
Abstract
Transcoding steganography (TranSteg) is a fairly new IP telephony steganographic method that functions by compressing overt (voice) data to make space for the steganogram by means of transcoding. It offers high steganographic bandwidth, retains good voice quality, and is generally harder to detect than other existing VoIP steganographic methods. In TranSteg, after the steganogram reaches the receiver, the hidden information is extracted, and the speech data is practically restored to what was originally sent. This is a huge advantage compared with other existing VoIP steganographic methods, where the hidden data can be extracted and removed, but the original data cannot be restored because it was previously erased due to a hidden data insertion process. In this paper, we address the issue of steganalysis of TranSteg. Various TranSteg scenarios and possibilities of warden(s) localization are analyzed with regards to the TranSteg detection. A novel steganalysis method based on Gaussian mixture models and mel-frequency cepstral coefficients was developed and tested for various overt/covert codec pairs in a single warden scenario with double transcoding. The proposed method allowed for efficient detection of some codec pairs (e.g., G.711/G.729), while some others remained more resistant to detection (e.g., iLBC/AMR).
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Transcoding steganography (TranSteg) is a new steganographic method that has been introduced recently by Mazurczyk et al. [25]. It is intended for a broad class of multimedia and real-time applications, but its main foreseen application is IP telephony. TranSteg can also be exploited in other applications and services (like video streaming) or wherever a possibility exists to efficiently compress the overt data (in a lossy or lossless manner).
TranSteg, like every steganographic method, can be described by the following set of characteristics: its steganographic bandwidth, its undetectability, and the steganographic cost. The term “steganographic bandwidth” refers to the amount of secret data that can be sent per time unit when using a particular method. Undetectability is defined as the inability to detect a steganogram within a certain carrier. The most popular way to detect a steganogram is to analyze the statistical properties of the captured data and compare them with the typical values for that carrier. Lastly, the steganographic cost characterizes the degradation of the carrier caused by the application of the steganographic method. In the case of TranSteg, this cost can be expressed by providing a measure of the conversation quality degradation induced by transcoding and the introduction of an additional delay.
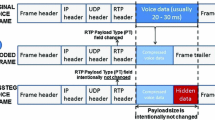
The general idea behind TranSteg is as follows (Fig. 1): Real-time transport protocol (RTP) [32] packets carrying the user's voice are inspected, and the codec originally used for speech encoding (here called the overt codec) is determined by analyzing the payload type (PT) field in the RTP header (Fig. 1.1). If typical transcoding occurs, then the original voice frames are usually recoded using a different speech codec to achieve a smaller voice frame (Fig. 1.2). But in TranSteg, an appropriate covert codec for the overt one is selected. The application of the covert codec yields a comparable voice quality but a smaller voice payload size than originally. Next, the voice stream is transcoded, but the original larger voice payload size and the codec type indicator are preserved (the PT field is left unchanged). Instead, after placing the transcoded voice of a smaller size inside the original payload field, the remaining free space is filled with hidden data (Fig. 1.3). Of course, the steganogram does not necessarily need to be inserted at the end of the payload field. It can be spread across this field or mixed with voice data as well. We assume that for the purposes of this paper, it is not crucial which steganogram spreading mechanism is used, and thus it is out of the scope of this work.

Frame bearing voice payload encoded with overt codec (1), typically transcoded (2), and encoded with covert codec (3)
The performance of TranSteg depends, most notably, on the characteristics of the pair of codecs; the overt codec originally used to encode user speech and the covert codec utilized for transcoding. In ideal conditions, the covert codec should not significantly degrade user voice quality compared to the quality of the overt codec (in an ideal situation, there should be no negative influence at all). Moreover, it should provide the smallest achievable voice payload size, as this result in the most free space in an RTP packet to convey a steganogram. On the other hand, the overt codec in an ideal situation should result in the largest possible voice payload size to provide, together with the covert codec, the highest achievable steganographic bandwidth. Additionally, it should be commonly used to avoid arousing suspicion.
In [25] a proof of concept, implementation of TranSteg was subjected to experimental evaluation to verify whether it is feasible. The obtained experimental results proved that it offers a high steganographic bandwidth (up to 32 kbit/s for G.711 as overt and G.726 as covert codecs) while introducing delays of about 1 ms and still retaining good voice quality.
In [16], the authors focused on analyzing how the selection of speech codecs affects hidden transmission performance, that is, which codecs would be the most advantageous ones for TranSteg. The results made it possible to recommend ten pairs of overt/covert codecs which can be used effectively in various conditions depending on the required steganographic bandwidth, the allowed steganographic cost, and the codec used in the overt transmission. In particular, these pairs were grouped into three classes based on the steganographic cost they introduced (Fig. 2). The pair G.711/G.711.0 is costless; nevertheless, it offers a remarkably high steganographic bandwidth, on average more than 31 kbps. However, caution must be taken, as the G.711.0 bitrate is variable and depends on an actual signal being transmitted in the overt channel. Also, the adaptive multi-rate (AMR) codec working in 12.2 kbps mode proved to be very efficient as the covert codec for TranSteg.

