
Abstract
Background
Cardiovascular risk models are based on traditional risk factors and investigations such as imaging tests. External validation is important to determine reproducibility and generalizability of a prediction model. We performed an external validation of t the Japanese Assessment of Cardiac Events and Survival Study by Quantitative Gated SPECT (J-ACCESS) model, developed from a cohort of patients undergoing stress myocardial perfusion imaging.
Methods
We included 3623 patients with suspected or known coronary artery disease undergoing stress single-photon emission computer tomography (SPECT) myocardial perfusion imaging at our academic center between January 2001 and December 2019.
Results
In our study population, the J-ACCESS model underestimated the risk of major adverse cardiac events (cardiac death, nonfatal myocardial infarction, and severe heart failure requiring hospitalization) within three-year follow-up. The recalibrations and updated of the model slightly improved the initial performance: C-statistics increased from 0.664 to 0.666 and Brier score decreased from 0.075 to 0.073. Hosmer–Lemeshow test indicated a logistic regression fit only for the calibration slope (P = .45) and updated model (P = .22). In the update model, the intercept, diabetes, and severity of myocardial perfusion defects categorized coefficients were comparable with J-ACCESS.
Conclusion
The external validation of the J-ACCESS model as well as recalibration models have a limited value for predicting of three-year major adverse cardiac events in our patients. The performance in predicting risk of the updated model resulted superimposable to the calibration slope model.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The evaluation of cardiovascular risk is based on traditional risk factors and data from clinical investigations such as imaging tests. This methodology is currently used to forecast the outcome of cardiovascular tests as well as risk of cardiac events.1,2,3,4,5,6,7,8,9 However, using these prediction models at different times or with different cohorts from which they derived, frequently they proved inadequate.5,10,11 The poor performance can be due to several factors. With regards to the time factor, in the last decades the prevention as well as the development of diagnostic and therapeutic techniques have reduced mortality and morbidity in cardiovascular patients.12,13 In several studies on temporal trend of single-photon emission computed tomography (SPECT) myocardial perfusion imaging, the total volume of performed studies declined, the number of traditional risk factors increased, and the prevalence of abnormal studies decreased.14,15,16,17,18,19 On the other hand, also a contemporary model can result inadequate when it is used with a different cohort. In particular, when a model results poor by external validation, a procedure of data adaptation consists in its recalibration.20,21 In this case, the risk evaluation is computed by one (additive) or more parameters (additive and multiplicative) that change the values of the intercept and covariate coefficients of the logistic regression, that represents the model. Instead, a model that became obsolete or remains poor can be updated using the same variables of the model but with new coefficients inferred from values observed in a new cohort. Therefore, new coefficients of the variables are obtained. In the present study we performed an external validation of the Japanese Assessment of Cardiac Events and Survival Study by Quantitative Gated SPECT (J-ACCESS) model7,8 to evaluate its ability for predicting cardiac events using data from our institution. To obtain a complete validation, we performed two recalibrations and the update of the model.
Methods
Patients
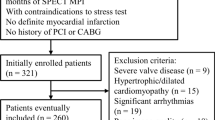
We included a total of 3623 patients undergoing stress and rest SPECT myocardial perfusion imaging at our academic center between January 2001 and December 2019, with available follow-up for major adverse cardiac event (MACE), defined as cardiac death, nonfatal myocardial infarction, and severe heart failure requiring hospitalization within 3 years of the imaging study. These patients were part of an ongoing prospective dedicated database.22
The criteria used for patient selection were the same reported in the J-ACCESS study.7,8 More in detail, the inclusion criteria were ≥ 20 years of age and stress and rest ECG-gated SPECT performed for suspected or known coronary artery disease (CAD). Patients with onset of myocardial infarction or unstable angina pectoris within 3 months, valvular heart disease, idiopathic cardiomyopathy, severe arrhythmia, heart failure with class III or higher New York Heart Association classification, and severe liver or renal disorders were excluded. In agreement with the J-ACCESS protocol, we also excluded patients submitted to coronary artery revascularization within 60 days of the SPECT study. At the time of testing, clinical teams collected pertinent demographic and clinical information, past cardiac history, and CAD risk factors based on patient report or available medical records. Patients were classified as having diabetes if they were receiving treatment with oral hypoglycemic drugs or insulin. The review committee of our institution approved this study (Ethics Committee, University Federico II, protocol number 110/17), and all patients gave informed consent.
