
Abstract
This study addresses primal–dual dynamics for a stochastic programming problem for capacity network design. It is proven that consensus can be achieved on the here and now variables which represent the capacity of the network. The main contribution is a heuristic approach which involves the formulation of the problem as a mean-field game. Every agent in the mean-field game has control over its own primal–dual dynamics and seeks consensus with neighboring agents according to a communication topology. We obtain theoretical results concerning the existence of a mean-field equilibrium. Moreover, we prove that the consensus dynamics converge such that the agents agree on the capacity of the network. Lastly, we emphasize the ways in which penalties on control and state influence the dynamics of agents in the mean-field game.
Similar content being viewed by others


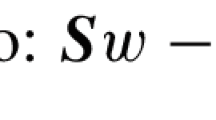
Avoid common mistakes on your manuscript.
1 Introduction
Motivated by a stochastic program for the network capacity design and flow optimization, we cast for the first time primal–dual dynamics in the framework of mean-field games. We consider a scenario where demand materializes at some geographic spots and goods are transported from warehouses to fulfill such demand. We first model the problem as a two stage stochastic program for supply chain network design in the same spirit as in Ch. 1.5 [28]. Demand materializes at some nodes and goods flow over the edges. The flow in each edge is subject to capacity constraints and the flows in and out of each node must satisfy flow conservation constraints. The resulting optimization model is a constrained stochastic nonlinear (quadratic) two-stage program.
Continuous-time primal–dual gradient dynamics, also known as saddle-point dynamics, were first introduced in [2, 20]. Primal–dual dynamics is used in a number of application domains such as energy resource allocation [17], cyber-physical systems [26], wireless communications networks [11], smart grids [34], just to name a few. Recent works have been dedicated to exponential stability analysis of primal–dual dynamics [12, 24, 27, 30]. Furthermore, analysis on robustness has been performed in [15, 19, 25]. Also, the global/local nature of the convexity-concavity properties of the primal–dual dynamics was examined. Explicit attention has been paid to asymptotic stability properties of the primal–dual dynamics in [13, 14, 16, 29]. Primal–dual dynamics and stochastic gradient descent has been recently studied in [8]. The extension to large scale problems is possible through parallelization and using elastic averaging stochastic gradient descent algorithms [9].
There is less work dedicated to the combination of primal–dual dynamics with mean-field games. However, there have been studies concerning Lagrangian relaxation methods to solve mean-field games, such as in [1], where a planning problem is discussed. Additionally, in [32] and [33] Lagrangian relaxation is used in mean-field game power control. More recently a primal–dual approach has been used to solve constrained mean-field games [10]. Mean-field games in the form of coupled partial differential equations originated in the works of Lasry and Lions [21,22,23]. Explicit closed-form expressions for mean-field equilibria were first proposed for linear-quadratic mean-field games [3] and have been extended to more general cases in [18]. This paper mainly follows the linear-quadratic mean-field game formulation as in [4,5,6].
The main contribution is a heuristic approach which involves the reformulation of the original problem into a large number of stochastic primal–dual dynamics which are coupled in the same spirit as in mean-field games. To be more specific, we consider the instance of a large number of agents, each assigned with a primal–dual dynamics subject to a specific realization of the demand. The players of the mean-field game have to obtain consensus over the here and now decision variables: the capacity of each edge of the supply chain network. We also consider wait and see decision variables for flow and the Lagrange multipliers coming from the primal–dual dynamics. Note the analogy with a two-player zero-sum game whereby the first player, the minimizer, sets the here and now variables required to accommodate for any potential scenario concerning flow and demand realization. Subsequently, the second player, the maximizer, sets the wait and see variables to maximize demand satisfaction given the decision of player 1 and the realized demand. The condition for convergence to a consensus value is that the communication network of agents needs to be connected, i.e., for any pair of nodes there exists a path connecting them. We first transform the primal–dual dynamics into a mean-field game, after which theoretical results are provided concerning a mean-field equilibrium solution in the same spirit as in [4,5,6]. Lastly, we provide numerical simulations to prove once again that consensus is obtained. Since the proposed methodology is heuristic in nature, the convergence values are in general sub-optimal.
The proposed model and methodology is original as it involves turning the micro-network model into a set of primal–dual dynamics and after that into a mean-field game in which each agent faces a different realization of the uncertain demand. We see this as a value and believe that the link between primal–dual dynamics and mean-field games expands the significance, meaning, and potential of mean-field games approaches beyond the ones already in the literature. Note also that the obtained mean-field game depends strongly on the micro-network optimization parameters. Actually, the incidence matrix, the penalty coefficients and the uncertain demand enter into the mean-field dynamics of the optimization flow and capacity variables as well as of the Lagrange multipliers.
This paper is organized as follows. In Sect. 2, we formulate the stochastic programming for network design. In Sect. 3, we present the primal–dual dynamics. In Sect. 4, we present the corresponding mean-field game. In Sect. 5, we state theoretical results on mean-field equilibrium and convergence. In Sect. 6, we provide a simulation example to corroborate our results. Lastly, in Sect. 7, we provide concluding remarks and discuss future works.
