
Abstract
The development of super-resolution imaging techniques has revolutionized our ability to study the nano-scale world, where objects are often smaller than the diffraction limit of traditional optical microscopes. Super-resolution superlenses have been proposed to solve this problem by manipulating the light wave in the near field. A superlens is a kind of metamaterial-based lens that can enhance the evanescent waves generated by nano-scale objects, utilizing the surface plasmon phenomenon. The superlens allows for the imaging of nano-scale objects that would otherwise be impossible to resolve using traditional lenses. Previous research has shown that nanostructures can be imaged using superlenses, but the exact shape of the superlens must be known in advance, and an analytical calculation is needed to reconstruct the image. Localized plasmon structured illumination microscopy is an approach to achieve super-resolution by imaging the superlens-enhanced evanescent wave with illumination shifts. This study proposes a new approach utilizing a conditional generative adversarial network to obtain super-resolution images of arbitrary nano-scale patterns. To test the efficacy of this approach, finite-difference time-domain simulation was utilized to obtain superlens imaging results. The data from the simulation were then used for deep learning to develop the model. With the help of deep learning, the inverse calculation of complex sub-diffraction-limited patterns can be achieved. The super-resolution feature of the superlens based on deep learning is investigated. The findings of this study have significant implications for the field of nano-scale imaging, where the ability to resolve arbitrary nano-scale patterns will be crucial for advances in nanotechnology and materials science.
Similar content being viewed by others

Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
1 Introduction
Optical microscopy is the most intuitive technique for humans to study small-scale objects. In semiconductor inspection, both scanning electron microscopy (SEM) and atomic force microscopy (AFM) can yield high-resolution images. However, these methods present unique challenges: SEM requires a vacuum environment, and AFM is time-intensive due to the physical scanning process. Conversely, optical microscopy provides benefits such as non-destructive, real-time observation and a large field of view. Yet, the resolution of microscopy is inherently restricted by the diffraction limit, as dictated by Rayleigh’s criterion. Thus, there is a pressing demand for super-resolution optical technologies that can exploit these benefits to explore the nano-scale world.
The diffraction limit is a physical constraint imposed by the numerical aperture of the objective lens and the non-propagation issue of evanescent components, which carry high-frequency information of samples.
Although several strategies without scanning processes like SNOM (scanning near-field microscopy) [1, 2] have been developed to break the diffraction limit based on luminescence techniques, such as STED (stimulated emission depletion microscopy) [3], STORM (stochastic optical reconstruction microscopy) [4] and SIM (structured illumination microscopy) [5], they are not direct imaging methods. STED and STORM methods require fluorescent labeling [6]. And the original SIM needs phase-shifted multiple illuminations for various Moiré fringes to reconstruct the super-resolution, and its super-resolution limit does not surpass half of the wavelength [7]. Compared to the reviewed super-resolution methods, the lens-based projection is the best option for high-speed microscopy [8].
Ideally, a lens should gather all light propagating in any direction to reconstruct the microscopic image. Significant efforts have been invested to engineer such a lens that can overcome the diffraction limit and emulate the ideal lens. These lenses, previously referred to as metalens, hyperlens, and superlens in the literature [9], employ specially engineered surface structures to capture evanescent waves from an object, which would typically fade when moving away from the near-field region of the sample, thereby achieving super-resolution imaging.
Nevertheless, the principles underlying superlenses impose constraints, primarily because they are heavily dependent on the plasmonic design. Their realization poses considerable challenges due to factors such as the narrow working wavelength, restrictions on metal materials, and the need for geometric perfection.
Highlighting the issues with such lenses, the far-field superlens (FSL) serves as a representative example. This device has overcome the challenge of near-field localization of evanescent components [10]. It amplifies evanescent waves and transforms them into propagating waves that can be measured in the far field. The FSL converts the incident near-field angular spectrum into a transmitted far-field angular spectrum, characterized by a one-to-one correspondence [11]. To reconstruct a super-resolution image, single-wavelength illumination and precise geometric information of the FSL are necessary. Image reconstruction is only feasible when the exact transmission function of the FSL is known. The fabrication of the FSL demands stringent precision to achieve the anticipated transmission characteristic for the proposed grating structure [12]. Furthermore, modifying the FSL’s geometry is required when adjusting for a different working wavelength [13]. The illumination bandwidth complicates the analytical reconstruction of super-resolution images, as the imaging process diverges from traditional lenses and necessitates reconstruction.
