
Abstract
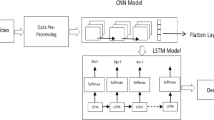
Visual Speech Recognition (VSR) is an appealing technology for predicting and analyzing spoken language based on lip movements. Previous research in this area has primarily concentrated on leveraging both audio and visual cues to achieve enhanced accuracy in speech recognition. However, existing solutions encounter significant limitations, including inadequate training data, variations in speech patterns, and similar homophones, which need more comprehensive feature representation to improve accuracy. This article presents a novel deep learning model for performing word level VSR. In this study, we have introduced a dynamic learning rate scheduler to adapt the learning parameter during model training. Additionally, we employ an optimized Three-Dimensional Convolution Neural Network for extracting spatio-temporal features. To enhance context processing and ensure accurate mapping of input sequences to output sequences, we combine Bidirectional Long Short Term Memory with the CTC loss function. We have utilized the GRID dataset to assess word-level metrics, including Word Error Rate (WER) and Word Recognition Rate (WRR). The model achieves 1.11% WER and 98.89% WRR, respectively, for overlapped speakers. This result demonstrates that our strategy outperforms and is more effective than existing VSR methods. Practical Implications - The proposed work aims to elevate the accuracy of VSR, facilitating its seamless integration into real-time applications. The VSR model finds applications in liveness detection for person authentication, improving password security by not relying on written or spoken passcodes, underwater communications and aiding individuals with hearing and speech impairments in the medical field.












Similar content being viewed by others


Data availability
No datasets were generated or analysed during the current study.
References
Wand, M., Schmidhuber, J., Vu, N.T.: Investigations on end-to-end audiovisual fusion, In: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 3041–3045, IEEE, (2018)
Afouras, T., Chung, J.S., Senior, A., Vinyals, O., Zisserman, A.: Deep audio-visual speech recognition. IEEE Trans. Pattern Anal. Mach. Intell. 44(12), 8717–8727 (2018)
Assael,Y.M., Shillingford, B., Whiteson, S., De Freitas, N.: Lipnet: End-to-end sentence-level lipreading, arXiv preprint arXiv:1611.01599, (2016)
Xu, K., Li, D., Cassimatis, N., Wang, X.: Lcanet: End-to-end lipreading with cascaded attention-ctc, in 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), 548–555, IEEE, (2018)
Yousaf, K., Mehmood, Z., Saba, T. , Rehman, A., Rashid, M., Altaf, M., Shuguang, Z.: A novel technique for speech recognition and visualization based mobile application to support two-way communication between deaf-mute and normal peoples. Wirel. Commun. Mob. Comput., 2018, (2018)
Thanda, A., Venkatesan, S.M.: Multi-task learning of deep neural networks for audio visual automatic speech recognition, arXiv preprint arXiv:1701.02477, (2017)
Kumar, L.A., Renuka, D.K., Rose, S.L., Shunmugapriya, M.: Attention based multi modal learning for audio visual speech recognition. In: 2022 4th International Conference on Artificial Intelligence and Speech Technology (AIST), 1–4, IEEE, (2022)
Liu, Y.-F., Lin, C.-Y., Guo, J.-M.: Impact of the lips for biometrics. IEEE Trans. Image Process. 21(6), 3092–3101 (2012)
Liu, M., Wang, L., Lee, K.A., Zhang, H., Zeng, C., Dang, J.: Deeplip: A benchmark for deep learning-based audio-visual lip biometrics. In: 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 122–129, IEEE, (2021)
Sankar, S., Beautemps, D., Hueber, T.: Multistream neural architectures for cued speech recognition using a pre-trained visual feature extractor and constrained ctc decoding. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 8477–8481, IEEE, (2022)
Wang, X., Han, Z., Wang, J., Guo, M.: Speech recognition system based on visual feature for the hearing impaired. In 2008 Fourth International Conference on Natural Computation, 2, 543–546, IEEE, (2008)
Hassanat, A.B.: Visual passwords using automatic lip reading, arXiv preprint arXiv:1409.0924, (2014)
Sadeghi, M., Leglaive, S., Alameda-Pineda, X., Girin, L., Horaud, R.: Audio-visual speech enhancement using conditional variational auto-encoders. IEEE/ACM Trans. Audio, Speech, Lang. Process. 28, 1788–1800 (2020)
Viola, P., Jones, M.: Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE computer society conference on computer vision and pattern recognition. CVPR 2001, 1, I–I, Ieee, (2001)
