
Abstract
Named-Data Networking (NDN) over Low Power and Lossy Networks (LLNs), employing IEEE 802.15.4 communication technology, is projected to provide native support for mobility and efficient content delivery for the emerging Internet of Things (IoT). While many interest forwarding strategies have been proposed for NDNs over LLNs, most existing studies have relied on software simulations to evaluate their performance due to the lack of analytical modeling tools. This paper introduces the first analytical model for estimating the Interest Satisfaction Ratio (ISR) in NDN over LLNs, which is a crucial metric for assessing the effectiveness of interest forwarding strategies. We develop the analytical model specifically for the broadcast forwarding strategy, which has been extensively studied due to its simplicity and ease of implementation. Simulation results confirm that the proposed model predicts the ISR with reasonable accuracy. The model is then used to elucidate the strong interaction between the CSMA/CA parameters of the IEEE 802.15.4 standard and the achieved ISR.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The widespread availability of low-cost sensing and actuating devices that can swiftly connect to the Internet has played a significant part in the fast development of the Internet of Things (IoT). These devices generally employ low-power communication protocols like IEEE 802.15.4 [1] and 6LoWPAN [2], enabling networks of small smart devices, or “things,” to exchange information with limited computation, storage, and communication resources. Such networks are commonly referred to as Low Power and Lossy Networks (LLNs).
Data transfer in LLNs presents several difficulties due to their constrained nature [3,4,5]. For instance, to guarantee reliable communication, it is crucial to carefully consider the limited communication capabilities of LLNs. Furthermore, applications must cope with highly dynamic network topologies resulting from disconnections due to lossy LLN links and the mobility of “things,” a dominant feature of many IoT applications in smart cities, smart agriculture, industrial automation, and e-health [6].
Information-Centric Networking (ICN) has emerged as a promising alternative to IP for IoT applications [7,8,9]. Named-Data Networking (NDN), which is a popular implementation of ICN [10, 11], offers a range of desirable features, including advanced naming mechanisms, stateful forwarding, and efficient in-network caching. In NDN, data is named independently of its location, and consumers send interests to request data from producers. NDN’s inherent capabilities include communication without the requirement of establishing end-to-end connections and the resolution of names to addresses. These features alleviate the complexities associated with managing device addresses, particularly in dynamic and heterogeneous IoT environments [10, 11], and thus offering native support for seamless connectivity in the presence of mobility. As a result, consumers can freely navigate across different locations while maintaining uninterrupted access to the desired data, independent of their address or network location.
NDN’s support for caching and multicast significantly improves data delivery efficiency in IoT applications [10, 11]. By caching frequently accessed data in the network instead of network edge servers, NDN reduces data transmission, thereby reducing congestion and improving network performance. Additionally, NDN’s multicast support enables efficient and scalable data dissemination to multiple devices simultaneously, crucial for IoT applications involving group communication.
Most NDN strategies employ a broadcast mechanism for interest forwarding [12]. When a consumer injects an interest packet into the network, all the neighboring nodes receive the packet. These nodes then broadcast, in turn, their copies to their neighbors. This operation continues until the interest packet reaches a data producer. A node can retransmit the first copy of any received interest packet; it drops all the subsequent duplicates to avoid routing loops. It is worth noting that this strategy is referred to as the “multicast” strategy in ndnSIM [13], which is one of the most popular software simulation tools in the NDN research community [12, 14,15,16,17,18,19,20,21].
Numerous forwarding strategies [14,15,16,17,18,19,20,21] have been developed for NDN over wireless networks based on the standards IEEE 802.15.4 [1] and IEEE 802.11 [22]. Most of these strategies rely on broadcasting as part of their operations to propagate interest packets inside the network. For example, in Deferred Blind Flooding (DBF) [14], a given node waits for a random period to listen to its surroundings before retransmitting an interest packet. The node broadcasts the interest packet if the number of received duplicates is below a threshold. Otherwise, the node drops the packet. Listen First Broadcast Later (LFBL) [15] improves DBF. Upon receiving an interest packet, a node determines whether it is an eligible forwarder based on the distance to data producers. If the node is an eligible forwarder, it delays for a period proportional to its distance to the producer before broadcasting an interest packet.
In Reactive Optimistic Name-based Routing (RONR) [9], interest packets are initially broadcast through the network. Once a consumer receives a data packet, subsequent interest packets issued by the consumer use the reverse path, formed by the initial data packet, to reach the producer. To handle mobility, Dual Mode Interest Forwarding (DMIF) [16] alternates between two interest forwarding modes: “directed” and “broadcast.” If a node knows a neighbor leading to the producer, it forwards interest packets to that neighbor using the directed mode. Otherwise, the node defaults to the broadcast mode, wherein all its neighbors receive the packet. The study in [17] has recently proposed a Learning-based Adaptive Forwarding Strategy (LAFS) for NDN-based IoT systems. LAFS consists of two phases. In the first phase, nodes utilize a mechanism similar to DBF [14] to broadcast interest packets. Once a producer responds with a data packet, the second phase commences. Upon receiving the data packet, an intermediate node stores relevant information regarding the previous sending node, such as the ID and distance to the data producer for each name. The node then designates the name as “marked” and forwards all subsequently received interest packets containing that name without delay. On the other hand, the node forwards interest packets containing an unmarked name after a random listening period, as in DBF.
The Interest Satisfaction Ratio (ISR) is one of the most extensively applied metrics for assessing the performance of NDN forwarding strategies [14,15,16,17,18,19,20,21]. The ISR is the total number of data packets received by the consumer over the total number of interest packets generated by the consumer. Although many forwarding strategies have been suggested over the past years [14,15,16,17,18,19,20,21], most existing studies have resorted to simulation, using the ndnSIM software tool [13], to analyze their performance in terms of the ISR. So far, no study has been conducted to estimate this critical performance measure analytically. This paper aims to bridge the gap in the current literature by developing a new analytical model for predicting the ISR in NDN over LLNs. Although the proposed analytical model is discussed in the context of LLNs [1], it can be easily adapted for other well-known technologies, such as IEEE 802.11 [22]. The model is derived for the square grid since this topology has been widely used in most existing research studies on NDN over LLNs [17,18,19,20,21]. For instance, the performance of LAFS [17], R-LF [20], and those in [16, 19] has been evaluated on the square grid topology. To the best of our knowledge, our study is the first to suggest an analytical model to estimate the achieved ISR without resorting to lengthy software simulations.
The rest of the paper is organized as follows. Section 2 provides a brief overview of the related work on the analytical modeling of NDN. Section 3 outlines the system model of NDN over LLNs, while Sect. 4 describes the Carrier Sense Multiple Access/Collision Avoidance (CSMA/CA) algorithm utilized in the IEEE 802.15.4 standard. Section 5 presents the derivation of the packet collision probability in IEEE 802.15.4-based networks. Subsequently, Sect. 5 presents the derivation of the analytical model for estimating the ISR in NDN over LLNs. Section 6 validates the model through extensive simulations. Section 5.2 assesses the impact of the CSMA/CA parameters on the achieved ISR. Finally, Sect. 6 concludes this study and offers possible research extensions for the future.
2 Related work
Most research efforts on the analytical modeling of NDN have focused on caching-related aspects, including cache decision-making, cache replacement, and cache deployment [23,24,25,26,27]. The work in [23] has developed analytical models to compare the performance of the transport and routing protocols in NDN and TCP/IP. Contrarily, other researchers [24,25,26] have developed models examining the interaction between caching and transport in NDN. Meanwhile, the study of [27] has utilized analytical models to explore caching with the Least Recently Used replacement policy. Nonetheless, most existing studies [24,25,26,27] have assumed an NDN deployment over wired networks.
Abane et al. [28] have proposed an analytical model for the broadcast forwarding strategy in NDN over LLNs. They have assumed a static tree topology to simplify the model derivation. The model estimates the average number of packets transmitted per request, which includes the number of interest data exchanges and the mean round-trip time based on content popularity considerations. The authors have then employed the analytical model with simulations to suggest an adapted version of the CSMA/CA algorithm for NDN over LLNs.
The study of [29] has recently described a statistical model based on linear regression to evaluate content delivery in terms of the ISR in NDN over wired networks under heavy traffic conditions. To accomplish this, the authors in [29] have employed a factorial design approach to create a dataset of various network parameters utilizing the ndnSIM simulator. The statistical model was then used to investigate the effects of different network parameters on the attained ISR.
To the best of our knowledge, hardly any study has proposed an analytical model for estimating ISR in NDN over wireless networks, whether constrained like LLNs or conventional mobile ad hoc networks based on IEEE 802.11 links.
3 System model of NDN over LLNs
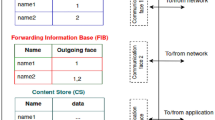
Figure 1 depicts a typical NDN node comprising three data structures, namely the Content Store (CS), Pending Interest Table (PIT), and Forwarding Information Base (FIB) [10, 11]. The CS temporarily caches data packets, allowing them to be stored closer to a consumer and thus enabling them to swiftly satisfy interest packets with fewer retransmissions to reach a consumer. The PIT in a given node records forwarded interest packets to determine corresponding data packets yet to reach the node. In addition, the PIT permits data packets to follow the reverse path to a consumer. The PIT also enables nodes to identify and remove duplicate packets (i.e., interests with the same name prefix) to avoid potential routing loops in the network. Lastly, the FIB is similar to a conventional routing table and is populated by a routing protocol. It contains name prefixes with the corresponding output interfaces (or faces) leading to potential data producers.

