a DPGAN Observation on Framingham Dataset, b DPGAN Observation on Heart Failure Dataset
1.3 CTGAN for heart stroke dataset
In the given experiments, we have a binary classification problem. We have predicted the target variable. We have made a comparison of the real and SD. First of all, we have presented the Pearson Correlation of both datasets in Fig. 8.

Pearson correlations for heart stroke dataset: a Results after 300 epochs, b Results after 500 epochs, c Results after 1000 epochs, d Results after 1500 epochs
1.4 CTGAN with Herat failure dataset
In this experiment, we have done binary classification on SD. We have predicted the target variable. First of all, we are presenting the Pearson Correlation of both datasets and presented the results in Fig. 9.

Pearson Correlation of Real and Synthetic Heart Failure Dataset: a Results after 300 epochs, b Results after 500 epochs, c Results after 1000 epochs, d Results after 1500 epochs
1.5 CTGAN for UCI dataset
UCI datasets are used in binary prediction on the target variable. First of all, we are presenting the Pearson Correlation of both datasets. For SD we have changed the number of epochs and results are presented in Fig. 10.

Pearson correlation of real and synthetic UCI dataset: a Results after 300 epochs, b Results after 500 epochs, c Results after 1000 epochs, d Results after 1500 epochs
We have compared both real and synthetic datasets by checking their accuracy. On our best model configuration, we have got an accuracy of 74%. The mean accuracy is presented in Table 7.
Appendix 2: DWP results
2.1 Dimension wise prediction for heart stroke dataset
In the below table Stroke is predicted on the remaining attributes. Al the other attributes are predicted in the same manner and results are presented in Table 12. The experiment is done on both SD and real data for every attribute.
2.2 Dimension wise prediction for UCI dataset
In the below table target variable is predicted on the remaining attributes. In the same manner, we have predicted the other variables. The experiment is done on both SD and real data for every attribute from Table 13 we can see that the prediction accuracy is very close in both datasets.
Appendix 3: TSTR and TRTS results
For quality evaluation of SD, we have performed two tests. In TRTS, as the name suggests, we trained our model on real datasets, once training is done then we performed testing on SD. We performed TRTS 50 times and every time our model generate different data. There is another way to evaluate the SD, that is, TSTR. In TSTR, we trained the model on SD and tested on real data. The results have similar accuracy as TRTS. Also, we iterate 50 times to get better results.
TRTS Results of Heart Stroke dataset:
Accuracy with the real dataset: 0.9572 | |||||||
|---|---|---|---|---|---|---|---|
Iteration | Accuracy | Iteration | Accuracy | Iteration | Accuracy | Iteration | Accuracy |
1 | 0.9256 | 7 | 0.8849 | 13 | 0.8849 | 19 | 0.8492 |
2 | 0.9345 | 8 | 0.9232 | 14 | 0.9232 | 20 | 0.9175 |
3 | 0.9226 | 9 | 0.8890 | 15 | 0.8800 | 21 | 0.8951 |
4 | 0.9144 | 10 | 0.9096 | 16 | 0.9096 | 22 | 0.8447 |
5 | 0.9491 | 11 | 0.8831 | 17 | 0.8831 | 23 | 0.7856 |
6 | 0.9002 | 12 | 0.9047 | 18 | 0.9042 | 24 | 0.9123 |
