
Abstract
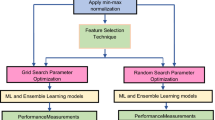
Detecting code smells and treating them with refactoring are trivial part of maintaining vast and sophisticated software. There is an urgent need for automatic system to treat code smells. Tools provide variable results, based on threshold values and subjective interpretation of smells. Machine learning is one of the best approaches that provides effective solution to this problem. Practitioners do not need expert knowledge on smell’s characteristics for detection, which makes this approach accessible. In this paper, we have implemented 32 machine learning algorithms after performing feature selection through six variations of the filter method. We have used multiple correlation methodologies to discard similar features. Mutual information, fisher score, and univariate ROC–AUC feature selection techniques were used with brute force and random forest correlation strategies. Feature selection eliminates dimensionality curse and improves performance measures drastically. It is the selection of relevant feature subset based on the relation between dependent and independent variables. We have compared performance of classifiers implemented with and without performing feature selection. Results show that accuracy of machine learning models has increased up to 26.5%, f-measure by 70.9%, area under ROC curve has surged up to 26.74%, and average training time has reduced up to 62 s as compared to performance measures of machine learning models executed without feature selection. Mutual information feature selection strategy with random forest correlation methodology has the highest impact on performance measures among all the filter methods. Among 32 classifiers, boosted decision trees (J48) and Naive Bayes algorithms gave best performance after dimensionality reduction.

Similar content being viewed by others

References
Tufano M, Palomba F, Bavota G, Oliveto R, Di Penta M, De Lucia A, Poshyvanyk D (2015) When and why your code starts to smell bad. In: 2015 IEEE/ACM 37th IEEE international conference on software engineering vol 1, IEEE, pp 403–414
Olbrich SM, Cruzes DS, Sjøberg DI (2010) Are all code smells harmful? a study of god classes and brain classes in the evolution of three open source systems. In: 2010 IEEE international conference on software maintenance, IEEE, pp 1–10
Fowler M (2018) Refactoring: improving the design of existing code. Addison-Wesley, Boston
Mantyla M (2003) Bad smells in software-a taxonomy and an empirical study. PhD thesis, PhD thesis, Helsinki University of Technology
Singh S, Kaur S (2018) A systematic literature review: Refactoring for disclosing code smells in object oriented software. Ain Shams Eng J 9(4):2129–2151
Travassos G, Shull F, Fredericks M, Basili VR (1999) Detecting defects in object-oriented designs: using reading techniques to increase software quality. ACM Sigplan Not 34(10):47–56
Langelier G, Sahraoui H, Poulin P (2005) Visualization-based analysis of quality for large-scale software systems. In: Proceedings of the 20th IEEE/ACM international conference on automated software engineering, pp 214–223
Ganea G, Verebi I, Marinescu R (2017) Continuous quality assessment with incode. Sci Comput Program 134:19–36
Li H, Thompson S (2012) Let’s make refactoring tools user-extensible! In: Proceedings of the fifth workshop on refactoring tools, pp 32–39
Marinescu R (2004) Detection strategies: metrics-based rules for detecting design flaws. In: Proceedings of 20th IEEE international conference on software maintenance, 2004, IEEE, pp 350–359
Kim M, Zimmermann T, Nagappan N (2014) An empirical study of refactoringchallenges and benefits at microsoft. IEEE Trans Softw Eng 40(7):633–649
Jain S, Saha A (2019) An empirical study on research and developmental opportunities in refactoring practices. In: Software Engineering and Knowledge Engineering
Mäntylä MV, Lassenius C (2006) Subjective evaluation of software evolvability using code smells: An empirical study. Empir Softw Eng 11(3):395–431
Fernandes E, Oliveira J, Vale G, Paiva T, Figueiredo E (2016) A review-based comparative study of bad smell detection tools. In: Proceedings of the 20th international conference on evaluation and assessment in software engineering, pp 1–12
Alpaydin E (2020) Introduction to machine learning. MIT Press, Cambridge
Fontana FA, Mäntylä MV, Zanoni M, Marino A (2016) Comparing and experimenting machine learning techniques for code smell detection. Empir Softw Eng 21(3):1143–1191