The three data structures found in a typical NDN node are the Content Store (CS), Pending Interest Table (PIT), and Forwarding Information Base (FIB)
Figure 2 illustrates the processing of interest and data packets through a given NDN node using the CS, PIT, and FIB. Specifically, a consumer generates an interest packet to request a data item identified with a specific name prefix. Each node through which the interest packet passes checks the CS for the corresponding data. If there is a hit in the CS, the node sends back the data packet to the consumer without further transmitting the interest packet. Conversely, the node verifies if there is a marked entry in the PIT corresponding to the interest packet. If there is a hit in the PIT, the node drops the interest packet. Otherwise, the node creates an additional entry in the PIT for the interest with the incoming interface. The node then consults the FIB to identify the output face through which it can forward the interest packet. Upon arriving at a given node, be it the original producer or an intermediate node caching the required data, the node sends back a data packet with the requested content following the reverse path of the interest packet using the “breadcrumb trail” in the PIT at the intermediate nodes.

The processing of interest (a) and data packets (b) in an NDN node using the CS, PIT, and FIB
In NDN over LLNs, a typical node implements three protocol layers, as shown in Fig. 3. The application layer in consumer nodes generates interest packets to request data from producers. On the other hand, the application layer in producer nodes generates data upon the reception of interest packets. The application layer hands interest/data packets to the NDN layer, which makes forwarding decisions, to ensure that interest packets cross from consumers to producers and data packets from producers to consumers. The NDN layer operates directly over the IEEE 802.15.4 link layer, which shifts interest/data packets from one node to the next. The data link layer consists of the Medium Access Control (MAC) and physical (or PHY) sublayers [1]. The MAC sublayer regulates access to the shared wireless medium through the CSMA/CA algorithm to avoid packet collisions. The PHY sublayer physically shifts the “bits” between two neighboring nodes using the wireless communication medium.

The protocol stack in a typical node in NDN over LLNs
The forwarding decisions when NDN operates over IEEE 802.15.4-based wireless networks differ from those when it operates over wired networks. The main reason is that a given node possesses only one network interface corresponding to the shared wireless medium; thus, it cannot use different network interfaces to distinguish between its next-hop neighbors, as in the wired case. Therefore, only broadcast communication is available at the data link layer without a mechanism, such as a source/destination address, to control packet retransmissions. Broadcast is the simplest way to forward packets in NDN over wireless networks. Broadcast is straightforward and efficient in finding data, even in the presence of node mobility and intermittent connectivity. However, broadcasting packets on a wireless medium generates communication overhead and consumes network resources (e.g., battery power) [14].
Many forwarding interest strategies which aim to attenuate the degrading effects of broadcasting have appeared in the literature [14,15,16,17]. Examples of these strategies include DBF [14], LFBL [15], DMIF [16], and LAFS [17]. Most of these “optimized” strategies rely on broadcast communication combined with “timers” to reduce the number of packet rebroadcasts. Consequently, it is crucial to develop analytical models for the basic “broadcast” forwarding strategy. Such an analytical tool can aid in gaining a quantitative understanding of the performance behavior of NDN under various network operating conditions. Additionally, the model can serve as a foundation for new analytical models for other forwarding strategies in the future [14,15,16,17].
4 The CSMA/CA algorithm in the IEEE 802.15.4 standard
The IEEE 802.15.4 standard [1] specifies two versions of the CSMA/CA algorithm: slotted and unslotted [1]. Most studies on NDN over IEEE 802.15.4 have assumed the unslotted version as the default implementation [16,17,18,19,20]. Contrary to its slotted counterpart, unslotted CSMA/CA is a contention-based protocol that requires no synchronization between nodes. A given node puts all packets in a FIFO queue. Before initiating a transmission, a node checks the availability of the wireless channel. If the channel is occupied, the node backs off for a random period and initiates a retransmission attempt after the backoff period expires. If a transmission is unsuccessful, the node will make a predetermined number of retransmission attempts before ultimately abandoning the packet.
Adopting the technical terms specified in the IEEE 802.15.4 standard [1], a given node keeps track of the two variables: NB and BE. The former is the number of times the node has backoffed while attempting the current transmission. NB is set to 0 before every new packet transmission. BE is the backoff exponent and is related to the number of backoff periods a node must wait before re-sensing the channel. The CSMA/CA algorithm employs time units called backoff periods, measured by aUnitBackoffPeriod symbols [1]. The parameters affecting the random backoff period are macMinBE and macMaxBE, which are the minimum and maximum values of BE, respectively, while macMaxCSMABackoff is the maximum value of NB. The parameters must satisfy the following conditions: macMinBE ≤ BE ≤ macMaxBE and 0 ≤ NB ≤ macMaxCSMABackoff [1].
Figure 4 illustrates the operations of the unslotted CSMA/CA algorithm. In step 1, NB and BE are initialized to 0 and macMinBE, respectively. In step 2, the MAC sublayer delays for a random number of complete backoff periods in the range 0 to 2BE − 1, and in step 3, it requests the PHY sublayer to perform a Clear Channel Assessment (CCA). If the channel is busy in step 4, the MAC sublayer increases NB and BE by one, ensuring that BE is not higher than macMaxBE. If the value of NB is less than or equal to macMaxBE, the algorithm must return to step 2 or terminate with a CCA status. If the channel is idle, in step 5, the MAC sublayer starts transmission immediately. Packet transmission starts when the backoff counter reaches zero. A collision occurs when the counters of two or more nodes reach zero simultaneously.