Myocardial perfusion imaging
Patients underwent stress-optional rest 99mTc-sestamibi SPECT myocardial perfusion imaging by physical exercise or pharmacologic stress using dipyridamole, according to the recommendations of the European Association of Nuclear Medicine.23 In all patients, beta-blocking medications and calcium antagonists were withhold for 48 hours and long-acting nitrates for 12 hours before testing. For patient undergoing exercise test, symptom-limited treadmill standardized protocols were performed. For dipyridamole stress test, patients were instructed not to consume products containing caffeine for 24 hours before the test. Dipyridamole was infused at dose of 0.142 mg⋅kg−1 min−1 intravenous over 4 minutes. A dose of 100 mg of aminophylline was administered intravenously in the event of chest pain or other symptoms, or after significant ST depression. At peak exercise, or 4 minutes after completion of dipyridamole infusion, patients were intravenously injected with 99mTc-sestamibi (8 to 10 mCi for stress and 32 to 40 mCi for rest). Imaging was started 30 to 45 minutes after tracer injection using a dual-head rotating gamma camera (E.CAM, Siemens Medical Systems, Hoffman Estates, IL, USA) equipped with a low-energy, high resolution collimator and connected with a dedicated computer system. No attenuation or scatter correction was used.
An automated software program (e-soft, 2.5, QGS/QPS, Cedars-Sinai Medical Center, Los Angeles, CA) was used to calculate left ventricular (LV) volumes and ejection fraction and the scores incorporating both the extent and severity of perfusion defects using standardized segmentation of 20 myocardial regions.24 Perfusion defects were quantified adding the scores of the 20 segments and expressed as summed stress score, representing the total myocardium abnormal. Summed stress and summed rest scores were measured independently from the stress and rest scans and summed difference score was defined as their difference. According to the J-ACCESS model, the severity of myocardial perfusion defects was defined with four grades of category (0, I, II, and III) using summed stress score: normal (score 0–3) and mildly (4–8), moderately (9–13), or severely (≥ 14) abnormal.7,8
Statistical analysis
Statistical analysis was performed using the R software, version 6.3.3 (The R Foundation for Statistical Software, Vienna, Austria). Continuous variables were expressed as mean ± standard deviation and categorical data as percentages. Differences between groups were analyzed by Student t test or χ2 test, as appropriate. Two-sided P values < .05 were considered statistically significant. Marginal probability was defined as the percentage of patients with major adverse cardiac event with respect to the entire study population. For the external validation, we used the coefficients obtained from the J-ACCESS study.7,8,9 In particular, logit and probability were computed by the following formulas:
For the J-ACCESS external validation, we plotted the predicted probability across deciles versus the observed probability. These values were fitted by a linear regression, and the coefficient of determination (R2) was reported to evaluate the goodness-of-the-fit. On the same plot, we also reported the continuous values of the predicted versus observed variables, and the 95% confidence interval (CI). In order to obtain an exhaustive external validation, we recalibrated this model (logit (p)) with the calibration-in-the-large and the calibration slope (also called Logistic recalibration).20,21 In the first case, the statistic is given as the intercept term α from the recalibration model [logit (p′) = α + logit (p)] that changes baseline hazard. In the second case, β coefficient for all the variables and a new intercept are estimated from the recalibration model [logit (p″) = α + β × logit (p)]. We also realized an update of the J-ACCESS model by our data, using the same variables and computing new coefficients by a multivariable logistic regression with MACE as dependent variable. A flow chart of the study methods is sketched in Figure 1.

