
Abstract
Purpose of Review
Despite the crucial role that prediction models play in guiding early risk stratification and timely intervention to prevent type 2 diabetes after gestational diabetes mellitus (GDM), their use is not widespread in clinical practice. The purpose of this review is to examine the methodological characteristics and quality of existing prognostic models predicting postpartum glucose intolerance following GDM.
Recent Findings.
A systematic review was conducted on relevant risk prediction models, resulting in 15 eligible publications from research groups in various countries. Our review found that traditional statistical models were more common than machine learning models, and only two were assessed to have a low risk of bias. Seven were internally validated, but none were externally validated. Model discrimination and calibration were done in 13 and four studies, respectively. Various predictors were identified, including body mass index, fasting glucose concentration during pregnancy, maternal age, family history of diabetes, biochemical variables, oral glucose tolerance test, use of insulin in pregnancy, postnatal fasting glucose level, genetic risk factors, hemoglobin A1c, and weight.
Summary
The existing prognostic models for glucose intolerance following GDM have various methodological shortcomings, with only a few models being assessed to have low risk of bias and validated internally. Future research should prioritize the development of robust, high-quality risk prediction models that follow appropriate guidelines, in order to advance this area and improve early risk stratification and intervention for glucose intolerance and type 2 diabetes among women who have had GDM.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Gestational diabetes mellitus (GDM) is a condition where women without a previous diagnosis of diabetes exhibit abnormal blood glucose levels during pregnancy [1, 2]. It is one of the most common pregnancy complications worldwide [3, 4], affecting up to 14 million women annually [5, 6]. The prevalence of GDM is increasing globally, due to changes in lifestyle, increasing rates of maternal obesity [7,8,9], and evolving diagnostic criteria. In 2021, according to the International Diabetes Association, the estimated pooled standardized prevalence of GDM globally was 14.0%, and regionally was 27.6% in the Middle East and North Africa, 20.8% in South-East Asia, 14.7% in Western Pacific, 14.2% in Africa, 10.4% in South America and Central America, 7.8% in Europe, and 7.1% in North America and the Caribbean [2].
Often, blood glucose levels associated with GDM will become normal after delivery; however, these women remain at high risk of developing postpartum metabolic abnormalities such as glucose intolerance and type 2 diabetes mellitus (T2DM). According to recent literature, 12.3 to 60.0% of pregnant women who had GDM will develop some form of glucose intolerance up to 15 years postpartum [10,11,12,13,14] which increases to 70.0% 28 years after pregnancy [11, 15], although this varies in different populations and ethnic groups. Hence, women with a history of GDM have a greater than sevenfold risk of developing postpartum glucose intolerance than those who were normoglycemic [5, 16]. For this reason, the American College of Obstetricians and Gynecologists (ACOG) and the American Diabetes Association (ADA) recommend postpartum screening of all mothers who had GDM from 4 to 12 weeks postpartum for timely intervention [17, 18].
Previous studies have reported a range of prognostic factors associated with risk of developing postpartum glucose intolerance after GDM, which include demographic and clinical factors, antepartum laboratory results, and metabolic factors. For example, factors including age, increased parity, higher pre-conception body mass index (BMI), family history of diabetes, insulin therapy during pregnancy, degree of hyperglycemia during pregnancy (higher area under the curve (AUC) of glucose, higher fasting plasma glucose (FPG)), and impaired pancreatic β-cell function were consistently found to be associated with postpartum glucose intolerance [11, 13, 19,20,21,22,23]. Abnormal findings on a variety of antepartum glucose tolerance tests (OGTT) [24,25,26,27,28] were also reported to be associated with a high risk of post-partum glucose intolerance (e.g., low insulinogenic index II levels on the antepartum 75-g OGTT (42)). More than 60 genetic factors have been identified in association with T2DM. Given women with GDM have a family history of T2DM, it has been found that some genetic variants of T2DM are also associated with early or late postpartum glucose intolerance among women who had GDM [29,30,31,32,33]. In addition, a range of specific metabolic biomarkers including amino acids (branched-chain amino acids, hexose), lipids (linoleic acid, phospholipids, lysophosphatidylcholines, acylcarnitines, sphingomyelins (i.e., SM (OH) C14:1)), p-cresol sulfate, and glycocholic acid have also been reported as predictive for postpartum glucose intolerance among women who had GDM [34,35,36,37,38].
Risk prediction models have the advantage of identifying women who are at high risk of developing glucose intolerance after GDM with greater accuracy than single markers and in a timely manner (e.g., years before development). This enables women and their healthcare providers to ensure ongoing screening and implementation of early prevention strategies to optimize health outcomes. Risk prediction models can be applied with each women at any time, which can be important as it has been shown that the majority of women (even those at high risk of postpartum T2DM) did not attend postpartum screening for glucose intolerance [39, 40]. Since glucose intolerance is well known to be effectively managed with lifestyle modification [41, 42], early identification of these at-risk women and more focused ongoing screening may prevent T2DM.
Prediction models that have strong predictive ability, validated, generalizable, and based on easily accessible variables, is required in order to effectively prevent postpartum T2DM risk. A systematic review is needed to aid clinicians in selecting postpartum T2DM risk prediction tools and to summarize all available prediction models for researchers. Therefore, this systematic review aims to summarize and critically evaluate the reporting quality, methodological characteristics, and risk of bias of studies reporting prediction models for developing postpartum glucose intolerance developing after GDM.
Methods
This study was conducted according to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) [43] and using The Checklist for critical Appraisal and data extraction for systematic Reviews of prediction Modelling Studies (CHARMS) checklist [44]. The protocol for this systematic review is registered at the international prospective register of systematic reviews (PROSPERO); CRD42022327239.
