
Abstract
We study the vacuum distribution, under an appropriate scaling, of a family of partial sums of nonsymmetric position operators on weakly monotone and monotone Fock spaces, respectively. We preliminary treat the case of weakly monotone Fock space, and show that any single operator has the vacuum law belonging to the free Meixner class. After establishing some relations between the combinatorics of Motzkin and Riordan paths, we give a recursive formula for the vacuum moments of the law of any finite sum. Since the operators are monotone independent, the distribution is the monotone convolution of the free Meixner law above. We also investigate the asymptotic measure for these sums, which can be seen as “Poisson type” limit law. It turns out to belong to the free Meixner class, with an atomic and an absolutely continuous part (w.r.t. the Lebesgue measure). Finally, we briefly apply analogous considerations to the case of monotone Fock space.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The present notes are a continuation of the investigation started by the authors in [8]. There we studied the vacuum distribution of sums of symmetric position operators on the weakly monotone Fock space (WM-Fock for short), based on a separable Hilbert space \({{\mathcal {H}}}\). The structure of WM-Fock was first defined in [28], where the interested reader is referred for a general presentation. A symmetric position operator is obtained by adding the basic operators, namely the creators \(A_i^{\dagger }\) and annihilators \(A_i\) by the test functions given by unit vectors \(e_i\) on \({{\mathcal {H}}}\) (details are explained in Sect. 2), and in noncommutative (free, monotone or boolean) probability it is often called gaussian. One of the reasons for such a name can be traced back to the notions of stochastic independence in the noncommutative realm. Indeed, when one drops commutativity, several inequivalent notions of independence appear among the random variables [23, 27], and consequently the appropriate central limit theorems give rise to limit laws different from the normal distribution. The operators above are therefore called gaussian since they realize, in suitable Hilbert spaces, natural examples of noncommutative random variables whose distributions, w.r.t. a distinguished vector state, are central limit laws. In fact, it was observed by Hudson and Parthasarathy [15] that the classical Brownian motion can be realized on the symmetric Fock space as the sum of creation and annihilation processes. In particular, the distribution of such operators w.r.t. the vacuum state is the gaussian law. This idea turned out to work also in free probability, where the sum of creation and annihilation operators acting on the free (full) Fock space, is the Wigner semicircle law, which is the central limit distribution for freely independent random variables. Similarly, Muraki [19] has constructed Brownian motion with monotone independent increments on the (continuous type) monotone Fock space as the sum of creation and annihilation processes, where every random variable in the family has the arcsine law. The latter is the central limit distribution in monotone probability, and a generalization of Muraki’s construction has been obtained in [17] for Brownian motions with multidimensional time parameter taken from a positive symmetric cone and with bm-independent increments.
On the other hand, the sum of creation and annihilation operators on the discrete monotone Fock space has just the Bernoulli distribution, which is far away from the arcsine law (see, e.g. [10] and the references therein). The construction of the WM-Fock space was the attempt to build a discrete model in which the position operators would have the arcsine distribution, and the result was partially satisfactory, since only some finite rank perturbations of the position operators were proved to have the arcsine distribution. In [8] we showed that a single position operator on the WM-Fock space has the Wigner semicircle distribution, which is also away from the arcsine law, but still absolutely continuous. We also noticed that sums of such position operators have absolutely continuous distributions and, by monotone independence, the latter are indeed the monotone convolution powers of the Wigner semicircle law.
The problem of finding suitable noncommutative random variables whose vacuum distributions of their sums weakly converge, under appropriate scaling, to the analogue of Poisson measure in the classical case (law of small numbers), has been extensively studied in noncommutative probability. The operators involved are generally constructed on appropriate Fock spaces as the combination \(A^{\dagger }+A+\lambda A^{0}\) of a position operator \(A^{\dagger }+A\) and a scalar multiple \(\lambda > 0\), called the intensity, of the so-called preservation operator \(A^0\). They are said nonsymmetric position operators, and usually one defines \(A^0:=A^{\dagger }A\), the first example in the literature going back to [1]. This is the way we do it as well, following the free [26] and the monotone [20] probability cases. The intensity \(\lambda \) introduces additional structure into the considerations, and is therefore worthwhile to study. This structure usually is related to the combinatorics of partitions combined with block orderings or labelings. Moreover, in the weakly monotone case, it significantly enlarges the class of partitions compared to the position operator case from [8], in which (for central limits) only noncrossing pair partitions appear. In free probability the analogue of the classical Poisson law is the Marchenko-Pastur distribution (see, e.g. [26]), whose moments can be computed by taking all noncrossing partitions and putting the parameter (label) \(\lambda \) on each block. A generalization of this result has been obtained in [5] for conditionally free convolution.
The situation in monotone probability is not as clear. Muraki found only implicit form of the distribution for the Poisson type limit theorem for the monotone convolution, however its moments are related to all noncrossing partitions with monotone order on blocks (see [13, 22]).
In this paper we study the Poisson type limit for random variables \(X_i(\lambda ):=G_i+\lambda A_i^{0}\). Here, \(\lambda >0\), \(G_i:=A_i+A_i^{\dag }\), and \(A_i\), \(A_i^{\dag }\), \(A^{0}_i:=A^{\dag }_iA_i\) denote respectively the annihilation, creation and preservation operators, by orthonormal basis vectors \(e_i\in {{\mathcal {H}}}\) on the WM-Fock space \({{\mathfrak {F}}}_{WM}({{\mathcal {H}}})\). In particular, after denoting
we compute
for each \(n\in {{\mathbb {N}}}\), where \(\Omega \) is the so-called weakly monotone vacuum vector. For n running in the positive integers, the limits above describe a sequence of moments of a distribution \(\nu _\lambda \). In the final part of these notes we compute \(\nu _\lambda \), and show that it belongs to the free Meixner class, and it is the same limit measure as the one for analogous sums of nonsymmetric monotone position operators, which first appeared in [20].
