
Abstract
We present a symbolic algorithmic approach that allows to compute invariant manifolds and corresponding reduced systems for differential equations modeling biological networks which comprise chemical reaction networks for cellular biochemistry, and compartmental models for pharmacology, epidemiology and ecology. Multiple time scales of a given network are obtained by scaling, based on tropical geometry. Our reduction is mathematically justified within a singular perturbation setting. The existence of invariant manifolds is subject to hyperbolicity conditions, for which we propose an algorithmic test based on Hurwitz criteria. We finally obtain a sequence of nested invariant manifolds and respective reduced systems on those manifolds. Our theoretical results are generally accompanied by rigorous algorithmic descriptions suitable for direct implementation based on existing off-the-shelf software systems, specifically symbolic computation libraries and Satisfiability Modulo Theories solvers. We present computational examples taken from the well-known BioModels database using our own prototypical implementations.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Biological network models describing elements in interaction are used in many areas of biology and medicine. Chemical reaction networks are used as models of cellular biochemistry, including gene regulatory networks, metabolic networks, and signaling networks. In epidemiology and ecology, compartmental models can be described as networks of interactions between compartments. Both in chemical reaction networks and in compartmental models, the probability that two elements interact is assumed proportional to their abundances. This property, called mass action law in biochemistry, leads to polynomial differential equations in the kinetics.
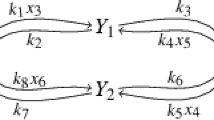
For differential equations that describe the development of such networks over time, a crucial question is concerned with reduction of dimension. We illustrate such a reduction and the steps involved for the classic Michaelis–Menten system, an archetype of enzymatic reactions. This system is described by the chemical reactions
where E, S, ES, and P are the enzyme, substrate, enzyme-substrate complex, and product, respectively. The mechanism has two conserved quantities \(\text {[E]} + \text {[ES]} = c_1\) and \(\text {[S]} + \text {[ES]} + \text {[P]} = c_2\), where \(c_1\) and \(c_2\) are constant functions representing the respective total concentrations. Let us choose the concentration units such that \(c_2=1\), and furthermore rename \(c_1 = \varepsilon \). In the ordinary differential equations describing the kinetics of [E], [S], [ES], and [P] according to [24, Sect. 2.1.2] we eliminate the variable \(\text {[E]}= \varepsilon - \text {[ES]}\). This yields a reduced system made of variables \(y_1 = \text {[S]}\) and \(y_2 = \text {[ES]}\) as follows:
Notice that \(\dot{\text {[P]}}\) is already determined by the algebraic conservation constraint \(\text {[P]} = 1 - y_1 - y_2\). The parameter \(\varepsilon \) represents the ratio of total concentrations \(c_1\) to \(c_2\). The general idea is that \(\varepsilon \) is small.
In a first step toward reduction, a scaling transformation \(y_1=x_1\) and \(y_2=\varepsilon x_2\) yields
In a second step, one uses singular perturbation theory to obtain the famous Michaelis–Menten equation. It consists of two components: First, we obtain a one dimensional invariant manifold given approximately by the quasi-steady state condition \(k_1x_1-(k_1x_1+k_{-1}+k_2)x_2=0\). This considers the fast variable \(x_2\) to be at the steady state and lowers dimension from two to one. Second, we obtain a reduced system for the slow variable:
With our example, we paraphrased the approach in a seminal paper by Heineken et al. [34], which was the first one to rigorously discuss quasi-steady state from the perspective of singular perturbation theory. Realistic network models may have many species and differential equations. Considerable effort has been put into model order reduction, i.e., finding approximate models with a smaller number of species and equations, where the reduced model can be more easily analyzed than the full model [58].
The scaling of parameters and variables by a small parameter \(\varepsilon \) and the study of the limit \(\varepsilon \rightarrow 0\) is central in singular perturbation theory. It is rather obvious that arbitrary scaling transformations are unlikely to provide useful information about a given system. Successful scalings, in contrast, are typically related to the existence of nontrivial invariant manifolds. Applications of scaling rely on the observation that, loosely speaking, any result that holds asymptotically for \(\varepsilon \rightarrow 0\) remains valid for sufficiently small positive \(\varepsilon _*\), provided some technical conditions are satisfied. To determine scalings of polynomial or rational vector fields that model biological networks, tropical equilibration methods were introduced and developed in a series of papers by Noel et al. [55], Radulescu et al. [59], Samal et al. [62, 63], and others. These methods open a feasible path for biological networks of high dimension. For a given system they provide a list of possible slow-fast systems, which may or may not yield invariant manifolds and reduced equations. Other methods due to Goeke et al. [31], and recently extended to multiple time scales by Kruff and Walcher [40], determine critical parameter values and manifolds for singular perturbation reductions.
The principal purpose of the present paper is to complement scaling with an algorithmic test for the existence of invariant manifolds and the computation of those manifolds along with corresponding reduced systems of differential equations. In the asymptotic limit, methods from singular perturbation theory, principally developed by Tikhonov [74] and Fenichel [25], are available. A recent extension to multiscale systems by Cardin and Teixeira [11] turns out to be a valuable tool for the systematic computation of reductions with nested invariant manifolds and allows an algorithmic approach.
In the language of dynamical systems, the behavior of systems with multiple time scales can be described as follows. All variables evolve towards the steady state of the ordinary differential equation that they follow, but not with the same speed, in other words, not within the same time scale. Slow variables correspond to long time scales, and fast variables correspond to short time scales. The steady state of a subset of the ordinary differential equations is called quasi-steady state, and the evolution of a variable or group of variables towards its quasi-steady state is called relaxation. At a given time scale, a group of variables relaxes towards one of their quasi-steady states. The set of all quasi-steady states of variables relaxing within the same time scale forms a critical manifold, which provides the lowest order approximation to the corresponding invariant manifold. In this article, we do not distinguish between critical and invariant manifolds, since we do not discuss higher order approximations. All slower variables can be considered fixed, and all faster variables have already relaxed and satisfy quasi-steady state conditions. As the number of relaxed variables increases and thus the set of quasi-steady state conditions grows, the respective invariant manifolds get nested so that later manifolds are contained in earlier ones. Local linear approximations of these manifolds were proposed by Valorani and Paolucci [75] using numerical methods based on the local Jacobian. However, to the best of our knowledge, constructive approaches providing nonlinear descriptions of these manifolds and reduced models are still missing.
From a computer science point of view, we propose a novel symbolic computation-based algorithmic workflow for the reduction process outlined above. This includes in particular the automatic verification of certain hyperbolicity conditions required for the validity of the reductions. We restrict ourselves to the case of polynomial differential equations that covers mass action chemical reaction networks and compartmental models. We present a series of algorithms that takes as input a system of polynomial autonomous ordinary differential equations together with numerical information related to the desired coarse graining of the scaling. As output one finally obtains a collection of nested invariant manifolds for the input system, associated with smaller dimensional systems that govern the dynamics on those manifolds. This output establishes the reduced systems discussed above.
The computationally hard parts of our methods are reduced to decision problems in interpreted first-order logic over various theories. It turns out that quantifier alternation can be entirely avoided, so that the Satisfiability Modulo Theories (SMT) framework by Nieuwenhuis et al. [52] can be applied. Several corresponding SMT solvers are freely available and professionally supported [1, 13, 17, 51]. It is remarkable that we arrive with our comprehensive algorithmic work here at SMT sub-problems for several different logics, viz. linear integer arithmetic, linear real arithmetic, and non-linear real arithmetic. The algorithms presented here are suitable for straightforward implementation provided that a symbolic computation library, or computer algebra system, and an SMT solver are available. We created two independent prototypical realizations in software ourselves, one in Python using freely available libraries, and one in Maple.
The plan of the paper is as follows: In Sect. 2.1 we introduce an abstract scaling procedure, which assumes, for given \(0< \varepsilon _* < 1\), the existence of families of exponents \(c_{k,J}\) and \(d_k\) for scaling polynomial coefficients and variables, respectively. From the scaled system, higher order terms are truncated, and the obtained system is partitioned into several time scales, ordered from fastest to slowest. A corresponding generic algorithm uses black-box functions c and d. In Sect. 2.2, we make precise one possible way to realize c and d, based on tropical geometry. So far, our transformations are mostly of formal nature. On these grounds, we algorithmically determine in Sect. 3 invariant manifolds and corresponding reduced systems, which makes the formal scaling meaningful in a mathematically precise way. In general, this is possible only for a certain number \(\ell \) of time scales, where \(\ell \) is explicitly found and—in contrast to existing alternative approaches—often larger than 2. Technically, we apply recent results by Cardin and Teixeira [11] based on Fenichel theory. In Sect. 4, we employ symbolic computation techniques, specifically Gröbner basis theory, to equivalently simplify our reduced systems, which are still scaled in terms of \(\varepsilon _*\), c, and d. In Sect. 5, we finally transform back to the principal scale of the original system while preserving the obtained multiple time scales and the structure of the corresponding reduced systems. In particular, the various time scale factors remain explicit. In Sect. 6, we summarize what we have gained from the overall procedure for our original input. At this point, the mathematical development of our framework has been accompanied by nine algorithms, and we give a tenth top-level algorithm, which makes precise how various modules are combined and interact with one another. In Sect. 7 we discuss computational examples with our prototypical software mentioned above. We consider models from the BioModels database, a repository of mathematical models of biological processes [57]. The focus is on successful reductions for biologically interesting examples. This is counterbalanced in Appendix A by further examples to support the understanding of our algorithms. This also provides some examples where we do not obtain meaningful reductions. In Sect. 8 we highlight some computational steps in our algorithms from the point of view of asymptotic worst-case complexity. In Sect. 9, we wrap up and point at possible future research directions.
2 Scaling of Polynomial Vector Fields
In what follows, we adopt a rather general scaling formalism that has been used recently in [54, 55, 58, 59, 63] and is recurrent in the literature on singular perturbations, see for instance [53, Sect. 3]. We use the convention that the natural numbers \(\mathbb {N}\) include 0.
2.1 An Abstract Scaling Procedure
Our starting point is a parameter dependent system S of polynomial differential equations
where the summation ranges over multi-indices \(J=(j_1,\ldots ,j_n)\in \mathbb {N}^n\), \(\gamma _{k,J} \in \mathbb {R}\), and only finitely many \(\gamma _{k,J}\) are non-zero. We abbreviate \(y^J=y_1^{j_1}\ldots y_n^{j_n}\), as usual. In terms of network models, \(y_k\) represents the concentration of either a chemical species or a type of individual in a compartment. Note that we use positive integers as indices, instead of concrete names for species and compartments. The real coefficients \(\gamma _{k,J}\) describe actions of other species or individuals on the species or individual k. If these actions are activations one has \(\gamma _{k,J}>0\), whereas for repressions one has \(\gamma _{k,J}<0\). Several species may interact to produce an action on a given species k. This information is contained in the number of non-zero components of J, which is called the order of the action. This terminology is inspired from chemical reactions, where the order represents essentially the number of reactant species.
Throughout this paper, we require that positive \(y_k\) remain positive as time progresses. In other words, the positive first orthant \(\mathcal {U}= (0, \infty )^n \subseteq \mathbb {R}^n\) is positively invariant for system (1), which is the case, e.g., in chemical reaction networks when \(\gamma _{k,J}y^J \ge 0\) on all intersections of hyperplanes \(\{\,(y_1, \ldots , y_n) \in \mathbb {R}^n \mid y_k = 0\,\}\) with \({\overline{\mathcal {U}}}\).
We fix some small \(\varepsilon _* \in (0,1)\), and we impose that
with rational numbers \(c_{k,J}\). The tacit understanding is that only nonzero \( \gamma _{k,J}\) are being considered. The intuitive idea, which will be made more precise in Sect. 2.2, is that the \(\bar{\gamma }_{k,J}\) are close to one. Moreover, we introduce a positive parameter \(\varepsilon \) and consider the system
with \(\varepsilon \)-dependent coefficients. Notice that (3) matches (1) at \(\varepsilon =\varepsilon _*\). By renormalizing \(y_k=\varepsilon ^{d_k}x_k\), \(d_k\in {\mathbb {Q}}\), one obtains a system in scaled variables
with \(D=(d_1,\ldots ,d_n)\) and the dot product in \(\mathbb {R}^n\) denoted by \(\left<\cdot ,\cdot \right>\). This transformation preserves the positive invariance of \(\mathcal {U}\). The scaling comes with the implicit assumption that for i, \(j \in \{1, \ldots , n\}\), the relative order of \(y_i\) with respect to \(y_j\) is bounded by \(y_i/y_j = \Theta (\varepsilon ^{d_i-d_j})\) for \(\varepsilon \rightarrow 0\), so that all \(x_k\) get the same order of magnitude. Continuing, we set \(\nu _k = \min \{\, c_{k,J}+\left<D,J\right>-d_k \mid \bar{\gamma }_{k,J}\not =0 \,\}\) to obtain
where now all exponents of \(\varepsilon \) inside the sums are nonnegative. Finally one may perform a preliminary time scaling \(\tau =\varepsilon ^\mu t\), \(\mu =\min \, \{ \nu _1, \ldots , \nu _n \}\) to arrive at
with all exponents nonnegative. We are interested in system (6) for variable \(\varepsilon >0\), in the asymptotic limit \(\varepsilon \rightarrow 0\).
We restructure (6) by collecting all variables with equal \(\nu _i-\mu \) in vectors \(z_1, \ldots ,z_m\), where \(z_k \in \mathbb {R}^{n_k}\) for \(k \in \{1, \ldots , m\}\), in ascending order of exponents and such that \(n_1 + \cdots + n_m = n\). We obtain a system of the form
where \(a_k\), \(a_{k,j}'\in \mathbb {Q}\), \(0=a_1<a_2<\cdots < a_m\), \(0 < a_{k,j}'\), and \(p_{k,j}\) are multivariate polynomials in z for \(1\le k\le m\) and \(2 \le j \le w_k\). Note that the case \(m=1\) is not excluded. By substituting \(\delta := \varepsilon ^{1/q}\) with a sufficiently large positive integer q, one ensures that only nonnegative integer powers of \(\delta \) appear:
where \(b_k\), \(b_{k,j}'\in \mathbb {N}\), \(0=b_1<b_2<\cdots < b_m\), \(0 < b_{k,j}'\) for \(1\le k\le m\) and \(2 \le j \le w_k\).
Our idea is that the indices k correspond to different time scales \(\delta ^{b_k}\tau \). For \(m>1\), system (8), as \(\delta \rightarrow 0\), may be thought of as separating fast variables from increasingly slow ones. It will turn out in Sect. 3 that the exact number of time scales finally obtained by our overall approach can actually be smaller than m.
Given certain conditions, which will be made explicit in Theorem 1 and with its application in Sect. 3.1, we may formally truncate the right hand sides of (8) and keep only terms of lowest order in \(\delta \):
In the following, we refer to the transformation process from (1) to (8) as scaling. Strictly speaking, this comprises scaling in combination with partitioning. We refer to the step from (8) to (9) as truncating.
Algorithm 1