The operations of the unslotted CSMA/CA algorithm in the IEEE 802.15.4 standard
5 The analytical model
The analytical model is based on the following assumptions, which have been commonly adopted in existing studies [16,17,18,19,20].
-
Nodes form an nxn square grid. Adjacent nodes are within the communication range of each other along the X and Y directions. Communication along the diagonal direction cannot occur as the wireless signal carrying packet bits loses much power due to the longer diagonal distance compared to that along X/Y directions.
-
One consumer at node (i, j), \((0\le i, j\le n-1)\), generates interest packets with a constant rate of f interests/second during a period of T seconds. Interest packets are independent of each other and have a fixed length. Furthermore, one producer at node (i’, j’), \(\left(0\le {i}^{\prime}, {j}^{\prime}\le n-1\right)\), generates data packets upon receiving interest packets. Data packets have a fixed length.
-
The MAC sublayer employs the unslotted CSMA/CA algorithm of the IEEE 802.15.4 standard with the default settings, where macMinBE = 3, macMaxBE = 5, macMaxCSMABackoff = 4 [1].
-
The PHY sublayer of the IEEE 8022.15.4 introduces no transmission errors. However, packets can be lost due to packet collision, which occurs when adjacent nodes transmit packets simultaneously.
-
The processing time of interest or data packets due to the protocol stack in a given node is negligible.
-
No faults occur in the network, and nodes never run out of battery power.
We will develop the analytical model in two steps. In the first step, we will determine the probability of packet collision in IEEE 802.15.4-based networks employing the unslotted CSMA/CA algorithm. In the second step, we will derive the model for calculating the ISR both in the absence and presence of node mobility. Table 1 provides a summary of the symbols used in our analytical model.
5.1 Derivation of the probability of packet collision
The probability of packet collision, which significantly impacts the performance of wireless networks, has been studied by several researchers [30,31,32,33]. The authors in [32] have derived an expression for the probability that a packet experiences a collision in IEEE 802.11-based networks. Moreover, the study of [33] has demonstrated that a mean value analysis would be adequate for obtaining good predictions of the probability of packet collision. The approach depends on a critical approximation, assuming that each packet collides with a constant and independent probability regardless of the channel status. The present study will adapt the derivation of [32] to capture the operations of the backoff procedure of the unslotted CSMA/CA algorithm and compute the probability of packet collision, \({p}_{c}\), in IEEE 802.15.4-based networks.
In the unslotted CSMA/CA algorithm of the IEEE 802.15.4 standard [1], the backoff period is initially uniformly distributed between 0 and \({b}_{0}=\left({2}^{MinBE}-1\right)\). If a node successfully transmits a packet without collision with a probability \(\overline{{p }_{c}}\) =1 − \({p}_{c}\), in such a case, the packet experiences an average backoff period of \({b}_{0}/2+1\); the “ + 1” accounts for the additional unit period a node utilizes to perform the CCA after the backoff period expires [1]. If the first transmission attempt fails, the node increases the backoff exponent BE by one, with the new backoff period uniformly distributed between 0 and \({b}_{1}=\left({2}^{BE}-1\right)\). If the node successfully transmits the packet on the second attempt with a probability \({p}_{c}(1-{p}_{c} )\), the packet experiences an average backoff period of \({b}_{1}/2+1\). The argument could continue up to the last macMaxCSMABackoff permitted transmission attempts. Nonetheless, the backoff exponent increases until it reaches macMaxBE, with the corresponding backoff period uniformly distributed between 0 and \(\left({2}^{macMaxBE}-1\right)\).
For the “default” values of the unslotted CSMA/CA [1], the average backoff period of the first transmission attempt is given by
On the other hand, the average backoff period of the second transmission attempt is
A packet sees the same average backoff period in the third, fourth, and fifth transmission attempts. Thus,
Assuming transmission attempts are independent of one another [32], we can express the overall average backoff period as
where \({p}_{c}\) is the probability of packet collision and \(\rho =(1-{p}_{c})/\left(1-{p}_{c}^{5}\right)\); ρ is a normalization term to ensure the probability of each backoff period follows a valid probability distribution.
Based on the overall average backoff period, the probability that a node attempts to transmit a packet in an arbitrary instant is given by 1/\(\overline{b }\) [32]. The probability, \(\overline{{p }_{c}}\), that there is no collision during packet transmission; in other words, there is no other active node transmitting another packet during that time, is given by [32, 33]
where η is the number of neighboring nodes. Due to the methods utilized by interest and data packets to propagate through the network in the NDN paradigm, as will be explained below, the number of neighboring nodes is assumed η = 2. Consequently, the packet collision probability, \({p}_{c}\), is found to be
Equation (6) reveals that \({p}_{c}\) depends on \(\overline{b }\), whereas Eq. (4) reveals that \(\overline{b }\) depends on \({p}_{c}\), establishing a fixed-point formulation from which the packet collision probability, \({p}_{c}\), can be calculated using numerical iterative techniques [32].
5.2 Derivation of the analytical model for estimating ISR
After thoroughly examining the simulation output, we have discovered that the producer’s location significantly affects the achieved ISR. In contrast, the consumer’s location has less impact on system performance. In light of this observation, we will present the derivation of the analytical model for estimating the ISR considering different locations for the producer in the square grid. We assume the network nodes are not mobile in the first two cases. In case 1, we derive the model’s equations when the producer is at a grid corner, whereas, in case 2, we derive the equations when the producer is not at a grid corner. In case 3, we adapt the analytical model to handle scenarios where the producer and consumer are mobile and move according to the well-known random waypoint mobility model [34].
Case 1: The producer is at a grid corner
To illustrate the derivation of the analytical model without the loss of generality, the discussion concentrates on the 6 × 6 square grid depicted in Fig. 5. Suppose the producer is at node (5, 5) while the consumer is at the diagonally opposite corner node (0, 0).

