
Abstract
Chatbots have in recent years increasingly been used by organizations to interact with their customers. Interestingly, most of these chatbots are gendered as female, displaying stereotypical notions in their avatars, profile pictures and language. Considering the harmful effects associated with gender-based stereotyping at a societal level—and in particular the detrimental effects to women—it is crucial to understand the effects of such stereotyping when transferred and perpetuated by chatbots. The current study draws on the Stereotype Content Model (SCM) and explores how the warmth (high vs. low) of a chatbot’s language and the chatbot’s assigned gender elicit stereotypes that affect the perceived trust, helpfulness, and competence of the chatbot. In doing so, this study shows how established stereotype theory can be used as a framework for human-machine communication research. Moreover, its results can serve as a foundation to explore ways of mitigating the perpetuation of stereotyping and bring forward a broader discussion on ethical considerations for human-machine communication.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Chatbots—often making use of AI techniques have increasingly become integrated into our everyday lives. They can be defined as a conversational agent that uses natural language dialogue to provide users with access to data and services (Følstad et al. 2019). These agents may be voice based personal assistants such as Alexa, Siri, Google Assistant, or text-based helpers on company websites or messaging applications. Text-based chatbots are increasingly used by organizations due to their potential to enhance the customer experience and streamline interaction between people and services (De Cicco et al. 2020). Chatbots are often designed to emulate human features or traits (Costa and Ribas 2019) through visual, identity or conversational cues (Go and Sundar 2019). These cues, defined here as anthropomorphic cues, may be manifested by how the chatbot looks like, its name, or the type of language it uses. Interestingly, most of these bots usually display female characteristics (or cues) as a default setting, through voices, avatars, colour scheme and language (Feine et al. 2020; West et al. 2019).
According to Nowak and Fox (2018), when avatars are gendered, they elicit gender stereotypes and people may then expect the avatars to have gendered knowledge. This might be due to the general stereotyping of women and men. Such attribution of (gendered) knowledge and stereotypes to chatbots may be partly explained by the Computers Are Social Actors framework (CASA) stating that people respond to media agents mindlessly and therefore interact with them using the same script as one would use for human-to-human interactions (Nass and Moon 2000). People tend to expect the qualities of women to be linked with communality; they should be warm, helpful to others and nurturing, while men’s stereotypical domain refers to their agency, their competence and authority (Ellemers 2018). These stereotypical responses and expectations could in theory be applied to chatbots as social agents. Gambino et al. (2020) suggest that although the social scripts we apply when talking human to human might not necessarily always apply directly to media agents (such as chatbots), given that these media agents are now so common, we as humans might have developed scripts that we use in interaction with them. These human-machine scripts may be, similarly to human-human scripts, applied mindlessly (Gambino et al. 2020). When it comes to gender, different streams of research on conversational agents suggest that a female voice is deemed as more helpful regardless of the gender of the individual who interacts with an agent (West et al. 2019). This might be linked to females in general being perceived as more friendly (warm) and more helpful (De Angeli and Brahnam 2006). However, we do not know enough about the extent to which the usage of gender cues within text-only chatbots—especially its language style or assigned identity—may elicit social gender stereotypes and how those stereotypes affect how chatbots are perceived in terms of their knowledge and helpfulness.
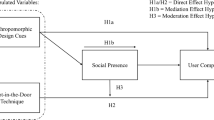
The current study aims to fill this gap in research by exploring how the mechanisms of stereotyping apply to AI (chatbot) settings and the potential consequences they can have for human-machine communication (HMC). Specifically, we investigate the extent to which a chatbot’s assigned gender interacts with gendered linguistic cues signaling strong (vs. weak) warmth influences trust, perceived helpfulness, and perceived competence of the chatbot. To do so, we use the stereotype content model (SCM) by Fiske et al. (2002), which states that all interpersonal impressions and group stereotypes form along two dimensions: competence and warmth. By using this framework to examine human-machine interaction the study is transferring previous knowledge into new settings (AI/chatbot) blazing a trail for future research. More specifically, we propose the following research question: To what extent do warmth traits and assigned gender chatbots jointly and independently influence its perceived trust, helpfulness and competence?
The present study aims to make three important contributions to human-machine communication research. First, it aims to extend emerging knowledge suggesting that female voice-based AI come off as more helpful (West et al. 2019) to text-only chatbots, and thus investigate potential boundary conditions for the effects of gender cues. Second, considering that chatbots tend to be assigned gendered cues mostly on the basis of identity (e.g., name or appearance) and language style (e.g., linguistic cues associated with warmth), we focus on how the usage of these cues influences two important perceptions about chatbots, namely perceived competence and helpfulness as, from a gender stereotypical view and expectation of gendered knowledge (Nowak and Fox 2018), both aspects (helpfulness and competence) could be affected by chatbots’ warmth (as warmth is usually attributed to women). Finally, we assess the extent to which gendered cues influence trust, given the key role of trust in the usage of automation (Hoff and Bashir 2015; Lee and See 2004) and AI (Glikson and Woolley 2020).
The current study brings together two strains of research, more specifically the literature on AI/human-machine communication (see Rapp et al. 2021 for a review) and literature on gender stereotypes (Ellemers 2018; Fiske et al. 2002). In doing so, this study helps shed light on the potential harmful effects of design choices in how AI interactions take place in society, by explicitly investigating how these design choices may also be reinforcing stereotypes. If gender stereotypes are being reinforced by chatbots, they can strengthen the perceived boundaries and differentiation and social inequality gender stereotypes bring with them (Ellemers 2018). Gender operates within a system of disadvantage and privilege, where women in general are seen as more communal (warm) and afforded a lower status than men who are afforded traits of high-status agency (competence) and are therefore seen as less competent (Cundiff 2021; Eagly et al. 2020). These differences portray themselves in for example educational context of science subjects, where women are seen as less talented than male students (Leslie et al. 2015), even though their grades are generally higher (Grunspan et al. 2016). In addition, gender stereotypes also influence promotions in a career context, lower wages, but also how we value the work of women less compared to men’s work (Cruz-Castro and Sanz-Menendez 2021). Furthermore, women in position of authority are usually given less slack and are treated less seriously than their male counterparts because the characteristics women “should” have (warmth/communality) is incomparable to the characteristics people in authority “should” have (competence/agency) (Baldner et al. 2021; Eagly and Karau 2002). However, there are also inequalities towards men based on stereotypes, for example in terms of parental leave (Ellemers 2018). When it comes to AI there are, according to Ågerfalk (2020), good reasons to worry about its misuses and its potential to perpetuate societal injustices and inequality through implicit bias (Gupta et al. 2021; Manyika et al. 2019). Because gender operates in the aforementioned system of disadvantage and privilege, it is important to understand if and how chatbots play a role in this system. Exploring the mechanisms of gender stereotyping in this context can help us recognize and mitigate injustices that might arise or be perpetuated by HMC.
2 Human-machine communication through a social perceptions lens
To explore the effect of chatbot’s assigned gender and gendered language on trust, perceived helpfulness, and perceived competence the current study draws on knowledge from social perception theories such as agency-communion and SCM as they create an interesting yet useful lens to look at the relationship through. In the vast majority of social cognition and perception theories and literature two dimensions appear, namely warmth-communion and competence-agency dimensions (Sainz et al. 2021), based in agency-communion literature and SCM literature. It has been demonstrated that these dimensions occur across regions and cultures (Cuddy et al. 2009; DeFranza et al. 2020; Durante et al. 2017).
