
Abstract
The surge in data-related investments has drawn the attention of both managers and academia to the question of whether and how this (re)shapes decision making routines. Drawing on the information processing theory of the organization and the agency theory, this paper addresses how putting a strategic emphasis on business analytics supports an analytical decision making culture that makes enhanced use of data in each phase of the decision making process, along with a potential change in authorities resulting from shifts in information asymmetry. Based on a survey of 305 medium-sized and large companies, we propose a multiple-mediator model. We provide support for our hypothesis that top management support for business analytics and perceived data quality are good predictors of an analytical culture. Furthermore, we argue that the analytical culture increases the centralization of data use, but interestingly, we found that this centralization is not associated with data-driven decision making. Our paper positions a long-running debate about information technology-related centralization of authorities in the new context of business analytics.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
There is a substantial body of research demonstrating the effects of information technology (IT) on organizations, which supports the idea that technological advancements are related to organizational change, although the nature of this relationship has been much debated (Orlikowski 1992; Robey et al. 2013). The seemingly endless stream of new IT solutions and the ever-expanding range of human activities affected by IT mean that research into the effects of IT must continue (Robey et al. 2013). Recently, digital technologies have been rightly at the center of research endeavors. The proliferation of newer and newer technologies enables data storage and processing and increases the accessibility of data. Due to this increased accessibility, data is no longer just a valuable asset used primarily to support management, but becomes the core of all organizational processes (Alaimo and Kallinikos 2022).
These new digital technologies have a distinctive nature in several aspects (Yoo 2012). The distinctive nature of recent business analytics (BA) techniques and related digital technologies challenges the reliability of previous results on IT-induced organizational change and calls for a rethinking of what we already know in this field. The emerging nature of these technologies does not only refer to the continuous development they undergo, but also signals that their use and organizational consequences remain diverse and unexplored (Bailey et al. 2022). Therefore, this paper is motivated by this serious interest in understanding the nature of organizational consequences related to the new emerging field of BA.
In the last 15 years, we have learned a lot about some aspects and organizational implications of BA use. With the growing adoption of BA, the attention of both practitioners and academics was first directed toward how it produces higher profits and growth (Davenport and Harris 2007), can create business value (Seddon et al. 2017; Krishnamoorthi and Mathew 2018; Grover et al. 2018), and improve overall firm performance (Ferraris et al. 2018; Aydiner et al. 2019; Karaboga et al. 2022). Despite repeated reinforcement of the relationship between BA and firm performance, the benefits of BA investments are far from evident (Ross et al. 2013). To reap the benefits of BA, top-level management must be open to putting data ahead of their instincts and prior knowledge (McAfee and Brynjolfsson 2012; Gupta and George 2016). Thus, if data-driven decision making is a prerequisite for generating value from BA, understanding organizational factors that support the use of data in the decision making process is vital.
Previous research had made significant efforts to identify these organizational factors, mainly in the context of business intelligence (BI) use. While some companies tend to have a longer, others shorter, or no tradition in data-driven decision making and fact-supporting culture, this is something that can be built and strengthened starting at the top (Ross et al. 2013). This facilitating role of top management has been repeatedly proven for various types of IT initiative (Young and Jordan 2008; Wirges and Neyer 2022). Due to increased organizational dependence on information systems and data, managerial attention is directed toward maintaining data quality (Gorla et al. 2010). The good quality of data has long been argued as an antecedent to benefiting from BI systems (Işık et al. 2013; Wieder and Ossimitz 2015) and more recently from BA (Seddon et al. 2017; Torres and Sidorova 2019), usually justified on the ground that improved data quality will likely support analytic culture (Popovič et al. 2012; Kulkarni et al. 2017) and improve decision making processes (Gorla et al. 2010; Côrte-Real et al. 2020).
Prior research endeavored to gather factors that support data-driven decision making, resulting in a growing but scattered body of evidence. However, the joint effects of these factors in the context of BA remain poorly understood. To address this gap, we present a top management perspective that explains the managerial choice to meet information processing needs. The proposed model, rooted in organizational information processing theory (OIPT), posits that BA enhances organizational information processing capabilities, allowing informed decisions by top management (Cao et al. 2015). Accentuating the choice of top management over technological options, top management support for BA initiatives is an exogenous construct that influences data quality perception factors and the development of an analytical decision making culture. Accordingly, we hypothesize that top management support, along with improved data quality perceptions, fosters an analytical decision making culture, facilitating the data-driven decision making process.
Moreover, we call attention to another, somewhat neglected means of managing the information processing capacity of organizations: the adequate organizational design (Tushman and Nadler 1978), particularly the decisions surrounding centralization. We propose that due to changes in information distribution, analytical decision making culture acts as a centralizing force, and centralization further motivates top management to rely on data in decision making. Agency theory explains the degree of centralization as a consequence of information asymmetry, where top management’s information disadvantage necessitates decentralization of decision making (Qiao 2022). Information systems can alter the level of information asymmetry (Jensen and Meckling 1976), although the impact of technologies remains ambiguous (Bloom et al. 2014). Furthermore, due to the unique nature of BA, previous research findings on the effects of technology on centralization cannot be directly extrapolated. Limited evidence suggests that BA may improve autonomy at lower levels due to cost reduction in data acquisition, but inexpensive communication may counteract this effect by allowing swift alerting of top management (Bloom et al. 2014). To fill this empirical gap, this paper addresses centralization in data use and introduces it as a factor that influences data-driven decision making in BA context.
To find support for our hypotheses, we analyzed the survey data of 305 mid-size and large companies registered in Hungary and suggested a multiple mediator model estimated by the WPLS algorithm with weights applied to ensure the representativeness of the results. Based on the opinion of the highest paid person (McAfee and Brynjolfsson 2012), we conclude that top management support of BA plays a crucial role in building an analytical decision making culture, an effect that is partially mediated by perceived data quality. Both the improvements in data quality and the analytical culture support the main endogenous construct, data-driven decision making. Interestingly, centralization in data use proved to be dual in nature: analytical culture strengthens centralization in data use without any consequences on the extent to which decision making will be data-driven.
Our research contributes to the literature in several ways. First, the paper verifies that the main drivers of an analytical culture emphasized in prior research are held upright in BA context. Second, we suggest a measurement scale of data-driven decision making, an organizational phenomenon investigated but measured in a somewhat fragmented way in the earlier literature. We rely on Herbert Simon, the ancestor of information processing in relation to decision making (Joseph and Gaba 2020). An 8-item scale has been proposed based on Simon’s (2013) decision making phases, a model that is often referred to and applied conceptually, but to our knowledge, not yet used for operationalization. Third, drawing on OIPT and agency theory, we identify centralization in data use as a consequence of analytical culture. Previous research has debated for decades whether the application of novel technologies causes centralization or decentralization. However, we hardly know the effect of current BA initiatives and the supporting organizational environment in this regard. This paper adds to this so far underinvestigated research topic by revealing the dual nature of centralization in data use. This duality can serve as an explanation for the contradictions reported in previous investigations.
In the remainder of the paper, we first introduce the concepts of information processing and information asymmetry, the interpreting frameworks for the key constructs of data-driven decision making and analytical decision making culture. We describe the phenomenon of centralization in data use drawing on agency theory and review the information system literature to show the controversies. On the basis of our theoretical foundations and findings of prior research, we develop several hypotheses resulting in a multiple-mediator model. The third chapter presents the data collection method, measurement properties, and the results of hypothesis testing. While most hypotheses have been supported, we pay more attention to the non-verified relationships in the discussion section. Finally, we draw implications for both theory and practice and outline further research possibilities that can overcome the limitations of current research.
2 Theoretical background and hypotheses development
2.1 Organizational information processing, information asymmetry and information systems
The OIPT conceptualizes organizations as open systems that seek to adapt to contextual factors by reducing uncertainty in decision making processes (Zhu et al. 2018). The open system approach does not simply mean that the system adapts to its environment, but that a failure of adaptation, mismatch, undermines the viability of the organization (Scott 1981; Scott and Davis 2015). OIPT conceptualizes the mismatch “between contextual factors and management practices as a gap between information-processing requirements and information-processing capacity” (Zelt et al. 2018, p. 70). To improve information processing capacity, organizations can invest in vertical information systems that process information gathered during task execution without overwhelming communication tiers. Alternatively, they establish lateral relationships that extend across the hierarchy and push decision making down within the organization (Galbraith 2014). Vertical information systems, such as an enterprise resource planning (ERP) system, allow organizations to process data efficiently and intelligently, and this increase in information processing capacity enables organizations to respond rapidly to the growing information processing needs (Srinivasan and Swink 2018). Information systems that improve information availability (visibility) support lateral relations. Corporate intranets, BI platforms, or systems that acquire current and valuable information from customers or suppliers enhance information processing capacity, result in more effective decision making, and contribute to the overall responsiveness of the organization (Bloom et al. 2014; Srinivasan and Swink 2018).
The term BI denotes the cluster of decision support technologies that aim to systematically gather and transform information from internal and external sources (systems) into actionable insights to support decision making (Rouibah and Ould-ali 2002; Chaudhuri et al. 2011). More recently, BA has been interpreted as evidence-based problem recognition and resolution by applying descriptive, predictive, or prescriptive analytical methods (Holsapple et al. 2014; Appelbaum et al. 2017), as well as a business application of data analytics in a broad sense (Duan and Xiong 2015). It is a subset of BI (Gudfinnsson et al. 2015) or an important extension of BI that goes beyond elementary reporting solutions (Laursen and Thorlund 2016), often referred to jointly as business intelligence and analytics (BI&A) (Kowalczyk and Gerlach 2015; Arnott and Pervan 2016). Informed by OIPT, researchers extensively investigated BI&A and confirmed that it strengthens information processing capacity with wide-ranging organizational impacts on decision making effectiveness (Cao et al. 2015), supply chain performance (Yu et al. 2021a, b), and resilience (Dubey et al. 2021).
OIPT further posits that organizations use information processing activities that are most suited for the type and quantity of information asymmetry with which they must deal (Aben et al. 2021). In this view, information asymmetry is understood as uncertainty and equivocality, where uncertainty refers to the lack of information and equivocality refers to its ambiguity (Weick 1979; Daft and Lengel 1986). This interpretation of information asymmetry replicates the information processing capacity requirement discussed above. Over and above, information asymmetry refers to the differences in information available to different decision makers within organizations (Saam 2007). This fundamental claim of another information theory, namely agency theory, draws attention to the unequal distribution of information and assumes that lower-level managers have an information advantage (Bergh et al. 2019). Since lower levels have the edge in terms of information, management is compelled to transfer decision making authority (Jensen and Meckling 1976), while also seeking to reduce information asymmetries.
Utilizing the possibilities provided by BA is capable of mitigating problems caused by equivocality and ambiguity in decision contexts (Kowalczyk and Buxmann 2014) by generating more data and making sense of it (Aben et al. 2021). Furthermore, BA moves information advantage from local to top management by establishing increased central control over data (Labro et al. 2022). Underpinned by these prior research results, we argue that BA is able to cope with information asymmetries both in terms of reducing uncertainty and equivocality and in terms of diminishing information disadvantage at the top. This potential of BA moves us forward to explain how BA shapes data utilization in a decision context.