The consumer is at the corner node (0, 0), while the producer is at node (5, 5) in the 6 × 6 grid
Figure 5 shows that nodes can communicate in two directions, “left-to-right” and “top-to-bottom,” as indicated by the arrows. The nodes have “directed” links so that the communication pattern between neighboring nodes corresponds precisely to the propagation of interest packets in the grid, as per the NDN paradigm. It is worth noting that intermediate nodes can retransmit the first copy of any received interest packet to avoid routing loops [10, 11]; nodes discard duplicate packets by inspecting the PIT and nonce field in the interest packets.
Let us illustrate the forwarding of interest packets in the square grid. When the consumer at node (0, 0) injects an interest packet into the network, it is received by the neighboring nodes (0, 1) and (1, 0) due to the broadcast nature of the IEEE 802.15.4 wireless medium. Node (1, 1) does not receive the packet due to the longer diagonal distance compared to the distance along the X/Y directions. When node (0, 1) retransmits the interest packet, node (0, 2), node (1, 1), and node (0, 0) receive a copy. While nodes (0, 2) and node (1, 1) retransmit the interest packet, node (0, 0) drops the packet since it recognizes that this is a duplicate with a registered entry in the PIT with the same nonce field. Similarly, when node (1, 0) retransmits the interest packet, it is received by node (2, 0) and node (1, 1). Again node (1, 1) does not retransmit the packet because node (1, 1) recognizes after consulting its PIT that it has already retransmitted a copy that arrived from node (0, 1). The net result of this propagation behavior is that nodes communicate according to the “directed links” shown in Fig. 5. In addition, a given node can receive packets from two preceding neighboring nodes, one along the X direction and another along the Y direction, except for the nodes situated at either the corners or edges of the square grid topology.
When the consumer transmits an interest packet, each neighboring node that receives the first copy of the interest packet retransmits the copy to its neighbors. The new intermediate nodes, in their turn, retransmit the packet. As a result, the interest packet is flooded in the network until reaching the producer. During the propagation through the network, copies of the interest packet may be lost due to collisions. As such, the primary step in developing the analytical model is determining the “reachability” probability, R(p), which is the probability of an interest packet generated by the consumer reaching the producer. At each hop, the interest packet is retransmitted to the next neighboring node with a certain probability p along the directed links portrayed in Fig. 5.
The researchers in [35, 36] have studied the problem of “directed connectivity in the 2-dimensional grid.” They have devised a technique to compute the reachability probability, R(p), for a source node and a packet with a certain probability p of being transmitted successfully between two adjacent nodes to reach a destination node in the 2-dimensional grid. R(p) is the probability that a packet sent by the source node (0, 0) reaches the destination node (i, j), \((0\le i, j\le n-1)\), through the directed links shown in Fig. 5. Notably, a given packet can explore all alternative paths between the source and destination nodes established by the directed links. The authors in [35, 36] have obtained closed-form expressions for the reachability probability, R(p), in the 2-dimensional grid of various sizes using a recursive decomposition approach and the well-known principle of “inclusion–exclusion of combinatorics” (please refer to the appendix for an outline of the approach of [35, 36] for computing R(p)).
The approach of [35, 36] for computing reachability probability, R(p), is adopted to develop our analytical model. Consider the 6 × 6 grid of Fig. 5 again. Let the consumer at node (0, 0) inject an interest packet into the network to search for the producer at node (5, 5). Each intermediate node broadcasts the interest packet, enabling the interest packet to explore all alternative paths between the consumer and producer according to the directed communication pattern depicted in Fig. 5. Suppose the interest packet has a probability p of being transmitted successfully to the next neighboring node. In that case, we obtain the following expressions for the reachability probability R(p) (we refer the reader to [37] to obtain equations for other grid sizes).
Owing to the broadcast nature of the wireless IEEE 802.15.4 transmission medium, a given interest packet has a probability \(\overline{{p }_{c}}\) (given by Eq. (5)) of being transmitted between two neighboring nodes without experiencing a collision. Consequently, the probability that an interest packet injected by the consumer at node (0, 0) reaches the producer at node (5, 5) is precisely the reachability probability R(\(\overline{{p }_{c}}\)), where the probability, p, in the above Eq. (7) is replaced by the probability of no packet collision, \(\overline{{p }_{c}}\).
According to the above-stated assumptions, the consumer generates interest packets with a constant rate of f packets/second during T seconds. Therefore, the total number of interest packets generated by the consumer, NIGC, is simply
After carefully analyzing the simulation results, we have noticed that Eq. (7) slightly overestimates the number of interest packets that reach the producer. The authors in [35, 36] have assumed “wired” links when deriving the different reachability probabilities for various grid networks. Consequently, in wired networks, packet transmission along the X direction is independent of that along the Y direction. However, in grid networks with “wireless” IEEE 802.15.4 links, packet transmissions along the X and Y directions are not independent. That is, when a node transmits a packet, it is broadcast along both the X and Y directions simultaneously due to the inherent broadcast nature of the wireless medium. Consequently, when a packet suffers a collision, it is lost along both the X and Y directions; thus, the neighboring nodes along the X and Y directions do not receive a copy of the packet. Therefore, multiplying Eq. (7) by a factor \(\overline{{p }_{c}}\) to account for the fact that an interest packet should not experience a collision to be able to move along both the X and Y directions simultaneously yields the fraction, NIRP, of interest packets that reach the producer as
When the producer receives an interest packet, it responds by issuing a data packet. The producer generates NIRP data packets in total. These data packets then cross the network following the reverse path initially formed by the interest packets. Our extensive simulation experiments have shown that most data packets (98% or higher) manage to reach the consumer. As a result, we can approximate the number of data packets, NDRC, reaching the consumer as
Finally, ISR, which is the ratio of the total number of data packets, NDRC, received by the consumer and the total number of interest packets, NIGC, generated by the consumer, is given by
Case 2: The producer is not at a grid corner
Suppose the consumer is at node (0, 0) while the producer is at any other location apart from the grid corner. For instance, let the producer be at node (3, 3), as illustrated in Fig. 6. Nodes (0, 0) and (3, 3) form a 4 × 4 square grid highlighted by the dashed line in Fig. 6. By employing the approach of [35, 36], the expression for the reachability probability, R(p), in the 4 × 4 grid is found to be

The consumer is at node (0, 0), while the producer is at node (3, 3) in the 6 × 6 grid
By following the same arguments of case 1, the number of interest packets reaching the producer at node (3, 3) within the 4 × 4 square grid is expressed as
The interest packets reach the producer within the 4 × 4 square grid containing the consumer and producer by exploring all the alternative paths between the consumer and the producer.
The probability of an interest packet not reaching the producer within the 4 × 4 square grid containing the consumer and producer is (1-R(\(\overline{{p }_{c}}\))) because the packet has experienced a collision. Copies of the packet could reach the producer at node (3, 3) through neighboring nodes, such as node (3, 4), outside the 4 × 4 square grid. Communication can occur in the opposite direction (i.e., from right to left) since when node (3, 4) retransmits the interest packet, node (3, 3) receives the packet for the first time. Thus, the likelihood of routing loops emerging is low. Consequently, the producer at node (3, 3) accepts the interest packet and responds by issuing the corresponding data packet. Therefore, the number of interest packets not reaching the producer is NIGC \(\cdot\) (1-R(\(\overline{{p }_{c}}\)))=T \(\cdot\) f \(\cdot (1-\) R(\(\overline{{p }_{c}}\))). Among these interest packets, a fraction of \(\overline{{p }_{c}}\) reach the producer at node (3, 3) from outside the 4 × 4 square grid.
The interest packets can reach the producer from a neighbor located in one of the 2 × 2 squares outside the 4 × 4 square. Figure 6 portrays (at most) three 2 × 2 squares adjacent to the producer and outside the 4 × 4 square containing the consumer and producer. Therefore, the number of interest packets reaching the producer from outside the 4 × 4 square grid can be estimated as
where α can be 1, 2, or 3, depending on the producer’s location in the grid; this factor accounts for the 2 × 2 squares adjacent to the producer and outside the larger 4 × 4 square containing the consumer and producer. So, the total number of interest packets that reach the producer is
Having computed NIRP, we use Eqs. (8) to (11) of case 1 to compute the ISR. Figure 7 summarizes the procedure for calculating the achieved ISR when the producer is not at a grid corner.

The procedure for computing the ISR when the producer is not at a grid corner
Case 3: The producer and consumer are mobile
In addition to the “static” nodes that form the square grid, the consumer and producer are two extra nodes that move within the square topology according to the random waypoint model [34]. The consumer is within a 2 × 2 square at any given time, as shown in Fig. 8. Similarly, the producer is within another 2 × 2 square. As the consumer and producer move to new locations across the grid topology, they move to other 2 × 2 squares. Although the consumer and producer are usually within two different 2 × 2 squares, it may sometimes happen during their movement that both the consumer and producer are within the same 2 × 2 square. Nonetheless, the analysis of all these cases is still the same.

The consumer and producer are mobile and in two different 2 × 2 squares
As the consumer and producer move across the square grid, the square formed by the consumer and producer, englobing the nodes between the producer and consumer (please refer to the square indicated by the dashed lines in Fig. 8), constantly changes size. For example, the square is small when the consumer and producer are close to each other. Similarly, the square is large as the two nodes move further apart. However, to manage the complexity of the analytical model when the consumer and producer are mobile, we consider only the two 2 × 2 squares containing the consumer and producer, respectively; the dotted lines show the 2 × 2 squares in Fig. 8. The simulation results below will confirm that our modeling approach for case 3 is still reasonable and enables the analytical model to make good ISR predictions while simplifying the calculations considerably.
We follow the steps outlined in case 2 to compute the ISR in the presence of mobility. However, only the 2 × 2 square containing the producer node is considered to calculate the reachability probability, R(\(\overline{{p }_{c}}\)). Using the method of [35, 36], the reachability probability, R(\(\overline{{p }_{c}}\)), when the producer is within a 2 × 2 square, is found to be
Having obtained R(\(\overline{{p }_{c}}\)), we follow the procedure depicted in Fig. 7 to calculate the ISR.
6 Model validation
The proposed analytical model has been validated through extensive simulation experiments. To conduct the experiments, we utilized the pre-existing broadcast forwarding strategy available in ndnSIM 2.8 [13]. The simulations were conducted on a square grid topology, where the distance between two adjacent nodes was 50 m along the X and Y directions. The IEEE 802.15.4 protocol was configured in each network node to facilitate a data link service to the NDN layer. Table 2 provides a summary of the main parameters used in the simulations. It is worth noting that these parameters have been widely used in existing research studies [16,17,18,19,20,21].
The following sections will evaluate the analytical model’s accuracy in predicting the number of interest packets reaching the producer and the achieved ISR. As we have established through simulation that 98% of the data packets generated by the producer successfully reach the consumer, we will not present findings for the number of data packets reaching the consumer. As the producer generates a data packet for each received interest packet, the number of interest packets that reach the producer reflects the number of data packets that reach the consumer.
Case 1: The producer is at a grid corner
In this set of experiments, we have examined four network sizes, notably 4 × 4, 6 × 6, 8 × 8, and 10 × 10 nodes, arranged in a square grid. The consumer is at the corner node (0, 0), whereas the producer is at the diagonally opposite corner. The consumer generates one interest packet every second.
Figure 9 depicts the results for the number of interest packets reaching the producer predicted by the analytical model and the simulation as a function of the network size. Specifically, the predictions of the analytical model are highly consistent with the simulation results, with an error margin not exceeding 5% for all network sizes. Furthermore, the number of interest packets reaching the producer does not change as the network size increases. The producer’s location significantly impacts the number of interest packets reaching the producer, thus considerably affecting the overall achieved ISR.