2 Stochastic programming for network design
Let us consider a physical flow network (referred to as micro-network) denoted as G(V, E). Let the set of nodes be \(V \in \{V_1, V_2,\ldots , V_n\}\), where each node corresponds to an agent in the network. The parameter n denotes the number of nodes present in the network. Let the set of edges be \(E \in \{E_1, E_2,\ldots ,E_m\}\). The parameter m denotes the number of edges in the network. The demand is described by a vector \(w \in {\mathbb {R}}^{n\times 1}\) and is an uncertain random parameter. The capacity of the edges are the here and now variables and are denoted by \(c \in {\mathbb {R}}^{m\times 1}\). The transported goods in each edge are the wait and see variables and are denoted by \(u \in {\mathbb {R}}^{m\times 1}\). A graphical representation of the micro-network can be found in Fig. 1.

A graphical representation of the directed network corresponding to the first problem instance
Let \(f_1(c)=\frac{1}{2}c^T{\tilde{Q}}_1c+{\tilde{f}}_1^Tc\) be the cost associated to the capacity of the edges in the micro-network, and \(f_2(u)=\frac{1}{2}u^T{\tilde{Q}}_2u+{\tilde{f}}_2^Tu\) be the cost charged for using the edges to transport goods such that the demand is satisfied. In the above costs we have a quadratic and a linear term. The matrices \({\tilde{Q}}_1,{\tilde{Q}}_2\in {\mathbb {R}}^{m\times m}\) are the cost coefficients for the quadratic term, and \({\tilde{f}}_1,{\tilde{f}}_2\in {\mathbb {R}}^m\) are the linear cost coefficients. We model the supply chain network design problem as a two-stage stochastic program as follows:
Note that the objective function that we wish to minimize describes the total cost of transporting goods. The optimization variables in this problem are the capacity of the edges \(c\in {\mathbb {R}}^{m\times 1}\), and the flow in the edges \(u\in {\mathbb {R}}^{m\times 1}\). The capacities c are the first-stage decision variables, and they are obtained before the realization of the demand. The optimal capacities are independent of the demand, however they have to accommodate any realization of it. On the other hand, the flows u are the second-stage decision variables, they depend on the values of the first-stage variables and they are obtained after observing the realized demand. In addition, \({{\tilde{B}}}\in {\mathbb {R}}^{n\times m}\) is the incidence matrix of the micro-network, \({\mathbb {E}}_w(.)\) denotes expectation with respect to w and \({\hat{Q}}(u,w)\) denotes the sub-optimal value of the second-stage problem, namely
Observe that as \({\hat{Q}}(c,w)\) depends on the capacities of the edges c and on the random variable w, the optimal value of the second-stage problem is also a random variable. Hence, we can obtain its expected value with respect to the demand, namely \({\mathbb {E}}_w{\hat{Q}}(c,w)\), which is included in the objective function of the two-stage stochastic program (1).
3 Primal–dual dynamics
In this section we introduce the stochastic primal–dual dynamic related to the two-stage stochastic program (1).
Let \(\omega\) be a constant demand vector randomly extracted from the same distribution of w. To obtain the primal–dual dynamics associated with this particular realization of the two-stage program (1) we first derive the Lagrangian function as follows:
where \(\mu \in {\mathbb {R}}^{m\times 1}\) and \(\lambda \in {\mathbb {R}}^{n\times 1}\) are the Lagrange multipliers.
The Lagrange dual problem can then be formulated as follows:
By imposing that the gradient of the Lagrangian with respect to u and c vanishes, we obtain the following Karush–Kuhn–Tucker (KKT) conditions:
The corresponding primal–dual dynamics are obtained from the gradient descent and gradient ascent dynamics over u and c respectively as shown next:
In compact form, the above set of differential equation can be written as
In the two-stage program (1) the capacity vector c needs to be the same for any realization of the demand w, namely for any value of \(\omega\) in the support of w. This implies that the primal–dual dynamics (4) obtained for different realization \(\omega\) need to reach consensus on c. We show that this is possible by developing an ad-hoc mean-field game model in the following section.
4 Construction of the mean-field game
Let us now introduce a two-layer network as in Fig. 2. Layer 1 involves the communication topology among different populations (henceforth referred to as macro-network) denoted as \({{\hat{G}}}({{\hat{V}}},{{\hat{E}}}),\) whereas layer 2 comprises the physical flow network (micro-network) as introduced in Sect. 2, denoted as G(V, E). Each node in the macro-network \({\hat{G}}({\hat{V}},{\hat{E}})\) represents a different population. All populations in \({\hat{G}}\) have the same topology of their micro-network G. Hence, they are characterized by the same incidence matrix \({\tilde{B}}\) and the same cost functions \(f_1\) and \(f_2\). However, each agent in the population has a different realization of the demand. The aim is to obtain a feasible solution to the two-stage stochastic program (1) by reaching consensus on the capacities of the edges between any agent in the population and across all populations.