Conversely, with the rapid advancement of artificial intelligence (AI) technology, the reconstruction of super-resolution images based on the complex response of meta-lenses exhibits significant potential [14]. In addition, the one-shot SIM [15, 16] has been demonstrated to recover high-frequency images from a single Moiré fringe, skipping the phase-shifted multiple illumination with the help of AI. Extensive applications of AI in measurement and evaluation in industry [17, 18] underscore the efficacy of AI in enhancing operational efficiencies and ensuring quality in manufacturing processes.
2 Proposal
The numerical reconstruction of super-resolution images from superlens is anticipated. With AI-assisted imaging, image reconstruction will become simpler without the need for precise knowledge of the superlens’s transmission function. This could enable superlens to accommodate LED illumination with a bandwidth that is different from the working wavelength and have ability of defect tolerance.
This study introduces a novel approach that employs a conditional generative adversarial network (cGAN) to obtain super-resolution images for arbitrary nano-scale patterns under incoherent illumination with bandwidth.
To evaluate the effectiveness of this method, finite-difference time-domain (FDTD) simulation was used to capture superlens imaging results of random samples. The simulation data was subsequently utilized for deep learning to develop the super-resolution reconstruction model. With deep learning, the inverse calculation of complex sub-diffraction-limited patterns can be accomplished. Initially, 1D imaging is simulated based on 2D FDTD simulations. Following this, a revised 1D version of the image translation tool, pix2pix cGAN [19] is used for studying the reconstruction of super-resolution images.
The proposed method has multiple benefits:
-
1.
The foremost is the adeptness of deep learning to manage uncertainties that arise during the fabrication of FSL, giving possibility for integrate more cost-efficient fabrication methods like printable nanoporous substrate [20].
-
2.
Additionally, simple LED lighting and one-shot super-resolution can be achieved.
-
3.
Importantly, this method is designed to boost super-resolution capabilities based on imaging principle. This approach is distinct from existing methods that typically concentrate on noise reduction or fidelity restoration to improve image resolution, such as the SR3 image refinement technique [21].
-
4.
Tough the training process is time consuming, the proposed method will reach high-speed super-resolution by application of the trained model.
3 Principle of Superlens and Imaging Reconstruction with Deep Learning
3.1 Superlens Theory
A superlens is a device that incorporates a subwavelength grating into a thin silver film. The Far-field Superlens (FSL) selectively amplifies the evanescent waves from the subwavelength objects in its near field and subsequently transforms these evanescent waves into propagating waves. These propagating waves are then collected by the objective lens and can be imaged by image sensors. FSL is depicted in Fig. 1a.

Illustration of far-field superlens (FSL) super-resolution process. a An FSL is put close to the specimen, and the interaction of the subwavelength specimen with the FSL will project special patterns which can be collected by the objective lens and imaging sensor. The near-field super-resolution imaging can be reconstructed from the far-field pattern. b The FSL is a device with gratings on thin silver film, which can enhance the evanescent wave of objects in near-field and turn them into 1st-order diffraction of the grating. c The ideal optical transfer function for FSL
The periodic gratings can couple out evanescent waves into propagating waves through a diffraction process, as detailed in the following equation. Here \(k\mathrm{^{\prime}}\) and \({k}_{in}\) are the wave vector of the propagating wave and incident wave, \(m\) is diffraction order, and \({k}_{\Lambda }\) is the grating wave number, and \({k}_{\Lambda }=2\pi /\Lambda\), \(\Lambda\) is the grating period. This process is illustrated in Fig. 1b by neglecting higher orders than the first order.
The angular spectrum of the E-field transmitted above grating and before transmission is written as \(\widetilde{E}(x,z)\) and \({\widetilde{E}}_{obj}(x,z)\). They are connected by the transfer function \({t}_{m}\) for the \(m\)-order diffraction.
FSL is a device whose optical transfer function (OTF) is uniquely designed to filter all components other than the first-order diffraction. The incident waves with high diffraction order are poorly transmitted in far-field as evanescent waves. In the previous research, the FSL was designed to suppress the propagating 0th-order wave to improve the Signal to Noise (SN) ratio [10]. The ideal OTF is depicted in Fig. 1c, where the 1st-order incident wave is enhanced due to the FSL grating.