The number of interest packets reaching the producer versus the network size. The consumer is at the corner node (0, 0), while the producer is at the diagonally opposite corner. The consumer generates one interest packet per second
As the number of interest packets reaching the producer does not change as the network size increases, Fig. 10 illustrates that the ISR is constant across the different network sizes. When the producer and consumer are at diagonally opposite grid corners, the achieved ISR is approximately 73% as the network size is varied. The ISR obtained when the producer is at a grid corner is lower than when it is elsewhere in the grid, as will be shown below. There are several reasons which can justify this finding. Firstly, communication between adjacent nodes occurs along the X/Y direction. As a result, the longest distance in the network (i.e., the network diameter) separates the consumer and the producer when they are both at grid corners. Such a long distance increases the chance of packets experiencing a collision while crossing the network. Secondly, packets encounter fewer alternative paths as they approach corners instead of other network regions, such as the network center. As a result, packets must compete for fewer network resources, such as channels, thus increasing their chance of experiencing collisions. The collisions reduce the number of interest packets reaching the producer and hence the number of data packets reaching the consumer. This leads to a lower ISR than the opposite scenario when the producer is not at a grid corner.

The achieved ISR versus the network size. The consumer is at the corner node (0, 0), while the producer is at the diagonally opposite corner. The consumer generates one interest packet per second
Figure 11 presents the number of interest packets reaching the producer, predicted by the analytical model and the simulation, in the 10 × 10 grid for varying interest generation rates. According to the figure, the predictions of the analytical model are in good agreement with the simulation results when the generation rate is lower than 14 interests/second. Furthermore, as the interest generation rate increases to 16 interests/second, the accuracy of the analytical degrades as the discrepancy between the model’s predictions and simulations grows. A similar trend is noticed for the ISR, as depicted in Fig. 12.

The number of interest packets reaching the producer versus the interest generation rate in the 10 × 10 grid. The consumer is at the corner node (0, 0), while the producer is at the opposite corner node (9, 9)

The achieved ISR versus the interest generation rate in the 10 × 10 grid. The consumer is at the corner node (0, 0), while the producer is at the opposite corner node (9, 9)
It is worth noting that as long as the interest generation rate does not cause the consumer to inject a new interest packet into the network until a data packet for the preceding injected interest packet is received, the ISR remains stable. In other words, if interest packets with different names do not co-exist inside the network competing for network resources, the ISR does not change much as the interest generation rate increases.
To justify this performance behavior, let us denote by L the time from when the consumer injects an interest packet into the network to when its corresponding data packet reaches the consumer. We have found that as long as the interest generation rate is lower than 1/L, the achieved ISR remains relatively stable at approximately 73%. For the parameters adopted in our simulation experiments (and summarized in Table 2), we have found that as long as the interest generation rate is lower than 14 interests/second, the ISR remains close to 73%, as shown in Fig. 12. When the generation rate increases beyond 14, the ISR starts to decrease. This decrease in the ISR occurs due to interest packets with different names existing concurrently inside the network. This increases packet collisions, leading to interest packets not reaching the consumer and data packets not reaching the producer, leading to a drop in the ISR.
The analytical model’s accuracy degrades at high interest generation rates due to the assumptions and approximations that simplify the model development. For instance, the analytical model tends to underestimate the probability of packet collision as we assumed that the number of neighbors is two instead of four. However, as traffic becomes heavy inside the network, a given node may receive interest and data packets from all the immediate neighbors along the X and Y directions. Additionally, we have assumed that the probability of packet collision is constant and independent of channel status to ease the model development.
Figures 13 and 14 display the number of interest packets reaching the producer and the attained ISR, respectively, as the consumer’s diagonal location varies in the 10 × 10 grid, and the consumer generates one interest packet every second. The results reveal that the number of interest packets reaching the producer is comparable to that of Fig. 9. Consequently, the achieved ISR is similar to that of Fig. 10, regardless of the consumer’s location. For instance, the realized ISR is 73% when the consumer is far from the producer, e.g., at node (1, 1), and it remains at that percentage when the consumer is near the producer, e.g., at node (8, 8).

The number of interest packets reaching the producer versus the consumer’s diagonal location in the 10 × 10 grid. The producer is at node corner (9, 9). On the X-axis, location “11” indicates that the consumer is at node (1, 1), while “22” indicates that the consumer is at node (2, 2). The consumer generates one interest packet per second

The achieved ISR versus the consumer’s diagonal location in the 10 × 10 grid. The producer is at the corner node (9, 9). The consumer generates one interest packet per second
Case 2: The producer is not at a grid corner
This section will examine only the 10 × 10 grid since we have discovered that the conclusions remain relatively the same for other network sizes. While the consumer is at the corner node (0, 0), the producer’s diagonal location varies from being far from the consumer, e.g., at node (8, 8), to being near the consumer, e.g., at node (1, 1). We will report results when the consumer generates one interest packet every second. We have found that the same performance trends as in case 1 are observed for higher interest generation rates.
Figure 15 depicts the number of interest packets arriving at the producer, as anticipated by the analytical model and the simulation, as a function of the producer’s diagonal location. In Fig. 15, the X-axis depicts the producer’s diagonal location in the grid. For instance, “11” on the X-axis indicates that the producer is at node (1, 1), while “22” is at node (2, 2), and so forth. This representation on the X-axis makes the graph clearer and less cluttered; when the network nodes are numbered successively starting at the first row from 0 to nxn-1, the diagonal nodes are numbered as 0, 11, 22,…, until 99. Figure 15 indicates that the simulation findings and the analytical model’s predictions agree well. More crucially, compared to case 1, more interest packets reach the producer. When the producer is not at a corner node, more neighboring nodes are available for an interest packet to reach the producer. Consequently, the number of data packets that can reach the consumer increases since the producer generates a data packet for each received interest packet.

The number of interest packets reaching the producer versus the producer’s diagonal location in the 10 × 10 grid. The consumer is at the corner node (0, 0). On the X-axis, “11” represents the producer at node (1, 1), while “22” represents the producer at node (2, 2). The consumer generates one interest packet per second
Figure 16 displays the ISR findings for different producer’s diagonal locations in the 10 × 10 grid. As more interest packets reach the producer than in case 1, a higher ISR is obtained in case 2. For instance, the attained ISR is approximately 81% when the producer is far from the consumer, e.g., at node (8, 8). In contrast, the ISR is 88% when the producer is close to the consumer, e.g., at node (1, 1).