25 | 0.8961 | ||||||
TSTR Results of Heart Stroke dataset:
Accuracy with the real dataset: 0.9467 | |||||||
|---|---|---|---|---|---|---|---|
Iteration | Accuracy | Iteration | Accuracy | Iteration | Accuracy | Iteration | Accuracy |
1 | 0.9498 | 7 | 0.9112 | 13 | 0.9387 | 19 | 0.9344 |
2 | 0.8964 | 8 | 0.8812 | 14 | 0.8890 | 20 | 0.9358 |
3 | 0.9176 | 9 | 0.8592 | 15 | 0.9166 | 21 | 0.9124 |
4 | 0.9287 | 10 | 0.9345 | 16 | 0.8986 | 22 | 0.9234 |
5 | 0.9191 | 11 | 0.8861 | 17 | 0.9153 | 23 | 0.9431 |
6 | 0.8912 | 12 | 0.8974 | 18 | 0.8443 | 24 | 0.9342 |
25 | 0.8976 | ||||||
TRTS Results for UCI datasets:
Accuracy with the real dataset: 0.8689 | |||||||
|---|---|---|---|---|---|---|---|
Iteration | Accuracy | Iteration | Accuracy | Iteration | Accuracy | Iteration | Accuracy |
1 | 0.6428 | 7 | 0.5564 | 13 | 0.6463 | 19 | 0.43548 |
2 | 0.6123 | 8 | 0.5457 | 14 | 0.5246 | 20 | 0.41140 |
3 | 0.6453 | 9 | 0.5545 | 15 | 0.6111 | 21 | 0.61243 |
4 | 0.6452 | 10 | 0.4657 | 16 | 0.6136 | 22 | 0.43584 |
5 | 0.6354 | 11 | 0.7146 | 17 | 0.5345 | 23 | 0.64537 |
6 | 0.6128 | 12 | 0.6751 | 18 | 0.5456 | 24 | 0.41751 |
25 | 0.6055 | ||||||
TSTR: Results for UCI datasets
Accuracy with the real dataset: 0.8645 | |||||||
|---|---|---|---|---|---|---|---|
Iteration | Accuracy | Iteration | Accuracy | Iteration | Accuracy | Iteration | Accuracy |
1 | 0.6317 | 7 | 0.7428 | 13 | 0.6670 | 19 | 0.5847 |
2 | 0.6114 | 8 | 0.7344 | 14 | 0.6073 | 20 | 0.6236 |
3 | 0.6338 | 9 | 0.6434 | 15 | 0.6754 | 21 | 0.7000 |
4 | 0.6358 | 10 | 0.7147 | 16 | 0.6476 | 22 | 0.7073 |
5 | 0.5387 | 11 | 0.6756 | 17 | 0.6175 | 23 | 0.6837 |
6 | 0.5175 | 12 | 0.7045 | 18 | 0.5751 | 24 | 0.6042 |
25 | 0.7031 | ||||||
TRTS for Heart Failure dataset
Accuracy with the real dataset: 0.8645 | |||||||
|---|---|---|---|---|---|---|---|
Iteration | Accuracy | Iteration | Accuracy | Iteration | Accuracy | Iteration | Accuracy |
1 | 0.6354 | 7 | 0.7123 | 13 | 0.6534 | 19 | 0.6564 |
2 | 0.6114 | 8 | 0.7812 | 14 | 0.7766 | 20 | 0.5246 |
3 | 0.5124 | 9 | 0.7453 | 15 | 0.6545 | 21 | 0.7344 |
4 | 0.6445 | 10 | 0.7111 | 16 | 0.6343 | 22 | 0.7133 |
5 | 0.5453 | 11 | 0.7312 | 17 | 0.6734 | 23 | 0.7334 |
6 | 0.6144 | 12 | 0.6128 | 18 | 0.6984 | 24 | 0.6456 |
25 | 0.7122 | ||||||
TSTR for Heart Failure dataset:
Accuracy with the real dataset: 0.8334 | |||||||
|---|---|---|---|---|---|---|---|
Iteration | Accuracy | Iteration | Accuracy | Iteration | Accuracy | Iteration | Accuracy |
1 | 0.7234 | 7 | 0.7089 | 13 | 0.5985 | 19 | 0.6114 |
2 | 0.6344 | 8 | 0.6567 | 14 | 0.6122 | 20 | 0.5433 |
3 | 0.6434 | 9 | 0.5434 | 15 | 0.6073 | 21 | 0.5358 |
4 | 0.7147 | 10 | 0.5985 | 16 | 0.5837 | 22 | 0.6387 |
5 | 0.6756 | 11 | 0.6751 | 17 | 0.5042 | 23 | 0.6147 |
6 | 0.7045 | 12 | 0.6845 | 18 | 0.5317 | 24 | 0.7300 |
25 | 0.5788 | ||||||
Appendix 4: Architectural details of GANs used in the experiments
4.1 CTGAN
CTGAN (Conditional Tabular Generative Adversarial Network) is a generative model designed to produce synthetic structured data while preserving its original statistical properties. Built upon the principles of Generative Adversarial Networks (GANs), CTGAN encompasses a generator and discriminator that work in tandem to create high-quality synthetic data.