Two-layer network: macro-network \({{\hat{G}}}({{\hat{V}}},{{\hat{E}}})\) in layer 1 and micro-network G(V, E) in layer 2
We use the macro-network to model a distributed optimization setting. In this section we present a heuristic approach that turns the two-stage stochastic program (1) into a mean-field game, where each player corresponds to an agent in each population, and it is assigned to a primal–dual dynamics according to its demand realization. This new approach represents a distributed optimization problem, which enables the agents to reach consensus on the edges’ capacities, and it provides a feasible solution to problem (1) by taking into account the communication between populations.
Consider \(|{\hat{V}}|=p\) populations such that each agent in our game belongs to a population \(k\in \left\{ 1,\ldots ,p\right\}\) and is characterized by a primal–dual dynamics (4) obtained for a particular realization \(\omega\) of the demand. The generic agent in population k is characterized by its state x(t) which involves the decision variables (flows and capacities) and the Lagrange multipliers of problem (1), namely \(x(t):=[u^T \, c^T \, \lambda ^T \, \mu ^T]^T \in {\mathbb {R}}^{3m+n}\). At each time t and for a given time horizon window [0, T], x(t) evolves according to the primal–dual dynamics in (4) under the control variable v as follows:
Here, \(\omega\) is a constant sample randomly extracted from the same distribution of the demand in (1) and v is an additional control input that we use to force consensus on the edge capacities c. Note that (5) can be written in compact form as \(\dot{x}=Ax+Bv+C=:f(x,v)\). Now let us consider a probability density function that describes the density of the agents in a population in state x at time t, \(m_k(x,t)\), with the property \(\int _{{\mathbb {R}}^{3m+n}} m_k(x,t)dx=1\). Then the mean states can be computed following \({\overline{m}}_k(t)=\int _{{\mathbb {R}}^{3m+n}} xm_k(x,t)dx\).
So far, we have considered the populations separately. To describe the interaction between populations we take into account the topology of the macro-network \({\hat{G}}\). Let us associate population k with agent k. Then we can introduce an interaction topology between agents, say \({{\hat{G}}}=\{{{\hat{V}}},{{\hat{E}}}\}\), and we can define the neighbors of an agent k in \({{\hat{G}}}\) as:
In order to reach consensus, each population is interested in knowing the local average state of its neighbours, which is given by:
Here, |N(k)| denotes the cardinality of neighbor set k. Let us now consider a running cost function \(g(x,\rho _k,v)\) and a terminal cost function \(\psi (\rho _k,x)\), which are defined as follows:
The first term in the expression for g assigns a penalty to the state deviating from the mean \(\rho _k\). The second term assigns a penalty on control. The matrices Q, S and R are diagonal matrices of compatible dimensions.
Every agent in population k wishes to solve the following problem:
subject to
The optimal control problem as in (7) has the structure of an optimal tracking problem. The objective function in (7) captures the minimization of the total expected cost. The aim is to reach consensus by minimizing the deviations of the state x from the local average of each population \(\rho _k\). This is denoted by the quadratic error term \((\rho _k-x)^TQ(\rho _k-x)\) in the running cost function g, and by \(S(\rho _k-x)^2\) in the terminal cost function \(\psi\). The term \(\frac{1}{2}v^TRv\) in the cost g penalises the energy of the control. The affine dynamics \(\dot{x}=Ax+B\nu +C\) in the constraints comes from the primal–dual dynamics explained in the previous section.
For every population k, denote the value of the optimization problem starting at time t and state x by \(\sigma _k(x,t)\). Let us also denote by \(m_k(x,0)=m_{k0}(x)\in {\mathbb {R}}\) the initial density of the agents of population k in state x. This results in the following mean-field game in \(\sigma _k(x,t)\) and \(m_k(x,t)\):
Any solution of (8) is referred to as the mean-field equilibrium, which provides the sub-optimal values for the wait and see variables. Note that the second and fourth equation from (8) are the boundary conditions, while the third equation is the advection equation.
The optimal time-varying state-feedback control can be computed for every single agent in population k and is given by:
In this expression, note that the Hamiltonian appears as the argument of the minimizer.
5 Mean-field equilibrium and convergence
In this section, we obtain an expression for the mean-field control and provide results for the mean-field equilibrium dynamics.
Lemma 1
The mean-field game takes the form:
Additionally, the optimal control is:
In this set of equations, the first equation corresponds to the Hamilton–Jacobi–Isaacs equation, and the third equation corresponds to the Fokker-Planck-Kolmogorov equation. The proof of Lemma 1 can be found in Appendix A.
We assume that the time evolution of the common state is known and, subsequently, investigate the solution of the Hamilton–Jacobi equation. Consider the following problem with known \(\rho _k\):
where
The next theoretical result presents the mean-field equilibrium control. In preparation to that, let us consider a probability density function that describes the density of the agents of a population in state c for the capacity of the edges at time t, \(m_k(c,t)\), with the property \(\int _{{\mathbb {R}}^{m}} m_k(c,t)dc=1\). Then the mean states can be computed following \({\overline{m}}_k^c(t)=\int _{{\mathbb {R}}^{m}} c m_k(c,t)dc\).