The achieved ISR versus the producer’s diagonal location in the 10 × 10 grid. The consumer is at the corner node (0, 0). The consumer generates one interest packet per second
We have performed additional simulation experiments by varying the consumer’s and producer’s diagonal locations in the 10 × 10 grid. Figure 17 shows the number of interest packets reaching the producer when the consumer generates one interest packet every second. On the X-axis of Fig. 17, the abscissa “11–88” indicates that the consumer is at node (1, 1), while the producer is at node (8, 8), and so on. The results demonstrate how well the analytical model predicts the number of interest packets reaching the producer. Similarly, Fig. 18 confirms that the analytical model makes fairly accurate ISR predictions.

The number of interest packets reaching the producer versus the consumer’s and producer’s diagonal locations in the 10 × 10 grid. On the X-axis, “11–88” indicates that the consumer is at node (1, 1) and the producer is at node (8, 8), while “22–77” indicates that the consumer is at node (2, 2) and the producer at node (7, 7). The consumer generates one interest packet per second

The achieved ISR versus the consumer’s and producer’s diagonal locations in the 10 × 10 grid. The consumer generates one interest packet per second
We notice that the number of interest packets reaching the producer in Fig. 17 is higher than in Fig. 9. Thus, the attained ISR in Fig. 18 is higher than in Fig. 10 and is approximately 88% in most examined cases.
Case 3: The producer and consumer are mobile
In this series of experiments, in addition to the 10 × 10 nodes arranged in a square grid, there are two extra nodes containing the consumer and producer, respectively. The consumer and producer move freely in the 10 × 10 grid according to the random waypoint mobility model [34] with speeds ranging from 0 to 30 m/s, whereas the pause time is always 0. The consumer generates one interest packet every second.
Figure 19 presents the number of interest packets reaching the producer versus consumer/producer speed. The analytical model makes predictions that agree with simulations and are within a 5% margin of error. We should mention that when there is mobility, more interest packets reach the producer than in the above two cases with no mobility. This causes the ISR to be high and over 97%, as depicted in Fig. 20.

The number of interest packets reaching the producer versus consumer/producer speed. The consumer and producer are mobile. The consumer generates one interest packet per second

The achieved ISR versus consumer/producer speed in the 10 × 10 grid. The consumer and producer are mobile. The consumer generates one interest packet per second
Figure 21 shows the number of interest packets reaching the producer versus the interest generation rate in the 10 × 10 grid. The consumer and producer move at a speed of 20 m/s. We notice that the number of interest packets reaching the consumer is comparable to the number of data packets reaching the consumer. In other words, the consumer receives a data packet for most interest packets injected into the network. As the generation rate of interest packets increases from 1 to 14 interest packets/second, the number of interest packets reaching the consumer rises accordingly. However, when the generation rate exceeds 14, the number of interest packets reaching the consumer decreases. This is because packet collisions increase as traffic increases inside the network. Figure 22 reveals that the model correctly predicts that the ISR is relatively stable as the interest generation rate varies from 1 to 14 interests/second. However, the model’s accuracy degrades when the generation rate exceeds 14 interest packets/second. This is due to the assumptions and approximations used to simplify the model development, as discussed in the analysis of the results reported above in Figs. 11 and 12.

The number of interest packets reaching the producer versus the interest generation rate in the 10 × 10 grid. The consumer and producer are mobile with a speed of 20 m/s

The achieved ISR versus the interest generation rate in the 10 × 10 grid. The consumer and producer are mobile with a speed of 20 m/s
In summary, the ISR is high in the presence of mobility compared to the static scenario because when the consumer and producer move across the grid topology, they visit new network regions. More crucially, interest packets can explore new alternative paths that may have a relatively low traffic load. In addition, mobility causes the consumer and producer nodes to get close to each other for some time. As a result, packets travel short distances to cross the network. Consequently, the probability of packet collisions decreases, enabling a high number of interest packets (and data packets) to reach the producer (and consumer). In contrast, in the absence of mobility, interest and data packets travel through the same paths and thus compete for the same network resources (e.g., channels), increasing the likelihood of packet collisions which reduce the achieved ISR.
7 The impact of the CSMA/CA parameters on the achieved ISR
This section will use the above analytical model to explore the critical interaction between the CSMA/CA parameters and the attained ISR in NDN over LLNs.
7.1 Increasing the backoff period
We will demonstrate how our analytical model can be applied to assess the impact of increasing the backoff period on the achieved ISR. To do so, let us set the parameters of the unslotted CSMA/CA algorithm in such a way as to increase the length of the backoff period. For instance, let us fix the parameters macMinBE = 4 and macMaxBE = 6 while macMaxCSMABackoff is unchanged. It is worth noting that such values are still within those recommended by the IEEE 802.15.4 standard [1]. With the new macMinBE and macMaxBE, the average backoff periods of the successive transmission attempts become
After replacing the above-average backoff periods in Eqs. 4 to 6, we can compute the new probabilities \({p}_{c}\) and \(\overline{{p }_{c}}\) using numerical iterative techniques [32]. We then use these new probabilities in the equations of the above analytical model to obtain the newly achieved ISR when the backoff period increases.
Figure 23 presents the number of interest packets reaching the producer for different network sizes when the consumer and producer are at the diagonally opposite grid corners. We have selected this case as it has been shown in case 1 that the achieved ISR is the lowest at approximately 73% compared to the other cases examined above. The consumer generates one interest packet every second. We have found that the conclusions remain mostly the same for higher interest generation rates. The figure shows that when the backoff period increases, the analytical model still reasonably forecasts the number of interest packets reaching the producer. Furthermore, the figure indicates that more interest packets reach the producer than with the default backoff period.

The number of interest packets reaching the producer versus the network size. The consumer is at the corner node (0, 0), while the producer is at the opposite corner node (9, 9). The consumer generates one interest packet per second
Figure 24 compares ISR results for the increased backoff period against those for the default backoff period. We can notice that when the backoff period increases, the ISR jumps from 73% to around 85%. We can justify this improvement in the ISR by noting that increasing the backoff period reduces the packet collision probability since the latter is inversely proportional to the length of the average backoff period, as revealed by Eq. (6). Consequently, more interest packets reach the producer, and more data packets reach the consumer compared to the “default” backoff period, resulting in the ISR exceeding 80%.

The achieved ISR versus network size. The consumer is at the corner node (0, 0), while the producer is at the opposite corner node (9, 9). The consumer generates one interest packet per second
Having said the above, the downside of increasing the parameters macMinBE and macMaxBE is that both interest and data packets experience longer times before accessing the wireless medium due to the increased backoff period. As a result, the latency of the interest packets to reach the producer rises, and the latency of the data packets to reach the consumer rises. This rise, in turn, increases “network latency,” which is when the consumer generates an interest packet until the associated data packet arrives at the consumer.
7.2 Randomizing the backoff period
Although increasing the backoff period improves the ISR, this has the drawback of increasing the overall network latency. We will demonstrate how we can improve the ISR without scanting network latency. We will set the CSMA/CA parameters to the default values. That is macMinBE = 3 and macMaxBE = 5. However, a given node can randomly select one of the permitted backoff periods at each transmission attempt. The node can still perform up to macMaxCSMABackoff transmission attempts. As a consequence, a message experiences the same average backoff period in all the transmission attempts, and thus, we obtain the following expression for the average backoff periods of the different transmission attempts.
We can compute the new probabilities \({p}_{c}\) and \(\overline{{p }_{c}}\) using the above-average backoff periods in Eqs. (4) to (6).
Consider the network scenario where the consumer and producer are at opposite corners of the 10 × 10 grid. Figure 25 reveals that the analytical model still makes good predictions of the number of interest packets reaching the producer for the randomized backoff period. Furthermore, the number of interest packets that reach the producer is higher than that for the default backoff period.

