
Abstract
Production environments bring inherent system challenges that are reflected in the high-dimensional production data. The data is often nonstationary, is not available in sufficient size and quality, and is class imbalanced due to the predominance of good parts. Data-driven manufacturing analytics requires data of sufficient quantity and quality. In order to predict quality characteristics, production data is collected across processes in the industrial use case at Bosch Rexroth AG for the purpose of inferring results in hydraulic final inspection using machine learning methods. Since high quality data generation is costly, synthetic data generation methodologies offer a promising alternative to improve prediction models and thus generate safer, more accurate predictions for manufacturing companies. Among the synthetic data generation methodologies used, variational autoencoders compared to generative adversarial networks and synthetic minority oversampling technique methods are best suited to synthesize the feature with highest feature importance from a small sample data set compared to the production data and improve the prediction for the target variable.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Data-driven analytics are moving into the workplace across domains due to great potential benefits [1]. Manufacturing companies have recognized this potential, but face high variant diversity and short product life cycles [2]. Dynamic production environments generate data sets whose variables behave in a non-stationary manner [3,4,5]. Without adaptations, machine learning models are not transferable from one product variant to another. The situation is similar with manufacturing systems in dynamic environments [6]. This often leads to data sets with small sample sizes for the different problems within manufacturing. The installation of additional sensor technology in existing manufacturing systems is time-consuming, often associated with high costs and sometimes technically not feasible at all [7]. Synthetic data generation offers a possibility to artificially enlarge the data base and to increase the predictive power of machine learning models.
In manufacturing, predictive quality, predictive maintenance and the prediction of process parameters are the most significant fields of application of machine learning methods [8]. Predictive quality control is attributed the greatest importance at German manufacturing companies [2]. Predictive quality is predominantly processed with supervised learning, in which an approximation function between the input and output data is derived from the training data [9]. If the number of input data is too small, the model does not generalize properly to predict future data points accurately enough. Adding artificial data points helps filling data gaps between existing data points by suggesting similar points based on the learned points. For tabular data, variational autoencoders (VAE), generative adversarial networks (GAN) and synthetic minority oversampling technique (SMOTE) and their extensions are currently common methods to generate synthetic data [10]. The aim of this work is to achieve safe and accurate classifications for the target variable of the production dataset with synthetic data generation methods. The tabular production dataset has an imbalance class ratio between good part and defect part class, high dimensionality of input data, and time-instationary data. In order to cope with the class imbalance, SMOTE methods are also applied and combined with the synthetic data generation into different class ratios [10]. As a representative use case, the data along the value chain of hydraulic directional control valves are used to make predictions of test results in final testing. The following research questions are investigated:
-
Which data generation methods achieve the best representation of the original data set with large class imbalance?
-
Which combination of oversampling and synthetic data generation methods is most successful for tabular data of directional control valves?
-
How much benefit in terms of accuracy gain is achieved from synthetic data generation in ratio of computation time used and model size?
2 Synthetic data generation and oversampling for imbalanced, tabular production data
In the field of medicine, bioinformatics, information technology, software fault detection, and also in manufacturing, real-world data sets are often given as values in a continuous spectrum and a tabular arrangement (instances:features) [11]. Real data sets almost always contain the problem of imbalanced distribution of features as well as of the target variable [12]. Here, synthetic data generation methods provide a standard method to address the imbalance. Furthermore, production systems are dynamic, so that the numerous changes in the system are also reflected in the data by concept drifts [10]. According to Sun et al. the SMOTE, VAE, and GAN methods with the appropriate extensions best solve the problem of class imbalance in multivariable, tabular, nonstationary data sets [10]. In the following, the competing basic methods for synthetic data generation are explained, which perform with different accuracy among themselves depending on the use case.
