
Abstract
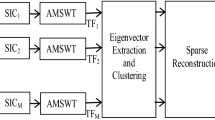
The aim of this article is estimating the number of simultaneous speakers from the overlapped speech signals. The percentage of correct number of speakers is an important factor for the proposed algorithm. The proposed method in this article is based on spectrum estimation by using the adaptive wavelet transform in combination with generalized eigenvalue–vector decomposition (GEVD) and K-means clustering. Firstly, the speech signals are obtained by a uniform circular array, and each adjacent microphone pairs are considered for the processing. Then, the spectral estimation method is implemented on all microphone signals to select the best part of the speech spectrum. Next, the microphone signals are divided into different subbands by using adaptive wavelet transform. The GEVD algorithm is implemented on each microphone pairs in different subbands and time frames to estimate the room impulse response and time difference of arrival (TDOA). Finally, the K-means clustering with silhouette criteria is used to estimate the number of speakers (K value). The proposed algorithm is implemented on simulated and real data to show the superiority of proposed method in comparison with PENS, Bessel, i-vector PLDA, Hilbert envelope and DNN-based method. The proposed scheme outperforms the other evaluated schemes by 18% in terms of correct estimations in noisy–reverberant conditions for five simultaneous speakers.








Similar content being viewed by others

References
Nakashima, H., Mukai, T.: 3D sound source localization system based on learning of binaural hearing. In: Proceedings of IEEE International Conference on Systems, Man, and Cybernetics (SMC), pp. 3534–3539 (2005)
Ikeda, A., Mizoguchi, H., Sasaki, Y., Enomoto, T., Kagami, S.: 2D sound source localization in azimuth and elevation from microphone array by using a directional pattern of element. In: Proceedings of IEEE Sensors, pp. 1213–1216 (2007)
Brandstein, M., Ward, D.: Microphone Arrays. Springer, Berlin (2001)
Han, K., Nehorai, A.: Improved source number detection and direction estimation with nested arrays and ULAs using jackknifing. IEEE Trans. Signal Process. 61(23), 6118–6128 (2013)
Arai, T.: Estimating number of speakers by the modulation characteristics of speech. In: Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 197–200 (2003)
Zwyssig, E., Renals, S., Lincoln, M.: Determining the number of speakers in a meeting using microphone array features. In: Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 4765–4768 (2012)
Swamy, R., Murty, K., Yegnanarayana, B.: Determining number of speakers from multispeaker speech signals using excitation source information. IEEE Signal Process. Lett. 14(7), 481–484 (2007)
Vinals, I., Gimeno, P., Ortega, A., Miguel, A., Lleida, E.: Estimation of the number of speakers with variational Bayesian PLDA in the DIHARD Diarization challenge. In: Proceedings of Interspeech 2018, pp. 2803–2807 (2018)
Sayoud, H., Ouamour, S.: Proposal of a new condense parameter estimating the number of speakers—an experimental investigation. J. Inf. Hiding Multimed. Signal Process. 1(2), 101–109 (2010)
Kumar, A., Balakrishna, P.V., Prakesh, C., Gangashetty, S.V.: Bessel features for estimating number of speakers from multispeaker speech signals. In: Proceedings of 18th International Conference on Systems, Signals and Image Processing (IWSSIP), pp. 1–4 (2011)
Stöter, F.R.; Chakrabarty, S., Edler, B., Habets, E.A.P.: Classification versus regression in supervised learning for single channel speaker count estimation. In: Proceedings of 43rd International Conference on Acoustics, Speech, and Signal Processing (ICASSP), pp. 436–440 (2018)
Maka, T., Lazoryszczak, M.: Detecting the number of speakers in speech mixtures by human and machine. In: Proceedings of 22nd Signal Processing, Algorithms, Architectures, Arrangements, and Applications (SPA), pp. 239–244 (2018)
Stöter, F.R., Chakrabarty, S., Edler, B., Habets, E.A.P.: CountNet: estimating the number of concurrent speakers using supervised learning. IEEE/ACM Trans. Audio Speech Lang. Process. 27(2), 268–282 (2019)
Rickard, S., Dietrich, F.: DOA estimation of many W-disjoint orthogonal sources from two mixtures using DUET. In: Proceedings of 10th IEEE Workshop on Statistical Signal and Array Processing (SSAP), pp. 311–314 (2000)
Santen, V., Sproat, J.: High-accuracy automatic segmentation. In: Proceedings of EUROSPEECH, pp. 2809–2812 (1999)
Dehghan Firoozabadi, A.: Extension and improvement of the methods for the localization of multiple simultaneous speech sources. PhD thesis, Electrical Engineering, Yazd University (2015)
Ghodrati Amiri, G., Asadi, A.: Comparison of different methods of wavelet and wavelet packet transform in processing ground motion records. Int. J. Civ. Eng. 7(4), 248–257 (2009)
Benesty, J.: Adaptive eigenvalue decomposition algorithm for passive acoustic source localization. J. Acoust. Soc. Am. 107(1), 384–391 (2000)
Peter, J.R.: Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 20, 53–65 (1987)
Garofolo, J.S., Lamel, L.F., Fisher, W.M., Fiscus, J.G., Pallett, D.S., Dahlgren, N.L., Zue, V.: TIMIT acoustic-phonetic continuous speech corpus LDC93S1. Web Download. Linguistic Data Consortium, Philadelphia. https://catalog.ldc.upenn.edu/LDC93S1. Accessed 20 May 2019
Cetin, O., Shriberg, E.: Analysis of overlaps in meetings by dialog factors, hot spots, speakers, and collection site: insights for automatic speech recognition. In: Proceedings of Interspeech, pp. 293–296 (2006)
Allen, J., Berkley, D.: Image method for efficiently simulating small-room acoustics. J. Acoust. Soc. Am. 65(4), 943–950 (1979)
Acknowledgements
The authors acknowledge financial support from FONDECYT postdoctorado No. 3190147, FONDECYT Nos. 11180107, 11160517.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Dehghan Firoozabadi, A., Irarrazaval, P., Adasme, P. et al. A novel method for estimating the number of speakers based on generalized eigenvalue–vector decomposition and adaptive wavelet transform by using K-means clustering. SIViP 14, 1017–1025 (2020). https://doi.org/10.1007/s11760-020-01634-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-020-01634-2