
Abstract
More than three decades ago, Boyd and Balakrishnan established a regularity result for the two-norm of a transfer function at maximizers. Their result extends easily to the statement that the maximum eigenvalue of a univariate real analytic Hermitian matrix family is twice continuously differentiable, with Lipschitz second derivative, at all local maximizers, a property that is useful in several applications that we describe. We also investigate whether this smoothness property extends to max functions more generally. We show that the pointwise maximum of a finite set of q-times continuously differentiable univariate functions must have zero derivative at a maximizer for \(q=1\), but arbitrarily close to the maximizer, the derivative may not be defined, even when \(q=3\) and the maximizer is isolated.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Let \({\mathbb {H}}^{n}\) denote the space of \(n\times n\) complex Hermitian matrices, let \({\mathcal {D}}\subseteq {\mathbb {R}}\) be open, and let \(H : {\mathcal {D}}\rightarrow {\mathbb {H}}^{n}\) denote an analytic Hermitian matrix family in one real variable, i.e., for each \(x\in {\mathcal {D}}\) and each \(i,j\in \{1,\ldots ,n\}\), there exist coefficients \(a_{0},a_{1},a_{2},\ldots \) such that the power series \(\sum _{k=0}^{\infty }a_{k}(t-x)^{k}\) converges to \(H_{ij}(t)=\overline{H_{ji}(t)}\) for all t in a neighborhood of \(x\). For a generic family H, the eigenvalues of H(t) are simple for all \(t \in {\mathcal {D}}\); often known as the von Neumann–Wigner crossing-avoidance rule [15], this phenomenon is emphasized in [11, section 9.5], where it is also illustrated on the front cover. The reason is simple: the real codimension of the subspace of Hermitian matrices with an eigenvalue of multiplicity m is \(m^{2}-1\), so to obtain a double eigenvalue one would need three parameters generically; when the matrix family is real symmetric, the analogous codimension is \(\tfrac{m(m+1)}{2}-1\), so one would need two parameters generically. When there are no multiple eigenvalues, the ordered eigenvalues of H(t), say, \(\mu _{j}(t)\) for \(j=1,\ldots ,n\), are all real analytic functions. Let  and
and  denote largest and smallest eigenvalue, respectively. In the absence of multiple eigenvalues,
denote largest and smallest eigenvalue, respectively. In the absence of multiple eigenvalues,  and
and  are both smooth functions of t. However, for the nongeneric family \(H(t)={{\,\mathrm{diag}\,}}(t,-t)\), a double eigenvalue occurs at \(t=0\). By a theorem of Rellich, given in Sect. 4, the eigenvalues can be written as two real analytic functions, \(\mu _{1}(t)=t\) and \(\mu _{2}(t)=-t\), but we must give up the property that these functions are ordered near zero. Consequently, the function
are both smooth functions of t. However, for the nongeneric family \(H(t)={{\,\mathrm{diag}\,}}(t,-t)\), a double eigenvalue occurs at \(t=0\). By a theorem of Rellich, given in Sect. 4, the eigenvalues can be written as two real analytic functions, \(\mu _{1}(t)=t\) and \(\mu _{2}(t)=-t\), but we must give up the property that these functions are ordered near zero. Consequently, the function  is not differentiable at its minimizer \(t=0\).
is not differentiable at its minimizer \(t=0\).
In contrast, the function  is unconditionally \({\mathcal {C}}^2\), i.e., twice continuously differentiable, with Lipschitz second derivative, near all its local maximizers, regardless of eigenvalue multiplicity at these maximizers. As we explain below, this observation is a straightforward extension of a well-known result of Boyd and Balakrishnan [2] established more than three decades ago. One purpose of this paper is to bring attention to the more general result, as it is useful in a number of applications. We also investigate whether this smoothness property extends to max functions more generally. We show that the pointwise maximum of a finite set of differentiable univariate functions must have zero derivative at a maximizer. However, arbitrarily close to the maximizer, the derivative may not be defined, even if the functions are three times continuously differentiable and the maximizer is isolated.
is unconditionally \({\mathcal {C}}^2\), i.e., twice continuously differentiable, with Lipschitz second derivative, near all its local maximizers, regardless of eigenvalue multiplicity at these maximizers. As we explain below, this observation is a straightforward extension of a well-known result of Boyd and Balakrishnan [2] established more than three decades ago. One purpose of this paper is to bring attention to the more general result, as it is useful in a number of applications. We also investigate whether this smoothness property extends to max functions more generally. We show that the pointwise maximum of a finite set of differentiable univariate functions must have zero derivative at a maximizer. However, arbitrarily close to the maximizer, the derivative may not be defined, even if the functions are three times continuously differentiable and the maximizer is isolated.
2 Properties of max functions at local maximizers
Let \({\mathcal {D}}\subset {\mathbb {R}}\) be open, \({\mathcal {I}}= \{1,\ldots ,n\}\), and \(f_j: {\mathcal {D}}\rightarrow {\mathbb {R}}\) be continuous for all \(j \in {\mathcal {I}}\), and define
Lemma 2.1
Let \(x\in {\mathcal {D}}\) be any local maximizer of \(f_\mathrm {max}\) with \(f_\mathrm {max}(x)=\gamma \) and let \({\mathcal {I}}_\gamma = \{ j \in {\mathcal {I}}: f_j(x) = \gamma \}\). Then
-
(i)
for all \(j \in {\mathcal {I}}_\gamma \), \(x\) is a local maximizer of \(f_j\) and
-
(ii)
for all \(j \in {\mathcal {I}}\setminus {\mathcal {I}}_\gamma \), \(f_j(x) < \gamma \).