A row of data points contains numerical, continuous features. To combat the class imbalance of target variables, there are generally methods of oversampling for the minority class and undersampling of the majority class. Oversampling addresses class imbalance by creating more instances of the minority class, improving the model’s ability to learn patterns from underrepresented data. In contrast, undersampling reduces the majority class instances, which may lead to a loss of valuable information. Consequently, oversampling often yields better performance by preserving data diversity and allowing for a more robust understanding of minority class characteristics. Thus, oversampling is used in this work. In the development of almost all oversampling methods devised for imbalance learning, SMOTE is referenced as a basis [11]. As the oversampling of the minority class increases, similar and more importantly more specific regions in the feature space are identified as the decision region for the minority class. First, the total oversampling examples \(n \in \mathbb {N}\) are searched so that an approximate 1:1 class distribution is obtained. Fernández et al. describe the iterative process that follows, which consists of several steps [13]. First, a positive class instance is randomly selected from the training set. Second, its k-nearest neighbors (KNN) (by default 5) are determined. Finally, n of these k instances are randomly selected to compute the new instances by interpolation. For this purpose, the difference between the considered feature vector (data point) and each of the n neighbors is determined. This difference is multiplied by a random number between 0 and 1 and then added to the previous feature vector. [14] This results in the selection of a random point between the features. For nominal attributes, one of the two values is selected at random. [13]
Goodfellow et al. propose synthetic data generation with adversarial networks G and D, where the generator G and the discriminator D are each constructed from multilayer perceptrons (MLP) with parameters \(\theta _d\) and \(\theta _g\) [15]. To learn the distribution of the generator \(p_g\) over the data x, an estimate for the input noise variable \(p_z(z)\) is specified and subsequently a mapping to the data space is represented as \(G(z,\theta _g)\), where G is a differentiable function. The generator can use both the random noise and the distribution of the real samples to generate fake samples to simulate real samples. Both the real and the fake samples go into the discriminator. D(x) represents the probability that x is from the data and not from \(p_g\). D is trained to maximize the probability of assigning the correct label to both the training samples and the samples from G. [16] The optimization function V(D, G) to minimize G and maximize D is given in Eq. (1) [15]:
To avoid overfitting the optimization function, in practice G is not trained to minimize \(\log (1- D(G(z)))\), but to maximize \(\log D(G(z))\). This objective function leads to the same fixed point of the dynamics of G and D, but yields much stronger gradients at the beginning of learning. Promising further developments for 2D, tabular (instances: features) data are the conditional tabular GAN (CTGAN) [17] and CopulaGAN [18]. CopulaGAN is a variation of CTGAN provided by the SDV library [18, 19]. CTGAN are an extension of GAN with the characteristics of mode-specific normalization to combat non-Gaussian distributions, and conditional generator and training-by-sampling to counter imbalance in discrete columns [17].
A variational autoencoder (VAE) has a similar architecture to autoencoders, but is described mathematically very differently from autoencoders. Kingma and Welling introduced VAE as a derivation from the families of probabilistic graphical models and variational Bayesian methods [20]. Like GANs, autoencoders consist of a feedforward MLP, which in turn consists of two parts, the encoder and the decoder, defined as transitions. Variational autoencoders allow statistical inference problems to be rewritten as statistical optimization problems. Accordingly, deriving the value of a random variable from another random variable is possible by searching for the parameter values that minimize an objective or loss function. The observed input variable of an x-space is mapped to a latent z-space by learning a multivariate joint distribution \(p_\psi (x,z)\). That means the input data is sampled from a parameterized distribution \(p_\psi (z)\) (prior), and the encoder \(q_\phi (z\vert x)\) and decoder \(p_\psi (x\vert z)\) are trained together such that the output minimizes a reconstruction error between the parametric posterior and the true posterior. The optimization function is given in equation (2) [20]:
Xu et al. introduce VAE for tabular data (TVAE) by using the same architecture and preprocessing steps, but applied with adjusted loss function for tabular data sets which leads to improved performance on real tabular data sets [17].
3 Predictive quality control in hydraulic testing of directional control valves
To exploit the cost potential of predictive quality, data along the value chain of hydraulic directional control valves at the Bosch Rexroth plant in Homburg, Germany, is being used to predict final inspection results using machine learning techniques [21]. The use of multistage production data is a promising approach for predicting quality characteristics based on geometric gauge blocks from machining, mating data from assembly, and hydraulic sensor data from end-of-line testing [22].
The target variable of this use case is the internal leakage volume flow between the ring gap of piston and housing bore of a directional control valve, which is significantly smaller than 20 micrometers [7]. The upper limit of leakage is ensured in one of more than 60 test steps as a safety-critical product feature during the final hydraulic inspection. An increased leakage volume flow leads to an unintentionally faster lowering of the load and thus represents a safety risk. Leakage measurement takes place indirectly in the form of a pressure drop measurement at the pressure chamber of customer port, which is reduced by the leakage volume flow via the ring gap into the tank. Accordingly, all data points of the target variables are automatically labeled being sensor signals from the hydraulic testing bench. [23].
