
Abstract
This paper presents a novel model-free method to solve linear quadratic (LQ) mean-field control problems with one-dimensional state space and multiplicative noise. The focus is on the infinite horizon LQ setting, where the conditions for solution either stabilization or optimization can be formulated as two algebraic Riccati equations (AREs). The proposed approach leverages the integral reinforcement learning technique to iteratively solve the drift-coefficient-dependent stochastic ARE (SARE) and other indefinite ARE, without requiring knowledge of the system dynamics. A numerical example is given to demonstrate the effectiveness of the proposed algorithm.



Similar content being viewed by others
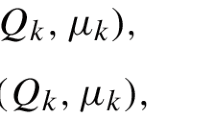

Data availability
In this article only numerical simulations are performed and no data from other repositories are used.
References
Lasry, J.-M., & Lions, P.-L. (2006). Jeux à champ moyen. I-Le cas stationnaire. Comptes Rendus Mathématique, 343(9), 619–625.
Lasry, J.-M., & Lions, P.-L. (2007). Mean field games. Japanese Journal of Mathematics, 2(1), 229–260.
Huang, M., Malhamé, R. P., & Caines, P. E. (2006). Large population stochastic dynamic games: Closed-loop Mckean–Vlasov systems and the Nash certainty equivalence principle. Communications in Information and Systems, 6(3), 221–252.
Huang, M., Caines, P. E., & Malhamé, R. P. (2007). Large-population cost-coupled LQG problems with nonuniform agents: Individual-mass behavior and decentralized \(\varepsilon \)-Nash equilibria. IEEE Transactions on Automatic Control, 52(9), 1560–1571.
Tembine, H., Le Boudec, J.-Y., El-Azouzi, R., & Altman, E. (2009). Mean field asymptotics of Markov decision evolutionary games and teams. In 2009 International conference on game theory for networks, pp. 140–150. IEEE.
Nourian, M., Caines, P. E., Malhame, R. P., & Huang, M. (2013). Nash, social and centralized solutions to consensus problems via mean field control theory. IEEE Transactions on Automatic Control, 58(3), 639–653.
Huang, M., Caines, P. E., & Malhamé, R. P. (2012). Social optima in mean field LQG control: Centralized and decentralized strategies. IEEE Transactions on Automatic Control, 57(7), 1736–1751.
Arabneydi, J., & Mahajan, A. (2015). Team-optimal solution of finite number of mean-field coupled LQG subsystems. In 2015 54th IEEE conference on decision and control (CDC), pp. 5308–5313. IEEE.
Wang, B.-C., & Zhang, J.-F. (2017). Social optima in mean field linear-quadratic-gaussian models with Markov jump parameters. SIAM Journal on Control and Optimization, 55(1), 429–456.
Huang, M., & Nguyen, S. L. (2016). Linear-quadratic mean field teams with a major agent. In 2016 IEEE 55th conference on decision and control (CDC), pp. 6958–6963. IEEE.
Wang, B.-C., Zhang, H., & Zhang, J.-F. (2020). Mean field linear-quadratic control: Uniform stabilization and social optimality. Automatica, 121, 109088.
Huang, M., & Yang, X. (2021). Linear quadratic mean field games: Decentralized O(1/N)-Nash equilibria. Journal of Systems Science and Complexity, 34(5), 2003–2035.
Du, K., & Wu, Z. (2022). Social optima in mean field linear-quadratic-gaussian models with control input constraint. Systems and Control Letters, 162, 105174.
Guo, X., Hu, A., Xu, R., & Zhang, J. (2019). Learning mean-field games. Advances in Neural Information Processing Systems. (Vol. 32). Curran Associates.
Anahtarci, B., Kariksiz, C. D., & Saldi, N. (2019). Fitted Q-learning in mean-field games. arXiv:1912.13309
Cui, K., & Koeppl, H. (2021). Approximately solving mean field games via entropy-regularized deep reinforcement learning. In International conference on artificial intelligence and statistics, pp. 1909–1917. PMLR.
Perrin, S., Laurière, M., Pérolat, J., Geist, M., Élie, R., & Pietquin, O. (2021). Mean field games flock! The reinforcement learning way. arXiv:2105.07933
Angiuli, A., Fouque, J.-P., & Laurière, M. (2022). Unified reinforcement Q-learning for mean field game and control problems. Mathematics of Control, Signals, and Systems, 34(2), 217–271.
Carmona, R., Laurière, M., & Tan, Z. (2019). Linear-quadratic mean-field reinforcement learning: convergence of policy gradient methods. arXiv:1910.04295.
uz Zaman, M. A., Zhang, K., Miehling, E., & Başar, T. (2020). Reinforcement learning in non-stationary discrete-time linear-quadratic mean-field games. In 2020 59th IEEE conference on decision and control (CDC), pp. 2278–2284. IEEE.
uz Zaman, M. A., Miehling, E., & Başar, T. (2023). Reinforcement learning for non-stationary discrete-time linear-quadratic mean-field games in multiple populations. Dynamic Games and Applications, 13(1), 118–164.
