
Abstract
Despite considerable concern about how human trafficking offenders may use the Internet to recruit their victims, arrange logistics or advertise services, the Internet-trafficking nexus remains unclear. This study explored the prevalence and correlates of a set of commonly-used indicators of labour trafficking in online job advertisements. Taking a case study approach, we focused on a major Lithuanian website aimed at people seeking work abroad. We examined a snapshot of job advertisements (n = 430), assessing both their general characteristics (e.g. industry, destination country) and the presence of trafficking indicators. The vast majority (98.4%) contained at least one indicator, suggesting certain "indicators" may in fact be commonplace characteristics of this labour market. Inferential statistical tests revealed significant but weak relationships between the advertisements’ characteristics and the number and nature of indicators present. While there may be value in screening job advertisements to identify potential labour trafficking and exploitation, additional information is needed to ascertain actual labour trafficking. We conclude with an outlook on automated approaches to identifying cases of possible trafficking and a discussion of the benefits and ethical concerns of a data science-driven approach.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Context
Although the scale of human traffickingFootnote 1 remains highly contested, recent decades have seen a rapid increase in legislation, policy-making, practical interventions and research designed to tackle this complex phenomenon (Cockbain and Bowers 2019; Gozdziak and Bump 2008; Weitzer 2015; Gallagher 2017). Among other socio-economic and socio-political factors, the globalisation of the world economy is thought to have expanded the transnational market for human trafficking (Aronowitz 2001). People can be trafficked for various purposes, including sexual exploitation, domestic servitude (exploitation within a private household), organ harvesting or labour exploitation across numerous licit and illicit markets (UNODC 2016; Cockbain and Bowers 2019; Cockbain and Olver 2019). This paper focuses specifically on trafficking for labour exploitation, hereafter "labour trafficking".
One of the pillars of the European Union (EU) is the free movement of people and goods across its Member States: while providing significant economic benefits (McCreevy 2011), it can also make it easier for offenders to move victims between countries. Europol’s (2016) report on human trafficking states Western and Southern European Member States are key destination countries within the EU.Footnote 2 Meanwhile, Eurostat’s (2015) data show that more registered victimsFootnote 3 per capita came from Romania, Bulgaria, Poland, Slovakia and Lithuania in 2010–2012 than any other Member State (Eurostat 2015). Although the traditional distinction between countries as "source", "transit" or "destination" has been challenged as reductiveFootnote 4 (Kragten-Heerdink et al. 2017), the issue of trafficking flows from poorer EU Member States to wealthier ones remains a substantial concern. In the United Kingdom (UK), for example, around 80% of labour trafficking victims identified between 2009 and 2014 came from within the EU (Cockbain and Bowers 2019), in particular from Slovakia, Poland, Lithuania, Romania, Czech Republic and Hungary. Although research and responses around human trafficking have long focused overwhelmingly on sex trafficking, recent years have seen growing concerns about labour trafficking (Cockbain et al. 2018; UNODC 2016). Labour trafficking is estimated to be the second most prevalent form of human trafficking in the EU overall (after sex trafficking) (Europol 2016). In the UK, labour trafficking is now the most common trafficking type among identified and suspected victims (Cockbain and Bowers 2019; National Crime Agency 2019).
The Internet has expedited globalisation and the disintegration of traditional state borders (Fox 2001). Internet usage has proliferated over the past decades with Eurostat estimating that 72% of individuals in the EU accessed the Internet on a daily basis in 2017, compared to 65% in 2014 (Eurostat 2014, 2018). This shift of activities to the online sphere is said to have happened within the human trafficking space too and internet-enabled trafficking is now identified as an emerging problem (Sykiotou 2007; Milivojevic 2012). Yet, research on the topic remains scarce and is disproportionately focused on sex trafficking (Latonero 2011; Musto and Boyd 2014; Latonero et al. 2015). Within trafficking research and responses in general, a tendency to conflate human trafficking with sex trafficking alone risks obscuring crucial differences between trafficking types and impeding more nuanced analysis and intervention (Laczko and Gozdziak 2005; Goodey 2008; Strauss 2016; Efrat 2016; Cockbain and Bowers 2019). Indeed, in research on the relationship between trafficking and the Internet, accounts based on a particular trafficking type (usually sex trafficking) are often used to draw a general picture (e.g. Latonero 2011; Latonero et al. 2015). According to opportunity theories of crime, however, specific crime types are each embedded within a unique combination of circumstances and opportunities and countering them requires targeted and context-specific interventions (see, e.g. Cohen and Felson 1979; Everson 2003; Farrell and Pease 2001; Brantingham and Brantingham 1993, 1984; Felson and Eckert 2015). Since globalisation and the Internet have created a set of specific opportunities and circumstances for offenders to traffic people for labour exploitation, we aim to contribute to the disentanglement of the nexus between labour trafficking and the Internet by examining online recruitment of migrant workers.
Internet-trafficking nexus
Within the limited literature on human trafficking and the Internet, certain themes recur. For example, offenders are said to use technology to recruit their victims, arrange their transportation and logistics, exert control over them through technological surveillance and advertise their services online (Greiman and Bain 2013; Dixon 2013; Europol 2014; Latonero et al. 2015; Europol 2016). Perhaps the most contested issue is the advertising of services, most commonly discussed in the context of sexual exploitation of women and childrenFootnote 5 (Latonero 2011; Heil and Nichols 2014). Here, debate centres around the ethics of allowing such advertisements in the digital domain. For instance, Craigslist removed its Adult Services section in 2010 after widespread public pressure and criticism for enabling sexual exploitation (Kunze 2010; Dixon 2013). After the shutdown, displacement was reported both to other sections of the website and to Backpage and other websites monitored (Heil and Nichols 2014). In April 2018, the Stop Enabling Sex Traffickers Act (SESTA) and Allow States and Victims to Fight Online Sex Trafficking Act (FOSTA) were signed into United States law. Among other things, these controversial acts allow sex trafficking victims to sue websites that facilitated their exploitation. Yet, such measures have been heavily criticised for doing little actually to combat sex trafficking, pushing sex work further underground and endangering the safety and welfare of already marginalised groups (Brooks-Gorden and Sanders 2018; Smith and Mac 2018). Debate around how the Internet fuels human trafficking is often highly emotive and centres on stereotypes of predatory offenders and naïve victims in need of rescue (Milivojevic 2012), serving to sideline complex but important questions around agency and alternatives, hidden agendas and unintended consequences of counter-measures.
Given the intense political attention on human trafficking, it is hardly surprising that academic interest is growing in how computational and data science techniques could be applied to help tackle this problem. For example, the United Nations hosted a workshop in New York in 2019 entitled "Using Computation Science and AI to End Modern Slavery". Some academics have also applied various indicators to research human trafficking in the online space. For example, as part of a larger research project into the role of social networking sites and online classifieds in human trafficking, Latonero (2011) used keyword analysis associated with sex trafficking on Backpage Dallas and Twitter. The study suggested that online content can help narrow down the pool of cases for further investigation (Latonero 2011). Ibanez and Suthers (2014) collected online advertisements from Backpage Hawaii to look for sex trafficking indicators, extracting telephone numbers to examine linkages between advertisements and assess geographical circuits using social network analysis and GIS tools (Ibanez and Suthers 2014). As in Latonero’s (2011) work, however, the "indicators" themselves were treated as unproblematic. Taking a different approach, Andrews et al. (2016) investigated mechanisms by which organised crime could be detected and corroborated online through social media scanning and automated content analysis. They used human trafficking (particularly for sex) as a case study and focused on what they call "weak signals": elements that "allude to the presence and/or emergence of criminality in citizen generated content" (Andrews et al. 2016, p.141).
Offline, "indicators" of human trafficking are also used by governmental, non-governmental bodies and private businesses to identify and assess individual instances of suspected trafficking. For example, the United Nations Office for Drugs and Crime (UNODC) and the International Labour Organization (ILO) have developed extensive lists of human trafficking indicators that include, for example, signs that a person has suffered injuries, which appear to result from control measures, allows others to speak for him/her or has false identity documents (UNODC 2018; ILO 2009). These indicators are then adopted and/or adapted for use by national agencies too (e.g. National Crime Agency 2014) and in popular "spot the signs" campaigns designed to increase public awareness and reporting (e.g. Andrijasevic and Anderson 2009). Yet, there is no consensus on a concrete set of indicators to be used across different organisations and their reliability has been questioned (Laczko 2002; Andrijasevic and Anderson 2009).