4 Experimental methodology
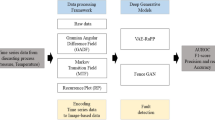
In the following applied research approach, the missing geometrical information in the production dataset should be minimized for developing a generalizing model through synthetic data generation. To create the experimental data set, experimental measurement runs were conducted that included complementary geometric gauge blocks from machining and other pairing data in addition to the information in the production data set. The overall objective is to find a correlation between the features of the production data set and the supplementary information from the experimental data set. These correlations are used to artificially augment the production data set with the final geometric dimensions of the bore. The series of measurements was generated with the same type of directional control valves on the same production machines and test bench. The most important feature for predicting gap leakage, in addition to the mixing temperature of all components and the fluid, is the gap height. The gap height is also temperature dependent. Due to its high predictive power, the aim is to approximate the gap height with higher information density from the experimental data set with a regression model and to make this generated feature available to the production data set. Figure 1 shows the workflow of synthetic data generation in this use case. In approach A, a meta regression model is developed to enhance the final classification of the target whereas in approach B the synthetic data are directly utilized for the final classification.

Workflow for synthetic data generation of the experimental dataset. Exemplary, the use of time-series CV is shown, although both approaches are additionally performed using stratified CV
To evaluate the results, the quality of the synthetically generated data is checked in several ways. Visual methods, such as viewing correlation plots (Fig. 2) and scatterplots of the first two principal components (Fig. 3), can be used to qualitatively evaluate how successfully the synthetic data generation approaches work in this use case. Not only the different data generation methods are compared with each other, but classifications for different good part/bad part ratios, so called imbalance ratios, are performed. Since only continuous features are considered in the data set, the two-sample Kolmogorov–Smirnov (KS) test is used to examine a statistical parameter that compares the empirical distribution functions of the original and synthetic data. The test statistic T describes the maximum distance between the empirical distribution functions of the two samples for one feature each. The statistical value \(1-T\) is determined, so that a value close to 1 indicates that the maximum distance T is small, i.e. the distribution functions are very similar. To calculate the test statistic, 50 data sets are sampled for each method and the KS test statistic is determined for each feature. Finally, the mean value of the test statistics is determined. In addition, a use case related analysis is performed in which the gap height is predicted by a regression model using the sensor data. Subsequently, it was determined which methods can improve the classification of the parts in the overall model the best. The goodness of classification for imbalanced datasets is surveyed with the metric F1 score.

Pairwise spearman correlation plots of the 75 features with the highest correlations for different generative models
5 Results
As described in the experimental methodology, the results for the different combinations are discussed. The correlation plots in Fig. 2 show the pairwise spearman correlations of all 276 features. The oversampling method SMOTE best preserves the correlations between features, but the generating method TVAE can also partially preserve them. The two GAN-based generating methods have correlations close to 0 for all variables. Similar patterns are also seen when SMOTE is combined with the generating procedures: In combination with CTGAN and CopulaGAN the correlations are lost, while in combinations with TVAE they are preserved.
Evaluating the scatterplots of the first two principal components in Fig. 3, only very small ranges of values for the two principal components are mapped by CTGAN and CopulaGAN. SMOTE and TVAE best represent the original data and additionally achieve a visible separation between the two leakage classes. SMOTE does a slightly better job at separating the two classes than TVAE, but SMOTE is less robust to outliers in the data. The explained variance in the first two principal components of the original data is \(18.07~\%\), with SMOTE \(20.02~\%\), and with TVAE \(17.65~\%\). For the CTGAN and CopulaGAN methods, it is only \(4.12~\%\) and \(3.72~\%\), respectively, which explains the differences for the other two methods.

Scatter plots of the first two principal components of the original data and synthetically generated data with a 1:1 good/bad distribution
Table 1 shows the results of the KS tests for each model configuration. The highest similarity to the original data is obtained with SMOTE. Of the three generative models, TVAE produces by far the most similar synthetic data. When SMOTE is combined with TVAE, the data is slightly less similar.
Random Forest regression was used for the gap height regression because it produces lower absolute mean errors (MAE) and results in higher \(R^2\) compared to other regression methods. Table 2 shows the MAE for training and testing of the regression for gap height in \(\mu\)m. The regression with the lowest test MAE is obtained using SMOTE. TVAE achieves the best results out of the generative models without oversampling. For both TVAE and CopulaGAN the use of SMOTE leads to an increase of the error, for CTGAN the combination with SMOTE leads to a significant decrease of the error.
