
Abstract
Software development analytics is a research area concerned with providing insights to improve product deliveries and processes. Many types of studies, data sources and mining methods have been used for that purpose. This systematic literature review aims at providing an aggregate view of the relevant studies on Software Development Analytics in the past decade, with an emphasis on its application in practical settings. Definition and execution of a search string upon several digital libraries, followed by a quality assessment criteria to identify the most relevant papers. On those, we extracted a set of characteristics (study type, data source, study perspective, development life-cycle activities covered, stakeholders, mining methods, and analytics scope) and classified their impact against a taxonomy. Source code repositories, exploratory case studies, and developers are the most common data sources, study types, and stakeholders, respectively. Testers also get moderate attention from researchers. Product managers’ concerns are being addressed frequently and project managers are also present but with less prevalence. Mining methods are rapidly evolving, as reflected in their identified long list. Descriptive statistics are the most usual method followed by correlation analysis. Being software development an important process in every organization, it was unexpected to find that process mining was present in only one study. Most contributions to the software development life cycle were given in the quality dimension. Time management and costs control were less prevalent. The analysis of security aspects is even more reduced, however, evidences suggest it is an increasing topic of concern. Risk management contributions are also scarce. There is a wide improvement margin for software development analytics in practice. For instance, mining and analyzing the activities performed by software developers in their actual workbench, i.e., in their IDEs. Together with mining developers’ behaviors, based on the evidences and trend, in a short term period we expect an increase in the volume of studies related with security and risks management.







Similar content being viewed by others

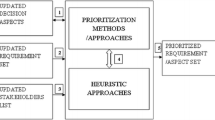
Notes
The sum of frequencies might be bigger than the total number of selected studies(n = 42) because some publications have been classified with more than one Study Type, Data Source, SDLC Activity, Stakeholder, Mining Method and/or Analytics Scope.
References
Abdellatif M, Capretz F, Ho D (2015) Software Analytics to software practice: a systematic literature review. In: 1st International workshop on big data software engineering, IEEE/ACM, New York, pp 30–36. https://doi.org/10.1109/BIGDSE.2015.14. https://www.eng.uwo.ca/Electrical/faculty/capretz_l/docs/publications/Tamer-BIGDSE-v2.pdf
AlOmar EA, Mkaouer MW, Ouni A (2021) Toward the automatic classification of self-affirmed refactoring. J Syst Softw 171:110821. https://doi.org/10.1016/J.JSS.2020.110821
Anwar H, Pfahl D (2017) Towards greener software engineering using software analytics: a systematic mapping. In: Proceedings of 43rd Euromicro conference on software engineering and advanced applications, SEAA 2017. Institute of Electrical and Electronics Engineers Inc., pp 157–166. https://doi.org/10.1109/SEAA.2017.56
Avila SDG, Cano PO, Mejia AM, Moreno IS, Lepe AN (2020) A data driven platform for improving performance assessment of software defined storage solutions. Adv Intell Syst Comput 1071:266–275. https://doi.org/10.1007/978-3-030-33547-2_20
Bangash AA, Sahar H, Hindle A, Ali K (2020) On the time-based conclusion stability of cross-project defect prediction models. Empir Softw Eng 25:5047–5083. https://doi.org/10.1007/S10664-020-09878-9
Buse RPL, Zimmermann T (2010) Analytics for software development. Tech. rep., Microsoft Research. https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/MSR-TR-2010-111.pdf
Buse RP, Zimmermann T (2012) Information needs for software development analytics. In: Proceedings - International Conference on Software Engineering, pp 987–996, https://doi.org/10.1109/ICSE.2012.6227122
Cai KY (2002) Optimal software testing and adaptive software testing in the context of software cybernetics. Inf Softw Technol 44(14):841–855. https://doi.org/10.1016/S0950-5849(02)00108-8
Cai KY, Chen T, Tse T (2002) Towards research on software cybernetics. In: 7th IEEE international symposium on high assurance systems engineering, 2002. Proceedings, pp 240–241. https://doi.org/10.1109/HASE.2002.1173129
Capizzi A, Distefano S, Araújo LJ, Mazzara M, Ahmad M, Bobrov E (2020) Anomaly detection in devops toolchain. Lecture notes in computer science (including subseries Lecture notes in artificial intelligence and Lecture notes in bioinformatics), vol 12055, pp 37–51. https://doi.org/10.1007/978-3-030-39306-9_3
Chen L, Babar MA (2011) A systematic review of evaluation of variability management approaches in software product lines. Inf Softw Technol 53(4):344–362
Chen C, Xing Z, Liu Y (2019) What’s Spain’s Paris? Mining analogical libraries from Q & A discussions. Empir Softw Eng 24(3):1155–1194. https://doi.org/10.1007/s10664-018-9657-y
Cosentino V, Izquierdo JL, Cabot J (2017) A systematic mapping study of software development with GitHub. IEEE Access 5:7173–7192. https://doi.org/10.1109/ACCESS.2017.2682323
Cruz L, Abreu R, Lo D (2019) To the attention of mobile software developers: guess what, test your app! Empir Softw Eng 24:2438–2468. https://doi.org/10.1007/s10664-019-09701-0
Dasanayake S, Markkula J, Oivo M (2014) Concerns in software development: a systematic mapping study. In: Proceedings of the 18th International conference on evaluation and assessment in software engineering. Association for Computing Machinery, pp 1–4. https://doi.org/10.1145/2601248.2601290