There has been little to no empirical research to establish how prevalent these indicators are among identified trafficking victims (whose experiences may of course not be representative of the wider population (see Cockbain et al. 2019a)), let alone to investigate their effectiveness at distinguishing between trafficked and non-trafficked populations at scale. Things commonly listed as "indicators" might apply to many people, in particular migrants (Andrijasevic and Anderson 2009), sex workers in general or even just lone women - as reactions to a major hotel chain’s recent "spot the signs" training neatly illustrated (Shand-Baptiste 2019). In a much-publicised exercise, the Marriott chain trained their staff across 7,000 hotels on the "signs" of human trafficking, including individuals who seem disoriented, have minimal luggage and clothing, or receive multiple (escorted) visitors to their rooms (Coughlan 2019). While proactive efforts to detect human trafficking are, of course, important, some of the so-called "signs" promoted here could easily apply to non-trafficking victims, particularly consenting sex workers. There are also important and often overlooked ethical considerations in asking hotel staff (many of whom may be subject to exploitative labour practices themselves) to surveil guests on behalf of the state.
A fundamental barrier to testing indicators is that the standard international definition of trafficking is itself broad and amorphous, making it difficult to distinguish between what might be labelled trafficking and neighbouring phenomena (O'Connell Davidson 2015). Indeed, researchers increasingly argue that labour trafficking is best seen not as a clear-cut phenomenon but part of a continuum that runs from decent work to forced labour (Laczko and Gozdziak 2005; O'Connell Davidson 2015; Quirk 2011; Spencer and Broad 2012; Skeldon 2000; Weitzer 2015).
The current study
To our knowledge, there has been very little research to date into how labour trafficking might better be identified online. The aim of this study was to explore the prevalence and correlates of commonly-used indicators of labour trafficking in online job advertisements. Identified cases of labour trafficking across Europe suggest that victims may be recruited through advertisements for nannies, waitresses or jobs in cleaning, construction, transportation and agriculture (e.g. Europol 2014). With more and more people seeking work online, the Internet may provide an effective and fairly low-risk forum for offenders to recruit people into exploitative work. If it were possible to identify potential trafficking more effectively at the recruitment stage, there would be considerable potential for prevention, detection, disruption and early intervention.
Since our study explored the feasibility of identifying potential labour trafficking in online open-source data, we chose a case study approach focusing on Lithuanians seeking work abroad. Lithuania is among the top countries of origin for trafficking victims in the EU at large (e.g. Eurostat 2015), as well as being a key source for particular member states such as the UK (National Crime Agency 2019).
Although literature on human trafficking in relation to Lithuania is not extensive, Janusauskiene’s (2013) qualitative research on Lithuanian migrants who were trafficked for labour exploitation provides some useful insights. As well as analysing legal instruments to combat human trafficking, interviewing experts and victims, the author examined a sample (size and parameters not specified) of online job advertisements for indicators of potential labour trafficking (Janusauskiene 2013). The author, through a mainly descriptive observation and narrative of these advertisements, argued that recurrent features included, for instance, the promise of high wages for a relatively simple job, free housing and transportation to the country in question and limited requirements of the candidates (Janusauskiene 2013).
In our exploratory study, we sought to address the following research questions:
- 1.
To what extent are commonly-used indicators of labour trafficking found in online job advertisements aimed at Lithuanians seeking work abroad?
- 2.
Which, if any, of the characteristics of advertisements predict the overall number of indicators present?
- 3.
Are particularly "strong" indicators (seemingly illegally low pay and excessive working hours) associated with particular characteristics of the advertisements?
Methods
This section covers the ethics, sampling, data and analytical procedure. We have not only reported all exclusions, manipulations and measures here but have also made our data and coding template publicly available on the Open Science Framework. In doing so, our aim was to ensure the study is fully transparent and replicable.
Compliance with ethical standards
This research received no specific grant from any funding agency in the public, private or not-for-profit sectors. The write up of this paper fell partially under an ESRC-funded grant on transnational human trafficking (grant reference: ES/S008624/1). We declare that we have no conflicts of interest.
The study was reviewed and approved by the Ethics Panel of the UCL Departement of Security and Crime Science. It only involved material already in the public domain. In writing this paper (e.g. in presenting an example job advertisement), we have removed company names and contact information to avoid singling out particular businesses.
Sampling and data
We ran initial scoping searches on a list of employment websites compiled by the Lithuanian Labour Exchange (2018), which is responsible for public employment services and implementation of labour market policies (results in ESM 1). We selected as our source darbasuzsienyje.org (translation: workabroad.org), a major website that contained the most job advertisements overall and caters specifically to those seeking work abroad.Footnote 6 All posts on darbasuzsienyje.org come from recruitment agencies, which may be notable as outsourcing, sub-contracting and temporary or otherwise precarious employment contracts are all thought to increase the risk of exploitation and work-based harm (Davies 2018; Scott 2017; Cockbain et al. 2019b).
On a single day (21st July 2018), we collected the full set of advertisements posted over the previous week (16th-21st inclusive), which numbered 679 in total. Although we attempted to collect the data for 7 days, there were no advertisements posted on Sunday 15th July. Most advertisements were posted on Tuesday 17th and Wednesday 18th July (34.3% (n = 233) and 17.5% (n = 119) respectively). The least amount of advertisements was posted on Friday 20th July (9.7%, n = 66). On average the advertisements were 184 words long (SD = 88). We assigned each a unique identifying number and screened out duplicates (n = 249) and one (anomalous) advertisement offering work in Lithuania, which brought the final study sample to 430.
Procedure
We processed the advertisements using quantitative content analysis (Bryman 2008). We developed the coding framework iteratively, informed by the existing literature on labour trafficking. After testing the coding framework on a subset of the data, we amended it as needed for a good fit. A copy of the full final template can be found in ESM 2. The remainder of this paper focuses on the variables used for the current analysis.
In total, we examined whether ten indicators were present in any given advertisement. Most of the indicators came from the United Nations (UNODC 2018). UNODC indicators have been developed through a process of expert consensus, informed by their understanding of recurrent features of human trafficking cases. Although variations of similar lists of indicators are often used by NGOs, law enforcement, government agencies and others (e.g. National Crime Agency 2014; Home Office 2016; STOP THE TRAFFIK 2019), there is considerable cross-over between the lists and UNODC provides one of the most comprehensive overviews. Academics have also used the UNODC indicators to research human trafficking, particularly online (e.g. Ibanez and Suthers 2014). Nevertheless, the indicators themselves have not been tested empirically and their ability to distinguish between trafficked and non-trafficked individuals remains unclear, especially at aggregate level or where other information is limited.
Of the full set of indicators published by the United Nations, we considered for this project only those that were listed either as generic to all human trafficking or as specific to labour trafficking (hence we excluded, for example, those listed as specific to sex trafficking). Of the 59 potential indicators in these two categories, we excluded a further 52 as they could not reasonably be assessed from an advertisement (e.g. suffering violence) (see ESM 3 for a list of those excluded). The fact that only seven indicators could be operationalised to use in the current study highlights the challenges of using indicators developed for offline use in the online sphere. Given the limited number of suitable indicators, we also added two indicators from elsewhere in the literature (Ollus et al. 2013; Europol 2016) that appeared relevant and well-suited to assessing indicators online.
Table 1 shows how we operationalised these indicators for the study, which gave us a final set of ten indicators. We also systematically extracted additional information relevant to the given indicator so as to enhance the analysis. For example, we collected information on what level of language skills was required (basic, intermediate, fluent) and whether there was a charge for the accommodation provided.
To assess the relationship between indicators and the type of work for which they were found, we also coded on the following descriptive characteristics of the advertisements:
Country of the job
Industry (or sector) of the job
Nature of the work (e.g. low-skilled manual, skilled manual)
Contract type (e.g. seasonal or temporary, long-term)
Gender of worker sought
Age (group) of worker sought (e.g. 18–24)
Language of the advertisementFootnote 7
As might be expected in dealing with unstructured data, the variety and inconsistency of the information in the advertisements posed challenges for coding. We coded the indicators in binary terms (either present or absent). The category "absent" includes both instances where an indicator was clearly not met and where there was insufficient information to establish whether it was met. Some advertisements included an option (but not a requirement) for something that would qualify as an indicator (e.g. travel to the destination country could be arranged if desired). Similarly, some advertisements stated that local language knowledge or previous work experience would be an advantage but not a necessity to get the job. In instances such as described above, we consistently took a conservative approach, coding the indicator as absent. We found the advertisements often detailed expected hours and wages as ranges (e.g. 45 to 60 h per week). For consistency, we took the midpoint of any range. The wage variable proved particularly challenging as it was reported in different formats (e.g. hourly, weekly, monthly), currencies (e.g. Euro or GBP) and tax-related status (e.g. gross, net or unclear). In each instance, we used all the available information to make a best estimate of whether the wage on offer violated the minimum wage legislation of the destination country (for more information see ESM 4). These challenges should be remembered when interpreting the wage-related results.