Xu, Z., & Shen, T. (2023). Decentralized \(\varepsilon \)-Nash strategy for linear quadratic mean field games using a successive approximation approach. Asian Journal of Control., 26(2), 565–574 https://doi.org/10.1002/asjc.3085.
Xu, Z., Shen, T., & Huang, M. (2023). Model-free policy iteration approach to NCE-based strategy design for linear quadratic gaussian games. Automatica, 155, 111162.
Wang, B.-C., & Zhang, H. (2020). Indefinite linear quadratic mean field social control problems with multiplicative noise. IEEE Transactions on Automatic Control, 66(11), 5221–5236.
Kizilkale, A. C., Salhab, R., & Malhamé, R. P. (2019). An integral control formulation of mean field game based large scale coordination of loads in smart grids. Automatica, 100, 312–322.
Gohberg, I., Lancaster, P., & Rodman, L. (1986). On Hermitian solutions of the symmetric algebraic Riccati equation. SIAM Journal on Control and Optimization, 24(6), 1323–1334.
Rami, M. A., & Zhou, X. Y. (2000). Linear matrix inequalities, Riccati equations, and indefinite stochastic linear quadratic controls. IEEE Transactions on Automatic Control, 45(6), 1131–1143.
Jiang, Y., & Jiang, Z.-P. (2012). Computational adaptive optimal control for continuous-time linear systems with completely unknown dynamics. Automatica, 48(10), 2699–2704.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Proof of Lemma 2
Convergence result of \(k_j\) follows with convergence of \(p_j\) by (11). To complete the proof, the rest is to show that \(\lim _{j\rightarrow \infty }p_j=p\). To this end, we first show that for all \(j\in {\mathbb {N}}_+\), \(p_j\) is a unique positive solution of Eq. (9) and \(k_j\) is a stabilizer.
If \(j\ge 1\), suppose that \(p_j\) is a unique positive solution of (9) and \(k_{j-1}\) is a stabilizer. Then, by (9)–(11), we obtain
Followed with the induction assumption and the fact \(q>0\), it is immediately concluded that \(K_j\) is a stabilizer by [27, Theorem 1]. Moreover, the Lyapunov function (9) with \(j=j+1\), rewritten by
admits a unique solution \(p_{j+1}>0\), since \(q_j>0\).
Then, we subtract (9) from (4) to obtain
Since \(k_{j-1}\) is a stabilizer and \((k_{j-1}-k)^2\ge 0\), the above equation admits a unique solution \(p_j-p\ge 0\), i.e., \(p_j\ge p\), \(j=1,2,\ldots \).
By (A1) and (9) with \(j=j+1\), we obtain
followed with the obtained result that \(k_j\) is a stabilizer and \((r+d^2p_j)(k_{j_1}-k_{j})^2\ge 0\), which implies \(p_{j}\le p_{j+1}\), \(j=1,2,\ldots \).
Therefore, \(\{p_j\}_1^{\infty }\) is monotonically decreasing sequence and has a lower bound. Combing with that (p, k) satisfies (9), it can be concluded that \(\lim _{j\rightarrow \infty }p_j=p\).
Appendix B: Proof of Lemma 3
Convergence result of \(k_s^j\) follows with convergence of \(p_j\) by (11). To complete the proof, the rest is to show that \(\lim _{j\rightarrow \infty }p_j=p\). We show the result by mathematical induction.
If \(j=1\), as \(a-bk<0\) and \(k_s^0=0\), \({\tilde{a}}_1<0\). One has
We subtract the above equation from (12) with \(j=1\) to obtain
which yields \(s_1\ge s\) as \(\upsilon >0\).
combining with \(\upsilon (k_s^1)^2+\upsilon (k_s-k_s^1)^2>0\), which yields \({\tilde{a}}_1<0\).
If \(j>1\), we suppose that \({\tilde{a}}_{j-1}\) is Hurwitz. Subtracting (B5) from (12) yields
By the induction assumption, we known that \(s_j\ge s\).
The above equation can be changed into
which yields \({\tilde{a}}_{j}<0\).
combining with the obtained result, which implies \(s_{j+1}\) \(\le s_j\).
Hence, \(\{s_j\}_1^{\infty }\) is monotonically decreasing sequence and has a lower bound s, leading to \(\lim \limits _{j\rightarrow \infty }s_j=s\).
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Xu, Z., Shen, T. Model-free method for LQ mean-field social control problems with one-dimensional state space. Control Theory Technol. (2024). https://doi.org/10.1007/s11768-024-00210-0
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11768-024-00210-0