Formulating the Review Question and Protocol
The review question was formulated based on the PICOTS framework (population, intervention, comparison, outcome, time, and settings) as recommended by the CHARMS checklist. The study protocol was developed by considering the rationale, objectives, design, methodology, and statistical considerations of the systematic review (Table 1).
Main outcome(s)
The main outcome of interest for this study is the development of glucose intolerance in women with a history of GDM. This encompasses metabolic conditions such as T2DM, pre-diabetes (impaired fasting glucose (IFG) and impaired glucose tolerance (IGT)) which developed within 20 years postpartum. These are defined and identified by fasting plasma glucose concentrations and/or OGTT results according to the World Health Organization criteria [45], national or regional Diabetes Association diagnostic criteria, or specified local criteria. Patients with IFG and/or IGT are now referred to as having “pre-diabetes” indicating the relatively high risk for the development of T2DM in these patients.
Eligibility Criteria
Prediction models were conducted to predict the risk of postpartum glucose intolerance among women who had GDM worldwide in all settings including hospitals, primary care, secondary, tertiary, and community-based settings. We included both prospective and retrospective cohort prognostic model studies. We did not restrict studies by ethnic origin or parity.
Studies with no original data (meetings, editorials, letters, narrative reviews, and commentaries), studies that were performed with a cohort of women with T2DM before pregnancy, and studies that were published in languages other than English were excluded.
Search Strategy and Screening
The search was conducted on May 21, 2022 across eight databases: Ovid Medline, Ovid Embase, Ovid Emcare, Scopus, Web of Science, CINHAL, Maternity & Infant Care Database (MIDIRS), and Global Health 1910 to 2022 Week 18 attached in Appendix S1. We also manually searched the references of the selected articles to identify additional eligible studies.
Studies identified on database searching were imported to Covidence web-based software (developed by Australian not-for-profit company called SaaS enterprise) for the title and abstract screening. Title and abstract screening and full-text reviews were done by two independent reviewers (YB and DH) based on the aforementioned eligibility criteria, and disagreement was resolved by discussion.
Critical Appraisal
The CHARMS tool was applied to assess the methodological quality and relevance of studies. The source of data used for prediction model development was assessed. Participants’ selection (method, setting, inclusion, and exclusion criteria); definition, clarity, consistency of outcome of interest, and candidate predictors’ assessment used; sample size used for prediction model development; missing data handling; methodologies used for model development, performance measurement, and model evaluation; and interpretation of the results were assessed by the checklist.
Risk of Bias (Quality) Assessment
Two researchers (YBM, DWH) assessed the risk of bias. In abstract and full-text screening, discrepancies were resolved by discussion, and consensus was reached on all discrepancies. Assessment of risk of bias and model applicability was conducted using the Prediction models Risk Of Bias Assessment Tool (PROBAST) tool. This involves the assessment of four domains (participants, predictors, outcome, and analysis) to cover key aspects of prediction model studies. Under these four domains, there are 20 signaling questions overall. These questions were scored as “Low,” “High,” or “Unclear.” A low score indicates a low risk of bias, whereas high shows the presence of bias, and unclear was used when there was insufficient reported information to decide on risk. The overall risk of bias was graded as low risk when all domains were considered low risk, and high risk when at least one of the domains was considered high risk. The first three domains (participants, predictors, outcome) were also rated for concern regarding applicability (low, high, or unclear) to the systematic review question. Concerns regarding applicability were rated similarly to risk of bias, but without signaling questions (Table S1).
Data Extraction (Selection and Coding)
A data extraction grid was created including all relevant variables and key elements in Transparent Reporting of a multivariable prediction model of Individual Prognosis Or Diagnosis (TRIPOD) checklist which was pilot tested by using sample articles and modified accordingly. The following variables were extracted by two authors independently: country, source of data, participants (ethnicity, maternal characteristics), outcomes to be predicted, candidate predictors (index tests), sample size, missing data, model development, model performance measurements (calibration discrimination), model evaluation, and results (Appendix S2).
Strategy for Data Synthesis
Data synthesis was performed using thematic and context analysis to summarize the methodologies used to develop the prediction studies, participant selection, predictor variable selection and collection, outcome determination, analysis used for model development, variables included in the final model, and performance measures used. Appropriate data was presented in the form of summary tables and, where relevant, graphical representations of the data. Where there was a lack of homogeneity in methods used to develop the prediction models and different sets of predictors used to develop different prediction models, meta-analysis was not performed as merging these models may lead to highly correlated data and inflated estimates [46, 47]. If meta-analysis was not indicated, then qualitative evaluation and synthesis of estimates were applied to summarize and appraise the available model estimates.
Results
Main Characteristics of Included Studies
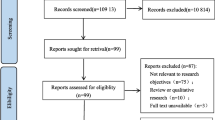
The systematic review process is presented on the flow chart in Fig. 1. The electronic search method yielded 3455 unique articles, of which 3402 articles were excluded on title and abstract screening leaving 53 studies to be assessed by full text. Following full-text review, a further 38 articles were excluded. Finally, fifteen studies reporting 15 risk prediction models were identified and included in this review. All included studies were model development studies, with no external validation studies found. Included models were developed in six different countries or regions: four in the USA [35, 48••, 49••, 50], six in Europe [24, 36, 51, 52••, 53, 54], two in Australia [37, 55••], and one in Asia [56], Canada [57], and Ethiopia [58••] between 1995 and 2022.