We define an agent’s objective in population k based on the aggregate kth state as:
In the following, given a generic matrix \(A \in {\mathbb {R}}^{(3m+n) \times (3m+n)}\) we denote by \(A_c \in {\mathbb {R}}^{m}\) the matrix obtained extracting the rows and columns associated with the only variables \(c \in {\mathbb {R}}^{m \times m}\). In addition, we consider the following value function:
and denote
Theorem 1
A mean-field equilibrium for the dynamics of (10) is obtained from the following set of equations:
where
Additionally, if the inverse matrix \({\widetilde{Z}}\) exists, the mean-field equilibrium control is:
If the inverse matrix \({\widetilde{Z}}\) does not exist, let us denote by \(\hat{H}(t)\) the approximation of matrix H(t) obtained by applying the least squares method. Then the mean-field equilibrium control is:
Furthermore, for infinite time horizon \(T \rightarrow \infty\), and for all aggregate states \({\overline{m}}^c = \left( {\overline{m}}_1^c,{\overline{m}}_2^c,\ldots ,{\overline{m}}_p^c \right)\), we have the following consensus-type dynamics:
where \({{\tilde{\mathbf {Q}}}_1}:=diag({{\tilde{Q}}}_1)\) (diagonal matrix with block entry \({{\tilde{Q}}}_1\)), \(\delta =R_c^{-1} \Big ( {\widetilde{Z}}_c \Phi _c^T \mu + (-{\widetilde{Z}}_cQ_c - \Phi _c^T) \rho _c^k \Big ) +(\mu -{{\tilde{f}}}_1)\) if the inverse matrix \({\widetilde{Z}}\) exists, or \(\delta =R_c^{-1} \Big (\hat{H} - \Phi _c^T\rho _c^k \Big )+(\mu -{{\tilde{f}}}_1)\) if the inverse does not exist, and L is defined as the graph-Laplacian matrix where the kjth entry is the block matrix:
This result is relevant since we can solve (15) in closed form and we show that consensus is ultimately achieved among agents. The proof of Theorem 1 can be found in Appendix B.
Remark 1
Note that based on the way in which we have defined the mean-field game it is not possible to guarantee convergence to the optimal solution. We can only guarantee convergence of the agents to a feasible solution. It is important to highlight that the mean-field game introduced in this manuscript has similarities with the distributed subgradient algorithm used to solve distributed optimization problems [26]. From (19) we can observe that the term \({{\tilde{\mathbf {Q}}}_1} {\overline{m}}^c(t)\), which corresponds to the costs of the edges capacities, is related to the gradient dynamics of variable c. On the other hand, the term \(L {\overline{m}}^c(t)\) enforces consensus, as it aims to minimize the deviation of \(\bar{m}_k^c\) from \(\rho _k^c\). It is worth mentioning that in the distributed subgradient method a step-size \(\gamma (t)\) is applied, and convergence to a feasible solution is only guaranteed for a diminishing step size. Nevertheless, based on (19), one can assume that the step-size for the approach introduced in this paper is always \(\gamma =1\). There exist other algorithms that can be applied to solve distributed optimization problems. One of these algorithms is the gradient tracking method [26]. This method tracks the gradient of the cost function and not only the value of the optimization variables. By applying the gradient tracking algorithm it has been proven that it is possible to reach consensus to the optimal value. However, the study of the gradient tracking algorithm is outside of the scope of this research.
6 Simulation example
In this section we present a numerical example of a capacity network design for a supply chain network. We show that the agents in the macro-network reach consensus on the edges’ capacities of their respective micro-networks. We analyse the ways in which penalties on control and state influence the dynamics of the agents in the mean-field game. Furthermore, we run various simulations under different scenarios to investigate the sub-optimality of the algorithm built on the mean-field game.
Consider a scale-free network where \(p=1000\) agents. The agents only consider the local average computed over its neighbors according to (6). Furthermore, we generate stochastic demand according to the normal distribution at every time instance for the nodes of the micro-networks displayed in Fig. 1. This makes the constant term vector C change over time since \(\omega\) is now renewed at every time instance. Prior to the simulation, we parametrize the system as follows:
Note that in our example, the penalty of using flow \(u_8\) is twice the penalty on the other flows since we wish to keep the flows balancing \(w_4\) and \(w_3\) as much distinct as possible. In general, any route can be incentivised by adjusting penalties and this emphasizes the versatility of our approach. Furthermore, in Table 1 the following additional simulation parameters are defined: time step \(\delta t\), mean and standard deviation of initial states of the primal–dual dynamics \({\widetilde{\sigma }}_0\) and \({\widetilde{\mu }}_0\); mean and standard deviation of demand at node 3, denoted \({\widetilde{\mu }}_{3}\) and \({\widetilde{\sigma }}_{3}\); and mean and standard deviation of demand at node 4, denoted \({\widetilde{\mu }}_{4}\) and \({\widetilde{\sigma }}_{4}\). The multi-population considered allows the simulation algorithm to be initialized with different initial conditions and also allows to accommodate different realizations of the wait and see variables.
