
Abstract
Tree mortality models play an important role in predicting tree growth and yield, but existing mortality models for Larix gmelinii subsp. principis-rupprechtii, an important species used for regeneration and afforestation in northern China, have overlooked potential regional influences on tree mortality. This study used data acquired from 102 temporary sample plots (TSPs) in natural stands of Prince Rupprecht larch in the state-owned Guandi Mountain Forest (n = 67) and state-owned Boqiang Forest (n = 35) in northern China. To model stand-level tree mortality, we compared seven model forms of county data. Three continuous (dominant height, plot mean diameter, and basal area per hectare) and one dummy variable with two levels (region) were used as fixed effects variables. Tree morality variations caused by forest blocks were accounted for using forest blocks as a random effect in selected models. Results showed that tree mortality significantly positively correlated with stand basal area and dominant height, but negatively correlated with stand mean diameter. Incorporating both the dummy variables and random effects into the tree mortality models significantly increased the fitting improvements, and Hurdle Poisson mixed-effects model showed the most attractive fit statistics (largest R2 and smallest RMSE) when employing leave-one-out cross-validation. These mixed-effects dummy variable models will be useful for accurately predicting Larix tree mortality in different regions.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Larix gmelinii subsp. principis-rupprechtii (Mayr) A. E. Murray (Pinaceae) is the main afforestation tree species in the mountains of northern China (Fu 2017) because of its faster growth, excellent wood materials, stronger resistance to bad weather and wind, and contributions to soil conservation. It is thus important in mountainous regions. In recent years, however, large-scale wilting has been found in Larix forests in these regions, although the death rate of Larix species differs significantly among regions due to differences in site conditions and environmental factors (Chen and Hua 1991; Ban et al. 1997).
Predicting tree mortality is one of the important parts of forest growth and yield models (Clutter and Jones 1980; Knoebel and Burkhart 1986). Information on tree mortality and potential causes are very important for understanding forest dynamics (Das and Nathan 2015) because mortality may strongly influence future stand status (Bircher et al. 2015). Mortality has a significant influence on the prediction accuracy of changes of global stand structures (Dietze and Jaclyn 2014). Because we lack a comprehensive understanding of tree mortality is incomprehensive, as tree mortality is rarely observed and its cause is unclear (Das and Nathan 2015; Vanoni et al. 2016). As a result, tree mortality is still the most difficult part to incorporate in models to predict forest growth and harvest (Hamilton and Edwards 1976).
Tree mortality results from the combined effect of environmental factors, stand factors and genetic characteristics of tree and thus differs among stands; trees most often gradually decline in vitality until they die. Tree mortality is highly complex, with a multifactor synergism and has considerable degree of the randomness; therefore, the underlying mechanisms are difficult to elucidate (Sala et al. 2010), limiting modeling capability (Galbraith et al. 2010; Adams et al. 2013).
The many factors and their interactions of the factors affecting mortality at the same time in the same place make it difficult to describe variability of the observed mortality data using traditional modelling approaches such as ordinary least square regression. Alternatively, mixed-effects modelling makes it possible to describe mortality more effectively than the traditional modeling approach (Zhang et al. 2014, 2017b). Thus, mixed-effects tree mortality models should be developed to improve predictions of forest damage at stand levels.
Stand level mortality is a count variable because there are often no dead trees in a stand. The least squares method implicitly presumes that the data are Gaussian distributed with constant variances or at least satisfy Gauss–Markov assumptions. If the least squares method is applied to data with a large proportion of zero counts, the estimated results would be biased. Thus, linear models are not appropriate to describe mortality. A generalized linear model is often used to describe the variability of tree mortality, in which a dependent variable follows an exponential distribution, which may not be appropriate for potential mortality patterns. Other probability distributions such as negative binomial distribution, binomial distribution and Poisson distribution are commonly used for mortality modeling with better results (Zhang et al. 2014).