This architecture operates within a conditional GAN framework, allowing it to generate data samples while considering specific attributes. By transforming discrete categorical attributes into continuous embeddings using embedding networks, CTGAN ensures that similar categorical values are closely represented in the synthetic data. The generator takes both continuous and categorical noise vectors as well as attribute values for conditioning. Through its layers, including fully connected ones, it transforms these inputs into realistic synthetic samples that mirror the original data. The discriminator, on the other hand, distinguishes between real and generated data by classifying input samples as authentic or synthetic.
To train CTGAN, adversarial and auxiliary loss functions come into play. The adversarial loss fine-tunes the generator and discriminator to create data that's indistinguishable from real data. Auxiliary losses, such as distance-based loss, guarantee that the synthetic samples align with the original data's statistical properties. CTGAN incorporates a strategic sampling strategy to ensure diversity in generated samples, mitigating the risk of the generator producing repetitive data (mode collapse). Moreover, post-processing is employed to conform to predefined constraints or business rules, enhancing the generated data's utility.
4.2 Architecture of DP-GAN
Privacy-preserving generative models, like the Deep Privacy Preserving Generative Model (DPGAN), are designed to generate synthetic data while protecting the privacy of individuals in the original dataset. These models are developed to ensure that generated data retains the statistical properties of the original data without revealing sensitive information.
The DPGAN framework comprises several key components. It starts with an original dataset containing sensitive information and defines privacy constraints that specify which attributes or attribute combinations should remain private. The generator, a neural network, takes random noise as input and produces synthetic data samples. To achieve privacy, the generator generates samples that adhere to the original data's statistical distribution while satisfying privacy constraints.
Privacy preservation is achieved through mechanisms like differential privacy, which adds noise to the generated output, ensuring that the synthetic samples do not divulge specific individual details. Privacy loss bounds are also enforced to maintain acceptable privacy levels. Balancing utility preservation alongside privacy is crucial. Utility ensures that the generated data remains useful for downstream tasks without compromising its privacy preservation objectives. Evaluation involves assessing both privacy and utility, often involving adversarial training to maintain data indistinguishability from the original while preserving privacy.
Post-processing might be applied to guarantee the synthetic data adheres to privacy constraints. Validation processes ensure the generated data's validity and privacy alignment using suitable metrics and tests. It's important to note that privacy-preserving generative models represent an evolving research field, and architecture specifics can vary based on the model's design and researchers' goals.
4.3 Architecture of LSTM GAN
The term "LSTMGAN" suggests a potential model that merges the capabilities of LSTM (Long Short-Term Memory) networks and GANs (Generative Adversarial Networks). While not a recognized model as of my last update in September 2021, we can conceptualize its architecture.
LSTMGAN could be a generative model designed to produce sequential data, leveraging LSTM's proficiency in capturing temporal patterns. Its components include a generator and a discriminator, fundamental to GANs. The generator employs LSTM architecture to create sequences of data points, using random noise as input. The discriminator's role is to differentiate real and generated sequences, steering the generator towards crafting more authentic sequences. Training involves an adversarial framework. The generator strives to make its sequences indistinguishable from real data, while the discriminator refines its classification abilities.
Loss functions encompass an adversarial loss and an LSTM loss. The former compels the generator to craft sequences resembling real data, while the latter ensures coherence and temporal consistency. Iterations of training refine both generator and discriminator through backpropagation, where the generator's parameters adapt to enhance sequence quality, and the discriminator becomes adept at classification.
The generator's sampling strategy ensures diverse sequences, sidestepping repetition and mode collapse issues. In applications, the LSTMGAN model could generate realistic time series data, text sequences, or other sequential data types. However, this interpretation is conceptual. For specific insights into a model named "LSTMGAN" developed after my last update, I suggest consulting original research papers and documentation for its precise architecture and methodology.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Khan, S.A., Murtaza, H. & Ahmed, M. Utility of GAN generated synthetic data for cardiovascular diseases mortality prediction: an experimental study. Health Technol. (2024). https://doi.org/10.1007/s12553-024-00847-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12553-024-00847-6