The agency and communion literature is rooted in Bakan’s theory from 1966, which states that people possess two fundamental modalities, namely agency or a person’s tendency to reflect on their individuality and communion referring to the connection to a larger organism and social relationships (Eagly and Karau 2002). Research has shown that in general, communion characteristics involve traits such as concern for others, kindness, cooperativeness, friendly, warm, polite, considerate, modest, team-player, charismatic, enthusiastic, gentle, sympathetic, and sensitive to others’ needs (Conway et al. 1996; Eagly et al. 2000; Eagly and Karau 2002; Kurt et al. 2011; McDonnell and Baxter 2019; Smith et al. 2018). Agency characteristics are traits such as competence, self-confidence, determination, authoritative, assertive, ambitious, courageous, decisive, proactive, resourceful, dominant and aggressive (Conway et al. 1996; Eagly et al. 2000; Eagly and Karau 2002; Kurt et al. 2011; McDonnell and Baxter 2019; Smith et al. 2018).
In comparable fashion, the SCM builds on the agency communion literature stating that all interpersonal impressions and group stereotypes form along two dimensions, competence and warmth (Fiske et al. 2002), warmth is comparable to communion and consist of traits such as sincere, helpful, good natured, tolerant and warm, while competence is comparable to agency and consists of traits such as independent, competent, intelligent, confident and competitive (Awale et al. 2019; Brambilla et al. 2011; Caprariello et al. 2009; Cuddy et al. 2009; DeFranza et al. 2020; Fiske et al. 2002; Fiske 2018; Kervyn et al. 2013; Nejat et al. 2020). The two theories are often used interchangeably. SCM explains how social structure (status and cooperation) predicts stereotypes which in turn influence emotional prejudice (how people react to these different stereotypical groups) and how these emotions predict discrimination in how we treat the different groups (Cuddy et al. 2009; Fiske et al. 2002; Fiske 2018). The two dimensions basically answer two evolutionary important questions: “What is this individual’s (or group’s) intention?” And: “Is this individual (or group) capable of carrying out their intention?” (Kervyn et al. 2013). Warmth capture’s people’s perception of someone’s cooperative intentions, while competence captures their perceived ability to execute those intentions (Fiske et al. 2002; Lou et al. 2021).
Research has shown that people tend to attribute chatbots with stereotypes (Nowak and Fox 2018) which makes the SCM a sensible choice to examine the possible stereotype effects chatbots can elicit or maintain. The current study focuses on warmth to manipulate the language of the chatbots in the study to create the different levels of warmth conditions as it has been found that stereotyping extends to machine interactions as well as human interactions (Nass et al. 1997). Furthermore, the focus lies on warmth because in both agency-communion literature and SCM literature emphasis is put on warmth as the most important aspect as it is fundamental for survival: Knowing if a person’s intentions are good or bad is more important than whether they can act on these intentions (Brambilla et al. 2011; Wojciszke 2005). In addition, competence is closely linked to status (Awale et al. 2019; Conway et al. 1996; Cuddy et al. 2008; Fiske et al. 2002) which is a more objective construct based on prestige and power, while warmth is more subjective (Fiske 2018). In the setting of chatbots a focus on warmth makes sense as chatbots have historically been judged by their personality and friendliness (warmth) rather than their status (competence), hence chatbots creators have prioritized chatbots personality and language when constructing the bots (Vorsino 2021). Stereotyping is indistinguishably related to language use, language reflects and maintains stereotypes specifically in how we label, describe, and categorize individuals (Beukeboom and Burgers 2019) and subsequently maintains inequality (Gaucher et al. 2011). In addition, a practical reason to focus on warmth is that organizations implementing chatbots as part of their customer services have arguably more control over warmth rather than its competence traits. In particular, perceived competence of a chatbot likely depends on a wide range of factors, from developments in the underlying technology or infrastructure (e.g., natural language understanding or processing, conversational modelling) or simply the specific context in which the conversation takes place (e.g., in the case of customer service, the extent to which the organization is able to provide a solution to an issue in the first place). Individual practitioners and small-scale organizations have limited control over these technical developments, and therefore perceived (and actual) competence of chatbots likely follows technological developments or contextual factors instead of decisions made in designing a chatbot. On the contrary, design choices may greatly influence the perceived degree of warmth. For example, when designing a chatbot, organizations have to make decisions about its communication style—such as the degree of warmth in communication. The current study adds to our understanding of the consequences of such decisions. Together, the current study investigates gendered language of chatbots by manipulating linguistic cues signaling varying levels of warmth.
The study’s goal is to explore how chatbot’s gender (female vs. male) as well as warm (rather than cold) language cues influences stakeholder trust, perceived helpfulness, and the perceived competence of the chatbot, as well as how this relation is affected by the chatbot’s gender.
2.1 The influence of warmth (vs. cold) language cues on trust, helpfulness, and competence
Trust is an important factor for the adoption of automation (Hoff and Bashir 2015; Lee and See 2004) and for AI in general (for an overview, see: Glikson and Woolley 2020). It not only influences adoption but also patterns of use and the extent to which individuals may rely on technology (Glikson and Woolley 2020). The process through which trust in chatbots is built, and how it can be fostered, is one of the challenging questions in HMC research considering that trust in humans may differ from trust in machines (Guzman 2015). Human advice is perceived as more expert and useful than machine advice (Prahl and Van Swol 2021) in some cases, while others prefer virtual agents. These differences are dependent on the ontology of the agent, and on how the person understands the agent (Guzman 2015). At the same time, individuals employ human social rules in interacting with virtual assistants, treating them as social entities (Pitardi and Marriott 2021). Such interpersonal connections can, in turn, foster trust (Gambino and Liu 2022).
Trust is inherently related to warmth (Chen et al. 2014) because when trusting you have to believe in the good intention of someone else (in this case, a chatbot) (DeCicco et al. 2020; Dippold et al. 2020; Mayer et al. 1995). Judging others’ intentions in terms of trust are often conceptualized as part of the warmth dimension (Kervyn et al. 2013). Similarly, helpfulness can also be traced back to warmth as a communal trait (Conway et al. 1996; De Angeli and Brahnam 2006; Eagly and Karau 2002; Fiske 2018; Kurt et al. 2011; Nejat et al. 2020; West et al. 2019), hence people that seem friendly are seen as more helpful than if they were unfriendly (cold). Competence on the other hand is related to status (Awale et al. 2019; Brambilla et al. 2011; Cuddy et al. 2009; Fiske 2018; Fiske et al. 2002; Kevryn et al. 2013) which is arguably less relevant for the current study as chatbots arguably elicit comparable levels of perceived status.
Thus, we believe that because warmth is related to communal traits which have historically been attributed to women and that women generally have lower status than men (Conway et al. 1996; Ellemers 2018) language of the chatbots will affect the three outcome variables differently. The warmth of the chatbot will evoke gender stereotypical responses namely that the bots using a friendly (warm) language will be seen as more trustworthy and helpful as these concepts relate to warmth, while the friendliness (warm language) will also make the perceived competence lower as stereotypically warmth is seen as “feminine” which leads to lower perceived status (competence). Hence:
H1a
Perceived trust is higher after exposure to a chatbot that communicates with high levels of warmth compared to chatbots with low levels of warmth.
H1b
Perceived helpfulness is higher after exposure to a chatbot that communicates with high levels of warmth compared to chatbots with low levels of warmth.