The paper is organized as follows. In Sect. 2 we present the WM-Fock space with creation, annihilation and preservation operators, and recall basic information about labeled noncrossing partitions, combinatorics of Motzkin and Riordan paths, basic properties of the Cauchy transform of a probability measure, and free Meixner laws as well. Based on Flajolet’s results [11], in Sect. 3 the vacuum law of any nonsymmetric position operator is seen to belong to the free Meixner class in Theorem 3.1. More precisely, the law is absolutely continuous w.r.t. the Lebesgue measure when \(0<\lambda \le 1\), and has both atomic and absolutely continuous parts if \(\lambda >1\). In addition, we highlight some relations between moments and Motzkin and Riordan paths. As nonsymmetric position operators with intensity \(\lambda \) are monotone independent random variables in the \(*\)-algebra generated by weakly monotone creation operators (see [8]), one naturally tries to get some information on the vacuum law of their partial sums \(\sum _{k=1}^m (G_k+\lambda A^0_k)\), which correspond to the m-fold monotone convolution of the free Meixner law aforementioned. To this aim is devoted Sect. 3.1, where in Theorem 3.5 we find a recursive formula for the vacuum moments of \(T_m(\lambda _m):=\sqrt{m}S_m(\lambda )\) via noncrossing weakly monotone labeled partitions, and moreover an explicit computation of the Cauchy transform of the measure in the case \(m=2\). In Sect. 4 we obtain the limit distribution of \(S_m(\lambda )\) in Theorem 4.1 as a free Meixner law containing atomic and absolutely continuous part. As one could expect it reduces to the standard arcsine law when \(\lambda \) equals zero. Finally, in Sect. 5, we perform analogous considerations for the case of monotone Fock space. Although the vacuum law of a single nonsymmetric position operator here is a two-points discrete measure, the Poisson type limit is the same as in the weakly monotone case.
2 Preliminaries
In this section we give a miscellany of definitions, notations and some known results frequently used in the sequel.
2.1 Weakly Monotone Fock space
Let \({{\mathcal {H}}}\) be a separable Hilbert space with a fixed orthonormal basis \((e_i)_{i\ge 1}\). By \({{\mathfrak {F}}}({{\mathcal {H}}})\) we denote the full Fock space on \({{\mathcal {H}}}\), whose vacuum vector is \(\Omega =1\oplus 0\oplus \cdots \). The weakly monotone Fock space, in the sequel denoted by \({{\mathfrak {F}}}_{WM}({{\mathcal {H}}})\), is the closed subspace of \({{\mathfrak {F}}}({{\mathcal {H}}})\) spanned by \(\Omega \), \({{\mathcal {H}}}\) and all the simple tensors of the form \(e_{i_k}\otimes e_{i_{k-1}}\otimes \cdots \otimes e_{i_1}\), where \(i_k\ge i_{k-1}\ge \cdots \ge i_1\) and \(k\ge 2\).
If the Hilbert space \({{\mathcal {H}}}\) is finite dimensional with \(n =\mathrm{dim}({{\mathcal {H}}})\ge 2\), then the basis for \({{\mathfrak {F}}}_{WM}({{\mathcal {H}}})\) consists of the vacuum and all the simple tensors
where \(k_n, k_{n-1},\ldots ,k_1\ge 0\), \(e_m^{k}:=\underbrace{e_m\otimes \cdots \otimes e_m}_k\) if \(k\ge 1\), and the convention that \(e^{k_i}_{i}\) does not appear in (2.1) if \(k_i=0\).
The weakly monotone creation and annihilation operators with "test function" \(e_i\), denoted by \(A^\dag _i\) and \(A_i\) respectively, are defined on the linear generators as follows. For any \(i_k\ge i_{k-1}\ge \cdots \ge i_1\), \(k\ge 2\), and \(j\ge 1\)
where \(\delta _{i,j}\) is the Kronecker symbol, and
where
They can be extended by linearity and continuity to the whole \({{\mathfrak {F}}}_{WM}({{\mathcal {H}}})\), are adjoint to each other, and of norm one. Furthermore, they satisfy the following relations
As it will be useful in the sequel, we report here Lemma 2.1 from [8] for the convenience of the reader.
Lemma 2.1
For any \(k,j\ge 1\), one has
Moreover, for \(j\ge k\)
For each \(i\in {{\mathbb {N}}}\), we denote \(A^0_i:= A^{\dag }_iA_i\) the orthogonal projection onto
As usual (see, e.g. [1]) we call it preservation (or conservation) operator. Its relations with the other basic operators in \({{\mathfrak {F}}}_{WM}({{\mathcal {H}}})\) are summarised below, and follow from (2.2)
2.2 Partitions of a Finite Set
For \(n,m\in {{\mathbb {N}}}\) with \(n<m\), let us denote \([n,m]:=\{n,n+1,\ldots , m\}\), and \([n]:=\{1,\ldots ,n\}\). Let S be a nonempty linearly ordered finite set. The collection \(\pi =\{B_1,\ldots , B_p\}\) is a partition of the set S if the \(B_i\) are disjoint nonempty subsets whose union is S. The \(B_i\) are also called blocks of the partition \(\pi \). Any \(B_k\in \pi \) is called a singleton if \(|B_k|=1\), where \(|\cdot |\) denotes the cardinality. The number of blocks of \(\pi \) is denoted by \(|\pi |\), and the set of all the partitions of S is P(S). In the special case \(S=[n]\) we denote this set by P(n). A similar notation for subsets of P(n) will be introduced in the next paragraph.
A block B of \(\pi \in P(n)\) is called an interval block if \(B=[l,m]\) for some \(1\le l\le m\le n\). An interval partition of [n] is an element of P(n) for which every block is an interval. In addition, the set V(n) of interval partitions on [n] is in bijection to the compositions of n, i.e the sequences of integers \((q_1,\ldots ,q_j)\) such that \(q_h>0\), and \(q_1+\cdots + q_j=n\).
A partition \(\pi \) has a crossing if it contains at least two distinct blocks \(B_i\) and \(B_j\), and elements \(v_1,v_2\in B_i\), \(w_1,w_2\in B_j\) s.t. \(v_1<w_1<v_2<w_2\). Otherwise, it is called noncrossing. We denote by \(NC_{2,1}(S)\) the set of noncrossing partitions such that each block contains at most two elements. If |S| is even, \(NC_2(S)\) denotes the set of noncrossing partitions with all blocks of cardinality 2.
A noncrossing partition of [n] is called irreducible if there is a block containing both 1 and n. Note that every partition is uniquely decomposed into irreducible (sub)partitions, generally called factors [3].
A block \(B_k\in \pi \) is called inner if there exist \(B_h\in \pi \) and \(v_1,v_2\in B_h\) such that \(v_1<w<v_2\) for all \(w\in B_k\). A block is called outer if it is not inner, and \(\pi \) is noncrossing. In this case, the subset collecting the partitions without outer singletons is denoted by PI(S). From now on, we put
For \(\pi \) a noncrossing partition of [n] with blocks \(\pi =\{B_1, \ldots , B_k\}\), one has a natural partial order \(\preceq _{\pi }\) on the blocks given by \(B_i\preceq _{\pi }B_j\) if \(B_j\) is nested inside \(B_i\), i.e. \(\mathrm{min}B_i\le \mathrm{min}B_j \le \max B_j \le \max B_i\), where \(\mathrm{min}B\) (resp. \(\max B\)) denotes the minimal (resp. maximal) element of the block B. When the extremal inequalities above are strong, we write \(B_i\prec _{\pi }B_j\).