In addition, Table 3 shows the \(R^2\) values for the different model configurations. Similar \(R^2\) values are obtained with SMOTE as with the original data. TVAE is the only one out of the three generative models, that can reliably produce a positive \(R^2\) value unless the procedure is combined with SMOTE.
Comparing the three methods another important criterion is the time needed to train the models and to sample new data. Three steps are defined for this purpose:
-
1.
training of the generative model with batch size = 100 and epochs = 300.
-
2.
sampling of synthetic data,
-
a.
\(n~=~465\) (size of the training data set)
-
b.
\(n~=~10000\)
-
a.
-
3.
developing the classification model
-
a)
without gap height regression (approach A),
-
b)
with gap height regression (approach B).
-
a)
The running times of the three steps are summarized in Table 4. By far, TVAE trains the fastest with about 267 s, and CopulaGAN trains the slowest with about 481.6 s. When sampling new data, TVAE is slightly faster than CTGAN, but CopulaGAN again takes by far the longest. The time difference becomes especially obvious when \(n~=~10000\) data are sampled instead of \(n~=~465\) data. Another big difference of the runtime can be identified for the two approaches without and with regression of the gap height: With regression, a run of the model takes up to 20.3 s, while it takes less than 0.4 s without regression.
TVAE is also the most efficient in terms of memory size of the trained models, as displayed in Table 5. While a TVAE model with \(n~=~465\) data points occupies about 1.6 MB of memory, it is significantly more for CTGAN and CopulaGAN. Applying SMOTE to the data set and then re-training the models with \(n~=~772\), the TVAE model becomes only slightly larger than SMOTE. But CTGAN and CopulaGAN models increase significantly in model size.
To validate the overall approach, good/bad predictions of the parts based on leakage are to be predicted using a XGBoost model for different configurations of the synthetic data. Time dependencies in the data are caused by state variables such as temperature, humidity, etc. Since the data in the production data set used in the final model have time dependencies, the behavior of the model in the case of a time dependency with a 10-fold time-series cross validation (CV) will be investigated in addition 10-fold stratified CV that is applied to the classification of the experimental data. This considers the sequence of data points so that information from the training data set does not recur in the test data. Table 6 shows the results for the good/bad prediction of the parts based on leakage. The results for the two CV strategies must be considered separately, since the time-series split considers the data distribution as it might be for real production data. With the stratified split, an embellished data distribution is considered, in which an approximately equal proportion of data on defective parts is present in each split. The used features of all models, except for the baselines, are the sensor features, as well as gap height, which is predicted based on a regression with the Random Forest regressor and a classification with XGBoost classifier. For stable results, F1 scores from approach A are the average of 10 models.
Regarding the following two baseline models, the large influence of the gap height on the F1 score of the classification becomes obvious. The first baseline with the gap height would be the optimal case, but there is no access to such geometric data in the production data set. Therefore, the gap height is predicted using a regression model. The second baseline, without gap height, thus represents the real baseline that is to be improved. Based on two approaches it shall be tested whether A) the regression of the gap height can improve the classification model based on the sensor data, or B) the addition of new data for the sensor data leads to an improvement of the model.
First, the second part of the Table 6 will be considered, where a regression of the gap height was performed in addition to the classification with XGBoost (approach A). The best F1 score of 0.2877 for this model using a time-series split is obtained by the prediction based on the CopulaGAN data with an imbalance ratio of 1:9. This is the only setting that can achieve an improvement even if it is very small. The other settings cannot achieve any improvements over the baseline, but the second and third best settings here are CopulaGAN with 1:2 imbalance ratio and TVAE with 1:1 imbalance ratio. Nevertheless, the models with the use of synthetic data are almost all better than with the regression is run on the original data only, since the F1 score of only about 0.196 is achieved.
Regarding the corresponding results for the stratified CV, the best F1 score of of 0.4464 is achieved by using SMOTE. Also the combinations of TVAE with imbalance ratio of 1:1 and 1:2 give good results, as well as the combination of SMOTE and TVAE. Comparing the results of the two training strategies for approach A, SMOTE provides significantly better results for a stratified CV than time-series CV.