H1c
Perceived competence is lower after exposure to a chatbot with high levels of warmth compared to chatbots with low levels of warmth.
2.2 The influence of gender (female vs male) on trust, helpfulness, and competence
Both in agency and communion literature, SCM literature and general stereotype literature one sees a tendency for warmth (communal traits) to be attributed to women, while competence (agency traits) are attributed to men (Awale et al. 2019; Brambilla et al. 2011; Caprariello et al. 2009; Conway et al. 1996; Cuddy et al. 2009; DeFranza et al. 2020; Eagly et al. 2000; Eagly and Karau 2002; Ellemers 2018; Fiske 2018; Fiske et al. 2002; Kevryn et al. 2013; Kurt et al. 2011; McDonnell and Baxter 2019; Nejat et al. 2020; Smith et al. 2018). The stereotypes that arise based on gender are prone to be high in one dimension; warmth (communion) or competence (agency) (Cuddy et al. 2009; Fiske et al. 1999). For example, traditionally women are attributed and expected to have warmth (communion traits) while men are attributed and expected to portray competence (agency traits) (Chen et al. 2014; Conway et al. 1996; DeFranza et al. 2020; Eagly et al. 2000; Fiske et al. 1999; Smith et al. 2018). Consequently, people have different expectations from women and men regardless of if they are real or artificial (Brahnam and De Angeli 2012; De Angeli and Brahnam 2006; Nass et al. 1997).
Most chatbots online are female (Feine et al. 2020; Vorsino 2021), likely because designers believe this would make them be perceived as helpful. Given that women are and have historically been expected to be friendly, trustworthy, and helpful, we posit that when the participants interact with a female bot will elicit gender stereotypical responses and perceive the female chatbots as more trustworthy and helpful. Similarly, we expect that the participant will elicit gender stereotypical responses to the chatbots in terms on competence, where male chatbots are seen as more competent than female bots because men, historically, have been perceived as more agentic, competent and of higher status (which relates to competence). Hence, user perceptions will be more positive for the bots that have the gender that fits the “knowledge” that is expected of them. In other words, we propose:
H2a
Perceived trust is higher after exposure to a female chatbot compared to a male chatbot.
H2b
Perceived helpfulness is higher after exposure to a female chatbot compared to a male chatbot.
H2c
Perceived competence is lower after exposure to a female chatbot compared to a male chatbot.
2.3 Interaction effects between warmth and gender cues in chatbots
The current study expects to find an effect of warmth language and gender on trust, helpfulness, and competence. As gendered language may reinforce stereotypes (see Beukenboom and Burgers 2019), we expect that chatbot’s gender and language use may interact in shaping perceptions of the bot.
Theory shows that failing to conform to such stereotypes can lead to social sanctions, while following them may lead to social approval (Fiske et al. 2002; Kurt et al. 2011; Niculescu et al. 2010). Women who act counter-stereotypically, by behaving agentically or at least not communal are perceived as less likeable and warm, which leads to social and economic consequences such as lower likelihood of being hired, promoted and lower salaries (He and Kang 2021; Heilman et al. 2004). Non “traditional” women that are seen as competent, but not warm such as businesswomen are often disliked, while traditional women that are seen as warm, but not competent are favoured as they conform to the stereotype of women (Fiske et al. 2002). The same backlash does not affect men in the same way, as counter-stereotypical behavior among men may even lead to favourable outcomes (Allen 2006; He and Kang 2021; Kidder and Parks 2001).
In other words, women who behave counter to stereotypes are consistently penalized, while men who behave counter to stereotypes do not incite the same backlash reaction. Building on these insights and extending them to the field of human-machine interactions, the current study therefore expects that the positive effect of warmth on all three dependent variables will be more pronounced when ‘female chatbots’ behave stereotype-consistent, i.e., when they communicate in a warm (rather than cold) manner. We therefore hypothesize that:
H3a
The positive effect of using warm rather than cold language on trust will be more pronounced when the chatbot is female compared to male.
H3b
The positive effect of using warm rather than cold language on helpfulness will be more pronounced when the chatbot is female compared to male.
H3c
The negative effect of using warm rather than cold language on competence will be more pronounced when the chatbot is female compared to male.
3 Methods
To examine to what extent a chatbot’s gender interacts with the warmth characteristics in predicting stakeholder trust, perceived helpfulness, and perceived competence of the chatbot, an online experiment was conducted based on a 2 (level of warmth low vs. high) × 2 (gender female vs. male) factorial design. Four different versions of a chatbot were designed for the purpose of this research showing the different levels of warmth and gender combinations.
Participants for the study were collected through the first author’s network in a snowball sampling where a link to the online survey was shared via WhatsApp, Facebook and LinkedIn, and was shared further by participants. As the participants of the pilot study prior to the main study were also collected from the first author’s network, they were contacted directly by the researcher and asked not to take the main survey as they had already been exposed to the different chatbots. The survey was active for two weeks, and yielded a sample consisting of 136 participants, 51.5% females, 47.8% male and = 0.7% who did not identify as either. Participants were from 28 different countries; however, the majority were either Norwegian (39.7%) or Dutch (12.5%), and their age varied from 16–67 years old where 66.2% were 30 years old or younger. Most participants (69.8%) reported a high level of education of a bachelor’s degree or higher. When asked if they had interacted with a chatbot before 91.9% (125) of participants agreed, however, when asked if they like chatbots, a neutral leaning toward a slightly negative view emerged (M = 3.33, SD = 1.52).
The participants were asked to fill in an online survey where they first had to answer basic demographic questions before having an interaction with one of the four chatbot conditions that were randomly assigned to the participants. Subsequently the participants were asked to imagine a situation where they were looking for nutritional advice and encountered a chatbot like the one they would be presented with shortly. Participants would then have a conversation with one of the chatbot conditions that was randomly assigned to them. After the conversation the participant answered questions about how they perceived the bot in terms of trust, helpfulness, and competence.
Google DialogFlow was utilized to create the chatbots, DialogFlow is part of Google Cloud and is a free natural language understanding platform to design conversational interfaces and integrate into bots’ websites and other systems. After a basic conversation flow (a picture of the basic flow of the chatbot can be found in Fig. 1 in the appendix) was decided on, the chatbot was integrated into Conversational Agent Research Toolkit (CART) by Araujo (2020) which allowed for the creation of the different conditions to be used in the experimental design. CART grants the ability to make the chatbot interact differently with the participant depending on the condition they are assigned to, in the current study gender and warmth.
For the chatbot conversation, a health (in this case nutrition) context was chosen as it is a field where chatbots are being used (Eastin 2001). The conversation was based on nutritional advice from a registered dietitian. The chatbot was a white window with a chatting function (see Fig. 2 in the appendix for a picture).
To create the different assigned gender categories of the chatbot, the chatbots state their name and their assigned pronouns in their first message as well as showing an emoji showing a man or a woman congruent with the pronouns mentioned. Names for the chatbot were chosen through an online API (Gender API 2021) that checks names and the perceived gender of that name across 189 countries, Anne was chosen for the female versions, while John was the chosen name for the male versions. The researchers chose to only include two assigned genders for the feasibility of collecting enough participants for all conditions. Additionally, research shows that even when presented with a seemingly neutral option, users attribute AI (like chatbots) a gender (Costa and Ribas 2019) which could confound the data.