The first author, a native Lithuanian speaker, coded all the advertisements, applying a consistent logic throughout. To test the reliability and replicability of our template, a random sample of 10% (n = 43) of the advertisements was then double-coded.Footnote 8 We tested intercoder reliability using Cohen’s Kappa for nominal variables and Krippendorff Alpha for ratio variables (ESM 5). Overall, the results showed good levels of consistency on almost all variables and many had almost perfect agreement (e.g. destination country, gender requirements and working hours). Lower agreement was exhibited by those variables that were subject to higher levels of interpretation, for example, previous work experience requirements.Footnote 9
Data analysis
Our analysis followed three main stages. First, we conducted a descriptive statistical analysis of the full study sample (n = 430). Second, we calculated the number of indicators (indicator count) per advertisement. Third, since the dependent variable (i.e. the number of trafficking indicators per advertisement) was a count variable, we ran a Poisson regression on the full study sample (n = 430) to test which, if any, of the descriptive characteristics of the advertisements (i.e. not the indicators themselves) predicted the overall count of labour trafficking indicators present. The model included the following predicator variables: language of the advertisement, destination country, industry of the job offered, gender and age requirements. Since some industries may typically require certain types of labour or contracts, we excluded “Job nature” and “Contract type” to avoid collinearity between predictor variables. Finally, we used chi-square testsFootnote 10 to examine further the associations between each of the descriptive characteristics and indicators of violations of a) national minimum wage and b) maximum working hours, arguably the most tangible and demonstrably concerning of all the indicators in the study. It is possible that the descriptive characteristics of advertisements are inter-dependent but exhibit equally-important associations with each of the indicators of national minimum wage and maximum working hours. Thus, using chi-square also enabled us to test the associations with “Job nature” and “Contract type”, which were excluded from the regression analysis. While the Poisson regression allowed us to test the combined effects of the descriptive characteristics of advertisements with all the indicators, chi-square tests enabled us to unpack those relationships in greater depth. Moreover, chi-square tests accommodate samples, which contain categories with relatively small counts. Thus, we conducted 14 separate chi-square tests. For both the Poisson regression and the chi-square tests, we combined certain sub-categories where necessary (i.e. where the numbers were very small) so as not to violate assumptions of the statistical tests or artificially inflate the test scores (ESM 6).
Results
In this section, we present the results of the three sets of analyses in turn.
- 1.
What type of jobs were advertised?
The descriptive statistical analysis showed certain clear commonalities between the typical jobs advertised, as well as various points of diversity. The overwhelming majority of advertisements on darbasuzsienyje.org were in Lithuanian only (95.3%, n = 410). A small proportion (4.4%, n = 19) used a mixture of Lithuanian and English (certain sentences in each language) and just one was exclusively in a foreign language (English). The Netherlands (43.0%, n = 185) and the UK (30.2%, n = 130) stood out as particularly common destinations for the work advertised, followed by Germany (12.6%, n = 54) and Cyprus (6.0%, n = 26). The rest of the work was spread across ten other countries, none of which accounted for more than 3% of the dataset: Ireland (n = 10), Denmark (n = 5), Spain (n = 5), Sweden (n = 4), Malta (n = 3), Norway (n = 3), Greece (n = 2), France (n = 1), Iceland (n = 1), and Croatia (n = 1).
As shown in Fig. 1, jobs were most commonly advertised in the following five industries: food production (26.5%, n = 114), non-food related packaging (17.2%, n = 74), hospitality (13.7%, n = 59), construction (11.4%, n = 49) and manufacturing (10.5%, n = 45). Together these five industries accounted for 79.3% (n = 341) of the dataset. The remainder of the sample was markedly more fragmented, with no other industry contributing more than 6% of advertisements.

Percentage of advertisements per industry
Figure 2 shows that the job nature (low-skilled and skilled manual labour) as well as contract type (short-term and long-term contracts) varied by industry. Across the whole dataset (n = 430), over half the advertisements were for low-skilled manual labour (55.6%, n = 239), although skilled manual labour was also offered (28.4%, n = 122).Footnote 11 However, in 51.4% (n = 221) of advertisements the type of contract on offer was not specified (51.4%, n = 221). Still, when the advertisements provided information on the length of contract it was mostly long-term (32.8%, n = 141) and greatly outnumbered short-term contracts (12.3%, n = 57).

Percentage of advertisements offering low-skilled manual, skilled manual labour as well as short-term and long-term contracts within the five most represented industries in the sample
As a rule, advertisements did not specify requirements of candidates in terms of gender (69.5%, n = 299) or age (78.4%, n = 337). If gender was stated at all, it was mostly a case of work explicitly being available for both men and women (17.7%, n = 76). Just 9.1% (n = 39) of advertisements catered exclusively to men and 3.7% (n = 16) to women. Where age requirements were stated this was generally for the broad category of 18–50-year-olds (16.0%, n = 69). All the other age groups together amounted to only 5.6% (n = 24) of the dataset.
- 2.
What trafficking indicators did the advertisements contain?
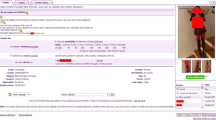
Of a possible ten indicators of trafficking, the median for the sample was 3 indicators, with a standard deviation of 1.5. Almost all advertisements had at least one indicator (only 1.6%, n = 7 had none at all) and most of the advertisements (63.7%, n = 274) had two to four indicators. Figure 3 provides an example of an advertisement containing six indicators, with brand names, websites and telephone numbers removed for confidentiality. In translating it from Lithuanian to English, we have retained the original formatting, grammar and any spelling or typographical errors.

Sample advertisement containing six indicators translated into English
Figure 4 shows the individual indicators in order of prevalence. The most common indicator by far was that accommodation was provided (95.1%, n = 409). Indeed, of those advertisements that contained only one indicator (19.8%, n = 85), nine times out of ten it was the provision of accommodation (91.8%, n = 78). Of those advertisements offering accommodation, 59.9% (n = 245) stated that the worker would pay and 26.4% (n = 108) that it would be free (payment was not specified for the rest). In a fifth of these cases (20.5%, n = 84), it was stated that the accommodation would be shared with other workers but most of the time (68.9%, n = 282) it was unclear whether accommodation would be private or shared.

Percentage of advertisements containing each indicator
Violations of national minimum wage and working hour regulations are arguably the most obvious indicators of intended exploitation - and hence potentially the ones with the greatest utility in screening high risk cases. These indicators were present in a significant minority of advertisements: 20.2% (n = 87) and 16.0% (n = 69) respectively. The two least common indicators related to no foreign language or previous work experience being needed for the work. In fact, four fifths of advertisements stipulated that some knowledge of the relevant foreign language knowledge was required (80.0%, n = 344) - although typically only to a basic level (64.2%, n = 276). Generally, previous work experience, skills or qualifications were said to be either necessary (39.1%, n = 168) or at least advantageous (10.9%, n = 47). Notably, a high proportion of advertisements simply did not specify whether previous work experience was required (37.7%, n = 162).
While detailed discussion of variation in indicators between advertisements for different countries, industries, job and contract types is beyond the remit of this study, a few brief points are worth noting. In all four countries where the most work was offered – the Netherlands, the UK, Germany and Cyprus – the most common indicator was accommodation provided.Footnote 12 Beyond this commonality, the next most prevalent indicators varied between these countries.Footnote 13 Similarly, when examined by industry, the most prevalent indicator across the industries that featured most heavily – food production, non-food related packaging, hospitality, manufacturing and construction – was the provision of accommodation too. Which of the other indicators featured most prominently then varied considerably between industries.Footnote 14 This was the case for both the job nature (low-skilled manual and skilled manual labour) as well as the contract type (long-term and short-term contracts) of the work offered.
The co-occurrence matrix presented in Table 2 shows the number of cases, in which each indicator occurred with another indicator. Because the most common indicator across the dataset was accommodation provided (95.1%, n = 409), it is perhaps unsurprising that it was an indicator that co-occurred with each of the other 9 indicators the most. The only other pair of indicators that stood out having been present together in a particularly large number of advertisements (n = 67) were help with settling in and transfer to destination provided.
- 3.
What characteristics predicted the overall number of indicators per advert?
We ran a Poisson regression on the full study sample (n = 430). The overall model was significant (at p < 0.001) in predicting the total number of labour trafficking indicators in an advertisement. The data were, however, under-dispersed (×2(410) = 255.07) with a deviance value of 0.619, indicating an acceptable although not a perfect fit. Even though the overall model was significant, of the individual variables only the destination country, industry and age requirements were significant predictors (at the threshold of p < 0.05) (see Table 3). When an advertisement was offering work in Germany, the indicator count was expected to decrease by 29% (Exp.(B) = 0.71) compared to the other countries. The rest of the destination countries had no predictive value over the indicator count.
Of the industries, only food production and hospitality were significant at predicting the indicator count (p < 0.05). Specifically, for an advertisement offering work in food production the indicator count was expected to increase by 22% (Exp.(B) = 1.22) while in hospitality the count was expected to decrease by 29% (Exp.(B) = 0.71) compared to the other industries. The rest of the industries had no predictive value.
Considering age requirements, only the category “young adult and adult (18-50)” was significant at predicting the indicator count (p < 0.01). Thus, when an advertisement required the candidates to be 18–50 years old, the indicator count was expected to increase by 31% (Exp.(B) = 1.31) compared to the reference category (advertisements where age was not specified).
- 4.