We use the parameters mentioned above as input for the following simulation algorithm by which we compute the states of each agent over time.

Figures 3a–c depict the evolution of the edges’ capacities over time for all agents. Figure 3a shows a simulation where the penalty on control equals the penalty on state deviation, i.e., \(Q=R=1\). Figure 3b presents a simulation of the mean-field game where the penalty on state deviation is increased, namely \(Q=10\), \(R=1\). On the contrary, the results of a mean-field game simulation where \(Q=1\), \(R=10\) can be found in Fig. 3c.

Simulation of the mean-field game for different values of the penalty on control R and the penalty on state deviations Q
By setting the penalty on state deviation sufficiently high as it was done in the simulation of Fig. 3b, the states converge to closer values compared to the case where Q and R are equal. This is in accordance to intuition as in the case of Fig. 3b states deviation from \(\rho_k\) incur in a higher penalty. Conversely, by setting the penalty on control sufficiently high, convergence is obtained quicker in comparison to the simulation where Q and R are equal. In this situation, the system is penalized more to make adjustments and this explains the thinner lines in the converged region. Another observation is that, in this case, the best strategy to pursue the minimization problem is to choose a different solution compared to the simulations of Fig. 3a, b.
From the examples presented above, let us consider the best strategy for the minimization, which is when the penalty on the states deviations is \(Q=1\) and the penalty on the control is \(R=10\). To analyse the sub-optimality of the algorithm for the mean-field game, we compare the flows and capacities obtained from the consensus in the mean-field game with the values obtained by solving the primal–dual dynamics as it is explained in Sect. 3, and with the real optimal values obtained by solving (1). We compare the capacities and flows obtained from the different methods by evaluating the values of the objective function in (1). Furthermore, for the mean-field game we obtain a lower bound of the objective function by relaxing the constraint on consensus on the capacities of the edges.
In Fig. 4a we display the evolution over time of the objective function for the different methods applied to solve the two-stage stochastic program (1). Note that when the agents reach consensus on the capacities, the value of the objective function obtained from the mean-field game becomes an upper bound of the real optimal value. On the other hand, we can observe that the value of the objective function when we relax the constraint on consensus becomes a lower bound of the value of the objective function of the mean-field game when we take into account the consensus constraint.
Let us denote by \(F_{MFG}\), \(F_{NC}\), \(F_{PD}\), \(F_{O}\) the value of the objective function obtained from the mean field game, the value of the objective function obtained by relaxing the constraints on consensus, the value of the objective function obtained from the primal–dual dynamics and the value of the objective function obtained from the real optimum, respectively. To analyse the differences between the different approaches, we compute the percentage errors between the values of the objective function obtained from the mean-field game and the values of the objective function using the other methods as follows:
In Fig. 4b we plot the percentage errors between the values of the objective function obtained from the mean-field game and the values of the objective function using the other methods. In the long term, the percentage error when we compare the results of the mean-field game with the results from the primal–dual dynamics is \(8.47\%\). On the other hand, compared to the optimal value obtained by solving (1), the percentage error in the long term is \(1.96\%\).

Values of the objective function and % error
We develop the same procedure explained above for fifteen different scenarios. In these scenarios we consider different distributions of the demand, different topology for the micro-network and for the macro-network, different vectors \({\tilde{f}}_1\) and \({\tilde{f}}_2\), and different values for the penalty on the states deviations and penalty on the control. We run fifty simulations of each scenario and we obtain the average of the percentage error over all simulations.
In the first three scenarios we change the mean and standard deviation of the demand at nodes 3 and 4, and we keep the rest of the simulation parameters as in the first example. For the first scenario the mean and standard deviation are \({\widetilde{\mu }}_{3}=10\), \({\widetilde{\mu }}_{4}=20\), \({\widetilde{\sigma }}_{3}=3\) and \({\widetilde{\sigma }}_{4}=1\). For the second scenario the parameters are \({\widetilde{\mu }}_{3}=30\), \({\widetilde{\mu }}_{4}=30\), \({\widetilde{\sigma }}_{3}=1\) and \({\widetilde{\sigma }}_{4}=3\). For the third scenario the mean and standard deviation are \({\widetilde{\mu }}_{3}=5\), \({\widetilde{\mu }}_{4}=5\), \({\widetilde{\sigma }}_{3}=3\) and \({\widetilde{\sigma }}_{4}=3\). The percentage error for each scenario is depicted in Fig. 5. Observe that for lower mean and higher variance, the average percentage error increases.