Let \(\pi =\{B_1, \ldots , B_k\}\) be a partition of [n] and J be a set. A labeling with values in J is a function \(L: \pi \rightarrow J\), and the pair \((\pi ,L)\) is called a labelled partition. We denote LP(J, n) the set of labelled partitions with labels in J.
In what follows the aforementioned partition \(\pi \) has to be taken noncrossing. Recall that for x, y arbitrary elements of a poset \((S,\le )\), one says that y covers x if \(x<y\) and there is no z such that \(x<z<y\). If \(\pi =\{B_1,\ldots , B_k\}\in LP(J,n)\) with label function L is such that \(L(B_j)=L(B_i)\) for every singleton \(B_j\) which covers a block \(B_i\) w.r.t. \(\preceq _{\pi }\), we say that \(\pi \) belongs to \(NCLP_s(J,n)\).
The label function L is called weakly monotone if it preserves the ordering of the blocks, i.e. \(L(B_i)\le L(B_j)\) when \(B_i\preceq _{\pi } B_j\). A weakly monotone label function is called monotone if \(L(B_i)< L(B_j)\) when \(B_i\) and \(B_j\) both contain at least two elements, and \(\mathrm{min}B_i< \mathrm{min}B_j< \max B_j < \max B_i\). The labelled partitions belonging to \(NCLP_s(J,n)\) whose label function is weakly monotone (monotone) are denoted by \(NCLP_s^{wm}(J,n)\) (\(NCLP_s^{m}(J,n)\)). Finally, by \(ANC^{wm}(J,n)\) we denote the noncrossing weakly monotone partitions on [n] without outer singletons, with labels in J and blocks of cardinality at most 2, and finally belonging to \(NCLP_s(J,n)\). In other words
In the case of monotone labelled partitions, one takes
The so-called nesting forest representation for noncrossing partitions (see, e.g. [3], Definition 3.1) appears useful to describe the latter classes (see Fig. 1). Each irreducible factor is seen as a Hasse diagram, where the labeling is not decreasing moving downward, and the same colour of vertices necessarily corresponds to the same labeling.

A partition in \(ANC^{wm}([7],18)\) and its nesting forest
2.3 Motzkin and Riordan Paths
Recall that a Motzkin path of size n is a lattice path in the integer plane \({{\mathbb {Z}}}\times {{\mathbb {Z}}}\) consisting of up-steps \(a:=(1, 1)\), down-steps \(b:=(1,-1)\) and level-steps \(c:=(1,0)\), beginning in (0, 0) and ending in (n, 0), which never passes below the x-axis. We denote by \({{\mathcal {M}}}(n)\) the set of all Motzkin paths of size n, and \(M_n:=|{{\mathcal {M}}}(n)|\) is called nth Motzkin number.
Following [11], \({{\mathcal {M}}}(n)\) reduces to the collection of words \(u_1u_2\cdots u_n\) on the alphabet \(\{a,b,c\}\) satisfying
where \(|x|_i\) denotes the number of occurrences of \(i\in \{a,b,c\}\) in x.
Remark 2.2
Removing the horizontal steps a Motzkin path results in a Dyck path, and immediately leads to the following relation [4]
where for any \(x\in {{\mathbb {R}}}\), [x] is the unique integer m such that \(m\le x< m+1\), and \((C_k)\) is the Catalan sequence.
Riordan paths are Motzkin paths without horizontal steps on the x-axis. The set of Riordan paths from (0, 0) to (n, 0) is denoted by \({{\mathcal {R}}}(n)\), and \(R_n\) is their number.
Motzkin and Riordan numbers are connected by the following formula [4]
Any of the aforementioned lattice paths is said irreducible if it does not touch the x-axis except at the beginning and at the end.
In the sequel it will be useful to replace the alphabet a, b, c with \(\dag ,1,0\), respectively. In this case, conditions (2.6) then realize any Motzkin path of length n by means of a sequence \(\varepsilon =(\varepsilon (1),\ldots , \varepsilon (n))\in \{1,0,\dag \}^n\) such that
-
(1)
\(|\varepsilon (1),\ldots , \varepsilon (n)|_1=|\varepsilon (1),\ldots , \varepsilon (n)|_\dag \)
-
(2)
\(|\varepsilon (1),\ldots , \varepsilon (j)|_1 \le |\varepsilon (1),\ldots , \varepsilon (j)|_\dag \) , for \(j=1,\ldots , n-1\) .
In this picture, \({{\mathcal {M}}}(n)\) is denoted by \(\{1,0,\dag \}^n_{M}\). When in particular \(\varepsilon (j)\in \{1,\dag \}\) for any j, by Remark 2.2\(\varepsilon \) uniquely corresponds to a Dyck path of length the necessarily even n, or equivalently to a unique partition in \(NC_2(n)\). If in addition,
-
(3)
\(\varepsilon (1)=\dag \)
-
(4)
\(|\varepsilon (1),\ldots , \varepsilon (j)|_1=|\varepsilon (1),\ldots , \varepsilon (j)|_\dag \Longrightarrow \varepsilon (j+1)=\dag \) , \(j\ge 2\)
there are no horizontal steps in the Motzkin path on the x-axis. If \(\{1,0,\dag \}^n_{+}\) denotes the sequences \(\varepsilon \in \{1,0,\dag \}^n\) satisfying (1) - (4), one finds that \(\{1,0,\dag \}^n_{+}\equiv {{\mathcal {R}}}(n)\). This gives sense to the notation \(\varepsilon \in {{\mathcal {R}}}(n)\) often used in the sequel, and therefore \(R_n=|\{1,0,\dag \}^n_{+}|\).
Finally, any \(\varepsilon \in \{1,0,\dag \}^n_{+}\) is decomposed as \(\varepsilon =\varepsilon '\sqcup \varepsilon ''\), where \(\varepsilon ''(j)\in \{1,\dag \}\) and \(\varepsilon '(j)=0\) for any j. Thus \(\varepsilon ''\) is identified to a Dyck path or, equivalently, \(\varepsilon ''\in NC_2(2r)\) for some \(r\le \frac{n}{2}\). Here, each block reduces to a pair (i, j) such that \(\varepsilon (i)=1\), and \(\varepsilon (j)=\dag \). The reader is referred to [9] for similar arguments in the setting of interacting Fock spaces.