Since the enhanced evanescent component is determined by the grating period, an FSL projects distinctive fringes for objects with different periods. This effect is similar to Moiré fringes but in the near-field region [22]. The projected far-field fringes for periodic objects can be explained in the following equation.
here \({k}_{obj}\) is the wavevector of objects and \({k}_{\Lambda }\) is the grating wavevector. \(\sigma\) is the far-field fringe period. The resolution limit of FSL is decided by the objective lens, of which only the far-field pattern larger than its diffraction limit can be collected. And for an objective lens with NA of 0.6, and wavelength at 420 nm, the relation of the objects period and diffraction limit of the objective lens is plotted in Fig. 2. In the frequency domain, the objects with frequency \({1.5k}_{0}\) to \({3.5k}_{0}\) can be imaged by FSL.

The resolution limit of FSL in a real domain and b frequency domain. Grey area shows the size of objects period that can be imaged by FSL
3.2 1D Version of pix2pix cGAN for Reconstruction
Direct calculation using Eq. (3) can be applied for periodic objects to reconstruct a super-resolution image with a frequency domain inside the resolution limit. Inverse Fourier transformations can be applied to image more complex objects. However, both amplitude and phase should be determined using diffraction microscopy, as mentioned in [11]. Moreover, the working wavelength should be monochronic to ensure a one-to-one relationship between the incident and diffraction waves.
Our approach introduces deep learning for super-resolution reconstruction. AI learned the rules of image reconstruction by approximating the complex OTF. It has the potential for a more straightforward reconstruction of complex objects under incoherent illumination with a bandwidth.
Near-field data of random samples are generated by FDTD simulation. Then, the far-field diffraction pattern is obtained by Fourier optics. A deep learning process is performed to reconstruct near-field intensity from the far-field intensity. For simplicity, 2D simulation and 1D data are used for learning.
In the process of model selection, Palette [23] and Cross GAN [24] represent the forefront of image-to-image diffusion models known for their ability to produce high-quality images. Nonetheless, our study focuses on utilizing a conditional Generative Adversarial Network (cGAN) due to its suitability for training with paired data. A cGAN consists of two main elements: a generator and a discriminator, operating under the principles of supervised learning. Through iterative refinement of these networks, the quality of the generation improves.
The pix2pix cGAN [19], initially developed for image translation tasks, has been adapted in our study to cater to one-dimensional data. The code was altered to accommodate a data structure of [512,1], enabling the training of a 1D pix2pix model. Figure 3 illustrates the redesigned discriminator, and we employed a 1D U-net architecture for the generator. The change is only made for dimension as in this work [25], and we used the same overall discriminator network architecture, U-net generator architecture and the same loss function as in the pix2pix paper.

Discriminator modified from pix2pix for the 1D training task in super-resolution reconstruction
3.3 FDTD of FSL Under Incoherent Illumination
To simulate a bandwidth illumination like LED, the incoherent simulation is conducted using MEEP FDTD tool [26]. The model geometry is illustrated in Fig. 4. A region of the incoherent source is put at the under part of the simulation region, which is surrounded by perfect matched layer (PML) boundaries. The polarization is TM, which is horizontal to the plane of the paper in 2D case. Then, the mask region is set to block light, of which the permittivity is set to be infinite. Random slits on the mask simulate the randomly distributed sample, which reflects lights with intensity proportional to its size. The randomness is decided by a random function generating 0 and 1 with a bin size of 200 nm. This is the same as a simulation of 200 nm size sample with random distribution in 1D. The electric field intensity distribution inside the mask is taken as the true value. Beyond the mask, there is an FSL, which is a periodic silver grating structure, the same as previous research [10], with the background material being PMMA. However, the original working wavelength is 377 nm and is different from this simulation. The simulation parameters are summarized in Table 1. Then, an observation line is set to record the near-field response, and the far-field response can be calculated using Fourier optics. Moreover, in order to simulate the incoherent behavior, 2000 dipoles are set in the source region with random wavelengths from 415 to 425 nm. Then, average intensity is taken after recording 50 simulation steps with a time difference at the step of the coherent time.

Simulation domain for incoherent response of random dipoles imaged by FSL. Far-field response is obtained by calculation of Fourier optics based on near-field electric field intensity
4 Results
4.1 Deep Learning Process of Super-Resolution Reconstruction
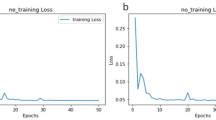
The training is performed on 1500 datasets and repeated for 60 epochs to ensure convergence without overlearning. The training process of cGANs is visualized in Fig. 5. The parameters are explained. D_Loss1 is the adversarial loss of the discriminator when it is fed with the real images, D_Loss2 is the adversarial loss of the discriminator when it is fed with fake images, and G_Loss is the adversarial loss that the generator tries to minimize during training. It can be seen that generator loss converges and does not decrease anymore, while the discriminator fails more and more on discriminating the fake image, which means that the fake image becomes much more similar to the real image at the end of training.