2.2 Link to decision making culture and data-driven decision making process
One of the main objectives of organizational information processing is to make decisions (Choo 1996). Recognizing the differences in the gathering and evaluation of managerial information, the literature proposed various decision strategies (Evans 2010). The nonintuitive analytic processing type focuses on collecting, collating, analyzing, and interpreting the available information and ends with consciously derived rational choices (Hammond 1996). Rationality in decision making manifests itself in the comprehensive search for information, inventorizing, and evaluation of alternatives (Thunholm 2004), suggesting the presence of rationality in the whole decision making process instead of limiting it to the final choice. This long-established process approach to decisions (Svenson 1979) requires the identification of a sequence of successive phases such as 3 phases of identification, development, and selection (Mintzberg et al. 1976) or 4 phases of problem identification, problem definition, prioritization, and test for cause-effect relationships (Kepner and Tregoe 2005). Process descriptions of decision making are rather rational approaches, whereby the most widely applied and referred model has been developed by Simon (2013), differentiating between the intelligence, design, choice, implementation, and monitoring phases. In line with these process approaches, we conceptualize data-driven decision making as collecting, analyzing, and using verifiable data (Maxwell et al. 2016) through each step of the decision making process. The existence of decision rationality and the use of available data can be interpreted and investigated not only at an individual level but also at the organizational level, referred to as analytical decision making culture (Popovič et al. 2012), analytical decision making orientation (Kulkarni et al. 2017), rational decision making praxis (Cabantous and Gond 2011), or data-driven culture (Karaboga et al. 2022). The literature argues that this organizational-level social practice promotes rationality and reliance on data in individual decisions.
Previous discussions of data-driven decision making are consistent in proving that characteristics of data strongly shape the use of data in a decision context (Popovič et al. 2012; Provost and Fawcett 2013; Puklavec et al. 2018), although data quality literature captured the categorization of requirements regarding the data to be used and its adequate measurement very differently (Wang and Strong 1996; Pipino et al. 2002; Batini et al. 2009; Knauer et al. 2020). While some scholars distinguish data and information (Davenport and Prusak 1998; Zack 2007), in this paper we do not interpret the differences, and we use data interchangeably with information in line with prominent studies on data and information quality (Wang 1998; Pipino et al. 2002). The diffuse set of quality attributes was investigated in the BI context to find evidence of how data quality is influenced by the analytical decision making orientation of the company (Kulkarni et al. 2017), how data quality impacts its use moderated by the decision making culture (Popovič et al. 2012), and how data quality and data use support higher perceived decision quality (Visinescu et al. 2017).
The access to the same set of high-quality data diminishes uneven distribution of information, and this decrease in information asymmetry directly influences decision making as it was repeatedly evidenced in inter-organizational settings (Afzal et al. 2009; Mandal and Jain 2021; Ahearne et al. 2022). Furthermore, information asymmetry might also arise from a lack of means through which organizational members process information and communicates it (Bergh et al. 2019), a problem that calls for enhancing the information processing capacity at the firm level. Consequently, mechanisms suggested for the solution of information asymmetry and related support of managerial decision making often rely on the implementation of various information systems (Saam 2007).
2.3 Centralization and information systems
Organizations centralize or decentralize decision making to varying degrees, and this is not independent of the technology that processes the data and supports the decisions (Robey and Boudreau 1999). Theorizing about whether and how these data-processing technologies induce organizational changes started with the deterministic approach of the technological imperative. It assumes that IT investments change the information processing capabilities of the firm, thereby determining the optimally feasible formal decision making structure (Jasperson et al. 2002). The first stream of research, studies made divergent observations about computerization of data and information processing. Arguments for recentralizing previously delegated decision making power in top management were published (Leavitt and Whisler 1958) along with surveys reporting that department-wide computer use is linked to decentralization (George and King 1991). With the proliferation of ERP systems, researchers demonstrated how these packaged software required standardization of business processes coupled with decentralization. Lower-level managers got the ability to make decisions, which was something they were unable to accomplish before the implementation of ERP (Järvenpää 2007; Doherty et al. 2010). Meanwhile, ERP systems also reduced information asymmetry and shifted the information advantage to higher management, allowing them to closely monitor inputs and outputs (Bloom et al. 2014). The effect of this was twofold, as it allowed high-level managers to take decisions themselves as their information disadvantage was diminished, but also reduced the risk of delegation, which gave managers a chance to relieve their overload.
Overcoming the above discussion on how IT constraints organizational changes, the organizational imperative (social determinism) approach proposed a reversed direction, arguing that companies are likely to choose technology that reinforces the existing power structures of the organization (George and King 1991; Robey and Boudreau 1999). Research has shown that top managers are prone to use IT to reduce the size of middle management when both IT and organizational decisions are centralized. Where these decisions are decentralized, the number of middle managers increases with the implementation of IT (Pinsonneault and Kraemer 1993). Information systems will be easily implemented to the extent that their implications for power distribution are consistent with other sources of power (Markus and Pfeffer 1983).
The reasoning of OIPT underpins the argumentation of the organizational imperative research stream by emphasizing that IT is not an independent factor, but the result of an organization’s information processing needs and its managers’ decisions on how to satisfy those needs (Markus and Robey 1988). When organizational actors make choices about IT, to meet information processing needs, they are guided by the characteristics of the technologies available. These perceived and actual properties of a technology, also referred to as materiality (Leonardi et al. 2012) or affordance (Davis and Chouinard 2016) in the literature, determine how it can be used and how it will shape the organization. In the perspective of the technological imperative, these properties project the trajectory of organizational structural change. However, in the perspective of the organizational imperative, these attributes would be the ones that managers or the particular group of decision makers consider when trying to choose the technology that best serves their interests.
With the advent of digital technologies, new properties have come to the foreground compared to previous organizational IT, such as the homogenization of data, reprogrammability, replicability, and its self-referential nature (Yoo 2012). In contrast to transactional systems that have been prevalent since the 1990s, today’s ERP systems and other core operations technologies tend to be characterized by strong standardization and reliability, less customization, or even the adoption of software as a service (SaaS) (Sebastian et al. 2017). The SaaS deployment mode results in a greater degree of standardization, as further adjustments of these off-the-shelf cloud solutions are expensive and difficult. This not only reduces the degree of freedom in system design, but also shifts the focus from local and tailor-made information production to organization-wide standard information consumption. This prefabricated information can benefit the central management by increasing their power (Carlsson-Wall et al. 2022). Digital technologies, on the other hand, are increasingly plug-and-play, which means that they allow for experimentation, rapid deployment, and quick replacement (Sebastian et al. 2017). This means that organizational decision makers of IT deployments, be they senior management or local leaders of bottom-up digital initiatives, have greater flexibility in choosing the right technology.
The variety of BA software solutions available and the constant renewal of the offerings suggest that the properties of emerging BA technologies are not predetermined, but depend on the choices of the organizational actors deciding on their adoption: the organization’s information processing needs and managers’ decisions about how to meet them are what drive BA. The proliferation of it not only has interesting behavioral aspects (e.g., changing managerial decision making habits, processes), but the organizational consequences are considerable (Lismont et al. 2017). As lower-level managers can more easily translate the data into actionable insights than the top management, the use of analytics might reproduce information asymmetry, a force in the direction of decentralization (Wohlstetter et al. 2008). At the same time, BA allows higher levels of management access to more comprehensive data, that is, the information asymmetry is reduced. In line with this, predictive analytics has been observed to be associated with increased top management control of data gathering and less delegation of decision making power to local managers (Labro et al. 2022).
2.4 Hypotheses development
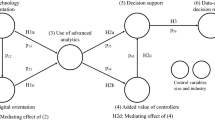
Similarly to all other types of organizational phenomena, the factors influencing analytical culture and decision making are numerous. Grounding our research on lenses of information processing and information asymmetry as discussed by OIPT and agency theory, we postulate successive effects of selected key constructs resulting in a multiple mediator model (Fig. 1).

Research model
Establishing and maintaining adequate information structures and information processing capability is argued to be among the major tasks of organizations (Daft and Lengel 1986). In a recent research, BA proved to be an effective tool for strengthening the information processing capability of organizations (Cao et al. 2015). At the same time, the literature in the context of BA argued that top management strongly influences changes in organizational information processing (Cruz-Jesus et al. 2018; Maroufkhani et al. 2020). More broadly, the IS literature considers top management support as highly important in implementation (Sharma and Yetton 2003) and adoption of new tools and emerging technologies (Khayer et al. 2020). Despite its essential role, the interpretation and measurement of top management support lack clarity and consistency. In their discussion, Kulkarni et al. (2017) differentiate the concepts of top management involvement (attitudinal intervention) and participation (behavioral intervention), both of them covered by the umbrella term top management support. In line with this view, where attitudes and supportive behaviors jointly shape the construct of top management support (Maroufkhani et al. 2020), in this paper we interpret top management support of BA as the extent to which a firm’s top management considers building and maintaining BA capability as strategically important (Kulkarni et al. 2017).
Although top management support is a crucial driving force behind the use of analytics (Chen et al. 2015), we cannot expect that the mere use of analytical tools alters managerial information processing. BA’s positive effect on information processing capabilities is expressed through the mediation of a data-driven environment that is understood as a set of organizational practices for the development of strategy, policies, and processes that ensure the embeddedness of BA (Cao et al. 2015). This supportive environment was also denoted as analytical decision making culture to emphasize the focus on decision making support (Popovič et al. 2012). The supporting culture is strongly shaped by top management, as it serves as a driver for altering corporate values, norms, and cultures, making it possible for other organization members to adopt the new analytics technologies (Chen et al. 2015). These findings suggest that the support of BA by top management strengthens the analytical decision making culture. On this basis, we formulate the following hypothesis.
H1a
Top management support of business analytics is positively associated with an analytical decision making culture.
Various technologies applied by the organization, each of them implemented with different purposes, shape the information structure of the organization. Organizations design BA to improve further aspects of data quality defined here as the accuracy, relevancy, representation, and accessibility of the data (in line with Wang and Strong 1996). By mitigating the problem of data reach, BA is expected to reduce uncertainty and by reducing the lack of clarity in data it is able to cope with equivocality (Kowalczyk and Buxmann 2014). As a result of its supportive attitude and behavior, top management can rightfully expect these improvements in data quality, which, in fact, was supported by previous findings about the link between top management support and detail, relevance, reliability, and timeliness of information (Kulkarni et al. 2017). Thus, we argue that the positive attitude of top management and its supportive behavior toward BA is a precursor of improved perceptions of data quality.
H1b
Top management support of business analytics is positively associated with data quality as perceived by the top management.
However, investing in data and analytical tools is not sufficient to cultivate a data-driven culture (Rikhardsson and Yigitbasioglu 2018), the whole set of applied assets, tools, and techniques powerfully shape social practice on the organizational level, i.e., the decision making culture (Cabantous and Gond 2011). As enterprise data is inimitable and, therefore, the most valuable strategic asset of companies (Djerdjouri and Mehailia 2017), improvements in the quality of this strategic asset will strengthen the perspective on using information to make decisions (Popovič et al. 2012). Thus, we assume that data quality is positively associated with analytical culture, and the above-mentioned catalyst effect of top management support on analytical culture is explained mainly by improved data quality. The proposed mediator effect of perceived data quality calls for two related hypotheses.
H1c
Perceived data quality is positively associated with analytical decision making culture.
H1d
Perceived data quality mediates between top management support and analytical decision making culture.
Organizational culture significantly impacts information processing (Stoica et al. 2004) by constraining or enabling individual behavior. Similarly, decision making culture shapes individual decision making processes, whereas an analytical culture helps individual actors to make rational decisions (Cabantous and Gond 2011), as decision makers are encouraged to systematically use and analyze data for their decision making tasks (Kulkarni et al. 2017). The positive and direct association between a data-driven environment and data-driven decision making demonstrated earlier (Cao et al. 2015) has been reasoned by Davenport et al. (2001, p. 127) emphasizing that "without solid values underlying analytic efforts, the already difficult-to-sustain behaviors … are easily neglected”. Based on these arguments, we postulate that organizational level attitudes to the use of data will support its individual level use in a decision context.
H2a
Analytical decision making culture is positively associated with data-driven decision making.