Steganographic cost against the steganographic bandwidth for the tested overt/covert codec pairs. Each point denotes the covert codec [16]
Our main contribution described in this paper is the development of an effective steganalysis method for TranSteg, on the assumption that we are able to capture and analyze only the voice signal near the receiver. We want to verify whether, based only on analysis of this signal, it is possible to detect TranSteg utilization for different voice codecs applied (both overt and covert). To the authors' best knowledge, this is the first approach that combines usage of mel-frequency cepstral coefficients (MFCC) with Gaussian mixture models (GMMs) for VoIP steganalysis purposes.
The rest of the paper is structured as follows: Sect. 2 presents related work on IP telephony steganalysis, Sect. 3 describes various hidden communication scenarios for TranSteg and discusses its detection possibilities considering various locations of warden(s), Sect. 4 presents the experimental methodology and results obtained, and finally, Sect. 5 concludes our work.
2 Related work
In this paper, we develop a TranSteg steganalysis method based on GMMs with the MFCCs used for signal parameterization. This method will be applied to various overt/covert codec configurations in the TranSteg technique, and its effectiveness will be verified. This section overviews existing research in two areas as follows:
-
VoIP steganalysis—Sect. 2.1.
-
Detection of double compression in digital objects and signals (images, audio, video)—Sect. 2.2.
2.1 VoIP steganalysis
Many steganalysis methods have been proposed so far. However, specific VoIP steganography detection methods are not so widespread. In this section, we consider only these detection methods that have been evaluated and proved feasible for VoIP. It must be emphasized that many so-called audio steganalysis methods were also developed for the detection of hidden data in audio files (so called audio steganography). However, they are beyond the scope of this paper.
Statistical steganalysis for least significant bits (LSB)-based VoIP steganography was proposed by Dittmann et al. [7]. They proved that it was possible to detect hidden communication with almost a 99 % success rate on the assumption that there are no packet losses, and the steganogram is unencrypted/uncompressed.
Takahasi and Lee [33] described a detection method based on calculating the distances between each audio signal and its de-noised residual by using different audio quality metrics. Then, a support vector machine (SVM) classifier is utilized for detection of the existence of hidden data. This scheme was tested on LSB, direct sequence spread spectrum, frequency-hopping spread spectrum, and echo hiding methods, and the results obtained show that for the first three algorithms, the detection rate was about 94 %, and for the last, it was about 73 %.
A Mel-cepstrum-based detection, known from speaker and speech recognition, was introduced by Kraetzer and Dittmann [19] for the purpose of VoIP steganalysis. On the assumption that a steganographic message is not permanently embedded from the start to the end of the conversation, the authors demonstrated that detection of an LSB-based steganography is efficient with a success rate of 100 %. This work was further extended by [21] employing an SVM classifier. In [20], it was shown for an example of VoIP steganalysis that channel character specific detection performs better than when channel characteristic features are not considered.
Steganalysis of LSB steganography based on a sliding window mechanism and an improved variant of the previously known regular singular (RS) algorithm was proposed by Huang et al. [14]. Their approach provides a 64 % decrease in the detection time over the classic RS, which makes it suitable for VoIP. Moreover, experimental results prove that this solution is able to detect up to five simultaneous VoIP covert channels with a 100 % success rate.
Huang et al. [13] also introduced the steganalysis method for compressed VoIP speech that is based on second order statistics. In order to estimate the length of the hidden message, the authors proposed to embed hidden data into sampled speech at a fixed embedding rate, followed by embedding other information at a different level of data embedding. Experimental results showed that this solution makes it possible not only to detect hidden data embedded in a compressed VoIP call, but also to accurately estimate its size.
Steganalysis that relies on the classification of RTP packets (as steganographic or non-steganographic ones) and utilizes specialized random projection matrices that take advantage of prior knowledge about the normal traffic structure was proposed by Garateguy et al. [10]. Their approach is based on the assumption that normal traffic packets belong to a subspace of a smaller dimension (first method), or that they can be included in a convex set (second method). Experimental results showed that the subspace-based model proved to be very simple and yielded very good performance, while the convex set-based one was more powerful, but more time consuming.
Arackaparambil et al. [1] analyzed how, in the distribution-based steganalysis, the length of the window of the detection threshold, and in which the distribution is measured, should be depicted to provide the greatest chance of success. The results obtained showed how these two parameters should be set for achieving a high rate of detection, while maintaining a low rate of false positives. This approach was evaluated based on real-life VoIP traces and a prototype implementation of a simple steganographic method.