PRISMA flow diagram showing the systematic review process
The primary outcomes of included studies were reported as follows: T2DM (n = 10) [35,36,37, 49••, 50, 51, 53, 55••, 56, 57], glucose intolerance (n = 4) [24, 52••, 54, 58••], and IGT (n = 1) [48••]. Muche et al. [58••] diagnosed glucose intolerance as postpartum pre-diabetes (IFG: FPG 100–125 mg/dL; IGT: 2-h plasma glucose in 75 g OGTT 140–199 mg/dL) or diabetes (FPG > 126 mg/dL, or 2-h plasma glucose > 200 mg/dL in OGTT or random plasma glucose > 200 mg/dL) (Table 2). Postpartum diagnosis of T2DM/prediabetes for Bartakova et al. [59] was performed based on the WHO criteria: FPG ≥ 7 mmol/L alone or 2 h after 75 g load glucose ≥ 11.1 mmol/L for T2DM, FPG 5.6–6.9 mmol/L or 2 h after 75 g load glucose 7.8–11.0 mmol/L for prediabetes. Bengtson et al. [48••] diagnosed impaired glucose tolerance as HbA1c ≥ 5.7%. Kondo et al. [24] diagnosed glucose intolerance with 75-g oral glucose tolerance tests. Among ten studies that reported T2DM as a primary outcome, greater than half used ADA criteria for diagnosis [60] (Table S2).
Predictors in the Final Model
A list of predictors included in the final model is presented in Table 3. The number of risk predictor variables included in the models ranged from three to seven. Age (n = 6), FPG level during pregnancy (n = 8), and BMI (n = 11) were the three most common predictor variables included in the final model to predict postpartum glucose intolerance. Four models included biochemical variables such as branched-chain amino acids (BCAAs) (Val, Leu, Ile), lipid metabolites (sphingomyelin (SM (OH) C14:1), cholesteryl palmitic acid (CE(16:0)), non-esterified fatty acids (NEFA(22:4)), triglycerides and their fatty acid combination (TAG 48:2 FA 16:1, TAG 54:0 FA 16:0, TAG 50:1 FA 16:0), cholesteryl icosatetraenoate (CE(20:4)), phosphatidylethanolamine (PE(P-18:0/18:1), PE(P-36:2)), phosphatidylcholine (PC ae C40:5), hexoses, and phosphatidylserine (PS 38:4) [35,36,37, 55••]. Five models included a family history of diabetes mellitus, and four models included a 2-h plasma glucose level during pregnancy. Postnatal fasting glucose level, postnatal 2-h plasma glucose level, insulin therapy during pregnancy, and genetic factors were also other common prognostic determinants considered for model building. GDM history in a prior pregnancy, GDM diagnosis at < 24 weeks gestation, personal history of hypothyroidism, instrumental delivery, lactation, ethnicity, antenatal depression, blood pressure, genetic risk factors, and insulinogenic index/fasting immunoreactive insulin were each included only in one model (Fig. 2).

Predictors commonly utilized for developing prediction models to predict postpartum glucose intolerance in studies included in this systematic review
Predictive Performance
Traditional statistical models were common, with only three applying machine learning (Table 4). The predictive performance of each study model is summarized in Table 3. The predictive performance of 13 studies that reported the area under the curve ranged from 0.66 to 0.92. However, none were externally validated. Only a few models were validated internally [35,36,37, 49••, 51, 55••]. Calibration was reported only for some models using Hosmer–Lemeshow test, calibration plot, and calibration slope [24, 51, 53].
Risk of Bias Assessment and Meta-analysis
The risk of bias and applicability assessment results are shown in Table S1. Overall low risk of bias was present in two (2/15) studies only. Three domains including participant selection, predictor assessment, and outcome assessment resulted in a low risk of bias for most studies. A high risk of bias for participant selection was mainly due to controversial inclusion or exclusion criteria Table S3. In addition, two studies selected participants for inclusion based on one question only asking “Have you ever been told that you had a high sugar level during pregnancy?” which is a less sensitive approach, potentially introducing serious bias and may compromise the transportability of the model [49••, 57]. The answer to the question “Were predictor assessments made without knowledge of outcome data?” resulted in a high risk of bias because the assessment of predictors was performed in retrospect after the outcome was known and/or there was no statement showing whether assessors were blinded or not. As most models had less than 10 events per variable (EPV) or the EPV was unable to be extracted (Table 2), this was scored as a high risk of bias for most models.
However, in the analysis section, most studies had a high risk of bias. In some studies, continuous and categorical variables were not handled appropriately. For instance, although using continuous variable is recommended in prediction model development, Man (2021) categorized age into six categories and BMI into three categories. The analysis did not include all enrolled participants and/or did not report on those who were excluded. Additionally, participants with missing data were not adequately addressed and/or were not reported. For example, Ignell (2016), which relies on prospective data collection, experienced a significant amount of lost to follow-up. The selection of predictors based on univariable analysis was applied and/or not reported [48••, 58••], and complexities in the data were not accounted for appropriately and/or not reported. Relevant model performance measures were not evaluated appropriately and/or not reported. Furthermore, model overfitting and optimism in model performance were not accounted for and/or not reported. Predictors and their assigned weights in the final model did not correspond to the results from the reported multivariable analysis and/or are not reported.
Meta-analysis was not possible due to the lack of homogeneity in methods used to develop the prediction models, different sets of predictors used to develop different prediction models, and heterogeneity in the prediction time interval ranging from 1 to 20 years postpartum.
Discussion
This systematic review of risk models predicting postpartum glucose intolerance among women who had GDM identified 15 models; however, none were externally validated and less than half were internally validated. No models had the same set of prognostic factors, and factors included a range of demographic, clinical, and biomarker factors. The most frequent factors were BMI (measured pre-pregnancy or early pregnancy), fasting glucose concentration during pregnancy, maternal age, and family history of T2DM. Some studies included only traditional clinical risk factors (e.g., age, BMI, pregnancy fasting OGTT, and postnatal fasting OGTT), while others included biochemical variables and genetic factors. Among traditional risk factors, the most common potentially modifiable factor was BMI (pre-pregnancy/early pregnancy). Predictive performances were suggested to be above chance (with AUC > 0.66); however, performance was difficult to evaluate as all included studies had a high risk of bias with various methodological shortcomings.