Anecdotal evidence in the scholarly and managerial literature suggests that BA eliminates the informational advantage of local or functional managers, and there is a tendency toward centralization of data use supported by central units dedicated to business analysis (Sharma et al. 2014). As the results generated by BA are typically more objective, measurable, and transmittable to headquarters (Labro et al. 2022), BA enhances the information processing capability: top management is no longer compelled to delegate decisions to avoid information overload. This suggests a possible shift of decision making power from local to top management. Drawing on agency theory and developing our arguments based on top management’s desire to reduce information asymmetry, we also posit that this shift might be associated with limiting the availability of information produced by BA. This corresponds to the arguments that a shift in the distribution of decision rights is possible if top management controls and accesses the output of analytics (Labro et al. 2022). Consequently, we introduce the term centralization in data use to denote the reduced availability of analytical results for lower-level managers accompanied by the reduced delegation of decision making and suggest that the analytical culture supports the centralization of data use.
H2b
Analytical decision making culture is positively associated with centralization in data use.
Furthermore, increased information availability at higher organizational levels has a comforting effect on managers who acquire a sense of control and manageability (Kuvaas 2002). As access to information makes them more confident, it can be assumed that top managers will rely more on data to make their decisions and also convincingly serve as a role model across the organization (Maroufkhani et al. 2020). Moreover, given sufficient information, managers can make decisions without the involvement of lower levels, thus becoming the driving force behind data-driven decisions (George and King 1991). Thus, we assume that the centralization of data use is positively associated with data-driven decision making, and that the increased centralization of data use partly explains the catalyst effect of analytical culture discussed above. The proposed mediator effect of centralization calls for two related hypotheses.
H2c
Centralization of data use is positively associated with data-driven decision making.
H2d
Centralization in data use mediates between analytical decision making culture and data-driven decision making.
Prior research suggests that information processing and data quality are closely related. Data quality aspects importance and usability are associated with the two aspects of information processing, perception, and judgment, highlighting that different modes of information processing prefer different sets of information (Blaylock and Rees 1984). Data accuracy and the amount of data have an impact on the decision making performance, while the consistency of the data was argued to affect the judgment time (Samitsch 2014). The link between data quality aspects and decision making quality aspects appears to be straightforward as management decisions based on these data analytics methodologies are only as good as the underlying data (Hazen et al. 2014). At the same time, we argue that this is a second-order link instead of a direct effect. This paper suggests a more direct link from data quality to data use in the decision context without judging time, effectiveness, or other quality criteria for decision making. We propose this first-order link based on the idea that first data needs to be utilized in the decision process before any quality assessment of the process can be made. As suspicion regarding data quality often prevents managers from making any decisions (Redman 1998), in the following hypothesis, we posit that good perceptions about data quality are required for utilizing the data during decision making.
H3a
Perceived data quality is positively related to data-driven decision making.
The possible adverse effect of poor data quality on its use in a decision context is reinforced by its negative consequences on the decision making culture. Data quality problems perceived by management will increase mistrust (Redman 1998) and undermine the positive attitude toward data use at the organizational level. Such damage to the supportive culture carries the risk of not being able to influence managerial behavior toward being data-driven in their decision making process. Therefore, we argue that the effect of data quality on data-driven decision making is mainly explained by the underlying decision making culture.
H3b
Analytical decision making culture mediates between perceived data quality and data-driven decision making.
In summary, the above hypotheses first examine the factors that influence data-driven decision making. Based on OIPT, we assume that data-driven decision making relies on the increase in information processing capacity enabled by BA technologies. As custodian of information processing needs, top management supports the establishment of an analytical decision making culture (H1a) and strives to improve data quality (H1b) that serves as mediator and it partially explains how top management supports results in an analytical culture (H1d). We hypothesize that these factors, namely analytical decision making culture (H2a) and perceived data quality (H3a) are the prerequisites for using data in the decision process. Properties of BA suggest us that it is more likely to channel a wide range of data towards top management, an opportunity for top management to reduce information asymmetries. Arguing for the organizational imperative, it will be the top management that will exploit the analytical decision making culture to shape BA practices to centralize data use (H2b), on which data-driven decisions can be built (H2c, H2d). Figure 1 provides a visual summary of the hypotheses concerning the relationships between the constructs.
3 Research method
3.1 Data collection and sample characteristics
The survey was conducted between March and April 2022, targeting medium-size and large companies registered in Hungary across all industries (covering all NACEFootnote 1 codes excluding 97–99). The size of the companies was primarily defined by their number of full-time employees (50–99 employees for smaller medium-sized companies, 100–249 employees for medium large, and 250 + employees for large companies). When implementing a stratified random sampling, the definitions of the strata were based on company size, industry, and region quotas provided by the Central Statistics Office of Hungary. Out of the total population of almost 6000 companies, 1369 were contacted by phone after a random selection by quota cell. In total, 306 companies responded to our survey questions, representing a response rate of 22.35%. The variables of the perception questionnaire were supplemented with the data of the balance sheet and income statement for the years 2017–2020, downloaded from the Electronic Reporting Portal database of the Ministry of Justice. Based on its incomplete financial data, one sample company was removed from the database, resulting in a final sample of 305 case companies. 53.5% of the companies in the sample are smaller medium-sized (50–99 employees), 29.7% medium-large (100–249 employees), and 16.8% large (250 + employees), reflecting the rates of the sampling frame. Table 1 contains the industry characteristics of the final sample.
The research was designed to investigate the perceptions of executives. Therefore, 125 top-level executives (CEO, Managing Director, Chief Executive Officer, President), 65 CXO-level executives (executives reporting to the top-level executive), and 115 strategic decision makers in other positions (e.g., board members) responded during the telephone inquiry in a total of 30–40 min. They typically have an economic qualification and 24.9 years of total work experience, as reported in Table 2.
Taking top executives’ perceptions as a point of reference is justified not only by their most extensive decision making authority and practice, but by their crucial influence on organizational data flows. We recognize that different levels of senior managers may have divergent perceptions of the investigated organizational phenomena, but based on the results of the non-parametric Kruskal–Wallis test we could exclude that the three executive positions perceive the two main dependent constructs differently: data-driven decision making (H = 0.344 and p = 0.844) and analytical culture (H = 5.705 and p = 0.058). Consequently, we conclude that positions do not significantly affect the results at a significance level of p = 0.05. However, studying organizational-level phenomena with a single respondent involves the risk of accelerated natural correlations between causes and outcomes (Van der Stede et al. 2005). To assess this common method bias, we executed the Harman’s Single Factor Test. The total variance extracted by one factor (41.5%) is below the recommended threshold of 50%, suggesting no issues with common method bias that may distort the data when the same measurement instrument is used for independent and dependent variables.
Using empirical data exclusively from a single country, namely Hungary, requires that country conditions allow the collection of relevant empirical data. Relevance is established by a satisfactory level of development of companies in order to be able to respond adequately. In 2022, Hungary ranked 22nd out of the 27 EU member states in the Digital Economy and Society Index, but it progressed in line with the EU over the last five years (European Commission 2022). Similarly to the other components measured by the index, the country scores below the EU average in integrating digital technology into the activities of enterprises, although significant improvements have been achieved. This allows us to conclude that the Hungarian sample will be sufficiently heterogeneous with regard to the phenomena under consideration: there will be companies that are more developed, as well as those where managerial attention is lacking, and therefore they do not exploit the opportunities offered by digital technologies, such as advancements on BA.
3.2 Measurement properties
For operationalization of most of the constructs presented in Fig. 1, multi-item scales were re-adopted from the BI literature, measured on a Likert-type scale from 1 to 5, as shown in Appendix I. Top management support is understood as the commitment of top-level management to BA measured by the 4-item of Kulkarni et al. (2017). The scale initially measuring top management support of BI initiatives could be readopted into the BA context without any additional change in the wording. Accordingly, the construct of top management support is operationalized here by the extent to which top-level managers consider BA as strategically important, the extent to which they sponsor related initiatives, their commitment to BA policy/guidelines, and their supportive behaviors expressed in hiring and retaining people with analytical skills.
Although researchers suggest extensive lists of items measuring different facets of perceived data quality (Batini et al. 2009), in our research setup, we strongly restricted the number of items to keep the survey length limited and balanced. Wang and Strong (1996) not only generated an extensive list of data quality attributes but also assessed the importance of these attributes as perceived by data consumers. Their hierarchical data quality framework resulted in four target categories of data accuracy, relevancy, representation, and accessibility. Based on Wang’s and Strong’s interpretation of these categories, we applied a four-item scale to assess data quality as perceived by top managers. Data accessibility is emphasized as a data quality attribute in this framework: data is available in the company’s information system or obtainable. Here, we suggest introducing a further aspect of data accessibility, namely the extent of managers with access rights, which is no longer a data quality attribute, but a system attribute, a question of top-level decision. This centralization of accessibility and a managerial desire toward concentrating decision making power in case sufficient data are available is denoted here as centralization in data use. We suggest this interpretation based on the idea of George and King (1991) about managerial action imperative. Consequently, this two-item scale merges two facets of supportive managerial behavior: a managerial action (decision about limited accessibility) and a managerial intent of possible centralization in the decision making process.
Analytical decision making culture is understood here as an attitude to use numerical information in decision making processes and is measured by the scale suggested and previously applied by Popovič et al. (2012). This construct covers the existence and awareness of the decision making process and the presence of policies about incorporating information in the process and general consideration of information during decision making. The latter item points in the direction of information use, but still measures an attitude instead of the actual extent of information use. Therefore, we propose to examine a data-driven decision making construct separately from the analytical culture and measure it by the degree to which top management relies on available data in the decision context. As decision making is a process rather than a single action (Rajagopalan et al. 1993), we need to delimit and operationalize the extent of data use in each step of the decision making process. Simon’s (2013) decision phases not only have a long tradition in management research, but are argued to fit the research context of recent data and decision-related studies (Chiheb et al. 2019; Liberatore and Wagner 2022). Thus, in our research setup, we distinguish between the four phases of intelligence, design, choice, and implementation and measure the extent of data use with two items in each of phases according to its content as described in a computerized decision support context by Turban et al. (2011).
The size of the company (measured by the number of employees) as a continuous variable and the industry as a binary variable were involved as control variables in the model. Although the sample companies cover all sectors, 37% are manufacturers, as reported in Table 1. Therefore, we control for the effect of the manufacturing industry by including the industry as a dummy variable, whether the firm is active in the manufacturing industry.
The method of partial least squares structural equation modeling (PLS-SEM) is used in the study that is widely applied in European management research (Richter et al. 2016). Preliminary data analysis was executed in SPSS 27, and the PLS model was calculated using SmartPLS4. Descriptive statistics reported in Appendix II show a low number of missing values per variable, ranging from 0 to 2%. Missing values were treated by mean value replacement, as suggested by Hair et al. (2021). Although the distribution of sample firms along different characteristics closely approximates the distributions found in the total population (see Table 1), to further improve the sample’s fit to the quotas (by company size, industry, and region), sampling weights have been calculated, and the weighted PLS-SEM algorithm was run. The weight variable is set close to one for all respondents (0.88–1.21), hence, non-weighted and weighted PLS results do not show much variation in the results. The estimation of the PLS model presented in the following incorporates sample weighting to obtain unbiased estimates of population effects (Sarstedt et al. 2018).
The survey also meets the minimum sample size requirements of conservative methods. At a significance level of 5% and with the lowest statistically significant path coefficient value of 0.2, the inverse square root method (Kock and Hadaya 2018) requires a minimum sample size of 155, which is considerably exceeded by the final sample size of 305.