Fontana FA, Zanoni M, Marino A, Mäntylä MV (2013) Code smell detection: Towards a machine learning-based approach. In: 2013 IEEE international conference on software maintenance, IEEE, pp 396–399
Freund Y, Schapire RE, et al. (1996) Experiments with a new boosting algorithm. In: icml. Volume 96., Citeseer, pp 148–156
Di Nucci D, Palomba F, Tamburri DA, Serebrenik A, De Lucia A (2018) Detecting code smells using machine learning techniques: are we there yet? 2018 IEEE 25th International Conference on Software Analysis. Evolution and Reengineering (SANER), IEEE, pp 612–621
Conover WJ, Conover WJ (1980) Practical nonparametric statistics. Wiley, Hoboken
Azeem MI, Palomba F, Shi L, Wang Q (2019) Machine learning techniques for code smell detection: a systematic literature review and meta-analysis. Inf Softw Technol 108:115–138
Vaucher S, Khomh F, Moha N, Guéhéneuc YG (2009) Tracking design smells: Lessons from a study of god classes. In: 2009 16th working conference on reverse engineering, IEEE, pp 145–154
Moha N, Gueheneuc YG, Duchien L, Le Meur AF (2009) Decor: A method for the specification and detection of code and design smells. IEEE Trans Software Eng 36(1):20–36
Khomh F, Vaucher S, Guéhéneuc YG, Sahraoui H (2009): A bayesian approach for the detection of code and design smells. In: 2009 Ninth international conference on quality software, IEEE, pp 305–314
Hassaine S, Khomh F, Guéhéneuc YG, Hamel S (2010) Ids: An immune-inspired approach for the detection of software design smells. In: 2010 seventh international conference on the quality of information and communications technology, IEEE, pp 343–348
Maneerat N, Muenchaisri P (2011) Bad-smell prediction from software design model using machine learning techniques. In: 2011 eighth international joint conference on computer science and software engineering (JCSSE), IEEE, pp 331–336
Khomh F, Vaucher S, Guéhéneuc YG, Sahraoui H (2011) Bdtex: a GQM-based bayesian approach for the detection of antipatterns. J Syst Softw 84(4):559–572
Maiga A, Ali N, Bhattacharya N, Sabané A, Guéhéneuc YG, Aimeur E (2012) Smurf: A svm-based incremental anti-pattern detection approach. In: 2012 19th working conference on reverse engineering, IEEE, pp 466–475
Brown WH, Malveau RC, McCormick HW, Mowbray TJ (1998) AntiPatterns: refactoring software, architectures, and projects in crisis. Wiley, Hoboken
Frank E, Hall M, Pfahringer B (2002) Locally weighted naive bayes. In: Proceedings of the nineteenth conference on uncertainty in artificial intelligence, Morgan Kaufmann Publishers Inc., pp 249–256
D’Agostini G (1994) A multidimensional unfolding method based on bayes’ theorem. Technical report, P00024378
Navot A, Gilad-Bachrach R, Navot Y, Tishby N (2005) Is feature selection still necessary? In: International statistical and optimization perspectives workshop” subspace, latent structure and feature selection”. Springer, pp 127–138
Weston J, Mukherjee S, Chapelle O, Pontil M, Poggio T, Vapnik V (2001) Feature selection for svms. In: Advances in neural information processing systems, pp 668–674
Hall MA, Holmes G (2003) Benchmarking attribute selection techniques for discrete class data mining. IEEE Trans Knowl Data Eng 15(6):1437–1447
Zhang M, Hall T, Baddoo N (2011) Code bad smells: a review of current knowledge. J Softw Maint Evolut Res Pract 23(3):179–202
Quinlan R (1993) 4.5: Programs for machine learning morgan kaufmann publishers inc. San Francisco, USA
Kotsiantis SB, Zaharakis I, Pintelas P (2007) Supervised machine learning: A review of classification techniques. Emerg Artif Intell Appl Comput Eng 160:3–24
Liaw A, Wiener M et al (2002) Classification and regression by randomforest. R News 2(3):18–22
Tarun IM, Gerardo BD, Tanguilig BT III (2014) Generating licensure examination performance models using part and JRIP classifiers: a data mining application in education. Int J Comput Commun Eng 3(3):203
Rish I et al. (2001) An empirical study of the naive bayes classifier. In: IJCAI 2001 workshop on empirical methods in artificial intelligence, vol 3, pp 41–46
Amari Si WuS (1999) Improving support vector machine classifiers by modifying kernel functions. Neural Netw 12(6):783–789
Platt J (1998) Sequential minimal optimization: a fast algorithm for training support vector machines
Liao Y, Vemuri VR (2002) Use of k-nearest neighbor classifier for intrusion detection. Comput Secur 21(5):439–448
Han J, Pei J, Kamber M (2011) Data mining: concepts and techniques. Elsevier, Amsterdam