We omit the proof as it is elementary.
Theorem 2.1
Let \(x\in {\mathcal {D}}\) be any local maximizer of \(f_\mathrm {max}\) with \(f_\mathrm {max}(x)=\gamma \). Suppose that for all \(j \in {\mathcal {I}}\), \(f_j\) is differentiable at \(x\). Then \(f_\mathrm {max}\) is differentiable at \(x\) with \(f_\mathrm {max}^\prime (x) = 0\).
Proof
Since the functions \(f_j\) are assumed to be continuous, clearly \(f_\mathrm {max}\) is also continuous, and without loss of generality, we can assume that \(\gamma =0\). Suppose that \(f_\mathrm {max}^\prime \) does not exist at \(x\) or does not equal zero, i.e., there exists some sequence \(\{\varepsilon _k\}\) with \(\varepsilon _k \rightarrow 0\) such that \(\lim _{k \rightarrow \infty } \frac{f_\mathrm {max}(x+ \varepsilon _k)}{\varepsilon _k}\) does not exist or is not zero. Since \({\mathcal {I}}\) is finite, there exist a \(j \in {\mathcal {I}}\) and a subsequence \(\{\varepsilon _{k_\ell }\}\) such that \(f_\mathrm {max}(x+ \varepsilon _{k_\ell }) = f_j(x+ \varepsilon _{k_\ell })\) for all \(k_\ell \), which implies that \(f_j^\prime \) either does not exist or is not zero at \(x\). However, as \(f_j\) is differentiable and with local maximizer \(x\) by Lemma 2.1, it must be that \(f_j^\prime (x) = 0\); hence, we have a contradiction. \(\square \)
We now consider adding additional assumptions on the smoothness of the \(f_j\), writing \(f_{j}\in {\mathcal {C}}^{q}\) to mean \(f_{j}\) is q-times continuously differentiable. Clearly, assuming that the \(f_j\) are \({\mathcal {C}}^1\) at (or near) a maximizer is not sufficient to obtain that \(f_\mathrm {max}\) is twice differentiable at this point. For example, if
then the second derivative of \(f_\mathrm {max}=\max (f_1,f_2)\) does not exist at the maximizer \(t=0\), as \(f_\mathrm {max}^\prime (t) = -2t\) on the left and \(-4t\) on the right, so \(\lim _{t \rightarrow 0} \tfrac{f_\mathrm {max}^\prime (t)}{t}\) does not exist at \(t=0\). In this example, \(f_\mathrm {max}\) is continuously differentiable at \(t=0\), but this does not hold in general, even when assuming that the \(f_j\) are \({\mathcal {C}}^3\) near a maximizer; see Remark 2.1 below. However, we do have the following result.
Theorem 2.2
Let \(x\in {\mathcal {D}}\) be any local maximizer of \(f_\mathrm {max}\) with \(f_\mathrm {max}(x)=\gamma \). Suppose that for all \(j \in {\mathcal {I}}\), \(f_j\) is \({\mathcal {C}}^3\) near \(x\). Then for all sufficiently small \(|\varepsilon |\),
where \(M = \tfrac{1}{2}\left( \max _{j \in {\mathcal {I}}_\gamma } f_j^{\prime \prime }(x) \right) \le 0\). If the \({\mathcal {C}}^3\) assumption is reduced to \({\mathcal {C}}^2\), then \(f_\mathrm {max}(x+\varepsilon ) = \gamma + O(\varepsilon ^2)\).
Proof
Let \(\gamma = f_\mathrm {max}(x)\) and let \({\mathcal {I}}_\gamma = \{ j \in {\mathcal {I}}: f_j(x) = \gamma \}\). By Lemma 2.1, we have that \(x\) is also a local maximizer of \(f_j\) for all \(j \in {\mathcal {I}}_\gamma \) and \(f_j(x) < \gamma \) for all \(j \in {\mathcal {I}}\setminus {\mathcal {I}}_\gamma \). Since the \(f_j\) are Lipschitz near \(x\),
holds for all sufficiently small \(|\varepsilon |\). For each \(j \in {\mathcal {I}}_\gamma \), by Taylor’s Theorem we have that
for \(\tau _j\) between x and \(x + \varepsilon \). Taking the maximum of the equation above over all \(j \in {\mathcal {I}}_\gamma \) yields (2.2). The proof for the \({\mathcal {C}}^2\) case follows analogously. \(\square \)
Remark 2.1
Even with the \({\mathcal {C}}^3\) assumption, \(f_\mathrm {max}\) is not necessarily continuously differentiable at maximizers. For example, consider \(f_1(t) = t^8 (\sin (\tfrac{1}{t}) - 1)\) and \(f_2(t) = t^8 (\sin (\tfrac{1}{2t}) - 1)\), with \(f_1(0) = f_2(0) = 0\), where \(f_1\) and \(f_2\) are \({\mathcal {C}}^3\) but not \({\mathcal {C}}^4\) at the maximizer \(t=0\). Although \(f_\mathrm {max}\) is differentiable at 0 by Theorem 2.1, it is easy to see that it is not \(C^1\) there. However, in this case, 0 is not an isolated maximizer of \(f_\mathrm {max}\). In contrast, in Sect. 3, we construct a counterexample where the \(f_j\) are \({\mathcal {C}}^3\) functions, and for which \(f_\mathrm {max}\) has an isolated maximizer, yet \(f_\mathrm {max}\) is not \(C^1\) there. It seems that this counterexample can be extended to apply to \({\mathcal {C}}^q\) functions for any \(q\ge 1\). The key point of both of these counterexamples is not that the \(f_j\) are insufficiently smooth per se, but that the \(f_j\) cross each other infinitely many times near maximizers.