Davenport TH, Harris JG, Morison R (2010) Analytics at work: smarter decisions, better results. Harvard Business Press. http://discovery.uoc.edu/iii/encore/record/C__Rb1049687__SAnalytics%20at%20Work__Orightresult__U__X7?lang=spi
D’Avila LF, Farias K, Barbosa JLV (2020) Effects of contextual information on maintenance effort: a controlled experiment. J Syst Softw. https://doi.org/10.1016/J.JSS.2019.110443
Dybå T, Dingsøyr T (2008) Strength of evidence in systematic reviews in software engineering. In: ESEM’08: proceedings of the 2008 ACM-IEEE international symposium on empirical software engineering and measurement, pp 178–187. https://doi.org/10.1145/1414004.1414034
Emam KE, Koru AG (2008) A replicated survey of IT software project failures. IEEE Softw 25(5):84–90. https://doi.org/10.1109/MS.2008.107. (ieeexplore.ieee.org/document/4602680/)
Fan Y, Xia X, Lo D, Li S (2018) Early prediction of merged code changes to prioritize reviewing tasks. Empir Softw Eng 23(6):3346–3393. https://doi.org/10.1007/s10664-018-9602-0
Fucci D, Turhan B (2014) On the role of tests in test-driven development: a differentiated and partial replication. Empir Softw Eng 19(2):277–302. https://doi.org/10.1007/s10664-013-9259-7
Garcia CdS, Meincheim A, Faria Junior ER, Dallagassa MR, Sato DMV, Carvalho DR, Santos EAP, Scalabrin EE (2019) Process mining techniques and applications—a systematic mapping study. Expert Syst Appl 133:260–295. https://doi.org/10.1016/j.eswa.2019.05.003
Gomes TL, Oliveira TC, Cowan D, Alencar P (2014) Mining reuse processes. In: CIBSE 2014: proceedings of the 17th Ibero-American conference software engineering. Curran Associates, Pucon, pp 179–191. https://dblp.org/rec/bib/conf/cibse/GomesOCA14
Guerrouj L, Kermansaravi Z, Arnaoudova V, Fung BC, Khomh F, Antoniol G, Guéhéneuc YG (2017) Investigating the relation between lexical smells and change- and fault-proneness: an empirical study. Softw Qual J 25(3):641–670. https://doi.org/10.1007/s11219-016-9318-6
Hassan S, Shang W, Hassan AE (2017) An empirical study of emergency updates for top android mobile apps. Empir Softw Eng 22(1):505–546. https://doi.org/10.1007/s10664-016-9435-7
Hassan S, Tantithamthavorn C, Bezemer CP, Hassan AE (2018) Studying the dialogue between users and developers of free apps in the Google Play Store. Empir Softw Eng 23(3):1275–1312. https://doi.org/10.1007/s10664-017-9538-9
IEEE Computer Society (2014) SWEBOK V3.0. No. V3.0 in 1. IEEE Computer Society. https://doi.org/10.1234/12345678, http://www4.ncsu.edu/~tjmenzie/cs510/pdf/SWEBOKv3.pdf
Izquierdo-Cortazar D, Sekitoleko N, Gonzalez-Barahona JM, Kurth L (2017) Using metrics to track code review performance. In: ACM international conference proceeding series. Association for Computing Machinery, vol Part F128635, pp 214–223. https://doi.org/10.1145/3084226.3084247
Jha AK, Lee S, Lee WJ (2019) An empirical study of configuration changes and adoption in Android apps. J Syst Softw 156:164–180. https://doi.org/10.1016/j.jss.2019.06.095
Jiang J, Lo D, He J, Xia X, Kochhar PS, Zhang L (2017) Why and how developers fork what from whom in GitHub. Empirical Softw Eng 22(1):547–578. https://doi.org/10.1007/s10664-016-9436-6
Kitchenham B, Brereton P (2013) A systematic review of systematic review process research in software engineering. Inf Softw Technol 55(12):2049–2075. https://doi.org/10.1016/j.infsof.2013.07.010
Kitchenham B, Pearl Brereton O, Budgen D, Turner M, Bailey J, Linkman S (2009) Systematic literature reviews in software engineering—a systematic literature review. Inf Softw Technol 5:7–15
Krishna R, Menzies T (2020) Learning actionable analytics from multiple software projects. Empir Softw Eng 25:3468–3500. https://doi.org/10.1007/S10664-020-09843-6
Li H, Shang W, Zou Y, Hassan E, A, (2017) Towards just-in-time suggestions for log changes. Empir Softw Eng 22(4):1831–1865. https://doi.org/10.1007/s10664-016-9467-z
Li H, Chen THP, Shang W, Hassan AE (2018) Studying software logging using topic models. Empir Softw Eng 23(5):2655–2694. https://doi.org/10.1007/s10664-018-9595-8
Liu Y, Wang J, Wei L, Xu C, Cheung SC, Wu T, Yan J, Zhang J (2019) DroidLeaks: a comprehensive database of resource leaks in Android apps. Empir Softw Eng 24(6):3435–3483. https://doi.org/10.1007/s10664-019-09715-8
McIlroy S, Ali N, Hassan AE (2016) Fresh apps: an empirical study of frequently-updated mobile apps in the Google play store. Empir Softw Eng 21(3):1346–1370. https://doi.org/10.1007/s10664-015-9388-2
Menzies T, Bird C, Zimmermann T, Schulte W, Kocaganeli E (2011) The inductive software engineering manifesto: principles for industrial data mining. In: Proceedings of the international workshop on machine learning technologies in software engineering. Association for Computing Machinery, pp 19–26. http://bit.ly/o02QZJ
Menzies T, Minku L, Peters F (2015) The art and science of analyzing software data; quantitative methods. In: Proceedings of the international conference on software engineering, vol 2. IEEE Computer Society, pp 959–960. https://doi.org/10.1109/ICSE.2015.306
Mittal M, Sureka A (2014a) MIMANSA: process mining software repositories from student projects in an undergraduate software engineering course categories and subject descriptors. Softw Eng Educ Train ICSE 2014:344–353
Mittal M, Sureka A (2014b) Process mining software repositories from student projects in an undergraduate software engineering course. In: 36th International conference on software engineering, ICSE Companion 2014—proceedings. Association for Computing Machinery, pp 344–353. https://doi.org/10.1145/2591062.2591152
Mohagheghi P, Conradi R (2007) Quality, productivity and economic benefits of software reuse: a review of industrial studies. Empir Softw Eng 12(5):471–516. https://doi.org/10.1007/s10664-007-9040-x
Mohagheghi P, Jorgensen M (2017) What contributes to the success of IT projects? Success factors, challenges and lessons learned from an empirical study of software projects in the Norwegian public sector. In: 2017 IEEE/ACM 39th international conference on software engineering companion (ICSE-C). IEEE, pp 371–373. https://doi.org/10.1109/ICSE-C.2017.146, http://ieeexplore.ieee.org/document/7965362/