Schuster, M., Paliwal, K.K.: Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 45(11), 2673–2681 (1997)
Graves, A., Fernández, S., Gomez, F., Schmidhuber, J.: Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In: Proceedings of the 23rd international conference on Machine learning, 369–376, (2006)
Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., Bengio, Y.: Learning phrase representations using rnn encoder-decoder for statistical machine translation, arXiv preprint arXiv:1406.1078, (2014)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Chung, J.S., Senior, A., Vinyals, O., Zisserman, A.: Lip reading sentences in the wild. In 2017 IEEE conference on computer vision and pattern recognition (CVPR), 3444–3453, IEEE, (2017)
Yang, S., Zhang, Y., Feng, D., Yang, M., Wang, C., Xiao, J., Long, K., Shan, S., Chen, X.: Lrw-1000: A naturally-distributed large-scale benchmark for lip reading in the wild. In: 2019 14th IEEE international conference on automatic face & gesture recognition (FG 2019), 1–8, IEEE, (2019)
Matthews, I., Cootes, T.F., Bangham, J.A., Cox, S., Harvey, R.: Extraction of visual features for lipreading. IEEE Trans. Pattern Anal. Mach. Intell. 24(2), 198–213 (2002)
Liu, H., Zhang, X., Wu, P.: Regression based landmark estimation and multi-feature fusion for visual speech recognition. In: 2015 IEEE International Conference on Image Processing (ICIP), 808–812, IEEE, (2015)
Afouras, T., Chung, J.S., Zisserman, A.: Lrs3-ted: a large-scale dataset for visual speech recognition, arXiv preprint arXiv:1809.00496, (2018)
Rekik, A., Ben-Hamadou, A., Mahdi, W.: A new visual speech recognition approach for rgb-d cameras. In: Image Analysis and Recognition: 11th International Conference, ICIAR 2014, Vilamoura, Portugal, October 22-24, 2014, Proceedings, Part II 11, 21–28, Springer, (2014)
Nemani, P., Krishna, G.S., Ramisetty, N., Sai, B.D.S., Kumar, S.: Deep learning based holistic speaker independent visual speech recognition, IEEE Transactions on Artificial Intelligence, (2022)
Petridis, S., Shen, J., Cetin, D., Pantic, M.: Visual-only recognition of normal, whispered and silent speech. In: 2018 ieee international conference on acoustics, speech and signal processing (icassp), 6219–6223, IEEE, (2018)
Anina, I., Zhou, Z., Zhao, G., Pietikäinen, M.: Ouluvs2: A multi-view audiovisual database for non-rigid mouth motion analysis. In 2015 11th IEEE international conference and workshops on automatic face and gesture recognition (FG), 1, 1–5, IEEE, (2015)
Cooke, M., Barker, J., Cunningham, S., Shao, X.: An audio-visual corpus for speech perception and automatic speech recognition. The J. Acoust. Soc. Am. 120(5), 2421–2424 (2006)
Petridis, S., Pantic, M.: Deep complementary bottleneck features for visual speech recognition. In: 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2304–2308, IEEE, (2016)
Garg, A., Noyola, J., Bagadia, S.: Lip reading using cnn and lstm, Technical report, Stanford University, CS231 n project report, (2016)
Wang, C.: Multi-grained spatio-temporal modeling for lip-reading, arXiv preprint arXiv:1908.11618, (2019)
Stafylakis, T., Tzimiropoulos, G.: Deep word embeddings for visual speech recognition. In: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 4974–4978, IEEE, (2018)
Liu, J., Ren, Y., Zhao, Z., Zhang, C., Huai, B., Yuan, J.: Fastlr: Non-autoregressive lipreading model with integrate-and-fire. In: Proceedings of the 28th ACM International Conference on Multimedia, 4328–4336, (2020)
Debnath, S., Roy, P., Namasudra, S., Crespo, R.G.: Audio-visual automatic speech recognition towards education for disabilities. J. Autism Dev. Disord., 1–14, (2022)
Huang, H., Song, C., Ting, J., Tian, T., Hong, C., Di, Z., Gao, D.: A novel machine lip reading model. Proced. Comput. Sci. 199, 1432–1437 (2022)
Ma, P., Martinez, ., Petridis, S., Pantic, M.: Towards practical lipreading with distilled and efficient models. In: ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 7608–7612, IEEE, (2021)
He, L., Ding, B., Wang, H., Zhang, T.: An optimal 3d convolutional neural network based lipreading method. IET Image Process. 16(1), 113–122 (2022)
Rahmani, M.H., Almasganj, F.: Lip-reading via a dnn-hmm hybrid system using combination of the image-based and model-based features. In: 2017 3rd International Conference on Pattern Recognition and Image Analysis (IPRIA), 195–199, IEEE, (2017)