reflects our discussions so far. It takes as input a list S of differential equations representing system (1) and a choice of \(0< \varepsilon _* < 1\) for (2). For our practical purposes, the polynomial coefficients in S as well as \(\varepsilon _*\) are taken from \(\mathbb {Q}\). Our algorithm is furthermore parameterized with a function c mapping suitable indices to rational numbers and a constant function d yielding either a tuple \(D=(d_1, \ldots , d_n)\) of rational numbers or \(\bot \). The black-box functions c and d reflect the mathematical assumptions around (2) and (4) that suitable \(c_{k,J}\) and \(d_k\) exist, respectively. Suitable instantiations for the parameters c and d can be realized, e.g., using tropical geometry, which will be the topic of the next section. It will turn out that instantiations of d can fail on the given combination of S and \(\varepsilon _*\), which is signaled by the return value \(\bot \) of d, and checked right away in l.1 of Algorithm 1.
2.2 Scaling via Tropical Geometry
So far, the above transformations leading to (4) are a formal exercise. No particular strategy was applied for choosing \(\varepsilon _* \in (0,1)\). Early model reduction studies used dimensional analysis to obtain \(\varepsilon _*\) as a power product in model parameters [34, 66].
Here we discuss a different approach, based on tropical geometry, also called max-plus or idempotent algebra. This is a relatively recent field of mathematics that draws its origins from fields as diverse as algebraic geometry, optimization, and physics [46]. In all these fields, tropical geometry appears as a technique to simplify non-linear objects. Polynomials are replaced by piecewise-linear functions, and geometric problems are transformed into combinatorial problems [50].
Tropical geometry is natural for any computation with orders of magnitude. In physics, it occurs as Litvinov–Maslov dequantization of real numbers leading to degeneration of complex algebraic varieties into tropical varieties [45, 77]. The name dequantization originates from the formal analogy between this limiting process and Schrödinger’s dequantization that turns quantum physics into classical physics when the Planck constant is considered a small parameter \(\varepsilon \) that tends to zero. Closer, in the physical world, to Litvinov–Maslov dequantization are the vanishing viscosity phenomena, well known in problems of wave propagation. In mathematics, tropical varieties and prevarieties establish a modern tool in the theory of Puiseux series [4].
In contrast to the dimensional analysis approach mentioned above, the value \(\varepsilon _*\) is now not dictated by physico-chemistry. Instead, it is freely chosen to provide “power” parametric descriptions of all the quantities occurring in the differential equations (parameters, monomials, time scales), in a similar way to describing curves by continuously varying real parameters.
Next, we explain how to obtain the orders \(c_{k,J}\) and D introduced in the previous section with (2) and (4), respectively. The orders \(c_{k,J}\) are computed from \(\varepsilon _* \in (0,1)\) and \(\gamma _{k,J}\) as
The function \({{\,\mathrm{round}\,}}: \mathbb {R}\rightarrow \mathbb {Z}\) rounds to nearest, ties to even, in the sense of IEEE 754 [37]. The positive integer p controls the precision of the rounding step. Using \({\bar{\gamma }}_{k,J} = \gamma _{k,J} / \varepsilon _*^{c_{k,J}}\) as defined in (2), our definition satisfies the constraint \(\varepsilon _*^{1/(2p)} \le | {\bar{\gamma }}_{k,J} | \le \varepsilon _*^{-1/(2p)}\). The orders \(D=(d_1, \ldots , d_n)\) satisfy certain constraints as well. Those constraints result heuristically from the idea of compensation of dominant monomials [54]. Slow dynamics is possible if for each dominant, i.e., much larger than the other, monomial on the right hand side of (6), there is at least one other monomial of the same order but with opposite sign. This condition, named tropical equilibration condition [54, 55, 58, 59, 62, 63], reads
On these grounds, given system (1), the choice of \(\varepsilon _*\) boils down to defining orders of magnitude. Model parameters are coarse-grained and transformed to orders of magnitude in order to apply tropical scaling. The result depends on which parameters are close and which are very different as dictated by the coarse-graining procedure, i.e., by the choice of \(\varepsilon _*\). Decreasing \(\varepsilon _*\) destroys details, and parameters tend to have the same order of magnitude. Increasing \(\varepsilon _*\) refines details, and parameters range over several orders of magnitude. For instance, using (10) and \(p=1\), parameters \(k_1=0.1\) and \(k_2=0.01\) have orders \(c_1 = 1\) and \(c_2 =2\) for \(\varepsilon _*=1/10\) but \(c_1=c_2=1\) for \(\varepsilon _*=1/50\). This is the perspective taken in [54, 55, 63].
On the one hand, we have just seen that smaller choices of \(\varepsilon _*\) possibly hide details. On the other hand, in the following section we are going to review singular perturbation methods, which provide asymptotic results as a small parameter \(\delta \) approaches zero. Following the construction in Sect. 2.1, small choices of \(\varepsilon _*\) lead to small \(\delta \), which gives a heuristic argument for choosing \(\varepsilon _*\) rather small. Thus in practice one has to reconcile two competing requirements, which unfortunately, still requires some human intuition.
We are now ready to instantiate the black-box functions c and d in our generic Algorithm 1 with tropical versions as given in Algorithm 2 and Algorithm 3, respectively. Algorithm 2 explicitly uses, besides the parameters k and J specified for c in Algorithm 1, also the right hand sides of the input system (1) and the choice of \(\varepsilon _*\). As yet another parameter it takes the desired precision p for rounding in (10). Notice that the use of this extra information is compatible with the abstract scaling procedure in Sect. 2.1. Currying [18] allows to use Algorithm 2 in place of c in a formally clean manner.



Similarly, Algorithm 3 takes parameters \(\varepsilon _*\) and p, while d is specified in Algorithm 1 to have no parameters at all. In l.1 we use Algorithm 4 as a subalgorithm for tropical equilibration. One obtains a disjunctive normal form \(\Pi \), which explicitly describes a set \(\mathcal {P}= \{\, p \in \mathbb {Q}^n \mid \Pi (p)\,\}\) as a finite union of convex polyhedra, as known from tropical geometry. Every \((d_1, \ldots , d_n) \in \mathcal {P}\) satisfies (11). The satisfiability condition in l.2 tests whether \(\mathcal {P}\ne \varnothing \). We employ Satisfiability Modulo Theories (SMT) solving [52] using the logic QF_LRA [2] for quantifier-free linear real arithmetic. The set \(\mathcal {P}\) can get empty, e.g, when all monomials on the right hand side of some differential equation have the same sign. Such an exceptional situation is signaled with a return value \(\bot \) in l.3. In the regular case \(\mathcal {P}\ne \varnothing \), the choice \((d_1, \ldots , d_n)\) in l.5 is provided by the SMT solver. From a practical point of view, the disjunctive normal form computation in Algorithm 4 is a possible bottleneck and requires good heuristic strategies [48].
With applications in the natural sciences one often wants to make in l.5 an adequate choice for \((d_1, \ldots , d_n)\) lying in a specific convex polyhedron \(P \subseteq \mathcal {P}\), which technically corresponds to one conjunction in \(\Pi \). Such choices are subtle and typically require human interaction. For instance, when the chain of reduced dynamical systems ends with a steady state, it is interesting to consider the polyhedron P that is closest to that steady state. Such strategies are not covered by our algorithms presented here.
At this stage we have obtained a scaled system as defined in Sect. 2.1, including partitioning. The focus of the next section is to utilize this scaling for analytically substantiated reductions.
3 Singular Perturbation Methods
The theory of singular perturbations is used to compute and justify theoretically the limit of system (8) when \(\delta \rightarrow 0\). There are several types of results in this theory. The results of Tikhonov, further improved by Hoppensteadt, show the convergence of the solution of system (8) to the solution of a differential-algebraic system in which the slowest variables \(z_m\) follow differential equations, and the remaining fast variables follow algebraic equations [35, 74]. The results of Fenichel are known under the name of geometric singular perturbations. He showed that the algebraic equations in Tikhonov’s theory define a slow invariant manifold that is persistent for \(\delta > 0\) [25]. For geometric singular perturbations, differentiability in \(\delta \) is needed in system (8).
Samal et al. have noted that Tikhonov’s theorem is applicable to tropically scaled systems [63]. For instance, with \(\delta _1 = \delta ^{b_2}\), system (8) may be rewritten as
However, this approach comes with certain limitations. To start with, it allows only two time scales. Furthermore, in case \(b_2>1\), there may be differentiability issues with respect to \(\delta _1\), and some care has to be taken when one tries to apply to (12) also Fenichel’s results [25]. In this section, we are going to generalize geometric singular perturbations, and compute invariant manifolds and reduced models for more than two time scales, introducing further \(\delta _2\), ..., \(\delta _{\ell -1}\). Our generalization is based on a recent paper by Cardin and Teixeira [11].
Section 3.1 presents relevant results from [11] adapted to our purposes here and applied to our system (8). In contrast to the original article, which is based on a series of hyperbolicity conditions, we introduce the notion of hyperbolic attractivity, which is stronger but still adequate for our purposes. In Sect. 3.2 we describe efficient algorithmic tests for hyperbolic attractivity. Section 3.3 gives sufficient algorithmic criteria addressing the above-mentioned differentiability issues.
3.1 Application of a Fenichel Theory for Multiple Time Scales
We consider our system (8) over the positive first orthant \(\mathcal {U}= (0, \infty )^n \subseteq \mathbb {R}^n\). A recent paper by Cardin and Teixeira [11] generalizes Fenichel’s theory to provide a solid foundation to obtain more than one nontrivial invariant manifold. This allows, in particular, the reduction of multi-time scale systems such as system (8). Technically, the approach considers a multi-parameter system using time scale factors \(\delta _1\), \(\delta _1\delta _2\), ... instead of increasing powers of one single \(\delta \).
We let \(\ell \in \{2, \ldots , m\}\) and define
and furthermore \(\delta _1 = \delta ^{\beta _1}\), ..., \(\delta _{\ell -1} = \delta ^{\beta _{\ell -1}}\), and \({\bar{\delta }}= (\delta _1, \ldots , \delta _{\ell -1})\).
These definitions allow us to express also all \(\delta ^{b_{k,j}'}\) occurring in (8) as products of powers of \(\delta _1\), ..., \(\delta _{\ell -1}\), with nonnegative but possibly non-integer rational exponents, via expressing each \(b_{k,j}'\) as a nonnegative rational linear combination of \(\beta _1\), ..., \(\beta _{\ell -1}\). This yields
Moreover, we express \(\delta ^{b_{\ell +1}}=\delta _1\cdots \delta _{\ell -1}\cdot \eta _{\ell +1}\), ..., \(\delta ^{b_m}=\delta _1\cdots \delta _{\ell -1}\cdot \eta _{m}\), via
which is obtained by writing each \(b_k - b_\ell \) as a nonnegative rational linear combination of \(\beta _1\), ..., \(\beta _{\ell -1}\). In these terms our system (8) translates to