The level of warmth was manipulated by having the chatbot use warm or cold language, derived from an agency-communion dictionary by Pietraszkiewicz et al. (2019). The dictionary provides words that are associated with agency (competence) and words that are associated with communion (warmth). Since the current study is interested in levels of warmth only the words belonging to communion (warmth) in the dictionary were utilized. By doing so one language option would be lacking warmth, hence cold, and one warm and friendly version.
The interaction between assigned gender and level of warmth created in total 4 conditions, a male and a female version for both warm and cold language. For an example of the conditions and their language, please check Table 1 in the appendix.
A pilot study was conducted to test if the manipulations were successful. The sample consisted of 30 participants (63.3% female, 33.3% male and 3.3% other) collected through the first author’s close network to allow for direct feedback from the participants. The age of the participants varied from 21 to 67 years old (70% of the sample was 30 years old or younger). Participants were from 12 different countries, but the majority were either from Norway (30%) or the Netherlands (23.2%).
A (repeated-measures) within-subjects design was used. The participants were asked to fill out an online questionnaire where they first were asked basic demographic questions before interacting with a chatbot and subsequently answering whether the chatbot they just talked to was male or female and to which degree they found the chatbot warm, measured on a 7-point likert scale (1 = totally disagree, 7 = otally agree). Participants would then be presented with another chatbot and would answer questions about the new chatbot until they had talked to all 4 chatbot conditions. The order of which of the chatbots were presented to the participant was random to strengthen the internal validity of the study. The pilot study was to check if participants would recognize the chatbot’s assigned gender and to see if the language options warm/cold were perceived as intended by the researcher.
A dependent samples t‑test revealed that perceived warmth of the chatbots was significantly higher after exposure to a chatbot conveying warm language (M = 6, SD = 1.07) rather than cold language (M = 4.08, SD = 1.60), t (29) = 7.66, p < 0.001, d = 1.40, 95% CI [0.89, 1.90]. This confirms that the manipulation of the levels of warmth through language was successful. In addition, participants generally recognize the gender of the chatbots successfully: in 96% of the cases, they correctly identified the female chatbot, and in 93% of the cases they correctly identified the male chatbot. Together, these findings confirm the successful manipulation of experimental factors.
The operationalization of trust, helpfulness, and competence is based on previous research. All items were measured on a 7-point scale ranging from totally disagree (1) to totally agree (7). A complete overview of all the original items and the adjusted items for the current study used can be found in Table 2 in the appendix.
Trust
on an overall level is the psychological state of willingness to accept being vulnerable to another party’s actions, based on the positive expectation that the other party will execute an action that is important to the first party (DeCicco et al. 2020; Dippold et al. 2020; Meyer et al. 1995; Rousseau et al. 1998, p. 395; Schoorman et al. 2007). Here, we consider trust towards the chatbot as the consumers’ attitude towards the bot, the belief that the bot has the consumers best intentions at heart and is honest and fair based on the framework of McKnight et al. (2002). Trust was measured with 5 items derived and adapted from Yen and Chiang (2020) and Beldad et al. (2016). The questions included statements such as “I can trust the chatbot” and “The chatbot is fair in dealing with me”. The reliability of the factor was good, Cronbach’s alpha = 0.92.
Helpfulness
is defined as the degree that the chatbot responses are perceived by the user to be relevant and therefore resolving the users’ problem (Zarouali et al. 2018). Helpfulness was measured using a total of 5 items derived and adapted from Yen and Chiang (2020), Beldad et al. (2016) and Pengnate and Sarathy (2017). Example items are “I get useful information from the chatbot”. The reliability of the factor was good, Cronbach’s alpha = 0.95.
Competence
is evaluated as the expertise, knowledge, and skill of chatbots to provide correct information (Yen et al. 2020). Hence this concept is about the perceived accuracy of the chatbot and the perceived knowledge behind the information given. Competence was measured using 5 items derived and adopted from Beldad et al. (2016), Nordheim et al. (2019) and McKnight et al. (2002). Example items read: “The chatbot is competent in giving advice”, “The chatbot appears knowledgeable”. The reliability of the factor was good, Cronbach’s alpha = 0.92.
Firstly, a review of the descriptive statistics for the dependent variables was conducted, showing that across all conditions the perceptions of the bots are in general positive in regard to trust (M = 4.38, SD = 1.28), helpfulness (M = 4.56, SD = 1.42) and competence (M = 4.78, SD = 1.36). Next a two-way multivariate analysis of variance (MANOVA) was conducted to examine the expected relationships of warmth, assigned gender, and the hypothesized interaction between them on trust, helpfulness, and competence. See Table 3 in the appendix for the Mean, Standard Deviation and Intercorrelations of the dependent variables. The key assumptions for a two-way MANOVA are fulfilled. First, there are three dependent variables measured at the continuous level. Second, the independent variables consist of two independent groups. Third, observations are independent. This analytical strategy is suitable for the goal of the current study as it allows for all hypotheses to be tested in one single model. Testing all the dependent variables in one increases the power of the study as it contributes to correcting for errors (Type II) and aids in making correct decisions on hypothesis retention or rejection.
4 Results
The results show that there is no significant effect of warmth on trust, helpfulness, or competence: F (3, 130) = 0.09, p > 0.05, Wilks’s λ = 0.99, partial η2 = 0.002. This means that, although it was hypothesized that high warmth would elicit gender stereotypical responses to the chatbot and hence lead to increased trust and helpfulness and lower competence, the current study does not provide evidence of this. Friendly (warm) language in chatbots does not evoke a stereotypical response to the chatbot in the dependent variables as far as the current study can show. Consequently, H1a, H1b and H1c are not supported.
Similarly, it was expected that a female chatbot would have a positive effect on trust (H2a) and helpfulness (H2b) and a negative effect on competence (H2c). It was hypothesized that the assigned gender of the chatbot would evoke gender stereotypical responses in the participants, hence female chatbots would be seen as more trustworthy and friendly, while male chatbots would be seen as more competent. To test this, the MANOVA model was inspected. The test showed that there was no significant effect of assigned gender on the dependent variables, F (3, 130) = 0.37, p > 0.05, Wilks’s λ = 0.99, partial η2 = 0.008. This means that the gender of the chatbot does not evoke a stereotypical response to the chatbot in the terms of trust, helpfulness, or competence. Consequently, H2a, H2b and H2c are not supported.
Lastly, it was expected that there would be an interaction effect between warmth and assigned gender that would result in the positive effects of warmth on trust (H3a), helpfulness (H3b) and negative effects for competence (H3c) to be more pronounced for females than for males following a stereotypical tendency. Meaning that when female chatbots used a warmer language that conformed to the stereotypical view and that therefore perceived trust and helpfulness was higher, while competence would be lower, because it conforms to the stereotypical view of what women should be. However, the effects would not be as strong for men because we expect them to be competent, but do not necessarily “punish” them for being warm. By inspection the interaction effect in the MANOVA models, the results showed no significant interaction effect of warmth and assigned gender on the dependent variables was found F (3, 130) = 0.78, p > 0.05, Wilks’s λ = 0.98, partial η2 = 0.018. Implying that when the participants were shown a female chatbot with a warm language, no stereotypical responses were evoked, hence people also did not react to whether these responses followed a stereotypical view or not. The same was shown for male chatbots. The interaction hypotheses H3a, H3b and H3c were therefore not supported.