When sample plots have little or no dead trees, a large amount of zero data may be possible, and the structure of this data is discrete (Eid and Tuhus 2001). The Poisson model is often used for counting; however, the Poisson regression must have equality of the mean and the variance, so the negative binomial model is sometimes used for counting (Rashid 2016; Zhang et al. 2017a). However, in practical situations, some data are too discrete, and the negative binomial model is not suitable. Sometimes, if the model is implemented, interpretation of the results can distort (Ping et al. 2008). In this situation, researchers have applied the zero-inflated model and Hurdle model to fit the mortality data because these methods can effectively solve the heterogeneity problems of the data (Hu et al. 2011; Yang 2014; Fang et al. 2016). Bayesian estimation methods have also been used (Alspach and Sorenson 1972) for mortality modeling. In forestry, counting models are mainly used for counting forest fire incidents (Kwak et al. 2012; Xiao et al. 2015; Susaeta et al. 2016) and rarely applied to tree mortality modeling (Affleck 2006; Li et al. 2019; Zhang et al. 2014). A two-step method has also been used to build stand-level mortality models (Woollons 1998; Eid and Oyen 2003) and involves fitting a logistic function to tree mortality data, and stand-level mortality is obtained by summing the number of dead trees in the stand. Because detailed information on individual trees is needed, with the chance of errors accumulating and thus reducing the accuracy of the stand-level mortality information.
Considering all these issues, here we used seven commonly used counting model (Poisson model and negative binomial model, zero-inflated Poisson model, zero-inflated negative binomial model, Hurdle Poisson model, Hurdle negative binomial model, and logistic regression model) to fit the tree mortality data. Considering different candidate models to fit data provides a good opportunity to select the most suitable model according to data patterns. The best-fitted model was then selected to describe the phenomenon of the regional random death of Larix. The presented mortality models will be useful for estimating comprehensive growth processes for Larix forests in northern China for developing more effective silvicutural strategies and forest management plans.
Materials and methods
1Data collection
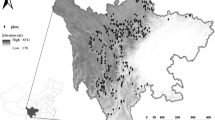
We established 102 temporary sample plots (TSPs) in state-owned Larix forests in Shanxi Province, China to collect mortality data (Fig. 1): 67 in the Guandi Mountain Forest and 35 in the Boqiang Forest. These 102 TSPs did not have any have obvious damage due to disease and pest. Each TSP was square-shaped and 0.04 ha. The TSPs were selected to provide representative information for a variety of stand structures and densities, tree heights and ages, and site productivity. Data was collected from July through September in 2015. For each stand structure, stand origin was recorded, stand age was determined, and canopy density, and height of Larix with DBH larger than 5 cm were measured. All 102 TSPs originated from natural forests. Tree height was measured with an ultrasonic altimeter; the crown was measured in four directions using a hand-held laser range finder; the age of each dominant tree was determined by counting rings obtained from cores drilled at breast height the dominant height of the stand was obtained as an average of the five tallest trees in each quadrat within the sample plot. Summary statistics are presented in Table 1. The climate in the studied area is temperate continental. In Guandi Mountain Forest, mean annual temperate ranges from 3 °C to 7 °C, and mean annual rainfall is 822.6 mm. In Boqiang Forest, mean annual temperate ranges from ‒1 °C to 8 °C, and mean annual rainfall is about 400 mm.

Study area showing the sample plot locations
Methods
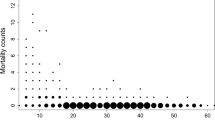
We mainly choose stand factors to assess their affected on tree mortality. Stand factors include stand density, competition index, stand productivity, stand structure, etc. In most cases, these factors may be considered simultaneously or several of them are considered (Affleck 2006; Zhang et al. 2014; Das and Nathan 2015). Based on the research data, the main factors affecting stand level mortality were calculated, including stand density, stand mean diameter, stand dominant height, basal area per hectare, relative spacing index. Tree mortality patterns are shown in Fig. 2.

Tree mortality distribution patterns by number of dead trees per sample plot
Variable selection
Stand variables characterized by a meaningful biological explanation were selected as predictor variables in the tree mortality models. The dominant height (DH), which describes the combined effects of stand development and site productivity calculated and evaluated its potential contribution to the tree mortality models. Similarly, sample plot mean diameter (D), number of trees (N) and basal area per hectare (S), and relative spacing index (RSI), which were assumed to describe stand density and competition, were also evaluated for their potential contributions to the tree mortality variations. Multicollinearity among the independent variables was verified with the variance inflation factor (VIF). According to a common rule-of-thumb, multicollinearity among variables was considered to occur when VIF > 5 (Akinwande et al. 2015). Thus, the variance inflation factor (VIF) was used to examine whether variables would be significantly correlated with each other, and variables with VIF < 5 were retained in our final models. We retained only three stand-level predictor variables in our tree mortality models, and they are DH, D, and S.