Training process of 1D pix2pix network to reconstruct the super-resolution image
4.2 Reconstruction of the Super-Resolution Image
An example of the reconstruction results of the trained network is shown. In Fig. 6, a training data example is shown in real space and frequency space. It can be found that good reconstruction has been achieved both in real space and frequency space. In real space, the peak position and intensity of each peak has been reconstructed correctly. And in frequency space, the resolution of the reconstructed image in Fig. 6C (b) surpasses the diffraction limit in Fig. 6B (b). The 200 nm super-resolution is achieved while the diffraction limit of microscopy is 427 nm. This 200 nm resolution capability can be explained by the FSL theory that 2 \({k}_{0}\) is in the resolvable region of Fig. 2b. It suggests that the proposed deep learning based super-resolution follows the physical resolution limitation in Eq. (3).

Reconstruction using trained network for a training data example. The comparison is conducted in a real space plot of intensity b frequency space plot. High fidelity has been confirmed in both real space and frequency space
To statistically investigate the trained data, 100 training data and 100 test data are reconstructed. The Zero Mean Normalized Cross-Correlation (ZNCC) value is used to justify the similarity of generated data (reconstructed by trained network) and true value in real space. ZNCC is defined in the Eq. (4). Higher ZNCC means two data have a higher correlation, with a value between 0 and 1. For building a standard line, we also compared the ZNCC of the far-field response and its near-field response in Fig. 7. Both training data and test data ZNCC has been investigated. Training data is the initial dataset used to train a machine learning model, allowing it to learn and identify patterns, whereas test data is a separate dataset used to evaluate the model’s performance, ensuring its accuracy and ability to generalize to unseen data.

Zero Normal Cross-Correlation (ZNCC) of a 100 training datasets and b 100 test datasets. The orange line illustrates the correlation between the generated near-field data and the true value in the near field. In contrast, the blue line depicts the correlation between the far-field data, calculated based on the true near-field data, and the true near-field data, serving as a reference line
From Fig. 7, the reconstruction data has a much higher value in ZNCC than the standard line. For training data in Fig. 7a, over 95% correlation can be found. For test data in Fig. 7b, over 85% correlation can be found.
Then, the reconstruction examples in test data are inspected in Fig. 8. In Fig. 8I one reconstruction example corresponding to over 85% ZNCC is plotted. Next, the reconstruction corresponding to the worst ZNCC value is plotted in Fig. 8II. In both results, the super-resolution is confirmed in frequency space and good reconstruction is confirmed in real space.

An example of the reconstructed result using the trained network based on the test data samples. Only 1 out of 100 reconstructions fell below the 90% mark. The comparison is conducted in a real space plot of intensity b frequency space plot
To summarize the results, even for test data that has not been trained, 99% of data reached over 90% correlation, while only 1% of data failed, which still has 85% correlation. Two examples are plotted in Fig. 8.
5 Conclusions
This study proposes a distinctive approach utilizing a conditional generative adversarial network to obtain super-resolution images for arbitrary nano-scale patterns under incoherent illumination. FDTD simulations are performed for data requirements. In pursuit of the goal of developing a versatile FSL for various working wavelength based on machine learning, the achievement can be summarized as follows:
-
1.
A superlens response has been obtained through incoherent simulations in FDTD.
-
2.
A 1D pix2pix learning model has been developed for the verification of the proposed method.
-
3.
The performance of the trained network aligns with over 95% of the training data. For the test data, a 90% correlation was reached in 99% of the verification process, while only 1% exhibited a correlation of 85%. This indicates a high level of accuracy in the super-resolution reconstruction offered by the proposed method.
-
4.
The learning results for super-resolution display a resolution of 200 nm, compared to the resolution limit of 427 nm.
-
5.
The super-resolution ability of the proposed deep learning based method has the same theoretical limitation of FSL. The advantage of deep learning is the improvement of flexibility. The proposed method can achieve super-resolution, even under incoherent illumination, and at a different working wavelength for the FSL.