5 Discussion
This study aimed to bridge largely isolated bodies of research by demonstrating how theoretical and empirical insights from stereotype research (e.g., Cuddy et al. 2009; Ellemers 2018; Fiske 2018; Fiske et al. 2002) can be transferred to research on machine communication (see Rapp et al. 2021 for a review), in this case chatbots. To accomplish this, the current study set out to answer to what extent a chatbots’ assigned gender and gendered language together can predict perceived trust, helpfulness and competence. The study found no significant effects of either warmth, assigned gender of the chatbot, or the interaction between them, on either trust, helpfulness nor competence, hence none of the expectations were confirmed.
This might imply that warmth and assigned gender do not seem to influence trust, helpfulness and competence in ways that were anticipated based on the stereotype-literature such as SCM and agency communion (Awale et al. 2019; Brambilla et al. 2011; Caprariello et al. 2009; Conway et al. 1996 Cuddy et al. 2009; DeFranza et al. 2020; Fiske et al. 2002; Fiske 2018; Kevryn et al. 2013; Kurt et al. 2011; Nejat et al. 2020; Sainz et al. 2021), and literature on how stereotypes are transferred to AI applications (Costa and Ribas 2019; Nowak and Fox 2018) which was surprising as the expectation of differences were grounded in a large quantity of literature. Based on the SCM model, the study should have shown differences in outcomes after exposure to both warmth and assigned gender, both because they evoke stereotypical responses as variations of warmth is related to expectations of gender, however the current study did not live up to these expectations as no such differences or responses were found.
We found that, in general, mean scores were higher on competence (M = 0.78, SD = 1.36), than on helpfulness (M = 0.56, SD = 1.42) and trust (M = 0.38, SD = 1.28). This could possibly be because the technology behind chatbots is evolving, rendering chatbots more competent over time. Usual chatbot stereotypes could in this case have been overruled because the chatbots did in general produce useful answers. This could be due to the fact that in this particular situation, the participants were primed to ask about nutritional advice regardless of them actually looking for such advice or not, so to the participants, basically any advice about nutrition is deemed as a competent answer.
However, there are different possible explanations as to why the study yielded no significant results of the anticipated effects. First, previous research has shown that we do tend to apply stereotypes to chatbots (Nowak and Fox 2018) and that chatbots are often gendered to reinforce and perpetuate such stereotypes (Costa and Ribas 2019). However, stereotypes have both implicit and explicit qualities (Rudman and McGhee, 2001) and the measures of the current study might not be strong enough to capture the implicit processes behind stereotyping that is it trying to explain. In so doing people might have explicitly changed their answers to not come across as conforming to stereotypes or the implicit reactions of participants is so small that the current study was not able to find them. Correcting one’s own behaviour/answers is a common reaction in socially sensitive domains such as prejudice (Buzinski and Kitchens 2017; Dovidio et al. 2002). Future research could therefore benefit from developing measures or utilizing existing measures that capture the implicit processes, e.g., the Implicit Association Test by Greenwald (Craig and Richeson 2014; Fazio and Olson 2003; Redford et al. 2018).
Second, although as mentioned above chatbots tend to exert stereotypes and we do have gendered expectations regarding men and women in regards to warmth (Awale et al. 2019; Brambilla et al. 2011; Caprariello et al. 2009; Conway et al. 1996; Cuddy et al. 2009; Eagly et al. 2000; Eagly and Karau 2002; Ellemers 2018; Fiske 2018; Fiske et al. 2002; Kevryn et al. 2013; Kurt et al. 2011; McDonnell and Baxter 2019; Nejat et al. 2020; Smith et al. 2018), the warmth of language might not be a strong enough cue in itself to elicit stereotypical responses. Research on whether cognitive stereotypical perceptions of warmth translate to natural language, especially in interaction with machines is not well-developed, hence we do not know if warmth on its own elicits stereotypical responses to chatbots or if that is dependent on the situation. Additionally, the conversations with the chatbots might also have been too short for people to register the language of the chatbot as warm or cold and therefore did not respond to it as expected. Furthermore, one could argue that if participants did not view the chatbot as human enough, the gender cues might be lost in translation and not apply, thus not elicit a stereotypical response that one may expect following the argumentation by the CASA framework (Nass and Moon 2000). Alternatively, individuals might be applying different scripts to interact with media, as suggested by calls to extend the CASA framework (Gambino et al. 2020). Along the same lines, Guzman (2015) mentions that some people have different ways of viewing virtual agents, for the participants that think of these agents as things, the characteristics of gender, or speech are simply programmed into the machines. As the current study did not measure how human or machine-like the chatbots were perceived, it could be the case that the participants in the current study viewed the agents merely as machines. A lack of ‘humanness’, in turn, may have hindered gendered cues to elicit effects. Future research should therefore investigate whether just written language alone can be enough to induce stereotypes on its own or if stronger measures are needed, as explicitly consider the perceived human-likeness of chatbots.
Third, previous work indicates that gendered effects of chatbots are context dependent; i.e., the (in) congruency between the gender of the chatbot and its application domain. Users expect chatbot to adhere to gender stereotypes elicited by their domain application. For example, previous work found that when chatbots are deployed in a gender-stereotypical consumer domain (e.g., ‘mechanics’) fail to conform to gender stereotypes, users are more likely to apply gender stereotypes (McDonnell and Baxter 2019). Similarly, congruency between the gender of chatbots and the gendered nature of recommended product types (e.g., male agents recommending utilitarian products, female agents recommending hedonic products) elicits the most favorable responses among users (Ahn et al. 2022). It might be that the application domain chosen in the current study (health) did not trigger specific gender-stereotypical expectations, and therefore failed to elicit gendered responses. Replicating the current design in different gender-(in)congruent domains could provide more insight into the potential interaction effects of the application domain and chatbot gender. In doing so, future work should consider manipulating competence and warmth, to better grasp the conditionality of ambivalent (e.g., high in competence, low in warmth) stereotypes in the domain of human-machine interactions.
Fourth and last, another cautious explanation for the lack of findings is that it simply does not matter what language the chatbot uses or its assigned gender. People do not transfer stereotypical responses to AI, in this case chatbots. This would be an interesting result as it contradicts what has been found by others and the framework the study has been built on (Fiske et al. 2002; Nowak and Fox 2018). In that sense the current study opens up for future research to be conducted exploring the relationship between certain characteristics, such as warmth and assigned gender, of chatbots and how these elicit or do not elicit stereotypical responses. Future studies should focus on how to make warmth and assigned gender explicit enough to incite reaction yet use measures that can completely capture the implicit processes of stereotyping.
Limitations to the current study should however be acknowledged. First, the assigned gender of the chatbot was only shown once in the first message of the chatbot, results might have been different if the participants had been reminded throughout of the assigned gender of the chatbot through for example an avatar or picture so that they connect the language spoken with the gendered “person” that is speaking. Second, the current study has manipulated warmth traits of gendered chatbots; yet, social perception is generally considered the outcome of the both warmth and competence dimensions. Moreover, our unidimensional rather than two-dimensional operationalization of stereotype content may have hindered ambivalent stereotypes (i.e., high in warmth, low in competence) to take full effect. Lastly, a power analysis showed that the study had enough power to detect medium-sized effects, but it might have been underpowered for small effects.