4 Results
4.1 Measurement model assessment
The reflective measurement model was assessed using reliability and validity measures, as shown in Table 3. We experienced high outer loadings, implying that indicators measure the same phenomenon, excluding one item of construct centralization in data use (CE_1) where an outer loading (0.694) just below the established threshold (0.7) was obtained. In the case of newly developed scales, Hulland (1999) suggested not automatically eliminating indicators with somewhat weaker outer loading but carefully investigating them. Having a solid theoretical rationale for including this variable and acceptable values for construct level reliability, we suggest keeping it in the model. The value of Cronbach’s alfa (0.604) is above the acceptable threshold recommended for exploratory research (Hair et al. 2021). Moreover, Cronbach’s alfa is sensitive to the number of items and assumes equal outer loadings on the construct, which has substantial limitations to measure internal consistency reliability in this case. Prioritized by the PLS-SEM algorithm, the composite reliability values of rho_a and rho_c reported over 0.8 show adequate reliability at the construct level for each construct. Convergent validity assessed by the average variance extracted (AVE) is clearly above the threshold of 0.5, which indicates that the items constituting each construct share a high proportion of variance.
As the square root of each construct’s AVE is higher than its highest correlation with any other construct, the Fornell-Larcker criterion establishes the discriminant validity. The heterotrait-monotrait ratio (HTMT), a newer criterion to assess discriminant validity, also supports it (Henseler et al. 2015) as correlation ratios are far below the conservative threshold of 0.85 (see Table 4). The values of the variation inflation factor (VIF) clearly below 3 (below 1.303 for the predictors of (3) AC and below 1.514 for the predictors of (5) DM) ensure that collinearity among the predictor constructs will have no substantial effect on the model estimation. Overall, the reflective measurement model assessment results point to an appropriate measurement model.
4.2 Structural model assessment
For the estimation of the structural model, we selected path weighting scheme, and bootstrapping was executed with 10,000 samples based on bias-corrected and accelerated (BCa) bootstrap confidence intervals, a bootstrapping procedure suggested by Henseler et al. (2009) to overcome shortcomings of other methods. Table 5 summarizes the results for the significance tests of the individual path coefficients, interpreted as standardized coefficients of ordinary least squares regressions. All direct effects are significant, with one exception: centralization in data use does not impact data-driven decision making.
The values of the significant path coefficients (b) indicate a varying degree of association. Based on Cohen’s (2013) suggestion that b-values of 0.5, 0.3, and 0.15 signify strong, medium, and weak effects, we can conclude that top management support is strongly related to perceived data quality, which in turn impacts analytical decision making culture, supporting H1b and H1c. Additionally, top management support is associated with analytical culture at the medium level, supporting H1a. Analytical culture moderately affects centralization in data use (H2b) and strongly influences data-driven decision making (H2a). Although perceived data quality is weakly but significantly associated with data-driven decision making (H3a), centralization in data use does contribute to the use of data in decision making. Therefore, the model does not support H2c.
Individual mediating effects of data quality, analytical culture, and centralization in data use were hypothesized and tested. Specific indirect effects through mediators are quantified by the multiplication of direct effects reported in Table 5. The significance test for specific indirect effects (see Table 6) supports the mediating role of perceived data quality. Thus, we can accept H1d. Similarly, analytical decision making culture underlies the relationship between perceived data quality and data-driven decision making. Thus, the model also confirms H3b. As both the indirect and direct effects are significant and point in the same direction, both mediations are complementary mediating relationships. H2d suggesting the mediator role of centralization in data use is not supported by the data. Although the direct effect of analytical culture on data-driven decision making is significant, the indirect effect is not, indicating a situation of direct-only non-mediation. Total effects calculated as the sum of direct and indirect effects (see Table 7) suggest strong relationships between the key target constructs (3) AC, (5) DM, and the predictor constructs, apart from the predictor role centralization in data use (see Table 6).
To rule out the confounding effect of company size and industry, we added two control variables to the model. The company size, measured by the number of employees, and the binary variable indicating manufacturing activity were involved and linked to each endogenous construct (model2). As the path coefficients of the hypothesized relationships in model 2 are very close to those in the original model not involving controls, we can rule out the confounding effect of company size and industry (see Table 7).
The model’s in-sample predictive power measured by the coefficient of determination (R2) is rated moderate concerning the key target constructs analytical decision making culture (0.373) and data-driven decision making (0.35), assessed based on prior classification of magnitudes (Chin 1998). This suggests that the model is able to fit the data at hand. The out-of-sample predictive power of the model was evaluated with Q2 statistics followed by a PLSpredict procedure (Shmueli et al. 2016) where the tenfold cross-validation was repeated r = 10 times. The Q2predict values of each indicator measuring the key target constructs analytical decision making culture and data-driven decision making are above zero (see Table 8), indicating that the model meets the minimum criteria. Then we calculated the differences between the predicted and observed values for the PLS-SEM model and for the linear regression model (LM) using the root mean square error (RMSE) as a prediction statistic. Drawing on the idea that PLS-SEM based predictions should outperform LM (Shmueli et al. 2016), RMSE values of LM and PLS-SEM are compared in Table 8. As not all but most of the indicators in the PLS model yield more minor prediction errors than the LM, the model has medium predictive power.
As shown in Table 8, the PLS-SEM RMSE value exceeds that of the linear model for one indicator (DM_6). Hair et al. (2021) suggest exploring the potential explanations for the low predictive power of indicators. As this indicator has the highest outer loading (0.826) among all indicators associated with the construct data-driven decision making, we can exclude problems arising from the measurement model. Data issues can be excluded as well as the indicator is characterized by a non-outstanding standard deviation (0.8092) and a non-extreme distribution (skewness −0.973, kurtosis 1.055). Overall, the structural model estimates suggest that the model is not confounded by a third variable, and it has a moderate in-sample and out-of-sample predictive power. Figure 2 provides a visual summary of the results concerning the relationships between the constructs.

Effect sizes of direct and specific indirect effects
5 Discussion
This study aimed to reveal insights on building an analytical decision making culture, as well as the driving forces of data-driven decision making, arguing that top management support for BA is a crucial foundation in related changes. The findings of the structural model confirm the claim in the literature that top management support is positively associated with analytical decision making culture (Popovič et al. 2012; Chen et al. 2015) in BA context. Prior evidence on that analytical culture is the greatest obstacle, thus the greatest challenge in benefiting from BA (LaValle et al. 2011; McAfee and Brynjolfsson 2012), draws attention to the importance of the finding that top management’s efforts are not in vain, but they can promote analytical decision making culture. Furthermore, the results confirm the importance of perceived data quality, as evidenced earlier in the BI context (Kulkarni et al. 2017). However, improved perceptions of data quality have been considered both as an antecedent and consequence of culture in the prior literature. While Kulkarni et al. (2017) proposed that analytical culture improves data quality perceptions, our research aimed to argue and reveal a positive effect in the opposite direction. The mismatch can be attributed to the fact that previous research has constructed a model to explain BI capabilities rather than decision making. Quality aspects, denoted by Kulkarni et al. (2017) as information capabilities, were considered part of the BI capability, understood as a firm’s ability to provide high-quality information and systems to support decision makers. In our model focusing on the driving forces of data-driven decision making, managerial perceptions about data quality represent a precursor to analytic decision making culture. The strong effect reveals that top management supports building an analytical culture, and the related improvements in managerial perceptions about data quality partially explain this effect. This partial mediation effect is explained by the fact that attitudes towards data use are expected to improve if the quality of data content is considered good (Popovič et al. 2012).
Reporting a significant effect, we found support for data quality that directly influences the nature of decision making. Although this effect is weak, the medium-strong total effect indicates the importance of data quality in decision making. Here, we measure and evaluate management perceptions about data quality. Data quality information, i.e., metadata that objectively describe data quality, is rarely found in organizational information systems, although it clearly impacts decision making (Chengalur-Smith et al. 1999). If data quality information is not provided, decision makers “develop a feel for the nuances and eccentricities of the data used” (Fisher et al. 2003, p. 170) and decide about the use of data based on their subjective judgment, making managerial perceptions of data quality crucial.
Reporting high values for both direct and indirect effects, we found support for analytical decision making culture positively influencing data-driven decision making. This highlights the importance of a supportive social practice on the organizational level in guiding individual behavior (Stoica et al. 2004) and supports the claim that utilizing analytical capabilities requires a change in corporate mentality to view data and information as vital organizational assets (Galbraith 2014). The literature is consistent in that analytical culture is difficult to create (Davenport and Bean 2018), but once established, it is a competitive force to support organizational performance (Karaboga et al. 2022). At the same time, the most common objectives of firms are not directly related to performance but to better decisions through advanced analytics (Davenport and Bean 2018), suggesting a direct link to data-driven decision making. The results supported this claim and verified our arguments leveraged by OIPT that analytical culture helps managers to make information processing consistently fact-based.
We argued that this effect of analytical culture on decision making can be partially explained by a shift in power balance, described as the centralization of data use. Although the results did not verify the existence of this mediation, we found that the analytical culture is associated with the centralization of data use, interpreted as the limited availability of analytical results accompanied by reduced delegation of decision making. BA tools and techniques frame the culture of evidence-based decision making that also does not leave existing structures, roles, and processes untouched (Ross et al. 2013). Although the broad organizational impact of analytical culture is undeniable, the direction of the changes is not apparent at all. Ross et al. (2013) argue that data analytics equips lower-level managers with the data that helps them make decisions locally, suggesting a wide availability of data along with a potential for enhanced delegation of operative decision making. If so, this would keep the information advantage at the local level, maintaining the information asymmetries. At the same time, predictive analytics is able to decrease the local information advantage because, unlike traditional local information, the results of BA are less subjective and require less local expertise to interpret (Labro et al. 2022). By reducing information asymmetry, BA can alter the existing power balance of the organization. A similar shift in information distribution has also been shown in the context of the use of predictive analytics in planning. The benefits of participative budgeting in case of high information asymmetry has long been argued in the accounting literature (Heinle et al. 2014). When employing predictive analytics in driver-based planning, which involves the systematic utilization of company data to investigate and verify causal relationships, data are capable of partially replacing local expertise (Valjanow et al. 2019). This not only counterbalances local information advantages by drawing on more objective methods in the planning process but also limits information availability by involving a relatively narrow group of analysts and executives in centralized, driver-based planning.
Our results show that analytical culture has the potential to alter the centralization of data use: it eliminates the information disadvantage at the top level and allows decisions not to be delegated. As an unexpected result, this is not associated with a more robust integration of data use into the decision making process. The availability of a large amount of information has been argued to be ambiguous. On the one hand, much information available to managers was reported to increase feelings of satisfaction (O’Reilly 1980), to improve perceptions about the level of control and manageability (Kuvaas 2002), and it was evidenced that accessibility predicts the frequency of data use in the decision context (O’Reilly 1982). However, studies rooted in OIPT draw attention to the possibility of information overload (O’Reilly 1980), where organizational information processing capacity could be improved, but at the level of individual information processing remains limited by nature (Simon 1978); therefore, patterns of individual decision making cannot be expected to be altered. Uncertainty, originally defined as the difference between the amount of information available and the amount of information required (Galbraith 1973), does not arise from the lack of information anymore but from the oversupply, resulting in information fatigue (Buchanan and Kock 2001). Therefore, reducing information asymmetry by increasingly more data available to top management cannot be expected to alter managerial decision making. Rejecting the mediation effect of centralization in data use suggests that top management’s effort should be directed towards establishing and maintaining a strong analytical culture and eliminating possible negative effects of information asymmetry by using other tools of alignment in decision making, such as incentives (Prendergast 2002). This is supported by the findings of Labro et al. (2022), who showed that the application of predictive analytics is related to more precise goals and stronger ties between employee rewards and measured performance.