Morales-Ramirez I, Kifetew FM, Perini A (2018) Speech-acts based analysis for requirements discovery from online discussions. Inf Syst 86:94–112. https://doi.org/10.1016/j.is.2018.08.003
Munaiah N, Meneely A (2016) Vulnerability severity scoring and bounties: why the disconnect. In: SWAN 2016 - Proceedings of the 2nd international workshop on software analytics, co-located with FSE 2016. Association for Computing Machinery, pp 8–14. https://doi.org/10.1145/2989238.2989239
Nakamoto S (2009) Bitcoin: A Peer-to-Peer Electronic Cash System. Tech. rep., http://www.bitcoin.org, www.bitcoin.org
Nayebi M, Ruhe G, Mota RC, Mufti M (2016) Analytics for software project management—wWhere are we and where do we go? In: Proceedings—2015 30th IEEE/ACM international conference on automated software engineering workshops, ASEW 2015. Institute of Electrical and Electronics Engineers, pp 18–21. https://doi.org/10.1109/ASEW.2015.28
Poncin W, Serebrenik A, Brand MVD (2011) Process mining software repositories. In: 2011 15th European conference on software maintenance and reengineering, pp 5–14. https://doi.org/10.1109/CSMR.2011.5
Prana GAA, Treude C, Thung F, Atapattu T, Lo D (2019) Categorizing the content of GitHub README files. Empir Softw Eng 24(3):1296–1327. https://doi.org/10.1007/s10664-018-9660-3
Qu Y, Yin H (2021) Evaluating network embedding techniques’ performances in software bug prediction. Empir Softw Eng. https://doi.org/10.1007/S10664-021-09965-5
Rakha MS, Shang W, Hassan AE (2016) Studying the needed effort for identifying duplicate issues. Empir Softw Eng 21(5):1960–1989. https://doi.org/10.1007/s10664-015-9404-6
Rakha MS, Bezemer CP, Hassan AE (2018) Revisiting the performance of automated approaches for the retrieval of duplicate reports in issue tracking systems that perform just-in-time duplicate retrieval. Empir Softw Eng 23(5):2597–2621. https://doi.org/10.1007/s10664-017-9590-5
Rana G, Haq EU, Bhatia E, Katarya R (2020) A study of hyper-parameter tuning in the field of software analytics. In: Proceedings of the 4th international conference on electronics, communication and aerospace technology, ICECA 2020, pp 455–459. https://doi.org/10.1109/ICECA49313.2020.9297613
Rodriguez D, Herraiz I, Harrison R (2012) On software engineering repositories and their open problems. In: 2012 1st International workshop on realizing AI synergies in software engineering, RAISE 2012—pProceedings, pp 52–56. https://doi.org/10.1109/RAISE.2012.6227971
Saborido R, Morales R, Khomh F, Guéhéneuc YG, Antoniol G (2018) Getting the most from map data structures in Android. Empir Softw Eng 23(5):2829–2864. https://doi.org/10.1007/s10664-018-9607-8
Salza P, Palomba F, Nucci DD, D’uva C, De Lucia A, Ferrucci F (2018) Do developers update third-party libraries in mobile apps. In: Proceedings of the 26th conference on program comprehension, vol 12. Association for Computing Machinery, pp 255–265
Sawant AA, Robbes R, Bacchelli A (2019) To react, or not to react: patterns of reaction to API deprecation. Empir Softw Eng 24(6):3824–3870. https://doi.org/10.1007/s10664-019-09713-w
Sultana KZ, Williams BJ, Bhowmik T (2019) A study examining relationships between micro patterns and security vulnerabilities. Softw Qual J 27(1):5–41. https://doi.org/10.1007/s11219-017-9397-z
Taba SES, Keivanloo I, Zou Y, Wang S (2017) An exploratory study on the usage of common interface elements in android applications. J Syst Softw 131:491–504. https://doi.org/10.1016/j.jss.2016.07.010
Tapscott D, Tapscott A (2016) Blockchain revolution: how the technology behind bitcoin is changing money, business, and the world. Portfolio
Thongtanunam P, Shang W, Hassan AE (2019) Will this clone be short-lived? Towards a better understanding of the characteristics of short-lived clones. Empir Softw Eng 24(2):937–972. https://doi.org/10.1007/s10664-018-9645-2
Tian Y, Nagappan M, Lo D, Hassan AE (2015) What are the characteristics of high-rated apps? A case study on free Android Applications. In: 2015 IEEE 31st International conference on software maintenance and evolution, ICSME 2015—proceedings. Institute of Electrical and Electronics Engineers, pp 301–310. https://doi.org/10.1109/ICSM.2015.7332476
Tim Menzies LW, Zimmermann T (2016) Perspectives on data science for software engineering. Elsevier, Amsterdam. https://doi.org/10.1016/C2015-0-00521-4
Van Der Aalst W (2016) Process mining: data science in action, 2nd edn. Springer, Berlin. https://doi.org/10.1007/978-3-662-49851-4
Van Der Aalst W, Adriansyah A, De Medeiros AKA, Arcieri F, Baier T, Blickle T, Bose JC, Van Den Brand P, Brandtjen R, Buijs J, Burattin A, Carmona J, Castellanos M, Claes J, Cook J, Costantini N, Curbera F, Damiani E, De Leoni M, Delias P, Van Dongen BF, Dumas M, Dustdar S, Fahland D, Ferreira DR, Gaaloul W, Van Geffen F, Goel S, Günther C, Guzzo A, Harmon P, Ter Hofstede A, Hoogland J, Ingvaldsen JE, Kato K, Kuhn R, Kumar A, La Rosa M, Maggi F, Malerba D, Mans RS, Manuel A, McCreesh M, Mello P, Mendling J, Montali M, Motahari-Nezhad HR, Zur Muehlen M, Munoz-Gama J, Pontieri L, Ribeiro J, Rozinat A, Seguel Pérez H, Seguel Pérez R, Sepúlveda M, Sinur J, Soffer P, Song M, Sperduti A, Stilo G, Stoel C, Swenson K, Talamo M, Tan W, Turner C, Vanthienen J, Varvaressos G, Verbeek E, Verdonk M, Vigo R, Wang J, Weber B, Weidlich M, Weijters T, Wen L, Westergaard M, Wynn M (2012) Process mining manifesto. Lecture notes in business information processing 99 (LNBIP), pp 169–194. https://doi.org/10.1007/978-3-642-28108-2_19
Vashisht R, Rizvi SAM (2021) An empirical study of heterogeneous cross-project defect prediction using various statistical techniques. Int J e-Collaboration 17:55–71. https://doi.org/10.4018/IJEC.2021040104
Wani ZH, Bhat JI, Giri KJ (2021) A generic analogy-centered software cost estimation based on differential evolution exploration process. Comput J 64:462–472. https://doi.org/10.1093/COMJNL/BXAA199