Model development
We considered seven commonly used versatile functions to develop the tree mortality models, such as Poisson model and negative binomial model (NB), which refer to as the standard function, zero-inflated Poisson model (ZIP), zero-inflated negative binomial model (ZINB), Hurdle Poisson model (HP), Hurdle negative binomial model (HNB), and logistic regression model. We expanded each of these functions through the inclusion of important stand-level variables (D, DH, S), random component and dummy variable. More details of the expanded models were given in Table 2.
When a dummy variable describing regional variations in tree mortality was added to parameter β1 in all the seven models, dummy variable tree mortality models were formed (Table 3).
We formulated the tree mortality models using each of the seven base models by incorporating dummy variable describing regional mortality variation and random effects accounting for forest block effects in the tree mortality models. The mixed-effects tree mortality models with dummy variables we formulated are given in Table 4.
In all the models in Table 4, the vectors of errors and block-level random effects (ui1, ui2) are defined by ζi ~ N(0, R) and μi ~ N(0, D), respectively, meaning that error vector is assumed to have a normal distribution with zero mean and within-block variance–covariance matrix Ri, defined by Eq. 22.
Vector μi of the random effects (ui1, ui2)in these models (Eqs. 15–21) was assumed to have a multivariate normal distribution with zero mean and block variance–covariance matrix D, defined by Eq. 23.
In this study, all parameter vectors can be estimated through the maximum likelihood method. Parameter estimation was implemented using the glmmTMB package (Brooks et al. 2017) in R 3.6.3 (R Core Team 2020).
Model selection and goodness of fit
Various statistical indicators were used to compare the fitting performance of the candidate models presented above. To contrast the goodness of fits between these models, coefficient of determination (R2), mean residual error (MD), total relative error (TRE), and root mean square error (RMSE) were used. The expressions of these indicators are given below:
where, n is the number of sample plots, MCi is the actual value of the tree mortality in the i th sample plot, \(\widehat{MC}\) is the estimated value of the tree mortality in the i th sample plot, and \(\stackrel{-}{\mathrm{MC}}\) is the average of the observed value of the tree mortality. The smaller the MD, TRE, RMSE, and the larger R2, the better is the fit performance of the models.
Using MD, TRE, RMSE and R2 alone does not ensure whether the models fitted data optimally. The validity of the tree mortality models developed from the seven different base models can be evaluated using an independent data set. However, such a validation procedure was not feasible in this study because of the limited availability of data. Instead, the predictive performance of the tree mortality models was evaluated using the leave-one-out cross-validation (LOOCV) approach (Nord-Larsen et al. 2009; Timilsina and Staudhammer 2013).
Results
Basic tree mortality models
The parameter estimates and fit statistics of all the seven candidate models using three stand-level variables (DH, D, S) as predictors, which we have defined as basic tree mortality models, are presented in Table 5, and their models in Table 2.
All the parameter estimates for each base model were significant at the 0.05 level. Model 3 and Model 5 showed better-fit statistics compared to the other models. Model 1 and Model 2 were inferior compared to the other models. The complex models provided better fits than the simpler ones did. These results also confirmed the superiority of the complex models or discrete data. Model 3 and Model 5 provided better fits than all other models did, suggesting that they were the best suited to the data structure and the sample plots with no mortality data (zero data).
Tree mortality models with dummy variable
When a dummy variable describing regional variations in tree mortality was added to parameter β1 in the seven models, fit statistics obtained were substantially better than those of their base model counterparts (Table 2) (see model forms in Table 3).
The parameter estimates of the dummy variable and all other parameters of each tree mortality model were significant (p < 0.05), except for β4 and β5 in the NB, ZINB and HNB models (Table 6). Model 10 and Model 12 provided a better fit than all the other models, with the greatest R2 and smallest RMSE and TRE. Model 9 was inferior to the other models, with the smallest R2 and greatest RMSE and TRE.
Mixed-effects models with dummy variable and random effect
We formulated the tree mortality models using each of the seven base models by incorporating a dummy variable describing regional mortality variation and random effects accounting for forest block effects into the tree mortality models (see model forms in Table 4).
Except for Model 18, which did not converge with global minimum, the fit statistics of all the other mixed-effects dummy variable models were significantly improved, and all the parameter estimates of each model were significant (Table 7). Model 15 fitted better than all the other models, with the greatest R2, and the smallest RMSE and TRE. Model 16 showed an inferior fitting to other models.