The type of prognostic factors used in the models depended on the time when risk for postpartum glucose intolerance was assessed. Some studies used clinical and biochemical factors collected during and/or before GDM diagnosis, thus making the GDM diagnosis the starting point (baseline) for the prediction. However, other studies had baseline risk assessments after delivery at 2 days [48••], 6–9 weeks [35, 36], 12 weeks [55••], 4–16 weeks [50], and 12 months [37]. In these latter studies, additional prognostic factors included postnatal fasting and 2-h plasma glucose [37, 51, 55••], mode of delivery [52••], lactation [51], and circulating miR-369-3p measured at 12 weeks postpartum [55••]. Future studies are warranted to examine which baseline time point and prognostic factors are associated with the most accurate prediction.
This review has highlighted that, although study participants were defined as women with GDM, the inclusion criteria applied were not always rigorous; for example, two studies selected participants based on one question only asking “Have you ever been told that you had a high sugar level during pregnancy?” 49••, 57. Instead, wherever possible, a diagnostic test or robust selection criteria should be applied to distinguish the target population to be included in the study [61, 62]. Otherwise, ambiguous population groups can lead to excess variability in the study data, making prediction difficult, therefore limiting any usefulness of the models and eventual inclusion in subsequent meta-analyses.
Many of these studies used routinely collected health data which is more generalizable at population level. However, missing data are not uncommon when examining routinely collected health data and retrospective cohort studies which may reduce the available evidence to build the model [63]. Instead of ignoring variables having missing data, which can introduce a source of serious bias, it is suggested that missing data should be replaced based on the available information by using advanced methods such as multiple imputations [64]. However, only a few models discussed missing data [48••, 53, 55••, 56], and only Bengtson et al. [48••] and Kwak et al. [56] applied multiple imputations to handle missing data. Where other studies instead excluded participants due to missing clinical data, this may aggravate the problem of small sample size and discards the information of nearly complete data [55••].
Comparing the predictive performance of the included studies is not a straightforward task, as the predictors utilized for each model’s development vary. Nonetheless, it can be observed that, on average, machine learning algorithms outperform traditional models in terms of sensitivity and specificity. This can be attributed to their capacity to identify complex patterns and relationships in the data that may not be apparent to the naked eye. It is worth noting, however, that traditional models may have advantages in terms of being more interpretable and simpler. Although some models show performance measures suggesting excellent predictive capabilities, our review found that none were externally validated and only a few were internally validated. This lack of validation puts their reproducibility under question. Therefore, testing the model performance in a new population in a different geographic region or in different time period is required to further this field and to assess the practical utility of the model.
Women who have experienced GDM are 8 to 10 times and 2 times at higher risk of developing type 2 diabetes and cardiovascular disease (CVD), respectively [5, 65,66,67,68]. The above emphasizes the pressing requirement for timely and continuous proactive monitoring, as well as efficient preventative measures, for type 2 diabetes and cardiovascular disease (CVD). Among these strategies, developing a well-designed clinical prediction model based on historical, antepartum, and even early postpartum variables is mandatory to early identification of at-risk women and early initiation of intervention. To be more precise, the screening and prevention of T2DM related to gestational diabetes is a subject that is challenging and controversial [69] and would benefit greatly from the development of a thoroughly planned and validated prediction model.
Strengths and Limitations
This is the first systematic review of risk prediction studies of postpartum glucose intolerance among women who have a history of GDM. Strengths of this review are that the search strategy was built based on a validated search strategy for prediction models, and the quality of risk prediction models was assessed by CHARMS guidelines. Limitations for deriving information from this review mostly arise from the low quality of the identified eligible studies. However, examining the overall quality and characteristics of existing models is important to understand the flaws and strengths of developed models, using these as stepping stones to build novel models in future.
A major limitation of the studies identified is that very few followed the reporting guidelines for prognostic risk prediction modeling. Researchers examining this area are strongly recommended to follow the appropriate guidelines so that this area can be advanced. Another major limitation of the models identified was that there was a high risk of bias evident in all included studies. The various methodological shortcomings included the use of inadequate sample sizes, uncertain inclusion or exclusion criteria, lack of missing data reporting and/or handling, inappropriate management of continuous and categorical variables, use of univariable analysis for selection of predictors, failing to evaluate/report relevant model performance measures, failing to consider model overfitting and optimism in model performance, lack of internal and external validation, the low trend of model performance measure reporting, and lack of model presentation.
Furthermore, only a fraction of models considered overfitting. Overfitting is especially prevalent when there are too few outcome events as compared with candidate prognostic determinants. Additionally, overfitting is expected when the model is developed in a small dataset, inappropriate continuous variables categorization is employed, and when stepwise predictor selection methods based on significance criteria are applied [70, 71]. In the included studies, some had very small sample sizes (n = 103, event = 21) [55••], (n = 104, event = 21) [37], (n = 112, event = 24) [58••], (n = 123, event = 45) [24] (n = 140, event = 55) [36], (n = 203, event = 71) [48••]. If the number of predictors considered for prediction is larger than the number of events of interest, the predictive performance will be overestimated. Preferably, predictive model studies necessitate a minimum of several hundred outcome events [72]. Small samples and a reduced number of events compared to several predictors will lead to overfitting and compromise the transportability of the model in a similar or a different population. This is important especially in regions with increasing migration, and the propensity for some groups to “adopt” a higher risk in the new home; therefore, external validation and ultimately generalisable models are needed more than ever.