We based our chain of thought on the argument that managers have unprecedented freedom to choose between technologies supporting BA, in contrast to robust backbone systems. This has two significant consequences. First, as the properties of BA result from the choices of the senior manager, it is more likely that they can choose the best solutions that serve their information needs and, even more importantly, their actual interests. Second, as the chosen solutions exhibit minimal localization potential, other users are confronted with all its constraints (Leonardi and Barley 2008). This concept of planned change, which refers to alterations conceived, directed, and managed by management, is analogous to the organizational imperative. Critics of technological and organizational imperative point out that it makes no difference if the technology or the organization is the dependent factor, these are both contingency approaches assuming that outcomes can be explained by a combination of known determinants (Markus and Robey 1988; Jasperson et al. 2002). Instead, the introduction of IT is associated with more complex social processes, as well as unanticipated and unintended organizational effects (Robey et al. 2013). The literature occasionally refers to this as the emergent perspective that sees organizational IT implementations as catalysts of the chain of causes and effects that creates the actual use of technology, as well as the organizational outcomes (Markus and Robey 1988; Orlikowski 1992; Pinsonneault and Kraemer 1993; Jasperson et al. 2002; Bailey et al. 2022). The complexity arises from the reciprocal and cyclical nature of changes, where the social system poses informational requirements to the IT system, while the corresponding IT system has organizational requirements (Lee 2010). We argued that these information requirements are articulated mainly by top management in the form of supporting or not supporting BA initiatives, and in turn this will shape social artifacts of organization, namely the decision making culture and process of decision making.
The socio-technical systems theorists, again aiming to overcome the dilemma of technological or organizational determinism, emphasize the system approach in which the continuously interacting elements make up the system (Robey et al. 2013), here the information system containing technology, data, and organization (Lee 2010). In their view, IS research must comprehend how to make changes in these elements to reach desired ends, where the term desired is determined by the subjective values of the key organizational actors, namely the managers (Lee 2010). Not only this intention is very close to that of what is called organizational imperative approach in which the strategic choice is emphasized, but socio-technical studies also suggest that IT can be adapted with various intentions and accordingly it will have different implications for the organization (Zuboff 1988).
6 Conclusions and limitations
BA, the fastest growing area within the domain of BI&A, is accompanied by a number of organizational changes inducing new fields of research. A stream of research with a clear focus on technology investigates emerging novel solutions, their implementation, and their use in organizations. Another stream with a managerial focus studies changes in the information environment, culture, organization, and processes, such as decision making. This paper, positioned in the latter, emphasizes the importance of building an analytical culture to foster data use in decision making, a prerequisite for a company to benefit from the BA. An analytical culture interpreted as social practice (Cabantous and Gond 2011) or corporate mindset (Galbraith 2014) is promoted as a precondition of the rational model of decision making, a position supported by this paper as well. While promoting the rational model relying on data instead of intuition or prior experience, we must acknowledge that it faces challenges arising from limited human cognition (Simon 1990). The claims on how analytical culture framed by the use of BA tools and techniques can support a more intense reliance on data seem to fail to take this limitation into account, implicitly assuming that BA is able to overcome it, at least partially.
As a key finding of this research, we showed that the deliberate focus of top management on business analytics can build a culture of analytical decision making and this alters managerial information processing, namely enhances reliance on data in each phase of the decision making process. Moreover, we argued that the existing information asymmetry within the organization changes due to the use of BA, and this can lead to a shift of authorities. Based on the results of the mediator model, we found support for this argument and evidenced that the analytical culture promotes the centralization of data usage, but does not further strengthen the data-driven nature of decision making at the top level. With these key findings, the paper contributes to the academic literature in different ways.
First, this research enriched the literature on managerial decision making through the OIPT lens, the theory aimed at identifying what factors improve an organization’s information processing capacity. Drawing on the idea that BA is a powerful means of increasing organizational information processing capabilities (Cao et al. 2015), we verified the influence of previously scattered validated organizational factors in the context of BA. The special context of BA is of importance here, responding to the criticism that, in many cases, technology itself seems to be forgotten when analyzing the induced human behavior and organizational processes (Leonardi et al. 2012). Materiality matters (Orlikowski 2007), that is, we cannot neglect the fact that recent developments of BA have distinctive nature and therefore they call for new evidence to explain how they shape the information processes of organizations. In an effort to explain the effects arising from BA, we argued that the choice of top management is what drives the related changes. The choice refers to the features of technologies that are embedded in the organizational context and internal social relationships where people develop, implement, and use them (Bailey et al. 2022).
Second, we suggested and validated Simon’s model as a measurement framework for the operationalization of the data-driven decision making process. Prior operationalizations of this concept are usually based on quantifying the opposing tendencies of relying more on intuition or on data in managerial decision making (Covin et al. 2001; LaValle et al. 2011; Szukits 2022). These were occasionally extended by some context specific dimensions (Bokrantz et al. 2020). Out of the many possible aspects of data-driven decision making (Colombari et al. 2023), our theoretical lens suggested to keep our focus on the dimension of information processing. The theorizing of information collection, analysis and synthesis processes by OIPT (Tushman and Nadler 1978) resonates with Simon’s (1978, 2013) process-oriented view of decision making. Therefore, our proposed scale (see Appendix I) measures data-driven decision making with eight variables that unfold the steps of Simon’s (2013) four phases from assessing the current situation to monitoring the implementation. Values reported for internal consistency and convergence in Table 3 are statistically convincing. This not only makes the scale suitable for future use, but confirms the scattered literature (Turban et al. 2011; Chiheb et al. 2019) that proposes to operationalize the use of data in decision making along the steps of rational decision making.
Third, our research joins the long-argued proposition about the continuing interplay of technologies and organizational design (Dibrell and Miller 2002; Sor 2004). It involves the potential shifts in authorities in the discussion based on the diminished information disadvantage at the top. Agency theory recognizes this information gap between local and top management as negative, as the lower-level manager is assumed to use the private information to make self-interested decisions, which is detrimental to the organization (Chia 1995). This underlying assumption of agency theory positions information asymmetry as an organizational phenomenon that should definitely be reduced by different means (Rajan and Saouma 2006). We argued that BA is a powerful means to mitigate information asymmetry and evidenced that analytical culture is associated with a possible change in authorities. In one of his last publications, Galbraith (2014), the father of OIPT, also argued that taking advantage of analytics capability shifts power in the organization. But instead of shifting the power to top management, he posited a shift to analytics experts who can analyze and read the data. This suggests that power in terms of information advantage and power in terms of decision making authority might develop differently. Analytical experts might gain an information advantage without broader authorities, as the right to decide remains with the top management. To fill this gap, a power shift from judgmental decision makers to digital decision makers is required (Galbraith 2014), devaluing the role of other decision making strategies in contemporary organizations.
Lastly, this paper contributed to theory by not only showing the revived relevance of information asymmetry and authorities in the BA context but also revealing its duality: analytical culture can alter power balance, but this does not affect the rational decision making model. To what extent decision making is data driven at the top, it is not dependent on a potential change in the information distribution to the detriment of lower-level managers. This conclusion adds to prior agency theory research investigating the ambiguity of behavioral implications and arguing that more comprehensive data on the top do not necessarily establish contextual experience that lower-level managers have (Brown-Liburd et al. 2015). The missing contextual experience along with the feeling of information fatigue does not support the use of available data in a decision context (Buchanan and Kock 2001).
As our main contribution to practice, we emphasize the role that top management has to play in achieving data-driven decision making. Resonating with the organizational imperative assumption, we attract attention to the amplifying influence of top management, as their choices have a significant impact on both perceived data quality and the analytical decision making culture. The literature extensively illustrates the significance of their commitment to the adoption of novel technology (Ross et al. 2013; Chen et al. 2015; Kulkarni et al. 2017; Cruz-Jesus et al. 2018). Our research has also shown that when senior managers support and choose BA technology that is suitable for their organization, they ascertain the trajectory of data access patterns within the organization. If additional information becomes available to lower-levels of management, it is possible to delegate decisions to them (Järvenpää, 2007; Wohlstetter et al. 2008), while more information at higher levels allows for tighter control of lower levels or even centralization of decisions (Sharma et al. 2014; Labro et al. 2022). Thus, top management needs to consciously consider to what extent the available solutions allow to reduce or occasionally reproduce information asymmetry. Furthermore, in this context, depending on whether centralization of data use or greater empowerment is the aim of the top management, they should look for a BA solution that best supports this aim (Robey and Boudreau 1999; Leonardi et al. 2012). The top management has a degree of freedom here, particularly because our research concludes that data-driven decision making can be achieved either way: it is definitely influenced by analytical decision making culture and perceived data quality, but not by the degree of centralization of data use.
When evaluating our results, it is important to keep in mind that this research did not inventory concrete BA techniques and tools used by organizations, even though the paper claims that the BA calls for new evidence. We justify this choice with three reasons. First, the underlying IT and statistical solutions are diverse and constantly growing, making a comprehensive survey difficult. Second, the number of techniques applied does not reveal anything. Third, the mere adoption of any tool or technique was argued not to transform decision making, but the relevance of a supporting culture is widely emphasized in studies (Popovič et al. 2012; Grublješič and Jaklič 2015; Kulkarni et al. 2017) and, to a lesser extent, in the context of BA (Cao et al. 2015).
Some other limitations of this research need to be acknowledged. First, by measuring data utilization in decision making, we do not explicitly address other information processing modes. By excluding the discussion of the possible dichotomy of intuitive and rational decision making (Sadler-Smith and Shefy 2004), the paper cannot conclude the shift of focus in information processing modes from a more intuitive to a less intuitive and more analytical one. Second, the data are based on single respondents, namely the senior managers of the case companies. The opinion of highest-paid persons (McAfee and Brynjolfsson 2012) neglects the opinion of lower-level managers and other employees, which can distort the results, as these groups were argued to express different perceptions of their organizations’ data-driven decision making and culture (Maxwell et al. 2016). Although test statistics did not report a significant effect of the investigated positions on our results, CEOs, CXO level executives, and other strategic decision makers cannot be handled as a homogeneous group, as CEOs differ from other top managers in many aspects (Kaplan and Sorensen 2021). A multi-respondent survey design is suggested to explore the potentially diverging perspectives of subordinates, different managerial levels, and the CEO. Third, the questionnaire survey was conducted among firms registered in Hungary, which could limit the generalizability of the results. We do not expect that country conditions, such as economic or political factors, will impact the relationships hypothesized in the study. At the same time, the social and cultural values of decision makers could affect decision making itself (Forquer Gupta 2012). Differences have been reported not only between distant cultures (Calhoun et al. 2002), but even between neighboring countries of the Central-Eastern European region (Dabić et al. 2015) in this respect. Thus, the suggested measurement model has the potential to be extended to other countries and regions to exclude possible bias arising from cultural contingency.
Data availability
The datasets generated and analyzed during the current study are available from the corresponding author on reasonable request. Database available in.sav and.csv format.
Code availability
SmartPLS 4.0.
Notes
NACE is the nomenclature for economic activities introduced by the European Commission for a standard delineating of industries, as shown in Table 1.