2.4 Cauchy Transform of a Measure
Let \(\mu \) be a probability measure defined on the Borel \(\sigma \)-field over \({{\mathbb {R}}}\) with finite moments. The moment sequence associated with \(\mu \) is denoted by \((m_n(\mu ))\). For each \(z\in {{\mathbb {C}}}\)
is called moment generating function, which is considered as a formal power series if the series is not absolutely convergent.
From now on \(\mathbb {C}^+\) and \(\mathbb {C}^-\) will be the upper and lower complex half-planes, respectively. The Cauchy transform of \(\mu \) is defined as
\({{\mathcal {G}}}_{\mu }(z)\) is analytic in \({{\mathbb {C}}}{\setminus } \mathrm{supp}({\mu })\), \({{\mathcal {G}}}_{\mu }(\overline{z})=\overline{{{\mathcal {G}}}_{\mu }(z)}\) and \({{\mathcal {G}}}_{\mu }\) maps \({{\mathbb {C}}}^+\) into \({{\mathbb {C}}}^-\). As a consequence, it suffices to consider it on the domain on \(\mathbb {C}^+\cup \mathbb {R}{\setminus } \mathrm{supp}({\mu })\). In this region it uniquely determines \(\mu \) as summarized below (see e.g. [14]):
-
(1)
The limit
$$\begin{aligned} {{\mathfrak {g}}}(x):=-\frac{1}{\pi }\lim _{y\rightarrow 0^{+}}\mathrm{Im}{{\mathcal {G}}}_{\mu }(x+iy) \end{aligned}$$(2.8)exists for a.e. \(x\in {{\mathbb {R}}}\), and \({{\mathfrak {g}}}(x)\,dx\) is the absolutely continuous part of \(\mu \). Formula (2.8) is called Stieltjes inversion formula.
-
(2)
\({{\mathcal {G}}}_{\mu }(z)\) has a simple pole in \(z=a\in \mathbb {R}\) if and only if a is an isolated point of \(\mathrm{supp}({\mu })\). In this case
$$\begin{aligned} \mu =c\delta _a+(1-c)\nu ,\,\,\,\,\, 0\le c \le 1 \end{aligned}$$and \(\nu \) is a probability measure for which \(\mathrm{supp}({\nu })\cap \{a\}=\emptyset \). Furthermore, \(c=\text {Res}_{z=a}{{\mathcal {G}}}_{\mu }(z)\).
We end the subsection by noticing that
2.5 Free Meixner Laws
We end the section briefly presenting free Meixner laws. The interested reader is referred to [16, 24] for further details. The family \(\mu _{{{\mathbf {u}}}}\) on \(\mathbb {R}\) of free Meixner laws is parametrized by \({{\mathbf {u}}}:=(a, b, c,\alpha )\in \mathbb {R}^4\) with \(b, c\ge 0\), which orthogonalize the family of polynomials \(P_n(x):=P^{{{\mathbf {u}}}}_n(x)\) given by the following recurrence
Moreover, the measure \(\mu _{{{\mathbf {u}}}}\) has absolutely continuous part \(\mu _C\) with density
where
Its discrete part \(\mu _D\) is 0 except possibly in the following cases:
-
(1)
f(x) has two real roots \(x_1\ne x_2\). Then
$$\begin{aligned} \mu _D=\gamma _1\delta _{x_1}+\gamma _2\delta _{x_2}\,, \end{aligned}$$(2.11)where
$$\begin{aligned} \gamma _i=\frac{1}{\sqrt{(\alpha -a)^2-4b(1-c)}}\bigg (\frac{bc}{|x_i-\alpha |}-\frac{|x_i-\alpha |}{c}\bigg )_{+}, \quad i=1,2\,. \end{aligned}$$(2.12) -
(2)
\(c=1\) and \(\alpha \ne a\), so that f(x) has one root \(x_1=\alpha +b/(\alpha -a)\). Then
$$\begin{aligned} \mu _D=\bigg (1-\frac{b}{(\alpha -a)^2}\bigg )_{+}\delta _{x_1}\,, \end{aligned}$$(2.13)where \((r)_{+}:=(r+|r|)/2\).
Finally, we recall that the Cauchy transform of \(\mu _{{{\mathbf {u}}}}\) is given by
where the branch of the analytic square root is determined by the condition \(\mathrm{Im}{{\mathcal {G}}}_{\mu _{{{\mathbf {u}}}}}(z)< 0\) when \(\mathrm{Im}z>0\).
3 The Vacuum Law of Nonsymmetric Position Operators
Motivated by the symmetric central limit theorem for weakly monotone selfadjoint operators [8], we first study the vacuum distribution, i.e. the law in the vacuum state \(\omega _\Omega :=\langle \cdot \Omega ,\Omega \rangle \), for sums of nonsymmetric position operators
where \(\lambda >0\), \(m\ge 1\), and \(G_k:=A_k+A^{\dag }_k\). The symmetric part, given by the sum of the so-called gaussian operators \(G_k\), and obtained by taking \(\lambda =0\), has been already treated in [8]. As \(S_m(\lambda )\) is bounded and selfadjoint for each m, the moment problem of its vacuum distribution has a unique solution.
For \(m\ge 1\), it seems convenient to introduce the operator
where \(\lambda _m:=\lambda \sqrt{m}\). Thus, we have to handle the nth moments for such sums, namely
We start with the case \(m=1\), where we simply denote the aforementioned objects by \(T_1(\lambda )\) and \(b_{1,n}(\lambda )\).
The law of the nonsymmetric position operator belongs to the free Meixner class, as shown by the following
Theorem 3.1
The distribution \(\mu _{1,\lambda }\) of \(T_1(\lambda )\) in the vacuum state is the free Meixner law with parameters \((\lambda ,1,1,0)\). Namely,
where \({\mu _{1,\lambda }}^{a.c.}\) is the absolutely continuous part, with the density function
and the above support reduces to \((-1,3]\) when \(\lambda =1\). In addition, for any n
where \(|\varepsilon |_0\) denotes the number of level-steps in \(\varepsilon \).
In Fig. 2 we report the plots of \(\mu _{1,\lambda }\) in the cases \(\lambda =0.5\), \(\lambda =1\) and \(\lambda =2\).