Flow chart of the study methods: external validation, recalibration procedures, and updated model
Statistic difference between initial and recalibration models was evaluated by residual deviance and likelihood ratio test (LRT) from χ2. We also computed the maximum (dmax) and mean (dmean) difference in predicted vs loess-calibrated probabilities. For all the models, statistic concordance was calculated by the C-statistic, that represents the probability that patients with the outcome receive a higher predicted probability than those without. We also computed the Brier score that includes components of discrimination and calibration for models. This score improves decreasing from one to zero value. Finally, we evaluated the Hosmer–Lemeshow test, as a measure of goodness of fit, for predictive models of binary outcomes (logistic regressions), and sometimes used as a proxy for calibration.25 The 95% confidence interval (CI) for the continuous values of the predicted versus observed variables, dmax, dmean, area under receiver operating characteristic curve, and Brier scores were computed by 1000 bootstrap resampling.
Results
The percentage of our patients with MACE was 8.2%, significantly higher compared to the 4.3% found in the J-ACCESS study (P < .001). More in detail, we observed 140 (47%) cardiac deaths, 88 (30%) nonfatal myocardial infarctions, and 70 (23%) severe heart failures requiring hospitalization. The clinical characteristics and imaging findings of patients according to the occurrence of MACE are reported in Table 1. Patients with MACE had a higher prevalence of history of myocardial infarction or revascularization, diabetes and hypertension, and had a higher summed stress and rest scores and a lower LV ejection fraction than those without MACE.
In our study population, myocardial perfusion was normal in 2177 (60%) and abnormal in 1446 (40%) patients. In these latter patients, 704 (19%) had mildly abnormal, 325 (9%) moderately abnormal, and 417 (12%) severely abnormal myocardial perfusion defects.
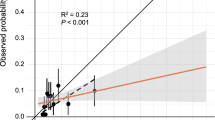
The statistics associated with the J-ACCESS, recalibration, and updated models are summarized in Table 2. For the calibration-in-the-large model α was 0.593, whereas for the calibration slope α was − 0.615 and β 0.564. The recalibrations improved the performance of the initial model. In fact, the residual deviance and dmean decreased (from 2090 to 1962 and from 0.034 to 0.005, respectively). Also, the C-statistics and Brier score improved slightly (from 0.664 to 0.666 and from 0.075 to 0.073, respectively), indicating a little better discrimination and calibration of the models. Confirming this improvement, the models were all different compared to the initial one by the LRT test (P < .001). The Hosmer–Lemeshow test (calculated on deciles) indicated a logistic regression fit for the calibration slope (P = .45) and updated model (P = .22). High similarity between these two models we also found by LRT (P = .58). Lastly, the fits obtained by deciles between predicted and calculated probabilities resulted significant (P < .001) and highly correlates (R2 ≥ 0.90), highlighting a linear relationship.
Figure 2 shows the predicted vs. observed probability for the J-ACCESS model (panel A), calibration-in-the-large (panel B), calibration slope (panel C), and updated model (panel D). These variables are presented both across deciles and as continuous. In general, the J-ACCESS model underestimates the observed data. For the calibration-in-the-large model is evident a shift toward the diagonal, with an underestimation for low values of the observed probability and an overestimation for those high. This effect was due to the intercept (α) introduced in the model. The logistic recalibration shows a better fit of the data than the initial model, mainly due to the β coefficient that causes a compression of probabilities. The updated model was no more performing than the recalibrated logistic model, highlighting a limited value of the J-ACCESS variables.