Overall, especially for a later application in a production data set with a time-series CV, the combination of gap height regression and classification does not provide a suitable approach. Since the gap height is the most important feature of the data set, a (not perfect) regression of this feature can strongly lead to a deterioration of the F1 score. The regression introduces an additional layer of complexity, since the regression model performs differently good depending on the hyperparameters and the seed. In addition, no correlation between the improvement of the regression and the goodness of the classification model could be identified.
For this reason, a second approach is followed in which synthetic data are only added to the original data set in order to improve the classification model (approach B). For the time-series split, only the TVAE model with an imbalance ratio of 1:1 can improve the F1 score to 0.3058. However, this model is better than the best CopulaGAN model from approach A. The second and third best models are SMOTE and TVAE with imbalance ratio of 1:2. Nevertheless, these two models do not improve the F1 score. Regarding stratified split and approach B, SMOTE performs better than time-series split again with F1 score of 0.5075. The second and third best model is achieved by TVAE with imbalance ratio 1:1 with and without combination of SMOTE. All three best models lead to an improvement of the F1 score.
Overall, the TVAE model with imbalance ratio of 1:1 in combination with approach B is preferable for application on time-dependent production data. For non-time-dependent data, SMOTE or a combination of SMOTE and TVAE with imbalance ratio of 1:1 can lead to better results. In addition, a time-series CV requires a better distribution of the two leakage classes in each split. Since the investigated experimental data set has no time dependence, this is not given and the investigated models for the time-series CV thus do not provide an improvement of the baseline in most cases. Since approach A produce worse F1 scores for all models, except CopulaGAN models, than approach B, approach A is rejected.
Within the framework of a hyperparameter optimization (HPO), it is to be investigated to what extent the classification model can be improved using TVAE model with imbalance ratio 1:1, since this model achieves good results in both split strategies. For this purpose, the training data are split into training and validation data. The model with the best hyperparameters is determined for each split. Using a random search, 20 random parameter combinations were used in this way for each split to determine the best validation F1 score. The best model on the validation data per split was then evaluated on the test data. The results of the test F1 scores before and after HPO can be seen in Table 7. The optimization improved the F1 score for the time-series CV using TVAE with an imbalance ratio of 1:1 from 0.3058 to 0.3343. This makes this model the best found for a time-series split. For the stratified split, an improvement from 0.4479 to 0.4702 was achieved. Nevertheless, this improved F1 score is still worse than the model using SMOTE with an F1 score of 0.5075 (Table 6).
In summary, the F1 score for the time-series split can be further improved using the TVAE model with an imbalance ratio of 1:1 and a larger-scale HPO. For the stratified split, a more complex HPO is not recommended, since significantly better results can already be achieved with considerably less effort using SMOTE.
6 Discussion and transferability
Synthetic data generation methods achieve outstanding results for image analysis applications. For 2D use cases, these approaches have not yet been explored in depth. This research aims to demonstrate, based on an industrial use case, the added value of synthetic data generation for 2D, tabular datasets and especially for production data set properties. Many production require continuous adjustments to the production system such as adjustments to software as well as hardware. These changes, as well as wear and tear and changing system conditions, are often reflected in the data. In addition, in some applications, the order of states and processes are relevant for modeling predictive models. A production strives to generate as many good parts as possible according to quality specifications. This is in conflict with the balance of defect and good part ratios for effective data analysis, since a population must be inferred from a smaller sample. Moreover, in practice, in some cases there are many data points, but also many production variables, whose importance for each data evaluation differs greatly. In some cases, it is only within a project that it becomes apparent that an additional physical quantity is irreplaceable for a predictive model, so that this quantity must be represented in the rest of the data set. Accordingly, production data often have the characteristics of being high dimensional, non-stationary, class imbalanced. However, predictive models are of value to production only if the prediction is available fast enough for the process and the model size does not overload the data flow in the production system. This work focuses on these general properties of production data sets and has several unique contributions and implications for production engineering based on this industrial application, which are listed below: (1.) TVAEs produce much smaller models and have low computation times than GANs. (2.) TVAEs produce significantly more stable results than GANs and preserve correlations between features in the same way as oversampling methods. (3.) The combinations of SMOTE and TVAE produce better predictions than the individual methods. As with any research, this research has certain limitations, which are listed below: (1.) Only one experimental data set and one production data set were considered in this research. Accordingly, no general statements can be made for the prediction performance of the procedures. (2.) The data quality affects the functioning of the methods, which is why this use case could not be finally solved. Nevertheless, this study has tackled the problems of common production data sets and generated insights for other use cases in production that will be useful in the implementation of prediction models with synthesized data.