Average percentage error of the objective function over fifty simulations for three scenarios by changing the mean and standard deviation of the demand
For the next three scenarios we change the topology of the micro-network, and we keep the rest of the simulation parameters as in the first example. In the first scenario the network consists of \(n=6\) nodes and \(m=11\) edges. For the second scenario the micro-network consists of \(n=6\) nodes and \(m=7\) edges. For the third scenario we increase the number of nodes to \(n=10\) and the number of edges to \(m=16\). The percentage error for each scenario is depicted in Fig. 6. Note that when we reduce the connections between the nodes, the average percentage error increases.

Average percentage error of the objective function over fifty simulations for three scenarios by changing the topology of the micro-network
Now we consider three different scenarios by changing the topology of the macro-network, and we keep the rest of the simulation parameters as in the first example. We design the topology of the macro-network by using a power law distribution, in which few nodes have high connectivity and most nodes have very low connectivity. In the first scenario the average degree of the nodes is four. In the second scenario the average degree is two. In the third scenario the average degree is six. The complex networks that we consider for these scenarios are depicted in Fig. 7a–c. As one can observe in Fig. 7d–f there is not a significant difference in the average percentage error between these three scenarios.

Average percentage error of the objective function over fifty simulations for three scenarios by changing the topology of the macro-network
The next three scenarios are generated by changing the cost coefficients \({\tilde{f}}_1\) and \({\tilde{f}}_2\) and by keeping the rest of the simulation parameters as in the first example. In the first scenario the cost coefficients are \({\widetilde{f}}_1 = \begin{bmatrix}1&1&1&1&1&1&1&1&1\end{bmatrix}^T\) and \({\widetilde{f}}_2 = \begin{bmatrix}1&1&2&1&1&2&1&2&1 \end{bmatrix}^T\). In the second scenario we have \({\widetilde{f}}_1 = \begin{bmatrix}1&1&1&1&1&1&1&2&1\end{bmatrix}^T\) and \({\widetilde{f}}_2 = \begin{bmatrix}1&1&2&1&1&2&1&2&1 \end{bmatrix}^T\). In the third scenario these coefficients are \({\widetilde{f}}_1 = \begin{bmatrix}1&1&1&2&2&1&2&3&1\end{bmatrix}^T\) and \({\widetilde{f}}_2 = \begin{bmatrix}1&1&1&2&2&1&2&3&1 \end{bmatrix}^T\). We can observe in Fig. 8 that when we increase the cost coefficients for the capacities and flows, the average percentage error with respect to the primal–dual dynamics and with respect to the real optimal value are very similar.

Average percentage error of the objective function over fifty simulations for three scenarios by changing the cost coefficients \({\tilde{f}}_1\) and \({\tilde{f}}_2\)
The last three scenarios consist in changing the penalty on state deviation Q and the penalty on control R, and keep the rest of the simulation parameters as in the first example. In the first scenario the penalty on state deviation and the penalty on control are the same, namely \(R=Q=1\). In the second scenario the penalty on state deviation is \(Q=10\) and the penalty on control is \(R=1\). In the third scenario we take the penalty on state deviation \(Q=1\) and the penalty on control \(R=10\). In accordance with the first examples analysed at the beginning of this section, we observe that when the penalty on control is sufficiently high the convergence is obtained quicker, and the percentage error is smaller than in the other two scenarios (Fig. 9).

Average percentage error of the objective function over fifty simulations for three scenarios by changing the penalty on state deviation and the penalty on control
The average percentage errors, in the long-term, for the different scenarios when we compare the results of the mean-field game with the results from the primal–dual dynamics and with the optimal value obtained by solving (1) are summarized in Table 2.
In the long term, the total average of the percentage error over all scenarios and simulations when we compare the results of the mean-field game with the results from the primal–dual dynamics is \(11.46\%\). On the other hand, compared to the optimal value obtained by solving (1), the average percentage error in the long term is \(7.43\%\).
7 Concluding remarks and future work
In this paper, we have provided a heuristic method to solve a two-stage stochastic program. We have illustrated the method on a supply-chain network design problem. The underlying idea of the method is to replace the original stochastic program with a mean-field game with a large number of agents. Each agent controls a primal–dual dynamics with the double aim of moving along the gradient descent/ascent while at the same time reaching consensus on the here and now variables, which are represented by the edge capacities. We show that the resulting mean dynamics mimics elastic averaging stochastic gradient algorithms. The heuristics has been implemented on a numerical example for different values of the parameters such as the penalties on state deviation and control.
Future work involves the generalization of the method to nonlinear convex problems, the analysis of the sub-optimality performance at least for specific scenarios, the extension to mean-field dynamics with implemented (online) forecasting algorithms based on regression learning models [7, 9].