Vacuum distribution of \(T_1(\lambda )\) for \(\lambda =0.5\), \(\lambda =1\) and \(\lambda =2\)
Proof
We first compute the moment generating function and the Cauchy transform for the sequence \((b_{1,n}(\lambda ))\) which indicate the relation of the latter with Riordan paths. Fix \(\lambda >0\). If for any i
where \(n=0\) corresponds to \(\Omega \), \(T_1(\lambda )\) has the following matrix representation
w.r.t. the canonical basis \((e_i^{\otimes n})_{n\ge 0}\). This is a Jacobi matrix, and its J-transform is the continued fraction of the Cauchy transform for \((b_{1,n}(\lambda ))\) [2]. It is given by
and then
By (2.9) one gets the moment generating function
The continued fraction version assumes the form
Arguing as in [11], Theorem 1, one finds that (3.4) is indeed the moment generating function of positive lattice paths with weight 1 on up and down-steps, and weight \(\lambda \) on horizontal steps except 0 on the x-axis. Thus (3.2) is achieved.
We note that the Cauchy transform in (3.3) is exactly the one given in (2.14) for \((a,b,c,\alpha )=(\lambda ,1,1,0)\), and \(f(z)=\lambda z+1\). Since
and
from (2.10) it follows that the probability measure \(\mu _{1,\lambda }\) has the absolutely continuous part given in (3.1). Finally, \(x_0=-\frac{1}{\lambda }\) is a root of f(x), and (2.13) entails \(x_0\) is an atom with mass
\(\square \)
One notices that for any \(n\ge 2\) and \(\lambda >0\), \(b_{1,n}(\lambda )\) is a monic polynomial of degree \(n-2\). Indeed, the degree is obtained by taking the unique path starting with an up-set, followed by \(n-2\) level-steps and ending with a down-step. As an example, a direct computation gives for \(n=0,\ldots ,5\) the following values for the moment sequence
A recursive formula for these moments is provided by the following
Proposition 3.2
For each \(n\ge 2\) and \(\lambda >0\), one has
where
Proof
Indeed, as \(b_{1,0}(\lambda )=1\), the basic step \(n=2\) in (3.5) is trivially satisfied.
Now we suppose that (3.5) holds for any \(s<n\). The definition of \(\{1,0,\dag \}^n_+\equiv {{\mathcal {R}}}(n)\) gives that any Riordan path of length n is uniquely decomposed into an irreducible Riordan path of length k, and a Riordan path of length \(n-k\), for \(k=2,\ldots ,n\). If \(\overline{{{\mathcal {R}}}}(k)\) denotes the set of irreducible Riordan paths of length k, from (3.2) it follows
the last equality coming from the induction assumption. For any fixed length \(k\ge 2\), irreducible Riordan paths and irreducible Motzkin paths coincide. In addition, after removing the first and the last step, the latter are in one-to-one correspondence with the Motzkin paths of length \(k-2\) (see Fig. 3). This ends the proof. \(\square \)

.
As for (2.7), it cannot be generalized to \(\lambda \ne 1\) by means of (3.6). Indeed, the sequences of paths considered here are usually called \(\lambda \)-colored Motzkin words in combinatorics [25].
Although the following result could be known to the experts, we add its proof since some of the tools used will be helpful in the sequel.
Proposition 3.3
For each \(n\ge 2\) and \(\lambda >0\)
where \(M_0(\lambda )=1, M_1(\lambda )=0\).
Proof
Fix a Motzkin path of length \(n\ge 2\). Then, it is uniquely decomposed into:
-
a path of k level-steps, for \(k=0,\ldots , n\);
-
an irreducible Motzkin path of length \(l-k\), for \(l=k+2,\ldots ,n\) in the case \(k\le n-2\) (since the \(k+1\)th step is an up-step);
-
a Motzkin path of length \(n-l\), in the case \(l\le n-1\).
As above, each irreducible Motzkin path of length \(l-k\) consists of an up step, a Motzkin path of length \(l-k-2\), and a down step (see Fig. 4). Therefore,

.
\(\square \)
The Jacobi continued fractionFootnote 1 and the bivariate generating function for the Motzkin numbers \((M_n(\lambda ))\) is shown in [11, p. 135] (with z instead of \(\lambda \)):
or, equivalently
For the Cauchy transform, (2.9) entails
Here, \(''+''\) has to be taken when \(\text {Re}(z)\ge \lambda \), or \(\text {Re}(z)<\lambda \) and \(\text {Im}(z)<\text {Im}\sqrt{(z-\lambda )^2-4}\), whereas one takes \(''-''\) in the remaining cases. Recalling that the Cauchy transform of the Wigner law is indeed
(3.7) gives that the distribution measure \(\mu ^M_{\lambda }\) induced by \((M_n(\lambda ))\) results to be a shifted semicircle law. Namely,
In addition, the periodic continued fraction expansion of \({{\mathcal {G}}}^M_{\lambda }(z)\) is the J-transform of the Jacobi matrix [2]
which is the matrix representation of every \(A_i+A^\dag _i+\lambda I\) w.r.t. the canonical basis \((e_i^{\otimes n})_{n\ge 0}\), where, as above, \(e_i^{\otimes 0}=\Omega \) and I denotes the identity of \({{\mathcal {B}}}({{\mathcal {F}}}_{WM}({{\mathcal {H}}}))\). Therefore, \((M_n(\lambda ))\) are the vacuum moments of \(A_i+A^\dag _i+\lambda I\), \(i\in {{\mathbb {N}}}\).
3.1 Distribution of the Sum of an Arbitrary Number of Operators
Here, we investigate the vacuum law for sums of at least 2 nonsymmetric positionoperators, and show that the moments depend on the number of some partitions introduced in Sect. 2.
Before proving the announced result, we introduce the following technical
Lemma 3.4
Fix \(n\ge 1\), \(\varepsilon \in \{1,0,\dag \}^n_{+}\), \(i_1,\ldots ,i_n\in [m]\), and define
Then, \(A_{i_n}^{\varepsilon (n)}\cdots A_{i_1}^{\varepsilon (1)}\) vanishes unless \(i_l=i_j=i_k\) for each \(j\in [n]\) such that \(l\le j<k\).
Proof
Indeed, when \(l=k-1\), the thesis follows from (2.2), since here \(j=l\). If \(l<k-1\), then for any j such that \(l<j<k\), one finds \(\varepsilon (j)=0\). In this case (2.5), (2.2) and (2.4) give the desired result. \(\square \)
Notice that for any \(m\ge 1\), \(b_{m,0}(\lambda _m)=1\) and \(b_{m,1}(\lambda _m)=0\).