A method for detecting complementary neighbor vertices-quantization index modulation steganography in G.723.1 voice streams was described by Li and Huang [22]. This approach is to build the two models, a distribution histogram and a state transition model, to quantify the codeword distribution characteristics. Based on these two models, feature vectors for training the classifiers for steganalysis are obtained. The technique is implemented by constructing an SVM classifier, and the results show that it can achieve an average detection success rate of 96 % when the duration of the G.723.1 compressed speech bit stream is less than 5 s.
2.2 Double compression detection
To detect TranSteg in some scenarios presented in detail in the next section, it is possible to look for artifacts caused by transcoding. Discovering the existence of double compression has been a subject of numerous analyses for digital images (e.g., [28], [35]) and digital audio (mostly wideband MP3 files [23], [24]) and video ([38], [34]) signals.
However, to the authors' best knowledge presented in this paper, approach is the first targeted for narrowband VoIP steganalysis that combines the usage of GMMs with the MFCCs for this purpose.
3 TranSteg detection possibilities
It must be emphasized that currently for network steganography, as well as for digital media (image, audio, video files) steganography, there is still no universal “one size fits all” detection solution, so steganalysis methods must be adjusted precisely to the specific information-hiding technique (see Sect. 2).
Typically, it is assumed that the detection of hidden data exchange is left for the warden [8]. In particular it:
-
is aware that users can be utilizing hidden communication to exchange data in a covert manner
-
has a knowledge of all existing steganographic methods, but not of the one used by those users
-
is able to try to detect and/or interrupt the hidden communication.
Let us consider the possible hidden communication scenarios (S1–S4 in Fig. 3), as they greatly influence the detection possibilities for the warden. For VoIP steganography, there are three possible localizations for a warden (denoted in Fig. 3 as W1–W3). A node that performs steganalysis can be placed near the sender or receiver of the overt communication or at some intermediate node. Moreover, the warden can monitor network traffic in single (centralized warden) or multiple locations (distributed warden). In general, the localization and number of locations in which the warden is able to inspect traffic influences the effectiveness of the detection method.

Hidden communication scenarios for VoIP
For TranSteg-based hidden communication, we assume that the warden will not be able to “physically listen” to the speech carried in RTP packets because of the privacy issues related with this matter. This means that the warden will be capable of capturing and analyzing the payload of each RTP packet, but not capable of replaying the call's conversation (its content), i.e., without a human-in-the-loop.
It is worth noting that communication via TranSteg can be thwarted by certain actions undertaken by the wardens. The method can be defeated by applying random transcoding to every non-encrypted VoIP connection to which the warden has access. Alternatively, only suspicious connections may be subject to transcoding. However, such an approach would lead to a deterioration of the quality of conversations. It must be emphasized that not only steganographic calls would be affected—the non-steganographic calls could also be “punished”.
To summarize, the successful detection of TranSteg mainly depends on:
-
the location(s) at which the warden is able to monitor the modified RTP stream
-
the utilized TranSteg scenario (S1—S4)
-
the choice of the covert and overt codec
-
whether encryption of RTP streams is used.
Let us now consider the distributed warden. When it inspects traffic in at least two localizations, three cases are possible.
-
DWC1: When the warden inspects traffic in localizations, in which RTP packet payloads are coded with overt and then with covert codec (e.g., in scenario S2 localizations W2&W3; in S3 localizations W1&W2). In that case, simple comparison of payloads of certain RTP packets is enough to detect TranSteg.
-
DWC2: When the warden inspects traffic in localizations, in which there is no change of transcoded traffic (e.g., scenario S1 and any two localizations; S2 and localizations W1&W2). In that case, comparing payloads of certain RTP packets is useless, as they are exactly the same. However, other detection techniques may be applied here. First, packets can undergo a codec validity test, i.e., they can be checked to determine if selected fields of their payload correspond to the codec type declared in the RTP header. This method can lead to successful detection of TranSteg in most cases. For example, in TranSteg with the Speex as the overt and G.723.1 as the covert codecs pair, if Speex is expected then the first five bits of the payload are supposed to contain the wideband flag and the mode type, while the first six bits of the G.723.1 payload contain one of the prediction coefficients, so they are variable. Another method consists of simply trying to decode speech with a codec declared in the RTP header. The output signal usually must not be exposed to any human due to the privacy issues mentioned earlier; however, it can undergo voice activity detection to check if it contains a speech-like signal [29]. However, it must be noted that if encryption of the data stream is applied, e.g., by means of the most popular secure RTP (SRTP) [2] protocol, then the abovementioned techniques would most likely fail.
-
DWC3: When the warden inspects traffic in localizations, in which the voice is coded with overt codec (scenario S4 and localizations W1&W3). In that case, only if lossless TranSteg transcoding was utilized (e.g., for G.711 as overt and G.711.0 as covert codecs), then the payload values are the same, and TranSteg detection is impossible. For other overt/covert codecs pairs, comparison of payloads of certain RTP packets would be enough to detect TranSteg.