In terms of the right hand sides of (16) the application of relevant results in [11] requires that \({\widehat{g}}_1\), ..., \({\widehat{g}}_\ell \) and \(\eta _{\ell +1}{\widehat{g}}_{\ell +1}\), ..., \(\eta _m{\widehat{g}}_m\) are smooth on an open neighborhood of \(\mathcal {U}\times [0,\vartheta _1) \times \cdots \times [0,\vartheta _{\ell -1})\) with \(\vartheta _1>0\), ..., \(\vartheta _{\ell -1}>0\). We are going to tacitly assume such smoothness here and address this issue from an algorithmic point of view in Sect. 3.3.
We are now ready to transform our system into \(\ell \) time scales as follows, where possibly \(\ell > 2\):
In time scale \(\tau _k\), with \(1\le k\le \ell \), system (16) then becomes

For \(k=1\) and \(k=\ell \) we obtain empty products, which yield the neutral element 1, as usual.
Similarly to Sect. 2.1, we are interested in the asymptotic behavior for \({\bar{\delta }}\rightarrow 0\), which is approximated by the elimination of higher order terms. We are now going to introduce a construction required for a justification of this approximation, which also clarifies the greatest possible choice for \(\ell \le m\) above. Define \(F_0 = 0\) and

With system (8) in mind, we are going to use \({\widehat{f}}_k(z, 0)\) in favor of \({\widehat{g}}_k(z, 0, \dots , 0)\). It is easy to see that both are equal. We define furthermore
The sets \(\mathcal {M}_k\) are obtained from varieties defined by the systems \(M_k\) via intersection with the first orthant. Furthermore,
establishes a chain of nested subvarieties, again intersected with the first orthant.
We define that \(\mathcal {M}_1\) is hyperbolically attractive on \(\mathcal {M}_0\), if \(\mathcal {M}_1 \ne \varnothing \), and for all \(z \in \mathcal {M}_1\) all eigenvalues of the Jacobian \(D_{z_1}{\widehat{f}}_1(z, 0)\) have negative real parts. Therefore \(\mathcal {M}_1\) is a manifold. For \(k \in \{ 2, \dots , m \}\), \(\mathcal {M}_{k}\) is hyperbolically attractive on \(\mathcal {M}_{k-1}\), if \(\mathcal {M}_{k} \ne \varnothing \), and the following holds. Recall that using the defining polynomials \(F_{k-1}\) of \(\mathcal {M}_{k-1}\), the implicit function theorem yields a unique local resolution of \(Z_{k-1}\) as functions of \(z_k\), ..., \(z_m\), provided that \(D_{Z_{k-1}}F_{k-1}\) has no zero eigenvalues. We thus obtain
For our definition we now require that for all \(z \in \mathcal {M}_{k}\) all eigenvalues of \(D_{z_k}{\widehat{f}}_k^*(z_k, \ldots , z_m, 0)\) have negative real parts. Again, \(\mathcal {M}_k\) is a manifold. When \(\mathcal {M}_k\) is hyperbolically attractive on \(\mathcal {M}_{k-1}\) we write \(\mathcal {M}_{k-1} \mathrel {\triangleright }\mathcal {M}_{k}\), where \(Z_k\) will be clear from the context.
If we find for some \(\ell \in \{1, \dots , m \}\) that \(\mathcal {M}_{0} \mathrel {\triangleright }\mathcal {M}_{1}\), \(\mathcal {M}_{1} \mathrel {\triangleright }\mathcal {M}_{2}\), ..., \(\mathcal {M}_{\ell -1} \mathrel {\triangleright }\mathcal {M}_{\ell }\), then we simply write \(\mathcal {M}_0 \mathrel {\triangleright }\dots \mathrel {\triangleright }\mathcal {M}_\ell \), and call this a hyperbolically attractive \(\ell \)-chain. Such a chain is called maximal if either \(\ell = m\) or \(\mathcal {M}_\ell \mathrel {\not \triangleright }\mathcal {M}_{\ell +1}\).
Let \(\mathcal {M}_0 \mathrel {\triangleright }\dots \mathrel {\triangleright }\mathcal {M}_\ell \) be a hyperbolically attractive \(\ell \)-chain. Consider for each \(k \in \{1, \dots , \ell \}\) the following differential-algebraic system:
In the limiting case \({\bar{\delta }}=0\), this corresponds to system (17). Recall that
and equivalently rewrite (20) as a triplet \((M_{k-1}, T_k, R_k)\) with entries as follows:
For a given index k, we call \((M_{k-1}, T_k, R_k)\) a reduced system on \(\mathcal {M}_{k-1}\), where the relevant hyperbolic attractivity relation is \(\mathcal {M}_{k-1} \mathrel {\triangleright }\mathcal {M}_{k}\). In order to indicate the relevance of \(\mathcal {M}_0 \mathrel {\triangleright }\dots \mathrel {\triangleright }\mathcal {M}_\ell \) we write \((M_0, T_1, R_1) \mathrel {\triangleright }\dots \mathrel {\triangleright }(M_{\ell -1}, T_\ell , R_\ell )\) also for reduced systems, where \(\mathcal {M}_\ell \) is not made explicit but relevant for the last triplet. Slightly abusing language, we speak of a hyperbolically attractive \(\ell \)-chain of reduced systems, which is maximal if \(\mathcal {M}_0 \mathrel {\triangleright }\dots \mathrel {\triangleright }\mathcal {M}_\ell \) is.
The following theorem is a consequence of [11, Theorem A and Corollary A], specialized to the situation at hand.
Theorem 1
Let \(\ell \ge 2\). Assume that \((M_0, T_1, R_1) \mathrel {\triangleright }\dots \mathrel {\triangleright }(M_{\ell -1}, T_\ell , R_\ell )\) is a hyperbolically attractive \(\ell \)-chain of reduced systems for system (16). Let \(K \subseteq \mathcal {U}\) be compact. Then for sufficiently small \({\bar{\delta }}\) and all \(k \in \{ 1, \dots , \ell \}\), system (16) admits invariant manifolds \(\mathcal {N}_{k-1}\) that depend on \({\bar{\delta }}\) and are \((\delta _1 + \cdots + \delta _{k-1})\)-close to \(\mathcal {M}_{k-1} \cap K\) with respect to the Hausdorff distance. Moreover, there exists \(T > 0\) such that solutions of system (16) on \(\mathcal {N}_{k-1}\) in time scale \(\tau _{k}\) converge to solutions of \((M_{k-1}, T_k, R_k)\), uniformly on any closed subinterval of \((0,\,T)\), as \({\bar{\delta }}\rightarrow 0\). \(\square \)
For \(k \in \{1, \ldots , \ell \}\), the \(\mathcal {M}_{k-1}\) are critical manifolds, which contain only stationary points. The systems \((T_k, R_k)\) of ordinary differential equations on \(\mathcal {M}_{k-1}\) approximate invariant manifolds \(\mathcal {N}_{k-1}\) in the sense of the theorem. They furthermore approximate solutions in time scale \(\tau _k\) of system (16), which is equivalent to our system (8). In other words, system (8) admits a succession of invariant manifolds, on which the behavior in the appropriate time scale is approximated by the respective reduced equations (20) and, equivalently, (21). Note that only the \(\delta ^{b_k}{\widehat{f}}_k(z,0)\) without the higher order terms enter the reduced systems \((M_{k-1}, T_k, R_k)\).
Algorithm 5 now starts with the output \([T_1, \dots , T_m]\) of Algorithm 1, which represents the scaled system (9). Notice that each \(T_k\) already meets the specification in (21). In l.1 we define U to contain defining inequalities of the first orthant \(\mathcal {U}\). Starting with \(k=1\), the for-loop in l.4–15 successively constructs \(M_k\) and \(R_k\) such that in combination with \(T_k\) from the input, \((M_{k-1}, T_k, R_k)\) forms a reduced system as in (21). The loop stops when either \(k=m+1\) or a test for hyperbolic attractivity in l.8 finds that \(\mathcal {M}_{k-1} \mathrel {\not \triangleright }\mathcal {M}_k\). We are going to discuss this test in detail in the next section. Note that we maintain a matrix A for storing information between the subsequent calls of our test. In either case we arrive at a maximal hyperbolically attractive \((k-1)\)-chain of reduced systems given as a list \([(M_{0}, T_1, R_1), \dots , (M_{k-2}, T_{k-1}, R_{k-1})]\). Following the notational convention used throughout this section we set \(\ell \) to \(k-1\) in l.17. The test in l.18–20 reflects the choice of \(\ell \in \{2, \dots , m\}\) at the beginning of this section. Finally, l.21 uses the second input \([P_1, \dots , P_m]\) of the algorithm to address the smoothness requirements for system (16). We are going to discuss the corresponding procedure in detail in Sect. 3.3. It will turn out that this procedure provides only a sufficient test. Therefore we issue in case of failure only a warning, allowing the user to verify smoothness a posteriori, using alternative algorithms or human intelligence. One might mention that it is actually sufficient to consider weaker, finite differentiability conditions instead of smoothness, which can be seen by inspection of the proofs in [11].

From an application point of view, attracting invariant manifolds are relevant in the context of biological networks, and our notion of hyperbolic attractivity holds for large classes of such networks [24]. This is our principal motivation for using hyperbolic attractivity here. From a computational perspective, hyperbolic attractivity can be tested based on Hurwitz criteria, as we are going to make explicit in the next section.
The relevant results in [11], in contrast, are based on a series of hyperbolicity conditions, which are somewhat weaker than hyperbolic attractivity. Hyperbolicity can be tested algorithmically as well, albeit with more effort. For approaches based on Routh’s work see, e.g., [27, Chapter V, §4], which checks the number of purely imaginary eigenvalues of a real polynomial via the Cauchy index of a related rational function.
3.2 Verification of Hyperbolic Attractivity
Our definition of hyperbolic attractivity \(\mathcal {M}_{k-1} \mathrel {\triangleright }\mathcal {M}_k\) refers to the eigenvalues of the Jacobians of the \({\widehat{f}}_k^*\), which cannot be directly obtained from the Jacobians of the \({\widehat{f}}_k\) [11, 12]. Generalizing work on systems with three time scales [40], we take in this section a linear algebra approach to obtain the relevant eigenvalues without computing the \({\widehat{f}}_k^*\).
To start with, recall the well-known Hurwitz criterion [36]:
Theorem 2
(Hurwitz, 1895). Consider \(f = a_0x^n+a_1x^{n-1}+\dots +a_n \in \mathbb {R}[x]\), \(a_0 > 0\). For \(i \in \{1, \dots , n\}\) define

Then all complex zeros of f have negative real parts if and only if \(\Delta _1 > 0\), ..., \(\Delta _n > 0\). Notice that \(\Delta _n = a_n\Delta _{n-1}\), and therefore \(\Delta _n > 0\) can be equivalently replaced with \(a_n > 0\).
We call \(H_n\) the Hurwitz matrix and \(\Delta _i\) the i-th Hurwitz determinant of f. Furthermore, we refer to \(\Gamma = (\Delta _1> 0 \wedge \dots \wedge \Delta _{n-1}> 0 \wedge a_n > 0)\) as the Hurwitz conditions for f.
Our first result generalizes [40, Proposition 1 (ii)]. The proof is straightforward by induction using the argument in [40, Lemma 3] and its proof.
Lemma 3
For \(k \in \{1, \dots , m\}\) define

Let \(\ell \in \{1, \dots , m\}\). Then \(\mathcal {M}_0 \mathrel {\triangleright }\dots \mathrel {\triangleright }\mathcal {M}_{\ell }\) if and only if \(\mathcal {M}_{\ell } \ne \varnothing \) and for all \(k \in \{1, \dots , \ell \}\), all sufficiently small \(\varrho _1^*>0\), ..., \(\varrho _{k-1}^*>0\), and all \(z^*\in \mathcal {M}_{k}\), all eigenvalues of \(J_k(\varrho _1^*, \dots , \varrho _{k-1}^*, z^*)\) have negative real parts.
In particular, one can choose \(\varrho _1^* = \dots = \varrho _{k-1}^* = \varrho ^*\) with sufficiently small \(\varrho ^*\) and consider \(J_k' = {\text {diag}}(1, \dots , \varrho ^{k-1}) \cdot D_{Z_k}F_k(z, 0)\).
Let \(\Gamma _k\) denote the Hurwitz conditions for the characteristic polynomial of \(J_k'\). Then Lemma 3 allows to state hyperbolic attractivity \(\mathcal {M}_0 \mathrel {\triangleright }\dots \mathrel {\triangleright }\mathcal {M}_\ell \) as a first-order formula over the reals as follows:
On these grounds, any real decision procedure [14, 73, 80] provides an effective test for hyperbolic attractivity. However, our formulation (22) uses a quantifier alternation \(\exists \sigma \forall \varrho \) in its second part. We would like to use this in order to use SMT solving over a quantifier-free logic. Our next result allows a suitable first-order formulation without quantifier alternation. Its proof combines [40, Lemma 3] with our Lemma 3.
Proposition 4
(Effective Characterization of Hyperbolically Attractive \(\ell \)-Chains).Define \(A_1 = D_{z_{1}}{\widehat{f}}_{1}(z,0)\). For \(k \in \{2, \dots , m\}\) define

and note that  .
.
Let \(\ell \in \{1, \dots , m\}\). Then \(\mathcal {M}_0 \mathrel {\triangleright }\dots \mathrel {\triangleright }\mathcal {M}_\ell \) if and only if
-
(i)
\(\mathcal {M}_\ell \ne \varnothing \),
-
(ii)
For all \(z^* \in \mathcal {M}_{1}\) all eigenvalues of \(W_1(z^*)\), where \(W_1 = A_1\), have negative real parts,
-
(iii)
For all \(k \in \{2, \dots , \ell \}\) and all \(z^* \in \mathcal {M}_{k}\), \(A_{k-1}(z^*)\) is regular and all eigenvalues of \(W_k(z^*)\), where \(W_k = V_{k}-C_{k}A_{k-1}^{-1}B_{k}\), have negative real parts.
Proof
Assume \(\mathcal {M}_0 \mathrel {\triangleright }\dots \mathrel {\triangleright }\mathcal {M}_\ell \). By Lemma 3 we have \(\mathcal {M}_\ell \ne \varnothing \). For all \(z^* \in \mathcal {M}_1\), all eigenvalues of the Jacobian \(W_1(z^*)\) have negative real parts by the definition of hyperbolic attractivity. Let now \(k \in \{2, \dots , \ell \}\), \(z^* \in \mathcal {M}_k\), and define \(\mathrm {P}= {\text {diag}}(1, \dots , \varrho ^{k-2})\). Using Lemma 3 we fix \(0< \tau ^* < 1\) such that for all \(0< \varrho ^* < \tau ^*\) all eigenvalues of \(J'_{k-1}(\varrho ^*, z^*) = \mathrm {P}(\varrho ^*)A_{k-1}(z^*)\) have negative real parts. It follows that \(\mathrm {P}(\varrho ^*)A_{k-1}(z^*)\), \(\mathrm {P}(\varrho ^*)\), and \(A_{k-1}(z^*)\) are all regular. Next, consider