In light of Remark 2.1, we now make a much stronger assumption.
Theorem 2.3
Given a maximizer \(x\) of \(f_\mathrm {max}\), suppose there exist \(j_1,j_2 \in {\mathcal {I}}\), possibly equal, such that, for all sufficiently small \(\varepsilon > 0\), \(f_\mathrm {max}(x- \varepsilon ) = f_{j_1}(x- \varepsilon )\) and \(f_\mathrm {max}(x+ \varepsilon ) = f_{j_2}(x+ \varepsilon )\), with \(f_{j_1}\) and \(f_{j_2}\) both \({\mathcal {C}}^3\) near \(x\). Then \(f_\mathrm {max}\) is twice continuously differentiable, with Lipschitz second derivative, near \(x\).
Proof
It is clear that \(f_{j_1}(x)=f_{j_2}(x)=\gamma \) and \(f_{j_1}^\prime (x)=f_{j_2}^\prime (x) = 0\). By Theorem 2.2, both \(f_{j_1}^{\prime \prime }(x)\) and \(f_{j_2}^{\prime \prime }(x)\) are equal to M, so \(f_\mathrm {max}\) is locally described by two \({\mathcal {C}}^3\) pieces whose function values and first and second derivatives agree at \(x\). Hence, \(f_\mathrm {max}\) is \({\mathcal {C}}^2\) with Lipschitz second derivative near \(x\). \(\square \)
Remark 2.2
The assumptions of Theorem 2.3 hold if the \(f_{j}\) are real analytic [10, Corollary 1.2.7].
In particular, the \(f_j\) are real analytic functions if they are eigenvalues of a univariate real analytic Hermitian matrix function, as we discuss in Sect. 4. First, we present the \({\mathcal {C}}^3\) counterexample mentioned above.
3 An example with \({\mathcal {C}}^3\) functions \(f_j\) and an isolated maximizer for which \(f_\mathrm {max}\) is not continuously differentiable at \(x\)
Let \(l_k = \tfrac{1}{2^k}\), and \(f_1 : [-1, 1] \rightarrow {\mathbb {R}}\) be defined by
where \(p_k\) is a (piece of a) degree-nine polynomial chosen such that at
-
1.
\(l_{k+1}\) (the left endpoint), \(p_k\) and \(-t^2\) agree up to and including their respective third derivatives,
-
2.
\(l_k\) (the right endpoint), \(p_k\) and \(-t^2\) agree up to and including their respective third derivatives,
-
3.
\(t_k = \tfrac{1}{2}(l_{k+1} + l_k)\) (the midpoint), \(p_k\) and \(-t^2\) agree, but the first derivative of \(p_k\) is \(s_k \ne 1\) times the value of the first derivative of \(-t^2\).

Plots of \(f_1\) and \(f_2\) with \(s_k = 2\); their \(-t^2\) parts are shown in solid, while their \(p_k\) parts are shown in dotted for k even and dash-dot for k odd
For any k, the degree-nine polynomial \(p_k\) is uniquely determined by the ten algebraic constraints given above. If we choose \(s_k = 1\), then \(p_k\) is simply \(-t^2\). However, by choosing \(s_k > 1\) but sufficiently close to 1, then \(p_k\) must be strictly decreasing between its endpoints \(l_{k+1}\) and \(l_k\) and cross \(-t^2\) at \(t_k\). If this is done for all k, it follows that \(t=0\) must be an isolated maximizer of \(f_1\). See Fig. 1a for a plot of \(f_1\) with \(s_k=2\) for all k; the choice \(s_{k}=2\) is not close to 1 but was chosen to make the features of \(f_{1}\) easily seen.
Now define \(f_2(t) = f_1(-t)\), i.e., the graph of \(f_{2}\) is a reflection of the graph of \(f_{1}\) across the vertical line \(t=0\). Figure 1b shows \(f_1\) and \(f_2\) plotted together, again with \(s_{k}=2\), showing how they cross at every \(t_k\). Recall that by our construction, their respective first three derivatives match at each \(l_k\), but their first derivatives do not match at any \(t_k\). Figure 2 shows plots of the first three derivatives of \(f_1\) for two different sequences \(\{s_k\}\) respectively defined by \(s_k = 1 + 2^{-k}\) and \(s_k = 1 + 2^{-2k}\). The rightmost plots in Fig. 2 indicate that the first choice for sequence \(\{s_k\}\) does not converge to 1 fast enough for \(f_1^{\prime \prime \prime }\) to exist and be continuous at \(t=0\), but that the second sequence does. In fact, for this latter choice of sequence, we have the following pair of theorems respectively proving that \(f_1\) is indeed \({\mathcal {C}}^3\) with \(t=0\) being an isolated maximizer. We defer the proofs to Appendix A as they are a bit technical, and in Appendix B, we discuss why \(s_k = 1 + 2^{-k}\) does not converge to 1 sufficiently fast for \(f_1^{\prime \prime \prime }(0)\) to exist.