References
Achdou, Y., Camilli, F., Capuzzo-Dolcetta, I.: Mean field games: numerical methods for the planning problem. SIAM J. Control. Optim. 50(1), 77–109 (2012)
Arrow, K.J., Hurwicz, L., Uzawa, H.: Studies in Linear and Non-linear Programming. Stanford University Press, Redwood City (1958)
Bardi, M.: Explicit solutions of some linear-quadratic mean field games. Netw. Heterog. Media 7, 243–261 (2012)
Bauso, D.: Consensus via multi-population robust mean-field games. Syst. Control Lett. 107, 76–83 (2017)
Bauso, D.: Dynamic demand and mean-field games. IEEE Trans. Autom. Control 62(12), 6310–6323 (2017)
Bauso, D., Mylvaganam, T., Astolfi, A.: Crowd-averse robust mean-field games: approximation via state space extension. IEEE Trans. Autom. Control 61(7), 1882–1894 (2016)
Bauso, D., Namerikawa, T.: 20. Electric vehicles and Mean-field, from Advanced Data Analytics for Power Systems edited by Ali Tajer; Samir M. Perlaza; H. Vincent Poor. Cambridge University Press (in print)
Boffi, N.M., Slotine, J.-J.: A continuous-time analysis of distributed stochastic gradient. Neural Comput. 32, 36–96 (2020)
Boyd, S., Parikh, N., Chu, E.: Distributed Optimization and Statistical Learning Via the Alternating Direction Method of Multipliers. Now Publishers Inc, New York (2011)
Briceño, A.L., Kalise, D., Kobeissi, Z., Laurière, M., González, Á.M., Silva, F.J.: On the implementation of a primal-dual algorithm for second order time-dependent mean field games with local couplings. ESAIM Proc. Surv. 65, 330–348 (2019)
Chen, J., Lau, V.K.N.: Convergence analysis of saddle point problems in time varying wireless systems-control theoretical approach. IEEE Trans. Signal Process. 60(1), 443–452 (2011)
Chen, X., Li, N.: Exponential stability of primal-dual gradient dynamics with non-strong convexity. In: Proceedings of the 2020 American Control Conference (ACC). arXiv:1905.00298 (2020)
Cherukuri, A., Gharesifard, B., Cortes, J.: Saddle-point dynamics: conditions for asymptotic stability of saddle points. SIAM J. Control. Optim. 55(1), 486–511 (2017)
Cherukuri, A., Mallada, E., Cortés, J.: Asymptotic convergence of constrained primal-dual dynamics. Syst. Control Lett. 87, 10–15 (2016)
Cherukuri, A., Mallada, E., Low, S., Cortés, J.: The role of convexity in saddle-point dynamics: Lyapunov function and robustness. IEEE Trans. Autom. Control 63(8), 2449–2464 (2017)
Feijer, D., Paganini, F.: Stability of primal-dual gradient dynamics and applications to network optimization. Automatica 46(12), 1974–1981 (2010)
Ferragut, A., Paganini, F.: Network resource allocation for users with multiple connections: fairness and stability. IEEE ACM Trans. Netw. (TON) 22(2), 349–362 (2014)
Gomes, D.A., Saúde, J.: Mean field games models—a brief survey. Dyn. Games Appl. 4(2), 110–154 (2014)
Jönsson, U.T.: Primal and dual criteria for robust stability and their application to systems interconnected over a bipartite graph. In: Proceedings of the 2010 American Control Conference, pp. 5458–5464. IEEE (2010)
Kose, T.: Solutions of saddle value problems by differential equations. Econom. J. Econom. Soc. 24(1), 59–70 (1956)
Lasry, J-M., Lions, P-L.: Jeux à champ moyen. i le cas stationnaire. Comptes Rendus Mathematique 343(9), 619–625 (2006)
Lasry, J.-M., Lions, P.-L.: Jeux à champ moyen. ii horizon fini et controle optimal. Comptes Rendus Mathematique 343(10), 679–684 (2006)
Lasry, J.-M., Lions, P.-L.: Mean field games. Jpn. J. Math. 2, 229–260 (2007)
Liang, S., Wang, L.Y., Yin, G.: Exponential convergence of distributed primal-dual convex optimization algorithm without strong convexity. Automatica 105, 298–306 (2019)
Nguyen, H.D., Vu, T.L., Turitsyn, K., Slotine, J.-J.: Contraction and robustness of continuous time primal-dual dynamics. IEEE Control Syst. Lett. 2(4), 755–760 (2018)
Notarstefano, G., Notarnicola, I., Camisa, A.: Distributed optimization for smart cyber-physical networks. Found. Trends Syst. Control 7(3), 253–383 (2019)
Qu, G., Li, N.: On the exponential stability of primal-dual gradient dynamics. IEEE Control Syst. Lett. 3, 43–48 (2019)
Shapiro, A., Dentcheva, D., Andrzej, R.: Modeling and Theory. MOS-SIAM Series on Optimization, Lectures on Stochastic Programming (2009)
Stolyar, A.L.: Greedy primal-dual algorithm for dynamic resource allocation in complex networks. Queueing Syst. 54(3), 203–220 (2006)
Tang, Y., Guannan, Q., Li, N.: Semi-global exponential stability of primal-dual gradient dynamics for constrained convex optimization. Syst. Control Lett. 144, 104754 (2020)
Tannenbaum, A.: \(\mathbb{H} ^\infty\)-optimal control and related minimax design problems (tamer basar and pierre bernhard). SIAM Rev. 35(3), 538–540 (1993)