If the warden is capable of inspecting traffic solely in a single localization (the more realistic assumption), then the detection is harder to accomplish than for a distributed warden. Also three cases are possible:
-
SLWC1: The warden analyzes the traffic that has not yet been subjected to transcoding caused by TranSteg, and the voice is coded with overt codec (scenarios S3 and S4, localization W1). In that case, it is obvious that TranSteg detection is impossible.
-
SLWC2: The warden analyzes the traffic that has been subjected to TranSteg transcoding, and the voice is coded with covert codec (e.g., scenario S1 and any localization, S2 and localization W1, or W2). This situation is the same as for case DWC2 for a distributed warden.
-
SLWC3: The warden analyzes the traffic that has been subjected to TranSteg re-transcoding, and the voice is again coded with overt codec (scenarios S2 and S4, localization W3). This situation is similar to the case DWC3 for a distributed warden, if lossless TranSteg transcoding was utilized. If a pair of lossy overt/covert codecs is used, the detection is not trivial, as only re-transcoded, but encoded with an overt codec, voice signal is available.
Table 1 summarizes the abovementioned TranSteg detection possibilities. It must be emphasized that if encryption of RTP streams is performed, then for scenarios S1–S3, it further masks TranSteg utilization and defeats the simple steganalysis methods indicated below. For scenario S4, encryption prevents TranSteg usage.
In this paper, we focus on TranSteg detection for the worst-case scenario from the warden's point of view. We assume that the warden is capable of inspecting the traffic only in single location (the most realistic assumption). Moreover, we exclude those cases where lossless compression was utilized—as stated above, in these situations, the warden is helpless. That is why we focus on the case SLWC3, i.e., that only re-transcoded voice is available, and a lossy pair of overt/covert codecs was used, i.e., scenario S4 and localization W3.
It must be emphasized that especially for this scenario, TranSteg steganalysis is harder to perform than for most of the existing VoIP steganographic methods. This is because after the steganogram reaches the receiver, the hidden information is extracted, and the speech data is practically restored to the originally sent data. As mentioned above, this is a huge advantage compared with existing VoIP steganographic methods, where the hidden data can be extracted and removed, but the original data cannot be restored because it was previously erased due to a hidden data insertion process.
4 TranSteg steganalysis experimental results
4.1 Experiment methodology
As mentioned in the previous section, in our experiments, we decided to check the possibility of TranSteg detection in the S4 scenario, when no reference signal is available, i.e., when a single warden is used at location W3 (case SLWC3). Since a comparison with the original data is not possible, we decided to use a detection method based on comparing parameters of the received signal against models of a normal (without TranSteg) and abnormal (with TranSteg) output speech signal.
We chose MFCCs as the type of parameters to be extracted from the speech signal. The MFCC parameters have been successfully used in speech analysis since the 1970s and have been continuously employed in both speech and speaker recognition [9], as they have proved able to describe efficiently spectral features of speech. On the other hand, lossy speech codecs affect the speech spectrum, e.g., by smoothing the spectral envelope of the signal, so we hoped that the MFCC parameters would be helpful in detecting transcoding present in TranSteg. The same parameters have already been used in steganalysis in [19] (see Sect. 2), where they fed an SVM-based classifier.
In our approach, however, as a modeling method, we decided to use GMMs [30], since, combined with MFCCs, they have proved successful in various applications, including text-independent speaker recognition [36] and language recognition [31]; however, no reports so far have been found on using GMMs in steganalysis.
The idea of GMMs modeling is to represent statistical parameters of, e.g., signal features using a linear combination of N (e.g., 16) Gaussian distributions. The GMM model is usually trained using expectation-maximization (EM) algorithm, during which λ i , μ i , and Σι (weight, mean values, and covariance matrix, respectively) of each of the ith Gaussian components are iteratively set. During recognition, the actual speech signal parameters are compared against the models of the signal trained on speech with and without TranSteg. If, e.g., 12 MFCC parameters are analyzed, 12-dimentional GMMs must be used. The number of MFCC parameters needed for effective steganalysis will be researched later in this study. Figure 4, created during one of our experiments, shows that MFCC parameters combined with GMM modeling are able to capture the differences between speech with and without TranSteg (for the sake of clarity, the cast of only the first three dimensions is shown).

Comparison of Gaussian mixture densities for normal G.711 transmission (black line) and transmission with TranSteg in S4 scenario (red line) for G.711/G.726 configuration. The first (left), second (middle), and third (right) MFCC coefficients are shown
A series of experiments for various overt/covert pairs of codecs were conducted, including all the pairs which were recommended in [16] due to their achievable low steganographic cost and high steganographic bandwidth.
For each overt/covert codec pair, the experiment consisted of the following stages:
-
A GMM model for normal speech transmission (no TranSteg) using a codec X was trained based on MFCC parameters extracted from the training speech signal.
-
A GMM model for abnormal speech transmission (TranSteg active) using a pair of codecs X/Y was trained based on MFCC parameters extracted from the training speech signal.