7 Conclusions and outlook
In this work, synthetic data generation and oversampling techniques are applied to improve the predictive performance of hydraulic test features on a data set with strong class imbalance, high dimensionality, and time influence, and compared for usefulness in industrial practice. To take the time influence into account, the time-series split was introduced alongside the stratified CV. Evaluating synthetic data generation, the correlation plots and similarity metrics only give a tendency which methods lead to success. In the case of TVAE, the imbalance ratio 1:1 for the KS and MAE does not show the best metrics, but it works very well for the main classification model. Regarding the overviews, the autoencoder tends to perform better than the GAN for this use case. Accordingly, the synthetic data generation must be evaluated for the final target variable. SMOTE and TVAE best reduce the information gap between the prediction model with and without split for leakage volume flow prediction, and also have the advantage of fast and low memory performance. Nevertheless, the information gap is not yet sufficiently closed to deploy this pipeline in practice. The HPO is computationally intensive due to the large number of splits and folds, but has achieved a remarkable 3 percentage point F1 score gain for the small number of 20 combinations in the random search. Further HPO offers immense potential for improvement and will be stressed in future work.
Data availability
The data will not be made available to the public. Nevertheless, the results are reproducible on similar use cases.
Abbreviations
- CopulaGAN:
-
Copula generative adversarial network
- GAN:
-
Generative adversarial network
- HPO:
-
Hyperparameter optimization
- KNN:
-
K-nearest neighbors
- KS:
-
Kolmogorov Smirnov
- MAE:
-
Mean absolute error
- MLP:
-
Multilayer perceptron
- SMOTE:
-
Synthetic minority oversampling technique
- TVAE:
-
Variational autoencoder for tabular data
- VAE:
-
Variational autoencoder
- \(\theta _{d}\) :
-
Weights of the discriminator
- \(\theta _{g}\) :
-
Weights of the generator
- D(x):
-
Discriminator
- \(G(z; \theta _g)\) :
-
Generator
- \(q_\phi (z | x)\) :
-
Conditional encoder distribution
- \(q_\psi (x | z)\) :
-
Conditional decoder distribution
- \(R^2\) :
-
Coefficient of determination
- T :
-
KS test statistic
- x :
-
Original data set
- z :
-
Latent data set
References
Ötter C (2018) Quick Guide: Machine Learning im Maschinen- und Anlagenbau, 9–28
Krüger J, Fleischer J, Franke J., Groche P (2018) WGP-Standpunkt: KI in der Produktion: Künstliche Intelligenz erschließen für Unternehmen., 9–13
Liu J, Cao X, Zhou H, Li L, Liu X, Zhao P, Dong J (2021) A digital twin-driven approach towards traceability and dynamic control for processing quality. Advanced Engineering Informatics 50. https://doi.org/10.1016/j.aei.2021.101395
Lughofer E, Sayed-Mouchaweh M (2019) Predictive Maintenance in Dynamic Systems, pp. 64–93. Springer International Publishing, Cham
Liang J, Pelzer L, Müller K, Cramer S, Greb C, Hopmann C, Schmitt RH (2021) Towards predictive quality in production by applying a flexible process-independent meta-model. Procedia CIRP 104:1251–1256. https://doi.org/10.1016/j.procir.2021.11.210
Agrahari S, Singh AK (2021) Concept Drift Detection in Data Stream Mining: a literature review. Journal of King Saud University – Computer and Information Sciences, 3–15. https://doi.org/10.1016/j.jksuci.2021.11.006
Neunzig C, Fahle S, Kuhlenkötter B, Möller M (2021) Feature Engineering For A Cross-process Quality Prediction Of An End-of-line Hydraulic Leakage Test Using An Experiment Sample, pp. 156–166. https://doi.org/10.15488/11229
Krauss J (2022) Optimizing Hyperparameters for machine learning in production. PhD thesis, RWTH Aachen University
Seifert I, Bürger M, Wangler L, Christmann-Budian S, Rohde M, Gabriel P, Zinke G (2018) Potenziale der künstlichen Intelligenz im produzierenden Gewerbe in Deutschland. Studie im Auftrag des Bundesministeriums für Wirtschaft und Energie (BMWi) im Rahmen der Begleitforschung zum Technologieprogramm PAiCE – Platforms \(\vert\) Additive Manufacturing \(\vert\) Imaging \(\vert\) Communication \(\vert\) Engineering, 5–7