Wohlin C (2014) Guidelines for snowballing in systematic literature studies and a replication in software engineering. In: Proceedings of the 18th international conference on evaluation and assessment in software engineering (EASE ’14), pp 1–10. https://doi.org/10.1145/2601248.2601268
Wu R, Wen M, Cheung SC, Zhang H (2018) ChangeLocator: locate crash-inducing changes based on crash reports. Empir Softw Eng 23(5):2866–2900. https://doi.org/10.1007/s10664-017-9567-4
Wu W, Khomh F, Adams B, Guéhéneuc YG, Antoniol G (2016) An exploratory study of api changes and usages based on apache and eclipse ecosystems. Empir Softw Eng 21(6):2366–2412. https://doi.org/10.1007/s10664-015-9411-7
Yan M, Xia X, Lo D, Hassan AE, Li S (2019) Characterizing and identifying reverted commits. Empir Softw Eng 24(4):2171–2208. https://doi.org/10.1007/s10664-019-09688-8
Yang XL, Lo D, Xia X, Wan ZY, Sun JL (2016) What security questions do developers ask? A large-scale study of stack overflow posts. J Comput Sci Technol 31(5):910–924. https://doi.org/10.1007/s11390-016-1672-0. (archive.org/details/stackexchange)
Yang H, Chen F, Aliyu S (2017) Modern software cybernetics: new trends. J Syst Softw 124:169–186. https://doi.org/10.1016/j.jss.2016.08.095
Ye D, Xing Z, Kapre N (2017) The structure and dynamics of knowledge network in domain-specific Q &A sites: a case study of stack overflow. Empir Softw Eng 22(1):375–406. https://doi.org/10.1007/s10664-016-9430-z
Zannier C, Melnik G, Maurer F (2006) On the success of empirical studies in the international conference on software engineering. In: Proceedings of international conference on software engineering, pp 341–350. https://doi.org/10.1145/1134285.1134333
Zhang D, Han S, Dang Y, Lou JG, Zhang H, Research Asia M, Xie T (2013a) Software analytics in practice. IEEE Softw. http://channel9.msdn
Zhang D, Han S, Dang Y, Lou JG, Zhang H, Xie T (2013b) Software analytics in practice. IEEE Softw 30(5):30–37. https://doi.org/10.1109/MS.2013.94
Zhang L, Tian JH, Jiang J, Liu YJ, Pu MY, Yue T (2018) Empirical research in software engineering—a literature survey. J Comput Sci Technol 33(5):876–899. https://doi.org/10.1007/s11390-018-1864-x
Acknowledgements
This work was partially funded by the Portuguese Foundation for Science and Technology, under ISTAR’s projects UIDB/04466/2020 and UIDP/04466/2020.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendices
1.1 Appendix 1: Data Extraction
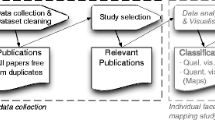
1.1.1 Selection Process

Study selection process stages
Appendix 2: Studies List
See Table 11.
1.1 Comments on Studies
[S01] explores the correlation between software vulnerabilities and code-level constructs called micro patterns. The authors analyzed the correlation between vulnerabilities and micro patterns from different viewpoints and explored whether they are related. The conclusion shows that certain micro patterns are frequently present in vulnerable classes and that there is a high correlation between certain patterns that coexist in a vulnerable class [58].
[S02] presents an empirical study to analyze commit histories of Android manifest files of hundreds of apps to understand their evolution through configuration changes. The results is a contribution to help developers in identifying change-proneness attributes, including the reasons behind the changes and associated patterns and understanding the usage of different attributes introduced in different versions of the Android platform. In summary, the results show that most of the apps extend core functionalities and improve user interface over time. It detected that significant effort is wasted in changing configuration and then reverting back the change, and that very few apps adopt new attributes introduced by the platform and when they do, they are slow in adopting new attributes. Configuration changes are mostly influenced by functionalities extension, platform evolution and bug reports [29].
[S03] studied updates in the Google Play Store by examining more than 44,000 updates of over 10,000 mobile apps, from where 1,000 were identified as emergency updates. After studying the characterirstics of the updates, the authors found that the emergency updates often have a long lifetime (i.e., they are rarely followed by another emergency update) and that updates preceding emergency updates often receive a higher ratio of negative reviews than the emergency updates [25].
[S04] analyzed and classified API changes and usages together in 22 framework releases from the Apache and Eclipse ecosystems and their client programs. The authors conclude that missing classes and methods happen more often in frameworks and affect client programs more often than the other API change types do, and that missing interfaces occur rarely in frameworks but affect client programs often. In summary, framework APIs are used on average in 35% of client classes and interfaces and most of such usages could be encapsulated locally and reduced in number. Around 11% of APIs usages could cause ripple effects in client programs when these APIs change. Some suggestions for developers and researchers were made to mitigate the impact of API evolution through language mechanisms and design strategies [70].
[S05] extracted commonly used UI elements, denoted as Common Element Sets (CESs), from user interfaces of applications. The highlight the characteristics of CESs that can result in a high user-perceived quality by proposing various metrics. From an empirical study on 1292 mobile applications, the authors observed that CESs of mobile applications widely occur among and across different categories, whilst certain characteristics of CESs can provide a high user-perceived quality. A recommendation is made, aiming to improve the quality of mobile applications, consisting on the adoption of reusable UI templates that are extracted and summarized from CESs for developers [59].
