
Abstract
Background
The goal of this article is to conduct an assessment of the peer-reviewed primary literature with study objectives to analyze Amazon.com’s Mechanical Turk (MTurk) as a research tool in a health services research and medical context.
Methods
Searches of Google Scholar and PubMed databases were conducted in February 2017. We screened article titles and abstracts to identify relevant articles that compare data from MTurk samples in a health and medical context to another sample, expert opinion, or other gold standard. Full-text manuscript reviews were conducted for the 35 articles that met the study criteria.
Results
The vast majority of the studies supported the use of MTurk for a variety of academic purposes.
Discussion
The literature overwhelmingly concludes that MTurk is an efficient, reliable, cost-effective tool for generating sample responses that are largely comparable to those collected via more conventional means. Caveats include survey responses may not be generalizable to the US population.
Similar content being viewed by others


Amazon.com’s Mechanical Turk (MTurk) is an online, web-based platform that started in 2005 as a service to allow researchers to “crowdsource” labor-intensive tasks for workers registered on the site to complete for compensation.1, 2 MTurk has rapidly become a source of subjects for experimental research and survey data for academic work, as its representativeness, speed, and low cost appeal to researchers.2, 3 Researchers post links to surveys and experiments and use MTurk to crowdsource the survey, collect the data, and compensate workers.4 A Google Scholar search of “Amazon Mechanical Turk” revealed 15,000 results published between 2006 and 20143 and 17,400 results by mid-2017. MTurk is the largest online crowdsourcing platform,4 with about one-third of the tasks related to academic tasks.5 The growing popularity of MTurk has led to questions about its soundness as a subject pool; MTurk is the most studied nonprobability sample available to researchers.3
The MTurk pool of potential workers is vast, diverse, and inexpensive. MTurk has 500,000 registered users3 with 15,000 individual US workers at any given time.6 MTurkers have been paid as little as $0.05 to complete 10- to 15-min tasks.4 Researchers can collect data from large enough samples to generate significant statistical power at one-tenth of the cost of traditional methods.4 The MTurk population is more representative of the population at large than other online surveys and produces reliable results.2, 3, 6,7,8,9,10,–11
There is a rapidly growing literature exploring the generalizability of MTurk responses to other data collection methods. Data obtained via MTurk surveys and experiments are at least as reliable as those obtained via traditional methods, are attractive for conducting internally and externally valid experiments, and the advantages outweigh the disadvantages.3, 8,9,10,11,12,13,14,–15 However, the benefits and drawbacks to using MTurk in the health and medical literature are largely unexplored beyond a taxonomy of how MTurk has been used in health and medical research.16 This article is the first synthesis to assess the peer-reviewed literature that has a study objective to analyze MTurk as research tool in a health services research and medical context and uses MTurk for part or all the results. The results from this synthesis can guide academic researchers as they explore the strengths and weaknesses of employing MTurk as an academic research platform.
METHODS
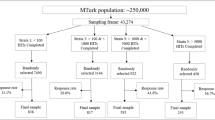
A literature search was performed for articles published between 2005 and mid-February 2017 using Google Scholar and PubMed databases. Searches for variations of the terms Mechanical Turk, MTurk, health, healthcare, clinic*, and medic yielded an initial total of 331 non-duplicative articles. Two reviewers (TH and KM) screened the articles first by title review, eliminating those that did not pertain to health as defined by the World Health Organization,17 leaving 181 articles. After abstract and full-text review, 35 articles were included in the final analysis.
RESULTS
The 35 articles that met the criteria of primary peer-reviewed article, MTurk used in part or all of the results, and an objective of the study was to analyze MTurk as a research tool in a health services research and medical context are described briefly in Table 1.12, 18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,–51 A number of strengths of using MTurk in an academic health services setting were identified in the literature. The studies were overwhelmingly supportive of the economical, cost-effective nature of MTurk.18, 19, 23, 25, 26, 29,30,31,32,33,–34, 37, 38, 40, 41, 45,46,47,48,–49, 51 Additional strengths include the time-saving component of using MTurk, reliability, and high quality. Accurate,34 effective,29, 30, 51 performance comparable to quality of medical experts,18, 26, 33, 34, 39, 41, 43, 48 high verification,42 reliable,27, 31 objective,32 statistically equivalent to data from other samples,12, 22, 24, 38, 49, 50 diverse,19, 21, 47, 49 and viable,28, 36 high quality,35, 42, 45 among other strengths, were consistent conclusions in the literature.