What types of jobs were associated with violations of national minimum wage and maximum working hour regulations?
Table 4 presents the results of 14 separate chi-square tests of association run between each of the descriptive advertisement characteristics and a) indicators of maximum working hour violations and b) indicators of national minimum wage violations.
The analyses showed that maximum working hour violations were significantly associated with four of the seven descriptive characteristics examined (destination country, industry, job nature and contract type). National minimum wage violations were significantly associated with six of the seven (language of advertisement, destination country, industry, job nature, gender and age requirements). Nevertheless, Cramer’s V statistics showed that the actual effect sizes were typically fairly small (meaning the relationship accounted for only a small proportion of the variance observed, i.e. indicating that other factors were at play too). The only statistically significant test that also had a moderate effect size (V = 0.421) was between the indicator of maximum working hour violations and destination country. Table 5 shows the ratios of observed and expected frequencies within chi-square tests where p < 0.001.
Jobs in the UK and Cyprus contained more indicators of excessive hours than expected (ratios of observed and expected frequencies of indicators were 1.49 and 4.31 respectively). On the other hand, those in the Netherlands and Germany had fewer indicators of excessive hours (ratios of observed and expected frequencies of indicators were 0.47 and 0.34 respectively). Moreover, advertisements offering work in Cyprus and the Netherlands were associated with higher counts of indicators of national minimum wage violations than expected while the UK and Germany were associated with lower counts.
The industries associated with more indicators of violations of maximum working hours than expected were horticulture/forestry and hospitality. On the other hand, higher counts of indicators of national minimum wage violations were observed in food production, hospitality and non-food related packaging jobs. Non-manual jobs were associated with both higher counts of indicators of maximum working hour and minimum wage violations. However, national minimum wage violations were also higher in low-skilled manual labour jobs. Interestingly, all gender requirement categories, namely, for females only, for males only and for both females and males, were associated with higher counts of indicators of national minimum wage violations than expected.
Discussion
Trying to identify possible trafficking from online job advertisements
Perhaps the most obvious finding of this study is just how challenging it is to try to identify potentially trafficking-related advertisements online. The vast majority of online advertisements (98.4%, n = 423) sampled contained at least one indicator of labour trafficking. It is highly unlikely - although theoretically possible - that all such activity was linked to intended trafficking and exploitation. It seems more plausible to conclude that the presence of a single indicator in a job advertisement has little utility in discerning between suspicious and routine activity. Indeed, indicators put forward for identifying trafficking are rarely intended to be used in isolation and the presence of more indicators would generally suggest a higher likelihood of abuse (ILO 2009). In this respect, those advertisements containing numerous indicators - for example, 15% (n = 65) had five or more - may be of particular concern.
Furthermore, exploring online job advertisements is complicated by the lack of consistency and structure of the information contained within them as seen on darbasuzsienyje.org where much of the information on any given indicator was not provided. For instance, information was often not provided on cost deduction from workers’ wages (76.5%, n = 329), transport to work provisions (75.6%, n = 325), sharing accommodation with other workers (65.6%, n = 282), help with settling in (62.8%, n = 270) and support with transfer to destination country (62.1%, n = 267). Similarly, 37.7% (n = 162) of advertisements did not specify whether previous work experience was required or not. We coded indicators as absent where there was an explicit statement contradicting the given indicator or there was no relevant information provided either way (ESM 7 shows how the absent indicators broke down across these two types). Our approach is therefore conservative: for certain indicators (e.g. previous work experience), it might seem reasonable to read the absence of any information on requirements as the absence of the necessity of having any experience or language knowledge. In turn, this may have resulted in our indicator counts being perhaps underestimated. In contrast, there were other indicators where not providing information would be more likely to mean that no such provisions were on offer, for example, support with transfer to destination country, transport to work or help with settling in. Thus, without the ability to clear up such information pre-travel, it is impossible to estimate whether such provisions would pose a risk.
Indicator utility
The task of using existing indicators to differentiate between potential trafficking activity and legitimate jobs is complicated by the fact that the indicators themselves vary in their apparent strength (or utility). Arguably, indicators of violations of national minimum wage and maximum working hours are more informative than the rest because they clearly suggest non-compliance with local labour market legislation. Conversely, such indicators as the provision of accommodation, transport to work, transfer to destination country and help with settling in are not necessarily indicative of criminal activity or exploitative conditions. While they could indicate trafficking, according to such organisations as UNODC (2018) or ILO (2009), they could also be present in legitimate work relations. Such services might be provided by employers in jobs that recruit migrant workers, who sometimes do not speak the language of the destination country or might require assistance navigating a new system. In fact, certain sectors in Western Europe are now dependent on relatively cheap migrant labour (e.g. agriculture, garments, construction, customer service, (Kelly 2005)). Therefore, it seems reasonable that employers (including employment agencies) seeking migrant labour would also be willing to provide additional support.
Nevertheless, such provisions can pose risks if they create additional dependence for workers on their employers. In some cases, this dependence can exacerbate standard power imbalances in the employer-employee relationship and serve to entrap workers in exploitative or harmful work, in most extreme cases in situations of debt bondage, forced labour or labour trafficking (Aronowitz 2001; Hopper and Hidalgo 2006; Skrivankova 2006; Craig et al. 2007). The risk of indebtedness amplifying workers’ vulnerability is particularly relevant when considering that nearly a quarter of advertisements (23.5%, n = 101) contained the indicator that costs would be deducted from workers’ wages.
Moreover, dependence can become particularly acute when the work is sub-contracted through labour market intermediaries as represented in our study. This situation arises because sub-contracting work to labour market intermediaries such as recruitment agencies complicates working relationships (Allain et al. 2013). Complex employment networks spanning multiple legal jurisdictions - as in the case of agency work involving migrant workers - increase the risk of masking exploitative labour practices due to unclear attribution of responsibility and diverse legal frameworks (Davies 2018). However, currently there is a lack of awareness on labour exploitation amongst the stakeholders responsible for labour market regulation and a lack of resources to implement effective monitoring and regulatory practices (Clark 2013). For instance, according to Lithuanian labour law, recruitment or employment agencies are not allowed to charge workers fees for their services and are required to submit a report four times a year on their activities (Law on the Ratification of the Private Employment Agencies Convention 2004). In practice, however, the reports are not available on the Lithuanian Labour Exchange website, which hinders a jobseeker from checking the credibility of a recruitment agency.
The limited job requirements in terms of language and work experience may well be related to the industries and the types of work offered rather than being indicative of exploitation per se. The indicators used in this paper, themselves taken from the human trafficking literature, could be representative of conditions that are offered to people willing to migrate for work in low-skilled industries. Note, however, that deception is said to be more common than outright coercion as a means of recruiting people - online included - into situations of labour trafficking (e.g. Ghinararu and van der Linden 2004; Ollus et al. 2013; Europol 2016; Milivojevic 2012; Dixon 2013; Europol 2014; Hughes 2014). In fact, Cockbain and Bowers (2018) found that out of all individuals from within the European Economic Area who were officially identified as labour trafficking victims in the UK in 2012 (n = 170), all of them were recruited through deception, most commonly relating to wages and the state of living conditions. Therefore, while accommodation, transfer to destination country, transport to work and help with settling in provisions might reflect the conditions that are offered to people willing to migrate, they may also be used as a recruitment method into jobs, where working conditions are not as good as they are advertised to be. After all, it is relatively easy to disguise intent to exploit in an advertisement posted online – a sphere, which provides anonymity and is un-regulated. More research is needed to explore such complexities further.
In the current paper, deception may also be relevant as jobs may be misleadingly advertised as having higher wages or lower hours than will actually be the case; in such instances, using the indicators we used would miss a crucial aspect of labour trafficking. Our analysis did not flag instances where the wage offered in the advertisement is higher than the market norm. Janusauskiene’s (2013) research on Lithuanians as victims of labour trafficking proposes that advertisements used to recruit victims into labour trafficking often offer wage that is too high for the position advertised. The working hours and wages data in the current study proved complex to process and, where ranges were given, we relied on the mean. Conversely, operationalising the wage offered in an advertisement in a way that could account for potentially deceptive wages could be useful in future research. We encourage other researchers to use our data and apply different techniques and transformations to illuminate relationships that were out of the scope of the current investigation.
Indicators are likely to be more useful when used in combination rather than alone. Therefore, the presence of multiple indicators might be taken as a particular red flag, especially if "stronger" indicators (e.g. wage violations) are found among them. For example, ILO (2009) differentiates between strong, medium or weak indicators and proposes a method of assessing individual cases for human trafficking based on the various combinations that the indicators make up. The ILO’s indicators (2009) were developed, however, through consensus from a group of experts and thereby reflect the working knowledge of experts rather than a rigorous empirical assessment. To our knowledge, there has yet to be empirical research evaluating the predictive utility of these indicators in practice in distinguishing between trafficked and non-trafficked populations.