-
Using the two above GMM models, we checked if it is possible to recognize normal (no TranSteg) from abnormal (TranSteg active) transmission for a speech signal from test corpora.
Speech analysis was performed with an analysis window of 30 ms and analysis step of 10 ms using the Voicebox toolkit [3] for Matlab®. MFCC parameters were extracted using the FilterBank consisting of 26 triangle filters spaced according to the mel scale. We used GMM models with 16 Gaussians and diagonal covariance matrixes. Transcoding was performed using the SoX package [26], Speex emulation [37], and “G.723.1 speech coder and decoder” [18] library. Packet losses were not considered in this study. The number of MFCC parameters, as well as the length of testing signal, was subjects of experiments, the results of which will be presented in the next section.
Speech data used in experiments was extracted from the following five different speech corpora:
-
TIMIT [11], containing speech data from 630 speakers of 8 main dialects of US English, each of them uttering 10 sentences;
-
TSP speech corpus [17], containing 1,400 recordings from 24 speakers, originally recorded with 48 kHz sampling, but also filtered and subsampled to different sample rates;
-
CHAINS corpus [6], with 36 speakers of Hiberno–English recorded under a variety of speaking conditions;
-
CORPORA—a speech database for Polish [12], containing over 16,000 recordings of 37 native Polish speakers reading 114 phonetically rich sentences and a collection of first names;
-
AHUMADA—a spoken corpus for Castilian Spanish [27], containing recordings of 104 male voices, recorded in several sessions in various conditions (in situ and telephony speech, read and spontaneous speech, etc.).
GMM models for normal and abnormal transmissions were trained using the EM algorithm. The initial position of Gaussian components was set using the vector quantization algorithm. As the training data, 1,600 recordings from the TIMIT corpus were used, originating from 200 speakers, each of them saying eight various sentences (two of the so-called SA TIMIT sentences were omitted because they were the same for all speakers, thus they could bias the acoustic models). In total, 90 min of speech were used to train both normal and abnormal models in each of the overt/covert scenarios.
Testing TranSteg detection was performed using the following test sets:
-
Fifty speakers from the TIMIT corpus, different from the ones used for training, hereinafter denoted as TIM;
-
Twenty-three speakers from the TSP speech corpus from the “16 k-LP7” subset, hereinafter denoted as TSP;
-
Thirty-six speakers from the CHAINS corpus from the “solo” subset, hereinafter denoted as CHA;
-
Thirty-seven adult speakers from the CORPORA corpus, hereinafter denoted as COR;
-
Twenty-five male speakers from the AHUMADA corpus from in situ recordings (read speech), hereinafter denoted as AHU.
So the three first test corpora contained speech in English and the last two ones in Polish and Spanish, respectively. Each speech signal being tested contained recordings of one speaker only, to imitate the most common case if analyzing one channel of a VoIP conversation. Both training and testing were realized in the Matlab® environment using the h2m toolkit [5].
TranSteg detection process is visualized in Fig. 5. First, the tested speech signal undergoes the MFCC extraction, similarly as in the training process. Next, two GMM models are used: the normal and abnormal ones, and the two probability scores are calculated based on the MFCC vectors extracted from the utterance. These two scores are compared, and, finally, a decision is made whether the spectral statistics of the speech signal are closer to the normal or the abnormal transmission model. In the latter case, it is believed that a transcoding took place. During experiments, it will be shown if this procedure is capable of detecting TranSteg for various combinations of overt and covert codecs.

Scheme of the TranSteg detection process
4.2 Experimental results
The experiments were evaluated by calculating the recognition accuracy as the percentage of correct detections of normal and abnormal transmissions against all recognition trials. Results as low as around 50 % mean that recognition accuracy is at a chance level; a result of 100 % would mean an errorless detection of the presence or absence of TranSteg.
The first experiments were run to estimate the length of speech data required for effective steganalysis of TranSteg. Since the technique applied is based actually on statistical analysis of spectral parameters of speech, the amount of data required for analysis must be sufficiently high—such an analysis cannot be performed on speech extracted from a single 20 ms VoIP packet, or even from a few packets in a row. We ran our experiments on test signals ranging from 260 ms to 10 s; if we consider 20 ms packets, these correspond to the range between 13 and 500 voice packets.
The results of TranSteg recognition accuracy show that in some cases, the accuracy grows steadily as the length of speech data increases and becomes saturated after ca. 5–6 s (see the G.711/G.726 case presented in Fig. 6 on the left). It turns out that steganalysis based on a hundred 20-ms packets with speech data from the CHAINS corpus is successful with only 70 % accuracy, but if we have a signal four times longer (8 s), the accuracy exceeds 90 %. This means that in this case, TranSteg needs to be active for a longer time in order to be spotted. In other cases (see,e.g., the G.711/Speex7 pair in Fig. 6 on the right, or Speex7/iLBC), the recognition accuracy initially grows, but after 2–3 s, it starts to oscillate around certain levels of accuracy. As an outcome of these experiments, for further analyses, we decided to choose 7 s long speech signals.