Theorem 3.5
For each \(m\ge 1\) and \(n\ge 2\), one has
where \(\lambda >0\), and \(|\varepsilon |_0\) denotes the number of singletons of the partition \(\varepsilon \). In addition,
where, for any \(j=1,\ldots , k-2\), \(\widetilde{b}_{m-l+1,k-2-j}(\lambda _m)\) is defined as
Proof
We first note that for each \(m\ge 2\), \(n\ge 0\), and \(\lambda >0\)
By the definition of \(\{1,0,\dag \}^n_+\), any partition \(\varepsilon \) on the right hand side of (3.11) has no outer singletons. As previously pointed out, \(\varepsilon =\varepsilon ' \sqcup \varepsilon ''\), where \(\varepsilon ''\) is a noncrossing pair partition, and now \(\varepsilon '\) collects the preservation operators organized in singletons. This gives \(\varepsilon \in NCI_{2,1}(n)\). Moreover, the Riordan path \(\varepsilon \) is uniquely decomposed into irreducible paths, the first one being \(\{\dag ,\varepsilon (2),\ldots ,\varepsilon (j-1),1\}\), for some \(j=2,\ldots n\). Lemma 3.4 and (2.4) give that the sequence
reduces to
for l and k defined as in (3.8). By (2.3), the above expression turns out to be equal to
Now both \(\varepsilon (l-1)\) and \(\varepsilon (l-2)\) belong to \(\{1,\dag \}\), and the following cases may appear
After replacing in (3.12) and iterating the procedure, one finds that any irreducible path realizes a partition which is weakly monotone ordered, where any block of cardinality 1 inherits the labeling from the block which covers. Since by Lemma 2.1\(\omega _{\Omega }(A_{i_n}^{\varepsilon (n)}\cdots A_{i_1}^{\varepsilon (1)})=1\), (3.9) follows.
In the aforementioned decomposition for \(\varepsilon \in ANC^{wm}([m],n)\), consider the first irreducible path of length \(k=2,\ldots , n\), and take the remaining path of length \(n-k\). Consequently, if \(ANC^{\overline{wm}}([m],k)\) is the subset of irreducible partitions \(\pi =\{B_1,\ldots ,B_p\}\) in \(ANC^{wm}([m],n)\), from (3.9) one finds
We label now \(L(B_1)=l\), \(l=1,\ldots ,m\). The weakly monotone ordering gives that for each \(h=2,\ldots , p\), \(L(B_h)=l+s\) for a suitable \(s\in \{0,\ldots , m-l\}\). Removing \(B_1\) provides a natural identification with a (unique) partition in \(ANC^{wm}([l,m],k-2-j)\), where j is the number of singletons. Consequently, for \(j=0\) (3.10) follows from (3.9), since in this case
where we identified \([m-l+1]\) with [l, m]. If instead \(j\ge 1\), denote by r the number of outer blocks with cardinality 2 in the partition. Then the indistinguishable outer singletons may occupy \(r+1\) positions, and (3.10) is verified using again (3.9). \(\square \)
The computation of the moment generating function and the Cauchy transform for \((b_{m,n}(\lambda _m))\) appears complicated when \(m\ge 2\), as a consequence of the recurrence relation (3.10).
In particular, when we replace \(\lambda _m\) simply with \(\lambda \) for any m, the vacuum law of the sum of m nonsymmetric position operators is the m-fold monotone convolution of \(\mu _{1,\lambda }\). Indeed, by means of Theorem 2.2 in [8], the random variables \(G_i+\lambda A^0_i\), \(i=1,\ldots , m\) are monotone independent. Also in this case, the (reciprocal) Cauchy transform appears not to be simple to handle. As an example, in the easiest case \(m=2\), since Theorem 3.1 in [21], one finds \({{\mathcal {G}}}_{2,\lambda }(z)={{\mathcal {G}}}_{1,\lambda }(\frac{1}{{{\mathcal {G}}}_{1,\lambda }(z)})\). This gives
as a consequence of (3.3).
4 Central Limit Theorem
In this section we provide a central limit theorem for the operator \(T_m(\lambda _m)\). More in detail, we find that the limit law belongs to the free Meixner class.
Theorem 4.1
For any \(\lambda >0\), the vacuum law of
weakly converges for \(m\rightarrow \infty \) to the free Meixner distribution \(\nu _\lambda \) with parameters \(\displaystyle \bigg (\lambda ,\frac{1}{2},2,0\bigg )\). Namely,
where the absolutely continuous part w.r.t. the Lebesgue measure \(\nu _\lambda ^{\text {a.c.}}\) has the density
Proof
As for any \(m\ge 1\) \(T_m(\lambda _m)\) is selfadjoint, it is enough to prove that the convergence is in the sense of moments to \(\nu _\lambda \), i.e.
for any \(n\ge 2\). From Theorem 3.5 it follows
As usual, any path in \(ANC^{wm}([m],n)\) is uniquely decomposed into \(j=1,\ldots , [\frac{n}{2}]\) irreducible paths of size \(q_h\), \(h=1,\ldots , j\). The latter indeed realize a partition \(\pi ^{(j)}\in V(n)\) whose corresponding composition of n is \((q_1,\ldots ,q_j)\). Therefore, (4.3) gives
For any h, let \(k_h+1\) be the number of blocks of cardinality 2 of \(\varepsilon _h\). Thus, the number of singleton blocks is \(q_h-2-2k_h\), and they are labelled as any block they cover. The right hand side of (4.4) is then
Here, l is the cardinality of the range of the label function \(L_h:\varepsilon _h\rightarrow [m]\), and \({{\mathcal {A}}}_{q_h,l}\) is the set of all the irreducible paths of length \(q_h\) with l blocks. Taking the limit for \(m\rightarrow \infty \) all the terms except \(l=k_h+1\) vanish, and one has
Every path above is irreducible. Then, by usual arguments, for the computation of \(|{{\mathcal {A}}}_{q_h,k_h+1}|\) we reduce to the case of a partition \(\widetilde{\varepsilon }_h\) of \(k_h\) blocks of cardinality 2. As the range of the label function \(L_{\widetilde{\varepsilon }_h}\) has cardinality \(k_h\), without loss of generality we suppose \(\text {Range}(L_{\widetilde{\varepsilon }_h})=[k_h]\). Under the above assumptions, there is a unique block \(B_{h_v}\) in \(\widetilde{\varepsilon }_h\) connecting two index consecutive elements and such that \(L_{\widetilde{\varepsilon }_h}(B_{h_v})=k_h\). Thus, \(B_{h_v}\) can be chosen in \((2k_h-1)\) ways, and the same argument holds for \(\widetilde{\varepsilon }_h{\setminus } \{B_{h_v}\}\). Consequently, an iteration procedure gives that \(|{{\mathcal {A}}}_{q_h,k_h+1}|=(2k_h-1)!!\). Recalling that \(A_n:=\frac{(2n-1)!!}{n!}\) is the 2nth moment of the standard arcsine law [18, 22], one has
Therefore, the moment generating function for the measure \(\nu \) is
in its set of convergence. After replacing any \(\pi ^{(j)}\in V(n)\) with its corresponding composition \((q_1,\ldots ,q_j)\) of n, the identity \(z^n=\prod _{h=1}^j z^{q_h}\) allows to reduce the right hand side as follows
and q denotes any of the \(q_h\), \(h=1,\ldots ,j\). This means that
where
As \(\frac{A_{k}}{k+1}=\frac{C_{k}}{2^k}\), \((C_k)\) being as usual the Catalan sequence, one has
and in the last equality we used the well known identity
(see, e.g. [12]). Recalling that the moment generating function of the standard Wigner law is
(see, e.g. [8]), it turns out that
From (4.5), after taking into account that \(\lim _{z\rightarrow 0} {{\mathcal {F}}}_{\nu _\lambda }(z)= 1\), one has that the moment generating function is
The previous formula represents the Cauchy transform of the free Meixner law with parameters \(\displaystyle \bigg (\lambda ,\frac{1}{2},2,0\bigg )\). Thus,
has two real roots \(x_1=\lambda -\sqrt{\lambda ^2+2}\), and \(x_2=\lambda +\sqrt{\lambda ^2+2}\). By (2.12), one finds \(\gamma _1=0\) and \(\gamma _2=\frac{\lambda }{\sqrt{\lambda ^2+2}}\).