Model evaluation with LOOCV
We used only those predictor variables in the tree mortality models, which had VIF < 5, to insure no collinearity occurred among them. We used the selected variables in all model types: basic models, dummy variable models, and mixed-effects dummy variable models. We evaluated all these model types using the LOOCV approach. The prediction improvement was substantial through adding the dummy variable and random effects to the basic models (Table 8). For Model 19, R2 is the largest and RMSE is 7.1% lower than that of Model 15. Among the basic models (Eqs. 1–7), Model 3 and Model 5 had the most attractive prediction statistics. Model 10 and Model 12, which are the dummy variable models and the mixed-effects dummy variable model, Model 19, appeared to be the best in their prediction performance.
When we compared the observed and predicted tree mortality distribution patterns (Fig. 3), base Model 5, dummy variable Model 12, and mixed-effects Model 19 showed better fitting effects.

Observed and predicted distributions of tree mortality for Larix gmelinii subsp. principis-rupprechtii
Discussion
In this study, seven different mortality functions were considered for fitting the mortality data collected from two different regions of northern China, and their fitting performances were evaluated using common statistical measures.
Sample plot mean diameter (D) and stand basal area (S), which reflect the stand diameter growth, may describe the morality caused by stand density and competition. Dominant height (DH) may reflect the combined effects of site quality and stand development on the tree mortality.
Stand variables S and D can be calculated simply and accurately using diameter at breast height, which was the most reliably measurable variable in field survey data. In our models, tree mortality is significantly related to S, DH and D in the sample plot. Variable S had a positive correlation with tree mortality, indicating that S raised the tree mortality rate, which may be due to resource limitations in the stand. An increase in basal area per hectare may cause crowding, and the intense competition may increase the mortality rate in the forest (Dieguezaranda et al. 2005; Wiegand et al. 2006; Moustakas et al. 2008; Zhang et al. 2015). DH was also positively correlated with tree mortality, and with larger DH, tree mortality increased. Site conditions differ among regions and may be responsible for differences in tree mortality between the two regions with trees of the same dominant height.
Conversely, the effect of D on tree mortality was negative; that is, as the stand mean diameter became smaller, the tree mortality increased. This result indicates that tree mortality was more likely in forests with many small trees compared to forests with larger trees (Juknys et al. 2006; Larson and Franklin 2010).
When the dummy variable accounting for mortality variations due to regional differences was added, the model fit statistics slightly improved. However, basal area per hectare (S) appeared insignificant in the dummy variable models (negative binomial model (NB), zero-inflated negative binomial model (ZINB), and Hurdle negative binomial model (HNB)). The reason may be due differences in regions, such as Guandi Mountain and Wutai Mountain. In the different regions, D would be significantly different due to different sites in the two regions. However, the models had higher fitting accuracy when tree mortality models including the dummy variables and random effects were considered based on the basic models. Because the random effects were added as D and the intercept, the differences wre explained as the effects of stand mean diameter in different blocks.
For discrete data, the Poisson model and the negative binomial model have poor prediction accuracy in the basic model, while the zero-inflated Poisson model (ZIP) and Hurdle Poisson model (HP) had unique advantages for prediction. The prediction accuracy of the zero-inflated negative binomial model is lower than that of the zero-inflated Poisson model, which may be due to the numerous zero data that would not be in the expansion state (Long and Freese 2006).
Compared to the basic models, parameters of dummy variable models increased to a certain extent, and models index have improved. The dummy variable models can well integrate different areas of Larix stands, improve the accuracy of the tree mortality model, and expand the compatibility of the model.
If the logistic model is based on the maximum likelihood estimation, it can only estimate the probability of the dependent variable. Thus, it is not appropriate to use maximum likelihood estimation in our study. Any of the maximum likelihood-based criteria for model selection, such as the Akaike information criterion (Strawderman et al. 2000) cannot be applied to the logistic model. Alternatively, the leave-one-out cross-validation (LOOCV) was applied to evaluate prediction performance of the models.