[S06] performed a qualitative study involving the manual annotation of 4,226 README file sections from 393 randomly sampled GitHub repositories and design and evaluate a classifier and a set of features that can categorize these sections automatically. The findings show that information discussing the ’What’ and ’How’ of a repository hapens very often, while at the same time, many README files lack information regarding the purpose and status of a repository. A classifier was built to predict multiple categories and the F1 score obtained encourages its usage by software repositories owners. The approach presented is said to improve the quality of software repositories documentation and it has the potential to make it easier for the software development community to discover relevant information in GitHub README files [49].
[S07] conducted an empirical study on characterizing the bug inducing changes for crashing bugs (denoted as crash-inducing changes). ChangeLocator was also proposed as a method to automatically locate crash-inducing changes for a given bucket of crash reports. The study approach is based on a learning model that uses features originated from the empirical study itself and a model was trained using the data from the historical fixed crashes. ChangeLocator was evaluated with six release versions of the Netbeans project. The analysis and results show that it can locate the crash-inducing changes for 44.7%, 68.5%, and 74.5% of the bugs by examining only top 1, 5 and 10 changes in the recommended list, respectively, which is said to outperform other approaches [69].
[S08] explored if one can characterize and identify which commits will be reverted. The authors characterized commits using 27 commit features and build an identification model to identify commits that will be reverted. Reverted commits were identified by analyzing commit messages and comparing the changed content, and extracted 27 commit features that were divided into three dimensions: change, developer and message. An identification model (e.g., random forest) was built and evaluated on an empirical study on ten open source projects including a total of 125,241 commits. The findings show that the ’developer’ is the most discriminative dimension among the three dimensions of features for the identification of reverted commits. However, using all the three dimensions of commit features leads to better performance of the created models [71].
[S09] conducted an empirical study on the evolution history of almost three hundred mobile apps, by investigating whether mobile developers actually update third-party libraries, checking which are the categories of libraries with respect to the developers’ proneness to update their apps, looking for what are the common patterns followed by developers when updating a software library, and whether high- and low-rated apps present any particular update patterns. Results showed that mobile developers rarely update their apps with respect to the used libraries, and when they do, they mainly tend to update the libraries related to the Graphical User Interface, with the aim of keeping the mobile apps updated with the latest design trends. In some cases developers ignore updates because of a poor awareness of the benefits, or a too high cost/benefit ratio [56].
[S10] extracted real resource leak bugs from a bug database named DROIDLEAKS. It consisted in mining 34 popular open-source Android apps, which resulted in a dataset having a total of 124,215 code revisions. After filtering and validating the data, the authors found, on 32 analyzed apps, 292 fixed resource leak bugs, which cover a diverse set of resource classes. To fully comprehend these bugs, they performed an empirical study, which revealed the characteristics of resource leaks in Android apps and common patterns of resource management mistakes made by developers [36].
[S11] built a merged code change prediction tool leveraging machine learning techniques, and extracted 34 features from code changes, which were grouped into 5 dimensions: code, file history, owner experience, collaboration network, and text. Experiments were executed on three open source projects (i.e., Eclipse, LibreOffice, and OpenStack), containing a total of 166,215 code changes. Across three datasets, the results show statistically significantly improvements in detecting merged code changes and in distinguishing important features on merged code changes from abandoned ones [20].
[S12] studied the frequency of updates of 10,713 mobile apps (the top free 400 apps at the start of 2014 in each of the 30 categories in the Google Play store). It was found that only \(\sim \)1% of the studied apps are updated at a very frequent rate - more than one update per week and 14% of the studied apps are updated on a bi-weekly basis (or more frequently). Results also show that 45% of the frequently-updated apps do not provide the users with any information about the rationale for the new updates and updates exhibit a median growth in size of 6%. The authors conclude that developers should not shy away from updating their apps very frequently, however the frequency should vary across store categories. It was observed that developers do not need to be too concerned about detailing the content of new updates as it appears that users are not too concerned about such information and, that users highly rank frequently-updated apps instead of being annoyed about the high update frequency [37].
[S13] studied the use of map data structure implementations by Android developers and how that relates with saving CPU, memory, and energy as these are major concerns of users wanting to increase battery life. The authors initially performed an observational study of 5713 Android apps in GitHub and then conducted a survey to assess developers’ perspective on Java and Android map implementations. Finally, they performed an experimental study comparing HashMap, ArrayMap, and SparseArray variants map implementations in terms of CPU time, memory usage, and energy consumption. The conclusions provide guidelines for choosing among the map implementations: HashMap is preferable over ArrayMap to improve energy efficiency of apps, and SparseArray variants should be used instead of HashMap and ArrayMap when keys are primitive types [55].
[S14] detected 29 smells consisting of 13 design smells and 16 lexical smells in 30 releases of three projects: ANT, ArgoUML, and Hibernate. Further, the authors analyzed to what extent classes containing lexical smells have higher (or lower) odds to change or to be subject to fault fixing than other classes containing design smells. The results obtained bring empirical evidence on the fact that lexical smells can make, in some cases, classes with design smells more fault-prone. In addition, it was empirically demonstrated that classes containing design smells only are more change- and fault-prone than classes with lexical smells only [24].
[S15] examined the nature of the relationship between tests and external code quality as well as programmers’ productivity in order to verify/refute the results of a previous study. With the focus on the role of tests, a differentiated and partial replication of the original study and related analysis was conducted. The replication involved 30 students, working in pairs or as individuals, in the context of a graduate course, and resulted in 16 software artifacts developed. Significant correlation was found between the number of tests and productivity. No significant correlation found between the number of tests and external code quality. For both cases we observed no statistically significant interaction caused by the subject units being individuals or pairs. Results obtained are consistent with the original study although, as the authors admit, there were changes in the timing constraints for finishing the task and the enforced development processes [21].