The weaknesses are dominated by the identified strengths, but important to note. Four studies20, 36,37,–38 noted three caveats: (1) researchers should exercise caution when generalizing MTurk findings to the US population;20, 36 (2) despite a high degree of inter-rater reliability in the MTurk sample, it is unknown whether the accuracy of the data is comparable to evaluations by trained ophthalmologic experts;37 (3) the data were not validated against a sample using face-to-face interview techniques.38 The literature overwhelming concludes that MTurk is an efficient, reliable, cost-effective tool for a variety of tasks with results comparable to those collected via more conventional means. However, results from surveys on MTurk should not be generalized to the US population.
References
Redmiles EM, Kross S, Pradhan A, Mazurek ML. How well do my results generalize? Comparing security and privacy survey results from MTurk and web panels to the US; 2017. Technical Report of the Computer Science Department at the University of Maryland. http://drum.lib.umd.edu/handle/1903/19164.
Paolacci G, Chandler J, Ipeirotis P. Running experiments on Amazon Mechanical Turk. Judgment and decision making. 2010;5(5):411–419. https://doi.org/10.2139/ssrn.1626226.
Chandler J, Shapiro DN. Conducting clinical research using crowdsourced convenience samples. Annual review of clinical psychology. 2016;12:53–81. https://doi.org/10.1146/annurev-clinpsy-021815-093623.
Pittman M, Sheehan K. Amazon’s Mechanical Turk a digital sweatshop? Transparency and accountability in crowdsourced online research. Journal of media ethics. 2016;31(4):260–262. https://doi.org/10.1080/23736992.2016.1228811.
Hitlin P. Research in the crowdsourcing Age, a case study.; 2016. http://www.pewinternet.org/2016/07/11/research-in-the-crowdsourcing-age-a-case-study/.
Stewart N, Harris AJL, Bartels DM, Newell BR, Paolacci G, Chandler J. The average laboratory samples a population of 7,300 Amazon Mechanical Turk workers. Judgment and decision making. 2015;10(5):479–491. https://doi.org/10.1017/CBO9781107415324.004.
Behrend TS, Sharek DJ, Meade AW, Wiebe EN. The viability of crowdsourcing for survey research. Behavioral research methods. 2011;43(3):800–813. https://doi.org/10.3758/s13428-011-0081-0.
Berinsky AJ, Huber GA, Lenz GS. Evaluating online labor markets for experimental tesearch: Amazon.com’s Mechanical Turk. Political analysis. 2012;20(3):351–368. https://doi.org/10.1093/pan/mpr057.
Buhrmester M, Kwang T, Gosling SD. Amazon’s Mechanical Turk: A new source of inexpensive, yet high-quality, data? Perspectives in psychological science. 2011;6(1):3–5. https://doi.org/10.1177/1745691610393980.
Woods AT, Velasco C, Levitan CA, Wan X, Spence C. Conducting perception research over the internet: a tutorial review. PeerJ. 2015;3:e1058. https://doi.org/10.7717/peerj.1058.
Sheehan KB. Crowdsourcing research: Data collection with Amazon’s Mechanical Turk. Commun Monogr. 2017;0(0):1–17. https://doi.org/10.1080/03637751.2017.1342043.
Shapiro DN, Chandler J, Mueller PA. Using Mechanical Turk to study clinical populations. Clinical psychological science. 2013;1(2):213–220. https://doi.org/10.1177/2167702612469015.
Casler K, Bickel L, Hackett E. Separate but equal? A comparison of participants and data gathered via Amazon’s MTurk, social media, and face-to-face behavioral testing. Computers in human behavior. 2013;29(6):2156–2160. https://doi.org/10.1016/j.chb.2013.05.009.
Horton JJ, Rand DG, Zeckhauser RJ. The online laboratory: Conducting experiments in a real labor market. Experimental economics. 2011;14(3):399–425. https://doi.org/10.1007/s10683-011-9273-9.
Mason W, Suri S. Conducting behavioral research on Amazon’s Mechanical Turk. Behavioral research methods. 2012;44(1):1–23. https://doi.org/10.3758/s13428-011-0124-6.
Ranard BL, Ha YP, Meisel ZF, et al. Crowdsourcing—harnessing the masses to advance health and medicine, a systematic review. Journal of general internal medicine. 2014;29(1):187–203. https://doi.org/10.1007/s11606-013-2536-8.