As a consequence, from (2.11) and (2.10) one has (4.1) and (4.2). \(\square \)
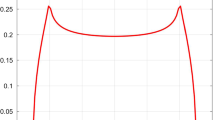
In Fig. 5 we report the plots of \(\nu _\lambda \) for \(\lambda =1\) and \(\lambda =4\).

Limit distribution for \(\lambda =1\) and \(\lambda =4\)
5 The Case of Monotone Fock Space
The previously achieved results can be translated, up to modifications, to the case of monotone Fock space. Some of the following properties have been already presented in [20]. We add them here for the sake of completeness, and to emphasise their role in our approach.
For our aim it appears at first useful to recall some notions about discrete monotone Fock space, the reader being referred to [6, 7, 22] for further details.
Let \({{\mathcal {H}}}\) be a separable Hilbert space, and \((e_i)_{i\ge 1}\) a fixed orthonormal basis. The monotone Fock space over \({{\mathcal {H}}}\), in the sequel denoted by \({{\mathfrak {F}}}_{M}({{\mathcal {H}}})\), is the closed subspace of the full Fock space \({{\mathfrak {F}}}({{\mathcal {H}}})\) spanned by \(\Omega \), \({{\mathcal {H}}}\) and all the simple tensors of the form \(e_{i_k}\otimes e_{i_{k-1}}\otimes \cdots \otimes e_{i_1}\), where \(i_k> i_{k-1}>\cdots > i_1\), and \(k\ge 2\). Let \((i_1,i_2,\ldots ,i_k)\) be a strictly decreasing sequence of natural integers. The generic element of the canonical basis of \({{\mathfrak {F}}}_M\) is denoted by \(e_{(i_1,i_2,\ldots ,i_k)}\). Very often, we write \(e_{(i)}\) as \(e_i\) to simplify the notations. The monotone creation and annihilation operators with test function \(e_i\) for any \(i\in \mathbb {N}\), are denoted by \(a^\dag _i:=a^\dag (e_i)\) and \(a_i:=a(e_i)\), respectively. They are given by \(a^\dag _i\Omega =e_i\), \(a_i\Omega =0\) and
One can check that both \(a^\dagger _i\) and \(a_i\) have unital norm, are mutually adjoint, and satisfy the following relations
As in the weakly monotone case, we introduce the preservation operator \(a_i^0:=a_i^\dag a_i\), \(i\in {{\mathbb {N}}}\), and recall that Lemma 5.4 in [6] gives
where
and further, for \(j\le k\)
We deal with the distribution in the vacuum state of the operator
where \(m\ge 1\), \(\lambda >0\) and \(\lambda _m:=\lambda \sqrt{m}\). As usual, the law of \(P_m(\lambda _m)\) is determined by the moments, and we introduce the following notation
We start from the case \(m=1\).
Proposition 5.1
For any \(\lambda >0\) the vacuum distribution of \(P_1(\lambda )\) is the two-points law
Proof
Fix \(\lambda >0\). The definition of monotone creation and annihilation operators gives the following Jacobi matrix representation for \(P_1(\lambda )\)
w.r.t. the canonical basis. Consequently, as in [2] we can write down the Cauchy transform \(\mathcal {C}_{1,\lambda }\) of the vacuum law of \(P_1(\lambda )\)
Finally, (5.2) follows as \(\mathcal {C}_{1,\lambda }(z)\) has two simple poles in \(\frac{\lambda \pm \sqrt{\lambda ^2+4}}{2}\), and
where \(z_0:=\frac{\lambda \pm \sqrt{\lambda ^2+4}}{2}\). \(\square \)
Notice that for \(n\ge 2\), \(g_{1,n}(1)\) is the Fibonacci sequence. For the general case covering the circumstance \(m\ge 2\), we have the analogue of Theorem 3.5. As usual, \(g_{m,0}(\lambda _m)=1\), and \(g_{m,1}(\lambda _m)=0\) for any \(m\ge 1\).
Proposition 5.2
For each \(m\ge 1\), \(n\ge 2\) and \(\lambda >0\) one has
where \(|\varepsilon |_0\) denotes the number of singletons in the partition \(\varepsilon \). In addition, the following recursion formula holds
where for each \(j=1,\ldots , k-2\), \(\widetilde{g}_{m-l+1,k-2-j}(\lambda _m)\) is defined as
Proof
Notice that (5.3) and (5.4) directly follow from (3.9) and (3.10), respectively. In fact, as a consequence of (5.1), for any n the nonvanishing partitions are those \(\pi :=\{B_1,\ldots ,B_p\}\in ANC^{wm}([m],n)\) for which \(L(B_i)<L(B_j)\) when \(|B_i|=|B_j|=2\), and \(\mathrm{min}B_i<\mathrm{min}B_j<\max B_j<\max B_i\), i.e. the partitions belonging to \(ANC^{m}([m],n)\). \(\square \)
In the next lines we show that the rescaled sums of nonsymmetric position operators in the monotone case weakly converge in the vacuum state to the same limit distribution \(\nu _\lambda \) found in the weakly monotone case. This exactly reflects what occurs in the symmetric case, where the standard arcsine law is the central limit distribution for position operators both in monotone [22] and in the weakly monotone [8] cases.