Conclusions
GDM is common, and rates are rising globally. Women with this condition have a high risk of conversion to glucose intolerance postpartum. Identification of those at risk can facilitate targeted screening and prevention strategies. Despite this, our systematic review identified that existing prognostic models for glucose intolerance following GDM were not externally validated, and only a few were internally validated. In addition, there was a high risk of bias, unreported model calibration, and low use of model presentation methods. Future research should focus on the development of robust, high-quality risk prediction models by incorporating easily accessible prognostic determinates to enhance the practical application and accuracy of risk prediction models for glucose intolerance and T2DM following GDM looking the summarized result of this review. External validation is also required before implementing these prediction models into clinical practice.
Data Availability
Data are available upon request from the corresponding author.
References
Papers of particular interest, published recently, have been highlighted as: • Of importance •• Of major importance
Steegers EAP, Fauser BCJM, Hilders CGJM, Jaddoe VWV, Massuger LFAG, van der Post JAM et al. Textbook of obstetrics and gynaecology: a life course approach. Bohn Stafleu Van Loghum. 2019. https://doi.org/10.1007/978-90-368-2131-5.
Wang H, Li N, Chivese T, Werfalli M, Sun H, Yuen L, et al. IDF diabetes atlas: estimation of global and regional gestational diabetes mellitus prevalence for 2021 by international association of diabetes in pregnancy study group’s criteria. Diabetes Res Clin Pract. 2022;183:109050. https://doi.org/10.1016/j.diabres.2021.109050.
McIntyre HD, Catalano P, Zhang C, Desoye G, Mathiesen ER, Damm P. Gestational diabetes mellitus. Nat Rev Dis Primers. 2019;5(1):47. https://doi.org/10.1038/s41572-019-0098-8.
Yogev Y, Visser GH. Obesity, gestational diabetes and pregnancy outcome. Semin Fetal Neonatal Med. 2009;14(2):77–84. https://doi.org/10.1016/j.siny.2008.09.002.
Song C, Lyu Y, Li C, Liu P, Li J, Ma RC, et al. Long-term risk of diabetes in women at varying durations after gestational diabetes: a systematic review and meta-analysis with more than 2 million women. Obes Rev. 2018;19(3):421–9. https://doi.org/10.1111/obr.12645.
Zhu Y, Zhang C. Prevalence of gestational diabetes and risk of progression to type 2 diabetes: a global perspective. Curr Diab Rep. 2016;16(1):7. https://doi.org/10.1007/s11892-015-0699-x.
Catalano PM, McIntyre HD, Cruickshank JK, McCance DR, Dyer AR, Metzger BE, et al. The hyperglycemia and adverse pregnancy outcome study: associations of GDM and obesity with pregnancy outcomes. Diabetes Care. 2012;35(4):780–6. https://doi.org/10.2337/dc11-1790.
Bennett CJ, Walker RE, Blumfield ML, Gwini SM, Ma J, Wang F, et al. Interventions designed to reduce excessive gestational weight gain can reduce the incidence of gestational diabetes mellitus: a systematic review and meta-analysis of randomised controlled trials. Diabetes Res Clin Pract. 2018;141:69–79. https://doi.org/10.1016/j.diabres.2018.04.010.
Rahati S, Shahraki M, Arjomand G, Shahraki T. Food pattern, lifestyle and diabetes mellitus. Int J High Risk Behav Addict. 2014;3(1):e8725. https://doi.org/10.5812/ijhrba.8725.
Moyer VA, U.S. Preventive Services Task Force. Screening for gestational diabetes mellitus: U.S. Preventive Services Task Force recommendation statement. Ann Intern Med. 2014;160(6):414–20. https://doi.org/10.7326/M13-2905.
Kim C, Newton KM, Knopp RH. Gestational diabetes and the incidence of type 2 diabetes: a systematic review. Diabetes Care. 2002;25(10):1862–8. https://doi.org/10.2337/diacare.25.10.1862.
Leuridan L, Wens J, Devlieger R, Verhaeghe J, Mathieu C, Benhalima K. Glucose intolerance in early postpartum in women with gestational diabetes: who is at increased risk? Prim Care Diabetes. 2015;9(4):244–52. https://doi.org/10.1016/j.pcd.2015.03.007.
Kim SH, Kim MY, Yang JH, Park SY, Yim CH, Han KO, et al. Nutritional risk factors of early development of postpartum prediabetes and diabetes in women with gestational diabetes mellitus. Nutrition. 2011;27(7–8):782–8. https://doi.org/10.1016/j.nut.2010.08.019.
Fatin AAB, Alina TI. Proportion of women with history of gestational diabetes mellitus who performed an oral glucose test at six weeks postpartum in Johor Bahru with abnormal glucose tolerance. Malays Fam Physician. 2019;14(3):2–9.
England LJ, Dietz PM, Njoroge T, Callaghan WM, Bruce C, Buus RM, et al. Preventing type 2 diabetes: public health implications for women with a history of gestational diabetes mellitus. Am J Obstet Gynecol. 2009;200(4):365.e1-8. https://doi.org/10.1016/j.ajog.2008.06.031.
Bellamy L, Casas JP, Hingorani AD, Williams D. Type 2 diabetes mellitus after gestational diabetes: a systematic review and meta-analysis. Lancet. 2009;373(9677):1773–9. https://doi.org/10.1016/S0140-6736(09)60731-5.
ACOG Practice Bulletin No. 190. ACOG Practice Bulletin No. 190 Summary: gestational diabetes mellitus. Obstet Gynecol. 2018;131(2):406–8. https://doi.org/10.1097/AOG.0000000000002498.
American Diabetes Association. 14. Management of diabetes in pregnancy: standards of medical care in Diabetes-2020. Diabetes Care. 2020;43(Suppl 1):183–92.