Zhao, X., Yang, S., Shan, S., Chen, X.: Mutual information maximization for effective lip reading. In: 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), 420–427, IEEE, (2020)
Ezz, M., Mostafa, A.M., Nasr, A.A.: A silent password recognition framework based on lip analysis. IEEE Access 8, 55354–55371 (2020)
Fenghour, S., Chen, D., Guo, K., Xiao, P.: Lip reading sentences using deep learning with only visual cues. IEEE Access 8, 215516–215530 (2020)
Martinez, B., Ma, P., Petridis, S., Pantic, M.: Lipreading using temporal convolutional networks. In: ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 6319–6323, IEEE, (2020)
Wand, M., Koutník, J., Schmidhuber, J.: Lipreading with long short-term memory. In: 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 6115–6119, IEEE, (2016)
Wand, M., Schmidhuber, J.: Improving speaker-independent lipreading with domain-adversarial training, arXiv preprint arXiv:1708.01565, (2017)
Rastogi,A. Agarwal,R., Gupta,V., Dhar,J., Bhattacharya,M.: Lrneunet: An attention based deep architecture for lipreading from multitudinous sized videos, in 2019 International Conference on Computing, Power and Communication Technologies (GUCON), 1001–1007, IEEE, 2019
Luo, M., Yang, S., Shan, S., Chen, X.: Pseudo-convolutional policy gradient for sequence-to-sequence lip-reading. In: 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), 273–280, IEEE, (2020)
Sarhan, A.M., Elshennawy, N.M., Ibrahim, D.M.: Hlr-net: a hybrid lip-reading model based on deep convolutional neural networks. Comput. Mater. & Contin. 68(2), 1531–1549 (2021)
Vayadande, K., Adsare, T., Agrawal, N., Dharmik, T., Patil, A., Zod, S.: Lipreadnet: A deep learning approach to lip reading. In: 2023 International Conference on Applied Intelligence and Sustainable Computing (ICAISC), 1–6, IEEE, (2023)
NadeemHashmi, S., Gupta, H., Mittal, D., Kumar, K., Nanda, A., Gupta, S.: A lip reading model using cnn with batch normalization. In: 2018 eleventh international conference on contemporary computing (IC3), 1–6, IEEE, (2018)
Xue, F., Yang, T., Liu, K., Hong, Z., Cao, M., Guo, D., Hong, R.: Lcsnet: End-to-end lipreading with channel-aware feature selection. ACM Trans. Multimed. Comput., Commun. Appl. 19(1s), 1–21 (2023)
Almajai, I., Cox, S., Harvey, R., Lan, Y.: Improved speaker independent lip reading using speaker adaptive training and deep neural networks. In: 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2722–2726, IEEE, (2016)
Cooke, M., Barker, J., Cunningham, S., Shao, X.: The grid audiovisual sentence corpus. https://spandh.dcs.shef.ac.uk/gridcorpus/, (2006)
Nair, V., Hinton, G.E.: Rectified linear units improve restricted boltzmann machines. In: Proceedings of the 27th international conference on machine learning (ICML-10), 807–814, (2010)
Agarap, A.F.: Deep learning using rectified linear units (relu), arXiv preprint arXiv:1803.08375, (2018)
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., et al.: Imagenet large scale visual recognition challenge. Int. J. Comput. Vision 115, 211–252 (2015)
Maas, A.L., Hannun, A.Y., Ng, A.Y., et al.: Rectifier nonlinearities improve neural network acoustic models. In: Proc. icml, 30, 3, Atlanta, GA, (2013)
Khalil, K., Dey, B., Kumar, A., Bayoumi, M.: A reversible-logic based architecture for long short-term memory (lstm) network. In: 2021 IEEE International Symposium on Circuits and Systems (ISCAS), 1–5, IEEE, (2021)
Hinton, G.E., Srivastava, N., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.R.: Improving neural networks by preventing co-adaptation of feature detectors, arXiv preprint arXiv:1207.0580, (2012)
Acknowledgements
This research received institutional support from the National Institute of Technology Tiruchirappalli. We thank the institute for providing access to the high-performance supercomputer (PARAM PORUL) for this research work.
Author information
Authors and Affiliations
Contributions
In the development of this article, V.C. authored the manuscript, designed the figures and tables, and executed the crucial experiments. Concurrently, S.D. diligently reviewed the paper, ensuring its accuracy, and provided valuable guidance, contributing insightful suggestions to enhance the overall quality of the work.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Chandrabanshi, V., Domnic, S. A novel framework using 3D-CNN and BiLSTM model with dynamic learning rate scheduler for visual speech recognition. SIViP (2024). https://doi.org/10.1007/s11760-024-03245-7
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11760-024-03245-7