Predicted vs. observed probability for the J-ACCESS (panel A), calibration-in-the-large (panel B), calibration slope (panel C), and updated (panel D) models. The full circles represent probability expressed in deciles, whereas the error bars highlight the standard deviations. The black dashed line represents the linear regression calculated by deciles. The red line is related to the continuous values of the variables, with the 95% CI highlighted by the shaded zone. The diagonal represents the best agreement line between predicted and observed probabilities. The histogram in the graph below reports the predicted probability distribution
The multivariable logistic regression findings related to the updated model are reported in Table 3. All the independent variables resulted significant (P < .01). With respect to age, the risk of MACE increased by 4% for each year. Patients with diabetes were found to have a 73% higher risk than those without. For summed stress score the risk was 16% higher for each gap between two categories. As expected, the increase in LV ejection fraction was protective (2% for each percent of increment). Within 3 standard errors, intercept, diabetes, and summed stress score categorized coefficients of the updated model were comparable with J-ACCESS ones.
To assess the time effects on the patient characteristics, we split our study population into group 1 (from 2001 to 2010, n = 1788) and group 2 (from 2011 to 2019, n = 1835). For group 1, more contemporary to the J-ACCESS model, we found a slightly better adaptation of data to the model (see Tables S1, S3 in the supplementary materials). There was a significant difference between the two groups only comparing the Brier score (0.052 vs 0.096). This difference was due to the lower number of events in patients of group 1 compared to those of group 2 (5.5% vs 10.8%). Investigating this difference, we found a higher number of patients with abnormal summed stress score in group 1 compared to group 2 (51% vs 70%). Regarding the updated models, group 1 and group 2 were superimposable, highlighting similar characteristics with respect to the J-ACCESS variables. In fact, the P resulted different in absolute value, but with same statistical significance (see Table S2 and Table S4 in the supplementary materials).
For the entire study population, we also evaluated a more complete updated model considering as covariates in the multivariable logistic regression the J-ACCESS variables and traditional risk factors (angina, dyspnea, gender, hyperlipidemia, hypertension, and smoking). We did not find significant differences between this model and the updated model with only the J-ACCESS variables (see Table S5 in the Supplementary materials).
Discussion
The present study was designed to obtain an external validation and an update of the J-ACCESS model, for predicting three-year major cardiac events in patients with and without history of CAD. Comparing our and J-ACCESS cohorts it is important to highlight that the variables between the group of patients with and without events showed significant different for body mass index, history of coronary artery revascularization, and hypertension. It should also be noted that the characteristics of J-ACCESS patients were obtained for hard events, i.e., without considering patients with heart failure requiring hospitalization. However, from the point of view of patients’ characteristics our and J-ACCESS cohorts were quite similar. Instead, a difference between the two cohorts was due to the percentage of patients with outcome that in J-ACCESS study was significantly lower than in our study. This finding is in line with a lower cardiovascular risk in Japan than in Italy.26
Using the J-ACCESS model in our study population, we observed an underestimation of the predicted risk compared to the observed risk. The effect is evident from the graph of predicted versus observed probabilities, where the full circles representing deciles are over the diagonal (i.e., equal probability line). We can likely explain the non-optimal fit of the J-ACCESS model to our data on the bases of the different marginal probability between the two cohorts.
To obtain a more accurate external validation, we considered the calibration-in-the-large and the logistic recalibration models. The term of intercept computed by the calibration-in-the-large model did not significantly improve the external validation findings. Instead, using the logistic recalibration model, we observed a better agreement between predicted versus observed probability. As a matter of fact, in comparison with the two previous models we obtained the lower dmean, the Hosmer–Lemeshow test indicated a good adaptation of the logistic regression fit to data, and the Brier score slightly increased. The improvement is explainable by the change in profile of the predicted probability distribution due to α and β terms of the recalibrated model. In general, nevertheless the models resulted different to the LRT, they did not show a significant improvement to the C-statistic and Brier score. Therefore, to verify the predictivity of the independent variables we also evaluated an update of the J-ACCESS model. As expected, we observed a good agreement between predicted and observed probabilities. However, we did not find significant improvements than to the calibration slope model by the statistics. In fact, the two model are superimposable with respect to all performed tests. This result brings to lite two aspects. On the one hand, we can infer that the features used for the model have a limited value for the prediction of risk. On the other hand, it indicates that the recalibration model used is an effective method because gives findings very similar to the model obtained with an internal cohort.