For future work, the 2D imaging can be achieved by rotating the FSL structure as mentioned in this work [6]. In this way, the expansion of observable frequency domain can cover whole 2D imaging plane. Moreover, more advanced neural network architectures are going to be developed for super-resolution tasks.
Change history
05 July 2024
The name of author Masaki Michihata has been corrected.
25 June 2024
A Correction to this paper has been published: https://doi.org/10.1007/s12541-024-01072-x
Abbreviations
- \({\upsigma }\) :
-
Fringe period of projected far-field response
- \({\text{NA}}\) :
-
Numerical aperture
- \({\text{k}}_{0}\) :
-
Wavevector of initial wavelength
- \({\text{k}}^{\prime }\) :
-
Wavevector of the propagating wave
- \({\text{k}}_{{{\text{in}}}}\) :
-
Wavevector of the incident wave
- \({\text{k}}_{{\Lambda }}\) :
-
Wavevector of grating
- \({\uplambda }\) :
-
Wavelength of illumination
- \({\Lambda }\) :
-
Period of the grating
- \({\text{m}}\) :
-
Diffraction order
- \({\text{t}}_{{\text{m}}}\) :
-
Transfer function of m-order
- \({\uplambda }\) :
-
Wavelength of illuminationa
- \({\text{E}}\) :
-
Electric field
- \({\tilde{\text{E}}}\) :
-
Angular spectrum of the electric field after transmission
- \({\tilde{\text{E}}}_{{{\text{obj}}}}\) :
-
Angular spectrum of the electric field reflected from an object in near-field
- \({\text{ZNCC}}\) :
-
Zero mean normalized cross-correlation
References
Adams, W., Sadatgol, M., & Güney, D. (2016). Review of near-field optics and superlenses for sub-diffraction-limited nano-imaging. AIP Advances, 10(1063/1), 4964498.
Hu, X., Zhou, L., Wu, X., & Peng, Y. (2023). Review on near-field detection technology in the biomedical field. Advanced Photonics Nexus, 2(4), 44002. https://doi.org/10.1117/1.APN.2.4.044002
Wu, Z., Xu, X., & Xi, P. (2021). Stimulated emission depletion microscopy for biological imaging in four dimensions: A review. Microscopy Research and Technique, 84(9), 1947–1958. https://doi.org/10.1002/jemt.23750
Xu, J., Ma, H., & Liu, Y. (2017). Stochastic optical reconstruction microscopy (STORM). Current Protocols in Cytometry, 81(1), 12–46. https://doi.org/10.1002/cpcy.23
Chen, X., et al. (2023). Superresolution structured illumination microscopy reconstruction algorithms: A review. Light: Science & Applications, 12(1), 1–34. https://doi.org/10.1038/s41377-023-01204-4
Xiong, Y., Liu, Z., Sun, C., & Zhang, X. (2007). Two-dimensional imaging by far-field superlens at visible wavelengths. Nano Letters, 7(11), 3360–3365. https://doi.org/10.1021/nl0716449
Lal, A., Shan, C., & Xi, P. (2016). Structured illumination microscopy image reconstruction algorithm. IEEE Journal of Selected Topics in Quantum Electronics, 22(4), 50–63. https://doi.org/10.1109/JSTQE.2016.2521542
Lu, D., & Liu, Z. (2012). Hyperlenses and metalenses for far-field super-resolution imaging. Nature Communications, 3, 1–9. https://doi.org/10.1038/ncomms2176
Li, T., Chen, C., Xiao, X., Chen, J., Hu, S., & Zhu, S. (2023). Revolutionary meta-imaging: From superlens to metalens. Photonics Insights, 2(11), R01.