Theorem 5.3
For any \(\lambda >0\), the vacuum law of \(\displaystyle \frac{P_m(\lambda _m)}{\sqrt{m}}\) weakly converges for \(m\rightarrow \infty \) to the distribution \(\nu _\lambda \) given in (4.1) and (4.2).
Proof
Indeed, one obtains the same result of Theorem 4.1. This is achieved using the arguments developed in its proof, and taking into account that:
-
(1)
the labels for singletons in the monotone and weakly monotone cases satisfy the same bounds,
-
(2)
under the notations introduced in the proof of Theorem 4.1, when \(l=k_h+1\), for \(h=1,\ldots , j\) and \(j=1,\dots , [\frac{n}{2}]\), the same partitions are involved for both weakly monotone and monotone label functions.
\(\square \)
Data availability statement
Data sharing not applicable to this article as no datasets were generated or analysed during the current study.
Notes
Which happens to be periodic in this particular example.
References
Accardi, L., Bach, A.: The harmonic oscillator as quantum central limit of Bernoulli processes (preprint) (1985)
Akhiezer, N.I.: The Classical Moment Problem and Some Related Questions in Analysis. Hafner Publishing Co., New York (1965)
Arizmendi, O., Hasebe, T., Lehner, F., Vargas, C.: Relations between cumulants in noncommutative probability. Adv. Math. 282, 56–92 (2015)
Bernhart, F.R.: Catalan, Motzkin, and Riordan numbers. Discrete Math. 204, 73–112 (1999)
Bożejko, M., Leinert, M., Speicher, R.: Convolution and limit theorems for conditionally free random variables. Pacific J. Math. 175(2), 357–388 (1996)
Crismale, V., Fidaleo, F., Lu, Y.G.: Ergodic theorems in quantum probability: an application to monotone stochastic processes. Ann. Sci. Norm. Super. Pisa Cl. Sci. XVII, 113–141 (2017)
Crismale, V., Fidaleo, F., Lu, Y.G.: From discrete to continuous monotone C*-algebras via quantum central limit theorems. Infinite Dimensional Analysis, Quantum Probability and Related Topics, 20(2), 18 (2017). https://doi.org/10.1142/S0219025717500138
Crismale, V., Griseta, M.E., Wysoczański, J.: Weakly Monotone Fock space and Monotone convolution of the Wigner law. J. Theor. Probab. 33, 268–294 (2020)
Crismale, V., Lu, Y.G.: Rotation invariant interacting Fock spaces. Infin. Dimens. Anal. Quantum Probab. Relat. Top. 10, 211–235 (2007)
Crismale, V., Lu, Y.G.: Vacuum distribution, norm and spectral properties for sums of monotone position operators. J. Oper. Theory 83, 495–515 (2020)
Flajolet, F.: Combinatorial aspects of continued fractions. Discrete Math. 32, 125–161 (1980)
Graham, R., Knuth, D.E., Patashnik, O.: Concrete Mathematics. Addison-Wesley, Reading (1989)
Hasebe, T., Saigo, H.: The monotone cumulants. Ann. Inst. Henri Poincaré Probab. Stat. 47(4), 1160–1170 (2011)
Hora, A., Obata, N.: Quantum Probability and Spectral Analysis of Graphs. Theoretical and Mathematical Physics. Springer, Berlin (2007)
Hudson, R.L., Parthasarathy, K.R.: Quantum Ito’s formula and stochastic evolutions. Commun. Math. Phys. 93(3), 301–323 (1984)
Kula, A., Wojtylak, M., Wysoczański, J.: Rank two perturbations of matrices and operators and operator model for t-transformation of probability measures. J. Funct. Anal. 272(3), 1147–1181 (2017)
Kula, A., Wysoczański, J.: Noncommutative Brownian motions indexed by partially ordered sets. Infin. Dimens. Anal. Quantum Probab. Relat. Top. 13(4), 629–661 (2010)
Lu, Y.G.: An interacting free Fock space and the arcsine law. Prob. Math. Stat. 17, 149–166 (1997)
Muraki, N.: Noncommutative Brownian motion in monotone Fock space. Commun. Math. Phys. 183(3), 557–570 (1997)
Muraki, N.: Analogue of Poisson distribution in monotone Fock space (preprint) (1999)
Muraki, N.: Monotonic convolution and monotonic Lévy-Hinčin formula (preprint) (2000)
Muraki, N.: Monotonic independence, monotonic central limit theorem and monotonic law of small numbers. Infin. Dimens. Anal. Quantum Probab. Relat. Top. 4(1), 39–58 (2001)
Muraki, N.: The five independences as quasi-universal products. Infin. Dimens. Anal. Quantum Probab. Relat. Top. 5(1), 113–134 (2002)
Saitoh, N., Yoshida, H.: The infinite divisibility and orthogonal polynomials with a constant recursion formula in free probability theory. Prob. Math. Stat. 21, 159–170 (2001)
Sapounakis, A., Tsikouras, P.: On k-colored Motzkin words. J. Integer Seq. 7 (2004)
Speicher, R.: A new example of independence and white noise. Probab. Theory Relat. Fields 84(2), 141–159 (1990)
Speicher, R.: On Universal Products. Free Probability Theory (Waterloo, ON, 1995). Fields Inst. Commun. vol. 12, pp. 257–266. Amer. Math. Soc., Providence (1997)
Wysoczański, J.: Monotonic independence on the weakly monotone Fock space and related Poisson type theorem. Infin. Dimens. Anal. Quantum Probab. Relat. Top. 8(2), 259–275 (2005)
Acknowledgements
V. Crismale and M. E. Griseta kindly acknowledge the support of the italian INDAM-GNAMPA and Fondi di Ateneo Università di Bari “Probabilità Quantistica e Applicazioni”. V. Crismale also aknowledges the FFABR project of italian MIUR. J. Wysoczański kindly aknowledges the support of the Polish National Center for Science grant 2016/21/B/ST1/00628.
Funding
Open access funding provided by Universitá degli Studi di Bari Aldo Moro within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Christian Le Merdy.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the topical collection “Infinite-dimensional Analysis and Non-commutative Theory” edited by Marek Bozejko, Palle Jorgensen and Yuri Kondratiev.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Crismale, V., Griseta, M.E. & Wysoczański, J. Distributions for Nonsymmetric Monotone and Weakly Monotone Position Operators. Complex Anal. Oper. Theory 15, 101 (2021). https://doi.org/10.1007/s11785-021-01146-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11785-021-01146-y
Keywords
- Noncommutative probability
- Weakly monotone Fock space
- Noncrossing labeled partitions
- Combinatorics
- Motzkin and Riordan paths
- Poisson limit theorem