Theorem 3.1
For \(f_1\) defined in (), if \(s_k = 1 + 2^{-2k}\), then \(f_1\) is \({\mathcal {C}}^3\) on its domain \([-1,1]\).
Theorem 3.2
For \(f_1\) defined in (), if \(s_k = 1 + 2^{-2k}\), then \(t=0\) is an isolated maximizer of \(f_1\), as well as an isolated maximizer of \(f_\mathrm {max}=\max (f_{1},f_{2})\).
Theorem 2.1 shows that \(f_\mathrm {max}= \max (f_{1},f_{2})\) is differentiable at \(t=0\) with \(f_\mathrm {max}^\prime (0) = 0\). However, even though \(f_1\) and \(f_2\) are \({\mathcal {C}}^3\) and \(t=0\) is an isolated maximizer of \(f_\mathrm {max}\) with the choice of \(s_k = 1 + 2^{-2k}\), by construction, we have that (i) \(t_k \rightarrow 0\) as \(k \rightarrow \infty \), and (ii) \(f_\mathrm {max}\) is nondifferentiable at every \(t_k\). Hence, although \(f_\mathrm {max}\) is differentiable at \(t=0\), it is not \({\mathcal {C}}^1\) at this point. Plots of \(f_\mathrm {max}\) and its first and second derivatives are shown in Fig. 3, where we see the discontinuities in \(f_\mathrm {max}^{\prime }\) for all \(t_k\) and \(-t_k\).
Remark 3.1
For any \(q \ge 1\), it seems that the same argument extends to show that \(f_\mathrm {max}\) is not necessarily \({\mathcal {C}}^1\) at \(t=0\) when defined by functions \(f_j\) that are \({\mathcal {C}}^q\), using polynomials \(p_k\) of degree \(2q+3\). From computational investigations for \(q \in \{1,2,3,4,5\}\), we conjecture that \(s_k = 1 + 2^{-(k+1)}\) for \(q=1\) and \(s_k = 1 + 2^{-(q-1)k}\) for \(q\ge 2\) are suitable choices in general to obtain that \(f_1\) is \({\mathcal {C}}^q\) with \(t=0\) being an isolated maximizer. It is not clear how to extend such an argument to the \({\mathcal {C}}^\infty \) case.

Plots of the first three derivatives of \(f_1\) for two different sequences \(\{s_k\}\); their \(-t^2\) parts are shown in solid, while their \(p_k\) parts are shown in dotted for k even and dash-dot for k odd

Plots of \(f_\mathrm {max}\) and its first and second derivatives; their \(-t^2\) parts are shown in solid, while their \(p_k\) parts are shown in dash-dot
4 Smoothness of eigenvalue extrema and applications
We will need the following well-known theorem, whose history is discussed in Kato’s treatise [9, pp. XI–XIII]; specifically, see Eq. (2.2) on p. XII and Theorem II-6.1 on p. 139 of [9].
Theorem 4.1
Let \(H : {\mathcal {D}}\rightarrow {\mathbb {H}}^{n}\) be an analytic Hermitian matrix family in one real variable. Let \(x\in {\mathcal {D}}\) be given, and let \(H(x)\) have eigenvalues \({{\tilde{\mu }}}_{j}\in {\mathbb {R}}\), \(j=1,\ldots ,n\), not necessarily distinct. Then, for sufficiently small \(|\varepsilon |\), the eigenvalues of \(H(x+ \varepsilon )\) can be expressed as convergent power series
We now apply Theorems 4.1 and 2.3 to obtain smoothness results for eigenvalue extrema of univariate real analytic Hermitian matrix families, as well as analogous results for singular value extrema. Subsequently, we discuss how these results are useful in several important applications.
Theorem 4.2
Let \(H : {\mathcal {D}}\rightarrow {\mathbb {H}}^{n}\) be an analytic Hermitian matrix family in one real variable on an open domain \({\mathcal {D}}\subseteq {\mathbb {R}}\), and let  denote largest eigenvalue. Then
denote largest eigenvalue. Then  is \({\mathcal {C}}^2\) with Lipschitz second derivative near all of its local maximizers.
is \({\mathcal {C}}^2\) with Lipschitz second derivative near all of its local maximizers.