Despite these limitations, the current study has implications and contributions of a theoretical nature, highlighting how established frameworks such as SCM can be used beyond human-to-human interactions and are extremely relevant for discussions on human-machine communication. Particularly, this framework helps researchers think about dimensions of social judgement that may translate to human-machine interactions. In addition, we argue that the literature on prescriptive gender stereotypes and expectations (Prentice and Carranza 2002; Rudman 1998; Rudman and Glick 1999) may inform the conversation on gendered (or otherwise biased) responses to chatbots. Together, the SCM and the literature on prescriptive stereotypes may help advance our understanding of the contextual situations that trigger gendered responses. On a more general level, this echoes previous work stressing the importance of context in chatbot design and understanding their effects (Gambino and Liu 2022). Together, by using state-of-the-art procedures and measures to explore the relation between stereotypes, chatbot characteristics and their outcomes, this study shows the potential and the urgency of combining previously separated strains of research on stereotypes and human-machine communication and using stereotype frameworks to explore consequences of gender cues in human-machine communication.
References
Ågerfalk, P. J. (2020). Artificial intelligence as digital agency. European Journal of Information Systems, 29(1), 1–8. https://doi.org/10.1080/0960085X.2020.1721947.
Ahn, J., Kim, J., & Sung, Y. (2022). The effect of gender stereotypes on artificial intelligence recommendations. Journal of Business Research, 146, 50–59. https://doi.org/10.1016/j.jbusres.2021.12.007.
Allen, T. D. (2006). Rewarding good citizens: The relationship between citizenship behavior, gender, and organizational rewards. Journal of Applied Social Psychology, 36(1), 120–143. https://doi.org/10.1111/j.0021-9029.2006.00006.x.
Araujo, T. (2020). Conversational agent research toolkit: an alternative for creating and managing chatbots for experimental research1. Computational Communication Research, 2(1), 35–51. https://doi.org/10.5117/CCR2020.1.002.ARAU.
Awale, A., Chan, C. S., & Ho, G. T. S. (2019). The influence of perceived warmth and competence on realistic threat and willingness for intergroup contact. European Journal of Social Psychology, 49(5), 857–870. https://doi.org/10.1002/ejsp.2553.
Baldner, C., Pierro, A., Santo, D., & Cabras, C. (2021). How the mere desire for certainty can lead to a preference for men in authority (particularly among political liberals). Journal of Applied Social Psychology. https://doi.org/10.1111/jasp.12830.
Beldad, A., Hegner, S., & Hoppen, J. (2016). The effect of virtual sales agent (VSA) gender—product gender congruence on product advice credibility, trust in VSA and online vendor, and purchase intention. Computers in Human Behavior, 60, 62–72. https://doi.org/10.1016/j.chb.2016.02.046.
Beukeboom, C. J., & Burgers, C. (2019). How stereotypes are shared through language: A review and introduction of the Social Categories and Stereotypes Communication (SCSC) framework. Review of Communication Research, 7(2019), 1–37. https://doi.org/10.12840/issn.2255-4165.017.
Brahnam, S., & De Angeli, A. (2012). Gender affordances of conversational agents. Interacting with Computers, 24(3), 139–153. https://doi.org/10.1016/j.intcom.2012.05.001.
Brambilla, M., Rusconi, P., Sacchi, S., & Cherubini, P. (2011). Looking for honesty: The primary role of morality (vs. sociability and competence) in information gathering. European Journal of Social Psychology, 41(2), 135–143. https://doi.org/10.1002/ejsp.744.
Buzinski, S. G., & Kitchens, M. B. (2017). Self-regulation and social pressure reduce prejudiced responding and increase the motivation to be non-prejudiced. The Journal of Social Psychology, 157(5), 629–644. https://doi.org/10.1080/00224545.2016.1263595.
Caprariello, P. A., Cuddy, A. J. C., & Fiske, S. T. (2009). Social structure shapes cultural stereotypes and emotions: a causal test of the stereotype content model. Group Processes & Intergroup Relations, 12(2), 147–155. https://doi.org/10.1177/1368430208101053.
Chen, F. F., Jing, Y., & Lee, J. M. (2014). The looks of a leader: Competent and trustworthy, but not dominant. Journal of Experimental Social Psychology, 51, 27–33. https://doi.org/10.1016/j.jesp.2013.10.008.
Conway, M., Pizzamiglio, M. T., & Mount, L. (1996). Status, communality, and agency: implications for stereotypes of gender and other groups. Journal of Personality and Social Psychology, 71(1), 25–38. https://doi.org/10.1037/0022-3514.71.1.25.
Costa, P., & Ribas, L. (2019). AI becomes her: Discussing gender and artificial intelligence. Technoetic Arts: A Journal of Speculative Research, 17(1), 171–193. https://doi.org/10.1386/tear_00014_1.
Craig, M. A., & Richeson, J. A. (2014). More diverse yet less tolerant? How the increasingly diverse racial landscape affects white americans’ racial attitudes. Personality & Social Psychology Bulletin, 40(6), 750–761. https://doi.org/10.1177/0146167214524993.
Cruz-Castro, L., & Sanz-Menendez, L. (2021). What should be rewarded? Gender and evaluation criteria for tenure and promotion. Journal of Informetrics, 15(3). https://doi.org/10.1016/j.joi.2021.101196.
Cuddy, A. J. C., Fiske, S. T., & Glick, P. (2008). Warmth and competence as universal dimensions of social perception: the stereotype content model and the BIAS map. Advances in Experimental Social Psychology, 40, 61–149. https://doi.org/10.1016/S0065-2601(07)00002-0.
Cuddy, A. J. C., Fiske, S. T., Kwan, V. S. Y., Glick, P., Demoulin, S., Leyens, J.-P., Bond, M. H., Croizet, J.-C., Ellemers, N., Sleebos, E., Htun, T. T., Kim, H.-J., Maio, G., Perry, J., Petkova, K., Todorov, V., Rodríguez-Bailón, R., Morales, E., Moya, M., et al. (2009). Stereotype content model across cultures: Towards universal similarities and some differences. British Journal of Social Psychology, 48(1), 1–33. https://doi.org/10.1348/014466608X314935.
Cundiff, J. L. (2021). The “princess syndrome”: an examination of gender harassment on a male-majority university campus. Sex Roles, 85(9–10), 587–605. https://doi.org/10.1007/s11199-021-01243-4.
De Angeli, A., & Brahnam, S. (2006). Sex stereotypes and conversational agents. In AVI 2006 Workshop Gender and Interaction: Real and Virtual Women in a Male World, Venice, Italy.
De Cicco, R., Silva, S. C., & Alparone, F. R. (2020). Millennials’ attitude toward chatbots: an experimental study in a social relationship perspective. International Journal of Retail & Distribution Management, 48(11), 1213–1233. https://doi.org/10.1108/IJRDM-12-2019-0406.
DeFranza, D., Mishra, H., & Mishra, A. (2020). How language shapes prejudice against women: an examination across 45 world languages. Journal of Personality and Social Psychology, 119(1), 7–22. https://doi.org/10.1037/pspa0000188.
Dippold, D., Lynden, J., Shrubsall, R., & Ingram, R. (2020). A turn to language: How interactional sociolinguistics informs the redesign of prompt:response chatbot turns. Discourse, Context & Media, 37. https://doi.org/10.1016/j.dcm.2020.100432.
Dovidio, J. F., Kawakami, K., & Gaertner, S. L. (2002). Implicit and explicit prejudice and interracial interaction. Journal of Personality and Social Psychology, 82(1), 62–68. https://doi.org/10.1037/0022-3514.82.1.62.