TranSteg recognition accuracy vs. duration of the test signal, for G.711/G.726 (left) and G.711/Speex7 (right) configurations, for various test sets
Next, experiments were aimed at deciding how many MFCC coefficients are needed for efficient TranSteg detection. In speech recognition, usually 12 coefficients are used, usually with dynamic derivatives. In speaker recognition 12, 16, 19, or even 21 coefficients are used, in order to capture individual characteristics of a speaker ([4], [15]). Since here we are dealing with a different task, the number of MFCC coefficients required experimental verification. We checked the recognition accuracy for various overt/covert pairs of codecs for the number of MFCC coefficients ranging from 1 to 19.
The results show that in most cases, the increase of the number of MFCC coefficients is beneficial, as presented for the configuration G.711/GSM06.10 in Fig. 7 (left). It is noteworthy that for the AHU, CHA, and COR test sets, recognition with less than five MFCCs is very poor. On the other hand, in some cases, as shown in Fig. 7 (right) for iLBC/AMR, when the number of MFCCs exceeds 10–12, the recognition accuracy starts to decrease. As a conclusion, it was decided to use 19 MFCC parameters in most cases and 12 MFCC parameters for just a few cases: G.711/G.726, G.711/Speex7, G.711/AMR, iLBC/GSM 06.10, and iLBC/AMR.

TranSteg recognition accuracy vs. number of MFCC coefficients used in recognition, for G.711/GSM06.10 (left) and iLBC/AMR (right) configurations, for various test sets
The detailed results of TranSteg recognition for various overt/covert codec configurations and various test sets are presented in Table 2. It shows that the performance varies from slightly over 58 % (which is close to random) for G.711/Speex7 for the COR test set, up to 100 % for Speex7/G.729 for the TIM test set. In general, the results for TIM usually outperformed the remaining test sets. This is understandable, considering the fact that other data from the same corpus (TIMIT) was used to train speech models, so similarities of recording conditions turned out to be an advantageous factor. This is why the results presented in Fig. 7 exclude the TIMIT corpus and instead show the recognition results for the remaining datasets on average, as well as being divided into English and non-English datasets.
Both Table 2 and Fig. 8 show that pairs G.711/Speex7, Speex7/AMR and the configurations with iLBC as the overt codec are quite resistant to steganalysis using the described method. The most resistant G.711/Speex7 and iLBC/AMR configurations can be detected with average recognition accuracy of only 63.3 and 67 %, respectively. Other pairs with G.711 as the overt codec are much easier to detect (provided that we analyze enough speech data, in this case: 7 s), for example, the pair G.711/G.726 was detected with 94.6 % accuracy. So was the pair Speex7/G.729, for which the presence (or absence) of TranSteg was correctly recognized in 90 % of cases.

Average TranSteg recognition accuracy for various overt/covert codec configurations, for English and non-English datasets (excluding TIM)
We found some correlation between steganographic cost and detectability of TranSteg, for example, the Speex7/G.729 pair offers a relatively high steganographic cost of 0.74 MOS, and at the same time, it can be relatively easily detected (90 % accuracy); the pair iLBC/AMR allows for TranSteg transmission with the cost of 0.46 MOS only, and is also difficult to detect. There are, however, a few exceptions to this rule, for example, the three covert codecs (G.726, AMR, and Speex7) offering similar steganographic cost with G.711 as the overt one (ca. 0.4 MOS, see Fig. 2) behave quite differently as concerns the TranSteg detectability; G.711/G.726 can be recognized quite easily, while G.711/Speex7 proved to be the most resistant to steganalysis using the GMM/MFCC technique.
In general, TranSteg configurations with Speex7 and AMR as the covert codecs proved to be the most difficult to detect. This is confirmed in Fig. 9 (left). Figures 8 and 9 show that the test sets for English were usually better recognized than non-English ones. This can be explained by the fact that the normal and abnormal speech models were trained just for English. Interestingly, a few configurations turned out to be “language-independent”, e.g., the pairs with G.723.1 and Speex7 as the covert codec have the same TranSteg recognition accuracy results for both English and non-English datasets (see Figs. 8 and 9).

Average TranSteg recognition accuracy for various covert codecs (left) and test sets (right)
5 Conclusions and future work
TranSteg is a fairly new steganographic method dedicated to multimedia services like IP telephony. In this paper, the analysis of its detectability was presented for a variety of TranSteg scenarios and potential warden configurations. Particular attention was turned towards the very demanding case of a single warden located at the end of the VoIP channel (scenario S4). For this purpose, a novel steganalysis method based on the GMM models and MFCC parameters was proposed, implemented, and thoroughly tested.