Kwak SH, Choi SH, Jung HS, Cho YM, Lim S, Cho NH, et al. Clinical and genetic risk factors for type 2 diabetes at early or late post partum after gestational diabetes mellitus. J Clin Endocrinol Metab. 2013;98(4):E744–52. https://doi.org/10.1210/jc.2012-3324.
Jang HC. Gestational diabetes in Korea: incidence and risk factors of diabetes in women with previous gestational diabetes. Diabetes Metab J. 2011;35(1):1–7. https://doi.org/10.4093/dmj.2011.35.1.1.
Buchanan TA, Xiang A, Kjos SL, Lee WP, Trigo E, Nader I, et al. Gestational diabetes: antepartum characteristics that predict postpartum glucose intolerance and type 2 diabetes in Latino women. Diabetes. 1998;47(8):1302–10. https://doi.org/10.2337/diab.47.8.1302.
Metzger BE, Cho NH, Roston SM, Radvany R. Prepregnancy weight and antepartum insulin secretion predict glucose tolerance five years after gestational diabetes mellitus. Diabetes Care. 1993;16(12):1598–605. https://doi.org/10.2337/diacare.16.12.1598.
Feig DS, Zinman B, Wang X, Hux JE. Risk of development of diabetes mellitus after diagnosis of gestational diabetes. CMAJ. 2008;179(3):229–34. https://doi.org/10.1503/cmaj.080012.
Kondo M, Nagao Y, Mahbub MH, Tanabe T, Tanizawa Y. Factors predicting early postpartum glucose intolerance in Japanese women with gestational diabetes mellitus: decision-curve analysis. Diabet Med. 2018;35(8):1111–7. https://doi.org/10.1111/dme.13657.
Kugishima Y, Yasuhi I, Yamashita H, Fukuda M, Kuzume A, Sugimi S, et al. Risk factors associated with abnormal glucose tolerance in the early postpartum period among Japanese women with gestational diabetes. Int J Gynaecol Obstet. 2015;129(1):42–5. https://doi.org/10.1016/j.ijgo.2014.09.030.
Kojima N, Tanimura K, Deguchi M, Morizane M, Hirota Y, Ogawa W, et al. Risk factors for postpartum glucose intolerance in women with gestational diabetes mellitus. Gynecol Endocrinol. 2016;32(10):803–6. https://doi.org/10.1080/09513590.2016.1177009.
Masuko N, Tanimura K, Kojima N, Imafuku H, Deguchi M, Okada Y, et al. Predictive factors for postpartum glucose intolerance in women with gestational diabetes mellitus. J Obstet Gynaecol Res. 2022;48(3):640–6. https://doi.org/10.1111/jog.15155.
Saisho Y, Miyakoshi K, Tanaka M, Matsumoto T, Minegishi K, Yoshimura Y, et al. Antepartum oral disposition index as a predictor of glucose intolerance postpartum. Diabetes Care. 2012;35(4):e32. https://doi.org/10.2337/dc11-2549.
Dupuis J, Langenberg C, Prokopenko I, Saxena R, Soranzo N, Jackson AU, et al. New genetic loci implicated in fasting glucose homeostasis and their impact on type 2 diabetes risk. Nat Genet. 2010;42(2):105–16. https://doi.org/10.1038/ng.520.
Voight BF, Scott LJ, Steinthorsdottir V, Morris AP, Dina C, Welch RP, et al. Twelve type 2 diabetes susceptibility loci identified through large-scale association analysis. Nat Genet. 2010;42(7):579–89. https://doi.org/10.1038/ng.609.
Cho YS, Chen CH, Hu C, Long J, Ong RTH, Sim X, et al. Meta-analysis of genome-wide association studies identifies eight new loci for type 2 diabetes in east Asians. Nat Genet. 2011;44(1):67–72. https://doi.org/10.1038/ng.1019,PMID22158537.
Morris AP, Voight BF, Teslovich TM, Ferreira T, Segrè AV, Steinthorsdottir V, et al. Large-scale association analysis provides insights into the genetic architecture and pathophysiology of type 2 diabetes. Nat Genet. 2012;44(9):981–90. https://doi.org/10.1038/ng.2383.
Wu NN, Zhao D, Ma W, Lang JN, Liu SM, Fu Y, et al. A genome-wide association study of gestational diabetes mellitus in Chinese women. J Matern Fetal Neonatal Med. 2021;34(10):1557–64. https://doi.org/10.1080/14767058.2019.1640205.
Wang XM, Gao Y, Eriksson JG, Chen W, Chong YS, Tan KH, et al. Metabolic signatures in the conversion from gestational diabetes mellitus to postpartum abnormal glucose metabolism: a pilot study in Asian women. Sci Rep. 2021;11(1):16435. https://doi.org/10.1038/s41598-021-95903-w.
Allalou A, Nalla A, Prentice KJ, Liu Y, Zhang M, Dai FF, et al. A predictive metabolic signature for the transition from gestational diabetes mellitus to type 2 diabetes. Diabetes. 2016;65(9):2529–39. https://doi.org/10.2337/db15-1720.
Khan SR, Mohan H, Liu Y, Batchuluun B, Gohil H, Al Rijjal D, et al. The discovery of novel predictive biomarkers and early-stage pathophysiology for the transition from gestational diabetes to type 2 diabetes. Diabetologia. 2019;62(4):687–703. https://doi.org/10.1007/s00125-018-4800-2.
Lappas M, Mundra PA, Wong G, Huynh K, Jinks D, Georgiou HM, et al. The prediction of type 2 diabetes in women with previous gestational diabetes mellitus using lipidomics. Diabetologia. 2015;58(7):1436–42. https://doi.org/10.1007/s00125-015-3587-7.