[S16] presented an application of mining three software repositories: team wiki (used during requirement engineering), version control system (development and maintenance) and issue tracking system (corrective and adaptive maintenance) in the context of an undergraduate Software Engineering course. Visualizations, metrics and algorithms to provide an insight into practices and procedures followed during various phases of a software development life-cycle were proposed and these provided a multi-faceted view to the instructor serving as a feedback tool on development process and quality by students. Event logs produced by software repositories were mined and derived insights such as degree of individual contributions in a team, quality of commit messages, intensity and consistency of commit activities, bug fixing process trend and quality, component and developer entropy, process compliance and verification. Experimentation revealed that not only product but process quality varies signicantly between student teams and mining process aspects can help the instructor in giving directed and specific feedback. Authors, observed that commit patterns characterizing equal and un-equal distribution of workload between team members, patterns indicating consistent activity in contrast to spike in activity just before the deadline, varying quality of commit messages, developer and component entropy, variation in degree of process compliance and bug fixing quality [41].
[S17] investigated the impact of the just-in-time duplicate retrieval on the duplicate reports that end up in the ITS of several open source projects, namelly Mozilla-Firefox, Mozilla-Core and Eclipse-Platform. The differences between duplicate reports for open source projects before and after the activation of this new feature were studied. Findings showed that duplicate issue reports after the activation of the just-in-time duplicate retrieval feature are less textually similar, have a greater identification delay and require more discussion to be retrieved as duplicate reports than duplicates before the activation of the feature [52].
[S18] exploited a linguistic technique based on speech-acts for the analysis of online discussions with the ultimate goal of discovering requirements-relevant information. The datasets used in the experimental evaluation, which are publicly available, were taken from a widely used open source software project (161120 textual comments), as well as from an industrial project in the home energy management domain. The approach used was able to successfully classify messages into Feature/Enhancement and Other, with significant accuracy. Evidence was found to support the rationale, that there is an association between types of speech-acts and categories of issues, and that there is correlation between some of the speechacts and issue priority, which could open other streams of research [44].
[S19] studied the relationship between the topics of a code snippet and the likelihood of a code snippet being logged (i.e., to contain a logging statement). The intuition driving this research, was that certain topics in the source code are more likely to be logged than others. To validate the assumptions a case study was conducted on six open source systems. The analysis gathered evidences that i) there exists a small number of “log-intensive” topics that are more likely to be logged than other topics; ii) each pair of the studied systems share 12% to 62% common topics, and the likelihood of logging such common topics has a statistically significant correlation of 0.35 to 0.62 among all the studied systems. In summary, the findings highlight the topics containing valuable information that can help guide and drive developers’ logging decisions [35].
[S20] revisits a previous work in more depth by studying 4.5 million reviews with 126,686 responses for 2,328 top free-to-download apps in the Google Play Store. One of the major findings is that the assumption that reviews are static is incorrect. In particular, it is found that developers and users in some cases use this response mechanism as a rudimentary user support tool, where dialogues emerge between users and developers through updated reviews and responses. In addition, four patterns of developers were identified: 1) developers who primarily respond to only negative reviews, 2) developers who primarily respond to negative reviews or to reviews based on their contents, 3) developers who primarily respond to reviews which are posted shortly after the latest release of their app, and 4) developers who primarily respond to reviews which are posted long after the latest release of their app. To perform a qualitative analysis of developer responses to understand what drives developers to respond to a review, the authors analyzed a statistically representative random sample of 347 reviews with responses for the top ten apps with the highest number of developer responses. Seven drivers that make a developer respond to a review were identified, of which the most important ones are to thank the users for using the app and to ask the user for more details about the reported issue. In summary, there were significant evidences found, that it can be worthwhile for app owners to respond to reviews, as responding may lead to an increase in the given rating and that studying the dialogue between user and developer can provide valuable insights which may lead to improvements in the app store and the user support process [26].
[S21] empirically examined the effort that is needed for manually identifying duplicate reports in four open source projects, i.e., Firefox, SeaMonkey, Bugzilla and Eclipse-Platform. Results showed that: (i) More than 50% of the duplicate reports are identified within half a day. Most of the duplicate reports are identified without any discussion and with the involvement of very few people; (ii) A classification model built using a set of factors that are extracted from duplicate issue reports classifies duplicates according to the effort that is needed to identify them with significant values for precision, recall and ROC area; and (iii) Factors that capture the developer awareness of the duplicate issues’ peers (i.e., other duplicates of that issue) and textual similarity of a new report to prior reports are the most influential factors found. The results highlight the need for effort-aware evaluation of approaches that identify duplicate issue reports, since the identification of a considerable amount of duplicate reports (over 50%) appear to be a relatively trivial task for developers. As a conclusion, the authors highlight the fact that, to better assist developers, research on identifying duplicate issue reports should put greater emphasis on assisting developers in identifying effort-consuming duplicate issues [51].
[S22] analyzed URL sharing activities in Stack Overflow. The approach was to use open coding method to analyze why users share URLs in Stack Overflow, and develop a set of quantitative analysis methods to study the structural and dynamic properties of the emergent knowledge network in Stack Overflow. The findings show: i) Users share URLs for diverse categories of purposes. ii) These URL sharing behaviors create a complex knowledge network with high modularity, assortative mixing of semantic topics, and a structure skeleton consisting of highly recognized knowledge units. iii) The structure of the knowledge network with respect to indegree distribution is scale-free (i.e., stable), in spite of the ad-hoc and opportunistic nature of URL sharing activities, while the outdegree distribution of the knowledge network is not scale-free. iv) The indegree distributions of the knowledge network converge quickly, with small changes over time after the convergence to the stable distribution. The conclusions highlight the fact that the knowledge network is a natural product of URL sharing behavior that Stack Overflow supports and encourages, and proposed an explanatory model based on information value and preferential attachment theories to explain the underlying factors that drive the formation and evolution of the knowledge network in Stack Overflow [74].