Yang, C., Dai, H., Li, J., Zhang, Y., Han, Z.: Distributed interference-aware power control in ultra-dense small cell networks: a robust mean field game. IEEE Access 6, 12608–12619 (2018)
Yang, C., Li, J., Semasinghe, P., Hossain, E., Perlaza, S.M., Han, Z.: Distributed interference and energy-aware power control for ultra-dense d2d networks: a mean field game. IEEE Trans. Wirel. Commun. 16(2), 1205–1217 (2016)
Zhao, C., Topcu, U., Low, S.: Swing dynamics as primal-dual algorithm for optimal load control. In: 2012 IEEE Third International Conference on Smart Grid Communications (SmartGridComm), pp. 570–575. IEEE (2012)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
A Proof of Lemma 1
To obtain the optimal control in (11), from (9) let us write the minimized Hamiltonian as:
By differentiating with respect to v and equalizing the gradient to zero we obtain:
Solving for v yields the expression for \(v^*\) from (11). Let us rewrite (8) in terms of the minimized Hamiltonian as:
Now by substituting the optimal value \(v^*\) in (11), in the Hamiltonian, we obtain:
Using this expression for the Hamiltonian in (22), we obtain the Hamilton-Jacobi-Bellman equation in (10). The third equation from (10) can be obtained by substituting the optimal control (11) in (22). This concludes the proof. \(\quad \square\)
B Proof of Theorem 1
We start the proof by isolating the Hamilton–Jacobi–Bellman part with fixed \(\rho _k\) from (10) and we obtain:
Now consider the following value function:
Then (24) can be rewritten as follows:
Since the equation above is an identity in x it reduces to the following set of three equations:
Furthermore, the optimal control is given by:
The existence of a solution for (27) is assured by the standard convexity-concavity assumptions, which justifies the choice for the quadratic value function [31].
Lastly, we average the expression for optimal control and by substitution in \(\tfrac{d}{dt}{\overline{m}}_k(t)=A{\overline{m}}_k+B{\overline{v}}^*+C\), we obtain the expression
which is the second equation from (15). Now considering the stationary case with \(T \rightarrow \infty\), we obtain the following set of equations:
Solving for H, when the inverse of \(\left[ A^T-2\Phi BR^{-1}B^T \right]\) exists, yields the following expression:
We now substitute (30) in (28) and we obtain:
where we denote \({\widetilde{Z}}:=\left[ A^T-2\Phi BR^{-1}B^T \right] ^{-1}\).
Averaging over population k we obtain for the mean control the following expression
This implies that the interaction of neighbors consists of local averaging and local adjustment as in the following mean state dynamics:
Isolating the dynamics for the here and now c vector components we obtain
If the inverse matrix \({\widetilde{Z}}\) does not exist, we can approximate the solution of H by finding the least squares solution. Let us define by \(\mathcal {Z}:=-2 \Phi BR^{-1}B^T H+A^TH+\Phi ^TC-Q\rho _k=(-2 \Phi BR^{-1}B^T+A^T)H-(Q\rho _k-\Phi ^TC)\in {\mathbb {R}}^{3m+n}\). Hence, finding the least squares solution consists of minimizing the sum of the squares of the difference \((-2 \Phi BR^{-1}B^T+A^T)H-(Q\rho _k-\Phi ^TC)\). This can be formally represented as follows:
The solution of the least squares method returns an approximation of H, denoted by \(\hat{H}\). The mean-field equilibrium control is then given by:
Hence, the mean state dynamics is as follows:
By isolating the dynamics for the here and now c vector components, we obtain:
For all aggregate states \({\overline{m}}^c = \left( {\overline{m}}_1^c,{\overline{m}}_2^c,\ldots ,{\overline{m}}_p^c \right)\), we have the following consensus-type dynamics:
Here, \({{\tilde{\mathbf {Q}}}_1}:=diag({{\tilde{Q}}}_1)\) (diagonal matrix with block entry \({{\tilde{Q}}}_1\)), \(\delta :=R_c^{-1} \Big ( {\widetilde{Z}}_c \Phi _c^T \mu + (-{\widetilde{Z}}_cQ_c - \Phi _c^T) \rho _c^k \Big ) +(\mu -{{\tilde{f}}}_1)\) if the inverse matrix \({\widetilde{Z}}\) exists, or \(\delta =R_c^{-1} \Big (\hat{H} - \Phi _c^T\rho _c^k \Big )+(\mu -{{\tilde{f}}}_1)\) if the inverse does not exist, and L is defined as the graph-Laplacian matrix where the kjth entry is the block matrix:
This concludes the proof of Theorem 1. \(\quad \square\)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Röling, C.T., Ramirez, S., Bauso, D. et al. Stochastic programming with primal–dual dynamics: a mean-field game approach. Optim Lett 17, 1005–1026 (2023). https://doi.org/10.1007/s11590-022-01910-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11590-022-01910-9