Constitution of the World Health Organization. 1946. http://www.who.int/about/mission/en/.
Aghdasi N, Bly R, White LW, Hannaford B, Moe K, Lendvay TS. Crowd-sourced assessment of surgical skills in cricothyrotomy procedure. Journal of surgical research. 2015;196(2):302–306. https://doi.org/10.1016/j.jss.2015.03.018.
Arch JJ, Carr AL. Using Mechanical Turk for research on cancer survivors. Psychooncology. 2016; https://doi.org/10.1002/pon.4173.
Arditte KA, Cek D, Shaw AM, Timpano KR. The importance of assessing clinical phenomena in Mechanical Turk research. Psychological assessment. 2016;28(6):684–691. https://doi.org/10.1037/pas0000217.
Bardos J, Friedenthal J, Spiegelman J, Williams Z. Cloud based surveys to assess patient perceptions of health care: 1000 respondents in 3 days for US $300. JMIR research protocols. 2016;5(3):e166. https://doi.org/10.2196/resprot.5772.
Boynton MH, Richman LS. An online daily diary study of alcohol use using Amazon’s Mechanical Turk. Drug and alcohol review. 2014;33(4):456–461. https://doi.org/10.1111/dar.12163.
Brady CJ, Villanti AC, Pearson JL, Kirchner TR, Gupta OP, Shah CP. Rapid grading of fundus photographs for diabetic retinopathy using crowdsourcing. Journal of medical internet research. 2014;16(10):e233. https://doi.org/10.2196/jmir.3807.
Briones EM, Benham G. An examination of the equivalency of self-report measures obtained from crowdsourced versus undergraduate student samples. Behavioral research methods. 2016. https://doi.org/10.3758/s13428-016-0710-8.
Brown AW, Allison DB. Using crowdsourcing to evaluate published scientific literature: Methods and example. PLoS One. 2014;9(7):e100647. https://doi.org/10.1371/journal.pone.0100647.
Chen C, White L, Kowalewski T, et al. Crowd-Sourced Assessment of Technical Skills: A novel method to evaluate surgical performance. Journal of surgical research. 2014;187(1):65–71. https://doi.org/10.1016/j.jss.2013.09.024.
Deal SB, Lendvay TS, Haque MI, et al. Crowd-sourced assessment of technical skills: an opportunity for improvement in the assessment of laparoscopic surgical skills. American journal of surgery. 2016;211(2):398–404. https://doi.org/10.1016/j.amjsurg.2015.09.005.
Gardner RM, Brown DL, Boice R. Using Amazon’s Mechanical Turk website to measure accuracy of body size estimation and body dissatisfaction. Body image. 2012;9(4):532–534. https://doi.org/10.1016/j.bodyim.2012.06.006.
Good BM, Nanis M, Wu C, Su AI. Microtask crowdsourcing for disease mention annotation in PubMed abstracts. Pacific symposium on biocomputing. 2015:282–293. https://doi.org/10.1142/9789814644730_0028.
Harber P, Leroy G. Assessing work–asthma interaction with Amazon Mechanical Turk. Journal of occupational medicine. 2015;57(4):381–385. https://doi.org/10.1097/JOM.0000000000000360.
Harris JK, Mart A, Moreland-Russell S, Caburnay CA. Diabetes topics associated with engagement on Twitter. Preventing chronic disease. 2015;12:E62. https://doi.org/10.5888/pcd12.140402.
Hipp JA, Manteiga A, Burgess A, Stylianou A, Pless R. Webcams, crowdsourcing, and enhanced crosswalks: Developing a novel method to analyze active transportation. Frontiers in public health. 2016;4:1–9. http://journal.frontiersin.org/article/10.3389/fpubh.2016.00097.
Holst D, Kowalewski TM, White LW, et al. Crowd-Sourced Assessment of Technical Skills (C-SATS): Differentiating animate surgical skill through the wisdom of crowds. Journal of endourology. 2015;29(10):1183–8. https://doi.org/10.1089/end.2015.0104.
Khare R, Burger JD, Aberdeen JS, et al. Scaling drug indication curation through crowdsourcing. Database. 2015;2015:bav016. https://doi.org/10.1093/database/bav016.
Kim HS, Hodgins DC. Reliability and validity of data obtained from alcohol, cannabis, and gambling populations on Amazon’s Mechanical Turk. Psychology of addictive behaviors. 2017;31(1):85–94. https://doi.org/10.1037/adb0000219.