The results showed that the proposed method allowed for efficient detection of some codec pairs, e.g., G.711/G.726, with an average detection probability of 94.6 %, or Speex7/G.729 with 89.6 % detectability, or Speex7/iLBC, with 86.3 % detectability. On the other hand, some TranSteg pairs remained resistant to detection using this method, e.g., the pair iLBC/AMR, with an average detection probability of 67 %, which we consider to be low. We found some correlation between steganographic cost of an overt/covert codec pair and detectability of TranSteg—usually the lower the cost, the more difficult the detection of TranSteg. However, some results were surprising, e.g., the G.711/G.726 pair, with low steganographic cost (0.42 MOS) turned out to be relatively easy to detect. In contrast, the pair G.711/Speex7, offering similar cost, proved to be resistant to steganalysis, with recognition accuracy of 63.3 % only, and, what is more, with higher steganographic bandwidth. This confirms that TranSteg with properly selected overt and covert codecs is an efficient steganographic method if analyzed with a single warden.
Successful detection of TranSteg using the described method, for a single warden at the end of the channel, requires at least 2 s of speech data to analyze, i.e., a hundred 20-ms VoIP packets. This should not be a problem, considering the fact that phone conversations last for minutes. However, if the overt channel contained not speech, but a piece of music, noise, or just silence, the detectability of TranSteg would be seriously affected.
It must also be noted that, especially for the inspected hidden communication scenario (S4), TranSteg steganalysis is harder to perform than most of the existing VoIP steganographic methods. This is because, after the steganogram reaches the receiver, the hidden information is extracted, and the speech data is practically restored to the data originally sent. If changes are made to the signal, they are not easily visible without a proper spectral and statistical analysis. This is a huge advantage compared with existing VoIP steganographic methods, where the hidden data can be extracted and removed, but the original data cannot be restored because it was previously erased due to a hidden data insertion process.
Future work will include developing an effective steganalysis method when encryption using SRTP is utilized. Efficiency of using alternatives to MFCC parameters, e.g., the use of linear prediction coding coefficients can be verified in future experiments too. We also plan to verify the suitability of the proposed in this paper steganalysis method for detection of other VoIP steganography solutions.
References
Arackaparambil C, Yan G, Bratus S, Caglayan A (2012) On Tuning the Knobs of Distribution-based Methods for Detecting VoIP Covert Channels. In: Proc. of Hawaii International Conference on System Sciences (HICSS-45), Hawaii, January 2012
Baugher M, Casner S, Frederick R, Jacobson V (2004) The Secure Real-time Transport Protocol (SRTP), RFC 3711
Brooks M, VOICEBOX: Speech Processing Toolbox for MATLAB, http://www.ee.ic.ac.uk/hp/staff/dmb/voicebox/voicebox.html.
Campbell WM, Broun CC (2000) A computationally scalable speaker recognition system. Proc. EUSIPCO 2000 Tampere, Finland, pp 457–460
Cappé O. h2m Toolkit. http://www.tsi.enst.fr/∼cappe/
Cummins F, Grimaldi M, Leonard T, Simko J (2006) The CHAINS corpus: CHAracterizing INdividual Speakers. In: Proc of SPECOM’06, St Petersburg, Russia, 2006, pp 431–435
Dittmann J, Hesse D, Hillert R (2005) Steganography and steganalysis in voice-over IP scenarios: operational aspects and first experiences with a new steganalysis tool set. In: Proc SPIE, Vol 5681, Security, Steganography, and Watermarking of Multimedia Contents VII, San Jose, pp 607–618
Fisk G, Fisk M, Papadopoulos C, Neil J (2002) Eliminating steganography in Internet traffic with active wardens, 5th international workshop on information hiding. Lect Notes Comput Sci 2578:18–35
Furui S (2009) Selected topics from 40 years of research in speech and speaker recognition, Interspeech 2009, Brighton UK
Garateguy G, Arce G, Pelaez J (2011) Covert Channel detection in VoIP streams. In: Proc. of 45th Annual Conference on Information Sciences and Systems (CISS), March 2011, pp 1–6
Garofolo J, Lamel L, Fisher W, Fiscus J, Pallett D, Dahlgren N et al (1993) TIMIT acoustic-phonetic continuous speech corpus. Linguistic Data Consortium, Philadelphia
Grocholewski S (1997) CORPORA—Speech Database for Polish Diphones, 5th European Conference on Speech Communication and Technology Eurospeech’97. Rhodes, Greece
Huang Y, Tang S, Bao C, Yip YJ (2011) Steganalysis of compressed speech to detect covert voice over Internet protocol channels. IET Inf Secur 5(1):26–32