The Poisson model performed well in principle with tree mortality, but was unable to account for the large zero fraction; the zero-inflated negative binomial, zero-inflated Poisson, and Hurdle negative binomial models overestimated the count part, but underestimated the zero part, resulting in a low prediction accuracy. Because of the complexity of tree mortality, it is difficult to interpret the fitted mortality function when the zero part was added. However, when the dummy variable (region) and random effects (block) were included into each of the seven base models, the prediction accuracy shown by LOOCV significantly improved, suggesting that there were significant variations in tree mortality caused by regional conditions and subject (forest block). This result justifies applying the mixed-effects dummy variable modeling approach in our study.
According to the field survey, altitude differenced inthe block is large, which is expected to greatly influence mortality of Larix species. However, we did not include any site variables such as altitude, aspect and slope into our models. In the future, these variables need to be considered in mortality modeling. Similarly, climate change also contributes to tree mortality on a large scale (Mantgem and Stephenson 2007; Kurz et al. 2008; Allen et al. 2010; Yang 2014; Hartmann et al. 2018), so climatic factors also need to incorporated into tree mortality models.
Conclusions
Fitting and comparison of the seven basic models through incorporation of the dummy variable describing regional effects and random components describing the forest block effects on the tree mortality led us to the following conclusions:
-
(1)
The models fitted with the dummy variable and random effects significantly improved fit statistics and prediction statistics compared with the basic models.
-
(2)
Among the various model formulations (basic, dummy, mixed models), the random effects for the Hurdle Poisson model described the largest variation in the tree mortality.
-
(3)
Tree mortality was significantly positively correlated with stand basal area and stand dominant height, but negatively correlated with sample plot mean diameter.
-
(4)
The models only considered mortality that was caused by competition; however, the impact of different regional climate scenarios on tree death is not yet clear and needs to be studied in the future.
References
Adams HD, Williams AP, Xu C, Rauscher SA, Jiang XY, Mcdowell NG (2013) Empirical and process-based approaches to climate-induced forest mortality models. Front Plant Sci 4(438):438–438. https://doi.org/10.3389/fpls201300438
Affleck DLR (2006) Poisson mixture models for regression analysis of stand-level mortality. Can J Forest Res 36(11):2994–3006. https://doi.org/10.1139/x06-189
Akinwande MO, Dikko HG, Samson A (2015) Variance inflation factor: as a condition for the inclusion of suppressor variable(s) in regression analysis. Open J Stats 05(7):754–767. https://doi.org/10.4236/ojs.2015.57075
Allen CD, Williams AP, Millar CI (2010) Forest responses to increasing aridity and warmth in the southwestern United States. Proc Natl Acad Sci USA 107(50):21289–21294. https://doi.org/10.1073/pnas.0914211107
Alspach D, Sorenson H (1972) Nonlinear Bayesian estimation using Gaussian sum approximations. IEEE Trans Autom Control 17(4):439–448. https://doi.org/10.1109/TAC.1972.1100034
Ban Y, Xu HC, Li ZD (1997) Mortality patterns of Larix gmelini and effect of fallen dead wood on regeneration of old Larixgmeliforest. Chin J Appl Ecol. https://doi.org/10.13287/j.1001-9332.1997.0089
Bircher NM, Cailleret BH (2015) The agony of choice: different empirical mortality models lead to sharply different future forest dynamics. Ecol Appl 25:1303–1318. https://doi.org/10.1890/14-1462.1
Brooks ME, Kristensen K, van Benthem KJ, Magnusson A, Berg CW, Nielsen A, Skaug HJ, Maechler M, Bolker BM (2017) glmmTMB balances speed and flexibility among packages for zero-inflated generalized linear mixed modeling. R J 9(2):378–400
Chen H, Xu ZB (1991) Preliminary study on the tree death of Korean pine deciduous mixed forest of Changbai Mountain. Chin J Appl Ecol. https://doi.org/10.13287/j.1001-9332.1991.0014