Kuang J, Argo L, Stoddard G, Bray BE, Zeng-Treitler Q. Assessing pictograph recognition: A comparison of crowdsourcing and traditional survey approaches. Journal of medical internet research. 2015;17(12):e281. https://doi.org/10.2196/jmir.4582.
Lee AY, Lee CS, Keane PA, Tufail A. Use of Mechanical Turk as a MapReduce framework for macular OCT segmentation. Journal of ophthalmology. 2016. https://doi.org/10.1155/2016/6571547.
Lloyd JC, Yen T, Pietrobon R, et al. Estimating utility values for vesicoureteral reflux in the general public using an online tool. Journal of pediatric urology. 2014;10(6):1026–1031. https://doi.org/10.1016/j.jpurol.2014.02.014.
MacLean DL, Heer J. Identifying medical terms in patient-authored text: a crowdsourcing-based approach. Journal of the american medical informatics association. 2013;20(6):1120–1127. https://doi.org/10.1136/amiajnl-2012-001110.
Mitry D, Peto T, Hayat S, et al. Crowdsourcing as a screening tool to detect clinical features of glaucomatous optic neuropathy from digital photography. PLoS One. 2015;10(2):1–8. https://doi.org/10.1371/journal.pone.0117401.
Mitry D, Zutis K, Dhillon B, et al. The accuracy and reliability of crowdsource annotations of digital retinal images. Translational vision science & technology. 2016;5(5):6. https://doi.org/10.1167/tvst.5.5.6.
Mortensen JM, Musen MA, Noy NF. Crowdsourcing the verification of relationships in biomedical ontologies. AMIA Annual symposium proceedings. 2013;2013:1020–1029.
Powers MK, Boonjindasup A, Pinsky M, et al. Crowdsourcing assessment of surgeon dissection of renal artery and vein during robotic partial nephrectomy: A novel approach for quantitative assessment of surgical performance. Journal of endourology. 2016;30(4):447–452. https://doi.org/10.1089/end.2015.0665.
Santiago-Rivas M, Schnur JB, Jandorf L. Sun protection belief clusters: Analysis of Amazon Mechanical Turk data. Journal of cancer education. 2016;31(4):673–678. https://doi.org/10.1007/s13187-015-0882-4.
Schleider JL, Weisz JR. Using Mechanical Turk to study family processes and youth mental health: A test of feasibility. Journal of child and family studies. 2015;24(11):3235–3246. https://doi.org/10.1007/s10826-015-0126-6.
Shao W, Guan W, Clark MA, et al. Variations in recruitment yield, costs, speed, and participant diversity across internet platforms in a global study examining the efficacy of an HIV/AIDS and HIV testing animated and live-action video. Digital culture & education. 2015;7(1):40–86.
Turner AM, Kirchhoff K, Capurro D. Using crowdsourcing technology for testing multilingual public health promotion materials. Journal of medical internet research. 2012;14(3):e79. http://www.jmir.org/2012/3/e79/.
White LW, Kowalewski TM, Dockter RL, Comstock B, Hannaford B, Lendvay TS. Crowd-Sourced Assessment of Technical Skill: A valid method for discriminating basic robotic surgery skills. Journal of endourology. 2015;29(11):1295–1301. https://doi.org/10.1089/end.2015.0191.
Wu C, Scott Hultman C, Diegidio P, et al. What do our patients truly want? Conjoint analysis of an aesthetic plastic surgery practice using internet crowdsourcing. Aesthet Surg J. 2017;37(1):105–118. https://doi.org/10.1093/asj/sjw143.
Wymbs BT, Dawson AE. Screening Amazon’s Mechanical Turk for adults with ADHD. J Atten Disord. 2015:1–10. https://doi.org/10.1177/1087054715597471.
Yu B, Willis M, Sun P, Wang J. Crowdsourcing participatory evaluation of medical pictograms using Amazon Mechanical Turk. Journal of medical internet research. 2013;15(6):e108. http://www.jmir.org/2013/6/e108/.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare no conflicts of interest.
Rights and permissions
About this article

Cite this article
Mortensen, K., Hughes, T.L. Comparing Amazon’s Mechanical Turk Platform to Conventional Data Collection Methods in the Health and Medical Research Literature. J GEN INTERN MED 33, 533–538 (2018). https://doi.org/10.1007/s11606-017-4246-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11606-017-4246-0