Huang Y, Tang S, Zhang Y (2011) Detection of covert voice-over internet protocol communications using sliding window-based steganalysis. IET Commun 5(7):929–936
Janicki A, Staroszczyk T (2011) Speaker Recognition from Coded Speech Using Support Vector Machines. In: Proc. TSD (2011) LNAI 6836. Springer, Berlin-Heidelberg, pp 291–298
Janicki A, Mazurczyk W, Szczypiorski S (2012) Influence of Speech Codecs Selection on Transcoding Steganography. Accepted for publication in Telecommunication Systems: Modeling, Analysis, Design and Management, to be published, ISSN: 1018–4864, Springer US, Journal no. 11235
Kabal P (2002) TSP speech database, Tech Rep, Department of Electrical & Computer Engineering, McGill University, Montreal, Quebec, Canada
Kabal P (2009) ITU-T G.723.1 Speech Coder: A Matlab Implementation, TSP Lab Technical Report, Dept. Electrical & Computer Engineering, McGill University, updated July 2009. http://www-mmsp.ece.mcgill.ca/Documents)
Kräetzer C, Dittmann J (2007) Mel-Cepstrum Based Steganalysis for VoIP-Steganography. In: Proc. of the 19th Annual Symposium of the Electronic Imaging Science and Technology, SPIE and IS&T, San Jose, CA, USA, February 2007
Kräetzer C, Dittmann J (2008) Cover Signal Specific Steganalysis: the Impact of Training on the Example of two Selected Audio Steganalysis Approaches. In: Proc. of SPIE-IS&T Electronic Imaging, SPIE 6819
Kräetzer C, Dittmann J (2008) Pros and cons of mel-cepstrum based audio steganalysis using SVM classification. Lect Notes Comput Sci LNCS 4567:359–377
Li S, Huang Y (2012) Detection of QIM Steganography in G.723.1 Bit Stream Based on Quantization Index Sequence Analysis, Journal of Zhejiang University Science C (Computers & Electronics) – to appear in 2012
Liu Q, Sung A, Qiao M (2010) Detection of double MP3 compression. Cogn Comput 2:291–296
Luo D, Luo W, Yang R, Huang J (2012) Compression history identification for digital audio signal, In Proc. of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2012)
Mazurczyk W, Szaga P, Szczypiorski K (2012) Using transcoding for hidden communication in IP telephony. In: Multimedia Tools and Applications, DOI 10.1007/s11042-012-1224-8
Norskog L, Bagwell C. SoX - Sound eXchange, available at http://sox.sourceforge.net/
Ortega García J, González Rodríguez J, Marrero-Aguiar V (2000) AHUMADA: a large speech corpus in Spanish for speaker characterization and identification. Speech Comm 31:255–264
Pevny T, Fridrich J (2008) Detection of double-compression in JPEG images for applications in steganography. IEEE Trans Inf Forensic Secur 3(2):247–258
Ramírez J, Górriz JM, Segura JC (2007) Voice Activity Detection. Fundamentals and Speech Recognition System Robustness. In: Grimm M, Krosche K (June 2007) Robust Speech Recognition and Understanding. I-Tech, Vienna, Austria
Reynolds DA (1995) Speaker identification and verification using Gaussian mixture speaker models. Speech Comm 17(1):91–108
Rodriguez-Fuentes LJ, Varona A, Diez M, Penagarikano M, Bordel G (2012) Evaluation of Spoken Language Recognition Technology Using Broadcast Speech: Performance and Challenges. In: Proc. Odyssey 2012, Singapore
Schulzrinne H, Casner S, Frederick R, Jacobson, V (2003) RTP: A Transport Protocol for Real-Time Applications. IETF, RFC 3550, July 2003
Takahashi T, Lee W (2007) An assessment of VoIP covert channel threats. In: Proc 3rd Int Conf Security and Privacy in Communication Networks (SecureComm 2007), Nice, France, pp 371–380
Wang W, Farid H (2006) Exposing digital forgeries in video by detecting double MPEG compression, MM&Sec’06, September 26–27, 2006. Switzerland, Geneva
Wang J, Liu G, Dai Y, Wang Z (2009) Detecting JPEG image forgery based on double compression. J Syst Eng Electron 20(5):1096–1103
Wildermoth BR, Paliwal KK (2003) GMM-based speaker recognition on readily available databases. Microelectronic Engineering Research Conference, Brisbane
Xiph-OSC: Speex: A free codec for free speech: Documentation, available at http://www.speex.org/docs/
Xu J, Su Y, You X (2012) Detection of video transcoding for digital forensics, Audio, Language and Image Processing (ICALIP), 2012 International Conference on, vol., no., pp.160,164, 16–18 July 2012
Acknowledgments
This research was partially supported by the Polish Ministry of Science and Higher Education and Polish National Science Center under grants: 0349/IP2/2011/71 and 2011/01/D/ST7/05054.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Janicki, A., Mazurczyk, W. & Szczypiorski, K. Steganalysis of transcoding steganography. Ann. Telecommun. 69, 449–460 (2014). https://doi.org/10.1007/s12243-013-0385-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12243-013-0385-4