Clutter JL, Jones EP (1980) Prediction of growth after thinning in old-field slash pine plantations. USDA For Serv, Res Pap. https://doi.org/10.1093/sjaf/7.1.20
Das AJ, Stephenson NL (2015) Improving estimates of tree mortality probability using potential growth rate. Can J For Res 45(7):920–928. https://doi.org/10.1139/cjfr-2014-0368
Dieguezaranda U, Castedodorado F, Alvarezgonzalez JG, Rodriguezsoalleiro R (2005) Modelling mortality of Scots pine (Pinus sylvestris L) plantations in the northwest of Spain. Eur J Forest Res 124(2):143–153. https://doi.org/10.1007/s10342-004-0043-5
Dietze MC, Jaclyn HM (2014) A general ecophysiological framework for modelling the impact of pests and pathogens on forest ecosystems. Ecol Lett 17:1418–1426. https://doi.org/10.1111/ele.12345
Eid T, Oyen BV (2003) Models for prediction of mortality in even-aged forest Scandinavian. J Forest Res 18(1):64–77. https://doi.org/10.1080/02827581.2003.10383139
Eid T, Tuhus E (2001) Models for individual tree mortality in Norway. For Ecol Manage 154(1–2):69–84. https://doi.org/10.1016/S0378-1127(00)00634-4
Fang R, Wagner BD, Harris JK, Fillon S (2016) Zero-inflated negative binomial mixed model: an application to two microbial organisms important in oesophagitis. Epidemiol Infect 144(11):2447–2455. https://doi.org/10.1017/S0950268816000662
Fu YJ (2017) Developing individual crown width models for Larix principis-rupprechtii. Study on crown model of single tree of natural Larch Forest in North China. Central South University of Forestry and Technology
Galbraith D, Levy PE, Sitch S, Huntingford CM, Cox P, Williams M, Meir P (2010) Multiple mechanisms of Amazonian forest biomass losses in three dynamic global vegetation models under climate change. New Phytol 187(3):647–665. https://doi.org/10.1111/j.1469-8137.2010.03350.x
Hamilton DA, Edwards BM (1976) Modeling the probability of individual tree mortality. USDA For Serv Res Pap. https://doi.org/10.5962/bhl.title.68792
Hartmann H, Moura C, Anderegg WR, Ruehr NR, Salmon Y, Allen CD (2018) Research frontiers for improving our understanding of drought-induced tree and forest mortality. New Phytol 218(1):15–28. https://doi.org/10.1111/nph.15048
Hu M, Pavlicova M, Nunes EV (2011) Zero-inflated and Hurdle Models of count data with extra zeros: Examples from an HIV-Risk reduction intervention trial. Am J Drug Alcohol Abuse 37(5):367–375. https://doi.org/10.3109/00952990.2011.597280
Juknys R, Vencloviene J, Jurkonist N, Bartkevi-cius E, Sepetiene J (2006) Relation between individual tree mortality and tree characteristics ina polluted and non-polluted environment. Environ Monit Assess 121:519–542. https://doi.org/10.1007/s10661-005-9152-y
Knoebel BC, Burkhart HE, Beck DE (1986) A growth and yield model for thinned stands of yellow-poplar. Forest Sci. https://doi.org/10.1093/forestscience/32.s2.a0001
Kurz W, Dymond CC, Stinson G, Rampley GJ, Safranyik L (2008) Mountain pine beetle and forest carbon feedback to climate change. Nature 452(7190):987–990. https://doi.org/10.1038/nature06777
Kwak H, Lee WK, Saborowski J, Lee SY, Won M, Koo K, Lee MB, Kim S (2012) Estimating the spatial pattern of human-caused forest fires using a generalized linear mixed model with spatial autocorrelation in South Korea. Int J Geogr Inf Sci 26(9):1589–1602. https://doi.org/10.1080/13658816.2011.642799
Larson AJ, Franklin JF (2010) The tree mortality regime in temperate old-growth coniferous forests: the role of physical damage. Can J For Res 40:2091–2103. https://doi.org/10.1139/X10-149
Li CM, Zhao LF, Li LX (2019) Modeling stand-level mortality of mongolian oak (Quercus mongolica) based on mixed effect model and zero-inflated model methods. Sci Silcae Sci 55(11):27–36. https://doi.org/10.11707/j.1001-7488.20191104
Long JS, Freese J (2006) Regression models for categorical dependent variables using Stata, Second Edition. College Station, TX: Stata Press. http://www.gbv.de/dms/zbw/504295756.pdf
Mantgem PJ, Stephenson NL (2007) Apparent climatically induced increase of tree mortality rates in a temperate forest. Ecol Lett 10(10):909–916. https://doi.org/10.1111/j.1461-0248.2007.01080.x
Moustakas A, Wiegand K, Getzin S, Ward D, Meyer KM, Guenther M, Mueller K (2008) Spacing patterns of an Acacia tree in the Kalahari over a 61-year period: How clumped becomes regular and vice versa. Acta Oecologica-international J Ecol 33(3):355–364. https://doi.org/10.1016/j.actao.2008.01.008