[S23] questioned if there was really a strong argument for the Java 9 language designers to change the implementation of the deprecation warnings feature after they notice no one was taking seriously those and continued using outdated features. The goal was to start by identifying the various ways in which an API consumer can react to deprecation and then to create a dataset of reaction patterns frequency consisting of data mined from 50 API consumers totalling 297,254 GitHub based projects and 1,322,612,567 type-checked method invocations. Findings show that predominantly consumers do not react to deprecation and a survey on API consumers was done to try to explain this behavior and by analyzing if the APIs deprecation policy had an impact on the consumers’ decision to react. The manual inspection of usages of deprecated API artifacts lead to the discovery of six reaction patterns. Only 13% of API consumers update their API versions and 88% of reactions to deprecation is doing nothing. However the survey got a different result, where 69% of respondents say they replace it with the recommended repalcement. Over 75% of the API barelly affect consumers with deprecation and 15% of the consumers are affected only by 2 APIs(hibernate-core and mongo-java-driver) [57].
[S24] investigated working habits and challenges of mobile software developers with respect to testing. A key finding of this exhaustive study, using 1000 Android apps, demonstrates that mobile apps are still tested in a very ad hoc way, if tested at all. However, it is shown that, as in other types of software, testing increases the quality of apps (demonstrated in user ratings and number of code issues). Furthermore, there is evidence that tests are essential when it comes to engaging the community to contribute to mobile open source software. The authors discuss reasons and potential directions to address the findings. Yet another relevant finding of this study is that Continuous Integration and Continuous Deployment (CI/CD) pipelines are rare in the mobile apps world (only 26% of the apps are developed in projects employing CI/CD) - authors argue that one of the main reasons is due to the lack of exhaustive and automatic testing [14].
[S25] tries to understand the reasons for log changes and, proposes an approach that can provide developers with log change suggestions as soon as they commit a code change, which is referred to as “just-in-time” suggestions for log changes. A set of measures is derived based on manually examining the reasons for log changes and individual experiences. Those measures were used as explanatory variables in random forest classifiers to model whether a code commit requires log changes. These classifiers can provide just-in-time suggestions for log changes and was evaluated with a case study on four open source projects: Hadoop, Directory Server, Commons HttpClient, and Qpid. Findings show that: i) the reasons for log changes can be grouped along four categories: block change, log improvement, dependence-driven change, and logging issue; ii) the random forest classifiers can effectively suggest whether a log change is needed; iii) the characteristics of code changes in a particular commit and the current snapshot of the source code are the most influential factors for determining the likelihood of a log change in a commit [34].
[S26] designed and conducted, with the continuous feedback of the Xen Project Advisory Board, a detailed analysis focused on finding problems associated with the large increase over time in the number of messages related to code review. The increase was being perceived as a potential signal of problems with their code review process and the usage of metrics was suggested to track the performance of it. As a result, it was learned how in fact the Xen Project had some problems, but at the moment of the analysis those were already under control. It was found as well how diferent the Xen and Netdev projects were behaving with respect to code review performance, despite being so similar from many points of view. A comprehensive methodology, fully automated, to study Linux-style code review was proposed [28].
[S27] analyzed the Common Vulnerability Scoring System (CVSS) scores and bounty awarded for 703 vulnerabilities across 24 products. CVSS is the de facto standard for vulnerability severity measurement today and is crucial in the analytics driving software fortification. It was found a weak correlation between CVSS scores and bounties, with CVSS being more likely to underestimate bounty. Such a negative result is suggested to be a cause for concern. The authors, investigated why the measurements were so discordant by i) analyzing the individual questions of CVSS with respect to bounties and ii) conducting a qualitative study to find the similarities and diferences between CVSS and the publicly-available criteria for awarding bounties. It was found that the bounty criteria were more explicit about code execution and privilege escalation whereas CVSS makes no explicit mention of those. Another lesson learnt was that bounty valuations are evaluated solely by project maintainers, whereas CVSS has little provenance in practice [45].
[S28] through a case study on 1,492 high-rated and low-rated free apps mined from the Google Play store, investigated 28 factors along eight dimensions to understand how high-rated apps are different from low-rated apps. The search for the most influential factors was also addressed by applying a random-forest classifier to identify high-rated apps. The results show that high-rated apps are statistically significantly different in 17 out of the 28 factors that we considered. The experiment also presents eveidences for the fact that the size of an app, the number of promotional images that the app displays on its web store page, and the target SDK version of an app are the most influential factors [62].
[S29] conducted a large-scale study on security-related questions on Stack Overflow. Two heuristics were used to extract from the dataset the questions that are related to security based on the tags of the posts. Later, to cluster different security-related questions based on their texts, an advanced topic model, Latent Dirichlet Allocation (LDA) tuned using Genetic Algorithm (GA) was used. Results show that security-related questions on Stack Overflow cover a wide range of topics, which belong to five main categories: web security, mobile security, cryptography, software security, and system security. Among them, most questions are about web security. In addition, it was found that the top four most popular topics in the security area are “Password”, “Hash”, “Signature” and “SQL Injection”, and the top eight most difficulty security-related topics are “JAVA Security”, “Asymetric Encryption”, “Bug”, “Browser Security”, “Windows Authority”, “Signature”, “ASP.NET” and “Password”, suggesting these are the ones in need for more attention [72].
[S30] present an approach to recommend analogical libraries based on a knowledge base of analogical libraries mined from tags of millions of Stack Overflow questions. The approach was implemented in a proof-of-concept web application and more than 34.8 thousands of users visited the website from November 2015 to August 2017. Results show evidences that accurate recommendation of analogical libraries is not only possible but also a desirable solution. Authors validated the usefulness of their analogical-library recommendations by using them to answer analogical-library questions in Stack Overflow [12].
[S31] explored why and how developers fork what from whom in GitHub. This approach was supported by collecting a dataset containing 236,344 developers and 1,841,324 forks. It was also validated by a survey in order to analyze the programming languages and owners of forked repositories. Among the main findings we have: i) Developers fork repositories to submit pull requests, fix bugs, add new features and keep copies etc. Developers find repositories to fork from various sources: search engines, external sites (e.g., Twitter, Reddit), social relationships, etc. More than 42% of developers that were surveyed agree that an automated recommendation tool is useful to help them pick repositories to fork, while more than 44.4% of developers do not value a recommendation tool. Developers care about repository owners when they fork repositories. ii) A repository written in a developers’ preferred programming language is more likely to be forked. iii) Developers mostly fork repositories from creators. In comparison with unattractive repository owners, attractive repository owners have higher percentage of organizations, more followers and earlier registration in GitHub. The results show that forking is mainly used for making contributions of original repositories, and it is beneficial for OSS community. In summary, there is evidence of the value of recommendation and provide important insights for GitHub to recommend repositories [30].