Durante, F., Fiske, S. T., Gelfand, M. J., Crippa, F., Suttora, C., Stillwell, A., Asbrock, F., Aycan, Z., Bye, H. H., Carlsson, R., Björklund, F., Dagher, M., Geller, A., Larsen, C. A., Latif, A.-H. A., Mähönen, T. A., Jasinskaja-Lahti, I., & Teymoori, A. (2017). Ambivalent stereotypes link to peace, conflict, and inequality across 38 nations. Proceedings of the National Academy of Sciences—PNAS, 114(4), 669–674. https://doi.org/10.1073/pnas.1611874114.
Eagly, A. H., & Karau, S. J. (2002). Role congruity theory of prejudice towards female leaders. Psychological Review, 109(3), 573–598. https://doi.org/10.1037/0033-295X.109.3.573.
Eagly, A. H., Wood, W., & Diekman, A. B. (2000). Social role theory of sex differences and similarities: A current appraisal. The developmental social psychology of gender, 12, 174.
Eagly, A. H., Nater, C., Miller, D. I., Kaufmann, M., & Sczesny, S. (2020). Gender stereotypes have changed: A cross-temporal meta-analysis of U.S. public opinion polls from 1946 to 2018. American Psychologist, 75(3), 301–315. https://doi.org/10.1037/amp0000494.
Eastin, M. S. (2001). Credibility assessments of online health information: the effects of source expertise and knowledge of content. Journal of Computer-Mediated Communication, 6(4), JCMC643. https://doi.org/10.1111/j.1083-6101.2001.tb00126.x.
Ellemers, N. (2018). Gender stereotypes. Annual Review of Psychology, 69(1), 275–298. https://doi.org/10.1146/annurev-psych-122216-011719.
Fazio, R., & Olson, M. A. (2003). Implicit measures in social cognition research: Their meaning and use. Annual Review of Psychology, 54(1), 297–327. https://doi.org/10.1146/annurev.psych.54.101601.145225.
Feine, J., Gnewuch, U., Morana, S., & Maedche, A. (2020). Gender bias in Chatbot design. In Chatbot research and design (pp. 79–93). Cham: Springer. https://doi.org/10.1007/978-3-030-39540-7_6.
Fiske, S. T. (2018). Stereotype content: warmth and competence endure. Current directions in psychological science. Journal of the American Psychological Society, 27(2), 67–73. https://doi.org/10.1177/0963721417738825.
Fiske, S. T., Xu, J., Cuddy, A. C., & Glick, P. (1999). (Dis)respecting versus (dis)liking: status and interdependence predict ambivalent stereotypes of competence and warmth. Journal of Social Issues, 55(3), 473–489. https://doi.org/10.1111/0022-4537.00128.
Fiske, S. T., Cuddy, A. J. C., Glick, P., & Xu, J. (2002). A model of (often mixed) stereotype content: competence and warmth respectively follow from perceived status and competition. Journal of Personality and Social Psychology, 82(6), 878–902. https://doi.org/10.1037/0022-3514.82.6.878.
Følstad, A., Skjuve, M., & Brandtzaeg, P. B. (2019). Different Chatbots for different purposes: towards a typology of Chatbots to understand interaction design. In Internet science (pp. 145–156). Cham: Springer. https://doi.org/10.1007/978-3-030-17705-8_13.
Gambino, A., & Liu, B. (2022). Considering the context to build theory in HCI, HRI, and HMC: Explicating differences in processes of communication and socialization with social technologies. Human-Machine Communication, 4, 111–130. https://doi.org/10.30658/hmc.4.6.
Gambino, A., Fox, J., & Ratan, R. (2020). Building a stronger CASA: extending the computers are social actors paradigm. Human-Machine Communication, 1, 71–86. https://doi.org/10.30658/hmc.1.5.
Gaucher, D., Friesen, J., & Kay, A. C. (2011). Evidence that gendered wording in job advertisements exists and sustains gender inequality. Journal of Personality and Social Psychology, 101(1), 109–128. https://doi.org/10.1037/a0022530.
Gender API (2021). GenderAPI. https://gender-api.com/. Accessed 10 Dec 2021.
Glikson, E., & Woolley, A. W. (2020). Human trust in artificial intelligence: review of empirical research. Academy of Management Annals, 14(2), 627–660. https://doi.org/10.5465/annals.2018.0057.
Go, E., & Sundar, S. S. (2019). Humanizing chatbots: The effects of visual, identity and conversational cues on humanness perceptions. Computers in Human Behavior, 97, 304–316. https://doi.org/10.1016/j.chb.2019.01.020.
Grunspan, D. Z., Eddy, S. L., Brownell, S. E., Wiggins, B. L., Crowe, A. J., & Goodreau, S. M. (2016). Males under-estimate academic performance of their female peers in undergraduate biology classrooms. PloS One, 11(2). https://doi.org/10.1371/journal.pone.0148405.
Gupta, M., Parra, C. M., & Dennehy, D. (2021). Questioning racial and gender bias in AI-based recommendations: do espoused national cultural values matter? Information Systems Frontiers. https://doi.org/10.1007/s10796-021-10156-2.
Guzman, A. L. (2015). Imagining the voice in the machine: the ontology of digital social agents. University of Illinois at Chicago. Thesis. https://hdl.handle.net/10027/19842. Accessed 21 December 2021.
He, J. C., & Kang, S. K. (2021). Covering in cover letters: gender and self-presentation in job application. Academy of Management Journal, 64(4), 1097–1126. https://doi.org/10.5465/amj.2018.1280.
Heilman, M. E., Wallen, A. S., Fuchs, D., & Tamkins, M. M. (2004). Penalties for success: reactions to women who succeed at male gender-typed tasks. Journal of Applied Psychology, 89(3), 416–427. https://doi.org/10.1037/0021-9010.89.3.416.
Hoff, K. A., & Bashir, M. (2015). Trust in automation: integrating empirical evidence on factors that influence trust. Human Factors: The Journal of the Human Factors and Ergonomics Society, 57(3), 407–434. https://doi.org/10.1177/0018720814547570.
Kervyn, N., Fiske, S. T., & Yzerbyt, V. Y. (2013). Integrating the stereotype content model (warmth and competence) and the Osgood semantic differential (evaluation, potency, and activity). European Journal of Social Psychology, 43(7), 673–681. https://doi.org/10.1002/ejsp.1978.
Kidder, D. L., & Parks, J. M. (2001). The good soldier: who is s(he)? Journal of Organizational Behavior, 22(8), 939–959. https://doi.org/10.1002/job.119.
Kurt, D., Inman, J. J., & Argo, J. J. (2011). The influence of friends on consumer spending: the role of agency—Communion orientation and self-monitoring. Journal of Marketing Research, 48(4), 741–754. https://doi.org/10.1509/jmkr.48.4.741.
Lee, J. D., & See, K. A. (2004). Trust in automation: designing for appropriate reliance. Human Factors, 46(1), 50–80.
Leslie, S.-J., Cimpian, A., Meyer, M., & Freeland, E. (2015). Expectations of brilliance underlie gender distributions across academic disciplines. Science (American Association for the Advancement of Science), 347(6219), 262–265. https://doi.org/10.1126/science.1261375.
Lou, C., Kang, H., & Tse, C. H. (2021). Bots vs. humans: how schema congruity, contingency-based interactivity, and sympathy influence consumer perceptions and patronage intentions. International Journal of Advertising, 41(4), 655-684. https://doi.org/10.1080/02650487.2021.1951510.
Manyika, J., Silberg, J., & Presten, B. (2019). What do we do about the biases in AI? https://hbr.org/2019/10/what-do-wedo-about-the-biases-in-ai. Accessed 7 Sept 2022.