The time effects on the study population characteristics were marginal, explainable by higher number of patients with major burden of disease in the more recent years. This situation was probably due to the greater appropriateness of clinical tests adopted in the last years.
Adding traditional risk factors to the updated model we did not find other significant variables. This result highlights that age and diabetes are predominant traditional risk factors. In fact, they, together with summed stress score and LV ejection fraction, adjust the other covariates making those not significant at the multivariable logistic regression nevertheless some of them resulted significant to the χ2 test (e.g., gender and hypertension).
With regards to the external validation related to major cardiac events, in another study we evaluated the performance of the CRAX2MACE model.11 Unlike what has happened in the present study, the risk evaluation was within two-year and only included subjects with suspect CAD. Moreover, the study was conducted in North America. The external validation of the CRAX2MACE model with our data resulted in overestimating the risk and the recalibration models did not give better results than the initial one.
The findings obtained through this study and previous investigations confirm that any prediction model performs best in the population it was derived from. Therefore, an optimal model for predicting of major cardiac events adaptable to generalized data does not seem currently available. Likely, a multicenter model obtained by a large amount of heterogeneous data, also supported from machine learning techniques, could carried out a more efficacy model. In particular, this technique of artificial intelligence is finding many applications from clinical imaging to pretest as a support to diagnosis in different medical fields, also with specific recommendations in cardiology.27,28,29,30,31
Another multicenter study, based on traditional risk factors, was conducted to estimate 10-year risk of cardiovascular disease in Europe (SCORE2).32 The authors derived risk prediction models using individual-participant data from 45 cohorts (677,684 individuals, 30,121 cardiovascular disease events), and defined four risk regions in Europe according to country-specific cardiovascular disease mortality, recalibrating models to each region using expected incidences and risk factor distributions. In particular, region-specific incidence was obtained by data over ten millions of persons, and for the external validation were used data from 25 additional cohorts (over one million of individuals, and 43,492 cardiovascular events). After applying the derived risk prediction models to external validation cohorts, C-statistic ranged from 0.67 (0.65–0.68) to 0.81 (0.76–0.86). These C-statistic values are in line with, or slightly better than, the cited studies based on traditional risk factors.
To improve the performance of cardiologic forecasting models, it may be necessary to find novel variables. An example of multicenter study obtained using non-traditional risk factors and finalized to fatal cardiovascular disease risk prediction was reported by Tillmann et al.33 Patients from various Eastern European states took part to the derivation cohort (~ 14,600), and patients from Estonia formed the validation cohort (~ 4,600). In this study three models were evaluated, also using variables such as education and depression. The authors found the area under receiver operating characteristic curve in the range 78–87%, with better values in the validation cohort.
In general, the research of new features is desirable also in other areas of cardiology. For example, in subjects with zero-calcium score who underwent coronary artery computer tomography, the predicted models were unable to identify individuals with a very low probability of an abnormal stress myocardial perfusion imaging.34 Efficiency of models in cardiology remains a field still to be improved, and the use of strategies as multicenter data, novel features, and machine learning techniques seems to be an interesting way to go.
To the best of our knowledge, the errors on the J-ACCESS intercept and coefficients are not available.7,8 Therefore, we compared our updated model with the J-ACCESS model considering our estimates of parameters and standard errors vs. the J-ACCESS parameters alone, without their errors. Patients’ characteristics in our study were computed with respect to major adverse cardiac events, while in J-ACCESS7 were computed for patients with “hard cardiac events”, that is only using cardiac death and nonfatal myocardial infarction. Our choice was due to the fact that the J-ACCESS parameters used in this study were given in several articles where were considered patients with major adverse cardiac events.7,8,9,35,36,37
New knowledge gained
This study confirms that clinical prediction models perform best in the population they were derived from. In addition, it supports the use of recalibration of predictive models to improve the model performance on external cohorts. Based on changes in diagnostic and therapeutic approaches for many diseases, predictive models may lose efficacy on time. Therefore, external validation and updating of the models in different cohorts is worthwhile to address the reproducibility and generalizability of any clinical prediction model.