Using Lemma 3 once more, we find \(0< \sigma ^* < \tau ^*\) such that for all \(0< \varrho ^* < \sigma ^*\) also all eigenvalues of \(J'_k(\varrho ^*, z^*)\) have negative real parts. Now \(J_k'(\varrho ^*, z^*)\) satisfies condition (ii) of [40, Lemma 3] with \(\delta = \sigma ^*\) and \(\varepsilon = (\varrho ^*)^{k-1}\), which allows us to conclude that all eigenvalues of \((V_k - C_k(\mathrm {P}A_{k-1})^{-1}\mathrm {P}B_k)(\varrho ^*, z^*) = (V_k - C_kA_{k-1}^{-1}\mathrm {P}^{-1}\mathrm {P}B_k)(\varrho ^*, z^*) = W_k (z^*)\) have negative real parts as well.
Assume, vice versa, that (i)–(iii) hold. We use induction on k to show \(\mathcal {M}_0 \mathrel {\triangleright }\dots \mathrel {\triangleright }\mathcal {M}_k\) for \(1 \le k \le \ell \). For \(k=1\) we have \(\mathcal {M}_0 \mathrel {\triangleright }\mathcal {M}_1\) by definition of hyperbolic attractivity. Assume that \(2 \le k \le \ell \) and \(\mathcal {M}_0 \mathrel {\triangleright }\dots \mathrel {\triangleright }\mathcal {M}_{k-1}\). By Lemma 3 there exists \(0 < \tau ^*\) such that for all \(0< \sigma ^* < \tau ^*\) and all \(z^* \in \mathcal {M}_{k-1}\) all eigenvalues of \(\mathrm {P}(\sigma ^*) A_{k-1}(z^*)\) have negative real parts, where \(\mathrm {P}= {\text {diag}}(1, \dots , (\sigma ^*)^{k-2})\). We rewrite \(W_{k} = V_{k}-C_{k}(\mathrm {P}A_{k-1})^{-1} \mathrm {P}B_{k}\). Then \(W_k(z^*)\) satisfies condition (i) of [40, Lemma 3] with \(A=\mathrm {P}(\sigma ^*) A_{k-1}(z^*)\), \(B=\mathrm {P}(\sigma ^*) B_k(z^*)\), \(C=C_k(z^*)\) and \(D=V_k(z^*)\). Thus there exists \(0 < \delta \) such that for all \(0< \varepsilon < \delta \) all eigenvalues of

have negative real parts. Choosing \(\varrho ^* = \min \{\sigma ^*, \root k-1 \of {\varepsilon }\}\) in Lemma 3 yields \(\mathcal {M}_0 \mathrel {\triangleright }\dots \mathrel {\triangleright }\mathcal {M}_k\). \(\square \)
From now on let \(\Gamma _k\) denote the Hurwitz conditions for the characteristic polynomial of \(W_k\), which—in contrast to the ones used in (22)—do not depend on \(\varrho \) anymore.
Corollary 5
(Logic-Based Test for Hyperbolically Attractive \(\ell \)-Chains). For \(k \in \{1, \dots , m\}\) define
Let \(\ell \in \{1, \dots , m\}\). Then \(\mathcal {M}_0 \mathrel {\triangleright }\dots \mathrel {\triangleright }\mathcal {M}_\ell \) if and only if \(\mathbb {R}\models \varphi _\ell \wedge \bigwedge _{k=1}^\ell \psi _k\).
Proof
Assume \(\mathcal {M}_0 \mathrel {\triangleright }\dots \mathrel {\triangleright }\mathcal {M}_\ell \). Then Proposition 4 yields its conditions (i)–(iii). Now, \(\varphi _\ell \) holds as a formalization of (i). Furthermore, \(\psi _1\) holds as a formalization of (ii), and the validity of \(\psi _2\), ..., \(\psi _\ell \) follows directly from (iii). Hence \(\mathbb {R}\models \varphi _\ell \wedge \bigwedge _{k=1}^\ell \psi _k\).
Assume, vice versa, that \(\mathbb {R}\models \varphi _\ell \wedge \bigwedge _{k=1}^\ell \psi _k\). We show \(\mathcal {M}_0 \mathrel {\triangleright }\dots \mathrel {\triangleright }\mathcal {M}_\ell \) by induction on \(\ell \). If \(\ell = 1\), then \(\varphi _1\) formalizes (i) and \(\psi _1\) formalizes (ii) in Proposition 4, and we obtain \(\mathcal {M}_0 \mathrel {\triangleright }\mathcal {M}_1\). Let now \(\ell > 1\). Then \(\varphi _\ell \) formalizes Proposition 4 (i). Our induction hypothesis yields \(\mathcal {M}_0 \mathrel {\triangleright }\dots \mathrel {\triangleright }\mathcal {M}_{\ell -1}\). By Lemma 3 there exists \(0 < \tau ^*\) such that for all \(0< \sigma ^* < \tau ^*\) and all \(z^* \in \mathcal {M}_{\ell -1} \supseteq \mathcal {M}_\ell \) all eigenvalues of \(\mathrm {P}(\sigma ^*) A_{\ell -1}(z^*)\), where \(\mathrm {P}= {\text {diag}}(1, \dots , (\sigma ^*)^{\ell -2})\), have negative real parts. In particular, \(\mathrm {P}(\sigma ^*) A_{\ell -1}(z^*)\) is regular and so is \(A_{\ell -1}(z^*)\). Furthermore, the Hurwitz conditions in \(\psi _\ell \) guarantee for all \(z^*\in \mathcal {M}_\ell \) that all eigenvalues of \(W_\ell (z^*)\) have negative real parts. Taking these observations together, Proposition 4 (iii) is satisfied, hence \(\mathcal {M}_0 \mathrel {\triangleright }\dots \mathrel {\triangleright }\mathcal {M}_\ell \). \(\square \)
In contrast to (22), our first-order characterization
in Corollary 5 has no quantifier alternation. Note that the two top-level components of (23) establish two independent decision problems, addressing non-emptiness of the manifold and our requirement on the eigenvalues, respectively.
It is easy to see that for all \(\ell \in \{1, \dots , m\}\) and all \(k \in \{1, \dots , \ell -1\}\), \(\varphi _\ell \) entails \(\varphi _k\). Thus (23) can be equivalently rewritten as \(\textstyle \bigwedge _{k=1}^\ell (\varphi _k \wedge \psi _k)\), explicitly:
Our approach tests the conjunction in (24) using a for-loop over k in Algorithm 5. Technically, this construction ensures with the test for \(\mathcal {M}_{k-1} \mathrel {\triangleright }\mathcal {M}_k\) in Algorithm 6

that \(\mathcal {M}_0 \mathrel {\triangleright }\cdots \mathrel {\triangleright }\mathcal {M}_{k-1}\) already holds, and exploits the fact that \(\psi _k\) and \(\varphi _k\) do not refer to smaller indices than k.
In l.1–3 we test the validity of \(\varphi _k\). Using from the input the defining inequalities and equations \(M = U \circ M_k\) of \(\mathcal {M}_{k}\) along with \(Z=Z_{k-1}\), \(z=z_k\), \(F=F_{k-1}\), \(f=f_k\), and \(A=A_{k-1}\), we construct in l.4–13\(A'=A_k\) as noted in Proposition 4. In l.14–19 we construct the Hurwitz conditions \(\Gamma =\Gamma _k\) according to Theorem 2. On the grounds of the validity of \(\varphi _k\) tested in l.1, we finally test in l.20 the validity of \(\psi _k\) and return a corresponding Boolean value. We additionally return \(A'=A_{k}\) for reuse with the next iteration. The validity tests for \(\varphi _k\) and \(\psi _k\) in l.1 and l.20, respectively, again amount to SMT solving, this time using the logic QF_NRA [2] for quantifier-free nonlinear real arithmetic. Recall the positive integer parameter p used for the precision with both Algorithm 2 and Algorithm 3. For \(p > 1\) symbolic computation possibly yields fractional powers of numbers in the defining equations for manifolds as well as in the vector fields of the differential equations. Such expressions are not covered by QF_NRA. When this happens, we catch the corresponding error from the SMT solver and restart with floats.
3.3 Sufficient Smoothness Criteria
Let us get back to the requirement in Sect. 3.1 that \({\widehat{g}}_1\), ..., \({\widehat{g}}_\ell \) and \(\eta _{\ell +1}{\widehat{g}}_{\ell +1} \), ..., \(\eta _m{\widehat{g}}_m\) occurring on the right hand sides of system (16) are all smooth on an open neighborhood of \(\mathcal {U}\times [0,\vartheta _1) \times \cdots \times [0,\vartheta _{\ell -1})\) with \(\vartheta _1>0\), ..., \(\vartheta _{\ell -1}>0\). A first sufficient criterion for smoothness is that all those expressions are polynomials in z and \({\bar{\delta }}\).
Recall the definitions of \({\widehat{g}}_k\) for \(k \in \{1, \dots , m\}\) in (14) and of \(\eta _k\) for \(k \in \{\ell +1, \dots , m\}\) in (15). For \(k \in \{1, \dots , m\}\) and \(j \in \{1, \dots , w_k\}\) one finds nonnegative \(r_1\), ..., \(r_{\ell -1} \in \mathbb {Q}\) such that
and for \(k \in \{\ell + 1, \dots , m\}\) one finds nonnegative \(r_1\), ..., \(r_{\ell -1} \in \mathbb {Q}\) such that
Such representations always exist but are not unique in general. If one even finds suitable nonnegative integers \(r_1\), ..., \(r_{\ell -1} \in \mathbb {N}\), which do not always exist, then one obtains \({\widehat{g}}_1\), ..., \({\widehat{g}}_m\) as polynomials in z and \({\bar{\delta }}\), and \(\eta _{\ell +1}\), ..., \(\eta _{m}\) as polynomials in \({\bar{\delta }}\), which is sufficient for our first criterion above.
An improved but still only sufficient criterion uses similar constructions to directly verify the existence of polynomial representations of the products \(\eta _{\ell +1}{\widehat{g}}_{\ell +1} \), ..., \(\eta _m{\widehat{g}}_m\), in contrast to considering the factors independently. From an algorithmic point of view, we furthermore have to take into account that \(P_1\), ..., \(P_m\) obtained in Algorithm 1 do not contain \(b_{k,j}'\) but \(b_k + b_{k,j}'\). For \(k \in \{1, \dots , \ell \}\) and \(j \in \{1, \dots , w_k\}\) we try to find \(r_1\), ..., \(r_{\ell -1} \in \mathbb {N}\) such that
and for \(k \in \{\ell + 1, \dots , m\}\) we try to find \(r_1\), ..., \(r_{\ell -1} \in \mathbb {N}\) such that
Notably, such representations exist whenever \(1 \in \{\beta _1, \dots , \beta _{\ell -1}\}\).
On these grounds, we introduce Algorithm 7,