Hall M, Frank E, Holmes G, Pfahringer B, Reutemann P, Witten IH (2009) The weka data mining software: an update. ACM SIGKDD Explor Newsl 11(1):10–18
Benesty J, Chen J, Huang Y, Cohen I (2009) Pearson correlation coefficient. In: Noise reduction in speech processing. Springer, pp 1–4
Hall MA (1999) Correlation-based feature selection for machine learning
Guyon I, Gunn S, Nikravesh M, Zadeh LA (2008) Feature extraction: foundations and applications. Volume 207. Springer
Guyon I, Elisseeff A (2003) An introduction to variable and feature selection. J Mach Learn Res 3(Mar):1157–1182
Sokolova M, Lapalme G (2009) A systematic analysis of performance measures for classification tasks. Inf Process Manag 45(4):427–437
Galar M, Fernandez A, Barrenechea E, Bustince H, Herrera F (2011) A review on ensembles for the class imbalance problem: bagging-, boosting-, and hybrid-based approaches. IEEE Trans Syst Man Cybern Part C (Appl Rev) 42(4):463–484
Sokolova M, Japkowicz N, Szpakowicz S (2006) Beyond accuracy, f-score and roc: a family of discriminant measures for performance evaluation. In: Australasian joint conference on artificial intelligence, Springer, 1015–1021
López V, Fernández A, Herrera F (2014) On the importance of the validation technique for classification with imbalanced datasets: addressing covariate shift when data is skewed. Inf Sci 257:1–13
Tempero E, Anslow C, Dietrich J, Han T, Li J, Lumpe M, Melton H, Noble J (2010) The qualitas corpus: A curated collection of java code for empirical studies. In: 2010 Asia Pacific Software Engineering Conference, IEEE, pp 336–345
Farquad M, Bose I (2012) Preprocessing unbalanced data using support vector machine. Decis Support Syst 53(1):226–233
Palomba F, Bavota G, Di Penta M, Fasano F, Oliveto R, De Lucia A (2018) On the diffuseness and the impact on maintainability of code smells: a large scale empirical investigation. Empir Softw Eng 23(3):1188–1221
Fontana FA, Dietrich J, Walter B, Yamashita A, Zanoni M (2016) Antipattern and code smell false positives: Preliminary conceptualization and classification. In: 2016 IEEE 23rd international conference on software analysis, evolution, and reengineering (SANER). vol1, IEEE, pp 609–613
Chidamber SR, Kemerer CF (1994) A metrics suite for object oriented design. IEEE Trans Softw Eng 20(6):476–493
Lorenz M, Kidd J (1994) Object-oriented software metrics: a practical guide. Prentice-Hall, Inc.,
Bansiya J, Davis CG (2002) A hierarchical model for object-oriented design quality assessment. IEEE Trans Softw Eng 28(1):4–17
Xiong H, Shekhar S, Tan PN, Kumar V (2004) Exploiting a support-based upper bound of pearson’s correlation coefficient for efficiently identifying strongly correlated pairs. In: Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining, 334–343
Jović A, Brkić K, Bogunović N (2015) A review of feature selection methods with applications. In: 2015 38th international convention on information and communication technology, electronics and microelectronics (MIPRO), IEEE, pp 1200–1205
Gray RM (2011) Entropy and information theory. Springer, Berlin
Hoque N, Bhattacharyya DK, Kalita JK (2014) MIFS-ND: a mutual information-based feature selection method. Expert Syst Appl 41(14):6371–6385
Kraskov A, Stögbauer H, Grassberger P (2004) Estimating mutual information. Phys Rev E 69(6):066138
Gu Q, Li Z, Han J (2012) Generalized fisher score for feature selection. arXiv preprint arXiv:1202.3725
Aggarwal CC (2014) Data classification: algorithms and applications. CRC Press, Boca Raton
Levner I (2005) Feature selection and nearest centroid classification for protein mass spectrometry. BMC Bioinf 6(1):68
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay E (2011) Scikit-learn: Machine learning in python. J Machine Learn Res 12:2825–2830
Tantithamthavorn C, McIntosh S, Hassan AE, Matsumoto K (2016) An empirical comparison of model validation techniques for defect prediction models. IEEE Trans Softw Eng 43(1):1–18
Kohavi R et al (1995) A study of cross-validation and bootstrap for accuracy estimation and model selection. In: IJCAI, vol 14. Montreal, Canada, pp 1137–1145
Wong TT (2015) Performance evaluation of classification algorithms by k-fold and leave-one-out cross validation. Pattern Recogn 48(9):2839–2846
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Jain, S., Saha, A. Rank-based univariate feature selection methods on machine learning classifiers for code smell detection. Evol. Intel. 15, 609–638 (2022). https://doi.org/10.1007/s12065-020-00536-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12065-020-00536-z