Conclusion
External validation of a predictive model is necessary to determine reproducibility and generalizability to new cohorts. This method is gaining increasing importance for considering a model clinically acceptable. The results of this study indicate that the J-ACCESS model have a limited value for predicting of three-year major cardiac events in our study population. The performance in predicting risk of the updated model resulted superimposable to the calibration slope model.
Abbreviations
- SPECT:
-
Single-photon emission computed tomography
- J-ACCESS:
-
Japanese Assessment of Cardiac Events and Survival Study by Quantitative Gated SPECT
- MACE:
-
Major adverse cardiac event
- CAD:
-
Coronary artery disease
- LV:
-
Left ventricular
- d max :
-
Maximum difference in predicted vs. loess-calibrated probabilities
- d mean :
-
Mean difference in predicted vs. loess-calibrated probabilities
- CI:
-
Confidence interval
References
Diamond GA, Forrester JS. Analysis of probability as an aid in the clinical diagnosis of coronary-artery disease. N Engl J Med 1979;300:1350‐8.
Genders TS, Steyerberg EW, Alkadhi H, Leschka S, Desbiolles L, Nieman K, et al. CAD Consortium. A clinical prediction rule for the diagnosis of coronary artery disease: Validation, updating, and extension. Eur Heart J 2011;32:1316-30.
Genders TS, Steyerberg EW, Hunink MG, Nieman K, Galema TW, Mollet NR. Prediction model to estimate presence of coronary artery disease: Retrospective pooled analysis of existing cohorts. BMJ 2012;344:e3485.
Reeh J, Therming CB, Heitmann M, Højberg S, Sørum C, Bech J, et al. Prediction of obstructive coronary artery disease and prognosis in patients with suspected stable angina. Eur Heart J 2019;40:1426‐35.
Megna R, Assante R, Zampella E, Gaudieri V, Nappi C, Cuocolo R, et al. Pretest models for predicting abnormal stress single-photon emission computed tomography myocardial perfusion imaging. J Nucl Cardiol 2021;28:1891‐902.
Leslie WD, Bryanton M, Goertzen A, Slomka P. Prediction of 2-year major adverse cardiac events from myocardial perfusion scintigraphy and clinical risk factors. J Nucl Cardiol 2021. https://doi.org/10.1007/s12350-021-02617-7.
Nishimura T, Nakajima K, Kusuoka H, Yamashina A, Nishimura S. Prognostic study of risk stratification among Japanese patients with ischemic heart disease using gated myocardial perfusion SPECT: J-ACCESS study. Eur J Nucl Med Mol Imaging 2008;35:319‐28.
Nakajima K, Nishimura T. Prognostic table for predicting major cardiac events based on J-ACCESS investigation. Ann Nucl Med 2008;22:891‐7.
Sakatani T, Nakajima K, Fujita H, Nishimura T. Cardiovascular event risk estimated after coronary revascularization and optimal medical therapy: J-ACCESS4 prognostic study. Ann Nucl Med 2021;35:241‐52.
Gibbons RJ, Miller TD. Declining accuracy of the traditional Diamond-Forrester estimates of pretest probability of coronary artery disease: Time for new methods. JAMA Intern Med 2021;181:579‐80.
Megna R, Petretta M, Assante R, Zampella E, Nappi C, Gaudieri V, et al. External validation of the CRAX2MACE model in an Italian cohort of patients with suspected coronary artery disease undergoing stress myocardial perfusion imaging. J Nucl Cardiol 2021. https://doi.org/10.1007/s12350-021-02855-9.