Proof
Let \(x\in {\mathcal {D}}\) be any local maximizer of  , with \(H(x)\) having eigenvalues \({\tilde{\mu }}_{j}\). By Theorem 4.1, in a neighborhood of \(x\), the eigenvalues of \(H(x+ \varepsilon )\) can be expressed as \(\mu _{j}(\varepsilon )\), \(j=1,\ldots ,n\), where the \(\mu _{j}(\varepsilon )\) are locally given by the power series (4.1). Since
, with \(H(x)\) having eigenvalues \({\tilde{\mu }}_{j}\). By Theorem 4.1, in a neighborhood of \(x\), the eigenvalues of \(H(x+ \varepsilon )\) can be expressed as \(\mu _{j}(\varepsilon )\), \(j=1,\ldots ,n\), where the \(\mu _{j}(\varepsilon )\) are locally given by the power series (4.1). Since  with all the \(\mu _j\) analytic, we can apply Theorem 2.3 to these functions, as mentioned in Remark 2.2, thus completing the proof. \(\square \)
with all the \(\mu _j\) analytic, we can apply Theorem 2.3 to these functions, as mentioned in Remark 2.2, thus completing the proof. \(\square \)
Remark 4.1
The proof of Theorem 4.2 is essentially the same as the proof given by Boyd and Balakrishnan [2], presented differently and in a more general context.
Corollary 4.1
Let \(H : {\mathcal {D}}\rightarrow {\mathbb {H}}^{n}\) be an analytic Hermitian matrix family in one real variable on an open domain \({\mathcal {D}}\subseteq {\mathbb {R}}\). Then:
-
(i)
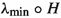 is \({\mathcal {C}}^2\) near all of its local minimizers, where
is \({\mathcal {C}}^2\) near all of its local minimizers, where 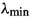 denotes algebraically smallest eigenvalue;
denotes algebraically smallest eigenvalue; -
(ii)
\(\rho \ \circ \ H\) is \({\mathcal {C}}^2\) near all of its local maximizers, where \(\rho \) denotes spectral radius
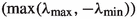 ;
; -
(iii)
\(\rho _\mathrm {in}\circ H\) is \({\mathcal {C}}^2\) near all of its local minimizers at which the minimal value is nonzero, where \(\rho _\mathrm {in}\) denotes inner spectral radius (0 if H is singular, \(\rho (H^{-1})^{{-1}}\) otherwise).
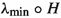 is
is 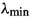 denotes algebraically smallest eigenvalue;
denotes algebraically smallest eigenvalue;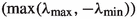 ;
;Furthermore, in each case the second derivative is Lipschitz near the relevant maximizers/minimizers.
Proof
Statements (i) and (ii) follow from applying Theorem 4.2 to \(-H\) and \({{\,\mathrm{diag}\,}}(H,-H)\), respectively. For (iii), apply (ii) to \(\rho \circ H^{-1}\) and take the reciprocal. \(\square \)
Corollary 4.2
Let \(A : {\mathcal {D}}\rightarrow {\mathbb {C}}^{m \times n}\) be an analytic matrix family in one real variable on an open domain \({\mathcal {D}}\subseteq {\mathbb {R}}\), let \(\sigma _\mathrm {max}\) denote largest singular value, and let \(\sigma _{\min }\) denote smallest singular value, noting that the latter is nonzero if and only if the matrix has full rank. Then:
-
(i)
\(\sigma _\mathrm {max}\circ A\) is \({\mathcal {C}}^2\) near all of its local maximizers, and
-
(ii)
\(\sigma _{\min }\circ A\) is \({\mathcal {C}}^2\) near all of its local minimizers at which the minimal value is nonzero.
Furthermore, in each case the second derivative is Lipschitz near the relevant maximizers/minimizers.
Proof
If \(m\ge n\), consider the real analytic Hermitian matrix family \(H: {\mathcal {D}}\rightarrow {\mathbb {H}}^{n}\) defined by
whose eigenvalues are the squares of the singular values of A(t). Then (i) and (ii), respectively, follow from applying Corollary 4.1 (ii) and (iii), respectively, to H(t), and then taking the square root. If \(n>m\), set \(H(t)=A(t)A(t)^{*}\) instead. \(\square \)
Corollary 4.2 (i) is the regularity result that Boyd and Balakrishnan established in [2]. For Corollary 4.2 (ii), note that the assumption that the minimal value of \(\sigma _{\min }\circ A\) is nonzero is necessary; e.g., \(\sigma _{\min }(t)\) is nonsmooth at its minimizer \(t=0\).
4.1 The \({\mathcal {H}}_\infty \) norm
This application was the original motivation for Boyd and Balakrishnan’s work. Let \(A \in {\mathbb {C}}^{n \times n}\), \(B \in {\mathbb {C}}^{n \times m}\), \(C \in {\mathbb {C}}^{p \times n}\), and \(D \in {\mathbb {C}}^{p \times m}\) and consider the linear time-invariant system with input and output:
Assume that A is asymptotically stable, i.e., its eigenvalues are all in the open left half-plane. An important quantity in control systems engineering and model-order reduction is the \({\mathcal {H}}_\infty \) norm of (4.2), which measures the sensitivity of the system to perturbation and can be computed by solving the following optimization problem:
where \(G(\lambda ) = C(\lambda I - A)^{-1}B + D\) is the transfer matrix associated with (4.2). Even though there is only one real variable, finding the global maximum of this function is nontrivial.