The number of interest packets reaching the producer versus network size. The consumer is at the corner node (0, 0), while the producer is at the opposite corner node (9, 9). The consumer generates one interest packet per second
Figure 26 compares the ISR results for the randomized backoff period against those for the default backoff period. Examining Figs. 26 and 24 reveals that the ISR for the randomized backoff period is higher than that for the default backoff period. Furthermore, the achieved ISR for the randomized backoff period is comparable to that for the increased backoff period. Randomizing the backoff period reduces the packet collision probability. Moreover, this probability for the randomized backoff period is similar to that for the increased backoff period. Nonetheless, the main advantage of the randomized backoff period is that it improves the achieved ISR and maintains the benefit of not increasing network latency. In other words, packets experience backoff periods comparable to those corresponding to the default CSMA/CA parameters.

The achieved ISR versus network size. The consumer is at the corner node (0, 0), while the producer is at the opposite corner node (9, 9). The consumer generates one interest packet per second
8 Conclusions
Numerous strategies have been developed for interest forwarding in Named-Data Networks (NDN) over Low Power and Lossy Networks (LLNs), based on the IEEE 802.15.4 communication standard. The performance attributes of these strategies have been primarily investigated through simulation, using popular software like ndnSIM, due to the absence of analytical modeling tools. In light of this observation, this paper has proposed a novel analytical model for estimating the Interest Satisfaction Ratio (ISR) in NDN over LLNs. This research is the first to quantitatively study the achieved ISR in NDN over LLNs. Specifically, the model has been developed for broadcast forwarding strategy, which has been extensively explored due to its simplicity and ease of implementation. Moreover, most forwarding strategies, including BDF [14], DMIF [16], LAFS [17], and R-LF [20], employ “broadcasting” combined with other techniques, such as timers, for interest forwarding to reduce communication overhead and battery power consumption.
The development of the analytical model was achieved in two stages. The first stage derived the probability of packet collision in IEEE 802.15.4-based networks. This probability significantly impacts the achieved ISR, as evidenced by the various equations of the analytical model. In the second stage, the model was derived considering different producer locations in the grid and stationary network nodes (i.e., in the absence of mobility). Subsequently, the analytical model was modified to accommodate mobility scenarios in which the consumer and producer move randomly according to the random waypoint mobility model.
Extensive simulation experiments have been conducted to evaluate the accuracy of the new analytical model. Based on the simulation results, the new model can predict the number of interest packets reaching the producer and the achieved ISR with reasonable accuracy in the three cases involving stationary and moving consumers and producers. The model’s prediction error is less than 5% in most examined scenarios. The analytical model and simulation results have also indicated that when there is no mobility and the producer is at a grid corner, the achieved ISR is well below 80%. On the other hand, when the producer is not at a grid corner, the ISR ranges between 80 and 90%. The ISR approaches 100% when the consumer and producer are mobile.
We have demonstrated how our analytical model can shed new light on the significant impact of the CSMA/CA parameters on the achieved ISR in NDN over LLNs. Specifically, our analysis, backed by simulations to verify the results, has shown that increasing macMinBE and macMaxBE by just one unit from the default values recommended by the IEEE 802.15.4 standard reduces the probability of packet collision. Consequently, the ISR increases from 73% to over 80%, even when the producer is at a grid corner. Furthermore, the analysis has revealed that randomizing the backoff period improves the ISR without compromising the overall network latency, even when the producer is at a grid corner.
As a natural continuation of our research, we plan to extend our analytical model to account for multiple consumers and producers within the network. We also aim to apply our analytical modeling approach to other forwarding strategies, including DBF [14] and DMIF [16].
Data availability
Not applicable.
References
IEEE (2016) IEEE Standard for low-rate wireless networks. In: IEEE Std 802.15.4-2015 (Revision of IEEE Std 802.15.4-2011), pp 1–709. https://doi.org/10.1109/IEEESTD.2016.7460875
Fazli F, Mansubbassiri M (2022) V-RPL: An effective routing algorithm for low power and lossy networks using multi-criteria decision-making techniques. Ad Hoc Networks 132(1):102868
Guna’thilake NA, Al-Dubai A, Buchanan WJ (2022) Internet of things: concept, implementation and challenges. Internet of Things and Its Applications, Springer, pp. 145–155
Majid M et al (2022) Applications of wireless sensor networks and Internet of things frameworks in the industry revolution 4.0: A systematic literature review. Sensors 22(6):2087
Yang Y, Wang H, Jiang R, Guo X, Cheng J, Chen Y (2022) A review of IoT-enabled mobile healthcare: technologies, challenges, and future trends. IEEE Internet Things J 9(12):9478–9502
Ghaleb B et al (2018) A survey of limitations and enhancements of the IPv6 routing protocol for low-power and lossy networks: a focus on core operations. IEEE Commun Surveys Tutorials 21:1607–1635
Xue K, Wei DSL, Bruschi R, Chih-Lin I (2019) The quest for information-centric networking. IEEE Commun Mag 57(6):12
Djama A, Djamaa B, Senouci MR (2020) Information-centric networking solutions for the Internet of things: a systematic mapping review. Comput Commun 159:37–59
Baccelli F, Mehlis C, Hahm O, Schmidt TC, Wählisch M (2014) Information-centric networking in the IoT: experiments with NDN in the wild. In: Proc. 1st ACM Conference on Information-Centric Networking (ICN’ 2014), ACM, NY, pp 77–86. https://doi.org/10.1145/2660129.2660144
Jacobson V, Smetters DK, Thornton JD, Plass MF, Briggs NH, Braynard RL (2009) Networking named content. In: Proc. 5th Int. Conf. Emerging Networking Experiments & Technologies, ACM, NY, pp 1–12. https://doi.org/10.1145/1658939.1658941
Wang L, Afanasyev A, Kuntz R, Vuyyuru R, Wakikawa R, Zhang L (2012) Rapid traffic information dissemination using named data. Proc. 1st ACM Workshop Emerging Name-Oriented Mobile Networking Design - Architecture, Algorithms, and Applications, vol. 12, ACM, NY, USA, pp. 7–12
Tariq A, Rehman RA, Kim BS (2020) Forwarding strategies on NDN-based wireless networks: a survey. IEEE Commun Surveys Tutorials 22(1):68–95
ndnSIM Simulator, 08, 2020. https://ndnsim.net/current/
Amadeo M, Molinaro A, Ruggeri G (2013) E-CHANET: routing, forwarding and transport in information-centric multi-hop wireless networks. Comput Commun 36(7):792–803
Michael M, Vasileios P, Lixia Z (2010) Listen first, broadcast later: topology-agnostic forwarding under high dynamics. In: Proc. Annual Conf. International Technology Alliance in Network and Information Science, pp 1–8. Available online: http://web.cs.ucla.edu/~lixia/papers/10ITA-LFBL.pdf
Gao Z, Zhang H, Zhang B (2016) Energy efficient interest forwarding in NDN-based wireless sensor networks. Mobile Information Systems, pp 15. https://doi.org/10.1155/2016/3127029
Djama A, Djamaa B, Senouci MR, Kameche N (2022) LAFS: a learning-based adaptive forwarding strategy for NDN-based IoT network. Ann Telecommun 77:311–330. https://doi.org/10.1007/s12243-021-00850-2
Yu YT, Dilmaghani RB, Calo S, Sanadidi MY, Gerla M (2013) Interest propagation in named data MANETs. In: Proc. 2013 Int. Conf. Computing, Networking & Communications (ICNC), pp 1118–1122. https://doi.org/10.1109/ICCNC.2013.6504249
Ould Khaoua AS, Boukra A, Bey F (2022) Probabilistic forwarding in named data networks for Internet of Things. In: Chikhi S, Diaz-Descalzo G, Amine A, Chaoui A, Saidouni DE, Kholladi MK (eds) Modelling and Implementation of Complex Systems. MISC 2022. Lecture Notes in Networks and Systems, vol 593. Springer, Cham. https://doi.org/10.1007/978-3-031-18516-8_2
Abane A, Daoui M, Bouzefrane S, Mühlethaler P (2019) A lightweight forwarding strategy for named data networking in low-end IoT. J Netw Comput Appl 148:102445
Aboud A, Touati H, Hnich B (2019) Efficient forwarding strategy in an NDN-based internet of things. Clust Comput 22(3):805–818
IEEE (2016) IEEE standard for information technology—telecommunications and information exchange between systems local and metropolitan area networks—specific requirements - part 11: Wireless lan medium access control (mac) and physical layer (phy) specifications. IEEE Std 802.11-2016 (Revision of IEEE Std 802.11-2012), pp 1–3534. https://doi.org/10.1109/IEEESTD.2016.7786995
Carofiglio G, Morabito G, Muscariello L, Solis I, Varvello M (2013) From content delivery today to information-centric networking. Comput Netw 57(16):3116–3127
Wang GQ, Huang T, Liu J, Chen JY, Liu YJ (2013) Modeling in-network caching and bandwidth sharing performance in information-centric networking. J China Univ Posts Telecommun 20(2):99–105
Ren Y, Li J, Li L, Shi S, Zhi J, Wu H (2017) Modeling content transfer performance in information-centric networking. Futur Gener Comput Syst 74:12–19
Udugama A, Palipana S, Goerg C (2013) Analytical characterization of multi-path content delivery in content-centric networks. In: Proc. Int. Conf. Future Internet Communications (CFIC), Coimbra, Portugal, pp 1–7. https://doi.org/10.1109/CFIC.2013.6566319
Carofiglio G, Gallo M, Muscariello L, Perino D (2011) Modeling data transfer in content-centric networking, Proc. 23rd International Tele-traffic Congress (ITC), pp. 111–118
Abane A, Muhlethaler P, Bouzefrane S (2021) Modeling and improving named data networking over IEEE 802.15.4. Ann Telecommun 76(11–12):839–850
Rehman MA, Kim D, Choi K, Ullah R, Kim BS (2019) A Statistical performance analysis of named data ultra-dense networks. Appl Sci 9:3714. https://doi.org/10.3390/app9183714
Kuan C, Dimyati K (2006) Analysis of collision probabilities for saturated IEEE 802.11 MAC protocol. Electron Lett 42(19):1125–1127
Sheikh SM, Wolhuter R, Engelbrecht HA (2017) A model for analyzing the performance of wireless multi-hop networks using a contention-based CSMA/CA strategy. KSII Trans Internet Inf Syst 11(5):2499–2522
Vu HL, Sakurai T (2006) Collision probability in saturated IEEE 802.11 networks. In: Proc. Australian Telecommunication Networks and Applications Conference (ATNAC), Australia, pp 1–5
Bianchi G (2000) Performance analysis of the IEEE 802.11 distributed coordination function. IEEE J Selected Areas Commun 18(3):535–547
Johnson DB, Maltz DA (1996) Dynamic source routing in ad hoc wireless networks, Mobile Computing. Kluwer Int Series Eng Comput Sci 353:153–181
Zhang L, Cai L, Pan J (2013) Connectivity in two-dimensional lattice networks. Proc IEEE INFOCOM, pp. 2814- 2822
Zhang L, Cai L, Pan J, Tong F (2014) A new approach to the directed connectivity in two-dimensional lattice networks. IEEE Trans Mob Comput 13(11):2458–2472
Zhang L et al. Square lattice network directed connectivity calculator. http://grp.pan.uvic.ca/~leiz/latticepoly.html
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix. Computing the reachability probability, R(p)
Appendix. Computing the reachability probability, R(p)
This appendix briefly presents the methodology of [35, 36] for computing the reachability probability in 2-dimensional grids. Consider Fig. 6, which illustrates a 6 × 6 square with directed links, and suppose a packet is originated at node (0, 0) and destined for node (5, 5). The objective is to determine the reachability probability, R(p). It is the likelihood that the packet from the source node (0, 0) reaches the destination node (5, 5), given that each network node retransmits the packet to the next adjacent node with probability p. We assume that the probability p is uniform across all nodes. Moreover, each node independently decides whether or not to retransmit a given packet.
Despite the above assumptions, it is challenging to derive the reachability probability that the packet from node (0, 0) will reach node (5, 5). This is because to reach node (5, 5), the packet may pass through node (4, 5) or node (5, 4) at the last hop. Even if the reachability probability to node (4, 5) and node (5, 4) are known, it will still be challenging to determine the reachability probability to node (5, 5) since the paths from node (0, 0) to node (5, 5) are not independent.
A brute force approach would examine all possible paths between the source and destination. However, this approach’s complexity is hampered by a combinatorial explosion due to the exponentially increasing number of paths as the grid grows. Furthermore, most paths share common links, making them non-independent.
To address this challenge, the authors of [35, 36] have developed a technique for computing the reachability probability in a 2-dimensional grid. They first calculated the reachability probability for the two fundamental paths: serial and parallel. These probabilities were subsequently used to determine the reachability probability for the 2 × 2 square and triangular grid. After that, the authors employed serial and parallel paths, 2 × 2 squares, and triangular grids as building blocks to create larger grids hierarchically. They combined their respective reachability probabilities to compute the reachability probability in larger grids, such as 3 × 3, 4 × 4, etc.
Let us illustrate the approach for computing the reachability probabilities for “serial” and “parallel” paths. As depicted in Fig.