which specifies the sufficient test applied in l.21 of Algorithm 5. The first two parameters \([T_1, \dots , T_m]\) and \([P_1, \dots , P_m]\) originate from Algorithm 1, while the last parameter \(\ell \) originates from the calling Algorithm 5.
In l.1–8 of Algorithm 7 we compute \(\beta _1\), ..., \(\beta _{\ell -1}\) as defined in (13) and simultaneously obtain \(b_1\), ..., \(b_\ell \). In l.9–14 we compute the right hand sides of the conditions in (25) or (26), depending on the current index k. For checking those conditions in l.16 we once more employ SMT solving, this time using the adequate logic QF_LIA [2] for quantifier-free linear integer arithmetic. Since we are aiming at nonnegative integer solutions, we introduce explicit non-negativity conditions \(r_1 \ge 0\), ..., \(r_{\ell -1} \ge 0\). In case of unsatisfiability Algorithm 7 returns “failed” in l.17. Recall that is this case the calling Algorithm 5 issues a warning but continues. In case of satisfiability, in contrast, smoothness is guaranteed, we reach l.20, and return “true.” We remark that the computation time spent on E is negligible compared to the SMT solving later on. The construction of the entire set E beforehand avoids duplicate SMT instances.
4 Algebraic Simplification of Reduced Systems
In the output \((M_0, T_1, R_1)\), ..., \((M_{\ell -1}, T_\ell , R_\ell )\) of Algorithm 5, the \(T_k\) are taken literally from the input, and the \(M_{k-1}\) and \(R_k\) are obtained via quite straightforward rewriting of the input. As a matter of fact, the computationally hard part of Algorithm 5 consists in the computation of the upper index \(\ell \). We now want to rewrite the triplets \((M_{k-1}, T_k, R_k)\) once more, aiming at less straightforward but simpler and, hopefully, more intuitive representations. The principal idea is to heuristically eliminate on the right hand side of the differential equations in \(T_k\) those variables whose derivatives have already occurred as left hand sides in one of the \(T_1\), ..., \(T_{k-1}\). Of course, our simplifications will preserve all relevant properties of \((M_0, T_1, R_1)\), ..., \((M_{\ell -1}, T_\ell , R_\ell )\), such as hyperbolic attractivity and sufficient differentiability. Technically, our next Algorithm 8

employs Gröbner basis techniques [3, 10].
Recall that \(z_k\) are the variables occurring on the left hand sides of differential equations in \(T_k\), and \(Z_{k-1} = (z_1, \dots , z_{k-1})\). In l.1–5 we construct a block term order \(\omega \) on all variables \(\{x_1, \dots , x_n\}\) so that variables from \(Z_{k-1}\) are larger than variables from \(z_k\). This ensures that all multivariate polynomial reductions with respect to \(\omega \) throughout our algorithm will eliminate variables from \(Z_{k-1}\) in favor of variables from \(z_k\) rather than vice versa. Prominent examples for such block orders are pure lexicographic orders, but ordering by total degree inside the \(z_1\), ..., \(z_\ell \), y will heuristically give more efficient computations.
Recall that the radical ideal \(\sqrt{\langle F \rangle }\) is the infinite set of all polynomials with the same common complex roots as F. In l.8, we compute a finite reduced Gröbner basis G with respect to \(\omega \) of that radical. If radical computation is not available on the software side, then the algorithm remains correct with a Gröbner basis of the ideal \(\langle F \rangle \) instead of the radical ideal, but might miss some simplifications.
In l.9, the polynomials in G equivalently replace the left hand side polynomials of the equations in \(M_{k-1}\). In l.12, reduction with respect to \(\omega \), which comes with heuristic elimination of variables, applies once more to the reduction results h obtained from right hand sides g of differential equations in \(T_k\). Since G is a Gröbner basis, the reduction in l.11–13 furthermore produces unique normal forms with the following property: if two polynomials \(g_1\), \(g_2\) coincide on the manifold \(\mathcal {M}_{k-1}\) defined by \(M_{k-1}\), then they reduce to the same normal form h. In particular, if \(g_1\) vanishes on \(\mathcal {M}_{k-1}\), then it reduces to 0. We call the output of Algorithm 8 simplified reduced systems.
5 Back-Transformation of Reduced Systems
Let \(\ell \in \{2, \dots , m\}\) and \(k \in \{1, \dots , \ell \}\). Recall that a triplet \((M_{k-1}, T_k, R_k)\) obtained from Algorithm 5 describes a reduced system according to (21):
A corresponding simplified system \((M_{k-1}', T_k', R_k)\) can be obtained from Algorithm 8 via an equivalence transformation on the set of equations \(M_{k-1}\) and further equivalence transformations modulo \(M_{k-1}\) on the right hand sides of the differential equations in \(T_k\), while the left hand sides of those differential equations remain untouched. It is not hard to see that for both these outputs scaling can be reversed using the substitution
obtained with Algorithm 1.
Using names \(M_{k-1}\), \(T_k\), \(R_k\) as in the unsimplified system, this yields a raw back-transformation \((M_{k-1}\sigma , T_k\sigma , R_k\sigma )\). We define \(M_{k-1}^* = M_{k-1}\sigma \). The system \(T_k\sigma \) can be written as
We multiply by \(\varepsilon _*^{\mu +d_j}\) in order to arrive at differential equations in \(\frac{{\text {d}}\!{y_j}}{{\text {d}}\!{t}}\). Furthermore, recall that the explicit factor \(\delta ^{b_k}\) in the original \(T_k\) corresponds to a time scale \(\delta ^{b_k}\tau \). The corresponding time scale in t is given by \((\delta ^{b_k} \tau )\sigma = \varepsilon _*^{b_k/q+\mu } t\), which we make explicit by equivalently rewriting \(T_k\sigma \) as \(T_k^*\) as follows:
Similarly, \(R_k\sigma \) can be rewritten as \(R_k^*\) as follows:
Recall that \(M_{k-1}\) describes a manifolds \(\mathcal {M}_{k-1}\) over the positive first orthant \(\mathcal {U}\), which is defined by inequalities \(U = \{ x_1>0, \dots , x_n>0 \}\) not explicit in \(M_{k-1}\). Following our construction above, this translates into \(U\sigma = \{ y_1/\varepsilon _*^{d_1}> 0, \dots , y_n/\varepsilon _*^{d_n} > 0 \}\), which describes again the positive first orthant. Furthermore, the nestedness (19) is preserved:
Finally, the system \((T_k^*,R_k^*)\) defines differential equations on \(\mathcal {M}_{k-1}^*\).
We call \((M_0^*, T_1^*, R_1^*)\), ..., \((M_{\ell -1}^*, T_\ell ^*, R_\ell ^*)\) back-transformed reduced systems. In terms of the definitions after (9) in Sect. 2.1 we have reverted the scaling but not the partitioning and not the truncating. Furthermore, we have preserved all information obtained with the computation of the reduced systems in Sect. 3, where we keep the time scale factors explicit, and with their algebraic simplification in Sect. 4.
Our back-transformation is realized in Algorithm 9. In l.3 we compute the time scale factor \(\varepsilon _*^{(b_k/q) + \mu }\) for \(T_k^*\) as described above, and in l.6 we compute its co-factor \(\varepsilon _*^{d_j} f\sigma \) as \((y_jf/x_j)\sigma \).

6 The Big Picture
Let us discuss what has been gained in \((M_0^*, T_1^*, R_1^*)\), ..., \((M_{\ell -1}^*, T_{\ell }^*, R_{\ell }^*)\) for our original system S in (1). We are faced with a discrepancy. On the one hand, we fix \(\varepsilon = \varepsilon _*\). On the other hand, the requirement that \({\bar{\delta }}\) be sufficiently small in Theorem 1 entails that \(\varepsilon \) be sufficiently small. It is of crucial importance whether invariant manifolds of (3), which do exist for sufficiently small \(\varepsilon \), persist at \(\varepsilon =\varepsilon _*\). We are not aware of any algorithmic results addressing this question. In particular, singular perturbation theory is typically concerned with asymptotic results, which are not helpful here.
In case of persistence, there exist nested invariant manifolds \(\mathcal {N}_{k-1}^*\) which are Hausdorff-close to \(\mathcal {M}_{k-1}^*\) for system (1). Moreover, the differential equations \(T_k^*\) associated with \(\mathcal {M}_{k-1}^*\) correspond to the kth level in a hierarchy of time scales and approximate the flow on \(\mathcal {N}_{k-1}^*\). We have achieved a decomposition of (1) into \(\ell \) systems of smaller dimension. At the very least, one obtains a well-educated guess about possible candidates for invariant manifolds and reductions. For the investigation of those candidates one may check the \(\mathcal {N}_k^*\) for approximate invariance using, e.g., numerical methods, or by applying criteria proposed in [56].
Algorithm 10 provides a wrapper combining all our algorithms to decompose input systems like (1) into several time scales. The underlying tropicalization is not made explicit, and the result is presented on the original scale. Figure 1 explains the functional dependencies and principal data flow between our algorithms graphically.


Functional dependencies (thin arrows) and principal data flow (thick arrows) between our algorithms
7 Computational Examples
Based on our explicit algorithms in the present work, we have developed two independent software prototypes realizing all methods described here. The first one is in Python using SymPy [49] for symbolic computation, pySMT [28] as an interface to the SMT solver MathSAT5 [13], and SMTcut for the computation of tropical equilibrations [48]. The second one is a Maple package, which makes use of Maple’s built-in SMTLIB package [26] for using the SMT solver Z3 [51]. For our computations here we have used our Python code. Computation results are identical with both systems, and timings are similar. We have conducted our computations on a standard desktop computer with a 3.3 GHz 6-core Intel 5820K CPU and 16 GB of main memory. Computation times listed are CPU times.
In the next section, we discuss in detail the computations for one specific biological input system from the BioModels database, a repository of mathematical models of biological processes [57]. The subsequent sections showcase several further such examples in a more concise style. The focus here is on biological results. For an illustration of our algorithms, we discuss in Appendix A examples where reduction stops at \(\ell < m\) for various reasons.
7.1 An Epidemic Model of Avian Influenza H5N6
We consider BioModel 716, which is related to the transmission dynamics of subtype H5N6 of the influenza A virus in the Philippines in August 2017 [42]. The model specifies four species: Susceptible birds (S_b), Infected birds (I_b), Susceptible humans (S_h), and Infected humans (I_a), the concentrations of which over time we map to differential variables \(y_1\), ..., \(y_4\), respectively. The input system is given by
We choose \(\varepsilon _* = \frac{1}{5}\), \(p = 1\), and Algorithm 3 non-deterministically selects \(D = (-1, -4, -7, -3)\) from the tropical equilibration. Algorithm 1 then yields the following scaled and truncated system with three time scales:
Notice that the lexicographic order of the differential variables is coincidence. From this input, Algorithm 5 produces the following reduced systems:

In that course, Algorithm 6 confirms hyperbolic attractivity according to Sect. 3.2 for all three scaled systems. Furthermore, Algorithm 7 applies the sufficient smoothness test from Sect. 3.3 with
This yields \(E = \{ 4 \}\), where 4 cannot be expressed as an integer multiple of 3. Thus the test fails, which causes a warning in Algorithm 5.
Algebraic simplification through Algorithm 8 yields the simplified reduced systems

Notice that our implementations conveniently rewrite equational constraints as monomial equations with numerical right hand sides when possible. This supports readability but is not essential for the simplifications applied here, which are based on Gröbner basis theory. Comparing \(T_2'\) with \(T_2\), we see that the equation for \(x_1x_2\) in \(M_1'\) is plugged in. Similarly, \(M_2\) is simplified to \(M_2'\), which is in turn used to reduce \(T_3\) to \(T_3'\).
The back-transformed reduced systems as computed by Algorithm 9 read as follows:

We compare \(T_1^*\), ..., \(T_3^*\) to the input system S: In the equation for \(\frac{{\text {d}}\!{}}{{\text {d}}\!{t}}y_1\), the monomial in \(y_1\) is identified as a higher order term with respect to \(\delta \) and discarded by Algorithm 1. In the equation for \(\frac{{\text {d}}\!{}}{{\text {d}}\!{t}}y_2\), the monomial in \(y_1 y_2\) has been Gröbner-reduced to a constant modulo the defining equation in \(M_1'\). Similarly, the equation for \(\frac{{\text {d}}\!{}}{{\text {d}}\!{t}}y_3\) loses its monomial in \(y_2 y_3\) by truncation of higher order terms, and in the equation for \(\frac{{\text {d}}\!{}}{{\text {d}}\!{t}}y_4\), the monomial in \(y_2 y_3\) is Gröbner-reduced to a monomial in \(y_3\).
Notice the explicit constant factors on the right hand sides of the differential equations in \(T_1^*\), ..., \(T_3^*\). They originate from factors \(\delta ^{b_k}\) in the respective scaled systems \(T_1\), ..., \(T_3\), corresponding to (8). They are left explicit to make the time scale of the differential equations apparent. We see that the system \(T_2^* \circ R_2^*\) is 125 times slower than \(T_1^* \circ R_1^*\), and \(T_3^* \circ R_3^*\) is another 125 times slower.
Figure 2 visualizes the direction fields of \(T_1^* \circ R_1^*\), ..., \(T_3^* \circ R_3^*\) on their respective manifolds \(\mathcal {M}_0^*\), ..., \(\mathcal {M}_2^*\) along with their respective critical manifolds \(\mathcal {M}_1^*\), ..., \(\mathcal {M}_3^*\), where \(\mathcal {M}_3^*\) can be derived from \(\mathcal {M}_2^*\) by additionally equating the vector field of \(T_3^* \circ R_3^*\) to zero:
This list \(M_3^*\) does not explicitly occur in the output. However, its preimage \(M_3\) is constructed in Algorithm 5 and justifies the presence of \((M_2, T_3, R_3)\) in the output there. The total computation time was 0.906 s.