By extending Byer’s breakthrough result on computing the distance to instability [5], Boyd et al. [3] developed a globally convergent bisection method to solve (4.3) to arbitrary accuracy. Shortly thereafter, a much faster algorithm, based on computing level sets of \(\sigma _\mathrm {max}(G(\mathrm {i}\omega ))\), was independently proposed in [2] and [4], with Boyd and Balakrishnan showing that this iteration converges quadratically [2, Theorem 5.1]. As part of their work, they showed that, with respect to the real variable \(\omega \), \(\sigma _\mathrm {max}(G(\mathrm {i}\omega ))\) is \({\mathcal {C}}^2\) with Lipschitz second derivative near any of its local maximizers [2, pp. 2–3]. Subsequently, this smoothness property has been leveraged to further accelerate computation of the \({\mathcal {H}}_\infty \) norm [1, 6].
4.2 The numerical radius
Now consider the numerical radius of a matrix \(A \in {\mathbb {C}}^{n \times n}\):
where \(W(A) = \{ v^*Av : v \in {\mathbb {C}}^n, \Vert v\Vert _2 = 1\}\) is the field of values (numerical range) of A. Following [8, Ch. 1], the numerical radius can be computed by solving either

where \(H(\theta ) = \tfrac{1}{2}\left( \mathrm {e}^{\mathrm {i}\theta }A + \mathrm {e}^{-\mathrm {i}\theta }A^*\right) \).
In [13], Mengi and the second author proposed the first globally convergent method guaranteed to compute r(A) to arbitrary accuracy. This was done by employing a level-set technique that converges to a global maximizer of  , similar to the aforementioned method of [2, 4] for the \({\mathcal {H}}_\infty \) norm, and observing, but not proving, quadratic convergence of the method. Quadratic convergence was later proved by Gürbüzbalaban in his PhD thesis [7, Lemma 3.4.2], following the proof used in [2], showing that
, similar to the aforementioned method of [2, 4] for the \({\mathcal {H}}_\infty \) norm, and observing, but not proving, quadratic convergence of the method. Quadratic convergence was later proved by Gürbüzbalaban in his PhD thesis [7, Lemma 3.4.2], following the proof used in [2], showing that  is \({\mathcal {C}}^2\) near maximizers.
is \({\mathcal {C}}^2\) near maximizers.
4.3 Optimization of passive systems
Let \({\mathcal {M}} = \{A,B,C,D\}\) denote the system (4.2), but now with \(m=p\) and the associated transfer function G being minimal and proper [16]. Mehrmann and Van Dooren [12] have recently shown that another important problem is to compute the maximal value \(\Xi \in {\mathbb {R}}\) such that for all \(\xi < \Xi \), the related system \({\mathcal {M}}_\xi = \{A_\xi ,B,C,D_\xi \}\) is strictly passiveFootnote 1, where \(A_\xi = A + \tfrac{\xi }{2}I_n\) and \(D_\xi = D - \tfrac{\xi }{2}I_m\). Letting \(G_\xi \) be the transfer matrix associated with \({\mathcal {M}}_\xi \), by [12, Theorem 5.1], the quantity \(\Xi \) is the unique root of

Note that in contrast to the univariate optimization problems discussed previously, computing
\(\Xi \) is a problem in two real parameters, namely,
\(\xi \) and
\(\omega \). In [12, section 5], Mehrmann and Van Dooren introduced both a bisection algorithm to compute
\(\Xi \), and an apparently faster “improved iteration" whose exact convergence properties were not established. However, using the fact that
 in (4.6) is
\({\mathcal {C}}^2\) with Lipschitz second derivative near all its minimizers, as well as some other tools, the first author and Van Dooren have since established a rate-of-convergence result for this “improved iteration" and also presented a much faster and more numerically reliable algorithm to compute
\(\Xi \) with quadratic convergence [14].
in (4.6) is
\({\mathcal {C}}^2\) with Lipschitz second derivative near all its minimizers, as well as some other tools, the first author and Van Dooren have since established a rate-of-convergence result for this “improved iteration" and also presented a much faster and more numerically reliable algorithm to compute
\(\Xi \) with quadratic convergence [14].
5 Concluding remarks
We have shown that the maximum eigenvalue of a univariate real analytic Hermitian matrix family is unconditionally \({\mathcal {C}}^2\) near all its maximizers, with Lipschitz second derivative. Although the result is well known in the context of the maximum singular value of a transfer function, its generality and simplicity have apparently not been fully appreciated. We believe that this result and its corollaries may be useful in many applications, some of which were summarized in this paper. We also investigated whether this smoothness property extends to max functions more generally, showing that the pointwise maximum of a finite set of q-times continuously differentiable univariate functions must have zero derivative at a maximizer for \(q=1\), but arbitrarily close to the maximizer, the derivative may not be defined, even when \(q=3\) and the maximizer is isolated.
All figures and the symbolically computed coefficients of \(p_k\) given in Appendices A and B were generated by MATLAB codes that can be downloaded from https://doi.org/10.5281/zenodo.5831694.
Notes
A strictly passive system is one whose stored energy is decreasing; for more a formal treatment, see [12].