Part of the challenge here is that trafficking is not a clear-cut phenomenon that can be neatly disentangled from neighbouring issues and is better seen as part of a broader continuum that runs from decent work to forced labour (Laczko and Gozdziak 2005; Andrees 2008; O'Connell Davidson 2015; Skrivankova 2010; Quirk 2011; Spencer and Broad 2012; Skeldon 2000; Weitzer 2015; Davies 2018; Cockbain et al. 2018). In between the two extremes are the exploitative labour practices that would not normally be considered severe enough to merit criminal justice responses. Such “routine” exploitation is likely more frequent and subtle than the severe extremes, although both can be embedded within otherwise legitimate business practices (France 2016; Shamir 2012; Davies 2018). However, they can cause considerable harm to workers and reputational damage to industries (Paoli and Greenfield 2015; Davies 2018). Thus, considering how exploitation can be identified and combatted across the continuum of exploitation – rather than focusing solely on practices that might constitute trafficking – could help encourage more holistic and inclusive responses to all abuses.
Embedding indicators in the labour trafficking literature
The choice of characteristics of job advertisements that we investigated (e.g. industry, type of contact, etc.) were informed by the literature on labour trafficking, so might reasonably have been expected to show significant associations with the indicators themselves. Yet, many of our results show inconsistencies and limited consistencies with the existing evidence base on labour trafficking. For instance, men are often found to make up the majority of (identified) labour trafficking victims (e.g. Rijken 2011; UNODC 2016; Cockbain and Bowers 2019). However, in the current sample, where gender requirements were specified, mostly advertised was work for both women and men (17.7%, n = 76). Moreover, Europol (2016) states that 25–50-year-olds are most commonly targeted. Although this constitutes a large range, meaning it would not be surprising if most Lithuanian labour trafficking victims fell into this age category, our analysis found few differences by age of worker sought. Our results showed that the largest category of required age was 18–50 (16.0%, n = 69), which is an even larger range than that suggested by the literature.
Meanwhile, Western European countries are often said to be countries of destination (e.g. Surtees 2008). Although the advertisements in the current sample mostly offered work in the Netherlands (43.0%, n = 185), the UK (30.2%, n = 130) and Germany (12.6%, n = 54), inferential statistics revealed key differences amongst them. Similarly, and in line with opportunity theories of crime (see, e.g. Cohen and Felson 1979; Everson 2003; Farrell and Pease 2001; Brantingham and Brantingham 1993, Brantingham and Brantingham 1984; Felson and Eckert 2015), risk is thought to concentrate in industries such as food processing, agriculture, horticulture, hospitality and construction (e.g. Kelly 2005; Ollus et al. 2013; Strauss 2016). Yet, we found key differences between construction on the one hand and hospitality and food production on the other. The risk of trafficking is thought to be highest in low-skilled (e.g. Dowling et al. 2007) and temporary, part-time or seasonal work (e.g. Ollus et al. 2013), but we found only limited differences on the variables related to job nature and contract type. Overall, few of the advertisements’ characteristics were predictive of the overall number of indicators. Our findings on associations between the advertisements’ characteristics and indicators of national minimum wage and maximum working hour violations suggest these relationships merit further exploration.
While current indicators of labour trafficking (e.g. UNODC 2018; ILO 2009) can be useful in assessing individual cases, this study suggests their utility in risk assessing job advertisements at scale is likely to be modest. Part of the challenge here is the limitations of the empirical evidence base on labour trafficking that could underpin such attempts. For example, a recent systematic literature review of the European evidence base on labour trafficking found that only a handful of publications met even basic criteria for scientific research (Cockbain et al. 2018). Despite growing interest in the topic, the human trafficking literature in general remains notorious for issues such as emotive overclaims, weak research designs, insufficient methodological transparency and questionable assumptions and inferences (e.g. Tyldum and Brunovskis 2005; Denton 2016; Strauss 2016; Cockbain et al. 2018; Zhang 2009; Weitzer 2015). Aside from fundamental definitional and conceptual challenges already discussed (see O’Connell Davidson 2015), accessing relevant participants and data for trafficking research is challenging, especially for quantitative studies. Trafficking victims are widely understood to belong to "hidden populations", meaning that sampling frames cannot be established and convenience samples prevail. Thus, findings are hard to generalise beyond the study samples (Tyldum and Brunovskis 2005; Cockbain et al. 2018, 2019a). In addition, comparison groups are rarely sought and the underdevelopment of the neighbouring literature on the scale and nature of labour rights abuses experienced among the working population at large (Cockbain et al. 2019b ) means there are few baselines against which to compare results.
Future research
Against this backdrop, it is hardly a surprise that the indicators set out in the literature are challenging to use in practice. In order for indicators to be a viable tool in the future, more expansive and reliable underpinning research would be needed. Research on the similarities and differences in experiences between low-wage economic migrants and identified victims of labour trafficking (and other forms of labour exploitation) could help determine which indicators are most useful and in what combination. Additionally, relating specific job advertisements to actual labour trafficking cases could help elicit specific red flags and help train and refine any automated systems, although under-reporting and institutional biases would likely pose challenges (see Cockbain et al. 2019a). Replicating our study in other contexts (including perhaps places where online job advertisements are less commonly used) and on a larger-scale could help identify how existing indicators concentrate in advertisements by industry, occupation, contract type, etc., which could help prioritise sectors and groups for targeted research into the scale and nature of labour rights abuses more generally and labour market enforcement that goes beyond the traditional reliance on a reactive, complaints-based approach (see, e.g., Cockbain et al. 2019b). Since most people who experience labour market abuses do not complainFootnote 15 and complaints are known to be imperfectly related to underlying workplace conditions (Noack et al. 2015; Weil and Pyles 2006), such knowledge could support more effective prioritisation among notoriously under-resourced labour inspectorates.
Overall, this paper highlights that using indicators to detect potential trafficking at the recruitment stage is complicated in practice and we should be wary of studies claiming to have uncovered trafficking when in fact they have simply applied untested indicators uncritically, treating instances with indicators as de facto trafficking. A vital first step before using human trafficking indicators in research, policy or practice is to assess empirically their reliability in distinguishing between instances or individuals that might reasonably be described as trafficking- or non-trafficking related.
An outlook on automated methods
Since stakeholders responsible for labour market regulation are often under-resourced when it comes to actively detecting labour exploitation (Clark 2013), it is worthwhile for researchers to explore computational approaches. Techniques from data science facilitate the data collection process, the extraction of information from unstructured data at scale, and introduce the field to data-driven methods that complement the as yet insufficiently empirically validated tools.
First, data collection could in future studies utilise web-scraping to retrieve data from websites in an automated manner. Using such tools would help to build more extensive and more diverse datasets that are hard to obtain in manual work. For example, web-scraping could be used to expand on our current study and download advertisements over longer time periods (e.g. a whole year), from more websites and across a range of countries automatically, thus supporting comparative research and more extensive analyses. The current study manually collected data for and analysed a relatively small sample of cases (n = 430). Small sample sizes were, in the past years, identified as a major limitation in the behavioural sciences due to the poor generalisation of results beyond the context of individual studies (Yarkoni and Westfall 2017). Aside from limited generalisability of the findings of individual studies, small sample sizes often present snap-shot representations of typically dynamic phenomena. For example, the present study examines labour trafficking in a static manner thereby neglecting a possible temporal evolution in the presence (or absence) of indicators. In order to enable research on temporal variations, larger datasets are needed, which are currently hampered by typically manual data collection. Automating the data collection would greatly help the field to provide high quality, large datasets and thereby open ways to study the problem of labour trafficking in more complexity.
Second, with online ads being in the form of unstructured text data, the dominant approach in many fields is to count the occurrence of indicators manually and assess the agreement between two or more independent judges (e.g. in verbal deception research, see the overviews in Kleinberg et al. 2019). This procedure, however, is costly, hence, it constitutes a key impediment for larger sample sizes and poses a threat to the reliability due to extensive human involvement. Methods from natural language processing are a worthwhile alternative to manual approaches, especially those techniques that help extract information automatically. For example, named entity recognition is a well-established technique to automatically “tag” entities such as persons, locations, languages, mentions of money, dates and organisations (Nadeau and Sekine 2007). Named entity recognition is particularly appealing because it does not rely on hand-crafted word lists but uses machine learning and the grammatical structure of the text to identify relevant information. Many of the indicators used in the current study can be operationalised through named entities and/or keyword techniques (e.g. extracting the offered wage and working hours). Such a hybrid approach uses computational methods to model the constructs that are deemed relevant by theory and has been proven useful in a context with similar challenges (i.e. moving from manual text annotation to automated methods, Kleinberg et al. 2017). As previously mentioned, advertisements containing multiple indicators may warrant particular attention. Thus, automating the identification of indicators could also allow the prioritisation of advertisements with higher overall counts of indicators or where particular combinations of indicators co-occur with one another or with other variables of theoretical relevance.