Two types of paths exist in the grid: serial and parallel paths
27, in a “serial” path where two directed links connect nodes A to C through a common node B, the reachability probability, \({R}_{0}\left(p\right)\), that a packet generated by node A reaches node C is given by.
On the other hand, Fig. 27 b shows two “parallel” paths connecting node A to node C, each of which is serial. The reachability probability, \({R}_{1}\left(p\right)\), can be expressed, using the principle of inclusion and exclusion because the two parallel paths are not independent, as.
The probability \({R}_{1}\left(p\right)\) can then be used to compute the reachability probability for the 2 × 2 square. Figure

The 2 × 2 square is composed of two parallel paths
28 reveals that the 2 × 2 square is composed of two parallel paths. Consequently, the reachability probability in the 2 × 2 square is \({R}_{1}\left(p\right)\), given by Eq. (A.2).
The authors in [35, 36] used the serial and parallel paths, and the 2 × 2 square, to compose larger grids hierarchically. In doing so, they encountered the triangular grid when dealing with larger grids. The triangular grid provides a means to summarize a path between two nodes at the opposite corner in a large grid. Figure

The triangular grid is composed of two parallel paths
29 indicates that the triangular grid consists of two parallel paths, each is a serial path. The first serial path consists of a single link; thus, its reachability probability is simply p. However, the second path is serial, and its reachability probability is.\({R}_{0}\left(p\right)\). Consequently, we can write the reachability probability of the triangular grid, \({R}_{T}\left(p\right)\) using the principle of inclusion and exclusion principle as
The study of [35, 36] has utilized the reachability probabilities obtained from Eqs. (A.1) to (A.3) to calculate the reachability probability of larger grids, including 3 × 3 and 4 × 4 squares, and so forth. It is important to note that constructing larger grids from fundamental components, such as serial paths, parallel paths, 2 × 2 squares, and triangular grids, requires addressing various unique scenarios separately. Due to the lengthy nature of explaining these cases, we refer the interested reader to [35, 36] for further information.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Ould Khaoua, A.S., Boukra, A. & Bey, F. On estimating the interest satisfaction ratio in IEEE 802.15.4-based named-data networks. Ann. Telecommun. 79, 111–130 (2024). https://doi.org/10.1007/s12243-023-00983-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12243-023-00983-6