References
Benner, P., Mitchell, T.: Faster and more accurate computation of the \({\cal{H}}_\infty \) norm via optimization. SIAM J. Sci. Comput. 40(5), A3609–A3635 (2018). https://doi.org/10.1137/17M1137966
Boyd, S., Balakrishnan, V.: A regularity result for the singular values of a transfer matrix and a quadratically convergent algorithm for computing its \({L}_\infty \)-norm. Syst. Control Lett. 15(1), 1–7 (1990). https://doi.org/10.1016/0167-6911(90)90037-U
Boyd, S., Balakrishnan, V., Kabamba, P.: A bisection method for computing the \({\cal{H}}_{\infty }\) norm of a transfer matrix and related problems. Math. Control Signals Syst. 2, 207–219 (1989)
Bruinsma, N.A., Steinbuch, M.: A fast algorithm to compute the \(H_{\infty }\)-norm of a transfer function matrix. Syst. Control Lett. 14(4), 287–293 (1990)
Byers, R.: A bisection method for measuring the distance of a stable matrix to unstable matrices. SIAM J. Sci. Stat. Comput. 9, 875–881 (1988). https://doi.org/10.1137/0909059
Genin, Y., Van Dooren, P., Vermaut, V.: Convergence of the calculation of \({\cal H\it }_\infty \)-norms and related questions. In: A. Beghi, L. Finesso, G. Picci (eds.) Mathematical Theory of Networks and Systems, 13 ed., Proceedings of the MTNS-98 Symposium, Padova, pp. 629–632 (1998)
Gürbüzbalaban, M.: Theory and methods for problems arising in robust stability, optimization and quantization. Ph.D. thesis, New York University, New York, NY, USA (2012). https://mert-g.org/wp-content/uploads/2018/06/Mert-Thesis.pdf
Horn, R.A., Johnson, C.R.: Topics in Matrix Analysis. Cambridge University Press, Cambridge (1991)
Kato, T.: A Short Introduction to Perturbation Theory for Linear Operators. Springer, New York (1982). https://doi.org/10.1007/978-1-4612-5700-4
Krantz, S.G., Parks, H.R.: A Primer of Real Analytic Functions. Birkhäuser Advanced Texts, 2nd edn. Birkhäuser, Boston, MA (2002). https://doi.org/10.1007/978-0-8176-8134-0
Lax, P.D.: Linear Algebra and its Applications, 2nd edn. Wiley, Hoboken, NJ (2007)
Mehrmann, V., Van Dooren, P.M.: Optimal robustness of port-Hamiltonian systems. SIAM J. Matrix Anal. Appl. 41(1), 134–151 (2020). https://doi.org/10.1137/19M1259092
Mengi, E., Overton, M.L.: Algorithms for the computation of the pseudospectral radius and the numerical radius of a matrix. IMA J. Numer. Anal. 25(4), 648–669 (2005). https://doi.org/10.1093/imanum/dri012
Mitchell, T., Van Dooren, P.: Root-max problems, hybrid expansion-contraction, and quadratically convergent optimization of passive systems. ArXiv arXiv:2109.00974 (2021)
von Neumann, J., Wigner, E.P.: Über merkwürdige diskrete Eigenwerte. Phys. Z. 40, 467–470 (1929)
Zhou, K., Doyle, J.C., Glover, K.: Robust and Optimal Control. Prentice-Hall, Upper Saddle River, NJ (1996). https://doi.org/10.1007/978-1-4471-6257-5
Acknowledgements
The second author was supported in part by U.S. National Science Foundation Grant DMS-2012250.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Proofs of Theorems 3.1 and 3.2
Lemma A.1
For \(f_1\) defined in (), if \(s_k=1 + 2^{-2k}\), then the coefficients of the polynomial \(p_k(t) = \sum _{j=0}^9 c_j t^j\) are:
Proof
The coefficients were computed symbolically in MATLAB by solving the linear system defined by the generalized Vandermonde matrix and right-hand side determining each \(p_k\) in (). These formulas were also verified by comparing with numerical computations. \(\square \)
Proof (of Theorem 3.1)
Function \(f_1\) defined in () is clearly \({\mathcal {C}}^3\) near any nonzero t, since our construction ensures that the first three derivatives of \(p_k\) and \(p_{k+1}\) match where they meet. We must show that it is also \({\mathcal {C}}^3\) at \(t=0\). First note that for the coefficients given in Lemma A.1, we can replace their dependency on k with a dependency on t by using \(k=-{\lceil }\log _2 t{\rceil }\). Thus, \(f_1\) can be written as follows:
where \({\tilde{c}}_j\) is obtained by replacing k in \(c_j\) with \(-{\lceil }\log _2 t{\rceil }\).
We begin by looking at the first derivative. For \(f_1^\prime \) to exist and be continuous at \(t=0\),
must hold, i.e., the derivative from the right (over the \(p_k\) pieces) must match the derivative from the left (over the \(-t^2\) piece). To show that (A.2) holds, we show that each term in the sum in (A.1) divided by t goes to zero as \(t \rightarrow 0^+\), i.e., that \(\lim _{t \rightarrow 0^+} {\tilde{c}}_j t^{j-1} = 0\) for \(j \in \{0,1,\ldots ,9\}\). It is obvious that this holds for \(j=4\) since \(c_4= {\tilde{c}}_4 = z_4\) is a fixed number. To show the highest-order term (\(j=9\)) vanishes as \(t \rightarrow 0^+\), we can make use of the fact that \(0 < 2^{-{\lceil }\log _2 t{\rceil }} \le 2^{-\log _2 t} = t^{-1}\) holds for all \(t > 0\), i.e.,
Similar arguments show that \(\lim _{t \rightarrow 0^+} {\tilde{c}}_j t^{j-1} = 0\) holds for \(j \in \{5,6,7,8\}\). Using the fact that \(0 < 2^{{\lceil }\log _2 t{\rceil }} \le 2^{1 + \log _2 t} = 2t\) for all \(t > 0\), for \(j=3\), we have that
while for \(j=2\) and \(j=1\) we respectively have that
and
Finally, for \(j=0\), we have that
Hence, we have shown that \(f_1\) is at least \({\mathcal {C}}^1\) on its domain.