Third, aside from using information extraction to model already identified indicators on a large scale, another line of future research could explore a data-driven approach. Here, an important step would be the construction of a large dataset that contains cases of known labour abuses and control cases (i.e. a so-called “ground truth” dataset). With such a gold standard of cases, future studies could use supervised machine learning to examine the predictive power of combinations of known indicators (i.e. theory-led investigations). Most importantly, the dataset would also allow for the discovery of patterns in online advertisements that might not be presently formulated as indicators. For example, an oft-used technique in text classification called “bag-of-words” represents a text (here: an online advertisement) through the frequency of all words occurring in the text (e.g. Ott et al. 2011). In supervised machine learning, the goal is to let a classification algorithm learn by itself from examples to separate the two outcome classes (e.g. labour abuse vs. no labour abuse). The performance of this classification function is then typically evaluated on “unseen” data. The latter represents a data-driven approach that might be particularly helpful considering that the validity of the existing indicators is debated. Ultimately, a fruitful way forward could lie in combining automated efforts with human expertise to make use of the distinguishing features of both (fast, reliable processing through computers and small-scale contextualising judgments from human experts). Such a “human-in-the-loop” system could ideally help in prioritising cases and improve detection accuracy to ameliorate the problem.
It is worth noting that predictive modelling efforts are fundamentally reliant on the validity of the labels of the data. That is, a machine learning system might be able to learn with high accuracy to separate two outcome classes that were fed into the system, but it cannot correct or revise the validity of the classes. Furthermore, systems that are self-learning (e.g. through updating databases) might be vulnerable to not only propagating invalid labels but also to zooming in on specific groups or destinations. Especially for a field with potentially far-reaching implications, ethical use of machine learning systems is advised. To avoid such downsides, we encourage joint work between domain experts and computational social scientists to pave the way for a more empirically informed research on labour abuse and trafficking.
The current research did not use any of the automated techniques discussed above because it was outside the aims and remit of this initial scoping study. Early studies like these are useful in testing new ground and identifying potential benefits and challenges in automating the process. The primary utility of using automated methods lies in the fact that they could help process the vast amount of unstructured data that can be found online. There were 679 advertisements posted on darbasuzsienyje.org over 7 days. This is a snapshot of one website. It is practically impossible to commit enough resources to manually go through the process of examining job advertisements for signs of possible labour trafficking activity. Thus, automated methods have considerable potential to make information extraction from labour ads more efficient, uncover patterns in the data that help detect cases of labour trafficking, and thereby facilitate the screening process as a whole.
Study limitations
Our study has some obvious limitations. It dealt with a small sample that was a snapshot from one particular website and the findings are not generalisable. This study lacks ground truth in that the data in our sample did not contain information whether some advertisements - if any - subsequently led to activity that would meet legal definitions of labour trafficking. As such, it remains unclear whether advertisements containing more indicators or certain specific indicators were indeed more likely to involve trafficking-type behaviour. We also only examined those indicators that could be operationalised in the context of online advertisements and even then found that some were challenging to apply. Information on certain variables of interest was rarely specified, so small numbers in sub-categories may have meant some analyses were underpowered to detect differences. Despite these limitations, this exploratory study provides insights into the prevalence, nature and associations of commonly-used indicators of labour trafficking within online job advertisements.
Conclusion
This exploratory study has clear implications for the use of online screening to improve detection of potential labour trafficking - as well as potential labour market abuses more generally. Our results demonstrate how challenging it is to apply commonly-used indicators of labour trafficking to identify potentially risky job advertisements. We found that the indicators are prevalent in online advertisements aimed at Lithuanians seeking work abroad. Although it is theoretically possible that the presence of even a single indicator is indicative of trafficking, this seems unlikely. Thus, our results raise the question as to whether existing indicators can actually differentiate well at scale between potential trafficking and commonplace practices, at least in the absence of other information. Our results add support to arguments that trafficking is better seen as part of a broader spectrum from decent work to highly exploitative and forced labour. Nevertheless, improved automation not just to identify trafficking but also other exploitative labour practices has the potential to support more effective prioritisation among regulatory bodies, law enforcement, international organisations and NGOs. To facilitate such automation and inform its underlying assumptions, indicators that are rigorously tested through empirical research are clearly needed. If deploying indicator-based interventions, the risk of unintended consequences for already marginalised groups must be carefully considered and their effectiveness properly evaluated.
Notes
In line with international law, we use the Palermo Protocol definition of human trafficking in this paper: “Trafficking in persons’ shall mean the recruitment, transportation, transfer, harboring, or receipt of persons, by means of the threat or use of force or other forms of coercion, of abduction, of fraud, of deception, of the abuse of power, or of a position of vulnerability or of the giving or receiving of payments or benefits to achieve the consent of a person having control over another person, for the purpose of exploitation"(Protocol to Prevent et al. 2000). When we talk about "labour trafficking" in this paper, we define it in line with Cockbain et al. (2018) as involving exploitation of all bodily labour except sexual services and domestic servitude. It is worth noting that definitions of human trafficking are notoriously broad and imprecise and, in reality, it can be difficult to distinguish consistently between "trafficking" and neighbouring phenomena (O'Connell Davidson 2015).
Here victims include both EU and non-EU nationals. Out of 7,500 registered victims/potential victims, 71% were EU nationals (Europol 2016).
Here registered victims are victims of trafficking that come into contact with authorities as victims of trafficking both in their own country and elsewhere in the EU.
Using the Netherlands as a case study, Kragten-Heerdink et al. (2017) demonstrate that the traditional distinction is in fact overly reductive and countries can play multiple roles simultaneously.
The US is fairly unusual in that most (commercial) sexual exploitation of children seems to be labeled as trafficking. Elsewhere, the term is still generally reserved for instances involving movement.
The movement of people with the intent to put them to work in an exploitative context (e.g. because of violations of local wage legislation) is generally construed as labour trafficking if some form of deception, coercion, abuse of a position of vulnerability or so forth is used, regardless of whether they consented to the work itself. Although trafficking can occur within a country, it is perhaps most commonly associated with international movements.
The cases for double coding were randomly sampled from the complete dataset using a web-based random number generator. The second coder was, like the first author, a native Lithuanian speaker.
For example, advertisements offering work for truck drivers required candidates to hold appropriate driving licences. This could be interpreted as both a requirement and a feature so intrinsic within the profession that it is not a specific requirement.
The variable “Advertisement language” violated the assumption of chi-square in that one of its categories had less than 5 cases so here we calculated the Fisher’s Exact test statistic instead.
Of the rest, 7.9% (n = 34) advertised low-skilled non-manual labour (here, these were all customer service jobs) or ‘other’ (8.1%, n = 35), a category in which we grouped various other work that did not fit neatly into the other categories or contained large enough numbers to be their own categories (e.g. work in an office or as a driver).
Accommodation was provided in 94.1% (n = 174), 96.2% (n = 125), 94.4% (n = 51) and 100.0% (n = 26) of ads for the Netherlands, the UK, Germany and Cyprus respectively.
For instance, the second most common indicator in ads for the Netherlands and the UK was help with settling in provided: 42.2% (n = 78) and 57.7% (n = 75) of cases respectively. Conversely, the second and third most common indicators amongst advertisements offering work in Germany were accommodation shared with other workers (25.9%, n = 14) and costs deducted from wages (25.9%, n = 14). Of ads for work in Cyprus, 69.2% (n = 18) and 42.3% (n = 11) contained indications of maximum working hour and minimum wage violations.
For example, the second most common indicator in ads for food production, non-food related packaging and manufacturing was help with settling in: 50.9% (n = 58), 47.3% (n = 35) and 42.2% (n = 19) respectively. Of ads for hospitality, 37.3% (n = 22) and 27.1% (n = 16) contained indicators of maximum working hour and minimum wage violations respectively
For example, Weil and Pyles (2006) have conservatively estimated for the United States that one complaint is made for every 130 violations of labour standards.