Nord-Larsen T, Meilby H, Skovsgaard JP (2009) Site-specific height growth models for six common tree species in Denmark Scand. Scand J For Res 24:194–204. https://doi.org/10.1080/02827580902795036
Ping Z, Liu GF, Cao HY (2008) Application of zero-inflated models in study of the impacting factors about segment number of myocardial ischemia. China Health Stat 05:464–466
Rashid A (2016) A new count data model with application in genetics and ecology. Electron J Appl Stat Anal 9(1):213–226. https://doi.org/10.1285/i20705948v9n1p213
R Core Team (2020) R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. URL http://www.R-project.org/
Sala A, Piper FI, Hoch G (2010) Physiological mechanisms of drought-induced tree mortality are far from being resolved. New Phytol 186(2):274–281. https://doi.org/10.1111/j.1469-8137.2009.03167.x
Strawderman RL, Burnham KP, Anderson DR (2000) Model selection and inference: a practical information-theoretic approach. J Am Stat Assoc. https://doi.org/10.1198/tech.2003.s146
Susaeta A, Carter DR, Chang SJ, Adams DC (2016) A generalized Reed model with application to wildfire risk in even-aged Southern United States pine plantations. Forest Policy Econ 67:60–69. https://doi.org/10.1016/j.forpol.2016.03.009
Timilsina N, Staudhammer CL (2013) Individual tree-based diameter growth model of slash pine in Florida using nonlinear mixed modeling. Forest Sci 59(1):27–31. https://doi.org/10.5849/forsci.10-028
Vanoni M, Bugmann H, Nötzli M, Bigler C (2016) Drought and frost contribute to abrupt growth decreases before tree mortality in nine temperate tree species. For Ecol Manage 382:51–63. https://doi.org/10.1016/j.foreco.2016.10.001
Wiegand T, Kissling WD, Cipriotti PA, Aguiar MR (2006) Extending point pattern analysis for objects of finite size and irregular shape. J Ecol 94(4):825–837. https://doi.org/10.1111/j.1365-2745.2006.01113.x
Woollons RC (1998) Even-aged stand mortality estimation through a two-step regression process. For Ecol Manage 105(1):189–195. https://doi.org/10.1016/S0378-1127(97)00279-X
Xiao YD, Zhang XQ, Ji P (2015) Modeling forest fire occurrences using count-data mixed models in qiannan autonomous prefecture of Guizhou Province in China. PLoS ONE 10(3):e0120621. https://doi.org/10.1371/journal.pone.0120621
Yang S (2014) A comparison of different methods of zero-inflated data analysis and its application in health surveys. J Modern Appl Stat Methods. https://doi.org/10.23860/thesis-yang-si-2014
Zhang J, Huang SM, He FL (2015) Half-century evidence from western Canada shows forest dynamics are primarily driven by competition followed by climate. Proc Natl Acad Sci USA 112(13):4009–4014. https://doi.org/10.1073/pnas.1420844112
Zhang XY, Mallick H, Tang ZX, Zhang L, Cui XQ, Benson AK, Yi NJ (2017) Negative binomial mixed models for analyzing microbiome count data. BMC Bioinf. https://doi.org/10.1186/s12859-016-1441-7
Zhang XQ, Lei YC, Liu XZ (2014) Modeling stand mortality using Poisson mixture models with mixed-effects. Iforest Biogeosci Forest. https://doi.org/10.3832/ifor1022-008
Zhang XQ, Cao QV, Duan AG, Zhang JG (2017) Modeling tree mortality in relation to climate, initial planting density and competition in Chinese fir plantations using a Bayesian logistic multilevel method. Can J Forest Res. https://doi.org/10.1139/cjfr-2017-0215
Acknowledgements
We thank Dr. Guangshuang Duan for his kind help on the seven methods with R.
Author information
Authors and Affiliations
Corresponding author
Additional information
Corresponding editor: Tao Xu.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Project funding: The work was supported by the National Natural Science Foundations of China (No. 31971653).
The online version is available at http://www.springerlink.com.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhou, X., Fu, L., Sharma, R.P. et al. Generalized or general mixed-effect modelling of tree morality of Larix gmelinii subsp. principis-rupprechtii in Northern China. J. For. Res. 32, 2447–2458 (2021). https://doi.org/10.1007/s11676-021-01302-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11676-021-01302-2