[S32] designed and executed an empirical study on six open source Java systems to better understand the life expectancy of clones. A random forest classifier was built with the aim of determining the life expectancy of a newly-introduced clone (i.e., whether a clone will be short-lived or longlived) and it was confimed to have good accuracy on that task. Results show that a large number of clones (i.e., 30% to 87%) lived in the systems for a short duration. Moreover, it finds that although short-lived clones were changed more frequently than long-lived clones throughout their lifetime, short-lived clones were consistently changed with their siblings less often than long-lived clones. Findings show that the churn made to the methods containing a newly-introduced clone, the complexity and size of the methods containing the newly- introduced clone are highly influential in determining whether the newly-introduced clone will be short-lived. Furthermore, the size of a newly-introduced clone shares a positive relationship with the likelihood that the newly introduced clone will be short-lived. Results suggest that, to improve the efficiency of clone management efforts, such as the planning of the most effective use of their clone management resources in advance, practitioners can leverage the presented classifiers and insights in order to determine the life expectancy of clones [61].
[S33] This paper introduces DDP (Data Driven Plataform) platform, a scalable platform to analyze and exploit performance data. This platform centralizes, analyzes and visualizes the performance data produced during the software development cycle. DDP employs big data and analytics technology to collect, store and process performance data in an efficient and integrated way. They have demonstrated the successful application of DDP for Spectrum Scale, a software defined storage solution, where they have been able to implement performance regression data analysis to validate the performance consistency of new produced builds [4].
[S34] To help the industry practitioners in these situations, a analogy-centered model based on differential evolution exploration process is proposed in this research study. The proposed model has been assessed on 676 projects from 5 different data sets and the results achieved are significantly better when compared with other benchmark analogy-based estimation studies [67].
[S35] The paper attempts to analyze and compare various methodologies to tune the defect predictors. The research papers which are analyzed here have used data-set from the PROMISE repository, open-source [53].
[S36] This paper evaluates empirically and theoretically heterogeneous Cross-project defect prediction (HCPDP) modeling, which comprises of three main phases: Feature ranking and feature selection, metric matching, and finally, predicting defects in the target application. The research work has been experimented on 13 benchmarked datasets of three open source projects. Results show that performance of HCPDP is very much comparable to baseline within project defect prediction [66].
[S37] An anomaly detection system can operate in the staging environment to compare the current incoming release with previous ones according to predefined metrics. The analysis is conducted before going into production to identify anomalies. In this paper, they describe a prototypical implementation of the aforementioned idea in the form of a proof-of-concept [10].
[S38] This article reports a controlled experiment that compares the effort to implement changes, the correctness and the maintainability of an existing application between two projects; one that uses qualitative dashboards depicting contextual information, and one that does not [17].
[S39] In this paper conducts an extensive empirical study to evaluate network embedding algorithms in bug prediction by utilizing and extending node2defect, a newly proposed bug prediction model that combines the embedded vectors with traditional software engineering metrics through concatenation. Experiments are conducted based on seven network embedding algorithms,two effort-aware models, and 13 open-source Java systems [50].
[S40] This paper presents a technology for prescriptive software analytics. Their planner offers users a guidance on what action to take in order to improve the quality of a software project. Our preferred planning tool is BELLTREE, which performs cross-project planning with encouraging results.With our BELLTREE planner, we show that it is possible to reduce several hundred defects in software projects [33].
[S41] In this paper they investigate whether conclusions in the area of defect prediction, if the claims of the researchers are stable throughout time. This case study provides evidence that in the field of defect prediction the context of evaluation (in our case, time) plays an important role [5].
[S42] In this paper, they propose a two-step approach to first identify whether a commit describes developer-related refactoring events, then to classify it according to the refactoring common quality improvement categories [2].
General Statistics
See Fig. 9, 10, 11, 12, 13 and Table 12, 13, 14, and 15.

Number of studies published by each main author over the years

Frequencies of studies per publisher over the years

Frequencies of studies for data sources

Frequencies of studies for mining methods

Frequencies of studies combining multiple RQs in the SLR
Appendix 3: Studies Appraisal
The following acronyms were used for SLR results interpretation (see Table 16):
-
Study Type
-
ACM—Analyze and Compare Methodologies, CS-Case Study, CE-Controlled Experiment
-
ECS—Exploratory Case Study, QE—Quasi-Experiment, S—Survey
-
-
SDLC Activities
-
D—Debugging, I—Implementation, M—Maintenance, O—Operations, T—Testing
-
-
Project Stakeholders
-
D—Developers, E—Educators, EU—End-Users, T—Testers, PM—Product Managers
-
PjM—Project Managers, R—Researchers, RE—Requirements Engineers
-
-
Analytics Scope
-
Des—Descriptive Analytics, Dia—Diagnostics Analytics
-
Pred—Predictive Analytics, Pres—Prescriptive Analytics
-
The following taxonomy was used to assess the SDLC contributions:
-
The benefit is:
-
Absent (0)
 Not addressed
Not addressed -
Weak (0.25)
 Implicitly addressed
Implicitly addressed -
Moderate (0.5)
 Explicitly addressed (not detailed)
Explicitly addressed (not detailed) -
Strong (0.75)
 Explained with details and implications
Explained with details and implications -
Complete (1)
 Fully explained, validated and replicable
Fully explained, validated and replicable
-
 Not addressed
Not addressed Implicitly addressed
Implicitly addressed Explicitly addressed (not detailed)
Explicitly addressed (not detailed) Explained with details and implications
Explained with details and implications Fully explained, validated and replicable
Fully explained, validated and replicableRights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Caldeira, J., Brito e Abreu, F., Cardoso, J. et al. Software Development Analytics in Practice: A Systematic Literature Review. Arch Computat Methods Eng 30, 2041–2080 (2023). https://doi.org/10.1007/s11831-022-09864-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11831-022-09864-y