References
Allain J, Crane A, LeBaron G, Behbahani L (2013) Forced labour’s business models and supply chains. Joseph Rowntree Foundation, York
Andrees, B. (2008). Forced Labour and Trafficking in Europe: How People are Trapped in, Live through and Come out [online] Geneva: International Labour Office. Available at: https://www.ilo.org/global/topics/forced-labour/publications/WCMS_090548/lang%2D%2Den/index.htm [Accessed 28 June 2019]
Andrews S, Brewster B, Day T (2016) Organised Crime And Social Media: Detecting And Corroborating Weak Signals Of Human Trafficking Online. Security Informatics 7(3):137–150
Andrijasevic R, Anderson B (2009) Anti-Trafficking Campaigns: Decent? Honest? Truthful? Feminist Review 92(1):151–155
Aronowitz AA (2001) Smuggling and Trafficking in Human Beings: The Phenomenon, the Markets that Drive It and the Organisations that Promote It. European Journal on Criminal Policy and Research 9(2):163–195
Brooks-Gorden, B. and Sanders, T. (2018). Banning Sex Work Advertising Online Will Put Sex Workers In Danger. The Independent [online]. Available at: https://www.independent.co.uk/voices/sex-work-online-advertising-ban-will-put-sex-workers-in-danger-a8436101.html [Accessed 12 February 2019]
Brantingham PJ, Brantingham PL (1984) Patterns in Crime. MacMillan, New York
Brantingham PJ, Brantingham PL (1993) Environment, routine, and situation: toward a pattern theory of crime. In: Clarke RVG, Felson M (eds) Routine Activity and Rational Choice. Transaction Publishers, New Brunswick, NJ
Bryman A (2008) Social research methods, 3rd edn. Oxford University Press, Oxford
Clark N (2013) Detecting and Tackling Forced Labour in Europe. Joseph Rowntree Foundation, York
Cockbain, E., Bowers, K. and Vernon, L. (2019a). Using law enforcement data in trafficking research. In: .J. Winterdyk and J. Jones, eds., The Palgrave International Handbook of Human Trafficking. Basingstoke: Palgrave Macmillan
Cockbain, E., Scott, S., Pósch K. and Bradford, B. (2019b). How can the scale and nature of labour market non-compliance in the UK best be assessed? Final report of a scoping study. London: UCL, University of Gloucestershire, LSE [online]. Available at: https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/814582/How_can_the_scale_and_nature_of_labour_market_non-compliance_in_the_UK_best_be_assessed_July_2019.pdf. Accessed 10 Dec 2019
Cockbain, E. and Bowers, K. (2018). Using Data Science Techniques Better to Understand Human Trafficking. In: The United Nations 4th International Conference on Governance, Crime and Justice Statistics. Lima, Peru, June 2018
Cockbain E, Bowers K (2019) Human Trafficking for Sex, Labour and Domestic Servitude: How Do Key Trafficking Types Compare and What Are Their Predictors? Crime, Law and Social Change, pp 1–26
Cockbain E, Bowers K, Dimitrova G (2018) Human Trafficking for Labour Exploitation: The Results of a Two-phase Systematic Review Mapping the European Evidence Base and Synthesising Key Scientific Research Evidence. Journal of Experimental Criminology 14(3):1–42
Cockbain E, Olver K (2019) Child trafficking: characteristics, complexities and challenges. In: Bryce I, Petherick W, Robinson Y (eds) Child Abuse and Neglect: Forensic Issues in Evidence, Impact and Management. Elsevier, New York, pp 95–116
Cohen EL, Felson M (1979) Social Change and Crime Rate Trends: A Routine Activity Approach. American Sociological Review 44(4):588–608
Coughlan S (2019) Hotels Train Staff to Spot Human Trafficking. BBC [online]. Available at: https://www.bbc.co.uk/news/business-47201210
Craig G, Gaus A, Wilkinson M, Skrivankova K, MsQuade A (2007) Contemporary slavery in the UK: Overview and key issues. Joseph Rowntree Foundation, York
Davies J (2018) From Severe to Routine Labour. The Case of Migrant Workers in the UK Food Industry. Criminology and Criminal Justice, Exploitation. https://doi.org/10.1177/1748895818762264
Denton E (2016) Anatomy of Offending: Human Trafficking in the United States, 2006–2011. Journal of Human Trafficking 2(1):32–62
Dixon HBJ (2013) Human trafficking and the internet* (*and other technologies, too). The Judges' Journal 52(1):36–39
Dowling, S., Moreton, K. and Wright, L. (2007). Trafficking for the Purposes of Labour Exploitation: A Literature Review. [online] Home Office. Available at: https://webarchive.nationalarchives.gov.uk/20110218141358/http://rds.homeoffice.gov.uk/rds/pdfs07/rdsolr1007.pdf [Accessed 15 Aug 2018]
Efrat A (2016) Global Efforts Against Human Trafficking: The Misguided Conflation Of Sex, Labor, And Organ Trafficking. International Studies Perspectives 17(1):34–54
Europol (2014). Intelligence Notification: Trafficking in Human Beings and the Internet. [online] The Hague: Europol. Available at: https://www.europol.europa.eu/publications-documents/trafficking-in-human-beings-and-internet [Accessed 21 Aug 2018]
Europol (2016). Situation Report: Trafficking in Human Beings in the EU. [online] The Hague: Europol. Available at: https://www.europol.europa.eu/publications-documents/trafficking-in-human-beings-in-eu [Accessed 21 Aug 2018]
Eurostat (2014). Internet Usage by Individuals in 2014. [online] Available at: https://ec.europa.eu/digital-single-market/en/news/internet-usage-individuals-2014
Eurostat (2015). Trafficking in Human Beings. [online] Luxembourg: Publications Office of the European Union. Available at: https://ec.europa.eu/anti-trafficking/sites/antitrafficking/files/eurostat_report_on_trafficking_in_human_beings_-_2015_edition.pdf [Accessed 21 Aug 2018]
Eurostat (2018). Digital Economy and Society Statistics - Households and Individuals. [online] Available at: https://ec.europa.eu/eurostat/statistics-explained/index.php?title=Digital_economy_and_society_statistics_-_households_and_individuals#Internet_usage. Accessed 28 Jan 2019
Everson S (2003) Repeat Victimisation and Prolific Offending: Chance or Choice? International Journal of Police Science & Management 5(3):180–194
Farrell G, Pease K (2001) Repeat Victimization. Criminal Justice Press, Monsey, NY
Felson M, Eckert M (2015) Crime and Everyday Life. Sage Publications, Thousand Oaks, CA
Fox R (2001) Someone to Watch Over Us: Back to the Panopticon? Criminal Justice 1(3):251–276
France B (2016) Labour Compliance to Exploitation and the Abuses In-between. Labour Exploitation Advisory Group (FLEX), London
Gallagher AT (2017) What's Wrong with the Global Slavery Index? Anti-Trafficking Review 8:90–112
Ghinararu, C. and van der Linden, M. N. J. (2004). Trafficking of Migrant Workers from Romania: Issues of Labour and Sexual Exploitation. [online] Geneva: International Labour Office. Available at: https://digitalcommons.ilr.cornell.edu/cgi/viewcontent.cgi?referer=https://www.google.com/&httpsredir=1&article=1013&context=forcedlabor [Accessed 21 July 2018]
Goodey J (2008) Human Trafficking: Sketchy Data and Policy Responses. Criminology and Criminal Justice 8(4):421–442
Gozdziak E, Bump M (2008) Data and research on human trafficking: Bibliography of research-based literature. Georgetown University, Washington, D.C.