Critical manifolds and direction fields of our reductions of BioModel 716. (a) The surface is the critical manifold \(\mathcal {M}_1^* \subseteq \mathcal {M}_0^* = \mathcal {U}\) projected from \(\mathbb {R}^4\) into real \((y_1, y_2, y_3)\)-space. The line located at \((y_1, y_2) \approx (1.4, 1166.8)\) is the critical submanifold \(\mathcal {M}_2^* \subseteq \mathcal {M}_1^*\). The dot located at \((y_1, y_2, y_3) \approx (1.4, 1166.8, 282049.2)\) is the critical submanifold \(\mathcal {M}_3^* \subseteq \mathcal {M}_2^*\). Both \(\mathcal {M}_1^*\) and \(\mathcal {M}_2^*\) extend to \(\pm \infty \) in both \(y_3\) and \(y_4\) direction, and \(\mathcal {M}_3^*\) is located near (1.4, 1166.8, 282049.2, 1349.6). (b) The direction field of \(T_1^*\circ R_1^*\) on \(\mathcal {M}_0^*=\mathcal {U}\) projected from \(\mathbb {R}^4\) into real \((y_1, y_2)\)-space. The curve is the critical submanifold \(\mathcal {M}_1^* \subseteq \mathcal {M}_0^*\). (c) The direction field of \(T_2^*\circ R_2^*\) on \(\mathcal {M}_1^*\) projected from \(\mathbb {R}^4\) into real \((y_3, y_2)\)-space. The line is the critical submanifold \(\mathcal {M}_2^* \subseteq \mathcal {M}_1^*\). The system here is slower than the one in (b) by a factor of 125. (d) The direction field of \(T_3^*\circ R_3^*\) on \(\mathcal {M}_2^*\) projected from \(\mathbb {R}^4\) into real \((y_3, y_4)\)-space. The dot is the critical submanifold \(\mathcal {M}_3^* \subseteq \mathcal {M}_2^*\). The system here is slower than the one in (c) by another factor of 125
This multiple-time scale reduction of the bird flu model emphasizes a cascade of successive relaxations of model variables. First, the population of susceptible birds relaxes. This relaxation is illustrated in Fig. 2(b). Then, the population of infected birds relaxes as shown in Fig. 2(c). Finally, the populations of susceptible and infected humans relax to a stable steady state as shown in Fig. 2(d), following a reduced dynamics described by \(T_3^*\).
7.2 TGF-\(\beta \) Pathway
BioModel 101 is a simple representation of the TGF-\(\beta \) signaling pathway that plays a central role in tissue homeostasis and morphogenesis, as well as in numerous diseases such as fibrosis and cancer [76]. Concentrations over time of species Receptor 1 (RI), Receptor 2 (RII), Ligand receptor complex-plasma membrane (lRIRII), Ligand receptor complex-endosome (lRIRII_endo), Receptor 1 endosome (RI_endo), and Receptor 2 endosome (RII_endo), are mapped to differential variables \(y_1\), ..., \(y_6\), respectively. The original BioModel 101 has a change of ligand concentration at time \(t=2500\). For our computation here, we ignore this discrete event. The input system is given by
We choose \(\varepsilon _* = \frac{1}{5}\), \(p = 1\), and select \(D = (0, -4, -1, -2, -1, -5)\) from the tropical equilibrium. Our back-transformed reduced systems read as follows:

The total computation time was 0.906 s.
The multiple-time scale reduction of the TGF-\(\beta \) model emphasizes a cascade of successive relaxations of concentrations of different species. First, the concentration of receptor 1 relaxes rapidly. Then follows the membrane complex, and, even slower, the relaxation of receptor 2.
7.3 Caspase Activation Pathway
BioModel 102 is a quantitative kinetic model that examines the intrinsic pathway of caspase activation that is essential for apoptosis induction by various stimuli including cytotoxic stress [43]. Species concentrations over time are mapped to differential variables \(y_1\), ..., \(y_{13}\) as described in Table 1.
The input system is given by
We choose \(\varepsilon _* = \frac{1}{2}\), \(p = 1\), and select \(D = (-4, 2, 3, 5, 5, 4, -6, -8, -4, -2, -2, 0, 0)\) from the tropical equilibration. Our back-transformed reduced systems read as follows:

The total computation time was 8.547 s, of which Algorithm 4 took 6.188 s.
The multiple-time scale reduction of the caspase activation model emphasizes a cascade of successive relaxations. First, the inhibitor of apoptosis XIAP binds rapidly to the cleaved caspase. Then, the four APAF complexes are formed. Finally, the Caspase 9 is recruited to the apoptosome.
7.4 Avian Influenza Bird-to-Human Transmission
BioModel 709 describes bird-to-human transmission of different strains of avian influenza A viruses, such as H5N1 and H7N9 [47]. Species concentrations over time of Susceptible avians (S_a), Infected avians (I_a), Susceptible humans (S_h), Infected humans (I_h), and Recovered humans (R_h) are mapped to differential variables \(y_1\), ..., \(y_5\), respectively. The input system is given by
We choose \(\varepsilon _* = \frac{1}{5}\), \(p = 1\), and select \(D = (-7, 0, -8, 3, -2)\) from the tropical equilibration. Our back-transformed reduced systems read as follows:

The total computation time was 0.578 s.
The multiple-time scale reduction of this avian influenza model emphasizes a cascade of successive relaxations of different model variables. First, the susceptible bird population relaxes rapidly. The reduced equation \(T_1\) and manifold \(M_1\) suggest that the bird population dynamics is of the Allee type and evolves toward the stable extinct state. It follows the relaxation of infected human population that also evolves toward the extinct state, the end of the epidemics.
8 Some Remarks on Complexity
A detailed complexity analysis of our approach is beyond the scope of this article. We collect some remarks on the asymptotic worst-case complexity of various computational steps required by our algorithms:
-
(i)
The existential decision problem over real closed fields, for which we use SMT solving over QF_NRA in Algorithm 6;
-
(ii)
Linear programming, for which we used SMT solving over QF_LRA in Algorithm 3;
-
(iii)
Integer linear programming, for which we used SMT solving over QF_LIA in Algorithm 7.
Problem (i) is in single exponential time [32]. Problem (ii) is in polynomial [38] time. Problem (iii) is NP-complete; a proof can be found in [65, Theorem 18.1], where it is essentially attributed to [16]. With all these problems, the dominant complexity parameter is the number of variables, which in our context corresponds to the number n of differential variables. Biological models impose reasonable upper bounds on n, which corresponds to the number of species occurring there. When n is bounded, problem (i) becomes polynomial [32]. The same holds for problem (iii); a proof based on Lenstra’s algorithm [44] can be found in [65, Corollary 18.7a].
When characterizing the decision in l.2 of Algorithm 3 as linear programming in (ii) above, we tacitly assume that it is not applied to the tropical equilibration \(\Pi \) as a whole but to each contained polyhedron independently. The number of contained polyhedra is in turn exponential in n, in the worst case. The motivation for the computation of a disjunctive normal form in Algorithm 4 is to support the choice of a suitable point \((d_1, \dots , d_n)\) in Algorithm 3 by providing information on the geometry of the tropical equilibration as a union of polyhedra. It is possible to omit this and accordingly drop the computation of the disjunctive normal form in l.23 of Algorithm 4 altogether. In that case, solving in l.2 of Algorithm 3 is applied to the formula \(\bigwedge \bigvee \bigwedge P\) instead of \(\Pi \). This is a linear decision problem over ordered fields, which is NP-complete [29], and solutions can be found in single exponential time [79].
Efficient implementations do not necessarily use theoretically optimal algorithms. At the time of writing, SMT solving and corresponding decision procedures are a very active field of research and thus subject to constant change. We deliberately refrain from going into details about the current state of the art at this point.
Beyond the examples and computation times discussed here, we currently have no systematic empirical data that would allow substantial statements on the practical performance and limits of our implementations.
9 Concluding Remarks
We provided a symbolic method for automated model reduction of biological networks described by ordinary differential equations with multiple time scales. Our method is applicable to systems with two time scales or more, superseding traditional slow-fast reduction methods that can cope with only two time scales. We also proposed, for the first time, the automatic verification of hyperbolicity conditions required for the validity of the reduction. Our theoretical framework is accompanied by rigorous algorithms and prototypical implementations, which we successfully applied to real-world problems from the BioModels database [57].
We would like to list some open points and possible extensions of our research here. Our reduction algorithm is based on a fixed scaling (8) leading to a fixed ordering of the time scales of different variables. In our reduction scheme, different variables relax hierarchically, first the fastest ones, then the second fastest, and finally the slowest ones, which justifies our geometric picture of nested invariant manifolds. However, there are situations, e.g. in models of relaxation oscillations, when the ordering of time scales changes with time: variables that were fast can become slow at a later time, and vice versa. In order to cope with such situations, one would like to use different scalings for different time segments. One attempt to implement such a procedure has been provided in [68].
Although our proposed method identifies the full hierarchy of time scales, the subsequent reduction may stop early in this hierarchy when hyperbolic attractivity is not satisfied at some stage. One possible reason is the presence of conservation laws, also known as first integrals, at the given reduction stage. Such conservation laws force an eigenvalue zero for the Jacobian. A theorem by Schneider and Wilhelm [64] can be employed to reduce such a setting to the hyperbolically attractive case. As for the behavior of first integrals when proceeding to the reduced system, see the discussion of the non-standard case in [41] for two time scales; an extension to multiple time scales should be straightforward. Work in progress is concerned with the introduction of new slow variables, one for each independent conservation law of the fast subsystem. This is applied to networks with multiple time scales and approximate linear and polynomial conservation laws.
More generally, it is of interest to consider cases when hyperbolic attractivity fails but hyperbolicity still holds: In such cases, Cardin and Teixeira show there still exist invariant manifolds [11]. Testing for hyperbolicity is more involved than testing for hyperbolic attractivity, but in theory it is well understood, and there exists an algorithmic approach due to Routh [27]. In the case of hyperbolicity, but not attractivity, the ensuing global dynamics may be quite interesting; for instance slow-fast cycles may appear.
Concerning differentiability requirements, we check in Sect. 3.3 for smoothness of the full system. However, Fenichel’s results, and in principle also those by Cardin and Teixeira, require only sufficient finite differentiability. Therefore, given a differential equation system and a scaling, invariant manifolds and corresponding reduced systems exist for \(C^p\) functions with fixed \(p<\infty \). Going through the details will involve intricate analysis that is left to future work.
In the introduction we sketched a Michaelis–Menten system abstracting from the known numerical values for the reaction rate constants \(k_1\), \(k_{-1}\), \(k_2\). It would be indeed interesting to work on such parametric data. In the presence of parameters, one would consider effective quantifier elimination over real closed fields [15, 20, 39, 69, 70, 80] as a generalization of SMT solving. Robust implementations are freely available [9, 19] and well supported. They have been successfully applied to problems in chemical reaction network theory during the past decade [7, 8, 21,22,23, 33, 67, 71, 72, 78]. Such a generalization is not quite straightforward. With the tropical scaling in Sect. 2.2, Algorithm 2 would introduce logarithms of polynomials in the parametric coefficients, which is not compatible with the logic framework used here. Similar tropicalization methods, which are unfortunately not compatible with our abstract view on scaling in Sect. 2.1, require only logarithms of individual parametric coefficients [63]. Such a more special form would allow the use of abstraction in the logic engine.
From a point of view of user-oriented software, it would be most desirable to develop automatic strategies for determining good values for \(\varepsilon _*\) and for choices of \((d_1, \dots , d_n)\) from the tropical equilibration in Algorithm 3.
References
Barrett, C., Conway, C.L., Deters, M., Hadarean, L., Jovanović, D., King, T., Reynolds, A., Tinelli, C.: CVC4. In: Gopalakrishnan, G., Qadeer, S. (eds.) Proc. CAV 2011. LNCS, vol. 6806, pp. 171–177. Springer (2011). https://doi.org/10.1007/978-3-642-22110-1_14
Barrett, C., Fontaine, P., Tinelli, C.: The SMT-LIB standard: version 2.6. Technical report, Department of Computer Science, The University of Iowa (2017)
Becker, T., Weispfenning, V., Kredel, H.: Gröbner Bases, a Computational Approach to Commutative Algebra. Graduate Texts in Mathematics, vol. 141. Springer, Berlin (1993). https://doi.org/10.1007/978-1-4612-0913-3
Bogart, T., Nedergaard Jensen, A., Speyer, D., Sturmfels, B., Thomas, R.R.: Computing tropical varieties. J. Symb. Comput. 42(1–2), 54–73 (2007). https://doi.org/10.1016/j.jsc.2006.02.004
Boulier, F., Fages, F., Radulescu, O., Samal, S.S., Schuppert, A., Seiler, W.M., Sturm, T., Walcher, S., Weber, A.: The SYMBIONT project: symbolic methods for biological networks. F1000Research 7(1341), 67–70 (2018). https://doi.org/10.7490/f1000research.1115995.1
Boulier, F., Fages, F., Radulescu, O., Samal, S.S., Schuppert, A., Seiler, W.M., Sturm, T., Walcher, S., Weber, A.: The SYMBIONT project: symbolic methods for biological networks. ACM Commun. Comput. Algebra 52(3), 67–70 (2018). https://doi.org/10.1145/3313880.3313885
Bradford, R., Davenport, J.H., England, M., Errami, H., Gerdt, V., Grigoriev, D., Hoyt, C., Košta, M., Radulescu, O., Sturm, T., Weber, A.: A case study on the parametric occurrence of multiple steady states. In: Burr, M. (ed.) Proc. ISSAC 2017, pp. 45–52. ACM (2017), https://doi.org/10.1145/3087604.3087622
Bradford, R., Davenport, J.H., England, M., Errami, H., Gerdt, V., Grigoriev, D., Hoyt, C., Košta, M., Radulescu, O., Sturm, T., Weber, A.: Identifying the parametric occurrence of multiple steady states for some biological networks. J. Symb. Comput. 98, 84–119 (2020). https://doi.org/10.1016/j.jsc.2019.07.008
Brown, C.W.: QEPCAD B: a program for computing with semi-algebraic sets using CADs. ACM SIGSAM Bull. 37(4), 97–108 (2003). https://doi.org/10.1145/968708.968710
Buchberger, B.: Ein Algorithmus zum Auffinden der Basiselemente des Restklassenringes nach einem nulldimensionalen Polynomideal. Doctoral dissertation, Mathematical Institute, University of Innsbruck, Innsbruck, Austria (1965)
Cardin, P.T., Teixeira, M.A.: Fenichel theory for multiple time scale singular perturbation problems. SIAM J. Appl. Dyn. Syst. 16(3), 1425–1452 (2017). https://doi.org/10.1137/16m1067202
Cardin, P.T., Teixeira, M.A.: Corrigendum: Fenichel theory for multiple time scale singular perturbation problems. SIAM J. Appl. Dyn. Syst. 18(2), 1223 (2019). https://doi.org/10.1137/19M1241660
Cimatti, A., Griggio, A., Schaafsma, B., Sebastiani, R.: The MathSAT5 SMT solver. In: Piterman, N., Smolka, S.A. (eds.) Proc. TACAS 2013. LNCS, vol. 7795, pp. 93–107. Springer (2013). https://doi.org/10.1007/978-3-642-36742-7_7
Collins, G.E.: Quantifier elimination for the elementary theory of real closed fields by cylindrical algebraic decomposition. In: Brakhage, H. (ed.) Automata Theory and Formal Languages. 2nd GI Conference. LNCS, vol. 33, pp. 134–183. Springer (1975). https://doi.org/10.1007/3-540-07407-4_17
Collins, G.E., Hong, H.: Partial cylindrical algebraic decomposition for quantifier elimination. J. Symb. Comput. 12(3), 299–328 (1991). https://doi.org/10.1016/S0747-7171(08)80152-6
Cook, S.A.: The complexity of theorem-proving procedures. In: Proc. STOC ’71, pp. 151–158. ACM Press, New York, NY (1971). https://doi.org/10.1145/800157.805047
Corzilius, F., Kremer, G., Junges, S., Schupp, S., Ábrahám, E.: SMT-RAT: an open source C++ toolbox for strategic and parallel SMT solving. In: Heule, M., Weaver, S. (eds.) Proc. SAT 2015. LNCS, vol. 9340, pp. 360–368. Springer (2015). https://doi.org/10.1007/978-3-319-24318-4_26
Curry, H.B., Feys, R.: Combinatory Logic. Studies in Logic and the Foundations of Mathematics, vol. I. North Holland Publishing Company, Amsterdam (1958)
Dolzmann, A., Sturm, T.: Redlog: computer algebra meets computer logic. ACM SIGSAM Bull. 31(2), 2–9 (1997). https://doi.org/10.1145/261320.261324
Dolzmann, A., Sturm, T., Weispfenning, V.: Real quantifier elimination in practice. In: Matzat, B.H., Greuel, G.-M., Hiss, G. (eds.) Algorithmic Algebra and Number Theory, pp. 221–247. Springer, Berlin (1998). https://doi.org/10.1007/978-3-642-59932-3_11
England, M., Errami, H., Grigoriev, D., Radulescu, O., Sturm, T., Weber, A.: Symbolic versus numerical computation and visualization of parameter regions for multistationarity of biological networks. In: Gerdt, V., Koepf, W., Seiler, W., Vorozhtsov, E. (eds.) Proc. CASC 2017. LNCS, vol. 10490, pp. 93–108. Springer (2017). https://doi.org/10.1007/978-3-319-66320-3_8
Errami, H., Eiswirth, M., Grigoriev, D., Seiler, W.M., Sturm, T., Weber, A.: Detection of Hopf bifurcations in chemical reaction networks using convex coordinates. J. Comput. Phys. 291, 279–302 (2015). https://doi.org/10.1016/j.jcp.2015.02.050
Errami, H., Seiler, W.M., Sturm, T., Weber, A.: On Muldowney’s criteria for polynomial vector fields with constraints. In: Gerdt, V.P., Koepf, W., Mayr, E.W., Vorozhtsov, E.V. (eds.) Proc. CASC 2011. LNCS, vol. 6885, pp. 135–143. Springer (2011). https://doi.org/10.1007/978-3-642-23568-9_11
Feinberg, M.: Foundations of Chemical Reaction Network Theory. Applied Mathematical Sciences, vol. 202. Springer, Berlin (2019). https://doi.org/10.1007/978-3-030-03858-8
Fenichel, N.: Geometric singular perturbation theory for ordinary differential equations. J. Differ. Equ. 31(1), 53–98 (1979). https://doi.org/10.1016/0022-0396(79)90152-9
Forrest, S.: Integration of SMT-LIB support into Maple. In: England, M., Ganesh, V. (eds.) Proc. Satisfiability Checking and Symbolic Computation 2017. CEUR Workshop Proceedings, vol. 1974. CEUR-WS, Kaiserslautern, Germany (2017)
Gantmacher, F.R.: The Theory of Matrices. Vol. 2. Translation from the Russian by K. A. Hirsch. Reprint of the 1959 translation edition. AMS Chelsea Publishing, Providence, RI (1998)
Gario, M., Micheli, A.: PySMT: a solver-agnostic library for fast prototyping of SMT-based algorithms. In: SMT Workshop 2015. 13th International Workshop on Satisfiability Modulo Theories, Affiliated With the 27th International Conference on Computer Aided Verification, San Francisco, CA (2015)
von zur Gathen, J., Sieveking, M.: Weitere zum Erfüllungsproblem polynomial äquivalente kombinatorische Aufgaben. In: Strassen, V. (ed.) Komplexität von Entscheidungsproblemen. LNCS, vol. 43, chapter 4, pp. 49–71. Springer (1976). https://doi.org/10.1007/3-540-07805-3_5
Geva-Zatorsky, N., Rosenfeld, N., Itzkovitz, S., Milo, R., Sigal, A., Dekel, E., Yarnitzky, T., Liron, Y., Polak, P., Lahav, G., Alon, U.: Oscillations and variability in the p53 system. Mol. Syst. Biol. 2(1), 2006–0033 (2006). https://doi.org/10.1038/msb4100068
Goeke, A., Walcher, S., Zerz, E.: Determining “small parameters” for quasi-steady state. J. Differ. Equ. 259(3), 1149–1180 (2015). https://doi.org/10.1016/j.jde.2015.02.038
Grigoriev, D.: Complexity of deciding Tarski algebra. J. Symb. Comput. 5(1–2), 65–108 (1988). https://doi.org/10.1016/S0747-7171(88)80006-3
Grigoriev, D., Iosif, A., Rahkooy, H., Sturm, T., Weber, A.: Efficiently and effectively recognizing toricity of steady state varieties. Math. Comput. Sci. 15(2), 199–232 (2021). https://doi.org/10.1007/s11786-020-00479-9
Heineken, F.G., Tsuchiya, H.M., Aris, R.: On the mathematical status of the pseudo-steady state hypothesis of biochemical kinetics. Math. Biosci. 1(1), 95–113 (1967). https://doi.org/10.1016/0025-5564(67)90029-6