Liu, Z., et al. (2007). Far-field optical superlens. Nano Letters, 7(2), 403–408. https://doi.org/10.1021/nl062635n
Durant, S., Liu, Z., Steele, J. M., & Zhang, X. (2006). Theory of the transmission properties of an optical far-field superlens for imaging beyond the diffraction limit. Journal of the Optical Society of America B: Optical Physics, 23(11), 2383. https://doi.org/10.1364/josab.23.002383
Durant, S., Liu, Z., Fang, N., & Zhang, X. (2006). Theory of optical imaging beyond the diffraction limit with a far-field superlens. Plasmonics: Metallic Nanostructures and Their Optical Properties, 6323, 63231H. https://doi.org/10.1117/12.680804
Li, H., Fu, L., Frenner, K., & Osten, W. (2018). Cascaded DBR plasmonic cavity lens for far-field subwavelength imaging at a visible wavelength. Optics Express, 26(15), 19574. https://doi.org/10.1364/oe.26.019574
Fan, Q., et al. (2022). Trilobite-inspired neural nanophotonic light-field camera with extreme depth-of-field. Nature Communications, 13(1), 1–10. https://doi.org/10.1038/s41467-022-29568-y
Chai, C., Chen, C., Liu, X., & Lei, Z. (2021). Deep learning based one-shot optically-sectioned structured illumination microscopy for surface measurement. Optics Express, 29(3), 4010. https://doi.org/10.1364/oe.415210
Cheng, X., Li, J., Dai, Q., Fu, Z., & Yang, J. (2022). Fast and lightweight network for single frame structured illumination microscopy super-resolution. IEEE Transactions on Instrumentation and Measurement, 71(9), 1–9. https://doi.org/10.1109/TIM.2022.3161721
Nam, J. S., & Kwon, W. T. (2022). A study on tool breakage detection during milling process using LSTM-autoencoder and gaussian mixture model. International Journal of Precision Engineering and Manufacturing, 23(6), 667–675. https://doi.org/10.1007/s12541-022-00647-w
Kim, I.-S., Lee, M.-G., & Jeon, Y. (2023). Review on machine learning based welding quality improvement. International Journal of Precision Engineering and Manufacturing Smart Technology, 1(2), 219–226. https://doi.org/10.57062/ijpem-st.2023.0017
Isola, P., Zhu, J. Y., Zhou, T., & Efros, A. A. (2017). Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1125-1134). https://doi.org/10.1109/CVPR.2017.632
Wi, J. S., Kim, J. D., Lee, W., Choi, H., Kwak, M., Song, J., Lee, T. G., & Ok, J. G. (2022). Inkjet printable nanoporous Ag disk arrays enabling coffee–ring effect–driven analyte enrichment towards practical SERS Applications. International Journal of Precision Engineering and Manufacturing-Green Technology, 9(2), 421–429. https://doi.org/10.1007/s40684-021-00351-6
Saharia, C., Ho, J., Chan, W., Salimans, T., Fleet, D. J., & Norouzi, M. (2023). Image super-resolution via iterative refinement. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(4), 4713–4726. https://doi.org/10.1109/TPAMI.2022.3204461
Liu, Z., et al. (2007). Experimental studies of far-field superlens for sub-diffractional optical imaging. Optics Express, 15(11), 6947. https://doi.org/10.1364/oe.15.006947
Saharia, C., et al. (2022). Palette: Image-to-image diffusion models (Vol. 1). Association for Computing Machinery. https://doi.org/10.1145/3528233.3530757
Peng, X., Li, Q., Wu, T., & Yuan, S. (2022). Cross-GAN: Unsupervised image-to-image translation. In 2022 IEEE 6th information technology and mechatronics engineering conference (ITOEC) (Vol. 6, pp. 1755-1759). https://doi.org/10.1109/ITOEC53115.2022.9734431
Murphy, C., & Kerekes, J. (2021). 1D conditional generative adversarial network for spectrum-to-spectrum translation of simulated chemical reflectance signatures. J. Spectr. Imaging, 10(1), a2. https://doi.org/10.1255/jsi.2021.a2
Oskooi, A. F., Roundy, D., Ibanescu, M., Bermel, P., Joannopoulos, J. D., & Johnson, S. G. (2010). Meep: A flexible free-software package for electromagnetic simulations by the FDTD method. Computer Physics Communications, 181(3), 687–702. https://doi.org/10.1016/j.cpc.2009.11.008
Acknowledgements
This work was supported by JST, CREST Grant Numbers JPMJCR2232 and JSPS KAKENHI Grant Number JP22J22125.
Funding
Open Access funding provided by The University of Tokyo.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
Satoru Takahashi is an editorial board member for “International Journal of Precision Engineering and Manufacturing” and was not involved in the editorial review, or the decision to publish this article. All authors declare that there are no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This paper was presented at ISMTII2023.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Guan, Y., Masui, S., Kadoya, S. et al. Super-Resolution Imaging of Sub-diffraction-Limited Pattern with Superlens Based on Deep Learning. Int. J. Precis. Eng. Manuf. (2024). https://doi.org/10.1007/s12541-024-00991-z
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12541-024-00991-z