References
Aben TAE, van der Valk W, Roehrich JK, Selviaridis K (2021) Managing information asymmetry in public–private relationships undergoing a digital transformation: The role of contractual and relational governance. Int J Oper Prod Manag 41(7):1145–1191. https://doi.org/10.1108/IJOPM-09-2020-0675
Afzal W, Roland D, Al-Squri MN (2009) Information asymmetry and product valuation: an exploratory study. J Inf Sci 35(2):192–203. https://doi.org/10.1177/0165551508097091
Ahearne M, Atefi Y, Lam SK, Pourmasoudi M (2022) The future of buyer–seller interactions: a conceptual framework and research agenda. J Acad Mark Sci 50(1):22–45. https://doi.org/10.1007/s11747-021-00803-0
Alaimo C, Kallinikos J (2022) Organizations decentered: data objects, technology and knowledge. Organ Sci 33(1):19–37. https://doi.org/10.1287/orsc.2021.1552
Appelbaum D, Kogan A, Vasarhelyi M, Yan Z (2017) Impact of business analytics and enterprise systems on managerial accounting. Int J Account Inf Syst 25:29–44. https://doi.org/10.1016/j.accinf.2017.03.003
Arnott D, Pervan G (2016) A critical analysis of decision support systems research revisited: the rise of design science. In: Willcocks LP, Sauer C, Lacity MC (eds) Enacting research methods in information systems: volume 3. Springer: Berlin, pp 43–103. https://doi.org/10.1007/978-3-319-29272-4_3
Aydiner AS, Tatoglu E, Bayraktar E, Zaim S, Delen D (2019) Business analytics and firm performance: the mediating role of business process performance. J Bus Res 96:228–237. https://doi.org/10.1016/j.jbusres.2018.11.028
Bailey DE, Faraj S, Hinds PJ, Leonardi PM, von Krogh G (2022) We are all theorists of technology now: a relational perspective on emerging technology and organizing. Organ Sci 33(1):1–18. https://doi.org/10.1287/orsc.2021.1562
Batini C, Cappiello C, Francalanci C, Maurino A (2009) Methodologies for data quality assessment and improvement. ACM Comput Surv 41(3):1–52. https://doi.org/10.1145/1541880.1541883
Bergh DD, Ketchen DJ, Orlandi I, Heugens PPMAR, Boyd BK (2019) Information asymmetry in management research: past accomplishments and future opportunities. J Manag 45(1):122–158. https://doi.org/10.1177/0149206318798026
Blaylock BK, Rees LP (1984) Cognitive style and the usefulness of information*. Decis Sci 15(1):74–91. https://doi.org/10.1111/j.1540-5915.1984.tb01197.x
Bloom N, Garicano L, Sadun R, Van Reenen J (2014) The distinct effects of information technology and communication technology on firm organization. Manage Sci 60(12):2859–2885. https://doi.org/10.1287/mnsc.2014.2013
Bokrantz J, Skoogh A, Berlin C, Wuest T, Stahre J (2020) Smart maintenance: an empirically grounded conceptualization. Int J Prod Econ 223:107534. https://doi.org/10.1016/j.ijpe.2019.107534
Brown-Liburd H, Issa H, Lombardi D (2015) Behavioral implications of big data’s impact on audit judgment and decision making and future research directions. Account Horiz 29(2):451–468. https://doi.org/10.2308/acch-51023
Buchanan J, Kock N (2001) Information overload: a decision making perspective. In: Köksalan M, Zionts S (eds) Multiple criteria decision making in the new millennium. Springer, Berlin, pp 49–58. https://doi.org/10.1007/978-3-642-56680-6_4
Cabantous L, Gond J-P (2011) Rational decision making as performative praxis: explaining rationality’s Éternel retour. Organ Sci 22(3):573–586. https://doi.org/10.1287/orsc.1100.0534Abstract
Calhoun KJ, Teng JTC, Cheon MJ (2002) Impact of national culture on information technology usage behaviour: an exploratory study of decision making in Korea and the USA. Behav Inf Technol 21(4):293–302. https://doi.org/10.1080/0144929021000013491
Cao G, Duan Y, Li G (2015) Linking business analytics to decision making effectiveness: a path model analysis. IEEE Trans Eng Manage 62(3):384–395. https://doi.org/10.1109/TEM.2015.2441875
Carlsson-Wall M, Goretzki L, Hofstedt J, Kraus K, Nilsson C-J (2022) Exploring the implications of cloud-based enterprise resource planning systems for public sector management accountants. Financ Account Manag 38(2):177–201. https://doi.org/10.1111/faam.12300
Chaudhuri S, Dayal U, Narasayya V (2011) An overview of business intelligence technology. Commun ACM 54(8):88–98. https://doi.org/10.1145/1978542.1978562
Chen DQ, Preston DS, Swink M (2015) How the use of big data analytics affects value creation in supply chain management. J Manag Inf Syst 32(4):4–39. https://doi.org/10.1080/07421222.2015.1138364
Chengalur-Smith IN, Ballou DP, Pazer HL (1999) The impact of data quality information on decision making: an exploratory analysis. IEEE Trans Knowl Data Eng 11(6):853–864. https://doi.org/10.1109/69.824597
Chia Y-M (1995) The interaction effect of information asymmetry and decentralization on managers’ job satisfaction: a research note. Hum Relations 48(6):609–624. https://doi.org/10.1177/001872679504800601
Chiheb F, Boumahdi F, Bouarfa H (2019) A new model for integrating big data into phases of decision-making process. Procedia Comput Sci 151:636–642. https://doi.org/10.1016/j.procs.2019.04.085
Chin WW (1998) The partial least squares approach to structural equation modeling. In: Marcoulides GA (ed), Modern methods for business research: vol. 295(2) (pp. 295–330). Psychology Press
Choo CW (1996) The knowing organization: How organizations use information to construct meaning, create knowledge and make decisions. Int J Inf Manage 16(5):329–340. https://doi.org/10.1016/0268-4012(96)00020-5
Cohen J (2013) Statistical power analysis for the behavioral sciences. Academic Press
Colombari R, Geuna A, Helper S, Martins R, Paolucci E, Ricci R, Seamans R (2023) The interplay between data-driven decision-making and digitalization: a firm-level survey of the Italian and US automotive industries. Int J Prod Econ 255:108718. https://doi.org/10.1016/j.ijpe.2022.108718
Côrte-Real N, Ruivo P, Oliveira T (2020) Leveraging internet of things and big data analytics initiatives in European and American firms: Is data quality a way to extract business value? Inf Manag 57(1):103141. https://doi.org/10.1016/j.im.2019.01.003
Covin JG, Slevin DP, Heeley MB (2001) Strategic decision making in an intuitive vs. technocratic mode: structural and environmental considerations. J Bus Res 52(1):51–67. https://doi.org/10.1016/S0148-2963(99)00080-6
Cruz-Jesus F, Oliveira T, Naranjo M (2018) Understanding the adoption of business analytics and intelligence. In: Rocha Á, Adeli H, Reis LP, Costanzo S (eds) Trends and advances in information systems and technologies (pp 1094–1103). Springer. https://doi.org/10.1007/978-3-319-77703-0_106
Dabić M, Tipurić D, Podrug N (2015) Cultural differences affecting decision-making style: a comparative study between four countries. J Bus Econ Manag 16(2):275–289. https://doi.org/10.3846/16111699.2013.859172
Daft RL, Lengel RH (1986) Organizational information requirements, media richness and structural design. Manage Sci 32(5):554–571
Davenport TH, Bean R (2018). Big companies are embracing analytics, but most still don’t have a data-driven culture
Davenport TH, Harris JG (2007) Competing on analytics: the new science of winning (1st edition). Harvard Business Review Press
Davenport TH, Harris JG, De Long DW, Jacobson AL (2001) Data to knowledge to results: building an analytic capability. Calif Manage Rev 43(2):117–138. https://doi.org/10.2307/41166078
Davenport TH, Prusak L (1998) Working knowledge: how organizations manage what they know. Harvard Business Press
Davis JL, Chouinard JB (2016) Theorizing affordances: from request to refuse. Bull Sci Technol Soc 36(4):241–248. https://doi.org/10.1177/0270467617714944
Dibrell CC, Miller TR (2002) Organization design: the continuing influence of information technology. Manag Decis 40(6):620–627. https://doi.org/10.1108/00251740210434016
Djerdjouri M, Mehailia A (2017). Adopting business analytics to leverage enterprise data assets. In: Benlamri R, Sparer M (eds) Leadership, innovation and entrepreneurship as driving forces of the global economy (pp 57–67). Springer. https://doi.org/10.1007/978-3-319-43434-6_5
Doherty NF, Champion D, Wang L (2010) An holistic approach to understanding the changing nature of organisational structure. Inf Technol People 23(2):116–135. https://doi.org/10.1108/09593841011052138
Duan L, Xiong Y (2015) Big data analytics and business analytics. J Manag Anal 2(1):1–21. https://doi.org/10.1080/23270012.2015.1020891
Dubey R, Gunasekaran A, Childe SJ, Fosso Wamba S, Roubaud D, Foropon C (2021) Empirical investigation of data analytics capability and organizational flexibility as complements to supply chain resilience. Int J Prod Res 59(1):110–128. https://doi.org/10.1080/00207543.2019.1582820
European Commission (2022) Digital economy and society index (DESI) 2022 | Shaping Europe’s digital future. https://digital-strategy.ec.europa.eu/en/library/digital-economy-and-society-index-desi-2022
Evans JSBT (2010) Intuition and reasoning: a dual-process perspective. Psychol Inq 21(4):313–326. https://doi.org/10.1080/1047840X.2010.521057
Ferraris A, Mazzoleni A, Devalle A, Couturier J (2018) Big data analytics capabilities and knowledge management: Impact on firm performance. Manag Decis 57(8):1923–1936. https://doi.org/10.1108/MD-07-2018-0825
Fisher CW, Chengalur-Smith I, Ballou DP (2003) The impact of experience and time on the use of data quality information in decision making. Inf Syst Res 14(2):170–188. https://doi.org/10.1287/isre.14.2.170.16017
Forquer Gupta S (2012) Integrating national culture measures in the context of business decision making: an initial measurement development test of a mid level model. Cross Cult Manag: Int J 19(4):455–506. https://doi.org/10.1108/13527601211269987
Galbraith JR (1973) Designing complex organizations. Addison-Welsey, Reading, MA
Galbraith JR (2014) Organizational design challenges resulting from big data (SSRN Scholarly Paper ID 2458899). Social Science Research Network. https://papers.ssrn.com/abstract=2458899
George JF, King JL (1991) Examining the computing and centralization debate. Commun ACM 34(7):62–72. https://doi.org/10.1145/105783.105796
Gorla N, Somers TM, Wong B (2010) Organizational impact of system quality, information quality, and service quality. J Strateg Inf Syst 19(3):207–228. https://doi.org/10.1016/j.jsis.2010.05.001
Grover V, Chiang RHL, Liang T-P, Zhang D (2018) Creating strategic business value from big data analytics: a research framework. J Manag Inf Syst 35(2):388–423. https://doi.org/10.1080/07421222.2018.1451951
Grublješič T, Jaklič J (2015) Business intelligence acceptance: the prominence of organizational factors. Inf Syst Manag 32(4):299–315. https://doi.org/10.1080/10580530.2015.1080000
Gudfinnsson K, Strand M, Berndtsson M (2015) Analyzing business intelligence maturity. J Decis Syst 24(1):37–54. https://doi.org/10.1080/12460125.2015.994287
Gupta M, George JF (2016) Toward the development of a big data analytics capability. Inf Manag 53(8):1049–1064. https://doi.org/10.1016/j.im.2016.07.004
Hair JF, Hult GTM, Ringle CM, Sarstedt M (2021) A primer on partial least squares structural equation modeling (PLS-SEM) (Third Edition). SAGE Publications. https://uk.sagepub.com/en-gb/eur/a-primer-on-partial-least-squares-structural-equation-modeling-pls-sem/book270548