Tobias DK, Clish C, Mora S, Li J, Liang L, Hu FB, et al. Dietary intakes and circulating concentrations of branched-chain amino acids in relation to incident type 2 diabetes risk among high-risk women with a history of gestational diabetes mellitus. Clin Chem. 2018;64(8):1203–10. https://doi.org/10.1373/clinchem.2017.285841.
Brown SD, Hedderson MM, Zhu Y, Tsai AL, Feng J, Quesenberry CP, et al. Uptake of guideline-recommended postpartum diabetes screening among diverse women with gestational diabetes: associations with patient factors in an integrated health system in the USA. BMJ Open Diabetes Res Care. 2022;10(3):e002726. https://doi.org/10.1136/bmjdrc-2021-002726.
Linnenkamp U, Greiner GG, Haastert B, Adamczewski H, Kaltheuner M, Weber D, et al. Postpartum screening of women with GDM in specialised practices: data from 12,991 women in the GestDiab register. Diabet Med. 2022;39(7):e14861. https://doi.org/10.1111/dme.14861.
Hu FB, Manson JE, Stampfer MJ, Colditz G, Liu S, Solomon CG, et al. Diet, lifestyle, and the risk of type 2 diabetes mellitus in women. N Engl J Med. 2001;345(11):790–7. https://doi.org/10.1056/NEJMoa010492.
Zhang Y, Pan XF, Chen J, Xia L, Cao A, Zhang Y, et al. Combined lifestyle factors and risk of incident type 2 diabetes and prognosis among individuals with type 2 diabetes: a systematic review and meta-analysis of prospective cohort studies. Diabetologia. 2020;63(1):21–33. https://doi.org/10.1007/s00125-019-04985-9.
Page MJ, Moher D, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD, et al. PRISMA 2020 explanation and elaboration: updated guidance and exemplars for reporting systematic reviews. BMJ. 2021;372:n160. https://doi.org/10.1136/bmj.n160.
Moons KGM, de Groot JAH, Bouwmeester W, Vergouwe Y, Mallett S, Altman DG, et al. Critical appraisal and data extraction for systematic reviews of prediction modelling studies: the CHARMS checklist. PLOS Med. 2014;11(10):e1001744. https://doi.org/10.1371/journal.pmed.1001744.
World Health Organization. HEARTS D: diagnosis and management of type 2 diabetes. World Health Organization. 2020. https://apps.who.int/iris/handle/10665/331710. License: CC BY-NC-SA 3.0 IGO.
Zidek JV, Wong H, Le ND, Burnett R. Causality, measurement error and multicollinearity in epidemiology. Environmetrics. 1996;7(4):441–51. https://doi.org/10.1002/(SICI)1099-095X(199607)7:4%3c441::AID-ENV226%3e3.0.CO;2-V.
Yoo W, Mayberry R, Bae S, Singh K, Peter He Q, Lillard JW. A study of effects of multicollinearity in the multivariable analysis. Int J Appl Sci Technol. 2014;4(5):9–19.
•• Bengtson AM, Dice ALE, Clark MA, Gutman R, Rouse D, Werner E. Predicting progression from gestational diabetes to impaired glucose tolerance using peridelivery data: an observational Study. Am J Perinatol. 2022. https://doi.org/10.1055/a-1877-9587. A prediction model was created to forecast the risk of postpartum glucose intolerance in women with gestational diabetes mellitus (GDM) using prognostic factors that are easily accessible.
•• Man B, Schwartz A, Pugach O, Xia Y, Gerber B. A clinical diabetes risk prediction model for prediabetic women with prior gestational diabetes. Plos One. 2021;16(6):e0252501. https://doi.org/10.1371/journal.pone.0252501. A prediction model was created to identify the risk of postpartum prediabetes in women with gestational diabetes mellitus (GDM) at an early stage. The model utilizes four prognostic factors to make the prediction.
Kjos SL, Peters RK, Xiang A, Henry OA, Montoro M, Buchanan TA. Predicting future diabetes in Latino women with gestational diabetes. Utility of early postpartum glucose tolerance testing. Diabetes. 1995;44(5):586–91. https://doi.org/10.2337/diab.44.5.586.
Köhler M, Ziegler AG, Beyerlein A. Development of a simple tool to predict the risk of postpartum diabetes in women with gestational diabetes mellitus. Acta Diabetol. 2016;53(3):433–7. https://doi.org/10.1007/s00592-015-0814-0.
•• Bartáková V, Barátová B, Pácal L, Ťápalová V, Šebestová S, Janků P, et al. Development of a new risk score for stratification of women with gestational diabetes mellitus at high risk of persisting postpartum glucose intolerance using routinely assessed parameters. Life (Basel). 2021;11(6):464. https://doi.org/10.3390/life11060464. Developed a prediction model for early risk stratification of post-partum glucose intolerance among women with GDM by using five prognostic factors.
Ignell C, Ekelund M, Anderberg E, Berntorp K. Model for individual prediction of diabetes up to 5 years after gestational diabetes mellitus. Springerplus. 2016;1(5):318. https://doi.org/10.1186/s40064-016-1953-7.
Bartáková V, Malúšková D, Mužík J, Bělobrádková J, Kaňková K. Possibility to predict early postpartum glucose abnormality following gestational diabetes mellitus based on the results of routine mid-gestational screening. Biochem Med. 2015;25(3):460–8. https://doi.org/10.11613/BM.2015.047.
•• Joglekar MV, Wong WKM, Ema FK, Georgiou HM, Shub A, Hardikar AA, et al. Postpartum circulating microRNA enhances prediction of future type 2 diabetes in women with previous gestational diabetes. Diabetologia. 2021;64(7):1516–26. https://doi.org/10.1007/s00125-021-05429-z. Developed an excellent performing type 2 diabetes prediction model among GDM women by using six traditional risk factors and one genetic factor.