Hoppensteadt, F.: On systems of ordinary differential equations with several parameters multiplying the derivatives. J. Differ. Equ. 5(1), 106–116 (1969). https://doi.org/10.1016/0022-0396(69)90106-5
Hurwitz, A.: Ueber die Bedingungen, unter welchen eine Gleichung nur Wurzeln mit negativen reellen Theilen besitzt. Math. Ann. 46, 273–284 (1895). https://doi.org/10.1007/BF01446812
IEEE Std. 754-2019: IEEE Standard for Floating-Point Arithmetic (2019). https://doi.org/10.1109/IEEESTD.2019.8766229
Khachiyan, L.G.: A polynomial algorithm in linear programming. Soviet Math. Dokl. 20(1), 191–194 (1979)
Košta, M.: New concepts for real quantifier elimination by virtual substitution. Doctoral dissertation. Saarland University, Germany (2016). https://doi.org/10.22028/D291-26679
Kruff, N., Walcher, S.: Coordinate-independent singular perturbation reduction for systems with three time scales. Math. Biosci. Eng. 16(5), 5062–5091 (2019). https://doi.org/10.3934/mbe.2019255
Lax, C., Walcher, S.: Singular perturbations and scaling. Discrete Cont. Dyn.-B 25(1), 1–29 (2020). https://doi.org/10.3934/dcdsb.2019170
Lee, H., Lao, A.: Transmission dynamics and control strategies assessment of avian influenza A (H5N6) in the Philippines. Infect. Dis. Model. 3, 35–59 (2018). https://doi.org/10.1016/j.idm.2018.03.004
Legewie, S., Blüthgen, N., Herzel, H.: Mathematical modeling identifies inhibitors of apoptosis as mediators of positive feedback and bistability. PLoS Comput. Biol. 2(9), e120 (2006). https://doi.org/10.1371/journal.pcbi.0020120
Lenstra Jr., H.W.: Integer programming with a fixed number of variables. Math. Oper. Res. 8(4), 538–548 (1983). https://doi.org/10.1287/moor.8.4.538
Litvinov, G.L.: Maslov dequantization, idempotent and tropical mathematics: a brief introduction. J. Math. Sci. 140(3), 426–444 (2007). https://doi.org/10.1007/s10958-007-0450-5
Litvinov, G.L., Sergeev, S.N.: Tropical and Idempotent Mathematics: International Workshop TROPICAL-07, Tropical and Idempotent Mathematics, August 25–30, 2007, Independent University of Moscow and Laboratory J.-V. Poncelet. Contemporary Mathematics, vol. 495. AMS (2009)
Liu, S., Ruan, S., Zhang, X.: Nonlinear dynamics of avian influenza epidemic models. Math. Biosci. 283, 118–135 (2017). https://doi.org/10.1016/j.mbs.2016.11.014
Lüders, C.: Computing tropical prevarieties with satisfiability modulo theories (SMT) solvers. In: Fontaine, P., Korovin, K., Kotsireas, I.S., Rümmer, P., Tourret, S. (eds.) Proc. SC-Square 2020, Co-Located With IJCAR 2020. CEUR Workshop Proceedings, vol. 2752, pp. 189–203. CEUR-WS, June–July (2020)
Meurer, A., Smith, C.P., Paprocki, M., Čertík, O., Kirpichev, S.B., Rocklin, M., Kumar, A., Ivanov, S., Moore, J.K., Singh, S., Rathnayake, T., Vig, S., Granger, B.E., Muller, R.P., Bonazzi, F., Gupta, H., Vats, S., Johansson, F., Pedregosa, F., Curry, M.J., Terrel, A.R., Roučka, Š., Saboo, A., Fernando, I., Kulal, S., Cimrman, R., Scopatz, A.: SymPy: symbolic computing in Python. PeerJ Comput. Sci. 3, e103 (2017). https://doi.org/10.7717/peerj-cs.103
Mikhalkin, G.: Enumerative tropical algebraic geometry in \(\mathbb{R}^2\). J. Am. Math. Soc. 18(2), 313–377 (2005). https://doi.org/10.1090/S0894-0347-05-00477-7
de Moura, L., Bjørner, N.: Z3: an efficient SMT solver. In: Ramakrishnan, C.R., Rehof, J. (eds.) Proc. TACAS 2008. LNCS, vol. 4963, pp. 337–340. Springer (2008). https://doi.org/10.1007/978-3-540-78800-3_24
Nieuwenhuis, R., Oliveras, A., Tinelli, C.: Solving SAT and SAT modulo theories: from an abstract Davis-Putnam-Logemann-Loveland procedure to DPLL(T). J. ACM 53(6), 937–977 (2006). https://doi.org/10.1145/1217856.1217859
Nipp, K.: An algorithmic approach for solving singularly perturbed initial value problems. In: Kirchgraber, U., Walther, H. (eds.) Dynamics Reported, vol. 1, pp. 173–263. John Wiley & Sons and B. G. Teubner, Hoboken (1988), https://doi.org/10.1007/978-3-322-96656-8_4
Noel, V., Grigoriev, D., Vakulenko, S., Radulescu, O.: Tropical geometries and dynamics of biochemical networks application to hybrid cell cycle models. In: Feret, J., Levchenko, A. (eds.) Proc. SASB 2011. ENTCS, vol. 284, pp. 75–91. Elsevier, Amsterdam (2012), https://doi.org/10.1016/j.entcs.2012.05.016
Noel, V., Grigoriev, D., Vakulenko, S., Radulescu, O.: Tropicalization and tropical equilibration of chemical reactions. In: Litvinov, G.L., Sergeev, S.N. (eds.) Tropical and Idempotent Mathematics and Applications. Contemporary Mathematics, vol. 616, pp. 261–277. AMS, Providence (2014), https://doi.org/10.1090/conm/616/12316
Noethen, L., Walcher, S.: Quasi-steady state and nearly invariant sets. SIAM J. Appl. Math. 70(4), 1341–1363 (2009). https://doi.org/10.1137/090758180
Le Novère, N., Bornstein, B., Broicher, A., Courtot, M., Donizelli, M., Dharuri, H., Li, L., Sauro, H., Schilstra, M., Shapiro, B., Snoep, J.L., Hucka, M.: BioModels database: a free, centralized database of curated, published, quantitative kinetic models of biochemical and cellular systems. Nucleic Acids Res. 34(supp\_1), D689–D691 (2006). https://doi.org/10.1093/nar/gkj092
Radulescu, O., Gorban, A.N., Zinovyev, A., Noel, V.: Reduction of dynamical biochemical reactions networks in computational biology. Front. Genet. 3, 131 (2012). https://doi.org/10.3389/fgene.2012.00131
Radulescu, O., Vakulenko, S., Grigoriev, D.: Model reduction of biochemical reactions networks by tropical analysis methods. Math. Model. Nat. Phenom. 10(3), 124–138 (2015). https://doi.org/10.1051/mmnp/201510310
Reddyhoff, D., Ward, J., Williams, D., Regan, S., Webb, S.: Timescale analysis of a mathematical model of acetaminophen metabolism and toxicity. J. Theor. Biol. 386, 132–146 (2015). https://doi.org/10.1016/j.jtbi.2015.08.021
Ruan, S.: Modeling the transmission dynamics and control of rabies in China. Math. Biosci. 286, 65–93 (2017). https://doi.org/10.1016/j.mbs.2017.02.005
Samal, S.S., Grigoriev, D., Fröhlich, H., Radulescu, O.: Analysis of reaction network systems using tropical geometry. In: Gerdt, V., Koepf, W., Seiler, W., Vorozhtsov, E. (eds.) Proc. CASC 2015. LNCS, vol. 9301, pp. 424–439. Springer (2015), https://doi.org/10.1007/978-3-319-24021-3_31
Samal, S.S., Grigoriev, D., Fröhlich, H., Weber, A., Radulescu, O.: A geometric method for model reduction of biochemical networks with polynomial rate functions. Bull. Math. Biol. 77(12), 2180–2211 (2015). https://doi.org/10.1007/s11538-015-0118-0
Schneider, K.R., Wilhelm, T.: Model reduction by extended quasi-steady-state approximation. J. Math. Biol. 40(5), 443–450 (2000). https://doi.org/10.1007/s002850000026
Schrijver, A.: Theory of Linear and Integer Programming. John Wiley & Sons, Chichester (1998). https://doi.org/10.1002/oca.4660100108
Segel, L.A., Slemrod, M.: The quasi-steady-state assumption: a case study in perturbation. SIAM Rev. 31(3), 446–477 (1989). https://doi.org/10.1137/1031091
Seiler, W.M., Seiß, M., Sturm, T.: A logic based approach to finding real singularities of implicit ordinary differential equations. Math. Comput. Sci. 15(2), 333–352 (2021). https://doi.org/10.1007/s11786-020-00485-x
Sommer-Simpson, J., Reinitz, J., Fridlyand, L., Philipson, L., Radulescu, O.: Hybrid reductions of computational models of ion channels coupled to cellular biochemistry. In: Bartocci, E., Lio, P., Paoletti, N. (eds.) Proc. CMSB 2016. LNCS, vol. 9859, p. 273. Springer (2016), https://doi.org/10.1007/978-3-319-45177-0_17
Sturm, T.: A survey of some methods for real quantifier elimination, decision, and satisfiability and their applications. Math. Comput. Sci. 11(3–4), 483–502 (2017). https://doi.org/10.1007/s11786-017-0319-z
Sturm, T. : Thirty years of virtual substitution: Foundations, techniques, applications. In: Arreche, C. (ed.) Proc. ISSAC 2018, pp. 11–16. ACM (2018), https://doi.org/10.1145/3208976.3209030
Sturm, T., Weber, A.: Investigating generic methods to solve Hopf bifurcation problems in algebraic biology. In: Horimoto, K. (ed.) Proc. Algebraic Biology 2008. LNCS, vol. 5147, pp. 200–215. Springer (2008), https://doi.org/10.1007/978-3-540-85101-1_15
Sturm, T., Weber, A., Abdel-Rahman, E.O., El Kahoui, M.: Investigating algebraic and logical algorithms to solve Hopf bifurcation problems in algebraic biology. Math. Comput. Sci. 2(3), 493–515 (2009). https://doi.org/10.1007/s11786-008-0067-1
Tarski, A.: A decision method for elementary algebra and geometry. Prepared for publication by J.C.C. McKinsey. R109, August 1, 1948, Revised May 1951, Second Edition. RAND Report. RAND, Santa Monica, CA (1957)
Tikhonov, A.N.: Systems of differential equations containing small parameters in the derivatives. Mat. Sb. (N. S.) 73(3), 575–586 (1952)
Valorani, M., Paolucci, S.: The G-scheme: a framework for multi-scale adaptive model reduction. J. Comput. Phys. 228(13), 4665–4701 (2009). https://doi.org/10.1016/j.jcp.2009.03.011
Vilar, J.M.G., Jansen, R., Sander, C.: Signal processing in the TGF-\(\beta \) superfamily ligand-receptor network. PLoS Comput. Biol. 2(1), e3 (2006). https://doi.org/10.1371/journal.pcbi.0020003
Viro, O.: Dequantization of real algebraic geometry on logarithmic paper. In: Casacuberta, C., Miró-Roig, R.M., Verdera, J., Xambó-Descamps, S. (eds.) European Congress of Mathematics, Progress in Mathematics, vol. 201, pp. 135–146. Springer, Berlin (2001), https://doi.org/10.1007/978-3-0348-8268-2_8
Weber, A., Sturm, T., Abdel-Rahman, E.O.: Algorithmic global criteria for excluding oscillations. Bull. Math. Biol. 73(4), 899–916 (2011). https://doi.org/10.1007/s11538-010-9618-0
Weispfenning, V.: The complexity of linear problems in fields. J. Symb. Comput. 5(1–2), 3–27 (1988). https://doi.org/10.1016/S0747-7171(88)80003-8
Weispfenning, V.: Quantifier elimination for real algebra—the quadratic case and beyond. Appl. Algebr. Eng. Commun. 8(2), 85–101 (1997). https://doi.org/10.1007/s002000050055
Wodarz, D., Hamer, D.H.: Infection dynamics in HIV-specific CD4 T cells: does a CD4 T cell boost benefit the host or the virus? Math. Biosci. 209(1), 14–29 (2007). https://doi.org/10.1016/j.mbs.2007.01.007
Acknowledgements
We are grateful to the anonymous referees for their thorough reviews and numerous helpful comments. This work has been supported by the interdisciplinary bilateral project ANR-17-CE40-0036 and DFG-391322026 SYMBIONT [5, 6]. The SYMBIONT project owes much to the interdisciplinary perspective, the scientific vision, and the enthusiasm of our colleague Andreas Weber, who unexpectedly passed away in March 2020. Andreas was also a major proponent of and contributor to tropical methods for the reduction of reaction networks, which are continued and extended in the present work. We miss him as an extraordinary scientist and person.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A. Further Computational Examples
Appendix A. Further Computational Examples
Recall that in Sect. 7 we have discussed computations for several systems from the BioModels database [57]. While the focus there was on biological results, we discuss here examples where reduction stops at \(\ell < m\) for various reasons. Again, we have conducted our computations on a standard desktop computer with a 3.3 GHz 6-core Intel 5820K CPU and 16 GB of main memory. Computation times listed are CPU times.
1.1 A.1. Hypertoxiticy of a Painkiller
BioModel 609 describes the metabolism and the related hepatotoxicity of acetaminophen, a pain killer [60]. The species concentrations over time of Sulphate PAPS, GSH, NAPQI, Paracetamol APAP, and Protein adducts are mapped to differential variables \(y_1\), ..., \(y_5\), respectively. The input system is given by
Since there is only one monomial on the right hand side of the equation for \(\frac{{\text {d}}\!{}}{{\text {d}}\!{t}}y_5\), equilibration is impossible. This causes Algorithm 4 to return in l.23 a disjunctive normal form \(\Pi \) equivalent to “false,” which describes the empty set. Hence Algorithm 3 returns \(\bot \), and Algorithm 1 returns the empty list. The total computation time was 0.006 s.
1.2 A.2. Transmission Dynamics of Rabies
BioModel 726 examines the transmission dynamics of rabies between dogs and humans [61]. Species concentrations over time are mapped to differential variables \(y_1\), ..., \(y_{8}\) as described in Table 2.
The input system is given by
We choose \(\varepsilon _* = \frac{1}{5}\), \(p = 1\), and Algorithm 3 selects \(D = (-10, -10, -11, -9, -14, -7, -8, -7)\) from the tropical equilibration. Algorithm 1 then yields the following scaled and truncated system with three time scales:
Equating the right hand sides \(F_1\) of the differential equations in \(T_1\) to zero equivalently yields
In l.1 of Algorithm 6, \(U \circ M_1\) is tested for satisfiability. This fails, which means that the corresponding manifold \(\mathcal {M}_1\) is empty over the positive first orthant. Consequently, Algorithms 5, 8, and 9 return empty lists. The total computation time was 0.921 s.
1.3 A.3. Negative Feedback Loop Between Tumor Suppressor and Oncogene
BioModel 156 describes the dynamics of a negative feedback loop between the tumor suppressor protein p53 and the oncogene protein Mdm2 in human cells [30]. The species concentrations over time for P53 (x), Mdm2 (y), and Precursor Mdm2 (y0) are mapped to differential variables \(y_1\), ..., \(y_3\), respectively. The input system is given by
We choose \(\varepsilon _* = \frac{1}{2}\), \(p = 1\), and select \(D = (2, 1, 1)\). Algorithm 1 then yields the following scaled and truncated system with two time scales:
Analogously to the previous section we obtain \(M_1 = [ - 37 x_{1} x_{2} + 40 x_{1} = 0 ]\), for which we find \(\mathcal {M}_1\) to be non-empty over the positive first orthant in l.1 of Algorithm 6. However in l.20, the test for hyperbolic attractivity fails with \(M_1\) and the Hurwitz conditions
so that “false” is returned. Therefore, Algorithm 5 breaks the for-loop in l.10 with \(k=1\) and returns the empty list in l.19. Obviously, the simplified and back-translated systems are empty lists as well. The total computation time was 0.453 s.
1.4 A.4. CD4 T-Cells in the Spread of HIV
BioModel 663 describes how CD4 T-cells can influence the spread of the HIV infection [81]. Species concentrations over time for Infected T-cells (x), Uninfected T-cells (y), and Free viruses (v) are mapped to variables \(y_1\), ..., \(y_3\), respectively. The input system is given by
We choose \(\varepsilon _* = \frac{1}{2}\), \(p = 5\), and \(D = (1, 4, 3)\). The choice of \(p=5\) causes fractional powers of numbers in the scaled and truncated system
However, such input is not accepted with the SMT logic QF_NRA used in Algorithm 6. As discussed in Sect. 3.2, we catch the corresponding error from the SMT solver, convert to floats, and restart, which solves the problem.
Similarly to the previous example, the Hurwitz test in l.20 of Algorithm 6 succeeds for \(k=1\) but fails for \(k=2\) in Algorithm 5. Since there are fewer than two reduced systems, we return the empty list. Consequently, the list of simplified reduced systems and the corresponding list of back-transformed systems are empty as well. The total computation time was 0.390 s.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kruff, N., Lüders, C., Radulescu, O. et al. Algorithmic Reduction of Biological Networks with Multiple Time Scales. Math.Comput.Sci. 15, 499–534 (2021). https://doi.org/10.1007/s11786-021-00515-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11786-021-00515-2
Keywords
- Chemical reaction network
- Compartmental model
- Dimension reduction
- Invariant set
- Logic computation
- Multiple time scales
- Polynomial differential equations
- Real algebraic computation
- Satisfiability modulo theories
- Singular perturbation
- Symbolic computation
- Tropical geometry