Hammond KR (1996) Human judgment and social policy: Irreducible uncertainty, inevitable error, unavoidable injustice. Oxford University Press
Hazen BT, Boone CA, Ezell JD, Jones-Farmer LA (2014) Data quality for data science, predictive analytics, and big data in supply chain management: an introduction to the problem and suggestions for research and applications. Int J Prod Econ 154:72–80. https://doi.org/10.1016/j.ijpe.2014.04.018
Heinle MS, Ross N, Saouma RE (2014) A theory of participative budgeting. Account Rev 89(3):1025–1050
Henseler J, Ringle CM, Sarstedt M (2015) A new criterion for assessing discriminant validity in variance-based structural equation modeling. J Acad Mark Sci 43(1):115–135. https://doi.org/10.1007/s11747-014-0403-8
Henseler J, Ringle C, Sinkovics R (2009) The use of partial least squares path modeling in international marketing. In: Advances in international marketing (vol 20, pp 277–319). https://doi.org/10.1108/S1474-7979(2009)0000020014
Holsapple C, Lee-Post A, Pakath R (2014) A unified foundation for business analytics. Decis Support Syst 64:130–141. https://doi.org/10.1016/j.dss.2014.05.013
Hulland J (1999) Use of partial least squares (PLS) in strategic management research: a review of four recent studies. Strateg Manag J 20(2):195–204
Işık Ö, Jones MC, Sidorova A (2013) Business intelligence success: the roles of BI capabilities and decision environments. Inf Manag 50(1):13–23. https://doi.org/10.1016/j.im.2012.12.001
Järvenpää M (2007) Making business partners: a case study on how management accounting culture was changed. Eur Account Rev 16(1):99–142. https://doi.org/10.1080/09638180701265903
Jasperson J, Carte TA, Saunders CS, Butler BS, Croes HJP, Zheng W (2002) Review: Power and information technology research: a metatriangulation review. MIS Q 26(4):397–459. https://doi.org/10.2307/4132315
Jensen MC, Meckling WH (1976) Theory of the firm: managerial behavior, agency costs and ownership structure. J Financ Economet 3(4):305–360. https://doi.org/10.1016/0304-405X(76)90026-X
Joseph J, Gaba V (2020) Organizational structure, information processing, and decision-making: a retrospective and road map for research. Acad Manag Ann 14(1):267–302. https://doi.org/10.5465/annals.2017.0103
Kaplan SN, Sorensen M (2021) Are CEOs different? J Finance 76(4):1773–1811. https://doi.org/10.1111/jofi.13019
Karaboga T, Zehir C, Tatoglu E, Karaboga HA, Bouguerra A (2022) Big data analytics management capability and firm performance: the mediating role of data-driven culture. RMS. https://doi.org/10.1007/s11846-022-00596-8
Kepner CH, Tregoe BB (2005) The new rational manager, rev. Kepner-Tregoe, NY
Khayer A, Talukder MdS, Bao Y, Hossain MdN (2020) Cloud computing adoption and its impact on SMEs’ performance for cloud supported operations: a dual-stage analytical approach. Technol Soc 60:101225. https://doi.org/10.1016/j.techsoc.2019.101225
Knauer T, Nikiforow N, Wagener S (2020) Determinants of information system quality and data quality in management accounting. J Manag Control 31(1):97–121. https://doi.org/10.1007/s00187-020-00296-y
Kock N, Hadaya P (2018) Minimum sample size estimation in PLS-SEM: the inverse square root and gamma-exponential methods. Inf Syst J 28(1):227–261. https://doi.org/10.1111/isj.12131
Kowalczyk M, Buxmann P (2014) Big data and information processing in organizational decision processes: a multiple case study. Bus Inf Syst Eng 6(5):267–278. https://doi.org/10.1007/s12599-014-0341-5
Kowalczyk M, Gerlach J (2015) Business intelligence and analytics and decision quality: Insights on analytics specialization and information processing modes. In: ECIS 2015 completed research papers. https://doi.org/10.18151/7217398
Krishnamoorthi S, Mathew SK (2018) Business analytics and business value: a comparative case study. Inf Manag 55(5):643–666. https://doi.org/10.1016/j.im.2018.01.005
Kulkarni U, Robles-Flores J, Popovič A (2017) Business intelligence capability: the effect of top management and the mediating roles of user participation and analytical decision making orientation. J Assoc Inf Syst 18(7). https://doi.org/10.17705/1jais.00462
Kuvaas B (2002) An exploration of two competing perspectives on informational contexts in top management strategic issue interpretation. J Manage Stud 39(7):977–1001. https://doi.org/10.1111/1467-6486.00320
Labro E, Lang M, Omartian JD (2022) Predictive analytics and centralization of authority. J Account Econ 101526. https://doi.org/10.1016/j.jacceco.2022.101526
Laursen GHN, Thorlund J (2016) Business analytics for managers: taking business intelligence beyond reporting. Wiley.
LaValle S, Lesser E, Shockley R, Hopkins MS, Kruschwitz N (2011) Big data, analytics and the path from insights to value. MIT Sloan Manag Rev 52(2)
Leavitt HJ, Whisler TL (1958) Management in the 1980’s. Harvard Bus Rev. https://hbr.org/1958/11/management-in-the-1980s
Lee AS (2010) Retrospect and prospect: Information systems research in the last and next 25 years. J Inf Technol 25(4):336–348. https://doi.org/10.1057/jit.2010.24
Leonardi PM, Barley SR (2008) Materiality and change: challenges to building better theory about technology and organizing. Inf Organ 18(3):159–176. https://doi.org/10.1016/j.infoandorg.2008.03.001
Leonardi PM, Nardi BA, Kallinikos J (2012) Materiality and organizing: Social interaction in a technological world. OUP Oxford
Liberatore MJ, Wagner WP (2022) Simon’s decision phases and user performance: an experimental study. J Comput Inf Syst 62(4):667–679. https://doi.org/10.1080/08874417.2021.1878476
Lismont J, Vanthienen J, Baesens B, Lemahieu W (2017) Defining analytics maturity indicators: a survey approach. Int J Inf Manage 37(3):114–124. https://doi.org/10.1016/j.ijinfomgt.2016.12.003
Mandal P, Jain T (2021) Partial outsourcing from a rival: quality decision under product differentiation and information asymmetry. Eur J Oper Res 292(3):886–908. https://doi.org/10.1016/j.ejor.2020.11.018
Markus ML, Pfeffer J (1983) Power and the design and implementation of accounting and control systems. Acc Organ Soc 8(2):205–218. https://doi.org/10.1016/0361-3682(83)90028-4
Markus ML, Robey D (1988) Information technology and organizational change: causal structure in theory and research. Manage Sci 34(5):583–598. https://doi.org/10.1287/mnsc.34.5.583
Maroufkhani P, Wan Ismail WK, Ghobakhloo M (2020) Big data analytics adoption model for small and medium enterprises. J Sci Technol Policy Manag 11(4):483–513. https://doi.org/10.1108/JSTPM-02-2020-0018
Maxwell NL, Rotz D, Garcia C (2016) Data and decision making: same organization, different perceptions; different organizations. Differ Percept Am J Eval 37(4):463–485. https://doi.org/10.1177/1098214015623634
McAfee, A., & Brynjolfsson, E. (2012). Big data: The management revolution. Harvard Business Review, 9.
Mintzberg H, Raisinghani D, Théorêt A (1976) The structure of ‘unstructured’ decision processes. Adm Sci Q 21(2):246–275. https://doi.org/10.2307/2392045
O’Reilly CA (1980) Individuals and information overload in organizations: Is more necessarily better? Acad Manag J 23(4):684–696. https://doi.org/10.2307/255556
O’Reilly CA (1982) Variations in decision makers’ use of information sources: the impact of quality and accessibility of information. Acad Manag J 25(4):756–771. https://doi.org/10.2307/256097
Orlikowski WJ (1992) The duality of technology: rethinking the concept of technology in organizations. Organ Sci 3(3):398–427
Orlikowski WJ (2007) Sociomaterial practices: exploring technology at work. Organ Stud 28(9):1435–1448. https://doi.org/10.1177/0170840607081138
Pinsonneault A, Kraemer KL (1993) The impact of information technology on middle managers. MIS Q 17(3):271–292. https://doi.org/10.2307/249772
Pipino LL, Lee YW, Wang RY (2002) Data quality assessment. Commun ACM 45(4):211–218. https://doi.org/10.1145/505248.506010
Popovič A, Hackney R, Coelho PS, Jaklič J (2012) Towards business intelligence systems success: effects of maturity and culture on analytical decision making. Decis Support Syst 54(1):729–739. https://doi.org/10.1016/j.dss.2012.08.017
Prendergast C (2002) The tenuous trade-off between risk and incentives. J Polit Econ 110(5):1071–1102. https://doi.org/10.1086/341874
Provost F, Fawcett T (2013) Data science and its relationship to big data and data-driven decision making. Big Data 1(1):51–59. https://doi.org/10.1089/big.2013.1508
Puklavec B, Oliveira T, Popovič A (2018) Understanding the determinants of business intelligence system adoption stages: an empirical study of SMEs. Ind Manag Data Syst 118(1):236–261. https://doi.org/10.1108/IMDS-05-2017-0170
Qiao Y (2022) To delegate or not to delegate? On the quality of voluntary corporate financial disclosure. Rev Manager Sci, 1–36. https://doi.org/10.1007/s11846-022-00576-y
Rajan MV, Saouma RE (2006) Optimal information asymmetry. Acc Rev 81(3):677–712. https://doi.org/10.2308/accr.2006.81.3.677
Rajagopalan N, Rasheed AMA, Datta DK (1993) Strategic decision processes: critical review and future directions. J Manag 19(2):349–384. https://doi.org/10.1016/0149-2063(93)90057-T
Redman TC (1998) The impact of poor data quality on the typical enterprise. Commun ACM 41(2):79–82. https://doi.org/10.1145/269012.269025
Richter NF, Cepeda G, Roldán JL, Ringle CM (2016) European management research using partial least squares structural equation modeling (PLS-SEM). Eur Manag J 34(6):589–597. https://doi.org/10.1016/j.emj.2016.08.001
Rikhardsson P, Yigitbasioglu O (2018) Business intelligence AND analytics in management accounting research: status and future focus. Int J Account Inf Syst 29:37–58. https://doi.org/10.1016/j.accinf.2018.03.001
Robey D, Anderson C, Raymond B (2013). Information technology, materiality, and organizational change: a professional odyssey. J Assoc Inf Syst14(7). https://doi.org/10.17705/1jais.00337
Robey D, Boudreau M-C (1999) Accounting for the contradictory organizational consequences of information technology: Theoretical directions and methodological implications. Inf Syst Res 10(2):167–185. https://doi.org/10.1287/isre.10.2.167
Ross JW, Beath CM, Quaadgras A (2013) You may not need big data after all. Harv Bus Rev 91(12):90–98
Rouibah K, Ould-ali S (2002) PUZZLE: a concept and prototype for linking business intelligence to business strategy. J Strateg Inf Syst 11(2):133–152. https://doi.org/10.1016/S0963-8687(02)00005-7
Saam NJ (2007) Asymmetry in information versus asymmetry in power: implicit assumptions of agency theory? J Socio-Econ 36(6):825–840. https://doi.org/10.1016/j.socec.2007.01.018
Sadler-Smith E, Shefy E (2004) The intuitive executive: understanding and applying ‘gut feel’ in decision-making. Acad Manag Perspect 18(4):76–91. https://doi.org/10.5465/ame.2004.15268692
Samitsch C (2014). Data quality and its impacts on decision-making: How managers can benefit from good data. Springer
Sarstedt M, Bengart P, Shaltoni AM, Lehmann S (2018) The use of sampling methods in advertising research: a gap between theory and practice. Int J Advert 37(4):650–663. https://doi.org/10.1080/02650487.2017.1348329
Scott WR (1981). Organizations: rational, natural and open systems. Prentice Hall, NJ