Kwak SH, Choi SH, Kim K, Jung HS, Cho YM, Lim S, et al. Prediction of type 2 diabetes in women with a history of gestational diabetes using a genetic risk score. Diabetologia. 2013;56(12):2556–63. https://doi.org/10.1007/s00125-013-3059-x.
Cormier H, Vigneault J, Garneau V, Tchernof A, Vohl MC, Weisnagel SJ, et al. An explained variance-based genetic risk score associated with gestational diabetes antecedent and with progression to pre-diabetes and type 2 diabetes: a cohort study. BJOG. 2015;122(3):411–9. https://doi.org/10.1111/1471-0528.12937.
•• Muche AA, Olayemi OO, Gete YK. Predictors of postpartum glucose intolerance in women with gestational diabetes mellitus: a prospective cohort study in Ethiopia based on the updated diagnostic criteria. BMJ Open. 2020;10(8):e036882. https://doi.org/10.1136/bmjopen-2020-036882. Developed a prediction model for predicting risk of postpartum glucose intolerance among women with GDM by using the following factors: advanced maternal age, overweight and/or obesity, high FPG at GDM diagnosis, and antenatal depression.
World Health Organization & International Diabetes Federation. Definition and diagnosis of diabetes mellitus and intermediate hyperglycaemia: report of a WHO/IDF consultation. World Health Organization. 2006. https://apps.who.int/iris/handle/10665/43588.
American Diabetes Association. Research, Education, Advocacy [cited Oct 6 2022]. Available from: https://diabetes.org/.
Grobbee DE, Hoes AW. Clinical epidemiology: principles, methods, and applications for clinical research. 2nd ed. Jones & Bartlett Learning; 2014.
Moons KGM, Altman DG, Reitsma JB, Ioannidis JPA, Macaskill P, Steyerberg EW, et al. Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD): explanation and elaboration. Ann Intern Med. 2015;162(1):W1-73. https://doi.org/10.7326/M14-0698.
Clark TG, Altman DG. Developing a prognostic model in the presence of missing data: an ovarian cancer case study. J Clin Epidemiol. 2003;56(1):28–37. https://doi.org/10.1016/s0895-4356(02)00539-5,PMID12589867.
Royston P, Moons KGM, Altman DG, Vergouwe Y. Prognosis and prognostic research: developing a prognostic model. BMJ. 2009;338:b604. https://doi.org/10.1136/bmj.b604.
Vounzoulaki E, Khunti K, Abner SC, Tan BK, Davies MJ, Gillies CL. Progression to type 2 diabetes in women with a known history of gestational diabetes: systematic review and meta-analysis. BMJ. 2020;369:m1361. https://doi.org/10.1136/bmj.m1361.
Li Z, Cheng Y, Wang D, Chen H, Chen H, Ming WK, Wang Z. Incidence rate of type 2 diabetes mellitus after gestational diabetes mellitus: a systematic review and meta-analysis of 170,139 women. J Diabetes Res. 2020;27:2020.
Nielsen KK, Kapur A, Damm P, de Courten M, Bygbjerg IC. From screening to postpartum follow-up – the determinants and barriers for gestational diabetes mellitus (GDM) services, a systematic review. BMC Pregnancy Childbirth. 2014;14(1):41. https://doi.org/10.1186/1471-2393-14-41.
Kramer CK, Campbell S, Retnakaran R. Gestational diabetes and the risk of cardiovascular disease in women: a systematic review and meta-analysis. Diabetologia. 2019;62(6):905–14. https://doi.org/10.1007/s00125-019-4840-2.
Balaji B, Ranjit Mohan AR, Rajendra P, Mohan D, Ram U, Viswanathan M. Gestational diabetes mellitus postpartum follow-up testing: challenges and solutions. Can J Diabetes. 2019;43(8):641–6. https://doi.org/10.1016/j.jcjd.2019.04.011.
Harrell FE. Regression modeling strategies: with applications to linear models, logistic regression, and survival analysis. New York: Springer; 2001. https://doi.org/10.1007/978-1-4757-3462-1
Ohlssen D. A review of: ”clinical prediction models: a practical approach to development, validation, and updating, by E.W. Steyerberg”. J Biopharm Stat. 2009;19(6):1165–7. https://doi.org/10.1080/10543400903244270.
Moons KGM, Royston P, Vergouwe Y, Grobbee DE, Altman DG. Prognosis and prognostic research: what, why, and how? BMJ. 2009;338:b375. https://doi.org/10.1136/bmj.b375.
Acknowledgements
We would like to acknowledge Monash University librarians Lorena Romero and Paula Todd for reviewing and giving constructive feedback on the search strategies used for this systematic review.
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions LM is funded by a Heart Foundation of Australia Future Leader Fellowship. VLV is funded by the Rural Health Multidisciplinary Training (RHMT) program through the Australian Government Department of Health and Aged Care. AM is funded by a biomedical research fellowship from the National Health and Medical Research Council (NHMRC) of Australia.
Author information
Authors and Affiliations
Contributions
YB and JE conceptualized the study. DWH performed the title and abstract screening and full-text review with YB. YB and DWH conducted data extraction. YB and JE wrote the first draft. All the remaining authors critically revised and provided comments on the final manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Human and Animal Rights and Informed Consent
This article is a review that summarizes studies that have been previously published involving human subjects. No experiments involving animals are documented within this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Belsti, Y., Moran, L., Handiso, D.W. et al. Models Predicting Postpartum Glucose Intolerance Among Women with a History of Gestational Diabetes Mellitus: a Systematic Review. Curr Diab Rep 23, 231–243 (2023). https://doi.org/10.1007/s11892-023-01516-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11892-023-01516-0