Piepoli MF, Hoes AW, Agewall S, Albus C, Brotons C, Catapano AL, et al. 2016 European Guidelines on cardiovascular disease prevention in clinical practice: The Sixth Joint Task Force of the European Society of Cardiology and Other Societies on Cardiovascular Disease Prevention in Clinical Practice (constituted by representatives of 10 societies and by invited experts) Developed with the special contribution of the European Association for Cardiovascular Prevention & Rehabilitation (EACPR). Eur Heart J 2016;37:2315‐81.
Mensah GA, Wei GS, Sorlie PD, Fine LJ, Rosenberg Y, Kaufmann PG, et al. Decline in cardiovascular mortality: Possible causes and implications. Circ Res 2017;120:366‐80.
Rozanski A, Gransar H, Hayes SW, Min J, Friedman JD, Thomson LE, et al. Temporal trends in the frequency of inducible myocardial ischemia during cardiac stress testing: 1991 to 2009. J Am Coll Cardiol 2013;61:1054‐65.
Duvall WL, Rai M, Ahlberg AW, O’Sullivan DM, Henzlova MJ. A multi-center assessment of the temporal trends in myocardial perfusion imaging. J Nucl Cardiol 2015;22:539‐51.
Thompson RC, Allam AH. More risk factors, less ischemia, and the relevance of MPI testing. J Nucl Cardiol 2015;22:552‐4.
Jouni H, Askew JW, Crusan DJ, Miller TD, Gibbons RJ. Temporal trends of single-photon emission computed tomography myocardial perfusion imaging in patients without prior coronary artery disease: A 22-year experience at a tertiary academic medical center. Am Heart J 2016;176:127‐33.
Jouni H, Askew JW, Crusan DJ, Miller TD, Gibbons RJ. Temporal trends of single-photon emission computed tomography myocardial perfusion imaging in patients with coronary artery disease: A 22-year experience from a tertiary academic medical center. Circ Cardiovasc Imaging 2017;10:e005628.
Megna R, Zampella E, Assante R, Nappi C, Gaudieri V, Mannarino T. Temporal trends of abnormal myocardial perfusion imaging in a cohort of Italian subjects: Relation with cardiovascular risk factors. J Nucl Cardiol 2020;27:2167‐77.
Huang Y, Li W, Macheret F, Gabriel RA, Ohno-Machado L. A tutorial on calibration measurements and calibration models for clinical prediction models. J Am Med Inform Assoc 2020;27:621‐33.
Ramspek CL, Jager KJ, Dekker FW, Zoccali C, van Diepen M. External validation of prognostic models: What, why, how, when and where? Clin Kidney J 2020;14:49‐58.
Megna R, Petretta M, Alfano B, Cantoni V, Green R, Daniele S, et al. A New relational database including clinical data and myocardial perfusion imaging findings in coronary artery disease. Curr Med Imaging Rev 2019;15:661‐71.
Verberne HJ, Acampa W, Anagnostopoulos C, Ballinger J, Bengel F, De Bondt P, et al. European Association of Nuclear Medicine (EANM). EANM procedural guidelines for radionuclide myocardial perfusion imaging with SPECT and SPECT/CT: 2015 revision. Eur J Nucl Med Mol Imaging 2015;42:1929-40.
Berman DS, Abidov A, Kang X, Hayes SW, Friedman JD, Sciammarella MG, et al. Prognostic validation of a 17-segment score derived from a 20-segment score for myocardial perfusion SPECT interpretation. J Nucl Cardiol 2004;11:414‐23.
Hosmer DW, Lemesbow S. Goodness of fit tests for the multiple logistic regression model. Commun Stat Theory Methods 1980;9:1043‐69.