Mayer, R. C., Davis, J. H., & Schoorman, F. D. (1995). An integrative model of organizational trust. The Academy of Management Review, 20(3), 709–734. https://doi.org/10.2307/258792.
McDonnell, M., & Baxter, D. (2019). Chatbots and gender stereotyping. Interacting with Computers, 31(2), 116–121. https://doi.org/10.1093/iwc/iwz007.
McKnight, D. H., Choudhury, V., & Kacmar, C. (2002). Developing and validating trust measures for e‑commerce: an integrative typology. Information Systems Research, 13(3), 334–359. https://doi.org/10.1287/isre.13.3.334.81.
Nass, C., & Moon, Y. (2000). Machines and mindlessness: Social responses to computers. Journal of Social Issues, 56, 81–103. https://doi.org/10.1111/0022-4537.00153.
Nass, C., Moon, Y., & Green, N. (1997). Are machines gender neutral? Gender-stereotypic responses to computers with voices. Journal of Applied Social Psychology, 27(10), 864–876. https://doi.org/10.1111/j.1559-1816.1997.tb00275.x.
Nejat, P., Bagherian, F., & Hatami, J. (2020). Do perceptions of warmth and competence explain moral norms regarding different social roles? Analyses of Social Issues and Public Policy, 20(1), 613–637. https://doi.org/10.1111/asap.12217.
Niculescu, A., Hofs, D., van Dijk, B., & Nijholt, A. (2010). How the agent’s gender influence users’ evaluation of a QA system. In 2010 International Conference on User Science and Engineering (i-USEr) (pp. 16–20). https://doi.org/10.1109/IUSER.2010.5716715.
Nordheim, C. B., Følstad, A., & Bjørkli, C. A. (2019). An initial model of trust in Chatbots for customer service—findings from a questionnaire study. Interacting with Computers, 31(3), 317–335. https://doi.org/10.1093/iwc/iwz022.
Nowak, K., & Fox, J. (2018). Avatars and computer-mediated communication: A review of the definitions, uses, and effects of digital representations. Review of Communication Research, 6, 30–53. https://doi.org/10.12840/issn.2255-4165.2018.06.01.015.
Pengnate, S., & Sarathy, R. (2017). An experimental investigation of the influence of website emotional design features on trust in unfamiliar online vendors. Computers in Human Behavior, 67, 49–60. https://doi.org/10.1016/j.chb.2016.10.018.
Pietraszkiewicz, A., Formanowicz, M., Gustafsson Sendén, M., Boyd, R. L., Sikström, S., & Sczesny, S. (2019). The big two dictionaries: Capturing agency and communion in natural language. European Journal of Social Psychology, 49(5), 871–887. https://doi.org/10.1002/ejsp.2561.
Pitardi, V., & Marriott, H. (2021). Alexa, she’s not human but… Unveiling the drivers of consumers’ trust in voice-based artificial intelligence. Psychology and Marketing, 38(4), 626–642. https://doi.org/10.1002/mar.21457.
Prahl, A., & Van Swol, L. M. (2021). Out with the humans, in with the machines?: Investigating the behavioral and psychological effects of replacing human advisors with a machine. Human-Machine Communication, 2, 209–234. https://doi.org/10.30658/hmc.2.11.
Prentice, D. A., & Carranza, E. (2002). What women and men should be, shouldn’t be, are allowed to be, and don’t have to be: The contents of prescriptive gender stereotypes. Psychology of women quarterly, 26(4), 269–281. https://doi.org/10.1111/1471-6402.t01-1-00066.
Rapp, A., Curti, L., & Boldi, A. (2021). The human side of human-chatbot interaction: A systematic literature review of ten years of research on text-based chatbots. International Journal of Human-Computer Studies, 151. https://doi.org/10.1016/j.ijhcs.2021.102630.
Redford, L., Howell, J. L., Meijs, M. H. J., & Ratliff, K. A. (2018). Implicit and explicit evaluations of feminist prototypes predict feminist identity and behavior. Group Processes & Intergroup Relations, 21(1), 3–18. https://doi.org/10.1177/1368430216630193.
Rousseau, D. M., Sitkin, S. B., Burt, R. S., & Camerer, C. (1998). Not so different after all: a cross-discipline view of trust. The Academy of Management Review, 23(3), 393–404. https://doi.org/10.5465/AMR.1998.926617.
Rudman, L. A. (1998). Self-promotion as a risk factor for women: The costs and benefits of counterstereotypical impression management. Journal of Personality and Social Psychology, 74, 629–645. https://doi.org/10.1037/0022-3514.74.3.629.
Rudman, A. G., & McGhee, D. E. (2001). Implicit self-concept and evaluative implicit gender stereotypes: self and ingroup share desirable traits. Personality & Social Psychology Bulletin, 27(9), 1164–1178. https://doi.org/10.1177/0146167201279009.
Rudman, L. A., & Glick, P. (1999). Implicit gender stereotypes and backlash toward agentic women: The hidden costs to women of a kinder, gentler image of managers. Journal of Personality and Social Psychology, 77, 1004–1010.
Sainz, M., Moreno-Bella, E., & Torres-Vega, L. C. (2021). A more competent, warm, feminine, and human leader: perceptions and effectiveness of democratic versus authoritarian political leaders. Revue Internationale de Psychologie Sociale. https://doi.org/10.5334/irsp.452.
Schoorman, F. D., Mayer, R. C., & Davis, J. H. (2007). An integrative model of organizational trust: past, present, and future. The Academy of Management Review, 32(2), 344–354. https://doi.org/10.5465/AMR.2007.24348410.
Smith, D. G., Rosenstein, J. E., Nikolov, M. C., & Chaney, D. A. (2018). The power of language: gender, status, and agency in performance evaluations. Sex Roles, 80(3), 159–171. https://doi.org/10.1007/s11199-018-0923-7.
Vorsino, Z. (2021). Chatbots, gender, and race on web 2.0 platforms: Tay.AI as monstrous femininity and abject whiteness. Signs: Journal of Women in Culture and Society, 47(1), 105–127. https://doi.org/10.1086/715227.
West, M., Kraut, R., & Chew, H. E. (2019). I’d blush if I could: closing gender divides in digital skills through education. EQUALS Global Partnership, UNESCO.
Wojciszke, B. (2005). Morality and competence in person- and self-perception. European Review of Social Psychology, 16(1), 155–188. https://doi.org/10.1080/10463280500229619.
Yen, C., & Chiang, M.-C. (2020). Trust me, if you can: a study on the factors that influence consumers’ purchase intention triggered by chatbots based on brain image evidence and self-reported assessments. Behaviour & Information Technology, 40(11), 1177–1194. https://doi.org/10.1080/0144929X.2020.1743362.
Zarouali, B., Van den Broeck, E., Walrave, M., & Poels, K. (2018). Predicting consumer responses to a Chatbot on Facebook. Cyberpsychology, Behavior and Social Networking, 21(8), 491–497. https://doi.org/10.1089/cyber.2017.0518.
Funding
Open access funding provided by University of Amsterdam.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix

Picture of the chatbots basic flow (high warmth and assigned gender female)

Picture of the chatbot
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bastiansen, M.H.A., Kroon, A.C. & Araujo, T. Female chatbots are helpful, male chatbots are competent?. Publizistik 67, 601–623 (2022). https://doi.org/10.1007/s11616-022-00762-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11616-022-00762-8