Scott WR, Davis G (2015) Organizations and organizing: rational, natural and open systems perspectives. Routledge. https://doi.org/10.4324/9781315663371
Sebastian I, Ross J, Beath C, Mocker M, Moloney K, Fonstad N (2017) How big old companies navigate digital transformation. MIS Q Execut 16(3). https://aisel.aisnet.org/misqe/vol16/iss3/6
Seddon PB, Constantinidis D, Tamm T, Dod H (2017) How does business analytics contribute to business value? Inf Syst J 27(3):237–269. https://doi.org/10.1111/isj.12101
Sharma R, Mithas S, Kankanhalli A (2014) Transforming decision-making processes: a research agenda for understanding the impact of business analytics on organisations. Eur J Inf Syst 23(4):433–441. https://doi.org/10.1057/ejis.2014.17
Sharma R, Yetton P (2003) The contingent effects of management support and task interdependence on successful information systems implementation. MIS Q 27(4):533–556. https://doi.org/10.2307/30036548
Shmueli G, Ray S, Velasquez Estrada JM, Chatla SB (2016) The elephant in the room: predictive performance of PLS models. J Bus Res 69(10):4552–4564. https://doi.org/10.1016/j.jbusres.2016.03.049
Simon HA (1978). Information processing theory of human problem solving. In: Estes WK (ed) Handbook of learning and cognitive processes: human information processing (vol. 5, pp 271–295). Psychology Press
Simon HA (1990). Bounded rationality. In: Eatwell J, Milgate M, Newman P (eds) Utility and probability (pp 15–18). Palgrave Macmillan UK. https://doi.org/10.1007/978-1-349-20568-4_5
Simon HA (2013) Administrative behavior, 4th edn. Simon and Schuster
Sor R (2004) Information technology and organisational structure: vindicating theories from the past. Manag Decis 42(2):316–329. https://doi.org/10.1108/00251740410513854
Srinivasan R, Swink M (2018) An investigation of visibility and flexibility as complements to supply chain analytics: an organizational information processing theory perspective. Prod Oper Manag 27(10):1849–1867. https://doi.org/10.1111/poms.12746
Stoica M, Liao J, Welsch H (2004) Organizational culture and patterns of information processing: the case of small and medium-sized enterprises. J Dev Entrepreneur 9(3)
Svenson O (1979) Process descriptions of decision making. Organ Behav Hum Perform 23(1):86–112. https://doi.org/10.1016/0030-5073(79)90048-5
Szukits Á (2022) The illusion of data-driven decision making: the mediating effect of digital orientation and controllers’ added value in explaining organizational implications of advanced analytics. J Manag Control 33(3):403–446. https://doi.org/10.1007/s00187-022-00343-w
Thunholm P (2004) Decision-making style: habit, style or both? Personal Individ Differ 36(4):931–944. https://doi.org/10.1016/S0191-8869(03)00162-4
Torres R, Sidorova A (2019) Reconceptualizing information quality as effective use in the context of business intelligence and analytics. Int J Inf Manage 49:316–329. https://doi.org/10.1016/j.ijinfomgt.2019.05.028
Turban E, Sharda R, Delen D, Aronson JE, Liang T-P, King D (2011) Decision support and business intelligence systems (9th ed). Pearson
Tushman ML, Nadler DA (1978) Information processing as an integrating concept in organizational design. Acad Manag Rev 3(3):613–624. https://doi.org/10.2307/257550
Valjanow S, Enzinger P, Dinges F (2019) Leveraging predictive analytics within a value driver-based planning framework. In: Liermann V, Stegmann C (eds) The impact of digital transformation and fintech on the finance professional (pp 99–115). Springer. https://doi.org/10.1007/978-3-030-23719-6_7
Van der Stede WA, Young SM, Chen CX (2005) Assessing the quality of evidence in empirical management accounting research: the case of survey studies. Acc Organ Soc 30(7):655–684. https://doi.org/10.1016/j.aos.2005.01.003
Visinescu LL, Jones MC, Sidorova A (2017) Improving decision quality: the role of business intelligence. J Comput Inf Syst 57(1):58–66. https://doi.org/10.1080/08874417.2016.1181494
Wang RY (1998) A product perspective on total data quality management. Commun ACM 41(2):58–65. https://doi.org/10.1145/269012.269022
Wang RY, Strong DM (1996) Beyond accuracy: what data quality means to data consumers. J Manag Inf Syst 12(4):5–33
Weick KE (1979) The social psychology of organizing, second edition. McGraw-Hill
Wieder B, Ossimitz M-L (2015) The impact of business intelligence on the quality of decision making: A mediation model. Procedia Comput Sci 64:1163–1171. https://doi.org/10.1016/j.procs.2015.08.599
Wirges F, Neyer A-K (2022) Towards a process-oriented understanding of HR analytics: implementation and application. RMS. https://doi.org/10.1007/s11846-022-00574-0
Wohlstetter P, Datnow A, Park V (2008) Creating a system for data-driven decision-making: applying the principal-agent framework. Sch Eff Sch Improv 19(3):239–259. https://doi.org/10.1080/09243450802246376
Yoo Y (2012) Digital materiality and the emergence of an evolutionary science of the artificial. In: Leonardi PM, Nardi BA, Kallinikos J (eds) Materiality and organizing (1st ed., pp. 134–154). Oxford University Press, Oxford. https://doi.org/10.1093/acprof:oso/9780199664054.003.0007
Young R, Jordan E (2008) Top management support: mantra or necessity? Int J Project Manage 26(7):713–725. https://doi.org/10.1016/j.ijproman.2008.06.001
Yu W, Wong CY, Chavez R, Jacobs MA (2021a) Integrating big data analytics into supply chain finance: the roles of information processing and data-driven culture. Int J Prod Econ 236: 108135. https://doi.org/10.1016/j.ijpe.2021.108135
Yu W, Zhao G, Liu Q, Song Y (2021b) Role of big data analytics capability in developing integrated hospital supply chains and operational flexibility: an organizational information processing theory perspective. Technol Forecast Soc Change 163:120417. https://doi.org/10.1016/j.techfore.2020.120417
Zack MH (2007) The role of decision support systems in an indeterminate world. Decis Support Syst 43(4):1664–1674. https://doi.org/10.1016/j.dss.2006.09.003
Zelt S, Schmiedel T, vom Brocke J (2018) Understanding the nature of processes: an information-processing perspective. Bus Process Manag J 24(1):67–88. https://doi.org/10.1108/BPMJ-05-2016-0102
Zhu S, Song J, Hazen BT, Lee K, Cegielski C (2018) How supply chain analytics enables operational supply chain transparency: an organizational information processing theory perspective. Int J Phys Distrib Logist Manag 48(1):47–68. https://doi.org/10.1108/IJPDLM-11-2017-0341
Zuboff S (1988). In the age of the smart machine: the future of work and power. Heinemann Professional
Funding
Open access funding provided by Corvinus University of Budapest. Project no. NKFIH-869-10/2019 has been implemented with the support provided from the National Research, Development and Innovation Fund of Hungary, financed under the ‘Tématerületi Kiválósági Program’ funding scheme.
Author information
Authors and Affiliations
Contributions
Both authors contributed to the study’s conception and design. Both authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix I: Questionnaire items and scales
Questionnaire items | Constructs and variable names | References |
|---|---|---|
1. To what extent do you consider the following statements about your company to be true? | TM: Top Management Support | Kulkarni et al. (2017) |
a) Top management considers that business analytics plays a strategically important role | TM_1 | |
b) Top management sponsors business analytics initiatives | TM_2 | |
c) Top management demonstrates commitment to business analytics via policy/guidelines | TM_3 | |
d) Top management hires and retains people with analytical skills | TM_4 | |
(1 = Not at all—5 = Completely) | ||
2. To what extent do you consider the following statements about the data available in your company's information system to be true? | DQ: Perceived data quality | Wang and Strong (1996) |
a) The data values are in conformance with the actual or true values | DQ_1 | |
b) The data are applicable (pertinent) to the task of the data user | DQ_2 | |
c) The data are presented in an intelligible and clear manner | DQ_3 | |
d) The data are available or obtainable | DQ_4 | |
(1 = Not at all—5 = Completely) | ||
3. To what extent do you consider the following statements about your company to be true? | AC: Analytical decision making culture | Popovic et al. (2012) |
a) The decision-making process is well established and known to its stakeholders | AC_1 | |
b) It is our organization's policy to incorporate available information within any decision-making process | AC_2 | |
c) We consider the information provided regardless of the type of decision to be taken | AC_3 | |
(1 = Strongly disagree … 5 = Strongly agree) | ||
4. To what extent do you consider the following statements about your company to be true? | CE: Centralization in data use | George and King (1991) |
a) The results of numerical analyses are only available to a narrow group of people | CE_1 | |
b) Where sufficient quantity and quality of data is available, senior management can easily make decisions without involving lower levels of management | CE_2 | |
(1 = Strongly disagree … 5 = Strongly agree) | ||
5. To what extent do you consider the following statements about your company to be true? | DM: Data-driven decision making | Simon (2013) |
In our organization, top management relies on available data | ||
a) … in assessing the current situation | DM_1 | |
b) … when identifying problems | DM_2 | |
c) … exploring alternative courses of action | DM_3 | |
d) … in the assessment of alternative courses of action | DM_4 | |
e) … when choosing between alternative courses of action | DM_5 | |
f) … when planning the implementation of decisions | DM_6 | |
g) … in communicating decisions | DM_7 | |
h) … to monitor the implementation of decisions | DM_8 | |
(1 = Strongly Disagree… 5 = Strongly Agree) | ||
Appendix II: Descriptive statistics of the variables
Variable name | Missing’s (count) | N | Theoretical range | Observed min | Observed max | Mean | SD |
|---|---|---|---|---|---|---|---|
TM_1 | 1 | 304 | 1–5 | 1 | 5 | 4.342 | 0.836 |
TM_2 | 4 | 301 | 1–5 | 1 | 5 | 4.272 | 0.932 |
TM_3 | 2 | 303 | 1–5 | 1 | 5 | 4.228 | 0.929 |
TM_4 | 3 | 302 | 1–5 | 1 | 5 | 4.205 | 0.958 |
DQ_1 | 4 | 301 | 1–5 | 2 | 5 | 4.628 | 0.572 |
DQ_2 | 3 | 302 | 1–5 | 1 | 5 | 4.52 | 0.708 |
DQ_3 | 2 | 303 | 1–5 | 2 | 5 | 4.564 | 0.625 |
DQ_4 | 3 | 302 | 1–5 | 2 | 5 | 4.533 | 0.639 |
AC_1 | 0 | 305 | 1–5 | 1 | 5 | 4.41 | 0.789 |
AC_2 | 0 | 305 | 1–5 | 1 | 5 | 4.334 | 0.861 |
AC_3 | 0 | 305 | 1–5 | 1 | 5 | 4.37 | 0.779 |
CE_1 | 0 | 305 | 1–5 | 1 | 5 | 3.931 | 1.052 |
CE_2 | 2 | 303 | 1–5 | 1 | 5 | 4.096 | 0.776 |
DM_1 | 4 | 301 | 1–5 | 1 | 5 | 4.312 | 0.726 |
DM_2 | 5 | 300 | 1–5 | 1 | 5 | 4.193 | 0.838 |
DM_3 | 3 | 302 | 1–5 | 1 | 5 | 4.159 | 0.764 |
DM_4 | 6 | 299 | 1–5 | 1 | 5 | 4.157 | 0.775 |
DM_5 | 6 | 299 | 1–5 | 2 | 5 | 4.194 | 0.769 |
DM_6 | 5 | 300 | 1–5 | 1 | 5 | 4.21 | 0.808 |
DM_7 | 4 | 301 | 1–5 | 1 | 5 | 4.173 | 0.849 |
DM_8 | 2 | 303 | 1–5 | 1 | 5 | 4.201 | 0.768 |
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Szukits, Á., Móricz, P. Towards data-driven decision making: the role of analytical culture and centralization efforts. Rev Manag Sci (2023). https://doi.org/10.1007/s11846-023-00694-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11846-023-00694-1