Analogously, for \(f_1^{\prime \prime }\) to exist and be continuous at \(t=0\),
must hold. We have that
and so we consider \(\lim _{t \rightarrow 0^+} j {\tilde{c}}_j t^{j-2} \) for \(j \in \{1,\ldots ,9\}\), i.e., the limit of each term in the sum in (A.4) divided by t. We show that for all but \(j = 2\), these values goes to zero, while the \(j=2\) value goes to \(-2\) as \(t\rightarrow 0^+\). For \(j=9\), we have that
with similar arguments showing that \(j\in \{5,6,7,8\}\) values also diminish to zero. For \(j=4\), we simply have \(\lim _{t\rightarrow 0^+} 4z_4 t^2 = 0\). For \(j=3\),
For \(j=2\), we have that
Lastly, for \(j=1\), we have that
and so we have now shown that \(f_2\) is at least \({\mathcal {C}}^2\) on its domain.
Finally, for \(f_1^{\prime \prime \prime }\) to exist and be continuous at \(t=0\),
must hold. We have that
and so we consider \(\lim _{t \rightarrow 0^+} j (j-1) {\tilde{c}}_j t^{j-3} \) for \(j \in \{2,\ldots ,9\}\), i.e., the limit of each term in the sum in (A.6) divided by t. For \(j \in \{5,6,7,8,9\}\), we again have similar arguments showing that the corresponding values vanish, so we just show the \(j=9\) case, which follows because
Again, it is clear that the value for \(j=4\) vanishes. For \(j=3\), we have that
Finally, for \(j=2\), we can rewrite (A.5) as follows, making use of these aforementioned limits which vanish and replacing \(\varepsilon \) by t, to obtain a limit only involving the \(j=2\) term:
Thus, \(f_1\) is indeed \({\mathcal {C}}^3\) on its domain. \(\square \)
Proof (of Theorem 3.2)
Since \(l_k\) is a power of two, we can rewrite the derivative of \(p_k\), i.e., \( p_k^\prime (t) = \sum _{j=1}^9 j c_j t^{j-1}, \) as a function of \(\zeta \in [1,2]\):
where \({\tilde{z}}_j = j z_j 2^{1 - j}\). From Lemma A.1, we see that \(z_2 - 2^{2k} < 0\) for all \(k \ge 10\), while for any k, we have that \({\tilde{z}}_j < 0\) for \(j \in \{1,3,5,7,9\}\) and \({\tilde{z}}_j > 0\) for \(j \in \{4,6,8\}\). Since \(\zeta \in [1,2]\), an upper bound for \({\tilde{p}}_k^\prime \) can be obtained by evaluating its negative terms at \(\zeta =1\) and its positive terms at \(\zeta = 2\), i.e., for all \(k \ge 10\) and any \(\zeta \in [1,2]\), we have that
For \(k\ge 13\), the upper bound on the derivative is negative. Thus, for \(k\ge 13\), \({\tilde{p}}_k^\prime (\zeta ) < 0\) for any \(\zeta \in [1,2]\), so \(p_k\) must be decreasing. Consequently, the \(t=0\) maximizer of \(f_1\) is isolated. Finally, it immediately follows that the \(t=0\) maximizer of \(f_\mathrm {max}=\max (f_{1},f_{2})\) is also isolated. \(\square \)
Why \(s_k=1+2^{-k}\) is insufficient to make () a \({\mathcal {C}}^3\) function
For \(s_k=1 + 2^{-k}\), symbolic computation shows that the coefficients of \(p_k(t) = \sum _{j=0}^9 c_j t^j\) are:
where the integers \(z_j\) remain the same as given in Lemma A.1. To see if (A.5) still holds for this new choice of \(s_k\) we look at \(\lim _{t \rightarrow 0^+} j (j-1) {\tilde{c}}_j t^{j-3} \) for \(j \in \{2,\ldots ,9\}\). However, now none of the individual limits vanish. For example, for \(j=9\), we have that
where we have used the fact that \(0 < 2^{-1}t^{-1} = 2^{-1 - \log _2 t} \le 2^{-{\lceil }\log _2 t{\rceil }}\); similarly, the limits for \(j\in \{4,5,6,7,8\}\) do not vanish either. For \(j=3\), we simply have that
Finally, even if all of the terms considered above were to vanish and we substitute in the value for \(j=2\) into (A.5), we nevertheless would end up attaining another limit that does not vanish:
The only remaining way that (A.5) could hold is if all of these non-vanishing terms cancel, but from our experiments (see Fig. 2a), we know this is not the case.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mitchell, T., Overton, M.L. On properties of univariate max functions at local maximizers. Optim Lett 16, 2527–2541 (2022). https://doi.org/10.1007/s11590-022-01872-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11590-022-01872-y