Sun Y, Xu L, Guo L, Li Y, Wang Y (2020) A Comparison Study of VAE and GAN for Software Fault Prediction. In: Wen, S., Zomaya, A., Yang, L. T. (eds.) Algorithms and Architectures for Parallel Processing vol. 11945, pp. 82–96. Springer International Publishing, Cham. https://doi.org/10.1007/978-3-030-38961-1_8
Haixiang G, Yijing L, Shang J, Mingyun G, Yuanyue H, Bing G (2017) Learning from class-imbalanced data: Review of methods and applications. Expert Syst Appl 73:220–239. https://doi.org/10.1016/j.eswa.2016.12.035
Fajardo V, Findlay D, Houmanfar R, Jaiswal C, Liang J, Xie H (2021) VOS: a Method for Variational Oversampling of Imbalanced Data. https://doi.org/10.48550/arxiv.1809.02596
Fernández A, García S, Galar M, Prati R, Krawczyk B, Herrera F (2018) Learning from Imbalanced Data Sets, pp 98–102. Springer, Cham. https://doi.org/10.1007/978-3-319-98074-4
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP (2002) SMOTE: synthetic minority over-sampling technique. J Artif Intell Res 16:321–357. https://doi.org/10.1613/jair.953
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative Adversarial Nets. In: Ghahramani Z, Welling M, Cortes C, Lawrence N, Weinberger KQ (eds) Advances in Neural Information Processing Systems, vol 27. Curran Associates Inc, Red Hook, NY, USA
Bourou S, El Saer A, Velivassaki T-H, Voulkidis A, Zahariadis T (2021) A Review of Tabular Data Synthesis Using GANs on an IDS Dataset. Information 12(9):1–14. https://doi.org/10.3390/info12090375
Xu L, Skoularidou M, Cuesta-Infante A, Veeramachaneni K (2019) Modeling Tabular data using Conditional GAN. In: 33rd Conference on Neural Information Processing Systems, Vancouver, Canada. https://doi.org/10.48550/arxiv.1907.00503
SDV: CopulaGAN Model (2022) https://sdv.dev/SDV/user_guides/single_table/copulagan.html, Accessed: 08.08.2022
Han G, Liu S, Chen K, Yu N, Feng Z, Song M (2022) Imbalanced Sample Generation and Evaluation for Power System Transient Stability Using CTGAN. In: Intelligent Computing & Optimization, pp. 555–565. Springer International Publishing, Cham. https://doi.org/10.1007/978-3-030-93247-3_55
Kingma DP, Welling M (2019) An Introduction to Variational Autoencoders. vol. 12, pp. 307–392. https://doi.org/10.48550/arXiv.1906.02691
Neunzig C, Fahle S, Schulz J, Möller M, Kuhlenkötter B (2022) Model Selection for Predictive Quality in Hydraulic Testing. Procedia CIRP 107:320–325. https://doi.org/10.1016/j.procir.2022.04.052
Neunzig C, Fahle S, Schulz J, Möller M, Kuhlenkötter B (2022) Approach To A Decision Support Method For Feature Engineering Of A Classification of Hydraulic Directional Control Valve Tests. In: Proceedings of the Conference on Production Systems and Logistics: CPSL 2022, pp. 101–110. https://doi.org/10.15488/12314
Neunzig C, Möllensiep D, Fahle S, Kuhlenkötter B, Möller M, Schulz J (2022) Approach to Data Pre-Processing for Predictive Quality of Hydraulic Test Results in a Dynamic Manufacturing Environment. Concept drift approach for ensemble classification for abrupt shift correction. In: 23. Leitkongress der Mess- und Automatisierungstechnik. Automation. Automation Creates Sustainability. VDI-Berichte vol. 2399, pp. 425–438. https://doi.org/10.51202/9783181023990
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
This appendix contains a code listing of the time-dependant splitting for the time-series CV to support researchers with applied research activities during implementation.

Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Neunzig, C., Möllensiep, D., Hartmann, M. et al. Enhanced classification of hydraulic testing of directional control valves with synthetic data generation. Prod. Eng. Res. Devel. 17, 669–678 (2023). https://doi.org/10.1007/s11740-023-01204-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11740-023-01204-8