Greiman V, Bain C (2013) The Emergence of Cyber Activity as a Gateway to Human Trafficking. Journal of Information Warfare 12(2):41–49
Heil E, Nichols A (2014) Hot Spot Trafficking: A Theoretical Discussion of the Potential Problems Associated with Targeted Policing and the Eradication of Sex Trafficking in the United States. Contemporary Justice Review 17(4):1–13
Home Office (2016). Victims of Modern Slavery – Frontline Staff Guidance. [online] Available at: https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/509326/victims-of-modern-slavery-frontline-staff-guidance-v3.pdf [Accessed 11 July 2019]
Hopper E, Hidalgo J (2006) Invisible Chains: Psychological Coercion of Human Trafficking Victims. Intercultural Human Rights Law Review 1:185–209
Hughes DM (2014) Trafficking in Human Beings in the European Union: Gender, Sexual Exploitation, and Digital Communication Technologies. Sage Open, pp.:1–8. https://doi.org/10.1177/2158244014553585
Ibanez M, Suthers DD (2014) Detection of Domestic Human Trafficking Indicators and Movement Trends Using Content Available on Open Internet Sources. In: In: 2014 47th Hawaii International Conference on System Sciences. Waikoloa: IEEE, pp 1556–1565
ILO (2009). Operational Indicators of Trafficking in Human Beings. [online] Available at: https://www.ilo.org/wcmsp5/groups/public/@ed_norm/@declaration/documents/publication/wcms_105023.pdf [Accessed 27 Aug 2018]
Janusauskiene, D. (2013). Lithuanian Migrants as Victims of Human Trafficking for Forced Labour and Labour Exploitation Abroad. In: N. Ollus, A. Jokinen and M. Joutsen, eds., Exploitation of Migrant Workers in Finland, Sweden, Estonia and Lithuania: Uncovering the Links Between Recruitment, Irregular Employment Practices and Labour Trafficking. Helsinki: European Institute for Crime Prevention and Control, affiliated with the United Nations (HEUNI), pp. 305–359
Kelly L (2005) “You Can Find Anything You Want”: A Critical Reflection on Research on Trafficking in Persons within and into Europe. In: Laczko F, Gozdziak E (eds) Data and Research on Human Trafficking: A Global Survey. International Organization for Migration, Geneva, pp 235–265
Kleinberg B, Arntz A, Verschuere B (2019) Detecting deceptive intentions: Possibilities for large-scale applications. T. Docan-Morgan, ed., The Handbook of Deceptive Communication, In
Kleinberg B, Mozes M, Arntz A, Verschuere B (2017) Using named entities for computer-automated verbal deception detection. Journal of forensic sciences 63(3):714–723
Kragten-Heerdink, S. L., Dettmeijer-Vermeulen, C. E., and Korf, D. J. (2017). More Than Just “Pushing and Pulling”: Conceptualizing Identified Human Trafficking in the Netherlands. Crime & Delinquency. doii: 0011128717728503
Kunze E (2010) Sex Trafficking Via the Internet: How International Agreements Address the Problem and Fail To Go Far Enough. Journal of High Technology Law 241(10):241–289
Laczko F (2002) Human Trafficking: The Need for Better Data. Migration Information Source 1:61–80
Laczko, F. and Gozdziak, E. (2005). Data and Research on Human Trafficking: A Global Survey. [online] Geneva: International Organization for Migration. Available at: http://publications.iom.int/system/files/pdf/global_survey.pdf [Accessed 22 July 2018]
Latonero, M. (2011). Human Trafficking Online: The Role of Social Networking Sites and Online Classifieds. [online] Los Angeles: Center on Communication Leadership and Policy, University of Southern California's Annenberg School for Communication and Journalism. Available at: https://technologyandtrafficking.usc.edu/files/2011/09/HumanTrafficking_FINAL.pdf [Accessed 15 July 2018]
Latonero, M., Wex, B. and Dank, M. (2015). Technology and Labor Trafficking in a Network Society. [online] Los Angeles: Center for Communication Leadership and Policy, University of Souther California's Annenberg School for Communication and Journalism. Available at: https://communicationleadership.usc.edu/files/2015/10/USC_Tech-and-Labor-Trafficking_Feb2015.pdf [Accessed 15 July 2018]
Law on the Ratification of the Private Employment Agencies Convention 2004, The Seimas of the Republic of Lithuania, Vilnius. Available at: https://e-seimas.lrs.lt/portal/legalAct/lt/TAD/TAIS.227715?jfwid=-9dzqnu3qj [Accessed 25 July 2018]
Lithuanian Labour Exchange (2018). Information, Lithuanian Labour Exchange. [online] Available at: http://www.ldb.lt/Informacija/Nuorodos/Puslapiai/default.aspx [Accessed 15 07 2018]
McCreevy C (2011) Europe - How Can Things Get Better? Economic Affairs 31(2):85–87
Milivojevic S (2012) The State, Virtual Borders and E-Trafficking: Between Fact and Fiction. In: McCulloch J, Pickering S (eds) Borders and Crime: Pre-Crime, Mobility and Serious Harm in an Age of Globalization. Palgrave Macmillan, Basingstoke, pp 72–89
Musto JL, Boyd D (2014) The Trafficking-Technology Nexus. Social Politics: International Studies in Gender, State & Society 21(3):461–483
Nadeau D, Sekine S (2007) A survey of named entity recognition and classification. Lingvisticae Investigationes 30(1):3–26
National Crime Agency (2014). Red Alert: Potential Indicators of Slavery and Human Trafficking. [online] Available at: http://www.nationalcrimeagency.gov.uk/publications/631-potential-indicators-of-slavery-and-human-trafficking [Accessed 13 June 2018]
National Crime Agency (2019). National Referral Mechanism Statistics - End of Year Summary 2018. [online] Available at: https://nationalcrimeagency.gov.uk/who-we-are/publications/282-national-referral-mechanism-statistics-end-of-year-summary-2018/file [Accessed 8 September 2019]
Noack A, Vosko L, Grundy J (2015) Measuring Employment Standards Violations, Evasion and Erosion-Using a Telephone Survey. Relations Industrielles/Industrial Relations 70(1):86–109
O'Connell Davidson J (2015) Modern Slavery: The Margins of Freedom. Palgrave Macmillan, London
Ollus, N., Jokinen, A. and Joutsen, M. (2013). Exploitation of Migrant Workers in Finland, Sweden, Estonia and Lithuania: Uncovering the Links Between Recruitment, Irregular Employment Practices and Labour Trafficking. Helsinki: European Institute for Crime Prevention and Control, affiliated with the United Nations (HEUNI)
Ott M, Choi Y, Cardie C, Hancock JT (2011) Finding Deceptive Opinion Spam by Any Stretch of the Imagination. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics 1:309–319
Paoli L, Greenfield VA (2015) Starting from the End: A Plea for Focusing on the Consequences of Crime. European Journal of Crime, Criminal Law and Criminal Justice 23(2):87–100
Petrunov G (2014) Human Trafficking in Eastern Europe: The Case of Bulgaria. Annals of the American Academy of Political and Social Science 653(1):162–182
Protocol to Prevent, Suppress and Punish Trafficking in Persons, Especially Women and Children 2000 (UN General Assembly) [online]. Available at: https://treaties.un.org/Pages/ViewDetails.aspx?src=TREATY&mtdsg_no=XVIII-12-a&chapter=18&clang=_en. Accessed 10 Dec 2019
Quirk J (2011) The anti-slavery project: from the slave trade to human trafficking. University of Pennsylvania Press, Philadelphia
Rijken C (2011) Challenges and Pitfalls in Combating Trafficking in Human Beings for Labour Exploitation. In: Rijken C (ed) Combating Trafficking in Human Beings for Labour Exploitation. Wolf Legal Publishers, Nijmegen, pp 393–424
Scott S (2017) Labour exploitation and work-based harm. Policy Press, Bristol
Shamir H (2012) A Labor Paradigm for Human Trafficking. UCLA Law Review 60(1):76–136
Shand-Baptiste, K. (2019). Don't Be Fooled by the Idea That Identifying Sex Trafficking Victims is Easy. The Independent [online]. Available at: https://www.independent.co.uk/voices/uber-rivers-sex-trafficking-how-spot-hotel-workers-marriott-modern-slavery-victims-signs-a8765981.html [Accessed 13 Feb 2019]
Skeldon R (2000) Trafficking: A Perspective from Asia. International Migration 38(3):7–30
Skrivankova, K. (2006). Trafficking for Forced Labour: UK Country Report. [online] Anti-Slavery International. Available at: http://www.antislavery.org/wp-content/uploads/2017/01/trafficking_for_forced_labour_uk_country_report.pdf [Accessed 21 July 2018]
Skrivankova K (2010) Between Decent Work and Forced Labour: Examining the Continuum of Exploitation. Joseph Rowntree Foundation, York
Smith M, Mac J (2018) Revolting Prostitutes: The Fight for Sex Workers' Rights. Verso, London
Spencer J, Broad R (2012) The ‘Groundhog Day’ of the Human Trafficking for Sexual Exploitation Debate: New Directions in Criminological Understanding. European Journal on Criminal Policy and Research 18(3):269–281
STOP THE TRAFFIK (2019). SPOT THE SIGNS. [online] Available at: https://www.stopthetraffik.org/about-human-trafficking/spot-the-signs/ [Accessed 11 July 2019]
Strauss K (2016) Sorting Victims from Workers. Progress in Human Geography: Forced Labour, Trafficking, and the Process of Jurisdiction 41(2):140–158
Surtees R (2008) Traffickers and Trafficking in Southern and Eastern Europe: Considering the Other Side of Human Trafficking. European Journal of Criminology 5(1):39–68
Sykiotou, A. P. (2007). Trafficking in Human Beings: Internet Recruitment: Misuse of the Internet for the Recruitment of Victims of Trafficking in Human Beings. [online] Strasbourg: Directorate General of Human Rights and Legal Affairs Council of Europe. Available at: https://rm.coe.int/16806eeec0 [Accessed 14 July 2018]
Tyldum G, Brunovskis A (2005) Describing the Unobserved: Methodological Challenges in Empirical Studies on Human Trafficking. International Migration 43(1–2):17–34
UNODC (2016). Global Report on Trafficking in Persons. [online] New York: United Nations. Available at: https://www.unodc.org/documents/data-and-analysis/glotip/2016_Global_Report_on_Trafficking_in_Persons.pdf [Accessed 6 July 2018]
UNODC (2018). Human Trafficking Indicators. [online] Available at: https://www.unodc.org/pdf/HT_indicators_E_LOWRES.pdf [Accessed 27 July 2018]
Weil D, Pyles A (2006) Why Complain? Complaints, Compliance, and the Problem of Enforcement in the US Workplace. Comp. Lab. L. & Pol'y. J. 27(59):59–92
Weitzer R (2015) Human trafficking and contemporary slavery. Annual review of sociology 41:223–242
Yarkoni T, Westfall J (2017) Choosing Prediction Over Explanation in Psychology: Lessons from Machine Learning. Perspectives on Psychological Science 12(6):1100–1122
Zhang SX (2009) Beyond the ‘Natasha’ story – a Review and Critique of Current Research on Sex Trafficking. Global Crime 10(3):178–195
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Volodko, A., Cockbain, E. & Kleinberg, B. “Spotting the signs” of trafficking recruitment online: exploring the characteristics of advertisements targeted at migrant job-seekers. Trends Organ Crim 23, 7–35 (2020). https://doi.org/10.1007/s12117-019-09376-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12117-019-09376-5