Roth GA, Mensah GA, Johnson CO, Addolorato G, Ammirati E, Baddour LM, et al. GBD-NHLBI-JACC Global Burden of Cardiovascular Diseases Writing Group. Global Burden of Cardiovascular Diseases and Risk Factors, 1990–2019: Update From the GBD 2019 Study. J Am Coll Cardiol 2020;76:2982-3021.
Deo RC. Machine Learning in medicine. Circulation 2015;132:1920‐30.
Rajkomar A, Dean J, Kohane I. Machine learning in medicine. N Engl J Med 2019;380:1347‐58.
Megna R, Cuocolo A, Petretta M. Applications of machine learning in medicine. Biomed J Sci & Tech Res 2019;20:15350‐2.
Stevens LM, Mortazavi BJ, Deo RC, Curtis L, Kao DP. Recommendations for reporting machine learning analyses in clinical research. Circ Cardiovasc Qual Outcomes 2020;13:e006556.
Ricciardi C, Cuocolo R, Megna R, Cesarelli M, Petretta M. Machine learning analysis: General features, requirements and cardiovascular applications. Minerva Cardiol Angiol 2022;70:67‐74.
SCORE2 working group and ESC Cardiovascular risk collaboration. SCORE2 risk prediction algorithms: new models to estimate 10-year risk of cardiovascular disease in Europe. Eur Heart J 2021;42:2439‐54.
Tillmann T, Läll K, Dukes O, Veronesi G, Pikhart H, Peasey A, et al. Development and validation of two SCORE-based cardiovascular risk prediction models for Eastern Europe: a multicohort study. Eur Heart J 2020;41:3325‐33.
Megna R, Nappi C, Gaudieri V, Mannarino T, Assante R, Zampella E, et al. Diagnostic value of clinical risk scores for predicting normal stress myocardial perfusion imaging in subjects without coronary artery calcium. J Nucl Cardiol 2022;29:323‐33.
Nakajima K, Matsuo S, Okuyama C, Hatta T, Tsukamoto K, Nishimura S, et al. Cardiac event risk in Japanese subjects estimated using gated myocardial perfusion imaging, in conjunction with diabetes mellitus and chronic kidney disease. Circ J 2012;76:168‐75.
Aburadani I, Usuda K, Sumiya H, Sakagami S, Kiyokawa H, Matsuo S, et al. Ability of the prognostic model of J-ACCESS study to predict cardiac events in a clinical setting: The APPROACH study. J Cardiol 2018;72:81‐6.
Nakajima K, Nakamura S, Hase H, Takeishi Y, Nishimura S, Kawano Y, et al. Risk stratification based on J-ACCESS risk models with myocardial perfusion imaging: Risk versus outcomes of patients with chronic kidney disease. J Nucl Cardiol 2020;27:41‐50.
Disclosures
Mario Petretta, Rosario Megna, Roberta Assante, Emilia Zampella, Carmela Nappi, Valeria Gaudieri, Teresa Mannarino, Roberta Green, Valeria Cantoni, Adriana D’Antonio, Mariarosaria Panico, and Alberto Cuocolo declare that they have no conflict of interest. Wanda Acampa is consultant of D-Spectrum.
Funding
Open access funding provided by Università degli Studi di Napoli Federico II within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The authors of this article have provided a PowerPoint file, available for download at SpringerLink, which summarises the contents of the paper and is free for re-use at meetings and presentations. Search for the article DOI on SpringerLink.com.
The authors have also provided an audio summary of the article, which is available to download as ESM, or to listen to via the JNC/ASNC Podcast.
All editorial decisions for this article, including selection of reviewers and the final decision, were made by guest editor Randy Thompson, MD.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Petretta, M., Megna, R., Assante, R. et al. External validation and update of the J-ACCESS model in an Italian cohort of patients undergoing stress myocardial perfusion imaging. J. Nucl. Cardiol. 30, 1443–1453 (2023). https://doi.org/10.1007/s12350-022-03173-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12350-022-03173-4